广度优先遍历以邻接表表示的图实践题
- 格式:doc
- 大小:29.00 KB
- 文档页数:4

一、单选题C01、在一个图中,所有顶点的度数之和等于图的边数的倍。
A)1/2 B)1 C)2 D)4B02、在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的倍。
A)1/2 B)1 C)2 D)4B03、有8个结点的无向图最多有条边。
A)14 B)28 C)56 D)112C04、有8个结点的无向连通图最少有条边。
A)5 B)6 C)7 D)8C05、有8个结点的有向完全图有条边。
A)14 B)28 C)56 D)112B06、用邻接表表示图进行广度优先遍历时,通常是采用来实现算法的。
A)栈 B)队列 C)树 D)图A07、用邻接表表示图进行深度优先遍历时,通常是采用来实现算法的。
A)栈 B)队列 C)树 D)图A08、一个含n个顶点和e条弧的有向图以邻接矩阵表示法为存储结构,则计算该有向图中某个顶点出度的时间复杂度为。
A)O(n) B)O(e) C)O(n+e) D)O(n2)C09、已知图的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是。
A)0 2 4 3 1 5 6 B)0 1 3 6 5 4 2 C)0 1 3 4 2 5 6 D)0 3 6 1 5 4 2B10、已知图的邻接矩阵同上题,根据算法,则从顶点0出发,按广度优先遍历的结点序列是。
A)0 2 4 3 6 5 1 B)0 1 2 3 4 6 5 C)0 4 2 3 1 5 6 D)0 1 3 4 2 5 6D11、已知图的邻接表如下所示,根据算法,则从顶点0出发按深度优先遍历的结点序列是。
A)0 1 3 2 B)0 2 3 1 C)0 3 2 1 D)0 1 2 3A12、已知图的邻接表如下所示,根据算法,则从顶点0出发按广度优先遍历的结点序列是。
A)0 3 2 1 B)0 1 2 3 C)0 1 3 2 D)0 3 1 2A13、图的深度优先遍历类似于二叉树的。
A)先序遍历 B)中序遍历 C)后序遍历 D)层次遍历D14、图的广度优先遍历类似于二叉树的。


、选择题(每小题 1 分,共 10分)1. 一个 n 个顶点的连通无向图,其边的个数至少为( C )。
A.n+l B.n C.n-l D.2n2. 下列哪一种图的邻接矩阵是对称矩阵( B )。
A. 有向图 B. 无向图 C.AOV 网 D.AOE 网5. 无 向 图 G=(V,E ), 其 中 : V={a,b,c,d,e,f}, E={(a,b ),(a,e ),(a,c ),(b,e ),(c,f ), (f,d ),(e,d )} ,由顶点 a 开始对该图进行深度优先遍历, 得到的顶点序列正确的是 ( D )。
A. a,b,e,c,d,f B. a,c,f,e,b,d C. a,e,b,c,f,d D. a,e,d,f,c,b6. 用邻接表表示图进行广度优先遍历时,通常是采用( B )来实现算法的。
A. 栈 B. 队列 C. 树 D. 图7. 以下数据结构中,哪一个是线性结构( D )。
A. 广义表 B. 二叉树 C. 图 D. 栈8. 下面哪一方法可以判断出一个有向图是否有环(回路) ( B )。
A. 最小生成树B. 拓扑排序C. 求最短路径D. 求关键路径 9. 在一个图中,所有顶点的度数之和等于图的边数的( C )倍。
10. 在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的(B )倍。
A. 1/2B. 1C. 2D. 411. 有 8 个顶点无向图最多有( B )条边。
A. 14 B. 28 C. 56 D. 11212. 有 8 个顶点无向连通图最少有( C )条边。
A. 5 B. 6 C. 7 D. 813. 有 8个顶点有向完全图有( C )条边。
A. 14 B. 28 C. 56 D. 11214. 下列说法不正确的是( A )。
A. 图的遍历是从给定的源点出发每一个顶点仅被访问一次 C. 图的深度遍历不适用于有向图B. 遍历的基本算法有两种:深度遍历和广度遍历 D •图的深度遍历是一个递归过程 二、判断题(每小题 1 分,共 10分)1. n 个顶点的无向图至多有 n (n-1) 条边。


《数据结构(C语言版第2版)》(严蔚敏著)第六章练习题答案第6章图1.选择题(1)在一个图中,所有顶点的度数之和等于图的边数的()倍。
A.1/2B.1C.2D.4答案:C(2)在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的()倍。
A.1/2B.1C.2D.4答案:B解释:有向图所有顶点入度之和等于所有顶点出度之和。
(3)具有n个顶点的有向图最多有()条边。
A.n B.n(n-1)C.n(n+1)D.n2答案:B解释:有向图的边有方向之分,即为从n个顶点中选取2个顶点有序排列,结果为n(n-1)。
(4)n个顶点的连通图用邻接距阵表示时,该距阵至少有()个非零元素。
A.n B.2(n-1)C.n/2D.n2答案:B所谓连通图一定是无向图,有向的叫做强连通图连通n个顶点,至少只需要n-1条边就可以了,或者说就是生成树由于无向图的每条边同时关联两个顶点,因此邻接矩阵中每条边被存储了两次(也就是说是对称矩阵),因此至少有2(n-1)个非零元素(5)G是一个非连通无向图,共有28条边,则该图至少有()个顶点。
A.7B.8C.9D.10答案:C解释:8个顶点的无向图最多有8*7/2=28条边,再添加一个点即构成非连通无向图,故至少有9个顶点。
(6)若从无向图的任意一个顶点出发进行一次深度优先搜索可以访问图中所有的顶点,则该图一定是()图。
A.非连通B.连通C.强连通D.有向答案:B解释:即从该无向图任意一个顶点出发有到各个顶点的路径,所以该无向图是连通图。
(7)下面()算法适合构造一个稠密图G的最小生成树。
A.Prim算法B.Kruskal算法C.Floyd算法D.Dijkstra算法答案:A解释:Prim算法适合构造一个稠密图G的最小生成树,Kruskal算法适合构造一个稀疏图G的最小生成树。
(8)用邻接表表示图进行广度优先遍历时,通常借助()来实现算法。
A.栈 B.队列 C.树D.图答案:B解释:广度优先遍历通常借助队列来实现算法,深度优先遍历通常借助栈来实现算法。

第7章 图 自测卷解答 姓名 班级一、单选题(每题1分,共16分) 前两大题全部来自于全国自考参考书!( C )1. 在一个图中,所有顶点的度数之和等于图的边数的 倍。
