1. 学习前的准备
Drools是一款基于Java的开源规则引擎,所以在使用Drools之前需要在开发机器上安装好JDK环境,Drools5要求的JDK版本要在1.5或以上。
1.1.开发环境搭建
大多数软件学习的第一步就是搭建这个软件的开发环境,Drools也不例外。本小节的内容就是介绍如何搭建一个Drools5的开发、运行、调试环境。
1.1.1.下载开发工具
Drools5提供了一个基于Eclipse3.4的一个IDE开发工具,所以在使用之前需要到https://www.doczj.com/doc/c616615177.html,网站下载一个 3.4.x版本的Eclipse,下载完成之后,再到https://www.doczj.com/doc/c616615177.html,/drools/downloads.html 网站,下载Drools5的Eclipse插件版IDE及Drools5的开发工具包,如图1-1所示。
除这两个下载包以外,还可以把Drools5的相关文档、源码和示例的包下载下来参考学习使用。
将下载的开发工具包及IDE包解压到一个非中文目录下,解压完成后就可以在Eclipse3.4上安装Drools5提供的开发工具IDE了。
1.1.
2. 安装Drools IDE
打开Eclipse3.4所在目录下的links目录(如果该目录不存在可以手工在其目录下创建
一个links目录),在links目录下创建一个文本文件,并改名为drools5-ide.link,用记事本打开该文件,按照下面的版本输入Drools5 Eclipse Plugin文件所在目录:
path=D:\\eclipse\\drools-5.0-eclipse-all
这个值表示Drools5 Eclipse Plugin文件位于D盘eclipse目录下的drools-5.0-eclipse-all
下面,这里有一点需要注意,那就是drools-5.0-eclipse-all文件夹下必须再包含一个eclipse 目录,所有的插件文件都应该位于该eclipse目录之下,接下来要在win dos下重启Eclipse 3.4,检验Drools5 IDE是否安装成功。
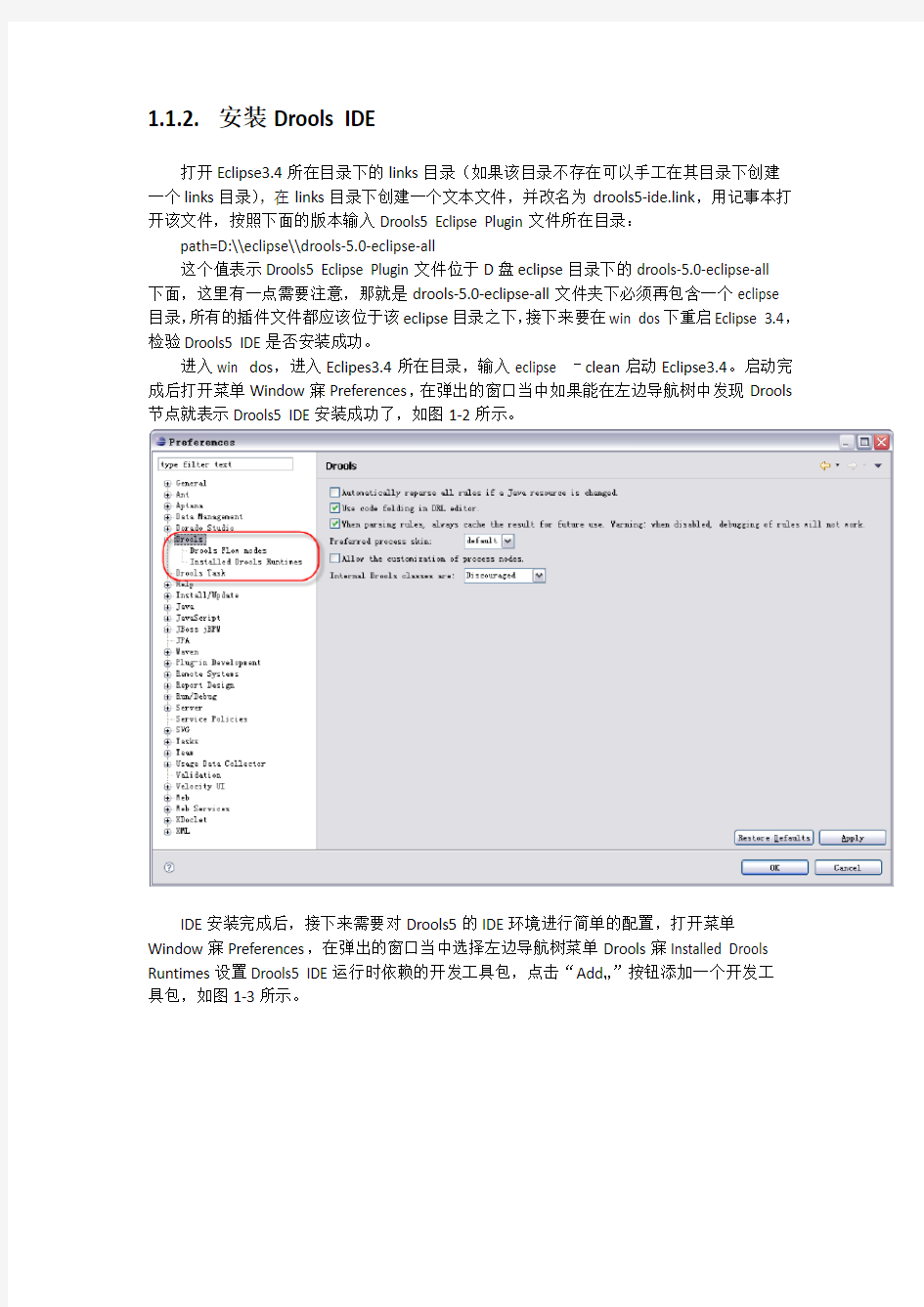
进入win dos,进入Eclipes3.4所在目录,输入eclipse –clean启动Eclipse3.4。启动完成后打开菜单Window寐Preferences,在弹出的窗口当中如果能在左边导航树中发现Drools 节点就表示Drools5 IDE安装成功了,如图1-2所示。
IDE安装完成后,接下来需要对Drools5的IDE环境进行简单的配置,打开菜单Window寐Preferences,在弹出的窗口当中选择左边导航树菜单Drools寐Installed Drools Runtimes设置Drools5 IDE运行时依赖的开发工具包,点击“Add…”按钮添加一个开发工具包,如图1-3所示。
图1-3当中添加了一个开发工具包,名称为“drools-5.0.0”,对应的工具包目录为D盘
doc\about rule\drools5.x\drools-5.0-bin目录。添加完成后这样Drools5的开发环境就搭好了。下面我们就来利用这个环境编写一个规则看看运行效果。
1.2.编写第一个规则
1.3.规则的编译与运行
在Drools当中,规则的编译与运行要通过Drools提供的各种API来实现,这些API总体来讲可以分为三类:规则编译、规则收集和规则的执行。完成这些工作的API主要有KnowledgeBuilder、KnowledgeBase、StatefulKnowledgeSession、StatelessKnowledgeSession、、等,它们起到了对规则文件进行收集、编译、查错、插入fact、设置global、执行规则或规则流等作用,在正式接触各种类型的规则文件编写方式及语法讲解之前,我们有必要先熟悉一下这些API的基本含义及使用方法。
1.3.1.KnowledgeBuilder
规则编写完成之后,接下来的工作就是在应用的代码当中调用这些规则,利用这些编写好的规则帮助我们处理业务问题。KnowledgeBuilder的作用就是用来在业务代码当中收集已经编写好的规则,然后对这些规则文件进行编译,最终产生一批编译好的规则包(KnowledgePackage)给其它的应用程序使用。KnowledgeBuilder在编译规则的时候可以通过其提供的hasErrors()方法得到编译规则过程中发现规则是否有错误,如果有的话通过其提供的getErrors()方法将错误打印出来,以帮助我们找到规则当中的错误信息。
创建KnowledgeBuilder对象使用的是KnowledgeBuilderFactory的newKnowledgeBuilder 方法。代码清单1-1就演示了KnowledgeBuilder的用法。
代码清单1-1:
import java.util.Collection;
import java.util.Iterator;
import org.drools.builder.KnowledgeBuilder;
import org.drools.builder.KnowledgeBuilderErrors;
import org.drools.builder.KnowledgeBuilderFactory;
import org.drools.builder.ResourceType;
import org.drools.io.ResourceFactory;
public class Test {
public static void main(String[] args) {
KnowledgeBuilder kbuilder =
KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("test.drl",Tes.clas s), ResourceType.DRL);
if (kbuilder.hasErrors()) {
System.out.println("规则中存在错误,错误消息如下:");
KnowledgeBuilderErrors kbuidlerErrors =
kbuilder.getErrors();
for (Iterator iter = kbuidlerErrors.iterator();
iter.hasNext();) {
System.out.println(iter.next());
}
}
Collection kpackage = kbuilder.getKnowledgePackages();// 产生规则包的集合
}
}
通过KnowledgeBuilder编译的规则文件的类型可以有很多种,如.drl文件、.dslr文件或一个xls文件等。产生的规则包可以是具体的规则文件形成的,也可以是规则流(rule flow)文件形成的,在添加规则文件时,需要通过使用ResourceType的枚举值来指定规则文件的类型;同时在指定规则文件的时候drools还提供了一个名为ResourceFactory的对象,通过该对象可以实现从Classpath、URL、File、ByteArray、Reader或诸如XLS的二进制文件里
添加载规则。
在规则文件添加完成后,可以通过使用hasErrors()方法来检测已添加进去的规则当中有没有错误,如果不通过该方法检测错误,那么如果规则当中存在错误,最终在使用的时候也会将错误抛出。代码清单1-2就演示了通过KnowledgeBuilder来检测规则当中有没有错误。
代码清单1-2:
import java.util.Collection;
import java.util.Iterator;
import org.drools.builder.KnowledgeBuilder;
import org.drools.builder.KnowledgeBuilderErrors;
import org.drools.builder.KnowledgeBuilderFactory;
import org.drools.builder.ResourceType;
import org.drools.io.ResourceFactory;
public class Test {
public static void main(String[] args) {
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory
.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("test.drl", Test.class), ResourceType.DRL);
if (kbuilder.hasErrors()) {
System.out.println("规则中存在错误,错误消息如下:");
KnowledgeBuilderErrors kbuidlerErrors =
kbuilder.getErrors();
for (Iterator iter = kbuidlerErrors.iterator();
iter.hasNext();) {
System.out.println(iter.next());
}
}
Collection kpackage = kbuilder.getKnowledgePackages();// 产生规则包的集合
}
}
后面随着介绍的深入我们还会看到KnowledgeBuilder的一些其它用法。
1.3.
