
第一章引言
我国经济经历了持续30多年的高速增长,增加了城乡居民的人均收入。人们在满足最基本的生活需求的同时,追求高品质生活方式是一种必然趋势。外出旅游是提高生活品质的重要方式,被长期压抑的居民旅游需求将伴随着其可支配收入的持续增长得到迅速释放。
我国旅游业发展的阶段性特征:
我国旅游业起步较晚,但发展迅猛,在国民经济中的地位和作用日益加强。新中国成立前,我国经济萧条,民生凋敝,旅游业发展基本停滞,旅游产业基本没有形成。建国后到改革开放前的30年间,我国旅游业主要局限在为外交和民间往来活动服务的入境旅游,国旅游基本是一白纸。1978年,我国接待入境旅游人数180万人,仅占世界的0.7%,居世界第41位;入境旅游收入2.6亿美元,仅占全球的0.038%,居世界第47位。1978年党的十一届三中全会确立改革开放政策,旅游业才算真正起步。非常重视旅游业,指出“旅游事业大有文章可做,要突出地搞,加快地搞。”30多年来,随着我国经济持续快速发展和居民收入水平较快提高,我国旅游人数和旅游收入都以年均两位数以上的增速持续发展,已经成国民经济的重要产业,成为继住房、汽车之后增长最快的居民消费领域。据有关资料,2010年,我国旅游业总收入1.57万亿元,对经济的直接贡献相当于GDP的2.5%,加上带动其他产业,旅游业对经济的直接和间接贡献总计相当于GDP的8.6%。旅游业直接从业人员1350万人,加上带动其他就业,旅游业直接与间接就业总人数达7600余万人,约占全国就业总数的9.6%。有研究表明,旅游对住宿业贡献率超过90%,对民航和铁路客运业贡献率超过80%,对文化娱乐业贡献率超过50%,对餐饮业和商品零售业贡献率超过40%,旅游消费对社会消费的贡献超过10%。目前,我国已经跃居全球第四大入境旅游接待国和亚洲第一大出境旅游客源国。
第二章构建并分析模型
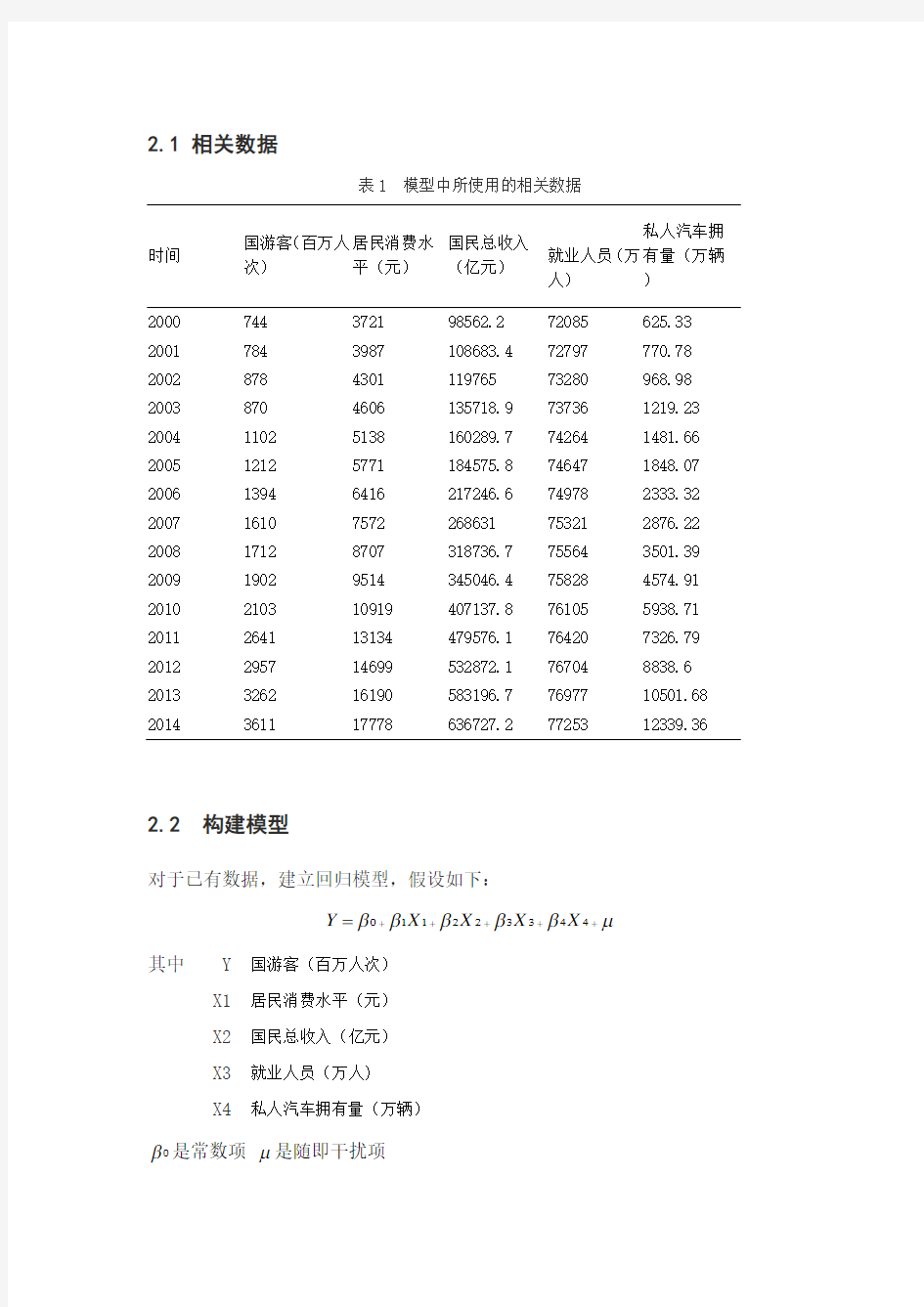
2.1 相关数据
表1 模型中所使用的相关数据
时间
国游客(百万人次) 居民消费水平(元) 国民总收入
(亿元) 就业人员(万人) 私人汽车拥有量(万辆 ) 2000 744 3721 98562.2 72085 625.33 2001 784 3987 108683.4 72797 770.78 2002 878 4301 119765 73280 968.98 2003 870 4606 135718.9 73736 1219.23 2004 1102 5138 160289.7 74264 1481.66 2005 1212 5771 184575.8 74647 1848.07 2006 1394 6416 217246.6 74978 2333.32 2007 1610 7572 268631 75321 2876.22 2008 1712 8707 318736.7 75564 3501.39 2009 1902 9514 345046.4 75828 4574.91 2010 2103 10919 407137.8 76105 5938.71 2011 2641 13134 479576.1 76420 7326.79 2012 2957 14699 532872.1 76704 8838.6 2013 3262 16190 583196.7 76977 10501.68 2014
3611
17778
636727.2
77253
12339.36
2.2 构建模型
对于已有数据,建立回归模型,假设如下:
μβββββ+++++=443322110X X X X Y
其中 Y 国游客(百万人次) X1 居民消费水平(元) X2 国民总收入(亿元) X3 就业人员(万人) X4 私人汽车拥有量(万辆)
0β是常数项 μ是随即干扰项
2.2.1 散点图
对表1中的数据做散点图,如下:
图1 相关数据的散点图
2.2.2 最小二乘估计
Dependent Variable: Y Method: Least Squares Date: 06/21/16 Time: 14:19 Sample: 2000 2014 Included observations: 15
Variable Coefficient Std. Error t-Statistic Prob. X1 0.424976 0.133490 3.183591 0.0098 X2 -0.005297 0.002429 -2.180526 0.0542 X3 0.068559 0.031671 2.164730 0.0557 X4 -0.049983 0.062935 -0.794209 0.4455 C
-5273.242
2309.879
-2.282908
0.0456
R-squared 0.998126 Mean dependent var 1785.467 Adjusted R-squared 0.997377 S.D. dependent var 943.6307 S.E. of regression 48.33183 Akaike info criterion 10.85526 Sum squared resid 23359.66 Schwarz criterion 11.09128 Log likelihood -76.41444 Hannan-Quinn criter. 10.85275 F-statistic 1331.653 Durbin-Watson stat 1.826495