A .1/2 B. 1 C. 2 D. 4 (B )2. 在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的 倍。
A .1/2 B. 1 C. 2 D. 4 ( B )3. 有8个结点的无向图最多有 条边。
A .14 B. 28 C. 56 D. 112 ( C )4. 有8个结点的无向连通图最少有 条边。
A .5 B. 6 C. 7 D. 8 ( C )5. 有8个结点的有向完全图有 条边。
A .14 B. 28 C. 56 D. 112 (B )6. 用邻接表表示图进行广度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列C. 树D. 图 ( A )7. 用邻接表表示图进行深度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列C. 树D. 图 ( )8. 已知图的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是( D )9. 已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按深度优先遍历的结点序列是A . 0 2 4 3 1 5 6 B. 0 1 3 5 6 4 2 C. 0 4 2 3 1 6 5 D. 0 1 3 4 2 5 6 ( )10. 已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是A . 0 2 4 3 6 5 1 B. 0 1 3 6 4 2 5 C. 0 4 2 3 1 5 6 D. 0 1 3 4 2 5 6 (建议:0 1 2 3 4 5 6) ( C )11. 已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按广度优先遍历的结点序列是A . 0 2 4 3 1 6 5 B. 0 1 3 5 6 4 2 C. 0 1 2 3 4 6 5 D. 0 1 2 3 4 5 6A .0 2 4 3 1 5 6B. 0 1 3 6 5 4 2C. 0 4 2 3 1 6 5D. 0 3 6 1 5 4 2建议:先画出图,再深度遍历⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡0100011101100001011010110011001000110010011011110( A )12. 已知图的邻接表如下所示,根据算法,则从顶点0出发不是深度优先遍历的结点序列是A.0 1 3 2 B. 0 2 3 1C. 0 3 2 1D. 0 1 2 3(A)14. 深度优先遍历类似于二叉树的A.先序遍历 B. 中序遍历 C. 后序遍历 D. 层次遍历(D)15. 广度优先遍历类似于二叉树的A.先序遍历 B. 中序遍历 C. 后序遍历 D. 层次遍历(A)16. 任何一个无向连通图的最小生成树A.只有一棵 B. 一棵或多棵 C. 一定有多棵 D. 可能不存在(注,生成树不唯一,但最小生成树唯一,即边权之和或树权最小的情况唯一)二、填空题(每空1分,共20分)1. 图有邻接矩阵、邻接表等存储结构,遍历图有深度优先遍历、广度优先遍历等方法。
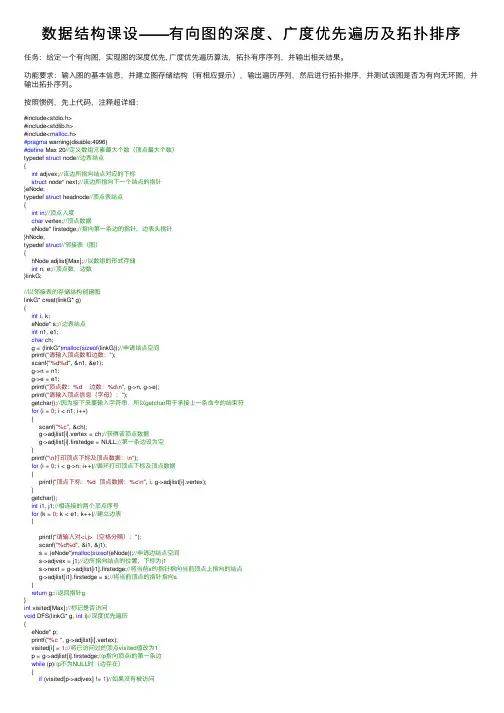
数据结构课设——有向图的深度、⼴度优先遍历及拓扑排序任务:给定⼀个有向图,实现图的深度优先, ⼴度优先遍历算法,拓扑有序序列,并输出相关结果。
功能要求:输⼊图的基本信息,并建⽴图存储结构(有相应提⽰),输出遍历序列,然后进⾏拓扑排序,并测试该图是否为有向⽆环图,并输出拓扑序列。
按照惯例,先上代码,注释超详细:#include<stdio.h>#include<stdlib.h>#include<malloc.h>#pragma warning(disable:4996)#define Max 20//定义数组元素最⼤个数(顶点最⼤个数)typedef struct node//边表结点{int adjvex;//该边所指向结点对应的下标struct node* next;//该边所指向下⼀个结点的指针}eNode;typedef struct headnode//顶点表结点{int in;//顶点⼊度char vertex;//顶点数据eNode* firstedge;//指向第⼀条边的指针,边表头指针}hNode;typedef struct//邻接表(图){hNode adjlist[Max];//以数组的形式存储int n, e;//顶点数,边数}linkG;//以邻接表的存储结构创建图linkG* creat(linkG* g){int i, k;eNode* s;//边表结点int n1, e1;char ch;g = (linkG*)malloc(sizeof(linkG));//申请结点空间printf("请输⼊顶点数和边数:");scanf("%d%d", &n1, &e1);g->n = n1;g->e = e1;printf("顶点数:%d 边数:%d\n", g->n, g->e);printf("请输⼊顶点信息(字母):");getchar();//因为接下来要输⼊字符串,所以getchar⽤于承接上⼀条命令的结束符for (i = 0; i < n1; i++){scanf("%c", &ch);g->adjlist[i].vertex = ch;//获得该顶点数据g->adjlist[i].firstedge = NULL;//第⼀条边设为空}printf("\n打印顶点下标及顶点数据:\n");for (i = 0; i < g->n; i++)//循环打印顶点下标及顶点数据{printf("顶点下标:%d 顶点数据:%c\n", i, g->adjlist[i].vertex);}getchar();int i1, j1;//相连接的两个顶点序号for (k = 0; k < e1; k++)//建⽴边表{printf("请输⼊对<i,j>(空格分隔):");scanf("%d%d", &i1, &j1);s = (eNode*)malloc(sizeof(eNode));//申请边结点空间s->adjvex = j1;//边所指向结点的位置,下标为j1s->next = g->adjlist[i1].firstedge;//将当前s的指针指向当前顶点上指向的结点g->adjlist[i1].firstedge = s;//将当前顶点的指针指向s}return g;//返回指针g}int visited[Max];//标记是否访问void DFS(linkG* g, int i)//深度优先遍历{eNode* p;printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已访问过的顶点visited值改为1p = g->adjlist[i].firstedge;//p指向顶点i的第⼀条边while (p)//p不为NULL时(边存在){if (visited[p->adjvex] != 1)//如果没有被访问DFS(g, p->adjvex);//递归}p = p->next;//p指向下⼀个结点}}void DFSTravel(linkG* g)//遍历⾮连通图{int i;printf("深度优先遍历;\n");//printf("%d\n",g->n);for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问{DFS(g, i);//调⽤DFS函数}}}void BFS(linkG* g, int i)//⼴度优先遍历{int j;eNode* p;int q[Max], front = 0, rear = 0;//建⽴顺序队列⽤来存储,并初始化printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已经访问过的改成1rear = (rear + 1) % Max;//普通顺序队列的话,这⾥是rear++q[rear] = i;//当前顶点(下标)队尾进队while (front != rear)//队列⾮空{front = (front + 1) % Max;//循环队列,顶点出队j = q[front];p = g->adjlist[j].firstedge;//p指向出队顶点j的第⼀条边while (p != NULL){if (visited[p->adjvex] == 0)//如果未被访问{printf("%c ", g->adjlist[p->adjvex].vertex);visited[p->adjvex] = 1;//将该顶点标记数组值改为1rear = (rear + 1) % Max;//循环队列q[rear] = p->adjvex;//该顶点进队}p = p->next;//指向下⼀个结点}}}void BFSTravel(linkG* g)//遍历⾮连通图{int i;printf("⼴度优先遍历:\n");for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问过{BFS(g, i);//调⽤BFS函数}}}//因为拓扑排序要求⼊度为0,所以需要先求出每个顶点的⼊度void inDegree(linkG* g)//求图顶点⼊度{eNode* p;int i;for (i = 0; i < g->n; i++)//循环将顶点⼊度初始化为0{g->adjlist[i].in = 0;}for (i = 0; i < g->n; i++)//循环每个顶点{p = g->adjlist[i].firstedge;//获取第i个链表第1个边结点指针while (p != NULL)///当p不为空(边存在){g->adjlist[p->adjvex].in++;//该边终点结点⼊度+1p = p->next;//p指向下⼀个边结点}printf("顶点%c的⼊度为:%d\n", g->adjlist[i].vertex, g->adjlist[i].in);}void topo_sort(linkG *g)//拓扑排序{eNode* p;int i, k, gettop;int top = 0;//⽤于栈指针的下标索引int count = 0;//⽤于统计输出顶点的个数int* stack=(int *)malloc(g->n*sizeof(int));//⽤于存储⼊度为0的顶点for (i=0;i<g->n;i++)//第⼀次搜索⼊度为0的顶点{if (g->adjlist[i].in==0){stack[++top] = i;//将⼊度为0的顶点进栈}}while (top!=0)//当栈不为空时{gettop = stack[top--];//出栈,并保存栈顶元素(下标)printf("%c ",g->adjlist[gettop].vertex);count++;//统计顶点//接下来是将邻接点的⼊度减⼀,并判断该点⼊度是否为0p = g->adjlist[gettop].firstedge;//p指向该顶点的第⼀条边的指针while (p)//当p不为空时{k = p->adjvex;//相连接的顶点(下标)g->adjlist[k].in--;//该顶点⼊度减⼀if (g->adjlist[k].in==0){stack[++top] = k;//如果⼊度为0,则进栈}p = p->next;//指向下⼀条边}}if (count<g->n)//如果输出的顶点数少于总顶点数,则表⽰有环{printf("\n有回路!\n");}free(stack);//释放空间}void menu()//菜单{system("cls");//清屏函数printf("************************************************\n");printf("* 1.建⽴图 *\n");printf("* 2.深度优先遍历 *\n");printf("* 3.⼴度优先遍历 *\n");printf("* 4.求出顶点⼊度 *\n");printf("* 5.拓扑排序 *\n");printf("* 6.退出 *\n");printf("************************************************\n");}int main(){linkG* g = NULL;int c;while (1){menu();printf("请选择:");scanf("%d", &c);switch (c){case1:g = creat(g); system("pause");break;case2:DFSTravel(g); system("pause");break;case3:BFSTravel(g); system("pause");break;case4:inDegree(g); system("pause");break;case5:topo_sort(g); system("pause");break;case6:exit(0);break;}}return0;}实验⽤图:运⾏结果:关于深度优先遍历 a.从图中某个顶点v 出发,访问v 。

