《统计分析与SPSS的应用(第五版)》(薛薇)
课后练习答案
第9章SPSS的线性回归分析
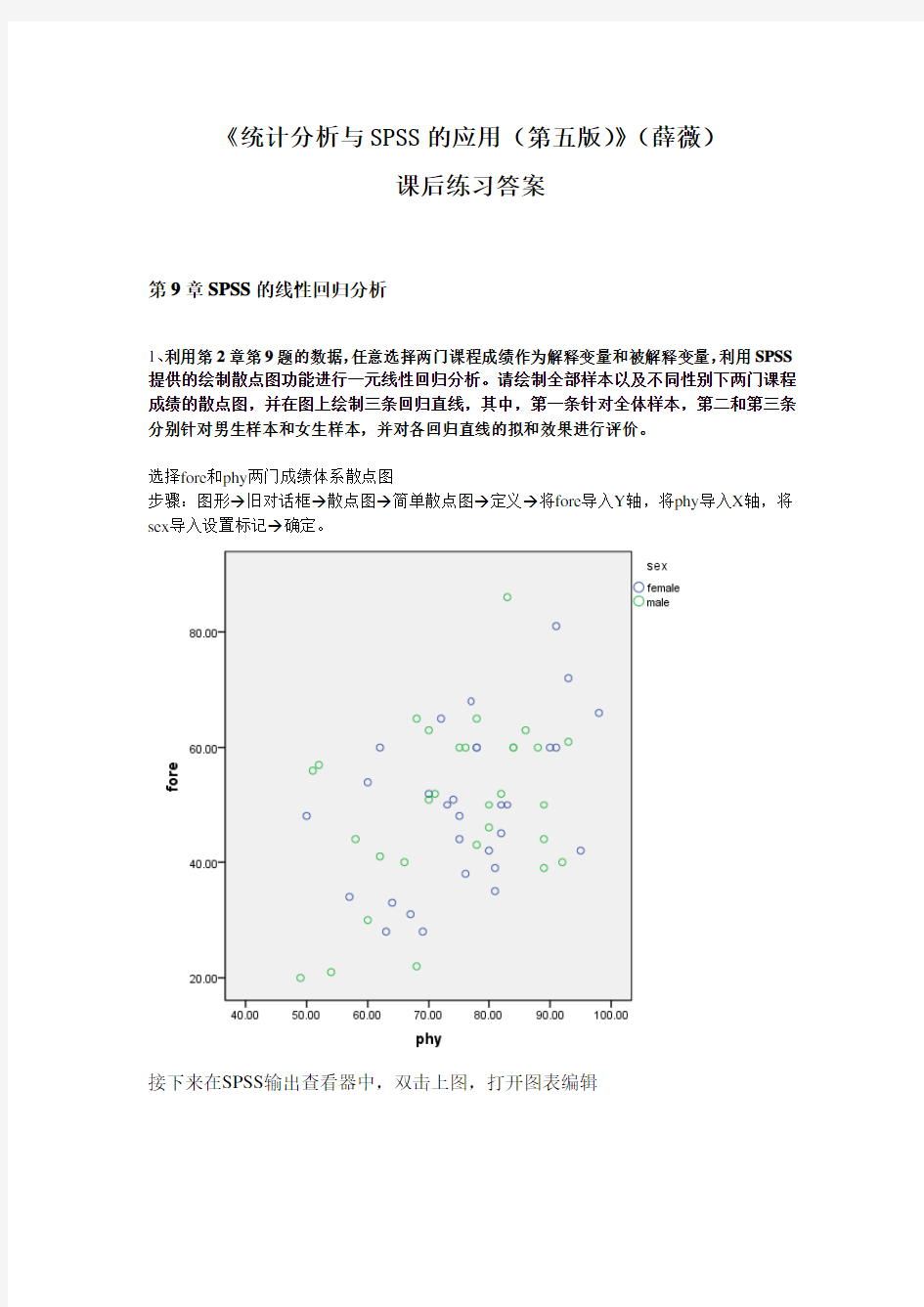
1、利用第2章第9题的数据,任意选择两门课程成绩作为解释变量和被解释变量,利用SPSS 提供的绘制散点图功能进行一元线性回归分析。请绘制全部样本以及不同性别下两门课程成绩的散点图,并在图上绘制三条回归直线,其中,第一条针对全体样本,第二和第三条分别针对男生样本和女生样本,并对各回归直线的拟和效果进行评价。
选择fore和phy两门成绩体系散点图
步骤:图形→旧对话框→散点图→简单散点图→定义→将fore导入Y轴,将phy导入X轴,将sex导入设置标记→确定。
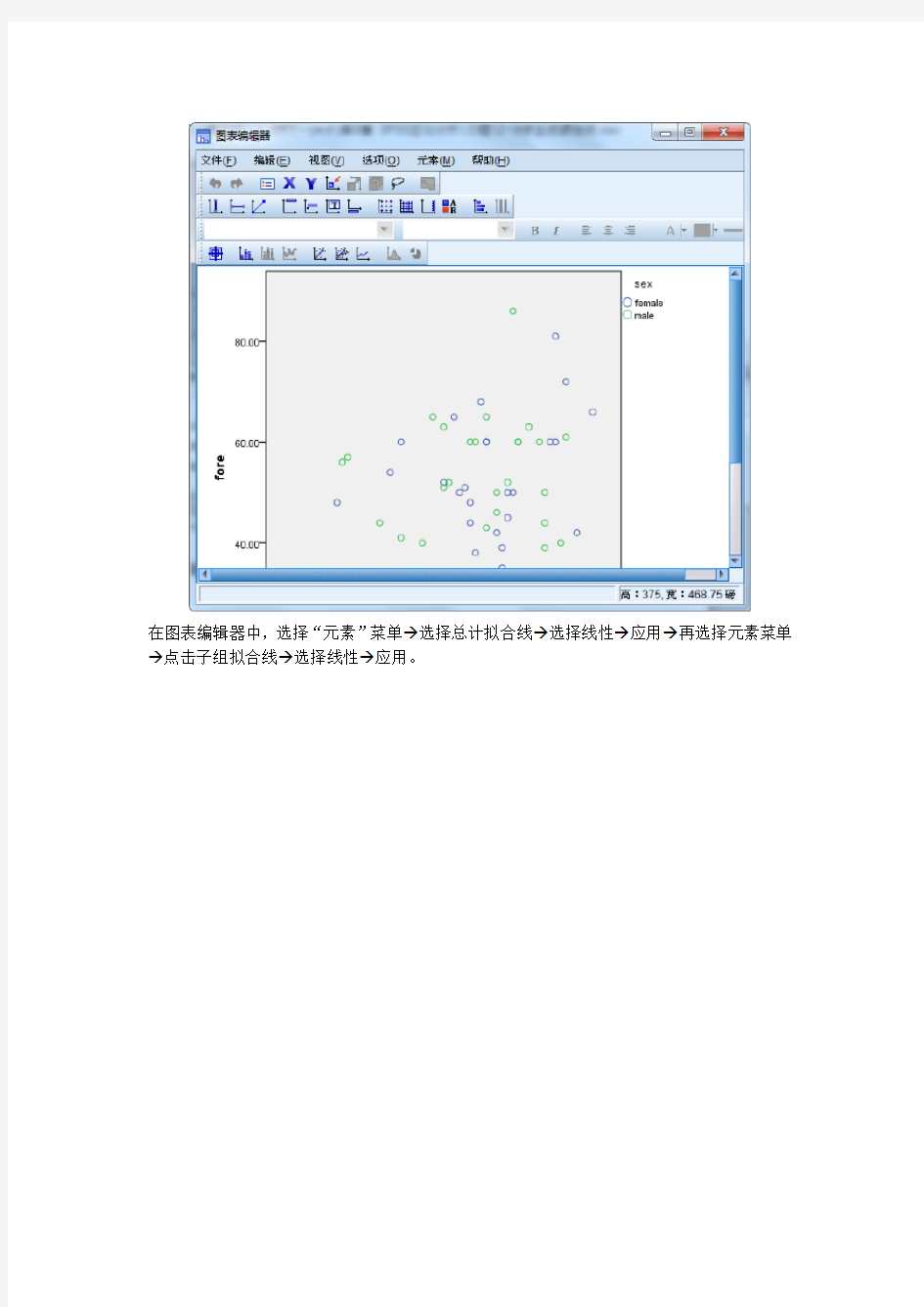
接下来在SPSS输出查看器中,双击上图,打开图表编辑
→点击子组拟合线→选择线性→应用。
分析:如上图所示,通过散点图,被解释变量y(即:fore)与解释变量phy有一定的线性关系。但回归直线的拟合效果都不是很好。
2、请说明线性回归分析与相关分析的关系是怎样的?
