
统计学参考答案
第01章习题解答
1. 随机变量:某一变量在实验、调查和观测之前,不能预知其数值的变量。随机变量的特点是:离散性、变异性、规律性。
总体(population)又叫“母体”,是指具有某一种特征的一类事物的全体。
个体亦称“单位”、“样品”,统计学术语,统计学术语指总体中的每一个单位、样品或成员。是统计调查、试验或观测的最基本对象,是构成样本、总体的最小单元。在心理学研究中,个体根据研究目的的不同,可以是人,也可以是人在某种实验条件下的某个反应,或每个实验结果、每个数据。
在总体中按照一定的规则抽取的部分个体,称为总体的一个样本(sample)。根据样本容量(通常以30为界线)的大小,可区分为大样本和小样本。根据两样本来自的两总体是相关还是独立,可分为相关样本和独立样本。
次数:某一随机事件在某一类别中出现的数据多少,亦称频数(frequency)。
频率:某一事件发生的次数与总事件的比率。
概率(probability):某随机事件在某一总体中出现的比率。
表示样本的数字特征的量叫统计量。如描述数据集中趋势的一些统计指标称为平均数;描述一组数据离散程度的统计指标称为标准差。
表示总体的数字特征的量叫参数。如反应总体集中情况的统计指标称为总体平均数;反应总体离散程度的统计指标称为标准差。观测值(observation):实验、调查和观测某些个体在某一变量上的具体的数值,即为观测值。
2. 何谓心理与教育统计学?学习它有何意义?心理与教育统计
学是专门研究如何搜集、整理、分析在心理教育方面由实验和调查所获得的数据资料,并如何根据这些数字所传递的信息,进行科学推论找出客观规律的一门学科。它是应用数理统计学的一个分支,是心理与教育研究中的科学工具。
意义:(1)研究心理与教育现象变化的统计规律;(2)为心理与教育研究提供科学的依据;(3)促进量化研究的发展……
3.选用统计方法有哪几个步骤?(1)实验或调查设计是否合理,即所获得的数据是否适合用统计方法去处理,正确将其数量化是应用统计方法的起步,如果对数量化的过程及其意义没有了解,将一些不着边际的数据加以统计处理是毫无意义的;(2)要分析实验或调查数据的类型,不同数据类型所使用的统计方法有很大差别,针对不同的数据类型选用与之相应的统计方法至关重要;(3)要分析数据的分布规律,看数据是正态分布还是非正态分布,方差是否已知,以及是大样本数据还是小样本数据。
4.随机变量:某一变量在实验、调查和观测之前,不能预知其数值的变量。随机变量的特点是:离散性、变异性、规律性。
心理与教育科学实验所获的数据大多是随机变量。5. 总体(population)是指具有某一种特征的一类事物的全体;如研究大学生的心理健康状况,全国的大学生即为总体。构成总体的每一个基本元素叫个体;如具体的每一个大学生即为个体。在总体中按照一定的规则抽取的部分个体,称为总体的一个样本(sample)。如湖北师范学校的大学生就为其中一个样本。
6.表示样本的数字特征的量叫统计量。如描述数据集中趋势的一些统计指标称为平均数;描述一组数据离散程度的统计指标称为标准差。表示总体的数字特征的量叫参数。如反应总体集中情况的统计指标称为总体平均数;反应总体离散程度的统计指标称为标准差。联系:参数通常通过样本的特征值来预测,已知总体的某一参数时,即可知道样本的随机变量的分布特点,当样本容量越来越大时,样本统计量与总体参数之间的误差会越来越小。区别:统计量表示样本的数据特征,参数反映的总体的状况;统计量是变量而参数是常量;统计量和参数所用的表示字母不同。
7. (1)计数数据和测量数据:计数数据指具有某一属性的个体的数目,一般都取整数是离散数据;测量数据借助测量工具获取的数据,是连续数据。(2)称名数据、顺序数据、等距数据、等比数据。称名数据说明一事物与它事物在属性上的不同或类别上的差异,一般取整数只计算个数不说明事物之间的差异大小。顺序数据是按次序对事物进行排序后所获得的数据,没有相等的单位和绝对的0点,不能说明事物之间的差异大小,不能进行加减乘除运算。等距数据有相等的单位,无绝对的0点的数据,能作加减运算,不能做乘除运算。等比数据是有相等的单位又有绝对0点的数据,能进行加减乘除运算。(3)离散数据与连续数据:离散数据一般取整数是不连续的数据,任意两点之间不能无限细分;连续数据的任意两个相邻数据之间可以无限细分。
8. (1)(2)(3)(6)是测量数据,(4)(5)是计数数据
9.
10.(1)心理统计是将心理现象以数据的形式进行量化
(2)心理统计是有用的,反映所研究的心理变量的变化的规律性(3)统计不是万能的,统计所得出的结论会有一定的偏差
(4)进行统计分析时,一定要依据数据类型选择正确的统计方法,作结论时一定要小心谨慎。……
Chapter 02 1. 统计分组应注意哪些问题?
答:进行统计分组进需要注意下列问题:
(1)分组要以被研究对象的本质特性为基础
面对大量原始数据进行分组进,有时需要先做初步的分类,分类或分组一定是要选择与被研究现象的本质有关的特性为依据,才能确保分类或分组的正确。在心理学与教育学研究方面,专业知识的了解和熟悉对分组的正确进行有重要作用。例如在学业成绩研究中按学科性质分类,在整理智力测验结果时,按言语智力、操作智力和总的智力分数分类等。
(2)分类标志要明确,要能包括所有的数据
对数据进行分组时,所依据的特性称为分组或分类的标志。整理数据时,分组标志要明确并且在整理数据的过程中前后一致。这就是说,关于被研究现象本质特性的概念要明确,不能既是这个又是那个。另外,所依据的标志必须能将全部数据包括进去,不能有遗漏,也不能中途改变。
2. 直条图适合哪种资料?自选数据绘制直条图。
直条图又叫条形图(bar charts),主要用于表示离散型数据资料,即计数资料。它是以条形的长短表示各事物间数量的大小与数量之间的差异情况。条形图中一个轴是分类轴,表示类别,描述计数数据;另一个轴是数量轴,表示大小多少,描述计量数据,在这个轴上数据单的大小取决于原始数据。条形图因使用的条形形状不同而有多种名称,如矩形条图、梯形条图、尖形条图等,其中矩形图应用最多,一般说的条形图就是指这种矩形条形图、条形图又分为简单条形图、分组条形图和分段条形图三种。
条形图与直方图的区别如下:
①描述的数据类型不同。条形图用来描述称名数据或计数数据,而直方图主要用来描述分组的连续数据;
②表示的数据多少的方式不同。条形图用直条的长短或高低表示数据的多少和大小,而直方图用面积表示数据的多少和大小。直方图的总面积与总次数相等。
③坐标轴上的标尺分点意义不同。条形图的一个坐标轴是分类轴,而直方图的一个坐标轴上表示的是另一个刻度值。
图形直观开关形状不同。
