
昨日,七牛数据平台工程师就七牛内部使用的数据平台,深入分享了该团队在Flume、Kafka、Spark以及Streaming上的实践经验,并讲解了各个工具使用的注意点。
分享人介绍:王团结,七牛数据平台工程师,主要负责数据平台的设计研发工作。关注大数据处理,高性能系统服务,关注Hadoop、Flume、Kafka、Spark 等离线、分布式计算技术。
下为讨论实录
数据平台在大部分公司属于支撑性平台,做的不好立刻会被吐槽,这点和运维部门很像。所以在技术选型上优先考虑现成的工具,快速出成果,没必要去担心有技术负担。早期,我们走过弯路,认为没多少工作量,收集存储和计算都自己研发,发现是吃力不讨好。去年上半年开始,我们全面拥抱开源工具,搭建自己的数据平台。
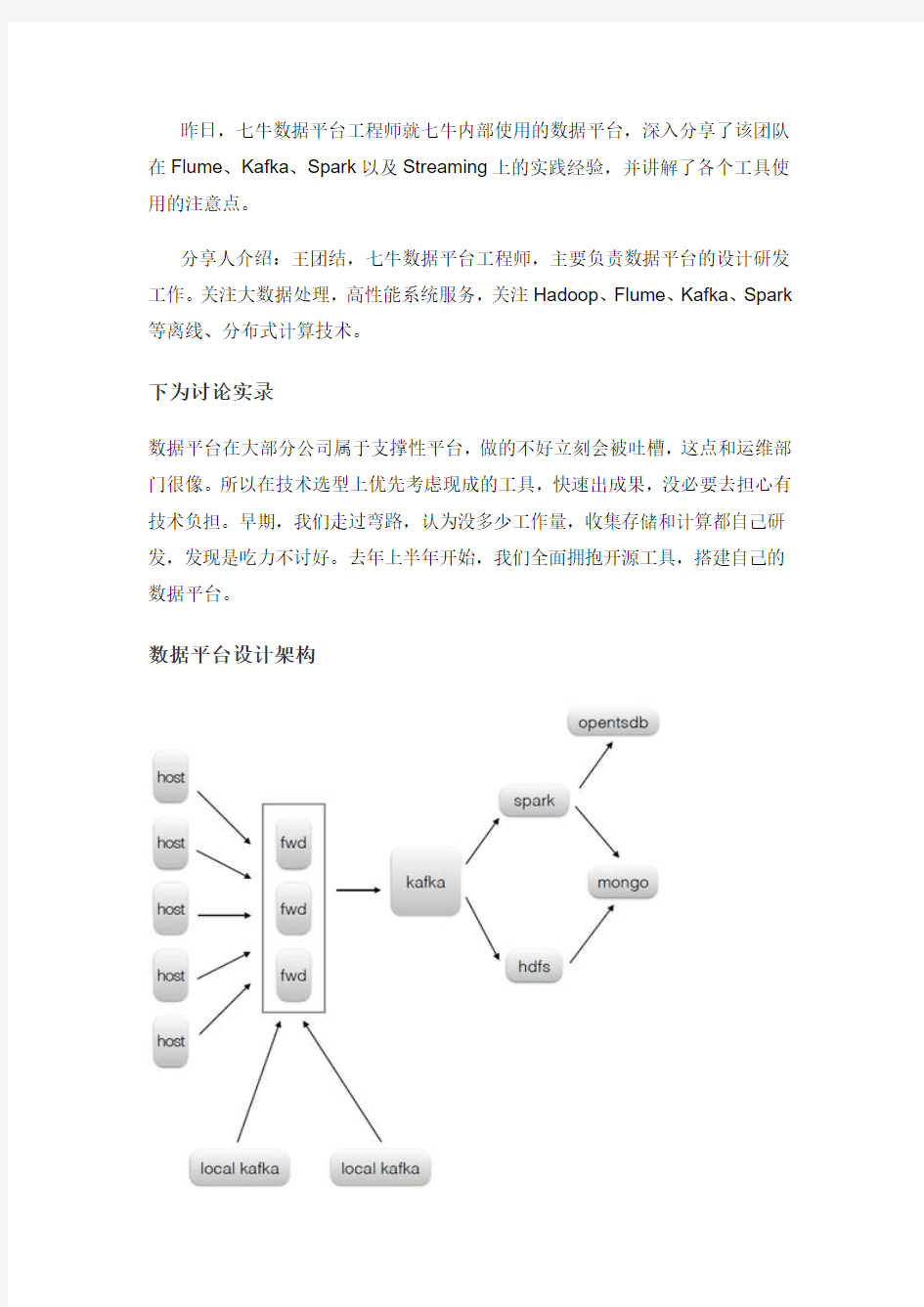
数据平台设计架构
公司的主要数据来源是散落在各个业务服务器上的半结构化的日志(系统日志、程序日志、访问日志、审计日志等)。大家有没考虑过为什么需要日志?日志是最原始的数据记录,如果不是日志,肯定会有信息上的丢失。说个简单的例子,需求是统计nginx上每个域名的的流量,这个完全可以通过一个简单的nginx模块去完成,但是当我们需要统计不同来源的流量时就法做了。所以需要原始的完整的日志。
有种手法是业务程序把日志通过网络直接发送出去,这并不可取,因为网络和接收端并不完全可靠,当出问题时会对业务造成影响或者日志丢失。对业务侵入最小最自然的方式是把日志落到本地硬盘上。
Agent设计需求
每台机器上会有一个agent去同步这些日志,这是个典型的队列模型,业务进程在不断的push,agent在不停的pop。agent需要有记忆功能,用来保存同步的位置(offset),这样才尽可能保证数据准确性,但不可能做到完全准确。由于发送数据和保存offset是两个动作,不具有事务性,不可避免的会出现数据不一致性情况,通常是发送成功后保存offset,那么在agent异常退出或机器断电时可能会造成多余的数据。
agent需要足够轻,这主要体现在运维和逻辑两个方面。agent在每台机器上都会部署,运维成本、接入成本是需要考虑的。agent不应该有解析日志、过滤、统计等动作,这些逻辑应该给数据消费者。倘若agent有较多的逻辑,那它是不可完成的,不可避免的经常会有升级变更动作。
数据收集流程
数据收集这块的技术选择,agent 是用go自己研发的,消息中间件kafka,数据传输工具flume。说到数据收集经常有人拿flume和kafka做比较,我看来这两者定位是不同的,flume更倾向于数据传输本身,kakfa是典型的消息中间件用于解耦生产者消费者。
具体架构上,agent并没把数据直接发送到kafka,在kafka前面有层由flume
构成的forward。这样做有两个原因
1. kafka的api对非jvm系的语言支持很不友好,forward对外提供更加通用的http接口
2. forward层可以做路由、kafka topic和kafka partition key等逻辑,进一步减少agent端的逻辑
forward层不含状态,完全可以做到水平扩展,不用担心成为瓶颈。出于高可用考虑,forward通常不止一个实例,这会带来日志顺序问题,agent 按一定规则(round-robin、failover等)来选择forward实例,即使kafka partition key一样,由于forward层的存在,最终落入kafka的数据顺序和agent发送的顺序可能会不一样。我们对乱序是容忍的,因为产生日志的业务基本是分布式的,保证单台机器的日志顺序意义不大。如果业务对顺序性有要求,那得把数据直接发到kafka,并选择好partition key,kafka只能保证partition级的顺序性。
跨机房收集要点
多机房的情形,通过上述流程,先把数据汇到本地机房kafka 集群,然后汇聚到核心机房的kafka,最终供消费者使用。由于kafka的mirror对网络不友好,这里我们选择更加的简单的flume去完成跨机房的数据传送。
flume在不同的数据源传输数据还是比较灵活的,但有几个点需要注意
