甘肃省各气象台站经度、纬度、海拔与年降
雨量的回归分析
数据来源:计量地理学(第二版)86~87页的表格数据
计算过程:
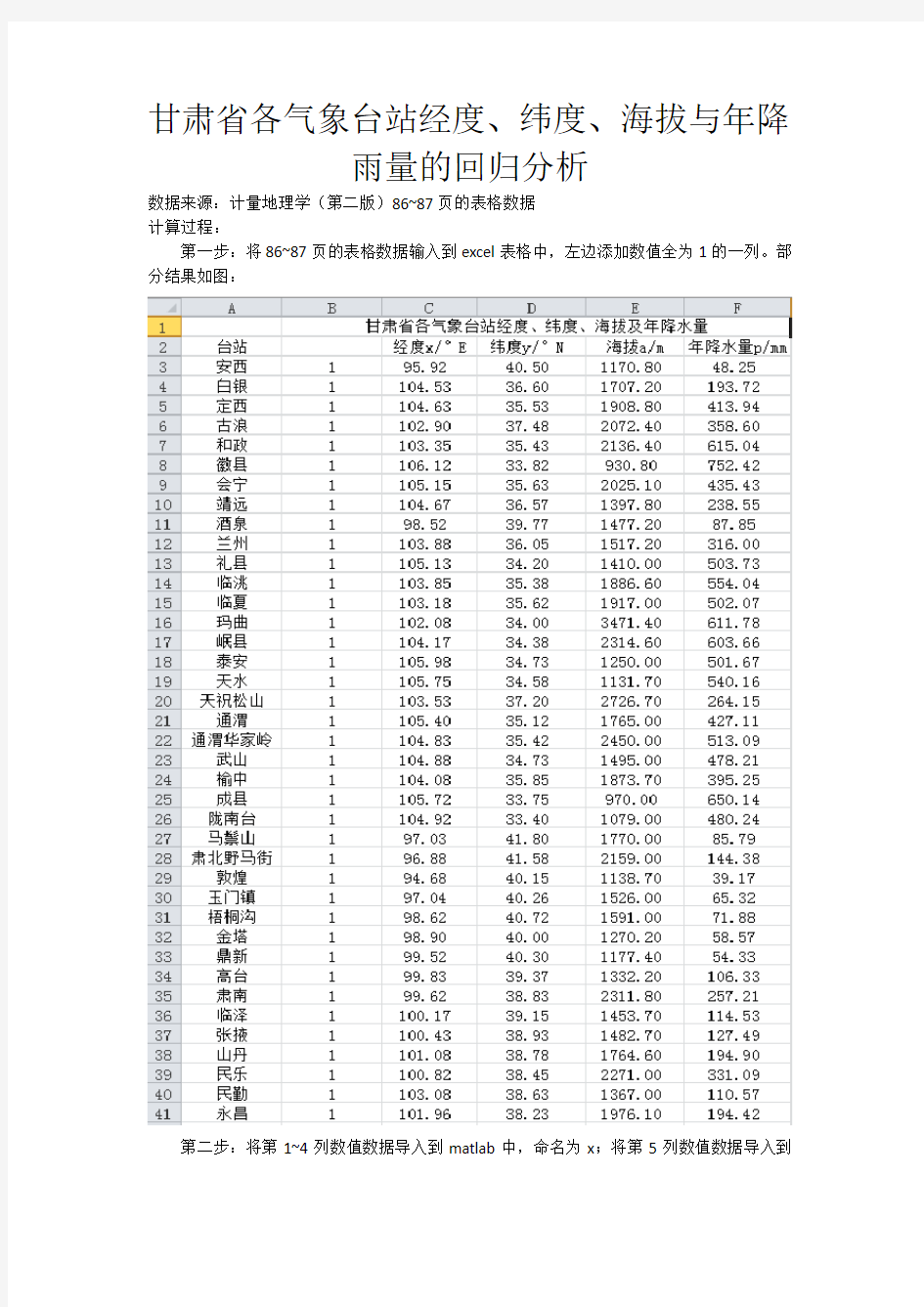
第一步:将86~87页的表格数据输入到excel表格中,左边添加数值全为1的一列。部分结果如图:
第二步:将第1~4列数值数据导入到matlab中,命名为x;将第5列数值数据导入到
matlab中,命名为y。
第三步:编写代码,求解回归系数矩阵b。
代码如下: x_ts=x.';
m=x_ts*x;
n=x_ts*y;
b=m^(-1)*n;
运行得到b为1338.132********
13.2743536510168
-65.7752217216806
0.0501769425976710
所以回归方程为:
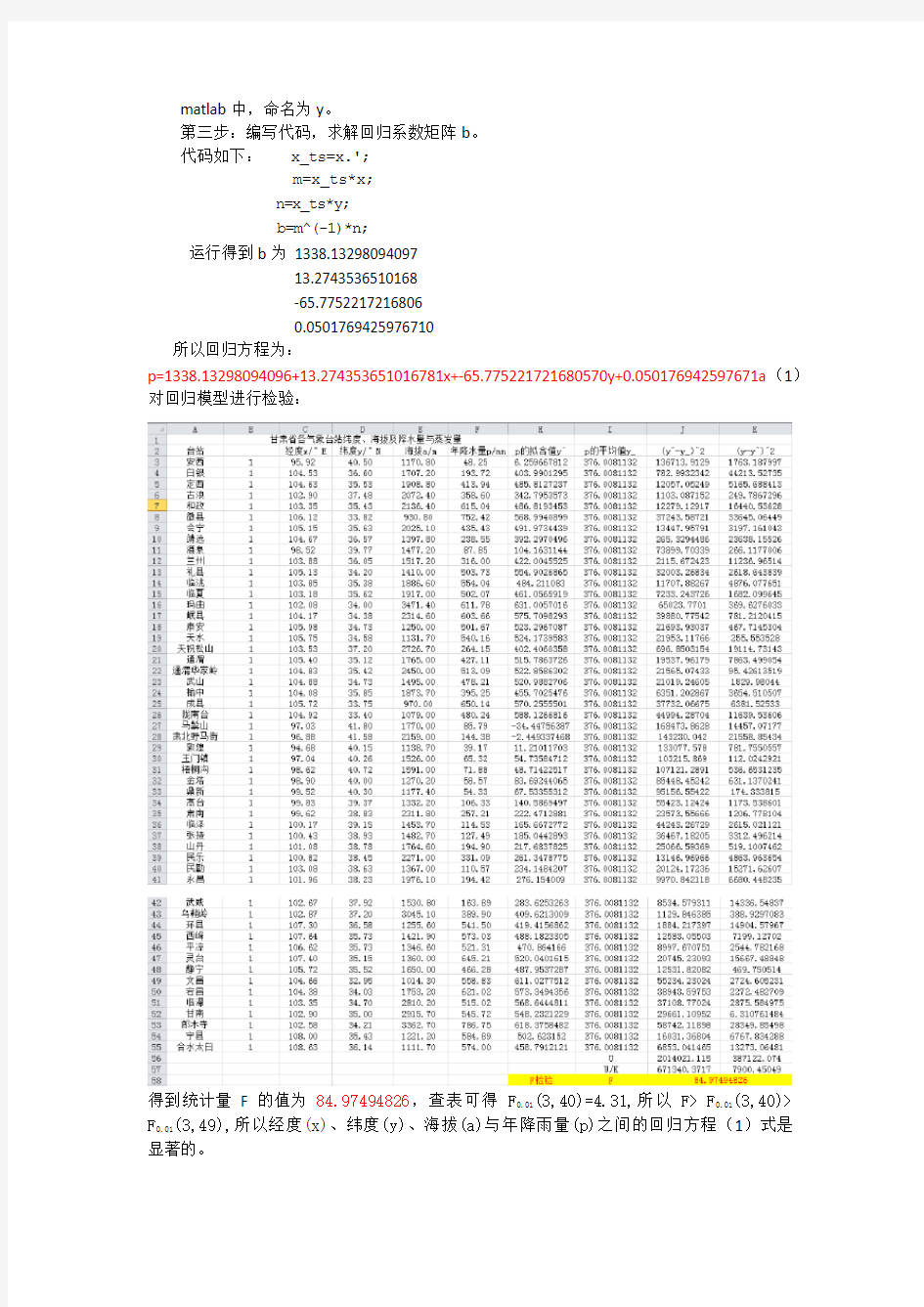
p=1338.132********+13.274353651016781x+-65.775221721680570y+0.050176942597671a(1)对回归模型进行检验:
得到统计量F的值为84.97494826,查表可得F0.01(3,40)=4.31,所以F> F0.01(3,40)> F0.01(3,49),所以经度(x)、纬度(y)、海拔(a)与年降雨量(p)之间的回归方程(1)式是显著的。
甘肃省各气象台站经度、纬度与年降雨量的
二次趋势面分析
数据来源:计量地理学(第二版)86~87页的表格数据
计算过程:
第一步:将86~87页的表格数据中的经度(x)、纬度(y)、年降雨量(p)输入到excel表格中,左边添加数值全为1的一列,然后添加三列用以计算x2,xy,y2。部分结果如图:
第二步:将第1~6列数值数据导入到matlab中,命名为X;将第7列数值数据导入到matlab中,命名为Z。
第三步:编写代码,求解回归系数矩阵b。
代码如下: x_ts=X.';
m=x_ts*X;
n=x_ts*Z;
b=m^(-1)*n;
运行得到b为99204.1161564589
-1286.77721269056
-1736.66634903476
4.63347056026396
9.38616701427964
9.48130331719585
所以该二次趋势面的拟合方程为:
p=9.920411615645885e+04-1.286777212690562e+03x-1.736666349034756e+03y+
4.633470560263959x^2+9.386167014279636x*y+9.481303317195852y^2 (2) 对该二次趋势面模型进行检验:
经检验,该二次趋势面的判定系数R2为0.840125016,可见该二次趋势面的拟合度较高;根据F检验方法计算,该二次趋势面统计量F的值为85.82982545,查表可得F0.01(5,40)=3.51,所以F> F0.01(5,40)> F0.01(5,47),所以经度(x)、纬度(y)与年降雨量(p)之间的二次趋势面拟合方程(2)式是显著的。
第九章 方差分析与回归分析习题参考答案 1. 为研究不同品种对某种果树产量的影响,进行试验,得试验结果(产量)如下表,试分析果树品种对产量是否有显着影响. (0.05(2,9) 4.26F =,0.01(2,9) 8.02F =) 34 2 11 1310ij i j x ===∑∑ 解:r=3, 12444n n 321=++=++=n n , T=120 ,120012 1202 2===n T C 3 4 2 211 131********(1)1110110T ij T i j SS x C S n s ===-=-==-=?=∑∑或S 322.1112721200724(31)429724A i A A i SS T C S s ==-=-==-=??=∑或S 3872110=-=-=A T e SS SS SS 计算统计值722 8.53, 389 A A A e e SS f F SS f = =≈…… 方差分析表 结论:由于0.018.53(2,9)8.02, A F F ≈>=故果树品种对产量有特别显着影响. 2. ..180x = 43 2 11 2804ij i j x ===∑∑ 解:22..4,3,12,180122700l m n lm C x n =======
43 2211 28042700104(1)119.45 104T ij T i j S x C S n s ===-=-==-=?≈∑∑&&或 422 .1 12790270090(1)331090 3A i A A i S x C S m l s ==-=-==-≈??=∑或322 .1 12710.5270010.5(1)8 1.312510.5 4B j B B j S x C S l m s ==-=-==-≈?=∑或1049010.5 3.5e T A B S S S S =--=--= 计算统计值90310.52 51.43,93.56 3.56 A A B B A B e e e e S f S f F F S f S f = =≈==≈ 结论: 由以上方差分析知,进器对火箭的射程有特别显着影响;燃料对火箭的射程有显着影响. 31,58,147,112,410.5,i i i i i i x y x y x y =====(1)求需求量Y 与价格x 之间 的线性回归方程; (2)计算样本相关系数; (3)用F 检验法作线性回归关系显着性检验. ??? ? ??