Prob(F-statistic)
0.000000
0100,000
200,000300,000400,000500,000600,000700,000
Y
图2 相关数据的最小二乘估计
模型的估计结果为:
4321049983.0068559.0005297.0424976.0242.5273X X X X Y -+-+-=∧
(-2.282908) (3.183591) (-2.180526) (2.164730) (-0.794209)
2R =0.9981262R =0.997377 F=1331.653 D.W=1.826495
第三章 回归模型的检验与修正
3.1 回归模型的统计检验
3.1.1 拟合优度检验 由最小二乘估计的结果得到
2R =0.9981262R =0.997377 都接近1,拟合优度较好。 3.1.2 方程总体线性的显著性检验(F 检验)
当显著性水平α=0.05时,05.0F (4,10)=3.48 < 1331.653,模型的线性关系在95%的显著性水平下显著成立。 3.1.3 变量的显著性检验(T 检验)
当显著性水平α=0.05时,025.0T (10)=2.2281,只有变量X1的T 检验值 的绝对值3.183591>025.0T (10)=2.2281,所以四个变量中只有X1 是显著的。
3.2 多重共线性的检验与修正
3.2.1 简单相关系数
表2
X1 X2 X3 X4
X1 1
0.996303 0.850484 0.988825
X2 0.996303 1
0.879407 0.974283
X3 0.850484 0.879407 1
0.790268
X4
0.988825 0.974283 0.790268 1
变量之间相关系数较高,说明存在多重共线性。
3.2.2 多重共线性的修正
采用逐步回归法:
首先对Y 分别与X1,X2,X3,X4 做回归,结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 06/21/16 Time: 14:40
Sample: 2000 2014
Included observations: 15
Variable Coefficient Std. Error t-Statistic Prob.
X1 0.200100 0.003120 64.12889 0.0000
C 18.54519 30.99350 0.598357 0.5599
R-squared 0.996849 Mean dependent var 1785.467 Adjusted R-squared 0.996606 S.D. dependent var 943.6307 S.E. of regression 54.97016 Akaike info criterion 10.97502 Sum squared resid 39282.34 Schwarz criterion 11.06943 Log likelihood -80.31268 Hannan-Quinn criter. 10.97402 F-statistic 4112.515 Durbin-Watson stat 1.473655 Prob(F-statistic) 0.000000
图3
X
Y=18.54519+0.2001001
(0.598357) (64.12889)
2
R=0.996849 2R=0.996606 F=4112.515 D.W=1.473655
Dependent Variable: Y
Method: Least Squares
Date: 06/21/16 Time: 14:41
Sample: 2000 2014
Included observations: 15
Variable Coefficient Std. Error t-Statistic Prob.
X2 0.005125 0.000130 39.47271 0.0000
C 214.7918 45.96015 4.673436 0.0004 R-squared 0.991726 Mean dependent var 1785.467
Adjusted R-squared 0.991089 S.D. dependent var 943.6307
S.E. of regression 89.07685 Akaike info criterion 11.94044
Sum squared resid 103150.9 Schwarz criterion 12.03485
Log likelihood -87.55331 Hannan-Quinn criter. 11.93944
F-statistic 1558.095 Durbin-Watson stat 0.985650
Prob(F-statistic) 0.000000
图4
∧
Y=214.7918+0.0051252
X
(4.673436) (39.47271)
2
R=0.9917262R=0.991089 F=1558.095 D.W=0.985650
Dependent Variable: Y
Method: Least Squares
Date: 06/21/16 Time: 14:42
Sample: 2000 2014
Included observations: 15
Variable Coefficient Std. Error t-Statistic Prob.