1. memory-channel效率高但可能有丢数据的风险,file-channel安全性高但性能不高。我们是用memory-channel,但把capacity设置的足够小,使内存中的数据尽可能少,在意外重启和断电时丢的数据很少。个人比较排斥file-channel,效率是一方面,另一个是对flume的期望是数据传输,引入file-channel时,它的角色会向存储转变,这在整个流程中是不合适的。通常flume的sink端是kafka 和hdfs这种可用性和扩张性比较好的系统,不用担心数据拥堵问题。
2. 默认的http souce 没有设置线程池,有性能问题,如果有用到,需要自己修改代码。
3. 单sink速度跟不上时,需要多个sink。像跨机房数据传输网络延迟高单rpc sink吞吐上不去和hdfs sink效率不高情形,我们在一个channel后会配十多个sink。
Kafka使用要点
kafka在性能和扩展性很不错,以下几个点需要注意下
1. topic的划分,大topic对生产者有利且维护成本低,小topic对消费者比较友好。如果是完全不相关的相关数据源且topic数不是发散的,优先考虑分topic。
2. kafka的并行单位是partition,partition数目直接关系整体的吞吐量,但parition 数并不是越大越高,3个partition就能吃满一块普通硬盘io了。所以partition 数是由数据规模决定,最终还是需要硬盘来抗。
3. partition key选择不当,可能会造成数据倾斜。在对数据有顺序性要求才需使用partition key。kafka的producer sdk在没指定partition key时,在一定时间内只会往一个partition写数据,这种情况下当producer数少于partition数也会造成数据倾斜,可以提高producer数目来解决这个问题。
数据到kafka后,一路数据同步到hdfs,用于离线统计。另一路用于实时计算。由于今天时间有限,接下来只能和大家分享下实时计算的一些经验
实时计算我们选择的spark streaming。我们目前只有统计需求,没迭代计算的需求,所以spark streaming使用比较保守,从kakfa读数据统计完落入mongo 中,中间状态数据很少。带来的好处是系统吞吐量很大,但几乎没遇到内存相关问题
spark streaming对存储计算结果的db tps要求较高。比如有10w个域名需要统计流量,batch interval为10s,每个域名有4个相关统计项,算下来平均是4w
tps,考虑到峰值可能更高,固态硬盘上的mongo也只能抗1w tps,后续我们会考虑用redis来抗这么高的tps
有外部状态的task逻辑上不可重入的,当开启speculation参数时候,可能会造成计算的结果不准确。说个简单的例子
这是个把计算结果存入mongo的task
这个任务,如果被重做了,会造成落入mongo的结果比实际多。
有状态的对象生命周期不好管理,这种对象不可能做到每个task都去new一个。我们的策略是一个jvm内一个对象,同时在代码层面做好并发控制。类似下面。
在spark 1.3的后版本,引入了kafka direct api试图来解决数据准确性问题,使
用direct在一定程序能缓解准确性问题,但不可避免还会有一致性问题。为什么这样说呢?direct api 把kafka consumer offset的管理暴露出来(以前是异步存入zookeeper),当保存计算结果和保存offset在一个事务里,才能保证准确。
这个事务有两种手段做到,一是用mysql这种支持事务的数据库保存计算结果offset,一是自己实现两阶段提交。这两种方法在流式计算里实现的成本都很大。其次direct api 还有性能问题,因为它到计算的时候才实际从kafka读数据,这对整体吞吐有很大影响。
要分享的就这些了,最后秀下我们线上的规模。flume +kafka +spark 8台高配机器,日均500亿条数据,峰值80w tps。
【问题1】请问机器配置是什么样的?
24核+96G 内存+10块机械盘+4张1G 网卡
【问题2】请问有没有用spark替代mapreduces的经验?
