sql server数据库实验完整版
- 格式:doc
- 大小:287.00 KB
- 文档页数:41

网络数据库技术实验指导书南京工业大学经济与管理学院2017年9月目录实验目的 (2)实验要求 (2)实验环境 (2)实验一、常用数据库管理系统介绍 (3)实验二、SQL Sever 数据库管理系统的基本操作 (10)实验三、基本表的定义 (26)实验四、基本表与删除索引的修改与删除 (30)实验五、条件及统计汇总查询 (35)实验六、数据表连接查询与数据更新操作 (39)实验七、视图的定义、查询与维护 (42)实验八、数据库的完整性实验 (43)实验九、触发器实验 (46)实验十、数据的导出与导入实验 (55)实验十一数据库备份与数据库还原技术 (72)实验十二、数据库用户管理技术 (77)实验十三、数据库综合设计与实现 (77)实验目的数据库原理是一门理论和实践很强的课程。
学生学习这门课程要求掌握两方面内容:数据库设计和上机实践。
因此数据库的实验要围绕这两方面进行。
通过对 Access、SQL Server 数据库管理系统的学习帮助学生巩固和加深理解所学过的理论知识,树立工程的观点和严谨的科学作风,使学生熟练掌握基本的 SQL 语句,熟悉 SQL Server 数据库管理系统的功能、数据管理、应用和开发技术。
熟练使用 SQL 语句创建数据库、表、索引、修改表结构,以及进行数据的查询、更新、定义视图等操作。
掌握 SQL Server 中触发器的创建方法,学会数据的导入和导出操作。
通过实验,培养学生的动手能力以及在实践中发现问题并能及时解决问题的能力,锻炼学生的逻辑思维能力,提高数据库应用开发能力。
为学生毕业后从事计算机应用职业做好必要的准备。
实验要求给出一个现实世界的应用问题要求学生在正确分析问题的基础上,完成以下任务:1、熟悉概念数据库的概念;2、熟悉运用 SQL操纵数据库;3、熟悉 SQL Server数据库管理系统环境,学会用该数据库管理系统创建数据库;4、理解范式的意义,能判断其能达到第几范式。

数据库实验指导书信息安全专业王爽2009一.概述1.SQL Server 2000 组成SQL Server是可缩放的高性能基于SQL和客户/服务器体系结构的关系数据库管理系统服务器软件包,是由Microsoft 公司推出的SQL Server 数据库管理系统的最新版本。
从图1 SQL Server 的体系结构示意图中看出,SQL Server 2000由4部分组成,在实验中,我们要求掌握基于SQL Server 2000的服务器的使用,也就是数据库管理员DBA的主要操作。
(注:本文所有内容均在SQLServer 2000上实现,读者也可在SQL Server 2005 上得到类似结果。
)图1 SQL Server 的体系结构示意图2. SQL Server 2000 的安装SQL Server 2000 的常见版本有:企业版、标准版、个人版、开发人员版等。
对软硬件的最低需求为:CPU Pentium 166MHz,内存64MB,硬盘180 MB。
SQL Server 2000企业版和标准版只能在windows2000 Server 版和Professional 版操作系统下运行。
下面介绍SQL Server 2000企业版在本地机上的安装过程。
1)插入SQL Server 2000 光盘,自动安装程序启动,屏幕上出现如图2所示画面,按图2 所示选择SQL Server 2000 组件;2) 选择安装数据库服务器,如图3所示,进入SQL Server2000 企业版安装向导;3)在安装向导对话框中点击下一步,进入计算机名对话框;4)选择本地安装,点击下一步,进入安装选择对话框;5)选择创建新的SQL Server 实例,点击下一步,进入用户信息对话框;6)输入用户信息,点击下一步,进入安装定义对话框;7)选择服务器和客户端工具,点击下一步,进入实例名对话框;8)输入实例名,点击下一步,进入安装类型选择对话框;9)选择典型安装,进入服务帐号设置对话框,如图4所示;10)选择对每一个用户使用同一个帐号,自动启动服务器,点击下一步,进入选择身份验证模式选择对话框,如图5所示;11)选择Windows 身份验证模式。

湖北国土资源职业学院SQL数据库实验报告2010-2011 学年第二学期实验名称数据库应用技术班级测量0902指导老师侯文平学生姓名杨然系(部)测绘工程系实训时间2011年5月实验一注册服务器与创建数据库一、实验目的1.熟悉SQL Server 2005管理平台的环境2.掌握注册服务器的过程3.了解Microsoft SQL Server中系统数据库中的数据4.掌握创建库5.掌握创建数据表二、实验内容1. 使用联机丛书2.注册服务器3.创建数据库4.创建数据表三、仪器、设备、材料微机四、实验准备1.理论知识预习及要求①服务器组的创建;②服务器的注册;③创建数据库;④创建数据表;2.实验指导书预习及要求上机前先预习第一、二章的内容及附录A中的实验一,理解注册服务器的作用。
3.其他准备无五、实验原理或操作要点简介注意服务器要先启动,才能与服务器建立连接。
六、注意事项要养成为文件取有意义名称的习惯。
要及时保存文件,避免死机或断电造成的文件丢失。
创建过程中,出现问题时,请保存,请老师解答。
创建过程中,若出现找不到相应的问题时,要看联机丛书,逐步学会自学。
七、实验过程与指导1. 使用联机丛书(操作步骤参考教材P273实验一中的操作步骤)2.注册服务器(操作步骤参考教材P8)3.创建数据库(操作步骤参考教材P12,要求将数据库存储在最后一个磁盘,以自己姓名命名的文件夹,如F:\hwp)4.创建数据表以界面方式建立一个学生基本情况表(tblStudent),建立的要求如下表。
以界面方式建立一个班级表(tblClass),建立的要求如下表。
5.往表中插入记录①往tblStudent表中插入记录。
观察:●蔡文姬的性别在输入的时,没有输入,输入完成后,变成了什么?为什么?●曹操的性别误输入为“国”,也成功的存储了。
我们可以在保存数据前做什么工作,防止用户输入错误的发生?继续,往tblStudent表中插入记录。
输入完成,提交更新行时,会出现下面错误提示:思考:该提示的含义是什么,由什么原因引起?②往tblClass表中插入记录。
实验一SQL Server 2005的安装与配置一、目标完成这个实验后,你将能够:1.熟悉SQL Server Management Studio环境。
2.掌握SQL Server 2005的安装与配置的相关内容。
3.在Microsoft SQL Server联机图书中查看内容、使用索引和查找信息。
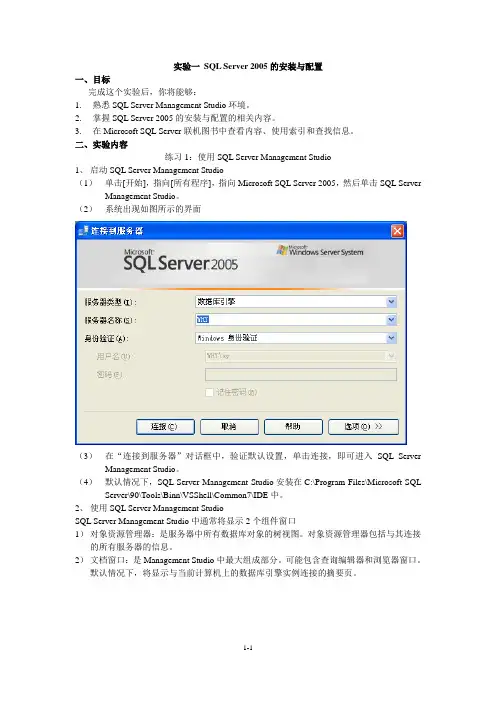
