
一、什么是全文检索与全文检索系统?
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
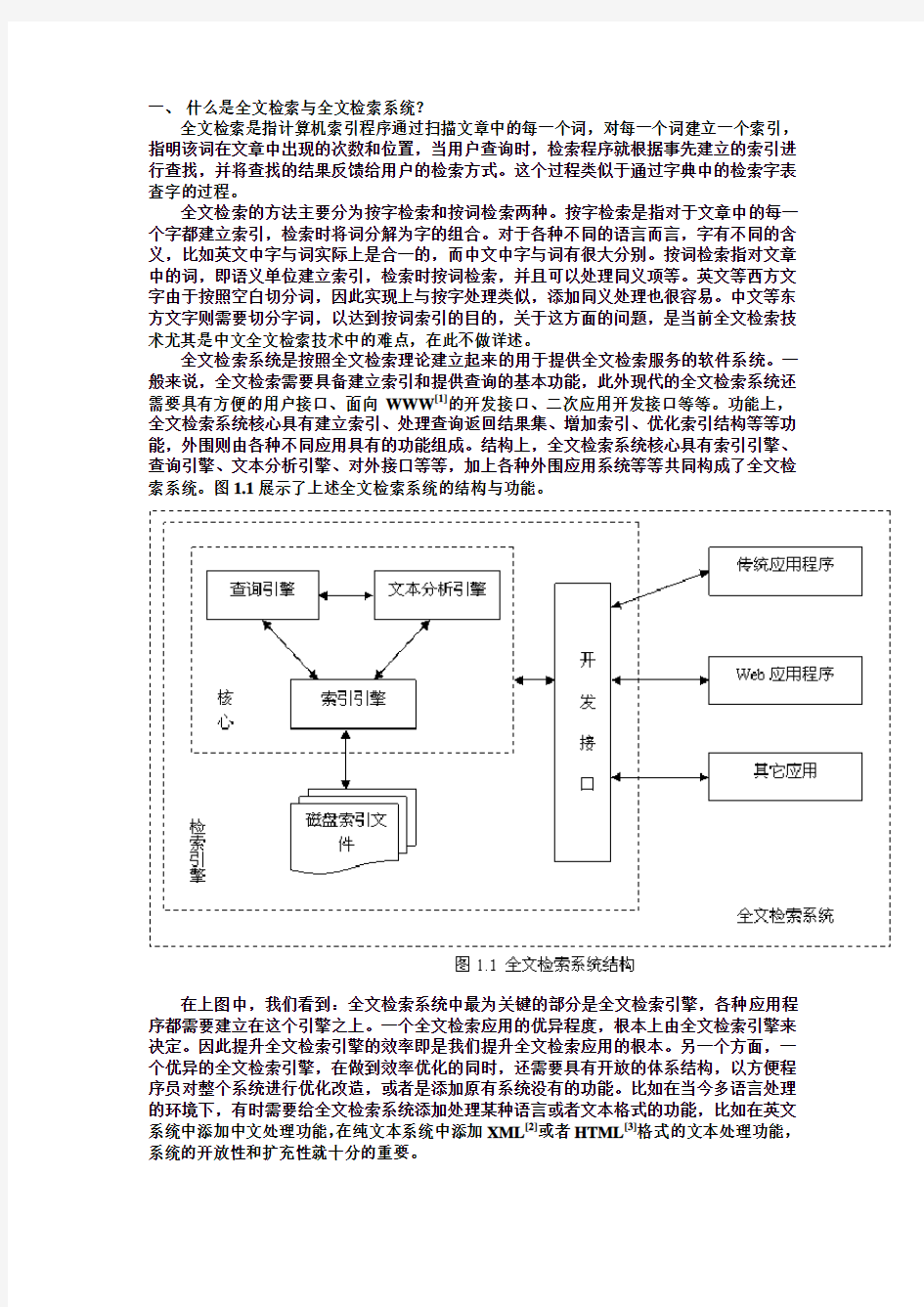
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般来说,全文检索需要具备建立索引和提供查询的基本功能,此外现代的全文检索系统还需要具有方便的用户接口、面向WWW[1]的开发接口、二次应用开发接口等等。功能上,全文检索系统核心具有建立索引、处理查询返回结果集、增加索引、优化索引结构等等功能,外围则由各种不同应用具有的功能组成。结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析引擎、对外接口等等,加上各种外围应用系统等等共同构成了全文检索系统。图1.1展示了上述全文检索系统的结构与功能。
在上图中,我们看到:全文检索系统中最为关键的部分是全文检索引擎,各种应用程序都需要建立在这个引擎之上。一个全文检索应用的优异程度,根本上由全文检索引擎来决定。因此提升全文检索引擎的效率即是我们提升全文检索应用的根本。另一个方面,一个优异的全文检索引擎,在做到效率优化的同时,还需要具有开放的体系结构,以方便程序员对整个系统进行优化改造,或者是添加原有系统没有的功能。比如在当今多语言处理的环境下,有时需要给全文检索系统添加处理某种语言或者文本格式的功能,比如在英文系统中添加中文处理功能,在纯文本系统中添加XML[2]或者HTML[3]格式的文本处理功能,系统的开放性和扩充性就十分的重要。
二、什么是Lucene?
