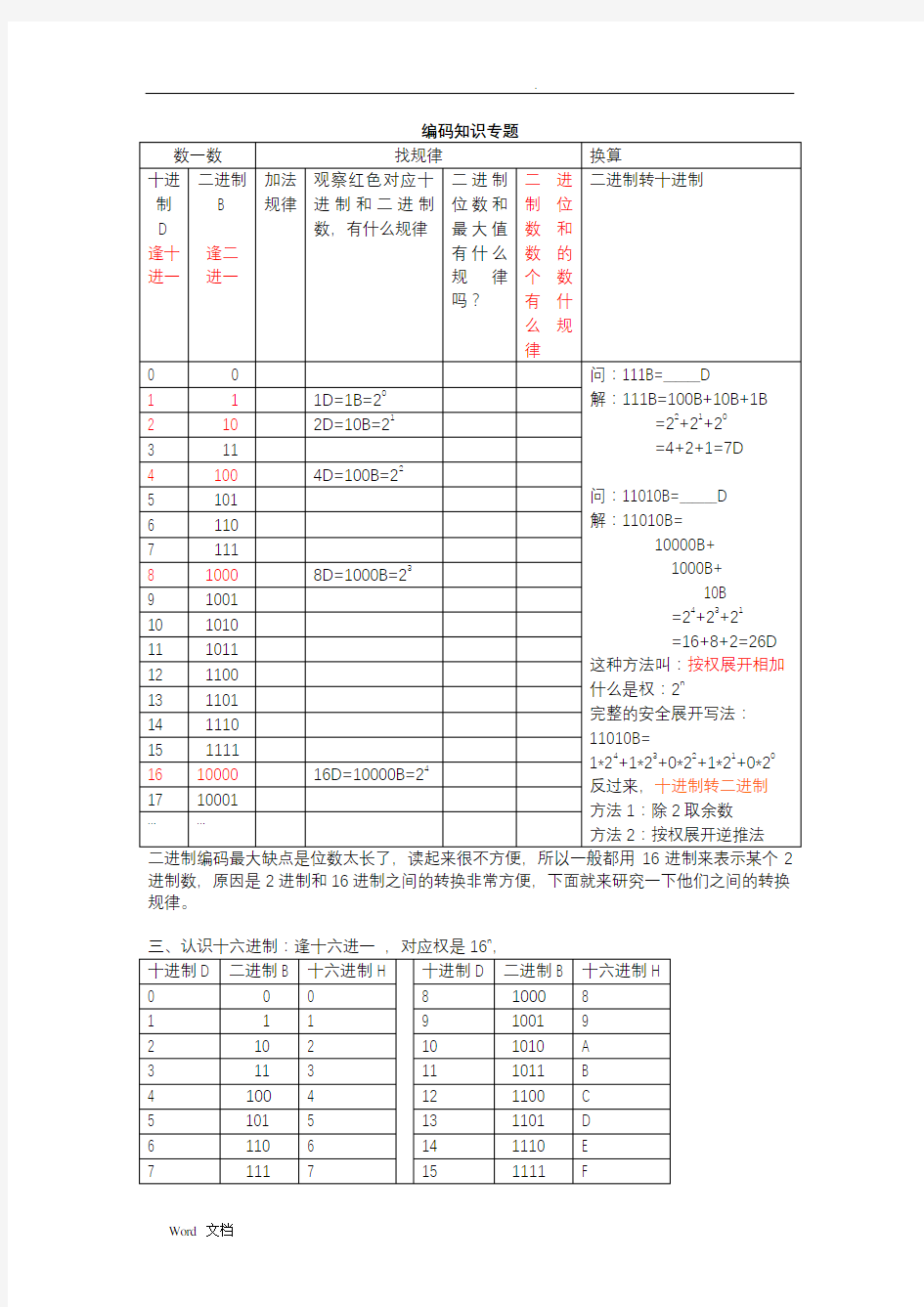

进制数,原因是2进制和16进制之间的转换非常方便,下面就来研究一下他们之间的转换规律。
n
找找16进制和二进制的转换关系:
用计算器转换以下进制:
A3H=______________B 3AH=_______________B
B9H=______________B 9BH=_______________B
1101 0111B=________H 0111 1101B=_________H
每4位二进制数转换成1位16进制数,当不够4位时,高位补0。
练习:
101011B=__________D=___________H
23D=______________B=___________H
23H=______________B=___________D
4位二进制数可以从0000到1111,请问四位的二进制数一共有几个?一个数对应一个信息,那么它可以表示多少个信息?
那么8位的二进制数一共有几个,一共能表示多少个信息?
8位的二进制数最大值是111 1111B,请问它对应十进制数是多少?
如果问你16位二进制数最大值是多少,你怎么表示最方便?
一、二进制权值,记住什么是权值
按10进制来理解,就是对应位数是10的几次方。比如28001D中的8,就是8000的意思,所以是10的3次,那么这个8的权值就是103.
那么2进制也是类似的理解。比如101100B,最高位的1就是100000,所以这个1的权值就是2的5次,即25.
