
第六章习题
6.1
(1)
Y=79.93004+0.690488X
(2)
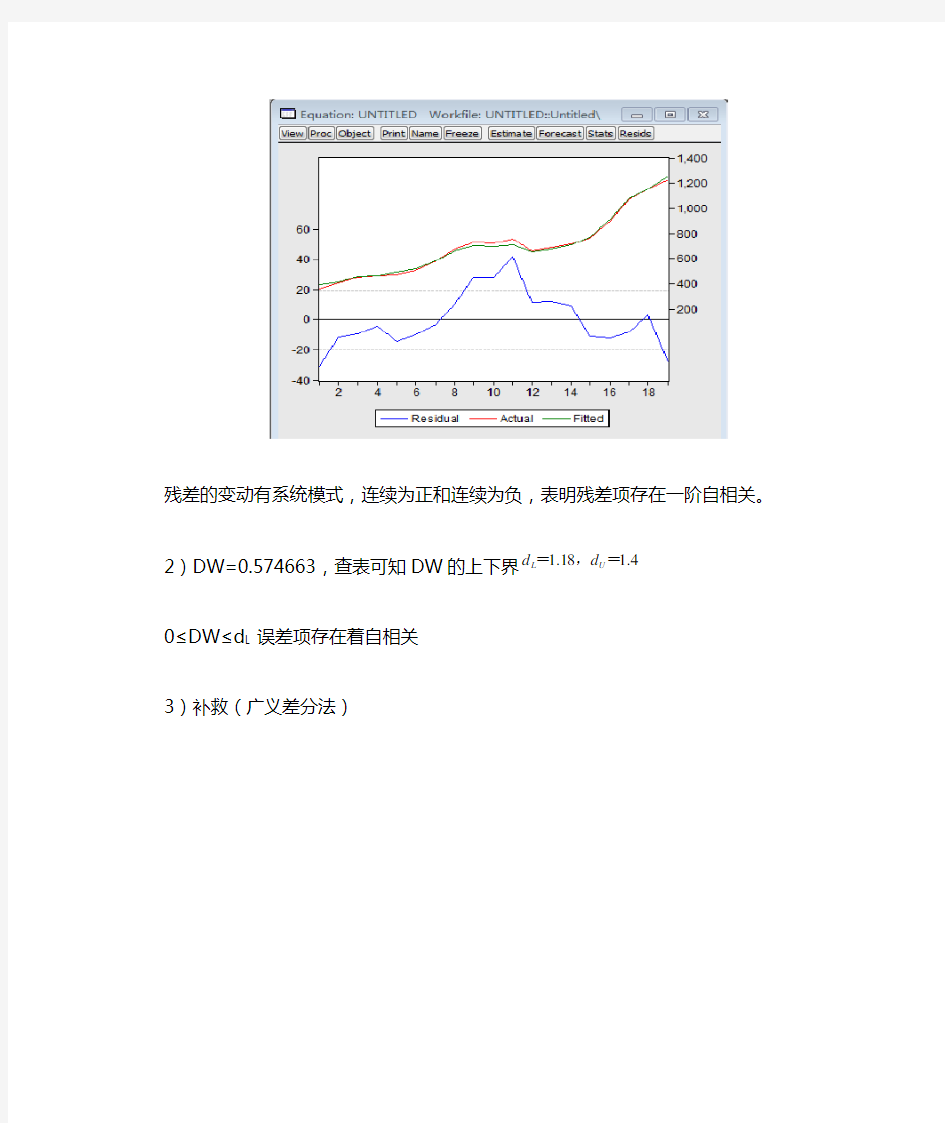
1)残差图
残差的变动有系统模式,连续为正和连续为负,表明残差项存在一阶自相关。
2)DW=0.574663,查表可知DW 的上下界4.118.1=,=U L d d 0≤DW ≤d L 误差项存在着自相关 3)补救(广义差分法)
ρ=0.657352
Yt *
=35.97761+0.668695Xt
*
其中,Yt *=Yt-0.657352Yt(-1), Xt *=Xt-0.657352Xt(-1)
4)检验
样本容量18个,在5%显著水平下DW 上下界,dL=1.158,dU=1.391 模型中DW=1,830746,dU 自相关。可决系数R 2 ,t ,F 统计量也均达到理想水平。 5)由差分方程,β1=35.97761/(1-0.657352)=104.9987 最终的消费模型为:Y=104.9987+0.668695X (3)经济意义:人均实际收入每增加1元,人均实际消费支出将增加0.669262元。 6.2 (1) DW=0.601376,查表可知DW 的上下界469.1316.1=,=U L d d ,0≤DW ≤d L 误差项存在着自相关. (2)广义差分法 1) ρ=0.700133 2) Yt*=-490.4053+0.260988Xt* 其中,Yt*=Yt-0.700133Yt(-1), Xt*=Xt-0.700133Xt(-1) 3)检验: 样本容量26个,在5%显著水平下DW上下界,dL=1.302,dU=1.461 模型中DW=1.652168,dU 4)由差分方程,β =-490.4053/(1-0.700133)=-1635.4093 1 最终的模型为:Y=-1635.4093+0.260988X 6.3 (1) (2) 1)检验:DW=0.440822,查表可知DW 的上下界461.1302.1=,=U L d d ,0≤DW ≤d L 误差项存在着自相关。 2)广义差分法 ρ=0.768816 Yt*=-653.9415+0.857233Xt* 其中,Yt*=Yt-0.768816Yt(-1), Xt*=Xt-0.768816Xt(-1) 3)检验: 样本容量25个,在5%显著水平下DW上下界,dL=1.288,dU=1.454 模型中DW=0.902421,依然存在自相关性。 4) LM=TR2=26×0.772794=20.092644 6.4 (1) 检验:DW=1.159788,查表可知DW 的上下界42.1221.1=,=U L d d ,0≤DW ≤d L 误差项存在着自相关。 (2) 1) ρ=0.400234 2) Yt*=-13.03313+6.57125Xt* 其中,Yt*=Yt-0.400234Yt(-1), Xt*=Xt-0.400234Xt(-1) 3)检验: 样本容量20个,在5%显著水平下DW上下界,dL=1.201,dU=1.411 模型中DW=1.966598,dU =-13.03313/(1-0.400234)=-21.730358 4)由差分方程,β 1 最终的模型为:Y=-21.730358+6.57125X (3) 模型样本容量为20,查5%显著水平的DW统计表可知,dL=1.201,dU=1.411模型中DW=1.590363,dU 6.5 (1) LOGPRICE=-8.00223+0.394039DEGREE-0.004297HRAIN +0.000264WRAIN+0.035379SER05 (2)在5%显著水平下DW上下界,dL=1.104,dU=1.747 模型中DW=2.262869,4-dU (3)若剔除HRAIN后 LOGPRICE=-9.936478+0.44671DEGREE+0.000955WRAIN+0.036455SER05 (4)后者更好。 因为在5%显著水平下DW上下界,dL=1.181,dU=1.65 模型中DW=2.229941,dU 第二章简单线性回归模型 2.1 (1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x1 ②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001 由上可知,关系式为y=38.79424+0.331971x2 ③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下: 第二章简单线性回归模型 第一节回归分析与回归函数P15 (一)相关分析与回归分析 1、相关关系 2、相关系数 3、回归分析 (二)总体回归函数(条件期望) (三)随机扰动项 (四)样本回归函数 第二节简单线性回归模型参数的估计P26 (一)简单线性回归的基本假定 (二)普通最小二乘法求样本回归函数 (三)OLS回归线的性质 (四)最小二乘估计量的统计性质 1、参数估计量的评价标准(无偏性、有效性、一致性) 2、OLS估计量的统计特性(线性特性、无偏性、有效性、高斯-马尔可夫定理) 第三节拟合优度的度量(RSS、ESS、TSS)P35 (一)总变差的分解 (二)可决系数 (三)可决系数与相关系数的关系 第四节回归系数的区间估计与假设检验P38 (一)OLS估计的分布性质 (二)回归系数的区间估值 (三)回归系数的假设检验 1、Z检验 2、t检验 第五节回归模型预测P43 第六节案例分析P48 第三章多元线性回归模型 第一节多元线性回归模型及古典假定P64 一、多元线性回归模型 二、多元线性回归模型的矩阵形式 三、多元线性回归模型的古典假定 第二节多元线性回归模型的估计P68 一、多元线性回归性参数的最小二乘估计 二、参数最小二乘估计的性质(线性特性、无偏性、有效性) 三、OLS估计的分布性质 四、随机扰动项方差的估计 五、多元线性回归模型参数的区间估计 第三节多元线性回归模型的检验P74 一、拟合优度检验(多重可决系数、修正的可决系数) 二、回归方程的显著性检验(F-检验) 三、回归参数的显著性检验(t-检验) 第四节多元线性回归模型的预测P79 第五节案例分析P81 第四章多重共线性第一节什么是多重共线性P94 第二节多重共线性产生的后果 第三节多重共线性的检验 第四节多重共线性的补救措施 第五节案例分析P109 思考题答案 第一章 绪论 思考题 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 1.4在计量经济模型中被解释变量和解释变量的作用有什么不同? 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 1.5一个完整的计量经济模型应包括哪些基本要素?你能举一个例子吗? 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。 例如研究消费函数的计量经济模型:u βX αY ++= 其中,Y 为居民消费支出,X 为居民家庭收入,二者是经济变量;α和β为参数;u 是随机误差项。 1.6假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提出建议, 计量经济学(第四版)习题参考答案 潘省初 第一章 绪论 试列出计量经济分析的主要步骤。 一般说来,计量经济分析按照以下步骤进行: (1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项? 为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。 什么是时间序列和横截面数据? 试举例说明二者的区别。 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。 横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。 估计量和估计值有何区别? 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。在一项应用中,依据估计量算出的一个具体的数值,称为估计值。如Y 就是一个估计量,1 n i i Y Y n == ∑。现有一样本,共4个数,100,104,96,130,则 根据这个样本的数据运用均值估计量得出的均值估计值为 5.1074 130 96104100=+++。 第二章 计量经济分析的统计学基础 略,参考教材。 请用例中的数据求北京男生平均身高的99%置信区间 N S S x = = 4 5= 用 =,N-1=15个自由度查表得005.0t =,故99%置信限为 x S t X 005.0± =174±×=174± 也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH 备择假设 120:1≠μH 检验统计量 () 10/2510/25 X X μσ-Z == == 查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH 备择假设 : 2500:1≠μH ()100/1200.83?480/16 X X t μσ-= === 查表得 131.2)116(025.0=-t 因为t = < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。 