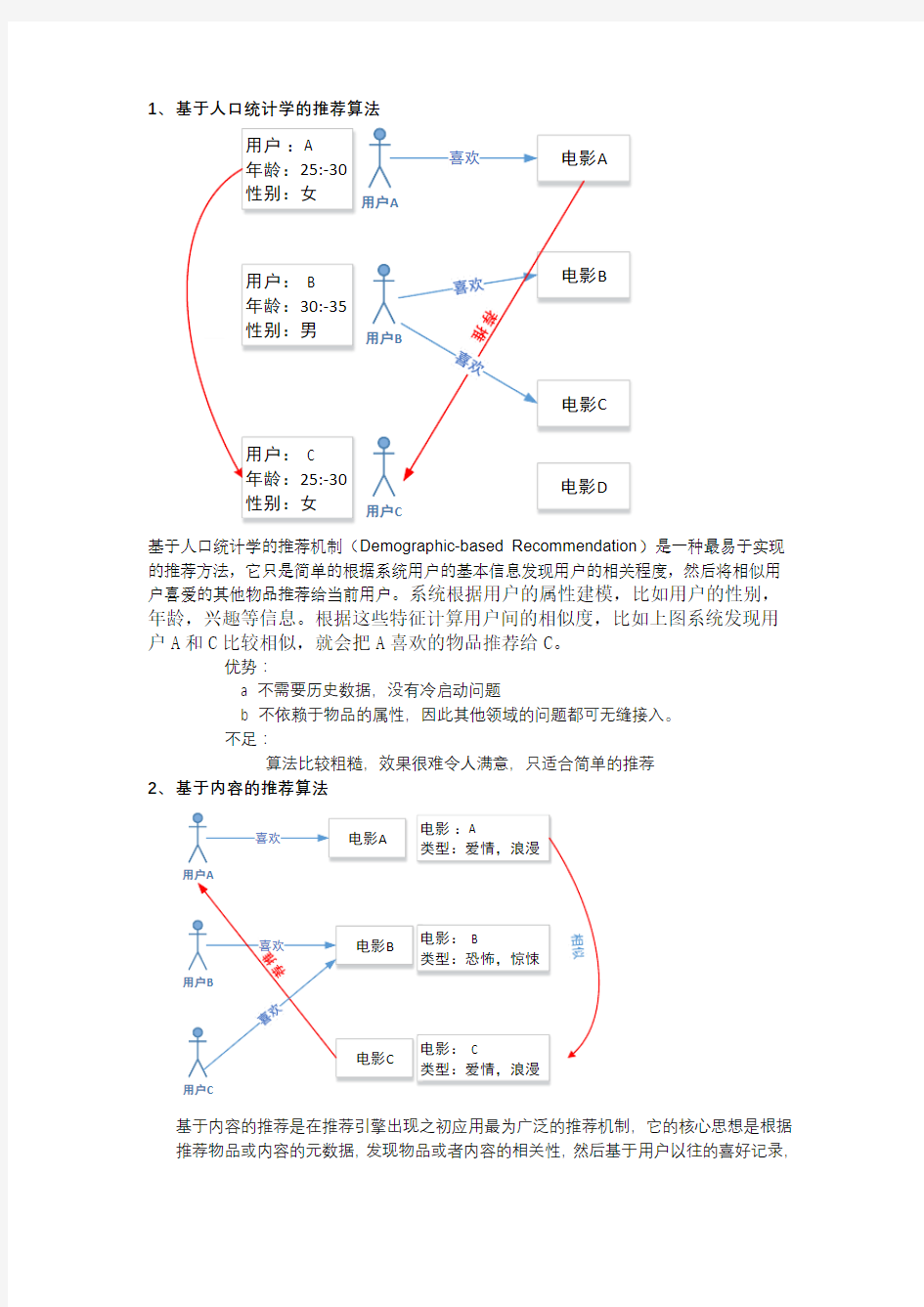

1、 基于人口统计学的推荐算法
用户A
用户B
用户C
电影A
电影B
电影C
电影D
喜欢
基于人口统计学的推荐机制(Demographic-based Recommendation )是一种最易于实现的推荐方法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。系统根据用户的属性建模,比如用户的性别,
年龄,兴趣等信息。根据这些特征计算用户间的相似度,比如上图系统发现用户A 和C 比较相似,就会把A 喜欢的物品推荐给C 。
优势:
a 不需要历史数据,没有冷启动问题
b 不依赖于物品的属性,因此其他领域的问题都可无缝接入。 不足:
算法比较粗糙,效果很难令人满意,只适合简单的推荐 2、 基于内容的推荐算法
电影: B
类型:恐怖,惊悚
电影:类型:爱情,浪漫
电影A
电影B
基于内容的推荐是在推荐引擎出现之初应用最为广泛的推荐机制,它的核心思想是根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,
推荐给用户相似的物品。这种推荐系统多用于一些资讯类的应用上,针对文章本身抽取一些tag作为该文章的关键词,继而可以通过这些tag来评价两篇文章的相似度。
系统根据电影的属性建模,比如电影的类型信息。根据这些特征计算电影间的相似度,比如上图系统发现电影A和C比较相似,系统还会发现用户A喜欢电影A,由此得出结论,用户A很可能对电影C也感兴趣,于是将电影C推荐给A。
优势:
对用户兴趣可以很好的建模,并通过对物品属性维度的增加,获得更好的推荐精度
不足:
a 物品的属性有限,很难有效的得到更多数据
b 物品相似度的衡量标准只考虑到了物品本身,有一定的片面性
c 需要用户的物品的历史数据,有冷启动的问题
3、协同过滤推荐算法
协同过滤(CF)推荐算法会寻找用户的行为模式,并据此创建用户专属的推荐内容。这种算法会根据系统中的用户使用数据——比如用户对读过书籍的评论来确定用户对其喜爱程度。关键概念在于:如果两名用户对于某件物品的评分方式类似,那么他们对于某个新物品的评分很可能也是相似的。值得注意的是:这种算法无需再额外依赖于物品信息(比如描述、元数据等)或者用户信息(比如感兴趣的物品、统计数据等)。协同过滤推荐算法可分为两类:基于邻域的与基于模型的。在前一种算法(也就是基于内存的协同过滤推荐算法)中,用户-物品评分可直接用以预测新物品的评分。而基于模型的算法则通过评分来研究预测性的模型,再根据模型对新物品作出预测。大致理念就是通过机器学习算法,在数据中找出模式,并将用户与物品间的互动方式模式化。
3.1
电影D
基于用户的 CF 的基本思想是基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 个邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。 下图给出了一个例子,对于用户 A ,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C ,然后将用户 C 喜欢的物品 D 推荐给用户 A 。
3.2
用户C
电影A
电影B
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。上图例子表示对于物品A ,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C ,得出物品A 和物品C 比较相似,而用户C 喜欢物品A ,那么可以推断出用户C 可能也喜欢物品C 。
3.3基于模型的协同过滤推荐算法
基于模型的协同过滤方式可以克服基于邻域方法的限制。与使用用户-物品评分直接预测新物品评分的邻域方式不同,基于模型的方法则使用评分来研究预测性模型,并根据模型来预测新物品。大致理念就是通过机器学习算法,在数据中找出模式,并将用户与物品间的互动方式模式化。总体来讲,基于模型的协同过滤方式是构建协同过滤更高级的算法。很多不同的算法都能用来构建模型,以进行预测;例如贝叶斯网络、集群、分类、回归、矩阵因式分
解、受限波尔兹曼机等,这些技术其中有些在获得Netflix Prize奖项时起到了关键性作用。Netflix在2006年到2009年间举办竞赛,当时还为能够生成准确度超过其系统10%的推荐系统制作团队提供100万美元的大奖。胜出的解决方案是一套综合了逾100种不同算法模型,并在生产环境中采用了矩阵因式分解与受限玻尔兹曼机的方法。