Lucene是apache软件基金会[4] jakarta项目组的一个子项目,是一个开放源代码[5]的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene的原作者是Doug Cutting,他是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎[6]的主要开发者,后在Excite[7]担任高级系统架构设计师,目前从事于一些Internet 底层架构的研究。早先发布在作者自己的https://www.doczj.com/doc/d010046641.html,/,后来发布在SourceForge[8],2001年年底成为apache软件基金会jakarta的一个子项目:https://www.doczj.com/doc/d010046641.html,/lucene/。
三、Lucene的应用、特点及优势
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse[9]的2.1版本中也采用了Lucene作为帮助子系统的全文索引引擎,相应的IBM的商业软件Web Sphere[10]中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy
Search[11])、分组查询等等。
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势。首先,它的开发源代码发行方式(遵守Apache Software License[12]),在此基础上程序员不仅仅可以充分的利用Lucene 所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面相对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,商业软件的灵活性远远不及Lucene。其次,Lucene秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构,程序员可以在Lucene 的基础上扩充各种功能,比如扩充中文处理能力,从文本扩充到HTML、PDF[13]等等文本格式的处理,编写这些扩展的功能不仅仅不复杂,而且由于Lucene恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。最后,转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是开放源代码社区的程序员正在不懈的将之使用各种传统语言实现(例如.net framework[14]),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选择。
四、本文的重点问题与cLucene项目
作为中国人民大学信息学院99级本科生的一个毕业设计项目,我们对Lucene进行了深入的研究,包括系统的结构,索引文件结构,各个部分的实现等等。并且我们启动了cLucene项目,做为一个Lucene的C++语言的重新实现,以期望带来更快的速度和更加广泛的应用范围。我们先分析了系统结构,文件结构,然后在研究各个部分的具体实现的同时
开始进行的cLucene实现。限于时间的限制,到本文完成为止,cLucene项目并没有完成,对于Lucene的具体实现部分也仅仅完成到了索引引擎部分。
接下来的部分,本文将对Lucene的系统结构、文件结构、索引引擎部分做一个彻底的分析。以期望提供对Lucene全文检索引擎的系统架构和部分程序实现的清晰的了解。cLucene项目则作为一个开放源代码的项目,继续进行的开发。
有关cLucene项目的一些信息:
?开发语言:ISO C++[15],STLport 4.5.3[16],OpenTop 1.1[17]
?目标平台:Win32,POSIX
?授权协议:GNU General Public License (GPL)[18]
Apache Lucene与其兄弟https://www.doczj.com/doc/d010046641.html,是经过了大规模测试的产品,他们已经为一些著名站点如Wikipedia、CNET及https://www.doczj.com/doc/d010046641.html,提供了搜索功能。因此,没人会怀疑其功能与未来的发展。
Lucene并不是一个爬行搜索引擎,也不会自动地索引内容。我们得先将要索引的文档中的文本抽取出来,然后再将其加到Lucene索引中。标准的步骤是先初始化一个Analyzer、打开一个IndexWriter、然后再将文档一个接一个地加进去。一旦完成这些步骤,索引就可以在关闭前得到优化,同时所做的改变也会生效。这个过程可能比开发者习惯的方式更加手工化一些,但却在数据的索引上给予你更多的灵活性。
我们可以借助于一个对象模型来完成搜索,通过查询来建立条件。其次,Lucene可以解析并执行(可能由最终用户输入的)普通文本搜索字符串。使用.NET 3.5或后续版本的.NET开发者还有第三种选择:LINQ to Lucene。其项目主页上有一张图清晰地描述了Lucene的搜索语法与相应的LINQ to Lucene语法的区别。
导言
说起Apache Lucene,可以说无人不知,无人不晓,但是说道Apache Solr,恐怕知道的不多。看看Apache Solr的说明:
Solr是一个基于Lucene java库的企业级搜索服务器,包含XML/HTTP,JSON API, 高亮查询结果,faceted search(不知道该如何翻译,片段式搜索),缓存,复制还有一个WEB管理界面。Solr运行在Servlet容器中。所以Solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。Lucene本质上是搜索库,不是独立的应用程序,而Solr是。Lucene专注于搜索底层的建设,而Solr专注于企业应用。Lucene不负责支撑搜索服务所必须的管理,而Solr负责。所以说,一句话概括Solr: Solr是Lucene面向企业搜索应用的扩展。
在本篇文章中,我们先看看Solr向我们承诺了什么,或者说Solr宣称的特性们。
无废话Solr
Solr是一个拥有象WebService一样接口的独立运行的搜索服务器。你将能够通过HTTP协议以XML格式将文档放入搜索服务器(这个过程叫做索引),你能够通过HTTP协议的GET来查询搜索服务器并且得到XML格式的结果。Solr的特性包括:
?高级的全文搜索功能
?专为高通量的网络流量进行的优化
?基于开放接口(XML和HTTP)的标准
?综合的HTML管理界面
?可伸缩性-能够有效地复制到另外一个Solr搜索服务器
?使用XML配置达到灵活性和适配性
?可扩展的插件体系
Solr使用Lucene并且扩展了它!
?一个真正的拥有动态域(Dynamic Field)和唯一键(Unique Key)的数据模式(Data Schema)
?对Lucene查询语言的强大扩展!
?支持对结果进行动态的分组和过滤
?高级的,可配置的文本分析
?高度可配置和可扩展的缓存机制
?性能优化
?支持通过XML进行外部配置
?拥有一个管理界面
?可监控的日志
?支持高速增量式更新(Fast incremental Updates)和快照发布(Snapshot Distribution)
Schema(模式)
?定义域类型和文档的域
?能够驱动智能处理
?声明式的Lucene分析器规范
?动态域能够随时增加域
?拷贝域功能允许对一个域进行多种方式的索引,或者将多个域联合成一个可搜索的域
?显式类型能够减少对域类型的猜测
?能够使用外部的基于文件的终止词列表,同义词列表和保护词列表的配置
查询
?拥有可配置响应格式(XML/XSLT,JSON,Python,Ruby)的HTTP接口
