2.1用户自定义函数介绍
1)用户自定义函数可以在Designer中定义,在Expression中使用。
2)可以使用任何有效的函数(除了Aggregation函数),也可以使用在同一个文件夹里的其它UDFs。
3)用户自定义函数UDFs是文件夹级别的对象。
4)在FCS中UDFs不支持快捷键,也就是说它们只能在自己被创建的文件夹中被访问。
2.2创建一个简单的UDFs
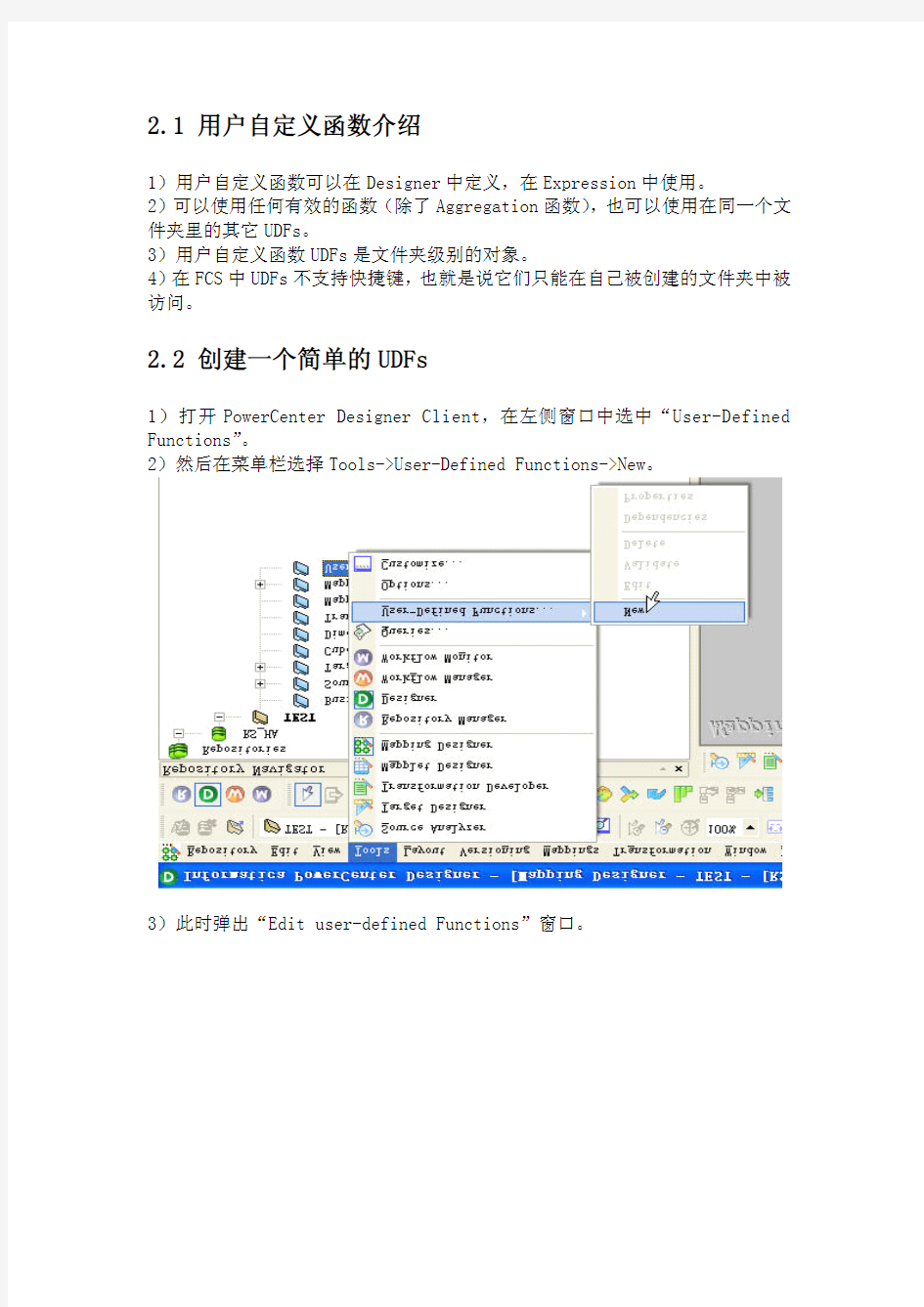
1)打开PowerCenter Designer Client,在左侧窗口中选中“User-Defined Functions”。
2)然后在菜单栏选择Tools->User-Defined Functions->New。
3)此时弹出“Edit user-defined Functions”窗口。
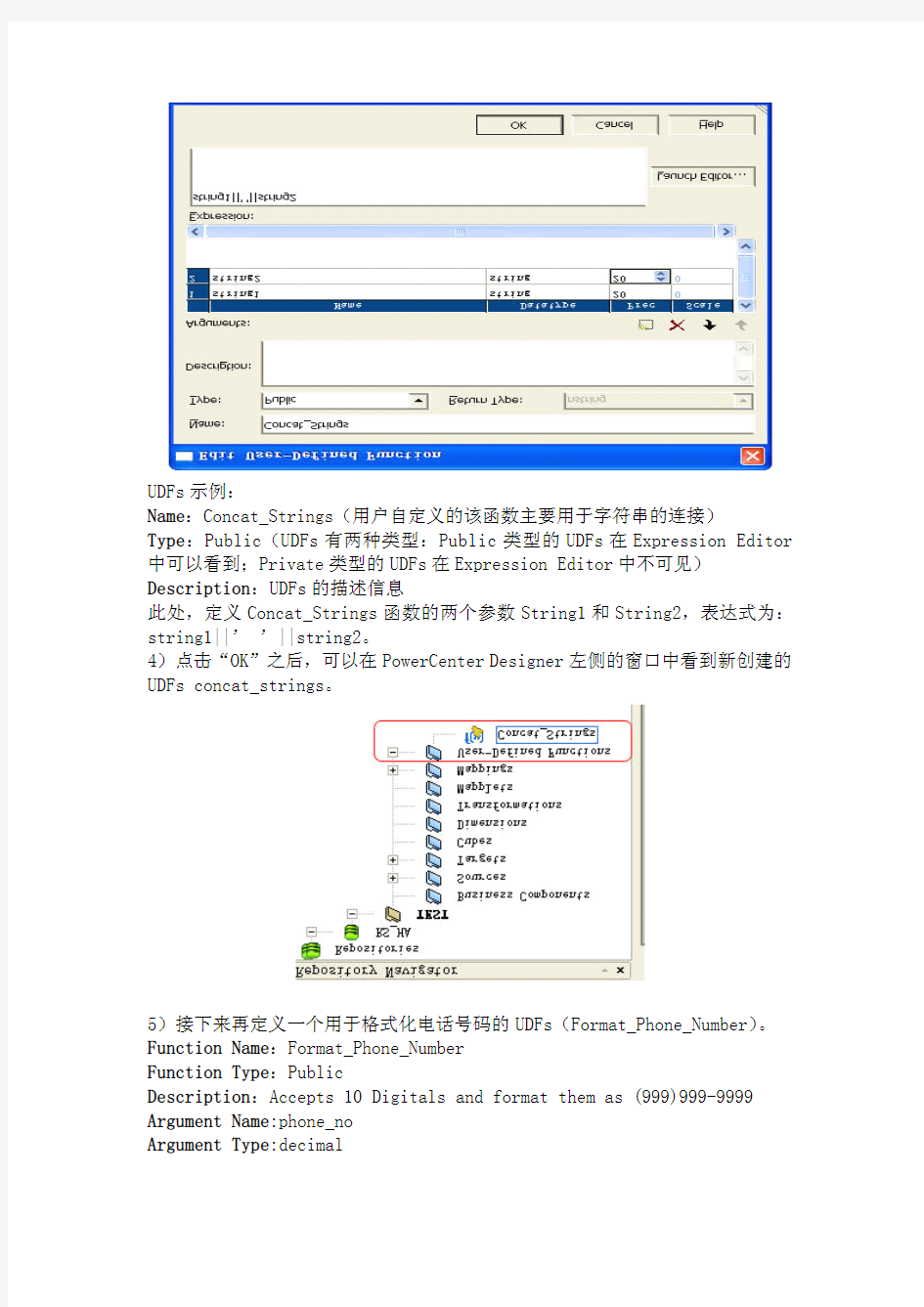
UDFs示例:
Name:Concat_Strings(用户自定义的该函数主要用于字符串的连接)
Type:Public(UDFs有两种类型:Public类型的UDFs在Expression Editor 中可以看到;Private类型的UDFs在Expression Editor中不可见)Description:UDFs的描述信息
此处,定义Concat_Strings函数的两个参数String1和String2,表达式为:string1||’’||string2。
4)点击“OK”之后,可以在PowerCenter Designer左侧的窗口中看到新创建的UDFs concat_strings。
5)接下来再定义一个用于格式化电话号码的UDFs(Format_Phone_Number)。Function Name:Format_Phone_Number
Function Type:Public
Description:Accepts10Digitals and format them as(999)999-9999 Argument Name:phone_no
Argument Type:decimal
Argument Precision:10
Argument Scale:0
Expression:
’(’||SUBSTR(TO_CHAR(phone_no),1,3)||’)’||SUBSTR(TO_CHAR(phone_no), 4,3)||’-’||SUBSTR(TO_CHAR(phone_no),7,4)
此时我们已经创建好两个UDFs用户自定义函数:
Concat_strings用于字符串的连接
Format_Phone_Number用于格式化电话号码为特定的格式
6)下面演示一下如何在Expression Editor中调用创建好的UDFs。