相关分析是回归分析的基础和前提,回归分析则是相关分析的深入和继续。相关分析需要依靠回归分析来表现变量之间数量相关的具体形式,而回归分析则需要依靠相关分析来表现变量之间数量变化的相关程度。只有当变量之间存在高度相关时,进行回归分析寻求其相关的具体形式才有意义。如果在没有对变量之间是否相关以及相关方向和程度做出正确判断之前,就进行回归分析,很容易造成“虚假回归”。与此同时,相关分析只研究变量之间相关的方向和程度,不能推断变量之间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况,因此,在具体应用过程中,只有把相关分析和回归分析结合起来,才能达到研究和分析的目的。
线性回归分析是相关性回归分析的一种,研究的是一个变量的增加或减少会不会引起另一个变量的增加或减少。
3、请说明为什么需要对线性回归方程进行统计检验?一般需要对哪些方面进行检验?
检验其可信程度并找出哪些变量的影响显著、哪些不显著。
主要包括回归方程的拟合优度检验、显著性检验、回归系数的显著性检验、残差分析等。
线性回归方程能够较好地反映被解释变量和解释变量之间的统计关系的前提是被解释变量和解释变量之间确实存在显著的线性关系。
回归方程的显著性检验正是要检验被解释变量和解释变量之间的线性关系是否显著,用线性模型来描述他们之间的关系是否恰当。一般包括回归系数的检验,残差分析等。
4、请说明SPSS多元线性回归分析中提供了哪几种解释变量筛选策略?
向前、向后、逐步。
5、先收集到若干年粮食总产量以及播种面积、使用化肥量、农业劳动人数等数据,请利用建立多元线性回归方程,分析影响粮食总产量的主要因素。数据文件名为“粮食总产量.sav”。
方法:采用“前进“回归策略。
步骤:分析→回归→线性→将粮食总产量导入因变量、其余变量导入自变量→方法项选“前进”→确定。如下图:(也可向后、或逐步)
已输入/除去变量a
模型已输入变量已除去变量方法
1
施用化肥量(kg/公顷) .
向前(准则:
F-to-enter 的
概率 <= .050)
2
风灾面积比例(%) .
向前(准则:
F-to-enter 的
概率 <= .050)
3
年份. 向前(准则:
F-to-enter 的概率 <= .050)
4
总播种面积(万公顷) .
向前(准则:
F-to-enter 的
概率 <= .050)
a. 因变量:粮食总产量(y万吨)
模型摘要
模型R R 平方调整后的 R 平
方标准估算的错误
1 .960a.92
2 .919 2203.30154
2 .975b.950 .947 1785.90195
3 .984c.969 .966 1428.73617
4 .994d.989 .987 885.05221
a. 预测变量:(常量),施用化肥量(kg/公顷)
b. 预测变量:(常量),施用化肥量(kg/公顷), 风灾面积比例(%)
c. 预测变量:(常量),施用化肥量(kg/公顷), 风灾面积比例(%), 年
份
d. 预测变量:(常量),施用化肥量(kg/公顷), 风灾面积比例(%), 年
份, 总播种面积(万公顷)
ANOVA a
模型平方和自由度均方 F 显著性1 回归1887863315.616 1 1887863315.616 388.886 .000b
残差160199743.070 33 4854537.669
总计2048063058.686 34
2 回归1946000793.422 2 973000396.711 305.069 .000c
残差102062265.263 32 3189445.789
总计2048063058.686 34
3 回归1984783160.329 3 661594386.776 324.106 .000d
残差63279898.356 31 2041287.044
总计2048063058.686 34
4 回归2024563536.011 4 506140884.003 646.150 .000e
残差23499522.675 30 783317.423
总计2048063058.686 34
a. 因变量:粮食总产量(y万吨)
b. 预测变量:(常量),施用化肥量(kg/公顷)
c. 预测变量:(常量),施用化肥量(kg/公顷), 风灾面积比例(%)
d. 预测变量:(常量),施用化肥量(kg/公顷), 风灾面积比例(%), 年份
e. 预测变量:(常量),施用化肥量(kg/公顷), 风灾面积比例(%), 年份, 总播种面积(万公顷)
系数a
模型
非标准化系数标准系数
t 显著性B 标准错误贝塔
1 (常量)17930.148 504.308 35.554 .000
施用化肥量(kg/公顷) 179.287 9.092 .960 19.720 .000 2 (常量)20462.336 720.317 28.407 .000
施用化肥量(kg/公顷) 193.701 8.106 1.037 23.897 .000 风灾面积比例(%) -327.222 76.643 -.185 -4.269 .000 3 (常量)-460006.046 110231.478 -4.173 .000
施用化肥量(kg/公顷) 137.667 14.399 .737 9.561 .000 风灾面积比例(%) -293.439 61.803 -.166 -4.748 .000 年份244.920 56.190 .323 4.359 .000 4 (常量)-512023.307 68673.579 -7.456 .000
施用化肥量(kg/公顷) 139.944 8.925 .749 15.680 .000 风灾面积比例(%) -302.324 38.305 -.171 -7.893 .000 年份253.115 34.827 .334 7.268 .000 总播种面积(万公顷) 2.451 .344 .141 7.126 .000 a. 因变量:粮食总产量(y万吨)
结论:如上4个表所示,影响程度中大到小依次是:施用化肥量(kg/公顷), 风灾面积比例(%), 年份, 总播种面积(万公顷)。(排除农业劳动者人数(百万人)和粮食播种面积(万公顷)对粮食总产量的影响)
剔除农业劳动者人数(百万人)和粮食播种面积(万公顷)后:
步骤:分析→回归→线性→将粮食总产量导入因变量、其余4个变量(施用化肥量(kg/公顷), 风灾面积比例(%), 年份, 总播种面积(万公顷))导入自变量→方法项选“输入”→确定。如下图:
系数a
模型
非标准化系数标准系数
t 显著性B 标准错误贝塔
1 (常量)-512023.307 68673.579 -7.456 .000
年份253.115 34.827 .334 7.268 .000 总播种面积(万公顷) 2.451 .344 .141 7.126 .000 施用化肥量(kg/公顷) 139.944 8.925 .749 15.680 .000 风灾面积比例(%) -302.324 38.305 -.171 -7.893 .000 a. 因变量:粮食总产量(y万吨)
粮食总产量回归方程:Y=-7.893X1+15.68X2+7.126X3+7.268X4-7.456
6、一家产品销售公司在30个地区设有销售分公司。为研究产品销售量(y)与该公司的销售价格(x1)、各地区的年人均收入(x2)、广告费用(x3)之间的关系,搜集到30个地区的有关数据。进行多元线性回归分析所得的部分分析结果如下:
Model Sum of Squares Df Mean Square F Sig. Regression 4008924.7 8.88341E-13 Residual
Total 13458586.7 29
Unstandardized Codfficients
B Std.Error
t Sig.
