实验五—缓冲区分析应用(综合实验)
实验报告
一、实验目的
缓冲区分析是用来确定不同地理要素的空间邻近性和邻近程度的一类重要的空间操作,通过本次实习,我们应达到以下目的:
1.加深对缓冲区分析基本原理、方法的认识;
2.熟练掌握距离制图创建缓冲区技术方法。
3.掌握利用缓冲区分析方法解决地学空间分析问题的能力。
二、实验数据准备
数据准备:图层文件point.shp,lline.shp,polygon.shp (ex6.rar)
三、实验内容与步骤
1. 距离制图-创建缓冲区
1.1 点要素图层的缓冲区分析
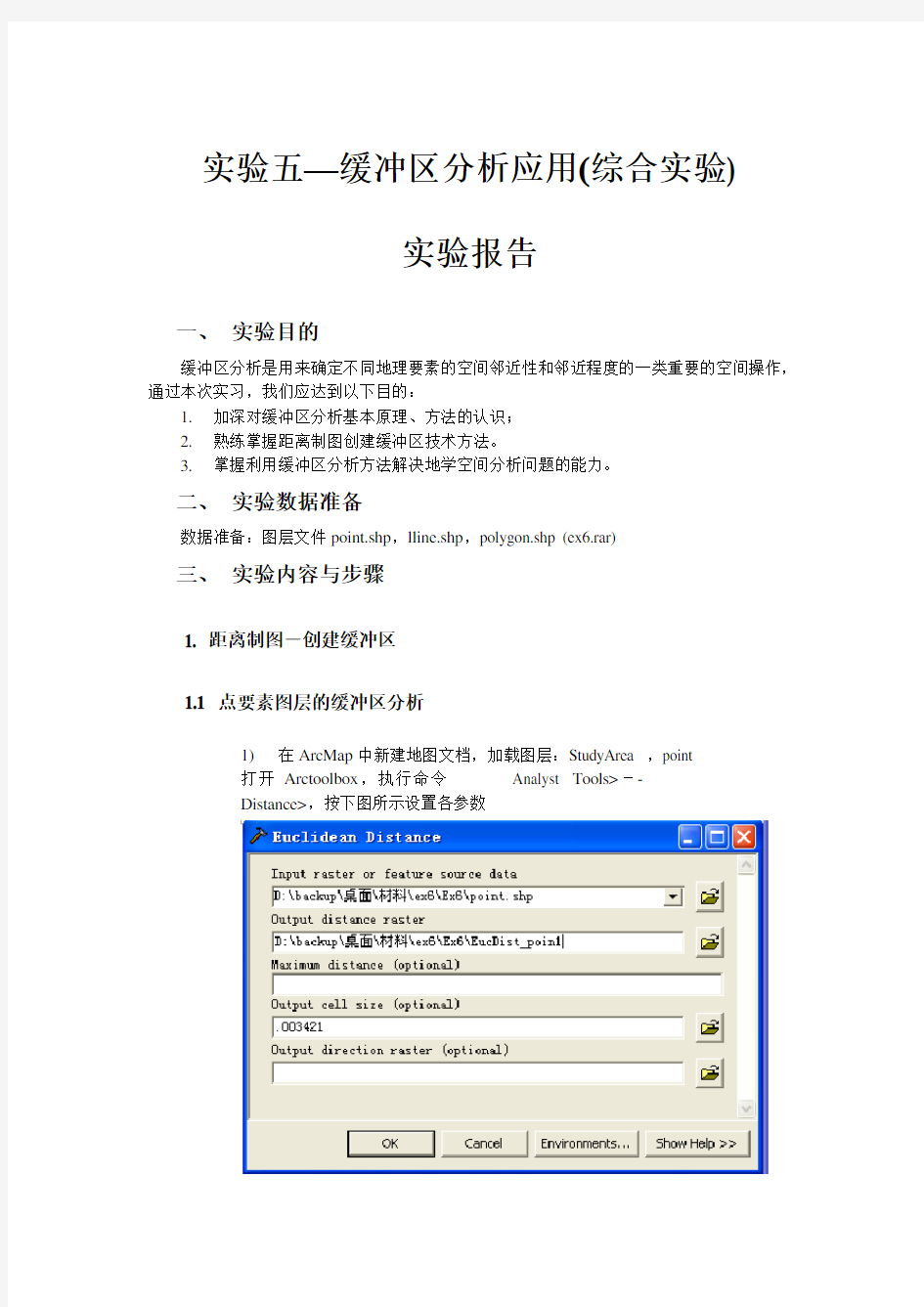
1)在ArcMap中新建地图文档,加载图层:StudyArea ,point
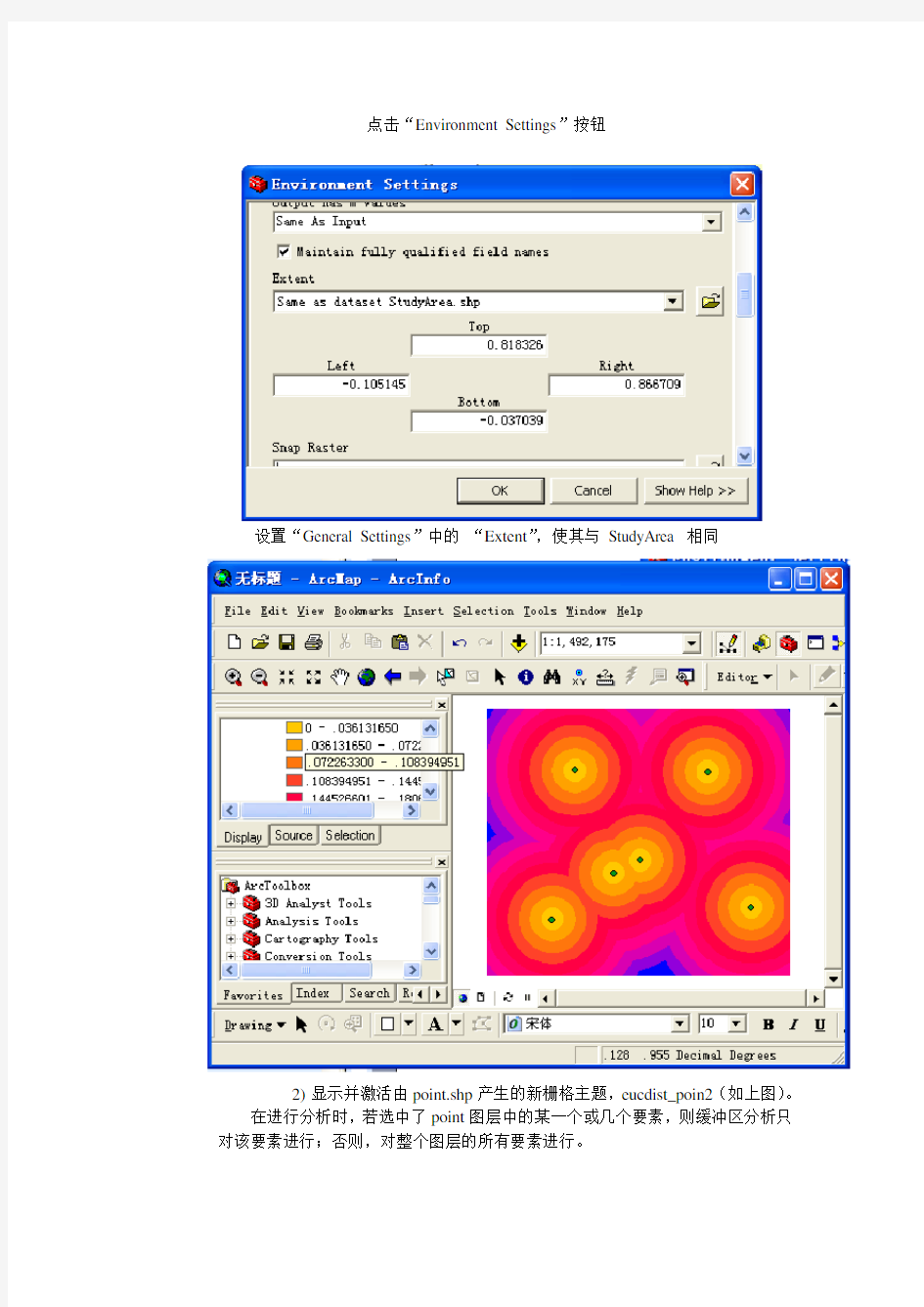
打开Arctoolbox,执行命令 Distance>,按下图所示设置各参数 点击“Environment Settings”按钮 设置“General Settings”中的“Extent”,使其与StudyArea 相同 2)显示并激活由point.shp产生的新栅格主题,eucdist_poin2(如上图)。 在进行分析时,若选中了point图层中的某一个或几个要素,则缓冲区分析只对该要素进行;否则,对整个图层的所有要素进行。 1.2 线要素图层的缓冲区分析 1)在ArcMap中,新建地图文档,加载line图层,点击常用工具栏中的 将地图适当缩小。 2)分别选中图层line中的两条线,进行缓冲区分析,注意比较线的缓冲 区分析与点的缓冲区分析有何不同。 方法:打开Arctoolbox,执行命令 设置“Environment Settings”中“General Settings”中的“Extent”为“Same As Display” 3)取消选定,对整个line层面进行缓冲区分析,观察与前两个分析结果的区别(如下图)。 1.3 多边形图层的缓冲区分析 在ArcMap中新建地图文档,添加图层:polygon,进行缓冲区分析,观察面的缓冲区分析与点、线的缓冲区分析有何区别。 与创建线的缓冲区相同,先将地图适当缩小,将“Environment Settings”中“General Settings”中的“Extent”为“Same As Display” 2.综合应用实验 2.1 水源污染防治 Point图层面表示了水源(如:水井)的位置分布,要求利用缓冲区分析找出水源污染防治的重点区域。 步骤: (1)在ArcMap中,新建地图文档,添加表示水源分布的点图层数据point.shp。 (2)打开ArcToolbox,执行 Distance >命令。 (3)显示并激活由point.shp产生的新栅格图层eucdist_poi1(如下图)。 (4)右键点击栅格图层eucdist_poi1,在右键菜单中执行“属性”命令,设置图层显示符号,可调整分类和设置图例显示方式。 新的栅格图层显示了区域内每个栅格距最近的水井的距离,其中黄色的栅格距各个井的距离最近,对水源的影响最大;蓝色的栅格距各个井的距离最远,影响最小。 (5).在本例中认为距各个水井0.1以内的区域对水质的影响和污染最大,因此,打开“Spatial Analyst”工具栏(首先要确保“Spatial Analyst”扩展模块已经加载),执行菜单命令< Spatial Analyst >- 2.2 受污染地区的分等定级 假定:point图层表示的是几个点状污染源,距污染源的远近不同,受污染的状况也不同,距污染源越近,受污染越严重,据此对污染源附近地区进行分等定级。 (1)在ArcMap中,新建地图文档,添加图层:point.、StudyArea。打开ArcToolbox, 执行 (2)打开“空间分析”工具栏,执行命令:<空间分析>-<栅格计算器>,基于栅格图层Dist_of_point进行栅格计算,分别提取([Dist_of_point2]≤0.1)和区域、及 ([dist_of_point2] >= 0.1 & [dist_of_point2] <= 0.15)的区域,分别得到栅格图层:“计算”和“计算2”; (3)对栅格图层:“计算2”进行重分类运算(执行命令<空间分析>-<重分类>命令),使得原来的True(1)值为0,False(0)值为1,得到新的栅格图层:Reclass of 计算2。 (4)将图层“计算”与“Reclass of 计算2”相加(执行命令:<空间分析>-<栅格计算器>),得到中间结果:计算3:执行命令<空间分析>-<重分类>对栅格图层“计算3”按分等定级的要求进行分类得到结果栅格图层“Reclass of计算3”。 (<=0.1的区域污染级别定为1,)=0.1且<=0.15的区域级别定为2, >0.15的区域级别定为3) 说明:本例中,第(2)-(4)操作实际可以直接对栅格图层dist_of_point进行重分类得到。 2.3 城市化的影响范围 假定:urban图层表示的是城市化进程中的一些工业小城镇,还包括一个自然生态保护区。这些小城镇的城市化会对周边地区产生一些扩张影响,但自然生态保护区周围0.05的范围内不能有污染性的工业,因此其城市化的范围就受到限制。 (1)在ArcMap中,新建地图文档,添加图层:urban.shp、UrbanArea,对urban 图层中的自然保护区图斑(属性Type=”保护区”)执行[ 注意:“环境设置”设置中,常规设置->的输出范围请选择为:Same As UrbanArea 保护区的缓冲区城镇的缓冲区 (2)对图层Dist_Nature执行栅格计算(使用空间分析工具中的栅格计算器),提取<=0.05的区域,并进行重分类,使得原来的True(1)值为0,False(0)值为1,得到“Reclass of 计算”。 HUNAN UNIVERSITY 课程实验报告 题目: Buflab-handout 学生姓名 学生学号 专业班级计科1403 (一)实验环境 联想ThinkPadE540 VM虚拟机ubuntu32位操作系统 (二)实验准备 1.使用tar xvf命令解压文件后,会有3个可执行的二进制文件bufbomb,hex2raw, makecookie。bufbomb运行时会进入getbuf函数,其中通过调用Gets函数读取字符 串。要求在已知缓冲区大小的情况下对输入的字符串进行定制完成特定溢出操作。 从给的PDF文件中我们得知getbuf函数为: / /Buffer size for getbuf #define NORMAL_BUFFER_SIZE 32 int getbuf() { char buf[NORMAL_BUFFER_SIZE]; Gets(buf); return 1; } 这个函数的漏洞在于宏定义的缓冲区的大小为32,若输入的字符串长于31(字符串末尾结束符)则会导致数据的覆盖,从而导致一系列损失;在此实验中,我们正是利用这个漏洞来完成实验。 2. hex2raw可执行文件就是将给定的16进制的数转成二进制字节数据。 Makecookie是产生一个userid。输入的相应的用户名产生相应的cookie值。 **我产生的cookie值为0x5eb52e1c,如下图所示: Level0: 实验要求:从英文的PDF文件中的“Your task is to get BUFBOMB to execute the code for smoke when getbuf executes its return statement, rather than returning to test. Note that your exploit string may also corrupt parts of the stack not directlyrelated to this stage, but this will not cause a problem, since smoke causes the program to exit directly.”这句话看出实验让我们在test运行完后,不直接退出,而是跳到smoke函数处执行然后退出,这点很重要!(本人之前一直没有成功就是错在这儿) Test源码: void test() { int val; // Put canary on stack to detect possible corruption volatile int local = uniqueval(); val = getbuf(); // Check for corrupted stack if (local != uniqueval()) { printf("Sabotaged!: the stack has been corrupted\n"); } else if (val == cookie) { printf("Boom!: getbuf returned 0x%x\n", val); validate(3); 《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日 1.实验目的 基于https://www.doczj.com/doc/c517999418.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.doczj.com/doc/c517999418.