2. KnowledgeBase
KnowledgeBase是Drools提供的用来收集应用当中知识(knowledge)定义的知识库对象,在一个KnowledgeBase当中可以包含普通的规则(rule)、规则流(rule flow)、函数定义(function)、用户自定义对象(type model)等。KnowledgeBase本身不包含任何业务数据对象(fact对象,后面有相应章节着重介绍fact对象),业务对象都是插入到由KnowledgeBase 产生的两种类型的session对象当中(StatefulKnowledgeSession和StatelessKnowledgeSession,后面会有对应的章节对这两种类型的对象进行介绍),通过session对象可以触发规则执行或开始一个规则流执行。
创建一个KnowledgeBase要通过KnowledgeBaseFactory对象提供的newKnowledgeBase ()方法来实现,这其中创建的时候还可以为其指定一个KnowledgeBaseConfiguration对象,KnowledgeBaseConfiguration对象是一个用来存放规则引擎运行时相关环境参数定义的配置对象,代码清单1-3演示了一个简单的KnowledgeBase对象的创建过程。
代码清单1-3:
import org.drools.KnowledgeBase;
import org.drools.KnowledgeBaseFactory;
public class Test {
public static void main(String[] args) {
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase();
}
}
代码清单1-4演示了创建KnowledgeBase过程当中,使用一KnowledgeBaseConfiguration 对象来设置环境参数。
代码清单1-4:
import org.drools.KnowledgeBase;
import org.drools.KnowledgeBaseConfiguration;
import org.drools.KnowledgeBaseFactory;
public class Test {
public static void main(String[] args) {
KnowledgeBaseConfiguration kbConf = KnowledgeBaseFactory
.newKnowledgeBaseConfiguration();
kbConf.setProperty("org.drools.sequential", "true");
KnowledgeBase kbase =
KnowledgeBaseFactory.newKnowledgeBase(kbConf);
}
}
从代码清单1-4中可以看到,创建一个KnowledgeBaseConfiguration对象的方法也是使用KnowldegeBaseFactory,使用的是其提供的newKnowledgeBaseConfiguration()方法,该方法创建好的KnowledgeBaseConfiguration对象默认情况下会加载drools-core-5.0.1.jar包下META-INF/drools.default.rulebase.conf文件里的规则运行环境配置信息,加载完成后,我们可以在代码中对这些默认的信息重新赋值,以覆盖加载的默认值,比如这里我们就把org.drools.sequential的值修改为true,它的默认值为false。
除了这种方式创建KnowledgeBaseConfiguration方法之外,我们还可以为其显示的指定一个Properties对象,在该对象中设置好需要覆盖默认值的相关属性的值,然后再通过newKnowledgeBaseConfiguration(Properties prop,ClassLoader loader)方法创建一个KnowledgeBaseConfiguration对象。该方法方法当中第一个参数就是我们要设置的Properties 对象,第二个参数用来设置加载META-INF/drools.default.rulebase.conf文件的ClassLoader,因为该文件在ClassPath下,所以采用的是ClassLoader方法进行加载,如果不指定这个参数,那么就取默认的ClassLoader对象,如果两个参数都为null,那么就和newKnowledgeBaseConfiguration()方法的作用相同了,代码清单代码清单1-5演示了这种用法。
代码清单1-5:
import java.util.Properties;
import org.drools.KnowledgeBase;
import org.drools.KnowledgeBaseConfiguration;
import org.drools.KnowledgeBaseFactory;
public class Test {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty("org.drools.sequential", "true");
KnowledgeBaseConfiguration kbConf = KnowledgeBaseFactory
.newKnowledgeBaseConfiguration(properties, null);
KnowledgeBase kbase =
KnowledgeBaseFactory.newKnowledgeBase(kbConf);
}
}
用来设置默认规则运行环境文件drools.default.rulebase.conf里面所涉及到的具体项内容如代码清单1-6所示:
代码清单1-6:
drools.maintainTms =
drools.assertBehaviour =
drools.logicalOverride =
drools.sequential =
drools.sequential.agenda =
drools.removeIdentities =
drools.shareAlphaNodes =
drools.shareBetaNodes =
drools.alphaNodeHashingThreshold =
https://www.doczj.com/doc/c616615177.html,positeKeyDepth =
drools.indexLeftBetaMemory =
drools.indexRightBetaMemory =
drools.consequenceExceptionHandler =
drools.maxThreads =
drools.multithreadEvaluation =
在后面的内容讲解过程当中,对于代码清单1-6里列出的属性会逐个涉及到,这里就不再多讲了。
KnowledgeBase创建完成之后,接下来就可以将我们前面使用KnowledgeBuilder生成的KnowledgePackage的集合添加到KnowledgeBase当中,以备使用,如代码清单1-7所示。
代码清单1-7:
import java.util.Collection;
import org.drools.KnowledgeBase;
import org.drools.KnowledgeBaseConfiguration;
import org.drools.KnowledgeBaseFactory;
import org.drools.builder.KnowledgeBuilder;
import org.drools.builder.KnowledgeBuilderFactory;
import org.drools.builder.ResourceType;
import org.drools.definition.KnowledgePackage;
import org.drools.io.ResourceFactory;
public class Test {
public static void main(String[] args) {
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory
.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("test.drl",
Test.class), ResourceType.DRL);
Collection kpackage = kbuilder.getKnowledgePackages();
KnowledgeBaseConfiguration kbConf = KnowledgeBaseFactory
.newKnowledgeBaseConfiguration();
kbConf.setProperty("org.drools.sequential", "true");
KnowledgeBase kbase =
KnowledgeBaseFactory.newKnowledgeBase(kbConf);
kbase.addKnowledgePackages(kpackage);// 将KnowledgePackage集合
添加到KnowledgeBase当中
}
}
1.3.3. StatefulKnowledgeSession
规则编译完成之后,接下来就需要使用一个API使编译好的规则包文件在规则引擎当中运行起来。在Drools5当中提供了两个对象与规则引擎进行交互:StatefulKnowledgeSession 和StatelessKnowledgeSession,本小节当中要介绍的是StatefulKnowledgeSession对象,下面的一节将对StatelessKnowledgeSession对象进行讨论。
StatefulKnowledgeSession对象是一种最常用的与规则引擎进行交互的方式,它可以与规则引擎建立一个持续的交互通道,在推理计算的过程当中可能会多次触发同一数据集。在用户的代码当中,最后使用完StatefulKnowledgeSession对象之后,一定要调用其dispose()方法以释放相关内存资源。
StatefulKnowledgeSession可以接受外部插入(insert)的业务数据——也叫fact,一个fact对象通常是一个普通的Java的POJO,一般它们会有若干个属性,每一个属性都会对应getter和setter方法,用来对外提供数据的设置与访问。一般来说,在Drools规则引擎当中,fact所承担的作用就是将规则当中要用到的业务数据从应用当中传入进来,对于规则当中产生的数据及状态的变化通常不用fact传出。如果在规则当中需要有数据传出,那么可以通过在StatefulKnowledgeSession当中设置global对象来实现,一个global对象也是一个普通的Java对象,在向StatefulKnowledgeSession当中设置global对象时不用insert方法而用setGlobal方法实现。
创建一个StatefulKnowledgeSession要通过KnowledgeBase对象来实现,下面的代码清单1-8就演示了StatefulKnowledgeSession的用法:
代码清单1-8:
import org.drools.KnowledgeBase;
import org.drools.KnowledgeBaseConfiguration;
import org.drools.KnowledgeBaseFactory;
import org.drools.builder.KnowledgeBuilder;
import org.drools.builder.KnowledgeBuilderFactory;
import org.drools.builder.ResourceType;