(Constant) 7589.1025 2445.0213 3.1039 0.00457
X1 -117.8861 31.8974 -3.6958 0.00103
X2 80.6107 14.7676 5.4586 0.00001
X3 0.5012 0.1259 3.9814 0.00049
1)将第一张表中的所缺数值补齐。
2)写出销售量与销售价格、年人均收入、广告费用的多元线性回归方程,并解释各回归系数的意义。
3)检验回归方程的线性关系是否显著?
4)检验各回归系数是否显著?
5)计算判定系数,并解释它的实际意义。
6)计算回归方程的估计标准误差,并解释它的实际意义。
(1)
模型平方和自由度均方 F 显著性
1
回归12026774.1 3 4008924.7 72.8 8.88341E-13b
残差1431812.626 55069.7154
总计13458586.7 29
(2)Y=7589.1-117.886 X1+80.6X2+0.5X3
(3)回归方程显著性检验:整体线性关系显著
(4)回归系数显著性检验:各个回归系数检验均显著
(5)略
(6)略
7、对参加SAT 考试的同学成绩进行随机调查,获得他们阅读考试和数学考试的成绩以及性别数据。通常阅读能力和数学能力具有一定的线性相关性,请在排除性别差异的条件下,分析阅读成绩对数学成绩的线性影响是否显著。
方法:采用进入回归策略。
步骤:分析→回归→线性→将MathSAT导入因变量、其余变量导入自变量→确定。
结果如下:
已输入/除去变量a
模型已输入变量已除去变量方法1 Gender, Verbal
SAT b
. 输入
a. 因变量:Math SAT
b. 已输入所有请求的变量。
模型摘要
模型R R 平方调整后的 R 平
方标准估算的错误
1 .710a.505 .499 69.495
a. 预测变量:(常量),Gender, Verbal SAT
ANOVA a
模型平方和自由度均方 F 显著性1 回归782588.468 2 391294.234 81.021 .000b
残差767897.951 159 4829.547
总计1550486.420 161
a. 因变量:Math SAT
b. 预测变量:(常量),Gender, Verbal SAT
系数a
模型非标准化系数标准系数
t 显著性B 标准错误贝塔
1 (常量)184.58
2 34.068 5.418 .000
Verbal SAT .686 .055 .696 12.446 .000
Gender 37.219 10.940 .190 3.402 .001
a. 因变量:Math SAT
因概率P值小于显著性水平(0.05),所以表明在控制了性别之后,阅读成绩对数学成绩有显著的线性影响。
8、试根据“粮食总产量.sav”数据,利用SPSS曲线估计方法选择恰当模型,对样本期外的粮食总产量进行外推预测,并对平均预测误差进行估计。
采用二次曲线
步骤:图形→旧对话框→拆线图→简单→个案值→定义→将粮食总产量导入线的表征→确定结果如下:
再双击上图→“元素”菜单→添加标记→应用
接下来:分析→回归→曲线估计→粮食总产量导入因变量、年份导入变量,点击年份→在模型中选择二次项、立方、幂→点击“保存”按钮→选择保存”预测值”→继续→确定。
曲线拟合
附注
已创建输出03-MAY-2018 09:28:44
注释
输入数据F:\SPSS\薛薇《统计分析与spss的应用
(第五版)》\PPT--jwd\第9章 SPSS回
归分析\习题\粮食总产量.sav
活动数据集数据集1
过滤器<无>
宽度(W) <无>
拆分文件<无>
工作数据文件中的行数35
缺失值处理对缺失的定义用户定义的缺失值被视作缺失。
已使用的个案任何变量中带有缺失值的个案不用于分
析。
语法CURVEFIT
/VARIABLES=lscl WITH nf
/CONSTANT
/MODEL=LINEAR QUADRATIC CUBIC
POWER
/PRINT ANOVA
/PLOT FIT
/SAVE=PRED .
资源处理器时间00:00:00.19
用时00:00:00.25
使用从第一个观测值
到最后一个观测值
预测从使用周期后的第一观察
到最后一个观测值
变量已创建或已修改FIT_1 CURVEFIT 和 MOD_1 LINEAR 中具有 nf
的 lscl 的拟合
FIT_2 CURVEFIT 和 MOD_1 QUADRATIC 中具有
nf 的 lscl 的拟合
FIT_3 CURVEFIT 和 MOD_1 CUBIC 中具有 nf
的 lscl 的拟合
FIT_4 CURVEFIT 和 MOD_1 POWER 中具有 nf
的 lscl 的拟合
时间序列设置 (TSET) 输出量PRINT = DEFAULT
保存新变量NEWVAR = CURRENT
自相关或偏自相关图中的最大
MXAUTO = 16
滞后数
每个交叉相关图的最大延迟数MXCROSS = 7
每个过程生成的最大新变量数MXNEWVAR = 4
每个过程的最大新个案数MXPREDICT = 1000
用户缺失值处理MISSING = EXCLUDE
置信区间百分比值CIN = 95
在回归方程中输入变量的容差TOLER = .0001
最大迭代参数变化CNVERGE = .001
计算标准的方法自相关的错误ACFSE = IND
季节周期长度未指定
值在绘图中标记观测值的变量未指定
包括方程CONSTANT
警告
由于模型项之间存在接近共线性,该二次模型无法拟合。
由于模型项之间存在接近共线性,该立方模型无法拟合。
模型描述
模型名称MOD_1
因变量 1 粮食总产量(y万吨)
方程式 1 线性(L)
2 二次项(Q)
3 立方(U)
4 幂a
自变量年份
常量已包括
值在绘图中标记观测值的变量未指定
对在方程式中输入项的容许.0001
a. 此模型需要所有非缺失值为正。
个案处理摘要
数字
个案总计35
排除的个案a0
预测的个案0
新创建的个案0
a. 任何变量中带有缺失值的
个案无需分析。
变量处理摘要
变量
从属自变量
粮食总产量(y万
吨) 年份
正值的数目35 35
零的数目0 0
负值的数目0 0
缺失值的数目用户缺失0 0
系统缺失0 0
粮食总产量(y万吨)
线性(L)
模型摘要
R R 平方调整后的 R 平方标准估算的错误
.935 .874 .870 2795.862
自变量为年份。
ANOVA
平方和自由度均方 F 显著性
回归(R) 1790107249.412 1 1790107249.412 229.006 .000 残差257955809.274 33 7816842.705
总计2048063058.686 34
自变量为年份。
系数
非标准化系数标准系数
B 标准错误贝塔
t 显著性
年份708.118 46.793 .935 15.133 .000
(常量)-1369647.904 92136.775 -14.865 .000 二次项(Q)
模型摘要
R R 平方调整后的 R 平方标准估算的错误
.936 .875 .872 2782.149
自变量为年份。
ANOVA
平方和自由度均方 F 显著性
回归(R) 1792631355.014 1 1792631355.014 231.596 .000 残差255431703.672 33 7740354.657
总计2048063058.686 34
自变量为年份。
系数
非标准化系数标准系数
t 显著性
B 标准错误贝塔
年份 ** 2 .180 .012 .936 15.218 .000 (常量)-673013.926 45845.338 -14.680 .000
已排除的项
输入贝塔t 显著性偏相关最小容差
年份a-125.061 -7.851 .000 -.811 .000
a. 已达到输入变量的容许界限。
立方(U)
模型摘要
R R 平方调整后的 R 平方标准估算的错误
.936 .877 .873 2768.471
自变量为年份。
ANOVA
平方和自由度均方 F 显著性
回归(R) 1795136897.274 1 1795136897.274 234.217 .000 残差252926161.411 33 7664429.134
总计2048063058.686 34
自变量为年份。
系数
非标准化系数标准系数
B 标准错误贝塔
t 显著性
年份 ** 3 6.097E-5 .000 .936 15.304 .000 (常量)-440802.441 30416.171 -14.492 .000
已排除的项
输入贝塔t 显著性偏相关最小容差
年份a-62.046 -7.785 .000 -.809 .000
年份 ** 2 -124.059 -7.779 .000 -.809 .000
a. 已达到输入变量的容许界限。
幂
模型摘要
R R 平方调整后的 R 平方标准估算的错误
.938 .880 .877 .108
自变量为年份。
ANOVA
平方和自由度均方 F 显著性
回归(R) 2.825 1 2.825 242.844 .000
残差.384 33 .012
总计 3.209 34
自变量为年份。
系数
非标准化系数标准系数
B 标准错误贝塔
t 显著性
ln(年份) 55.391 3.554 .938 15.583 .000 (常量)7.936E-179 .000 . .