05 图【单选题】1. 设无向图G 中有五个顶点,各顶点的度分别为2、4、3、1、2,则G 中边数为(C )。
A、4条 B、5条 C、6条 D、无法确定2. 含n 个顶点的无向完全图有(D )条边;含n 个顶点的有向图最多有(C )条弧;含n 个顶点的有向强连通图最多有(C )条弧;含n 个顶点的有向强连通图最少有(F)条弧;设无向图中有n 个顶点,则要接通全部顶点至少需(G )条边。
A 、n 2B 、n(n+1)C 、n(n-1)D 、n(n-1)/2E 、n+1F 、nG 、n-13. 对下图从顶点a 出发进行深度优先遍历,则(A )是可能得到的遍历序列。
A 、acfgdebB 、abcdefgC 、acdgbefD 、abefgcd对下图从顶点a 出发进行广度优先遍历,则(D )是不可能得到的遍历序列。
A 、abcdefgB 、acdbfgeC 、abdcegfD 、adcbgef4. 设图G 的邻接矩阵A=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡010101010,则G 中共有(C )个顶点;若G 为有向图,则G 中共有(D )条弧;若G 为无向图,则G 中共有(B )条边。
A 、1B 、2C 、3D 、4E 、5F 、9G 、以上答案都不对5. 含n 个顶点的图,最少有(B )个连通分量,最多有(D )个连通分量。
A 、0B 、1C 、n-1D 、n6. 用邻接表存储图所用的空间大小(A )。
A 、与图的顶点数和边数都有关B 、只与图的边数有关C 、只与图的顶点数有关D 、与边数的平方有关7. n 个顶点的无向图的邻接表最多有(B )个表结点。
A 、n 2B 、n(n-1)C 、n(n+1)D 、n(n-1)/28. 无向图G=(V ,E),其中:V={a,b,c,d,e,f},E={(a,b),(a,e),(a,c),(b,e),(c,f),(f,d),(e,d)},对该图进行深度优先遍历,得到的顶点序列正确的是(D )。


第7章图一、选择题(每小题1分,共10分)1.一个n个顶点的连通无向图,其边的个数至少为( C )。
A.n+lB.nC.n-lD.2n2.下列哪一种图的邻接矩阵是对称矩阵( B )。
A.有向图B.无向图C.AOV网D.AOE网3.为解决计算机和打印机之间速度不匹配的问题,通常设置一个打印数据缓冲区,主机将要输出的数据依次写入缓冲区,而打印机则依次从该缓冲区中取出数据。
该缓冲区的逻辑结构应该是( B )。
A.栈B.队列C.树D.图4.设无向图的顶点个数为n,则该图最多有( C )条边。
A. n-1B. n(n-1)/2C. n(n+1)/2D. 2n5.无向图G=(V,E),其中:V={a,b,c,d,e,f}, E={(a,b),(a,e),(a,c),(b,e),(c,f), (f,d),(e,d)},由顶点a开始对该图进行深度优先遍历,得到的顶点序列正确的是( D )。
A. a,b,e,c,d,fB. a,c,f,e,b,dC. a,e,b,c,f,dD. a,e,d,f,c,b6.用邻接表表示图进行广度优先遍历时,通常是采用( B )来实现算法的。
A.栈B.队列C.树D.图7.以下数据结构中,哪一个是线性结构( D )。
A.广义表B.二叉树C.图D.栈8.下面哪一方法可以判断出一个有向图是否有环(回路)( B )。
A.最小生成树B.拓扑排序C.求最短路径D.求关键路径9.在一个图中,所有顶点的度数之和等于图的边数的( C )倍。
A. 1/2B. 1C. 2D. 410.在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的( B )倍。
A. 1/2B. 1C. 2D. 411.有8个顶点无向图最多有( B )条边。
A. 14B. 28C. 56D. 11212.有8个顶点无向连通图最少有( C )条边。
A. 5B. 6C. 7D. 813.有8个顶点有向完全图有( C )条边。
A. 14B. 28C. 56D. 11214.下列说法不正确的是( A )。

摘要本课程设计主要实现用邻接表存储结构对图进行操作。
在课程设计中,程序以邻接表对图进行存储,并利用数组、队列等结构加以辅助存储;最终实现图的建立,图的链表结构的输出,图的深度优先遍历与广度优先遍历。
关键字: 图邻接表队列遍历Abstract This curriculum design is designed to achieve operations of graph with adjacency table storage structure.In the curriculum design, the program is stored wiht the adjacency table, and be assisted by arrays, queue, and so on.Finally, to achieve the construction of a graph, output the list structure of the graph, depth-first traversal graph and breadth-first traversal graph.Keyword: Graph Adjacency list Queue Traversal1.引言本学期我们学习了很多图的存储结构,有邻接矩阵、邻接表、十字链表等。
其中邻接矩阵和邻接表为图的主要存储结构。
图的邻接矩阵存储结构的主要特点是把图的边信息存储在一个矩阵中,是一种静态存储方法。
图的邻接表存储结构是一种顺序存储与链式存储相结合的存储方法。
从空间性能上说,图越稀疏邻接表的空间效率相应的越高。
从时间性能上来说,邻接表在图的算法中时间代价较邻接矩阵要低。
本课程设计主要是实现使用邻接表存储结构存储一个图,并在所存储的图中实现深度优先和广度优先遍历以与其链表结构的输出。
2.需求分析2.1 原理当图比较稀疏时,邻接表存储是最佳的选择。
个城市,假设城市间有m条路径(有向图),每条路径的长度已知。