第三章习题 3.1 (1)2011年各地区的百户拥有家用汽车量及影响因素数据图形 可以看出,2011年各地区的百户拥有家用汽车量及影响因素的差异明显,其变动的方向基本相同,相互间可能具有一定的相关性,因而将其模型设定为线性回归模型形式: Y=β1+β2X2+β3X3+β4X4 估计参数 Y=246.854+5.996865X 2-0.524027X 3-2.26568X 4 模型检验 ① R 2是0.666062,修正的R 2为0.628957,说明模型对样本拟合较好 ② F 检验,分别针对H0:βj=0(j=1,2,3,4),给定显著性水平α=0.05,在F 分布表中查出自由度为k-1=3,n-k=27的临界值F α(3,27)=3.65,由表可知,F=17.95108>F α(3,27)=3.65,应拒绝原假设,回归方程显著。 ③ t 检验,分别针对H0:βj=0(j=1,2,3,4),给定显著性水平α=0.05,查t 分布表得自由度为n-k=27临界值t 2 05.0(n-k )=2.0518。对应的t 统计量分 别为 4.749476,4.265020,-2.922950,-4.366842,其绝对值均大于t (27) =2.0518,所以这些系数都是显著的。 (2)人均GDP增加1万元,百户拥有家用汽车增加5.996865辆, 城镇人口比重增加1个百分点,百户拥有家用汽车减少0.524027辆, 交通工具消费价格指数每上升1,百户拥有家用汽车减少2.265680辆。 (3)将其模型设定为 Y=β1+β2X 2+β3LnX 3+β4LnX 4 271 APPENDIX E SOLUTIONS TO PROBLEMS E.1 This follows directly from partitioned matrix multiplication in Appendix D. Write X = 12n ?? ? ? ? ? ???x x x , X ' = (1'x 2'x n 'x ), and y = 12n ?? ? ? ? ? ??? y y y Therefore, X 'X = 1 n t t t ='∑x x and X 'y = 1 n t t t ='∑x y . An equivalent expression for ?β is ?β = 1 11n t t t n --=??' ???∑x x 11n t t t n y -=??' ??? ∑x which, when we plug in y t = x t β + u t for each t and do some algebra, can be written as ?β= β + 1 11n t t t n --=??' ???∑x x 11n t t t n u -=??' ??? ∑x . As shown in Section E.4, this expression is the basis for the asymptotic analysis of OLS using matrices. E.2 (i) Following the hint, we have SSR(b ) = (y – Xb )'(y – Xb ) = [?u + X (?β – b )]'[ ?u + X (?β – b )] = ?u '?u + ?u 'X (?β – b ) + (?β – b )'X '?u + (?β – b )'X 'X (?β – b ). But by the first order conditions for OLS, X '?u = 0, and so (X '?u )' = ?u 'X = 0. But then SSR(b ) = ?u '?u + (?β – b )'X 'X (?β – b ), which is what we wanted to show. (ii) If X has a rank k then X 'X is positive definite, which implies that (?β – b ) 'X 'X (?β – b ) > 0 for all b ≠ ?β . The term ?u '?u does not depend on b , and so SSR(b ) – SSR(?β) = (?β– b ) 'X 'X (?β – b ) > 0 for b ≠?β. E.3 (i) We use the placeholder feature of the OLS formulas. By definition, β = (Z 'Z )-1Z 'y = [(XA )' (XA )]-1(XA )'y = [A '(X 'X )A ]-1A 'X 'y = A -1(X 'X )-1(A ')-1A 'X 'y = A -1(X 'X )-1X 'y = A -1?β . (ii) By definition of the fitted values, ?t y = ?t x β and t y = t z β. Plugging z t and β into the second equation gives t y = (x t A )(A -1?