import org.drools.definition.KnowledgePackage;
import org.drools.io.ResourceFactory;
import org.drools.runtime.StatefulKnowledgeSession;
public class Test {
public static void main(String[] args) {
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory
.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("test.drl",
Test.class), ResourceType.DRL);
Collection kpackage = kbuilder.getKnowledgePackages();
KnowledgeBaseConfiguration kbConf = KnowledgeBaseFactory
.newKnowledgeBaseConfiguration();
kbConf.setProperty("org.drools.sequential", "true");
KnowledgeBase kbase =
KnowledgeBaseFactory.newKnowledgeBase(kbConf);
kbase.addKnowledgePackages(kpackage);// 将KnowledgePackage集合
添加到KnowledgeBase当中
StatefulKnowledgeSession statefulKSession = kbase
.newStatefulKnowledgeSession();
statefulKSession.setGlobal("globalTest", new Object());// 设置一
个global对象
statefulKSession.insert(new Object());// 插入一个fact对象
statefulKSession.fireAllRules();
statefulKSession.dispose();
}
}
代码清单1-8当中同时也演示了规则完整的运行处理过程,可以看到,它的过程是首先需要通过使用KnowledgeBuilder将相关的规则文件进行编译,产生对应的KnowledgePackage 集合,接下来再通过KnowledgeBase把产生的KnowledgePackage集合收集起来,最后再产生StatefulKnowledgeSession将规则当中需要使用的fact对象插入进去、将规则当中需要用到的global设置进去,然后调用fireAllRules()方法触发所有的规则执行,最后调用dispose() 方法将内存资源释放。
1.3.4. StatelessKnowledgeSession
StatelessKnowledgeSession的作用与StatefulKnowledgeSession相仿,它们都是用来接收业务数据、执行规则的。事实上,StatelessKnowledgeSession对StatefulKnowledgeSession做了包装,使得在使用StatelessKnowledgeSession对象时不需要再调用dispose()方法释放内存资源了。
因为StatelessKnowledgeSession本身所具有的一些特性,决定了它的使用有一定的局限性。在使用StatelessKnowledgeSession时不能进行重复插入fact的操作、也不能重复的调用fireAllRules()方法来执行所有的规则,对应这些要完成的工作在StatelessKnowledgeSession 当中只有execute(…)方法,通过这个方法可以实现插入所有的fact并且可以同时执行所有的规则或规则流,事实上也就是在执行execute(…)方法的时候就在StatelessKnowledgeSession 内部执行了insert()方法、fireAllRules()方法和dispose()方法。
代码清单1-9演示了StatelessKnowledgeSession对象的用法。
代码清单1-9:
import java.util.ArrayList;
import java.util.Collection;
import org.drools.KnowledgeBase;
import org.drools.KnowledgeBaseConfiguration;
import org.drools.KnowledgeBaseFactory;
import org.drools.builder.KnowledgeBuilder;
import org.drools.builder.KnowledgeBuilderFactory;
import org.drools.builder.ResourceType;
import org.drools.definition.KnowledgePackage;
import org.drools.io.ResourceFactory;
import org.drools.runtime.StatelessKnowledgeSession;
public class Test {
public static void main(String[] args) {
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory
.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("test.drl", Test.class), ResourceType.DRL);
Collection kpackage = kbuilder.getKnowledgePackages();
KnowledgeBaseConfiguration kbConf = KnowledgeBaseFactory
.newKnowledgeBaseConfiguration();
kbConf.setProperty("org.drools.sequential", "true");
KnowledgeBase kbase =
KnowledgeBaseFactory.newKnowledgeBase(kbConf);
kbase.addKnowledgePackages(kpackage);// 将KnowledgePackage集合
添加到KnowledgeBase当中
StatelessKnowledgeSession statelessKSession = kbase
.newStatelessKnowledgeSession();
ArrayList list = new ArrayList();
list.add(new Object());
list.add(new Object());
statelessKSession.execute(list);
}
}
代码清单1-9当中,通过新建了一个ArrayList对象,将需要插入到StatelessKnowledgeSession当中的对象放到这个ArrayList当中,将这个ArrayList作为参数传给execute(…)方法,这样在StatelessKnowledgeSession内部会对这个ArrayList进行迭代,取出其中的每一个Element,将其作为fact,调用StatelessKnowledgeSession对象内部的StatefulKnowledgeSession对象的insert()方法将产生的fact逐个插入到
StatefulKnowledgeSession当中,然后调用StatefulKnowledgeSession的fireAllRules()方法,最后执行dispose()方法释放内存资源。
在代码清单1-9当中,如果我们要插入的fact就是这个ArrayList而不是它内部的Element 那该怎么做呢?在StatelessKnowledgeSession当中,还提供了execute(Command cmd)的方法,在该方法中通过CommandFactory可以创建各种类型的Command,比如前面的需求要直接将这个ArrayList作为一个fact插入,那么就可以采用CommandFactory.newInsert(Object obj) 来实现,代码清单1-9当中execute方法可做如代码清单1-10所示的修改。
代码清单1-10:
statelessKSession.execute(CommandFactory.newInsert(list));
如果需要通过StatelessKnowledgeSession设置global的话,可以使用CommandFactory.newSet Global(“key”Object obj)来实现;如果即要插入若干个fact,又要设
置相关的global,那么可以将CommandFactory产生的Command对象放在一个Collection当中,然后再通过CommandFactory.newBatchExecution(Collection collection)方法实现。代码清单1-11演示了这种做法。
代码清单1-11
import java.util.ArrayList;
import java.util.Collection;
import org.drools.KnowledgeBase;
import org.drools.KnowledgeBaseConfiguration;
import org.drools.KnowledgeBaseFactory;
import org.drools.builder.KnowledgeBuilder;
import org.drools.builder.KnowledgeBuilderFactory;
import org.drools.builder.ResourceType;
import https://www.doczj.com/doc/c616615177.html,mand;
import https://www.doczj.com/doc/c616615177.html,mandFactory;
import org.drools.definition.KnowledgePackage;
import org.drools.io.ResourceFactory;
import org.drools.runtime.StatelessKnowledgeSession;
public class Test {
public static void main(String[] args) {
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory
.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("test.drl", Test.class), ResourceType.DRL);
Collection kpackage = kbuilder.getKnowledgePackages();
KnowledgeBaseConfiguration kbConf = KnowledgeBaseFactory
.newKnowledgeBaseConfiguration();
kbConf.setProperty("org.drools.sequential", "true");
KnowledgeBase kbase =
KnowledgeBaseFactory.newKnowledgeBase(kbConf);
kbase.addKnowledgePackages(kpackage);// 将KnowledgePackage集合
添加到KnowledgeBase当中
StatelessKnowledgeSession statelessKSession = kbase