因变量为 ln(粮食总产量(y万吨))。
分析:如上表所示,粮食总产量总体呈现上升趋势,在对回归进行检验时,sig值为0<0.05,故拒绝原假设,即认为回归方程中解释变量与被解释变量间显著。
预测值:
社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% +=-=+B 产品产量计划超额完成程度 。 9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。 10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由 总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于 数量 指标;单位成本属于 质量 指标。 13、如果相关系数r=0,则表明两个变量之间 不存在线性相关关系 。 二、判断题
第三章节:数据的图表展示 (1) 第四章节:数据的概括性度量 (15) 第六章节:统计量及其抽样分布 (26) 第七章节:参数估计....................................................... (28) 第八章节:假设检验........................................................ (38) 第九章节:列联分析........................................................ (41) 第十章节:方差分析........................................................ (43) 3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C E E A B D D C A D B C C A E D C B C B C E D B C C B C 要求: (1)指出上面的数据属于什么类型。 顺序数据 (2)用Excel制作一张频数分布表。 用数据分析——直方图制作: 接收频率 E16 D17 C32 B21 A14 (3)绘制一张条形图,反映评价等级的分布。 用数据分析——直方图制作: (4)绘制评价等级的帕累托图。 逆序排序后,制作累计频数分布表:
第七章练习题及答案 一、单项选择题 1.马克思主义经典作家揭示了未来社会发展的() A.具体细节 B.一般特征 C.具体阶段 D.特殊规律 2.马克思主义指出,在共产主义社会,劳动是() A.人们谋生的手段 B.人们生活的第一需要 C.休闲的手段 D.完全由个人自由选择的活动 3.自由王国是指() A.共产主义社会 B.社会主义社会 C.资本主义社会 D.原始社会 4.必然王国是指() A.共产主义社会以前的社会状态 B.原始社会 C.文明社会 D.社会主义社会 5.“各尽所能,按需分配”是() A.原始社会的分配方式 B.社会主义的分配方式 C.共产主义的分配方式 D.资本主义的分配方式 6.自由王国和必然王国是人类社会发展的() A.两种不同的状态 B.两种不同的道路 C.两种不同的理想 D.两种不同的选择 7.实现共产主义社会的根本条件和基础是() A.社会生产力的高度发展 B.社会生产关系的高度发展 C.人的思想觉悟的极大提高 D.自然环境的优化 8.马克思主义认为,自由是() A.人们选择的主动性 B.人们能够随心所欲 C.人们能够摆脱必然性 D.人们在对必然的认识基础上对客观的改造 9.共产主义理想之所以能够实现,是因为它() A.具有客观可能性 B.人类向往的美好境界 C.具有客观必然性 D.人类追求的目标 10.无产阶级解放斗争的最终目是()
A.夺取政权 B.消灭阶级 C.消灭剥削 D.实现共产主义 二、多项选择题 1.共产主义社会的基本特征是() A.物质财富极大丰富,消费资料按需分配 B.社会关系高度和谐,人们精神境界极大提高 C.每个人自由全面发展,人类从必然王国过渡到自由王国 D.劳动全部由机器人承担 2.必然王国和自由王国是两种不同的社会状态,这两种社会状态是() A.共产主义以前的社会 B.共产主义 C.社会主义 D.资本主义 3.下列属于共产主义涵义的有() A.共产主义是一种科学理论 B.共产主义一种现实运动 C.共产主义是一种社会制度 D.共产主义是一种社会理想 4.自由王国是指() A.人们不受任何制约的自由状态 B.人们完全认识了自然和社会的必然性 C.人们摆脱了盲目必然性的奴役而成为自己和社会关系的主人 D.共产主义的社会状态 5.19世纪三大空想社会主义者是指() A.欧文 B.圣西门 C.傅立叶 D.斯密 6.下列属于必然王国社会状态的有() A.原始社会 B.奴隶社会 C.资本主义社会 D.共产主义社会 7.共产主义理想之所以能够实现,是因为() A人类社会发展的规律为依据 B.以资本主义社会基本矛盾的发展为依据 C.可以用社会主义运动的实践来证明 D.要靠社会主义的不断完善和发展来实现 8.在共产主义社会() A.工农差别将消失 B.城乡差别将消失 C.脑力劳动和体力劳动的差别将消失 D.人与人之间的差别将消失 9.人的全面发展包括()
第一章:一、单选题 1.以下的英文缩写中表示数据库管理系统的是( B)。 A. DB B.DBMS C.DBA D.DBS 2.数据库管理系统、操作系统、应用软件的层次关系从核心到外围分别是(B )。 A. 数据库管理系统、操作系统、应用软件 B. 操作系统、数据库管理系统、应用软件 C. 数据库管理系统、应用软件、操作系统 D. 操作系统、应用软件、数据库管理系统 3.DBMS是(C )。 A. 操作系统的一部分B.一种编译程序 C.在操作系统支持下的系统软件 D.应用程序系统 4.数据库系统提供给用户的接口是(A )。A.数据库语言 B.过程化语言 C.宿主语言D.面向对象语 5.(B )是按照一定的数据模型组织的,长期存储在计算机内,可为多个用户共享的数据的聚集。 A.数据库系统 B.数据库C.关系数据库D.数据库管理系统 6. ( C)处于数据库系统的核心位置。 A.数据模型 B.数据库C.数据库管理系统D.数据库管理员 7.( A)是数据库系统的基础。 A.数据模型B.数据库C.数据库管理系统D.数据库管理员 8.( A)是数据库中全部数据的逻辑结构和特征的描述。 A.模式B.外模式 C.内模式 D.存储模式 9.(C )是数据库物理结构和存储方式的描述。 A.模式 B.外模式 C.内模式D.概念模式 10.( B)是用户可以看见和使用的局部数据的逻辑结构和特征的描述》 A.模式B.外模式C.内模式D.概念模式 11.有了模式/内模式映像,可以保证数据和应用程序之间( B)。 A.逻辑独立性B.物理独立性C.数据一致性D.数据安全性 12.数据管理技术发展阶段中,文件系统阶段与数据库系统阶段的主要区别之一是数据库系统( B)。 A.有专门的软件对数据进行管理 B.采用一定的数据模型组织数据 C.数据可长期保存 D.数据可共享 13.关系数据模型通常由3部分组成,它们是(B )。 A. 数据结构、数据通信、关系操作 B. 数据结构、关系操作、完整性约束 C. 数据通信、关系操作、完整性约束 D. 数据结构、数据通信、完整性约束 14.用户可以使用DML对数据库中的数据进行(A )操纵。 A.查询和更新B.查询和删除 C.查询和修改D.插入和修改 15.要想成功地运转数据库,就要在数据处理部门配备( B)。 A.部门经理B.数据库管理员 C.应用程序员 D.系统设计员 16.下列说法不正确的是(A )。 A.数据库避免了一切数据重复 B.数据库减少了数据冗余 C.数据库数据可为经DBA认可的用户共享 D.控制冗余可确保数据的一致性 17.所谓概念模型,指的是( D)。 A.客观存在的事物及其相互联系 B.将信息世界中的信息数据化 C.实体模型在计算机中的数据化表示 D.现实世界到机器世界的一个中间层次,即信息世界 18.数据库的概念模型独立于( A)。 A.具体的机器和DBMS B.E-R图C.数据维护 D.数据库 19.