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度; 练习 6 综合练习:缓冲区分析的应用 缓冲区分析是用来确定不同地理要素的空间邻近性和邻近程度的一类重要的空间操作,通过本次实习,我们应达到以下目的: 1、加深对缓冲区分析基本原理、方法的认识; 2、熟练掌握距离制图创建缓冲区技术方法。 3、掌握利用缓冲区分析方法解决地学空间分析问题的能力。 1. 距离制图-创建缓冲区 (1) 1.1 点数据的缓冲区分析 (1) 1.2 线要素图层的缓冲区分析 (4) 1.3 多边形图层的缓冲区分析 (6) 2.综合应用实验 (7) 2.1 水源污染防治 (7) 2.2 受污染地区的分等定级 (9) 2.3 城市化的影响范围 (12) 1. 距离制图-创建缓冲区 数据准备:图层文件point.shp,lline.shp,polygon.shp 1.1 点要素图层的缓冲区分析 1)在ArcMap中新建地图文档,加载图层:StudyArea ,point 2)打开Arctoolbox,执行命令 注:在ArcView GIS 3.x中Find Distance功能与ArcGIS 中<<欧几里德距离>制图功能相同。 点击“环境设置”按钮 设置“常规选项”中的“输入范围”,使其与 StudyArea 相同 3)显示并激活由point.shp产生的新栅格主题,eucdist_poin(如上图)。 在进行分析时,若选中了point图层中的某一个或几个要素,则缓冲区分析只对该 要素进行;否则,对整个图层的所有要素进行。 1.2 线要素图层的缓冲区分析 1)在ArcMap中,新建地图文档,加载line图层,点击常用工具栏中的将地 图适当缩小。 缓冲区溢出漏洞实验 一、实验描述 缓冲区溢出是指程序试图向缓冲区写入超出预分配固定长度数据的情况。这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片段。这一漏洞的出现是由于数据缓冲器和返回地址的暂时关闭,溢出会引起返回地址被重写。 二、实验准备 本次实验为了方便观察汇编语句,我们需要在32位环境下作操作,因此实验之前需要做一些准备。 1、输入命令安装一些用于编译32位C程序的东西: sudo apt-get update sudo apt-get install lib32z1 libc6-dev-i386 sudo apt-get install lib32readline-gplv2-dev 2、输入命令“linux32”进入32位linux环境。此时你会发现,命令行用起来没那么爽了,比如不能tab补全了,所以输入“/bin/bash”使用bash: 三、实验步骤 3.1 初始设置 Ubuntu和其他一些Linux系统中,使用地址空间随机化来随机堆(heap)和栈(stack)的初始地址,这使得猜测准确的内存地址变得十分困难,而猜测内存地址是缓冲区溢出攻击的关键。因此本次实验中,我们使用以下命令关闭这一功能: sudo sysctl -w kernel.randomize_va_space=0 此外,为了进一步防范缓冲区溢出攻击及其它利用shell程序的攻击,许多shell程序在被调用时自动放弃它们的特权。因此,即使你能欺骗一个Set-UID程序调用一个shell,也不能在这个shell中保持root权限,这个防护措施在/bin/bash中实现。 linux系统中,/bin/sh实际是指向/bin/bash或/bin/dash的一个符号链接。为了重现这一防护措施被实现之前的情形,我们使用另一个shell程序(zsh)代替/bin/bash。下面的指令描述了如何设置zsh程序: sudo su cd /bin rm sh ln -s zsh sh exit 3.2 shellcode 一般情况下,缓冲区溢出会造成程序崩溃,在程序中,溢出的数据覆盖了返回地址。而如果覆盖返回地址的数据是另一个地址,那么程序就会跳转到该地址,如果该地址存放的是一段精心设计的代码用于实现其他功能,这段代码就是shellcode。 观察以下代码: #include 数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602 一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include 实验三缓冲区分析及地图输出 一、实验要求 1.了解缓冲区的用途 2.学会缓冲区设置方法 分别以东陵路及三环路为中心设置100米间隔的5条缓冲带;以校食堂为中心设置500米间隔的1条缓冲带。 3.分类显示矢量要素 实验材料:landuse.shp 4.