总结2进制权值2n,10进制的权值10n,16进制权值是16n。
加法运算规则:2进制满2进1,10进制满10进1,16进制满16进1
减法运算规则:2进制借1当2,10进制借1当10,16进制借1当16
1.二进制数码在不同的数位上,对应不同的权值,有二进制数,其中虚线框中红色的"1"对应的权值为
(A)23(B)22 (C)21(D)20
2.有二进制数(100111)2,红色的“0”对应位的权值为
A. 21
B. 22
C. 23
D. 24
3.二进制数在不同的数位上,对应不同的权值,有二进制数(1011011)2,其中下划线标注的“1”对应的权值为()A.2 B.16 C.8 D.32
4.16进制数在不同的数位上,对应不同的权值,有16进制数(1011)16,则下划线标注的
的“1”对应的权值为
A.16 B.1 C.162D.32
二、二进制和十进制转换,16进制转10进制:都是按权展开相加
5.下列将二进制数(10011)2转换成十进制数的算式中,正确的是
(A)1×24+1×23+1×22+0×21+0×20
(B)1×24+0×23+0×22+1×21+1×20
(C)1×24+0×23+1×22+1×21+0×20
(D)1×24+1×23+0×22+0×21+1×20
6.十进制数71转换成二进制数是(除2取余数)2进制—取4位转10进制—16进制(A)(1000111)2(B)(1110001)2(C)(1001100)2(D)(1000011)2
7.【扩展】算式10100B-10D的结果是()
A.10B B.1010D C.10D D.1011B
8. 下列将16进制数(FA91)16转换成十进制数的算式中,正确的是
(A)F×163+A×162+0×161+0×160= 15×163+10×162+0×161+0×160
(B)F×163+A×162+9×161+1×160= 15×163+10×162+9×161+1×160
(C)F×163+A×162+9×161+0×160= 15×163+10×162+9×161+0×160
(D)F×163+0×162+0×161+1×160= 15×163+ 0×162+0×161+1×160
9. 有一个16进制数FFH,将其转换成二进制和10进制后,下列正确的是:A.11111111B和255D B.11101110B 和254D
C.11001100B和253D D.11001100B 和252D
三、4位二进制先转成10进制数,再对应到对应的1位16进制,
如1011B=2^3+2^1+2^0=8+2+1=11D=BH,所以就是16进制数中的B
总结:用8421规则,快速转换成10进制数,然后对应到16进制数。
10.与十六进制1B6相等的二进制数是
A.110100110 B.110110010 C.110110110 D.110110101
11.十六进制数2CH转换成二进制数是
(A)(100100)2(B)(101100)2 (C)(111000)2(D)(111100)2
12.二进制数(1111010)2转换成十六进制数是
A.6AH B.6BH C.7AH D.710H
13. 二进制数(1011100)2转换成十六进制数是()
A. 4CH
B. 4DH
C. 5CH
D. 5EH
14.【扩展】算式110B+2H的值是
A. 1000B
B. 11010B
C. 1010H
D. 112B
15. 算式10H-10B的值是:
A. 0B
B. 10B
C. 8D
D. EH
16.某四位二进制数10■1,其中有一位模糊不清,则可能与此二进制数等值的十进制数是
A. 9或11
B.18或22
C. 1001或1011
D. 1001或1101
四、四则运算(至少要掌握二进制和16进制的加法和减法运算)
17.我们知道10进制加法运算,当满10要进1,所以19D+22D=41D,而2进制加法运算,当满2时要进1,所以111B+111B,结果应该是:
A.1000B B. 1010B C.1110B D.1100B
18 我们知道10进制加法运算,当满10要进1,所以19D+22D=41D,而16进制加法运算,当满16时要进1,所以19H+91H,结果应该是:
A.100H B. 100D C.1010H D.AAH
19 我们知道10进制加法运算,当满10要进1,所以19D+22D=41D,而16进制加法运算,当满16时要进1,所以FFH+11H,结果应该是:
A.110H B. 110D C.1010H D. FF0H
20 我们知道10进制减法运算,借1当10用,所以21D-3D=18D,而16进制减法运算,借1当16用,所以11H-2H,结果应该是:
A.9H B. 9D C.FH D. FD
五、与二进制有关的题型。
但基本思想是对有顺序的内容进行编码时,编码一般都是按顺序下来。
21.字符“T”的ASCII码对应的二进制数为1010100,则大写字符“O”的ASCII码对应的二进制是()
A.1011001 B.1001111 C.1011101 D.1000111
比如字母的编码就是按字母的顺序,看下表来理解
22 将十进制数从左至右每位分别转换成对应的4位二进制编码(不足4位的左边补0,例如2转换成0010),然后依次连接。则十进制数109转换后的编码是
A.100100000001
B.000001101101
C.101000001001
D.000100001001
23.图像的编码取决于每个像素的RGB颜色编码,比如RGB(255,0,0)就表示红色R编码是255,绿色G编码为0,蓝色B编码为0,最终看到的就是红色;而RGB(0,255,0)则是绿色。而计算机内一般用16进制表示,那么上面两种RGB编码,红色表示成FF0000H,绿色表示成00FF00H。由此可知,蓝色用16进制编码应该表示为:
A. 00FFFFH
B. FF00FFH
C. 0000FFH
D. FFFF00H
24.用RGB编码模式,黄色是有红色和绿色组合而成的,那么下面表示黄色的RGB编码是
A. 00FFFFH
B. FF00FFH
C. 0000FFH
D. FFFF00H
25.有一种图像加密技术的原理是把每个像素的RGB编码加上一个密钥(正整数),得到加
密后的RGB编码。已知某24位色的图像中,RGB(0,0,255)的像素,经过加密后得到RGB 编码为00010FH,则密钥的值是( )
A.10B B.10D C.16H D.16D
26.如上题所讲,如果原RGB(0,1,255)的像素,同样加上该密钥值后,RGB的颜色该表是为:
A.RGB(0,1,271) B.RGB(0,2,15) C.RGB(0,2,271) D.RGB(0,1,15)
27.【201510】用24位二进制数来表示的RGB颜色,将其每位二进制数取反(0改为1,1改为0),即变为另一种颜色,这种操作称为颜色反相。若某RGB颜色值用十六进制表示为123456H,则其反相后的颜色值用十六进制表示为
A.654321H
B. 987654H
C. EDCBA9H
D. FEDCBAH
28.已知某进制数的等式满足:36+2=40和40+41=101,则下列说法正确的是:
A.该等式为四进制数加法运算B.该等式计算结果101,转换为十进制数为65 C.该等式为十六进制数加法运算D.该等式计算结果40,转换为十进制数为38
总结:x进制加法运算基本规则:满x进一。用此规则先弄清楚上面案例是几进制
x进制转10进制,都是按权展开相加,x n就是x进制的权值
10进制转x进制,都是除x取余数
29.若在二进制整数1111后加上两个0形成一个新的二进制整数111100,则新数值是原数值的
A.2倍
B. 4倍
C. 10倍
D. 100倍
30.下列选项中比十六进制数1AFFH大1的是
A.1AFGH
B. 1AGFH
C. 1AG0H
D. 1B00H
31.某颜色对应的十进制RGB值为(213,36,125),在图片处理过程中将绿色颜色分量的值增加了30,则处理后的绿色分量对应的二进制值为( )
A.11110011
B. 1000010
C. 10011011
D. 10000110
32.同上31题所描述,最后RGB用16进制表示为:
A.D5427DH
B. D7427DH
C. D3448DH
D. D3447DH
33.某RGB模式的图片如果每个颜色通道采用8位二进制编码,则白色为RGB (255,255,255),如果没通道改为采用4位二进制编码,则绿色的RGB值为:
A. RGB(0,255,0)
B.RGB(0,16,0)
C.RGB(0,15,0)
D.RGB(255,0,255)
34.某压缩算法,采用一个字节来表示连续的一串0(或1)。字节最左边的一位是0,则表示该字节代表一串0,否则代表一串1。如压缩后编码00001101,表示连续13个0,10000100表示连续4个1。现有如下一组数据:00000000 00011111 11100000 00000000,经过上述算法压缩后的编码用16进制数表示为:
A.0B 88 0D
B. 0B 08 0D
C. 0B 18 0D
D. 0B 88 8D
35.[浙江名校联盟]一个7位二进制数1■01■■1,其中有三位数字模糊不清,下列数中,可能与此二进制数相等的是:
A.5FH B. 109D C.67H D. 72D
36.(2014上海学考)■■■B是一个三位的二进制数,以下表达式肯定能成立的是:
①■■■B>7D ②■■■B=7D ③■■■B<7D ④■■■B<=7D
A. ①②③④
B. ②③④
C. ③④
D. ④
C C B A B A C B A C B C C A D
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
A C D A C
B D
C
D D B C B B D
31 32 33 34 35 36
B A
C A B D
编码的基本思想:
当一段信息可以被分成2种状态时,其中一种状态用1表示,另一个状态就用0表示。
1.小李用示波器测得的某次电压曲线如下图所示:
对其进行二进制编码,若将第1段曲线
编码为10,则第2段曲线的编码为
A. 011010
B. 100101
C. 101001
D. 101010
2.若用0和1表示波形电平的两种状态,则与10110101相符的波形是()
