
A Ala Alanine M Met Methionine G Gly Glycine S Ser Serine
C Cys Cysteine N Asn Asparagine H His Histidine T Thr Threonine
D Asp Aspartic Acid P Pro Proline I Ile IsoleTcine V Val Valine
Q Gln GlTtamine K Lys Lysine W Trp Tryptophan E GlT GlTtamic
Acid
F Phe Phenylalanine R Arg Arginine L LeT LeTcine Y Tyr Tyrosine
B Asx Aspartic Acid or Asparagine Z Glx GlTtamic Acid or GlTtamine
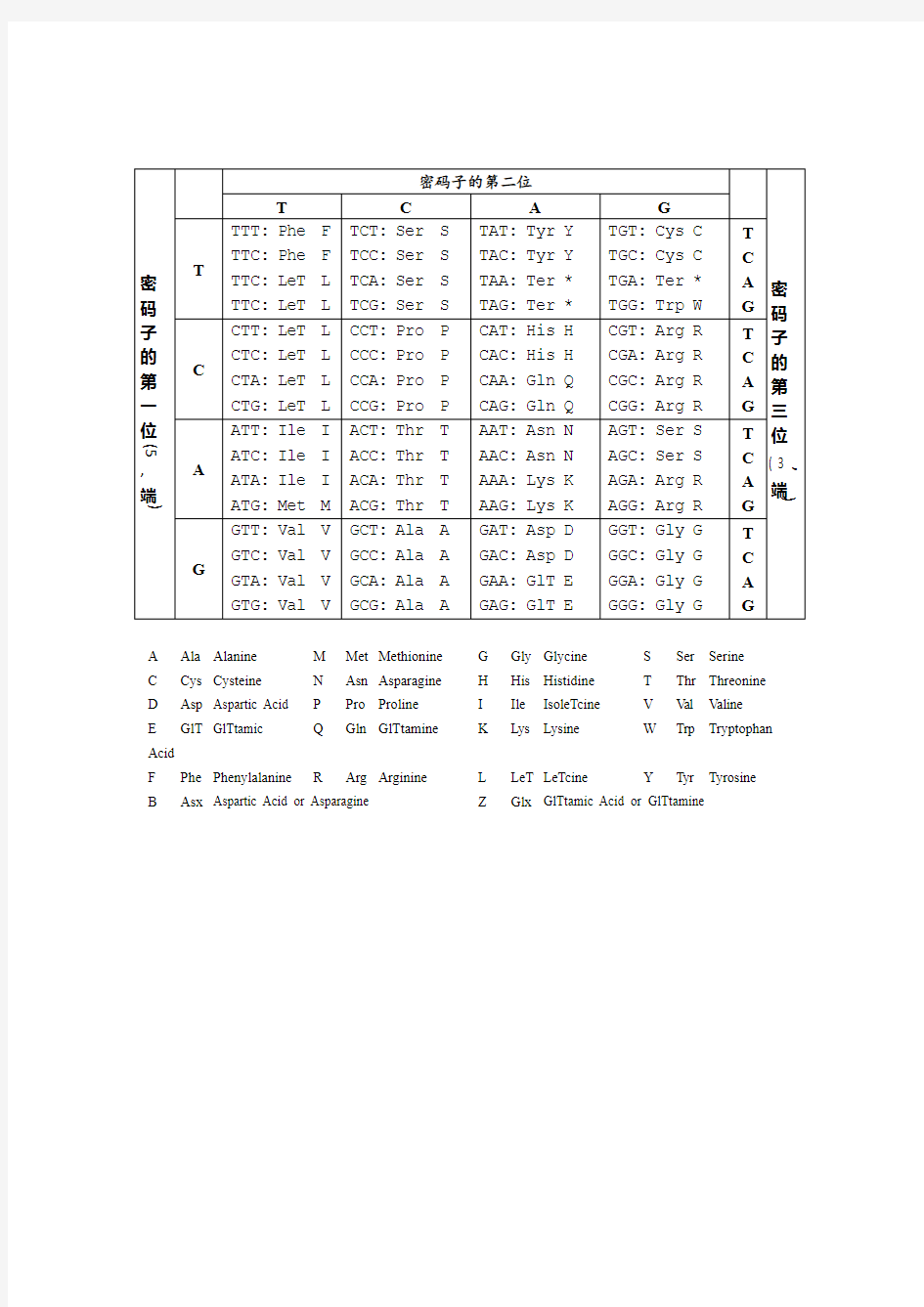
小结遗传密码性质及应用 本文结合一些高考题或冲刺题,浅谈遗传密码子的有关性质,以便师生对遗传密码表引起足够重视以及对遗传密码子有关性质的应用。 1、审察人教版高中《生物》第二册表6-1的遗传密码,可以看出如下特点:(1)简并性:除色氨酸和甲硫氨酸只有1个密码子外,其它18种氨基酸均有1个以上的密码子,其中有2至4个密码子的氨基酸密码子分布在同一方框内,即第一和第二个碱基相同,只有第三个碱基不同;有6个密码子的氨基酸(如亮氨酸、丝氨酸)密码子分别在不同方框内,它们的第一或第一和第二碱基不同。密码子的简并性,特别是第三位的C和U或G和A的简并性常常等同,这说明为什么在不同生物的DNA中的AT/GC比率会有很大的变异,而其蛋白质的氨基酸相对比例却没有很大的变化。换句话说,只改变一个碱基(称为点突变),并不一定编码“错误”氨基酸。 (2)通用性:除某些线粒体、叶绿体和原生生物外(如Barrell等在1979年发现人的线粒体中,通用的密码子AUA却是编码甲硫氨酸,而不是异亮氨酸,UGA 不是作为终止密码子,而是编码色氨酸),所有生物的遗传密码都是相同的。这也是基因工程得以实现的重要理论基础之一。如1993年,中国农业科学院的科学家成功地将苏云金孢杆菌的抗虫基因转入棉植株,培育成了能产生毒蛋白来抵抗棉铃虫的转基因抗虫棉。 (3)起始密码子兼职性:64个密码子中,其中3个并不编码氨基酸的却起着终止肽链合成作用的密码子,称为无义密码子(又称终止密码子);另61个是编码各种氨基酸的密码子,称为有义密码子,在61个有义密码子中,编码氨基酸同时兼职于启动蛋白质形成的两个密码子(AUG和GUG),称为起始密码子。(4)非重叠性:在mRNA模板上的密码子是连续的,在前一个密码子与后一个密码子之间没有间隔,即没有一个间断的信号。因此,在进行翻译时,解读的框架决定于起始的碱基。如果核糖体在mRNA链上移动时,偶然跳越了1个核苷酸,便会生成“不完全”蛋白质,原因是mRNA上密码子中增加或减少一个碱基将引起后续密码子的改变。 (5)方向性:在mRNA模板上密码子读取顺序只能由起始密码子开始,按顺序顺延下去(即5′—3′方向),不能反读。 2、精选习题演练 (1)(2004年江西卷)自然界中,一种生物某一基因及其三种突变基因决定的蛋白质的部分氨基酸序列如下: 正常基因精氨酸苯丙氨酸亮氨酸苏氨酸脯氨酸 突变基因1 精氨酸苯丙氨酸亮氨酸苏氨酸脯氨酸 突变基因2 精氨酸亮氨酸亮氨酸苏氨酸脯氨酸 突变基因3 精氨酸亮氨酸苏氨酸酪氨酸丙氨酸 根据上述氨基酸序列确定这三种突变基因DNA分子的改变是() A、突变基因1和2为一个碱基的替换,突变基因3为一个碱基的增添
【基本字母表】 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 | 13 | I A | B | C | D | E | F | G | H | I | J | K | L M | | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | I N | O | P | Q | R | S | T | U | V | W | X | Y | Z | 1QWE加密表〗 | | | ----- 其实QWE加密可以表示成这种形式 【QWE解密表】 | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z 门 卜-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-T k | x | v | m | c| n| o | p | h | q | r| s | z| y | I |j | a | d| l | e | g | w | b u| f | t | 【电脑键盘表】 丁@ 丁#丁$丁% 丁A