遥感影像波段设置 5.分级显示栅格文件 实验材料:depth(grid文件) 6.实验结果一:制作土地分类图;实验结果二:栅格文件分级图 将第3步结果图件,即根据landuse按土地分类制作土地利用分类图;将第5步结果文件depth分级图插入实验结果中。 二、实验步骤 1.了解缓冲区的用途 缓冲区是指以点、线、面实体为基础,自动建立其周围一定宽度围的缓冲区多边形图层。缓冲区分析是地理信息系统重要的空间分析功能之一,它在交通、林业资源管理、城市规划中有着广泛的应用,例如湖泊和河流周围的保护区的定界、汽车服务区的选择、民宅区远离街道网络的缓冲区的建立等。 2. 学会缓冲区设置方法 分别以东陵路及三环路为中心设置100米间隔的5条缓冲带;以校食堂为中心设置500米间隔的1条缓冲带。 步骤 软件打开后,在tools工具栏下找到customize,具体操作如图所示, 最后把设置缓冲区的快捷键拖出到工具栏上。 打开图像,按要求分别在三环和东陵路上创建线条,图层选择线的图层b, 点击设置缓冲区的快捷键,对话框中图层选择b,点击下一步 按要求具体操作如图所示,注意单位是米,点击下一步 注意文件名和储存位置,以便下次使用,点击完成 输出图像如图所示 接下来做食堂的缓冲区,注意图层不要选错。点击下一步。 Ex7:缓冲区分析 一、 目的 缓冲区分析是用来确定不同地理要素的空间邻近性和邻近程度的一类重要的空间操作,通过本次实习,我们应达到以下目的: 1、 加深对缓冲区分析基本原理、方法的认识; 2、 熟练掌握ARCVIEW 缓冲区分析的技术方法。 3、 掌握利用缓冲区分析方法解决地学空间分析问题的能力。 二、 实验准备 1、 软件准备:Arcview 2、 数据准备:文件point.dbf ,point.shp ,point.shx (点文件),文件line.dbf , line.shp ,line.shx (线文件),文件polygon.dbf ,polygon.shp ,polygon.shx (面文件), 三、 实验内容 1、 原理验证实验 (1) 点数据的缓冲区分析 1) 新建视图,在视图中添加point 层面并激活; 2) 在【Analysis 】菜单中选择【Find mapping 】命令; 3) 显示并激活由point.shp 产生的新栅格主题,Distance to point.shp (如图 1)。 在进行分析时,若选中了point 层面中的某一个或几个要素,则缓冲区分析只对该要素进行;否则,对整个层面的所有要素进行。 (2) 线数据的缓冲区分析 1) 新建视图,在视图中添加line 层面并激活; 2) 分别选中line 层面中的两条线,进行缓冲区分析,注意比较线的缓冲区分析 与点的缓冲区分析有何不同。 3) 取消选定,对整个line 层面进行缓冲区分析,观察与前两个分析结果的区别 (如图2)。 (3) 面数据的缓冲区分析 新建视图,添加polygon 层面,进行缓冲区分析,观察面的缓冲区分析与点、线的缓冲区分析有何区别。(如图3) 图1. point 层面的缓冲区分析 深圳大学实验报告课程名称:计算机系统(2) 实验项目名称:缓冲区溢出攻击实验 学院:计算机与软件学院 专业:计算机科学与技术 指导教师:罗秋明 报告人: 实验时间:2016年5月8日 实验报告提交时间:2016年5月22日 教务处制 一、实验目标: 1.理解程序函数调用中参数传递机制; 2.掌握缓冲区溢出攻击方法; 3.进一步熟练掌握GDB调试工具和objdump反汇编工具。 二、实验环境: 1.计算机(Intel CPU) 2.Linux64位操作系统(CentOs) 3.GDB调试工具 4.objdump反汇编工具 三、实验内容 本实验设计为一个黑客利用缓冲区溢出技术进行攻击的游戏。我们仅给黑客(同学)提供一个二进制可执行文件bufbomb和部分函数的C代码,不提供每个关卡的源代码。程序运行中有3个关卡,每个关卡需要用户输入正确的缓冲区内容,否则无法通过管卡! 要求同学查看各关卡的要求,运用GDB调试工具和objdump反汇编工具,通过分析汇编代码和相应的栈帧结构,通过缓冲区溢出办法在执行了getbuf()函数返回时作攻击,使之返回到各关卡要求的指定函数中。第一关只需要返回到指定函数,第二关不仅返回到指定函数还需要为该指定函数准备好参数,最后一关要求在返回到指定函数之前执行一段汇编代码完成全局变量的修改。 实验代码bufbomb和相关工具(sendstring/makecookie)的更详细内容请参考“实验四缓冲区溢出攻击实验.p ptx”。 本实验要求解决关卡1、2、3,给出实验思路,通过截图把实验过程和结果写在实验报告上。 