?高亮的上下文搜索结果
?基于域值和显式查询的片段式搜索(Faceted Search)
?对查询语言增加了排序规范
?常量的打分范围(Constant scoring range)和前缀式查询-没有idf,coord,或者lengthNorm因子,对查询匹配的词没有数量限制?函数查询(Function Query)-通过关于一个域的数值或顺序的函数对打分进行影响
?性能优化
核心
?可插拔的查询句柄(Query Handler)和可扩展的XML数据格式
?使用唯一键的域能够增强文档唯一性
?能够高效地进行批量更新和删除
?用户可配置的文档索引变化触发器(命令)
?并发控制的搜索器
?能够正确处理数字类型,从而能够进行排序和范围搜索
?能够控制缺失排序域的文档
?支持搜索结果的动态分组
缓存
?可配置的查询结果,过滤器,和文档缓存实例
?可插拔的缓存实现
?后台缓存热启:当一个新的搜索器被打开时,可配置的搜索将它热启,避免第一个结果慢下来,当热启时,当前搜索器处理目前的请求(???)。
?后台自动热启:当前搜索器缓存中最常访问的项目在新的搜索器中再次生成,能够在索引器和搜索器变化的时候高速缓存常查询的结果?快速和小的过滤器实现
?支持自动热启的用户级别的缓存
复制
?能够将使用rsync传输时改变的索引部分有效的发布
?使用拉策略(Pull Strategy)来简化增加搜索器
?可配置的发布间隔能够允许对时间线和缓存使用进行权衡选择
管理接口
?能够对缓存使用,更新和查询进行综合统计
?文本分析调试器,能够显示每个分析器每个阶段的结果
?基于WEB的查询和调试输出:解析查询输出,Lucene的explain方法细节,能够解释为何某个文档打分低,被排除在结果中等等
索引和搜索
索引是现代搜索引擎的核心,建立索引的过程就是把源数据处理成非常方便查询的索引文件的过程。为什么索引这么重要呢,试想你现在要在大量的文档中搜索含有某个关键词的文档,那么如果不建立索引的话你就需要把这些文档顺序的读入内存,然后检查这个文章中是不是含有要查找的关键词,这样的话就会耗费非常多的时间,想想搜索引擎可是在毫秒级的时间内查找出要搜索的结果的。这就是由于建立了索引的原因,你可以把索引想象成这样一种数据结构,他能够使你快速的随机访问存储在索引中的关键词,进而找到该关键词所关联的文档。Lucene 采用的是一种称为反向索引(inverted index)的机制。反向索引就是说我们维护了一个词 / 短语表,对于这个表中的每个词 / 短语,都有一个链表描述了有哪些文档包含了这个词 / 短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果。我们将在本系列文章的第二部分详细介绍 Lucene 的索引机制,由于 Lucene 提供了简单易用的 API,所以即使读者刚开始对全文本进行索引的机制并不太了解,也可以非常容易的使用 Lucene 对你的文档实现索引。
对文档建立好索引后,就可以在这些索引上面进行搜索了。搜索引擎首先会对搜索的关键词进行解析,然后再在建立好的索引上面进行查找,最终返回和用户输入的关键词相关联的文档。
图1. 搜索应用程序和Lucene 之间的关系
3本文为国家社会科学基金项目“基于中文X ML 文档的全文检索研究”的成果之一,项目编号:04CT Q005。 ●熊回香,夏立新(华中师范大学 信息管理系,湖北 武汉 430079) 自然语言处理技术在中文全文检索中的应用 3 摘 要:自然语言处理技术是中文全文检索的基础。首先介绍了全文检索技术及自然语言处理技术,接着详细地阐述了自然语言处理技术在中文全文检索中的应用,并对目前基于自然语言处理技术的中文全 文检索技术的局限性进行了分析,探讨了中文全文检索技术的未来发展方向。 关键词:自然语言处理;全文检索;智能检索 Abstract:Natural language p r ocessing technol ogy is the basis of Chinese full 2text retrieval .This paper firstly intr oduces the full 2text retrieval technol ogy and natural language p r ocessing technol ogy .Then,it gives a detailed 2descri p ti on of the app licati on of natural language p r ocessing technol ogy in Chinese full 2text retrieval .The p resent li m itati ons of the Chinese full 2text retrieval system based on natural language p r ocessing technol ogy is als o ana 2lyzed .Finally,the paper exp l ores the devel opment trend of Chinese full 2text retrieval technol ogy in future . Keywords:natural language p r ocessing;full text retrieval;intelligent retrieval 随着社会网络化、信息化程度的日益提高,网上信息呈指数级剧增,人们越来越强烈地希望用自然语言同计算机交流,并能方便、快捷、准确地从互联网上获得有价值的信息,因此,自然语言处理技术和中文全文检索技术成为当今计算机科界、语言学界、情报学界共同关注的课题,并共同致力于将自然语言处理技术的研究成果充分运用到全文检索中,从而促进了全文检索技术的发展。 1 全文检索技术 全文检索是一种面向全文和提供全文的检索技术,其核心技术是将文档中所有基本元素的出现信息记录到索引库中,检索时允许用户采用自然语言表达其检索需求,并借助截词、邻词等匹配方法直接查阅文献原文信息,最后将检索结果按相关度排序返回给用户。因而索引数据库的建立是全文检索系统实现的基础,它以特定的结构存储了数据资源的全文信息,从而为全文检索系统提供可检索的数据对象。在中文全文检索系统中,建立索引库的前提是运用自然语言处理技术对中文信息进行基于词(字)、句、段落等更深层次的处理。 2 自然语言处理技术 自然语言是指作者所使用的书面用语,在信息检索中包括关键词、自由词和出现在文献题名、摘要、正文或参 考文献中的具有一定实质意义的词语[1]。自然语言处理 (Natural Language Pr ocessing,NLP )是语言信息处理的一 个重要分支,在我国就是中文信息处理。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,具体来说就是用计算机对包括汉语(字)的形、音、义等信息及词、句子、篇章的输入、输出、存储和识别、分析、理解、生成等多方面的加工处理[2]。由于自然语言处理侧重于词、句子、篇章,因而词法分析、句法分析、语义分析、语用分析、语境分析便构成了自然语言处理研究内容的基础部分。 211 词法分析 词法分析包括词形和词汇两个层次,其中词形主要是对各种词形和词的可识别部分的处理。如前缀、后缀及复合词的分析;词汇的重点在于复合对词操作和词汇系统的控制。其主要目的是有助于确认词性以及做到部分理解词与词、词与文档之间的关系,提高检索的效率。由于计算机内部存储的中文信息没有明显的词与词之间的分隔符,因此,在中文全文检索系统中,词法分析首要任务之一是对文本信息进行词语切分,即汉语自动分词,汉语自动分词是中文信息处理中的关键技术,也是中文全文检索的瓶颈,只有对汉语词进行正确的切分后,才能准确地提取文献的特征信息,对文献进行正确标引,才能正确分析用户的查询意图,为用户提供准确的信息服务。 212 句法分析 句法分析是对句子中词汇短语进行分析以便揭示句子的语法结构。目的是通过对句型结构的分析,自动抽取复
