讲解Sphinx、Coreseek在windows下的配置安装及测试
- 格式:doc
- 大小:220.00 KB
- 文档页数:8


Coreseek/Sphinx环境安装与部署一、环境安装:1. Microsoft Visual C++ 运行环境,一般系统自带;如果运行提示“应用程序错误”,则需要安装coreseek-4.x版本, Microsoft Visual C++ 2008 运行环境 (x86)(32位系统和64位系统均安装该版本);注意:是运行环境,不是开发环境,才1.7M大小,从微软官方网站下载Microsoft Visual C++ 2008 Redistributable Package (x86),然后安装(压缩包里面有我下好的可以直接使用);2. 安装 Coreseek-win32(必须):【2011年1月12日更新,支持命令行中文搜索测试】从Coreseek官方网站下载/uploads/csft/4.0/corese ek-4.1-win32.zip(压缩包里面有我下好的可以直接使用);3. 安装Python 2.6 Windows (x86)(必须,32位系统和64位系统均安装该版本),从ActiveState官方网站下载ActivePython 2.6 Windows (x86),然后安装;也可从华军软件园下载ActivePython 2.6 Windows (x86),然后安装(压缩包里面有我下好的可以直接使用);4.安装cx_Oracle-5.0.4-11g.win32-py2.6.msi这个是针对python连接oracle的插件,压缩包里面也有直接安装就行。
二、Coreseek/Sphinx安装:1.安装前,建议查看:Win版本README.txt;如遇到问题,就是环境安装出错;2.下载coreseek win32版本:coreseek 4.1;3.点击压缩包,压缩出来即可。
4.目录中的README.txt文件中,有所有配置和test测试文件的说明。
三、python连接oracleSphinx使用oracle数据源需要python脚本的支持才可以创建索引。
简介:Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。
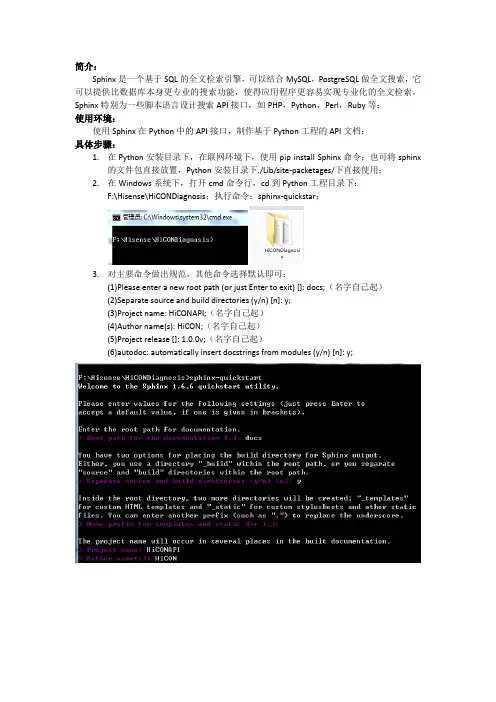
Sphinx特别为一些脚本语言设计搜索API接口,如PHP,Python,Perl,Ruby等;使用环境:使用Sphinx在Python中的API接口,制作基于Python工程的API文档;具体步骤:1.在Python安装目录下,在联网环境下,使用pip install Sphinx命令;也可将sphinx的文件包直接放置,Python安装目录下./Lib/site-packetages/下直接使用;2.在Windows系统下,打开cmd命令行,cd到Python工程目录下:F:\Hisense\HiCONDiagnosis;执行命令:sphinx-quickstar;3.对主要命令做出规范,其他命令选择默认即可:(1)Please enter a new root path (or just Enter to exit) []: docs;(名字自己起)(2)Separate source and build directories (y/n) [n]: y;(3)Project name: HiCONAPI;(名字自己起)(4)Author name(s): HiCON;(名字自己起)(5)Project release []: 1.0.0v;(名字自己起)(6)autodoc: automatically insert docstrings from modules (y/n) [n]: y;4.配置conf.py文件在F:\Hisense\HiCONDiagnosis\docs\source\conf.py文件中加入如下代码,导入自己的项目路径;5.生成各模块的.rst文件:执行命令:sphinx-apidoc -o ./docs/source ./注意:-o 后面跟的是保存rst文件的路径,index.rst文件在哪个目录,就指定哪个目录(文中为./docs/source)。

查阅地址/sphinx-tutorial一.#MySQL数据源配置,详情请查看:/products-install/mysql/#请先将var/test/documents.sql导入数据库,并配置好以下的MySQL用户密码数据库#源定义source mysql{type = mysqlsql_host = localhostsql_user = rootsql_pass =sql_db = testsql_port = 3306sql_query_pre = SET NAMES utf8#sql_query第一列goods_id需为整数可以写lift joinsql_query = SELECT goods_id, goods_name FROM td_goods#筛选可多个条件sql_attr_multi = uint cate_id from query; SELECT goods_id,cat_id FROM td_category_goodssql_attr_uint = cate_id #从SQL读取到的值必须为整数}#index定义index taidu{source = baidu #对应的source名称path = var/data/mysql #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...docinfo = externmlock = 0morphology = nonemin_word_len = 1html_strip = 0#中文分词配置,详情请查看:/products-install/coreseek_mmseg/ #charset_dictpath = /usr/local/mmseg3/etc/ #BSD、Linux环境下设置,/符号结尾charset_dictpath = etc/ #Windows环境下设置,/符号结尾,最好给出绝对路径,例如:C:/usr/local/coreseek/etc/...charset_type = zh_cn.utf-8}#全局index定义indexer{mem_limit = 128M}#searchd服务定义searchd{listen = 9312 #开启端口read_timeout = 5max_children = 30max_matches = 1000seamless_rotate = 0preopen_indexes = 0unlink_old = 1pid_file = var/log/searchd_mysql.pid #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...log = var/log/searchd_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...query_log = var/log/query_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...binlog_path = #关闭binlog日志}二.Php调用ecmall sphinx 已集成进去了产品筛选$_cs = &sphinx_server();$_cs->SetServer('localhost',9312); //设置服务器和端口$_cs->setMatchMode(SPH_MATCH_ANY);//设置匹配模式$_cs->setMaxQueryTime(3);//设置最大查询时间//$result = $_sphinx_server->query('test');//test为关键字//$_cs->SetFilter('cate_id', array(95,35,36));//$result = $_cs->query('搜索','*');//查询cate_id 为95,35,36下的$_cs->SetFilter('cate_id', array(95,35,36));$r = $_cs->query('','*');rdump($r);全文检索数据源sql_query = SELECT goods_id,cate_id,UNIX_TIMESTAMP(date_added) AS date_added, goods_name, description FROM td_goods #sql_query第一列id需为整数#goods_name、description作为字符串/文本字段,被全文索引sql_attr_uint = cate_id #从SQL读取到的值必须为整数sql_attr_timestamp = date_added #从SQL读取到的值必须为整数,作为时间属性sql_query_info_pre = SET NAMES utf8直接调用query 就可以返回数据$result = $_cs->query('搜索','*');。

Sphinx 的安装及使用一、为什么要使用sphinx假设你现在运营着一个论坛,论坛数据已经超过100W,很多用户都反映论坛搜索的速度非常慢,那么这时候你就可以考虑使用 sphinx了二、Sphinx是什么它是一个高性能的全文搜索软件包。
全文搜索是指以文档的全部文本信息作为检索对象的一种信息检索技术,检索的对象有可能是文章的标题,也有可能是文章的作者,也有可能是文章摘要或内容。
三、Sphinx的特性高速索引(在新款CPU上,近10M/s)高速搜索(在2-4G的文本量中平均查询速度不到0.1秒)高可用性(单CPU上最大可支持100GB的文本,100M文档)提供良好的相关性排名支持分布式搜索提供文档摘要生成支持每个文档多属性支持断词四、下载并安装sphinx/news/7/52/找到适合自己操作系统的版本,linux下下载源码包,编译安装。
Coreseek是基于sphinx开发的一款软件,对sphinx做了一些改动,在中文方面支持得比sphinx好。
下载完成后,解压到想解压的地方,比如E盘根目录下,更名为coreseek。
Coreseek就安装完成了。
解压后的目录如下:五、Sphinx的使用要使用sphinx需要做以下几件事1)首先数据库里得有数据2)建立sphinx配置文件3)生成索引4)启动sphinx5)在程序中通过api调用 sphinx,获取数据1)、导入数据解压的文件里找到 var/test/documents.sql 执行,建立documens表。
2)、建立配置文件接下来我们需要建立一个sphinx的配置文件 E:\coreseek\etc\mysql.conf,将其内容改为下面这些:source mysql{Type= mysqlsql_host = localhostsql_user = rootsql_pass =sql_db = testsql_port = 3306sql_query_pre = SET NAMES utf8sql_query = SELECT id,group_id,UNIX_TIMESTAMP(date_added) AS date_added,title,content FROM documents WHERE id<=(SELECT max_doc_id FROM sph_counter WHERE counter_id=1)sql_attr_uint = group_idsql_attr_timestamp = date_added}index mysql{source = mysqlpath = E:/coreseek/var/data/mysqlcharset_dictpath = E:/coreseek/etc/charset_type= zh_cn.utf-8}searchd{Listen= 9312max_matches = 1000pid_file = E:/coreseek/var/log/searchd_mysql.pidlog = E:/coreseek/var/log/searchd_mysql.logquery_log = E:/coreseek/var/log/query_mysql.log}先讲一下这个配置文件中每项的含义。

PHP中提高搜索性能的Coreseek(Sphinx)1.PHP中提高搜索性能的Coreseek(Sphinx)1.1.什么是Coreseek(Sphinx)Coreseek 是一款中文全文检索/搜索软件,基于Sphinx研发并独立发布,专攻中文搜索和信息处理领域.Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。
1.2.为什么使用Sphinx和数据库相比Sphinx是专业做搜索,相比数据库的效率要高很多.1. 索引和搜索性能优异;2. 先进的索引和查询工具 (灵活且功能丰富的文本分析器,查询语言,以及多种不同的排序方式等等);3. 先进的结果集分析处理 (SELECT 可以使用表达式, WHERE, ORDER BY, GROUP BY 等对全文搜索结果集进行过滤);4. 实践证实可扩展性支持数十亿文档记录,TB级别的数据,以及每秒数千次查询;5. 易于集成SQL和XML数据源,并可使用SphinxAPI、SphinxQL或者SphinxSE搜索接口6. 易于通过分布式搜索进行扩展1.3.Sphinx在哪里使用适用于行业/垂直搜索、论坛/站内搜索、数据库搜索、文档/文献检索、信息检索、数据挖掘等应用场景. 只要需要搜索的地方都可以使用Sphinx提高搜索效率.2.Sphinx核心概念2.1.全文检索程序的工作流程如果信息检索系统在用户发出了检索请求后再去互联网上找答案,根本无法在有限的时间内返回结果。
所以要先把要检索的资源集合放到本地,并使用某种特定的结构存储,称为索引(中国叫做目录),这个索引的集合称为索引库。
由于索引库的结构是按照专门为快速查询设计的,所以查询的速度非常快。
我们每次搜索都是在本地的索引库中进行,如下图:从图片上可以看出,我们不仅要搜索,还要保证数据集合与索引库的一致性。

Sphinx Windows 版安装配置极简版以下内容以Sphinx 2.0.5,PHP 为例。
需要提前说明一下,官方版本对中文支持不好。
1,下载安装包,并解压到某个目录,比如解压到D:/sphinx/2,该文件夹下一共有如下几个比较重要的文件。