给定地图的一个起点城市和终点城市,利用Dijsktra算法求出起点到终点、核心算法或代码片段:int no; //顶点编号InfoType info; //顶点其他信息} VertexType; //顶点类型typedef struct //图的定义{int edges[MAXV][MAXV]; //邻接矩阵int n, e; //顶点数,边数VertexType vexs[MAXV]; //存放顶点信息} MGraph; //图的邻接矩阵类型//以下定义邻接表类型typedef struct ANode //边的节点结构类型{int adjvex; //该边的终点位置struct ANode *nextarc; //指向下一条边的指针InfoType info; //该边的相关信息,这里用于存放权值} ArcNode;typedef int Vertex;typedef struct Vnode //邻接表头节点的类型{Vertex data; //顶点信息ArcNode *firstarc; //指向第一条边} VNode;typedef VNode AdjList[MAXV]; //AdjList是邻接表类型typedef struct{AdjList adjlist; //邻接表int n, e; //图中顶点数n和边数e} ALGraph; //图的邻接表类型//-------------------------------------//--------带权图的算法-----------------//-------------------------------------void MatToList1(MGraph g, ALGraph *&G)//将邻接矩阵g转换成邻接表G{int i, j;ArcNode *p; //表结点结构类型G = (ALGraph *)malloc(sizeof(ALGraph));for (i = 0; i<g.n; i++) //给邻接表中所有头节点的指针域置初值G->adjlist[i].firstarc = NULL;for (i = 0; i<g.n; i++) //检查邻接矩阵中每个元素for (j = g.n - 1; j >= 0; j--)if (g.edges[i][j] != 0 && g.edges[i][j] != INF) //存在一条边{p = (ArcNode *)malloc(sizeof(ArcNode)); //创建一个节点*pp->adjvex = j; //终点信息p->info = g.edges[i][j]; //权值信息p->nextarc = G->adjlist[i].firstarc; //将*p链到链表后G->adjlist[i].firstarc = p;}G->n = g.n; G->e = g.e;}void DispMat1(MGraph g)//输出邻接矩阵g{int i, j;for (i = 0; i<g.n; i++){for (j = 0; j<g.n; j++)if (g.edges[i][j] == INF)printf("%3s", "∞");elseprintf("%3d", g.edges[i][j]);printf("\n");}}void DispAdj1(ALGraph *G)//输出邻接表G{int i;ArcNode *p;for (i = 0; i<G->n; i++){p = G->adjlist[i].firstarc;printf("%3d: ", i);while (p != NULL){printf("%3d(%d)", p->adjvex, p->info);p = p->nextarc;}printf("\n");}}int visited[MAXV] = { 0 }; //全局数组void DFS(ALGraph *G, int v) //深度优先递归算法{ArcNode *p;visited[v] = 1; //置已访问标记printf("%3d", v); //输出被访问顶点的编号p = G->adjlist[v].firstarc; //p指向顶点v的第一条弧的弧头结点while (p != NULL){if (visited[p->adjvex] == 0) //若p->adjvex顶点未访问,递归访问它DFS(G, p->adjvex);p = p->nextarc; //p指向顶点v的下一条弧的弧头结点}}void BFS(ALGraph *G, int v) //广度优先遍历{ArcNode *p;int queue[MAXV], front = 0, rear = 0; //定义循环队列并初始化int visited[MAXV]; //定义存放结点的访问标志的数组int w, i;for (i = 0; i<G->n; i++) visited[i] = 0; //访问标志数组初始化printf("%3d", v); //输出被访问顶点的编号visited[v] = 1; //置已访问标记rear = (rear + 1) % MAXV;queue[rear] = v; //v进队while (front != rear) //若队列不空时循环{front = (front + 1) % MAXV;w = queue[front]; //出队并赋给wp = G->adjlist[w].firstarc; //找与顶点w邻接的第一个顶点while (p != NULL){if (visited[p->adjvex] == 0) //若当前邻接顶点未被访问{printf("%3d", p->adjvex); //访问相邻顶点visited[p->adjvex] = 1; //置该顶点已被访问的标志rear = (rear + 1) % MAXV; //该顶点进队queue[rear] = p->adjvex;}p = p->nextarc; //找下一个邻接顶点}}printf("\n");}void Prim(MGraph g, int v) //prim 算法求最小生成树{int lowcost[MAXV], min, n = g.n;int closest[MAXV], i, j, k;/***初始化lowcost数组,closest数组(即从起点开始设置lowcost数组,closest 数组相应的值,以便后续生成使用)***/for (i = 0; i < g.n; i++)//赋初值,即将closest数组都赋为第一个结点v,lowcost 数组赋为第一个结点v到各结点的权重{closest[i] = v;lowcost[i] = g.edges[v][i];//g.edges[v][i]的值指的是结点v到i节点的权重}/**********************************开始生成其他的结点*********************************/for (i = 1; i < g.n; i++)//接下来找剩下的n-1个结点(g.n是图的节点个数){/*****找到一个结点,该节点到已选节点中的某一个结点的权值是当前最小的*****/min = INF;//INF表示正无穷(每查找一个结点,min都会重新更新为INF,以便获取当前最小权重的结点)for (j = 0; j < g.n; j++)//遍历所有结点{if (lowcost[j] != 0 && lowcost[j] < min)//若该结点还未被选且权值小于之前遍历所得到的最小值{min = lowcost[j];//更新min的值k = j;//记录当前最小权重的结点的编号}}/****************输出被连接结点与连接结点,以及它们的权值***************/printf("边(%d,%d)权为:%d\n", closest[k], k, min);/***********更新lowcost数组,closest数组,以便生成下一个结点************/lowcost[k] = 0;//表明k结点已被选了(作标记)//选中一个结点完成连接之后,作数组相应的调整for (j = 0; j < g.n; j++)//遍历所有结点{/* if语句条件的说明:* (1)g.edges[k][j] != 0是指k!=j,即跳过自身的结点* (2)g.edges[k][j]是指刚被选的结点k到结点j的权重,lowcost[j]是指之前遍历的所有结点与j结点的最小权重。
习7判断题:1.在n个结点的无向图中,若边数 > n-1,则该图必是连通图。
()2.邻接表法只能用于有向图的存储,而邻接矩阵法对于有向图和无向图的存储都适用。
()3.图的深度优先搜索序列和广度优先搜索序列不一定是唯一的。
( √ )4.有回路的图不能进行拓扑排序。
( )5.任何AOV网拓扑排序的结果都是唯一的。
( )6.在AOV-网中,如果得到的拓扑有序序列中顶点个数小于网中顶点数n,则说明网中存在环,不能求关键路径。
( )7.图的邻接矩阵中矩阵元素的行数只与顶点个数有关()8.图的邻接矩阵中矩阵中非零元素个数与边数有关()9.在拓扑排序序列中,任意两个相继结点V i和Vj都存在从V i到Vj的路径()10.若一个图的邻接矩阵为对称矩阵,则该图必为无向图。
()11.任一AOE网中至少有一条关键路径,且是从源点到汇点的路径中最长的一条()单选题:13.在一个图中,所有顶点的度数之和等于所有边数的( )倍,在一个有向图中,所有顶点的入度之和等于所有顶点出度之和的( C )倍。
A. 1/2B. 2C. 1D. 414.具有n个顶点的有向图最多有( )条边。
A.n B. n(n-1) C. n(n+1) D. 2n15.在一个具有n个顶点的无向图中,要连通全部顶点至少需要( )条边。
A. nB. n+1C. n-1D. n/216.一个有n个顶点的无向连通图,它所包含的连通分量个数为( )。
A.0 B. 1 C. n D. n+117. n个顶点的强连通图至少有( )条边。
A. nB. n-1C. n+1D. n(n-1)18. 在一个具有n个顶点的有向图中,若所有顶点的出度之和为s,则所有顶点的入度之和为( )。
A.s B. s-1 C. s+1 D. n19. 对于一个具有n个顶点和e条边的无向图,若采用邻接表表示,则表头向量的大小为( ① );所有邻接表中的结点总数是( ② )。
① A. n B. n+1 C. n-1 D. n+e② A. e/2 B. e C. 2e D. n+e20. 对于一个有向图,若一个顶点的入度为k1、出度为k2,则对应邻接表中该顶点的单链表中的结点数为( )。
24秋学期《数据结构》作业参考1.堆的形状是一棵()选项A:二叉排序树选项B:满二叉树选项C:完全二叉树选项D:平衡二叉树参考答案:C2.用邻接表表示图进行深度优先遍历时,通常是采用()来实现算法的选项A:栈选项B:队列选项C:树选项D:图参考答案:A3.栈中元素的进出原则是()选项A:先进先出选项B:后进先出选项C:栈空则进选项D:栈满则出参考答案:B4.若一组记录的排序码为(46, 79, 56, 38, 40, 84),则利用堆排序的方法建立的初始堆为()选项A:79,46,56,38,40,84选项B:84,79,56,38,40,46选项C:84,79,56,46,40,38选项D:84,56,79,40,46,38参考答案:B5.有8个结点的无向图最多有()条边选项A:14选项B:28选项C:56选项D:112参考答案:B6.链表是一种采用存储结构存储的线性表选项A:顺序选项B:链式选项C:星式选项D:网状参考答案:B7.下列关键字序列中,()是堆选项A:16,72,31,23,94,53选项B:94,23,31,72,16,53选项C:16,53,23,94,31,72选项D:16,23,53,31,94,72参考答案:D8.折半查找有序表(4,6,10,12,20,30,50,70,88,100)。
若查找表中元素58,则它将依次与表中()比较大小,查找结果是失败。
选项A:20,70,30,50选项B:30,88,70,50选项C:20,50选项D:30,88,50参考答案:A9.已知图的邻接矩阵,根据算法,则从顶点0出发,按深度优先遍历的结点序列是()选项A:0 2 4 3 1 5 6选项B:0 1 3 5 6 4 2。
中国人民理工大学指挥自动化学院试卷解放军考试科目:第4 章图结构队别专业:学号:姓名:考试日期:年月日1.单项选择题(每题2分,共36分)【1】在一个无向图中,所有顶点的度数之和等于所有边数的倍。
A.1/2 B.1 C.2 D.4【2】在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的倍。
A.1/2 B.1 C.2 D.4【3】一个有n个顶点的无向图最多有条边。
A.n B.n(n-1) C.n(n-1)/2 D.2n【4】具有4个顶点的无向完全图有条边。
A.6 B.12 C.16 D.20【5】具有6个顶点的无向图至少应有条边才能确保是一个连通图。
A.5 B.6 C.7 D.8【6】在一个具有n个顶点的无向图中,要连通全部顶点至少需要条边。
A.n B.n+1 C.n-1 D.n/2【7】对于一个具有n个顶点的无向图,若采用邻接矩阵表示,则该矩阵的大小是。