—94— 一种基于Lucene 的中文全文检索系统 苏潭英1,郭宪勇2,金 鑫3 (1. 解放军信息工程大学电子技术学院,郑州 450004;2. 北京飞燕技术公司,北京 100072;3. 解放军通信指挥学院,武汉 430010)摘 要:在开源全文索引引擎Lucene 的基础上,设计了一个中文全文检索系统模型,该模型系统由7个模块组成,索引模块、检索模块是其中的核心部分。论述了模型的整体结构,分析设计了索引及检索模块,通过具体的索引技术和检索技术来提高整个系统的检索效率。该系统增加了加密模块,实现对建立的全文索引进行加密处理,增强了信息的安全性。 关键词:全文检索;Lucene ;倒排索引 Chinese Full-text Retrieval System Based on Lucene SU Tan-ying 1, GUO Xian-yong 2, JIN Xin 3 (1. Institute of Electronic Technology, PLA Information Engineering University, Zhengzhou 450004; 2. Technology Company of Beijing Feiyan, Beijing 100072; 3. Institute of PLA Communication Command, Wuhan 430010) 【Abstract 】This paper proposes a model of Chinese full-text retrieval system based on Lucene which is an open source full-text retrieval engine,and expatiates its frame. This model is composed of seven modules, among which the index module and the search module are the core parts. It designs them concretely, and improves the search efficiency of the full-text retrieval system with index technology and search technology. The system model concludes an encryption module to encrypt the index and increases the system security. 【Key words 】full-text retrieval; Lucene; inverse index 计 算 机 工 程Computer Engineering 第33卷 第23期 Vol.33 No.23 2007年12月 December 2007 ·软件技术与数据库· 文章编号:1000—3428(2007)23—0094—03 文献标识码:A 中图分类号:TP391 1 中文全文检索系统 全文检索技术是一个最普遍的信息查询应用,人们每天在网上使用Google 、百度等搜索引擎查找自己所需的信息,这些搜索引擎的核心技术之一就是全文检索。随着文档处理电子化、无纸化的发展,图书馆、新闻出版、企业甚至个人的电子数据激增,如何建立数据库、管理好自己的数据,是亟待解决的问题,而全文检索是其中一个非常实用的功能。全文检索产品实际上是一个内嵌该项技术的数据库产品[1]。 西文的全文检索已有许多成熟的理论与方法,其中,开放源代码的全文检索引擎Lucene 是Apache 软件基金会Jakarta 项目组的一个子项目,它的目的是为软件开发人员提供一个简单易用的工具包,方便在目标系统中实现全文检索的功能。很多项目使用了Lucene 作为其后台的全文索引引擎,比较著名的有: (1)Jive :Web 论坛系统; (2)Cocoon :基于XML 的Web 发布框架,全文检索部分使用了Lucene ; (3)Eclipse :基于Java 的开放开发平台,帮助部分的全文索引使用了Lucene 。 Lucene 不支持中文,但可以通过扩充它的语言分析器实现对中文的检索。本文在深入学习研究Lucene 的前提下,设计了一个中文的全文检索系统,对其核心的索引模块和检索模块进行了阐释,并添加了加密模块对索引信息加密,增强了系统的安全性。 2 系统的总体结构 本模型总体上采用了Lucene 的架构。Lucene 的体系结构如表1所示,它的源代码程序由7个模块组成。 表1 Lucene 的组成结构 模块名 功能 org.apache.Lucene.search 搜索入口 org.apache.Lucene.index 索引入口 org.apache.Lucene.analysis 语言分析器 org.apache.Lucene.queryParser 查询分析器 org.apache.Lucene.document 存储结构 org.apache.Lucene.store 底层IO/存储结构 org.apache.Lucene.util 一些公用的数据结构 本文通过扩充Lucene 系统来完成中文的全文检索系统,Lucene 包含了大量的抽象类、接口、文档类型等,需要根据具体应用来定义实现,本文对其作了如下扩充修改: (1)按照中文的词法结构来构建相应的语言分析器。Lucene 的语言分析器提供了抽象的接口,因此,语言分析(analyser)是可以定制的。Lucene 缺省提供了2个比较通用的分析器SimpleAnalyser 和StandardAnalyser ,但这2个分析器缺省都不支持中文,因此,要加入对中文语言的切分规则,需要对其进行修改。 (2)按照被索引的文件的格式对不同类型的文档进行解析,进而建立全文索引。例如HTML 文件,通常需要把其中的内容分类加入索引,这就需要从org.apache.lucene.子document 中定义的类Document 继承,定义自己的HTMLDocument 类,然后将之交给org. apache.lucene.index 模块写入索引文件。Lucene 没有规定数据源的格式,只提供 作者简介:苏潭英(1981-),女,硕士研究生,主研方向:数据库全文检索;郭宪勇,高级工程师;金 鑫,硕士研究生 收稿日期:2007-01-10 E-mail :sutanyingwendy@https://www.doczj.com/doc/d010046641.html,
法规标准库及全文检索系统 一、产品研发背景 为了使电力企业相关人员更方便的查询到国家、行业发布的各种法律、法规及行业标准,避免企业自己搜索各种文件时,不能保证文件信息、版本的正确性和及时性,提高工作效率。开发法规标准库及全文检索系统。 二、产品特点 内容齐全 由中电方大上传和管理软件数据库中文件,上传文件包括电力行业的法律、法规、行业标准和各企业集团规定,还包含一些对这些法律、法规解读的文章或论文,对法律、法规进行更深层次的挖掘理解。企业在生产、培训时使用该软件可以更方便的查询到需要的文件。 文件实时更新 系统中的文件由中电方大进行管理,对每一个文件的过期或作废等,中电方大都保持实时更新,保持系统的与时俱进,保证文件为实时适用的最新版本。 文件查询方便 文件的查询搜索功能,即能输入文件名或关键字在数据库中全部搜索,又能按照法律、法规、标准或是生效年份等不同条件进行查询搜索。 全文所搜功能 此功能是系统的一大亮点。为了便于查询文件及对应文件内容的搜索,系统支持全文搜索功能。如在搜索界面输入“压力容器”,在结果列表中即会显示相关文件的名称,也会显示部分带有关键字的内容。