I I I I I I I I I I I I I I 「-丄-丄-丄-丄-丄-丄-丄-丄-丄-丄-丄-丄o 盘表】 【埃特巴什加密/解密表】 I a I b I c I d I e I f I g I h I i I j I k I l I m I n I o | p I q I r I s I t I u I v I w I x I y I z I 卜-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-T I Z I Y I X I W I V I U I T I S I R I Q I P I O I N I M I L I K I J I I I H I G I F I E I D I C I B I A I 1反序QWE 加密表〗 I a I b I c I d I e I f I g I h I i I j I k I l I m I n I o I p I q I r I s I t I u I v I w I x I y I z I 卜-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-十-T I M I N I B I V I C I X I Z I L I K I J I H I G I F I D I S I A I P I O I I I U I Y I T I R I E I W I Q I (a,m,f,x,e,c,b,n ,d,v,t,u,y,w,r,o,s,i,k,h,l,g, z,q,p)(j) 【反序QWE 解密表】 I A I B I C I D I E I F I G I H I I I J I K I L I M I N I O I P I Q I R I S I T I U I V I W I 3ZXCVBNM / 1/2/3 -- Shift
摩斯密码以及十种常用加密方法 ——阿尔萨斯大官人整理,来源互联网摩斯密码的历史我就不再讲了,各位可以自行百度,下面从最简单的开始:时间控制和表示方法 有两种“符号”用来表示字元:划(—)和点(·),或分别叫嗒(Dah)和滴(Dit)或长和短。 用摩斯密码表示字母,这个也算作是一层密码的: 用摩斯密码表示数字:
用摩斯密码表示标点符号: 目前最常用的就是这些摩斯密码表示,其余的可以暂时忽略 最容易讲的栅栏密码: 手机键盘加密方式,是每个数字键上有3-4个字母,用两位数字来表示字母,例如:ru用手机键盘表示就是:7382, 那么这里就可以知道了,手机键盘加密方式不可能用1开头,第二位数字不可能超过4,解密的时候参考此
关于手机键盘加密还有另一种方式,就是拼音的方式,具体参照手机键盘来打,例如:“数字”表示出来就是:748 94。在手机键盘上面按下这几个数,就会出现:“数字”的拼音 手机键盘加密补充说明:利用重复的数字代表字母也是可以的,例如a可以用21代表,也可以用2代表,如果是数字9键上面的第四个字母Z也可以用9999来代表,就是94,这里也说明,重复的数字最小为1位,最大为4位。 电脑键盘棋盘加密,利用了电脑的棋盘方阵,但是个人不喜这种加密方式,因需要一个一个对照加密
当铺密码比较简单,用来表示只是数字的密码,利用汉字来表示数字: 电脑键盘坐标加密,如图,只是利用键盘上面的字母行和数字行来加密,下面有注释: 例:bye用电脑键盘XY表示就是: 351613
电脑键盘中也可参照手机键盘的补充加密法:Q用1代替,X可以用222来代替,详情见6楼手机键盘补充加密法。 ADFGX加密法,这种加密法事实上也是坐标加密法,只是是用字母来表示的坐标: 例如:bye用此加密法表示就是:aa xx xf 值得注意的是:其中I与J是同一坐标都是gd,类似于下面一层楼的方法:
终止密码子 .蛋白质翻译过程中终止肽链合成地信使核糖核酸()地三联体碱基序列. 翻译过程中,起蛋白质合成终止信号作用地密码子.分子中终止蛋白质合成地密码子.是终止密码子 发现过程 年在研究色氨酸合成酶蛋白时推测无义密码子地存在.他地推测是从 两个不同地角度:一是为编码地还编码了,,和.即一个分子中可以作为不同多肽地模板,那么有可能在翻译时中途在某个位点(两个肽地连接处〕停止,然后再从下一个新地起点翻译,这样使各个肽可以分开,而不至于产生一条很长地肽链.这就意味着终止密码子地存在.另一个角度是他发现地突变株是不能合成完整地色氨酸合成酶蛋白,但继续对它进行诱变可以得到回复突变.回复突变中有两种,一种是个别发生了变化,而另一种是完全回复,没有任何氨基酸组成地变化,这表明,不可能是任何移码突变地结果,那么这类地突变很可能携带有阻止合成地无义密码子. 年和他地学生对Ⅱ突变地研究时发现野生型地Ⅱ这段有两个顺反子Ⅱ和Ⅱ,共同转录一个多顺反子,但翻译成两个分开地蛋白和.当发生缺失突变时,其中有一个突变型为,证明是缺失所造成,缺失地区域含Ⅱ基因右边地大部分,和Ⅱ左边地小部分.互补实验表明地产物是一条多肽,但无蛋白地活性,但有蛋白地活性.认为,这种缺失可能使失去了蛋白合成“终止”和“”蛋白合成“起始”地密码子,因此翻译时沿着一条阅读下去,产生了一条长地肽链. 年及其同事获得了噬菌体编码头部蛋白基因地琥珀突变(),并进行了精细作图,并分离研究了各种突变型地多肽.突变型地肽链比野生型地要短,因此可以推测琥珀突变可能产生终止密码子,使肽地合成在中途停止下来;由于突变位点越靠近基因地左端,所产生地肽链越短,越靠近右端越接近野生型,据此可以推测翻译地过程是从地’端向’阅读.肽链地合成是从端向端延伸. 由于头部蛋白%是由新合成地蛋白质组成.因此他们将各种突变型及 野生型噬菌体侵染后分钟,把14C标记地氨基酸加到培养基中,过一段时间,从感染地中抽提蛋白,头部蛋白可以通过14C标记来加以鉴别.RTCrp. 实验方法 他们地实验方法不是对各种突变型地产物测序,而是先将野生型地头部蛋白用胰蛋白酶和糜蛋白酶来处理,消化后所产生地极复杂地混合物中,通过电泳能分离、鉴定出个各有特征地头部蛋白蛋白片段,分别是, 7C(), (), (), 2a(), (), ()和()片段.然后再测出各头部蛋白突变型产物含有几个以上地肽段来排序.表示排序地结果和精细作图地序列相一致,不仅表明了基因和蛋白质地共线性关系,同时证明突变型头部蛋白基因内有无义突变地存在,其位置应在各种突变产物地末端. 关键破译 直到年.和由碱性磷酸酶基因中色氨酸位点地氨基酸地置换证明中无 义密码子地碱基组成揭示了琥珀和赭石()突变基因分别是终止密码子和.当时个密码中地个已破译,只留下了、和有待确定.等为了鉴定无义密码子采用了和相似地策略.他们从地碱性磷酸酯酶基因 ( )中地一个无义突变