这个有但今天没讲到。数据会半实时落入hdfs,会有一些临时的统计需求,先前是用mapreduce做这类统计,后来用spark shell替换了,写起来简单多了。
【问题3】为什么不能直接用flume去代替每个机器的agent
这个问题很好
1. 我们的运维体系对java没有支持
2. flume-agent 关于offset的处理,不够好
3. 当有日志接入变更时,配置文件维护成本高
Hadoop大数据平台架构与实践--基础篇 大数据时代已经到来,越来越多的行业面临着大量数据需要存储以及分析的挑战。Hadoop,作为一个开源的分布式并行处理平台,以其高扩展、高效率、高可靠等优点,得到越来越广泛的应用。 本课旨在培养理解Hadoop的架构设计以及掌握Hadoop的运用能力。 导师简介 Kit_Ren,博士,某高校副教授,实战经验丰富,曾担任过大型互联网公司的技术顾问,目前与几位志同道合的好友共同创业,开发大数据平台。 课程须知 本课程需要童鞋们提前掌握Linux的操作以及Java开发的相关知识。对相关内容不熟悉的童鞋,可以先去《Linux达人养成计划Ⅰ》以及《Java入门第一季》进行修炼~~ 你能学到什么? 1、Google的大数据技术 2、Hadoop的架构设计 3、Hadoop的使用 4、Hadoop的配置与管理 大纲一览 第1章初识Hadoop 本章讲述课程大纲,授课内容,授课目标、预备知识等等,介绍Hadoop的前世今生,功能与优势 第2章 Hadoop安装 本章通过案例的方式,介绍Hadoop的安装过程,以及如何管理和配置Hadoop 第3章 Hadoop的核心-HDFS简介 本章重点讲解Hadoop的组成部分HDFS的体系结构、读写流程,系统特点和HDFS
的使用。 第4章 Hadoop的核心-MapReduce原理与实现 本章介绍MapReduce的原理,MapReduce的运行流程,最后介绍一个经典的示例WordCount 第5章开发Hadoop应用程序 本章介绍在Hadoop下开发应用程序,涉及多个典型应用,包括数据去重,数据排序和字符串查找。 课程地址:https://www.doczj.com/doc/cd10066264.html,/view/391
Hadoop是什么 Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Hadoop名字的由来 Hadoop was created by Doug Cutting and Mike Cafarella in 2005 Named the project after son's toy elephant
从移动数据到移动算法
Hadoop的核心设计理念?可扩展性 ?可靠性
相对于传统的BI 架构转变 数据仓库电子表格 视觉化工 具 数据挖掘集成开发工具 数据集市 企业应用工具 传统文件日志社交& 网络遗留系 统结构化 非结构化 音视频数据应用非关系型数据库内存数据库NO SQL 应用 Nod e Nod e Nod e Hadoop * Web Apps MashUps 导出/导入INSIGHTS 消费Create Map 存储/计算实时数据处理通道(Spark,Storm)数据交换平台数据存储计算平台数据访问 层Kafka Flume Goldengat e Shareplex ..传感器传感器
hadoop 的适用场景 小数据+ 小计算量OLTP 业务系统:ERP/CRM/EDA 大数据+ 小计算量如全文检索,传统的ETL 小数据+大计算量D a t a Compute 数据 计算 实时性
Hadoop大数据平台测试报告及成功案例
目录 1技术规范书应答书 ................................. 错误!未定义书签。2技术方案建议 ......................................... 错误!未定义书签。3测试及验收 ............................................. 错误!未定义书签。4项目实施与管理 ..................................... 错误!未定义书签。5人员资质与管理 ..................................... 错误!未定义书签。6技术支持及保修 ..................................... 错误!未定义书签。7附录 ......................................................... 错误!未定义书签。