β ) = ?t x β = ?t y . (iii) The estimated variance matrix from the regression of y and Z is 2σ(Z 'Z )-1 where 2σ is the error variance estimate from this regression. From part (ii), the fitted values from the two 班级:金融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAW sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出一个模型,容许u的方差在男女之间有所不同。这个方差不应该取决于其他因素。 在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u方差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。所以,当方差在male=1时,即为男性时,结果为δ0+δ1;当为女性时,结果为δ0。 将sleep对totwork,educ,age,age2,yngkid和male进行回归,回归结果如下: (ⅱ)利用SLEEP75.RAW的数据估计异方差模型中的参数。u的估计方差对于男人和女人而言哪个更高? 由截图可知:u2=189359.2?28849.63male+r 20546.36 (27296.36) 由于male 的系数为负,所以u 的估计方差对女性而言更大。 (ⅲ)u 的方差是否对男女而言有显著不同? 因为male 的 t 统计量为?1.06,所以统计不显著,故u 的方差是否对男女而言并没有显著不同。 C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利用HPRICE 1.RAW 中的数据得到方程(8.17)的异方差—稳健的标准误。讨论其与通常的标准误之间是否存在任何重要差异。 ● 先进行一般回归,结果如下: ● 再进行稳健回归,结果如下: 由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms 29.48 0.00064 0.013 (9.01) 37.13 0.00122 0.018 [8.48] n = 88, R 2=0.672 比较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较大。而sqrft 的稳健标准误也比通常的大,但相差不大,bdrms 的稳健标准误比通常的要小些。 (ⅱ)对方程(8.18)重复第(ⅰ)步操作。 n =706,R 2=0.0016 第七章习题 7.1 (1) 1) PCE=-216.4269+1.008106PDI 2) PCE=-233.2736+0.982382PDI+0.037158PEC T-1 (2)模型一MPC=1.008106;模型二短期MPC=0.982382,长期 MPC=0.982382/(1+0.037158)=0.9472 7.2 (1) i t u X X X X X Y ++β+β+β+β=α+β4-t 43-t 32-t 21-t 1t 0 令 2 1042 103210221010 01649342 α+α+=αβα+α+=αβα+α+=αβ+α+α=αβ=αβ 模型变形为i t u Z Z Z Y ++α+α=α+α2t 21t 10t 0 其中4 -t 3-t 2-t 1-t 2t 4-t 3-t 2-t 1-t 1t 4 -t 3-t 2-t 1-t t 0t 1694432X X X X Z X X X X Z X X X X X Z +++=+++=++++= 2t 1t 0t 104392.0669904.0-891012.049234.35-Z Z Z Y t ++= 可得11833 .0-17917 .0-3123.0-3255 .0891012.043210=β=β=β=β=β,所以4 -t 3-t 2-t 1-t t 11833.0-17917.0-3123.0- 3255.0891012.049234.35-X X X X X Y t ++= 7.3 (1)估计t t u Y X Y *1-t 1*t 0**++β+β=α 1-t t 271676.0629273.010403.15-Y X Y t ++= 1)根据局部调整模型的参数关系,有δαα=*,δββ=*,δβ-1=1*,t t u u δ=* 将估计结果带入可得:728324.0=271676.0-1=-1=1*βδ 738064.20-==* δαα 864001.0==* 0δ ββ 局部调整模型估计结果为:t *864001.0738064.20X Y t += 2)经济意义:销售额每增加1亿元,未来预期最佳新增固定资产投资增加0.864001亿元。 