矩阵因式分解(比如奇异值分解、SVD++)将物品与用户都转化为同一个隐空间,表现了用户与物品间的底层互动(上图)。矩阵因式分解背后的原理在于:其潜在特性代表了用户如何对物品进行评分。根据用户与物品的潜在表现,我们就可以预测用户对未评分的物品的喜爱程度。
绍的主要方法有六种,分别为:1、对比分析法:将A公司和B公司进行对比、2、外部因素评价模型(EFE)分析、3、内部因素评价模型(IFE)分析、4、swot 分析方法、5、三种竞争力分析方法、6、五种力量模型分析。对比分析法是最常用,简单的方法,将一个管理混乱、运营机制有问题的公司和一个管理有序、运营良好的公司进行对比,观察他们在组织结构上、资源配臵上有什么不同,就可以看出明显的差别。在将这些差别和既定的管理理论相对照,便能发掘出这些差异背后所蕴含的管理学实质。企业管理中经常进行案例分析,将A和B公司进行对比,发现一些不同。各种现象的对比是千差万别的,最重要的是透过现象分析背后的管理学实质。所以说,只有表面现象的对比是远远不够的,更需要有理论分析。外部因素评价模型(EFE)和内部因素评价模型(IFE)分析来源于战略管理中的环境分析。因为任何事物的发展都要受到周边环境的影响,这里的环境是广义的环境,不仅指外部环境,还指企业内部的环境。通常我们将企业的内部环境称作企业的禀赋,可以看作是企业资源的初始值。公司战略管理的基本控制模式由两大因素决定:外部不可控因素和内部可控因素。其中公司的外部不可控因素主要包括:政府、合作伙伴(如银行、投资商、供应商)、顾客(客户)、公众压力集团(如新闻媒体、消费者协会、宗教团体)、竞争者,除此之外,社会文化、政治、法律、经济、技术和自然等因素都将制约着公司的生存和发展。由此分析,外部不可控因素对公司来说是机会与威胁并存。公司如何趋利避险,在外部因素中发现机会、把握机会、利用机会,洞悉威胁、规避风险,对于公司来说是生死攸关的大事。在瞬息万变的动态市场中,公司是否有快速反应(应变)的能力,是否有迅速适应市场变化的能力,是否有创新变革的能力,决定着公司是否有可持续发展的潜力。公司的内部可控因素主要包括:技术、资金、人力资源和拥有的信息,除此之外,公司文化和公司精神又是公司战略制定和战略发展中不可或缺的重要部分。一个公司制定公司战略必须与公司文化背景相联。内部
图片简介:
本技术介绍了一种改进了协同过滤推荐算法的推荐系统,属于推荐系统技术相关领域。该推荐系统包括输入模块、推荐算法和输出模块三个部分,输入模块用于输入用户个人基本信息、用户对项目的评分和用户历史信息等;推荐算法根据输入信息分析用户兴趣爱好,寻找最相似用户和项目,给出预测的评分结果;输出模块依据用户输入请求,输出相应的推荐项目。其中改进部分是对推荐算法中冷启动问题进行优化。针对新用户、新项目和新系统不同的冷启动问题,提出了优化解决方法。 技术要求 1.一种改进了协同过滤推荐算法的推荐系统,其特征在于,包括输入模块、推荐算法和输出模块;输入模块用于输入用户个人基本信息、用户对项目的评分、用户历史信息和当 前的点击操作;推荐算法根据输入信息分析用户兴趣爱好,寻找最相似用户和项目,给 出预测的评分结果;输出模块依据用户输入请求,输出相应的推荐项目到客户端。 2.如权利要求1所述的一种改进了协同过滤推荐算法的推荐系统,其特征在于,所述推荐算法为协同过滤推荐算法,所述协同过滤推荐算法冷启动实现方式为:一、提供非个性 化的推荐,非个性化推荐的最简单例子就是热门排行榜,可以给用户推荐热门排行榜, 然后等到用户的反馈足够多,数据收集到一定的时候,再转换为个性化推荐;二、利用 用户的注册信息,提供的年龄、性别、职业等数据做粗粒度的个性化;三、利用用户的 社交网络账号登录,导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的 物品;四、利用物品的内容信息计算物品相关表,利用专家进行标注。 3.如权利要求2所述的一种改进了协同过滤推荐算法的推荐系统,其特征在于,在所述推荐算法中,用户点击商品链接后,推荐系统会记录用户的点击行为,然后系统计算用户 间相似度,找出与当前用户最相似的前N个用户,接着在这前N个用户中找出当前用户没有点击的商品,将点击率最高的几个商品加入推荐列表,最后将推荐列表发往客户端向 用户展示推荐的商品。
