关于润乾报表的补充说明
- 格式:docx
- 大小:647.34 KB
- 文档页数:22

数据集函数Avg函数说明:从数据集中,从满足条件的记录中,算出给定字段或表达式的平均值语法:datasetName.avg(selectExp{,filterExp})datasetName.average(selectExp{,filterExp})参数说明:selectExp 需要计算平均值的字段或表达式,数值类型filterExp 过滤条件表达式返回值:实数举例:例1:ds1.avg(score,sex="1")表示从数据集的当前记录行集中过滤出sex为"1"的记录集合,求得其score字段的平均值,score字段要求为数值型。
例2:ds2.avg(quantity*price)表示对数据集的当前记录行集求得表达式quantity*price的平均值函数说明:此函数功能等同select1(),但是算法不同,采用二分法,适用于数据集记录已经按照参考字段排好序的情况,运算速度比select1()快bselect1语法:datasetName.bselect_one(selectExp,referExp1,referDescExp1,referV alueExp1{,referExp2,referDescExp2,referV alueExp2{....}}})datasetName.bselect1(selectExp,referExp1,referDescExp1,referV alueExp1)参数说明:selectExp 选出字段或表达式referExp1 参考字段表达式referDescExp1 参考字段表达式的数据顺序,true表示降序排列,false表示升序排列referV alueExp1 参考字段的值表达式,一旦找到参考字段和该值相同的记录,即返回selectExp的值返回值:数据类型不定,由selectExp的运算结果决定示例:例1:ds1.bselect1(name,id,false,@value)采用二分法,找到数据集ds1中id和当前格的值相等的记录,返回其name字段值例2:ds1.bselect1(name,id,false,@value,class,false,A1,sex,true,B1)采用二分法,找到数据集ds1中id和当前格的值相等、class和A1相等且sex和B1相等的记录,返回其name字段值Bselect_one()此函数同数据集函数bselect1colcount()函数说明:获得数据集的列数语法:datasetName.colcount()返回值:整数举例:例1:ds1.colcount() 获得ds1数据集的列数,整数类型函数说明:计算数据集当前记录行集中,满足条件的记录数count()语法:datasetName.count({filterExp})参数说明:filterExp 条件表达式,如果全部选出,则不要此参数,返回值:整数举例:例1:ds1.count()例2:ds1.count(true)含义同上,但是运算速度比ds1.count()慢,因此当记录全部选出时,建议不要true例3:ds1.count(quantity>500)表示从ds1当前记录行集中选出quantity>500的记录进行计数,返回记录数。
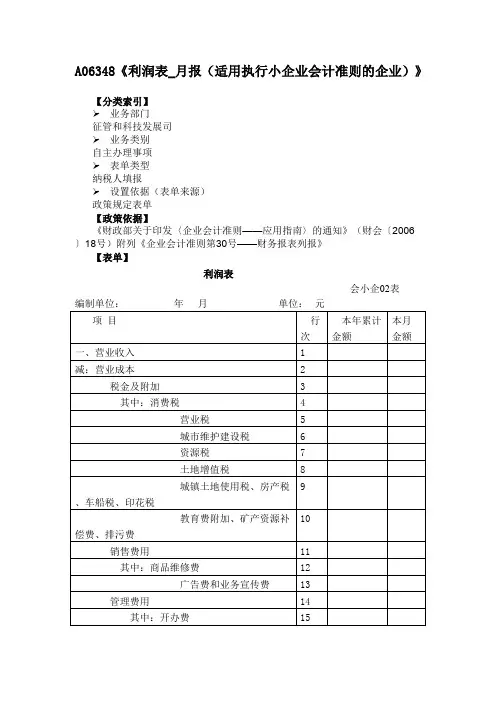


利润表填表说明利润表依据“收⼊-费⽤=利润”的平衡公式来编制,主要反映企业⼀定时期内营业收⼊减去营业⽀出之后的净收益。
下⾯店铺⼩编来为你解答,希望对你有所帮助。
利润表填表说明(⼀)“本⽉数”栏利润表“本⽉数”栏反映各项⽬的本⽉实际发⽣数。
在编报中期和年度财务报表时,应将“本⽉数”栏改成“上年数”栏。
1.⼀般根据账户的本期发⽣额分析填列由于该表是反映企业⼀定时期经营成果的动态报表,因此,该栏内各项⽬⼀般根据账户的本期发⽣额分析填列。