三、产品功能 系统支持相关法律法规的全面搜索及预览功能。 四、产品解决问题 系统解决了企业在需要获取相关法规文件时不能确定文件的准确性、最新性等问题。 五、提供的产品服务 ◆提供本产品终身更新服务 ◆提供功能个性化开发服务 六、产品适用范围 产品适用于各类企业 七、公司简介 北京中电方大科技股份有限公司,成立于2004年,新三板挂牌上市公司(证券代码430411,简称:中电方大)。 本公司是处于软件和信息技术服务业的安全与应急服务提供商,为电力企业用户提供安全与应急管理及信息化及对应的整体解决方案。公司于2012年获得国家电监会(现国家能源局)颁发的电力安全生产标准化一级评审机构资质,从事发电企业、电力建设企业的安全生产标准化评审业务。于2014年获得国家能源局指定的电力安全培训机构资质,为发电企业、电网企业相关负责人和安全生
搜索引擎简介 专业:智能1001 学号:06103008 姓名:周树亮
搜索引擎 有人说,会搜索才叫会上网,搜索引擎在我们日常生活中的地位已是举足轻重。 你也许是个刚要兴冲冲地要上网冲浪,也许已经在互联网上蛰伏了好几年,无论怎样,要想在浩如烟海的互联网信息中找到自己所需的信息,都需要一点点技巧。 对于企业而言,学习搜索,提高技巧,就能找到更多的潜在客户。对于大家而言,学习搜索引擎技巧可以有助我们的学习和生活! 一、搜索引擎含义由来及发展历史 1、搜索引擎(search engines)px+no2end px 是对互联网上的信息资源进行搜集整理,然后供你查询的系统,它包括信息搜集、信息整理和用户查询三部分。 搜索引擎是一个为你提供信息“检索”服务的网站,它使用某些程序把因特网上的所有信息归类以帮助人们在茫茫网海中搜寻到所需要的信息。 早期的搜索引擎是把因特网中的资源服务器的地址收集起来,由其提供的资源的类型不同而分成不同的目录,再一层层地进行分类。人们要找自己想要的信息可按他们的分类一层层进入,就能最后到达目的地,找到自己想要的信息。这其实是最原始的方式,只适用于因特网信息并不多的时候。随着因特网信息按几何式增长,出现了真正意义上的搜索引擎,这些搜索引擎知道网站上每一页的开始,随后搜索因特网上的所有超级链接,把代表超级链接的所有词汇放入一个数据库。这就是现在搜索引擎的原型。 2.搜索引擎发展史 在互联网发展初期,网站相对较少,信息查找比较容易。然而伴随互联网爆炸性的发展,普通网络用户想找到所需的资料简直如同大海捞针,这时为满足大众信息检索需求的专业搜索网站便应运而生了。现代意义上的搜索引擎的祖先,是1990年由蒙特利尔大学学生Alan Emtage发明的Archie。虽然当时World Wide Web还未出现,但网络中文件传输还是相当频繁的,而且由于大量的文件散布在各个分散的FTP主机中,查询起来非常不便,因此Alan Emtage想到了开发一个可以以文件名查找文件的系统,于是便有了Archie。Archie工作原理与现在的搜索引擎已经很接近,它依靠脚本程序自动搜索网上的文件,然后对有关信息进行索引,供使用者以一定的表达式查询。由于Archie深受用户欢迎,受其启发,美国内华达System Computing Services 大学于1993年开发了另一个与之非常相似的搜索工具,不过此时的搜索工具除了索引文件外,已能检索网页。当时,“机器人” 一词在编程者中十分流行。 二、搜索引擎介绍及其使用技巧 人们经常问我搜索技巧,虽然要成为一个搜索专家远非学几条技巧那么简单,但确实有些精彩的搜索技巧能够极大的提高你的搜索能力,帮你成为不错的网络侦探。 这里是我的十条最精华的搜索技巧,它们大致分为基础技巧、通用搜索策略、以及何时使用专业搜索工具的建议。 每一个搜索都是不同的,如果你为每一个搜索都选择最好的搜索工具,那么每次你都会得到最好的搜索结果。最常见的选择是使用全文搜索引擎还是网站分类目录。 一般的规则是,如果你在找什么特殊的内容或文件,那么使用全文搜索引擎如google和altavista,如果你想从总体上或比较全面的了解一个主题,那么使用网站分类目录如yahoo和odp。 对于特殊类型的信息考虑使用特殊的搜索工具,比如你要找人或找地点,那么使用专业的寻人引擎或地图和位置搜索网站。 事实上几乎每种主题都有特殊的搜索工具。 如果有个陌生人跑过来对你说"anchovy paste!" 或 "sibberidge!" ,你会有什么反映呢?大多数人会笑,或者询问那个人到底想说什么。可是搜索引擎无法作出这种选择——它们只能猜测你的问题,然后提供它们利用这有限的信息能够得到的最好结果。 好的搜索请求应该包含多个能限制搜索范围的关键词。 多数搜索引擎对自然语言的处理很好。事实上,搜索引擎能够从语句结构得到很有用的信息,不会象仅得到几个关键词那样容易迷失。 与其输入几个不合语法的关键词,还不如试一下一句自然的提问。与其搜索“北京公交车路线”,不如试一下 "我在北京如何乘坐公交车?"
数据库中全文搜索与Like的差别 在SQL Server中,Like关键字可以实现模糊查询,即确定特定字符串是否与制定模式相匹配。这里的模式可以指包含常规字符和通配符。在模式匹配过程中,常规字符必须与字符串中指定的字符完全匹配。不过通过使用通配符可以改变这个规则,如使用?等通配符可以与字符串的任意部分相匹配。故Like关键字可以在数据库中实现模糊查询。 另外数据库库管理员也可以利用全文搜索功能对SQL Server数据表进行查询。在可以对给定的标进行全文查询之前,数据库管理元必须对这个数据表建立全文索引。全文索引也可以实现类似Like的模糊查询功能。如在一张人才简历表中查找符合特定字符串的信息等等。虽然说Like关键字与全文搜索在功能上大同小异,但是在实现细节上有比较大的差异。作为数据库管理员需要了解这个差异,并选择合适的实现模式。 一、查询效率上的差异。 通常情况下,Like关键字的查询效率还是比较快的。特别是对于结构化的数据,Like的查询效率、灵活性方面是值得称道的。但是对于一些非机构化的文本数据,如果通过Like 关键字来进行模糊查询的话,则其执行效率并不是很理想。特别是对于全文查询来说,其速度要慢得多。而且随着记录数量的增多,类似的差异更明显。如在一张表中,有三百万行左右的文本数据,此时如果利用Like关键字来查找相关的内容,则可能需要几分钟的时间才能够返回正确的结果。相反,对于同样的数据通过采用全文搜索功能的话,则可能只需要1分钟不到甚至更多的时间及可以返回结果。故当文本数据的行数比较多时,如在一万行以上,则此时数据库管理员若采用全文搜索功能的话,则可以比较明显的改善数据库的查询效率。 二、对空格字符的敏感性。 在数据库中如果采用Like关键字进行模糊查询,则在这个关键字后面的所有字符都有意义。如现在用户使用like “abcd ”(带有两个空格)查询时,则后面的空格字符对于Like 关键字也是敏感的。也就是说,如果用户利用上面这条语句进行查询时,则被查询的内容必须也是“abcd ”(带有两个空格)这种类型的数据才会被返回。如果被查询的内容是“abcd ”(不带空格或者带有一个空格)则数据库系统会认为这与查询条件不相符合,故不会返回相关的记录。故Like关键字对于空格是比较敏感的。为此在使用Like关键字时候需要特别注意这个问题。如果用户或者程序开发人员不能够确定abcd后面到底是否有空格,则可以通过通配符拉实现。即可以利用”%abcd%”为条件语句。如此的话,无论abcd前面或者后面是否有空格,则都会被查询出来。但是全文搜索的话,通常情况下系统会把空格忽略掉。即在全文搜索功能中,系统会先对查询条件语句进行优化。如果发现空格的话,则往往会实现把空格过滤掉。故全文搜索的话,对于空格等特殊字符往往是不敏感的。 三、对于一些特殊字符的处理要求。 由于数据类型不同,其数据存储方式也不同。为此某些特殊的数据类型可能无法通过Like关键字来实现模糊查询。如对于办好char和varchar数据的模式的字符串比较可能无法通过Like关键字来实现。也就是说,Like关键字后面带的条件语句仅对字符模式有效,不能够使用Like条件语句来查询格式化的二进制数据等等。为此如果数据库管理元要采用Like 关键字,则其必须了解每种数据类型的存储方式以及导致Like关键字比较失败的原因。知己知彼,百战百胜。只有如此数据库管理员才能够避免因为在不恰当的地方采用了Like关键字而造成查询的错误。不过值得高兴的是,Like关键字支持ASCII模式匹配与Unicode模式匹配。如果Like关键字的所有参数都为ASCII字符数据类型,则Like关键字会自动采用ASCII 模式匹配。如果其中任何一个参数为Unicode数据类型,则系统会把所有的参数都转换为Unicode数据类型,并执行Unicode模式匹配。另外需要注意的是,如果Like关键字加上Unicode的数据类型则后面条件语句的空格是有效的,即比较时会考虑到后面出现的空格。
