Redis Cluster介绍
- 格式:pdf
- 大小:488.21 KB
- 文档页数:6

Redis配置参数详解Redis是⼀个应⽤⾮常⼴泛的⾼性能Key-Value型数据库,与memcached类似,但功能更加强⼤!本⽂将按照不同功能模块的⽅式,依次对各个功能模块的配置参数进⾏详细介绍。
GENERAL./redis-server /path/to/redis.conf 按照指定的配置⽂件启动include /path/to/other.conf 包含其它的redis配置⽂件daemonize yes 启⽤后台守护进程运⾏模式pidfile /var/run/redis.pid redis启动后的进程ID保存⽂件port 6379 指定使⽤的端⼝号bind IP 监听指定的⽹络接⼝unixsocket /tmp/redis.sock 指定监听的socket,适⽤于unix环境timeout N 客户端空闲N秒后断开连接,参数0表⽰不启⽤loglevel notice 指定服务器信息显⽰的等级,4个参数分别为debug\verbose\notice\warninglogfile “” 指定⽇志⽂件,默认是使⽤系统的标准输出syslog-enabled no 是否启⽤将记录记载到系统⽇志功能,默认为不启⽤syslog-ident redis 若启⽤⽇志记录,则需要设置⽇志记录的⾝份syslog-facility local0 若启⽤⽇志记录,则需要设置⽇志facility,可取值范围为local0~local7,表⽰不同的⽇志级别databases 16 设置数据库的数量,默认启动时使⽤DB0,使⽤“select <dbid>”可以更换数据库tcp-backlog 511 此参数确定TCP连接中已完成队列(3次握⼿之后)的长度,应⼩于Linux系统的/proc/sys/net/core/somaxconn的值,此选项默认值为511,⽽Linux的somaxconn默认值为128,当并发量⽐较⼤且客户端反应缓慢的时候,可以同时提⾼这两个参数。

Redis使⽤规范本⽂主要介绍在使⽤阿⾥云Redis的开发规范,从下⾯⼏个⽅⾯进⾏说明。
键值设计命令使⽤客户端使⽤通过本⽂的介绍可以减少使⽤Redis过程带来的问题。
⼀、键值设计1、key名设计可读性和可管理性以业务名(或数据库名)为前缀(防⽌key冲突),⽤冒号分隔,⽐如业务名:表名:idugc:video:1简洁性保证语义的前提下,控制key的长度,当key较多时,内存占⽤也不容忽视,例如:user:{uid}:friends:messages:{mid}简化为u:{uid} m:{mid}。
不要包含特殊字符反例:包含空格、换⾏、单双引号以及其他转义字符2、value设计拒绝bigkey防⽌⽹卡流量、慢查询,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
反例:⼀个包含200万个元素的list。
⾮字符串的bigkey,不要使⽤del删除,使⽤hscan、sscan、zscan⽅式渐进式删除,同时要注意防⽌bigkey过期时间⾃动删除问题(例如⼀个200万的zset设置1⼩时过期,会触发del操作,造成阻塞,⽽且该操作不会不出现在慢查询中(latency可查)),查找⽅法和删除⽅法选择适合的数据类型例如:实体类型(要合理控制和使⽤数据结构内存编码优化配置,例如ziplist,但也要注意节省内存和性能之间的平衡) 反例:set user:1:name tomset user:1:age =19set user:1:favor football正例:hmset user:1 name tom age =19 favor football控制key的⽣命周期redis不是垃圾桶,建议使⽤expire设置过期时间(条件允许可以打散过期时间,防⽌集中过期),不过期的数据重点关注idletime。
⼆、命令使⽤1、O(N)命令关注N的数量例如hgetall、lrange、smembers、zrange、sinter等并⾮不能使⽤,但是需要明确N的值。
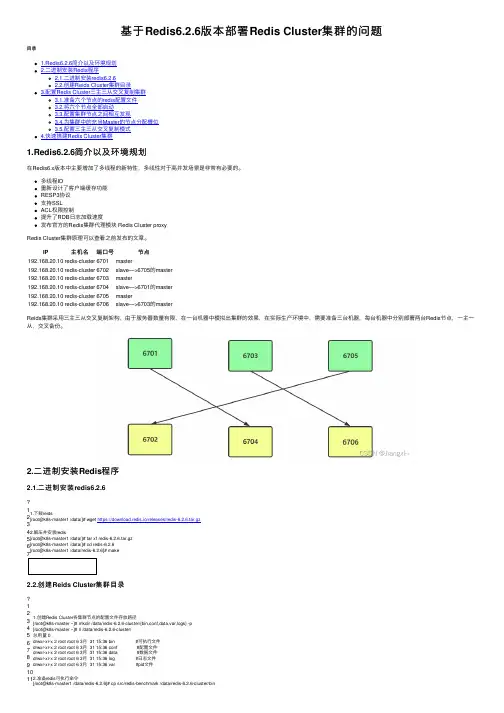
基于Redis6.2.6版本部署Redis Cluster 集群的问题⽬录1.Redis6.2.6简介以及环境规划2.⼆进制安装Redis 程序2.1.⼆进制安装redis6.2.62.2.创建Reids Cluster 集群⽬录3.配置Redis Cluster 三主三从交叉复制集群3.1.准备六个节点的redis 配置⽂件3.2.将六个节点全部启动3.3.配置集群节点之间相互发现3.4.为集群中的充当Master 的节点分配槽位3.5.配置三主三从交叉复制模式4.快速搭建Redis Cluster 集群1.Redis6.2.6简介以及环境规划在Redis6.x 版本中主要增加了多线程的新特性,多线性对于⾼并发场景是⾮常有必要的。
多线程IO 重新设计了客户端缓存功能RESP3协议⽀持SSLACL 权限控制提升了RDB ⽇志加载速度发布官⽅的Redis 集群代理模块 Redis Cluster proxyRedis Cluster 集群原理可以查看之前发布的⽂章。
IP 主机名端⼝号节点192.168.20.10redis-cluster 6701master192.168.20.10redis-cluster 6702slave—>6705的master192.168.20.10redis-cluster 6703master192.168.20.10redis-cluster 6704slave—>6701的master192.168.20.10redis-cluster 6705master192.168.20.10redis-cluster 6706slave—>6703的master Reids 集群采⽤三主三从交叉复制架构,由于服务器数量有限,在⼀台机器中模拟出集群的效果,在实际⽣产环境中,需要准备三台机器,每台机器中分别部署两台Redis 节点,⼀主⼀从,交叉备份。

springboot以lettuce连接池整合redis-cluster(单机及集群版)⼀.添加相关pom依赖commons依赖主要应⽤于单机版<!--redis--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!-- redis依赖commons-pool 这个依赖⼀定要添加 --><dependency><groupId>mons</groupId><artifactId>commons-pool2</artifactId></dependency>⼆.修改application.ymla. 单机版:#redis单机版redis:host: 192.168.40.156port: 6379# 密码没有则可以不填password: 123456# 如果使⽤的jedis 则将lettuce改成jedis即可lettuce:pool:# 最⼤活跃链接数默认8(使⽤负值表⽰没有限制)max-active: 8# 最⼤空闲连接数默认8max-idle: 8# 最⼩空闲连接数默认0min-idle: 0# 连接池最⼤阻塞等待时间(使⽤负值表⽰没有限制)max-wait: -1b.集群版:#redis集群版redis:timeout: 6000msdatabase: 0cluster:nodes:- 192.168.40.156:7001- 192.168.40.156:7002- 192.168.40.157:7003- 192.168.40.157:7004- 192.168.40.158:7005- 192.168.40.158:7006max-redirects: 3 # 获取失败最⼤重定向次数lettuce:pool:max-active: 1000 #连接池最⼤连接数(使⽤负值表⽰没有限制)max-idle: 10 # 连接池中的最⼤空闲连接min-idle: 5 # 连接池中的最⼩空闲连接max-wait: -1 # 连接池最⼤阻塞等待时间(使⽤负值表⽰没有限制)三.