(1)“营业收⼊”项⽬,反映企业经营业务所得的收⼊总额。
本项⽬应根据“主营业务收⼊”和“其他业务收⼊”账户的发⽣额分析填列。
(2)“营业成本”项⽬,反映企业经营业务发⽣的实际成本。
本项⽬应根据“主营业务成本”和“其他业务成本”账户的发⽣额分析填列。
(3)“营业税⾦及附加”项⽬,反映企业经营业务应负担的营业税、消费税、城市维护建设税、资源税、⼟地增值税和教育费附加等。
本项⽬应根据“营业税⾦及附加”账户的发⽣额分析填列。
(4)“销售费⽤”项⽬,反映企业在销售商品和商品流通企业在购⼊商品等过程中发⽣的费⽤。
本项⽬应根据“营业费⽤”账户的发⽣额分析填列。
(5)“管理费⽤”项⽬,反映企业⾏政管理等部门所发⽣的费⽤。
本项⽬应根据“管理费⽤”账户的发⽣额分析填列。
(6)“财务费⽤”项⽬,反映企业发⽣的利息费⽤等。
本项⽬应根据“财务费⽤”账户的发⽣额分析填列。
(7)“资产减值损失”项⽬,反映企业发⽣的各项减值损失。
本项⽬应根据“资产减值损失”账户的发⽣额分析填列。
(8)“公允价值变动损益”项⽬,反映企业交易性⾦融资产等公允价值变动所形成的当期利得和损失。
本项⽬应根据“公允价值变动损益”账户的发⽣额分析填列(8)“投资收益”项⽬,反映企业以各种⽅式对外投资所取得的收益。
本项⽬应根据“投资收益”账户的发⽣额分析填列;如为投资损失,以“⼀”号填列。
(9)“营业外收⼊”项⽬和“营业外⽀出”项⽬,反映企业发⽣的与其⽣产经营⽆直接关系的各项收⼊和⽀出。

基于Tomcat的润乾数据源配置第一步、配置连接池在tomcat安装目录下进入conf/Catalina/localhost文件夹新建.xml文件,文件名为你项目名称,如,然后打开文件开始配置数据源的连接池,输入<?xml version='1.0' encoding='utf-8'?><Context docBase="/slarms" path="/slarms" ><Resource name="AB" auth="Container" type="javax.sql.DataSource"maxActive="100" maxIdle="30" maxWait="10000"username="slarms"password="oracle"driverClassName="oracle.jdbc.driver.OracleDriver"url="jdbc:oracle:thin:@192.168.1.248:1521:bksvr" /></Context>需要配置参数说明:docBase、path:直接把斜杠“/”后的改成你的项目名称name:数据源名字,现在统一用AB;username:数据库登录用户名password:数据库登录密码driverClassName:数据库驱动url:数据库连接地址。
第二步、添加oracle驱动把数据库驱动ojdbc14.jar考到tomcat服务器的common/bin目录下第三部、配置reportConfig.xml文件进入slarms\WebRoot\WEB-INF目录打开reportConfig.xml文件,配置数据源<config><name>dataSource</name><value>AB,oracle,GBK</value></config>AB:为你刚才配置连接池时的数据源名称oracle:数据库名GBK :数据库编码。

润乾报表设计器简易教程建立一个新的报表由存储过程的编写和表样的设计两部分组成,其中,表样的设计是利用润乾设计器进行的。
用润乾建立一个新的表样可以分为以下几步:新建数据源、连接数据源、设置参数、设置数据集、绘制表样、预览表样。
在以下步骤说明中,以预算上报下达差异表为例进行说明。
该报表的查询条件包括年度、单位和模板。