1全文检索系统方案 1.1全文检索需求 1)系统提供模糊检索、分类搜索、高级复合搜索、全文检索、图片内容 检索、跨库检索等多种检索途径; 2)支持字索引和词索引; 3)检索条件具有完整的关键词布尔逻辑运算AND、OR、NOT能力,支持 复合式布尔逻辑运算查询,并且可以配合多组左括号"("与右括号")"作 关键词查询优先级的设置; 4)提供用户多次递进查询的功能,用户可根据上一次查询关键词得到的 检索结果集,增加查询关键词与缩小搜索日期范围,而得到更准确的 查询结果集; 5)能够支持对以上文件中的中文(简体/繁体)、英文、日语、韩语内容 实现关键字检索; 6)支持对Word、TXT、PDF等多种主流文档格式全文检索,并提供开发 接口以支持特殊文档格式的全文检索; 7)在数据源数据发生更新时,能在索引库中反映出来,保证搜索的信息 为最新,即支持增量索引机制; 8)用户可自行设定时间,让系统自动定时进行更新索引; 9)对于百万级记录数的搜索以及结合模糊搜索等查询方式,搜索时间不 得超过10秒; 10)提供跨数据源、数据格式的搜索;
11)同过相关性搜索,能够把和搜索条件相关联的信息搜索出来; 12)不但能够对图片的描述信息进行搜索,还能对图片内容的检索; 13)提供COM与SOAP的搜索接口(Interface) 可让其它应用程序或查询网 页能够提供用户查询入口和查询结果的呈现,用户可通过应用程序或 浏览器访问全文检索服务器,提交查询条件,可在浏览器中查看检索 结果; 14)查询结果集中应包含结果集总数、命中的结果文件的完整路径,以及 符合关键词出现的内容片断; 15)在搜索结果集中,关键词应被标识出来,用特殊的字体及颜色和其他 文字进行区别,查询者可在查询结果片断中一目了然的看到关键词出 现的位置; 16)查询结果可按照关键词命中次数,命中结果文件的修改时间,大小等 条件进行排序; 17)可提供用户对检索命中结果文件在索引库中进行标记,从而再次检索 时,不在标记过的文件中进行查询; 1.2全文检索系统总体方案 系统将采用以下全文检索流程。
搜索引擎发展状态及未来趋势 【摘要】 搜索引擎包括图片搜索引擎、全文索引、目录索引等,其发展历史可分为五个阶段,目前企业搜索引擎和网站运营搜索引擎运用范围较广。在搜索引擎的未来发展中,呈现出个性化,多元化,智能化,移动化,社区化等多个趋势。 【关键词】 发展起源、索引、数据库、网站运营、未来趋势 【参考文献】 《个性化搜索引擎原理与技术》《搜索引擎的设计与实现》搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。其工作作原理分为抓取网页,处理网页和提供检索服务。抓取每个独立的搜索引擎都有自己的网页抓取程序,它顺着网页中的超链接,连续地抓取网页。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引文件。 搜索引擎的发展起源可以追溯到第一个Gopher搜索工具Veronica。后来的搜索引擎的发展分为五个阶段。第一阶段,出现World wide Web Wanderer,用于追踪互联网发展规模。刚开始它只用来统
计互联网上的服务器数量,后来则发展为也能够捕获网址。第二阶段,出现了以概念搜索闻名的Excite以及元搜索引擎Dogpile。第三阶段,即yahoo的出现。随着访问量和收录链接数的增长,Yahoo目录开始支持简单的数据库搜索。Yahoo以后陆续有Google等提供搜索引擎服务,但不可否认的是,Yahoo几乎成为20世纪90年代的因特网的代名词。第四阶段,一种新的搜索引擎形式出现了,即元搜索引擎。用户只需提交一次搜索请求,由元搜索引擎负责转换处理后提交给多个预先选定的独立搜索引擎,并将从各独立搜索引擎返回的所有查询结果,集中起来处理后再返回给用户。第五阶段的代表是智能检索的产生:它利用分词词典、同义词典,同音词典改善检索效果,进一步还可在知识层面或者说概念层面上辅助查询,给予用户智能知识提示,最终帮助用户获得最佳的检索效果。 搜索引擎目前包括图片搜索引擎、全文索引、目录索引、元搜索引擎、垂直搜索引擎等。全文索引引擎是名副其实的搜索引擎,国外代表有Google,国内有百度、搜狐等。它们从互联网提取各个网站的信息,建立起数据库,并能检索与用户查询条件相匹配的记录,按一定的排列顺序返回结果。搜索引擎的自动信息搜集功能分为定期搜索和提交网站搜索。它的特点是搜全率比较高。目录索引,就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。与全文搜索引擎相比,目录索引有许多不同之处。首先,搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。其次,搜索引擎收录网站时,只要网站本身
在应用中加入全文检索功能 ——基于java的全文索引引擎lucene简介 作者:车东 email: https://www.doczj.com/doc/d010046641.html,/https://www.doczj.com/doc/d010046641.html, 写于:2002/08 最后更新: 版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明 https://www.doczj.com/doc/d010046641.html,/tech/lucene.html 关键词:lucene java full-text search engine chinese word segment 内容摘要: lucene是一个基于java的全文索引工具包。 1.基于java的全文索引引擎lucene简介:关于作者和lucene的历史 2.全文检索的实现:luene全文索引和数据库索引的比较 3.中文切分词机制简介:基于词库和自动切分词算法的比较 4.具体的安装和使用简介:系统结构介绍和演示 5.hacking lucene:简化的查询分析器,删除的实现,定制的排序,应用接口的扩展 6.从lucene我们还可以学到什么 基于java的全文索引/检索引擎——lucene lucene不是一个完整的全文索引应用,而是是一个用java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。 lucene的作者:lucene的贡献者doug cutting是一位资深全文索引/检索专家,曾经是v-twin搜索引擎(apple的copland操作系统的成就之一)的主要开发者,后在excite担任高级系统架构设计师,目前从事于一些internet底层架构的研究。他贡献出的lucene的目标是为各种中小型应用程序加入全文检索功能。 lucene的发展历程:早先发布在作者自己的https://www.doczj.com/doc/d010046641.html,,后来发布在sourceforge,2001年年底成为apache基金会jakarta的一个子项目:https://www.doczj.com/doc/d010046641.html,/lucene/ 已经有很多java项目都使用了lucene作为其后台的全文索引引擎,比较著名的有: ?jive:web论坛系统; ?eyebrows:邮件列表html归档/浏览/查询系统,本文的主要参考文档“thelucene search engine: powerful, flexible, and free”作者就是eyebrows系统的主要开发者之一,而eyebrows已 经成为目前apache项目的主要邮件列表归档系统。 ?cocoon:基于xml的web发布框架,全文检索部分使用了lucene ?eclipse:基于java的开放开发平台,帮助部分的全文索引使用了lucene