添加RedisConfig 添加序列化⽅式以及缓存配置@Configuration@EnableCaching // 开启缓存⽀持public class RedisConfig extends CachingConfigurerSupport {@Resourceprivate LettuceConnectionFactory lettuceConnectionFactory;@Beanpublic KeyGenerator keyGenerator() {return new KeyGenerator() {@Overridepublic Object generate(Object target, Method method, Object... params) {StringBuffer sb = new StringBuffer();sb.append(target.getClass().getName());sb.append(method.getName());for (Object obj : params) {sb.append(obj.toString());}return sb.toString();}};}// 缓存管理器@Beanpublic CacheManager cacheManager() {RedisCacheManager.RedisCacheManagerBuilder builder = RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory(lettuceConnectionFactory);@SuppressWarnings("serial")Set<String> cacheNames = new HashSet<String>() {{add("codeNameCache");}};builder.initialCacheNames(cacheNames);return builder.build();}/*** RedisTemplate配置*/@Beanpublic RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory) {// 设置序列化Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<Object>( Object.class);ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, Visibility.ANY);om.enableDefaultTyping(DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(om);// 配置redisTemplateRedisTemplate<String, Object> redisTemplate = new RedisTemplate<String, Object>();redisTemplate.setConnectionFactory(lettuceConnectionFactory);RedisSerializer<?> stringSerializer = new StringRedisSerializer();redisTemplate.setKeySerializer(stringSerializer);// key序列化redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);// value序列化redisTemplate.setHashKeySerializer(stringSerializer);// Hash key序列化redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);// Hash value序列化redisTemplate.afterPropertiesSet();return redisTemplate;}}四.使⽤。

redis monitor 用法-回复Redis是一种开源的内存数据存储系统,常用于构建高性能、高可扩展性的应用程序。
其中一个常用的工具就是Redis Monitor,它允许我们实时监视Redis数据库的活动。
本文将一步一步回答关于Redis Monitor 的用法,并介绍如何使用它监控Redis数据库。
一、什么是Redis MonitorRedis Monitor是Redis自带的一个命令行工具,它用于实时监视Redis数据库的各种操作,包括读取和写入操作,以及键的删除和过期等行为。
通过使用Redis Monitor,我们可以查看Redis数据库中每个命令的执行情况,以及获取实时的数据库活动日志。
二、Redis Monitor的启动要启动Redis Monitor,首先需要连接到Redis数据库的命令行界面。
打开终端(或命令提示符窗口),输入以下命令:redis-cli这将打开Redis的命令行界面。
三、启动Redis Monitor在Redis命令行界面中,输入以下命令来启动Redis Monitor:monitor启动之后,Redis Monitor将开始监视Redis数据库的活动,并将所有操作实时显示在命令行界面上。
四、监视Redis数据库的活动一旦Redis Monitor启动,它将记录并显示所有发送到Redis数据库的命令。
这些命令通常以二进制协议或文本协议的形式发送。
Redis Monitor的输出将以以下格式显示:[时间戳] "执行命令的客户端" "Redis命令" "命令参数"例如:1621974415.250648 [0 127.0.0.1:54738] "SET" "mykey" "myvalue" 1621974416.330927 [0 127.0.0.1:54738] "GET" "mykey"通过分析这些输出,我们可以了解Redis数据库中的各种活动,如键的创建、读取和删除等。

springbootredis使⽤lettuce配置多数据源的实现⽬前项⽬上需要连接两个redis数据源,⼀个redis数据源是单机模式,⼀个redis数据源是分⽚集群模式,这⾥将具体配置列⼀下。
项⽬⽤的springboot版本为<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.1.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent>⼀、在yml中配置redis数据源信息redis:cluster:nodes: 127.0.0.1:9001lettuce:#连接池配置pool:#连接池最⼤连接数max-active: 20#连接池最⼤等待时间,负数表⽰不做限制max-wait: -1#最⼤空闲连接max-idle: 9#最⼩空闲连接min-idle: 0timeout: 500000redis2:host: 127.0.0.1port: 6385lettuce:pool:max-active: 20max-idle: 8max-wait: -1min-idle: 0timeout: 500000(这⾥的redis都没有配置密码)⼆、添加redis配置类package com.cq.config;import cn.hutool.core.convert.Convert;import mons.pool2.impl.GenericObjectPoolConfig;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.beans.factory.annotation.Value;import org.springframework.boot.context.properties.ConfigurationProperties;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Primary;import org.springframework.core.env.Environment;import org.springframework.core.env.MapPropertySource;import org.springframework.data.redis.connection.RedisClusterConfiguration;import