====56.10)9,1(,26.11)8,1(12.5)9,1(,32.5)8,1(01.001.005.005.0F F F F 解:引入记号 10, 3.1, 5.8n x y === ()()14710 3.1 5.832.8xy i i i i l x x y y x y nx y =--=-=-??=-∑∑ 2 222()11210 3.115.9xx i i l x x x nx =-=-=-?=∑∑ 22 ()(1)9 1.766715.9xx i x l x x n s =-=-≈?≈∑或 2 222()410.510 5.874.1yy i i l y y y ny =-=-=-?=∑∑ 22()(1)98.233374.1yy i y l y y n s =-=-≈?≈∑或 ?(1) b Q 32.8??2.06, 5.8 2.06 3.112.1915.9xy xx l a y bx l -==≈-=-≈+?≈ ∴需求量Y 与价格x 之间的线性回归方程为 ?y ??12.19 2.06a bx x =+≈-
空间分析的概念空间分析:是基于地理对象的位置和形态特征的空间数据分析技术,其目的在于提取和传输空间信息。包括空间数据操作、空间数据分析、空间统计分析、空间建模。 空间数据的类型空间点数据、空间线数据、空间面数据、地统计数据 属性数据的类型名义量、次序量、间隔量、比率量 属性:与空间数据库中一个独立对象(记录)关联的数据项。属性已成为描述一个位置任何可记录特征或性质的术语。 空间统计分析陷阱1)空间自相关:“地理学第一定律”—任何事物都是空间相关的,距离近的空间相关性大。空间自相关破坏了经典统计当中的样本独立性假设。避免空间自相关所用的方法称为空间回归模型。2)可变面元问题MAUP:随面积单元定义的不同而变化的问题,就是可变面元问题。其类型分为:①尺度效应:当空间数据经聚合而改变其单元面积的大小、形状和方向时,分析结果也随之变化的现象。②区划效应:给定尺度下不同的单元组合方式导致分析结果产生变化的现象。3)边界效应:边界效应指分析中由于实体向一个或多个边界近似时出现的误差。生态谬误在同一粒度或聚合水平上,由于聚合方式的不同或划区方案的不同导致的分析结果的变化。(给定尺度下不同的单元组合方式) 空间数据的性质空间数据与一般的属性数据相比具有特殊的性质如空间相关性,空间异质性,以及有尺度变化等引起的MAUP效应等。一阶效应:大尺度的趋势,描述某个参数的总体变化性;二阶效应:局部效应,描述空间上邻近位置上的数值相互趋同的倾向。 空间依赖性:空间上距离相近的地理事物的相似性比距离远的事物的相似性大。 空间异质性:也叫空间非稳定性,意味着功能形式和参数在所研究的区域的不同地方是不一样的,但是在区域的局部,其变化是一致的。 ESDA是在一组数据中寻求重要信息的过程,利用EDA技术,分析人员无须借助于先验理论或假设,直接探索隐藏在数据中的关系、模式和趋势等,获得对问题的理解和相关知识。 常见EDA方法:直方图、茎叶图、箱线图、散点图、平行坐标图 主题地图的数据分类问题等间隔分类;分位数分类:自然分割分类。 空间点模式:根据地理实体或者时间的空间位置研究其分布模式的方法。 茎叶图:单变量、小数据集数据分布的图示方法。 优点是容易制作,让阅览者能很快抓住变量分布形状。缺点是无法指定图形组距,对大型资料不适用。 茎叶图制作方法:①选择适当的数字为茎,通常是起首数字,茎之间的间距相等;②每列标出所有可能叶的数字,叶子按数值大小依次排列;③由第一行数据,在对应的茎之列,顺序记录茎后的一位数字为叶,直到最后一行数据,需排列整齐(叶之间的间隔相等)。 箱线图&五数总结 箱线图也称箱须图需要五个数,称为五数总结:①最小值②下四分位数:Q1③中位数④上四分位数:Q3⑤最大值。分位数差:IQR = Q3 - Q1 3密度估计是一个随机变量概率密度函数的非参数方法。 应用不同带宽生成的100个服从正态分布随机数的核密度估计。 空间点模式:一般来说,点模式分析可以用来描述任何类型的事件数据。因为每一事件都可以抽象化为空间上的一个位置点。 空间模式的三种基本分布:1)随机分布:任何一点在任何一个位置发生的概率相同,某点的存在不影响其它点的分布。又称泊松分布
一、方差分析和回归分析的区别与联系?(以双变量为例) 联系: 1、概念上的相似性 回归分析是为了分析变量间的因果关系,研究自变量X取不同值时,因变量平均值丫的变化。运用回归分析方法,可以从变量的总偏差平方和中分解出已被自变量解释掉的误差(解释掉误差)和未被解释掉的误差(剩余误差); 方差分析是为了分析或检验总体间的均值是否有所不同。通过对样本中自变量X取不同值时 所对应的因变量丫均值的比较,推论到总体变量间是否存在关系。运用方差分析,也可以从变量的总离差平方和中分解出已被自变量解释掉的误差和未被自变量解释掉的误差。因此两种分析在概念上所具有的相似性是显而易见的。 2、统计分析步骤的相似性 回归分析在确定自变量X是否为因变量丫的影响因素时,从分析步骤上先对X和丫进行相关分析,然后建立变量间的回归模型。最后再进行参数的统计显着性检验或对回归模型的统计显着性进行检验。 方差分析在确定X是否是丫的影响因素时,是先从样本所的数据的分析入手,然后考察数据模型,最后对样本均值是否相等进行显着性检验。二者在分析步骤上也具有相似性。 3、假设条件具有一定的相似性 回归分析有五个基本假定,分别是:自变量可以是随机变量也可以是非随机变量;X与丫之 间存在的非确定性的相关关系,要求丫的所有子总体,其方差都相等;子总体均值在一条直线上;随机变量丫是统计独立的,即丫1的数值不影响丫2的数值,各丫值之间都没有关系;丫值的每一个子总体都满足正态分布。 方差分析的基本假定有:等方差性(总体中自变量的每一取值所对应因变量丫的分布都具有 相同方差);丫的分布为正态分布。 