A.n B.(n-1)2 C.n-1 D.n2【8】对于一个具有n个顶点和e条边的无向图,若采用邻接表表示,则表头向量的大小为①:所有邻接表中的结点总数是②。
①A.n B.n+1 C.n-1 D.n+e②A.e/2 B.e C.2e D.n+e【9】对某个无向图的邻接矩阵来说,。
A.第i行上的非零元素个数和第i列的非零元素个数一定相等B.矩阵中的非零元素个数等于图中的边数C.第i行上,第i列上非零元素总数等于顶点v i的度数D.矩阵中非全零行的行数等于图中的顶点数【10】已知一个图如图所示,若从顶点a出发按深度搜索法进行遍历,则可能得到的一种顶点序列为①;按广度搜索法进行遍历,则可能得到的一种顶点序列为②。
①A.a,b,e,c,d,f B.a,c,f,e,b,dC.a,e,b,c,f,d D.a,e,d,f,c,b②A.a,b,c,e,d,f B.a,b,c,e,f,dC.a,e,b,c,f,d D.a,c,f,d,e,b【11】已知一有向图的邻接表存储结构如图所示。
深度遍历和广度遍历例题摘要:深度遍历和广度遍历例题I.深度优先遍历A.定义和概念B.深度优先遍历的例子C.深度优先遍历的性质D.应用场景II.广度优先遍历A.定义和概念B.广度优先遍历的例子C.广度优先遍历的性质D.应用场景III.深度遍历和广度遍历的比较A.遍历策略的差异B.时间和空间复杂度C.应用场景的优劣IV.总结A.深度优先遍历和广度优先遍历的联系与区别B.在实际问题中的应用选择C.对图论算法的影响和意义正文:深度遍历和广度遍历例题深度优先遍历(Depth-First Search, DFS)和广度优先遍历(Breadth-First Search, BFS)是两种常用的图遍历算法。
在图论和计算机科学中,遍历算法是研究图的基本操作之一,它从图中的一个顶点开始,访问图中的所有顶点一次且只一次。
深度优先遍历和广度优先遍历是两种不同的遍历策略,分别有不同的性质和应用场景。
深度优先遍历是一种树形遍历策略,遵循“先深后浅”的原则。
它从起始顶点开始,沿着一条路径一直向下访问,直到无法继续向下访问为止,然后回溯到上一个节点,继续访问其邻接节点。
深度优先遍历的例子可以帮助我们更好地理解这种遍历策略,如遍历二叉树的前序遍历、中序遍历和后序遍历。
深度优先遍历具有以下性质:1.深度优先遍历可以访问到所有的顶点,没有遗漏。
2.深度优先遍历可以发现所有可达路径,但不能保证是最短路径。
3.深度优先遍历的时间复杂度为O(n),空间复杂度为O(n)。
深度优先遍历在图论和计算机科学中有广泛的应用,如寻找连通分量、拓扑排序、求解迷宫等问题。
广度优先遍历是一种层次遍历策略,遵循“先浅后深”的原则。
它从起始顶点开始,逐层访问其邻接节点,每层节点都按顺序访问。
广度优先遍历的例子可以帮助我们更好地理解这种遍历策略,如遍历二叉树的层序遍历。
广度优先遍历具有以下性质:1.广度优先遍历可以访问到所有的顶点,没有遗漏。
2.广度优先遍历可以发现所有最短路径,但不能保证是最优路径。
数据结构课程设计——无向图学校专业班级姓名学号任课教师题目3:以邻接链表的方式确定一个无向网,完成:⑴建立并显示出它的邻接矩阵;⑵对该图进行广度优先遍历,显示遍历的结果,(并随时显示队列的入、出情况);⑶普里姆算法构造其最小生成树,随时显示其构造的过程;⑷用克鲁斯卡尔算法构造其最小生成树,随时显示其构造的过程。
一、需求分析1.运行环境:Microsoft Visual Studio 20122.程序所实现的功能:a)建立并显示图的邻接矩阵;b)广度优先遍历该图,显示遍历结果;c)用普里姆算法构造该图的最小生成树,显示构造过程;d)用克鲁斯卡尔算法构造该图的最小生成树,显示构造过程。
3.程序的输入,包含输入的数据格式和说明:a)输入顶点数,及各顶点信息(数据格式为整形);b)输入弧以及其权值(数据格式为整形)。
1.程序的输出,程序输出的形式:a)输出图的邻接矩阵;b)广度优先遍历结果;c)普里姆算法构造最小生成树的结果;d)克鲁斯卡尔算法构造最小生成树的结果。
2.测试数据,如果输入的数据量较大,需要给出测试数据:a)顶点个数:5b)各个顶点为:A B C D Ec)输入所有的弧(格式为“顶点顶点权值”)为:A B 10 A C 4 B D 3 C D 5 B E 6 D E 9二、设计说明算法设计的思想:建立图类,建立相关成员函数。
最后在主函数中实现。
具体成员函数的实现请参看源程序。
在本次的设计中,我采用的是多文件的编程方式。
每个类写成了一个头文件。
这样有助于阅读和查看源程序。
1.邻接链表:邻接链表是一种链式存储结构。
在邻接链表中,对图中每个顶点建立一个单链表,第i个单链表中的结点表示依附于顶点Vi的边(对有向图是以顶点Vi为尾的弧)。
每个结点由3个域组成,其中邻接点域指示与顶点Vi邻接的点在图中的位置,链域指示下一条边或弧的结点;数据域存储和边或弧相关的信息,如权值等。
所以一开始必须先定义邻接链表的边结点类型以及邻接链表类型,并对邻接链表进行初始化,然后根据所输入的相关信息,包括图的顶点数、边数、是否为有向,以及各条边的起点与终点序号,建立图的邻接链表。
*test7.c*/
#include
#include
#define MaxVertexNum 10 /*设最大顶点数为10*/
typedef struct node{ /*边表结点*/
int adjvex;
struct node *next;
}EdgeNode;
typedef char Vertextype;
typedef struct vnode{ /*顶点表结点*/
char vertex;
EdgeNode *firstedge;
}VertexNode;
typedef VertexNode AdjList[10];
typedef struct{
AdjList adjlist;
int n,e;
}ALGraph;
#define FALSE 0
#define TRUE 1
#define NULL 0
#define Error printf
int visited[10];
void CreateALGraph(ALGraph *G);
void DFSTraverseAL(ALGraph *G);
void BFSTraverseAL(ALGraph *G);
void DFSAL(ALGraph *G,int i);
void BFSAL(ALGraph *G,int i);
#define QueueSize 30 /*假定预分配的队列空间最多为30*/
typedef int DataType; /*队列中的元素类型为字符型*/
typedef struct{