org.springframework.data.redis.connection.RedisConnectionFactory;import org.springframework.data.redis.connection.RedisStandaloneConfiguration;import org.springframework.data.redis.connection.lettuce.LettuceClientConfiguration;import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;import org.springframework.data.redis.connection.lettuce.LettucePoolingClientConfiguration;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.serializer.RedisSerializer;import org.springframework.data.redis.serializer.StringRedisSerializer;import java.io.Serializable;import java.util.HashMap;import java.util.Map;/*** @author cccccloud on 2020/11/16 17:16*/@Configurationpublic class RedisConfig {@Autowiredprivate Environment environment;@Value("${spring.redis2.host}")private String host;@Value("${spring.redis2.port}")private String port;@Value("${spring.redis2.lettuce.pool.max-active}")private String max_active;@Value("${spring.redis2.lettuce.pool.max-idle}")private String max_idle;@Value("${spring.redis2.lettuce.pool.max-wait}")private String max_wait;@Value("${spring.redis2.lettuce.pool.min-idle}")private String min_idle;/*** 配置lettuce连接池** @return*/@Bean@Primary@ConfigurationProperties(prefix = "spring.redis.cluster.lettuce.pool")public GenericObjectPoolConfig redisPool() {return new GenericObjectPoolConfig();}/*** 配置第⼀个数据源的** @return*/@Bean("redisClusterConfig")@Primarypublic RedisClusterConfiguration redisClusterConfig() {Map<String, Object> source = new HashMap<>(8);source.put("spring.redis.cluster.nodes", environment.getProperty("spring.redis.cluster.nodes"));RedisClusterConfiguration redisClusterConfiguration;redisClusterConfiguration = new RedisClusterConfiguration(new MapPropertySource("RedisClusterConfiguration", source));redisClusterConfiguration.setPassword(environment.getProperty("spring.redis.password"));return redisClusterConfiguration;}/*** 配置第⼀个数据源的连接⼯⼚* 这⾥注意:需要添加@Primary 指定bean的名称,⽬的是为了创建两个不同名称的LettuceConnectionFactory** @param redisPool* @param redisClusterConfig* @return*/@Bean("lettuceConnectionFactory")@Primarypublic LettuceConnectionFactory lettuceConnectionFactory(GenericObjectPoolConfig redisPool, @Qualifier("redisClusterConfig") RedisClusterConfiguration redisClusterConfig) { LettuceClientConfiguration clientConfiguration = LettucePoolingClientConfiguration.builder().poolConfig(redisPool).build();return new LettuceConnectionFactory(redisClusterConfig, clientConfiguration);}/*** 配置第⼀个数据源的RedisTemplate* 注意:这⾥指定使⽤名称=factory 的 RedisConnectionFactory* 并且标识第⼀个数据源是默认数据源 @Primary** @param redisConnectionFactory* @return*/@Bean("redisTemplate")@Primarypublic RedisTemplate redisTemplate(@Qualifier("lettuceConnectionFactory") RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> template = new RedisTemplate<>();template.setConnectionFactory(redisConnectionFactory);StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();// key采⽤String的序列化⽅式template.setKeySerializer(stringRedisSerializer);// hash的key也采⽤String的序列化⽅式template.setHashKeySerializer(stringRedisSerializer);// value序列化⽅式采⽤jacksontemplate.setValueSerializer(stringRedisSerializer);// hash的value序列化⽅式采⽤jacksontemplate.setHashValueSerializer(stringRedisSerializer);template.afterPropertiesSet();return template;}@Beanpublic GenericObjectPoolConfig redisPool2() {GenericObjectPoolConfig config = new GenericObjectPoolConfig();config.setMinIdle(Convert.toInt(min_idle));config.setMaxIdle(Convert.toInt(max_idle));config.setMaxTotal(Convert.toInt(max_active));config.setMaxWaitMillis(Convert.toInt(max_wait));return config;}@Beanpublic