点击OUT_CUST_NAME对应的表达式,则弹出表达式编辑窗口。
这是未使用UDFs之前Expression Editor内所定义的用于字符串连接的表达式语句:IN_FIRSTNAME||’’||IN_LASTNAME
将原来的表达式语句(IN_FIRSTNAME||’’||IN_LASTNAME)替换为调用UDFs 的语句(:UDF.CONCAT_STRINGS(IN_FIRSTNAME,IN_LASTNAME))。即完成了对用户自定义函数的调用。
同理,将OUT_PHONE_NUMBER字段的Expression表达式也替换成调用UDFs的语句表达式。
只是原来的Expression Editor的表达式语句
用调用UDFs函数format_phone_number的语句(:UDF.FORMAT_PHONE_NUMBER(IN_PHONE_NUMBER))来替换原来的表达式语句。7)保存修改后的mapping以及对应的Workflow后,运行Workflow并在Workflow Monitor中观察该Workflow的运行状态。
Workflow的运行结果无误。
最新文件---------------- 仅供参考--------------------已改成-----------word文本 --------------------- 方便更改 赠人玫瑰,手留余香。 Origin 是一款科研和工程领域颇受欢迎的数据分析和绘图软件(A Date Analysis and Graphing Software)。 在数据分析功能中,它包涵了峰形分析、曲线拟合、统计、信号处理等功能。在曲 线拟合功能中,用户可以使用Origin自带的内置函数(Built-in Function),然而自带 函数不一定满足实际需要,用户还可以根据实际需求自定义拟合函数,并使之进行特 殊形态曲线的拟合,得到用户自己关心的曲线参数。 比如在介电材料的阻抗谱研究中,想知道Cole-Cole半圆与实部的两个交点,那么 就需要知道这个半圆的方程,从而解出想要的参数。 这里以半圆形曲线拟合为例简单介绍用户自定义拟合函数(User Defined Fitting Function)的建立和使用。 建立用户自定义函数的步骤: 1.选择 Tools: Fitting Function Organizer (快捷键F9) ,打开 Fitting function organizer. 单击 New Category 按钮,创建一个函数类,可以根据自己需要重命名,比如 My functions.然后单击 New Function,在这个类下面创建一个新的函数,然后命名,比如Semi-circle function:
2. 对该函数进行简短的描述,定义函数所需参数,输入函数方程。然后,进行最最关键的一步:函数编译!