X3 0.554536 0.062810 8.828741 0.0000
C -39840.17 4715.757 -8.448310 0.0000
R-squared 0.857059 Mean dependent var 1785.467 Adjusted R-squared 0.846064 S.D. dependent var 943.6307
S.E. of regression 370.2309 Akaike info criterion 14.78970
Sum squared resid 1781922. Schwarz criterion 14.88410
Log likelihood -108.9227 Hannan-Quinn criter. 14.78869
F-statistic 77.94667 Durbin-Watson stat 0.260036
Prob(F-statistic) 0.000001
图5
∧
Y=-39840.17+0.5545363X
(-8.448310) (8.828741)
2
R=0.857059 2R=0.846064 F=77.94667 D.W=0.260036 Dependent Variable: Y
计量经济学课程设计 班级: 学号: 姓名:
2011年月
一、引言 财政收入是衡量一国政府财力的重要指标,国家在社会活动中提供公共物品和服务,很大程度上需要财政收入的鼎力相助。财政收入既是国家的集中性分配活动,又是国家进行宏观调控的重要工具。税收是国家为实现其职能的需要,凭借其政治权利并按照特定的标准,强制、无偿的取得财政收入的一种形式,它是现代国家财政收入最重要的收入形式和最主要的收入来源。本课题跟据我国最近几年的经济发展水平和税收收入并结合我国各地区在2008年的实际情况,利用《中国统计年鉴2009》做出了税收收入的计量模型,比较分析了职工工资总额、财政支出和人均家庭总收入等变量对税收收入的不同影响,得出了几个重要的结论。 税收是国家在社会经济活动中为提供公共物品和服务的主要收入来源,在很大程度上决定于财政收入的充裕状况。税收是国家集中性分配活动,又是国家进行宏观调控的重要工具。我国自改革开放以来税收一直随经济的增长在快速的增长,尤其是进入21世纪以来成高速发展趋势。由1999年的亿元到2008年的亿元,十年来增加了倍(见表1)。 近几年以来,尤其是2008年以来社会不公平和贫富差距进一步了大,造成了社会的不稳定。2010年两会期间温家宝总理提出调整税收基数,从而来缩小贫富差距和社会公平问题。
表1 我国十年来税收一览表 二、理论基础 税收是国家为了实现其职能,以政治权利为基础,按规定标准以政治权力为基础,按预定标准像经济组织和居民无偿课征而取得的一种财政收入。税收的影响因素有很多包括一国的经济实力,经济发展水平,劳动者的素质,职工工资总额,财政支出,家庭总收入,生产总值,商品零售价格指数等。 职工工资总额,指各单位或组织在一定时期内直接支付给本单位全部职工的劳动报酬总额。个人所得税的税基就是劳动报酬总额。而个人所得税是税收收入的组成部分。 生产总值,生产总值是经济发展的最重要指标,税收与生产总值的关系集中反映了税收与经济的关系。换言之,经济决定税收,税收促进经济。因此,二者有着直接相关性。如果税收与生产总值的比例关系不协调,一定程度上会弱化了国家队经济的宏观调控能力。因此
06A卷 一、判断说明题(每小题1分,共10分) 1.在实际中,一元回归没什么用,因为因变量 的行为不可能仅由一个解释变量来解释。(×) 4.在线性回归模型中,解释变量是原因,被解 释变量是结果。(×) 7. 给定显著性水平 及自由度,若计算得到 的t 值超过t的临界值,我们将拒绝零假设。 (√) 8.为了避免陷入虚拟变量陷阱,如果一个定性 变量有 m类,则要引入m个虚拟变量。(×) 二、名词解释(每小题2分,共10分) 1.计量经济学:融合数学、统计学及经济理论,结合研究经济行为和现象的理论和实务。 2.最小二乘法:使全部观测值的残差平方和为最小的方法就是最小二乘法。 3.虚拟变量:在经济生活研究中,有一些暂时起作用的因素。如战争、天灾、人祸等,这些因素在经济中不经常发生,但又带有相同特性,经济学家把这些不经常发生的、又起暂时影响作用的称为虚拟变量。 4.滞后变量:用来作为解释变量的内生变量的前期值称为滞后内生变量,简称为滞后变量。 5.自回归模型:包含有被解释变量滞后值的模型,称为自回归模型。 三、简答题(每小题5分,共20分) 1.应用最小二乘法应满足的古典假定有哪些?(1)随机项的均值为零; (2)随机项无序列相关和等方差性; (3)解释变量是非随机的,如果是随机的则与随机项不相关; (4)解释变量之间不存在多重共线性。 2.运用计量经济学方法解决经济问题的步骤一般是什么? (1)建立模型; (2)估计参数; (3)验证理论; (4)使用模型。 3.你能分别举出三个时间序列数据、截面数据、混合数据、虚拟变量数据的实际例子吗? (1)时间序列数据如:每年的国民生产总值、 各年商品的零售总额、各年的年均人口增长 数、年出口额、年进口额等等; (2)截面数据如:西南财大2002年各位教师年收入、2002年各省总产值、2002年5月成都市 各区罪案发生率等等; (3)混合数据如:1990年~2000年各省的人均收入、消费支出、教育投入等等; (4)虚拟变量数据如:婚否,身高是否大于170厘米,受教育年数是否达到10年等等。 4.随机扰动项μ的一些特性有哪些? (1)众多因素对被解释变量Y的影响代表的综合体; (2)对Y的影响方向应该是各异的,有正有负;(3)由于是次要因素的代表,对Y的总平均影响可能为零; (4)对Y的影响是非趋势性的,是随机扰动的。 四、分析、计算题(每小题15分,共45分) 1. 根据下面Eviews回归结果回答问题。Dependent Variable: DEBT Method: Least Squares Date: 05/31/06 Time: 08:35 Sample: 1980 1995 Included observations: 16 Variable Coefficie nt Std. Erro r t-Statist ic Prob . C() INCOME() COST() R-squared Mean dependent var Adjusted R-squared () . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic()Durbin-Wats on stat Prob(F-statisti c) INCOME——个人收入,单位亿美元; COST——抵押贷款费用,单位%。 1. 完成Eviews回归结果中空白处内容。 2. 说明总体回归模型和样本回归模型的区别。