.newStatelessKnowledgeSession();
ArrayList list = new ArrayList();
list.add(CommandFactory.newInsert(new Object()));
list.add(CommandFactory.newInsert(new Object()));
list.add(CommandFactory.newSetGlobal("key1", new Object()));
list.add(CommandFactory.newSetGlobal("key2", new Object()));
statelessKSession.execute(CommandFactory.newBatchExecution(list)) ;
}
}
1.4. Fact对象
Fact是指在Drools规则应用当中,将一个普通的JavaBean插入到规则的WorkingMemory 当中后的对象。规则可以对Fact对象进行任意的读写操作,当一个JavaBean插入到WorkingMemory当中变成Fact之后,Fact对象不是对原来的JavaBean对象进行Clon,而是原来JavaBean对象的引用。规则在进行计算的时候需要用到应用系统当中的数据,这些数据设置在Fact对象当中,然后将其插入到规则的WorkingMemory当中,这样在规则当中就可以通过对Fact对象数据的读写,从而实现对应用数据的读写操作。一个Fact对象通常是一个具有getter和setter方法的POJO对象,通过这些getter和setter方法可以方便的实现对
Fact对象的读写操作,所以我们可以简单的把Fact对象理解为规则与应用系统数据交互的桥梁或通道。
当Fact对象插入到WorkingMemory当中后,会与当前WorkingMemory当中所有的规则进行匹配,同时返回一个FactHandler对象。FactHandler对象是插入到WorkingMemory 当中Fact对象的引用句柄,通过FactHandler对象可以实现对对应的Fact对象的删除及修改等操作。
在前面介绍StatefulKnowledgeSession和StatelessKnowledgeSession两个对象的时候也提到了插入Fact对象的方法,在StatefulKnowledgeSession当中直接使用insert方法就可以将一个Java对象插入到WokingMemory当中,如果有多个Fact需要插入,那么多个调用insert 方法即可;对于StatelessKnowledgeSession对象可利用CommandFactory实现单个Fact对象或多个Fact对象的插入。
2. 规则
学习Drools规则语法的目的是为了在应用当中帮助我们解决实际的问题,所以学会并
灵活的在规则当中使用就显的尤为重要。本章的内容包括规则的基本的约束部分语法讲解(LHS)、规则动作执行部分语法讲解及规则的各种属性介绍。
2.1.规则文件
在Drools当中,一个标准的规则文件就是一个以“.drl”结尾的文本文件,由于它是一个标准的文本文件,所以可以通过一些记事本工具对其进行打开、查看和编辑。规则是放在规则文件当中的,一个规则文件可以存放多个规则,除此之外,在规则文件当中还可以存放用户自定义的函数、数据对象及自定义查询等相关在规则当中可能会用到的一些对象。
一个标准的规则文件的结构如代码清单2-1所示。
代码清单2-1:
Package
imports
globals
functions
queries
rules
对于一个规则文件而言,首先声明package是必须的,除package之外,其它对象在规
则文件中的顺序是任意的,也就是说在规则文件当中必须要有一个package声明,同时package声明必须要放在规则文件的第一行。
规则文件当中的package和Java语言当中的package有相似之处,也有不同之处。在Java 当中package的作用是用来对功能相似或相关的文件放在同一个package下进行管理,这种package管理既有物理上Java文件位置的管理也有逻辑上的文件位置的管理,在Java当中这种通过package管理文件要求在文件位置在逻辑上与物理上要保持一致;在Drools的规则文件当中package对于规则文件中规则的管理只限于逻辑上的管理,而不管其在物理上的位置如何,这点是规则与Java文件的package的区别。
对于同一package下的用户自定义函数、自定义的查询等,不管这些函数与查询是否在同一个规则文件里面,在规则里面是可以直接使用的,这点和Java的同一package里的Java 类调用是一样的。
2.2.规则语言
规则是在规则文件当中编写,所以要编写一个规则首先需要先创建一个存放规则的规则文件。一个规则文件可以存放若干个规则,每一个规则通过规则名称来进行标识。代码清单2-2说明了一个标准规则的结构。
rule"name"
attributes
when
LHS
then
RHS
end
从代码清单2-2中可以看到,一个规则通常包括三个部分:属性部分(attribute)、条件部分(LHS)和结果部分(RHS)。对于一个完整的规则来说,这三个部分都是可选的,也就是说如代码清单2-3所示的规则是合法的。
代码清单2-3
rule"name"
when
then
end
对于代码清单2-3所示的这种规则,因为其没有条件部分,默认它的条件部分是满足的,因为其结果执行部分为空,所以即使条件部分满足该规则也什么都不做。接下来我们就分别来对规则的条件部分、结果部分和属性部分进行介绍。
2.2.1. 条件部分
条件部分又被称之为Left Hand Side,简称为LHS,下文当中,如果没有特别指出,那么所说的LHS均指规则的条件部分,在一个规则当中when与then中间的部分就是LHS部分。在LHS当中,可以包含0~n个条件,如果LHS部分没空的话,那么引擎会自动添加一个eval(true)的条件,由于该条件总是返回true,所以LHS为空的规则总是返回true。所以代码清单2-3所示的规则在执行的时候引擎会修改成如代码清单2-4所示的内容。
代码清单2-4
rule"name"
when
eval(true)
then
end
LHS部分是由一个或多个条件组成,条件又称之为pattern(匹配模式),多个pattern
之间用可以使用and或or来进行连接,同时还可以使用小括号来确定pattern的优先级。一个pattern的语法如代码清单2-5所示:
[绑定变量名:]Object([field约束])
对于一个pattern来说“绑定变量名”是可选的,如果在当前规则的LHS部分的其它的pattern要用到这个对象,那么可以通过为该对象设定一个绑定变量名来实现对其引用,对于绑定变量的命名,通常的作法是为其添加一个“$”符号作为前缀,这样可以很好的与Fact 的属性区别开来;绑定变量不仅可以用在对象上,也可以用在对象的属性上面,命名方法与对象的命名方法相同;“field约束”是指当前对象里相关字段的条件限制,代码清单2-6规则中LHS部分单个pattern的情形。
代码清单2-6:
rule"name"
when
$customer:Customer();
then
end
代码清单2-6规则中“$customer”是就是一个绑定到Customer对象的“绑定变量名”,该规则的LHS部分表示,要求Fact对象必须是Customer类型,该条件满足了那么它的LHS 会返回true。代码清单2-7演示了多个约束构成的LHS部分。
代码清单2-7:
rule"name"
when
$customer:Customer(age>20,gender==’male’);
Order(customer==$customer,price>1000);
then
end
代码清单2-7中的规则就包含两个pattern,第一个pattern有三个约束,分别是:对象
类型必须是Cutomer;同时Cutomer的age要大于20且gender要是male;第二个pattern 也有三个约束,分别是:对象类型必须是Order,同时Order对应的Cutomer必须是前面的那个Customer且当前这个Order的price要大于1000。在这两个pattern没有符号连接,在Drools当中在pattern中没有连接符号,那么就用and来作为默认连接,所以在该规则的LHS 部分中两个pattern只有都满足了才会返回true。默认情况下,每行可以用“;”来作为结束符(和Java的结束一样),当然行尾也可以不加“;”结尾。
2.2.1.1. 约束连接
对于对象内部的多个约束的连接,可以采用“&&”(and)、“||”(or)和“”(and)来实现,代码清单2-7中规则的LHS部分的两个pattern就里对象内部约束就采用“”来实现,“&&”(and)、“||”(or)和“”这三个连接符号如果没有用小括号来显示的定义优先级的话,那么
它们的执行顺序是:“&&”(and)、“||”(or)和“”。代码清单2-8演示了使用“&&”(and)、“||”(or)来连接约束的情形。
代码清单2-8:
rule"name"
when
Customer(age20 || gender==’male’&& city==’sh’);
then
end
代码清单2-8中规则的LHS部分只有一个pattern,在这个pattern中有四个约束,首先
必须是一个Customer对象,然后要么该对象gender=’male’且city=’sh’,要么age20,在Customer对象的字段约束当中,age20和gender=’male’且city=’sh’这两个有一个满足就可以了,这是因为“&&”连接符的优先级要高于“||”,所以代码清单2-8中规则的LHS 部分pattern也可以写成代码清单2-9的样子,用一小括号括起来,这样看起来就更加直观了。
代码清单2-9
rule"name"
when
Customer(age20 || (gender==’male’&& city==’sh’))
then
end
表面上看“”与“&&”具有相同的含义,但是有一点需要注意,“,”与“&&”和“||”不能混合使用,也就是说在有“&&”或“||”出现的LHS当中,是不可以有“,”连接符出现的,反之亦然。
2.2.1.2. 比较操作符
在前面规则例子当中,我们已经接触到了诸如“”、“= =”之类的比较操作符,在Drools5 当中共提供了十二种类型的比较操作符,分别是:、=、、、= =、!=、contains、not contains、memberof、not memberof、matches、not matches;在这十二种类型的比较操作符当中,前六个是比较常见也是用的比较多的比较操作符,本小节当中将着重对后六种类型的比较操作符进行介绍。
2.2.1.2.1. contains
比较操作符contains是用来检查一个Fact对象的某个字段(该字段要是一个Collection 或是一个Array类型的对象)是否包含一个指定的对象。代码清单2-10演示了contains比较操作符的用法。
代码清单2-10
package test
rule"rule1"
when
$order:Order();
$customer:Customer(age 20orders contains $order);
then
System.out.println($customer.getName());
End
contains操作符的语法如下:
Object(field[Collection/Array] contains value)
contains只能用于对象的某个Collection/Array类型的字段与另外一个值进行比较,作为比较的值可以是一个静态的值,也可以是一个变量(绑定变量或者是一个global对象),在代码清单2-10当中比较值$order就是一个绑定变量。
2.2.1.2.2. not contains