一、描述统计描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策 树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W 检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数卩与已知的某一总体均数卩0 (常为理论值或标准值)有无差别; B 配对样本t 检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t 检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10 以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析用于分析离散变量或定型变量之间是否存在相关。对于二维表,可进行卡 方检验,对于三维表,可作Mentel-Hanszel 分层分析列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以
本文从互联网收集并整理了推荐系统的架构,其中包括一些大公司的推荐系统框架(数据流存储、计算、模型应用),可以参考这些资料,取长补短,最后根据自己的业务需求,技术选型来设计相应的框架。后续持续更新并收集。。。 图1 界面UI那一块包含3块东西:1) 通过一定方式展示推荐物品(物品标题、缩略图、简介等);2) 给的推荐理由;3) 数据反馈改进个性化推荐;关于用户数据的存放地方:1)数据库/缓存用来实时取数据;2) hdfs文件上面; 抽象出来的三种推荐方式 图2
图3 图3中,推荐引擎的构建来源于不同的数据源(也就是用户的特征有很多种类,例如统计的、行为的、主题的)+不同的推荐模型算法,推荐引擎的架构可以试多样化的(实时推荐的+离线推荐的),然后融合推荐结果(人工规则+模型结果),融合方式多样的,有线性加权的或者切换式的等 图4 图4中,A模块负责用户各类型特征的收集,B模块的相关表是根据图3中的推荐引擎来生成的,B模块的输出推荐结果用来C模块的输入,中间经过过滤模块(用户已经产生行为的物品,非候选物品,业务方提供的物品黑名单等),排名模块也根据预设定的推荐目标来制定,最后推荐解释的生成(这是可能是最容易忽视,但很关键的一环,微信的好友推荐游戏,这一解释已经胜过后台的算法作用了) HULU的推荐系统
总结:这个也就跟图3有点类似了,葫芦的推荐系统,至少在他blog中写的比较简单。更多的是对推荐系统在线部分的一种描述,离线部分我猜想也是通过分布式计算或者不同的计算方式将算法产生的数据存储进入一种介质中,供推荐系统在线部分调用。系统的整个流程是这样的,首先获取用户的行为,包括(watch、subscribe、vote),这样行为会到后台获取show-show对应的推荐数据。同时这些行为也会产生对应的topic,系统也会根据topic 到后台获取topic-show对应的推荐数据。两种数据进行混合,然后经过fliter、explanation、ranking这一系列过程,最后生成用户看到的推荐数据。 淘宝的推荐系统(详细跟简单版)
基于协同过滤的推荐算法与代码实现 什么是协同过滤? 协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤(Collaborative Filtering, 简称CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。 协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你。当然其中有一个核心的问题: 如何确定一个用户是不是和你有相似的品位? 如何将邻居们的喜好组织成一个排序的目录? 简单来说: 1. 和你兴趣合得来的朋友喜欢的,你也很有可能喜欢; 2. 喜欢一件东西A,而另一件东西B 与这件十分相似,就很有可能喜欢B; 3. 大家都比较满意的,人人都追着抢的,我也就很有可能喜欢。 三者均反映在协同过滤的评级(rating)或者群体过滤(social filtering)这种行为特性上。 深入协同过滤的核心 首先,要实现协同过滤,需要一下几个步骤: 1. 收集用户偏好 2. 找到相似的用户或物品 3. 计算推荐 (1)收集用户偏好 要从用户的行为和偏好中发现规律,并基于此给予推荐,如何收集用户的偏好信息成为系统推荐效果最基础的决定因素。用户有很多方式向系统提供自己的偏好信息,而且不同的应用也可能大不相同,下面举例进行介绍:
以上列举的用户行为都是比较通用的,推荐引擎设计人员可以根据自己应用的特点添加特殊的用户行为,并用他们表示用户对物品的喜好。 在一般应用中,我们提取的用户行为一般都多于一种,关于如何组合这些不同的用户行为,基本上有以下两种方式: 将不同的行为分组:一般可以分为“查看”和“购买”等等,然后基于不同的行为,计算不同的用户/物品相似度。类似于当当网或者Amazon 给出的“购买了该图书的人还购买了...”,“查看了图书的人还查看了...”