四、实验步骤和结果 步骤1 返回到smoke() 1.1 解题思路 首先弄清楚getbuf()的栈帧结构,知道存放字符数组buf地址的单元和存放getbuf()返回地址的单元之间相差多少个字节。假设两者之间相差x个字节。 然后找到smoke()函数的入口地址。该值为4个字节。 再构造exploit.txt,前x个字节随意填,然后再填入4个字节的smoke()地址,注意是小端方式存储。 这样操作完成,就可以得到预期结果了。 1.2 解题过程 首先进入GDB对bufbomb进行调试,先在调用getbuf()处设置断点,然后运行。 注:此时的输入文件exploit_raw.txt文件中是随便填的,并不影响我调用smoke(),因为我会在gdb中使用set指令直接修改getbuf()的返回地址。 此时查看运行程序的调用栈帧结构,如下所示: 上图说明当getbuf()执行完后,会返回到test()函数中(返回到地址0x08048db2,我们要修改存放这个值的地址单元,改为smoke的入口地址值)。 大数据理论与技术读书报告 -----K最近邻分类算法 指导老师: 陈莉 学生姓名: 李阳帆 学号: 201531467 专业: 计算机技术 日期 :2016年8月31日 摘要 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。K 近邻算法(KNN)是基于统计的分类方法,是大数据理论与分析的分类算法中比较常用的一种方法。该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。本文主要研究了K 近邻分类算法,首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,最后在matlab环境里仿真实现,并对实验结果进行分析,提出了改进的方法。 关键词:K 近邻,聚类算法,权重,复杂度,准确度 1.引言 (1) 2.研究目的与意义 (1) 3.算法思想 (2) 4.算法实现 (2) 4.1 参数设置 (2) 4.2数据集 (2) 4.3实验步骤 (3) 4.4实验结果与分析 (3) 5.总结与反思 (4) 附件1 (6) 1.引言 随着数据库技术的飞速发展,人工智能领域的一个分支—— 机器学习的研究自 20 世纪 50 年代开始以来也取得了很大进展。用数据库管理系统来存储数据,用机器学习的方法来分析数据,挖掘大量数据背后的知识,这两者的结合促成了数据库中的知识发现(Knowledge Discovery in Databases,简记 KDD)的产生,也称作数据挖掘(Data Ming,简记 DM)。 数据挖掘是信息技术自然演化的结果。信息技术的发展大致可以描述为如下的过程:初期的是简单的数据收集和数据库的构造;后来发展到对数据的管理,包括:数据存储、检索以及数据库事务处理;再后来发展到对数据的分析和理解, 这时候出现了数据仓库技术和数据挖掘技术。数据挖掘是涉及数据库和人工智能等学科的一门当前相当活跃的研究领域。 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地抽取出有价值的知识模式,以满足人们不同应用的需要[1]。目前,数据挖掘已经成为一个具有迫切实现需要的很有前途的热点研究课题。 2.研究目的与意义 近邻方法是在一组历史数据记录中寻找一个或者若干个与当前记录最相似的历史纪录的已知特征值来预测当前记录的未知或遗失特征值[14]。近邻方法是数据挖掘分类算法中比较常用的一种方法。K 近邻算法(简称 KNN)是基于统计的分类方法[15]。KNN 分类算法根据待识样本在特征空间中 K 个最近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无师学习等特点,从而成为非参数分类的一种重要方法。 大多数分类方法是基于向量空间模型的。当前在分类方法中,对任意两个向量: x= ) ,..., , ( 2 1x x x n和) ,..., , (' ' 2 ' 1 'x x x x n 存在 3 种最通用的距离度量:欧氏距离、余弦距 离[16]和内积[17]。有两种常用的分类策略:一种是计算待分类向量到所有训练集中的向量间的距离:如 K 近邻选择K个距离最小的向量然后进行综合,以决定其类别。另一种是用训练集中的向量构成类别向量,仅计算待分类向量到所有类别向量的距离,选择一个距离最小的类别向量决定类别的归属。很明显,距离计算在分类中起关键作用。由于以上 3 种距离度量不涉及向量的特征之间的关系,这使得距离的计算不精确,从而影响分类的效果。 实验六、缓冲区分析应用(综合实验) 一、实验目的 缓冲区分析是用来确定不同地理要素的空间邻近性和邻近程度的一类重要的空间操作, 通过本次实习,我们应达到以下目的: 1.