A. B.
C. D.
3.二维码是用特定黑白相间的图形来表示一定的信息,如果用黑色的方形色块表示二进制“1”,白色的方形色块表示二进制“0”,如下图所示二维码第一行表示的二进制值为“101010101010”,则能正确表示该图像第二行信息的二进制编码是()
A.(100110101110)2B.(101100110000)2
C.(111010010000)2D.(101010101010)2
4.某编码盘如上右图所示:
该编码盘由四道圆环组成,沿半径方向的四个色块依次组成一组数据,如果图中2号位的数据用二进制编码为0010,则6号位的二进制编码为
A.0101 B.0110 C.0111 D.1001
5.九连环流传于中国民间,是一种有意义的智力游戏。下图是九连环的操作图,如果图1用二进制编码表示为101000011,则图2的二进制编码为()
图1 图2
A.101001111 B.101001011 C.010101011 D.010110100
6.【加试题】某十字路口有四个车道,每车道用一个指示灯指明通行状态,表10 中是每个指示灯的控制编码与对应的状态。某一时段允许中间2个车道直行对应的控制码如图10所示。
编码状态
00 不亮
01 红灯
10 黄灯
11 绿灯
第10题表第10题图
若某一时段允许车辆左转,但不允许车辆直行和右转,则此时的控制码应该是A.01111101 B.11010101 C.11111101 D.01111101
1 2 3 4 5 6
B C B B B B
提升:如果一种信息被分成多种(2种以上,如4种,8种甚至更多),那么如何用二进制数进行编码,从而将这多种信息都能表达出来,它应该满足什么样的基本规律。
编码本质:就是要满足这么一个规律:有多少种信息,就要有多少个二进制数与其一一对应。
因此,如果有4种信息,就要有4个二进制数,而编码总是从0开始,所以也就
是从0到3,总共4个数,3D=11B,所以用到2位编码
如果有8种信息,就要有4个二进制数,而编码总是从0开始,所以也就
是从0到7,总共4个数,7D=111B,所以用到3位编码
如果有256种信息,就要有4个二进制数,而编码总是从0开始,所以就是从0到255,总共256个数,255D=1111 1111B,所以用到8位编码
字符编码本质是一样的:ASCII码共收录了128个符号,就需要0到127共128个数与之对应,而127D=111 1111B,所以ASCII码采用7位有效编码,但由于计算机中还要存汉字等其他信息,为了与汉字编码区分,所有ASCII码最前面的最高位都加了0,而汉字最高位都加1。从而进行区别。
字符编码知识和专题练习
1.西文字符(ASCII码中的字符)占1个字节
2.中文字符占2个字节
3.UE截图中0到f对应的数字都是16进制数,所以每2位就是一个字节,如下面第1个
截图中的32就是一个字节,对应的字符就是2012年中的第一个字符2,年是中文字占2个字节,所以是C4 EA
4.ASCII码最高位是0,所以其内码最大可能是0111 1111B,转换成十六进制就是7FH,
所以ASCII在UE里面的截图中每2位数的前面那一位肯定是小于等于7的,如果大于7的就绝对不是ASCII码里面的字符了。
一、有字有内码,判断字节数
1.使用UltraEdit软件观察字符内码,结果如下图所示:
则存储字符“2012年09月11日”所需的字节数为
A. 7
B. 11
C. 12
D. 14
2.使用UltraEdit软件观察字符内码,结果如图所示:
则存储字符“#正能量#”需要的字节数是
A. 4
B. 5
C. 7
D. 8
3.使用UltraEdit软件观察字符内码,结果如下图所示:
则下列说法正确的是
(A)"A"占用一个字节(B)"计"占用一个字节
(C)"A"的内码为A3 (D)"计"的内码为BC C6
4.用UltraEdit软件观察字符内码,结果如下图所示:
问“中华美食”占用的字节数是()
A.10 B.8 C.4 D.2
二、给你文字,判断内码
5.使用UltraEdit软件观察字符内码,结果如下图所示:
则字符"apple"的内码为
(A)61 70 70 6C 65 (B)65 6C 6C 70 70 (C)62 70 70 6C 65 (D)63 65 65 6C 65 6.用UltraEdit软件观察“Mpeg压缩标准”几个字,显示的十六进制内码如下图所示,从中可以推断出“Jpeg标准”字符的内码应该是()
A.4A 70 65 67 B1 EA D7 BC B.50 70 65 67 B1 EA D7 BC
C.4A 70 65 67 D1 B9 CB F5 D.50 70 65 67 D1 B9 CB F5
7.使用UltraEdit软件观察字符内码,结果如图所示:
则字符“TOP3”的内码是
A. 54 4F 50 30
B. 54 4F 50 31
C. 54 4F 50 32
D. 54 4F 50 33
8.使用UltraEdit软件观察字符内码,结果如下图所示:
则字符"Asia"的内码为
(A)41 6D 65 72 (B)41 71 69 61 (C)41 73 69 61 (D)41 72 69 61 9.使用UltraEdit软件观察“马航客机MH370”这几个字符的内码,结果如图所示:
则字符“MINI2”的内码是()
A. 2D 4E 4D 4E 32
B. 2D 49 4E 49 34
C. 4D 47 4E 47 32
D. 4D 49 4E 49 32
10.使用UltraEdit软件观察字符内码,结果如下图所示:
则图中字符“!”的内码是
A. CA
B. A1
C. CA C7
D. A3 A1
三、给你内码,判断是什么文字
11.用UltraEdit软件观察“A’、“B”和“或”这几个字符的内码,部分截留如图所示:
则可能的字符序列为
A.A或B B.B或A C.或AB D.AB或
12.字符“1+1=2”的十六进制内码如下图所示:
则内码“31 2B 32 3D 33”对应的字符为
A. 1+2<3
B. 1+2>3
C. 1+2=3
D. 3=1+2
13.使用UltraEdit软件观察“E”、“F”和“与”这几个字符的内码,结果如下图所示:
则可能的字符序列为()
A.E与F
B.EF与
C.FE与
D.F与E
14.用UltraEdit软件观察字符内码,结果如下图所示:
则图中内码表示的可能是()
A.12个英文字符B.4个英文字符4个汉字
C.6个汉字D.6个英文字符3个汉字
15.用Ultraedit软件观察某字符串内码如下图所示:
从中可以观察得知,英文字符与汉字的个数分别为
A.4个,4个
B.6个,3个C.8个,2个D.6个,6个
16.【加试题】用UltraEdit软件观察“苹果apple”这几个字符的内码,如下图所示:
则“iPhone”中的小写字母“o”的二进制编码是:
A.01000101
B.01101001
C.01101111
D.01000111
17.小李在网络中获取一串二进制数,其中部分二进制数为“11000000 11010110”,结合UltraEdit
软件(如第6题图)的部分界面推断,该部分二进制数所表示的字符为