RedisStandaloneConfiguration redisConfig2() {RedisStandaloneConfiguration redisConfig = new RedisStandaloneConfiguration(host,Convert.toInt(port));return redisConfig;}@Bean("factory2")public LettuceConnectionFactory factory2(@Qualifier("redisPool2") GenericObjectPoolConfig config,@Qualifier("redisConfig2") RedisStandaloneConfiguration redisConfig) {//注意传⼊的对象名和类型RedisStandaloneConfigurationLettuceClientConfiguration clientConfiguration = LettucePoolingClientConfiguration.builder().poolConfig(config).build();return new LettuceConnectionFactory(redisConfig, clientConfiguration);}/*** 单实例redis数据源** @param connectionFactory* @return*/@Bean("redisTemplateSingle")public RedisTemplate<String, Object> redisTemplateSingle(@Qualifier("factory2")LettuceConnectionFactory connectionFactory) {//注意传⼊的对象名RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(connectionFactory);RedisSerializer<String> redisSerializer = new StringRedisSerializer();redisTemplate.setKeySerializer(redisSerializer);redisTemplate.setValueSerializer(redisSerializer);redisTemplate.setHashKeySerializer(redisSerializer);redisTemplate.setHashValueSerializer(redisSerializer);return redisTemplate;}}三、使⽤redis使⽤单实例redis/*** redis 单节点*/@Resource(name = "redisTemplateSingle")private RedisTemplate redisTemplateSingle;使⽤redis集群/*** redis 集群*/@Resource(name = "redisTemplate")private RedisTemplate redisTemplate;到此这篇关于springboot redis使⽤lettuce配置多数据源的实现的⽂章就介绍到这了,更多相关springboot lettuce多数据源内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
redisredis-trib.rb安装集群一、redis安装1.下载地址:$ wget http://download.redis.io/releases/redis-3.2.8.tar.gz 2.解压缩$ tar xzf redis-3.2.8.tar.gz3.编译$ln -s redis-3.2.8 redis建立软链接,有利于未来升级,是一个比较好的做法$ cd redis$ make编译,有的时候会报错a、确保安装gccb、fatal error: jemalloc/jemalloc.h: No such file or directory 解决办法:make MALLOC=libc$make install安装放入到/usr/local/bin$redis-cli -v查看redis版本redis集群一般由多个节点组成,节点数量至少6个才能保证组成完整高可用的集群。
操作系统centos7.2-mini版一、redis安装略二、使用redis-trib.rb 安装工具1、安装rubyyum install ruby -y2、安装rubygemredis依赖wget /downloads/redis-3.3.0.gemgem install -l redis-3.3.0 gemcp /{redishome}/scr/redis-trib.rb /usr/local/bin3、测试redis-trib.rb二、准备节点1、创建文件夹mkdir /redis-cluster-tribcd /redis-cluster-tribmkdir 6379 6380 6381 6382 6383 63842、创建并配置redis.conf分别在6379-6384六个文件夹中创建redis-node.conf文件,并添加配置,配置内容如下redis-6379.conf,每个文件根据对应名修改一下vim redis-6379.confport 6379daemonize yeslogfile "6379.log"dbfilename "dump-6379.rdb"dir "/redis-cluster-trib/6379/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6379.conf"vim redis-6380.confport 6380daemonize yeslogfile "6380.log"dbfilename "dump-6380.rdb"dir "/redis-cluster-trib/6380/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6380.conf"vim redis-6381.confport 6381daemonize yeslogfile "6381.log"dbfilename "dump-6381.rdb"dir "/redis-cluster-trib/6381/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6381.conf"vim redis-6382.confport 6382daemonize yeslogfile "6382.log"dbfilename "dump-6382.rdb"dir "/redis-cluster-trib/6382/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6382.conf"vim redis-6383.confport 6383daemonize yeslogfile "6383.log"dbfilename "dump-6383.rdb"dir "/redis-cluster-trib/6383/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6383.conf"vim redis-6384.confport 6384daemonize yeslogfile "6384.log"dbfilename "dump-6384.rdb"dir "/redis-cluster-trib/6384/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6384.conf"3、启动各个节点redis-server redis-6379.confredis-server redis-6380.confredis-server redis-6381.confredis-server redis-6382.confredis-server redis-6383.confredis-server