绘图(略)
3.圆形图适合哪种资料?自选数据绘制图形图。
圆形图又称饼图,主要用于描述间断性资料,目的是为显示各部分在整体中所占的比重大小,以及各部分之间的比较。
绘图(略)
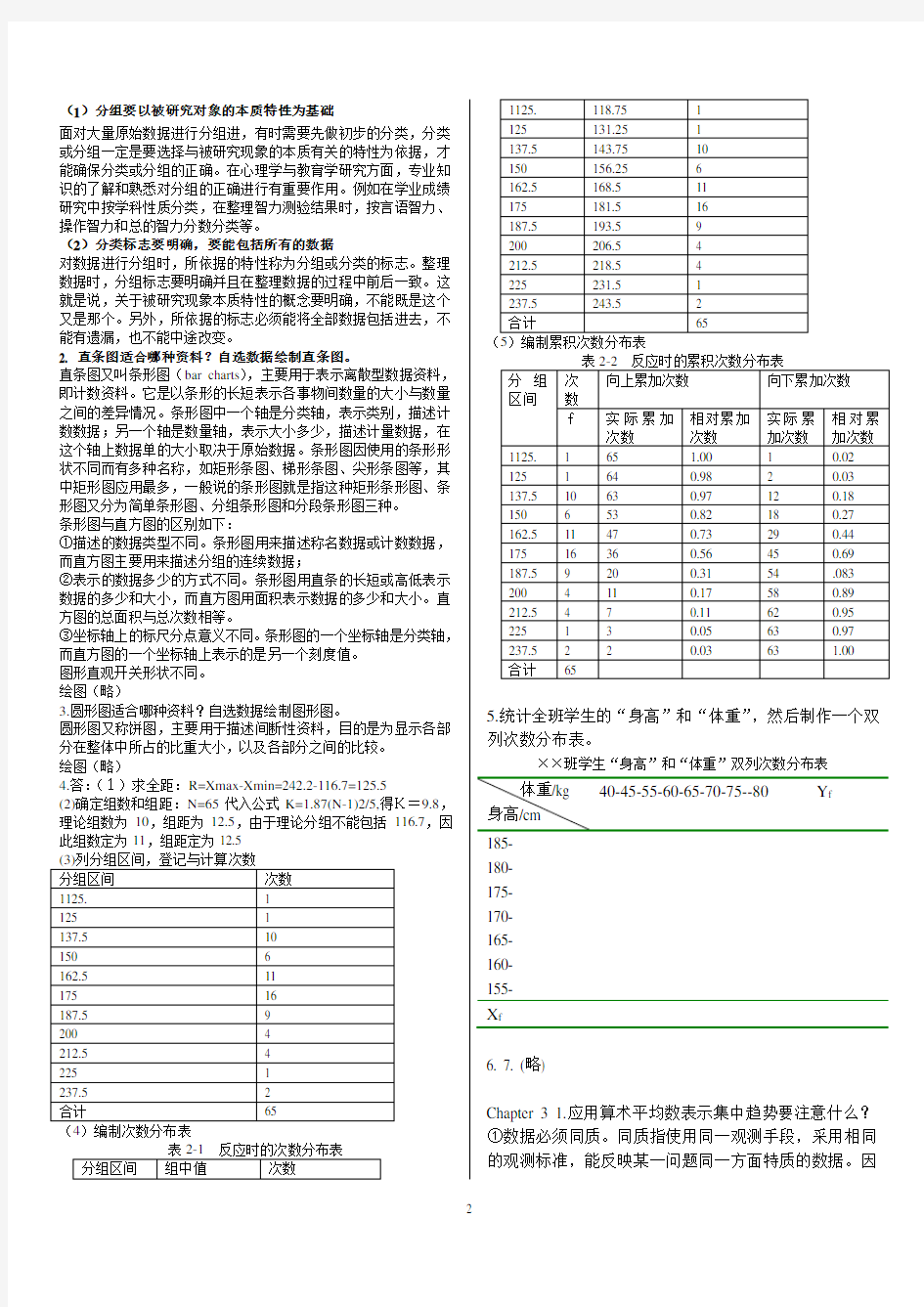
4.答:(1)求全距:R=Xmax-Xmin=242.2-116.7=12
5.5
(2)确定组数和组距:N=65代入公式K=1.87(N-1)2/5,得K=9.8,理论组数为10,组距为12.5,由于理论分组不能包括116.7,因此组数定为11,组距定为12.5
5.统计全班学生的“身高”和“体重”,然后制作一个双列次数分布表。
××班学生“身高”和“体重”双列次数分布表
185-
180-
175-
170-
165-
160-
155-
X f
6. 7. (略)
Chapter 3 1.应用算术平均数表示集中趋势要注意什么?
①数据必须同质。同质指使用同一观测手段,采用相同的观测标准,能反映某一问题同一方面特质的数据。因
为不同质的数据观测手段、测量标准不一致。
②平均数与个体数据相结合。在作出结论时,把总体的平均水平与个体数据结合起来会能更加说明问题。 ③将平均数与标准差和方差结合。平均数只是反映数据的集中趋势,而标准差和方差能够反映数据差异趋势,将二者结合起来才能全面准确的反映总体数据的分布特征。④当出现极端数据或模糊数据时,用中数或众数表示数据的集中趋势会更好。
2.中数、众数、几何平均数、调和平均数各适合哪些资料?
①中数适用于:一组观测数据中出现极端数据时;一组数据的两端有模糊数据出现;需要快速估计一组数据的代表值时。
②众数适用于:当一组数据出现不同质的情况或分布中出现极端数据时;数据分布中出现双众数时。
③几何平均数主要适用于:一组数据中有少量数据偏大或偏小,数据分布呈偏态分布;数据按一定的比例关系变化。
④调和平均数主要用于描述学习速度方面的问题。 3.对于下列数据,使用何种集中量数表示集中趋势更好?并计算其值。
(1)4 5 6 6 7 29。――>中数或众数6 (2)3 4 5 5 7 5 ------- 平均数,其值为5 (3)2 3 5 6 7 8 9 ――>平均数40/7=5.71 4.求下列次数分布的平均数、中数
127
.36157654626578521647157
24
423437213216271122917712=+?+?+?+?+?+?+?+?+?+?+?=
∑n fx
X c
=
5.求下列四个年级的总平均成绩
6.求平均联想速度:
答:平均联想速度为1.3个
7.平均增加率是多少?估计10年后毕业人数有多少
1120×1.1110=3180
答:平均增长率为11%,10后毕业人数为3180人
Chapter4
1. 度量离中趋势的量有哪些?为何要度量离中趋势? 度量离中趋势的量有全距、离均差、标准差或方差、全距、平均差、四分差及各种百分差。
要准确的反映一组数据的变化趋势,既要度量其集中趋势又要度量其离中趋势。
2.各种差异量数各有什么特点?
全距:优点:全距是最简单,最容易理解的差异量数;缺点:不稳定、不可靠、不灵敏,受抽样变动的影响,是一种低效的差异量数。
平均差:优点:平均差是一个很好的差异量数,容易计算理解,说明全部数据的差异情况;缺点:易受两极数据的影响,由于取绝对值应用受限制,不利于代数方法运算;不具备标准差的优越性不用于进一步的分析,故被列入低效差异量数。
标准差:基本具备了良好的差异量数所具备的条件: 反映灵敏,每个数据的取值变化它们也随着变化;有一定的计算公式严密规定;容易计算;适合代数运算;受抽样变动的影响不大,即不同样本的标准差或方差比较稳定;简单明了。
缺点:较难理解、计算复杂,易受极端数据影响。 方差:优点:可加,通过方差分析可以分辨不同来源的变异对总变异贡献的大小。缺点:较难理解、计算复杂,易受极端数据影响。
百分位差:优点:容易理解、计算、不受极端值影响;缺点:不能反映其他数据的差异情况。
四分差:优点:计算简便,意义明确,对极端值不敏感;缺点:不能反映所有数据的差异情况,受抽样变化的影响较大。
3. 标准差的其他用途
①和平均数一起,计算差异系数,即进行不同质数据的差异大小比较
②计算标准分数,将等级数据转化成等距数据,由此可知个体在群体的相对位置。
959.36537
642/157352/=?-+=?-+=i f F N L Md Md b b 72
.91969200
9421592318912365.90212211=+++????=
++++++=∑
∑i
i
i k k k w
n x n n n n x n x n x n X ΛΛ3.113
25
1331323
11111121=++∑=???
?
??+++=i n H X N
X X X N M Λ11.0542/11207
11
112312===---N n N n n g x x x x x x x x M Λ
4.应用标准分数求不同质的数据总和时,应注意哪些问题?
(1)这些不同质的数据须服从正态分布; (2)求各个标准分数的代数和;
(3)为了符合人们的习惯计算出Z 分数的总和可以用10Z +50转化成T 分数。 5.S=1.37; AD=1.19
6.S=26.3; Q1=159.1,Q3=192.45,Q=16.68.
7.解此题它们的平均数相差较大,故用差异系数比较其离散程度的大小
5厘米组的误差的离散程度大于10厘米组。 8.解
9解
所以四分差为Q=Q3-Q1/2=7.61175
Chaper 5
1. 解释相关系数时应注意什么?
相关系数的值表示两个变量之间的关联程度,但只说明其大概的趋势,不存在精确的数值关系。
相关系数的数值大小,表示两个变量关联的强弱。 相关系数即使是1,也不能推出因果关系的结论。
要能区分虚假相关,不能仅依据相关系数的大小确定变量的相关。
在纯理论研究中,即使有很小的相关,如果在统计上有显著性,也能说明心理规律。
2. 假设两变量为线性关系,计算下列各种相关应用什
么方法?
(1)积差相关(2)斯皮尔曼等级相关(3)二列相关 (4)多列相关(5)点二列相关(6)等级相关(斯皮尔曼或肯德尔和谐系数)
3.如何区别点二列和二列相关?
主要看是人为的划分还是自然划分,而为为二列相关,自然为点二列相关
4.品质相关有几种?各种品质相关的条件? 主要有四分相关、φ相关、列联表相关
四分相关:当两个变量都是连续变量,且每一个变量的变化都被人为地分为两种类型时, 求两个变量之间的相关。
Φ相关:当两变量是真正(自然)的二分变量时,求两变量之间的相关。
列联相关:当两个变量都是计数数据时,求它们的相关。 5.