3)运用德宾h 检验一阶自相关: 29728.1=0.114858 ×12-121 )21.518595-1(=)(-1)2d -1(=21*βnVar n h 在0.05显著水平下,临界值 1.96=h 2 α,因为h=1.29728< 1.96=h 2 α,接受原假 设,模型不存在一阶自相关性。 第二章 简单线性回归模型 2.1 (1) ①首先分析人均寿命与人均GDP 的数量关系,用Eviews 分析: Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x 1 ②关于人均寿命与成人识字率的关系,用Eviews 分析如下: Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22 Variable Coefficien t Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 第二章练习题及参考解答 表中是1992年亚洲各国人均寿命(Y)、按购买力平价计算的人均GDP(X1)、成人识字率(X2)、一岁儿童疫苗接种率(X3)的数据 表亚洲各国人均寿命、人均GDP、成人识字率、一岁儿童疫苗接种率数据 (1)分别分析各国人均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的数量关系。 (2)对所建立的回归模型进行检验。 【练习题参考解答】 (1)分别设定简单线性回归模型,分析各国人均寿命与人均GDP、成人识字率、一岁 儿童疫苗接种率的数量关系: 1)人均寿命与人均GDP 关系 Y i 1 2 X1i u i 估计检验结果: 2)人均寿命与成人识字率关系 3)人均寿命与一岁儿童疫苗接种率关系 (2)对所建立的多个回归模型进行检验 由人均GDP、成人识字率、一岁儿童疫苗接种率分别对人均寿命回归结果的参数t 检 验值均明确大于其临界值,而且从对应的P 值看,均小于,所以人均GDP、成人识字率、一 岁儿童疫苗接种率分别对人均寿命都有显着影响. (3)分析对比各个简单线性回归模型 人均寿命与人均GDP 回归的可决系数为人均寿命与成人识字率回归的可决系数为人 均寿命与一岁儿童疫苗接种率的可决系数为 相对说来,人均寿命由成人识字率作出解释的比重更大一些 为了研究浙江省财政预算收入与全省生产总值的关系,由浙江省统计年鉴得到以下数据:表浙江省财政预算收入与全省生产总值数据 的显着性,用规范的形式写出估计检验结果,并解释所估计参数的经济意义 (2)如果2011 年,全省生产总值为32000 亿元,比上年增长%,利用计量经济模型对浙江省2011 年的财政预算收入做出点预测和区间预测 (3)建立浙江省财政预算收入对数与全省生产总值对数的计量经济模型,. 估计模型的参数,检验模型的显着性,并解释所估计参数的经济意义 【练习题参考解答】建议学生独立完成 由12对观测值估计得消费函数为: (1)消费支出C的点预测值; (2)在95%的置信概率下消费支出C平均值的预测区间。 (3)在95%的置信概率下消费支出C个别值的预测区间。 【练习题参考解答】 假设某地区住宅建筑面积与建造单位成本的有关资料如表:表某地区住 宅建筑面积与建造单位成本数据 第七章 课后练习答案 7.1 (1)已知:96.1%,951,25,40,52/05.0==-===z x n ασ。 样本均值的抽样标准差79.0405== = n x σ σ (2)边际误差55.140 5 96.12/=? ==n z E σ α 7.2 (1)已知:96.1%,951,120,49,152/05.0==-===z x n ασ。 样本均值的抽样标准差14.249 15== = n x σ σ (2)边际误差20.449 1596.12 /=? ==n z E σ α (3)由于总体标准差已知,所以总体均值μ的95%的置信区间为 20.412049 1596.11202 /±=? ±=±n z x σ α 即()2.124,8.115 7.3 已知:96.1%,951,104560,100,854142/05.0==-===z x n ασ。 由于总体标准差已知,所以总体均值μ的95%的置信区间为 144.16741104560100 8541496.11045602 /±=? ±=±n z x σ α 即)144.121301,856.87818( 7.4 (1)已知:645.1%,901,12,81,1002/1.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的90%的置信区间为: 974.181100 12645.1812 /±=? ±=±n s z x α 即)974.82,026.79( (2)已知:96.1%,951,12,81,1002/05.