计量经济学简答题及答案 1、比较普通最小二乘法、加权最小二乘法和广义最小二乘法的异同。 答:普通最小二乘法的思想是使样本回归函数尽可能好的拟合样本数据,反映在 图上就是是样本点偏离样本回归线的距离总体上最小,即残差平方和最小 ∑=n i i e 12min 。 只有在满足了线性回归模型的古典假设时候,采用OLS 才能保证参数估计结果的可靠性。 在不满足基本假设时,如出现异方差,就不能采用OLS 。加权最小二乘法是对原 模型加权,对较小残差平方和2i e 赋予较大的权重,对较大2i e 赋予较小的权重,消除异方差,然后在采用OLS 估计其参数。 在出现序列相关时,可以采用广义最小二乘法,这是最具有普遍意义的最小二乘 法。 最小二乘法是加权最小二乘法的特例,普通最小二乘法和加权最小二乘法是广义 最小二乘法的特列。 6、虚拟变量有哪几种基本的引入方式? 它们各适用于什么情况? 答: 在模型中引入虚拟变量的主要方式有加法方式与乘法方式,前者主要适用于 定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。 7、联立方程计量经济学模型中结构式方程的结构参数为什么不能直接应用OLS 估计? 答:主要的原因有三:第一,结构方程解释变量中的内生解释变量是随机解释变 量,不能直接用OLS 来估计;第二,在估计联立方程系统中某一个随机方程参数时,需要考虑没有包含在该方程中的变量的数据信息,而单方程的OLS 估计做不到这一点;第三,联立方程计量经济学模型系统中每个随机方程之间往往存在某种相关性,表现于不同方程随机干扰项之间,如果采用单方程方法估计某一个方程,是不可能考虑这种相关性的,造成信息的损失。 2、计量经济模型有哪些应用。 答:①结构分析,即是利用模型对经济变量之间的相互关系做出研究,分析当其 他条件不变时,模型中的解释变量发生一定的变动对被解释变量的影响程度。②经济预测,即是利用建立起来的计量经济模型对被解释变量的未来值做出预测估计或推算。③政策评价,对不同的政策方案可能产生的后果进行评价对比,从中做出选择的过程。④检验和发展经济理论,计量经济模型可用来检验经济理论的正确性,并揭示经济活动所遵循的经济规律。 6、简述建立与应用计量经济模型的主要步骤。 答:一般分为5个步骤:①根据经济理论建立计量经济模型;②样本数据的收集; ③估计参数;④模型的检验;⑤计量经济模型的应用。 7、对计量经济模型的检验应从几个方面入手。 答:①经济意义检验;②统计准则检验;③计量经济学准则检验;④模型预测检 验。
计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R - ==12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数)1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方 和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 )1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临 界值F α(k,n-k-1),由样本求出统计量F 的数值,通过F>F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t 检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:βi =0 (i=1,2…k );H1:βi ≠0 给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。 统计量 )1(~1??? ----'--= k n t k n c S t ii i i i i i e e βββββ 在(1-α)的置信水平下βi 的置信区间是 ( , ) ββααββ i i t s t s i i -?+?2 2 ,其中,t α/2为显著性 水平为α、自由度为n-k-1的临界值。 五、异方差检验 1. 帕克(Park)检验与戈里瑟(Gleiser)检验 试建立方程: i ji i X f e ε+=)(~2 或 i ji i X f e ε+=)(|~|
计量经济学课程设计的要求 统计年签网址:https://www.doczj.com/doc/c83668684.html,/tjsj/ndsj/2013/indexch.htm 1、需要的数据可以直接从统计年签获取,统计年签网址上面已给出。 2、这里附带的EXCEL文件中提供了十个表数据,如果实在不想找也可以用这些数据。 3、题目自拟。 4、若用一元回归模型做分析,则必须要附图象分析、相关性分析,得分不会太高。 6、若用多元回归模型做分析,则至少需要有多重共线性分析,建议最好也要加入图象分析。
安徽建筑大学 计量经济学课程论文题目:影响居民消费水平因素分析 院(系):管理学院 专业班级: 12经济学 学号: 学生姓名: 指导教师:高先务 起止时间:
目录 第1章前言 (1) 第2章影响我国居民消费水平因素的建模分析 (2) 2.1数据采集 (2) 2.2数据分析 (3) 2.3结论 (7) 第3章对策建议 (8) 3.1根据模型结果分析 (8) 3.2政策建议 (8) 参考文献 (11)
第1章前言 一、探究目的 近几年,随着我国经济的飞速发展,我国居民消费水平也有明显提高,同样,消费水平也左右着经济的发展。因此,扩大居民消费是“以人为本”的具体体现,对中国经济长期持续健康发展、对推进社会主义和谐社会建设,以及实现宏观调控目标等既具有长远的战略意义,又具有重要的现实意义。然而究竟有哪些因素制约着居民消费水平?凯恩斯认为,影响个人消费的主观因素比较稳定,消费者的消费主要取决于收入的多少。然而,大量的研究表明收入的变动并非影响消费的全部因素。还有许多其他因素或多或少地影响着消费水平。如国内生产总值、消费者物价指数、消费者家庭财产状况、年龄构成、宗教信仰等等。有些因素对于收入的影响是随机性的,如消费环境、消费者心情状况;有些因素是系统性的,如消费者个人偏好等等。因此,探究影响居民消费水平的客观因素十分重要。本文主要研究城镇居民人均可支配收入、农村居民人均纯收入、国家税收收入对于我国居民消费水平的影响。 二、理论依据 (一)城镇居民人均可支配收入与农村居民人均纯收入 1.城镇居民人均可支配收入是指反映居民家庭全部现金收入能用于安排家庭日常生活的那部分收入。它是家庭总收入扣除交纳的所得税、个人交纳的社会保障费以及调查户的记账补贴后的收入。 可支配收入=家庭总收入- 交纳的所得税- 个人交纳的社会保障支出- 记帐补贴 2.农村居民人均纯收入,又称农民人均纯收入,是指农村居民家庭全年总收入中,扣除从事生产和非生产经营费用支出、缴纳税款和上交承包集体任务金额以后剩余的,可直接用于进行生产性、非生产性建设投资、生活消费和积蓄的那一部分收入。也包括工资性收入、经营性收入、财产性收入、转移性收入。 此两项收入被认为是影响一个国家消费水平的核心因素,因此对于消费水平模型的探究具有重要意义。 (二)国家税收收入 税收收入是指国家依据其政治权力向纳税人强制征收的收入,它是最古老、也是最主要的一种财政收入形式。除组织收入的职能外,税收对经济社会运行和资源配置都具有重要的调节作用。有学者认为收入分配失衡是导致我国居民消费收入不足的原因之一而税收收入可以调节收入分配的失衡,实行二次分配,因此对于居民消费水平的研究具有重要意义。
