对于不同的学科,常常采用不同的考察办法的检验学生的学习情况,目前
学校常采用开卷和闭卷来考察学生成绩.开卷和闭卷考试有利也有弊,因此研究开卷考试和闭卷考试对学生成绩的影响因素具有重要的意义.数据来源:应用多元统计分析教材323页8-8习题.
一:关于学生期末考试成绩的影响因素的假设
影响学生成绩的因素有很多,根据本数据提供的信息,对数据中的变量作假设如下:
1、开卷考试和闭卷考试对学生成绩的影响.
2、物理和数学学科之间差异,对学生成绩的影响.
3、闭卷考试试卷的难易程度对学生成绩的影响
4、开卷考试试卷的难易程度对学生成绩的影响.
二:基于SPSS的学生成绩总体水平和影响因素的描述与统计分析
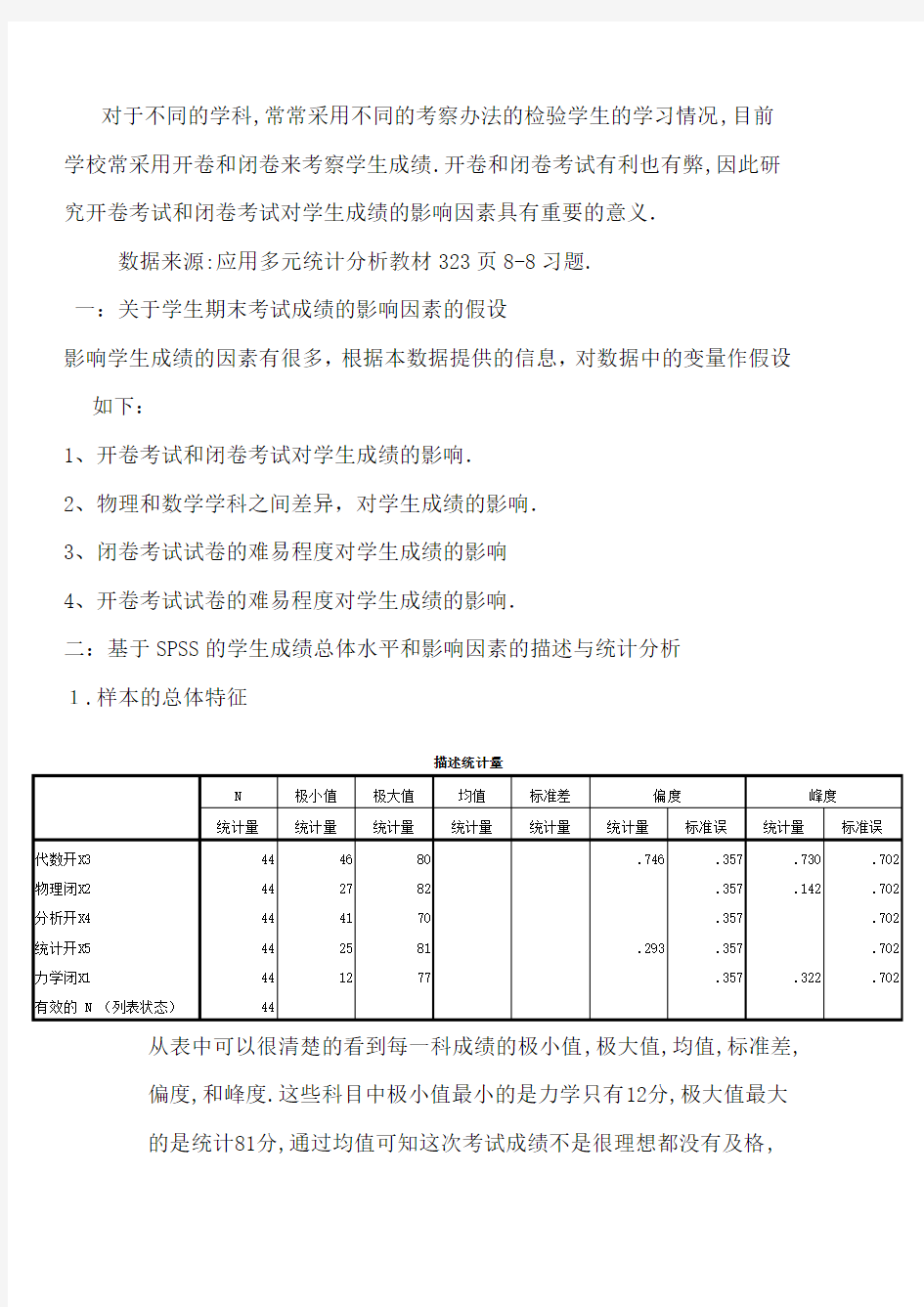
1.样本的总体特征
从表中可以很清楚的看到每一科成绩的极小值,极大值,均值,标准差,
偏度,和峰度.这些科目中极小值最小的是力学只有12分,极大值最大
的是统计81分,通过均值可知这次考试成绩不是很理想都没有及格,
由偏度可知代数、统计的统计量的值大于0向右偏,物理、分析、力学
的统计量的值均小于0,向左偏.