用肯德尔和谐系数
6.将数据带入公式计算得: 解
7.此题的数据为非正态的等距数据,故用斯皮尔曼等级相关求相关系数
8.解此题符合点二列相关的条件
85=男X 91=女X 8.3=X S
成绩与性别有关,即男女生的成绩存在显著差异
53
.03.17
.0111==X S CV =279
.03.42
.1222==X S CV =()()03
.6182
3.12.12.03.02.5438.5485.6512.6402
2222222211
1
22
=+++++++????+++-+=∑∑==k
k i k
i i i i
i T n n n Xt X n n S Λσ4375.5858355.4055*43
214.4357
95.1340*341
1
=-+==-+=?-+=?+=-i f F N L Q i L Q b
b f F N b b 837.125*5539553355*/)()
(2
2
2
22
2
=??
?
??+=???
?
??-=
-=
-=
∑∑∑∑∑∑∑∑n fd n
fd
f
f
fx fx
f
x x f S )(()
819
.0222
2=∑
∑∑
∑
∑∑∑---=Y Y N X X N Y
X XY N r ()()794
.011413=++???
?????-?-=∑
n n n R R n r y x R ()()972.011413
=++???
?????-?-=∑
n n n R R n r y x R 7890418
38591./.pq S X X r x q P pb
=?-=-=
9.此题该用二列相关求解 2.88=奇X 8.87=偶X 8.3=X S
在某题上及格或不及格对总分的影响不大,亦即该题几乎没有区分度。
10.该题属于多列相关
8620101032410344422
2
.i n fd n
fd S =???? ??+=????
?
??+∑∑=
8.69103655
5.54=+
=优?x
5.59102412
5.54=+=良?x
81
.44103332
5.54=-+=中?x
25102059
5.54=-+=及格?x
[]
997.14=-∑i h l
x y y )(
()[]
925.0/2
=-∑i h l
p y y
11.下表是9名被试评价10名著名天文学家的等级评定结果,问这9名被试的等级评定是否具有一致性?
被试 被评价者
A B C D E F G H I J 1 1 2 4 3 9 6 5 8 7 10 2 1 4 2 5 6 7 3 10 8 9 3 1 3 4 5 2 8 9 6 10 7 4 1 3 4 5 2 6 10 8 7 9 5 1 9 2 5 6 3 4 8 10 7 6 1 4 9 2 5 6 9 7 8 4 7 1 3 5 10 2 6 9 7 8 4 8 1 3 5 7 6 4 8 10 2 9
该题应求肯德尔和谐系数
其相关系数为0.481,说明对天文学家的等级评定一致性不高。 12解
对11题的数据两两进行比较形成对偶等级表,然后根据数据等级计算肯德尔U 系数。 A B C D E F G H I J A 9 9 9 9 9 9 9 9 9 B 0 7 7 5 8 7 7 8 8 C 0 2 6 5 6 7 7 7 2 D 0 2 3 5 6 5 8 7 8 E 0 4 4 4 5 5 6 6 9 F 0 1 3 3 4 6 7 2 7 G 0 2 2 4 4 3 5 6 6 H 0 2 2 1 3 2 4 4 5 I 0 1 2 2 3 2 3 5 5 J
1
2
1
2
3
4
4
Chaper6
概率的定义与性质
反应随机事件出现可能性大小的统计指标即为概率。概率有两类 :
后验概率(统计概率):指对随机事件进行n 次观测时,其中某一事件出现的次数m 与总的次数n 的比值。
065.03989.025
.08.38.872.88=-=??-=y pq S X X r t q P b ()[
]
()777092508620997142
....P y y s X y y r i H L t i H L s =?-?-=∑
∑=()
5.32161049527719222
=-=N R R SS i i Ri ∑∑
-=
()
481.012/101000815.321612132=-=)-(=N N K SS W Ri 195
0189910949194811182.)()K (K )N (N )r K r (U ij ij =+????-=+-?--=∑∑
先验概率是指在特殊情况下,直接计算的比值。这种特殊情况是:
(1)试验(基本事件)的每一种可能结果是有限的;(2)每一个基本事件出现的可能性相等。如果基本事件的总数为n,事件A包括m个基本事件,则事件A的概率为:P(A)=m/n
概率的性质
有关概率的一些公理
(1)任何随机事件A的概率都是非负的。
(2)必然事件的概率为1,但是概率等于1的某个事件,并不能断定它是必然事件,只能说它出现的可能性非常大。
(3)不可能事件的概率为0,但是概率为0的事件,也不能说它是不可能事件,只能说它出现的可能性非常小,几乎接近于0。
(4)随机事件的概率介于0到1之间,越接近1说明发生的可能性很大,越接近0说明发生的可能性很小。
概率的加法定理:是指两个互不相容事件A和B之和的概率,等于这两个事件的概率的和。
写作P(A+B)=P(A)+P(B)。互不相容(非独立相关)事件:是指在一次试验或者调查中,若事件A发生,事件B就一定不会发生,则事件A和B为互不相容事件。由此可以推到出n个互不相容事件中去:P(A1+A2+A3+…+An)=P(A1)+P(A2)+P(A3)+…+P (An)
概率的乘法定理:两个独立事件同时出现的概率,等于两个事件概率的乘积。独立(相容无关)事件是指一个事件的出现对另一个事件的出现不发生影响。若A和B是两个相互独立的事件,则A和B同时发生的概率为:P (A*B)=P(A)×P(B)。由此推到n个独立事件同时发生的概率为:P(A1A2…An)=P(A1)P(A2)…P(A3)。
2概率分布的类型?简述其特点
概率分布是指对随机变量取值的概率分布情况用数学方法进行描述。
1.离散分布与连续分布
离散分布的随机变量是计数数据(离散数据)。常用的离散分布为二项分布、泊松分布、超几何分布。
连续分布的随机变量是连续数据(测量数据)。常见的连续分布为正态分布、负指数分布、威布尔分布。
2.经验分布与理论分布
经验分布是指根据观察和实验所得的数据而编制的次数分布或相对频数分布。
理论分布①指随机变量概率分布的函数(数学模型);②指依据某种数学模型推算出的总体的次数分布。
3.基本随机变量分布和抽样分布
基本随机变量分布有正态分布和二项分布。
抽样分布是样本统计量的理论分布。
3.何谓样本平均数的分布?
样本平均数的分布是指从基本随机变量为正态分布的总体中,采用放回式随机抽样的方法,每次从这个总体中抽取大小为n的一个样本计算出它的平均数(x1),然后将这些样本放回总体中,再次取n个个体,又可计算出一个(x2)……这样反复可以计算出无限多个x,这无限多个样本平均数的分布为正态分布。
4.0.35
5.1/36
6.6/25,9/25,4/25
7.2/27,13/54,13/545/27.
8.1/4,1/16,1/8,1/16,1/256.
9.该二项式为(1/5+4/5)25
平均数为标准差为
5
5
1
25=
=?
μ2
5
4
5
1
25=
=?
?
σ
10-12(略)
13解
6σ/6=1σ,要使各个等级等距每个等级应占1个标准差
答:略
14解
15解
依题意有:
答:略 16解
此题np>5,所以
32645.1330
.44
3
*41*10025
4/1*100=+故=σμσμ=====npq np
所以作对32题以上是真会而不是猜测。 17解此题P =1/15 该题np<5,所以
985.591514151151,15,51191.01514151151,15,610*783.51514151151,15,710*936.11514151151,15,810147.61514151151,15,910
68.31514151151,15,1010
5
515596
6156587
715777
8
81589
6
9
91599
5
10101510=??
?
????
? ??=??? ??=??? ????? ??=??? ??=??
? ????
? ??=??? ??=??
? ????
? ??=??? ???=??
? ????? ??=??? ???=??? ????? ??=??? ??--C b C b C b C b C b C b --
猜测答对的平均6题(95%的概率) 18此题np<5所以
08651733
.0434141,8,40230712
.0434141,8,500384
.0434141,8,6000366
.0434141,8,70000152.04141,8,84
4
4843
5
5852
6
6867
7878
888=??
?
????? ??=??? ??=???
????? ??=??? ??=???
????? ??=??? ??=???
????? ??=??? ??=??? ??=??? ??C b C b C b C b C b
须5个以上才是真能看清
19.略(和上面的题是类型题) 20.解
按照录取率20个学生,只有8人能被录取。 所以至少有10人被录取的概率为8/10=80%。 随着录取人数的增多,录取概率随着下降。 21-23略
()()()000128600.0616/1,6,6000643004.065*616/1,6,50080375
.065*616/1,6,4053.0)6
5()61()6/163(6
6665
565
2
446
43
3363=??? ??==??
? ????? ??==??? ????? ??==C b C b C b C b =,,
24.解
1
21012=-=Z Z 以上的概率为0.5-0.34134=
0.15866
25由于总体方差未知用样本的标准差作为总体的代表值,所以
5
.065053=-=Z ,大于 该平均数的概率为:0.5-
0.19146=0.30854
26.查表可知df =7时,卡方为12以上的概率为0.1,以下的概率为0.9
27.此题须先计算卡方值 以df=14查表得:概率值为0.25,所以该卡方值以下的概率为0.75
28该题须先求样本标准差
8.302
2
2=????