二、实验内容练习1:使用SQL Server Management Studio1、启动SQL Server Management Studio(1)单击[开始],指向[所有程序],指向Microsoft SQL Server 2005,然后单击SQL Server Management Studio。
(2)系统出现如图所示的界面(3)在“连接到服务器”对话框中,验证默认设置,单击连接,即可进入SQL Server Management Studio。
(4)默认情况下,SQL Server Management Studio安装在C:\Program Files\Microsoft SQL Server\90\Tools\Binn\VSShell\Common7\IDE中。
2、使用SQL Server Management StudioSQL Server Management Studio中通常将显示2个组件窗口1)对象资源管理器:是服务器中所有数据库对象的树视图。
对象资源管理器包括与其连接的所有服务器的信息。
2)文档窗口:是Management Studio中最大组成部分。
可能包含查询编辑器和浏览器窗口。
默认情况下,将显示与当前计算机上的数据库引擎实例连接的摘要页。
文档窗口对象资源管理3、新建数据库Projects1)在Management Studio工具栏上,单击“新建查询”,输入脚本2)执行下列脚本新建数据库,适当修改文件路径CREATE DATABASE ProjectsONPRIMARY(NAME=ProjectPrimary,FILENAME='D:\Projects_Data\ProjectPrimary.mdf',SIZE=100MB,MAXSIZE=200,FILEGROWTH=20),FILEGROUP ProjectsFG(NAME=ProjectData1,FILENAME='E:\Projects_Data\ProjectData1.ndf',SIZE=200MB,MAXSIZE=1200,FILEGROWTH=100),(NAME=ProjectData2,FILENAME='E:\Projects_Data\ProjectData2.ndf',SIZE=200MB,MAXSIZE=1200,FILEGROWTH=100),FILEGROUP ProjectsHistoryFG(NAME=ProjectHistory1,FILENAME='E:\Projects_Data\ProjectHistory1.ndf',SIZE=100MB,MAXSIZE=500,FILEGROWTH=50)LOG ON(NAME=Archlog1,FILENAME='F:\Projects_Data\ProjectLog.ldf',SIZE=300MB,MAXSIZE=800,FILEGROWTH=100)3)在对象资源管理器下,展开“数据库”节点,右击Projects节点,选择“属性”,查看该数据库信息。
数据库原理及应用实验报告实验12 SQL Server安全管理实验目的:掌握创建登录账号的方法;掌握创建数据库用户的方法;掌握语句级许可权限管理;掌握对象级许可权限管理实验内容:12.1实验题目:创建登陆账号实验过程:1)创建使用Windows身份验证的登录账号WinUser2)创建使用SQL Server身份验证的登录账号SQLUser,设置可访问数据库jxsk实验结果:12.2实验题目:创建数据库用户实验过程:1)为登陆账号WinUser创建访问MXM实例中数据库jxsk的用户账号2)为登陆账号SQLUser创建访问MXM实例中所有数据库的用户账号实验结果:12.3实验题目:语句级许可权限管理实验过程:1)展开实例MXM中数据库节点,右击jxsk,选属性项2)授予用户WinUser只可以在数据库jxsk中创建视图和表3)授予用户SQLUser权限:不允许用户SQSUser在数据库jxsk 中创建视图和表,但允许其他操作。
实验结果:12.4实验题目:对象级许可权限管理实验过程:1)授予用户WinUser对数据库jxsk表S的INSERT,UPDATE权限2)授予用户SQLUser对数据库jxsk表S的INSERT权限;废除对表S的UPDATE权限3)授予用户WinUser对数据库jxsk表S的列SNO的SELECT,UPDATE权限,对SN的SELECT权限实验结果:实验13 SQL Server事务设计实验目的:1,理解和掌握事务的概念、特性以及事务的设计思想。
2,学习和掌握事务创建、执行的方法。
实验13.1 设计并执行事务实验目的:掌握事务的设计思想和方法。
实验内容:基于数据库jiaoxuedb进行下面设计:(1)设计并执行事务1:将学生陈东辉的计算机基础课程成绩改为77分。
(2)设计并执行事务2:将课程数据结构的课号与微机原理的课号互换。
(3)设计并执行事务3教师许永军退休,由他讲授的2门课程中,课程微机原理转给教师张朋讲授,数据库转给李英讲授。

实验五 存储过程创建与应用
一、实验目的
使学生理解存储过程的概念,掌握创建存储过程的使用、执行存储过程和查看、修改、删除存储过程的方法。
二、实验内容
(1)利用企业管理器创建存储过程student_grade,要求实现如下功能:查询“学生-课程”数据库中每个学生各门功课的成绩,其中包括每个学生的sno,sname,cname,grade。
(2)利用查询分析器创建名为proc_exp的存储过程,要求实现如下功能:从sc表中查询某一学生考试平均成绩。
(3)修改存储过程proc_exp,要求实现如下功能:输入学生学号,根据该学生所选课程的平均成绩显示提示信息,即如果平均成绩在60分以上,显示“此学生综合成绩合格,成绩为XX分”,否则显示“此学生总和成绩不合格,成绩为XX分”。
(4)创建名为proc_add的存储过程,要求实现如下功能:向sc表中添加学生成绩记录。
调用proc_add,向sc表中添加学生成绩记录。
(5)调用存储过程proc_exp,输入学生学号,显示学生综合成绩是否合格。
(6)删除刚刚创建的proc_add和proc_exp两个存储过程。
三、实验过程
(1)
(2)
(3)
(4)
(5)
(6)
四、实验总结
本次试验主要实现的是对储存过程的各种应用。
储存过程的建立(create语句)与调用(exec语句),无参数储存过程和有参数储存过程的相对比的应用以更好的理解参数在储存过程中的具体作用,最后是储存过程的删除,利用 drop 语句即可实现。
数据库实验报告全实验⼀实验⽬的1.熟悉SQL Server Management Studio(SSMS)的⼯作环境2.掌握使⽤和命令建⽴数据库的⽅法3.熟练掌握使⽤SSMS和T-SQL语句创建、修改和删除表。