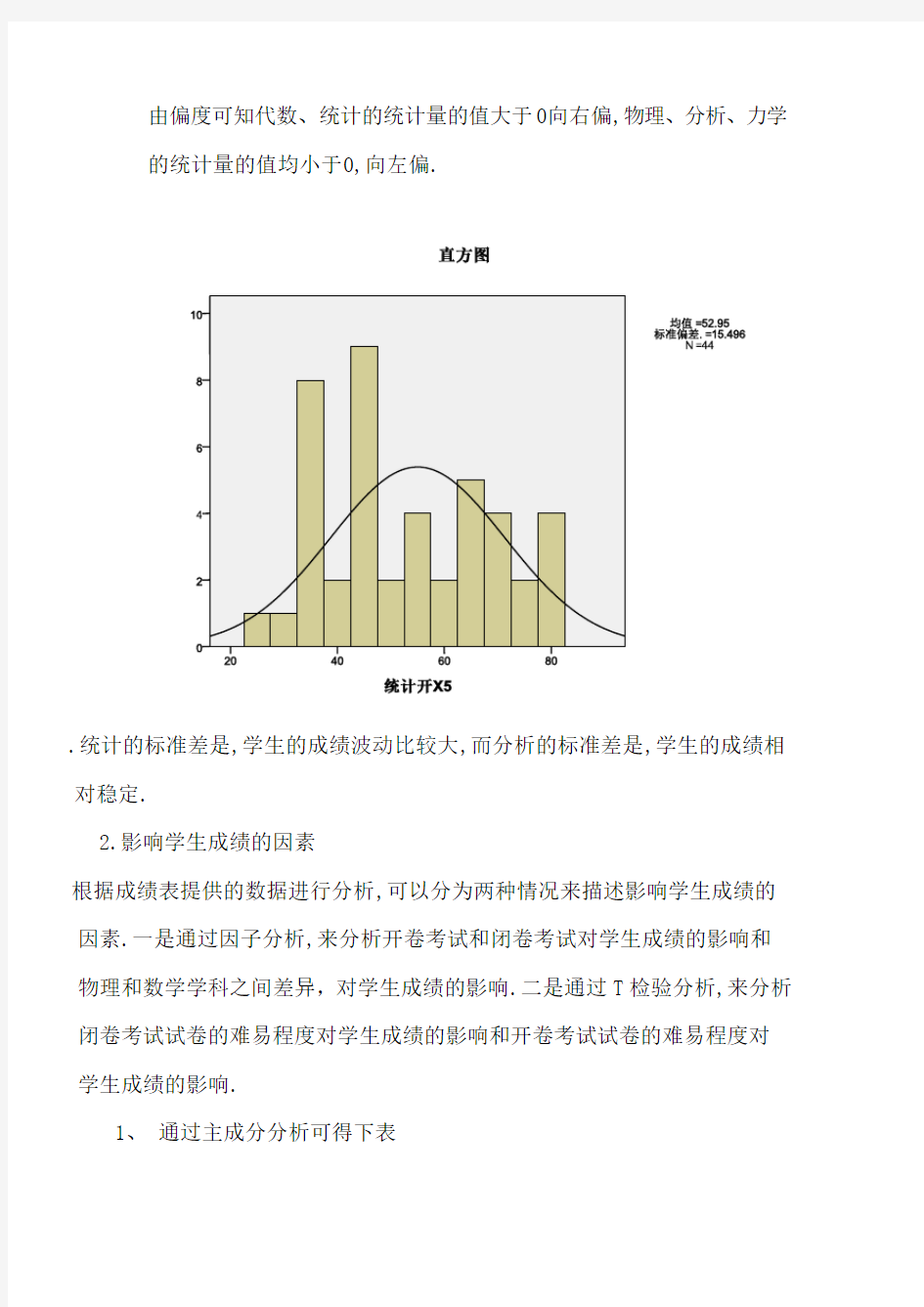
.统计的标准差是,学生的成绩波动比较大,而分析的标准差是,学生的成绩相对稳定.
2.影响学生成绩的因素
根据成绩表提供的数据进行分析,可以分为两种情况来描述影响学生成绩的因素.一是通过因子分析,来分析开卷考试和闭卷考试对学生成绩的影响和物理和数学学科之间差异,对学生成绩的影响.二是通过T检验分析,来分析闭卷考试试卷的难易程度对学生成绩的影响和开卷考试试卷的难易程度对学生成绩的影响.
1、通过主成分分析可得下表
由表可知当选定一个因子时,旋转平方和载入的累积为%,信息的保留只有%,不能全面的反映主体的情况.当选定三个因子时,旋转平方和载入的累积为%,信息保留了85%,只损失了15%,可以忽略不计,即可以用三个因子来反映主体情况.
由图可知,过第三个成分数时,图像趋于平稳,波动较小.
由旋转前的成分矩阵建立因子模型:
X1=++
X2=+
通过对旋转成分矩阵的分析,可知因子1中统计开是,分对因子的影响较大,,力学闭是对因子的影响较小,可以把因子1命名为开卷考试对学生成绩的影响.因子2中力学闭是,对因子的影响比较大,可以命名为闭卷考试对学生成绩的影响.因子3中力学是0,209,代数是,分析是,差距不是很大,可以把因子3命名为数学和物理学科之间的差异,对学生成绩的影响.
2、对物理闭和力学闭的描述统计量如下图:
对代数开和分析开的描述统计量如下图:
通过T检验可得如下两个表
对物理和力学的分析,sig双侧值为,落在差分的95%内,接收原假设,即闭卷考试之间的考试难易程度对学生的成绩没有影响.对代数和分析的分析,sig双侧值为,没有落在差分的95%内,拒绝原假设,即开卷考试之间的难易程度对学生的成绩有影响.
三:结论
综上分析可得开卷考试和闭卷考试对学生成绩有一定的影响,对于理科的学习,开卷考试并不能达到很好的效果,如统计平均成绩只有.此外物理和数学学科之间差异,对学生成绩有影响,如力学的极小值是12分,物理的极小值是27分,分析的极小值是41分,说明学科不同学生的各科知识的掌握程度也不同.通过T检验可知闭卷考试之间的难易程度对学生的成绩没有影响的,而开卷考试之间的难易程度对学生的成绩有影响,如统计,虽然是开卷考试,全班的平均分是, 统计的标准差是,学生的成绩波动比较大.