进入hive shell #hive或者hive --service cli Hive 的启动方式: hive 命令行模式,直接输入/hive/bin/hive的执行程序,或者输入hive –service cli hive web界面的启动方式,hive –service hwi hive 远程服务(端口号10000) 启动方式,hive --service hiveserver hive 远程后台启动(关闭终端hive服务不退出): nohup hive -–service hiveserver & 显示所有函数: hive> show functions; 查看函数用法: hive> describe function substr; 查看hive为某个查询使用多少个MapReduce作业 hive> Explain select a.id from tbname a; -------------------------------------------------------------------------- 表结构操作: 托管表和外部表 托管表会将数据移入Hive的warehouse目录;外部表则不会。经验法则是,如果所有处理都由Hive完成, 应该使用托管表;但如果要用Hive和其它工具来处理同一个数据集,则使用外部表。 创建表(通常stored as textfile): hive> create table tbName (id int,name string) stored as textfile; 创建表并且按分割符分割行中的字段值(即导入数据的时候被导入数据是以该分割符划分的,否则导入后为null,缺省列为null); hive> create table tbName (id int,name string) row format delimited fields terminated by ','; 创建外部表: hive>create external table extbName(id int, name string); 创建表并创建单分区字段ds(分区表指的是在创建表时指定的partition的分区空间。): hive> create table tbName2 (id int, name string) partitioned by (ds string); 创建表并创建双分区字段ds: hive> create table tbname3 (id int, content string) partitioned by (day string, hour string); 表添加一列: hive> alter table tbName add columns (new_col int); 添加一列并增加列字段注释: hive> alter table tbName add columns (new_col2 int comment 'a comment'); 更改表名: hive> alter table tbName rename to tbName3; 删除表(删除表的元数据,如果是托管表还会删除表的数据): hive>drop table tbName; 只删除内容(只删除表的内容,而保留元数据,则删除数据文件): hive>dfs –rmr ‘warehouse/my-table’; 删除分区,分区的元数据和数据将被一并删除: hive>alter table tbname2 drop partition (dt='2008-08-08', hour='09'); -------------------------------------------------------------------------- 元数据存储(从HDFS中将数据导入到表中都是瞬时的):
本帖包括两个话题:1. 自定义函数的建立 2. 自定义函数的调用。 为什么要建立自定义函数? 如果你没遇到这个问题,没想过这个问题,说明你origin还用得不够,你还只停留在数据绘图的层面上,数据分析功能还值得再拓展。 Origin 是一款科研和工程领域颇受欢迎的数据分析和绘图软件(A Date Analysis and Graphing Software)。 在数据分析功能中,它包涵了峰形分析、曲线拟合、统计、信号处理等功能。在曲线拟合功能中,用户可以使用Origin自带的内置函数(Built-in Function),然而自带函数不一定满足实际需要,用户还可以根据实际需求自定义拟合函数,并使之进行特殊形态曲线的拟合,得到用户自己关心的曲线参数。 比如在介电材料的阻抗谱研究中,想知道Cole-Cole半圆与实部的两个交点,那么就需要知道这个半圆的方程,从而解出相关参数。 这里以半圆形曲线拟合为例简单介绍用户自定义拟合函数(User Defined Fitting Function)的建立和使用。 一、建立用户自定义函数的步骤: 1.选择 Tools: Fitting Function Organizer (快捷键F9) ,打开 Fitting function organizer. 单击New Category 按钮,创建一个函数类,可以根据自己需要重命名,比如 My functions.然后单击 New Function,在这个类下面创建一个新的函数,然后命名,比如 Semi-circle function: 2. 对该函数进行简短的描述,定义函数所需参数,输入函数方程。然后,进行最最关键的一步:函数编译!