4.熟练掌握使⽤SSMS和T-SQL语句插⼊、修改和删除表数据。
实验内容1.采⽤SQL Server Management Studio 、T-SQL语句两种⽅式创建产品销售数据库,要求:1)使⽤SSMS创建数据库CPXS_bak,数据⽂件初始⼤⼩为5MB,最⼤⼤⼩50MB,按5MB增长;⽇志⽂件初始为2MB,最⼤可增长到10MB,按2MB增长;其余参数取默认值。
2)⽤T-SQL语句创建数据库CPXS,数据⽂件的增长⽅式改为增长⽅式按10%⽐例增长,其余与CPXS_bak。
3)⽤T-SQL语句删除数据库CPXS_bak。
2.CPXS数据库包含如下三个表:1)产品(产品编号,产品名称,价格,库存量)2)客户(客户编号,客户名称,地区,负责⼈,电话)3)销售(产品编号,客户编号,销售⽇期,数量,销售额)三个表结构如资料中图3.1~图3.3所⽰,请写出创建以上三个表的T-SQL语句并在查询分析器中运⾏。
3.在SSMS中输⼊如资料中图3.4~图3.6的商品表、客户表和销售表的样本数据。
6.将CP表中每种商品的价格打8折。
7.将CP表中价格打9折后⼩于1500的商品删除。
⼆.实验步骤与结果(说明:要写出相关步骤和SQL语句,实验结果可以是运⾏画⾯的抓屏,抓屏图⽚要尽可能的⼩。
)1.1)使⽤SSMS创建数据库CPXS_bak效果图为2)⽤T-SQL语句创建数据库CPXS:CREATE DATABASE CPXSON PRIMARY(NAME='CPXS_DATA',FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\CPXS_DATA.MDF', SIZE=5MB,MAXSIZE=50MB,FILEGROWTH=10%)LOG ON(NAME='CPXS_LOG',FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\CPXS_LOG.LDF', SIZE=2MB,MAXSIZE=10MB,FILEGROWTH=2MB)3) DROP DATABASE CPXS_bak刷新数据库会看到CPXS_bak不存在2.1) USE CPXSGOCREATE TABLE产品(产品编号char(6)PRIMARY KEY,产品名称char(30)NOT NULL,价格float(8),库存量int,)2) USE CPXSGOCREATE TABLE客户(客户编号char(6)PRIMARY KEY,客户名称char(30)NOT NULL,地区char(10),负责⼈char(8),电话char(12))3)USE CPXSGOCREATE TABLE销售(产品编号char(6),客户编号char(6),销售⽇期datetime,数量int NOT NULL,销售额float(8)NOT NULL,CONSTRAINT pk_js PRIMARY KEY(产品编号,客户编号,销售⽇期))/*pk_js为约束名*/ 执⾏完上⾯的操作就能看见表已经添加进数据库中,如图所⽰:3. 打开表:在其中添加数据:4.1)USE CPXSINSERT INTO产品(产品编号,产品名称,价格,库存量) VALUES('200001','柜式空调','3000','200')2)USE CPXSINSERT INTO产品(产品编号,产品名称,价格,库存量) VALUES('200002','微波炉','1000','100')3)USE CPXSINSERT INTO产品(产品编号,产品名称,价格,库存量) VALUES('200003','抽油烟机','1200','50')可以看见图中的产品表增加了如下内容:5.USE CPXSALTER TABLE产品Add产品简列varchar(50)6. USE CPXSUPDATE产品set价格=价格*0.87. USE CPXSDELETE产品WHERE价格*0.9<1500三.实验中的问题及⼼得(说明:此处应写明此次实验遇到的问题有哪些,如何解决的,不能够空。

实验3 表数据插入、修改和删除1、目的与要求(1)学会在对象资源管理器中对数据库表进行插入、修改和删除数据操作。
(2)学会使用T-SQL语句对数据库表进行插入、修改和删除数据操作。
(3)了解数据更新操作时要注意数据完整性。
2、实验内容(1)实验题目。
分别使用对象资源管理器和T-SQL语句,向在实验2中建立的数据库YGGL 的三个表Employees、Departments和Salary中插入多行数据记录,然后修改和删除一些记录。
使用T-SQL语句进行有限制的修改和删除。
(2)实验准备首先,了解对表数据的插入、删除、修改都属于表数据的更新操作。
对表数据的操作可以再对象资源管理器中进行,也可以由T-SQL语句实现。
其次,要掌握T-SQL中用于对表数据的插入、删除和修改的命令分别是INSERT、DELETE和UPDATE.另外还可以使用MERGE语句根据在一个表中找到的差异在另一个表中插入、更新和删除行,可以对两个表进行信息同步。
要特别注意的是:在执行插入、修改、删除等数据更新操作室,必须保证数据完整性。
此外,还要了解使用T-SQL语句在对表数据进行插入、修改以及删除时,比在对象资源管理器中操作表数据更为灵活,功能更强大。
在实验2中,用于实验的YGGL数据库中的3个表已经建立,现在要将各表的样本数据添加到表中。
样本数据如表T3.1、表T3.2和表T3.3所示。
3、实验步骤(1)在对象资源管理器中初始化数据库YGGL中所有表的数据。
①在对象资源管理器中展开‘数据库YGGL’节点,选择要进行操作的表‘employees’,右击鼠标,在弹出的快捷菜单上选择“编辑前200行”菜单项,进入“表数据窗口”。
在此窗口中,表中的记录按行显示,每个记录占一行。
用户可通过“表数据窗口”向表中加入表T3.1中的记录,输完一行记录后将光标移到下一行即保存了上一行记录。
②用同样的方法向Departments和Salary表中分别插入表T3.2和T3.3中的记录。

一、存储过程1. 创建存储过程,使用Employees表中的员工人数来初始化一个局部变量,并调用这个存储过程。
CREATE PROCEDURE TEST@NUMBER1INT OUTPUTASBEGINDECLARE@NUMBER2INTSET@NUMBER2=(SELECT COUNT(*)FROM Employees)SET@NUMBER1=@NUMBER2END执行该存储过程,查看结果。
DECLARE@num INTEXEC TEST@num OUTPUTSELECT@num2. 创建存储过程,比较两个员工的实际收入,若前者比后者高就输出1,否则就输出0。