redis-6384.conf4、检查启动情况cat 6379/6379.logcat 6380/6380.logcat 6381/6381.logcat 6382/6382.logcat 6383/6383.logcat 6384/6384.logps -ef |grep redis四、创建集群1、创建集群redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384replicas 表示为每个主节点设置多少个从节点,如果部署节点使用不同的ip,会尽可能保证主从不在一个节点上2、健康性检查redis-trib.rb check 127.0.0.1:6380四、扩容集群1、添加2个节点mkdir 6385 6386vim redis-6385.confport 6385daemonize yeslogfile "6385.log"dbfilename "dump-6385.rdb"dir "/redis-cluster-trib/6385/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6385.conf"vim redis-6386.confport 6386daemonize yeslogfile "6386.log"dbfilename "dump-6386.rdb"dir "/redis-cluster-trib/6386/"cluster-enabled yescluster-node-timeout 15000cluster-config-file "nodes-6386.conf"2、启动节点redis-server redis-6385.confredis-server redis-6386.conf3、添加入集群redis-trib.rb add-node 127.0.0.1:6385 127.0.0.1:6379redis-trib.rb add-node 127.0.0.1:6386 127.0.0.1:6379注意这里还是显示为主节点,要设置它为从节点要redis-trib.rb add-node 127.0.0.1:6386 127.0.0.1:6379 --slave --master-id<arg> 或者看后面变化(在缩减章节)4、迁移槽redis-trib.rb info127.0.0.1:6379可以看到各个主节点槽情况5、批量迁移redis-trib.rbreshard 127.0.0.1:6379数据迁移之前会打印迁移计划,确认后进行迁移四、收缩集群跟上面一样,将要清空节点移至其他节点上。
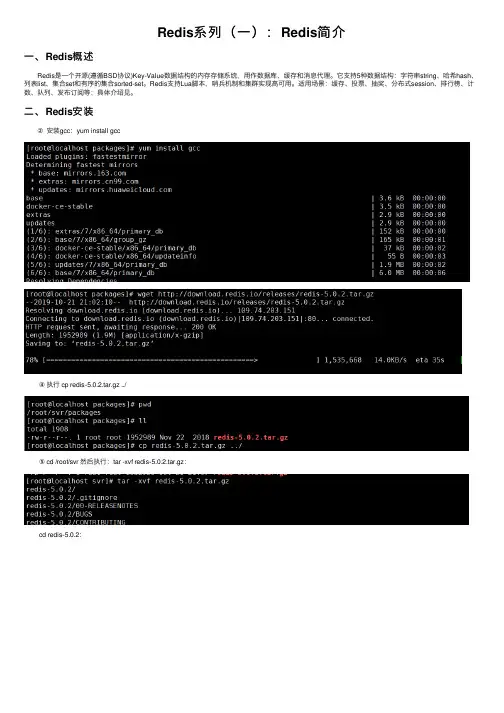
Redis系列(⼀):Redis简介⼀、Redis概述 Redis是⼀个开源(遵循BSD协议)Key-Value数据结构的内存存储系统,⽤作数据库、缓存和消息代理。
它⽀持5种数据结构:字符串string、哈希hash、列表list、集合set和有序的集合sorted-set。
Redis⽀持Lua脚本,哨兵机制和集群实现⾼可⽤。
适⽤场景:缓存、投票、抽奖、分布式session、排⾏榜、计数、队列、发布订阅等;具体介绍见。
⼆、Redis安装 ②安装gcc:yum install gcc ④执⾏ cp redis‐5.0.2.tar.gz ../ ⑤ cd /root/svr 然后执⾏:tar -xvf redis‐5.0.2.tar.gz: cd redis‐5.0.2: ⑥执⾏:make install PREFIX=/root/svr/redis-5.0.2 ⑦启动redis 执⾏:bin/redis-server ../redis.conf (注意:如果要后台启动需要把redis.conf配置⾥⾯的daemonize改为yes) ⑧验证是否启动成功 ps -ef|grep redis ⑨进去redis客户端:bin/redis-cli ⑩退出客户端:quit三、redis.conf主要配置详解参数解释bind指定 Redis 只接收来⾃于该 IP 地址的请求,如果不进⾏设置,那么将处理所有请求port监听端⼝,默认6379timeout设置客户端连接时的超时时间,单位为秒。
当客户端在这段时间内没有发出任何指令,那么关闭该连接daemonize默认情况下,redis不是在后台运⾏的,如果需要在后台运⾏,把该项的值更改为yesloglevel log等级分为4级,debug, verbose, notice, 和 warning。
⽣产环境下⼀般开启noticelogfile配置log⽂件地址,默认使⽤标准输出,即打印在命令⾏终端的窗⼝上save save <seconds> <changes>⽐如save 60 10000意思60秒(1分钟)内⾄少10000个key值改变(则进⾏数据库保存--持久化rdb)dbfilename rdb⽂件的名称dir数据⽬录,2种持久化rdb、aof⽂件就在这个⽬录replicaof replicaof <masterip> <masterport>:该配置是主从的配置表⽰该redis实例是masterip:masterport的从节点masterauth master连接密码replica-serve-stale-data 当slave跟master失去连接或者正在同步数据,slave有两种运⾏⽅式:1) 如果replica-serve-stale-data设置为yes(默认设置),slave会继续响应客户端的请求。

RedisCluster报错:ToomanyClusterredirections报错信息Spring Boot项⽬中访问redis cluster报错:redis.clients.jedis.exceptions.JedisClusterMaxRedirectionsException: Too many Cluster redirections?(集群重定向过多)原因分析redis 绑定了多个ipeg:1. redis.conf ⽂件中bind 127.0.0.1 192.168.186.12. 在创建集群时host使⽤127.0.0.1 eg: redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1问题修复bind配置为主机ip(不要配置多个ip,也不要配置为回环地址127.0.0.1,配置为回环地址只有本机能访问,其他主机⽆法访问),重建集群eg:redis-cli --cluster create 192.168.186.1:7000 192.168.186.1:7001 192.168.186.1:7002 192.168.186.1:7003 192.168.186.1:7004 192.168.186.1:7005 --cluster-replicas 11. 所有节点redi.conf⽂件中bind配置为主机ip2. 删除所有节点中的nodes.conf 、rdb⽂件3. kill所有redis进程4. 重新启动所有redis实例5. 重建集群 redis-cli --cluster create 192.168.186.1:7000 192.168.186.1:7001 192.168.186.1:7002 192.168.186.1:7003192.168.186.1:7004 192.168.186.1:7005 --cluster-replicas 16. 重启项⽬即可正常访问如果重建集群时报错:ERR] Node 192.168.186.1:7001 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.可参考。

jedis、jedisPool、jedisCluster的使⽤⽅法jedis 连接redis(单机):使⽤jedis如何操作redis,但是其实⽅法是跟redis的操作⼤部分是相对应的。