在数据库技术中,实体-联系模型是一种( C)。 A. 逻辑数据模型 B. 物理数据模型 C. 结构数据模型 D. 概念数据模型 20.用二维表结构表示实体以及实体间联系的数据模型为(C )。 A.网状模型 B.层次模型 C.关系模型 D.面向对象模型 二、填空题 1.数据库领域中,常用的数据模型有(层次模型)、网状模型和(关系模型)。 2.关系数据库是采用(关系数据模型)作为数据的组织方式。 3.数据库系统结构由三级模式和二级映射所组成,三级模式是指(内模式、模式、外模式),二级映射是指 (模式/内模式映射、外模式/模式映射)。 4.有了外模式/模式映像,可以保证数据和应用程序之间的(逻辑独立性)。 5.有了模式/内模式映像,可以保证数据和应用程序之间的(物理独立性)。 6.当数据的物理存储改变了,应用程序不变,而由DBMS处理这种改变,这是指数据的(物理独立性)。 三、简答题 1.在一个大型公司的账务系统中,哪种类型的用户将执行下列功能? a)响应客户对他们账户上的各种查询;b)编写程序以生成每月账单;c)为新类型的账务系统开发模式。 答:a)最终用户;b)应用程序员;c)该部门的DBA或其助手。 2.用户使用DDL还是DML来完成下列任务? a)更新学生的平均成绩;b)定义一个新的课程表;c)为学生表格加上一列。 答:a——DML,更新是在操作具体数据;b和c——DDL,建立和修改表结构属于数据定义。 第二章:一、单选题
统计学各章练习题答案第1章绪论(略) 第2章统计数据的描述 2.1 (1)属于顺序数据。 (2)频数分布表如下: 服务质量等级评价的频数分布 服务质量等级家庭数(频率)频率% A1414 B2121 C3232 D1818 E1515 合计100100 (3)条形图(略) 2.2 (1)频数分布表如下: (2)某管理局下属40个企分组表 按销售收入分组(万元)企业数(个)频率(%) 先进企业良好企业一般企业落后企业11 11 9 9 27.5 27.5 22.5 22.5 合计40 100.0 2.3 频数分布表如下: 某百货公司日商品销售额分组表 按销售额分组(万元)频数(天)频率(%) 25~30 30~35 35~40 40~45 45~50 4 6 15 9 6 10.0 15.0 37.5 22.5 15.0 合计40 100.0 直方图(略)。
2.4 (1)排序略。 (2)频数分布表如下: 100只灯泡使用寿命非频数分布 按使用寿命分组(小时)灯泡个数(只)频率(%)650~660 2 2 660~670 5 5 670~680 6 6 680~690 14 14 690~700 26 26 700~710 18 18 710~720 13 13 720~730 10 10 730~740 3 3 740~750 3 3 合计100 100 直方图(略)。 2.5 (1)属于数值型数据。 (2)分组结果如下: 分组天数(天) -25~-20 6 -20~-15 8 -15~-10 10 -10~-5 13 -5~0 12 0~5 4 5~10 7 合计60 (3)直方图(略)。 2.6 (1)直方图(略)。 (2)自学考试人员年龄的分布为右偏。 2.7 (1
第七章 刚体力学 7.1.1 设地球绕日作圆周运动.求地球自转和公转的角速度为多少rad/s?估算地球赤道上一点因地球自转具有的线速度和向心加速度.估算地心因公转而具有的线速度和向心加速度(自己搜集所需数据). [解 答] 7.1.2 汽车发动机的转速在12s 内由1200rev/min 增加到3000rev/min.(1)假设转动是匀加速转动,求角加速度.(2)在此时间内,发动机转了多少转? [解 答] (1)22(30001200)1/60 1.57(rad /s )t 12ωπβ?-?= ==V V (2) 2222 20 ( )(30001200)302639(rad) 2215.7 π ωω θβ --= ==? 所以 转数=2639 420() 2π=转 7.1.3 某发动机飞轮在时间间隔t 内的角位移为 球t 时刻的角速度和角加速度. [解 答] 7.1.4 半径为0.1m 的圆盘在铅直平面内转动,在圆盘平面内建立O-xy 坐标系,原点在轴上.x 和y 轴沿水平和铅直向上的方向.边缘上一点A 当t=0时恰好在x 轴上,该点的角坐标满足2 1.2t t (:rad,t :s).θθ=+求(1)t=0时,(2)自t=0开始转45o 时,(3)转过90o 时,A 点的速度和加速度在x 和y 轴上的投影. [解 答] (1) A ??t 0,1.2,R j 0.12j(m/s). 0,0.12(m/s) x y ωνωνν====∴==v (2)45θ=o 时,
由 2 A 1.2t t,t0.47(s) 4 2.14(rad/s) v R π θ ω ω =+== ∴= =? v v v 得 (3)当90 θ=o时,由 7.1.5 钢制炉门由两个各长1.5m的平行臂AB和CD支承,以角速度10rad/s ω=逆时针转动,求臂与铅直45o时门中心G的速度和加速度. [解答] 因炉门在铅直面内作平动,门中心G的速度、加速度与B或D点相同。所以: 7.1.6 收割机拔禾轮上面通常装4到6个压板.拔禾轮一边旋转,一边随收割机前进.压板转到下方才发挥作用,一方面把农作物压向切割器,另一方面把切割下来的作物铺放在收割台上,因此要求压板运动到下方时相对于作物的速度与收割机前进方向相反. 已知收割机前进速率为1.2m/s,拔禾轮直径1.5m,转速22rev/min,求压板运动到最低点挤压作物的速度. [解答] 取地面为基本参考系,收割机为运动参考系。 取收割机前进的方向为坐标系正方向 7.1.7 飞机沿水平方向飞行,螺旋桨尖端所在半径为150cm,发动机转速2000rev/min.(1)桨尖相对于飞机的线速率等于多少?(2)若飞机以250km/h的速率飞行,计算桨尖相对于地面速度的大小,并定性说明桨尖的轨迹. [解答] 取地球为基本参考系,飞机为运动参考系。 (1)研究桨头相对于运动参考系的运动: (2)研究桨头相对于基本参考系的运动: 由于桨头同时参与两个运动:匀速直线运动和匀速圆
1.以下的英文缩写中表示数据库管理系统的是( B)。 A. DB B.DBMS C.DBA D.DBS 2.数据库管理系统、操作系统、应用软件的层次关系从核心到外围分别是(B )。 A. 数据库管理系统、操作系统、应用软件 B. 操作系统、数据库管理系统、应用软件 C. 数据库管理系统、应用软件、操作系统 D. 操作系统、应用软件、数据库管理系统 3.DBMS是(C )。 A. 操作系统的一部分B.一种编译程序 C.在操作系统支持下的系统软件 D.应用程序系统 4.数据库系统提供给用户的接口是(A )。A.数据库语言 B.过程化语言 C.宿主语言D.面向对象语 5.(B )是按照一定的数据模型组织的,长期存储在计算机内,可为多个用户共享的数据的聚集。 A.数据库系统 B.数据库C.关系数据库D.数据库管理系统 6. ( C)处于数据库系统的核心位置。 A.数据模型 B.数据库C.数据库管理系统D.数据库管理员 7.( A)是数据库系统的基础。 A.数据模型B.数据库C.数据库管理系统D.数据库管理员 8.( A)是数据库中全部数据的逻辑结构和特征的描述。 A.模式B.外模式 C.内模式 D.存储模式 9.(C )是数据库物理结构和存储方式的描述。 A.模式 B.外模式 C.内模式D.概念模式 10.( B)是用户可以看见和使用的局部数据的逻辑结构和特征的描述》 A.模式B.外模式C.内模式D.概念模式 11.有了模式/内模式映像,可以保证数据和应用程序之间( B)。 A.逻辑独立性B.物理独立性C.数据一致性D.数据安全性 12.数据管理技术发展阶段中,文件系统阶段与数据库系统阶段的主要区别之一是数据库系统( B)。 A.有专门的软件对数据进行管理 B.采用一定的数据模型组织数据 C.数据可长期保存 D.数据可共享 13.关系数据模型通常由3部分组成,它们是(B )。 A. 数据结构、数据通信、关系操作 B. 数据结构、关系操作、完整性约束 C. 数据通信、关系操作、完整性约束 D. 