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的95%的置信区间为: 352.281100 1296.1812 /±=? ±=±n s z x α 即)352.83,648.78( (3)已知:58.2%,991,12,81,1002/05.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的99%的置信区间为: 096.381100 1258.2812 /±=? ±=±n s z x α 即)096.84,940.77( 7.5 (1)已知:96.1%,951,5.3,25,602/05.0==-===z x n ασ。 由于总体标准差已知,所以总体均值μ的95%的置信区间为: 89.02560 5.39 6.1252 /±=? ±=±n z x σ α 即)89.25,11.24( (2)已知:33.2%,981,89.23,6.119,752/02.0==-===z s x n α。 由于75=n 为大样本,所以总体均值μ的98%的置信区间为: 43.66.11975 89.2333.26.1192 /±=? ±=±n s z x α 即)03.126,17.113( (3)已知:645.1%,901,974.0,419.3,322/1.0==-===z s x n α。 由于32=n 为大样本,所以总体均值μ的90%的置信区间为: 283.0419.332 974.0645.1419.32 /±=? ±=±n s z x α 即)702.3,136.3( 第二章 欧阳学文 2.2 (1) ①对于浙江省预算收入与全省生产总值的模型,用Eviews 分析结果如下: Dependent Variable: Y Method: Least Squares Date: 12/03/14 Time: 17:00 Sample (adjusted): 1 33 Included observations: 33 after adjustments Variable Coefficient Std. Error t-Statistic Prob. X0.1761240.00407243.256390.0000 C-154.306339.08196-3.9482740.0004 R-squared0.983702 Mean dependent var902.5148 Adjusted R-squared0.983177 S.D. dependent var1351.009 S.E. of regression175.2325 Akaike info criterion13.22880 Sum squared resid951899.7 Schwarz criterion13.31949 Log likelihood-216.2751 Hannan-Quinn criter.13.25931 F-statistic1871.115 Durbin-Watson stat0.100021 Prob(F-statistic)0.000000 ②由上可知,模型的参数:斜率系数0.176124,截距为—154.3063 ③关于浙江省财政预算收入与全省生产总值的模型,检验模 思考题答案 第一章绪论 思考题 怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 理论计量经济学和应用计量经济学的区别和联系是什么 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 怎样理解计量经济学与理论经济学、经济统计学的关系 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 在计量经济模型中被解释变量和解释变量的作用有什么不同 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 一个完整的计量经济模型应包括哪些基本要素你能举一个例子吗 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。 例如研究消费函数的计量经济模型:u + = α βX Y+ 其中,Y为居民消费支出,X为居民家庭收入,二者是经济变量;α和β为参数;u是随机误差项。 