CREATE PROCEDURE COMPA@ID1char(6),@ID2char(6),@BJ int OUTPUTASBEGINDECLARE@SR1float,@SR2floatSET@SR1=(SELECT InCome-OutCome FROM Salary WHERE EmployeeID=@ID1) SET@SR2=(SELECT InCome-OutCome FROM Salary WHERE EmployeeID=@ID2) IF@SR1>@SR2SET@BJ=1ELSESET@BJ=0END执行该存储过程,查看结果。
DECLARE@BJ intEXEC COMPA'504209','302566',@BJ OUTPUTSELECT@BJ3. 创建添加职员记录的存储过程EmployeeAdd。
CREATE PROCEDURE EmployeeADD(@employeeid char(6),@name char(10),@education char(4),@birthday datetime,@workyear tinyint,@sex bit,@address char(40),@phonenumber char(12), @departmentID char(3))ASBEGININSERT INTO EmployeesVALUES(@employeeid,@name,@education,@birthday,@workyear,@sex,@address,@phonenumber,@departmentID)ENDRETURNGO执行该存储过程。

课后实训参考答案单元1(SQL Server概述)1、使用SQL语句。
在Sale数据库中创建名为MyDataType的用户定义数据类型,数据类型为NV ARCHAR,长度为20,该列允许为NULL。
USE SaleGOEXEC sp_addtype MyDataType,'NVARCHAR(20)','NULL' GO单元2(单表数据)使用查询窗口或sqlcmd实施查询。
本实训使用Xk数据库。
--1.查看系部编号为“03”的系部名称。
USE XkGOSELECT DepartNameFROM DepartmentWHERE DepartNo='03'GO--2.查看系部名称中包含有“工程”两个字的系的全名。
USE XkGOSELECT DepartNameFROM DepartmentWHERE DepartName LIKE'%工程%' GO--3.显示共有多少个系部。
USE XKGOSELECT'系部总数'=COUNT(*)FROM DepartmentGO--4.显示“01”年级共有多少个班级。
USE XKGOSELECT'01 级班级数'=COUNT(*)FROM ClassWHERE ClassNo LIKE'2001%'GOSELECT'01 级班级数'=COUNT(*)FROM ClassWHERE ClassName LIKE'01%'GOSELECT'01 级班级数'=COUNT(*)FROM StudentWHERE ClassNo LIKE'2001%'GO--5.查看在“周二晚”上课的课程名称和教师。
USE XKGOSELECT'课程名称'=CouName,'任课教师'=TeacherFROM CourseWHERE SchoolTime='周二晚'GO--6.查看姓“张”、“陈”、“黄”同学的基本信息,要求按照姓名降序排序查询结果。

实验八(上)用户自定义函数和触发器一、实验目的1、掌握SQLServer中用户自定义函数的使用方法。
2、掌握SQL Server中触发器的使用方法。
二、实验内容和要求1.创建一个返回标量值的用户定义函数RectangleArea:输入矩形的长和宽就能计算矩形的面积。
自选2种实例调用该函数。
create function RectangleArea(@a int,@b int)returns intasbeginreturn @a*@benddeclare @area intexecute @area=RectangleArea 3,5print('矩形面积是:')print @areadeclare @area intexecute @area=RectangleArea 7,8print('矩形面积是:')print @area2.创建一个用户自定义函数(内嵌表值函数),功能为产生某个系的学生选修信息,内容为学号,姓名,课程名,成绩。
调用这个函数,显示信息系有选课学生的信息。
create function Search (@sdept char(10))returns tableasreturn(select sc.sno 学号,student.sname 姓名,ame 课程名,sc.grade 成绩,student.sdept 系别from sc,student,course where o=o andsc.sno = student.sno and sdept=@sdept)select*from Search('cs')3.创建一个作用在P表上的触发器P_checks,确保用户在插入或更新P表的WEIGHT值时,所提供的WEIGHT值介于20与40之间,否则给出错误提示并回滚此操作。
请测试该触发器,测试方法自定。
create trigger P_checks on p for insertasbegindeclare @weight intselect @weight=weight from insertedif @weight<10 or @weight>20beginRAISERROR('weight 必须在~20之间!',16,1)ROLLBACK TRANSACTIONendendinsert into p(pno,pname,color,weight)values('p7','刀片','红',40)insert into p(pno,pname,color,weight)values('p7','刀片','红',15)select*from p4.创建一个作用在J表上的触发器J_Update,禁止同时修改项目的名称和所在城市,并进行相应的错误提示。