Hive自定义函数说明函数清单:
用法: getID 通过UUID来生成每一行的唯一ID: select getid() ; oracle_concat hive的concat函数遇到空值的情况下会直接返回空,而在oracle中对于字符串类型空字符串与null是等价对待的 select default.oracle_concat('ff-',null,'','--cc'); Select concat('ff-',null,'','--cc'); getBirthDay 从身份证号码中截取生日信息,返回日期格式为’yyyy-MM-dd’
getGoodsInfo self_date_format 为格式化来自oracle的时间格式,将格式为’yyyy/MM/dd’和’yyyy/MM/dd HH:mm:ss’的日期格式转换为’yyyy-MM-dd’ Select default. self_date_format(‘2012-12-12’); Select default. self_date_format(‘20121212’,’yyyyMMdd’); oracle_months_between 由于当前版本hive不带months_between函数,所以添加 oracle_decode hive中的decode函数为字符编码函数和encode对应。Oracle中decode函数类似case when 函数,添加oracle_decode函数减少sql的改写。与为与oracle功能同步,本函数将null和字符串’’等价对待。 select default.oracle_decode('',null,1,2) r1, default.oracle_decode(null,'',1,2) r2, default.oracle_decode('aaa','','Nnull','aaa','is a*3','aaa') r3, default.oracle_decode('ccc','', 'Nnull','aaa','is a*3','aaa') r4, default.oracle_decode('','', 'Nnull','aaa','is a*3','aaa') r5; BinomialTest _FUNC_(expr1, expr2, p_value, alternativeHypothesis) alternativeHypothesis: 接受指定值的字符串 取值:TWO_SIDED , GREATER_THAN , LESS_THAN 二项分布检测函数。实现oracle中的二项分布检测功能。 计算expr1 等于exper2 的值占数据总数的二项分布检测结果,类型依据alternativeHypothesis 确定
目录 一、关系运算: (4) 1. 等值比较: = (4) 2. 不等值比较: <> (4) 3. 小于比较: < (4) 4. 小于等于比较: <= (4) 5. 大于比较: > (5) 6. 大于等于比较: >= (5) 7. 空值判断: IS NULL (5) 8. 非空判断: IS NOT NULL (6) 9. LIKE比较: LIKE (6) 10. JAVA的LIKE操作: RLIKE (6) 11. REGEXP操作: REGEXP (7) 二、数学运算: (7) 1. 加法操作: + (7) 2. 减法操作: - (7) 3. 乘法操作: * (8) 4. 除法操作: / (8) 5. 取余操作: % (8) 6. 位与操作: & (9) 7. 位或操作: | (9) 8. 位异或操作: ^ (9) 9.位取反操作: ~ (10) 三、逻辑运算: (10) 1. 逻辑与操作: AND (10) 2. 逻辑或操作: OR (10) 3. 逻辑非操作: NOT (10) 四、数值计算 (11) 1. 取整函数: round (11) 2. 指定精度取整函数: round (11) 3. 向下取整函数: floor (11) 4. 向上取整函数: ceil (12) 5. 向上取整函数: ceiling (12) 6. 取随机数函数: rand (12) 7. 自然指数函数: exp (13) 8. 以10为底对数函数: log10 (13) 9. 以2为底对数函数: log2 (13) 10. 对数函数: log (13) 11. 幂运算函数: pow (14) 12. 幂运算函数: power (14) 13. 开平方函数: sqrt (14) 14. 二进制函数: bin (14)
实验报告 课程名称:数据库系统概论实验时间:2012.5.10 学号:姓名:班级: 一、实验题目:存储过程与用户自定义函数 二、实验目的: 1)掌握SQLServer中存储过程的使用方法。 2)掌握SQLServer中用户自定义函数的使用方法。 三、实验内容:(记录每个实验步骤内容、命令、截屏结果) (一)存储过程 1、对学生课程数据库,编写2个存储过程,分别完成下面功能: 1)统计某一门课的成绩分布情况,即按照各分数段统计人数,要求使用游标。 create proc TotalByCnoNum ( @cno varchar(6) ) as begin declare @num1 int,@num2 int, @num3 int,@num4 int,@num5 int,@grade int,@cname char(20) select @num1=0,@num2=0,@num3=0,@num4=0,@num5=0 declare cur_cno cursor for select grade from sc where cno=@cno open cur_cno fetch next from cur_cno into @grade while@@fetch_status=0 begin if @grade between 90 and 100 set @num1=@num1+1 else if @grade between 80 and 89 set @num2=@num2+1 else if @grade between 70 and 79 set @num3=@num3+1 else if @grade between 60 and 69 set @num4=@num4+1 else set @num5=@num5+1 fetch next from cur_cno into @grade end close cur_cno deallocate cur_cno select @cname=cname from course where cno=@cno print'课程:'+@cname print'分数段人数统计'