not contains作用与contains作用相反,not contains是用来判断一个Fact对象的某个字段(Collection/Array类型)是不是包含一个指定的对象,和contains比较符相同,它也只能用在对象的field当中,代码清单2-11演示了not contains用法。\
代码清单2-11:
package test
rule"rule1"
when
$order:Order(items not contains"手机");
then
System.out.println($customer.getName());
End
代码清单2-11的规则当中,在判断订单(Order)的时候,要求订单当中不能包含有“手机”的货物,这里的规则对于比较的项就是一个表态固定字符串。
2.2.1.2.
3. memberOf
memberOf是用来判断某个Fact对象的某个字段是否在一个集合(Collection/Array)当中,用法与contains有些类似,但也有不同.
memberOf的语法如下:
Object(fieldName memberOf value[Collection/Array])
可以看到memberOf中集合类型的数据是作为被比较项的,集合类型的数据对象位于memberOf操作符后面,同时在用memberOf比较操作符时被比较项一定要是一个变量(绑定变量或者是一个global对象),而不能是一个静态值。代码清单2-12是一个演示memberOf
使用的规则示例。
代码清单2-12:
package test
global String[] orderNames;
rule"rule1"
when
$order:Order(name memberOf orderNames);
then
System.out.println($order.getName());
End
代码清单2-12中被比较对象是一个String Array类型的global对象。
2.2.1.2.4. not memberOf
该操作符与memberOf作用洽洽相反,是用来判断Fact对象当中某个字段值是不是中某个集合(Collection/Array)当中,同时被比较的集合对象只能是一个变量(绑定变量或global 对象),代码清单2-13演示了not memberOf的用法。
代码清单2-13
package test
import java.util.List;
rule"rule1"
when
$orderList:String[]();
$order:Order(name not memberOf $orderList);
then
System.out.println($order.getName());
end
代码清单2-13中表示只有订单(Order)的名字(name)在订单集合($orderList)时
LHS才能返回true,该例子当中被比较的集合$orderList是一个字符串数组的类型的绑定
变量对象。
2.2.1.2.5. matches
matches是用来对某个Fact的字段与标准的Java正则表达式进行相似匹配,被比较的字符串可以是一个标准的Java正则表达式,但有一点需要注意,那就是正则表达式字符串当中不用考虑“\”的转义问题。matches使用语法如下:
代码清单2-14演示了matches的用法
代码清单2-14
package test
import java.util.List;
rule"rule1"
when
$customer:Customer(name matches"李.*");
then
System.out.println($order.getName());
end
在清单代码清单2-14中示例的规则就像我们展示了matches的用法,该规则是用来查
找所有Customer对象的name属性是不是以“李”字开头,如果满足这一条件那么就将该Customer对象的name属性打印出来,代码清单2-15是对该规则的测试类源码。
代码清单2-15
import java.util.Collection;
import org.drools.KnowledgeBase;
import org.drools.KnowledgeBaseFactory;
import org.drools.builder.KnowledgeBuilder;
import org.drools.builder.KnowledgeBuilderFactory;
import org.drools.builder.ResourceType;
import org.drools.io.impl.ClassPathResource;
import org.drools.runtime.StatefulKnowledgeSession;
import com.test.Customer;
public class Test {
public static void main(String[] args) {
KnowledgeBuilder kb =
KnowledgeBuilderFactory.newKnowledgeBuilder();
kb.add(new ClassPathResource("test/test.drl"),
ResourceType.DRL);
Collection collection = kb.getKnowledgePackages();
KnowledgeBase knowledgeBase =
KnowledgeBaseFactory.newKnowledgeBase();
knowledgeBase.addKnowledgePackages(collection);
StatefulKnowledgeSession statefulSession = knowledgeBase
.newStatefulKnowledgeSession();
Customer cus1 = new Customer();
cus1.setName("张三");
Customer cus2 = new Customer();
cus2.setName("李四");
Customer cus3 = new Customer();
cus3.setName("王二");
Customer cus4 = new Customer();
应用业务规则管理技术构建 灵活的BSS/OSS 何仁杰 3G不仅仅是一种新的无线技术,更是一种新的业务平台。许多新业务将随着3G的出现而应运而生。作为运营商,他们很难准确预知未来3G的新业务到底以何种业务策略进行运作,一切将由市场决定。因此一个能够灵活应对策略变化的业务运营支撑系统(BSS/OSS)对运营商来讲至关重要。经验证明,使用传统的系统开发思路和技术已无法满足运营商对灵活性的要求,业务规则管理技术作为一种经过实践考验的技术在灵活性和应对市场变化方面体现出了独特的优势。 四层结构的BSS/OSS 目前,许多BSS/OSS都实现了三层结构,即接入层(包括展现层)、应用逻辑层和数据层。三层结构由于使用了数据库管理系统(DBMS),很好地实现了数据集中管理和数据在应用层上的共享,使新应用的添加和修改比传统方式方便了许多。但是这种三层结构系统在灵活性方面还是存在着瓶颈,主要表现在: 1)业务规则还是驻留在程序中,无法被有效的管理。规则无法被查询、无法被共享。 2)业务规则的实现非常复杂繁琐。几乎很难解决规则之间的复杂关联关系(如互斥、并发、顺序、多选一等)。 3)业务规则的维护十分困难,在程序代码级上的规则维护不仅耗时,而且风险很大。虽然有些系统使用了所谓的参数化和模板化来试图提供灵活性,但经验证明,这种方式的效果依然有限。 4)业务人员无法接触到他们的业务规则。更无从参与业务规则的开发。 由于业务规则在BSS/OSS中是最活跃的元素,为了能够真正实现灵活性,我们必须把业务规则作为一种特殊的“对象”转移到程序之外,在一个特殊的层面,即“业务规则层”上进行管理。这个“业务规则层”结合原来三层结构中的“接入层”、“应用层”和“数据层”就构成了四层结构的 BSS/OSS。 业务规则层与其它层的最大区别在于它完全向精通业务策略的非技术人员开放。过去所有的开发工作都由IT人员承担;现在,通过业务规则层上提供的各种服务(Service),业务人员可以参与规则的开发和管理。 四层结构的好处不言而喻:它实现了业务规则的集中统一的控制,实现了规则的共享和复用、缩短了的业务策略的定制周期,改变了业务规则的开发方式。这种结构使得运营商们第一次有机会能够把业务规则变化成他们的特殊资产,第一次能够自如地调整他们的运营策略。
Drools规则引擎 1. 概述: Drools分为两个主要部分:构建(Authoring)和运行时(Runtime)。 构建的过程涉及到.drl或.xml规则文件的创建,它们被读入一个解析器,使用ANTLR 3 语法进行解析。解析器对语法进行正确性的检查,然后产生一种中间结构“descr”,descr 用AST来描述规则。AST然后被传到PackageBuilder,由PackagBuilder来产生Packaged对象。PackageBuilder还承担着一些代码产生和编译的工作,这些对于产生Package对象都时必需的。Package对象是一个可以配置的,可序列化的,由一个或多个规则组成的对象。下图阐明了上述过程: Figure 1.1 Authoring Components RuleBase 是一个运行时组件,它包含了一个或多个 Package 对象。可以在任何时刻将一个 Package 对象加入或移出 RuleBase 对象。一个 RuleBase 对象可以在任意时刻实例化一个或多个 WorkingMemory 对象,在它的内部保持对这些WorkingMemory 的弱引用。 WorkingMemory 由一系列子组件组成。当应用程序中的对象被 assert 进 WorkingMemory ,可能会导致一个或多个 Activation 的产生,然后由 Agenda 负责安排这些 Activation 的执行。下图说明了上述过程:
Figure 1.2 . Runtime Components 2.构建(Authoring): 主要有三个类用来完成构建过程:DrlParser, XmlParser 和 PackageBuilder。两个解析器类从传入的Reader实例产生descr AST模型。PackageBuilder提供了简便的API,使你可以忽略那两个类的存在。这两个简单的方法是:“addPackageFromDrl”和“addPackageFromXml”,两个都只要传入一个Reader 实例作为参数。下面的例子说明了如何从classpath中的xml和drl文件创建一个Package对象。注意:所有传入同一个PackageBuilder实例的规则源,都必须是在相同的package 命名空间(namespace)中。 PackageBuilder builder = new PackageBuilder(); builder.addPackageFromDrl( new InputStreamReader( getClass().getResourceAsStream( " package1.drl" ) ) ); builder.addPackageFromXml( new InputStreamReader( getClass().getResourceAsStream( " package2.drl" ) ) ); Package pkg = builder.getPackage();