数据结构、数据通信、完整性约束 14.用户可以使用DML对数据库中的数据进行(A )操纵。 A.查询和更新B.查询和删除 C.查询和修改D.插入和修改 15.要想成功地运转数据库,就要在数据处理部门配备( B)。 A.部门经理B.数据库管理员 C.应用程序员 D.系统设计员 16.下列说法不正确的是(A )。 A.数据库避免了一切数据重复 B.数据库减少了数据冗余 C.数据库数据可为经DBA认可的用户共享 D.控制冗余可确保数据的一致性 17.所谓概念模型,指的是( D)。 A.客观存在的事物及其相互联系 B.将信息世界中的信息数据化 C.实体模型在计算机中的数据化表示 D.现实世界到机器世界的一个中间层次,即信息世界 18.数据库的概念模型独立于( A)。 A.具体的机器和DBMS B.E-R图C.数据维护 D.数据库 19.在数据库技术中,实体-联系模型是一种( C)。 A. 逻辑数据模型 B. 物理数据模型 C. 结构数据模型 D. 概念数据模型 20.用二维表结构表示实体以及实体间联系的数据模型为(C )。 A.网状模型 B.层次模型 C.关系模型 D.面向对象模型 二、填空题 1.数据库领域中,常用的数据模型有(层次模型)、网状模型和(关系模型)。 2.关系数据库是采用(关系数据模型)作为数据的组织方式。 3.数据库系统结构由三级模式和二级映射所组成,三级模式是指(内模式、模式、外模式),二级映射是指 (模式/内模式映射、外模式/模式映射)。 4.有了外模式/模式映像,可以保证数据和应用程序之间的(逻辑独立性)。 5.有了模式/内模式映像,可以保证数据和应用程序之间的(物理独立性)。 6.当数据的物理存储改变了,应用程序不变,而由DBMS处理这种改变,这是指数据的(物理独立性)。 三、简答题 1.在一个大型公司的账务系统中,哪种类型的用户将执行下列功能? a)响应客户对他们账户上的各种查询;b)编写程序以生成每月账单;c)为新类型的账务系统开发模式。 答:a)最终用户;b)应用程序员;c)该部门的DBA或其助手。 2.用户使用DDL还是DML来完成下列任务? a)更新学生的平均成绩;b)定义一个新的课程表;c)为学生表格加上一列。 答:a——DML,更新是在操作具体数据;b和c——DDL,建立和修改表结构属于数据定义。
第十二章 相关与回归分析 第一节 变量之间的相关关系 相关程度与方向·因果关系与对称关系 第二节 定类变量的相关 双变量交互分类(列联表)·削减误差比例(PRE )·λ系数与τ系数 第三节 定序变量的相关分析 同序对、异序对和同分对·Gamma 系数·肯德尔等级相关系数(τa 系数、τb 与τc 系数)·萨默斯系数(d 系数)·斯皮尔曼等级相关(ρ相关)·肯德尔和谐系数 第四节 定距变量的相关分析 相关表和相关图·积差系数的导出和计算·积差系数的性质 第五节 回归分析 线性回归·积差系数的PRE 性质·相关指数R 第六节 曲线相关与回归 可线性化的非线性函数·实例分析(二次曲线指数曲线) 一、填空 1.对于表现为因果关系的相关关系来说,自变量一般都是确定性变量,依变量则一般是( 随机性 )变量。 2.变量间的相关程度,可以用不知Y 与X 有关系时预测Y 的全部误差E 1,减去知道Y 与X 有关系时预测Y 的联系误差E 2,再将其化为比例来度量,这就是( 削减误差比例 )。 3.依据数理统计原理,在样本容量较大的情况下,可以作出以下两个假定:(1)实际观察值Y 围绕每个估计值c Y 是服从( );(2)分布中围绕每个可能的c Y 值的( )是相同的。 4.在数量上表现为现象依存关系的两个变量,通常称为自变量和因变量。自变量是作为( 变化根据 )的变量,因变量是随( 自变量 )的变化而发生相应变化的变量。 5.根据资料,分析现象之间是否存在相关关系,其表现形式或类型如何,并对具有相关关系的现象之间数量变化的议案关系进行测定,即建立一个相关的数学表达式,称为( 回归方程 ),并据以进行估计和预测。这种分析方法,通常又称为( 回归分析 )。 6.积差系数r 是( 协方差 )与X 和Y 的标准差的乘积之比。 二、单项选择 1.当x 按一定数额增加时,y 也近似地按一定数额随之增加,那么可以说x 与y 之间 存在( A )关系。 A 直线正相关 B 直线负相关 C 曲线正相关 D 曲线负相关
统计学课后习题答案(袁卫、庞皓、曾五一、贾俊平)第三版 第1章绪论 1.什么是统计学?怎样理解统计学与统计数据的关系? 2.试举出日常生活或工作中统计数据及其规律性的例子。 3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。因此,他们开始检查供货商的集装箱,有问题的将其退回。最近的一个集装箱装的是2 440加仑的油漆罐。这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。装满的油漆罐应为4.536 kg。要求: (1)描述总体; (2)描述研究变量; (3)描述样本; (4)描述推断。 答:(1)总体:最近的一个集装箱内的全部油漆; (2)研究变量:装满的油漆罐的质量; (3)样本:最近的一个集装箱内的50罐油漆; (4)推断:50罐油漆的质量应为4.536×50=226.8 kg。 4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。要求: (1)描述总体; (2)描述研究变量; (3)描述样本; (4)一描述推断。 答:(1)总体:市场上的“可口可乐”与“百事可乐” (2)研究变量:更好口味的品牌名称; (3)样本:1000名消费者品尝的两个品牌 (4)推断:两个品牌中哪个口味更好。 第2章统计数据的描述——练习题 ●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C D E A B D D C A D B C C A E D C B C B C E D B C C B C (1) 指出上面的数据属于什么类型;
第七章 课后练习答案 7.1 (1)已知:96.1%,951,25,40,52/05.0==-===z x n ασ。 样本均值的抽样标准差79.0405== = n x σ σ (2)边际误差55.140 5 96.12/=? ==n z E σ α 7.2 (1)已知:96.1%,951,120,49,152/05.0==-===z x n ασ。 样本均值的抽样标准差14.249 15== = n x σ σ (2)边际误差20.449 1596.12 /=? ==n z E σ α (3)由于总体标准差已知,所以总体均值μ的95%的置信区间为 20.412049 1596.11202 /±=? ±=±n z x σ α 即()2.124,8.115 7.3 已知:96.1%,951,104560,100,854142/05.0==-===z x n ασ。 由于总体标准差已知,所以总体均值μ的95%的置信区间为 144.16741104560100 8541496.11045602 /±=? ±=±n z x σ α 即)144.121301,856.87818( 7.4 (1)已知:645.1%,901,12,81,1002/1.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的90%的置信区间为: 974.181100 12645.1812 /±=? ±=±n s z x α 即)974.82,026.79(