1. 以下哪一项不属于Hadoop可以运行的模式___C___。 A. 单机(本地)模式 B. 伪分布式模式 C. 互联模式 D. 分布式模式 2. Hadoop 的作者是下面哪一位__B____。 A. Martin Fowler B. Doug cutting C. Kent Beck D. Grace Hopper 3. 下列哪个程序通常与NameNode 在同一个节点启动__D___。 A. TaskTracker B. DataNode C. SecondaryNameNode D. Jobtracker 4. HDFS 默认Block Size 的大小是___B___。 A.32MB B.64MB C.128MB D.256M 5. 下列哪项通常是集群的最主要瓶颈____C__。 A. CPU B. 网络 C. 磁盘IO D. 内存 6. 下列关于MapReduce说法不正确的是_____C_。 A. MapReduce 是一种计算框架 B. MapReduce 来源于google 的学术论文 C. MapReduce 程序只能用java 语言编写 D. MapReduce 隐藏了并行计算的细节,方便使用 8. HDFS 是基于流数据模式访问和处理超大文件的需求而开发的,具有高容错、高可靠性、高可扩展性、高吞吐率等特征,适合的读写任务是__D____。 A.一次写入,少次读 B.多次写入,少次读 C.多次写入,多次读 D.一次写入,多次读
7. HBase 依靠__A____存储底层数据。 A. HDFS B. Hadoop C. Memory D. MapReduce 8. HBase 依赖___D___提供强大的计算能力。 A. Zookeeper B. Chubby C. RPC D. MapReduce 9. HBase 依赖___A___提供消息通信机制 A. Zookeeper B. Chubby C. RPC D. Socket 10. 下面与HDFS类似的框架是___C____? A. NTFS B. FAT32 C. GFS D. EXT3 11. 关于SecondaryNameNode 下面哪项是正确的___C___。 A. 它是NameNode 的热备 B. 它对内存没有要求 C. 它的目的是帮助NameNode 合并编辑日志,减少NameNode 启动时间 D. SecondaryNameNode 应与NameNode 部署到一个节点 12. 大数据的特点不包括下面哪一项___D___。 A. 巨大的数据量 B. 多结构化数据 C. 增长速度快 D. 价值密度高 HBase测试题 9. HBase 来源于哪一项? C
HiveQL详解 HiveQL是一种类似SQL的语言, 它与大部分的SQL语法兼容, 但是并不完全支持SQL标准, 如HiveQL不支持更新操作, 也不支持索引和事务, 它的子查询和join操作也很局限, 这是因其底层依赖于Hadoop云平台这一特性决定的, 但其有些特点是SQL所无法企及的。例如多表查询、支持create table as select和集成MapReduce脚本等, 本节主要介绍Hive的数据类型和常用的HiveQL操作。 1.hive client命令 a.hive命令参数 -e: 命令行sql语句 -f: SQL文件 -h, --help: 帮助 --hiveconf: 指定配置文件 -i: 初始化文件 -S, --silent: 静态模式(不将错误输出) -v,--verbose: 详细模式 b.交互模式 hive> show tables; #查看所有表名 hive> show tables 'ad*' #查看以'ad'开头的表名 hive>set命令 #设置变量与查看变量; hive>set-v #查看所有的变量 hive>set hive.stats.atomic #查看hive.stats.atomic变量 hive>set hive.stats.atomic=false #设置hive.stats.atomic变量 hive> dfs -ls #查看hadoop所有文件路径 hive> dfs -ls /user/hive/warehouse/ #查看hive所有文件 hive> dfs -ls /user/hive/warehouse/ptest #查看ptest文件 hive> source file
Hadoop、openstack、nos ql、虚拟化云资源资料大全 about云资源汇总指引V1.4 hadoop资料 云端云计算2G基础课程 (Hadoop简介、安装与范例) 炼数成金3G视频分享下载 虚拟机三种网络模式该如何上网指导此为视频 Hadoop传智播客七天hadoop(3800元)视频,持续更新 Hadoop传智播客最新的hadoop学习资料第一季 (1)需要简单了解Linux操作系统(本课程使用CentOS6.4操作系统); (2)需要java基础,因为hadoop是java语言写的,课程中会对hadoop源码进行简析。 第一天资料: 传智播客hadoop教程01-课程介绍以及hadoop的国内外发展状况 传智播客hadoop教程02-hadoop生态圈介绍,介绍hadoop周边的很多框架 传智播客hadoop教程03-hadoop的概念及其发展历程 传智播客hadoop教程04-HDFS和MapReduce的体系结构 传智播客hadoop教程05-hadoop的特点和集群特点 传智播客hadoop教程06-配置Linux的环境,为搭建hadoop做准备 传智播客hadoop教程07-介绍如何使用SSH进行免密码登陆以及如何安装JDK
传智播客hadoop教程08-介绍hadoop的伪分布安装过程 传智播客hadoop教程09-使用eclipse查看hadoop源码 传智播客hadoop教程10-去除hadoop的启动过程中警告信息 第二天资料: 传智播客hadoop教程11-分布式文件系统简介 传智播客hadoop教程12-HDFS的shell操作 传智播客hadoop教程13-NameNode体系结构 传智播客hadoop教程14-DataNode体系结构 传智播客hadoop教程15-使用浏览器查看HDFS目录结构 传智播客hadoop教程16-使用java操作HDFS 传智播客hadoop教程17-Hadoop的RPC通信原理 传智播客hadoop教程18-NameNode的RPC通信过程 ....... Hadoop技术内幕深入解析HADOOP COMMON和HDFS架构设计与实现原理大全1-9章如何进行Hadoop二次开发指导视频下载 hadoop架构40篇文档下载 DaaS for Iaas.pdf IaaS 存储架构分析 Oracle性能优化精髓 OpenShift:从中间件到PaaS云 软件架构趋势 OPenstack建设公有云平台 从企业角度重塑企业IT架构 SAE落地过程中的经验分享 大型企业集团于SaaS的核心业务平台建设 云计算加速企业创新 hadoop平台大数据整合 Cloud Foundry Paas平台对软件开发的影响 专家集成系统开启企业云计算之旅 我们为什么不赞同openstack 基于web标准的移动开发和测试 分布式存储在网盘和在线备份的应用研究 当当在大数据挖掘分析与管理一个性话精准营销方面的探索 高并发环境下数据产品的架构设计 低成本构建有效的云存储运维体系 将企业级软件迁移到共有云平台