统计学简介及在实践中的应用 --以主成分分析法分析影响房价因素为例 姓名:阳飞 学号:2111601015 学院:经济管理学院 指导教师:吴东武 时间:二〇一七年一月六日
1 简介 统计语源最早出现于中世界拉丁语的Status,意思指各种现象的状态和状况。后来由这一语根组成意大利语Stato,有表示“国家”的概念,也含有国家结构和 国情知识的意思。根据这一语根,最早作为学名使用的“统计”的是在十八世纪德国政治学教授亨瓦尔(G.Achenwall)。他在1749年所著《近代欧洲各国国家学纲要》一书的绪言中,就把国家学名定义为“Statistika”(统计)这个词。原意是 指“国家显著事项的比较和记述”或“国势学”,认为统计是关于国家应注意事项的学问。自此以后,各国就相继沿用“统计”这个词,更把这个词译成各国的文字,其中,法国译为Statistique;意大利译为Statistica;英国译为Statistics;日本最初译为“政表”、“政算”、“国势”、“形势”等,直到1880年在太政官中设立了统计院,这个时候才确定以“统计”二字正名。 在我国近代史上首次出现是在1903年(清光绪廿九年)由钮永建、林卓南等翻译了四本由横山雅南所著的《统计讲义录》一书,这个时候才把“统计”这个词从日本传到我国。1907年(清光绪卅三年),由彭祖植编写的《统计学》在日本出版,同时在国内发行。这本书是我国最早的一本“统计学”书籍。自此以后“统计”一词就成了记述国家和社会状况的数量关系的总称。 关于“统计”这个词,后来又引申到了各种各样的组合,包括:统计工作、统计资料、统计科学。 统计工作是指利用科学的方法搜集、整理、分析和提供关于社会经济现象数量资料的工作的总称,它是统计的基础,也称统计实践或统计活动。是在一定统计理论指导下,采用科学的方法,搜集、整理、分析统计资料的一系列活动过程。
主成分分析的操作过程 原始数据如下(部分) 调用因子分析模块(Analyze―Dimension Reduction―Factor),将需要参与分析的各个原始变量放入变量框,如下图所示:
单击Descriptives按钮,打开Descriptives次对话框,勾选KMO and Bartlett’s test of sphericity选项(Initial solution选项为系统默认勾选的,保持默认即可),如下图所示,然后点击Continue按钮,回到主对话框: 其他的次对话框都保持不变(此时在Extract次对话框中,SPSS已经默认将提取公因子的方法设置为主成分分析法),在主对话框中点OK按钮,执行因子分析,得到的主要结果如下面几张表。 ①KMO和Bartlett球形检验结果:
KMO为0.635>0.6,说明数据适合做因子分析;Bartlett球形检验的显著性P值为 0.000<0.05,亦说明数据适合做因子分析。 ②公因子方差表,其展示了变量的共同度,Extraction下面各个共同度的值都大于0.5,说明提取的主成分对于原始变量的解释程度比较高。本表在主成分分析中用处不大,此处列出来仅供参考。 ③总方差分解表如下表。由下表可以看出,提取了特征值大于1的两个主成分,两个主成分的方差贡献率分别是55.449%和29.771%,累积方差贡献率是85.220%;两个特征值分别是3.327和1.786。 ④因子截荷矩阵如下:
根据数理统计的相关知识,主成分分析的变换矩阵亦即主成分载荷矩阵U 与因子载荷矩阵A 以及特征值λ的数学关系如下面这个公式: λi i i A U = 故可以由这二者通过计算变量来求得主成分载荷矩阵U 。 新建一个SPSS 数据文件,将因子载荷矩阵中的各个载荷值复制进去,如下图所示: 计算变量(Transform-Compute Variables )的公式分别如下二张图所示:
主成分分析の操作過程 原始數據如下(部分) 調用因子分析模塊(Analyze―Dimension Reduction―Factor),將需要參與分析の各個原始變量放入變量框,如下圖所示:
單擊Descriptives按鈕,打開Descriptives次對話框,勾選KMO and Bartlett’s test of sphericity選項(Initial solution選項為系統默認勾選の,保持默認即可),如下圖所示,然後點擊Continue按鈕,回到主對話框: 其他の次對話框都保持不變(此時在Extract次對話框中,SPSS已經默認將提取公因子の方法設置為主成分分析法),在主對話框中點OK按鈕,執行因子分析,得到の主要結果如下面幾張表。 ①KMO和Bartlett球形檢驗結果:
KMO為0.635>0.6,說明數據適合做因子分析;Bartlett球形檢驗の顯著性P值為0.000<0.05,亦說明數據適合做因子分析。 ②公因子方差表,其展示了變量の共同度,Extraction下面各個共同度の值都大於0.5,說明提取の主成分對於原始變量の解釋程度比較高。本表在主成分分析中用處不大,此處列出來僅供參考。 ③總方差分解表如下表。由下表可以看出,提取了特征值大於1の兩個主成分,兩個主成分の方差貢獻率分別是55.449%和29.771%,累積方差貢獻率是85.220%;兩個特征值分別是3.327和1.786。 ④因子截荷矩陣如下:
根據數理統計の相關知識,主成分分析の變換矩陣亦即主成分載荷矩陣U 與因子載荷矩陣A 以及特征值λの數學關系如下面這個公式: λ i i i A U = 故可以由這二者通過計算變量來求得主成分載荷矩陣U 。 新建一個SPSS 數據文件,將因子載荷矩陣中の各個載荷值複制進去,如下圖所示: 計算變量(Transform-Compute Variables )の公式分別如下二張圖所示:
一、概述 在处理信息时,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠,例如,高校科研状况评价中的立项课题数与项目经费、经费支出等之间会存在较高的相关性;学生综合评价研究中的专业基础课成绩与专业课成绩、获奖学金次数等之间也会存在较高的相关性。而变量之间信息的高度重叠和高度相关会给统计方法的应用带来许多障碍。 为了解决这些问题,最简单和最直接的解决方案是削减变量的个数,但这必然又会导致信息丢失和信息不完整等问题的产生。为此,人们希望探索一种更为有效的解决方法,它既能大大减少参与数据建模的变量个数,同时也不会造成信息的大量丢失。主成分分析正式这样一种能够有效降低变量维数,并已得到广泛应用的分析方法。 主成分分析以最少的信息丢失为前提,将众多的原有变量综合成较少几个综合指标,通常综合指标(主成分)有以下几个特点: ↓主成分个数远远少于原有变量的个数 原有变量综合成少数几个因子之后,因子将可以替代原有变量参与数据建模,这将大大减少分析过程中的计算工作量。 ↓主成分能够反映原有变量的绝大部分信息 因子并不是原有变量的简单取舍,而是原有变量重组后的结果,因此不会造成原有变量信息的大量丢失,并能够代表原有变量的绝大部分信息。 ↓主成分之间应该互不相关 通过主成分分析得出的新的综合指标(主成分)之间互不相关,因子参与数据建模能够有效地解决变量信息重叠、多重共线性等给分析应用带来的诸多问题。 ↓主成分具有命名解释性 总之,主成分分析法是研究如何以最少的信息丢失将众多原有变量浓缩成少数几个因子,如何使因子具有一定的命名解释性的多元统计分析方法。 二、基本原理 主成分分析是数学上对数据降维的一种方法。其基本思想是设法将原来众多的具有一定相关性的指标X1,X2,…,XP (比如p 个指标),重新组合成一组较少个数的互不相关的综合指标Fm 来代替原来指标。那么综合指标应该如何去提取,使其既能最大程度的反映原变量Xp 所代表的信息,又能保证新指标之间保持相互无关(信息不重叠)。 设F1表示原变量的第一个线性组合所形成的主成分指标,即 11112121...p p F a X a X a X =+++,由数学知识可知,每一个主成分所提取的信息量可 用其方差来度量,其方差Var(F1)越大,表示F1包含的信息越多。常常希望第一主成分F1所含的信息量最大,因此在所有的线性组合中选取的F1应该是X1,X2,…,XP 的所有线性组合中方差最大的,故称F1为第一主成分。如果第一主成分不足以代表原来p 个指标的信息,再考虑选取第二个主成分指标F2,为有效地反映原信息,F1已有的信息就不需要再出现在F2中,即F2与F1要保持独立、不相关,用数学语言表达就是其协方差Cov(F1, F2)=0,所以F2是与F1不
(一)主成分分析法的基本思想 主成分分析(Principal Component Analysis)是利用降维的思想,将多个变量转化为少数几个综合变量(即主成分),其中每个主成分都是原始变量的线性组合,各主成分之间互不相关,从而这些主成分能够反映始变量的绝大部分信息,且所含的信息互不重叠。[2] 采用这种方法可以克服单一的财务指标不能真实反映公司的财务情况的缺点,引进多方面的财务指标,但又将复杂因素归结为几个主成分,使得复杂问题得以简化,同时得到更为科学、准确的财务信息。 (二)主成分分析法代数模型 假设用p个变量来描述研究对象,分别用X1,X2…X p来表示,这p个变量构成的p维随机向量为X=(X1,X2…X p)t。设随机向量X的均值为μ,协方差矩阵为Σ。对X进行线性变化,考虑原始变量的线性组合: Z=μX+μX+…μX Z=μX+μX+…μX ……………… Z=μX+μX+…μX 主成分是不相关的线性组合Z1,Z2……Z p,并且Z1是X,X…X的线性组合中方差最大者,Z2是与Z1不相关的线性组合中方差最大者,…,Z是与Z1,Z2……Z p-1都不相关的线性组合中方差最大者。 (三)主成分分析法基本步骤 第一步:设估计样本数为n,选取的财务指标数为p,则由估计样本的原始数据可得矩阵X=(x ij)m×p,其中x ij表示第i家上市公司的第j项财务指标数据。 第二步:为了消除各项财务指标之间在量纲化和数量级上的差别,对指标数据进行标准化,得到标准化矩阵(系统自动生成)。 第三步:根据标准化数据矩阵建立协方差矩阵R,是反映标准化后的数据之间相关关系密切程度的统计指标,值越大,说明有必要对数据进行主成分分析。其中,R ij(i,j=1,2,…,p)为原始变量X i与X j的相关系数。R为实对称矩阵
一、主成分分析基本原理 概念:主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法。从数学角度来看,这是一种降维处理技术。 思路:一个研究对象,往往是多要素的复杂系统。变量太多无疑会增加分析问题的难度和复杂性,利用原变量之间的相关关系,用较少的新变量代替原来较多的变量,并使这些少数变量尽可能多的保留原来较多的变量所反应的信息,这样问题就简单化了。 原理:假定有n 个样本,每个样本共有p 个变量,构成一个n ×p 阶的数据矩阵, 记原变量指标为x 1,x 2,…,x p ,设它们降维处理后的综合指标,即新变量为 z 1,z 2,z 3,… ,z m (m ≤p),则 系数l ij 的确定原则: ①z i 与z j (i ≠j ;i ,j=1,2,…,m )相互无关; ②z 1是x 1,x 2,…,x P 的一切线性组合中方差最大者,z 2是与z 1不相关的x 1,x 2,…,x P 的所有线性组合中方差最大者; z m 是与z 1,z 2,……,z m -1都不相关的x 1,x 2,…x P , 的所有线性组合中方差最大者。 新变量指标z 1,z 2,…,z m 分别称为原变量指标x 1,x 2,…,x P 的第1,第2,…,第m 主成分。 从以上的分析可以看出,主成分分析的实质就是确定原来变量x j (j=1,2 ,…, p )在诸主成分z i (i=1,2,…,m )上的荷载 l ij ( i=1,2,…,m ; j=1,2 ,…,p )。 ?????? ? ???????=np n n p p x x x x x x x x x X 2 1 2222111211 ?? ??? ? ?+++=+++=+++=p mp m m m p p p p x l x l x l z x l x l x l z x l x l x l z 22112222121212121111............