ILOG 规则引擎系统运维手册 一、 ILOG 规则引擎系统介绍 ? 为什么使用ILOG 规则引擎系统? 保险行业是大量业务规则的处理过程,投承保规则、保费计算规则、核保规则、核批规则、费用规则、核赔规则。。。业务规则无所不在,且随着行业监管、市场环境、业务管理等因素不断变化。 业务规则管理混乱、业务规则变更过分依赖技术人员,业务人员无法单独完成业务规则变更,维护成本高昂,由此带来的问题: ? 业务规则变更周期长、成本高 ? 规则重用性差 ? 业务规则知识随着时间被淡忘 基于ILOG 的规则管理,可实现: ? 业务规则与保险应用剥离,业务规则易于管理 ? 使用集中规则库进行管理,业务人员可单独变更业务规则 ? 实现历史规则追溯 ? 规则可重用 ? 缩短新业务发布周期 ? ILOG 在都邦保险的运用 Ilog 规则引擎系统目前维护的规则有车险核保规则和车险费用规则。 自动核保规则是指根据某些核保因子判断当前保单是否能够自动核保通过或者不能够自动核保通过的规则。 其中,不能够自动核保通过的规则,一般又分为数据校验规则、打回出单规则以及自动核保校验规则(转人工核保)等。 人工核保权限规则是指在人工核保环节,不同级别的核保员具有不同的核保权限,配置不同级别的核保员核保权限的规则就是人工核保权限规则。 ? 产品组件 Rule Studio (规则开发环境) 用于对基于规则的应用程序进行编码、调试和部署; Rule Execution Server (规则执行服务器) RES 执行部署的规则应用,业务规则调用的组件,并包括一个web 的管理控制台,业务人员/技术人员编写的业务规则只有部署在规则的执行环境中才能被执行,才能起到作用; 核保规则 自动核保规则 人工核保规则 ——维护各核保级别的权限 打回出单(数据校验或拒保)规则 转人工核保规则 自动核保通过规则
规则引擎Version 1.0.0 作者:Johnny Leon发布日期:2016-08—08
目录 1 业务规则?错误!未定义书签。 1.1?什么是业务规则 ............................................................................... 错误!未定义书签。 1。2?业务规则的例子?错误!未定义书签。 1。3?业务规则的分类?错误!未定义书签。 1.4 业务规则的特性?错误!未定义书签。1.5?业务规则的要素 .......................................................................... 错误!未定义书签。 2 规则引擎?错误!未定义书签。 2.1 规则引擎是什么?错误!未定义书签。 2.2?规则引擎的组成?错误!未定义书签。 2。3 规则引擎的推理?错误!未定义书签。 2.4 规则引擎的应用 ........................................................................... 错误!未定义书签。 2.5 业务规则的提取?错误!未定义书签。 2。6?业务规则的管理?错误!未定义书签。 3?典型案例?错误!未定义书签。案例1:信用卡申请 ................................................................................ 错误!未定义书签。 案例2:企业薪资计算?错误!未定义书签。 案例3:保险公司核保理赔?错误!未定义书签。案例4:快递产品报价 ............................................................................... 错误!未定义书签。案例5:电商促销 ....................................................................................... 错误!未定义书签。
规则引擎研究——Rete算法介绍 一、R ETE概述 Rete算法是一种前向规则快速匹配算法,其匹配速度与规则数目无关。Rete是拉丁文,对应英文是net,也就是网络。Rete算法通过形成一个rete网络进行模式匹配,利用基于规则的系统的两个特征,即时间冗余性(Temporalredundancy)和结构相似性(structuralsimilarity),提高系统模式匹配效率。 二、相关概念 2.1事实(FACT): 事实:对象之间及对象属性之间的多元关系。为简单起见,事实用一个三元组来表示:(identifier^attributevalue),例如如下事实: w1:(B1^onB2)w6:(B2^colorblue) w2:(B1^onB3)w7:(B3^left-ofB4) w3:(B1^colorred)w8:(B3^ontable) w4:(B2^ontable)w9:(B3^colorred) w5:(B2^left-ofB3) 2.2规则(RULE): 由条件和结论构成的推理语句,当存在事实满足条件时,相应结论被激活。一条规则的一般形式如下: (name-of-this-production LHS/*oneormoreconditions*/ --> RHS/*oneormoreactions*/ ) 其中LHS为条件部分,RHS为结论部分。 下面为一条规则的例子: (find-stack-of-two-blocks-to-the-left-of-a-red-block (^on) (^left-of) (^colorred) -->
...RHS... ) 2.3模式(PATTEN): 模式:规则的IF部分,已知事实的泛化形式,未实例化的多元关系。 (^on) (^left-of) (^colorred) 三、模式匹配的一般算法 规则主要由两部分组成:条件和结论,条件部分也称为左端(记为LHS,left-handside),结论部分也称为右端(记为RHS,right-handside)。为分析方便,假设系统中有N条规则,每个规则的条件部分平均有P个模式,工作内存中有M个事实,事实可以理解为需要处理的数据对象。 规则匹配,就是对每一个规则r,判断当前的事实o是否使LHS(r)=True,如果是,就把规则r的实例r(o)加到冲突集当中。所谓规则r的实例就是用数据对象o的值代替规则r的相应参数,即绑定了数据对象o的规则r。 规则匹配的一般算法: 1)从N条规则中取出一条r; 2)从M个事实中取出P个事实的一个组合c; 3)用c测试LHS(r),如果LHS(r(c))=True,将RHS(r(c))加入冲突集中; 4)取出下一个组合c,goto3; 5)取出下一条规则r,goto2; 四、RETE算法 Rete算法的编译结果是规则集对应的Rete网络,如下图。Rete网络是一个事实可以在其中流动的图。Rete网络的节点可以分为四类:根节点(root)、类型节点(typenode)、alpha节点、beta节点。其中,根结点是一个虚拟节点,是构建rete网络的入口。类型节点中存储事实的各种类型,各个事实从对应的类型节点进入rete网络。 4.1建立RETE网络 Rete网络的编译算法如下: 1)创建根; 2)加入规则1(Alpha节点从1开始,Beta节点从2开始); a.取出模式1,检查模式中的参数类型,如果是新类型,则加入一个类型节点;
Java规则引擎工作原理及其应用 作者:缴明洋谭庆平出处:计算机与信息技术责任编辑:方舟[ 2006-04-06 08:18 ] Java规则引擎是一种嵌入在Java程序中的组件,它的任务是把当前提交给引擎的Java数据对象与加载在引擎中的业务规则进行测试和比对 摘要Java规则引擎是一种嵌入在Java程序中的组件,它的任务是把当前提交给引擎的Java数据对象与加载在引擎中的业务规则进行测试和比对,激活那些符合当前数据状态下的业务规则,根据业务规则中声明的执行逻辑,触发应用程 序中对应的操作。 引言 目前,Java社区推动并发展了一种引人注目的新技术——Java规则引擎(Rule Engine)。利用它就可以在应用系统中分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时可以动态地管理和修改,从而为企业保持灵活性和竞争力 提供有效的技术支持。 规则引擎的原理 1、基于规则的专家系统(RBES)简介 Java规则引擎起源于基于规则的专家系统,而基于规则的专家系统又是专家系统的其中一个分支。专家系统属于人工智能的范畴,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。为了更深入地了解Java规则引擎,下面简要地介绍基于规则的专家系统。RBES包括三部分:Rule Base(knowledge base)、Working Memory(fact base)和Inference Engine。它们的结构如下系统所示: 图1 基于规则的专家系统构成 如图1所示,推理引擎包括三部分:模式匹配器(Pattern Matcher)、议程(Agenda)和执行引擎(Execution Engine)。推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。模式
Drools规则动态更新 在常规开发方式中,如果涉及规则的变更(比如将物流费用从6元调整为8元),可以通过重新完成规则的开发并发布应用来更新。或在设计上,将可能变更的规则以配置(比如数据库)方式管理。发生规则变更时,只需修改配置即可。事实上,Drools提供了另一种规则更新的方式--扫描Maven仓库(本地或远程)来自动发现规则模块的更新。 我们知道,Drools可以利用KieServices来创建基于classpath的KieContainer(即使用KieServices.newKieClasspathContainer()方法)。其实,KieServices还提供了从Maven 仓库加载并创建KieContainer的方法--newKieContainer(ReleaseId)。与通过classpath 创建KieContainer类似,使用Maven仓库加载的方法,会尝试读取对应jar包中的META-INF/kmodule.xml文件,基于此,我们可以完成KieSession的创建。 我们通过一个简单的例子来观察规则的动态更新。在这个例子中,我们会将商品的折扣进行动态调整。我们需要构建规则,并安装到Maven仓库中--简单起见,我们将应用发布到本地Maven仓库中。首先,我们创建一个Maven项目: $mvn-B archetype:generate-DarchetypeGroupId=org.apache.maven.archetypes\ -DgroupId=com.sharp.rules-DartifactId=discount 如果没什么问题,我们可以得到一个名为discount的文件夹,其中的pom.xml看起来像这样:
基于SaaS的规则引擎在企业流程中的应用引言规则引擎原理流程应用基于saas的模式意义 1、引言 目前,B2B电子商务平台发展了大量的中小企业用户,提供具有共性的信息管理服务,但是这些服务对于特定用户来说,无法根据该用户的业务流程来构造与其自身业务相匹配的管理过程;同时,平台亦无法应对会员企业将来发展带来的管理过程的不断变化。 在这种情况下,为中小企业用户提供个性化的服务,对企业的意义是非常重大的。 尽管现在有些软件开发商为企业提供量身定制的功能需要,但这种方式开发成本很高,而且基本上是按照当时或者用户可以预见的方式进行开发,不可避免的出现一些弊端:(1)需要安装专门的管理系统软件,维护困难; (2)功能的灵活性较小,只能符合某些行业的特点,不符合B2B电子商务平台上广大行业的需求; (3)功能的配置操作复杂,不利于中小企业用户的使用; (4)功能维护和修改的成本高。 为了解决上述弊端,基于SaaS的业务规则引擎的方法被提了出来,这种方法充分利用了SaaS(软件即服务)的特点,不需要在中小企业的计算机上安装任何软件,把系统的日常维护工作都交给软件服务运营商;而且使用成本低廉,符合中小企业的信息化成本要求。同时通过企业业务流程与规则引擎的结合应用,把商业规则与应用开发代码,让中小企业的工作人员能在运行时可以动态地管理和修改商业规则,保证了软件系统的柔性和自适应性,使电子商务平台为中小企业用户提供个性化的服务打下了良好的基础。 2、业务流程与规则引擎 2.1 业务流程与流程引擎 业务流程属于工作流的范畴。工作流指全部或者部分由计算机自动处理的业