int front; /*队头指针,队非空时指向队头元素*/
int rear; /*队尾指针,队非空时指向队尾元素的下一位置*/
int count; /*计数器,记录队中元素总数*/
DataType data[QueueSize];
}CirQueue;
void InitQueue(CirQueue *Q) /*初始队列*/
{Q->front=Q->rear=0;
Q->count=0;
}
int QueueEmpty(CirQueue *Q) /*判队空*/
{return Q->count==0;
}
int QueueFull(CirQueue *Q) /*判队满*/
{return Q->count==QueueSize;
}
void EnQueue(CirQueue *Q,DataType x) /*入队*/
{if (QueueFull(Q))
Error("Queue overflow"); /*队满上溢*/
else {Q->count++; /*队列元素个数加1*/
Q->data[Q->rear]=x; /*新元素插入队列*/
Q->rear=(Q->rear+1)%QueueSize; /*循环队列的尾指针加1*/
}
}
DataType DeQueue(CirQueue *Q) /*出队*/
{DataType temp;
if (QueueEmpty(Q))
Error("Queue underflow"); /*队空下溢*/
else {temp=Q->data[Q->front];
Q->count--; /*队列元素个数减1*/
Q->front=(Q->front+1)%QueueSize; /*循环队列的头指针加1*/
return temp;
}
}
main()
{ALGraph *G;
char ch1,ch2;
printf("建立一个有向图的邻接表表示/n");
CreateALGraph(G);
printf("已创建了一个邻接表存储的图/n");
ch1='y';
while(ch1=='y' || ch1=='Y')
{printf("/n请选择下列操作:");
printf("/nA------------------更新邻接表存储的图");
printf("/nB------------------广度优先遍历");
printf("/nC------------------退出/n");
scanf("/n%c",&ch2);
switch (ch2)
{case 'A':
case 'a':CreateALGraph(G);
printf("创建一个图的邻接表的操作完成。/n");
break;
case 'B':
case 'b':BFSTraverseAL(G);break;
case 'C':
case 'd':ch1='n';break;
default:ch1='n';
}
}
}
void CreateALGraph(ALGraph *G)
{/*建立有向图的邻接表存储*/
int i,j,k;
EdgeNode * s;
printf("请输入顶点数和边数(输入格式为:顶点数,边数):/n");
scanf("%d,%d",&(G->n),&(G->e)); /*读入顶点数和边数*/
printf("请输入顶点信息(输入格式为:顶点号
for (i=0;i
{scanf("/n%c",&(G->adjlist[i].vertex)); /*读入顶点信息*/
G->adjlist[i].firstedge=NULL; /*顶点的边表头指针设为空*/
}
printf("请输入边的信息(输入格式为:i,j):/n");
for (k=0;k
/****************************************************************/
{scanf("/n%d,%d",&i,&j); /*读入边
s=(EdgeNode*)malloc(sizeof(EdgeNode)); /*生成新边表结点s*/
请考生填写(1)
G->adjlist[i].firstedge=s;
}
/****************************************************************/
}/*CreateALGraph*/
void BFSTraverseAL(ALGraph *G)
{/*广度优先遍历以邻接表存储的图G*/
int i,num=0;
for (i=0;i
visited[i]=FALSE; /*标志向量初始化*/
/********************************************************/
for (i=0;i
if (!visited[i]) {请考生填写(2)} /* Vi未访问过,从Vi开始BFS搜索*/
/********************************************************/
printf("该图有%d个连通分支/n",num);
}/*BFSTraverseAL*/
void BFSAL(ALGraph *G,int k)
{/*以Vk为出发点对邻接表存储的图G进行BFS搜索*/
int i;
CirQueue Q;
EdgeNode *p;
InitQueue(&Q); /*初始化队列*/
printf("visit vertex:V%c/n",G->adjlist[k].vertex); /*访问原点Vk*/
visited[k]=TRUE;
EnQueue(&Q,k); /*访问Vk后将其序号入队列*/
while(!QueueEmpty(&Q)) /*队非空则执行*/
{i=DeQueue(&Q); /*相当于Vi出队*/
p=G->adjlist[i].firstedge; /*取Vi的边表指针*/
/**************************************************************/
while(p) /*依次搜索Vi的邻接点Vj*/
{if (!visited[p->adjvex]) /*若Vj未访问过访问Vj*/
{printf("visit vertex:V%c/n",G->adjlist[p->adjvex].vertex);
请考生填写(3)
}
p=p->next; /*找Vi的下一个邻接点*/
}
/*************************************************************/
}
}/*BFSAL*/