常用函数大全 mysql_affected_rows
mysql_affected_rows — 取得前一次 MySQL 操作所影响的记录行数 mysql_fetch_array —从结果集中取得一行作为关联数组或数字数组或二者兼 有:
mysql_fetch_array($result, MYSQL_NUM) , MYSQL_NUM 可用 MYSQL_BOTH 或
MYSQL_ASSOC 代替,也可以不写,默认为 MYSQL_BOTH
mysql_fetch_row — 从结果集中取得一行作为枚举数组: mysql_fetch_row($result); mysql_fetch_assoc($result)
mysql_fetch_row()从和指定的结果标识关联的结果集中取得一行数据并作为数组返回。每个结果 的列储存在一个数组的单元中,偏移量从 0 开始。 依次调用 mysql_fetch_row()将返回结果集中的下一行,如果没有更多行则返回 FALSE。 mysql_fetch_assoc — 从结果集中取得一行作为关联数组 :
mysql_fetch_assoc() 和用 mysql_fetch_array() 加上第二个可选参数 MYSQL_ASSOC 完全相同。它 仅仅返回关联数组。这也是 mysql_fetch_array()起初始的工作方式。如果在关联索引之外还需要数字 索引,用 mysql_fetch_array()。 如果结果中的两个或以上的列具有相同字段名,最后一列将优先。要访问同名的其它列,要么用 mysql_fetch_row()来取得数字索引或给该列起个别名。参见 mysql_fetch_array() 例子中有关别名说 明。 有一点很重要必须指出,用 mysql_fetch_assoc()并不明显 比用 mysql_fetch_row()慢,而且还提供了 明显更多的值。
mysql_query()
仅对 SELECT,SHOW,EXPLAIN 或 DESCRIBE 语句返回一个资源标识符,
如果查询执行不正确则返回 FALSE。对于其它类型的 SQL 语句,mysql_query()在执行成功时返回 TRUE,出错时返回 FALSE。非 FALSE 的返回值意味着查询是合法的并能够被服务器执行。这并不说明 任何有关影响到的或返回的行数。 很有可能一条查询执行成功了但并未影响到或并未返回任何行。
关系运算 等值比较: = 语法:A = B 操作类型: 所有基本类型 描述: 如果表达式A与表达式B相等,则为TRUE;否则为FALSE 举例: hive> select 1 from dual where 1=1; 1 不等值比较: <> 语法: A <> B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A 与表达式B不相等,则为TRUE;否则为FALSE 举例: hive> select 1 from dual where 1 <> 2; 1 小于比较: < 语法: A < B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A 小于表达式B,则为TRUE;否则为FALSE 举例:
hive> select 1 from dual where 1 < 2; 1 小于等于比较: <= 语法: A <= B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A 小于或者等于表达式B,则为TRUE;否则为FALSE 举例: hive> select 1 from dual where 1 <= 1; 1 大于比较: > 语法: A > B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A 大于表达式B,则为TRUE;否则为FALSE 举例: hive> select 1 from dual where 2 > 1; 1 大于等于比较: >= 语法: A >= B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A 大于或者等于表达式B,则为TRUE;否则为FALSE
函数 在Transact - SQL语言中,函数被用来执行一些特殊的运算以支持SQL Server的标准命令。 (1 )?行集函数:行集函数可以在transact?SQL语句中当作表引用。 (2).聚合函数:用于一组值执行计算并返回一个单一的值。 (3 ).标量函数:用于对传递给它的一个或者多个参数值进行处理和计算,并返回一个单一的值. (一)、标量函数的分类 1 ?配置函数:返回当前的配置信息 2 ?游标函数:返回有关游标的信息 3 ?日期和时间函数:用于对日期和时间类型的输入值进行操作,返回一个了子符串,数字或日期和时间值 4 ?数学函数:用于对作为函数参数提供的输入值执行操作,返冋一个数字值 5 ?元数据函数:返回有关数据库和对象和信息 6 ?字符串函数:对字符串输入值执行操作,并返回一个字中或数字值 7 ?系统函数:执行系统操作 8 ?系统统计函数:返回系统的统计信息 9 ?文本和图像函数:对于文本或图像输入值或列执行操作,返冋有关这些值的信息。 (二)、具体讲解: 1 ?系统函数 用于返回有关SQL Server系统,用户,数据库和数据库对彖的信息。系统函数可以让用户在得到信息后,使用条件语句,根据返回的信息进行不同的操作。与其它函数- 样,可以在select语句的select和where子句经及表达式中使用系统函数。 例:返回taihang数据库的yuan表中的第二列的名称。 use taihang select col_name ( object_id ( * yuan *),2) 注:col_name为系统函数,object_id :返回对彖的id。 2 ?日期和时间类型 日期和时间函数用于对日期和时间数据进行各种不同的处理和运算,并返回一个字符串,数字值或日期和时间值。 dateadd ( datepart , number ,date) dated iff ( datepart ,date1 ,date2) datename ( datepart ,date) datepart ( datepart ,date) day (date) getdate () month (date) year (date) 例1:从getdate函数返回的日期中提取月份数 select datepart ( month , getdate ()) as * month number * 注:datepart为系统函数 例2:从03/12/ 1998中返回月份、天数和年份数