a)D:/sphinx/sphnix.conf.in 配置文件参考b)D:/sphinx/bin/indexer.exe 索引生成命令c)D:/sphinx/bin/searchd.exe 服务(包括search.exe)d)D:/sphinx/api/sphinxapi.php PHP接口3,在D:/sphinx/ 下建立data 和log 文件夹。
4,将D:/sphinx/ 建立文件sphinx.conf,内容可参考附录1,或者sphinx.conf.in。
5,然后更新索引,运行服务。
具体可以以管理员身份执行命令(CMD)D:cd "D:/sphinx/bin"indexer.exe --config "D:/sphinx/sphinx.conf" --allsearchd.exe --config "D:/sphinx/sphinx.conf"如果没有报错,应该就没什么问题了。
6,如无其它意外,此时应该已经安装配置成功。
可以管理员身份执行命令search.exe testwords –config “D:/sphinx/sphinx.conf”其中testwords 是要查询的词语。
7,下面来使用API 来搜索字词。
可参考api 文件夹下的test2.php,此文件可通过WEB 方式访问。
或者参考附录2。
补充:如需更新配置文件,需先停掉服务,等配置文件更新完成后,再重新开启服务。
附录1 sphinx.confsource src_test{type = mysqlsql_host = localhostsql_user = rootsql_pass = 123456sql_db = testdatasql_port = 3306 # optional, default is 3306sql_query_pre = SET NAMES utf8sql_query = \SELECT id, 1 as idd, province, location_full \FROM ip_database}index test{source = src_testpath = D:/sphinx/data/testdocinfo = externcharset_type = utf-8}附录2<?php/*** sphinx 接口** 传入要查询的 base64 加密的 url* ?q=xxx* 返回查到的对应的id** filename: index.php* charset: UTF-8* create date: 2012-8-28** @author Zhao Binyan <itbudaoweng@>* @copyright 2011-2012 Zhao Binyan* @link * @link /itbudaoweng*///引入 sphinx API 文件include "../../../sphinx/api/sphinxapi.php";header('Content-Type:text/html; charset=utf-8'); error_reporting(0);$ret = array();$q = $_GET['q'];//$q = base64_decode($q);if (!is_int($q)) {$q = "\"$q\"";}$index = '*';//sphinx$sphinx = new SphinxClient();$sphinx->SetServer('localhost');$sphinx->SetMatchMode(SPH_MATCH_EXTENDED); $sphinx->SetRankingMode(SPH_RANK_NONE);//搜索词切记使用双引号包裹一下$q = $sphinx->Query($q, $index);if ($q['total'] > 0) {$ret = array_keys($q['matches']);}echo json_encode($ret);更多内容请参考:/docs/2.0.5/赵彬言(IT不倒翁)/itbudaoweng2012年8月29日星期三。

在windows下Coreseek的配置安装与测试一、安装:1. 安装Python2.6 Windows (x86)(必须,32位系统和64位系统均安装该版本):从ActiveState官方网站下载ActivePython 2.6 Windows (x86),然后安装;您也可从华军软件园下载ActivePython 2.6 Windows (x86),然后安装;2. 安装 Microsoft Visual C++ 2005 Redistributable Package (x86)(必须,32位系统和64位系统均安装该版本):从微软官方网站下载Microsoft Visual C++ 2005 Redistributable Package (x86),然后安装;3. 安装 Coreseek-3.2.13(必须):【2010年11月14日更新,支持命令行中文搜索测试】从Coreseek官方网站下载/uploads/csft/3.2/coreseek-3.2.13-win32.zip解压coreseek-3.2.13-win32.zip到coreseek-3.2.13-win32目录,重命名为sphinx,任意存放。
二、coreseek中文全文检索测试直接运行coreseek-3.2.13-win32目录下的test.cmd文件,如果没出任何问题,则一切测试正常,相关手工命令测试请访问:/products-install/install_on_windows/三、部分命令的说明使用这一切命令的输入都在“cmd命令提示符”窗口里操作,假如:把sphinx目录放在D 盘下,以下的所有例子将以这路径操作,不再说明。
1)、创建全部索引:(注:这里的索引不是数据库里的索引,是不同的概念,这只对于coreseek而言,别混淆)bin\indexer –c etc\csft_mysql.conf --all备注:其中etc\csft_mysql.conf就是刚才的配置文件相对路径;如果修改了数据库中的数据,则要重建索引,类似于刷新,因为创建索引后会自动把数据库中的数据存储到内存中,所以必须重建索引。