1.1 大数据平台测试报告 1.1.1某银行Cloudera CDH 性能测试测试 某银行现有HODS在支撑行内业务方面已经遇到瓶颈。希望通过搭建基于Hadoop 的历史数据平台(新HODS),以提升平台运行效率及数据覆盖面,支撑未来大数据应用,满足未来业务发展需求。本次POC测试的主要目的是验证Hadoop商业发行版(EDH) 是否可以满足某银行HODS应用特点,主要考察点包括: ?验证产品本身的易用性、可扩展性,主要涉及集群的部署、运维、监控、升级等; ?验证产品对安全性的支持,包括认证、授权、审计三大方面; ?验证产品对资源分配的控制与调度; ?验证Hadoop基本功能,包括可靠性、稳定性、故障恢复等; ?验证Hadoop子系统(包括HDFS、HBase、Hive、Impala等) 的性能、使用模式、设计思想、迁移代价等。 1.1.1.1基础设施描述 1.1.1.1.1硬件配置 硬件配置分为两类:管理节点(master node) 与计算节点(worker node)。 管理节点配置(2) CPU Intel? Xeon? E5-2650 v3 2.3GHz,25M Cache,9.60GT/s QPI,Turbo,HT,10C/20T (105W) Max Mem 2133MHz (40 vcore) 内存16GB RDIMM, 2133MT/s, Dual Rank, x4 Data Width (128GB) 网络Intel X520 DP 10Gb DA/SFP+ Server Adapter, with SR Optics
基于Hadoop的大数据平台实施——整体架构设计大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星。我们暂不去讨论大数据到底是否适用于您的公司或组织,至少在互联网上已经被吹嘘成无所不能的超级战舰。好像一夜之间我们就从互联网时代跳跃进了大数据时代!关于到底什么是大数据,说真的,到目前为止就和云计算一样,让我总觉得像是在看电影《云图》——云里雾里的感觉。或许那些正在向你推销大数据产品的公司会对您描绘一幅乌托邦似的美丽画面,但是您至少要保持清醒的头脑,认真仔细的慎问一下自己,我们公司真的需要大数据吗? 做为一家第三方支付公司,数据的确是公司最最重要的核心资产。由于公司成立不久,随着业务的迅速发展,交易数据呈几何级增加,随之而来的是系统的不堪重负。业务部门、领导、甚至是集团老总整天嚷嚷的要报表、要分析、要提升竞争力。而研发部门能做的唯一事情就是执行一条一条复杂到自己都难以想象的SQL语句,紧接着系统开始罢工,内存溢出,宕机........简直就是噩梦。OMG!please release me!!! 其实数据部门的压力可以说是常人难以想象的,为了把所有离散的数据汇总成有价值的报告,可能会需要几个星期的时间或是更长。这显然和业务部门要求的快速响应理念是格格不入的。俗话说,工欲善其事,必先利其器。我们也该鸟枪换炮了......。 网上有一大堆文章描述着大数据的种种好处,也有一大群人不厌其烦的说着自己对大数据的种种体验,不过我想问一句,到底有多少人多少组织真的在做大数据?实际的效果又如何?真的给公司带来价值了?是否可以将价值量化?关于这些问题,好像没看到有多少评论会涉及,可能是大数据太新了(其实底层的概念并非新事物,老酒装新瓶罢了),以至于人们还沉浸在各种美妙的YY中。 做为一名严谨的技术人员,在经过短暂盲目的崇拜之后,应该快速的进入落地应用的研究中,这也是踩着“云彩”的架构师和骑着自行车的架构师的本质区别。说了一些牢骚话,
Hadoop大数据平台建设要求及应答方案