二者在假设条件上存在着相同。 4、在总离差平方和中的分解形式和逻辑上的相似性 回归分析中,TSS=RSS+RS,S而在方差分析中,TSS=RSS+BS二者均是以已解释掉的误差与未被解释掉的误差之和为总离差平方和。 5、确定影响因素上的相似性 为简化分析起见,我们假设只有一个自变量X影响因变量丫。在回归分析中,要确定X是否是丫的影响因素,就要看当X已知时,对丫的总偏差有无影响。如果X不是影响丫的因素,等同于只 知变数丫的数据列一样,此时用丫去估计每个丫的值,所犯的错误(即偏差)为最小。如果因素X 是影响丫的因素,那么当已知X值后 6、在统计显着性检验上具有相似性 回归分析的总显着性检验,是一种用R2测量回归的全部解释功效的检验。检验RSSR*(N-2) /RS,S 方差分析的显着性检验是一种根据样本数据提取信息所进行的显着性检验。它也是通过F 检 验进行的。 区别: 1、研究变量的分析点不同 回归分析法既研究变量丫又研究变量X并在此基础上集中研究变量丫与X的函数关系,得到的是在不独立的情况下自变量与因变量之间的更加精确的回归函数式,也即判断相关关系的类 型,因此需建立模型并估计参数。方差分析法集中研究变量丫的值及其变差而变量X值仅用 来把丫值划分为子群或组,得到的是自变量(因素)对总量Y是否具有显着影响的整体判断,因
SPSS—非线性回归(模型表达式)案例解析 2011-11-16 10:56 由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二! 非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型 还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢? 答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究: 第一步:非线性模型那么多,我们应该选择“哪一个模型呢?” 1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型 点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高! 点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S" 两个模型,点击确定,得到如下结果: 通过“二次”和“S “ 两个模型的对比,可以看出S 模型的拟合度明显高于
趋势面法的工作原理 Resource Center ? 专业库? 地理处理? 地理处理工具参考? Spatial Analyst 工具箱? 插值工具集? 插值工具集概念 趋势面法工具可通过全局多项式插值法将由数学函数(多项式)定义的平滑表面与输入采样点进行拟合。趋势表面会逐渐变化,并捕捉数据中的粗尺度模式。 概念的背景 在概念上,趋势插值法类似于取一张纸将其插入各凸起点之间(凸起到一定高度)。下图展示的是从平缓山丘采集而来的一组高程采样点。使用的纸张为洋红色。 趋势平面的图示 平整的纸张无法完全覆盖包含山谷的地表。但如果将纸张略微弯曲,覆盖效果将会好的多。 为数学公式添加一个项也可以达到类似的效果,即平面的弯曲。平面(纸张无弯曲)是一个一阶多项式(线性)。二阶多项式(二次)允许一次弯曲,三阶多项式(三次)允许两次弯曲,依此类推。使用此工具最多允许 12 次弯曲(十二阶多项式)。下图在概念上展示出一个与山谷拟合的二阶多项式。
趋势曲面的图示 纸张几乎无法穿过各实际测量点,从而使趋势插值法成为不精确的插值器。有些测量点位于纸张上方,而其他点则位于纸张下方。但是,如果将测量点高出纸张的距离相加,并将测量点低于纸张的距离也相加,得到的这两个和值应该相近。以洋红色表示的表面是通过最小二乘回归拟合得到的结果。该生成表面将使凸起点与纸张之间的平方差最小化。 均方根 (RMS) 误差越小,插值表面就越能代表各输入点。一阶多项式到三阶多项式最为常见。 利用趋势面插值法可创建平滑表面。 何时使用趋势插值法 使用趋势插值法可获得表示感兴趣区域表面渐进趋势的平滑表面。此种插值法适用于以下几种情况 ?感兴趣区域的表面在各位置间出现渐变时,可将该表面与采样点拟合,例如,工业区的污染情况。 ?检查或排除长期趋势或全局趋势的影响。此类情况下,采用的方法通常为趋势面分析。 在趋势插值法中,将通过可描述物理过程的低阶多项式创建渐变表面,例如,污染情况和风向。但使用的多项式越复杂,为其赋予物理意义就越困难。此外,计算得出的表面对异常值(极高值和极低值)非常敏感,尤其是在表面的边缘处。 趋势插值法的类型 趋势插值法共有两种基本类型:线性和逻辑型。 线性趋势
相关分析与回归分析 一、试验目标与要求 本试验项目的目的是学习并使用SPSS软件进行相关分析和回归分析,具体包括: (1)皮尔逊pearson简单相关系数的计算与分析 (2)学会在SPSS上实现一元及多元回归模型的计算与检验。 (3)学会回归模型的散点图与样本方程图形。 (4)学会对所计算结果进行统计分析说明。 (5)要求试验前,了解回归分析的如下内容。 参数α、β的估计 回归模型的检验方法:回归系数β的显着性检验(t-检验);回归方程显着性 检验(F-检验)。 二、试验原理 1.相关分析的统计学原理 相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson简单相关系数。 2.回归分析的统计学原理 相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数和模型进行检验和判断,并进行预测等。 线性回归数学模型如下: 在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数: 回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量和解释变量及其函数形式,或者对数据进行加工整理之后再次估计参数。回归模型的检验包括一级检验和二级检验。一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟和优度评价和显着性检验;二级检验又称为经济计量学检验,它是对线性回归模型的假定条件能否得到满足进行检验,具体包括序列相关检验、异方差检验等。 三、试验演示内容与步骤 1.连续变量简单相关系数的计算与分析