搭建coreseek(sphinx+mmseg3)社工库环境:Centos6.6 x64 + Nginx1.8 (或Apache2.x)版本:Coreseek-4.1功能演示:/[第一步] 先安装mmseg3安装支持库yum install -y make gcc g++ gcc-c++ libtool autoconf automake imake mysql-devel libxml2-devel expat-devel php-devel //如果后面编译时缺少,再重装一次提前安装PHP支持yum remove php php-bcmath php-cli php-common php-devel php-fpm php-gd php-imap php-ldapphp-mbstring php-mcrypt php-mysql php-odbc php-pdo php-pear php-pecl-igbinary php-xmlphp-xmlrpc //如安装先卸载rpm -Uvh /yum/el6/latest.rpmyum install -y php54w php54w-bcmath php54w-cli php54w-common php54w-devel php54w-fpmphp54w-gd php54w-mbstring php54w-mcrypt php54w-mysql php54w-odbc php54w-pdo php54w-pear php54w-pecl-igbinary php54w-xml php54w-xmlrpc php54w-opcache php54w-intl php54w-pecl-memcachecd /optwget /uploads/csft/4.0/coreseek-4.1-beta.tar.gztar zxvf coreseek-4.1-beta.tar.gzcd coreseek-4.1-beta/mmseg-3.2.14./bootstrap./configure --prefix=/usr/local/mmseg3make && make install遇到的问题:error: cannot find input file: src/Makefile.in或者遇到其他类似error错误时...解决方案:依次执行下面的命令,我运行'aclocal'时又出现了错误,解决方案请看下文描述yum -y install libtoolaclocallibtoolize --forceautomake --add-missingautoconfautoheadermake clean安装好'libtool'继续从'aclocal'开始执行上面提到的一串命令,执行完后再运行最开始的安装流程即可。

Sphinx使用手册在上一篇中,我们完成了Sphinx的安装,在这篇中我们使用php程序操作Sphinx,做个小的站内搜素引擎。
Sphinx集成到程序中,有两种方式:Sphinxapi类、SphinxSE存储引擎。
我们要使用Sphinx需要做以下几件事:1、首先得有数据(安装篇我们已经导入数据了)2、建立Sphinx配置文件(在安装篇我们已经配置完成了)3、生成索引(在安装篇我们也做了)4、启动Sphinx (从这里开始吧)5、使用之(调用api进行查询或使用sphinxSE)一、启用sphinx服务。
想要在程序中使用Sphinx必须开启Sphinx服务。
启动进程命令:searchd-c 指定配置文件--stop 是停止服务--pidfile 用来显式指定一个PID文件。
最好指定,要不然,合并索引时,会报错-p 指定端口/usr/local/coreseek/bin/searchd -c /usr/local/coreseek/etc/sphinx.conf注意:这里启动的服务是searchd ,不是 search。
Sphinx默认的端口是9312端口。
如果出现这个问题:说明端口已经被占用了,可以用netstat -tnl查看下,9312已经运行。
解决的办法是:netstat -apn | grep 9312 找出进程IDkill -9 进程id 再开启就可以了。
二、使用php程序使用sphinx (sphinxapi类)(1)、在php手册中有相应的函数。
需要到coreseek解压包中找到sphinxapi.php文件,放到程序目录下。
cp /lamp/coreseek-3.2.14/csft-3.2.14/api/sphinxapi.php /usr/local/apache2/htdocs/ include 'sphinxapi.php';// 加载Sphinx API$sphinx = new SphinxClient(); //创建sphinx对象$sphinx->SetServer("localhost", 9312); //建立连接,第一个参数sphinx服务器地址,第二个sphinx监听端口$result = $sphinx->query($keyword,"*"); // 执行查询,第一个参数查询的关键字,第二个查询的索引名称,多个索引名称用(逗号)分开,也可以用*表示全部索引。
Coreseek 全文检索服务器 2.0 (Sphinx 0.9.8)参考手册文档版本:v0.9目录1. 简介1.1. 什么是Sphinx1.2. Sphinx 的特性1.3. 如何获得Sphinx1.4. 许可协议1.5. 作者和贡献者1.6. 开发历史2. 安装2.1. 支持的操作系统2.2. 依赖的工具2.3. 安装Sphinx2.4. 已知的问题和解决方法2.5. Sphinx 快速入门教程3. 建立索引3.1. 数据源3.2. 属性3.3. 多值属性 (MV A: multi-valued attributes)3.4. 索引3.5. 数据源的限制3.6. 字符集 , 大小写转换 , 和转换表3.7. SQL 数据源 (MySQL, PostgreSQL)3.8. xmlpipe 数据源3.9. xmlpipe2 数据源3.10. 实时索引更新3.11. 索引合并4. 搜索4.1. 匹配模式4.2. 布尔查询4.3. 扩展查询4.4. 权值计算4.5. 排序模式4.6. 结果分组(聚类)4.7. 分布式搜索4.8. searchd日志格式5. API 参考5.1. 通用API 方法5.1.1. GetLastError5.1.2. GetLastWarning5.1.3. SetServer5.1.4. SetRetries5.1.5. SetArrayResult5.2. 通用搜索设置5.2.1. SetLimits5.2.2. SetMaxQueryTime5.3. 全文搜索设置5.3.1. SetMatchMode5.3.2. SetRankingMode5.3.3. SetSortMode5.3.4. SetWeights5.3.5. SetFieldWeights5.3.6. SetIndexWeights5.4. 结果集过滤设置5.4.1. SetIDRange5.4.2. SetFilter5.4.3. SetFilterRange5.4.4. SetFilterFloatRange5.4.5. SetGeoAnchor5.5. GROUP BY 设置5.5.1. SetGroupBy5.5.2. SetGroupDistinct5.6. 搜索5.6.1. Query5.6.2. AddQuery5.6.3. RunQueries5.6.4. ResetFilters5.6.5. ResetGroupBy5.7. 额外的方法5.7.1. BuildExcerpts5.7.2. UpdateAttributes6. MySQL 存储引擎 (SphinxSE)6.1. SphinxSE 概览6.2. 安装SphinxSE6.2.1. 在MySQL 5.0.x 上编译SphinxSE6.2.2. 在MySQL 5.1.x 上编译SphinxSE6.2.3. SphinxSE 安装测试6.3. 使用SphinxSE7. 