表样如下所示:2010年预算上报下达差异表制表部门:查询单位期间:2010年单位:万元预算科目本单位下级单位1 下级单位2 上报值下达值差异上报值下达值差异…预算科目1预算科目2预算科目3预算科目4预算科目5合计制表人:登录用户制表时间:2010-07-261新建数据源配置数据源的目的是为了连接数据库。
配置的步骤如下:➢打开设计器后,点击配置——数据源,打开配置数据源的界面。
➢点击新建,在数据库类型中根据实际情况选择数据库类型,针对TBM系统,选择的是关系数据库,点击确定。
➢在数据源常规属性设置页面进行数据源的设置,如下图所示:✓数据源名称:可以任意指定,建议采取tbmbj等名称对各地数据库进行直观性区分。
✓数据库类型:选择对应数据库类型,TBM系统采用的是DB2数据库。
✓客户端字符集:指的是从数据库取出的数据在客户端展现时的字符编码,可以采用默认的GBK。
✓数据库字符集:指的是从数据库中取过来的字符编码,根据数据库的编码类型选择,可以采用默认的GBK。
✓驱动程序:输入“com.ibm.db2.jcc.DB2Driver”即可。
✓数据源URL:数据源URL的输入格式为jdbc:db2:// IP地址:端口号/数据库名,例如:jdbc:db2://192.168.168.6:50000/tbmbj。
✓用户、口令:数据库用户名和密码。
➢设置完成后,点击【确定】按钮,回到数据源配置界面,关系数据库类型的数据源就配置完成了,数据源配置界面中就列出了新建的数据源。
2连接和断开数据源选中需要连接和断开的数据源后,点击数据源配置窗口的连接或断开即可。
润乾报表⼊门1 前⾔鉴于⽬前报表开发没有⼀个统⼀的规范,每个开发的风格和习惯也不⼀致,所以动⼿写了这份报表开发⽂档,⼀来有助于统⼀⼤家的报表的风格,提供⼀些常见问题的解决⽅案,⼆来⽅便以后新⼈的学习使⽤。
本⼈也是略懂⽪⽑,有什么错误和不⾜之处,欢迎⼤家补充修改。
2.报表⼯具安装解压后运⾏runqian-v4.5.5-install.exe安装⽂件,按引导完成安装。
其中,在初次打开报表⽂件和发布报表⽂件的时候(后续会提到),会提⽰我们需要lic⽂件,就是下图中的两个lic⽂件。
Figure 13.报表⼯具的使⽤3-1 配置数据源使⽤报表时需要先对数据源进⾏配置:Figure 2选择新建⼀个数据源:Figure 3项⽬中默认使⽤的数据源名称为reportjndi.参考图3进⾏配置后,点击连接,进⾏数据源连接,这样就完成了报表服务器与数据库的连接。
3-2 新建报表⽬前的报表形式分为两部分,⼀是⽤来显⽰查询结果的“报表名.raq”⽂件,另⼀个是⽤来提供查询条件的“报表名_arg.raq”⽂件。
我们只需要在保存⽂件的时候,按上述格式命名,打开.raq⽂件时,会⾃动打开相关的_arg.raq⽂件。
3-3 结果显⽰报表设计⾸先新建⼀张报表,直接点击左上⾓⼯具栏上的即可。
按照给定的表样设计好报表名名、列名。
如下图,这⾥提供⼀种样式当做参考模板,如客户⽆特殊需求,希望各开发按照统⼀的样式标准进⾏设计,有助于提⾼所有报表的统⼀性,后⾯还会提到⼀些规范,希望⼤家也可以遵守起来。
Figure 4报表名这⼀⾏,采⽤⿊⾊、⼆号字,加粗。
列名采⽤⽩⾊、三号字,加粗,背景⾊使⽤淡紫⾊(颜⾊相近即可)。
若每⼀列下⾯还要分列,则使⽤⿊⾊、⼩三号字,结果数据使⽤⿊⾊、四号字。
Figure 5设定好报表样式后,开始根据逻辑进⾏取数,设置每⼀列的宽度时,如果需要在⼀⾏中完整显⽰的,要选择“按单元格内容扩⼤”,并去掉“⾃动换⾏”。
Figure 6报表通过配置的“数据集”进⾏取数。