项目八假设检验、回归分析与方差分析 实验3 方差分析 实验目的学习利用Mathematica求单因素方差分析的方法. 基本命令 1.调用线性回归软件包的命令< 中,向量Y是因变量,也称作响应变量.矩阵X称作设计矩阵, ?是参数向量??是误差向量? ????????DesignedRegress也是作一元和多元线性回归的命令, 它的应用范围更广些. 其格式与命令Regress的格式略有不同: DesignedRegress[设计矩阵X,因变量Y的值集合, RegressionReport ->{选项1, 选项2, 选项3,…}] RegressionReport(回归报告)可以包含:ParameterCITable(参数?的置信区间表???? ?PredictedResponse (因变量的预测值), MeanPredictionCITable(均值的预测区间), FitResiduals(拟合的残差), SummaryReport(总结性报告)等, 但不含BestFit. 实验准备—将方差分析问题纳入线性回归问题 在线性回归中, 把总的平方和分解为回归平方和与误差平方和之和, 并在输出中给出了方差分析表. 而在方差分析问题 中, 也把总的平方和分解为模型平方和与误差平方和之和, 其方法与线性回归中的方法相同. 因此只要把方差分析问题转化为线性模型的问题, 就可以利用线性回归中的设计回归命令DesignedRegress 做方差分析. 单因素试验方差分析的模型是 ?? ? ??==+=. ,,2,1;,,2,1,),,0(~,2s j n i N Y j ij ij ij j ij ΛΛ独立各εσεεμ (3.1) 上式也可改写成 ?? ? ??===+-+==+=.,,2,1;,,2,1,),,0(~; ,,3,2,)(, ,,2,1,2111111s j n i N s j Y n i Y j ij ij ij j ij i i ΛΛΛΛ独立各εσεεμμμεμ (3.2) 给定具体数据后, 还可(2.2)式写成线性模型的形式: 多元数据处理 ---因子分析方法 多元数据处理主要包括多元随机变量,协方差分析,趋势面分析,聚类分析,判别分析,主成分分析,因子分析,典型相关分析,回归分析以及各个分析方法的相互结合等等。本文主要针对其中的因子分析方法展开了论述,并举了一个因子分析法在我国房地产市场绩效评价中的应用实例。 第一章因子分析方法概述 1.1因子分析的涵义 为了更全面和准确的测量和评估对象的特征,在实际的应用中,我们往往尽可能多的选用特征指标进行系统评估,选取的指标越多,就越能全面、客观的反映评价对象的特征。选取众多指标的同时也带来了统计分析的困难:一、不同的指标,不同重要程度需要赋予不同的权重,而靠主观的评价避免不了一些失误与错误。二、收集到的指标之间可能存在较大的相关性,大量收集指标带来了人力、物力和财力的浪费。而因子分析方法则较好的解决了上述问题。 因子分析[1]是一种多元统计方法,该方法起源于20世纪初Karl Pearson 和Charles Spearman 等人关于心理测试的统计分析,它的核心是用最少的相互独立的因子反映原有变量的绝大部分信息。[2]通过分析事物内部的因果关系来找出其主要矛盾,找出事物内在的基本规律。 因子分析的基本思想是通过变量的相关系数矩阵内部结构的研究,找出能控制所有变量的少数几个随机变量去描述多个变量之间的相关关系,但是,这少数几个随机变量是不可观测的,通常称为因子。然后根据相关性的大小把变量分组,使得同组内的变量之间相关性较高,使不同组内的变量相关性较低[3]。对于所研究的问题就可试图用最少个数的所谓因子的线性函数与特殊因子之和来描述原来观测的每一变量[4]。因子变量的特点:第一,因子变量的数量远小于原指标的数量,对因子变量的分析能够减少分析的工作量;第二,因子变量不是原有变量的简单取舍,而是对原有变量的 物源分析研究方法 物源分析在确定沉积物物源位置和性质及沉积物搬运路径,甚至整个盆地的沉积作用和构造演化等方面意义重要。近年来已发展成为多方法、多技术的一门综合研究领域。电子探针、质谱分析、阴极发光等先进技术在物源分析中应用日益广泛;同时,各种沉积、构造、地震、测井等地质方法与化学、物理、数学等学科的应用及相互结合,使物源判定更具说服力。它在原盆地恢复、古地理再造、限定造山带的侧向位移量,确定地壳的特征,验证断块或造山带演化模型,绘制沉积体系图,进行井下地层对比以及在评价储层的品质等方面,都可起到重要作用。 物源分析已经成为连接沉积盆地与造山带的纽带,为学者提供了一个研究盆山相互作用的有效切入点。其研究内容不仅包括物源区的方位、侵蚀区与母岩区的位置、母岩的性质及组合特征,还包括沉积物的搬运距离、搬运路径;而且,根据物源分析资料还可以进一步了解物源区的气候条件和大地构造背景,进行沉积体系分析,重建古地理面貌。因此进行物源研究既是沉积地质学、构造地质学、岩石学的重要研究内容,也是古海洋学、石油地质学的重要课题。 