报告bugs8. sphinx.conf选项参考8.1. Data source 配置选项8.1.1. type8.1.2. sql_host8.1.3. sql_port8.1.4. sql_user8.1.5. sql_pass8.1.6. sql_db8.1.7. sql_sock8.1.8. mysql_connect_flags8.1.9. sql_query_pre8.1.10. sql_query8.1.11. sql_query_range8.1.12. sql_range_step8.1.13. sql_attr_uint8.1.14. sql_attr_bool8.1.15. sql_attr_timestamp8.1.16. sql_attr_str2ordinal8.1.17. sql_attr_float8.1.18. sql_attr_multi8.1.19. sql_query_post8.1.20. sql_query_post_index8.1.21. sql_ranged_throttle8.1.22. sql_query_info8.1.23. xmlpipe_command8.1.24. xmlpipe_field8.1.25. xmlpipe_attr_uint8.1.26. xmlpipe_attr_bool8.1.27. xmlpipe_attr_timestamp8.1.28. xmlpipe_attr_str2ordinal8.1.29. xmlpipe_attr_float8.1.30. xmlpipe_attr_multi8.2. 索引配置选项8.2.1. type8.2.2. source8.2.3. path8.2.4. docinfo8.2.5. mlock8.2.6. morphology8.2.7. stopwords8.2.8. wordforms8.2.9. exceptions8.2.10. min_word_len8.2.11. charset_type8.2.12. charset_table8.2.13. ignore_chars8.2.14. min_prefix_len8.2.15. min_infix_len8.2.16. prefix_fields8.2.17. infix_fields8.2.18. enable_star8.2.19. ngram_len8.2.20. ngram_chars8.2.21. phrase_boundary8.2.22. phrase_boundary_step8.2.23. html_strip8.2.24. html_index_attrs8.2.25. html_remove_elements8.2.26. local8.2.27. agent8.2.28. agent_connect_timeout8.2.29. agent_query_timeout8.2.30. preopen8.2.31. charset_dictpath8.3. indexer程序配置选项8.3.1. mem_limit8.3.2. max_iops8.3.3. max_iosize8.4. searchd程序配置选项8.4.1. address8.4.2. port8.4.3. log8.4.4. query_log8.4.5. read_timeout8.4.6. max_children8.4.7. pid_file8.4.8. max_matches8.4.9. seamless_rotate8.4.10. preopen_indexes8.4.11. unlink_old1. 简介1.1. 什么是SphinxSphinx 是一个在GPLv2 下发布的一个全文检索引擎,商业授权(例如, 嵌入到其他程序中)需要联系我们()以获得商业授权。
首先了解一下sphinx全文索引的相关知识官方网站:/官方文档:/docs/中文支持:/中文使用手册下载:/uploads/pdf/sphinx_doc_zhcn_0.9.pdf基本上看看上面的官方教程和中文使用手册,你应该会安装和使用Sphix全文索引,当然,还有一些细节,需要不断的google和baidu,那为了节省大家的时间,就出一个完整的Sphinx安装教程和结合PHPWI ND程序的使用教程(PHPWIND7.5版本支持)。
接下来开始Sphinx的技术之旅吧!考虑到Sphinx全文索引使用的实际需要,主要介绍Sphinx全文索引中文方面的支持。
这里需要感谢李沫南同学对Sphinx全文索引中文支持的贡献!一,Windows下安装Sphinx1,开始前的准备工作来源:/products/ft_down/下载csft3.1:/uploads/csft/3.1/win32/csft3.1.bin.zip下载标准词库:/uploads/csft/3.1/data.zip解压:csft3.1.bin.zip 如下目录,解压在C:\csft3.1目录下解压:data.zip,解压在C:\csft3.1\data目录下[分词包]需要新建log文件夹(1)复制 C:\csft3.1\conf\csft.conf.in 文件到 C:\csft3.1\bin\ 目录下,并重命名为csft. conf注意csft.conf文件里的类似:path = @CONFDIR@/data/test1把@CONFDIR@替换为C:\csft3.1\ 如上更改为:path = C:\csft3.1\ data\test1(2)把测试数据 C:\csft3.1\conf\example.sql 导入数据库[这个基本都会吧!](3)建立索引,在DOC界面下运行:indexer.exe --all 如下图,建立索引过程需要仔细检查csft.conf数据库配置是否正确。
windows下的coreseek安装及PHP调用入门按:这几天安装coreseek,官方的教程是专业手册,不适合新手入门,网络上有一些文章介绍,但错漏不少,让我走了不少弯路,终于运行成功了。
我下面把安装流程整理一下,希望对新上手的同学有帮助。
把我的运行环境简单说一下:windows XP,装了php/mysql下面进入正题:1.到官网下载coreseek2.到微软官网下载C++运行环境/downloads/details.aspx?FamilyID=9b2da534-3e03-4391-8a4d-074b9 f2bc1bf&displayLang=zh-cn注意:coreseek3.x和4.x要求的C++环境有差异,详情见这里:/products-install/install_on_windows/3.将下载的coreseek压缩包解压到你觉得合适的位置,把主文件夹的名字改为你觉得合适的名字。
执行C++运行环境的文件。
coreseek就算安装完了。
4.MYSQL测试:在MYSQL的test数据库中,导入coreseek文件夹下的sql文件: var\test\documents.sql 这样就生成了测试用的数据表 test.documents下面这一步很关键,我就在这一步上被卡了好长时间:打开etc下的csft_mysql.conf,填入登陆mysql需要的基本信息。
但是很关键的是,千万不要用记事本、写字板这些文本编辑器编辑,不知什么原因,用这些编辑器编辑后,里面可能就产生了coreseek系统不能识别的字符。
以前遇到过类似情况,所以今天遇到这种情况,郁闷了差不多一个小时后,终于想到了原因。
然后我用NodePad++进行编辑,就解决了这个问题。