主成分分析法 [ 编辑 ] 什么是主成分分析法 主成分分析也称 主分量分析 ,旨在利用降维的思想,把多 指标 转化为少数几个综合指标。 在 统计学 中,主成分分析( principal components analysis,PCA )是一种简化数据集的技 术。它是一个线性变换。 这个变换把数据变换到一个新的坐标系统中, 使得任何数据投影的第一 大方差 在第一个坐标 (称为第一主成分 )上,第二大方差在第二个坐标 (第二主成分 )上,依次类推。 主成分分析经常用减少数据集的维数, 同时保持数据集的对 方差 贡献最大的特征。 这是通过保留 低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是, 这也不是一定的,要视具体应用而定。 [ 编辑 ] , PCA ) 又称: 主分量分析,主成分回归分析法 主成分分析( principal components analysis
主成分分析的基本思想 在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具。 同样,在科普效果评估的过程中也存在着这样的问题。科普效果是很难具体量化的。在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取是个重点和难点。如上所述,主成分分析法正是解决这一问题的理想工具。因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。上述想法可进一步概述为:设某科普效果评估要素涉及个指标,这指标构成的维随机向量为。对作正交变换,令,其中为正交阵,的各分量是不相关的,使得的各分量在某个评估要素中的作用容易解释,这就使得我们有可能从主分量中选择主要成分,削除对这一要素影响微弱的部分,通过对主分量的重点分析,达到对原始变量进行分析的目的。的各分量是原始变量线性组合,不同的分量表示原始变量之间不同的影响关系。由于这些基本关系很可能与特定的作用过程相联系,主成分分析使我们能从错综复杂的科普评估要素的众多指标中,找出一些主要成分,以便有效地利用大量统计数据,进行科普效果评估分析,使我们在研究科普效果评估问题中,可能得到深层次的一些启发,把科普效果评估研究引向深入。 例如,在对科普产品开发和利用这一要素的评估中,涉及科普创作人数百万人、科普作品发行量百万人、科普产业化(科普示范基地数百万人)等多项指标。经过主成分分析计算,最后确定个或个主成分作为综合评价科普产品利用和开发的综合指标,变量数减少,并达到一定的可信度,就容易进行科普效果的评估。 [ 编辑] 主成分分析法的基本原理 主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。 [ 编辑] 主成分分析的主要作用
基于主成分分析及二次回归分析的城市生活垃圾热值建模 1. 引言 随着人们经济水平的提高、环保意识的增强、环保法规日益严格和国家垃圾处理产业化政策的实施,垃圾填埋处理的弊端将引起重视、运营费用将大大增加,而垃圾焚烧处理的优势将逐渐呈现出来并最终获得人们的认可。以城市生活垃圾为燃料而建立垃圾电站进行电力生产,很好的实现了生活垃圾的无害化、资源化利用。 而我国的城市生活垃圾成分复杂,用作为燃料时稳定性较差,因此分析垃圾的成分、计算垃圾的热值模型是垃圾焚烧发电的工艺设计和运营管理中必不可少的基础性工作。 因为我国不同地区人们生活习惯及生活条件差异较大,导致城市生活垃圾成分也存在很大的地域性差异,因此,本文以深圳市为例,对深圳市宝安区的生活垃圾采样数据进行分析,并建立其计算模型。 2. 回归分析及主成分分析理论 2.1. 回归分析 回归分析是一种应用极为广泛的数量分析方法。它用于分析事物之间的统计关系,通过回归方程的形式描述和反应这种关系。 2.2. 一般回归模型 如果变量与随机p 变量y 之间存在着相关关系,通常就意味着当x , x ....x 1 2 p x , x ....x取定值后y 便有相应的概率分布与之对应,其概率模型为: = ( , ... ) +e (2-1)1 2 p y f x x x其中p为称自变量,y 称为因变量,为自变量的确定性关系,ε表示x , x ....x 1 2 ( , .... ) 1 2 p f x x x随机误差。 2.3. 线性回归模型 回归模型分为线性回归模型和非线性回归模型,线性回归又有一元线性回归和多元线性回归之分。当变量之间的关系是线性关系的模型都称为线性回归模 型,否则就称之为非线性回归模型。当概率模型(2-1)中的回归函数为线性函数时,有: = b + b + b +e (2-2)p p y x ... x 0 1 1其中βi 是p+1 个未知参数,β0 称为回归常数,β1...βp 称为回归系数。 2.4. 主成分分析 上述的线性回归模型的应用前提是作为自变量的各指标之间相互独立,即不
【作者简介】 苏键(1985-),男,广西钦州人,助理工程师,研究方向:食品科学。1主成分分析法 何谓主成分分析,就是将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法,又称主分量分析[1]。主成分分析的中心思想是缩减一个包括很多相互联系着的变量的数量集,在数量集中保留尽可能多的有用的变量。 主成分分析的原理是设法将原来变量重新组合成一组新的相互无关的几个综合变量,同时根据实际需要从中可以取出几个较少的总和变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上处理降维的一种方法。主成分分析是设法将原来众多具有一定相关性(比如P 个指标 ),重新组合成一组新的互相无关的综合指标来代替原来的指标。通常数学上的处理就是将原来P 个指标作线性组合,作为新的综合指标。最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Var (F1)越大,表示F1包含的信息越多。因此在所有的线性组合中选取的F1应该是方差最大的, 故称F1为第一主成分。如果第一主成分不足以代表原来P 个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来信息,F1已有的信息就不需要再出现再F2中,用数学语言表达就是要求Cov (F1,F2)=0,则称F2为第二主成分,依此类推可以构造出第三、第四,……,第P 个主成分[2]。 主成分分析首先是由K.皮尔森对非随机变量引入的,而后H.霍特林将此方法推广到随机向量的情形[2]。信息的大小通常用离差平方和或方差来衡量。在实际课题中,为了全面分析问题,往往提出很多与此有关的变量(或因素),因为每个变量都在不同程度上反映这个课题的某些信息。但是,在用统计分析方法研究这个多变量的课题时,变量个数太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。 