第5章 使用VBA开发自定义函数 在第1章中曾经提到过,可以在VBA中创建的两种过程——子过程和函数过程。在前面的例子中,我们创建和使用的都是子过程,它通常都可以完成某一种功能。而函数过程则是为了完成某种计算,并返回一个计算结果。在VBA中创建的函数过程不但可以在VB A中使用,而且还可以像其他 Excel内置工作表函数一样,在工作表的公式中使用。本章将重点介绍创建自定义函数并在工作表公式中使用的方法。 5.1了解函数过程中的参数 在Excel工作表公式中使用不同的函数时,通常都需要输入函数的参数,然后函数才能得出正确结果。当然,有极少一部分函数不需要参数,例如时间函数Now,在单元格中输入“=Now()”并按【Enter】键后,将得到当前的时间。 在VBA中编写自定义函数时,也要根据函数的功能为自定义函数设计不定数量的参数,以便在使用中用户可以给函数参数赋值而获得想要的结果。本节将介绍自定义函数参数的几种类型。 5.1.1不使用参数的函数 自定义函数可以不使用任何参数,这通常在需要通过自定义函数返回一个信息时使用。例如,下面的自定义函数返回当前工作簿的路径,它不需要使用任何参数:Function GetPath() GetPath = ActiveWorkbook.FullName End Function 当在单元格中输入“=GetPath()”并按【Enter】键后,将在单元格中显示当前工作簿的路径,如图5-1所示。当在单元格输入等号“=”后,可以通过Excel 2007的自动完成功能在列表中找到自定义函数。 图5-1 使用无参数函数返回工作簿路径
提示:与Excel内置的工作表函数一样,即使自定义函数不使用参数,但是在输入函数时也要包含一对圆括号。 5.1.2使用有—个参数的函数 有时可能需要通过给定一个数值来获得结果。例如,在使用Excel的工作表函数ABS 时,通过给定一个数字,返回它的绝对值。那么在自定义函数时,也可以为函数设置一个参数,在公式中使用自定义函数时,也要输入一个参数,才能得出正确结果。 例如,下面的自定义函数通过用户输入一个数字,来求得该数字的阶乘: Function CountF(Num) Dim i As Integer Dim Total As Long Total = 1 For i = 1 To Num Total = Total * i Next i CountF = Total End Function 在工作表中输入该函数时,要求输入一个参数,例如,输入“=CountF(5)”,按【Ente r】键后,将得到给定参数值的阶乘,如图5-2所示。 图5-2 使用一个参数的函数计算数字的阶乘 5.1.3使用多个参数的函数 如果需要参与计算的条件较多,一个参数不够用时,那么可以在自定义函数中设置多个参数。例如,可以创建一个自定义函数,根据给定的商品单价和销售数量,计算员工的销售提成金额。当销售额小于20000时,以销售额的6%作为提成金额;当销售额在20001到40000之间时,以销售额的8%作为提成金额;如果销售额大于40000,那么以销售额的10%作为提成金额。下面的自定义函数正是用来计算这种提成方法的: Function GetBonus(UPrice, Amount)
一、文档说明 熟悉Hive功能,了解基本开发过程,及在项目中的基本应用。 注意:本文档中但凡有hive库操作的语句,其后面的“;”是语句后面的,非文档格式需要。每个hive语句都要以“;”来结束,否则将视相邻两个分号“;”之间的所有语句为一条语句。 二、Hive(数据提取)概述 Hive是构建在HDFS 和Map/Reduce之上的可扩展的数据仓库。是对HADOOP的Map-Reduce进行了封装,类似于sql语句(hive称之为HQL)计算数据从而代替编写代码对mapreduce的操作,数据的来源还是HDFS上面的文件。 Hive中的表可以分为托管表和外部表,托管表的数据移动到数据仓库目录下,由Hive管理,外部表的数据在指定位置,不在Hive 的数据仓库中,只是在Hive元数据库中注册。创建外部表采用“create external tablename”方式创建,并在创建表的同时指定表的位置。 Hive本身是没有专门的数据存储格式,也没有为数据建立索引,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。所以往Hive表里面导入数据只是简单的将数据移动到表所在的目录中(如果数据是在HDFS上;但如果数据是在本地文件系统中,那么是将数据复制到表所在的目录中)。
三、Hive的元数据 Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。由于Hive的元数据需要不断的更新、修改,而HDFS系统中的文件是多读少改的,这显然不能将Hive的元数据存储在HDFS中。目前Hive将元数据存储在数据库中,如Mysql、Derby中。 Hive metastore 三种存储方式: Hive的meta 数据支持以下三种存储方式,其中两种属于本地存储,一种为远端存储。远端存储比较适合生产环境。 1、使用derby数据库存储元数据(内嵌的以本地磁盘作为存储),这称为“内嵌配置”。 这种方式是最简单的存储方式,只需要在或做如下配置便可。使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,否则会提示如下错误(这是一个很常见的错误)。 2、使用本机mysql服务器存储元数据,这称为“本地metastore”。这种存储方式需要在本地运行一个mysql服务器, 3、使用远端mysql服务器存储元数据。这称为“远程metastore”。这种存储方式需要在远端服务器运行一个mysql服务器,并且需要在Hive服务器启动meta服务。
函数分类 HIVE CLI命令 显示当前会话有多少函数可用 SHOW FUNCTIONS; 显示函数的描述信息 DESC FUNCTION concat; 显示函数的扩展描述信息 DESC FUNCTION EXTENDED concat; 简单函数
函数的计算粒度为单条记录。 关系运算 数学运算 逻辑运算 数值计算 类型转换 日期函数 条件函数 字符串函数 统计函数 聚合函数 函数处理的数据粒度为多条记录。sum()—求和 count()—求数据量 avg()—求平均直 distinct—求不同值数 min—求最小值 max—求最人值 集合函数 复合类型构建 复杂类型访问 复杂类型长度 特殊函数 窗口函数
应用场景 用于分区排序 动态Group By Top N 累计计算 层次查询 Windowing functions lead lag FIRST_VALUE LAST_VALUE 分析函数 Analytics functions RANK ROW_NUMBER DENSE_RANK CUME_DIST PERCENT_RANK NTILE 混合函数 java_method(class,method [,arg1 [,arg2])reflect(class,method [,arg1 [,arg2..]])hash(a1 [,a2...])