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度1. 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。 列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的自变量和因变量相关; 3、偏相关:在某一现象与多种现象相关的场合,当假定其他变量不变时,其中两个变量之间的相关关系称为偏相关。
个性化推荐系统研究综述 【摘要】个性化推荐系统不仅在社会经济中具有重要的应用价值,而且也是一个非常值得研究的科学问题。给出个性化推荐系统的定义,国内外研究现状,同时阐述了推荐系统的推荐算法。最后对个性化推系统做出总结与展望。 【关键词】推荐系统;推荐算法;个性化 1.个性化推荐系统 1.1个性化推荐系统的概论 推荐系统是一种特殊形式的信息过滤系统(Information Filtering),推荐系统通过分析用户的历史兴趣和偏好信息,可以在项目空间中确定用户现在和将来可能会喜欢的项目,进而主动向用户提供相应的项目推荐服务[1]。传统推荐系统认为推荐系统通过获得用户个人兴趣,根据推荐算法,并对用户进行产品推荐。事实上,推荐系统不仅局限于单向的信息传递,还可以同时实现面向终端客户和面向企业的双向信息传递。 一个完整的推荐系统由3个部分组成:收集用户信息的行为记录模块,分析用户喜好的模型分析模块和推荐算法模块,其中推荐算法模块是推荐系统中最为核心的部分。推荐系统把用户模型中兴趣需求信息和推荐对象模型中的特征信息匹配,同时使用相应的推荐算法进行计算筛选,找到用户可能感兴趣的推荐对象,然后推荐给用户。 1.2国内外研究现状 推荐系统的研宄开始于上世纪90年代初期,推荐系统大量借鉴了相关领域的研宄成果,在推荐系统的研宄中广泛应用了认知科学、近似理论、信息检索、预测理论、管理科学以及市场建模等多个领域的知识。随着互联网的普及和电子商务的发展,推荐系统逐渐成为电子商务IT技术的一个重要研究内容,得到了越来越多研究者的关注。ACM从1999年开始每年召开一次电子商务的研讨会,其中关于电子商务推荐系统的研究文章占据了很大比重。个性化推荐研究直到20世纪90年代才被作为一个独立的概念提出来。最近的迅猛发展,来源于Web210技术的成熟。有了这个技术,用户不再是被动的网页浏览者,而是成为主动参与者[2]。 个性化推荐系统的研究内容和研究方向主要包括:(1)推荐系统的推荐精度和实时性是一对矛盾的研究;(2)推荐质量研究,例如在客户评价数据的极端稀疏性使得推荐系统无法产生有效的推荐,推荐系统的推荐质量难以保证;(3)多种数据多种技术集成性研究;(4)数据挖掘技术在个性化推荐系统中的应用问题,基于Web挖掘的推荐系统得到了越来越多研究者的关注;(5)由于推荐系统需要分析用户购买习惯和兴趣爱好,涉及到用户隐私问题,如何在提供推荐服务的
Hans Journal of Data Mining 数据挖掘, 2019, 9(3), 81-87 Published Online July 2019 in Hans. https://www.doczj.com/doc/c112153910.html,/journal/hjdm https://https://www.doczj.com/doc/c112153910.html,/10.12677/hjdm.2019.93010 Overview and Prospect of Personalized Recommendation Algorithm Xinxin Li Dalian University of Foreign Languages, Dalian Liaoning Received: Jun. 19th, 2019; accepted: Jul. 2nd, 2019; published: Jul. 9th, 2019 Abstract In recent years, the word “information overload” frequently appears in people’s vision, it has be-come a hot word in the field of computer, and it is also an important problem that researchers ur-gently need to solve. In order to solve the problem of information overload, researchers in the field of computer constantly optimize the personalized recommendation algorithm, strive to re-duce the difficulty of information retrieval for users, to provide users with the best personalized recommendation results. This paper gives a brief overview of the personalized recommendation methods which are widely used and common. Combined with the experience of using personalized recommendation algorithm to generate results in daily life, the author puts forward expectations for the development of personalized recommendation algorithm in the future. Keywords Personalized Recommendation, Collaborative Filtering, Hybrid Recommendation 个性化推荐算法概述与展望 李鑫欣 大连外国语大学,辽宁大连 收稿日期:2019年6月19日;录用日期:2019年7月2日;发布日期:2019年7月9日 摘要 近年来,“信息过载”一词频繁出现在人们的视野中,它成为了计算机相关领域中的热门词汇,同时它也是研究人员急待解决的重要问题。为解决信息超载的问题,计算机领域研究人员不断优化个性化推荐