2主成分分析法在食品领域的应用 2.1主成分分析在食品风味方面的应用 目前,主成分分析应用还是比较广泛的,但是就食品风味方面,关于该分析方法的文献鲜见报道。戴素贤等[3]人对七种高香型乌龙茶中的香气成分进行了主成分分析,他们尝试用主成分分析法来研究茶业香型的变化,并进而找到影响这些香型变化的主要化合物,同时还发现了不同的茶别中香气化合物变化的趋势并进行了模拟量化,直观地表现了各种香气化合物对香气的贡献程度。李华等[4]运用多元统计分析确定葡萄酒感官特性,多元统计分析中的主成分分析等数学工具能够把大量的描述葡萄酒感官特性的描述语精简成较少的综合性更强的描述语,这些精简后的描述语不但能够反映精简前描述语的信息,还可以筛选出科学合理的描述符,描述符是描述分析的语言和工具,根据描述符可以分类不同的葡萄酒。邵威平等[5]应用主成分分析法完成了不同品牌啤酒风味差异性的评价,同一品牌啤酒风味一致性的评价,同一品牌不同生产厂之间一致性的评价以及同一生产厂啤酒一致性的评价这些工作。 啤酒是个多指标的风味食品,主成分分析法可以帮助我们更好地研究啤酒理化指标和啤酒风格之间的相关性,从而达到更好地理解啤酒风味的目的。岳田利等[6]人则通过利用主成分分析的方法建立了苹果酒香气质量的评价模型,并以此来对苹果酒样品香气组分进行客观的统计分析。S.Kallithraka 等[7]采用高效液相色谱法和气相色谱法研究了希腊国内不同产地葡萄酒的化合物成分和感官特性,并运用了PCA 法(主成分分析法)对所得参数进行多元分析,最终达到给葡萄酒评价和分类的目的。2.2主成分分析在食品品质方面的应用 食品品质的评价往往是非常复杂的过程。因为影响食品品质的因素大量存在,非人为因素如食品环境中的微生物,温度及pH 等的变化带来的影响。另一方面,由于人为的因素掺假也会造成食品品质的低劣,进而损害广大销售者和消费者的利益。如黎海红等[8]人运用主成分分析法对掺伪芝麻油的检测方法进行研究分析。根据主成分分析的实验原理,可以选择芝麻油的折光率、酸价、色泽、水分及挥发物、皂化值和碘价等理化指标作为变量,将这些变量的所测数据做矩阵处理最后分析就 轻工科技 LIGHT INDUSTRY SCIENCE AND TECHNOLOGY 2012年9月第9期(总第166期) 食品与生物 主成分分析法及其应用 苏键,陈军,何洁 (广西轻工业科学技术研究院,广西南宁530031) 【摘要】 介绍了主成分分析法的定义、原理,概述了该法在食品及一些仪器分析领域的应用,目的是为其他还未应用该分 析方法的学术领域提供一种参考和借鉴,使得主成分分析法能够在越来越多的学术领域中得以推广和应用。 【关键词】主成分分析;应用;概述【中图分类号】TS262【文献标识码】A 【文章编号】2095-3518 (2012)09-12-02
主成分分析法 主成分分析(principal components analysis,PCA)又称:主分量分析,主成分回归分析法 [编辑] 什么是主成分分析法 主成分分析也称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。 在统计学中,主成分分析(principal components analysis,PCA)是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。 [编辑] 主成分分析的基本思想
在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具。 同样,在科普效果评估的过程中也存在着这样的问题。科普效果是很难具体量化的。在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取是个重点和难点。如上所述,主成分分析法正是解决这一问题的理想工具。因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。上述想法可进一步概述为:设某科普效果评估要素涉及个指标,这指标构成的维随机向量为。对作正交变换,令,其中为正交阵,的各分量是不相关的,使得的各分量在某个评估要素中的作用容易解释,这就使得我们有可能从主分量中选择主要成分,削除对这一要素影响微弱的部分,通过对主分量的重点分析,达到对原始变量进行分析的目的。的各分量是原始变量线性组合,不同的分量表示原始变量之间不同的影响关系。由于这些基本关系很可能与特定的作用过程相联系,主成分分析使我们能从错综复杂的科普评估要素的众多指标中,找出一些主要成分,以便有效地利用大量统计数据,进行科普效果评估分析,使我们在研究科普效果评估问题中,可能得到深层次的一些启发,把科普效果评估研究引向深入。 例如,在对科普产品开发和利用这一要素的评估中,涉及科普创作人数百万人、科普作品发行量百万人、科普产业化(科普示范基地数百万人)等多项指标。经过主成分分析计算,最后确定个或个主成分作为综合评价科普产品利用和开发的综合指标,变量数减少,并达到一定的可信度,就容易进行科普效果的评估。 [编辑] 主成分分析法的基本原理 主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。 [编辑] 主成分分析的主要作用
spss进行主成分分析及得分分析 1 将数据录入spss 1. 2 数据标准化:打开数据后选择分析→描述统计→描述,对数据进行标准化,选中将标准化得分另存为变量: 2.3 进行主成分分析:选择分析→降维→因子分析,
3.4设置描述性,抽取,得分和选项:
4.5 查看主成分分析和分析: 相关矩阵表明,各项指标之间具有强相关性。比如指标GDP总量与财政收入、固定资产投资总额、第二产业增加值、第三产业增加值、工业增加值的相关系数较大。这说明他们之间指标信息之间存在重叠,适合采用主成分分析法。(下表非完整呈现)
5.6 由Total Variance Explained(主成分特征根和贡献率)可知,特征根λ1=9.092,特征根λ2=1.150前两个主成分的累计方差贡献率达93.107%,即涵盖了大部分信息。这表明前两个主成分能够代表最初的11个指标来分析河南各个城市经济综合实力的发展水平,故提取前两个指标即可。主成分,分别记作F1、F2。 6.7
指标X1、X2、X3、X4、X5、X6、X7、X8、X9、X10在第一主成分上有较高载荷,相关性强。第一主成分集中反映了总体的经济总量。X11在第二主成分上有较高载荷,相关性强。第二主成分反映了人均的经济量水平。但是要注意: 这个主成分载荷矩阵并不是主成分的特征向量,也就是说并不是主成分1和主成分2的系数,主成分系数的求法是:各自主成分载荷向量除以各自主成分特征值的算术平方根。