实验一熟悉SQL SERVER的环境(验证型实验2学时)1.目的要求:了解SQL Server management studio的使用2.实验内容:回答下面每一个问题,写出实验步骤1)在“已注册服务器窗口”中注册sql server数据库服务器在视图中点击已注册的服务器,右键点击数据库引擎新建,选择服务器注册,输入服务器名称sql server2)在“对象资源管理器”中创建名字为sc的数据库右击数据库,选择新建数据库,输入数据库名称sc3)在sc数据库中创建一个名字为student的基本表点击sc的数据库,右点击表,新建表,输入相应的属性名称,选择相应的数据类型,保存时输入表名student4)在查询窗口中里创建名为S_C的数据库输入sql语句create database S_C,然后执行5)在查询窗口中使用sql语言创建名字为course的基本表输入sql语句,create table coure3.主要仪器设备及软件:(1)PC(2)Microsoft SQL Server 2005实验二建立表格,并插入若干记录(验证型实验2学时)1.目的要求:学会使用Create Table语句和Insert语句2.实验内容:1)使用sql语言建立student,course和sc共三张表格(包括主键,外码的指定),分析具体情况适当给出一些用户自定义的约束.create database studentcreate table student(Sno char(9) primary key,Sname char(20) unique,Ssex char(2),Sage smallint,Sdept char(20));create table course(Cno char(4) primary key,Cname char(40),Cpno char(4),Ccredit smallint,foreign key (Cpno )references course(Cno));create table sc( Sno char(9),Cno char(4),Grade smallint,primary key(Sno,Cno),foreign key (Sno) references student(Sno), foreign key (Cno) references course(Cno));2)使用Insert语句向这四张表格里添加至少10条记录(数据如教材56页所示),如果出现错误,分析错误原因insert into student(Sno, Sname,Ssex,Sage ,Sdept )values('95001','李勇','男',20,'CS');insert into student(Sno, Sname,Ssex,Sage ,Sdept )values('95002','刘晨','女',19,'IS');insert into student(Sno, Sname,Ssex,Sage ,Sdept )values('95003','王敏','女',18,'MA');insert into student(Sno, Sname,Ssex,Sage ,Sdept )values('95004','张立','男',19,'IS');……插入时遇到的问题:insert语句与表的外键约束发生冲突不能正确插入;输入SQL语言标点符号时必须关掉中文输入法。
SQLSERVER2008实用教程实验参考答案解析(实验4)实验4 数据库的查询和视图一、SELECT语句的基本使用1. 查询Employees表中所有数据2. 查询Employees表中指定字段数据3. 查询Employees表中的部门号和性别,要求使用Distinct消除重复行4. 使用WHERE子句查询表中指定的数据查询编号为’000001’的雇员的地址和查询月收入高于2000元的员工查询1970年以后出生的员工的和住址5. 使用AS子句为表中字段指定别名查询Employees表中女雇员的地址和,并将列标题显示为地址和查询Employees表中男雇员的和出生日期,并将列标题显示为和出生日期6. 使用使用CASE子句查询Employees表中员工的和性别,要求Sex值为1时显示“男”,为0时显示“女”查询Employees表中员工的、住址和收入水平,2000元以下显示为低收入,2000~3000地显示为中等收入,3000元以上显示为高收入。
7. 使用SELECT语句进行简单计算计算每个雇员的实际收入8. 使用置函数获得员工总数计算Salary表中员工月收入的平均数获得Employees表中最大的员工计算Salary表中所有员工的总支出查询财务部雇员的最高和最低实际收入9. 模糊查询找出所有姓王的雇员的部门号找出所有地址中含有“”的雇员的及部门号找出员工中倒数第二个数字为0的员工的、地址和学历10. Between…And…和Or的使用找出收入在2000~3000元之间的雇员编号找出部门为“1”或“2”的雇员的编号11. 使用INTO子句,由源表创建新表由表Salary创建“SalaryNew”表,要求包括编号和收入,选择收入在1500元以上的雇员由表Employees创建“EmployeesNew”表,要求包括编号和,选择所有男员工二、子查询的使用1. 查找在财务部工作的雇员情况2. 用子查询的方法查找所有收入在2500以下的雇员的情况3. 查找财务部年龄不低于研发部雇员年龄的雇员4. 用子查询的方法查找研发部比所有财务部雇员收入都高的雇员的5. 查找比所有财务部的雇员收入都高的雇员的6. 用子查询的方法查找所有年龄比研发部雇员年龄都大的雇员的三、连接查询的使用1. 查询每个雇员的情况及薪水的情况2. 查询每个雇员的情况及其工作部门的情况3. 使用连接的方法查询名字为“王林”的雇员所在的部门4. 使用连接的方法查找出不在财务部工作的所有雇员信息5. 使用外连接方法查找出所有员工的月收入6. 查找财务部收入在2000元以上的雇员及其薪水详情7. 查询研发部在1976年以前出生的雇员及其薪水详请四、聚合函数的使用1. 求财务部雇员的平均收入2. 查询财务部雇员的最高和最低收入3. 求财务部雇员的平均实际收入4. 查询财务部雇员的最高和最低实际收入5. 求财务部雇员的总人数6. 统计财务部收入在2500元以上的雇员人数五、GROUP BY、ORDER BY子句的使用1. 查找Employees表中男性和女性的人数2. 按部门列出在该部门工作的员工的人数3. 按员工的学历分组,排列出本科、大专、硕士的人数4. 查找员工数超过2的部门名称和雇员数量5. 按员工的工作年份分组,统计各个工作年份的人数,例如工作1年的多少人,工作2年的多少人6. 将雇员的情况按收入由低到高排列7. 将员工信息按出生时间从小到大排列8. 在ORDER BY 子句中使用子查询,查询员工、性别和工龄信息,要求按实际收入从大到小排列六、视图的使用1. 创建视图(1)在数据库YGGL上创建视图Departments_View,视图包含Department表的全部列(2)创建视图Employees_Departments_View,视图包含员工、、所在部门名称(3)创建视图Employees_Salary_View,视图包含员工、和实际收入三列2. 查询视图从视图Employees_Salary_View中查询出为“王林”的员工的实际收入3. 