随着现代分析手段的提高,物源分析方法日趋增多,并不断的相互补充和完善。目前应用较多的为:重矿物法、碎屑岩类分析法、沉积法、裂变径迹法、地球化学法和同位素法等。主要研究岩石、矿物成分及其组合特征、地层的发育状况(包括接触关系和沉积界面等)、岩相的侧向变化和纵向迭置、地球化学特征及其组合变化等,其依据在于不同的物源在沉积物的搬运和沉积过程中就会有不同的岩性、岩相和地球化学特征响应。 一、重矿物分析法 由于电子探针技术的应用及其分析水平、精度的不断提高,重矿物分析法应用广泛。重矿物因其耐磨蚀、稳定性强,能够较多的保留其母岩的特征,其在物源分析中占有重要地位。它包括单矿物分析法和重矿物组合分析法。 1、单矿物分析法 用于重矿物分析的单矿物颗粒主要有:辉石、角闪石、绿帘石、十字石、石榴石、尖晶石、硬绿泥石、电气石、锆石、磷灰石、金红石、钛铁矿、橄榄石等。用电子探针可分析上述矿物的含量、化学组分及其类型、光学性质等,针对每个重矿物的特性及其特定元素含量,用其典型的化学组分判定图或指数来判定其物源。如Morton用辉石矿物对南Uplands 地区奥陶系Portpa2t rik组进行物源判断,依据Let terier提出的Ca2Ti2Cr2Na2Al 组分图解,用Ti2(Ca + Na)来判定其物源是拉斑玄武岩或碱性玄武岩,用( Ti + Cr)2a 图解区分辉石源区为造山带还是非造山带环境,指出该区辉石源自钙碱性火山岩。另外,单颗粒重矿物含量比值亦具有一定的源区意义。独居石/锆石比值( MZi)可显示深埋砂岩物源区的情况;石榴石/锆石比值(GZi)用来判断层序中石榴石是否稳定;磷灰石/电气石比值(ATi)指示层序是否受到酸性地下水循环的影响。单颗粒重矿物含量的平面变化可用来判定物源方向,如磁铁矿等。 2、重矿物组合法 矿物之间具有严格的共生关系,所以重矿物组合是物源变化的极为敏感的指示剂。在同一沉积盆地中,同时期的沉积物的碎屑组分一致,而不同时期的沉积物所含的碎屑物质不同,据此,利用不同时期水平方向上重矿物种类和含量变化图,可推测物质来源的方向〔5。重矿物组合分析法对物源区用处颇大,尤其是在矿物种类较复杂、受控因素较多的地区特别有用。具体组合形式、分析方法根据不同地区特点不同而有差异。目前,主要引用一些数学分析方法,如聚类分析(R型或Q 型) 、因子分析、趋势面分析等方法来研究矿物组合特征、相似性等指数,从而提取反映物源的信息。重矿物方法对母岩性质具有一定的要求,对火山岩和变质岩作为母岩时,其中的重矿物所经历的搬运、沉积次数较少,受后期的影响小,保 设计说明 设计人:刘畅何晓姣 负责部分:二次回归的模型分析 一个完整的模型应该包括模型的建立、检验以及优选。在前面的几部分内容中分别通过正交设计、正交旋转设计以及通用旋转设计的方法来进行二次回归设计以及检验。在该部分我们的主要任务是选择最优水平和置信区间。 一、确定最优水平 在此部分中我们采用极值理论选择最优水平。首先,寻找可能的极值点即稳定点,而稳定点的计算可以直接根据偏导数为零直接得出,根据所得的稳定点求得预测值。之后,我们判断稳定点的特征以及响应曲面的最陡方向,具体的操作是判断和赛(Hesse)矩阵的正定性,可以通过矩阵的特征值来作出判断,当稳定点在拟和二次模型的讨论区域内时,当特征值均为正,则稳定点为极大值点;当特征值均为负,则稳定点位极小值点;当特征值有正有负时稳定点为鞍点。此外,特征值绝对值最大的点代表的方向为响应曲面的最陡方向。 二、统计选优 上述选优方法在实际操作中会遇到一系列问题,例如所选取得点不是极值点,选取的电部在讨论的范围内等,这样做有时候会增加计算机的负担,浪费资源,而且不能达到选优的目的,因此我们需要用一种更为简单实用的方法代替它。 在此部分在中我们采用统计选优的方法,得出各因素的置信区间,虽然不是一个精确的点,但是为用户预测选优提供了一定的参照范围。 我们选取得默认置信度为95%,在95%的知置信度下,根据y值满足目标要求的组合点数l可求出各自变量z的平均值以及标准差,则当z在区间内取值时就有95%的可能使得y满足目标要求。 (附:程序代码) %计算最优点 for i=1:p for j=1:p if j~=i B(i,j)=b2(i,j)*0.5; else B(i,j)=b3(j); end end end b=b1(1:p); %hang b=b'; %lie Z0=-0.5*inv(B)*b; % lie r0=X(3,:); %计算零水平hang V=X(2,:)-X(3,:); %hang X0=Z0'.*V+r0; %计算出稳定点的坐标Y0=b0+0.5*Z0'*b; %在稳定点的预测值[V,D]=eig(B); %计算特征值 w1=abs(D(1,1)); %选择曲面的最陡方向for i=2:p if abs(D(i,i)) 趋势面分析实验报告 实验目的: 趋势面分析是利用数学曲面模拟地理系统要素在空间上的分布以及变化趋势的一种方法。趋势面分析方法常常被用来模拟资源,环境人口及经济要素在空间上的分布规律。利用趋势分析的方法来检测各个数据在空间分布上的特点。 实验要求: 对某城市郊区垃圾占用农田面积的数量在平面上的分布规律进行计算和分析。 实验步骤: 步骤一:导入数据EXCEL格式 步骤三:建立趋势面模型,分析,回归,线性输入自变量和因变量,算出二次拟合方程 Z=2.160+0.638x-0.80y-0.52x*x+0.07xy-0.011y*y (R的平方=0.593 F=2.620) 步骤四:三次趋势面分析,求出X6,X7,X8,X9,建立三次趋势面模型 4 Z=-5.571+2.002x+3.889y-0.154x*x-0.182xy-0.573y*y-0.001x*x*x+0.015x*x*y+0.001x*y *y+0.024y*y*y (R的平方=0.921 F=6.474) 步骤五:模型检验 (1)结果表明二次趋势面的判定系数为0.593,三次的趋势面判定系数为0.921,可见三次 趋势面回归模型的拟合程度高。 (2)趋势面适度的显著性F检验。二次和三次的趋势面的F值分别为2.620和6.474 。二 次趋势面F=2.2620 趋势面分析 案例:某流域一月降水量与各观测点的坐标位置数据如表,我们设降水量为因变量Z,地 2、Y2、XY、X22、X 3、Y3 2、建立趋势面模型 1)二次多项式 a.我们先将各变量数值输入SPSS软件中,然后选择“分析—回归—线性”工具,将Z送进因变量框中,然后再将其他的自变量送进自变量框中,点击确定便可求的解。 b.运行结果如下 图1 图1中B列的数据为拟合方程的各系数,根据表中的数值及所对应的常量,我们求得的拟合方程为: Z=5.998+17.438X+29.787Y-3.588X2+0.357XY-8.070Y2 图2 图2显示该拟合二次趋势面的判定系数R2=0.839,显著性F=6.232 2)三次多项式 a.方法与二次多项式类似,将所有的变量输入SPSS,选择“分析—回归—线性”工具,将Z 送进因变量框中,然后再将其他的自变量送进自变量框中,点击确定便可求解。 b.运行结果如下 图1 图1中数列B的数据为拟合方程的各系数,根据表中的数值及所对应的常量,我们求得的拟合方程为: Z=-48.810+37.557X+130.130Y+8.389X2-33.166XY-62.740Y2- 4.133X3+6.138X2Y+2.566XY2+9.785Y3 图2 图2显示,该拟合二次趋势面的判定系数R2=0.965,显著性F=6.054 3、检验模型 1)趋势面拟合适度检验。根据两次拟合的输出结果表明,二次趋势面的判定系数为R2=0.839,三次趋势面的判定系数为R2=0.965,可见二者趋势面回归模型的显著性都较高(>0.8),且三次趋势面较二次趋势面具有更高的拟合程度(数值更大)。 2)趋势面适度的显著性检验。根据两次拟合的输出结果表明,两者趋势面的F值分别为F2=6.236、和F3=6.054,在置信水平a=0.05下,查F分布表得F2a=F0.05(5,6)=4.53,F3a=F0.05(9,2)=19.4,我们得出F2>F2a F3 < F3a,因此我们判定用二次趋势面进行拟合比较合理。3)趋势面适度的逐次检验。 用SPSS软件对检验两个阶次趋势面模型的适度值进行计算,然后比较分析。 一、趋势面分析法 (2007-03-06 14:45:57) 转载 下面将就趋势面分析、克里金、形函数法三种算法作简单介绍,以后将进一步整理一些资料,介绍更多优秀的实用算法。 一、趋势面分析法 趋势面分析法是针对大量离散点信息,从整体插值角度出发,来进行趋势渐变特征分析的最简单的方法。趋势面分析一般是采取多项式进行回归分析。趋势面通常应用多项式回归,主要是因为多项式回归的求解比较简单,通常可以得到显示的数学解答。回归方法采用最小二乘法原理,其本质就是对回归函数在某个区间上的极值求取。 M阶N项多项式趋势面基本可以表示以下形式: 要注意在上式中,是参变量,但不是每个参变量都是独立参变量。 在实际分析中,M一般取1,2,3。一般来说来M不取超过3以上的高阶,主要基于两方面,一是高阶求解相对复杂,二是高级很难赋予物理意义。N取多参变量在生产实践中是很常见的。 对于任何一组离散型数据,多项式趋势面到底取多少阶和多少个参变量,有一个临界限制:就是不管你取多少阶和多少个参变量,只要待求趋势面中的独立参变量总数小于或者等于已知离散控制点的数量就可以。 事实上,趋势面分析并不限制只取多项式趋势面,可以取任何函数构成的趋势面,如以下形式: 上式为任意函数,为待求参变量。在实际应用中,即使碰到了用一般多项式趋势面解决不了的拟合问题,往往也不采取以上方法,因为其求取复杂和费时。通常做法是大致估算出其函数形式,将原始数据进行相应转换,然后再采取多项式趋势面方法来进行分析和求解。 在空间分析中,最简单的趋势面分析函数大致有以下一些类型。 1、空间趋势平面模型。数学函数如下所示: 2、简单二次曲面模型。数学函数如下所示: 或 3、复杂二次曲面模型。数学函数如下所示: 所谓趋势面,顾名思义只是从趋势上来进行拟合,严格意义说它是平滑函数。一般趋势面不经过原始数据点,除非趋势面中待求参变量的个数与已知离散控制点所确定的线性不相关方程组的个数相等。 趋势面分析中另一个重要特性就是揭示了分析区域中不同于总趋势的最大偏离部分。这个特性是非常重要的,因为在生产实践中,取样往往存在很多人为因素和非人为因素的影响,通过趋势面分析可以找出这种与整体格格不入的信息特征,然后按照一定的准则进行剔除,然后再分析求解最佳趋势结果。常用的 方差分析与回归分析 Company number:【WTUT-WT88Y-W8BBGB-BWYTT-19998】 第八章 方差分析与回归分析 §1 单因素试验的方差分析 试验指标:研究对象的某种特征。 例 各人的收入。 因素:与试验指标相关的条件。 例 各人的学历,专业,工作经历等与工资有关的特征。 因素水平:因素所在的状态 例 学历是因素,而高中,大学,研究生等,就是学历因素水平;数学,物理等就是专业的水平。 问题:各因素水平对试验指标有无显着的差异 单因素试验方差分析模型 假设 1)影响试验指标的因素只有一个,为A ,其水平有r 个:1,,r A A ; 2)每个水平i A 下,试验指标是一个总体i X 。各个总体的抽样过程是独立的。 3)2~(,)i i i X N μσ,且22i j σσ=。 