(2)已知:96.1%,951,12,81,1002/05.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的95%的置信区间为: 352.281100 1296.1812 /±=? ±=±n s z x α 即)352.83,648.78( (3)已知:58.2%,991,12,81,1002/05.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的99%的置信区间为: 096.381100 1258.2812 /±=? ±=±n s z x α 即)096.84,940.77( 7.5 (1)已知:96.1%,951,5.3,25,602/05.0==-===z x n ασ。 由于总体标准差已知,所以总体均值μ的95%的置信区间为: 89.02560 5.39 6.1252 /±=? ±=±n z x σ α 即)89.25,11.24( (2)已知:33.2%,981,89.23,6.119,752/02.0==-===z s x n α。 由于75=n 为大样本,所以总体均值μ的98%的置信区间为: 43.66.11975 89.2333.26.1192 /±=? ±=±n s z x α 即)03.126,17.113( (3)已知:645.1%,901,974.0,419.3,322/1.0==-===z s x n α。 由于32=n 为大样本,所以总体均值μ的90%的置信区间为: 283.0419.332 974.0645.1419.32 /±=? ±=±n s z x α 即)702.3,136.3(
第一章数据库系统概述 选择题 1实体-联系模型中,属性是指(C) A.客观存在的事物 B.事物的具体描述 C.事物的某一特征 D.某一具体事件 2对于现实世界中事物的特征,在E-R模型中使用(A) A属性描述B关键字描述C二维表格描述D实体描述 3假设一个书店用这样一组属性描述图书(书号,书名,作者,出版社,出版日期),可以作为“键”的属性是(A) A书号B书名C作者D出版社 4一名作家与他所出版过的书籍之间的联系类型是(B) A一对一B一对多C多对多D都不是 5若无法确定哪个属性为某实体的键,则(A) A该实体没有键B必须增加一个属性作为该实体的键C取一个外关键字作为实体的键D该实体的所有属性构成键 填空题 1对于现实世界中事物的特征在E-R模型中使用属性进行描述 2确定属性的两条基本原则是不可分和无关联 3在描述实体集的所有属性中,可以唯一的标识每个实体的属性称为键 4实体集之间联系的三种类型分别是1:1 、1:n 、和m:n 5数据的完整性是指数据的正确性、有效性、相容性、和一致性 简答题 一、简述数据库的设计步骤 答:1需求分析:对需要使用数据库系统来进行管理的现实世界中对象的业务流程、业务规则和所涉及的数据进行调查、分析和研究,充分理解现实世界中的实际问题和需求。 分析的策略:自下而上——静态需求、自上而下——动态需求 2数据库概念设计:数据库概念设计是在需求分析的基础上,建立概念数据模型,用概念模型描述实际问题所涉及的数据及数据之间的联系。 3数据库逻辑设计:数据库逻辑设计是根据概念数据模型建立逻辑数据模型,逻辑数据模型是一种面向数据库系统的数据模型。 4数据库实现:依据关系模型,在数据库管理系统环境中建立数据库。 二、数据库的功能 答:1提供数据定义语言,允许使用者建立新的数据库并建立数据的逻辑结构 2提供数据查询语言 3提供数据操纵语言 4支持大量数据存储 5控制并发访问 三、数据库的特点 答:1数据结构化。2数据高度共享、低冗余度、易扩充3数据独立4数据由数据库管理系统统一管理和控制:(1)数据安全性(2)数据完整性(3)并发控制(4)数据库恢复 第二章关系模型和关系数据库 选择题 1把E-R模型转换为关系模型时,A实体(“一”方)和B实体(“多”方)之间一对多联系在关系模型中是通过(A)来实现的
思考题与练习题 参考答案 【友情提示】请各位同学完成思考题与练习题后再对照参考答案。回答正确,值得肯定;回答错误,请找出原因更正,这样使用参考答案,能力会越来越高,智慧会越来越多。学而不思则罔,如果直接抄答案,对学习无益,危害甚大。想抄答案者,请三思而后行! 第一章绪论 思考题参考答案 1.不能,英军所有战机=英军被击毁的战机+英军返航的战机+英军没有弹孔的战机,因为英军被击毁的战机有的掉入海里、敌军占领区,或因堕毁而无形等,不能找回;没有弹孔的战机也不可能自己拿来射击后进行弹孔位置的调查。即便被击毁的战机找回或没有弹孔的战机自己拿来射击进行实验,也不能从多个弹孔中确认那个弹孔就是危险的。 2.问题:飞机上什么区域应该加强钢板?瓦尔德解决问题的思想:在她的飞机模型上逐个不重不漏地标示返航军机受敌军创伤的弹孔位置,找出几乎布满弹孔的区域;发现:没有弹孔区域就是军机的危险区域。 3.能,拯救与发展自己的参考路径为:①找出自己的优点,②明确自己大学阶段的最佳目标,③拟出一个发扬自己优点,实现自己大学阶段最佳目标的可行计划。 练习题参考答案 一、填空题 1.调查。
2.探索、调查、发现。 3、目的。 二、简答题 1.瓦尔德;把剩下少数几个没有弹孔的区域加强钢板。 2.统计学解决实际问题的基本思路,即基本步骤就是:①提出与统计有关的实际问题;②建立有效的指标体系;③收集数据;④选用或创造有效的统计方法整理、显示所收集数据的特征;⑤根据所收集数据的特征、结合定性、定量的知识作出合理推断;⑥根据合理推断给出更好决策的建议。不解决问题时,重复第②-⑥步。 3.在结合实质性学科的过程中,统计学就是能发现客观世界规律,更好决策,改变世界与培养相应领域领袖的一门学科。 三、案例分析题 1.总体:我班所有学生;单位:我班每个学生;样本:我班部分学生;品质标志:姓名;数量标志:每个学生课程的成绩;指标:全班学生课程的平均成绩 ;指标体系:上学期全班同学学习的科目 ;统计量:我班部分同学课程的平均成绩 ;定性数据:姓名 ;定量数据: 课程成绩 ;离散型变量:学习课程数;连续性变量:学生的学习时间;确定性变量:全班学生课程的平均成绩;随机变量:我班部分同学课程的平均成绩,每个同学进入教室的时间;横截面数据:我班学生月门课程的出勤率;时间序列数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;面板数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;选用描述统计。 2.(1)总体:广州市大学生;单位:广州市的每个大学生。(2)如果调查中了解的就是价格高低,为定序尺度;如果调查中了解的就是商品丰富、价格合适、节约时间,为定类尺度。(3)广州市大学生在网上购物的平均花费。(4)就是用统计量作为参数的估计。(5)推断统计。 3.(1)10。(2)6。(3)定类尺度:汽车名称,燃油类型;定序尺度:车型大小;定距尺度:引擎的汽缸数;定比尺度:市区驾车的油耗,公路驾车的油耗。(4)定性变量:汽车名称,车型大小,燃油类型;定量变量:引擎的汽缸数,市区驾车的油耗,公路驾车的油耗。(5)40%;(6)30%。 第二章收集数据 思考题参考答案
第七章习题参考答案 一.回答问题 1.软件测试的基本任务? 软件测试是按照特定的规则,发现软件错误的过程;好的测试方案是尽可能发现迄今尚未发现错误的测试;成功的测试方案是发现迄今尚未发现错误的测试; 2.测试与调试的主要区别? (1)(1) 测试从一个侧面证明程序员的失败;调试证明程序员的正确; (2)(2) 测试从已知条件开始,使用预先定义的程序,且有预知的结果,不 可预见的仅是程序是否通过测试;调试从不可知内部条件开始,除统计 性调试外,结果是不可预见的; (3)(3) 测试有计划并且要进行测试设计;调试不受时间约束; (4)(4) 测试是发现错误、改正错误、重新测试的过程;调试是一个推理的 过程; (5)(5) 测试执行是有规程的;调试执行要求程序员进行必要的推理; (6)(6) 测试由独立的测试组在不了解软件设计的件下完成;调试由了解详 细设计的程序员完成; (7)(7) 大多数测试的执行和设计可由工具支持;调试用的工具主要是调试 器。 3.人工复审的方式和作用? 人工复审的方式:代码会审、走查和排练和办公桌检查; 人工复审的作用:检查程序的静态错误。 4.什么是黑盒测试?黑盒测试主要采用的技术有哪些? 黑盒测试也称为功能测试,它着眼于程序的外部特征,而不考虑程序的内部逻辑结构。测试者把被测程序看成一个黑盒,不用关心程序的内部结构。黑盒测试是在程序接口处进行测试,它只检查程序功能是否能按照规格说明书的规定正常使用,程序是否能适当地接收输入数据产生正确的输出信息,并且保持外部信息(如数据库或文件)的完整性。 黑盒测试主要采用的技术有:等价分类法、边沿值分析法、错误推测法和因果图等技术。 5.什么是白盒测试?白盒测试主要采用的技术有哪些? 测试者了解被测程序的内部结构和处理过程,对程序的所有逻辑路径进行测试,在不同点检查程序状态,确定实际状态与预期状态是否一致。