18.【原创】小丽用UltraEdit软件观察"新高考‘7选3’"这几个字,显示的十六进制内码如
第2题图所示。则"7选4"这几个字对应得内码用十六进制表示是(
)
A.37 D1 A1 34 B.D1 A1 33 A1 AF
C.37 D1 A1 33 D.D1 A1 33 A1 B0
19.字符“1+1=2”的十六进制内码如下图所示:(前面第12题对比一下)
则字符串“6+7>10”的内码是:
A. 36 2B 37 3D 40
B. 36 2B 37 3E 31 30
C. 36 2B 37 3E 3A
D. 36 2B 37 3D 31 30
20.用UE软件观察“hello,一高”这几个字符的内容,如下图所示
则“hi,jack”这几个字符的内码可能是()
A. 68 69 A3 70 61 63 71
B. 68 69 A3 6A 61 63 6B
C. 68 69 A3 AC 70 61 63 71
D. 68 69 A3 AC 6A 61 63 6B
21. 字符“1+1=2”的十六进制内码如下图所示:
则字符串“5+6<>11”的内码是:
A. 35 2B 36 3C 3E 31 31
B. 35 2B 36 3C 3E 3B
C. 35 2B 36 3E 3C 3B
D. 35 2B 36 3C 31 31
22.在UltraEdit软件中,为了观察“瓯海一高”
四个汉字的字符内码,在UltraEdit软件中输入
A.“快”B.“乐”C.“20”D.“16”
“瓯海一高”之后,接下来应该点()按钮,可以观察到内码
先介绍函数,我们一共要用到三个函数,fopen,fread,fwrite。二进制读写的顺序是用fopen以二进制方式打开读写文件,然后使用fread和fwrite两个函数将数据写入二进制文件中。下面我们看看一个拷贝程序的源码:
2中,注意fread的返回值,这个值需要在fwrite的时候将会用到。 后面是关于fopen,fread,fwrite三个函数的详细说明。 fopen(打开文件) 相关函数open,fclose 表头文件#include
上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等 组合,加入b 字符用来告诉函数库打开的文件为二进制文件,而非 纯文字文件。不过在POSIX系统,包含Linux都会忽略该字符。由 fopen()所建立的新文件会具有S_IRUSR|S_IWUSR|S_IRGRP|S_I WGRP|S_IROTH|S_IWOTH(0666)权限,此文件权限也会参考um ask值。 返回值文件顺利打开后,指向该流的文件指针就会被返回。若果文件打开失败则返回NULL,并把错误代码存在errno 中。 附加说明一般而言,开文件后会作一些文件读取或写入的动作,若开文件失败,接下来的读写动作也无法顺利进行,所以在fopen()后请作错误 判断及处理。 范例#include
使用文本文件txt 进行数据存取的技 巧总结相当 使用文本文件(.txt)进行数据存取的技巧总结 由于本帖内容较多,部分转自他人的心得,因此,凡转贴的地方仅用"--转--"标注,原作者略去,在此对所有原作者表示感谢! 特别说明:由于大家在I/O存取上以txt文件为主,且读取比存储更麻烦(存储的话fwrite,fprintf基本够用),因此下面的讨论主要集中在"txt文件 的读取"上。除了标注了"转"之外,其余心得均出于本人经验之结果,欢迎大家指正、补充。 一.基本知识: --转-- 1.二进制文件与文本文件的区别: 将文件看作是由一个一个字节(byte)组成的,那么文本文件中的每个字节 的最高位都是0,也就是说文本文件使用了一个字节中的七位来表示所有的信息,而二进制文件则是将字节中的所有位都用上了。这就是两者的区别;接着,第二个问题就是文件按照文本方式或者二进制方式打开,两者会有什么不同呢?其实不管是二进制文件也好,还是文本文件也好,都是一连串的0和1,但是 打开方式不同,对于这些0和1的处理也就不同。如果按照文本方式打开,在 打开的时候会进行translate,将每个字节转换成ASCII码,而以按照二进制 方式打开的话,则不会进行任何的translate;最后就是文本文件和二进制文 件在编辑的时候,使用的方式也是不同的。譬如,你在记事本中进行文本编辑 的时候,你进行编辑的最小单位是字节(byte);而对二进制文件进行编辑的话,最小单位则是位(bit),当然我们都不会直接通过手工的方式对二进制文件进行编辑了。 从文件编码的方式来看,文件可分为ASCII码文件和二进制码文件两种:
二进制文件读写分析 有关TXT文件以及bin文件处理的测试代码 int main() { //fstream file("D:\\test.dat",ios_base::in|ios_base::out|ios_base::app); fstream file; file.open("D:\\test1.dat",ios_base::out); { int temp[10] = {0x11,0x13,0x14,0x1F,0x1D,0x11,0x11,0x12,0x11,0x11}; int temp1[10]; file.write((char *)temp,sizeof(temp)); file.close(); file.open("D:\\test1.dat",ios_base::in); file.read((char *)temp,sizeof(temp)); unsigned int i; cout< C++中Txt文件读取和写入 标签:c++nullstringios文本编辑file 2012-10-07 16:58 45182人阅读评论(3) 收藏举报 分类: C/C++基础(75) C++中Txt文件读取和写入 一、ASCII 输出 为了使用下面的方法, 你必须包含头文件 解码labview读写二进制文件格式 一直觉得NI 很恶心,最近越发觉得恶心,竟知道骗钱,我花了2 周去探它该死的数据格式,问他们售后居然说不知道...还得我亲自动手...现在把数据格式写下来,为大家做点贡献吧...关于用matlab/vc 读二进制文件write to binary file 的数据NI 可以直接用这个函数把数据写下来,但是读取格式不告诉你,要你用它的软 件去读...读的方法:1) 用uchar 去读,将数据转置存储;2)用浮点去读,倒序;-------- 这些在网上可以查到,下面才是关键.... 对64 位数据:3)每个通道有21 个数据是头文件,即21*64bit 的头信息,可以不去管它,跳过; 4)除了头文件外,每个通道还有1-3 个字节的信息(不知道什么玩意儿),要跳过;具体来讲是这样,如果有6 个通道, 第一个通道存储了1 个字节,要扣除;第2,4,5 个通道多了2 个字节,要扣除;第3,6 通道多了3 个字节要扣除.但是必须从3 开始扣.即假如总共N 字节数据,则第一个通道读N-3 个,接下来2,4,5 要读N-4 个,剩下的3,6 要读N-5 个.只有这样才能正确的读取.不过要注意数据倒序的问题,实际的数据可能正好通道顺序相反.5) 剩下的就是编程的问题了,还有很多细节大家可以自己解决,再看怎么要内存最小,耗时最短...