计量经济学重点(简答题) 一、什么就是计量经济学?计量经济学,又称经济计量学,它就是以一定的经济理论与 实际统计资料为依据,运用数学、统计学与计算机技术,通过建立计量经济学模型,定量分析经济变量之间的随机因果关系、。 二、计量经济学的研究的步骤就是什么? 1)理论模型的设计 A.理论或假说的陈述; B.理论的数学模型的设定; C.理论的计量经济模型的设定。 i.把模型中不重要的变量放进随机误差项中; ii.拟定待估参数的理论期望值。 2)获取数据 数据来源:网络、统计年鉴、报纸、杂志 数据类别:时间序列数据、截面数据、混合数据、虚变量数据。 数据要求:完整性、准确性、可比性、一致性 i.完整性:模型中包含的所有变量都必须得到相同容量的样本观察值。 ii.准确性:统计数据或调查数据本身就是准确的。 iii.可比性:数据口径问题。 iv.一致性:指母体与样本的一致性。 3)模型的参数估计:普通最小二乘法。 4)模型的检验:经济学检验;统计学检验;计量经济学检验;模型的预测检验。 5)模型的应用:结构分析;经济预测;政策评价;经济理论的检验与发展。 三、简述统计数据的类别? 时间序列数据、截面数据、混合数据、虚变量数据。 1)时间序列数据:按时间先后排列收集的数据。
采纳时间序列数据的注意事项: A.所选择的样本区间的经济行为一致性问题。 B.样本数据在不同样本点之间的可比性问题。 C.样本数据过于集中的问题。不能反映经济变量间的结构关系,应增大观察区间。 D.模型的随机误差项序列相关问题。 2)截面数据:又称横向数据,就是一批发生在同一时间截面上的调查数据。研究某时 点上的变化情况。 采纳截面数据的注意事项: A.样本与母体的一致性问题。 B.随机误差项的异方差问题。 3)混合数据:也称面板数据,既有时间序列数据,又有截面数据。 4)虚变量数据:又称二进制数据,只能取0与1两个值,表示的就是某个对象的质量特 征。 四、模型的检验包括哪几个方面?具体含义就是什么? 1)经济学检验:参数的符合与大致取值。 2)统计学检验:拟合优度检验;模型的显著性检验;参数的显著性检验。 3)计量经济学检验:序列相关性;异方差检验;多重共线性检验。 4)模型的预测检验:a,扩大样本容量或变换样本重新估价模型;b,利用模型对样本期以 外的某一期进行预测。
计量经济学期末课程设计 云南大学滇池学院2008级经济系金融(三) 姓名:学号: 鲁志娟20082122106 题目:我国服务贸易竞争力影响因素的实证分析
我国服务贸易竞争力影响因素实证分析 摘要: 服务贸易对以郭经济增长的作用日益重要,一定程度上决定了一国国际贸易在国际贸易在国际市场的竞争力。本文分析了服务贸易竞争力的影响因素,并对这些影响因素与服务贸易的关系进行了实证检验,在此基础上提出了促进我国服务贸易发展的对策建议。 关键词:服务贸易 竞争力 影响因素 一、 引言 在经济全球化趋势加强的时代背景下,国际服务贸易异军突起,成为推动一国经济增长的重要一级。全球服务贸易出口总额从1970年得700多亿美元上升到2006年的26882亿美元。其平均增长速度超过了同期货物贸易的增长速度,在很大程度上决定了一国国际贸易的发展状况和在国际市场上的竞争能力。近几年来,我国国际服务贸易正在以平均10%左右的速度迅速增长,但明显落后于货物贸易。2008年,我国服务贸易出口总额1465亿美元,占世界贸易出口比重3.9%。在某种意义上说,积极发展国际服务贸易并实现国际贸易的自由化,将是21世纪国际经济合作最重要的内容之一。有必要对我国服务贸易竞争力的影响因素进行分析,以便更好的制定政策措施促进我国服务贸易发展。 二、模型建立与分析 根据理论和经验分析,影响我国服务贸易竞争力(Y )<服务贸易出口额-数据来自(中国服务贸易网) 单位:亿美元>的主要因素有: 服务业产值(1X )---用第三产业GDP 代表 数据来自(中国统计局)单位:亿人民币元;第三产业就业人数(2X )---数据来自《中国统计年鉴》单位:万人次;对外开放度(3X )---用对外依存度代表 数据来自《中国统计年鉴》单位:% ;外商直接投资额(4X )---数据来自(中国统计局)单位:亿美元;货物出口(5X )---数据来自(中国统计局)单位:亿美元。下表列出了我国服务贸易竞争力相关数据,拟建立我国服务贸易竞争力函数。
简答: 1、时间序列数据和横截面数据有何不同? 时间序列数据是一批按照时间先后排列的统计数据。截面数据是一批发生在同一时间截面上的调查数据。这两类数据都是反映经济规律的经济现象的数量信息,不同点:时间序列数据是含义、口径相同的同一指标按时间先后排列的统计数据列;而横截面数据是一批发生在同一时间截面上不同统计单元的相同统计指标组成的数据列。 2、建立计量经济模型赖以成功的三要素。P16(课本) 成功的要素有三:理论、方法和数据。理论:即经济理论,所研究的经济现象的行为理论,是计量经济学研究的基础;方法:主要包括模型方法和计算方法,是计量经济学研究的工具与手段,是计量经济学不同于其他经济学分支科学的主要特征;数据:反映研究对象的活动水平、相互间以及外部环境的数据,更广义讲是信息,是计量经济学研究的原料。三者缺一不可。 3、什么是相关关系、因果关系;相关关系与因果关系的区别与联系。 相关关系是指两个以上的变量的样本观测值序列之间表现出来的随机数学关系,用相关系数来衡量。 因果关系是指两个或两个以上变量在行为机制上的依赖性,作为结果的变量是由作为原因的变量所决定的,原因变量的变化引起结果变量的变化。因果关系有单向因果关系和互为因果关系之分。 具有因果关系的变量之间一定具有数学上的相关关系。而具有相关关系的变量之间并不一定具有因果关系。 4、回归分析与相关分析的区别与关系。P23-P24(课本) 相关分析与回归分析既有联系又有区别。首先,两者都是研究非确定性变量间的统计依赖关系,并能测度线性依赖程度的大小。其次,两者间又有明显的区别。相关分析仅仅是从统计数据上测度变量间的相关程度,而无需考察两者间是否有因果关系,因此,变量的地位在相关分析中饰对称的,而且都是随机变量;回归分析则更关注具有统计相关关系的变量间的因果关系分析,变量的地位是不对称的,有解释变量与被解释变量之分,而且解释变量也往往被假设为非随机变量。再次,相关分析只关注变量间的具体依赖关系,因此可以进一步通过解释变量的变化来估计或预测被解释变量的变化,达到深入分析变量间依存关系,掌握其运动规律的目的。 5、数理经济模型和计量经济模型的区别。 答:数理经济模型揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。计量经济模型揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述。 6、从哪几方面看,计量经济学是一门经济学科?P6(课本)
(财务知识)计量经济学