第二章关系数据库 1 .试述关系模型的三个组成部分。 答:关系模型由关系数据结构、关系操作集合和关系完整性约束三部分组成。 2 .试述关系数据语言的特点和分类。 答:关系数据语言可以分为三类: 关系代数语言。 关系演算语言:元组关系演算语言和域关系演算语言。 SQL:具有关系代数和关系演算双重特点的语言。 这些关系数据语言的共同特点是,语言具有完备的表达能力,是非过程化的集合操作语言,功能强,能够嵌入高级语言中使用。 3 (略) 4 . 5 . 述关系模型的完整性规则。在参照完整性中,为什么外部码属性的值也可以为空?什么情况下才可以为空? 答:实体完整性规则是指若属性A是基本关系R的主属性,则属性A不能取空值。 若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须为:或者取空值(F的每个属性值均为空值);或者等于S中某个元组的主码值。即属性F本身不是主属性,则可以取空值,否则不能取空值。 6.设有一个SPJ数据库,包括S,P,J,SPJ四个关系模式: 1)求供应工程J1零件的供应商号码SNO: πSno(σJno=‘J1’(SPJ)) 2)求供应工程J1零件P1的供应商号码SNO: πSno(σJno=‘J1’∧Pno=‘P1‘(SPJ)) 3)求供应工程J1零件为红色的供应商号码SNO: πSno(πSno,,Pno(σJno=‘J1‘(SPJ))∞πPno(σCOLOR=’红‘(P))) 4)求没有使用天津供应商生产的红色零件的工程号JNO: πJno(SPJ)- πJNO(σcity=‘天津’∧Color=‘红‘(S∞SPJ∞P) 5)求至少用了供应商S1所供应的全部零件的工程号JNO: πJno,Pno(SPJ)÷πPno(σSno=‘S1‘(SPJ)) 7. 试述等值连接与自然连接的区别和联系。 答:连接运算符是“=”的连接运算称为等值连接。它是从关系R与S的广义笛卡尔积中选取A,B属性值相等的那些元组 自然连接是一种特殊的等值连接,它要求两个关系中进行比较的分量必须是相同的属性组,并且在结果中把重复的属性列去掉。 8.关系代数的基本运算有哪些? 如何用这些基本运算来表示其他运算? 答:并、差、笛卡尔积、投影和选择5种运算为基本的运算。其他3种运算,即交、连接和除,均可以用这5种基本运算来表达。 第三章关系数据库语言SQL 1 .试述sQL 语言的特点。 答: (l)综合统一。sQL 语言集数据定义语言DDL 、数据操纵语言DML 、数据控制语言DCL
社会统计学复习题有答 案 集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#
社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=- =-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% += -=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于品质标志;学生的体重、年龄、成绩属于数量标志。 10、从内容上看,统计表由主词和宾词两个部分组成;从格式上看,统计表由 总标题、横行标题、纵栏标题和指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于正相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于负相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于数量指标;单位成本属于质量指标。 13、如果相关系数r=0,则表明两个变量之间不存在线性相关关系。 二、判断题 1、在季节变动分析中,若季节比率大于100%,说明现象处在淡季;若季节比率小于100%,说明现象处在旺季。(×;答案提示:在季节变动分析中,若季节比率大于100%,说明现象处在旺季;若季节比率小于100%,说明现象处在淡季。 ) 2、工业产值属于离散变量;设备数量属于连续变量。(×;答案提示:工业产值属于连续变量;设备数量属于离散变量) 3、中位数与众数不容易受到原始数据中极值的影响。(√;) 4、有意识地选择十个具有代表性的城市调查居民消费情况,这种调查方式属于典型调查。(√)
附录:教材各章习题答案 第1章统计与统计数据 1.1(1)数值型数据;(2)分类数据;(3)数值型数据;(4)顺序数据;(5) 分类数据。 1.2(1)总体是“该城市所有的职工家庭”,样本是“抽取的2000个职工家 庭”;(2)城市所有职工家庭的年人均收入,抽取的“2000个家庭计算出的年人均收入。 1.3(1)所有IT从业者;(2)数值型变量;(3)分类变量;(4)观察数据。 1.4(1)总体是“所有的网上购物者”;(2)分类变量;(3)所有的网上购物 者的月平均花费;(4)统计量;(5)推断统计方法。 1.5(略)。 1.6(略)。 第2章数据的图表展示 2.1(1)属于顺序数据。 (2)频数分布表如下 (4)帕累托图(略)。 2.2(1)频数分布表如下
2.5(1)排序略。 (2)频数分布表如下 (4)茎叶图如下
2.6 (3)食品重量的分布基本上是对称的。 2.7 2.8(1)属于数值型数据。
2.9 (1)直方图(略)。 (2)自学考试人员年龄的分布为右偏。 比A 班分散, 且平均成绩较A 班低。 2.11 (略)。 2.12 (略)。 2.13 (略)。 2.14 (略)。 2.15 箱线图如下:(特征请读者自己分析) 第3章 数据的概括性度量 3.1 (1)100=M ;10=e M ;6.9=x 。
(2)5.5=L Q ;12=U Q 。 (3)2.4=s 。 (4)左偏分布。 3.2 (1) 19 0=M ; 23 =e M 。 (2)5.5=L Q ;12=U Q 。 (3)24=x ;65.6=s 。 (4)08.1=SK ;77.0=K 。 (5)略。 3.3 (1)略。 (2)7=x ;71.0=s 。 (3)102.01=v ;274.02=v 。 (4)选方法一,因为离散程度小。 3.4 (1)x =274.1(万元);M e=272.5 。 (2)Q L =260.25;Q U =291.25。 (3)17.21=s (万元)。 3.5 甲企业平均成本=19.41(元),乙企业平均成本=18.29(元);原 因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。 3.6 (1)x =426.67(万元);48.116=s (万元)。 (2)203.0=SK ;688.0-=K 。 3.7 (1)(2)两位调查人员所得到的平均身高和标准差应该差不多相 同,因为均值和标准差的大小基本上不受样本大小的影响。 (3)具有较大样本的调查人员有更大的机会取到最高或最低者,因为样本越大,变化的围就可能越大。 3.8 (1)女生的体重差异大,因为女生其中的离散系数为0.1大于男 生体重的离散系数0.08。 (2) 男生:x =27.27(磅),27.2=s (磅); 女生:x =22.73(磅),27.2=s (磅); (3)68%; (4)95%。 3.9 通过计算标准化值来判断,1=A z ,5.0=B z ,说明在A项测试中 该应试者比平均分数高 出1个标准差,而在B 项测试中只高出平均分数0.5个标准差,由于A 项测试的标准化值高于B 项测试,所以A 项测试比较理想。 3.10 通过标准化值来判断,各天的标准化值如下表 日期 周一 周二 周三 周四 周五 周六 周日 标准化值Z 3 -0.6 -0.2 0.4 -1.8 -2.2 0 周一和周六两天失去了控制。