基于内容推荐方法的优点是: 1)不需要其它用户的数据,没有冷开始问题和稀疏问题。 2)能为具有特殊兴趣爱好的用户进行推荐。 3)能推荐新的或不是很流行的项目,没有新项目问题。 4)通过列出推荐项目的内容特征,可以解释为什么推荐那些项目。 5)已有比较好的技术,如关于分类学习方面的技术已相当成熟。 缺点是要求内容能容易抽取成有意义的特征,要求特征内容有良好的结构性,并且用户的口味必须能够用内容特征形式来表达,不能显式地得到其它用户的判断情况。 二、协同过滤推荐 协同过滤推荐(Collaborative Filtering Recommendation)技术是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐。协同过滤最大优点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。 协同过滤是基于这样的假设:为一用户找到他真正感兴趣的内容的好方法是首先找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给此用户。其基本思想非常易于理解,在日常生活中,我们往往会利用好朋友的推荐来进行一些选择。协同过滤正是把这一思想运用到电子商务推荐系统中来,基于其他用户对某一内容的评价来向目标用户进行推荐。 基于协同过滤的推荐系统可以说是从用户的角度来进行相应推荐的,而且是自动的,即用户获得的推荐是系统从购买模式或浏览行为等隐式获得的,不需要用户努力地找到适合自己兴趣的推荐信息,如填写一些调查表格等。 和基于内容的过滤方法相比,协同过滤具有如下的优点: 1)能够过滤难以进行机器自动内容分析的信息,如艺术品,音乐等。 2)共享其他人的经验,避免了内容分析的不完全和不精确,并且能够基于一些复杂的,难以表述的概念(如信息质量、个人品味)进行过滤。 3)有推荐新信息的能力。可以发现内容上完全不相似的信息,用户对推荐信息的内容事先是预料不到的。这也是协同过滤和基于内容的过滤一个较大的差别,基于内容的过滤推荐很多都是用户本
基于内容的推荐算法(Content-Based Recommendation)1.基本思想 基本思想就是给用户推荐与他们曾经喜欢的项目内容相匹配的新项目。 基于内容的推荐的基本思想是:对每个项目的内容进行特征提取(FeatureExtraction),形成特征向量(Feature Vector);对每个用户都用一个称作用户的兴趣模型(User Profile)的文件构成数据结构来描述其喜好;当需要对某个用户进行推荐时,把该用户的用户兴趣模型同所有项目的特征矩阵进行比较得到二者的相似度,系统通过相似度推荐文档。 (基于内容的推荐算法不用用户对项目的评分,它通过特定的特征提取方法得到项目特征用来表示项目,根据用户所偏好的项目的特征来训练学习用户的兴趣模型,然后计算一个新项目的内容特征和用户兴趣模型的匹配程度,进而把匹配程度高的项目推荐给用户。) 2.基于内容的推荐层次结构图:
CB的过程一般包括以下三步: (1)Item Representation:为每个item抽取出一些特征(也就是item的content 了)来表示此item;对应着上图中的Content Analyzer。 (2)Profile Learning:利用一个用户过去喜欢(及不喜欢)的item的特征数据,来学习出此用户的喜好特征(profile);对应着上图中的Profile Learner。 (3)Recommendation Generation:通过比较上一步得到的用户profile与候选item 的特征,为此用户推荐一组相关性最大的item。对应着上图中的Filtering Component。 3.详细介绍上面的三个步骤: 3.1 Item Representation 项目表示:对项目进行特征提取,比如最著名的特征向量空间模型,它首先将一份文本(项目)以词袋形式来表示,然后对每一个词用词频-逆向文档频率(TF-IDF)来计算权重,找出若干权重较大的词作为关键词(特征)。每个文本(项目)都可以表示成相同维度的一个向量 TF-IDF词频-逆文档频率计算: TF 词项t在文档d中出现的次数,df 表示词项t在所有文档出现的次数,idf 为反向文档频率,N为文档集中所有文档的数目。 TF-IDF公式同时引入词频和反向文档频率,词频TF表示词项在单个文档中的局部权重,某一词项在文档中出现的频率越高,说明它区分文档内容的属性越强,权重越大。IDF表示词项在整个文档集中的全局权重,某一词项在各大文档都有出现,说明它区分文档类别属性的能力越低,权值越小。
高级数据挖掘期末大作业
基于协同过滤算法的电影推荐系统 本电影推荐系统中运用的推荐算法是基于协同过滤算法(Collaborative Filtering Recommendation)。协同过滤是在信息过滤和信息系统中正迅速成为一项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。 电影推荐系统中引用了Apache Mahout提供的一个协同过滤算法的推荐引擎Taste,它实现了最基本的基于用户和基于内容的推荐算法,并提供了扩展接口,使用户方便的定义和实现自己的推荐算法。 电影推荐系统是基于用户的推荐系统,即当用户对某些电影评分之后,系统根据用户对电影评分的分值,判断用户的兴趣,先运用UserSimilarity计算用户间的相似度.UserNeighborhood根据用户相似度找到与该用户口味相似的邻居,最后由Recommender提供推荐个该用户可能感兴趣的电影详细信息。将用户评过分的电影信息和推荐给该用户的电影信息显示在网页结果页中,推荐完成。 一、Taste 介绍 Taste是Apache Mahout 提供的一个个性化推荐引擎的高效实现,该引擎基于java实现,可扩展性强,同时在mahout中对一些推荐算法进行了MapReduce 编程模式转化,从而可以利用hadoop的分布式架构,提高推荐算法的性能。 在Mahout0.5版本中的Taste,实现了多种推荐算法,其中有最基本的基于用户的和基于内容的推荐算法,也有比较高效的SlopeOne算法,以及处于研究阶段的基于SVD和线性插值的算法,同时Taste还提供了扩展接口,用于定制化开发基于内容或基于模型的个性化推荐算法。 Taste 不仅仅适用于Java 应用程序,还可以作为内部服务器的一个组件以HTTP 和Web Service 的形式向外界提供推荐的逻辑。Taste 的设计使它能满足企业对推荐引擎在性能、灵活性和可扩展性等方面的要求。 下图展示了构成Taste的核心组件:
Xiaol v2009-Relevance is more significant than correlation: Information filtering on sparse data 本文提出了在针对数据稀疏时,使用相关性信息比关联性信息效果更好,因为在关联性信息中,会用到更多的数据, Recommendation System 推荐系统存在的主要挑战: 1.Data sparsity. 2.Scalability 解决该问题的一般方法(28-30) a)有必要考虑计算成本问题和需找推荐算法,这些算法要么是小点的要求 或易于并行化(或两者) b)使用基于增量的算法,随着数据的增加,不重新计算所有的数据,而是 微调的进行 3.Cold start 解决该问题的方法一般有 a)使用混合推荐技术,结合content和collaborative数据,或者需 要基础信息的使用比如用户年龄、位置、喜好genres(31、32) b)识别不同web服务上的单独用户。比如Baifendian开发了一个可以 跟踪到单独用户在几个电子商务网站上的活动,所以对于在网站A的一 个冷启动用户,我们可以根据他在B,C,D网站上的记录来解决其冷启 动问题。 4.Diversity vs. Accuracy(多样性和精确性) 将一些很受欢迎的且高评分的商品推荐给一个用户时,推荐非常高效,但是这种推荐不起多少作用,因为这些商品可以很容易的找到。因此一个好的推荐商
品的列表应该包含一些不明显的不容易被该用户自己搜索到的商品。解决该问题 的方法主要是提高推荐列表的多样性,以及使用混合推荐方法。(34-37) 5.Vulnerability to attacks 6.The value of time. 7.Evaluation of recommendations 8.er interface. 除了这些问题外,还有其他的。随着相关学科分支的出现,特别是网络分析工具,科学家考虑网络结构对推荐的效果影响,以及如何有效使用已知的结构属性来提 高推荐。比如,(45)分析了消费者-商品网络并提出了一个基于喜好边(preferring edges)改进的推荐算法,该算法提高了局部聚类属性。(46)设计并提高了算法,该算法充分利用了社区结构(community structure)。随之而来的挑战主要有:带有GPS移动手机成为主流,并且可以访问网络,因此,基于位置的推荐更需要精确的推荐,其需要对人的移动有一个高效预测能力(47、48)并且高质量的定义位置和人之间的相似性的方法。(49、50)。智能推荐系统需考虑不同人的不同行为模式。比如新用户比较喜欢访问popular商品并且选择相似的商品,而老的用户有更不同的喜好(51,52)用户行为在低风险商品和高风险商品之间更加的不同。(53,54) 推荐系统的一些概念 网络 网络分析对于复杂系统的组织原则的发现是一个万能的工具(5-9)。网络是 由一些元素点和连接点的边组成的。点即为个人或者组织,边为他们之间的交互。 网络G可用(V,E)表示,V(vertice)为节点的集合,E为边(edge)的 集合。在无向网络中,边无方向。在有向网络中,边有向。我们假设网络中不存 在回路以及两个节点之间不存在多条边。G(V,E)图中,一些参数表示是指与节点x连接的节点(即x的邻居)的集合。 即为x节点的度。
推荐系统的出现 推荐系统的任务就是解决,当用户无法准确描述自己的需求时,搜索引擎的筛选效果不佳的问题。联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对他感兴趣的人群中,从而实现信息提供商与用户的双赢。 推荐算法介绍 基于人口统计学的推荐 这是最为简单的一种推荐算法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。 系统首先会根据用户的属性建模,比如用户的年龄,性别,兴趣等信息。根据这些特征计算用户间的相似度。比如系统通过计算发现用户A和C比较相似。就会把A喜欢的物品推荐给C。 优缺点: ?不需要历史数据,没有冷启动问题 ?不依赖于物品的属性,因此其他领域的问题都可无缝接入。 ?算法比较粗糙,效果很难令人满意,只适合简单的推荐 基于内容的推荐 与上面的方法相类似,只不过这次的中心转到了物品本身。使用物品本身的相似度而不是用户的相似度。
系统首先对物品(图中举电影的例子)的属性进行建模,图中用类型作为属性。 在实际应用中,只根据类型显然过于粗糙,还需要考虑演员,导演等更多信息。 通过相似度计算,发现电影A和C相似度较高,因为他们都属于爱情类。系统还会发现用户A喜欢电影A,由此得出结论,用户A很可能对电影C也感兴趣。 于是将电影C推荐给A。 优缺点: ?对用户兴趣可以很好的建模,并通过对物品属性维度的增加,获得更好的推荐精度 ?物品的属性有限,很难有效的得到更多数据 ?物品相似度的衡量标准只考虑到了物品本身,有一定的片面性 ?需要用户的物品的历史数据,有冷启动的问题 协同过滤 协同过滤是推荐算法中最经典最常用的,分为基于用户的协同过滤和基于物品的协同过滤。那么他们和基于人口学统计的推荐和基于内容的推荐有什么区别和联系呢? 基于用户的协同过滤——基于人口统计学的推荐 基于用户的协同过滤推荐机制和基于人口统计学的推荐机制都是计算用户的相似度,并基于“邻居”用户群计算推荐,但它们所不同的是如何计算用户的相似度,基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好。 基于物品的协同过滤——基于内容的推荐