目录 2技术规范书应答书 (2) 2.1业务功能需求 (4) 2.1.1系统管理架构 (4) 2.1.2数据管理 (12) 2.1.3数据管控 (26) 2.1.4数据分析与挖掘 (27) 2.2技术要求 (30) 2.2.1总体要求 (30) 2.2.2总体架构 (31) 2.2.3运行环境要求 (32) 2.2.4客户端要求 (35) 2.2.5数据要求 (36) 2.2.6集成要求 (36) 2.2.7运维要求 (37) 2.2.8性能要求 (49) 2.2.9扩展性要求 (50) 2.2.10可靠性和可用性要求 (52) 2.2.11开放性和兼容性要求 (57) 2.2.12安全性要求 (59)
1大数据平台技术规范要求 高度集成的Hadoop平台:一个整体的数据存储和计算平台,无缝集成了基于Hadoop 的大量生态工具,不同业务可以集中在一个平台内完成,而不需要在处理系统间移动数据;用廉价的PC服务器架构统一的存储平台,能存储PB级海量数据。并且数据种类可以是结构化,半结构化及非结构化数据。存储的技术有SQL及NoSQL,并且NoSQL能提供企业级的安全方案。CDH提供统一的资源调度平台,能够利用最新的资源调度平台YARN分配集群中CPU,内存等资源的调度,充分利用集群资源; 多样的数据分析平台–能够针对不用的业务类型提供不同的计算框架,比如针对批处理的MapReduce计算框架;针对交互式查询的Impala MPP查询引擎;针对内存及流计算的Spark框架;针对机器学习,数据挖掘等业务的训练测试模型;针对全文检索的Solr搜索引擎 项目中所涉及的软件包括: ?Hadoop软件(包括而不限于Hadoop核心) ?数据采集层:Apache Flume, Apache Sqoop ?平台管理:Zookeeper, YARN ?安全管理:Apache Sentry ?数据存储:HDFS, HBase, Parquet ?数据处理:MapReduce, Impala, Spark ?开发套件:Apache Hue, Kite SDK ?关系型数据库系统:SAP HANA企业版 ?ETL工具:SAP Data Services 数据管控系统的二次开发量如下: ?主数据管理功能 通过二次开发的方式实现主数据管理功能,并集成甲方已有的主数据管理系统。
课题:项目3 部署Hadoop大数据平台第2部分部署Hadoop平台课次:第7次教学目标及要求: (1)任务1 JDK的安装配置(熟练掌握) (2)任务2部署Hadoop(熟练掌握) (3)任务3 理解启动Hadoop(熟练掌握) 教学重点: (1)任务1 JDK的安装配置 (2)任务2 部署Hadoop (3)任务3 启动Hadoop 教学难点: (1)任务2 部署Hadoop (2)任务3 启动Hadoop 思政主题: 旁批栏: 教学步骤及内容: 1.课程引入 2.本次课学习内容、重难点及学习要求介绍 (1)任务1 JDK的安装配置 (2)任务2 部署Hadoop (3)任务3 启动Hadoop 3.本次课的教学内容 (1)任务1 JDK的安装配置(熟练掌握) Hadoop的不同版本与JDK的版本存在兼容性问题,所有必须选择对应 版本的JDK进行安装,表中列出了Hadoop和JDK兼容表。我们通过测试 使用Hadoop3.0.0 和JDK1.8。 安装JDK我们使用JDK包安装的方式。首先我们新建JDK的安装目录 /opt/bigddata。操作步骤为://定位opt目录【操作新建目录/opt/bigdata】
[root@master /]# cd /opt/ //在opt目录下新建bigdata文件夹 [root@master /]# mkdir bigdata //查看opt目录下文件夹是否存在 [root@master /]# ls bigdata [root@master /]# Jdk解压安装,步骤为:【操作解压步骤】 [root@master opt]# cd / [root@master /]# cd /opt/ [root@master opt]# ls bigdata jdk-8u161-linux-x64.tar.gz //解压jdk压缩包 [root@master opt]# tar -zxvf jdk-8u161-linux-x64.tar.gz [root@master opt]# ls bigdata jdk1.8.0_161 jdk-8u161-linux-x64.tar.gz //把Jdk目录移动至bigdata目录 [root@master opt]# mv jdk1.8.0_161/ bigdata [root@master opt]# cd bigdata/ //查看是否移动成功 [root@master bigdata]# ls jdk1.8.0_161 [root@master bigdata]# JDK配置环境变量,此步骤为添加JA V A_HOME变量,并配置JDK。