所有的redis命令都对应jedis的⼀个⽅法1、在macen⼯程中引⼊jedis的jar包<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId></dependency>2、建⽴测试⼯程public class JedisTest {@Testpublic void testJedis()throws Exception{Jedis jedis = new Jedis("192.168.241.133",6379);jedis.set("test", "my forst jedis");String str = jedis.get("test");System.out.println(str);jedis.close();}}3.点击运⾏若报下⾯连接超时,则须关闭防⽕墙(命令 service iptables stop)再次运⾏每次连接需要创建⼀个连接、执⾏完后就关闭,⾮常浪费资源,所以使⽤jedispool(连接池)连接jedisPool连接redis (单机)@Testpublic void testJedisPool()throws Exception{//创建连接池对象JedisPool jedispool = new JedisPool("192.168.241.133",6379);//从连接池中获取⼀个连接Jedis jedis = jedispool.getResource();//使⽤jedis操作redisjedis.set("test", "my forst jedis");String str = jedis.get("test");System.out.println(str);//使⽤完毕,关闭连接,连接池回收资源jedis.close();//关闭连接池jedispool.close();}jedisCluster连接redis(集群)jedisCluster专门⽤来连接redis集群jedisCluster在单例存在的@Testpublic void testJedisCluster()throws Exception{//创建jedisCluster对象,有⼀个参数 nodes是Set类型,Set包含若⼲个HostAndPort对象Set<HostAndPort> nodes = new HashSet<>();nodes.add(new HostAndPort("192.168.241.133",7001));nodes.add(new HostAndPort("192.168.241.133",7002));nodes.add(new HostAndPort("192.168.241.133",7003));nodes.add(new HostAndPort("192.168.241.133",7004));nodes.add(new HostAndPort("192.168.241.133",7005));nodes.add(new HostAndPort("192.168.241.133",7006));JedisCluster jedisCluster = new JedisCluster(nodes);//使⽤jedisCluster操作redisjedisCluster.set("test", "my forst jedis");String str = jedisCluster.get("test");System.out.println(str);//关闭连接池jedisCluster.close();}进集群服务器查看值。

Redis的新特性懒惰删除LazyFree详解前⾔Redis4.0新增了⾮常实⽤的lazy free特性,从根本上解决Big Key(主要指定元素较多集合类型Key)删除的风险。
笔者在redis运维中也遇过⼏次Big Key删除带来可⽤性和性能故障。
本⽂分为以下⼏节说明redis lazy free:lazy free的定义我们为什么需要lazy freelazy free的使⽤lazy free的监控lazy free实现的简单分析lazy free的定义lazy free可译为惰性删除或延迟释放;当删除键的时候,redis提供异步延时释放key内存的功能,把key释放操作放在bio(Background I/O)单独的⼦线程处理中,减少删除big key对redis主线程的阻塞。
有效地避免删除big key带来的性能和可⽤性问题。
我们为什么需要lazy freeRedis是single-thread程序(除少量的bio任务),当运⾏⼀个耗时较⼤的请求时,会导致所有请求排队等待redis不能响应其他请求,引起性能问题,甚⾄集群发⽣故障切换。
⽽redis删除⼤的集合键时,就属于这类⽐较耗时的请求。
通过测试来看,删除⼀个100万个元素的集合键,耗时约1000ms左右。
以下测试,删除⼀个100万个字段的hash键,耗时1360ms;处理此DEL请求期间,其他请求完全被阻塞。
删除⼀个100万字段的hash键127.0.0.1:6379> HLEN hlazykey(integer) 1000000127.0.0.1:6379> del hlazykey(integer) 1(1.36s)127.0.0.1:6379> SLOWLOG get1) 1) (integer) 02) (integer) 15013143853) (integer) 13609084) 1) "del"2) "hlazykey"5) "127.0.0.1:35595"6) “"测试估算,可参考;和硬件环境、Redis版本和负载等因素有关Key类型Item数量耗时Hash~100万~1000msList~100万~1000msSet~100万~1000msSorted Set~100万~1000ms在redis4.0前,没有lazy free功能;DBA只能通过取巧的⽅法,类似scan big key,每次删除100个元素;但在⾯对“被动”删除键的场景,这种取巧的删除就⽆能为⼒。
Redis集群模式是一种在多个Redis实例之间分布数据和负载的解决方案,它提供了高可用性和可伸缩性。
以下是Redis集群模式的基本原理:
数据分片(Sharding):
Redis集群将数据分散存储在多个Redis节点上。
采用哈希算法(如CRC16)对键进行分片,根据键的哈希值将数据分配到不同的节点上。
每个节点负责一部分数据。
节点间通信:
Redis集群使用Gossip协议实现节点间的信息交换和发现。
每个节点通过集群总线(cluster bus)广播自己的状态信息和集群拓扑结构。
通过交换信息,节点能够了解其他节点的状态、可用性和负载情况。
主从复制:
Redis集群中的每个节点都可以配置为主节点或从节点。
主节点负责接收写入请求,并将数据复制到从节点。
从节点负责处理读取请求,并复制主节点的数据。
主从复制提供了数据的冗余和高可用性。
故障检测和故障转移:
Redis集群会监控节点的可用性。
如果某个主节点出现故障,集群会自动将从节点升级为新的主节点,并将数据迁移到新的主节点上。
故障转移过程中,集群会通过选举机制选择新的主节点,并更新集群的拓扑结构。
客户端路由:
客户端通过与集群中的任一节点通信来访问Redis集群。
客户端会根据键的哈希值将请求路由到相应的节点上。
节点会返回请求的数据或将请求转发给适当的节点。
通过以上机制,Redis集群实现了数据的分布存储、负载均衡和高可用性。
它允许在需要大规模数据处理和高并发访问的场景下,提供稳定可靠的性能和服务。
springboot中使用redis集群操作步骤在Spring Boot中使用Redis集群,主要涉及以下几个步骤:1. 添加相关依赖:在`pom.xml`文件中添加Redis客户端依赖。
Spring Boot的官方推荐依赖是`spring-boot-starter-data-redis`,它包含了Spring Data Redis的依赖。
2. 配置Redis集群连接信息:在`application.properties`(或`application.yml`)文件中配置Redis集群的连接信息。
可以使用以下属性进行配置:```````spring.redis.cluster.nodes`用于指定Redis集群中各个节点的连接地址和端口。
`spring.redis.cluster.max-redirects`用于指定在进行节点重定向操作时,最大的重定向次数。
这些配置项可以根据实际情况进行修改。
3. 创建RedisTemplate实例:在Spring Boot的配置类中创建`RedisTemplate`的实例。