修辞手法解答疑惑:(1-4) 1.表現手法——(象征手法就是通过相似联想,把写作内容从自然界引申到人类社会生活中来,用原先所写的那些特点来象征某种精神品质或性格,从而把主题思想提高到一个新的境界。如茅盾的散文《白杨礼赞》就是很好的一例。文章先极力表现白杨树“正直”、“朴质”、“倔强挺立”、“努力向上”的特点,然后通过相似联想,把对白杨树的描写赞扬引申到北方农民身上,进而用白杨树来象征我们民族的一种可贵的“精神和意志”。这样,就通过象征的手法,把对白杨树的赞美变成了对一种民族“精神和意志”的赞美,至此,主题也就升华到了一个崇高的境界。) 2 什么是互喻? 设两个比喻句,第一个比喻句先用喻体比喻本体,第二个比喻句再用本体比喻喻体,这种互相设喻的比喻形式叫做互喻。其格式为:甲像乙,乙像甲。例如: ①远远的街灯明了,好像闪着无数的明星。天上的明星现了,好像点着无数的街灯。(郭沫若《天上的街市》) ②她是美丽的,眼睛像秋水那样明亮。她到池边去洗脸,池里的水被她的纤手划出几圈漪涟,像她闪动的眼睛。(耘铧《桂美》)③早晨的花云潭是粉红色的,云溪中流下来的云像花一般艳丽,花泉里淌出来的花像云一般轻盈,它们汇在一起,像万花筒一般奇幻,最能勾起人心中的遐想了……(王小鹰《金泉女与小溪妹》) 上面例①中先用“明星”(喻体)比喻“街灯”(本体),再用“街灯”(本体)比喻“明星”(喻体);例②中先用“水”(喻体)比喻“眼睛”(本体),再用“眼睛”(本体)比喻“水”(喻体);例③中先用“花”(喻体)比喻“云”(本体),再用“云”(本体)比喻“花”(喻体)。 这样互相比喻,使本体和喻体融为一体,能加深人们的印象。 3 什么是通感? 通感又叫“移觉”“联觉”,就是把人们某个感官上的感觉移植到另一个感官上,各种感觉之间彼此贯通。如:“红杏枝头春意闹”(宋祁《玉楼春》)是把杏花的无声的姿态和色彩说成好像有声音的波动,让人在视觉里获得听觉的感受。“促织声尖尖似针”(贾岛《客思》)是用触觉形象来描摹听觉。朱自清的《荷塘月色》中的写景名句:“微风过处,送来缕缕清香,仿佛远处高楼上缈茫的歌声似的。”是用歌声来比喻嗅觉上的荷花的清香。这些都是视觉、触觉、嗅觉、听觉之间相互挪移、“叠合”后而获得的独特感受。 注:通感是一种独立的“修辞手法”,不同于比喻,但是在运用通感的时候,一般兼有“比喻”的修辞格。 4 什么是互文? 在连贯性的语句中,某些词语依据上下文的条件互相补充,合在一起共同表达一个完整的意思。或者说上下文相补充,合在一起共同表达一个完整的意思。或者说上文省了下文的词语,下文里省了上文出现的词语,参互成文,合而见义。”单句互文(即在一个句子中的互文): (1)烟笼寒水月笼沙。(杜牧《泊秦淮》)
常用的推荐方法 【导读】 随着互联网特别是社会化网络的快速发展,我们正处于信息过载的时代。用户面对过量的信息很难找到自己真正感兴趣的内容,而内容提供商也很难把优质的内容准确推送给感兴趣的用户。推荐系统被认为是解决这些问题的有效方法,它对用户的历史行为进行挖掘,对用户兴趣进行建模,并对用户未来的行为进行预测,从而建立了用户和内容的关系。本文详细介绍了推荐系统中的常用算法及优缺点对比,以便我们能在不同的情况下,选择合适的推荐技术和方案。 【算法】 推荐方法是整个推荐系统中最核心、最关键的部分,很大程度上决定了推荐系统性能的优劣。目前,主要的推荐方法包括:基于内容推荐、协同过滤推荐、基于关联规则推荐、基于效用推荐、基于知识推荐和组合推荐。
一、基于内容推荐 基于内容的推荐(Content-based Recommendation)是信息过滤技术的延续与发展,它是建立在项目的内容信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。在基于内容的推荐系统中,项目或对象是通过相关的特征的属性来定义,系统基于用户评价对象的特征,学习用户的兴趣,考察用户资料与待预测项目的相匹配程度。用户的资料模型取决于所用学习方法,常用的有决策树、神经网络和基于向量的表示方法等。基于内容的用户资料是需要有用户的历史数据,用户资料模型可能随着用户的偏好改变而发生变化。 基于内容推荐方法的优点是: 1)不需要其它用户的数据,没有冷开始问题和稀疏问题。
2)能为具有特殊兴趣爱好的用户进行推荐。 3)能推荐新的或不是很流行的项目,没有新项目问题。 4)通过列出推荐项目的内容特征,可以解释为什么推荐那些项目。 5)已有比较好的技术,如关于分类学习方面的技术已相当成熟。 缺点是要求内容能容易抽取成有意义的特征,要求特征内容有良好的结构性,并且用户的口味必须能够用内容特征形式来表达,不能显式地得到其它用户的判断情况。 二、协同过滤推荐 协同过滤推荐(Collaborative Filtering Recommendation)技术是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐。协同过滤最大优点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。 协同过滤是基于这样的假设:为一用户找到他真正感兴趣的内容的好方法是首先找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给此用户。其基本思想非常易于理解,在日常生活中,我们往往会利用好朋友的推荐来进行一些选择。协同过滤正是把这一思想运用到电子商务推荐系统中来,基于其他用户对某一内容的评价来向目标用户进行推荐。 基于协同过滤的推荐系统可以说是从用户的角度来进行相应推荐的,而且是自动的,即用户获得的推荐是系统从购买模式或浏览行为等隐式获得的,不需要用户努力地找到适合自己兴趣的推荐信息,如填写一些
