空间统计分析实验报告
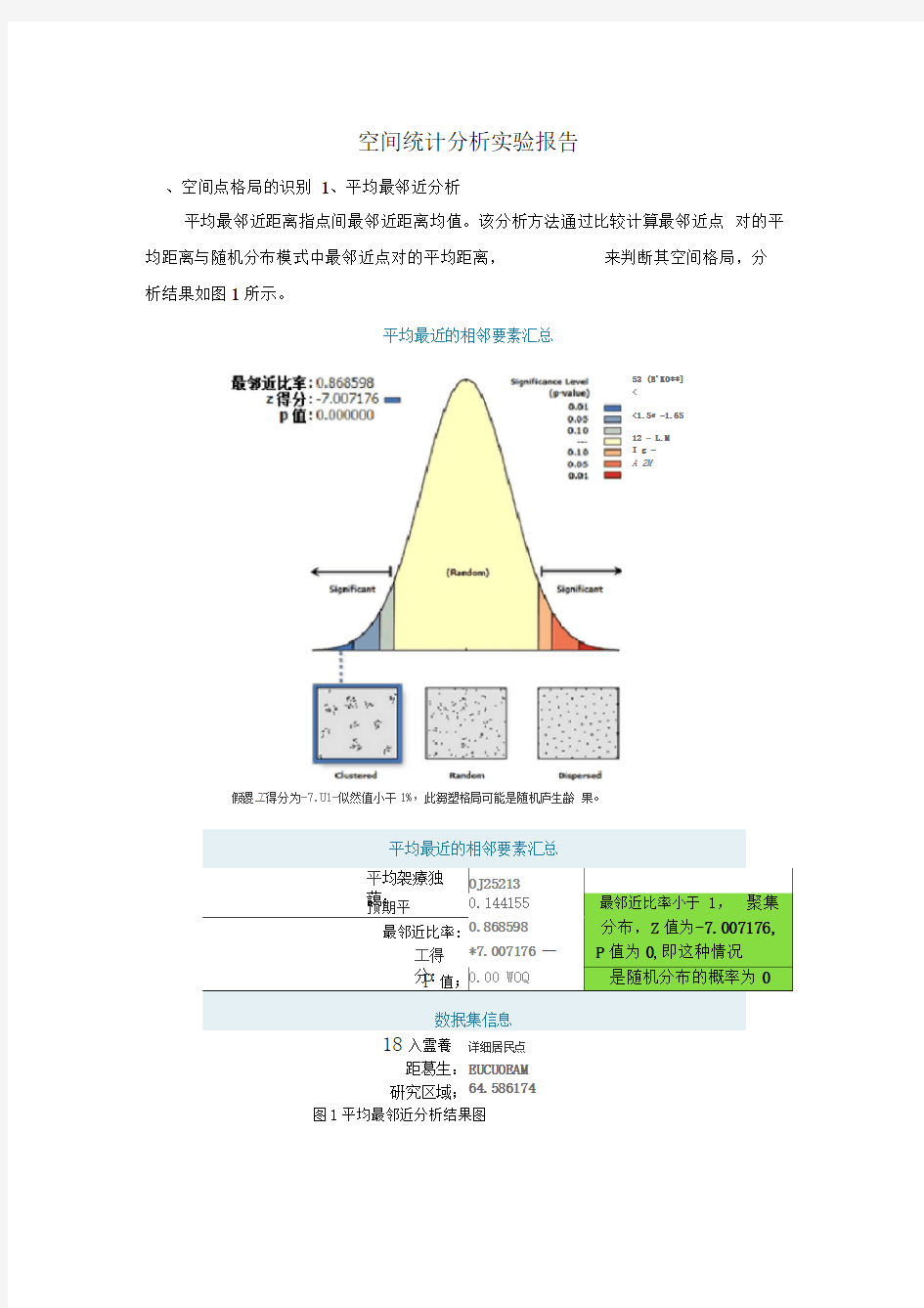
、空间点格局的识别 1、平均最邻近分析
平均最邻近距离指点间最邻近距离均值。该分析方法通过比较计算最邻近点 对的平均距离与随机分布模式中最邻近点对的平均距离,
来判断其空间格局,分
析结果如图1所示。
平均最近的相邻要素汇总
假谡工
得分为-7.U1-似然值小干1%,此芻塑格局可能是随机庐生齢 果。
平均最近的相邻要素汇总
平均袈療独
藹; OJ25213 预期平 0.144155 最邻近比率小于 1, 聚集
最邻近比率: 0.868598
分布,Z 值为-7.007176, 工得分: *7.007176 — P 值为0,即这种情况
P 值;
0.00 WOQ 是随机分布的概率为0
数抿集信息
18入霊養详细居民点
距葛生: E UCUOEAM
硏究区域;
64.586174 图1平均最邻近分析结果图
53 (E'KO**]
<
<1.5? -1.65
12 - L.M
I g - A 2M
计算结果共有5个参数,平均观测距离,预期平均距离,最邻近比率,得分,P 值。
P值就是概率值,它表示观测到的空间模式是由某随机过程创建而成的概率,
P值越小,也就是观测到的空间模式是随机空间模式的可能性越小,也就是我们越可以拒绝开始的零假设。最邻近比率值表示要素是否有聚集分布的趋势,对于趋势如何,要根据Z值和P值来判断。
本实验中的最邻近比率小于1 ,聚集分布,Z值为-7.007176, P值为0,即这种情况是随机分布的概率为0,该结果说明云南省详细居民点的分布是聚集分布的,不存在随机分布。
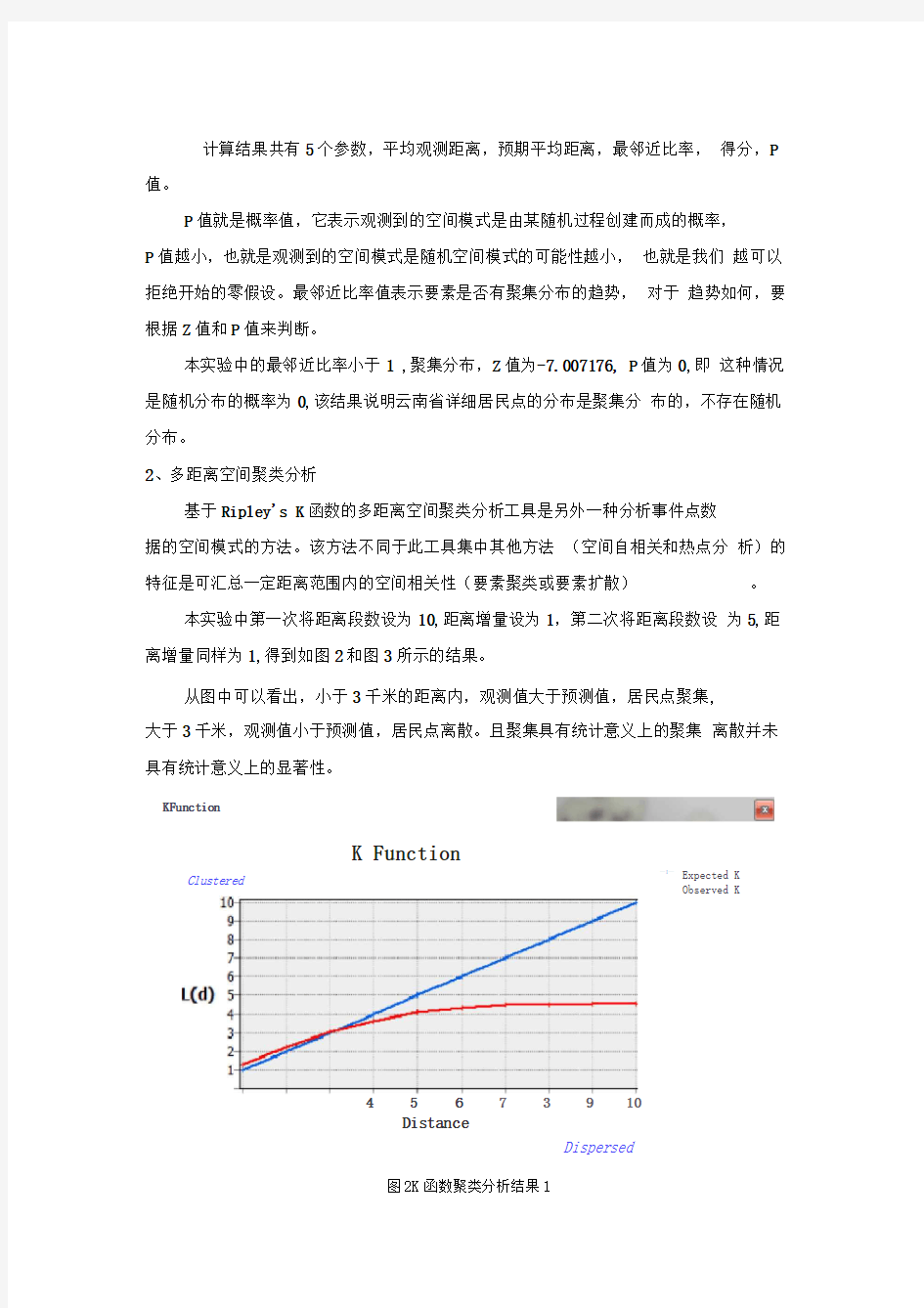
2、多距离空间聚类分析
基于Ripley's K函数的多距离空间聚类分析工具是另外一种分析事件点数