我是没有在NI 的说明文档里面找对相关的数据存储格式,这里是 6 个通道的举例,要是5 个通道又得慢慢试了...再来一句,NI 真恶心,其实没必要 保留数据格式...搞的人家都要用它的软件...tips:感谢大家的阅读,本文由我司收集整编。仅供参阅! 二进制文件和文本文件的详细以及如何生成二进制文件? 技术随笔 2010-05-01 19:13:56 阅读226 评论0 字号:大中小订阅 这个问题一直困扰了很多年,可能是我没有认真的去思考。我相信很多人可能和我一样很纠葛,到底编译器也好,汇编器也好是如何工作的呢?到底怎么回事?为什么会运行呢?这是让我们这些看着windows 学习电脑的人真的很难去理解计算机的内部结构。其实,这一切都只是障眼法,下面我就来给大家细细说说我对计算机的理解。 解答1:编译器是怎么回事? 所谓编译器,顾名思义就是将一种文本格式转换成另一种文本格式。比如将字符串echo "hello"; 转换成printf("hello"); 这其实是php语言转成c语言的一种表示。这只是一种简单的描述,其实很大一部分的编译器是将源语言转换成了汇编语言。下面我们来看看 C 语言中的经典hello word,通过gcc编译后生成的汇编是怎么回事。 c语言源码: #include C打开文件文本方式二进制方式 2009年11月01日星期日 22:53 Windows平台下 如果以“文本”方式打开文件,当读取文件的时候,系统会将所有的"\r\n"转换成"\n";当写入文件的时候,系统会将"\n"转换成"\r\n"写入。 如果以"二进制"方式打开文件,则读/写都不会进行这样的转换。 在Unix/Linux平台下,“文本”与“二进制”模式没有区别。 数据有字符型和非字符型(数)两种。按文本方式写文件指的是将数据转换为对应的字符型数据之后再写入文件。对于字符型数据,由于其本身就是ASCII码字符,一般不必转换,直接写入文件。但是,由于不同的系统对于换行符('\n')有不同的处理(转换)方式,在有的系统(如Windows)下也会对 '\n' 作适当的转换。 对于非字符型数据,都要进行转换处理。例如:int m = 12; 以及 double f = 2.3;,分别按照 "%d"、"%lf" 方式将 m 和 f 写入文件的时候,写入的分别是 '1'、'2' 两个字符以及 '2'、'.'、'3' 等三个字符的ASCII码值。显然,如果按照二进制方式写的话,在文件中一般 m 要占 4 个字节、f 要占 8 个字节。 一、文本文件与二进制文件的定义 大家都知道计算机的存储在物理上是二进制的,所以文本文件与二进制文件的区别并不是物理上的,而是逻辑上的。这两者只是在编码层次上有差异。 简单来说,文本文件是基于字符编码的文件,常见的编码有ASCII编码,UNICODE编码等等。二进制文件是基于值编码的文件,你可以根据具体应用,指定某个值是什么意思(这样一个过程,可以看作是自定义编码)。 从上面可以看出文本文件基本上是定长编码的(也有非定长的编码如 UTF-8),基于字符嘛,每个字符在具体编码中是固定的,ASCII码是8个比特的编码,UNICODE一般占16个比特。而二进制文件可看成是变长编码的,因为是值编码嘛,多少个比特代表一个值,完全由你决定。大家可能对BMP文件比较熟悉,就拿它举例子吧,其头部是较为固定长度的文件头信息,前2字节用来记录文件为BMP格式,接下来的8个字节用来记录文件长度,再接下来的4字节用来记录bmp文件头的长度。。。大家可以看出来了吧,其编码是基于值的(不定长的,2、4、8字节长的值都有),所以BMP是二进制文件。 二、文本文件与二进制文件的存取 文本工具打开一个文件的过程是怎样的呢?拿记事本来说,它首先读取文件物理上所对应的二进制比特流(前面已经说了,存储都是二进制的),然后按照你所选择的解码方式来解释这个流,然后将解释结果显示出来。一般来说,你选取的解码方式会是ASCII码形式(ASCII码的一个字符是8个比特),接下来,它8个比特8个比特地来解释这个文件流。例如对于这么一个文件流"01000000_01000001_01000010_01000011"(下划线''_'',是我为了增强可读性,而手动添加的),第一个8比特''01000000''按ASCII码来解码的 本文由我司收集整编,推荐下载,如有疑问,请与我司联系 Linux下二进制方式读写文件 2017/03/29 0 最近在做项目需要把内存数据写入到文件中,然后再从文件中以二进制方式读出使用。由于接触Linux开发时间不长,开始询问度娘,度娘的 回答是使用以wb方式打开文件后使用fwrite把数据写入文件,以rb方式打开文件 后使用fread读出数据。下面详细介绍一下相关的函数极其使用说明。需要用的头文件为stdio.h,函数结构为fwrite、fread、fseek、ftell、fstat。1. fwrite size_t fwrite(const void* buffer, size_t size, size_t count, FILE* stream); 返回:返回实际写入的数据块数目(1)buffer:是一个指针,对fwrite来说,是要获取数据的地址;(2)size:要写入内容的单字节数;(3)count: 要进行写入size 字节的数据项的个数;(4)stream: 目标文件指针;(5)返回实际写入的数据项个数count。说明:写入到文件的哪里?这个与文件的打开模式有关,如果是w ,则是从file pointer指向的地址开始写,替换掉之后的内容,文件的长度可以不变,stream的位置移动count个数;如果是a ,则从文件的末尾开始添加,文件长度加大。注意:这个函数以二进制形式对文件进行操作,不局限于文本文件2. fread size_t fread(void *buffer, size_t size, size_t count, FILE *stream) ; 返回:返回真实写入的项数,若大于count则意味着产生了错误。另外,产生错误后,文件 位置指示器是无法确定的。若其他stream或buffer为空指针,或在unicode模式中 写入的字节数为奇数,此函数设置errno为EINVAL以及返回0. (1)buffer:用于接收数据的内存地址;(2)size:要读的每个数据项的字节数,单位是字节;(3)count:要读count个数据项,每个数据项size个字节.;(4)stream: 目标文件指针;3. fseek int fseek(FILE * stream,long offset,int whence); 返回:成功返回0,失败返回-1,errno会存放错误代码。(1)stream: 目标文件指针;(2)offset: 相对于whence的偏移量;(3)whence:绝对位置。说明:fseek()用来移动文件流的读写位置。参数stream为已打开的文件指针,参数offset为根据参数whence来移动读写位置的位移数。注意1:参数whence为下列其中一种:: fopen , fread fwrite 函数读写二进制文件 1#include Matlab中如何实现二进制文件的读写 1、文件的打开与关闭 1)打开文件 在读写文件之前,必须先用fopen函数打开或创建文件,并指定对该文件进行的操作方式。