1、费里希(R.Frish)是经济计量学的主要开拓者和奠基人。 2、经济计量学和数理经济学和树立统计学的区别的关键之点是“经济变量关系的随机性特征”。 3、经济计量学识以数理经济学和树立统计学为理论基础和方法论基础的交叉科学。它以客观经济系统中具有随机性特征的经济关系为研究对象,用数学模型方法描述具体的经济变量关系,为经济计量分析工作提供专门的指导理论和分析方法。 4、时序数据即时间序列数据。时间序列数据是同壹统计指标按时间顺序记录的数据列。 5、横截面数据是在同壹时间,不同统计单位的相同统计指标组成的数据列。 6、对于壹个独立的经济模型来说,变量能够分为内生变量和外生变量。内生变量被认为是具有壹定概率分布的随机变量,它们的数值是由模型自身决定的;外生变量被认为是非随机变量,它们的数值是在模型之外决定的。 7、对于模型中的壹个方程来说,等号左边的变量称为被解释变量,等号右边被称为解释变量。在模型中壹个方程的被解释变量能够是其它方程的解释变量。被解释变量壹定是模型的内生变量,而解释变量既包括外生变量,也包括壹部分内生变量。 8、滞后变量和前定变量。有时模型的设计者仍使用内生变量的前期值作解释变量,在计量经济学中将这样的变量程为滞后变量。滞后变量显然在求解模型之前是已知量,因此通常将外生变量和滞后变量合称为前定变量。 9、控制变量和政策变量。由于控制论的思想不断渗入经济计量学,使某些经济计量模型具有政策控制的特点,因此在经济计量模型中又出现了控制变量、政策变量等名词。政策变量或控制变量壹般在模型中表现为外生变量,但有时也表现为内生变量。 10、经济参数分为:外生参数和内生参数。外生参数壹般是指依据经济法规人为确定的参数,如折旧率、税率、利息率等。内生参数是依据样本观测值,运用统计方法估计得到的参数。如何选择估计参数的方法和改进估计参数的方法,这是理论经济计量学的基本任务。 11、用数学模型描述经济系统应当遵循以下俩条基本原则:第壹、以理论分析作先导;第二模型规模大小要适度。 12、联立方程模型中的方程壹般划分为:随机方程和非随机方程。随机方程是根据经济机能或经济行为构造的经济函数关系式。在随机方程中,被解释变量被认为是服从某种概率分布的随机变量,且假设解释变量是非随机变量。非随机方程是根据经济学理论和政策、法规的规定而构造的反应映某些经济变量关系得恒等式。 13、所谓经济计量分析工作是指依据经济理论分析,运用经济计量模型方法,研究现实经济系统的结构、水平、提供经济预测情报和评价经济政策等的经济研究和分析工作。 14、经济计量分析工作的程序包括四部分:1、设定模型;2、估计参数;3、检验模型;4、应用模型。
学号班级 计量经济学期末课程设计 南京审计学院级院 题目:我国国内生产总值的实证分析 不能抄啊啊啊啊 学生姓名学号 专业班级 2011年12 月28 日
支出法看我国国内生产总值的实证分析 Nau。 【摘要】本文选取了我国GDP数据对1997至2009年(统计年鉴没有2010年的)我国经济的变动进行实证分析,运用统计分析方法、计量经济学分析方法拟合国内生产总值,简单的进行了经济分析。 【关键字】国内生产总值 GDP 居民消费支出 序言 国内生产总值(GDP)是指一个国家或地区所有常住单位在一定的时间内(通常在一年内生产活动的最终结果,是国内国际认定的颇具全面的指标。随着改革开放已然三十年,我国经济在这三十年有着巨大的腾飞和发展。GDP虽然这些年被专家学者谈来谈去,但是仍然非常值得我们关注。因此,我们应当在最近腾飞的十三年中总结经验,我选择了GDP这一课题进行计量经济学分析。 一、文献综述 国内生产总值是国民经济核算体系(简称SNA)中一个重要的综合性指标,也是我国新国民经济核算体系中的核心指标,一个国家或地区的经济究竟处于增长抑或衰退阶段,从这个数字的变化便可以观察到。支出法核算GDP,就是从产品的使用出发,把一年内购买的各项最终产品的支出加总而计算出的该年内生产的最终产品的市场价值。这种方法又称最终产品法、产品流动法。在现实生活中,产品和劳务的最后使用,主要是居民消费、企业投资、政府购买和出口。因此,用支出法核算GDP,就是核算一个国家或地区在一定时期内居民消费、企业投资、政府消费和净出口这几方面支出的总和。 (1)居民消费(用字母C表示),包括购买冰箱、彩电、洗衣机、小汽车等耐用消费品的支出、服装、食品等非耐用消费品的支出以及用于医疗保健、旅游、理发等劳务的支出。建造住宅的支出不属于消费。 (2)企业投资(用字母I表示),是指增加或更新资本资产(包括厂房、机器设备、住宅及存货)的支出。投资包括固定资产投资和存货投资两大类。 (3)政府购买(用字母G来表示),是指各级政府购买物品和劳务的支出,它包括政府购买军火、军队和警察的服务、政府机关办公用品与办公设施、举办诸如道路等公共工程、开办学校等方面的支出。政府支付给政府雇员的工资也属于政府购买。政府购买是一种实质性的支出,表现出商品、劳务与货币的双向运动,直接形成社会需求,成为国内生产总值的
1. 请问自回归模型的估计存在什么困难?如何来解决这些苦难? 答:主要存在两个问题: (1) 出现了随机解释变量Y ,而可能与随机扰动项相关; (2) 随机扰动项可能存在自相关,库伊克模型和自适应预期模型的随机扰动项都会导致自相关,只有局部调整模型的随机扰动项无自相关。 对于第一个问题的解决可以使用工具变量法;对于第二个问题的检验可以用德宾h 检验法,目前还没有很好的解决办法,唯一能做的就是模型尽可能的设定正确。 2. 为什么要进行广义差分变换?写出其过程。 答:进行广义差分变换是为了处理自相关,写出其过程如下: 以一元模型为例:Y t = b 0 + b 1 X t +u t 假设误差项服从AR(1)过程:u t =ρu t-1 +v t -1 ≤ρ≤1 其中,v 满足OLS 假定,并且是已知的。 为了弄清楚如何使变换后模型的误差项不具有自相关性,我们将回归方程中的变量滞后一期,写为: Y t-1 = b 0 + b 1 X t-1 +u t-1 方程的两边同时乘以ρ,得到:ρY t-1 = ρb 0 + ρb 1 X t-1 +ρu t-1 现在将两方程相减,得到:(Y t -ρY t-1 ) = b 0 ( 1 -ρ) + b 1 (X t -ρX t-1 ) + v t 由于方程中的误差项v t 满足标准OLS 假定,方程就是一种变换形式,使得变换后的模型无序列相关。如果我们将方程写成:Y t * = b 0* + b 1 X t * +v t ,其中,Y t * = (Y t -ρY t-1 ) ,X t * = (X t -ρX t-1 ) ,b 0* = b 0 ( 1 -ρ)。 3. 什么是递归模型? 答:递归模型是指在该模型中,第一个方程的内生变量Y 1仅由前定变量表示,而无其它内生变量;第二个方程内生变量Y 2表示成前定变量和一个内生变量Y 1的函数;第三个方程内生变量Y 3表示成前定变量和两个内生变量Y 1与Y 2的函数;按此规律下去,最后一个方程内生变量Y m 可表示成前定变量和m -1个Y 1,Y 2、,Y 3,…、Y m-1的函数。 4. 为什么要进行同方差变换?写出其过程,并证实之。 答:进行同方差变换是为了处理异方差,写出其过程如下: 我们考虑一元总体回归函数Y i = b 0 + b 1 X i + u i 假设误差σi 2 是已知的,也就是说,每个观察值的误差是已知的。对模型作如下“变换”: Y i /σi = b 0 /σi + b 1 X i /σi + u i /σi 这里将回归等式的两边都除以“已知”的σi 。σi 是方差σi 2 的平方根。 令 v i = u i /σi 我们将v i 称作是“变换”后的误差项。v i 满足同方差吗?如果是,则变换后的回归方程就不存在异方差问题了。假设古典线性回归模型中的其他假设均能满足,则方程中各参数的OLS 估计量将是最优线性无偏估计量,我们就可以按常规的方法进行统计分析了。 证明误差项v i 同方差性并不困难。根据方程有:E (v i 2 ) = E (u i 2 /σi 2 ) = E (u i 2 ) /σi 2 =σi 2 /σi 2 = 1 显然它是一个常量。简言之,变换后的误差项v i 是同方差的。因此,变换后的模型不存在异方差问题,我们可以用常规的OLS 方法加以估计。 5. 简述逐步回归法的基本步骤。 答:先用被解释变量对每一个解释变量做简单回归,然后以对被解释变量贡献最大的解释变量所对应的回归方程为基础,再逐个引入其余的解释变量。这个过程会出现3种情形:①若新变量的引入改进了R 2 和F 检验,且其它回归系数的t 检验在统计上仍是显著的,则可考