据的空间模式的方法。该方法不同于此工具集中其他方法(空间自相关和热点分析)的特征是可汇总一定距离范围内的空间相关性(要素聚类或要素扩散)。
本实验中第一次将距离段数设为10,距离增量设为1,第二次将距离段数设为5,距离增量同样为1,得到如图2和图3所示的结果。
从图中可以看出,小于3千米的距离内,观测值大于预测值,居民点聚集,
大于3千米,观测值小于预测值,居民点离散。且聚集具有统计意义上的聚集离散并未具有统计意义上的显著性。
KFunction
K Function
图2K函数聚类分析结果1—I—Expected K
Observed K
Clustered
4 5 6 7 3 9 10
Distance
Dispersed
3、密度制图
前面的最邻近分析和 K 函数聚类分析只能得到从数值上的出空间分布的 状态,但并不能直观看到分布集聚或分散的位置、形状和大小。密度制图根据
输入点要素的数值及其分布来计算整个区域的密度分布状况,
并产生一个连续
图3K 函数聚类分析结果 2
的栅格图形,利用密度制图可以通过密度显示点的聚集情况 D - g :4g.675.444
坯弘16^7.152^
MJ 祁卫?9.岀?
3X154.705.?* ?閱 245.WJJ
<1,24^,30 -幅屈盟◎也如
43」號』弘陡亠
54iM<7a512 MJW-lll
图4核密度制图结果
在核密度分析中,落入搜索区内的点具有不同的权重,靠近网格搜索中心的点会被赋予较大的权重,随着与其网格中心距离的加大,权重降低。图4中
的值为详细居民点之间的距离的密度,从图中可以看出居民点密集的地方核密度分析的值越大,居民点越密集,如上图中用红色椭圆圈出来的区域,该地区位于滇东南,居民点比较密集,可能与该地区的地形、气候等因素有关。
二、中心位置测度分析
本实验中的测度分析包括云南省居民点的中心要素、平均中心和中位数中