务过程。而工作流管理系统是这样的一个系统:详细定义、管理并执行“工作流”,系统通过运行一些软件来执行工作流,这些软件的执行顺序由工作流逻辑的计算机表示形式(流程定义)来驱动。 工作流系统与业务系统的关系如下图所示: 国际标准化组织WFMC(工作流管理联盟)发布了一个通用的工作流系统实现模型,这个模型可以适用于市场上的大多数产品,因此为开发协同工作的工作流系统奠定了基础。 把工作流系统中的主要功能组件,以及这些组件间的接口看成抽象的模型。考虑到会有许多其他的具体实现不同于这个抽象模型,因此,特定的接口在不同的平台中会采用不同的技术,有不同的实现方式。而且并不是所有的开发商都会暴漏功能组件间的每一个接口,具体的规范会定义接口之间的相互操作功能,不同的厂商必须支持这些开放接口才能实现不同工作流之间的协作。 通用的工作流系统实现参考模型如下所示:
中国XXXXXXXX系统 for J2EE 规则引擎解决方案调研报告 Version 1.0
目录 1.规则引擎4 1.1概述4 2.应用方案的一般实现5 2.1建立规则集7 2.2部署规则集7 2.3规则服务接口-JSR94 7 2.4对规则的计算7 2.5规则的过滤8 2.6使用计算结果8 3.现有的商业解决方案8 3.1ILOG新产品ILOGJRules8 3.2操作人员已经显示提单列表错误!未定义书签。 4.其它解决方案10 4.1提单和报检单完成对碰10 5.评估11
规则引擎解决方案调研报告 1. 规则引擎 规则引擎是解决可变的商业规则的问题的 1.1 概述 规则引擎(Rules Engine)的运作机制是在内存中向对象应用一套规则。首先内存使用来自调用对象的输入,例如用户档案请求会话。这样,在任何规则实际激活之前,在内存中就已经有了一份用户档案的内容。 规则只能在一个上下文环境中执行,上下文环境把规则集和内存关联起来。该环境提供了到Rules Engine的接口,Rules Engine控制着应用程序的规则部分与内存之间的关系。 内存由生产规则(production rules)负责操作,生产规则包含在规则集里。,依照规则的左半边(left-hand sides,LHS)针对内存中的对象进行计算。如果内存中的对象与LHS中描述的模式匹配,就会触发规则的右半边(right-hand side,RHS)指定的操作。此外某些操作可能会在内存中加入新的对象。例如,规则 Classifier 对用户年龄进行测试,如果 USER.age > 45,就在内存中加入一个新的Classification 对象。 生产系统的运行,要执行以下操作: 1.匹配: 估计规则的LHS,判断哪个规则与当前内存中的内容匹配。 2.冲突解决:选择一个LHS匹配的规则。如果没有规则匹配,就停止解释。 3.操作: 执行选中规则RHS中指定的动作。 4.返回第1步。 规则会一直在内存中执行,直到冲突解决集变为0时才停止(也就是没有规则能激活了)。 在Rules Engine停止之后,规则管理器组件会返回一个对象列表,列表中包含内存中仍然存在的对象。一个可能的场景就是,还剩下一个类型为“Classification”或“ContentQuery”的对象。 Rules Manager接着对剩下的对象进行迭代,用可选的对象过滤器过滤它们。过滤器可以有选择地忽略某些对象或者对某些对象进行变换。 1.2 规则引擎分类 值得注意的是,存在不同类型的规则引擎,在决定如何应用一种工具之前理解这种工具的用途是极其重要的。当您跨业务规则领域进行调查研究时,您将注意到这些工具可以分为以下几类: ?简单业务规则(simple business rule)——通过一张简化的、直观的词汇表来表达并且是在应用程序或业务流程的可变性情况下调用的一种业务规则。这种规则引擎的一个很好的例子就是 ilog、Blaze 和 IBM 的 BRBeans。
前一段时间在开发了一个做文本分析的项目。 在项目技术选型的过程中, 尝试使用了 Drools 规则引擎。让它来作为项目中有关模式分析和关键词匹配的任务。但后来,因为某种原因, 还是撇开 了 Drools 。现将这个过程中使用 Drools 的一些经验和心得记录下来。 (一)什么时候应该使用规则引擎 ~这实际是一个技术选型的问题。 但这个问题又似乎是一个很关键的问题 (一旦返工的话, 你就知道这个问题是多么重要了)。不知大家有没有过这样的经验和体会。 往往在项目开始 的时候,总会遇到应该选用什么技术?是不是应该使用最新的技术?或者应该选用什么技术 呢(PS : 现在计算机软件中的各种技术层出不穷,具有类似功能的技术很多 )? 不管怎么样,这些问题总会困扰着我。比如,这次的这个项目。项目要求是要在一些 文件中(这些log 文件都是很大的应用系统所产生的,但由于legacy 的原因,log 本身的维 护 和规范工作一直没有得到改善,所以想借助于一些外部应用对这些 log 做以分析和清洗) 抽取出有用的信息。 于是,第一个想到的就是,这是一个文本挖掘类的项目。但又想,要抽取有用信息,必 须得建立一些规则或 pattern (模式)。所以,我第一个想到了规则引擎。因为这里面要建 立好多规则,而这些规则可以独立于代码级别( 引擎去解析和执行。另一个重要的原因是,我原来用 过,比较熟悉。这样,也可以节省开发 时间吧。于是,好不犹豫的就开始做了 Demo.... 但事实上,在经历了一个多星期的编码、 测试后,我发现运用规则引擎实在是太笨拙了。 (1)首先必须建立一些数据模型。通过这些模型来 refer 规则文件中的LHS 和Action 。 (2 )还要考虑规则的 conflict 。如果有一些规则同时被触发,就要考虑设定规则的优先 级或者 是设定activiation-group 来保证在一个group 中的规则只有一个规则可以被触发。 (3)对于 流'规则group ruleflow-group 的使用。如果要控制在 workingmemory 中的规 则被触发的顺序,则可以将这些规则分组。然后, 通过规则建模的方式来实现。但这也添加 了一定的effort 。修改或者更新不大方便。 ~所以,基于上述体会,我更认为规则引擎更适用于那些对非流程性规则匹配的应用。当 然,Drools 也支持对流程性规则的建模过程。但,这也许不是最好的方式。 (二) Drools 规则引擎的使用杂记 (1) Fact 的变更监听。在Drools 里,如果一个Fact 通过规则而改变,则需将这种 改变通知 给规则引擎。这里,一般有两种方式:显式和隐式。 显式---在drl 文件中通过 up date 、modify 来通知;在程序中,通过 Fact 的引用调用 modifyObject 等方法来实现。 隐式---通过在Java bea n 实现property Liste ner In terface 来让引擎自动监听到属性 值的变化。我更习惯于这种方式。因为,一般看来凡是在规则引擎中添加到 fact 都是希望 引擎来帮你进行管理的。所以,那它自己看到 fact 的变化是种很省事的办法。也很简单, 就是用Java bean property 监听的方式。 通过 StatefulSession 来注册。 调用 StatefulSession 的某个 instanee 的 insert ( Object ,true )实现。而这个 object 是一个java bean 。其中,要实现 P rivate final Prop ertyCha ngeS upport cha nges Prop ertyCha ngeS upp ort( this ); public void add PropertyChangeListener(final PropertyChangeListener l) { this.cha nges.add Prop ertyCha ngeListe ner( l ); log 放到一个单独的drl 文件里)并可以用规则 =new
规则引擎原理 本文对Java规则引擎与其API(JSR-94)及相关实现做了较详细的介绍,对其体系结构和API应用有较详尽的描述,并指出Java规则引擎,规则语言,JSR-94的相互关系,以及JSR-94的不足之处和展望。 复杂企业级项目的开发以及其中随外部条件不断变化的业务规则(businesslogic),迫切需要分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时(即商务时间)可以动态地管理和修改从而提供软件系统的柔性和适应性。规则引擎正是应用于上述动态环境中的一种解决方法。 本文第一部分简要介绍了规则引擎的产生背景和基于规则的专家系统, 第二部分介绍了什么是规则引擎及其架构和算法, 第三部分介绍了商业产品和开源项目实现等各种Java规则引擎, 第四部分对Java规则引擎API(JSR-94)作了详细介绍,讲解了其体系结构,管理API 和运行时API及相关安全问题, 第五部分则对规则语言及其标准化作了探讨, 第六部分给出了一个使用Java规则引擎API的简单示例, 第七部分给予小结和展望。 1.介绍 1.1. 规则引擎产生背景 企业管理者对企业级IT系统的开发有着如下的要求: (1)为提高效率,管理流程必须自动化,即使现代商业规则异常复杂 (2)市场要求业务规则经常变化,IT系统必须依据业务规则的变化快速、低成本的更新 (3)为了快速、低成本的更新,业务人员应能直接管理IT系统中的规则,不需要程序开发人员参与。 而项目开发人员则碰到了以下问题: (1)程序=算法+数据结构,有些复杂的商业规则很难推导出算法和抽象出数据模型 (2)软件工程要求从需求->设计->编码,然而业务规则常常在需求阶段可能还没有明确,在设计和编码后还在变化,业务规则往往嵌在系统各处代码中 (3)对程序员来说,系统已经维护、更新困难,更不可能让业务人员来管理。 基于规则的专家系统的出现给开发人员以解决问题的契机。规则引擎由基于规则的专家系统中的推理引擎发展而来。下面简要介绍一下基于规则的专家系统。
Drools是一个基于java的规则引擎,开源的,可以将复杂多变的规则从硬编码中解放出来,以规则脚本的形式存放在文件中,使得规则的变更不需要修正代码重启机器就可以立即在线上环境生效。 1、Drools语法 开始语法之前首先要了解一下drools的基本工作过程,通常而言我们使用一个接口来做事情,首先要穿进去参数,其次要获取到接口的实现执行完毕后的结果,而drools也是一样的,我们需要传递进去数据,用于规则的检查,调用外部接口,同时还可能需要获取到规则执行完毕后得到的结果。在drools 中,这个传递数据进去的对象,术语叫Fact对象。Fact 对象是一个普通的java bean,规则中可以对当前的对象进行任何的读写操作,调用该对象提供的方法,当一个java bean插入到workingMemory中,规则使用的是原有对象的引用,规则通过对fact对象的读写,实现对应用数据的读写,对于其中的属性,需要提供getter setter访问器,规则中,可以动态的往当前workingMemory中插入删除新的fact对象。 规则文件可以使用 .drl文件,也可以是xml文件,这里我们使用drl文件。规则语法: package:对一个规则文件而言,package是必须定义的,必须放在规则文件第一行。特别的是,package的名字是随意的,不必必须对应物理路径,跟java 的package的概念不同,这里只是逻辑上的一种区分。同样的package下定义的function和query等可以直接使用。 比如:package com.drools.demo.point import:导入规则文件需要使用到的外部变量,这里的使用方法跟java相同,但是不同于java的是,这里的import导入的不仅仅可以是一个类,也可以是这个类中的某一个可访问的静态方法。 比如: import com.drools.demo.point.PointDomain; import com.drools.demo.point.PointDomain.getById; rule:定义一个规则。rule "ruleName"。一个规则可以包含三个部分: 属性部分:定义当前规则执行的一些属性等,比如是否可被重复执行、过期时间、生效时间等。 条件部分,即LHS,定义当前规则的条件,如 when Message(); 判断当前workingMemory中是否存在Message对象。 结果部分,即RHS,这里可以写普通java代码,即当前规则条件满足后执行的操作,可以直接调用Fact对象的方法来操作应用。