??-∑∑n x n x S =
以自由度为9查表得:P=0.25,所以该卡方值以下的概率为0.75 29.解 与上体无大的区别,如果要更精确可以用直线内插法。 30
解该题属于F 分布
查表得其临界值为:F(14,15)=2.86 故:两样本方差无显著性差异
1. 何谓点估计与区间估计,它们各有哪些优缺点?
点估计就是总体参数不清楚时,用一个特定的值,即样本统计量对总体参数进行估计,但估计的参数为数轴上某一点。 区间估计是用数轴上的一段距离来表示未知参数可能落入的范围,它不具体指出总体参数是多少,能指出总体未知参数落入某一区间的概率有多大。
点估计的优点是能够提供总体参数的估计值,缺点是点估计总以误差的存在为前提,且不能提供正确估计的概率。
区间估计的优点是用概率说明估计结果的把握程度,缺点是不能确定一个具体的估计值。
2以方差的区间估计为例说明区间估计的原理 根据χ2分布:
总体方差的.95或.99置信区间为: 即总体参数(方差) 落入上述区间的概率为1-α,其值为95%或99% 3.总体平均数估计的具体方法有哪些?
总体方法为点估计好区间估计,区间估计又分为: (1)
当总体分布正态方差已知时,样本平均的分布为正态分
布,故依据正态分布理论估计其区间;(2)当总体分布正态方差未知时,样本平均数的分布为T 分布,依据T 分布理论估计其区间;(3)当总体非分布正态方差未知时,只有在n 大于30时渐近T 分布,样本平均数的分布渐近T 分布,依据T 分布理论估计其区间。
4总体相关系数的置信区间,应根据何种分布计算? 应根据Fisher 的Z 分布进行计算
5.解:依据样本分布理论该样本平均数的分布呈正态 其标准误为:
其置信区间为:
该科成绩的真实分数有95%的可能性在78.55----83.45之间。 6.解:此题属于总体分布正态总体方差未知的情形,故样本平均数的分布呈T 分布 其标准误为:
用df=99差T 值表,然后用直线内插法求得t α/2=1.987 其置信区间为:
该学区教学成绩的平均值有95%的可能在78.61---81.39之间。
(
)
181012152222
2
==?=-=∑σ
σχnS X X i (
)
2.122530822222
==σ
σχnS X X i =-=
∑(
)
72.122
2
2=σχ∑-=X X i
176.117202122
11===--n n S S F ()()2
22212
2
2
1σσσχ
nS S n X X n =
-=-=
-∑()()2
2/1212
22/2
111)
(ααχσχ----<<-n n S n S n 25
.116
5==
=
n
x σ
σ45
.8355.7825.1*96.18125.1*96.1812/2/<<+<<-?+<
.099
71
==
-=
n s x n σ39
.8161.787.0*987.1807.0*987.1802/2
<<+<<-+<<-μμσμσαα即:x
x t X t X
7. 解:此题属于总体分布正态总体方差已知 计算标准误
总体平均数的.95置信区间为 所以总体平均数Λ在167.493―――174.506之间,作出这种判断
的时候犯错误的比率是5%。 8
解:此题属于总体方差未知,样本平均数的分布是t 分布 计算标准误:
查t 值表,查t.05(149)=1.98(实际查df =120所对应的t 值,因为没有149所对应的t 值),所以总体平均数Λ的.95置信区间为
455
.178735.0*98.1782/±=±=±=X t X σμα,即在
76.544―――79.455之间
正式测验的平均成绩在76.544――79.455之间,犯错误的百分率为5%。
9.解:此题的样本容量n 大于30,其样本标准差可以看成渐近正态分布 计算标准误 总
体
的
标
准
差
的
置
信
区
间
为
:
118.1*96.1102/1±=?±=-s n Z S σσα,即为7.8――12.2之间。 总体标准差的.95置信区间为7.8――12.2之间 10.解:此题总体分布为正态,应查卡方值表确定: χ2.025(15)=27.5,χ2.975(15)=6.26 由
得总体的方差在2.727――11.98之间
总体方差的.95置信区间在2.727――11.98之间 11.(略超范围,下一章更适合) 该题样本的方差的比率的分布为F 分布
两样本的方差相等 12.解:
总体方差比率的0.95置信区间为0.16-6.23之间。
13.解方法1 所
以总
体
相
关
系数
153
.056.00782.096.156.02/±=?±=?±=r Z r σρα
总体相关系数的.95置信区间为0.407――0.713之间 方法2:利用费舍Z 函数计算
查r-Zr 转换表得Zr=0.633 计算Zr 的置信区间为 总体相关系数的的.95置信区间为.386-.695之间。
14.解
(1)假设:总体相关系数为0 其标准误为
t (8)0.05/2=2.306
因此,总体相关系数为0的假设不成立。 (2)利用费舍Z 函数分布计算 Zr=1.071
总体相关系数在0.32---0.995之间
15.已知-----
解:此题n>20其样本相关系数的分布渐近正态分布,
其置信区间为:
789
.120
8==
=
n
x σ
σ506.3171789.1*96.11712
1±=±=±-x z x σα735
.0150
91==
=
-n
s x n σ118
.180
10221==
=
=
-n
S n
n s σ
σ()()2
2
/12
122
2
/2111ααχ
σχ-----n n S n S
n ππ
78.35625.016
9
2/05.0)10,9(21
2211=<==
=
--F S
S F n n 16.0123.6975
..0)6,4(025.0)6,4(===F F 115
.075
1
31
==
-=
n SE z 858
.0407.0225.0633.011
.0*96.1633.02/--=±=±=±z r SE Z Z α0782.077
56.011
12
2=-=
--=
n r r σ1329
.08
3759.02
79.012
12
2==
--=
--=
n n r r σ09
.14835.00
*306.279.01329.0*306.279.02/2/<<+<<-?+<
r t r t r 378
.07
13
1==
-=
n SE z 之间
的值在所以70.2331.378
.0*96.1071.12/--±±r z
r Z SE Z Z α150
.02
2946.012
122=--=
--=
n r SE R r 755
.0166.0150
.0*96.146.02
12
2/----=±=--?