加深对缓冲区分析基本原理、方法的认识; 2.熟练掌握距离制图创建缓冲区技术方法。 3.掌握利用缓冲区分析方法解决地学空间分析问题的能力。 二、实验准备 数据准备:图层文件point.shp,lline.shp,polygon.shp 三、实验内容及步骤 1. 距离制图-创建缓冲区 1.1 点要素图层的缓冲区分析 1)在ArcMap中新建地图文档,加载图层:StudyArea ,point 2)打开Arctoolbox,执行命令 设置“常规选项”中的“输入范围”,使其与StudyArea 相同 3)显示并激活由point.shp产生的新栅格主题,eucdist_poin(如上图)。 在进行分析时,若选中了point图层中的某一个或几个要素,则缓冲区分析只对该要素进行;否则,对整个图层的所有要素进行。 1.2 线要素图层的缓冲区分析 1)在ArcMap中,新建地图文档,加载line图层,点击常用工具栏中的 将地图适当缩小。 2)分别选中图层line中的两条线,进行缓冲区分析,注意比较线的缓冲 区分析与点的缓冲区分析有何不同。 方法:打开Arctoolbox,执行命令 山东大学软件学院 信息安全导论课程实验报告 学号:201300301385 姓名:周强班级: 2013级八班 实验题目:缓冲区溢出实验 实验学时:日期: 实验目的: (1)了解缓冲区溢出的原理 (2)利用缓冲区溢出现象构造攻击场景 (3)进一步思考如何防范基于缓冲区溢出的攻击 硬件环境: 软件环境: WindowsXP操作系统 VS2008 实验步骤与内容: (1)了解缓冲区溢出的原理 缓冲区溢出简单来说就是计算机对接收的输入数据没有进行有效的检测(理情况下是程序检测数据长度并不允许输入超过缓冲区长度的字符),向缓冲区内填充数据时超过了缓冲区本身的容量,而导致数据溢出到被分配空间之外的内存空间,使得溢出的数据覆盖了其他内存空间的数据。 看一个代码实例,程序如下: void function(char *str) { char buffer[16]; strcpy(buffer,str); } 上面的strcpy()将直接把str中的内容copy到buffer中。这样只要str的长度大于16,就会造成buffer的溢出,使程序运行出错。 (2)利用缓冲区溢出现象构造攻击场景 首先打开Microsoft Visual C++,新建工程和cpp文件,复制实验指导书的代码进行编译连接: 单击运行按钮,然后第1次输入“zhouqianga”,第2次输入2个“ga”,即可看到输出“correct”。 按F10开始进行逐步调试: 当第一次执行gets()函数之前,内存情况如下图所示 在最新的版本中gets被认为是不安全的,gets从标准输入设备读字符串函数。可以无限读取,不会判断上限,以回车结束读取,所以程序员应该确保buffer的空间足够大,以便在执行读操作时不发生溢出。现在都被要求改为get_s。来防止溢出。 如下图所示。 (3)学习例子程序2:数据被执行 在xp系统下,直接运行Exploit-1.1.exe,如下图所示: 数据挖掘实验报告(二)关联规则挖掘 姓名:李圣杰 班级:计算机1304 学号:1311610602 一、实验目的 1. 1.掌握关联规则挖掘的Apriori算法; 2.将Apriori算法用具体的编程语言实现。 二、实验设备 PC一台,dev-c++5.11 三、实验内容 根据下列的Apriori算法进行编程: 四、实验步骤 1.编制程序。 2.调试程序。可采用下面的数据库D作为原始数据调试程序,得到的候选1项集、2项集、3项集分别为C1、C2、C3,得到的频繁1项集、2项集、3项集分别为L1、L2、L3。 代码 #include 实验五—缓冲区分析应用(综合实验) 实验报告 一、实验目的 缓冲区分析是用来确定不同地理要素的空间邻近性和邻近程度的一类重要的空间操作,通过本次实习,我们应达到以下目的: 1.加深对缓冲区分析基本原理、方法的认识; 2.熟练掌握距离制图创建缓冲区技术方法。 3.掌握利用缓冲区分析方法解决地学空间分析问题的能力。 二、实验数据准备 据准备:图层文件point.shp,lline.shp,polygon.shp (ex6.rar) 三、实验内容与步骤 1. 距离制图-创建缓冲区 1.1 点要素图层的缓冲区分析 1)在ArcMap中新建地图文档,加载图层:StudyArea ,point 打开Arctoolbox,执行命令 点击“Environment Settings”按钮 设置“General Settings”中的“Extent”,使其与StudyArea 相同 2)显示并激活由point.shp产生的新栅格主题,eucdist_poin2(如上图)。 