5.建立索引通过修改csft_mysql.conf的配置或者创建新的conf文件,就可以指定要建立索引的数据表以及建立索引的方式。
如何配置请参看官方手册,或者这篇文章:/Linux/2013-05/83857.htm这里只是对coreseek默认的测试数据表 test.documents,以其默认的方式建立索引。
SphinxSE的安装SphinxSE是一个可以编译进MySQL 5.x版本的MySQL存储引擎,尽管被称作“存储引擎”,SphinxSE自身其实并不存储任何数据。
它其实是一个允许MySQL服务器与searchd交互并获取搜索结果的嵌入式客户端,所有的索引和搜索都发生在MySQL之外。
它有一个很大的特点呢,就是如果不支持Sphinxapi的语言,也可以使用Sphinx,理论上说,Sphinapi能做的,SphinxSE都能做。
第一步、安装SphinxSESphinxSE的插件,在Sphinx(Coreseek)解压文件中/sphinx/mysqlse(1)、删除mysql因为安装sphinxSE是嵌入到MySQL中,所以我们要重新编译安装一次MySQL。
(2)、复制sphinx中的mysqlse创建sphinx文件夹:复制mysqlse文件夹到mysql的制定目录下(3)、编译安装复制完后进入到mysql源码文件进行编译安装,如下:cd/lamp/m环境检测:./configure --prefix=/usr/local/mysql --with-charset=utf8--enable-thread-safe-client --enable-assembler --with-readline --with-big-tables --with-named-curses-libs=/usr/lib/libncursesw.so.5 --with-plugins=sphinx环境检测的时候如果出现这个configure: error: unknown plugin: sphinx错误没执行sh BUILD/autorun.sh的原因。
sh BUILD/autorun.sh执行后还会报个错误:BUILD/autorun.sh: line 41: aclocal: command not foundCan't execute aclocal是因为aclocal的问题,需要安装3个依赖包在我们的镜像中都有,直接yum安装就可以。
sphinx详细安装配置⽂档SphinxSphinxSphinxSphinx详细安装配置详细安装配置详细安装配置详细安装配置项⽬中需要重新做⼀个关于商品的全⽂搜索功能,于是想到了⽤Sphinx,因为需要中⽂分词,所以选择了Sphinx for chinese,当然你也可以选择coreseek,建议这两个中选择⼀个,暂时不要选择原版Sphinx(对中⽂的⽀持不是很好).⼜因为服务器所⽤ MySQL在当时编译时并没有编译Sphinx扩展,⽽重新编译MySQL并加⼊Sphinx暂时⼜⽆法实现(项⽬⽤到了多台服务器,在不影响现有业务的情况下不可能去重新编译MySQL的),所以采⽤的是程序通过API来外部调⽤Sphinx.Sphinx⾃带的API有 PHP,Python,Ruby,Java等众多版本,所以基本也够⽤了,本⼈使⽤的编程语⾔是PHP所以下⽂的条⽤⽰例采⽤的是PHP版的API.⼀.安装及配置Sphinx及准备测试数据1.安装前的准备⼯作(1)请确认安装了MySQL,Gcc及常⽤的开发环境包(2)下载sphinx-for-chinese-1.10.1及中⽂分词词典xdict_1.1(下⾯两个⽅式,选⼀个即可)[1]到sphinx-for-chinese官⽅下载(强烈推荐使⽤这个)cd /usr/local/srcwget -c/files/sphinx-for-chinese-1.10.1-dev-r2287.tar.gzwget -c/files/xdict_1.1.tar.gz[2]到本站下载(国外vps,性能不怎么好,⽽且速度慢,不推荐,只做备⽤)cd /usr/local/srcwget -c/source/soft/sphinx-for-chinese-1.10.1/sphinx-for-chinese-1.10.1-dev-r2287.tar.gzwget -c/source/soft/sphinx-for-chinese-1.10.1/xdict_1.1.tar.gz2.安装sphinx-for-chinese-1.10.1cd /usr/local/srctar zxvf sphinx-for-chinese-1.10.1-dev-r2287.tar.gzcd sphinx-for-chinese-1.10.1-dev-r2287#MySQL安装在默认位置的使⽤如下命令./configure --prefix=/usr/local/sphinx-for-chinese-1.10.1 --with-mysql 如果出现如下图所⽰错误,表明MySQL不是安装在默认位置,请执⾏下⾯的命令# 如果MySQL不是安装在默认位置(特别是⾃⼰编译MySQL的,请注意),请指定MySQL的相关位置,主要是MySQL的include和lib⽬录 (Sphinx编译的时候要⽤到⾥⾯的.h头⽂件),--with-mysql-includes及--with-mysql-libs就是为了指定这两个位置的./configure --prefix=/usr/local/sphinx-for-chinese-1.10.1--with-mysql-includes=/usr/local/webserver/mysql/include/mysql--with-mysql-libs=/usr/local/webserver/mysql/lib/mysql显⽰如下图所⽰内容时,表⽰可以接着执⾏下⾯的make及make install命令makemake install#最后执⾏命令ls /usr/local/sphinx-for-chinese-1.10.1/如果显⽰bin,etc和var三个⽬录表⽰安装成功3.让Sphinx⽀持中⽂分词cd /usr/local/srctar zxvf xdict_1.1.tar.gz/usr/local/sphinx-for-chinese-1.10.1/bin/mkdict xdict_1.1.txtxdict_1.1 哪⾥都可以,包含的时候4Q 驆如果提⽰bin/mkdict: error while loading shared libraries:libmysqlclient.so.16等错误(以下命令中的libmysqlclient.so.16.0.0的位置取决于我们mysql编译安装的位置)ln -s /usr/local/webserver/mysql/lib/mysql/libmysqlclient.so.16.0.0/usr/lib/libmysqlclient.so.16再次执⾏/usr/local/sphinx-for-chinese-1.10.1/bin/mkdict xdict_1.1.txtxdict_1.1#提⽰Chinese dictionary was successfully created!表⽰中⽂分词词典⽣成成功cp xdict_1.1 /usr/local/sphinx-for-chinese-1.10.1/etc/xdict_1.14.