假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提 DATA SET HANDBOOK Introductory Econometrics: A Modern Approach, 4e Jeffrey M. Wooldridge This document contains a listing of all data sets that are provided with the fourth edition of Introductory Econometrics: A Modern Approach. For each data set, I list its source (wherever possible), where it is used or mentioned in the text (if it is), and, in some cases, notes on how an instructor might use the data set to generate new homework exercises, exam problems, or term projects. In some cases, I suggest ways to improve the data sets. Special thanks to Edmund Wooldridge, who provided valuable assistance in updating the page numbers for the fourth edition. 401K.RAW Source:L.E. Papke (1995), “Participation in and Contributions to 401(k) Pension Plans: Evidence from Plan Data,”Journal of Human Resources 30, 311-325. Professor Papke kindly provided these data. She gathered them from the Internal Revenue Service’s Form 5500 tapes. Used in Text: pages 64, 80, 135-136, 173, 217, 685-686 Notes: This data set is used in a variety of ways in the text. One additional possibility is to investigate whether the coefficients from the regression of prate on mrate, log(totemp) differ by whether the plan is a sole plan. The Chow test (see Section 7.4), and the less restrictive version that allows different intercepts, can be used. 401KSUBS.RAW Source: A. Abadie (2003), “Semiparametric Instrumental Variable Estimation of Treatment Response Models,”Journal of Econometrics 113, 231-263. Professor Abadie kindly provided these data. He obtained them from the 1991 Survey of Income and Program Participation (SIPP). Used in Text: pages 165, 182, 222, 261, 279-280, 288, 298-299, 336, 542 Notes: This data set can also be used to illustrate the binary response models, probit and logit, in Chapter 17, where, say, pira (an indicator for having an individual retirement account) is the dependent variable, and e401k [the 401(k) eligibility indicator] is the key explanatory variable. 