润乾报表工具软件集成版V4.0预览说明:预览图片所展示的格式为文档的源格式展示,下载源文件没有水印,内容可编辑和复制润乾报表工具软件集成版V4.01.产品说明:采购软件名称:润乾报表V4.0集成版2.采购数量:1套,介质包括光盘及厂商授权证书3.采购版本: V4.0集成版4.保修期限:两年(原厂认证技术支持服务)技术指标要求:一.环境支持(提供相应的成功案例)1.报表工具采用纯java开发,支持嵌入式部署,无缝集成2.服务器端支持各种常见的操作系统,如Windows系列,Linux 系列,unix系列等;3.支持各种常见的关系数据库,如Oracle,SQL Server,Sybase,DB2等;4.支持各种J2EE的应用服务器,如Weblogic,WebSphere,Tomcat,JBoss等;5.客户端采用标准纯html方式展现,支持ie和netscape;二.绘制与展现1.采用类excel的方式设计报表2.增删、复制/剪切/粘贴单元格或行列时,表达式引用的单元格会自动跟着变化。
3.支持不失真导入导出excel模板;4.支持带公式导出excel模板5.支持但不限于HTML、EXCEL、WORD、TEXT和PDF等多种展现方式6.导出EXCEL、PDF能够加密和进行权限控制;7.数据过长时允许自动缩小填充到格子里;8.支持滚动式报表,即固定上表头和左表头,表体滚动条滚动浏览;9.提供但不限于仪表盘、甘特图、雷达图、双轴柱线图、饼图、柱图、线图等多种二维三维统计图;10.支持统计图上自定义显示信息11.支持统计图上鼠标挪上去显示自定义信息12.统计图提供开发接口,支持通过二次开发和第三方产品,实现丰富的展现效果。
13.报表中能够展现图片,特别地,该图片可以来自文件,也可以来自数据库14.打印时可以自动适应纸张大小15.打印时可以选择打印奇数页或者偶数页,以便支持双面打印16.支持套打17.支持一纸多页的卡片式报表打印18.支持分栏19.打印时可以在客户端保存打印配置信息(如选择打印机、页边距等)20.打印时,报表可以在页面中进行自动对齐,提供靠左、靠右、居中等对齐方式三.语义解释1.为数据库的表、字段提供中文的强关联语义层2.业务人员可以基于中文语义视图,通过鼠标选择和拖拽设计报表,基本不用手工输入公式3.中文语义视图能够提供计算列(指标)的定义4.中文语义视图支持编辑风格、显示格式、显示值的定义5.中文语义视图支持条件语句的预定义,用户基于语义层设计报表时,可以自由选择使用哪个条件语句6.中文语义视图能够提供表间关系定义,并且在制作报表时,能够把表间关系自动带进报表中7.支持数据的管理与维护,可以批量编辑修改数据库中的数据,维护数据库表结构,提供数据的备份与恢复功能。

润乾报表附加数据集在集算报表中的处理方案
在润乾报表中提供了附加数据集功能,可以在一个单元格(主格)中关联多个数据集,关联后多个数据集如同一个数据集使用。
当数据集较多需要相互关联,甚至多个数据集来源于不同数据库时,使用附加数据集可以快速完成关联且能够获得更高的报表性能。
集算报表在润乾报表的基础上去掉了附加数据集的功能,取而代之可以使用集算器或脚本数据集完成多数据集关联,通过脚本返回的层次数据集快速完成这类报表的开发。
下面通过例子来比较一下二者的不同。
润乾报表附加数据集
一个报表中需要使用来源于三个数据集(ds1:订单、ds2:客户、ds3:运货商)的数据,在润乾报表使用使用附加数据集可以这样完成:
在A2格中增加“附加数据集表达式”:
ds2.select(客户ID,,客户ID==ds1.客户ID)
ds3.select(运货商ID,,运货商ID==ds1.运货商),如图示:
完成后,加入B2-F2的表达式,直接使用取值表达式,使用方式与主数据集ds1一致。
集算报表的处理方案
在集算报表中新建报表并新增脚本数据集ds1,脚本内容如下:
取得三张表数据后,在脚本中完成关联,并将关联后的结果集返回给报表。
值得注意的是,在脚本数据集中关联后的结果集是带有层次的,称为层次数据集。
在报表中的表现形式为:
编写报表表达式,使用脚本返回的层次数据集:
可以看到在集算报表中通过脚本数据集处理多数据源关联的方式,如果在脚本编写过程中还需要使用编辑调试功能,可以使用独立的集算脚本编辑器,编写后的脚本文件可以在集算报表的“集算器数据集”中调用。
报表展现结果如下:。
润乾报表实现无数据源的规则报表及改进某报表系统中有部分报表需要按照一定规则显示数据,如:显示查询日期范围内的奇数日数据,要求数据库中即使无记录该日期也显示(内容为空)。
本文重点来实现奇数日期序列,数据区不是重点,故置空。
以上述报表需求为例,这里来看一下润乾报表的实现过程,以及改进方法。
润乾报表实现以下为润乾报表的实现方式,考虑跨年和跨月份的情况使用时要对辅助列A列进行隐藏,以及对第2行进行条件隐藏,偶数的日期不显示。
所以报表工具实现要依靠大量隐藏行列。
报表工具实现需要借助隐藏行格完成,主要原因是数据计算和报表呈现混在一起导致,既要完成报表展现,又要兼顾数据计算,往往导致报表计算能力不足。
如果能将数据计算和报表呈现剥离开,那么报表开发将更加快捷。
润乾集算报表5.0是在保留原有润乾报表核心功能的情况下,推出的强计算报表工具,其内置的集算器非常适合完成数据计算,从而将报表数据准备和呈现分开。
本例的需求采用集算报表实现要简单得多,方法如下:集算报表实现编写集算脚本首先使用集算器编写计算逻辑,为报表输出两个日期之间的奇数日。
A1:根据起止日期参数,列出该日期段中的所有日期A2:选出奇数日A3:为报表返回结果集报表调用使用集算报表设计器,新建报表,使用“集算器”数据集类型,选择上面编辑好的集算脚本(time.dfx)设置报表模板及表达式报表中只简单的列表取值即可,无需再完成复杂计算。
由于集算器对集合运算的有效支持,使得从一个集合(所有日期)中选出部分数据(奇数日)非常容易。
不同于在一般报表工具中计算,集算器进行数据计算时不带有任何展现属性,因此效率更高;同时,由于报表端不再包含大量的隐藏格,报表效率得到了进一步提升。
此外,对于代码很简单的脚本,可以不必独立编辑出脚本文件,而使用集算报表内置的脚本数据集,把脚本直接嵌入到报表模板。
方法如下:1、在数据集设置窗口中点击“增加”按钮,弹出数据集类型对话框,选择“脚本数据集”2、在弹出的脚本数据集编辑窗口中编写集算脚本脚本数据集中可以直接使用报表定义的参数,如上述脚本中的begin、end即为报表参数。
润乾报表技术白皮书北京润乾软件技术有限公司2006年3月目录第1章总体说明1.1 润乾报表软件概述润乾报表是用于统计报表制作及数据填报的大型企业级报表软件,它提供了高效的报表设计方案、强大的报表展现能力、灵活的部署机制,并且具备强有力的填报功能,配合以全面的用户权限管理、报表调度功能和交互功能,为企业级统计分析、展现提供了高性能、高效率的报表系统解决方案。
润乾报表软件的核心特点在于开创性地提出了新一代报表数学模型,采用了革命性的多源分片、不规则分组、自由格间运算、行列对称等技术,使得复杂报表的设计简单化,以往难以实现的报表可以轻松实现,避免了大量的复杂SQL编写与前期数据准备,报表设计的效率提高了一个数量级。
润乾报表是一个纯Java报表工具,提供了全面的API接口,是开发Web报表软件的理想选择。
Java报表工具的跨平台特性,使得它能良好地支持大型系统的需要。
润乾报表不需安装控件,可以实现纯HTML报表方式,可以支持PDF,EXCEL等输出,提供了全面的页面与打印控制,能很多地满足Web报表的展现需要。
同时,润乾报表对图表有良好的支持,可以生成柱图、饼图、折线图等二十几种图表。
润乾报表提供基于动态库表关联技术的填报功能,完美解决数据入库的难题,极大提高填报表单的处理效率,扩展了Web报表工具的应用方式。
润乾报表提供了报表管理中心,可以对报表建立多层次的目录管理,进行全面的用户和基于角色的权限管理。
润乾报表还提供了调度器模块,可以实现定时、批量等报表自动处理和报表的自动分发。