四)利用英文全文数据库——Elsevier,Springer,EBSCO(BSP/ASP) 1、检索课题名称:探析公益广告中的商业元素 2、课题分析: 中文关键词为:公益广告,商业元素 英文关键词为:PSAs Commercial elements Business Elements 3、选择检索工具:Elsevier 数据库,Springer数据库,EBSCO(BSP/ASP)数据库。 4、构建检索策略:Commercial elements and the public service ads 5、简述检索过程: ①,选定在Elsevier 中期刊、图书、文摘数据库等全部文献资源中检索2000 年以后的关于公益广告中的商业元素的文献 利用确定的检索策略(Commercial elements and the public service ads ),文献全文(含文献题目、摘要、关键词)中检索,检到184 篇相关文献。 ②,选定在Springer 中期刊、图书、文摘数据库等全部文献资源中检索2000 年以后的关于公益广告中的商业元素的文献 利用确定的检索策略(Commercial elements and the public service ads ),文献全文(含文献题目、摘要、关键词)中检索,检到64篇相关文献。③,选定在EBSCO(BSP/ASP)中期刊、图书、文摘数据库等全部文献资源中检索2000 年以后的关于公益广告中的商业元素的文献 利用确定的检索策略(Commercial elements and the public service ads ),文献全文(含文献题目、摘要、关键词)中检索,检到381篇相关文献。 6、整理检索结果: 从以上文献中选择出3 条切题文献 ①、Constructing female identities through feminine hygiene TV commercials M a Milagros Del Saz-Rubio a, , and Barry Pennock-Speck b, [Author vitae] a Universidad Politécnica de Valencia, Camino de Vera s/n 46022, Valencia, Spain b Universitat de València, Avenida Blasco Ibá?ez 32, 46010, València, Spain Received 9 July 2008; revised 10 January 2009; accepted 18 April 2009. Available online 3 June 2009. In this paper we report the results of a qualitative multimodal analysis of a corpus of Spanish and British TV ads featuring female hygiene products such as tampons, liners and sanitary towels/pads. We contend that advertisers of menstruation-related products employ a wide range of strategies to convey both overt information about the products advertised, as well as to –and more importantly –indirectly transmit stereotypical beliefs of women which inevitably helps reproduce and sometimes perpetuate a gender-biased type of discourse (Holmes and Marra, 2005). Crook's (2004) distinction between the product-claim and the reward dimension in ads has been taken as the starting point for our analysis. Within the product-claim dimension we have focused on what information is transmitted through the application of some of Brown and Levinson's (1987) generic positive and off-record politeness strategies. On the other hand, within the reward dimension attention is shifted to how information surfaces the language in an indirect fashion through attention to different format types, visual imagery, voices and music. Results indicate that ads either tend
如何用C#实现数据库全文检索 目前行业网站的全文检索的方式主要有两种 方式一:通过数据库自带的全文索引 方式二:通过程序来自建全文索引系统 以Sql Server 2005为例 2005本身就自带全文索引功能,你可以先对数据库表建立索引,具体如何建索引网上搜索一下,建立完索引之后,你就可以用SQL来实现检索功能,例如:select * from ytbxw where contaiins(字段,' 中国');多个查询值之间可以用and 或or来实现,在单表以及单表视图上建全文索引对2005来说根本不是问题,但在多表视图建全文索引2005目前还无法实现这个功能,拿https://www.doczj.com/doc/d010046641.html,为例,其每个栏目的信息都是分开存放的,所以在检索上就无法用该方法来解决这个问题. 下面重点说一下如何用程序来实现检索功能 如果你想自己开发一个全文检索系统,我想这是相当复杂事情,要想实现也不是那么容易的事情,所以在这里我推荐一套开源程序,那就是 DotLucene,我想大家可能都听过这个东东吧,那我就讲讲如何来实现多表情况下的全文检索. 1、新建winform项目,把https://www.doczj.com/doc/d010046641.html,.dll添加到该项目中来 2、创建一个类,类名可以自己取 public class Indexer { private IndexWriter writer; //在指定路径下创建索引文件 public Indexer(string directory) { writer = new IndexWriter(directory, new StandardAnalyzer(), true); writer.SetUseCompoundFile(true); }