?生命的密语? ——遗传密码子的破译 --------------------------------------------------------------------------------------------------- 姓名:学院:培养单位:学号: 姓名:学院:培养单位:学号: ----------------------------------------------------------------------------------------------------------------- 进入国科大已经一月有半,对于自己所在实验室的科研内容已经有了相对具体的了解,也适应了国科大相对紧张的课程进度。迎面而来的都是具体的专业知识和局限的研究内容,尽管我们都是抱着对生命科学的热情而来,还是在现实的科研环境中略感枯索。 为什么会这样呢?我觉得是由于对生命科学这个学科的了解太少。每个学科都有它自己的历史和文化,对于真正醉心科学魅力的人来说,这种文化渗透在他们的筋骨血脉之中,成为一个科研群体独有的性格传承,让科研人和科研事业两相吸引。就像爱因斯坦说过的,人知道的越多,越觉得自己的无知。从而对未知更渴望和敬畏。对于刚刚踏上科研道路的我们来说,正是“无所知”,造成了“无所求知”。 所以,这一次作业,给了我们一个机会,静下心来了解一段生命科学“咿咿学语”的岁月。我们如今已经熟稔于胸的遗传密码子,这门精密简练的语言,是如何普知于世的。 第一部分:前人栽树,后人乘凉——遗传密码子破译史 一、三联体密码子的提出及其性质——理论研究阶段(1953-1961): 事情要从沃森克里克这对分子生物学创始人开始讲起。 1953 年,克里克和沃森在《Nature》杂志上发表了文章《DNA 结构的遗传学意义》,引起了许多人DNA如何携带遗传信息的诸多猜想,这其中包括物理学家伽莫夫。 基于DNA双螺旋模型的基础,伽莫夫上提出一种设想,并于发表在1954年登上了《Nature》。他把双螺旋结构中由于氢键生成而形成的空穴用氨基酸填
终止密码子 1.蛋白质翻译过程中终止肽链合成的信使核糖核酸(mRNA)的三联体碱基序列。 2.mRNA翻译过程中,起蛋白质合成终止信号作用的密码子。 3.mRNA分子中终止蛋白质合成的密码子。UAG,UAA,UGA是终止密码子 发现过程 1964年Yanofsky在研究E.coli色氨酸合成酶A蛋白时推测无义密码子的存在。他的推测/是从两个不同的角度:一是为trp A编码的mRNA还编码了trpB,trpC,trpD和trpE。即一个mRNA 分子中可以作为不同多肽的模板,那么有可能在翻译时中途在某个位点(两个肽的连接处〕停止,然后再从下一个新的起点翻译,这样使各个肽可以分开,而不至于产生一条很长的肽链。这就意味着终止密码子的存在。另一个角度是他发现E.coli Trp-的突变株是不能合成完整的色氨酸合成酶蛋白,但继续对它进行诱变可以得到回复突变。回复突变中有两种,一种是个别发生了变化,而另一种是完全回复,没有任何氨基酸组成的变化,这表明,E.coliTrp-不可能是任何移码突变的结果,那么这类的突变很可能携带有阻止合成的无义密码子。 1962年Benzer和他的学生S.Champe对T4 r Ⅱ突变的研究时发现野生型的T4rⅡ这段有两个顺反子rⅡA和rⅡB,共同转录一个多顺反子mRNA,但翻译成两个分开的蛋白A和B。当发生缺失突变时,其中有一个突变型为r l589,证明是缺失所造成,缺失的区域含rⅡA基因右边的大部分,和rⅡB 左边的小部分。互补实验表明rl589的产物是一条多肽,但无蛋白A的活性,但有B蛋白的活性。Benzer认为,这种缺失可能使mRNA失去了A蛋白合成“终止”和“B”蛋白合成“起始”的密码子,因此翻译时沿着一条mRNA阅读下去,产生了一条长的肽链。 1964年Brenner及其同事获得了T4噬菌体编码头部蛋白基因的琥珀突变(amber),并进行了精细作图,并分离研究了各种突变型的多肽。突变型的肽链比野生型的要短,因此可以推测琥珀突变可能产生终止密码子,使肽的合成在中途停止下来;由于突变位点越靠近基因的左端,所产生的肽链越短,越靠近右端越接近野生型,据此可以推测翻译的过程是从mRNA 的5’端向3’阅读。肽链的合成是从N端向C端延伸。 由于头部蛋白80%是由新合成的蛋白质组成。因此他们将各种突变型及野生型T4噬菌体侵染E.coli后10分钟,把14C标记的氨基酸加到培养基中,过一段时间,从感染的E.coli 中抽提蛋白,头部蛋白可以通过14C 标记来加以鉴别。 实验方法 他们的实验方法不是对各种突变型的产物测序,而是先将野生型的头部蛋白用胰蛋白酶和糜蛋白酶来处理,消化后所产生的极复杂的混合物中,通过电泳能分离、鉴定出8个各有特征的头部蛋白蛋白片段,分别是Cys, T7C(His), C12b(Tyr), T6(Trp), T2a(Pro), T2(Trp), C2(Tyr)和C5(His)片段。然后再测出各T4头部蛋白突变型产物含有几个以上的肽段来排序。表示排序的结果和精细作图的序列相一致,不仅表明了基因和蛋白质的共