第二章 2.2 (1) ①对于浙江省预算收入与全省生产总值的模型,用Eviews 分析结果如下: Dependent Variable: Y Method: Least Squares Date: 12/03/14 Time: 17:00 Sample (adjusted): 1 33 Included observations: 33 after adjustments Variable Coefficie nt Std. Error t-Statistic Prob. X 0.176124 0.004072 43.25639 0.0000 C -154.306 3 39.08196 -3.94827 4 0.0004 R-squared 0.983702 Mean dependent var 902.514 8 Adjusted R-squared 0.983177 S.D. dependent var 1351.00 9 S.E. of regression 175.2325 Akaike info criterion 13.2288 Sum squared resid 951899.7 Schwarz criterion 13.3194 9 Log likelihood -216.2751 Hannan-Quinn criter. 13.2593 1 F-statistic 1871.115 Durbin-Watson stat 0.10002 1 Prob(F-statistic) 0.000000 ②由上可知,模型的参数:斜率系数0.176124,截距为—154.3063 ③关于浙江省财政预算收入与全省生产总值的模型,检验模型的显著性: 1)可决系数为0.983702,说明所建模型整体上对样本数据拟合较好。 2)对于回归系数的t 检验:t (β2)=43.25639>t 0.025(31)=2.0395,对斜率系数的显著性 班级:金融学×××班姓名:××学号:×××××××C6.9 NBASAL.RAW points=β0+β1exper+β2exper2+β3age+β4coll+u 解:(ⅰ)按照通常的格式报告结果。 由上图可知:points=35.22+2.364exper?0.077exper2?1.074age?1.286coll 6.9870.4050.02350.295 (0.451) n=269,R2=0.1412,R2=0.1282。 (ⅱ)保持大学打球年数和年龄不变,从加盟的第几个年份开始,在NBA打球的经历实际上将降低每场得分?这讲得通吗? 由上述估计方程可知,转折点是exper的系数与exper2系数的两倍之比:exper?= β12β2= 2.364[2×?0.077]=15.35,即从加盟的第15个到第16个年份之间,球员在NBA打球的经历实际上将降低每场得分。实际上,在模型所用的数据中,269名球员中只有2位的打球年数超过了15年,数据代表性不大,所以这个结果讲不通。 (ⅲ)为什么coll具有负系数,而且统计显著? 一般情况下,NBA运动员的球员都会在读完大学之前被选拔出,甚至从高中选出,所以这些球员在大学打球的时间少,但每场得分却很高,所以coll具有负系数。同时,coll的t统计量为-2.85,所以coll统计显著。 (ⅳ)有必要在方程中增加age的二次项吗?控制exper和coll之后,这对年龄效应意味着什么? 增加age的二次项后,原估计模型变成: points=73.59+2.864exper?0.128exper2?3.984age+0.054age2?1.313coll 35.930.610.05 2.690.05 (0.45) n=269,R2=0.1451,R2=0.1288。 由方程可知:age的t统计量为?1.48,age2的t统计量为1.09,所以age和age的二次项统计都不显著,而当不增加age2时,age的t统计量为?3.64,统计显著,因此完全没有必要在方程中增加age的二次项。当控制了exper和coll之后,年龄对points的负效应将会增大。 (ⅴ)现在将log?(wage)对points,exper,exper2,age和coll回归。以通常的格式报告结论。 所以,log wage=6.78+0.078points+0.218exper?0.0071exper2?0.048age?0.040coll 0.850.0070.0500.00280.035 (0.053) n=269,R2=0.4878,R2=0.4781。 (ⅵ)在第(ⅴ)部分的回归中检验age和coll是否联合显著。一旦控制了生产力和资历,这对考察年龄和受教育程度是否对工资具有单独影响这个问题有何含义?计量经济学-庞皓-第三版课后答案
计量经济学第三版庞皓
计量经济学(庞皓)课后思考题答案
计量经济学习题及参考答案解析详细版
计量经济学第三版庞浩第三章习题
伍德里奇计量经济学第六版答案Appendix-E
伍德里奇---计量经济学第8章部分计算机习题详解(STATA)
计量经济学第三版庞浩第七章习题答案
计量经济学庞皓第三版课后答案解析
庞皓计量经济学第三版课后习题及答案 顶配
计学(第六版)第七章课后练习答案
计量经济学第三版(庞浩)版课后答案全之欧阳学文创作
计量经济学 庞皓 课后思考题答案
计量经济学导论:现代观点第四版习题答案
计量经济学第三版庞浩版课后答案
伍德里奇---计量经济学第6章部分计算机习题详解(STATA)
相关主题
文本预览