更新视图(1)向视图Departments_View中添加一条记录(‘6’,‘广告部’,‘广告业务’)执行完命令后,分别查看Departments_View和Department表中发生的变化(2)尝试向Employees_Departments_View中添加一条记录,看看会发生什么情况(3)尝试向Employees_Salary_View中添加一条记录,看看会发生什么情况(4)将视图Departments_View中,部门号为‘6’的部门名称修改为‘生产车间’(5)删除视图Departments_View中最新增加的的一条记录4. 删除视图Employees_Departments_View5. 在界面工具中操作视图一、SELECT语句的基本使用1. 查询Employees表中所有数据SELECT*FROM Employees;2. 查询Employees表中指定字段数据SELECT EmployeeID,Name,DepartmentID FROM Employees;3. 查询Employees表中的部门号和性别,要求使用Distinct消除重复行SELECT Distinct DepartmentID,Sex FROM Employees;4. 使用WHERE子句查询表中指定的数据查询编号为’000001’的雇员的地址和Select Address,PhoneNumber FROM Employees WHERE EmployeeID='000001';查询月收入高于2000元的员工SELECT EmployeeID FROM Salary WHERE InCome>2000;查询1970年以后出生的员工的和住址SELECT Name,Address FROM Employees WHERE YEAR(Birthday)>'1970';SELECT Name,Address FROM Employees WHERE Birthday>'1970';5. 使用AS子句为表中字段指定别名查询Employees表中女雇员的地址和,并将列标题显示为地址和SELECT Address AS地址,PhoneNumber AS FROM Employees;查询Employees表中男雇员的和出生日期,并将列标题显示为和出生日期SELECT Name AS,Birthday AS出生日期FROM Employees WHERE Sex=1;6. 使用使用CASE子句查询Employees表中员工的和性别,要求Sex值为1时显示“男”,为0时显示“女”SELECT Name AS,CASEWHEN Sex=1 THEN'男'WHEN Sex=0 THEN'女'ENDAS性别FROM Employees;查询Employees表中员工的、住址和收入水平,2000元以下显示为低收入,2000~3000地显示为中等收入,3000元以上显示为高收入。
数据库实验报告班级:07111103学号:**********姓名:***实验一:[实验内容1 创建和修改数据库]分别使用SQL Server Management Studio和Transact-SQL语句,按下列要求创建和修改用户数据库。
1.创建一个数据库,要求如下:(1)数据库名"testDB"。
(2)数据库中包含一个数据文件,逻辑文件名为testDB_data,磁盘文件名为testDB_data.mdf,文件初始容量为5MB,最大容量为15MB,文件容量递增值为1MB。
(3)事务日志文件,逻辑文件名为TestDB_log, 磁盘文件名为TestDB_log.ldf,文件初始容量为5MB, 最大容量为10MB,文件容量递增值为1MB。
2.对该数据库做如下修改:(1)添加一个数据文件,逻辑文件名为TestDB2_data,实际文件为TestDB2_data.ndf,文件初始容量为1MB,最大容量为6MB,文件容量递增值为1MB。
(2)将日志文件的最大容量增加为15MB,递增值改为2MB。
方法一:使用SQL Server Management Studio创建和修改数据库TestDB方法二:使用Transact-SQL语句创建和修改数据库TestDB方法一过于简单,暂不做讨论。
下面学习方法二。
首先,在sql sever 2008中单击新建查询。
然后键入下面的代码。
建立新的数据库。
1. 创建一个数据库,要求如下:2.对该数据库做如下修改:对刚刚的操作进行验证数据均已更新完毕。
[实验内容2 数据表的创建、修改和查询]1.熟悉有关数据表的创建和修改等工作,并了解主键、外键以及约束的创建和应用,熟练掌握使用SQL Server Management Studio和CREATE TABLE、ALTER TABLE等Transact-SQL语句对数据表的操作方法字段名数据类型字段长度注释项目编码char 10 主键名称varchar负责人编码char 10客户int开始日期datetime结束日期datetime员工数据表(Employee)字段名数据类型字段长度注释方法一:使用SQL Server Management Studio创建数据表并添加约束方法二:使用Transact-SQL语句创建数据表并添加约束2.向数据库TestDB中的两个数据表"项目数据表"和"员工数据表"中添加记录3.在查询分析器中书写Transact-SQL语句完成数据查询。
一、实验目的1. 了解数据库常用对象及组成;2. 了解SQL Server 数据库的逻辑结构和物理结构;3. 掌握在企业管理器中创建、修改和删除数据库的方法;4. 熟练掌握使用T-SQL 语句创建、修改和删除数据库的方法;5. 熟悉在企业管理器中和使用系统的存储过程分离和附加数据库。
二、实验环境SQL Server 2008三、实验原理(或要求)假设SQL Server 服务已启动,并以Administrator 身份登录计算机;请分别使用Management 界面方式和T-SQL 语句实现以下操作:(创建新的文件夹存放数据库)1.要求在本地磁盘D 创建一个学生-课程数据库(名称为s_+人名汉语拼音首字母+学号尾数),只有一个数据文件和日志文件,文件名称分别为stu 和stulog,物理名称为stu_data.mdf 和stu_log.ldf,初始大小都为5MB,增长方式分别为10%和3MB,数据文件最大为50MB,日志文件大小不受限制。
2. 在数据库s 中增加数据文件db2,初始大小为10MB,最大大小为50 MB,按10%增长;3. 在数据库中添加日志文件db_log,初始大小为3MB,最大无限制,增长方式按照1MB 增长;4. 修改数据库student 主数据文件的大小,将主数据文件的初始大小修改为10Mb,增长方式为20%;5. 修改数据库student 辅助数据文件初始大小为3MB,最大为100MB,按照10%增长,名称为db;6. 删除数据库student 辅助数据文件和第二个日志文件;7. 使用sp_attach_db 和sp_detach_db 附加和分离student 数据库。