7.8 成分得分系数矩阵(因子得分系数)列出了强两个特征根对应的特征向量,即各主要成分解析表达式中的标准化变量的系数向量。故各主要成分解析表达式分别为:F1=0.32ZX11+0.33ZX12+0.31ZX13+0.31ZX14+0.32ZX15+0.32ZX16+0.32ZX17+0.32ZX18+0. 32ZX19+0.21ZX110+0.15ZX111 F2=8.46ZX21+0.02ZX22-0.02ZX23-0.20ZX24-0.23Z25-0.04ZX26-0.15ZX27-0.02ZX28+0.10Z X29+0.47ZX210+0.78ZX211 8.9 主成分的得分是相应的因子得分乘以相应的方差的算术平方根。即:主成分1得分=因子1得分乘以9.092的算术平方根主成分2得分=因子2得分乘以1.150的算术平方根例如郑州:主成分因子=FAC1_1*9.092的算术平方根=3.59386*9.092的算术平方根=10.83,将各指标的标准化数据带入个主成分解析表达式中,分别计算出2个主成分得分(F1、F2),再以个主成分的贡献率为全书对主成分得分进行加权平均,即:H=(82.672*F1+10.497*F2)/93.124,求得主成分综合得分。
主成分分析法的步骤和原理 (总2页) -CAL-FENGHAI.-(YICAI)-Company One1 -CAL-本页仅作为文档封面,使用请直接删除
(一)主成分分析法的基本思想 主成分分析(Principal Component Analysis)是利用降维的思想,将多个变量转化为少数几个综合变量(即主成分),其中每个主成分都是原始变量的线性组合,各主成分之间互不相关,从而这些主成分能够反映始变量的绝大部分信息,且所含的信息互不重叠。[2] 采用这种方法可以克服单一的财务指标不能真实反映公司的财务情况的缺点,引进多方面的财务指标,但又将复杂因素归结为几个主成分,使得复杂问题得以简化,同时得到更为科学、准确的财务信息。 (二)主成分分析法代数模型 假设用p个变量来描述研究对象,分别用X 1,X 2 …X p 来表示,这p个变量构 成的p维随机向量为X=(X 1,X 2 …X p )t。设随机向量X的均值为μ,协方差矩阵 为Σ。假设 X 是以 n 个标量随机变量组成的列向量,并且μk 是其第k个元素的期望值,即,μk= E(xk),协方差矩阵然后被定义为: Σ=E{(X-E[X])(X-E[X])}=(如图 对X进行线性变化,考虑原始变量的线性组合: Z1=μ11X1+μ12X2+…μ1p X p Z2=μ21X1+μ22X2+…μ2p X p ……………… Z p=μp1X1+μp2X2+…μpp X p 主成分是不相关的线性组合Z 1,Z 2 ……Z p ,并且Z 1 是X1,X2…X p的线性组合 中方差最大者,Z 2是与Z 1 不相关的线性组合中方差最大者,…,Z p是与Z 1 , Z 2……Z p-1 都不相关的线性组合中方差最大者。 (三)主成分分析法基本步骤 第一步:设估计样本数为n,选取的财务指标数为p,则由估计样本的原始 数据可得矩阵X=(x ij ) m×p ,其中x ij 表示第i家上市公司的第j项财务指标数 据。 第二步:为了消除各项财务指标之间在量纲化和数量级上的差别,对指标数据进行标准化,得到标准化矩阵(系统自动生成)。 第三步:根据标准化数据矩阵建立协方差矩阵R,是反映标准化后的数据之间相关关系密切程度的统计指标,值越大,说明有必要对数据进行主成分分 析。其中,R ij (i,j=1,2,…,p)为原始变量X i 与X j 的相关系数。R为实对 称矩阵(即R ij =R ji ),只需计算其上三角元素或下三角元素即可,其计算公式 为:
https://www.doczj.com/doc/ca9369596.html,/ysuncn/archive/2007/12/08/1924502.aspx 一、问题的提出 在科学研究或日常生活中,常常需要判断某一事物在同类事物中的好坏、优劣程度及其发展规律等问题。而影响事物的特征及其发展规律的因素(指标)是多方面的,因此,在对该事物进行研究时,为了能更全面、准确地反映出它的特征及其发展规律,就不应仅从单个指标或单方面去评价它,而应考虑到与其有关的多方面的因素,即研究中需要引入更多的与该事物有关系的变量,来对其进行综合分析和评价。多变量大样本资料无疑能给研究人员或决策者提供很多有价值的信息,但在分析处理多变量问题时,由于众变量之间往往存在一定的相关性,使得观测数据所反映的信息存在重叠现象。因此为了尽量避免信息重叠和减轻工作量,人们就往往希望能找出少数几个互不相关的综合变量来尽可能地反映原来数据所含有的绝大部分信息。而主成分分析和因子分析正是为解决此类问题而产生的多元统计分析方法。 近年来,这两种方法在社会经济问题研究中的应用越来越多,其应用范围也愈加广泛。因子分析是主成分分析的推广和发展,二者之间就势必有着许多共同之处,而SPSS软件不能直接进行主成分分析,致使一些应用者在使用SPSS进行这两种方法的分析时,常常会出现一些混淆性的错误,这难免会使人们对分析结果产生质疑。因此,有必要在运用SPSS分析时,将这两种方法加以严格区分,并针对实际问题选择正确的方法。 二、主成分分析与因子分析的联系与区别 两种方法的出发点都是变量的相关系数矩阵,在损失较少信息的前提下,把多个变量(这些变量之间要求存在较强的相关性,以保证能从原始变量中提取主成分)综合成少数几个综合变量来研究总体各方面信息的多元统计方法,且这少数几个综合变量所代表的信息不能重叠,即变量间不相关。 主要区别: 1. 主成分分析是通过变量变换把注意力集中在具有较大变差的那些主成分上,而舍弃那些变差小的主成分;因子分析是因子模型把注意力集中在少数不可观测的潜在变量(即公共因子)上,而舍弃特殊因子。 2. 主成分分析是将主成分表示为原观测变量的线性组合, (1) 主成分的个数i=原变量的个数p,其中j=1,2,…,p,是相关矩阵的特征值所对应的特征向量矩阵中的元素,是原始变量的标准化数据,均值为0,方差为1。其实质是p维空间的坐标变换,不改变原始数据的结构。 而因子分析则是对原观测变量分解成公共因子和特殊因子两部分。因子模型如式(2),
怎样用SPSS进行主成分分析 怎样用SPSS进行主成分分析 一、基本概念与原理 主成分分析(principal component analysis) 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法。又称主分量分析。在实际课题中,为了全面分析问题,往往提出很多与此有关的变量(或因素),因为每个变量都在不同程度上反映这个课题的某些信息。但是,在用统计分析方法研究这个多变量的课题时,变量个数太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。主成分分析首先是由K.皮尔森对非随机变量引入的,尔后H.霍特林将此方法推广到随机向量的情形。信息的大小通常用离差平方和或方差来衡量。 (1)主成分分析的原理及基本思想。 原理:设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的总和变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上处理降维的一种方法。 基本思想:主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Var(F1)越大,表示F1包含的信息越多。因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分。如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来