问题:分析水平对指标的影响是否相同 1)对每个总体抽样得到样本{,1}ij i X j n ≤≤,由其检验假设: 原假设0:i j H μμ=,,i j ?;备选假设:1:i j H μμ≠,,i j ?; 2)如果拒绝原假设,则对未知参数21,,,r μμσ进行参数估计。 注 1)接受假设即认为:各个水平之间没有显着差异,反之则有显着差异。 2)在水平只有两个时,问题就是双正态总体的均值假设检验问题和参数估计问题。 检验方法 数据结构式:ij i ij i ij X μεμδε=+=++,偏差2~(0,)ij N εσ是相互独立的, 11r i i i n n μμ==∑。不难验证,1 0r i k δ==∑。 各类样本均值 水平i A 的样本均值:1 1i n i ij j i X X n == ∑; 水平总样本均值:11111i n r r ij i i i j i X X n X n n =====∑∑∑,1 r i i n n ==∑; 偏差平方和与效应 应用趋势面模型分析传染性疾病的地理分布趋势 裘炯良1,王旭波2,郑剑宁1,孙智夫3 【摘要】 目的 应用趋势面模型分析传染性疾病的地理分布趋势。方法 以多元回归分析理论为基础,构造趋势面回归数学模型,并依据模型方程绘制趋势面层次分析图。结果 获得对传染性疾病地理分布进行监测的定量方法。结论 该方法可用于分析疾病地理分布系统和局部变异情况,并可直观地表示不同地理位置疾病严重程度的变化状况,可作为探讨传染性疾病地理流行病学发病机制的有效工具。 【关键词】 模型,理论;传染病;地理学 【中图分类号】R195;R511 【文献标识码】A 【文章编号】100826013(2005)022******* Analysis of geographical distribution of contagious diseases by trend2surface model Q IU Jiong2liang1, WAN G Xu2bo2,ZHEN G Jian2ning1,SUN Zhi2fu3. 1.Departnent of Health and Quarantine, N ingbo Ent ry2Exit Inspection and Quarantine B ureau,N ingbo 315012,China;2.Institute of Medicine,L ishui Norm al School,L ishui 323000,China;3.Center f or Disease Cont rol and Prevention of Daishan,Daishan 316200,China 【Abstract】 Objective To explore the application of the trend2surface model on geographical distribution of contagious diseases.Methods The trend2surface regressional model was based on multiple regression.Then trend2surface diagram was drawed according to the mathematical model. R esults The quantitative method for monitoring geographical distribution of contagious diseases was obtained.Conclusions This method can be used for analyzing the geographical distribution of contagious diseases and demonstrating the variational trend of prevalence rate.It is a useful tool for exploring the pathogenesis of contagious diseases in geographical epidemiology. 【K ey w ords】 Models,theoretical;Contagious disease;G eographical distribution (Chin J Dis Cont rol Prev2005,9(2):1312133) 趋势面模型分析(trend2surface analysis)作为近年发展起来的新的地理流行病学方法,已逐渐在传染性疾病的监测研究中得到广泛的应用1。由于其具有较强的整体空间分析能力,因而在疾病病因的探索方面、 “三间”(即人群、空间、时间)分布的研究方面有较大的使用价值。趋势面模型分析是以多元回归分析理论为基础的一种统计分析方法,它从整体出发,将地理位置上具有一定分布特征的数据划分为趋势部分和剩余部分2,用以分析疾病地理分布系统和局部变异情况。趋势分析图则是根据最小二乘法原理,剔除局部和随机变异影响后得到的趋势面,更能准确反映传染性疾病空间分布的总变化趋势,因而更易于监测及预测疾病。同时这种定【作者单位】1宁波出入境检验检疫局卫生检疫处,浙江 宁波 315012 2丽水师范专科学校医学部,浙江丽水 323000 3岱山疾病预防控制中心,浙江岱山 316200【作者简介】裘炯良(1975-),男,浙江宁波人,硕士。主要研究方向:卫生检疫工作及流行病学研究。量分析方法为传染性疾病的区域差异研究提供了新的研究技术和方法。 1 原理与方法 1.1 原理 趋势面模型分析是用空间坐标法进行多项式回归,从中估计出最佳的回归模型。 