可以使用`LettuceConnectionFactory`作为Redis连接工厂,并将其注入到`RedisTemplate`中。
示例代码如下:```javapublic class RedisConfigprivate String clusterNodes;private Integer maxRedirects;public RedisConnectionFactory redisConnectionFactorRedisClusterConfiguration clusterConfiguration = new RedisClusterConfiguration(Arrays.asList(clusterNodes.split(",")) );clusterConfiguration.setMaxRedirects(maxRedirects);return new LettuceConnectionFactory(clusterConfiguration);}public RedisTemplate<String, Object> redisTemplatRedisTemplate<String, Object> redisTemplate = new RedisTemplate<>(;redisTemplate.setConnectionFactory(redisConnectionFactory();return redisTemplate;}```4. 使用RedisTemplate进行操作:在代码中使用`RedisTemplate`的实例进行Redis操作。
redis 集群端口表示方法**Redis 集群端口表示方法**Redis 集群是Redis提供的分布式数据库解决方案,它能够提供高可用性和扩展性。
在Redis集群中,不同的端口用于不同的通信目的。
以下是Redis 集群中常见的端口表示方法及其功能描述。
### 1.Redis标准端口(6379)Redis默认的端口号是6379,通常用于客户端与Redis节点进行通信。
在集群模式下,每个Redis节点都会监听这个端口,用于处理客户端的读写请求。
### 2.集群总线端口(通常为16379)除了标准的6379端口,Redis集群还使用一个额外的端口作为集群总线。
这个端口通常设置为标准端口号加上10000,即16379。
集群总线用于节点之间的内部通信,包括故障转移、配置更新等。
### 3.端口分配在Redis集群中,端口的使用通常遵循以下规则:- **数据端口**:即上述的6379端口,用于处理客户端的数据操作请求。
- **集群总线端口**:用于节点间的通信,确保集群的各个节点能够相互发现和交换信息。
### 4.端口配置在配置Redis集群时,以下是一些关键的端口配置项:- **bind选项**:可以在`redis.conf`配置文件中使用`bind`选项来指定Redis服务监听的IP地址和端口。
- **port选项**:通过`port`选项,可以指定Redis服务的数据端口,默认是6379。
- **cluster-announce-port选项**:在集群模式下,使用该选项可以指定集群总线端口,确保节点能够使用正确的端口进行通信。
### 5.故障诊断如果Redis集群出现通信问题,以下是一些检查端口的方法:- 确保所有节点的数据端口(默认6379)和集群总线端口(默认16379)没有被防火墙阻挡。
- 使用`telnet`或其他网络工具检查端口是否可以连接。
- 查看Redis日志,确认是否有端口相关的错误信息。
hiredis-cluster get put例子-回复如何使用hirediscluster 库进行get 和put 操作的例子Hirediscluster 是Redis 客户端库hiredis 的扩展,它支持在Redis 集群中进行get 和put 操作。
Redis 集群是Redis 官方提供的分布式解决方案,它可以将数据分布在多个节点上,以提供更高的可用性和扩展性。
在本文中,我们将探讨如何使用hirediscluster 库进行get 和put 操作的例子,并逐步讲解每个步骤。
步骤一:安装hirediscluster首先,我们需要安装hirediscluster 库。
可以通过以下方式进行安装:1. 打开终端窗口。
2. 使用以下命令克隆hirediscluster 库的源代码:git clone3. 进入克隆的hirediscluster 目录:cd hiredis-cluster4. 使用以下命令进行编译和安装:make && make install5. 安装完成后,可以在项目中包含hirediscluster 头文件,并链接相应的库文件。
步骤二:连接Redis 集群在进行get 和put 操作之前,我们需要先连接Redis 集群。
可以通过以下代码来实现:credisClusterContext* context =redisClusterConnect("127.0.0.1:7000,127.0.0.1:7001,127.0.0.1:7002" ,HIRCLUSTER_FLAG_NULL);if (context == NULL context->err) {if (context) {printf("Error: s\n", context->errstr);连接失败后需要释放资源redisClusterFree(context);} else {printf("Can't allocate redis context\n");}return -1;}上述代码通过`redisClusterConnect` 函数连接了一个Redis 集群。
Redis集群介绍 Redis集群实现的功能 Redis 集群是分布式(distributed)的 Redis 实现,具有一定的容错性(fault-tolerant)和线性可扩展性(linear scalability)。 功能: 可线性扩展到上千个节点 可使数据自动路由到多个节点 实现了多个节点间的数据共享 可支持动态增加或删除节点 可保证某些节点无法提供服务时不影响整个集群的操作 不保证数据的强一致性 命令: 支持Redis所有处理单个数据库键的命令 不支持对多个数据库键的操作,比如MSET、SUNION 不能使用 SELECT 命令,集群只使用默认的0号数据库
Redis集群的数据分布
Hash Slot Redis集群没有使用一致性hash,而是引入了哈希槽(Hash Slot)的概念。 Redis集群一共有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定对应哪个槽。 HASH_SLOT = CRC16(key) mod 16384
Node 每个主节点都负责处理 16384 个哈希槽的其中一部分,由于Redis 集群的key被分割为 16384 个slot, 所以集群的最大节点数量也是 16384 个。推荐的最大节点数量为1000个左右。 比如当前集群有3个节点A,B,C那么: 节点 A 包含 0 到 5500号哈希槽 节点 B 包含5501 到 11000 号哈希槽 节点 C 包含11001 到 16383号哈希草槽 说明: 所有的哈希槽必须配置在集群中的某一个节点上。 节点和哈希槽之间的对应关系在搭建集群时配置,集群使用中也支持动态迁移 Redis集群的主从复制 节点分为主节点和从节点,为了保证集群的高可用性,每个主节点可配置多个从节点。主从节点数据不能保证强一致性,使用中有如下两种场景可能会发生写丢失的情况: 场景一:数据的异步复制 对集群中某一节点执行写操作过程: Step1 客户端向主节点B写入一条命令 Step2 主节点B向客户端回复命令状态 Step3 主节点将写操作复制给从节点 B1, B2和B3 这里主节点对命令的复制工作发生在返回命令回复之后,如果Step3之前主节点B宕机,其中一个从节点升级为主节点后就出现了数据不一致的情况。 不过,如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低,所以需要在性能和一致性之间做出权衡。Redis 集群可能会在将来提供同步写的方法。 场景二:节点间网络分区