基于Java的规则引擎
目录 1.简介 (3) 1.1业务规则 (3) 1.2规则引擎产生背景 (3) 2.规则引擎 (4) 2.1业务规则 (4) 2.2规则引擎 (4) 2.3规则引擎的使用方式 (4) 2.4规则引擎架构与推理 (5) 2.5规则引擎的算法 (6) 3.Java规则引擎 (7) 3.1Java规则引擎商业产品 (7) 3.2规则引擎产品特点分析 (8) 3.2.1IBM WebSphere ILOG JRules (8) 3.2.2Redhat JBoss Dools (11) 3.2.3JESS (11) 4.Java规则引擎API(JSR94) (13) 4.1简介 (13) 4.2简介Java规则引擎API体系结构 (13) 3.2.4规则管理API (13) 3.2.5运行时API (14) 4.3Java规则引擎API安全问题 (15) 4.4异常与日志 (15) 4.5JSR94小结 (16) 5规则语言 (17)
1.简介 1.1业务规则 一个业务规则包含一组条件和在此条件下执行的操作.它们表示业务规则应用程序的一段业务逻辑。业务规则通常应该由业务分析人员和策略管理者开发和修改,但有些复杂的业务规则也可以由技术人员使用面向对象的技术语言或脚本来定制。 业务规则的理论基础是:设置一个或多个条件,当满足这些条件时会触发一个或多个操作。 1.2规则引擎产生背景 复杂企业级项目的开发以及其中随外部条件不断变化的业务规则(business logic),迫切需要分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时(即商务时间)可以动态地管理和修改从而提供软件系统的柔性和适应性。规则引擎正是应用于上述动态环境中的一种解决方法。 企业管理者对企业级IT系统的开发有着如下的要求: 1.为提高效率,管理流程必须自动化,即使现代商业规则异常复杂; 2.市场要求业务规则经常变化,IT系统必须依据业务规则的变化快速、低成本的更 新; 3.为了快速、低成本的更新,业务人员应能直接管理IT系统中的规则,不需要程序 开发人员参与。 而项目开发人员则碰到了以下问题: 4程序=算法+数据结构,有些复杂的商业规则很难推导出算法和抽象出数据模型; 5软件工程要求从需求->设计->编码,然而业务规则常常在需求阶段可能还没有明确,在设计和编码后还在变化,业务规则往往嵌在系统各处代码中; 6对程序员来说,系统已经维护、更新困难,更不可能让业务人员来管理。 基于规则的专家系统的出现给开发人员以解决问题的契机。规则引擎由基于规则的专家系统中的推理引擎发展而来。
业务规则配置操作说明 一、业务规则配置相关的功能模块 组织机构→机构管理:该模块主要是对全辖社(合行)的网点进行地区发展分类,系统最多可分为五类:分别为A 发达地区、B较发达地区、C发展中地区、D 欠发达地区、E 不发达地区。此模块主要业务规则中对各分类地区网点的贷款审批额度的授权。 组织机构→用户管理:该模块主要是对用户岗位的配置,即在流程审批过程中各用户的权限。主要岗位为:受理申请(受理岗)、提交申请(出账申请岗)、提交申请(贷后检查岗)、提交申请(调查岗)、调查分析(调查岗)、调查分析(接收方调查岗)、调查分析(移交方调查岗)、审核(调查主管)、审查(出账审查岗)、审查(审查岗)、审查(稽核岗)、审查(信用等级评审秘书岗)、审核(审查主管)、审核(接收方主任岗)、审核(资产保全岗)、审核(资产保全主管)、审核(风险审核岗)、审核(风险审核主管)、审查(贷款审批秘书岗)、审查(不良贷款责任认定秘书岗)、审核(风险审核秘书岗)、审核(副主任岗)、审核(主任岗)、审核(不良贷款责任认定)、审批、上报审核。 资源管理→机构组配置:该模块主要是业务规则的配置。各联社(合行总行)业务主管部门的系统维护员根据联社(合行总行)的业务授权书进行业务规则配置。授权书一般有两份:一份为联社(合行总行)理事长授权给本级主任(行长)授权书;一份为联社(合行总行)主任(行长)转授权给基层网点主任(支行行长)的授权书。 二、业务规则配置操作 1、机构配置组:主要是根据授权书的授权范围建立机构组。如:联社(合行总行)这一级的联社理事长对联社主任(或联社主任对分管的联社副主任)的授权分为一组(图1);联社主任转授权给基层网点(支行)的可按地区发展分类建立机构组(图2),对基层网点有统一授权的独立建立机构组(图3)。 (图1)联社(合行总行)本级授权
中国XXXXXXXX系统 for J2EE 错误!未指定书签。 Version 1.0
目录 1.规则引擎4 1.1概述4 2.应用方案的一般实现5 2.1建立规则集7 2.2部署规则集7 2.3规则服务接口-JSR94 7 2.4对规则的计算7 2.5规则的过滤8 2.6使用计算结果8 3.现有的商业解决方案8 3.1ILOG新产品ILOGJRules8 3.2操作人员已经显示提单列表错误!未定义书签。 4.其它解决方案10 4.1提单和报检单完成对碰10 5.评估11
错误!未指定书签。 1. 规则引擎 规则引擎是解决可变的商业规则的问题的 1.1 概述 规则引擎(Rules Engine)的运作机制是在内存中向对象应用一套规则。首先内存使用来自调用对象的输入,例如用户档案请求会话。这样,在任何规则实际激活之前,在内存中就已经有了一份用户档案的内容。 规则只能在一个上下文环境中执行,上下文环境把规则集和内存关联起来。该环境提供了到Rules Engine的接口,Rules Engine控制着应用程序的规则部分与内存之间的关系。 内存由生产规则(production rules)负责操作,生产规则包含在规则集里。,依照规则的左半边(left-hand sides,LHS)针对内存中的对象进行计算。如果内存中的对象与LHS中描述的模式匹配,就会触发规则的右半边(right-hand side,RHS)指定的操作。此外某些操作可能会在内存中加入新的对象。例如,规则 Classifier 对用户年龄进行测试,如果 USER.age > 45,就在内存中加入一个新的Classification 对象。 生产系统的运行,要执行以下操作: 1.匹配: 估计规则的LHS,判断哪个规则与当前内存中的内容匹配。 2.冲突解决:选择一个LHS匹配的规则。如果没有规则匹配,就停止解释。 3.操作: 执行选中规则RHS中指定的动作。 4.返回第1步。 规则会一直在内存中执行,直到冲突解决集变为0时才停止(也就是没有规则能激活了)。 在Rules Engine停止之后,规则管理器组件会返回一个对象列表,列表中包含内存中仍然存在的对象。一个可能的场景就是,还剩下一个类型为“Classification”或“ContentQuery”的对象。 Rules Manager接着对剩下的对象进行迭代,用可选的对象过滤器过滤它们。过滤器可以有选择地忽略某些对象或者对某些对象进行变换。 1.2 规则引擎分类 值得注意的是,存在不同类型的规则引擎,在决定如何应用一种工具之前理解这种工具的用途是极其重要的。当您跨业务规则领域进行调查研究时,您将注意到这些工具可以分为以下几类: 简单业务规则(simple business rule)——通过一张简化的、直观的词汇表来表达并且是在应用程序或业务流程的可变性情况下调用的一种业务规则。这种规则引擎的一个很好的例子就是 ilog、Blaze 和 IBM 的 BRBeans。
国内外主流工作流引擎及规则引擎分析2013年2月创新研发部
目录
一.背景 目前中心建成的“一大核心系统,七大共享平台”以及OA系统,对工作流应用程度高,但各系统实现工作流程管理没有建立在统一的工作流平台上,导致流程割裂、重复开发、不易于管理等问题。 备付金管控项目涉及多个岗位之间工作的审核步骤,同时还要与多个系统进行交互,因此,为了提高管理效率,降低业务流转时间,同时还要结合农信银中心的总体IT战略规划,备付金管控项目技术组决定选择一款先进的工作流引擎和一款规则引擎,作为备付金管控项目的核心技术架构。 二.原则 备付金管控项目组通过梳理各信息系统流程现状和未来需求,形成农信银中心工作流平台的发展规划,从而更全面的满足农信银各项关键业务、更好的支撑现有和未来的信息系统建设。项目组充分研究国内外领先的工作流产品和案例,同厂商交流。从用户界面生成、流程建模、流程引擎、规则引擎、组织模型、模拟仿真、后端集成/SOA、变更及版本管理、移动设备解决方案、监控分析能力等多方面考察工作流产品,进行工作流产品选型。 目前国内外的工作流引擎层出不穷,行业标准多种多样,通过对比不同工作流公司产品,本次工作流技术选型决定分析商业工作流引擎4款,开源工作流引擎2款。其中国际知名厂商的商业工作流引擎2款,本土厂商的商业工作流引擎2款。由于本次技术选型是以工作流引擎为主,选型工作将不再单独分析规则引擎,而是直接使用与所选工作流引擎搭配最好的或者是同一厂商的规则引擎。根据国内外知名度、厂商的规模和与符合农信银中心的SOA体系架构等原则,将选取以下6种工作流引擎与规则引擎进行研究与分析:
规则引擎 Version 1.0.0 作者:Johnny Leon 发布日期:2016-08-08
目录 1业务规则 (3) 1.1什么是业务规则 (3) 1.2业务规则的例子 (3) 1.3业务规则的分类 (3) 1.4业务规则的特性 (4) 1.5业务规则的要素 (4) 2规则引擎 (5) 2.1规则引擎是什么 (5) 2.2规则引擎的组成 (6) 2.3规则引擎的推理 (6) 2.4规则引擎的应用 (7) 2.5业务规则的提取 (9) 2.6业务规则的管理 (10) 3典型案例 (10) 案例1:信用卡申请 (11) 案例2:企业薪资计算 (13) 案例3:保险公司核保理赔 (13) 案例4:快递产品报价 (14) 案例5:电商促销 (14)
1业务规则 1.1什么是业务规则 与业务相关的操作规范、管理章程、规章制度、行业标准等,都可以称为业务规则(Business Rules ,简称BR)。业务规则描述了业务过程中重要的且值得记录的对象、关系和活动。其中包括业务操作中的流程、规范与策略。业务规则保证了业务能满足其目标和义务。 业务规则实质上也可以理解为一组条件和在此条件下的操作,是一组准确凝练的语句,用于描述、约束及控制企业的结构、运作和战略,是应用程序中的一段业务逻辑。该业务逻辑通常由业务人员、企业的管理人员和程序开发人员共同开发和修改。 业务规则的理论基础是:设臵一个条件集合,当满足这个条件集合时候,触发一个或者多个动作。 以规则形式捕捉策略语句能提供极大的灵活性和良好的适应性,是企业保持竞争优势的决定性因素。在市场驱动的情况下,系统架构和模型必须对客户、竞争对手、合作伙伴和整个市场情况的各种变更及时响应,同时将这些变更产生的需求作为业务规则体现到系统中去。 业务规则技术的基本思想是将系统处理的业务逻辑从程序代码中抽取出来,将其转变为简单的业务规则,以结构化的业务规则数据来表示业务行为,采用类自然语言来描述,并集中存储在规则库中。业务规则由业务人员创建、实时更新和调试,业务规则之问的复杂逻辑关系由规则引擎处理。业务规则技术改变了传统的、以过程形式处理业务逻辑的方式。1.2业务规则的例子 生活中的一些业务规则可能是: 当顾客进入店内,最近的员工须向顾客打招呼说:“欢迎来到×××”。 当客户兑换超过200元的奖券时,柜员须要求查看客户的身份证并复印。 当兑换的奖券金额小于25元时,无需客户签字。 早上第一个进办公室的人需要把饮水机加热按钮打开。 找一些数据相关的业务规则,一些例子如下: ?只有当客户产生第一个订单时才创建该客户的记录。 ?若一名学生没有选任何一门课程,把他的状态字段设为空。 ?若销售员在一个月中卖出10套沙发,奖励500元。 ?一个收件人必须至少有1个电话号码和1个收货地址。 ?若一个订单的除税总额超过1000元则能有5%的折扣。 ?若一个订单的除税总额超过500元则免运费。 ?员工购买本公司商品能有5%的折扣。 ?若仓库中某货品的存量低于上月卖出的总量时,则需要进货。 1.3业务规则的分类