【基本字母表】 ┃01┃02┃03┃04┃05┃06┃07┃08┃09┃10┃11┃12┃13┃ ┠--╂--╂--╂--╂--╂--╂--╂--╂--╂--╂--╂--╂--┨ ┃A ┃B ┃C ┃D ┃E ┃F ┃G ┃H ┃I ┃J ┃K ┃L ┃M ┃ ====================================================== ┃14┃15┃16┃17┃18┃19┃20┃21┃22┃23┃24┃25┃26┃ ┠--╂--╂--╂--╂--╂--╂--╂--╂--╂--╂--╂--╂--┨ ┃N ┃O ┃P ┃Q ┃R ┃S ┃T ┃U ┃V ┃W ┃X ┃Y ┃Z ┃ ================ 〖QWE加密表〗 ┃a┃b┃c┃d┃e┃f┃g┃h┃i┃j┃k┃l┃m┃n┃o┃p┃q┃r┃s┃t┃u┃v┃w┃x┃y┃z ┃ ┠-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-┨ ┃Q┃W┃E┃R┃T┃Y┃U┃I┃O┃P┃A┃S┃D┃F┃G┃H┃J┃K┃L┃Z┃X┃C┃V┃B┃N┃M┃ --------其实QWE加密可以表示成这种形式; --------(a,q,j,p,h,i,o,g,u,x,b,w,v,c,e,t,z,m,d,r,k)(f,y,n)(l,s) --------至于它是什么意思,自己去琢磨. --------至于这种形式比表形式有什么优点,自己去琢磨. 【QWE解密表】 ┃A┃B┃C┃D┃E┃F┃G┃H┃I┃J┃K┃L┃M┃N┃O┃P┃Q┃R┃S┃T┃U┃V┃W ┃X┃Y┃Z┃ ┠-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-╂-┨ ┃k┃x┃v┃m┃c┃n┃o┃p┃h┃q┃r┃s┃z┃y┃i┃j┃a┃d┃l┃e┃g┃w┃b┃u┃f┃t ┃ ================ 【电脑键盘表】 ┏!┯@┯#┯$┯%┯^┯&┯*┯(┯)┯_┯+┯|┓ ┃1│2│3│4│5│6│7│8│9│0│-│=│\┃ ┃│ │ │ │ │ │ │ │ │ │ │ │ ┃ 1┃Q│W│E│R│T│Y│U│I│O│P│[│]│ ┃7/8/9 -- Tab ┃│ │ │ │ │ │ │ │ │ │ │ │ ┃ 2┃A│S│D│F│G│H│J│K│L│;│'│ │ ┃4/5/6 -- Caps Lock ┃│ │ │ │ │ │ │ │ │ │ │ │ ┃
论述遗传学诞生到遗传密码破译这一时期里具有重大意义的遗传学研 究成果及其特点与意义 1865年2月8日孟德尔根据他8年的植物杂交试验结果,在当地的科学协会上宣读了一篇题为《植物杂交实验》的论文。但这一伟大发现被埋没了35年后才受到人们重视。1900年遗传学诞生了。 遗传学是生物科学领域中发展最快的一门学科,几乎所有生物学科都与遗传学形成交叉学科,可见遗传学的重要性。要想了解遗传学,就得先了解它的历史。遗传学诞生到遗传密码破译这一时期有许多遗传学研究成果,它们对遗传学的发展有着重大的意义。根据研究的特点,现代遗传学的发展大致可分为三个时期。 一、细胞遗传学时期(约1910-1940) 1、确立了遗传的染色体学说 1910年摩尔根创立了连锁定律并证明了基因在染色体上以直线方式排列,并提出了遗传的染色体理论。这一成果还获得了1933年的诺贝尔奖。这是一个伟大的结论,它指出了遗传的染色体学说不再是空洞抽象的概念,为遗传基因找到了物质基础;同时,它指出了某一遗传基因是在某一染色体上,为人们探索生物遗传机理开拓出了一条新路。他阐述的基因的连锁和互换规律,解开了生物变异之迷,弥补了达尔文进化论的不足,为人们杂交育种指明了方向,为预防遗传性疾病提供了理论。 二、微生物遗传及生化遗传学时期(1941-1960) 1、一个基因一个酶假说的提出 G.W.Beadle和E.L.Tatum在1941年发表了链孢霉中生化反应遗传控制的研究;进而使应用各种生化突变型对基因作用的研究有了发展。Beadle在1945年总结了这些结果,提出了一个基因一个酶的假说,认为一个基因仅仅参与一个酶的生成,并决定该酶的特异性和影响表型。随着酶学、蛋白质化学的进展、遗传学方法的进步,进一步弄清楚了基因与酶的关系是建立在基因与多肽链严密对应的关系基础上的,表示这种对应关系的学说就是一个基因一条多肽链假说。这一假说获得了1958年的诺贝尔奖。这一假说为遗传物质的化学本质及基因的功能奠定了初步的理论基础。 2、遗传的物质基础是DNA的提出 1944年 Avery,Macleod 和 McCarty 等从肺炎双球菌的转化试验中发现,转化因子是DNA而不是蛋白质。他们首次提出遗传的物质基础是DNA。1952年 Hershey 和
遗传密码 遗传密码- 概述 遗传密码 遗传密码又称密码子、遗传密码子、三联体密码。指信使RNA(mRNA)分子上从5'端到3'端方向,由起始密码子AUG 开始,每三个核苷酸组成的三联体。它决定肽链上某一个氨基酸或蛋白质合成的起始、终止信号。 遗传密码决定蛋白质中氨基酸顺序的核苷酸顺序,由3个连续的核苷酸组成的密码子所构成。由于脱氧核糖核酸(DNA)双链中一般只有一条单链(称为有义链或编码链)被转录为信使核糖核酸(mRNA),而另一条单链(称为反义链)则不被转录,所以即使对于以双链DNA作为遗传物质的生物来讲,密码也用核糖核酸(RNA)中的核苷酸顺序而不用DNA中的脱氧核苷酸顺序表示。 遗传密码- 简介