四、实验步骤准备知1. 数据库相关属性1)逻辑名称:数据文件和日志文件名称2)文件类型:数据文件及日志文件3)文件组:各个数据文件所属的文件组名称4)初始大小:文件的最原始大小5)自动增长:文件按指定的大小增长,也可限制到最大容量。
实验一SQL Server的安装及其组件工具的使用实验指导一、安装SQL Server根据安装机器软硬件的要求,选择一个合适的版本,以下以SQL Server 2008为例。
1.在安装文件setup.exe上,单击鼠标右键选择“以管理员的身份运行”,如图1所示:图1 右键“以管理员的身份运行”2.双击SQL Server 2008安装盘中的Setup.exe,在出现的如图2所示的“SQL Server安装中心”窗口中,单击左侧窗格中的“安装”,然后在右侧窗格中单击“全新SQL Server 独立安装或向现有安装添加功能”。
图2 “SQL Server安装中心”窗口3.显示“安装程序支持规则”窗口,如图3所示。
安装程序支持规则可以发现在安装SQL Server过程中可能发生的问题。
必须更正所有失败,安装程序才能继续。
单击“确定”按钮。
图3 “安装程序支持规则”窗口4.显示“产品密钥”窗口,如图4所示。
如果有产品密钥,应选中“输入产品密钥”单选项,并输入25个字符的产品密钥,安装程序会根据输入的产品密钥来确定将要安装的版本。
如果没有产品密钥,可以从下拉列表中指定“Enterprise Evaluation”或“Express”等版本,将有180天的试用期。
单击下一步按钮。
5.显示“许可条款”窗口,如图5所示,勾上“我接受许可条款”,单击下一步按钮。
图5 “许可条款”窗口6.显示如图6所示的“安装程序支持文件”窗口,单击“安装”按钮,进入如图7和图8所示的“安装程序支持文件”和“安装程序支持规则”窗口。
系统将在安装继续之前检验计算机的系统状态,检查完成后单击下一步按钮。
图6 “安装程序支持文件”窗口(1)图6 “安装程序支持文件”窗口(2)图7 “安装程序支持规则”窗口7.显示“功能选择”窗口,如图8所示。
选择好功能后,单击下一步按钮,这里选择了全部安装。
图8 “功能选择”界面8.显示“实例配置”窗口,如图9所示。
基于SQL SERVER的数据库技术实验指导计算机科学系软件教研室实验一数据库和表的管理实验目的掌握SQL SERVER常用组件的使用学会数据库的建立和使用学会表的建立和使用实验内容1.SQL SERVER常用组件的使用2.使用企业管理器和T-SQL语句来建立数据库3.使用企业管理器和T-SQL语句建立表实验步骤1、实例一本实例讲解企业管理器的使用(1)在“开始”|“程序”|“Microsoft SQL Server”中选择“企业管理器”,打开企业管理器。
界面如图所示。
图1.1 企业管理器主界面(2)双击“控制台根目录”下的“Microsoft SQL Servers”,出现“SQL Server组”,在组中选择相应的SQL Server注册服务器。
如下图所示。
图1.2 SQL SERVER服务器注册(3)双击“数据库”可以打开本服务器中的相应数据库,之后可以对数据库进行建立、更改、删除和对数据库中的表进行建立、更改和删除操作。
结果如下图所示。
图1.3 建立数据库(4)在企业管理器中可以对服务器的属性进行相应的设置。
右键单击服务器“SYS\SYS(WindowNT)”选择属性,出现下图所示属性对话框。
通过该对话框,可以对服务器和数据库进行适当的设置。
图1.4 SQL SERVER属性窗口(5)企业管理器也可以设置数据库的属性,右键单击某一数据库,选择“属性”,则会出现数据库属性对话框。
设置该对话框可以设置数据库的属性。
图1.5 数据库属性窗口2、实例二本实例讲解查询分析器的使用(1)在“开始”|“程序”|“Microsoft SQL Server”中选择“查询分析器”,打开查询分析器。
界面如图所示。
图1.6 SQL 查询分析器窗口(2)如果用户已经设置了密码,则会出现“连接SQL Server”对话框,输入相应的用户名和密码即可进入查询分析器窗口。
对话框窗口如下图所示。
图1.7 新建查询窗口(3)进入查询分析器窗口后,即可使用查询分析器的各项功能,如使用T-SQL语言查询数据库中的相关信息等。
邯 郸 学 院 实验教学讲稿
2013~2014学年 第一学期
分院(系、部): 信息工程学院 教 研 室: 网络工程 课 程 名 称: 数据库原理 授 课 班 级: 网络工程2011级本科班
主 讲 教 师: 李 娜 职 称: 讲师 使 用 教 材: 《数据库系统概论》
邯郸学院制 实验1 认识DBMS系统、数据库及数据库表的建立实验 一、 实验目的 本实验的目的是使学生熟悉SQL Server Management Studio的使用方 法,熟悉SQL SERVER的常用数据类型,加深对SQL语言的数据定义语句的理解。熟练掌握数据库及数据库表的创建、修改和删除。 二、 实验时数: 2学时 三、 实验内容 分别使用SQL语言和对象资源管理器完成以下操作: 1. 创建数据库 创建数据库名为COMPANY1 ,主数据文件的逻辑名称为COMPANY_DATA,操作系统文件的名称为D:\MSSQL\DATA\COMPANY.MDF,大小为20MB,最大为50MB,以25%的速度增长。日志文件的逻辑名称为COMPANY_LOG,操作系统文件的名称为D:\MSSQL\DATA\COMPANY.LDF,大小为3MB,最大为10MB,以1MB的速度增长。 Create database company1 On primary (name=company1_data, Filename=’D:\MSSQL\DATA\COMPANY.MDF’, Size=20mb, Maxsize=50mb, Filegrowth=25%) Log on (name=company_log, Filename=’D:\MSSQL\DATA\COMPANY.LDF’, Size=3mb, Maxsize=10mb, Filegrowth=1mb) 2. 修改数据库 (1)将数据库COMPANY1的主数据文件的初始分配空间大小扩充到40MB. use company1 go alter database company1 modify file (name='D:\MSSQL\DATA\COMPANY.MDF',
size=40mb)