在进行分析时,若选中了point图层中的某一个或几个要素,则缓冲区分析只对该要素进行;否则,对整个图层的所有要素进行。 1.2 线要素图层的缓冲区分析 1)在ArcMap中,新建地图文档,加载line图层,点击常用工具栏中的 将地图适当缩小。 2)分别选中图层line中的两条线,进行缓冲区分析,注意比较线的缓冲 区分析与点的缓冲区分析有何不同。 方法:打开Arctoolbox,执行命令 一、实验目的: 理解缓冲区分析和叠置分析的基本原理,学习利用arcgis进行缓冲区分析、叠加分析的操作,掌握如何合理利用空间分析中的缓冲区分析和叠置分析解决实际问题。 二、实验准备 1、实验背景: A.市区择房 随着商品房的发展,由于房屋的可选择余地越来越大,而且综合考虑小孩成长的缘故,所以越来越多的购房者对房屋的地段、环境,上学是否便捷,是否靠近名校等方面都提出了要求,所以综合考虑上述的因素,购房者就需要从总体上对商品房的信息进行研究分析,从而选择最适宜的购房地段。要求:所寻求的市区是噪声要小,距离商业中心要近,要和各大名牌高中离的近以便小孩容易上学,离名胜古迹较近环境优雅。综合上述条件,给定一个定量的限定如下: 离主要市区交通要道200米之外,交通要道的车流量大,噪音产生主要源于此;(ST为道路类型中的主要市区交通要道) 距大型商业中心的影响,以商业中心的大小来确定影响区域,具体是以其属性字段YUZHI; 距名牌高中在750米之内,以便小孩上学便捷; 距名胜古迹500米之内。 最后分别将满足上述条件的其中一个条件的取值为1,不满足的取值为0,即如果满足距主要市区交通要道200米之内,取值为1,反之为0;其他亦是如此,最后将其累加得到分级。即满足三个条件的累加得到3,满足2个条件的得到2,最后将全部分成4级。 B.学校选址 学校的选址问题需要考虑地理位置、学生娱乐场所配套、与现有学校的距离间隔等因素,从总体上把握这些因素能够确定出适宜性比较好的学校选址区。综合上述条件,给定新学校选址要求: 新学校应位于地势较平坦处; 新学校的建立应结合现有土地利用类型综合考虑,选择成本不高的区域; 新学校应该与现有娱乐设施相配套,学校距离这些设施愈近愈好; 新学校应避开现有学校,合理分布。 各数据层权重比为:距离娱乐设施占0.5,距离学校占0.25,土地利用类型和地势位置因素各占0.125。最后必须给出适合新建学校的适宜地区图,并对其简要进行分析。 2、实验材料: 软件:ArcGIS Desktop 9.x , 实验数据:文件夹ex5中 (1)市区择房数据:城市市区交通网络图“network.shp”、商业中心分布图 课程实验报告课程名称:计算机系统基础 专业班级: 学号: 姓名: 指导教师: 报告日期:年月日 计算机科学与技术学院 目录 实验1: (1) 实验2: (7) 实验3: (24) 实验总结 (34) 实验1:数据表示 1.1 实验概述 实验目的:更好地熟悉和掌握计算机中整数和浮点数的二进制编码表示。 实验目标:加深对数据二进制编码表示的了解。 实验要求:使用有限类型和数量的运算操作实现一组给定功能的函数。 实验语言:c。 实验环境:linux 1.2 实验内容 需要完成bits.c中下列函数功能,具体分为三大类:位操作、补码运算和浮点数操作。 1)位操作 表1列出了bits.c中一组操作和测试位组的函数。其中,“级别”栏指出各函数的难度等级(对应于该函数的实验分值),“功能”栏给出函数应实现的输出(即功能),“约束条件”栏指出你的函数实现必须满足的编码规则(具体请查看bits.c中相应函数注释),“最多操作符数量”指出你的函数实现中允许使用的操作符的最大数量。 你也可参考tests.c中对应的测试函数来了解所需实现的功能,但是注意这些测试函数并不满足目标函数必须遵循的编码约束条件,只能用做关于目标函数正确行为的参考。 表1 位操作题目列表 2)补码运算 表2列出了bits.c中一组使用整数的补码表示的函数。可参考bits.c中注释说明和tests.c中对应的测试函数了解其更多具体信息。 表2 补码运算题目列表 3)浮点数操作 表3列出了bits.c中一组浮点数二进制表示的操作函数。可参考bits.c中注释说明和tests.c中对应的测试函数了解其更多具体信息。注意float_abs的输入参数和返回结果(以及float_f2i函数的输入参数)均为unsigned int类型,但应作为单精度浮点数解释其32 bit二进制表示对应的值。 