人体遗传密码正在被逐步破译图册 在转移核糖核酸 (tRNA)分子中有一组与mRNA中的密码子配对的三联体,称为反密码子 。每种tRNA携带一种特定的氨基酸,在遗传密码的解读中起着关键性的作用。1961年英国分子生物学家F·H·C·克里克 等在大肠杆菌 噬菌体T4中用遗传学方法证明密码子由三个连续的核苷酸所组成。美国 生物化学家M·W·尼伦伯格 等从1961年开始用生物化学 方法进行解码研究。1964年尼伦伯格等人进行人工合成的三核苷酸和氨基酰-tRNA、核糖体三者的结合试验,证明三核苷酸已经具备信使的作用。通过种种实验,遗传密码已于1966年全部阐明。表中所列的64个密码子编码18种氨基酸和两种酰胺。至于胱氨酸、羟脯氨酸、羟赖氨酸等氨基酸则都是在肽链合成后再行加工而成的。64个密码子中还包括3个不编码任何氨基酸的终止密码子,它们是UAA、UAG、UGA。这种由3个连续的核苷酸组成的密码称为三联体密码。
遗传密码特点例析 遗传密码又称密码子、三联体密码。是指信使RNA(mRNA)分子上从5'端到3'端方向,由起始密码子AUG开始,每三个核苷酸组成的三联体。它决定肽链上某一个氨基酸或蛋白质合成的起始、终止信号。1967年科学家破译了全部密码子并绘制了密码子表。下面结合实例对遗传密码子的特点进行解读,以便对遗传密码表的信息有较全面地把握。 1 三联体密码 例1.细胞内编码20种氨基酸的密码子总数为:() A.4 B.64 C.20 D.61 解析:蛋白质由20种基本氨基酸组成,而mRNA只含有4种核苷酸,由4种核苷酸构成的序列是如何决定多肽链中多至20种氨基酸的序列的呢?显然,在核苷酸和氨基酸之间不能采取简单的一对一的对应关系。2个核苷酸决定一个氨基酸也只能编码16种氨基酸,如果用3个核苷酸决定一个氨基酸,43=64,就足以编码20种氨基酸了,这说明可能需要3个或更多个核苷酸编码一个氨基酸。1961年Francis Crick及其同事的遗传实验进一步肯定3个碱基编码一个氨基酸,此三联体碱基即称为密码子。在64个密码子中,有3个密码子不编码任何氨基酸,从而成为肽链合成的终止信号,称为终止密码子或无义密码子,它们是UAA、UAG、UGA。其余的61个密码子均编码不同的氨基酸,其中AUG和GUG分别是甲硫氨酸和缬氨酸的密码子,同时二者又是肽链合成的起始信号,称为起始密码子。 答案:D 2 不间断性 例2.如果……CGUUUUCUUACGCCU……是某基因产生的 mRNA 中的一个片断 , 如果在序列中某一位置增添了一个碱基 , 则表达时可能发生 ( )。 ①肽链中的氨基酸序列全部改变②肽链提前中断③肽链延长④没有变化⑤不能表达出肽链 A.①②③④⑤ B.①②③④ C.①③⑤ D.②④⑤ 解析: mRNA的三联体密码是连续排列的,相邻密码之间无核苷酸间隔。翻译从起始码AUG开始,3个碱基代表1个氨基酸,从mRNA的5’→3’方向构成1个连续的阅读框,直至终止码。所以,若在某基因编码区的DNA序列或其mRNA中间插入或删除1~2个核苷酸,则其后的三联体组合方式都会改变,不能合成正常的蛋白质,这样的突变亦称移码突变,对微生物常有致死作用。 若增添一个碱基后,导致密码子编组改变,从添加一个碱基的那个密码子开始,一直到末尾都出现误读,相应的氨基酸序列也会从某个氨基酸开始发生全面的改变。这种情况就有可能发生①;若增添一个碱基后,使正常的密码子变成终止密码子,则肽链将提前中断。这
密码子表 标准密码子表: =============================================== F ttt S tct Y tat C tgt F ttc S tcc Y tac C tgc L tta S tca * taa * tga L ttg S tcg * tag W tgg =============================================== L ctt P cct H cat R cgt L ctc P ccc H cac R cgc L cta P cca Q caa R cga L ctg P ccg Q cag R cgg =============================================== I att T act N aat S agt I atc T acc N aac S agc I ata T aca K aaa R aga M atg T acg K aag R agg =============================================== V gtt A gct D gat G ggt V gtc A gcc D gac G ggc V gta A gca E gaa G gga V gtg A gcg E gag G ggg =============================================== 脊椎动物线粒体密码子表: =============================================== F ttt S tct Y tat C tgt F ttc S tcc Y tac C tgc L tta S tca * taa W tga L ttg S tcg * tag W tgg =============================================== L ctt P cct H cat R cgt L ctc P ccc H cac R cgc L cta P cca Q caa R cga L ctg P ccg Q cag R cgg =============================================== I att T act N aat S agt I atc T acc N aac S agc M ata T aca K aaa * aga