±n r Z r R R α
总体相关系数在0.166-----0.755之间。
16.解:该题属于比率分布
P=125/362=0.345,由于np>5时,率的置信区间为
总体比率在0.2961---0.3939之间,不能说患者接近半数
《统计原理》第五章练习题答案 5.1 (1)平均分数是范围在0-100之间的连续变量,Ω=[0,100] (2)已经遇到的绿灯次数是从0开始的任意自然数,Ω=N (3)之前生产的产品中可能无次品也可能有任意多个次品,Ω=[10,11,12,13…….] 5.2 设订日报的集合为A ,订晚报的集合为B ,至少订一种报的集合为A ∪B ,同时订两种报的集合为A ∩B 。 P(A ∩B)=P(A)+ P(B)-P(A ∪B)=0.5+0.65-0.85=0.3 5.3 P(A ∪B)=1/3,P(A ∩B )=1/9, P(B)= P(A ∪B)- P(A ∩B )=2/9 5.4 P(AB)= P(B)P(A ∣B)=1/3*1/6=1/18 P(A ∪B )=P(B A )=1- P(AB)=17/18 P(B )=1- P(B)=2/3 P(A B )=P(A )+ P(B )- P(A ∪B )=7/18 P(A ∣B )= P(B A )/P(B )=7/12 5.5 设甲发芽为事件A ,乙发芽为事件B 。 (1)由于是两批种子,所以两个事件相互独立,所以有:P(AB)= P(B)P(B)=0.56 (2)P(A ∪B)=P(A)+P(B)-P(A ∩B)=0.94 (3)P(A B )+ P(B A )= P(A)P(B )+P(B)P(A )=0.38 5.6 设合格为事件A ,合格品中一级品为事件B P(AB)= P(A)P(B ∣A)=0.96*0.75=0.72 5.7 设前5000小时未坏为事件A ,后5000小时未坏为事件B 。 P(A)=1/3,P(AB)=1/2, P(B ∣A)= P(AB)/ P(A)=2/3 5.8 设职工文化程度小学为事件A ,职工文化程度初中为事件B ,职工文化程度高中为事件C ,职工年龄25岁以下为事件D 。 P(A)=0.1 P(B)=0.5, P(C)=0.4 P(D ∣A)=0.2, P(D ∣B)=0.5, P(D ∣C)=0.7 P(A ∣D)=2/55)C P(C)P(D )B P(B)P(D )A P(A)P(D ) A P(A)P(D =++ 同理P(B ∣D)=5/11, P(C ∣D)=28/55 5.9 设次品为D ,由贝叶斯公式有: P(A ∣D)=)C P(C)P(D )B P(B)P(D )A P(A)P(D ) A P(A)P(D ++=0.249 同理P(B ∣D)=0.112 5.10 由二项式分布可得:P (x=0)=0.25, P (x=1)=0.5, P (x=2)=0.25 5.11 (1) P (x=100)=0.001, P (x=10)=0.01, P (x=1)=0.2, P (x=0)=0.789
第一章绪论 一、单项选择题 答案 1. D 2. E 3. D 4. B 5. A 6. D 7. A 8. C 9. E 10. D 二、简答题 1答由样本数据获得的结果,需要对其进行统计描述和统计推断,统计描述可以使数据更容易理解,统计推断则可以使用概率的方式给出结论,两者的重要作用在于能够透过偶然现象来探测具有变异性的医学规律,使研究结论具有科学性。 2答医学统计学的基本内容包括统计设计、数据整理、统计描述和统计推断。统计设计能够提高研究效率,并使结果更加准确和可靠,数据整理主要是对数据进行归类,检查数据质量,以及是否符合特定的统计分析方法要求等。统计描述用来描述及总结数据的重要特征,统计推断指由样本数据的特征推断总体特征的方法,包括参数估计和假设检验。 3答统计描述结果的表达方式主要是通过统计指标、统计表和统计图,统计推断主要是计算参数估计的可信区间、假设检验的P 值得出相互比较是否有差别的结论。 4答统计量是描述样本特征的指标,由样本数据计算得到,参数是描述总体分布特征的指标可由“全体”数据算出。 5答系统误差、随机测量误差、抽样误差。系统误差由一些固定因素产生,随机测量误差是生物体的自然变异和各种不可预知因素产生的误差,抽样误差是由于抽样而引起的样本统计量与总体参数间的差异。 6答三个总体一是“心肌梗死患者”所属的总体二是接受尿激酶原治疗患者所属的总体三是接受瑞替普酶治疗患者所在的总体。 第二章定量数据的统计描述 一、单项选择题 答案 1. A 2. B 3. E 4. B 5. A 6. E 7. E 8. D 9. B 10. E 二、计算与分析 2
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下: 2 4 7 10 10 10 12 12 14 15 要求:(1)计算汽车销售量的众数、中位数和平均数。(2)根据定义公式计算四分位数。 (3)计算销售量的标准差。 (4)说明汽车销售量分布的特征。 解: Statistics 汽车销售数量 N Valid10 Missing0 Mean Median Mode10 Std. Deviation Percentiles25 50 75 4.2 随机抽取25个网络用户,得到他们的年龄数据如下: 1915292524 2321382218 3020191916 2327223424 4120311723 要求;(1)计算众数、中位数: 1、排序形成单变量分值的频数分布和累计频数分布: 网络用户的年龄
从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。 (2)根据定义公式计算四分位数。 Q1位置=25/4=,因此Q1=19,Q3位置=3×25/4=,因此Q3=27,或者,由于25 和27都只有一个,因此Q3也可等于25+×2=。 (3)计算平均数和标准差; Mean=;Std. Deviation= (4)计算偏态系数和峰态系数: Skewness=;Kurtosis= (5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=、呈右偏分布。如需看清楚分布形态,需要进行分组。 为分组情况下的直方图: 为分组情况下的概率密度曲线: 分组: 1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103 n K =+ =+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=,取5 3、分组频数表 网络用户的年龄 (Binned)
第五章 一、单项选择题 1.抽样推断的目的在于() A.对样本进行全面调查 B.了解样本的基本情况 C.了解总体的基本情况 D.推断总体指标 2.在重复抽样条件下纯随机抽样的平均误差取决于() A.样本单位数 B.总体方差 C.抽样比例 D.样本单位数和总体方差 3.根据重复抽样的资料,一年级优秀生比重为10%,二年级为20%,若抽样人数相等时,优秀生比重的抽样误差() A.一年级较大 B.二年级较大 C.误差相同 D.无法判断 4.用重复抽样的抽样平均误差公式计算不重复抽样的抽样平均误差结果将()A.高估误差 B.低估误差 C.恰好相等 D.高估或低估 5.在其他条件不变的情况下,如果允许误差缩小为原来的1/2,则样本容量()A.扩大到原来的2倍 B.扩大到原来的4倍 C.缩小到原来的1/4 D.缩小到原来的1/2 6.当总体单位不很多且差异较小时宜采用() A.整群抽样 B.纯随机抽样 C.分层抽样 D.等距抽样 7.在分层抽样中影响抽样平均误差的方差是() A.层间方差 B.层内方差 C.总方差 D.允许误差 二、多项选择题 1.抽样推断的特点有() A.建立在随机抽样原则基础上 B.深入研究复杂的专门问题 C.用样本指标来推断总体指标 D.抽样误差可以事先计算 E.抽样误差可以事先控制 2.影响抽样误差的因素有() A.样本容量的大小 B.是有限总体还是无限总体 C.总体单位的标志变动度 D.抽样方法 E.抽样组织方式 3.抽样方法根据取样的方式不同分为() A.重复抽样 B.等距抽样 C.整群抽样 D.分层抽样 E.不重复抽样 4.抽样推断的优良标准是() A.无偏性 B.同质性 C.一致性 D.随机性 E.有效性 5.影响必要样本容量的主要因素有() A.总体方差的大小 B.抽样方法
第五章 5.1 设总体x 是用无线电测距仪测量距离的误差,它服从( α,β)上的均匀分布,在200次测量中,误差为xi 的次数有ni次: Xi:3 5 7 9 11 13 15 17 19 21 Ni:21 16 15 26 22 14 21 22 18 25 求α,β的矩法估计值 α=u- 3s β=u+ 3s 程序代码: x=seq(3,21,by=2) y=c(21,16,15,26,22,14,21,22,18,25) u=rep(x,y) u1=mean(u) s=var(u) s1=sqrt(s) a=u1-sqrt(3)*s1 b=u1+sqrt(3)*s1b=u1+sqrt(3)*s1 得出结果: a= 2.217379 b= 22.40262 5.2 为检验某自来水消毒设备的效果,现从消毒后的水中随机抽取
50L,化验每升水中大肠杆菌的个数(假设1L 水中大肠杆菌的个数服从泊松分布),其化验结果如下表所示:试问平均每升水中大肠杆菌 个数为多少时,才能使上述情况的概率达到最大 大肠杆菌数/L:0 1 2 3 4 5 6 水的升数:17 20 10 2 1 0 0 γ=u 是最大似然估计 程序代码: a=seq(0,6,by=1) b=c(17,20,10,2,1,0,0) c=a*b d=mean(c) 得出结果: d= 7.142857 5.3 已知某种木材的横纹抗压力服从正态分布,现对十个试件做横纹抗压力试验,得数据如下:482 493 457 471 510 446 435 418 394 469 ( 1)求u 的置信水平为0.95 的置信区间程序代码: x=c(482 493 457 471 510 446 435 418 394 469 ) t.test(x) 得出结果: data: x t = 6.2668, df = 9, p-value = 0.0001467 alternative hypothesis: true