具体步骤为:【操作JDK的配置】 //进入环境变量配置文件 [root@master /]# vi /etc/profile //添加如下信息 export JA V A_HOME="/opt/bigdata/jdk1.8.0_161" export PATH=$JA V A_HOME/bin:$PATH //激活环境变量配置文件 [root@master /]# source /etc/profile //验证JDK是否配置完成 [root@master /]# java -version java version "1.8.0_161" Java(TM) SE Runtime Environment (build 1.8.0_161-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
HADOOP大数据平台配置方法(完全分布式,懒人版) 一、规划 1、本系统包括主节点1个,从节点3个,用Vmware虚拟机实现; 2、主节点hostname设为hadoop,IP地址设为192.168.137.100; 3、从节点hostname分别设为slave01、slave02,slave03,IP地址设为192.168.137.201、192.168.137.202、192.168137.203。今后如要扩充节点,依此类推; 基本原理:master及slave机器的配置基本上是一样的,所以我们的操作方式就是先配置好一台机器,然后克隆3台机器出来。这样可以节省大量的部署时间,降低出错的概率。安装配置第一台机器的时候,一定要仔细,否则一台机器错了所有的机器都错了。 二、前期准备 1、在Vmware中安装一台CentOS虚拟机; 2、设置主机名(假设叫hadoop)、IP地址,修改hosts文件; 3、关闭防火墙; 4、删除原有的JRE,安装JDK,设置环境变量; 5、设置主节点到从节点的免密码登录(此处先不做,放在第七步做); 三、安装Hadoop 在hadoop机上以root身份登录系统,按以下步骤安装hadoop: 1、将hadoop-1.0.4.tar.gz复制到/usr 目录; 2、用cd /usr命令进入/usr目录,用tar –zxvf hadoop-1.0.4.tar.gz进行 解压,得到一个hadoop-1.0.4目录; 3、为简单起见,用mv hadoop-1.0.4 hadoop命令将hadoop-1.0.4文件夹 改名为hadoop; 4、用mkdir /usr/hadoop/tmp命令,在hadoop文件夹下面建立一个tmp 目录; 5、用vi /etc/profile 修改profile文件,在文件最后添加以下内容: export HADOOP_HOME=/usr/hadoop export PATH=$PATH:$HADOOP_HOME/bin 6、用source /usr/profile命令使profile 立即生效; 四、配置Hadoop Hadoop配置文件存放在/usr/hadoop/conf目录下,本次有4个文件需要修改。这4个文件分别是hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml。 1、修改hadoop-env.sh,在文件末添加如下内容: export JAVA_HOME=/usr/jdk (此处应与Java所在的目录一致) 2、修改core-site.xml文件,在文件中添加如下内容(教材109):