摩尔斯电码由点(.)嘀、划(-)嗒两种符号按以下原则组成: 1,一点为一基本信号单位,每一划的时间长度相当于3点的时间长度。 2,在一个字母或数字内,各点、各划之间的间隔应为两点的长度。 3,字母(数字)与字母(数字)之间的间隔为7点的长度。 Atbash码凯撒码字码+摩尔斯电码QWE码键盘码 z d 1 A .- q 1 2 3 y e 2 B -... w __ abc def x f 3 C -.-. e w g 4 D -.. r 4 5 6 v h 5 E . t ghi jkl mn o u i 6 F ..-. y t j 7 G --. U 7 8 9 s k 8 H .... I pqrs tuv wxy z r l 9 I .. o q m 10 J .--- p p n 11 K -.- a o o 12 L .-.. s n p 13 M -- d m q 14 N -. f l r 15 O --- g k s 16 P .--. h j t 17 Q --.- j i u 18 R .-. k h v 19 S ... l g w 20 T - z f x 21 U ..- x e y 22 V ...- c d z 23 W .-- v c a 24 X -..- b b b 25 Y -.-- n a c 26 Z --.. m 密匙3 1 .---- 2 ..--- 3 ...-- 4 ....- 5 ..... 6 -.... 7 --... 8 ---.. 9 ----. 0 ----- ? ..--.. / -..-. () -.--.- - -....- . .-.-.-
遗传密码的发现——从DNA到蛋白质,冲破思想的牢笼 如果对于同一现象有两种不同的假说,我们应该采取比较简单的那一种。 ——奥卡姆剃刀理论1.沃森和克里克的诺贝尔颁奖典礼-不是DNA,而是RNA 《On the Genetic Code》 …… At the present time, therefore, the genetic code appears to have the following general properties: (1) Most if not all codons consist of three (adjacent) bases. (2) Adjacent codons do not overlap. (3) The message is read in the correct groups of three by starting at some fixed point. (4) The code sequence in the gene is co-linear with the amino acid sequence, the polypeptide chain being synthesized sequentially from the amino end. (5) In general more than one triplet codes each amino acid. (6) It is not certain that some triplets may not code more than one amino acid, i.e. they may be ambiguous. (7) Triplets which code for the same amino acid are probably rather similar. (8) It is not known whether there is any general rule which groups such codons together, or whether the grouping is mainly the result of historical accident. (9) The number of triplets which do not code an amino acid is probably small. (10) Certain codes proposed earlier, such as comma-less codes, two- or three-letter codes, the combination code, and various transposable codes are all unlikely to be correct. (11) The code in different organisms is probably similar. It may be the same in all organisms but this is not yet known. Finally one should add that in spite of the great complexity of protein synthesis and in spite of the considerable technical difficulties in synthesizing polynucleotides with defined sequences it is not unreasonable to hope that all these points will be clarified in the near future, and that the genetic code will be completely established on a sound experimental basis within a few years. ——Francis Crick在1962年诺贝尔生理与医学奖颁奖典礼上的致辞 沃森和克里克在五十年代发现DNA双螺旋结构普遍被认为是现代生物学的开端,可以说是20世纪最伟大的生命科学发现。然而此时,分子生物学只是刚刚起步,虽然关于遗传物质为何物的争论暂告一个段落,然而作为生物学重要大分子的蛋白质怎样合成,如果DNA 就是基因它是如何复制的,它与蛋白质合成有什么关系……种种问题,包围在传统的生物化学的酶学研究、名噪一时的噬菌体研究和大举进入的物理化学研究中的新兴分子生物学怎样既取长补短,又摒弃既有的陈旧的观念和无知的偏见,真正建立分子生物学的大厦、破解生命的密码还是一个令一大批科学家头疼而又迫切需要解决的问题。