1、什么是统计学? 统计学是一门收集、分析、表述、解释数据的科学和艺术。 2、描述统计:研究的是数据收集、汇总、处理、图表描述、概括与分析等统计方法。 推断统计:研究的是如何利用样本数据来推断总体特征。 3、统计学据可以分成哪几种类型,个有什么特点? 按照计量尺度不同,分为:分类数据、顺序数据、数值型数据。 分类数据:只能归于某一类别的,非数字型数据。 顺序数据:只能归于某一有序类别的,非数字型数据。 数值型数据:按数字尺度测量的观察值,结果表现为数值。 按收集方法不同。分为:观测数据、和实验数据 观测数据:通过调查或观测而收集到的数据;不控制条件; 社会经济领域 实验数据:在试验中收集到的数据;控制条件;自然科学领域。 按时间不同,分为:截面数据、时间序列数据 截面数据:在相同或近似相同的时间点上收集的数据。 时间序列数据:在不同时间收集的数据。 4、举例说明总体、样本、参数、统计量、变量这几个概念。 总体:是包含全部研究个体的集合,包括有限总体和无限总体(围、数目判定) 样本:从总体中抽取的一部分元素的集合。 参数:用来描述总体特征的概括性数字度量。(平均数、标准差、比例等) 统计量:用来描述样本特征的概括性数字度量。(平均数、标准差、比例等) 变量:是说明样本某种特征的概念,其特点:从一次观察到下一次观察结果会呈现出差别或变化。(商品销售额、受教育程度、产品质量等级等) (对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。) 5、变量可以分为哪几类? 分类变量:说明事物类别;取值是分类数据。 顺序变量:说明事物有序类别;取值是顺序数据 数值型变量:说明事物数字特征;取值是数值型数据。 变量也可以分为:随机变量和非随机变量;经验变量和理论变量 6、举例说明离散型变量和连续型变量。 离散型变量:只能取有限个、可数值的变量。(企业个数、产品数量) 连续型变量:可以在一个或多个区间中取任何值的变量。(年龄、温度、零件尺寸误差)7、请举出统计应用的几个例子。 市场调查、人口普查等。 8、请举出应用统计学的几个领域。 社会科学中的经济分析、政府政策制定等;自然科学中的物理、生物领域等。
第五章指数 一﹑单项选择题 1.广义的指数是指反映 A.价格变动的相对数 B.物量变动的相对数 C.总体数量变动的相对数 D.各种动态相对数 2.狭义的指数是反映哪一总体数量综合变动的相对数? A.有限总体 B.无限总体 C.简单总体 D.复杂总体 3.指数按其反映对象范围不同,可以分为 A.个体指数和总指数 B.数量指标指数和质量指标指数 C.定基指数和环比指数 D.平均指数和平均指标指数 4.指数按其所表明的经济指标性质不同可以分为 A.个体指数和总指数 B.数量指标指数和质量指标指数 C.定基指数和环比指数 D.平均指数和平均指标指数 5.按指数对比基期不同,指数可分为 A.个体指数和总指数 B.定基指数和环比指数 C.简单指数和加权指数 D.动态指数和静态指数 6.下列指数中属于数量指标指数的是 A.商品价格指数 B.单位成本指数 C.劳动生产率指数 D.职工人数指数 7.下列指数中属于质量指标指数的是 A.产量指数 B.销售额指数 C.职工人数指数 D.劳动生产率指数 8.由两个总量指标对比所形成的指数是 A.个体指数 B.综合指数 C.总指数 D.平均指数 9.综合指数包括 A.个体指数和总指数 B.数量指标指数和质量指标指数 C.定基指数和环比指数 D.平均指数和平均指标指数 10.总指数编制的两种基本形式是 A.个体指数和综合指数 B.综合指数和平均指数 C.数量指标指数和质量指标指数 D.固定构成指数和结构影响指数 11.数量指标指数和质量指标指数的划分依据是 A.指数化指标性质不同 B.所反映的对象范围不同 C.所比较的现象特征不同 D.指数编制的方法不同 12.编制综合指数最关键的问题是确定 A.指数化指标的性质 B.同度量因素及其时期 C.指数体系 D.个体指数和权数 13.编制数量指标指数的一般原则是采用下列哪一指标作为 同度量因素 A.基期的质量指标 B.报告期的质量指标 C.报告期的数量指标 D.基期的数量指标 14.编制质量指标指数的一般原则是采用下列哪一指标作为
第一章总论 一、填空题 1.威廉·配弟、约翰·格朗特 2.统计工作、统计资料、统计学、统计工作、统计资料、统计学3.数量对比分析 4.大量社会经济现象总体的数量方面 5.大量观察法、统计分组法、综合指标法、统计推断法 6.统计设计、统计调查、统计整理、统计分析 7.信息、咨询、监督 8.同质性 9.大量性、同质性、差异性 10.研究目的、总体单位 11.这些单位必须是同质的 12.属性、特征 13.变量、变量值 14.总体单位、总体 15.是否连续、离散、性质 二、是非题 1.非2.非3.是4.非5.是6.非7.是8.是9.是10.非11.非12.非13.非14.是15.非 三、单项选择题 1.C 2.B 3.C 4.A 5.C 6.C 7.A 8.A 9.C 10.B 11.A 12.B 13.C 14.A 15.A 四、多项选择题 1.BC 2.ABC 3.ABE 4.ABCD 5.BCDE 6.AC 7.ABCDE 8.BD 9.AB 10.ABCD 11.BD 12.ABCD 13.BD 14.ABD 15.ABC 五、简答题 略 第二章统计调查
一、填空题 1.统计报表普查重点调查抽样调查典型调查 2.直接观察法报告法采访法 3. 统计报表专门调查 4. 经常性一次性 5. 调查任务和目的调查项目组织实施计划 6. 单一表一览表 7. 基层填报单位综合填报单位 8. 原始记录统计台帐 9. 单一一览 二、是非题 1.是 2.是 3.非 4.是 5.非 6.是 7.是 8.非 9.是 10.是 三、单项选择题 1. D 2. A 3. C 4. A 5. B 6. C 7. B 8. D 9. C 10. B 四、多项选择题 1. BCE 2. ABCDE 3. ADE 4. ADE 5.ACDE 6. ABD 7. BCDE 8. ABE 9.ACD 五、简答题 略 第三章统计整理 一、填空题 1.统计汇总选择分组标志 2.资料审核统计分组统计汇总编制统计表 3.不同相同 4.频率比率(或频率) 5.全距组距 6.上限以下 7.组中值均匀 8.离散连续重叠分组 9.手工汇总电子计算机汇总 10.平行分组体系复合分组体系 11.主词宾词
思考题与练习题 参考答案 【友情提示】请各位同学完成思考题与练习题后再对照参考答案。回答正确,值得肯定;回答错误,请找出原因更正,这样使用参考答案,能力会越来越高,智慧会越来越多。学而不思则罔,如果直接抄答案,对学习无益,危害甚大。想抄答案者,请三思而后行! 第一章绪论 思考题参考答案 1.不能,英军所有战机=英军被击毁的战机+英军返航的战机+英军没有弹孔的战机,因为英军被击毁的战机有的掉入海里、敌军占领区,或因堕毁而无形等,不能找回;没有弹孔的战机也不可能自己拿来射击后进行弹孔位置的调查。即便被击毁的战机找回或没有弹孔的战机自己拿来射击进行实验,也不能从多个弹孔中确认那个弹孔就是危险的。 2.问题:飞机上什么区域应该加强钢板?瓦尔德解决问题的思想:在她的飞机模型上逐个不重不漏地标示返航军机受敌军创伤的弹孔位置,找出几乎布满弹孔的区域;发现:没有弹孔区域就是军机的危险区域。 3.能,拯救与发展自己的参考路径为:①找出自己的优点,②明确自己大学阶段的最佳目标,③拟出一个发扬自己优点,实现自己大学阶段最佳目标的可行计划。 练习题参考答案 一、填空题 1.调查。
2.探索、调查、发现。 3、目的。 二、简答题 1.瓦尔德;把剩下少数几个没有弹孔的区域加强钢板。 2.统计学解决实际问题的基本思路,即基本步骤就是:①提出与统计有关的实际问题;②建立有效的指标体系;③收集数据;④选用或创造有效的统计方法整理、显示所收集数据的特征;⑤根据所收集数据的特征、结合定性、定量的知识作出合理推断;⑥根据合理推断给出更好决策的建议。不解决问题时,重复第②-⑥步。 3.在结合实质性学科的过程中,统计学就是能发现客观世界规律,更好决策,改变世界与培养相应领域领袖的一门学科。 三、案例分析题 1.总体:我班所有学生;单位:我班每个学生;样本:我班部分学生;品质标志:姓名;数量标志:每个学生课程的成绩;指标:全班学生课程的平均成绩 ;指标体系:上学期全班同学学习的科目 ;统计量:我班部分同学课程的平均成绩 ;定性数据:姓名 ;定量数据: 课程成绩 ;离散型变量:学习课程数;连续性变量:学生的学习时间;确定性变量:全班学生课程的平均成绩;随机变量:我班部分同学课程的平均成绩,每个同学进入教室的时间;横截面数据:我班学生月门课程的出勤率;时间序列数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;面板数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;选用描述统计。 2.(1)总体:广州市大学生;单位:广州市的每个大学生。(2)如果调查中了解的就是价格高低,为定序尺度;如果调查中了解的就是商品丰富、价格合适、节约时间,为定类尺度。(3)广州市大学生在网上购物的平均花费。(4)就是用统计量作为参数的估计。(5)推断统计。 3.(1)10。(2)6。(3)定类尺度:汽车名称,燃油类型;定序尺度:车型大小;定距尺度:引擎的汽缸数;定比尺度:市区驾车的油耗,公路驾车的油耗。(4)定性变量:汽车名称,车型大小,燃油类型;定量变量:引擎的汽缸数,市区驾车的油耗,公路驾车的油耗。(5)40%;(6)30%。 第二章收集数据 思考题参考答案