心,结果如图5所示。中心要素表示居民点中处在最中心的居民点,平均中心计算的是所有居民点质心的平均中心,中位数中心计算的是可使所有居民点的欧式距离达到最小的点。
平均中心和中位数中心的计算以GDP为权重,所以计算出来的平均中心和中位数中心为云南省的经济中心,而中位数中心在计算的时候受异常值的影响较小,所以计算经济中心时一般以中位数中心为准,如图5中以GDP为权
重计算出的中位数中心位于昆明市,与昆明市是云南省的经济中心相一致。
图5中心位置测度分析结果
、离散度的测度分析
图6离散度测度分析结果 离散度测度分析的结果如图6所示,本实验中的离散度分析采用的是标准 距离和标准差椭圆。标准距离创建的是一个包含以平均中心点为中心的圆面, 半径为标准距离值,表示要素集中分布的范围;标准差椭圆创建的椭圆的中心 同样为平均中心,有两个不同的标准距离,表示要素集中分布的趋势。本实验 中的离散度分析以GDP 为权重来进行分析,结果如图6所示。图中的数据显 示云南省居民点主要集中分布在中部和东部地区,是一个以安宁市为中心,半 径为198千米的圆,说明云南省经济较发达的区域集中在以安宁市为中心的, 半径为198千米的圆内,集中分布的趋势为东北西南走向。
四、空间自相关和事物属性的空间分布格局
某类事物的出现(例如犯罪、某类用地、某居住空间等)是否造成了周边 同类或异类事物或现象的出现,即空间是否自相关;找到某类事物或现象异常 聚集的空间位置(例如低收入阶层聚集),以利于分析聚集的原因。
空间自相关是指分布于不同空间位置的地理事物, 热门的某一属性存在同 价相关性,通常距离越近的两值之间的相关性越大, 具体可分为空间正相关和 负相关,常用Moran 指数来表示。
本实验通过分析来判断是否存在高收入和高收入聚集,低收入和低收入聚
云
南
省
居民
点离
骰
度
测度分析
国