遗传密码子的破译教案 一、教学内容:遗传密码子的破译 二、教学目标: 1.知识与技能: 了解遗传密码子的定义,知道遗传密码子的破译过程。 掌握遗传密码子的内容,特性,特殊的密码子及其发现的意义。 2.过程与方法: 分析遗传密码子的发现过程及其特性,总结其规律。 3.情感、态度与价值观: 通过遗传密码子的破译的学习,培养学生的辩证思维能力和实验动手能力。 通过分析遗传密码子的破译意义,初步训练学生分析实际问题的能力。 三、学习者分析: 通过调查问卷的形式对学习者进行遗传密码子的破译的前概念的调查,通过分析调查结果发现大家对遗传密码子的认识很浅,只有1/2的学生知道遗传密码子的作用及其阅读方式,而只有1/5的知道起始密码子和终止密码子的个数和其是否编码氨基酸,基本上没人知道总共有多少个遗传密码子,因而在教学过程中应该注意在这些方面的教学。 四、教材分析: 遗传密码子是一节选学课,课程主要讲遗传密码子的探索发现过程,其探索过程主要通过实验的形式进行发现,对于没怎么进行实验的中学生来说有一定难度,前面课程已经学习了转录翻译过程,已经知道什么是密码子和密码子的作用,有一定的基础。 五、教学重难点: 1.教学重点:三个碱基决定一个氨基酸这一结论的探索过程。 2.教学难点:重叠阅读方式和非重叠阅读方式 六、教学用具与教学方法 1.教学准备:多媒体PPT 2.教学方法: 以讲授法为主,以讨论、探究、实验教学法为辅。 分组学习,问题讨论,激发思维,实施探究,分析归纳,总结梳理。 七、教学设计 教学安排:1课时 时间安排:用5-10分钟时间进行新课的导入,30-35分钟进行新课的展开,最后花5-10分钟进行课程总结。
一、几种常见密码形式: 1、栅栏易位法。 即把将要传递的信息中的字母交替排成上下两行,再将下面一行字母排在上面一行的后边,从而形成一段密码。 举例: TEOGSDYUTAENNHLNETAMSHVAED 解: 将字母分截开排成两行,如下 T E O G S D Y U T A E N N H L N E T A M S H V A E D 再将第二行字母分别放入第一行中,得到以下结果 THE LONGEST DAY MUST HAVE AN END. 课后小题:请破解以下密码Teieeemrynwetemryhyeoetewshwsnvraradhnhyartebcmohrie 2、恺撒移位密码。 也就是一种最简单的错位法,将字母表前移或者后错几位,例如: 明码表:ABCDEFGHIJKLMNOPQRSTUVWXYZ 密码表:DEFGHIJKLMNOPQRSTUVWXYZABC 这就形成了一个简单的密码表,如果我想写frzy(即明文),那么对照上面密码表编成密码也就是iucb(即密文)了。密码表可以自己选择移几位,移动的位数也就是密钥。 课后小题:请破解以下密码 dtzwkzyzwjijujsixtsdtzwiwjfrx 3、进制转换密码。 比如给你一堆数字,乍一看头晕晕的,你可以观察数字的规律,将其转换为10进制数字,然后按照每个数字在字母表中的排列顺序, 拼出正确字母。 举例:110 10010 11010 11001 解: 很明显,这些数字都是由1和0组成,那么你很快联想到什么?二进制数,是不是?嗯,
那么就试着把这些数字转换成十进制试试,得到数字6 18 26 25,对应字母表,破解出明文为frzy,呵呵~ 课后小题:请破解以下密码 11 14 17 26 5 25 4、摩尔斯密码。 翻译不同,有时也叫摩尔密码。*表示滴,-表示哒,如下表所示比如滴滴哒就表示字母U,滴滴滴滴滴就表示数字5。另外请大家不要被滴哒的形式所困,我们实际出密码的时候,有可能转换为很多种形式,例如用0和1表示,迷惑你向二进制方向考虑,等等。摩尔斯是我们生活中非常常见的一种密码形式,例如电报就用的是这个哦。下次再看战争片,里面有发电报的,不妨自己试着破译一下电报 内容,看看导演是不是胡乱弄个密码蒙骗观众哈~由于这密码也比较简单,所以不出小题。 A *- B -*** C -*-* D -** E * F **-* G --* H **** I ** J *--- K -*- L *-** M -- N -* O --- P *--* Q --*- R *-* S *** T - U **- V ***- W *-- X -**- Y -*-- Z --** 数字 0 ----- 1 *---- 2 **--- 3 ***-- 4 ****- 5 ***** 6 -**** 7 --*** 8 ---** 9 ----* 常用标点 句号*-*-*- 逗号--**-- 问号**--** 长破折号-***- 连字符-****- 分数线-**-* 5、字母频率密码。 关于词频问题的密码,我在这里提供英文字母的出现频率给大家,其中数字全部是出现的百分比: a 8.2 b 1.5 c 2.8 d 4.3 e 12.7 f 2.2 g 2.0 h 6.1 i 7.0 j 0.2 k 0.8 l 4.0 m 2.4 n 6.7 o 7.5 p 1.9 q 0.1 r 6.0 s 6.3 t 9.1 u 2.8 v 1.0 w 2.4 x 0.2 y 2.0 z 0.1 词频法其实就是计算各个字母在文章中的出现频率,然后大概猜测出明码表,最后验证自己的推算是否正确。这种方法由于要统计字母出现频率,需要花费时间较长,本人在此不举例和出题了,有兴趣的话,参考《跳舞的小人》和《金甲虫》。