第5章 参数估计 ●1. 从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。 (1) 样本均值的抽样标准差x σ等于多少? (2) 在95%的置信水平下,允许误差是多少? 解:已知总体标准差σ=5,样本容量n =40,为大样本,样本均值x =25, (1)样本均值的抽样标准差 x σ=0.7906 (2)已知置信水平1-α=95%,得 α/2Z =1.96, 于是,允许误差是E = α/2 Z 6×0.7906=1.5496。 ●2.某快餐店想要估计每位顾客午餐的平均花费金额,在为期3周的时间里选取49名顾客组成了一个简单随机样本。 (3) 假定总体标准差为15元,求样本均值的抽样标准误差; (4) 在95%的置信水平下,求允许误差; (5) 如果样本均值为120元,求总体均值95%的置信区间。 解:(1)已假定总体标准差为σ=15元, 则样本均值的抽样标准误差为 x σ15=2.1429 (2)已知置信水平1-α=95%,得 α/2Z =1.96, 于是,允许误差是E = α/2 Z 6×2.1429=4.2000。 (3)已知样本均值为x =120元,置信水平1-α=95%,得 α/2Z =1.96, 这时总体均值的置信区间为 α/2 x Z 0±4.2=124.2115.8 可知,如果样本均值为120元,总体均值95%的置信区间为(115.8,124.2)元。 ●3.某大学为了解学生每天上网的时间,在全校7500名学生中采取不重复抽样方法随机抽取36人,调查他们每天上网的时间,得到下面的数据(单位:小时): 3.3 3.1 6.2 5.8 2.3 4.1 5.4 4.5 3.2 4.4 2.0 5.4 2.6 6.4 1.8 3.5 5.7 2.3 2.1 1.9 1.2 5.1 4.3 4.2 3.6 0.8 1.5 4.7 1.4 1.2 2.9 3.5 2.4 0.5 3.6 2.5
第一部分 课程指导 第一章绪论 一、本章重点 1.统计的基本涵义。统计工作、统计资料和统计学,统计资料是统计工作的成果;统计学是统计工作的经验总结和理论概括,统计学与统计工作是理论与实践的关系。 2.统计学的历史大体可分为古典统计学时期、近代统计学时期、现代统计学时期。曾经产生过记述学派、政治算术学派、数理统计学派和社会经济统计学派等流派。赫尔曼·康令、特弗里德·阿亨瓦尔、威廉·配第、约翰·格朗特、阿道夫·凯特勒、克尼斯等是各个不同时期、不同流派的代表人物。《政治算术》、《社会物理学》是统计学说史上的典型著作。 3.统计的研究对象是大量社会经济现象的数量方面,社会经济现象的数量表现,现象变化的数量关系和数量界限,通过这个对象的研究以认识和利用社会经济发展变化的规律。 4.统计具有数量性、总体性、具体性、社会性等特点。大量观察法、统计分组法、综合指标法和归纳推理法是统计研究的基本方法。 5.统计的基本任务是对国民经济与社会发展情况进行统计调查、统计分析、提供统计资料和统计咨询意见,实行统计监督。统计具有信息的职能、咨询的职能、监督的职能。一个完整的统计工作过程包括:统计设计、统计调查、统计整理和统计分析四个阶段。 6.总体与总体单位、标志与指标、变异与变量是统计中常用的基本概念。同质性、大量性、差异性是统计总体的基本特征。统计指标具有数量性、综合性、具体性三个特点。指标的构成必须完整、指标的名称必须具有正确的涵义和理论依据、要明确指标的计算口径和范围、要有科学的计算方法等是对一个统计指标的基本要求。掌握统计指标体系的概念和基本分类。 二、难点释疑 1.对于社会经济统计的性质及研究对象,要从马克思主义认识论的基本原理,客观事物质与量的辩证统一关系出发,从统计总体本身具有大量性、同质性、差异性特点出发,联系社会经济统计的实践,从统计要发现规律、描述规律、认识规律、利用规律等递进关系上来深刻正确的理解。 2.熟记、掌握以下基本概念:统计总体与总体单位,标志与指标、统计指标体系。要掌握这些重要概念的联系与区别、特点、表现形式及其基本分类等。 三、练习题: (一)填空题 1.“统计”一词有三种涵义,即统计工作、()和()。
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第5章SPSS的参数检验 1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为 75分。现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。 原假设:样本均值等于总体均值即u=u0=75 步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;) 采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异); 单个样本统计量 N 均值标准差均值的标准误 成绩11 73.73 9.551 2.880 单个样本检验 检验值 = 75 t df Sig.(双侧) 均值差值差分的 95% 置信区间下限上限 成绩-.442 10 .668 -1.273 -7.69 5.14 分析:指定检验值:在test后的框中输入检验值(填75),最后ok! 分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。 2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时): (1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。 (2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。 (1)分析→描述统计→描述、频率
第五章 练习题 一、单项选择题 1.抽样推断的目的在于() A.对样本进行全面调查 B.了解样本的基本情况 C.了解总体的基本情况 D.推断总体指标 2.在重复抽样条件下纯随机抽样的平均误差取决于() A.样本单位数 B.总体方差 C.抽样比例 D.样本单位数和总体方差 3.根据重复抽样的资料,一年级优秀生比重为10%,二年级为20%,若抽样人数相等时,优秀生比重的抽样误差() A.一年级较大 B.二年级较大 C.误差相同 D.无法判断 4.用重复抽样的抽样平均误差公式计算不重复抽样的抽样平均误差结果将()A.高估误差 B.低估误差 C.恰好相等 D.高估或低估 5.在其他条件不变的情况下,如果允许误差缩小为原来的1/2,则样本容量()A.扩大到原来的2倍 B.扩大到原来的4倍 C.缩小到原来的1/4 D.缩小到原来的1/2 6.当总体单位不很多且差异较小时宜采用() A.整群抽样 B.纯随机抽样 C.分层抽样 D.等距抽样 7.在分层抽样中影响抽样平均误差的方差是() A.层间方差 B.层内方差 C.总方差 D.允许误差 二、多项选择题 1.抽样推断的特点有() A.建立在随机抽样原则基础上 B.深入研究复杂的专门问题 C.用样本指标来推断总体指标 D.抽样误差可以事先计算 E.抽样误差可以事先控制 2.影响抽样误差的因素有() A.样本容量的大小 B.是有限总体还是无限总体 C.总体单位的标志变动度 D.抽样方法 E.抽样组织方式 3.抽样方法根据取样的方式不同分为() A.重复抽样 B.等距抽样 C.整群抽样 D.分层抽样 E.不重复抽样 4.抽样推断的优良标准是() A.无偏性 B.同质性 C.一致性 D.随机性 E.有效性 5.影响必要样本容量的主要因素有() A.总体方差的大小 B.抽样方法
第一章总论(16页) 一、判断题 1、统计学是数学的一个分支 答:错。统计学和数学都是研究数量规律的,虽然两者关系非常密切,但有不同的性质特点。数学撇开具体的对象,以最一般的形式研究数量的联系和空间形式;统计学的数据则总是与客观的对象联系在一起,特别是统计学中的应用统计学与各不同领域的实质性学科有着非常密切的联系,是有具体对象的方法论。从研究方法看,数学的研究方法主要是逻辑推理和演绎论证的方法,而统计学的方法本质上是归纳的方法。统计学家特别是应用统计学家需要深入实际,进行调查或试验区取得数据,研究时不仅要运用统计学的方法,而且要掌握某一专门领域的知识,才能得到有意义的成果。从成果评价标准看,数学注意方法推导的严谨性和正确性;统计学则更加注意方法的适用性和操作性。 2、统计学是一门独立的社会科学。 答、错。统计学是横跨社会科学领域和自然科学领域的多学科性的科学。 3、统计学是一门实质性科学。 答:错。实质性的科学研究该领域现象的本质关系和变化规律;而统计学则是为研究认识这些关系和规律提供数量分析的方法。 4、统计学是一门方法论科学。 答:对统计学是有关如何测定、收集和分析反映客观现象总体数量的数据,以帮助人们正确认识客观世界数量规律的方法论科学。 5、描述统计是用文字和图标对客观世界进行描述 答:错。描述统计是对彩机的数据进行登记、审核、整理、归类,在此基础上进一步计算出各种能反映总体数量特征的综合指标,并用图标的形式表示经过归纳分析而得到的各种有用信息,描述统计不仅仅使用文字和图表来描述,更重要的是要利用有关统计指标反映客观事物的数量特征。 6、对于有限总体不必应用推断统计方法。 答:错。一些有限总体,由于各种原因,并不一定能采用全面调查的方法。例如,某一批电视机是有限总体,要检验其显像管的寿命,不可能对每一台都进行观察和试验,只能采用抽样调查方法得到样本,并结合推断统计方法估计显像管的寿命。 7、社会经济统计问题都属于有限总体的问题。 答:错。不少社会经济的统计问题属于无限总体。例如要研究消费者的消费倾向,消费者不仅包括现在的消费者而且还包括未来的消费者,因而实际上是一个无限总体。 8、理论统计学与应用统计学是两类性质不同的统计学。 答:对。理论统计学具有通用方法论的性质,而应用统计学则与各不同领域的实质性学科有着非常密切的联系,具有边缘交叉和复合型学科的性质。 二、选择题 1、社会经济统计学的研究对象是(A) A. 社会经济现象的数量方面, B. 统计工作, C. 社会经济的内在规律, D. 统计方法 2、考察全国的工业企业的情况时,以下标志中属于不变标志的有(A) A. 产业分类, B. 职工人数, C. 劳动生产率, D. 所有制 3、要考察全国居民的人均住房面积,其统计总体是(A) A. 全国说有居民, B. 全国的住宅, C. 各省市自治区, D. 某一居民户 4、最早使用统计学这一学术用语的是(B) A. 政治算数学派, B. 国势学派, C. 社会统计学派, D. 树立统计学派