全文检索需求 档案管理系统 需求整理 1、一个文档有多个附件; 2、文档支持格式:pdf,CEB,txt,html,office(world、excel)、wps 文档,tf、tff; Ceb格式,目前在档案系统已经存在一个对应的txt文件; 现在有两种方案来处理ceb格式:一是把档案系统中的ceb对应的txt文件,迁移过来;二是ceb文件重新转换一次。 3、权限管理,权限有个人、角色、部门分类; 4、检索的内容包括,结构化数据和非结构化数据;可以支持定制查询;可以分多个字段查询(比如:档案类型、查询年份) 5、准确显示摘要和高亮显示; 6、矩阵分析(智能分析相似文档,数据挖掘的一部分); 档案的现在方案 a)使用lucene2.x 版本; b)系统是二级部署;
c)每个网点比如福建,按地市创建索引文件。每个地市的索引文 件的大小在800M左右,这样单个档案系统的一个网点的索引 总大小应该在10G左右(目前的大小)。 d)每个地市只可以单独查询,目前没有实现合并查询。 e)新建索引和增量索引是分开处理的。 f)权限控制,目前是用户在请求单个文档的时候才验证权限;在 索引和检索两个层次上没有做控制。 其他特点 知识管理系统 需求整理 1、目前是一个文档对应一个附件,但以后有可能支持多个附件; 文档支持格式:知识管理中各种文档都会存在,尽量支持大部分数据格式。 2、支持的格式可以灵活扩展。 3、权限管理,权限有个人、角色、组织、部门等层次; 4、检索的内容包括,结构化数据和非结构化数据;可以支持定制查询; 5、准确显示摘要和高亮显示; 6、智能分析(相似文档,数据挖掘的一部分);
全文检索(NC65版本) NC65全文检索的配置和使用需要3步,具体如下: 一.在第一次启动环境,或要改变服务器结构,比如从单机改为集群,在服务停止时需要删除Nchome下anteindex文件夹。如果没有这个文件夹,不需要进行这一步。如果搜索不能正常工作,也可以通过在停服务时删除这个文件夹,重启集群服务器,尝试解决搜索的出现的相关问题。在其他正常情况下,服务器的停止和重启,不需要删除anteindex文件夹。 二.数据源配置。搜索需要在配置界面中,指定可以进行搜索服务的数据源。 点击Nchome\bin\sysconfig.bat,会出现以下界面。 在NC63中,我们使用的是档案索引这个页签的配置,到了NC65,配置移到了搜索引擎下。如上图所示,在【搜索引擎】的【搜索源分组】页签下,选择要提供搜索的表,比如bd_material_table物料表,点击设置数据源按钮,在弹框中勾选要提供服务的数据源,点击确定。每一张要提供搜索服务的表都需要设置数据源,如果客户不知道哪些要用哪些不要用,就请为每一张表都配置数据源。数据源配置完成后点击保存按钮。 搜索的数据源配置只需要进行一次。如果要更改数据源,就需要重新配置。 三.建立索引。
在第一次使用搜索服务,或者因为上文提到的某种原因删除anteindex后,需要手动一键重建索引。 一键手动重建索引需要在服务器完全启动后,也就是说客户端可以正常登录的时候,才能进行。(删anteindex文件夹需要在停服务时进行,一键重建索引需要在服务器完全启动时进行)。如下图所示: 在【搜索引擎】的【搜索管理】页签,在服务器完全启动后点击重爬全部按钮,只需要点一次,一两分钟后,搜索服务就可以正常使用了,也不需要点击保存按钮。如果不是第一次使用搜索服务,或者没有删除anteindex 文件夹,正常的服务停止和重启不需要再点击重爬全部按钮。 图中大红框选中的是,可以为每一张表设置更新的频率,比如一天更新一次,又或者每隔一段时间周期性的更新。这是索引更新的补偿机制,用户在前台操作的时候,对数据进行增添删改,索引会实时自动更新。所以这个补偿机制也可以不进行关注。 全文检索不能生效的常见问题解答? a、检查数据源配置的是否正确。项目上出现过配置为其他数据源或者修改数据源名称后,没有同步修改此处的数据源的现象。后续这一块有望实现自动配置正确的数据源。
李慕红 全球知名搜索引擎介绍 李慕红 https://www.doczj.com/doc/d010046641.html,/mayyenen 2009-07-25 09:06:15 Google https://www.doczj.com/doc/d010046641.html, Google 简介 Google 目前被公认为全球最大的搜索引擎,最优秀的支持多语种的搜索引擎, 提供网站、图像、新闻组等多种资源的查询。包括中文简体、繁体、英语等35个国家和地区的语言的资源。您可以搜索超过 10 亿幅的图片,并能够细读全球最大的 Usenet 消息存档,其中提供的帖子超过 10 亿个,时间可以追溯到 1981 年。Google每天处理的搜索请求已达2亿次!而且这一数字还在不断增长。Google数据库存有42.8亿个Web文件。属于全文(Full Text)搜索引擎。Google成立于1997年,几年间迅速发展成为目前规模最大的搜索引擎,并向AOL、Compuserve、Netscape等其他门户和搜索引擎提供后台网页查询服务。Google借用Dmoz的目录索引提供分类目录查询,但默认网站排列顺序并非按照字母顺序,而是根据网站PageRank的分值高低排列。 Google Inc. 创建于 1998 年 9 月,创始人为斯坦福大学博士生 Larry Page 和 Sergey Brin,他们开发的 Google 搜索引擎屡获殊荣,是一个用来在互联网上搜索信息的简单快捷的工具。Google 的复杂的自动搜索结构设计确保了它绝对诚实公正。 Google 是万维网上最大的搜索引擎,使用户能够访问一个包含超过 80 亿个网址的索引。2000年7月份,Google替代Inktomi成为Yahoo公司的搜索引擎,同年9月份,Google成为中国网易公司的搜索引擎。98年至今,Google已经获得30多项业界大奖。 Google提供常规及高级搜索功能。通过对30 多亿网页进行整理,可为世界各地的用户提供适需的搜索结果,而且搜索时间通常不到半秒。 搜索规则:以关键词搜索时,返回结果中包含全部及部分关键词;短语搜索时默认以精确匹配方式进行;不支持单词多形态(Word Stemming)和断词(Word Truncation)查询;字母无大小写之分,默认全部为小写。 Google一般每隔28天派出“蜘蛛”程序检索现有网站一定IP地址范围内的新网站,而对现有网站的更新则根据该网站的等级不同有快慢之分。一般来说,网站网页等级越高,更新的频率就越快。登录Google的周期一般为3个星期(从提交网站到被索引)。 Google以32%的市场份额高居第一,雅虎则以25%排名第二。如果将所有利用Google服务的合作伙伴如雅虎、AOL和MSN计算在内,Google的市场份额将达到76%,毫无疑问,5年前由美国斯坦福大学两名博士生创办的Google公司,是继比尔·盖茨的"微软帝国"之后,IT业内曝出的又一神话。 数字 搜索的网页:80 亿+ 图片:10 亿+ Usenet 信息:10 亿+ Google 界面的可用语言:100 多种 Google 搜索结果所采用的语言:35 国际域名:100 多个员工:全球 3,000 多人 Google 的含义 “Googol”是一个数学名词,表示一个 1 后面跟着 100 个零。这个词汇是由美国数学家 Edward Kasner 的外甥 Milton Sirotta 创造的,随后通过 Kasner 和 James Newman 合著 的“Mathematics and the Imagination”一书广为流传。Google 使用这一术语体现了公司整合网上海量信息的远大目标。 Google 怎么念 Google进入中国人的视野后,就有了它的中国名,似乎还有不同版本。有的叫“狗狗”,有的叫“古狗”,有的叫“咕狗”,有的叫“孤狗”,有的叫“酷狗”,发音不尽相同。从