遗传密码的起源 遗传密码又称密码子、遗传密码子、三联体密码。指信使RNA(mRNA)分子上从5'端到3'端方向,由起始密码子AUG开始,每三个核苷酸组成的三联体。它决定肽链上某一个氨基酸或蛋白质合成的起始、终止信号。 遗传密码是一组规则,将DNA或RNA序列以三个核苷酸为一组的密码子转译为蛋白质的氨基酸序列,以用于蛋白质合成。几乎所有的生物都使用同样的遗传密码,称为标准遗传密码;即使是非细胞结构的病毒,它们也是使用标准遗传密码。但是也有少数生物使用一些稍微不同的遗传密码。 遗传密码的发现是20世纪50年代的一项奇妙想象和严密论证的伟大结晶。mRNA由四种含有不同碱基腺嘌呤[简称A]、尿嘧啶(简称U)、胞嘧啶(简称C)、鸟嘌呤(简称G)的核苷酸组成。最初科学家猜想,一个碱基决定一种氨基酸,那就只能决定四种氨基酸,显然不够决定生物体内的二十种氨基酸。那么二个碱基结合在一起,决定一个氨基酸,就可决定十六种氨基酸,显然还是不够。如果三个碱基组合在一起决定一个氨基酸,则有六十四种组合方式,看来三个碱基的三联体就可以满足二十种氨基酸的表示了,而且还有富余。猜想毕竟是猜想,还要严密论证才行。 自从发现了DNA的结构,科学家便开始致力研究有关制造蛋白质的秘密。伽莫夫指出需要以三个核酸一组才能为20个氨基酸编码。1961年,美国国家卫生院的Matthaei与马歇尔·沃伦·尼伦伯格在无细胞系统 (Cell-free system)环境下,把一条只由尿嘧啶(U)组成的RNA转释成一条只有苯丙氨酸(Phe)的多肽,由此破解了首个密码子(UUU -> Phe)。随后哈尔·葛宾·科拉纳破解了其它密码子,接着罗伯特·W·霍利发现了负责转录过程的tRNA。1968年,科拉纳、霍利和尼伦伯格分享了诺贝尔生理学或医学奖。 一、遗传密码起源的时间 M. Eigen通过rRNA序列比较的统计学评价得出遗传密码出现的时间在36亿年前 二、起源的地点应该与生物大分子起源地方一致 三、起源的学说 凝固事件学说 1968年,Crick在《the Origin of the Genetic Code》提出有一种观点:密码子与氨基酸的关系是在某一时期固定的,以后就不再改变。 理由:现在生物体中只要密码子有微小的改变,将会致死。 立体化学学说 1966年,韦斯(C. R. Woese)提出了立体化学理论,认为:遗传密码的起源和分配与RNA和氨基酸之间的直接化学作用密切相关,最终密码的立体化学本质扩展到氨基酸与相应的密码子之间物理和化学性质的互补性,。理由:。一些研究表明编码氨基酸的三联体密码或反密码子出乎意料地经常出现在对应的氨基酸在RNA上的结合位点 氨基酸与反密码子的直接作用以及疏水-亲水相互作用在遗传密码的起源中可能
丙氨酸A l a n i n e A 或A l a 89.079C H 3- 脂肪族G C U G C C G C A G C G 终止密码子:U A A U A G U G A 精氨酸A r g i n i n e R 或A r g 174.188H N =C (N H 2)-N H -(C H 2)3-碱性氨基酸类C G U C G C C G A C G G A G A A G G 天冬酰胺A s p a r a g i n e N 或A s n 132.104H N 2-C O -C H 2-酰胺类A A U A A C 天冬氨酸A s p a r t i c a c i d D 或A s p 133.089H O O C -C H 2-酸性氨基酸G A U G A C 半胱氨酸C y s t e i n e C 或C y s 121.145H S -C H 2-含硫类U G U U G C 谷氨酰胺G l u t a m i n e Q 或G l n 146.131H 2N -C O -(C H 2)2-酰胺类C A A C A G 谷氨酸G l u t a m i c a c i d E 或G l u 147.116H O O C -(C H 2)2-酸性氨基酸G A A G A G
甘氨酸G l y c i n e G 或G l y 75.052 H -脂肪族G G U G G C G G A G G G 终止密码子:U A A U A G U G A 组氨酸H i s t i d i n e H 或H i s 155.141N =C H -N H -C H =C -C H 2-碱性氨基酸类C A U C A C 异亮氨酸I s o l e u c i n e I 或I l e 131.160H 3C -C H 2-C H (C H 3)-脂肪族类A U U A U C A U A 亮氨酸L e u c i n e L 或L e u 131.160(C H 3)2-C H -C H 2-脂肪族类U U A U U G C U U C U C C U A C U G 赖氨酸L y s i n e K 或L y s 146.17H 2N -(C H 2)3-碱性A A A A A G 蛋氨酸M e t h i o n i n e M 或M e t 149.199C H 3-S -(C H 2)2-含硫类A U G 起始