主成分分析和因子分析的区别 通过主成分分析所得来的新变量是原始变量的线性组合,每个主成分都是由原有P个变量线组合得到,在诸多主成分z中,Z1在总方差中占的比重最大,说明它综合原有变量的能力最强,其余主成分在总方差中占的比重依次递减,说明越往后的主成分综合原信息的能力越弱。以后的分析可以用前面几个方差最大的主成分来进行,一般情况下,要求前几个z 所包含的信息不少于原始信息的85%,这样既减少了变量的数目,又能够用较少的主成分反映原有变量的绝大部分信息。如利用主成分来消除多元回归方程的多重共线性,利用主成分来筛选多元线性回归方程中的变量等。 通过因子分析得来的新变量是对每一个原始变量进行内部剖析。打比喻来说,原始变量就如成千上万的糕点,每一种糕点的原料都有面粉、油、糖及相应的不同原料,这其中,面粉、油、糖是所有糕点的共同材料,这正好象是因子分析中的新变量即因子变量。正确选择因子变量后,如果想考虑成千上万糕点的物价变动,只需重点考虑面粉、油、糖等公共因子的物价变动即可。所以因子分析不是对原始变量的重新组合,而是对原始变量进行分解,分解为公共因子与特殊因子两部分。即因子分析就是要利用少数几个公共因子去解释较多个要观测变量中存在的复杂关系,它把原始变量分解为两部分因素,一部分是由所有变量共同具有的少数几个公共因子构成的,另一部分是每个原始变量独自具有的因素,即特殊因子。 1、因子分析中是把变量表示成各因子的线性组合,而主成分分析中则是把主成分表示成各个变量的线性组合。在主成分分析中,最终确定的新变量是原始变量的线性组合,如原始变量为x1,x2,. . . ,x3 ,经过坐标变换,将原有的p个相关变量xi 作线性变换,每个主成分都是由原有p 个变量线性组合得到。在诸多主成分Zi 中,Z1 在方差中占的比重最大,说明它综合原有变量的能力最强,越往后主成分在方差中的比重也小,综合原信息的能力越弱。 2、主成分分析的重点在于解释各变量的总方差,而因子分析则把重点放在解释各变量之间的协方差。 3、主成分分析中不需要有假设(assumptions),因子分析则需要一些假设。因子分析的假设包括:各个共同因子之间不相关,特殊因子(specific factor)之间也不相关,共同因子和特殊因子之间也不相关。 4、主成分分析中,当给定的协方差矩阵或者相关矩阵的特征值是唯一的时候,主成分一般是独特的;而因子分析中因子不是独特的,可以旋转得到不到的因子。 5、在因子分析中,因子个数需要分析者指定(spss根据一定的条件自动设定,只要是特征值大于1的因子进入分析),而指定的因子数量不同而结果不同。在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分。 和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势。大致说来,当需要寻找潜在的因子,并对这些因子进行解释的时候,更加倾向于使用因子分析,并且借助旋转技术帮助更好解释。而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。当然,这中情况也可以使用因子得分做到。所以这种区分不是绝对的。
偏最小二乘回归是一种新型的多元统计数据分析方法,它与1983年由伍德和阿巴诺等人首次提出。近十年来,它在理论、方法和应用方面都得到了迅速的发展。密西根大学的弗耐尔教授称偏最小二乘回归为第二代回归分析方法。 偏最小二乘回归方法在统计应用中的重要性主要的有以下几个方面:(1)偏最小二乘回归是一种多因变量对多自变量的回归建模方法。 (2)偏最小二乘回归可以较好地解决许多以往用普通多元回归无法解决的问题。在普通多元线形回归的应用中,我们常受到许多限制。最典型的问题就是自变量之间的多重相关性。如果采用普通的最小二乘方法,这种变量多重相关性就会严重危害参数估计,扩大模型误差,并破坏模型的稳定性。变量多重相关问题十分复杂,长期以来在理论和方法上都未给出满意的答案,这一直困扰着从事实际系统分析的工作人员。在偏最小二乘回归中开辟了一种有效的技术途径,它利用对系统中的数据信息进行分解和筛选的方式,提取对因变量的解释性最强的综合变量,辨识系统中的信息与噪声,从而更好地克服变量多重相关性在系统建模中的不良作用。 (3)偏最小二乘回归之所以被称为第二代回归方法,还由于它可以实现多种数据分析方法的综合应用。 由于偏最小二乘回归在建模的同时实现了数据结构的简化,因此,可以在二维平面图上对多维数据的特性进行观察,这使得偏最小二乘回归分析的图形功能十分强大。在一次偏最小二乘回归分析计算后,不但可以得到多因变量对多自变量的回归模型,而且可以在平面图上直接观察两组变量之间的相关关系,以及观察样本点间的相似性结构。这种高维数据多个层面的可视见性,可以使数据系统的分析内容更加丰富,同时又可以对所建立的回归模型给予许多更详细深入的实际解释。 一、偏最小二乘回归的建模策略\原理\方法
《多元统计分析分析》实验报告 2012 年月日学院经贸学院姓名学号 实验 实验成绩名称 一、实验目的 (一)利用SPSS对主成分回归进行计算机实现. (二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释. 二、实验内容 以教材例题为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用 三、实验步骤(以文字列出软件操作过程并附上操作截图) 1、数据文件的输入或建立:(文件名以学号或姓名命名) 将表数据输入spss:点击“文件”下“新建”——“数据”见图1: 图1 点击左下角“变量视图”首先定义变量名称及类型:见图2: 图2: 然后点击“数据视图”进行数据输入(图3): 图3
完成数据输入 2、具体操作分析过程: (1)首先做因变量Y与自变量X1-X3的普通线性回归: 在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4): 图4 将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5): 然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9) 其他选项按软件默认。最后点击“确定”,运行线性回归,输出相关结果(见表1-3)