表3 浮点数操作题目列表 一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff) 对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮: 缓冲区溢出攻击实验报告 班级:10网工三班学生姓名:谢昊天学号:46 实验目的和要求: 1、掌握缓冲区溢出的原理; 2、了解缓冲区溢出常见的攻击方法和攻击工具; 实验内容与分析设计: 1、利用RPC漏洞建立超级用户利用工具文件检测RPC漏洞,利用工具软件对进行攻击。攻击的结果将在对方计算机上建立一个具有管理员权限的用户,并终止了对方的RPC服务。 2、利用IIS溢出进行攻击利用软件Snake IIS溢出工具可以让对方的IIS溢出,还可以捆绑执行的命令和在对方计算机上开辟端口。 3、利用WebDav远程溢出使用工具软件和远程溢出。 实验步骤与调试过程: 1.RPC漏洞出。首先调用RPC(Remote Procedure Call)。当系统启动的时候,自动加载RPC服务。可以在服务列表中看到系统的RPC服务。利用RPC漏洞建立超级用户。首先,把文件拷贝到C盘跟目录下,检查地址段到。点击开始>运行>在运行中输入cmd>确定。进入DOs模式、在C盘根目录下输入 -,回车。检查漏洞。 2.检查缓冲区溢出漏洞。利用工具软件对进行攻击。在进入DOC模式、在C盘根目录下输入 ,回车。 3,利用软件Snake IIS溢出工具可以让对方的IIS溢出。进入IIS溢出工具软件的主界面. PORT:80 监听端口为813 单击IDQ溢出。出现攻击成功地提示对话框。 4.利用工具软件连接到该端口。进入DOs模式,在C盘根目录下输入 -vv 813 回车。5.监听本地端口(1)先利用命令监听本地的813端口。进入DOs模式,在C盘根目录下输入nc -l -p 813回车。(2)这个窗口就这样一直保留,启动工具软件snake,本地的IP 地址是,要攻击的计算机的IP地址是,选择溢出选项中的第一项,设置IP为本地IP地址,端口是813.点击按钮“IDQ溢出”。(3)查看nc命令的DOS框,在该界面下,已经执行了设置的DOS命令。将对方计算机的C盘根目录列出来,进入DOC模式,在C盘根目录下输入nc -l -p 813回车。 6.利用WebDav远程溢出使用工具软件和远程溢出。(1)在DOS命令行下执行,进入DOC 模式,在C盘根目录下输入回车。(2)程序入侵对方的计算机进入DOC模式,在C盘根目录下输入nc -vv 7788 回车。 实验结果: 1.成功加载RPC服务。可以在服务列表中看到系统的RPC服务,见结果图。 2.成功利用工具软件对进行攻击。 3.成功利用IIS溢出进行攻击利用软件Snake IIS溢出工具让对方的IIS溢出,从而捆绑 实验五、缓冲区分析应用 一、实验目的 缓冲区分析是用来确定不同地理要素的空间邻近性和邻近程度的一类重要的空间操作,通过本次实习,我们应达到以下目的: 1.加深对缓冲区分析基本原理、方法的认识; 2.熟练掌握距离制图创建缓冲区技术方法。 3.掌握利用缓冲区分析方法解决地学空间分析问题的能力。 二、实验准备 数据准备:图层文件point.shp,lline.shp,polygon.shp 三、实验内容及步骤 1. 距离制图-创建缓冲区 1.1 点要素图层的缓冲区分析 1)在ArcMap中新建地图文档,加载图层:StudyArea ,point 2)打开Arctoolbox,执行命令 点击“Environment Settings”按钮 设置“General Settings”中的“Extent”,使其与StudyArea 相同 3)显示并激活由point.shp产生的新栅格主题,eucdist_poin(如上图)。在进行分析时,若选中了point图层中的某一个或几个要素,则缓冲区分析只 对该要素进行;否则,对整个图层的所有要素进行。 1.2 线要素图层的缓冲区分析 1)在ArcMap中,新建地图文档,加载line图层,点击常用工具栏中的 将地图适当缩小。 2)分别选中图层line中的两条线,进行缓冲区分析,注意比较线的缓冲 区分析与点的缓冲区分析有何不同。 方法:打开Arctoolbox,执行命令缓冲区溢出攻击实验
数据挖掘实验报告
缓冲区分析的综合应用
SEED信息安全实验系列:缓冲区溢出漏洞实验
数据挖掘实验报告(一)
GIS缓冲区分析与地图输出
GIS缓冲区分析报告
实验4 缓冲区溢出攻击实验
数据挖掘实验报告资料
实验6、缓冲区分析应用(综合实验)
山东大学信息安全实验报告
数据挖掘实验报告-关联规则挖掘
缓冲区实验分析
ArcGIS空间叠加分析与缓冲区分析
华科_计算机系统实验报告
大数据挖掘weka大数据分类实验报告材料
缓冲区溢出攻击实验报告
Arcgis实验五缓冲区分析应用
相关主题
文本预览