fopen函数的调用格式为: fid=fopen(文件名,‘打开方式’) 说明:其中fid用于存储文件句柄值,如果返回的句柄值大于0,则说明文件打开成功。文件名用字符串形式,表示待打开的数据文件。常见的打开方式如下: ‘r’:只读方式打开文件(默认的方式),该文件必须已存在。 ‘r+’:读写方式打开文件,打开后先读后写。该文件必须已存在。 ‘w’:打开后写入数据。该文件已存在则更新;不存在则创建。 ‘w+’:读写方式打开文件。先读后写。该文件已存在则更新;不存在则创建。 ‘a’:在打开的文件末端添加数据。文件不存在则创建。 ‘a+’:打开文件后,先读入数据再添加数据。文件不存在则创建。 另外,在这些字符串后添加一个“t”,如‘rt’或‘wt+’,则将该文件以文本方式打开;如果添加的是“b”,则以二进制格式打开,这也是fopen函数默认的打开方式。 2)关闭文件 文件在进行完读、写等操作后,应及时关闭,以免数据丢失。关闭文件用fclose函数,调用格式为: sta=fclose(fid) 说明:该函数关闭fid所表示的文件。sta表示关闭文件操作的返回代码,若关闭成功,返回0,否则返回-1。如果要关闭所有已打开的文件用fclose(‘all’)。 2、二进制文件的读写操作 1)写二进制文件 fwrite函数按照指定的数据精度将矩阵中的元素写入到文件中。其调用格式为: COUNT=fwrite(fid,A,'precision') 说明:其中COUNT返回所写的数据元素个数(可缺省),fid为文件句柄,A用来存放写入文件的数据,precision代表数据精度,常用的数据精度有:char、uchar、int、long、float、double等。缺省数据精度为uchar,即无符号字符格式。 例6.8 将一个二进制矩阵存入磁盘文件中。 >> a=[1 2 3 4 5 6 7 8 9]; >> fid=fopen('d:\test.bin','wb') %以二进制数据写入方式打开文件 fid = 3 %其值大于0,表示打开成功 >> fwrite(fid,a,'double') ans = 9 %表示写入了9个数据 >> fclose(fid) ans = 0 %表示关闭成功 2)读二进制文件 fread函数可以读取二进制文件的数据,并将数据存入矩阵。其调用格式为: [A,COUNT]=fread(fid,size,'precision') 说明:其中A是用于存放读取数据的矩阵、COUNT是返回所读取的数据元素个数、fid为文件句柄、size为可选项,若不选用则读取整个文件内容;若选用则它的值可以是下列值:N (读取N个元素到一个列向量)、inf(读取整个文件)、[M,N](读数据到M×N的矩阵中,数据按列存放)。precision用于控制所写数据的精度,其形式与fwrite函数相同。 %写一维数据至数据文件 n=0:pi/10:4*pi; y=sin(n); fip=fopen('C:\binary3.bin','wb'); fwrite(fip,Pxx,'double'); fclose(fip); %从数据文件读取一维数据 fip=fopen('C:\binary3.bin','rb'); [SIN,num]=fread(fip,[2,20],'double');%inf表示读取文件中的所有数据,[M,N]表示 %将读取的数据放置在M行N列中,N表示将读取的数据放置在1列中 Matlab中如何实现二进制文件的读写 说明:matlab产生的是.bin二进制文件。.bit是FPGA的比特流文件 1、文件的打开与关闭 1)打开文件 在读写文件之前,必须先用fopen函数打开或创建文件,并指定对该文件进行的操作方式。fopen 函数的调用格式为: fid=fopen(文件名,‘打开方式') 说明:其中fid用于存储文件句柄值,如果返回的句柄值大于0,则说明文件打开成功。文件名用字符串形式,表示待打开的数据文件。常见的打开方式如下: ‘r':只读方式打开文件(默认的方式),该文件必须已存在。 ‘r+':读写方式打开文件,打开后先读后写。该文件必须已存在。 ‘w':打开后写入数据。该文件已存在则更新;不存在则创建。 ‘w+':读写方式打开文件。先读后写。该文件已存在则更新;不存在则创建。 ‘a':在打开的文件末端添加数据。文件不存在则创建。 ‘a+':打开文件后,先读入数据再添加数据。文件不存在则创建。 另外,在这些字符串后添加一个“t”,如‘rt'或‘wt+',则将该文件以文本方式打开;如果添加的是“b”,则以二进制格式打开,这也是fopen函数默认的打开方式。 2)关闭文件 文件在进行完读、写等操作后,应及时关闭,以免数据丢失。关闭文件用fclose函数,调用格式为: sta=fclose(fid) 说明:该函数关闭fid所表示的文件。sta表示关闭文件操作的返回代码,若关闭成功,返回0,否则返回-1。如果要关闭所有已打开的文件用fclose(‘all')。 2、二进制文件的读写操作 1)写二进制文件 fwrite函数按照指定的数据精度将矩阵中的元素写入到文件中。其调用格式为: COUNT=fwrite(fid,A,'precision') 说明:其中COUNT返回所写的数据元素个数(可缺省),fid为文件句柄,A用来存放写入文件的数据,precision代表数据精度,常用的数据精度有:char、uchar、int、long、float、double等。缺省数据精度为uchar,即无符号字符格式。 例6.8 将一个二进制矩阵存入磁盘文件中。 >> a=[1 2 3 4 5 6 7 8 9]; >> fid=fopen('d:\test.bin','wb') %以二进制数据写入方式打开文件 fid = 3 %其值大于0,表示打开成功 >> fwrite(fid,a,'double') ans = 9 %表示写入了9个数据 >> fclose(fid) ans = 0 %表示关闭成功 2)读二进制文件 fread函数可以读取二进制文件的数据,并将数据存入矩阵。其调用格式为: [A,COUNT]=fread(fid,size,'precision') 说明:其中A是用于存放读取数据的矩阵、COUNT是返回所读取的数据元素个数、fid为文件句柄、size为可选项,若不选用则读取整个文件内容;若选用则它的值可以是下列值:N(读取N 个元素到一个列向量)、inf(读取整个文件)、[M,N](读数据到M×N的矩阵中,数据按列存放)。precision用于控制所写数据的精度,其形式与fwrite函数相同。 %写一维数据至数据文件 n=0:pi/10:4*pi; y=sin(n); fip=fopen('C:\binary3.bin','wb'); fwrite(fip,Pxx,'double'); fclose(fip); %从数据文件读取一维数据 fip=fopen('C:\binary3.bin','rb'); [M,N]表示[SIN,num]=fread(fip,[2,20],'double');%inf表示读取文件中的所有数据,1列中列中,N 表示将读取的数据放置在将读取的数据放置在%M行N fclose(fip) %写二维数据至数据文件n=0:pi/10:4*pi; y1=sin(n);y2=sin(n);y3=0.5*sin(n); y=[y1;y2;y3]; fip=fopen('C:\binary4.bin','wb'); fwrite(fip,y,'double'); ,则表示存储数据正常fclose(fip); %返回指针的值为0 从数据文件读取二维数据% fip=fopen('C:\binary4.bin','rb'); 表示表示读取文件中的所有数据,[M,N][Array_2D,num]=fread(fip,inf,'double');%inf 1列中N行N列中,表示将读取的数据放置在%将读取的数据放置在M fclose(fip) Matlab中如何实现二进制文件的读写1、文件的打开与关闭 1)打开文件 在读写文件之前,必须先用fopen函数打开或创建文件,并指定对该文件进行的操作方式。fopen函数的调用格式为: fid=fopen(文件名,‘打开方式’) 说明:其中fid用于存储文件句柄值,如果返回的句柄值大于0,则说明文件打开成功。文件名用字符串形式,表示待打开的数据文件。常见的打开方式如下: ‘r’:只读方式打开文件(默认的方式),该文件必须已存在。 ‘r+’:读写方式打开文件,打开后先读后写。该文件必须已存在。 ‘w’:打开后写入数据。该文件已存在则更新;不存在则创建。 ‘w+’:读写方式打开文件。先读后写。该文件已存在则更新;不存在则创建。 ‘a’:在打开的文件末端添加数据。文件不存在则创建。 ‘a+’:打开文件后,先读入数据再添加数据。文件不存在则创建。 另外,在这些字符串后添加一个“t”,如‘rt’或‘wt+’,则将该文件以文本方式打开;如果添加的是“b”,则以二进制格式打开,这也是fopen函数默认的打开方式。 2)关闭文件 文件在进行完读、写等操作后,应及时关闭,以免数据丢失。关闭文件用fclose函数,调用格式为: sta=fclose(fid) 说明:该函数关闭fid所表示的文件。sta表示关闭文件操作的返回代码,若关闭成功,返回0,否则返回-1。如果要关闭所有已打开的文件用fclose(‘all’)。 2、二进制文件的读写操作 1)写二进制文件 fwrite函数按照指定的数据精度将矩阵中的元素写入到文件中。其调用格式为: COUNT=fwrite(fid,A,'precision') 说明:其中COUNT返回所写的数据元素个数(可缺省),fid为文件句柄,A用来存放写入文件的数据,precision代表数据精度,常用的数据精度有:char、uchar、int、long、float、 很长时间不用c++了,都快忘了,转个文章以作备份 文章详细解释ASCII和二进制文件的输入输出的每个细节,值得注意的是,所有这些都是用C++完成的。 一、ASCII 输出 为了使用下面的方法, 你必须包含头文件(译者注:在标准C++中,已经使用取代,所有的C++标准头文件都是无后缀的。)。这是的一个扩展集, 提供有缓冲的文件输入输出操作. 事实上, 已经被包含了, 所以你不必包含所有这两个文件, 如果你想显式包含他们,那随便你。我们从文件操作类的设计开始, 我会讲解如何进行ASCII I/O操作。如果你猜是"fstream," 恭喜你答对了!但这篇文章介绍的方法,我们分别使用"ifstream"?和"ofstream" 来作输入输出。 如果你用过标准控制台流"cin"?和"cout," 那现在的事情对你来说很简单。我们现在开始讲输出部分,首先声明一个类对象。 ofstream fout; 这就可以了,不过你要打开一个文件的话, 必须像这样调用ofstream::open()。 fout.open("output.txt"); 你也可以把文件名作为构造参数来打开一个文件. ofstream fout("output.txt"); 这是我们使用的方法, 因为这样创建和打开一个文件看起来更简单. 顺便说一句, 如果你要打开的文件不存在,它会为你创建一个, 所以不用担心文件创建的问题. 现在就输出到文件,看起来和"cout"的操作很像。对不了解控制台输出"cout"的人, 这里有个例子。 int num = 150; char name[] = "John Doe"; fout << "Here is a number: " << num << "\n"; fout << "Now here is a string: " << name << "\n"; 现在保存文件,你必须关闭文件,或者回写文件缓冲. 文件关闭之后就不能再操作了, 所以只有在你不再操作这个文件的时候才调用它,它会自动保存文件。回写缓冲区会在保持文件打开的情况下保存文件, 所以只要有必要就使用它。回写看起来像另一次输出, 然后调用方法关闭。像这样: fout << flush; fout.close(); 现在你用文本编辑器打开文件,内容看起来是这样:Here is a number: 150 Now here is a string: John Doe 很简单吧! 现在继续文件输入, 需要一点技巧, 所以先确认你已经明白了流操作,对"<<" 和">>" 比较熟悉了, 因为你接下来还要用到他们。继续… 二、ASCII 输入 输入和"cin" 流很像. 和刚刚讨论的输出流很像, 但你要考虑几件事情。在我们开始复杂的内容之前, 先看一个文本: Fortran 二进制文件读写【给新手】 2008-05-17 11:43:18| 分类:胡说八道|字号订阅 一些朋友总是咨询关于二进制文件的读写和转化。这里就我自己的理解说一说。 一).一般问题 二进制文件与我们通常使用的文本文件储存方式有根本的不同。这样的不同很难用言语表达,自己亲自看一看,理解起来会容易得多。因此,我推荐学习二进制文件读写的朋友安装一款十六进制编辑器。这样的编辑器有很多,在我们的 CVF 附带的集成开发环境下就可以(将二进制文件拖动到 IDE 窗口后松开)。Visual Studio 2005 也是可以的。(不过需要在 File 菜单下 Open,File) 另外推荐一款使用较多的软件,叫做 UltraEdit(以下简称 UE)。是很不错的文本编辑器,也能做十六进制编辑器使用。 为什么要用十六进制编辑器?而不用 2 进制呢?因为 2 进制实在太小,书写起来会很长,很不直观。而我们的计算机把 8 位作为一个字节。刚好2 ** 8 = 256 = 16 ** 2。用 8 位 2 进制表达的数,我们用 2 个十六进制数据来表达,更直观和方便。 二).文件格式 所有文件,笼统意义上将可以区分为两类,一类是文本文件,一类是二进制文件。 1).文本文件 文本文件用记事本等文本编辑器打开,我们可以看懂上面的信息。所以使用比较广泛。通常一个文本文件分为很多很多行,作为数据储存时,还有列的概念。实际上,储存在硬盘或其他介质上,文件内容是线一样储存的,列是用空格或 Tab 间隔,行是用回车和换行符间隔。 以 ANSI 编码(使用较多)的文本文件来说,例如我们储存如下信息: 10 11 12 需要的空间是:3 行 × 每行 2 个字符 + 2 个回车符 + 2 个换行符 = 10 字节。文本文件储存数据是有格式,无数据类型的。比如 10 这个数据,并不指定是整型还是实型还是字符串。它有长度,就是2,两个字节。储存时计算机储存它的 ASCII 码:31h,30h。