UDTF lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (‘,‘ columnAlias)*fromClause: FROM baseTable (lateralView)* ateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。 常用函数Demo: create table employee( id string, money double, type string)row format delimited fields terminated by‘\t‘ lines terminated by‘\n‘ stored as textfile;load data local inpath ‘/liguodong/hive/data‘into table employee;select*from employee; 优先级依次为NOT AND OR select id,money from employee where(id=‘1001‘or id=‘1002‘)and money=‘100‘;
实验11 存储过程和用户自定义函数 实验目的 1.掌握通过企业管理器创建、修改、删除存储过程和用户自定义函数的方法 2.学会编写存储过程和用户自定义函数 3.掌握存储过程的执行方法 4.学会编写、调用三类用户自定义函数 实验准备 1.学习存储过程和用户自定义函数相关知识。 2.已掌握常程序控制流语句。 3.熟练使用T-SQL完成数据查询和程序设计。 4.还原studentdb数据库 实验内容和步骤 1.打开企业管理器,展开studentdb子目录,选中“存储过程”,单击鼠标右键,弹出 快捷菜单,选择【新建存储过程(S)…】,打开新建存储过程窗口,如图11- 1。 图11- 1 新建存储过程
2.新建并执行存储过程“字母打印”。 (1)在新建存储过程窗口输入以下代码。 CREATE PROCEDURE 字母打印AS 注解:该存储过程是将26个小写英文字母按a~z的顺序输出,其中ascii()函 数——返回字符对应ASCII码,char()函数——把ASCII码转换成对应字符。 (2)输入完成后,单击【检查语法】按钮,确认输入内容正确后,单击【确认】按 钮完成存储过程的创建。 (3)打开查询分析器,输入: exec 字母打印 (4)执行,查看运行结果。 3.修改存储过程“字母打印”并执行。 (1)在企业管理器存储过程列表窗格中,选中存储过程“字母打印”,弹出快捷菜 单,选择【属性(R)】,或直接双击该存储过程,打开属性窗口,如图11- 2。
图11- 2 存储过程“字母打印”属性窗口 (2)修改代码内容,将“print char(ascii('a')+@count)”改为“print char(ascii('A')+@count)”。 (3)单击【确认】按钮,完成存储过程的修改。 (4)重新在查询分析器执行该存储过程,查看运行结果。 4.新建并执行带输入参数的存储过程。 (1)在企业管理器中新建存储过程“成绩查询”,代码如下: (2)在查询分析器窗口中,选择studentdb数据库。要求:通过存储过程“成绩查 询”查看学号为“2007224117”的成绩。 ●方法一:输入exec 成绩查询‘2007224117’,并执行。 ●方法二:输入 执行,查看该同学的成绩。 注:以上是执行含输入参数存储过程的常用方法,参数可以直接通过值传递, 也可以通过变量传递。 5.练习:请新建存储过程“学生信息”,输入参数仍为学号,返回学号对应的“学生” 表信息,并通过该存储过程查看学号为“2007224117”的个人信息。 6.新建带返回参数的存储过程并执行。 (1)在企业管理器中新建存储过程“学生平均成绩”,代码如下:
用户自定义函数 函数是过程的另一种形式,又称为Function过程。它与过程不同的是,函数必须有返回值,向调用程序返回结果。 定义Function过程,语句格式如下: Function 函数名[(参数列表)][As 类型] …… Return value / 函数名=value End Function Function过程的调用比较简单,可以像使用https://www.doczj.com/doc/cf13980032.html,内部函数一样来调用Function过程,即将其名称和参数放在赋值语句的右边或表达式中。 例:定义并调用Function过程,求1~10的和 参数---形参和实参 在定义Sub和Function的过程中,“参数列表”中的参数称为“形式参数”,简称“形参”。形参用于接收数据,因此形参不能是常数。 在调用语句中使用的参数称为“实际参数”,简称“实参”。 实参可以是变量元素(已知变量、数组元素等)和非变量元素(常数、文本、枚举、表达式),在调用一个过程时,必须把实参传递给过程,完成实参和形参的结合。一般情况下实参按位置传给形参。
参数传递 在调用过程中,一般主过程与被调用过程之间有数据传递,即将主过程的实参传递给被调用过程中的形参,完成实参与形参的结合。 在参数传递过程中有两种方式,一种为值传递,使用ByVal关键字;另一种为按地址传递也称为引用,使用ByRef关键字。 在https://www.doczj.com/doc/cf13980032.html,中默认的参数传递机制是值传递。 按值传递 按值传递时,系统将实参复制给形参,然后实参与形参就断开了联系,形参只是接收到实参传递过来的值,实参和形参在各自独立的存储单元中,在调用过程中对形参的任何操作不会影响到实参,因此值传递可以保护实参中的数据不被过程所改变
hive默认的函数并不是太完整,以后我们使用的使用肯定需要自己补充一些。 下面这个例子是个简单的测试,关于自定义函数的。 函数代码 package com.example.hive.udf; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; public final class Lower extends UDF { public Text evaluate(final Text s) { if (s == null) { return null; } return new Text(s.toString().toLowerCase()); } } 打包 javac -d Lower Lower.java jar -cvf Lower.jar -C Lower/ . 在hive中添加包 hive> add jar /home/hjl/sunwg/Lower.jar; Added /home/hjl/sunwg/Lower.jar to class path 在hive中创建函数 hive> create temporary function my_lower as …com.example.hive.udf.Lower?; OK Time taken: 0.407 seconds 使用函数 hive> select my_lower(name) from test10; 上面介绍了HIVE中的自定义函数,有一些函数是比较基础的,公用的,每次都要create temporary function不免太麻烦了。 这样的基础函数需要直接集成到hive中去,避免每次都要创建。 1,添加函数文件 $HIVE_HOME/src/ql/src/java/org/apache/hadoop/hive/ql/udf/UDFSunwg.java package org.apache.hadoop.hive.ql.udf; import org.apache.hadoop.hive.ql.exec.Description; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text;