1.2 产品构成1.2.1基础部件润乾报表由两大核心部分组成:●报表设计器:设计编辑报表,自带报表运算引擎,连接数据库后可预览打印报表,并可生成其它格式保存。
设计器不依赖于其它部分,可独立工作;设计器以Java应用程序(JavaApplication)的形式提交。
●报表服务器:在后台提供统计报表运算和数据填报处理的服务,开放各层次的API接口调用,由程序员调用生成结果报表;服务器运行不依赖设计器;服务器以Java类包(jar)的形式提交,一般情况下不需要物理上的独立服务器。
java开发润乾报表润乾报表设计1、安装润乾报表设计器2、设计报表模板3、数据集为存储过程的报表设计4、将设计好的模板部署到应用中过去5、存储过程1安装润乾报表设计器1.1获取安装包安装包在svn上:http://10.120.23.41/svn/core/开发组资料/开发工具/润乾报表v4.5.exe Check后安装即可.安装后的目录结构如下:1.2完成相关授权使用润乾报表设计器需要完成两次授权:A: 润乾报表设计器授权B: 设计完成后发布应用的服务器授权目前我们本机采用的是Windows的授权,服务器上的ycps项目采用的是Linux授权版本,所以我们在开发完成后不要commit授权文件1.3授权完成授权完成,启动后的界面如下:2简单报表设计2.1配置数据源A: 配置>数据源B: 数据源配置界面C: 点击新建自己的数据源D: 数据源配置细节,为了开发的统一数据源名称统一采用“oracle”E: 确定之后F: 连接成功2.2数据集的配置A: 新建报表如图:A: 配置数据集,也可以直接F11快捷键B: 数据集配置C: 选择模式、表、字段D:选择需要的字段E:此时你可以点击语法选项卡看看,聪明的你就明白了,然后确定即可F:数据集ds1已经创建完成2.3简单报表的实现A:利用配置好的数据集设计简单模板B:启动tomcat、发布模板、在浏览器中浏览C:浏览3数据集为存储过程的报表设计3.1配置数据源见2.13.2配置数据集3.2.1配置存储过程数据集B:弹出存储过程数据集,在此之前存储过程一定要测试成功C:配置数据集参数说明:1、参数的个数、顺序要和procedure严格一致2、结果类型应该指定具体类型如字符串3、注意输出参数及类型D:确定,但是没有完!3.2.2配置模板参数可以这样理解:刚才配置的数据集参数需要由报表模板来提供,那模板也需要配置参数A:配置> 参数B:参数编辑,然后确定模板设计完毕3.2.3在设计器中浏览报表A:按F11进入数据集设置B:点击浏览数据C:填入必填的参数确定即可浏览,注意此处的浏览只是证明数据集设置的正确性D:数据集设置完成且正确后会出现如下。
润乾报表实现动态数据源报表及改进经常会遇到一些报表需要根据不同的情况(参数)连接不同的数据源从而完成相应的数据的展现,也就是经常说的动态数据源报表。
报表工具通常的做法有两种,一是不同的情况加载不同的数据源连接参数,如:url、driver、username、password等;二是利用已配置的多个连接池,根据不同情况选择。
这里通过一个实例,说明润乾报表的实现过程及改进方案。
报表说明应用中需要通过参数控制报表连接的数据源,当参数flag为1时连接数据源一(db1),否则连接数据源二(db2)。