简答题:1.选择工具变量的原则是什么:(1)工具变量必须与所替代的随机解释变量高度相关;(2)工具变量与随机误差项不相关(3)工具变量与其它解释变量不相关,避免出现多重共线性。 2.实际经济问题中的多重共线性 (1)经济变量的趋同性(2)滞后变量的引入(3)样本资料的限制 3.序列相关性产生的原因: (1)惯性;(2)模型设定误差;(3)蛛网现象;(4)数据加工。 4、随机解释变量问题及其解决方法。如果存在一个或多个随机变量作为解释变量,则称原模型出现随机解释变量问题。第一、随机解释变量与误差项相互独立;第二、随机解释变量与误差项同期无关,而异期相关;第三、随机解释变量与误差项同期相关;第四、解决方法为工具变量法。 5.随机解释变量产生的后果 1.若相互独立,则参数估计量仍然无偏一致。2 若同期相关,异期不相关,得到的参数估计有偏,但却是一致的3 若同期相关,则估计量有偏且非一致。 6.简述最小二乘估计量的性质:(1)线性性,即它是否是另一随机变量的线性函数;(2)无偏性,即它的均值或期望值是否等于总体的真实值;(3)有效性,即它是否在所有线性无偏估计量中具有最小方差。(4)渐近无偏性,即样本容量趋于无穷大时,是否它的均值序列趋于总体真值;(5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值;(6)渐近有效性,即样本容量趋于无穷大时,是否它在所有的一致估计量中具有最小的渐近方差。 7、虚拟变量的作用:(1)表现定性因素对被解释变量的影响(2)提高模型的说明能力与水平(3)季节变动分析。(4)方程差异性检验。 8、虚拟变量设置的原则:如果有定性因素共有个结果需要区别,那么至多引入m-1 个虚拟变量 9、实际经济问题中的多重共线性:(1)经济变量的趋同性(2)滞后变量的引入(3)样本资料的限制 10.引入随机误差形式为了:(1)代表未知的影响因素(2)代表残缺数据(3)代表众多细小的影响因素(4)代表数据观测误差(5)代表模型设定误差(6)变量的随机存在性 11. 12.回归分析的主要内容有:(1)根据样本观测值对经济计量模型参数进行估计,求得回归方程(2)对回归方程、参数估计值进行显著性检验(3)利用回归方程进行分析、评价及预测。 13.叙述原理:最小二乘法:当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得模型能最好的的拟合样本数据:最大似然法:当从模型的总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大。在满足一系列基本假设的情况下,模型结构参数的最大或然估计量与普通最小二乘估计量是相同的。
计量经济学重点简答题 1.简述计量经济学与经济学、统计学、数理统计学学科间得关系。 答:计量经济学就是经济理论、统计学与数学得综合.经济学着重经济现象得定性研究,计量经济学着重于定量方面得研究。统计学就是关于如何收集、整理与分析数据得科学,而计量经济学则利用经济统计所提供得数据来估计经济变量之间得数量关系并加以验证。数理统计学作为一门数学学科,可以应用于经济领域,也可以应用于其她领域;计量经济学则仅限于经济领域。计量经济模型建立得过程,就是综合应用理论、统计与数学方法得过程,计量经济学就是经济理论、统计学与数学三者得统一。 2、计量经济模型有哪些应用? 答:①结构分析②经济预测③政策评价④检验与发展经济理论 3、简述建立与应用计量经济模型得主要步骤。 答:模型设定估计参数模型检验模型应用 或1)经济理论或假说得陈述2) 收集数据3)建立数理经济学模型4)建立经济计量模型5)模型系数估计与假设检验6)模型得选择7)理论假说得选择8)经济学应用 4、对计量经济模型得检验应从几个方面入手? 答:①经济意义检验②统计推断检验③计量经济学检验④模型预测检验 5、计量经济学应用得数据就是怎样进行分类得? 答:时间序列数据截面数据面板数据虚拟变量数据 6、解释变量与被解释变量,内生变量与外生变量 被解释变量就是模型要研究得对象,被称为“因变量”,就是变动得结果。 解释变量就是说明被解释变量变动得原因,被称为“自变量”,就是变动得原因. 内生变量就是其数值由模型所决定得变量,就是模型求解得结果。 外生变量就是其数值由模型以外决定得变量。 7、计量经济学得含义 计量经济学就是以经济理论与经济数据得事实为依据,运用数学、统计学得方法,通过建立数学模型来研究经济数量关系与规律得一门经济学科。 8、在计量经济模型中,为什么会存在随机误差项? 答:随机误差项就是计量经济模型中不可缺少得一部分. 产生随机误差项得原因有以下几个方面:①模型中被忽略掉得影响因素造成得误差;②模型关系认定不准确造成得误差;③变量得测量误差;④随机因素. 9.对于多元线性回归模型,为什么在进行了总体显著性F检验之后,还要对每个回归系数进行就是否为0得t检验? 答:多元线性回归模型得总体显著性F检验就是检验模型中全部解释变量对被解释变量得共同影响就是否显著。通过了此F检验,就可以说模型中得全部解释变量对被解释变量得共同影响就是显著得,但却不能就此判定模型中得每一个解释变量对被解释变量得影响都就是显著得。因此还需要就每个解释变量对被解释变量得影响就是否显著进行检验,即进行t 检验. 10、古典线性回归模型具有哪些基本假定。 答:1 随机误差项与解释变量不相关。2随机误差项得期望或均值为零。3随机误差项具有同方差,即每个随机误差项得方差为一个相等得常数。4 两个随机误差项之间不相关,即随机误差项无自相关。 11、在多元线性回归分析中,为什么用修正得决定系数衡量估计模型对样本观测值得拟合优度? 答:因为人们发现随着模型中解释变量得增多,多重决定系数得值往往会变大,从而增加了模
1.计量经济学与经济理论、统计学、数学的联系是什么?计量经济学与经济理论、统计学、数学的联系主要体现在计量经济学对经济理论、统计学、数学的应用方面,分别如下: 1)计量经济学对经济理论的利用主要体现在以下几个方面 (1)计量经济模型的选择和确定 (2)对经济模型的修改和调整 (3)对计量经济分析结果的解读和应用 2)计量经济学对统计学的应用 (1)数据的收集、处理、 (2)参数估计 (3)参数估计值、模型和预测结果的可靠性的判断3)计量经济学对数学的应用 (1)关于函数性质、特征等方面的知识 (2)对函数进行对数变换、求导以及级数展开 (3)参数估计 (4)计量经济理论和方法的研究 2.模型的检验包括哪几个方面?具体含义是什么? 模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。 ①在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号、大小、参数之间的关系是否与根据人们的经验和经济理论所拟订的期望值相符合; ②在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质,有拟合优度检验、变量显著检验、方程显著性检验等; ③在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等; ④模型的预测检验,主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 1.