配置Sphinxvi /usr/local/sphinx-for-chinese-1.10.1/etc/sphinx.conf输⼊以下内容# sphinx基本配置# 索引源source goods_src{# 数据库类型type = mysql# MySQL主机IPsql_host = localhost# MySQL⽤户名sql_user = sphinxuser# MySQL密码sql_pass = sphinxpass# MySQL数据库sql_db = sphinx# MySQL端⼝(如果防⽕墙有限制,请开启)sql_port= 3306# MySQL sock⽂件设置(默认为/tmp/mysql.sock,如果不⼀样,请指定)sql_sock = /tmp/mysql.sock 剉a # MySQL检索编码(数据库⾮utf8的很可能检索不到) sql_query_pre = SET NAMES UTF8# 获取数据的SQL语句sql_query = SELECT goods_id,goods_id ASgoods_id_new,goods_name,goods_color,goods_name ASgoods_name_search,goods_color AS goods_color_search From goods_test# 以下是⽤来过滤或条件查询的属性(以下字段显⽰在查询结果中,不在下⾯的字段就是搜索时要搜索的字段,如SQL语句中的goods_color_search,goods_name_search)# ⽆符号整型#goods_id为主键,如果加在这⾥在⽣成索引的时候会报attribute'goods_id' not found,这⾥⽤goods_id_new来变通sql_attr_uint = goods_id_new# 字符串类型sql_attr_string = goods_namesql_attr_string = goods_color# ⽤于命令界⾯端(CLI)调⽤的测试(⼀般来说不需要)#sql_query_info = SELECT * FROM goods_test Where goods_id =$goods_id;}# 索引index goods{# 索引源声明source = goods_src# 索引⽂件的存放位置path = /usr/local/sphinx-for-chinese-1.10.1/var/data/goods# ⽂件存储模式(默认为extern)docinfo = extern# 缓存数据内存锁定mlock = 0# 马⽒形态学(对中⽂⽆效)morphology = none# 索引词最⼩长度min_word_len = 1 ict_1.1.txtxdict_1.1#提⽰ChinesQ > ? # 数据编码(设置成utf8才能索引中⽂)charset_type = utf-8# 中⽂分词词典chinese_dictionary =/usr/local/sphinx-for-chinese-1.10.1/etc/xdict_1.1# 最⼩索引前缀长度min_prefix_len = 0# 最⼩索引中缀长度min_infix_len = 1# 对于⾮字母型数据的长度切割(for CJK indexing)ngram_len = 1# 对否对去除⽤户输⼊查询内容的html标签html_strip = 0}# 索引器设置indexer{# 内存⼤⼩限制默认是 32M, 最⼤ 2047M, 推荐为 256M 到 1024M之间mem_limit = 256M}# sphinx服务进程search的相关配置searchd{# 监测端⼝及形式,⼀下⼏种均可,默认为本机9312端⼝# listen = 127.0.0.1# listen = 192.168.0.1:9312# listen = 9312# listen = /var/run/searchd.sock# search进程的⽇志路径log = /usr/local/sphinx-for-chinese-1.10.1/var/log/searchd.log# 查询⽇志地址query_log = /usr/local/sphinx-for-chinese-1.10.1/var/log/query.log# 读取超时时间read_timeout = 5sql_sock = /tmp/mysql.sock 剉/Q ? # 请求超时市时间client_timeout = 300# searche进程的最⼤运⾏数max_children = 30# 进程ID⽂件pid_file =/usr/local/sphinx-for-chinese-1.10.1/var/log/searchd.pid# 最⼤的查询结果返回数max_matches = 1000# 是否⽀持⽆缝切换(做增量索引时需要)seamless_rotate = 1# 在启动运⾏时是否提前加载所有索引⽂件preopen_indexes = 0# 是否释放旧的索引⽂件unlink_old = 1# MVA跟新池⼤⼩(默认为1M)mva_updates_pool = 1M# 最⼤允许的⽹络包⼤⼩(默认8M)max_packet_size = 8M# 每个查询最⼤允许的过滤器数量(默认256)max_filters = 256#每个过滤器最⼤允许的值的个数(默认4096)max_filter_values = 4096# 每个组的最⼤查询数(默认为32)max_batch_queries = 32}# Sphinx配置⽂件结束中⽂在linux下可能会看到乱码,不⽤管5.创建测试数据库并添加测试内容(请先连上⾃⼰的MySQL数据库),在MySQL中执⾏如下命令 -1.10.1/var/log/query.log# $Q 鈲 mysql> create database sphinx collate 'utf8_general_ci';mysql> grant all privileges on sphinx.* to 'sphinxuser'@'%' identifiedby 'sphinxpass';mysql> grant all privileges on sphinx.* to 'sphinxuser'@'localhost'identified by 'sphinxpass';mysql> use sphinx;mysql> CREATE TABLE IF NOT EXISTS `goods_test` (\`goods_id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '商品id',\ `goods_name` varchar(255) NOT NULL COMMENT '商品名称',\`goods_color` varchar(60) NOT NULL COMMENT '商品颜⾊',\PRIMARY KEY (`goods_id`)\) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='商品表,sphinx⽰例' AUTO_INCREMENT=11 ;\mysql> INSERT INTO `goods_test` (`goods_id`, `goods_name`, `goods_color`) VALUES\(1, '热卖时尚双肩背包', '⿊⾊'),\(2, '热卖时尚电脑双肩背包', '灰⾊'),\(3, '缤纷炫动时尚化妆包', '⿊⾊'),\(4, '缤纷炫动时尚化妆包', '蓝⾊'),\(5, '缤纷炫动时尚化妆包', '粉红'),\(6, '极致性感⼥款衬衫', '⿊⾊'),\(7, '个性宣⾔男款短袖衬衫', '蓝⾊'),\(8, '个性宣⾔男款短袖衬衫', '红⾊'),\(9, '个性宣⾔男款短袖衬衫', '绿⾊'),\(10, '个性宣⾔男款短袖衬衫', '⿊⾊');\好了,万事俱备了,可以开始实战操作Sphinx了⼆.