Computer Science and Application 计算机科学与应用, 2019, 9(9), 1803-1813 Published Online September 2019 in Hans. https://www.doczj.com/doc/c112153910.html,/journal/csa https://https://www.doczj.com/doc/c112153910.html,/10.12677/csa.2019.99202 Review of Classical Recommendation Algorithms Chunhua Zhou, Jianjing Shen, Yan Li, Xiaofeng Guo Information Engineering University, Zhengzhou Henan Received: Sep. 3rd, 2019; accepted: Sep. 18th, 2019; published: Sep. 25th, 2019 Abstract Recommender systems are effective tools of information ?ltering that are prevalent due to cont i-nuous popularization of the Internet, personalization trends, and changing habits of computer us-ers. Although existing recommender systems are successful in producing decent recommend a-tions, they still suffer from challenges such as cold-start, data sparsity, and user interest drift. This paper summarizes the research status of recommendat ion system, presents an overview of the field of recommender systems, describes the classical recommendation methods that are usually classified into the following three main categories: content-based, collaborative and hybrid recommendation algorithms, a nd prospects future research directions. Keywords Recommender Systems, Cold-Start, Data Sparsity, Collaborative Filtering 经典推荐算法研究综述 周春华,沈建京,李艳,郭晓峰 信息工程大学,河南郑州 收稿日期:2019年9月3日;录用日期:2019年9月18日;发布日期:2019年9月25日 摘要 推荐系统作为一种有效的信息过滤工具,由于互联网的不断普及、个性化趋势和计算机用户习惯的改变,将变得更加流行。尽管现有的推荐系统也能成功地进行推荐,但它们仍然面临着冷启动、数据稀疏性和用户兴趣漂移等问题的挑战。本文概述了推荐系统的研究现状,对推荐算法进行了分类,介绍了几种经
1. 前言 随着互联网技术和社会化网络的发展,每天有大量包括博客,图片,视频,微博等等的信息发布到网上。传统的搜索技术已经不能满足用户对信息发现的需求,原因有多种,可能是用户很难用合适的关键词来描述自己的需求,也可能用户需要更加符合他们兴趣和喜好的结果,又或是用户无法对自己未知而又可能感兴趣的信息做出描述。推荐引擎的出现,可以帮用户获取更丰富,更符合个人口味和更加有意义的信息。 个性化推荐根据用户兴趣和行为特点,向用户推荐所需的信息或商品,帮助用户在海量信息中快速发现真正所需的商品,提高用户黏性,促进信息点击和商品销售。推荐系统是基于海量数据挖掘分析的商业智能平台,推荐主要基于以下信息: ●热点信息或商品 ●用户信息,如性别、年龄、职业、收入以及所在城市等等 ●用户历史浏览或行为记录 ●社会化关系 2. 个性化推荐算法 2.1. 基于人口统计学的推荐(同类人喜欢什么就推荐什么) 基于人口统计学的推荐机制(Demographic-based Recommendation)是一种最易于实现的推荐方法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。 首先,系统对每个用户都有一个用户 Profile 的建模,其中包括用户的基本信息,例如用户的年龄,性别等等;然后,系统会根据用户的 Profile 计算用户的相似度,可以看到用 户 A 的 Profile 和用户 C 一样,那么系统会认为用户 A 和 C 是相似用户,在推荐引擎中,可以称他们是“邻居”;最后,基于“邻居”用户群的喜好推荐给当前用户一些物品。 这种基于人口统计学的推荐机制的好处在于: ●因为不使用当前用户对物品的喜好历史数据,所以对于新用户来讲没有“冷启动(Cold Start)”的问题。 ●这个方法不依赖于物品本身的数据,所以这个方法在不同物品的领域都可以使用,它是领域独立的(domain-independent)。 然后,这个方法的缺点和问题就在于,这种基于用户的基本信息对用户进行分类的方法过于粗糙,尤其是对品味要求较高的领域,比如图书,电影和音乐等领域,无法得到很好的推荐效果。另外一个局限是,这个方法可能涉及到一些与信息发现问题本身无关却比较敏感的信息,比如用户的年龄等,这些用户信息不是很好获取。 2.2. 基于内容的推荐(用户喜欢什么,就推荐相同类型的) 基于内容的推荐是在推荐引擎出现之初应用最为广泛的推荐机制,它的核心思想是根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。这种推荐系统多用于一些资讯类的应用上,针对文章本身抽取一些tag作为该文章的关键词,继而可以通过这些tag来评价两篇文章的相似度。