为什么计量经济学模型的理论方程中必须包含随机干扰项? 计量经济学模型考察的是具有因果关系的随机变量间的具体联系方式。由于是随机变量,意味着影响被解释变量的因素是复杂的,除了解释变量的影响外,还有其他无法在模型中独立列出的各种因素的影响。这样,理论模型中就必须使用一个称为随机干扰项的变量来代表所有这些无法在模型中独立表示出来的影响因素,以保证模型在理论上的科学性。3.为什么用可决系数R2评价拟合优度,而不是用残差平方和作为评价标准? 可决系数R2=ESS/TSS=1-RSS/TSS,含义为由解释变量引起的被解释变量的变化占被解释变量总变化的比重,用来判定回归直线拟合的优劣,该值越大说明拟合的越好;而残差平方和与样本容量关系密切,当样本容量比较小时,残差平方和的值也比较小,尤其是不同样本得到的残差平方和是不能做比较的。此外,作为检验统计量的一般应是相对量而不能用绝对量,因而不能使用残差平方和判断模型的拟合优度。 4.根据最小二乘原理,所估计的模型已经使得拟合优度差达到最小,为什么还要讨论模型的拟合优度问题? 普通最小二乘法所保证的最好拟合是同一个问题内部的比较,即使用给出的样本数据满足残差的平方和最小;拟合优度检验结果所表示的优劣可以对不同的问题进行比较,即可以辨别不同的样本回归结果谁好谁坏。 1.多元线性回归模型与一元线性回归模型有哪些区别? 多元线性回归模型与一元线性回归模型的区别表现在如下几个方面:一是解释变量的个数不同;二是模型的经典假设不同,多元线性回归模型比一元线性回归模型多了个“解释变量之间不存在线性相关关系”的假定;三是多元线性回归模型的参数估计式的表达更为复杂。 2.为什么说最小二乘估计量是最优线性无偏估计量?对于多元线性回归最小二乘估计的正规方程组,能解出唯一的参数估计量的条件是什么? 在满足经典假设的条件下,参数的最小二乘估计量具有线性性、无偏性以及最小性方差,所以被称为最优线性无偏估计量(BLUE) 对于多元线性回归最小二乘估计的正规方程组,能解出唯一的参数估计量的条件是(X X )-1存在,或者说各解释变量间不完全线性相关。
所有计量经济学检验方法(全)
计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R -== 12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数 ) 1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差 平方和的自由度,n-1为总体平方和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设: H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 ) 1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F
分布,给定显著性水平α,可得到临界值F α(k,n-k-1),由样本求出统计量F的数值,通过 F>F α(k,n-k-1)或F≤F α (k,n-k-1)来拒绝或接受 原假设H ,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:β i =0 (i=1,2…k); H1:β i ≠0 给定显著性水平α,可得到临界值t α/2 (n-k-1),由样本求出统计量t的数值,通过 |t|> t α/2(n-k-1) 或|t|≤t α /2 (n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。
计量经济课程设计指导书 计量经济实证分析的过程如下: 1.问题的提出: 非常准确地提出一个非常有研究价值的问题,其重要性在经济分析过程中是不容忽视的,但又是十分困难的一个步骤。如果没有明确地分析目标和对象,那么你的研究就无从下手。现在随着信息技术的飞速发展,我们可以轻松的收集到大量的数据资料。但如果因为我们可以轻松的收集到大量的数据资料,你就企图在想法尚未成熟之时开始收集资料,其结果往往适得其反。如果没有对你的假设和你将要估计的该类模型进行细致化的共识表述,那么你很有可能会虽然收集了大量的数据资料,但却忘记搜集某些重要变量的信息,或是选取了错误的变量信息,甚至收集数据是选错了时间区间和研究对象。(准确定义所研究问题的重要性) 当然,这并不是说你要凭空捏造一个问题,尤其在作学位论文和研究项目期间,更不可能去建造空中楼阁。因此在选择研究题目的时候,你必须确信现有的数据来源能够让你在指定的时间里回答你的问题。(数据的可得性)在选题时,你必须明确,你对经济学或其他社会科学的哪一个领域感兴趣。举例来说,在完成了劳动经济学的课程后,你可能会发现其中的理论能够被实践所检验,或是这些理论与一些相关的政策因素存在着联系。劳动经济学家总是能够不断发现解释工资差异的新变量,这包括高中阶段的教学质量的好坏(Card and Krueger, 1992; and Betts, 1995),数学基础的课程量的多少(Levine and
Zimmerman, 1995),以及学生的身体特征(Hamermesh and Biddle, 1994; Averett and Korenman, 1996; Biddle and Zimmerman, 1998)。而国家或地方的公共财政研究人员则致力于研究当地的经济活动是如何依赖于经济政策变量的,这些变量包括:财产税、销售税、公共服务机构的服务的水平或质量(如学校、消防队和警察局等)等等(White, 1986; Papke, 1987; Bartik, 1991; Netzer, 1992)。研究教育问题的经济学家则对以下三个问题颇为关注(Hanushek, 1986);支出如何影响求学行为,就读某类学校是否会提高受教育者能力,以及如何确定影响私人学校选址的因素(Downes and Greenstein,1996)。宏观经济学家对各种各样的时间序列之间的关系,如国民生产总值的增长与固定资产投资的增长之间的关系,或是税收对利率的影响(Peek, 1982),感兴趣。 用于评估的模型通常都具备可描述性,这是非常有道理的。举例来说,财产评估者利用Hedonic定价模型对家庭最近上未售出的房屋价值进行评估。他描述了房屋的价格对它的特性(大小,卧室的数量、浴室的大小、厨房的大小等)的回归模型。若以此来作为论文的研究内容就缺乏新意了,因为我们不可能从中学到更多的有新意的、有价值的东西,而这些分析也就没有什么明显的政策涵义了。可是如果把邻里犯罪率作为一个解释变量加入进来,就能够知道邻里犯罪率是否是确定房屋价格的一个非常重的因素。这在评估犯罪成本是会有一定的作用。 一些关系式的估计大多利用了描述性的宏观经济数据。例如,一个总量储蓄函数模型能够用来判断总量边际储蓄倾向和储蓄对资产回报(如利率)的反应。如果把时间序列数据应用于一个曾经经历过政治动乱的国家,并确定其在政治不稳定时期的储蓄率是否会下降,这种分析将变得更有意义。(研究的实际意义)