实战操作Sphinx1.建⽴索引(如果配置⽂件有改动,应该重新⽣成索引⽂件,如果下⾯第3点中的searchd进程已经开启的话,应先关闭)#⽣成goods索引[需要确保要连接的主机的MySQL数据库正常运⾏,并且3306端⼝可以访问]/usr/local/sphinx-for-chinese-1.10.1/bin/indexer -c/usr/local/sphinx-for-chinese-1.10.1/etc/sphinx.conf goods#如果配置⽂件⾥有多个索引,需要⼀次⽣成使⽤--all参数/usr/local/sphinx-for-chinese-1.10.1/bin/indexer -c/usr/local/sphinx-for-chinese-1.10.1/etc/sphinx.conf --all2.在linux命令⾏下测试搜索/usr/local/sphinx-for-chinese-1.10.1/bin/search -c/usr/local/sphinx-for-chinese-1.10.1/etc/sphinx.conf 个性⿊⾊ sql_port= 3306# MySQL sock⽂件设置(膖Q Gx?搜索结果如下图⽰3.开启守护进程(供API调⽤,如果配置⽂件改动,应重新启动这个进程,不然搜到的数据不是最新)/usr/local/sphinx-for-chinese-1.10.1/bin/searchd -c/usr/local/sphinx-for-chinese-1.10.1/etc/sphinx.conf & #执⾏后记得再按回车# 防⽕墙需要开放9312端⼝供外部访问9312端⼝(3306是MySQL的端⼝)/sbin/iptables -I INPUT -p tcp --dport 3306 -j ACCEPT/sbin/iptables -I INPUT -p tcp --dport 9312 -j ACCEPT/etc/rc.d/init.d/iptables save三.外部API调⽤(PHP版)注意使⽤时前提是执⾏了如下命令,⽽且防⽕墙也开启了9312端⼝/usr/local/sphinx-for-chinese-1.10.1/bin/searchd -c/usr/local/sphinx-for-chinese-1.10.1/etc/sphinx.conf & #执⾏后记得再按回车1. 把/usr/local/src/sphinx-for-chinese-1.10.1-dev-r2287/api/sphinxapi.php弄出来,和下⾯第2点中的search.php放在同级⽬录(这个只是⽰例,放在哪⾥都可以,包含的时候找到正确的sphinxapi.php的位置即可)2.编辑search.php⽂件,内容如下(具体内容请读者⾃⼰定,我这⾥只是⽰例) <?phpheader('Content-Type: text/html;charset="UTF-8"');if ($_GET) {// 关键词$keyword = urldecode(trim(strip_tags($_GET['keyword'])));if ($keyword) {// 包含Sphinx的api⽂件 require_once 'sphinxapi.php';// sphinx服务器地址$server = '192.168.128.130';// 端⼝$port = 9312;// 索引名为*时表⽰搜索所有索引$indexName = 'goods';// 分页页码$page = intval($_GET['page']) > 1 ? intval($_GET['page']) : 1;// 每页显⽰的数量$pageSize = 30;$sphinx = new SphinxClient();// 建⽴连接$sphinx->SetServer($server, $port);// 连接超时时间(⾮常必要,⽐如sphinx服务器挂了等异常情况) 单位为s,秒$sphinx->SetConnectTimeout(3);// 最⼤查询时间单位为ms,毫秒$sphinx->SetMaxQueryTime(2000);// 按分页取结果$sphinx->SetLimits(($page-1)*$pageSize, $pageSize); //第⼀个参数为offset,第⼆个参数为limit// 模式// $sphinx->SetMatchMode(SPH_MATCH_EXTENDED);// 取到的原始数据$orgDatas = $sphinx->Query($keyword, $indexName);// 调试⽤,如果有错误的话,可以打印$errors的值$errors = $sphinx->GetLastError();var_dump($errors);echo '<pre>';var_dump($orgDatas);/* // 下⾯是对结果的处理$datas = array('goods'=>array(),'total'=>0);if ($orgDatas['total'] > 0) {$datas['total'] = $orgDatas['total'];foreach ($orgDatas['matches'] AS $val) {$val['attrs']['goods_id'] =$val['attrs']['goods_id_new'];unset($val['attrs']['goods_id_new']);$datas['goods'][] = $val['attrs'];}}var_dump($datas); ?./configure --prefix=/usr/local/sphinx-for_Q lT? */}} else {echo '<form method="get"><input type="type" name="keyword"><input type="submit" value="商品搜索"></form>';}>代码可以点此处下载/source/soft/sphinx-for-chinese-1.10.1/sphinxapi.tar.gz更多详细配置请参看/usr/local/sphinx-for-chinese-1.10.1/etc/sphinx.conf.dist⽂件⾥⾯有包括实时索引,增量索引等很多内容,英⽂原版的,很详细 ?。
矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。