第四章 数据分布特征的测度 4.6 解:先计算出各组组中值如下: 4.8 解: ⑴ ⑵体重的平均数 体重的标准差 ⑶ 55—65kg 相当于μ-1σ到μ+1σ 根据经验法则:大约有68%的人体重在此范围内。 ⑷ 40—60kg 相当于μ-2σ到μ+2σ 2501935030450425501865011426.7120116.5 i M f x f s ?+?+?+?+?=====∑∑ 大。所以,女生的体重差异===离散系数===离散系数女 男10 .010 1 505v 08.012 1 605v =μσ=μσσσ) (1102.250)(1322.260磅=磅=女男=?μ=?μ) (112.25磅==?σ
根据经验法则:大约有95%的人体重在此范围内。 4.9 解: 在A 项测试中得115分,其标准分数为: 在B 项测试中得425分,其标准分数为: 所以,在A 项中的成绩理想。 4.11 解: 成年组的标准差为: 幼儿组的标准差为: 所以,幼儿组身高差异大。 115 100 115X Z =-=σμ-=5.050 400425X Z =-=σμ-= 172.1 4.24.2 2.4%172.1s x x n s s V x = == ====∑ 71.3 2.52.5 3.5% 71.3s x x n s s V x = =====∑
第七章 参数估计 7.7 根据题意:N=7500,n=36(大样本) 总体标准差σ未知,可以用样本标准差s 代替 32 .336 4.119n x x ===∑样本均值 2 1.61 s z α= =样本标准差: 边际误差为:22222 90 1.645 1.6451.61 1.6450.446 3.320.44 (2.883.76)95 1.9699 2.58(2.803.84)(2.634.01) z z x z z z ααααα==?=±=±置信水平%时,=平均上网时间的置信区间为: ,同理,置信水平%时,=;置信水平%时,=平均上网时间的置信区间分别为:,;,
《统计分析与SPSS的应用(第五版)》 课后练习答案 第5章SPSS的参数检验 1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为 75分。现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。 原假设:样本均值等于总体均值即u=u0=75 步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;) 采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异); 单个样本统计量 N 均值标准差均值的标准误 成绩11 73.73 9.551 2.880 单个样本检验 检验值 = 75 t df Sig.(双侧) 均值差值差分的 95% 置信区间下限上限 成绩-.442 10 .668 -1.273 -7.69 5.14 分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。 2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时): (1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。 (2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。 (1)分析→描述统计→描述、频率
第一章导论 1.1.1 (1)数值型变量。 (2)分类变量。 (3)离散型变量。 (4)顺序变量。 (5)分类变量。 1.2 (1)总体是该市所有职工家庭的集合;样本是抽中的2000个职工家庭的集合。 (2)参数是该市所有职工家庭的年人均收入;统计量是抽中的2000个职工家庭的年人均收入。 1.3 (1)总体是所有IT从业者的集合。 (2)数值型变量。 (3)分类变量。 (4)截面数据。 1.4 (1)总体是所有在网上购物的消费者的集合。 (2)分类变量。 (3)参数是所有在网上购物者的月平均花费。 (4)参数 (5)推断统计方法。
第二章数据的搜集 1.什么是二手资料?使用二手资料需要注意些什么? 与研究内容有关的原始信息已经存在,是由别人调查和实验得来的,并会被我们利用的资料称为“二手资料”。使用二手资料时需要注意:资料的原始搜集人、搜集资料的目的、搜集资料的途径、搜集资料的时间,要注意数据的定义、含义、计算口径和计算方法,避免错用、误用、滥用。在引用二手资料时,要注明数据来源。 2.比较概率抽样和非概率抽样的特点,举例说明什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。 概率抽样是指抽样时按一定概率以随机原则抽取样本。每个单位被抽中的概率已知或可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽中的概率,概率抽样的技术含量和成本都比较高。如果调查的目的在于掌握和研究总体的数量特征,得到总体参数的置信区间,就使用概率抽样。 非概率抽样是指抽取样本时不是依据随机原则,而是根据研究目的对数据的要求,采用某种方式从总体中抽出部分单位对其实施调查。非概率抽样操作简单、实效快、成本低,而且对于抽样中的专业技术要求不是很高。它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备。非概率抽样也适合市场调查中的概念测试。 3.调查中搜集数据的方法主要有自填式、面方式、电话式,除此之外,还有那些搜集数据的方法? 实验式、观察式等。 4. 自填式、面方式、电话式调查个有什么利弊? 自填式优点:调查组织者管理容易,成本低,可以进行较大规模调查,对被调查者可以刻选择方便时间答卷,减少回答敏感问题的压力。缺点:返回率低,调查时间长,在数据搜
统计学课后习题答案 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
第四章 统计描述 【】某企业生产铝合金钢,计划年产量40万吨,实际年产量45万吨;计划降低成本5%,实际降低成本8%;计划劳动生产率提高8%,实际提高10%。试分别计算产量、成本、劳动生产率的计划完成程度。 【解】产量的计划完成程度=%5.112100%40 45 100%=?=?计划产量实际产量 即产量超额完成%。 成本的计划完成程=84%.96100%5%-18% -1100%-1-1≈?=?计划降低百分比实际降低百分比 即成本超额完成%。 劳动生产率计划完= 85%.101100%8%110% 1100%11≈?++=?++计划提高百分比实际提高百分比 即劳动生产率超额完成%。 【】某煤矿可采储量为200亿吨,计划在1991~1995年五年中开采全部储量的%, 试计算该煤矿原煤开采量五年计划完成程度及提前完成任务的时间。 【解】本题采用累计法: (1)该煤矿原煤开采量五年计划完成=100% ?数 计划期间计划规定累计数 计划期间实际完成累计 = 75%.1261021025357 4 =?? 即:该煤矿原煤开采量的五年计划超额完成%。 (2)将1991年的实际开采量一直加到1995年上半年的实际开采量,结果为2000万吨,此时恰好等于五年的计划开采量,所以可知,提前半年完成计划。 【】我国1991年和1994年工业总产值资料如下表:
要求: (1)计算我国1991年和1994年轻工业总产值占工业总产值的比重,填入表中; (2)1991年、1994年轻工业与重工业之间是什么比例(用系数表示)? (3)假如工业总产值1994年计划比1991年增长45%,实际比计划多增长百分之几? 1991年轻工业与重工业之间的比例=96.01.144479 .13800≈; 1994年轻工业与重工业之间的比例=73.04.296826 .21670≈ (3) %37.25 1%) 451(2824851353 ≈-+ 即,94年实际比计划增长%。 【】某乡三个村2000年小麦播种面积与亩产量资料如下表: 要求:(1)填上表中所缺数字; (2)用播种面积作权数,计算三个村小麦平均亩产量; (3)用比重作权数,计算三个村小麦平均亩产量。
亲爱的,一章一章来,肯定能弄完的,你是最棒的! 统计学(第五版)贾俊平课后习题答案(完整版) 第一章思考题 1.1 什么是统计学 统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。 1.2 解释描述统计和推断统计 描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。 推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。 1.3 统计学的类型和不同类型的特点 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类 别,用文字来表述; (定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分; 截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。 时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 1.4 解释分类数据,顺序数据和数值型数据 答案同 1.3 1.5 举例说明总体,样本,参数,统计量,变量这几个概念 对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就 是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的 寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比 如说灯泡的寿命。 1.6 变量的分类 变量可以分为分类变量,顺序变量,数值型变量。 变量也可以分为随机变量和非随机变量。经验变量和理论变量。 1.7 举例说明离散型变量和连续性变量 离散型变量,只能取有限个值,取值以整数位断开,比如“企业数” 连续型变量,取之连续不断,不能一一列举,比如“温度”。 1.8 统计应用实例 人口普查,商场的名意调查等。 1.9 统计应用的领域 经济分析和政府分析还有物理,生物等等各个领域。 第二章思考题 2.1 什么是二手资料?使用二手资料应注意什么问题 与研究内容有关,由别人调查和试验而来已经存在,并会被我们利用的资料为“二手资料”。使用时要进