润乾报表实现首先根据flag参数为context设置不同数据源(这里以两个hsql数据库为例):String flag=request.getParameter("flag");Connection con1 = null;Connection con2 = null;try{Driver driver = (Driver)Class.forName("org.hsqldb.jdbcDriver").newInstance();DriverManager.registerDriver(driver);con1=DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/runqianDB","sa"," ");con2=DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/demo","sa","");}catch (Exception e){e.printStackTrace();}Context cxt= new Context();String defDsName = cxt.getDefDataSourceName ();if ("1".equals(flag) || "1"==flag){cxt.setConnection(defDsName, con1);}else{cxt.setConnection(defDsName, con2);}将cxt存入request:request.setAttribute("myContext", cxt );以context方式发布报表:<report:html name="report1"contextName=”myContext”/>通过使用润乾报表的API可以完成动态数据源报表,详尽的API的确为应用开发人员提供了诸多便利。
分页说明:为方便大家开发,本人在工资系统中作出一个DEMO,经过测试后能正常使用。先将部分代码与注意事项发给大家看一下
第一步: 如果该报表需要分页的话,请将下面的
$j("#countSql").val("分页语句"); 请注意字符串的 要写单引号: 并且 写成如下形式:\\'${字符串}\\'
ShowExt.jsp 修改成 funcBarLocation="" params="<%=param.toString()%>" needPageMark="yes" pageCount="20" totalCountExp="<%=countSql%>" paperHeight="600" />
附录: 3.8. 分页计算标签 本功能采用报表组的原理来实现,因此需要支持报表组的授权 3.8.1. 概念定义 使用分页计算标签可以在报表比较大的情况下实现以页为单位对数据进行读取和展现及导出等操作。
3.8.2. 功能背景 报表大到一定程度,必然会内存溢出,此时比较好的解决办法是边算边输出。分页计算标签是利用报表组来实现的逐页计算逐页输出的tag标签。
可以大大降低内存占有量,提高运行效率,避免内存溢出等问题。
3.8.3. 使用方法 在这个标签中,主要增加了以下属性: totalCountExp——总记录数(必填属性) 分页就是基于这个总记录数来的。它的值是一个润乾的非数据集函数,并且返回的值应该是一个整型数据。如用query执行一个count的sql。如:
totalCountExp="query('SELECT count(*) FROM table1')" pageCount——每页记录数(非必填) 分页后每一页包含的记录数,其值需为整数。 默认值为20。 cachePageNum——缓存页数(非必填)
根据pageCount和cachePageNum,每次取pageCount* cachePageNum条记录,其值需为整数,默认值为100
设置该属性,可保证缓存页数内的翻页效率。(reportconfig.xml文件里的alwaysReloadDefine设置为no,exthtml标签里useCache设置为yes,该属性才生效) startRowParamName/ endRowParamName——起始行参数名/结束行参数名(非必填)
对应报表数据集记录行中设置的起始行和结束行的参数名。 默认值为startRow和endRow。 其他属性说明,与html标签基本一致: 图 3.2.