假设集群包含A、B、C、A1、B1、C1六个节点,其中A、B、C为主节点,A1、B1、C1为A,B,C的从节点,还有一个客户端 Z1。 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点A、C、A1、B1和C1,小部分的一方则包含节点B和客户端Z1 。 Z1仍然能够向主节点B中写入,如果网络分区发生时间较短,那么集群将会继续正常运作。如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中的数据便丢失了。 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项: 对于大多数一方来说,如果一个主节点未能在节点超时时间内重新联系上集群, 那么集群会将这个主节点视为failing, 并使用从节点来代替这个主节点继续工作。 对于少数一方, 如果一个主节点未能在节点超时时间内重新联系上集群, 那么它将停止处理写命令, 并向客户端报告错误。
A1 A B B1 C1 C Z1 A1 A B1 C1 C B Z1 network partition Redis集群间节点交互 Redis 集群中的节点不仅记录哈希槽到正确节点的映射,还能够自动发现其他节点、识别异常节点以及在有需要时在从节点中选举出新的主节点,并更新保存最新的集群状态。 交互内容说明 Redis 集群中的节点间相互建立一个TCP连接,使用二进制协议相互通讯各自的节点属性信息和掌握的集群状态信息。 节点属性信息 每个节点在集群中都有一个独一无二的ID,该ID是一个十六进制表示的160位随机数,在节点第一次启动时由 /dev/urandom 生成。节点会将它的ID保存到配置文件,只要这个配置文件不被删除,节点就会一直沿用这个ID。 节点ID用于标识集群中的每个节点。一个节点可以改变它的IP和端口号,而不改变节点ID。集群可以自动识别出IP/端口号的变化,并将这一信息通过Gossip协议广播给其他节点知道。 以下是每个节点都有的关联信息, 并且节点会将这些信息发送给其他节点: 节点所使用的 IP 地址和 TCP 端口号。 节点的标志,即节点ID。 节点负责处理的哈希槽。 节点最近一次使用集群连接发送 PING 数据包的时间。 节点最近一次在回复中接收到 PONG 数据包的时间。 集群将该节点标记为下线的时间。 该节点的从节点数量。 如果该节点是从节点的话,那么它会记录主节点的节点 ID 。 集群状态信息 集群状态信息是该集群中所有节点属性信息的汇总,每个节点都会保存一份集群信息在cluster_file配置文件中,可以通过向集群中的任意节点(主或从节点都可以)发送 CLUSTER NODES 命令来获得:
在上面列出的三行信息中, 从左到右的各个域分别是: 节点 ID , IP 地址和端口号, 标志(flag), 最后发送 PING 的时间,最后接收 PONG 的时间, 连接状态, 节点负责处理的槽。 节点识别方式 一种是节点使用 MEET message 介绍自己:这里 MEET message 命令是强制其他节点把自己当成是集群的一部分。只有系统管理员使用CLUSTER MEET ip port 命令,节点才会发送MEET message给指定节点。 另外一种方式就是通过集群节点间的推荐机制。例如,如果A节点知道B节点属于集群,而B知道C节点属于集群,那么B将会发送Gossip信息告知A:C是属于集群的。当A获得Gossip信息之后就会尝试去连接C。 这意味着,集群具备自动识别所有节点的功能。当系统管理员强制为新节点与集群中任意节点建立信任连接,集群中所有节点都会自动对新节点建立信任连接。 Redis集群的容错机制 Redis 集群中的节点间相互建立集群连接后,节点间使用Gossip协议进行强制发送、信息传播、随机检测三种方式的交互。 在上一章节中,集群识别新加入节点的两种方法就是利用了强制发送、信息传播两种交互的功能,此处随机检测功能可用于检测集群中节点的存活状态,发现失效的节点后再由集群的容错机制进行相应处理。 节点失效检测 一般地,集群中的节点会向其他节点发送PING数据包,同时也总是应答(accept)来自集群连接端口的连接请求,并对接收到的PING数据包进行回复。 当一个节点向另一个节点发PING命令,但是目标节点未能在给定的时限(node timeout)内回复时,那么发送命令的节点会将目标节点标记为PFAIL(possible failure)。 由于节点间的交互总是伴随着信息传播的功能,此时每次当节点对其他节点发送 PING 命令的时候,就会告知目标节点此时集群中已经被标记为PFAIL或者FAIL标记的节点。 相应的,当节点接收到其他节点发来的信息时, 它会记下那些被其他节点标记为失效的节点。 这称为失效报告(failure report)。 如果节点已经将某个节点标记为PFAIL,并且根据节点所收到的失效报告显式,集群中的大部分其他主节点也认为那个节点进入了失效状态,那么节点会将那个PFAIL节点的状态标记为FAIL。 一旦某个节点被标记为FAIL,关于这个节点已失效的信息就会被广播到整个集群,所有接收到这条信息的节点都会将失效节点标记为FAIL。
A B
C D
A B C D A B
C D
A B C D D PFAIL
D PFAIL
D FAIL D FAIL 集群状态检测 集群有OK和FAIL两种状态,可以通过CLUSTER INFO命令查看。当集群发生配置变化时, 集群中的每个节点都会对它所知道的节点进行扫描,只要集群中至少有一个哈希槽不可用,集群就会进入FAIL状态,停止处理任何命令。 另外,当大部分主节点都进入PFAIL状态时,集群也会进入FAIL状态。这是因为要将一个节点从PFAIL状态改变为FAIL状态,必须要有大部分主节点认可,当集群中的大部分主节点都进入PFAIL时,单凭少数节点是没有办法将一个节点标记为FAIL状态的。 因此,只要集群中的大部分主节点进入了下线状态,那么集群就可以在不请求这些主节点的意见下,将某个节点判断为FAIL状态,从而让整个集群FAIL,停止处理命令请求。 从节点选举 一旦某个主节点进入 FAIL 状态, 如果这个主节点有从节点存在, 那么其中一个从节点会被升级为新的主节点,而其他从节点则会开始对这个新的主节点建立新的主从关系同步数据。整个从节点选举的过程可分为申请、授权、升级、同步四个阶段: Step1 申请 新的主节点由原已失效的主节点属下的所有从节点中自行选举产生,从节点的选举遵循以下条件: 这个节点是已下线主节点的从节点 已下线主节点负责处理的哈希槽数量非空 主从节点之间的复制连接的断线时长有限 如果一个从节点满足了以上的所有条件,那么这个从节点将向集群中的其他主节点发送授权请求,询问它们是否允许自己升级为新的主节点。 Step2 授权 其他主节点会遵信以下三点标准来进行判断: 发送授权请求的是从节点,而且它所属的主节点处于FAIL状态 在已下线主节点的所有从节点中,这个从节点的ID在排序中最小 这个从节点处于正常的运行状态,没有被标记为FAIL或PFAIL状态 如果发送授权请求的从节点满足以上标准,那么主节点将同意从节点的升级要求,向从节点返回FAILOVER_AUTH_GRANTED授权。 Step3 升级 一旦某个从节点在给定的时限内得到大部分主节点的授权,它就会接管所有由已下线主节点负责处理的哈希槽,并主动向其他节点发送一个PONG数据包,包含以下内容: 告知其他节点自己现在是主节点了 告知其他节点自己是一个ROMOTED SLAVE,即已升级的从节点 告知其他节点都根据自己新的节点属性信息对配置进行相应的更新 注意:这里的ROMOTED SLAVE采取主动向其他节点发送一个PONG数据包的方式,而不是等待定时的PING / PONG 数据包,是为了加速其他节点识别的该节点的速度。 Step4 同步 其他节点在接收到ROMOTED SLAVE的告知后,会根据新的主节点对配置进行相应的更新,而且所有被新的主节点接管的哈希槽会被更新。 已下线主节点的其他从节点会察觉到PROMOTED标志开始对新主节点进行复制;已下线的主节点若重新回到上线状态, 那么它会察觉到PROMOTED标志,并将自身调整为现任主节点的从节点 在集群的生命周期中,如果一个带有PROMOTED标识的主节点因为某些原因转变成了从节点,那么该节点将丢失它所带有的PROMOTED标识。