浅谈大数据Hadoop技术 摘要:随着移动互联网、物联网、共享经济的高速发展,互联网每天都会产生数以万亿 的数据,这些海量数据被称作为大数据。在这个大数据时代,数据资源对我们生活产 生了巨大影响,对企业经营决策也有着前瞻性指导意义。因此,大数据已经被视为一 种财富、一种被衡量和计算价值的不可或缺的战略资源。该文从大数据Hadoop技术谈起、分别从Hadoop的核心技术、生态系统和Hadoop技术在教学中的应用四个方面进 行了阐述。 关键词:大数据;Hadoop; HDFS; MapReduce 中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2019)32-0010-02 当前,我国以信息技术为主导的创新经济高速发展,特别是依托于移动互联网和物联 网技术的网络购物、移动支付、共享单车、微信通信交流等等,给人们生活方式带来 了深刻的变革。整个互联网正在从IT(Information Technology)时代向DT(Data Technology)时代D变,在这个DT时代,人们从被动的数据浏览者转变为主动的数据 生产者,人们每天的网络购物信息、各种电子支付信息、使用共享单车信息、微信中 浏览朋友圈的信息等等,都会产生数以万亿级的数据,这样庞大的数据如何存储、如 何传输、如何计算、如何分析、如何保证数据的完整性和安全性等等一系列新的技术 挑战应运而生。然而,Hadoop技术代表着最新的大数据处理所需的新的技术和方法, 也代表着大数据分析和应用所带来的新发明、新服务和新的发展机遇。 1 什么是Hadoop Hadoop是一个由Apache基金会所开发的,开源的分布式系统基础架构。简单地说就是一套免费的分布式操作系统。我们以前使用的计算机系统,都是安装在一台独立主机 上的单机版操作系统。例如我们熟知的微软公司的Windows操作系统和苹果公司的Mac OS。而分布式系统则是通过高速网络把大量分布在不同地理位置、不同型号、不同硬 件架构、不同容量的服务器主机连结在一起,形成一个服务器集群。分布式系统把集 群中所有硬件资源(CPU、硬盘、内存和网络带宽)进行整合统一管理,形成具有极高 运算能力,庞大存储能力和高速的传输能力的系统。 Hadoop就是以Linux系统为原型开发的大数据分布式系统。Hadoop具有很强的扩展性,只要是接通网络它就可以不断加入不同地域、不同型号、不同性能的服务器主机,以 提升集群的运算、存储和网络带宽,以满足大数据所需要的硬件要求。此外,Hadoop 还具有极强的安全性,由于分布式系统数据是存储在不同物理主机上的,而且Hadoop 数据一般每个数据存储三份,而且分布不同物理主机上,一旦其中一份数据损坏,其 余正常数据会很快替代它,这样很好地解决了数据完整性和安全性问题,为大数据提 供了安全高速稳定的系统平台。
hadoop是什么_华为大数据平台hadoop你了解多少 Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。Hadoop是一个能够对大量数据进行分布式处理的软件框架。Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理PB 级数据。此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。 华为大数据平台hadoop你了解多少提到大数据平台,就不得不提Hadoop。Hadoop有三大基因:第一,Hadoop需要sharenothing的架构,所以它可以scale-out。第二,它是一个计算存储解耦的架构,好处是计算引擎可以多样化。举个例子,批处理有Hive,交互查询有Spark,机器学习还可以有后面的tensorflow这些深度学习的框架。第三,Hadoop是近数据计算的。因为大数据平台是一个数据密集的计算场景,在这种非场景下,IO会是个瓶颈,所以把计算移动到数据所在地会提升计算的性能。 网络技术的发展是推动大数据平台发展的一个关键因素。2012年以前是一个互联网的时代,这个时期互联网公司和电信运营商,掌握着海量的数据,所以他们开始利用Hadoop 平台来进行大数据的处理。那时候程序员自己写程序跑在Hadoop平台上来解决应用问题。2012年以后移动互联网的迅猛发展,这使得服务行业率先数字化。例如在金融行业,手机App让用户可以随时随地查询、转账,此时银行开始面临海量数据和高并发的冲击,就需要一个大数据平台来解决这个问题。这也就是为什么华为在2013年面向行业市场推出大