(2) 将数据库COMPANY1改名为COMPANY Exec sp_renamedb’company1’,’company’ 3. 创建表 在名为COMPANY数据库中创建以下四个表: (1)部门表,表名DEPA 列名 数据类型 描述 DNO DECIMAL(2) 部门编号 DNAME VARCHAR(16) 部门名称 ADDR VARCHAR(20) 部门地址 USE COMPANY GO CREATE TABLE DEPA (DNO DECIMAL(2), DNAME VARCHAR(16), ADDR VARCHAR(20) GO) (2)雇员表,表名EMPL 列名 数据类型 描述 ENO DECIMAL(4) 员工编号 ENAME CHAR(8) 员工姓名 BIRTHDATE DATETIME 出生日期 SALARY DECIMAL(7,2) 工资 DNO DECIMAL(2) 所在部门编号 USE COMPANY CREATE TABLE EMPL (ENO DECIMAL(4), ENAME CHAR(8), BIRTHDATE DATETIME, SALARY DECIMAL(7,2), DNO DECIMAL(2) ) (3)项目表,表名PROJ 列名 数据类型 描述 PNO DECIMAL(3) 项目编号 PNAME VARCHAR(24) 项目名称 USE COMPANY CREATE TABLE PROJ (PNO DECIMAL(3), PNAME VARCHAR(24) ) (4)工作表,表名JOB 列名 数据类型 描述 ENO DECIMAL(4) 员工编号 PNO DECIMAL(3) 项目编号 DAYS INT 工作天数 USE COMPANY CREATE TABLE JOB (ENO DECIMAL(4), PNO DECIMAL(3), DAYS INT ) 4. 修改表结构 1)修改部门表DEPA,添加一列部门电话,列名Telephone,数据类型VARCHAR(15)。 use company go alter table depa add Telephone varchar(15) null go
2)为项目表PROJ添加Begindate和Enddate列,数据类型为DATETIME。 use company go alter table proj add begindate datetime null Add enddate datetime null
go
3)删除项目表PROJ中的Enddate列。 use company go alter table proj drop column enddate
go
5. 删除表 1)删除项目表PROJ。 drop table proj 6、添加记录: 1)向DEPA表添加14号部门,客户中心,地址为开发区紫光路2号。 use company insert into depa values('14','客户中心',‘开发区紫光路2号’,,null) go
2)向DEPA表添加 15号部门,技术支持部,地址未详。 use company insert into depa values('15',技术支持部',null,null) go
3)向DEPA表添加 13号部门,财务部,地址未详。 use company insert into depa values('13','财务部',null,null) go
„„ 4)向EMPL表添加1401号员工,张山,出生日期1977年9月1日,工资4050元,14号部门。 use company insert into empl values('1401','张山','1977-9-1','4050','14') go
5)向EMPL表添加1402号员工,何宜,生日不祥,工资不祥,15号部门。 „„ use company insert into empl values('1402','何宜',null,null,'15') go 6)向PROJ表添加103号项目,历史学院档案库管理系统。 use company insert into proj values('103','历史学院档案库管理系统') go
7)向PROJ表添加104号项目,ATM机管理系统。 use company insert into proj values('104','ATM机管理系统') go
8)向JOB表添加1401号员工,参与了104号项目35天。 use company insert into job values('1401','104',‘35') go
9)向JOB表添加1402号员工,参与了103号项目20天。 use company insert into job values('1402','103','20') go
7、修改记录: 1)把DEPA表中’客户中心’的地址改为’大连甘井子区红岭路’; use company update depa set ADDR='大连甘井子区红岭路' where DNO=14
2)把DEPA表中15号部门的地址用沈阳东郊路120号填充。 use company update depa set ADDR=沈阳东郊路120号' where DNO=15
3)把EMPL表中何宜的生日、工资用1981年12月20日,3000元填充。 use company update empl set BIRTHDATE='1981-12-20',SALARY='3000' where ENAME='何宜' GO
4)把EMPL表中张山的部门号改为15号。 use company update empl set DNO='15' where ENAME='张山' GO
5)把JOB表中参与104号项目的每人增加5天。 use company update job set DAYS=DAYS+5 where PNO='104' GO
6)把JOB表中参与103号项目的每人天数乘以系数0.8。 use company update job set DAYS=DAYS*0.8 where PNO='103' GO
8、删除记录: 1)删除地址为空的部门。 delete from depa where ADDR=null 2)删除JOB表中参与104号项目的员工。 delete from job where PNO='104' 3)删除JOB表中天数低于25天的员工。 delete from job where DAYS<25 4)删除生于1980年后,且工资低于4000的员工。
5)删除属于14号部门的员工。 delete from empl where DNO=14 6)删除15号部门的信息 。delete from empl where DNO=15
9.使用对象资源管理器分离和附加数据库COMPANY