(十六进制表示)。回车符是:0Dh,换行符:0Ah。 因此,这个数据储存是这样的: 31 30 0D 0A 31 31 0D 0A 31 32 (红色为回车符和换行符) 31h 30h 就是 10,31h 31h 就是 11,31h 32h 就是 12。因此我们也可以认为文本文件是特殊的二进制文件。 C语言实现myql中存取二进制文件 include 二进制文件读写 一).一般问题 二进制文件与我们通常使用的文本文件储存方式有根本的不同。这样的不同很难用言语表达,自己亲自看一看,理解起来会容易得多。因此,我推荐学习二进制文件读写的朋友安装一款十六进制编辑器。这样的编辑器有很多,在我们的 CVF 附带的集成开发环境下就可以(将二进制文件拖动到 IDE 窗口后松开)。Visual Studio 2005 也是可以的。(不过需要在 File 菜单下 Open,File) 另外推荐一款使用较多的软件,叫做 UltraEdit(以下简称 UE)。是很不错的文本编辑器,也能做十六进制编辑器使用。 为什么要用十六进制编辑器?而不用 2 进制呢?因为 2 进制实在太小,书写起来会很长,很不直观。而我们的计算机把 8 位作为一个字节。刚好 2 ** 8 = 256 = 16 ** 2。用 8 位 2 进制表达的数,我们用 2 个十六进制数据来表达,更直观和方便。 二).文件格式 所有文件,笼统意义上将可以区分为两类,一类是文本文件,一类是二进制文件。 1).文本文件 文本文件用记事本等文本编辑器打开,我们可以看懂上面的信息。所以使用比较广泛。通常一个文本文件分为很多很多行,作为数据储存时,还有列的概念。实际上,储存在硬盘或其他介质上,文件内容是线一样储存的,列是用空格或 Tab 间隔,行是用回车和换行符间隔。 以 ANSI 编码(使用较多)的文本文件来说,例如我们储存如下信息: 10 11 12 需要的空间是:3 行 ×每行 2 个字符 + 2 个回车符 + 2 个换行符 = 10 字节。文本文件储存数据是有格式,无数据类型的。比如 10 这个数据,并不指定是整型还是实型还是字符串。它有长度,就是 2,两个字节。储存时计算机储存它的 ASCII 码:31h,30h。(十六进制表示)。回车符是:0Dh,换行符:0Ah。 因此,这个数据储存是这样的: 31 30 0D 0A 31 31 0D 0A 31 32 (红色为回车符和换行符) 31h 30h 就是 10,31h 31h 就是 11,31h 32h 就是 12。因此我们也可以认为文本文件是特殊的二进制文件。 2).二进制文件 二进制文件,是无格式有数据类型的。比如上面的 10 11 12 三个数。但二进制文件没有行的概念。我们要紧凑地储存他们。(当然也可以中间加入一些空白的字节) 从数据类型上来说,我们首先考虑整型。如果把 10 11 12 当作 2 字长的整型。则 10 表示为:0Ah 00h。因为 0Ah 对应十进制 10。而后面的 00h 是空白位。2 字长的整型如果不足 FFh,也就是不足 255,则需要一个空白位。类似的:11 表示为 0Bh 00h,12 表示为 0Ch 00h。 当整型数据超过 255 时,我们需要 2 个字节来储存。比如 2748(ABCh),则表示为:BCh 0Ah。要把低位写在前面(BCh),高位写在后面(0Ah)。 当整型数据超过 65535 时,我们就需要 4 个字节来储存。比如 439041101(1A2B3C4Dh),则表示成:4Dh 3Ch 2Bh 1Ah。当数据再大时,我们就需要 8 字节储存了。 二进制文件的实型数据也有字节长度的区分,比如 4 字长,8 字长。但实型数据的长度并不仅仅代表它的表达的范围,更多的代表精度。所以,8 字长的我们又称为双精度。关于实型数据如何储存为 2 进制。则有很多套规则。现在都广泛使用的是 IEEE 标准浮点格式。关于这样的规则,我还正在了解,比较麻烦。就不多说了。在这里也没有必要了解。 二进制文件也可以储存字符型数据,储存方法和文本文件一样。都是使用 ASCII 编码储存的。所以我们用记事本打开某些二进制文件时,也能看到一些有意义的字符串。(无意义的乱码我们可以认为是整型或实 2005-5-11 C++读写二进制文件 前几天写一个音频隐藏程序时碰到点问题,要读写二进制文件。 一开始,我的程序看起来像是这样: //... static string FILENAME = "test.wav"; ifstream iStream; iStream.open(FILENAME.c_str()); char buffer[1024]; while (iStream.read(buffer, sizeof(buffer) / sizeof(char))) { //...这里对读到的字节进行处理 } iStream.close(); //... 可是循环几次后就“无故”跳出,文件根本没读完,可是程序码好像也没错。 为了测试二进制的读取,我特地写了个程序,看起来像这样: //... static string FILENAME = "test.wav"; ifstream iStream; iStream.open(FILENAME.c_str()); char ch; while (iStream.get(ch)) { cout << ch; } iStream.close(); //... 程序输出一部分字符后,就不再输出了,怎么回事?我把iostream以及fstreamr的读取、写入API都查了个便,好像没有什么发现,这段程序码 应该不会有问题的! 回忆以前写C代码的日子,fopen函数有个b参数,表示是二进制读写方式打开, 是否fstream也有二进制开启的参数?一查MSDN果然如此,这 个参数是 ios_base::binary。 马上行动,以上程序改成这样: //... static string FILENAME = "test.wav"; ifstream iStream; iStream.open(FILENAME.c_str(), ios_base::binary); // 二进制模式 char ch; while (iStream.get(ch)) { cout << ch; } iStream.close(); //... 哈哈,这回程序终于可以读取全部字节了,而且喇叭还嘟嘟地叫呢(二进制码当作字符输出,有些是空白,有的还会鸣喇叭(07h),呵呵)。 可是为什么?读出都是字节,都是无格式,打开时以二进制和默认方式打开有什么区别吗? 别急,上面解决了怎么读,下面让我们"写"一点东西吧! #include C++中Txt文件读取和写入
解码labview读写二进制文件格式
二进制文件和文本文件的详细以及如何生成二进制文件-推荐下载
C打开文件 文本方式 二进制方式
【IT专家】Linux下二进制方式读写文件
fopen , fread fwrite 函数读写二进制文件
Matlab中如何实现二进制文件的读写
1使用Matlab产生二进制文件bin
Matlab中如何实现二进制文件的读写
ASCII和二进制文件的输入输出
Fortran 二进制文件读写
C语言实现读写二进制文件
二进制文件读写
C++读写二进制文件
相关主题
文本预览