应用举例一: 下面以订单明细列表为例,按照常规做出一张订单明细的清单式列表。
然后为其添加两个参数:起始行参数名startRow和结束行参数名endRow。注意参数类型要求是整型。 图 3.4. 并且在数据集设置的参数标签页设置好起始行和结束行的对应参数@startRow和@endRow。
图 3.5.
下面是最简jsp发布文件,只定义了三个必须属性,其余均采用默认值: 图 3.6. 运行结果如下: 图 3.7. 下面是定义了各种属性之后的jsp: 图 3.8. 运行效果如下: 图 3.9. 这种做法的缺点:当数据量足够大的时候,某些jdbc包的resultset本身会内存溢出;而且从理论上看,当调用api接口将resultset的指针定位到某一行的时候,其底层其实是一行一行跳转的,虽然速度非常快,但是数据量超过几百万甚至几千万的时候,还是会消耗一些时间。因此当记录数大到一定程度,翻到最后一页的速度会比开头几页慢。
这种做法的优点:和数据库类型无关,任何一种数据库都可以采取这种方式,用户不用研究不同数据库的差别。 emerito_info.raq 的分页count语句 ----------------------------------------------------------------------------
select count(*) from RETIRER_SALARY rs, RETIRER_SALARY_DETAIL rsd WHERE rsd.retierer_salary_id = rs.retierer_salary_id and (rs.unit_id = ? or ? is null) and (rs.retierer_salary_id in (${rsid}) or ? =2)
and rs.giveyearmonth = ? ORDER BY rs.fullname
---------------------------------------------------------------------------
emerito_salary.raq 的分页count语句
SELECT count(*) from RETIRERS r, RETIRER_SALARY rs, RETIRER_SALARY_DETAIL rsd WHERE r.RETIRER_ID = rs.RETIRER_ID and rsd.retierer_salary_id = rs.retierer_salary_id and (r.unit_id = ? or ? is null) and (rs.retierer_salary_id in (${rsid}) or ? =2)
and rs.giveyearmonth=? ORDER BY rs.fullname
----------------------------------------------------------------------------
job_base.raq 的分页 count语句
SELECT count(*) from workersalary WHERE (unit_id = ? or ? is null) and (worker_id in (${workerid}) or ? =2) ORDER BY departmentname,fullname
unitid = ? unitid = ? workerid = ${workerid} 为 , , , , falg = ?
----------------------------------------------------------------------------
job_salary.raq 的分页 count语句 SELECT count(*) from workersalary a, WORKER_SALARY_DETAIL b WHERE a.SALARY_ID = b.SALARY_ID and (a.unit_id = ? or ? is null) and (a.worker_id in (${workerid}) or ? =2)
and a.giveyearmonth = ?
----------------------------------------------------------------------------
jobn_bfgz.raq 的分页 count语句 SELECT count(*) from WORKER_SALARY_DETAIL_ADD wsda, WORKERSALARY w WHERE wsda.salary_id = w.salary_id and w.unit_id = ?
----------------------------------------------------------------------------
jobn_jsgz.raq 的分页 count语句 SELECT count(*) from ( select r.worker_id as last_worker_id, r.Totalsalary as last_Totalsalary, r.salary_id as last_salary_id from WORKERSALARY r join worker_salary_detail wsd on r.salary_id = wsd.salary_id
and r.giveyearmonth = '2011-11'
and r.unit_id = 613 and wsd.giveyearmonth = '2011-11') l1
left join (select r.worker_id as current_worker_id, r.Totalsalary as current_Totalsalary,
r.salary_id as current_salary_id from WORKERSALARY r join worker_salary_detail wsd on r.salary_id = wsd.salary_id
and r.giveyearmonth = '2011-12'
and r.unit_id = 613