设观察点(X,Y)处传染性疾病的患病率为Z,现以n阶多项式函数拟合,即得到矩阵: Z=G?B+ε 其中Z和ε为N阶向量,N为观测点数,G为N ×Q阶矩阵,B为Q阶向量。Q与多项式阶数n有以下关系:Q=(n+1)?(n+2)?(n+3)/6。 1.2 方法 1.2.1 趋势面模型的建立 以经度(X)、纬度(Y)和发病率(Z)数据建立二元多项式模型方程,进行趋势面分析。趋势面模型通式为: Z K=B0+B1X+B2Y+B3X2+B4XY+B5Y2+……+B p X n 按最小二乘法原理分别对B向量求一阶偏导 ? 1 3 1 ? 疾病控制杂志2005年4月第9卷第2期 基于主成分分析及二次回归分析的城市生活垃圾热值建模 1. 引言 随着人们经济水平的提高、环保意识的增强、环保法规日益严格和国家垃圾处理产业化政策的实施,垃圾填埋处理的弊端将引起重视、运营费用将大大增加,而垃圾焚烧处理的优势将逐渐呈现出来并最终获得人们的认可。以城市生活垃圾为燃料而建立垃圾电站进行电力生产,很好的实现了生活垃圾的无害化、资源化利用。 而我国的城市生活垃圾成分复杂,用作为燃料时稳定性较差,因此分析垃圾的成分、计算垃圾的热值模型是垃圾焚烧发电的工艺设计和运营管理中必不可少的基础性工作。 因为我国不同地区人们生活习惯及生活条件差异较大,导致城市生活垃圾成分也存在很大的地域性差异,因此,本文以深圳市为例,对深圳市宝安区的生活垃圾采样数据进行分析,并建立其计算模型。 2. 回归分析及主成分分析理论 2.1. 回归分析 回归分析是一种应用极为广泛的数量分析方法。它用于分析事物之间的统计关系,通过回归方程的形式描述和反应这种关系。 2.2. 一般回归模型 如果变量与随机p 变量y 之间存在着相关关系,通常就意味着当x , x ....x 1 2 p x , x ....x取定值后y 便有相应的概率分布与之对应,其概率模型为: = ( , ... ) +e (2-1)1 2 p y f x x x其中p为称自变量,y 称为因变量,为自变量的确定性关系,ε表示x , x ....x 1 2 ( , .... ) 1 2 p f x x x随机误差。 2.3. 线性回归模型 回归模型分为线性回归模型和非线性回归模型,线性回归又有一元线性回归和多元线性回归之分。当变量之间的关系是线性关系的模型都称为线性回归模 型,否则就称之为非线性回归模型。当概率模型(2-1)中的回归函数为线性函数时,有: = b + b + b +e (2-2)p p y x ... x 0 1 1其中βi 是p+1 个未知参数,β0 称为回归常数,β1...βp 称为回归系数。 2.4. 主成分分析 上述的线性回归模型的应用前提是作为自变量的各指标之间相互独立,即不 《统计学》实验五 一、实验名称:方差分析 二、实验日期: 2010年12月3日 三、实验地点:经济管理系实验室 四、实验目的和要求 目的:培养学生利用EXCEL进行数据处理的能力,熟练掌握利用EXCEL 进行方差分析,对方差分析结果进行分析 要求:就本专业相关问题收集一定数量的数据,用EXCEL进行方差分析 五、实验仪器、设备和材料:个人电脑(人/台),EXCEL 软件 六、实验过程 (一)问题与数据 消费者与产品生产者、销售者或服务的提供者之间经常发生纠纷。当分生纠纷后,消费者常常会向消费者协会投诉。为了对几个行业的服务质量进行评价,消费者协会在零售业、旅游业、航空公司、家电制造业分别抽取了不同的企业作为样本。其中零售业抽取7家、旅游业抽取6家、航空公司抽取5家、家电制造业抽取5家。具体数据如下: 取显著性水平α=0.05,检验行业不同是否会导致消费者投诉的显著性差异?(二)实验步骤 1、进行假设 2、将数据拷贝到EXCEL表格中 3、选择“工具——数据分析——单因素方差分析”,得到如下结果: (三)实验结果分析:由以上结果可知:F>F crit=3.4066或P-value=0.0387657<0.05,拒绝原假设,表明行业对消费者投诉有着显著差异。 实验心得体会 在这学习之前我们只学习了简单的方差计算,现在运用计算机进行方差分析,可以做出更多的比较。通过使用计算机可以很快的计算出组间和组内的各种数值,便于我们进行比较分析。 《统计学》实验六 一、实验名称:相关分析与回归分析 二、实验日期: 2010年12月3日 三、实验地点:经济管理系实验室 四、实验目的和要求 目的:培养学生利用EXCEL进行数据处理的能力,熟练掌握EXCEL绘制散点图,计算相关系数,拟合线性回归方程,拟合简单的非线性回归方程,利用回归方程进行预测。 要求:就本专业相关问题收集一定数量的数据,用EXCEL进行相关回归分析(计算相关系数,一元线性回归分析,一元线性回归预测) 五、实验仪器、设备和材料:个人电脑(人/台),EXCEL 软件 六、实验过程 (一)问题与数据 10个学生每天用于学习英语的时间和期末考试的成绩的数据如下表所示。要求, (1)绘制学习英语的时间和期末考试的成绩的散点图,判断2者之间的关系 形态 (2)计算学习英语的时间和期末考试的成绩的线性相关系数 (3)用学习英语的时间作自变量,期末考试成绩作因变量,求出估计的回归方程。 (4)求每天学习英语的时间为150分钟时,销售额95%的置信区间和预测区间。 学生时间(分钟)成绩(分) A 120 85 B 60 65 C 100 76 D 70 71 E 80 74 F 60 65 G 30 54 H 40 60 I 50 62多元数据处理——因子分析法
物源分析方法及进展
二次回归模型分析软件设计说明
趋势面分析实验报告
趋势面分析
趋势面分析法
方差分析与回归分析
应用趋势面模型分析传染性疾病的地理分布趋势
主成分分析及二次回归分析的
方差分析和相关分析与回归分析
相关主题
文本预览