
package cn.action; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.util.ArrayList; import java.util.Date; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Set; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.NodeList; import sun.misc.BASE64Encoder; public class XmlWord { private Map
JAXB(Java API for XML Binding),提供了一个快速便捷的方式将Java对象与XML进行转换。在JAX-WS(Java的WebService规范之一)中,JDK1.6 自带的版本JAX-WS2.1,其底层支持就是JAXB。 JAXB 可以实现Java对象与XML的相互转换,在JAXB中,将一个Java对象转换为XML 的过程称之为Marshal,将XML转换为Java对象的过程称之为UnMarshal。我们可以通过在Java 类中标注注解的方式将一个Java对象绑定到一段XML,也就是说,在Java类中标注一些注解,这些注解定义了如何将这个类转换为XML,怎么转换,以及一段XML如何被解析成这个类所定义的对象;也可以使用JAXB的XJC工具,通过定义schema的方式实现Java 对象与XML的绑定(这个下次研究)。 下面来了解一下如何通过标注注解来完成 Marshal 和 UnMarshal 的过程。我用的是JAXB2_20101209.jar ,可以到[url]https://www.doczj.com/doc/be16297051.html,/[/url] 下载最新版本。 首先看个小例子 定义一个java类 Java代码 package com.why.jaxb; import javax.xml.bind.annotation.XmlRootElement; @XmlRootElement public class People { public String id = "001"; public String name = "灰太狼"; public int age = 26; } Java To XML(Marshal) Java代码 package com.why.jaxb; import javax.xml.bind.JAXBContext; import javax.xml.bind.JAXBException; import javax.xml.bind.Marshaller; public class Java2XML { /** * @param args * @throws JAXBException */ public static void main(String[] args) throws JAXBException { JAXBContext context = JAXBContext.newInstance(People.class);
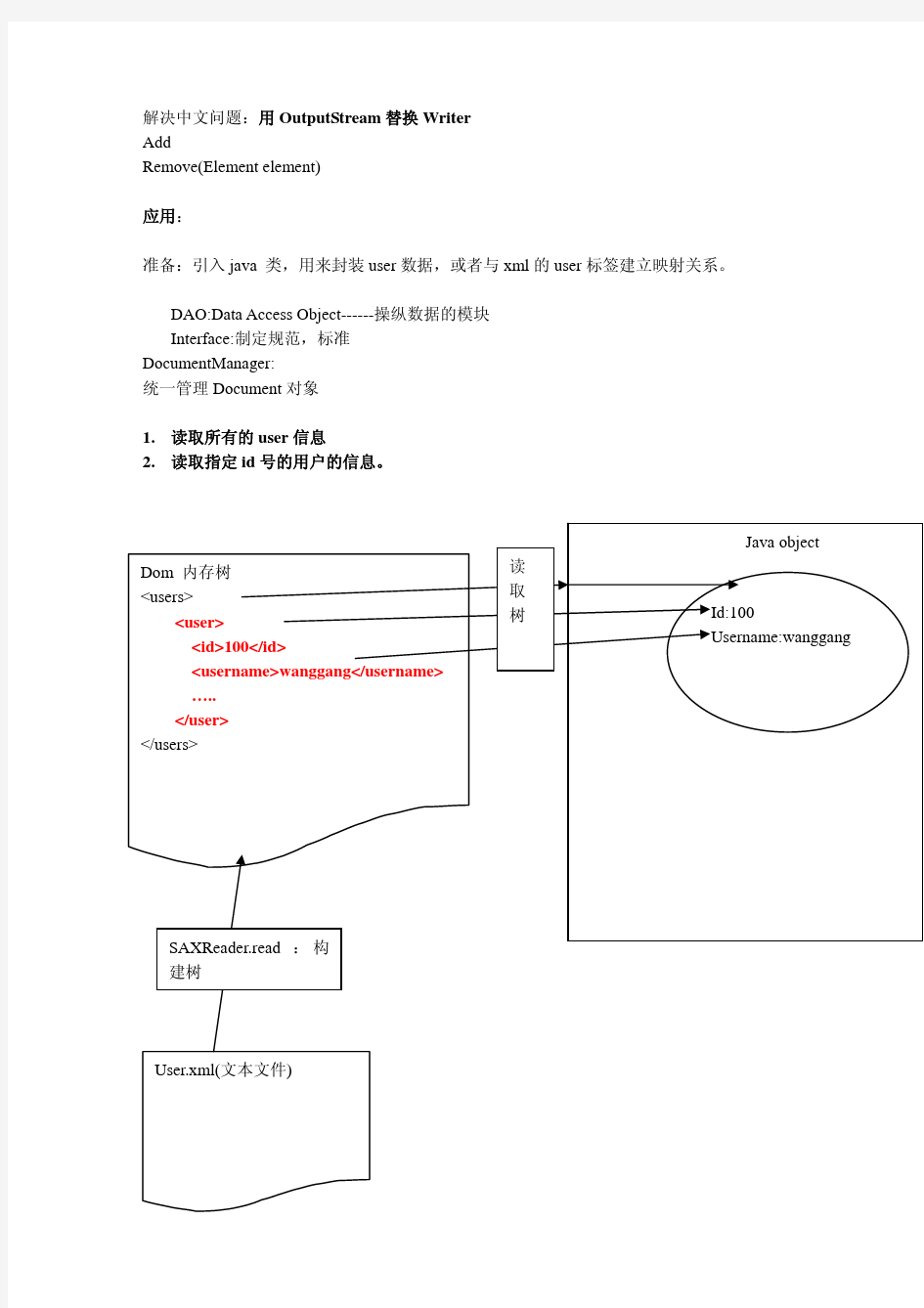
使用要导入dom4j-1.6.1.jar文件 我的dom4j文件在 讲解 生成xml 1:先通过DocumentHelper类的.createDocument()方法生成Document文件2:接着通过DocumentHelper类的createElement("根节点字符串形式")创建根节点 3:通过通过生成的Document的实例的setRootElement(根节点)设置根节点 4:接着可以通过Document的实例的getRootElement()方法得到根节点 5:接着通过根节点(Element类的实例)的.addElement("子节点的字符串形式")添加子节点 6:通过节点类(Element类的实例)的setText("字符串“)设置节点对应的值 7:通过Document类的实例的.asXML();的方式的得到xml字符串; (注意:xml 是字符串String的形式。 可以设置几个同名的根节点(
Java XML绑定技术 --- 快速操作XML文档 注: 本文系原创, 转载请注明作者 -------- 叶瑞金 /06/10 在开发中, 我们常见XML来存储一些数据。相对于普通的文本文件, XML具 有开放性、支持多语言编码、支持结构性数据等优越性, 我们常见它存储配置 信息, 甚至直接使用它当作数据库使用。 最近由于项目需要, 我对Java XML绑定技术作了些研究, 现在把一些心得 与大家分享一下。 其实用Java读写XML的技术由来已久, 比如Apache的XML API、 xalan、 xerces都是很出名的项目, 都有将近十多年历史了吧。这些API对XML的操作 都是基于XML最底层的DOM和SAX模式, 原来也不算很复杂。我在以前项目中很 多关于配置文件的管理部分都是用这些API来完成的。但不论是用DOM还是SAX, 都要求XML的格式是预先定义好的。也就是说, 如果你已经写好了一份读写XML 的程序, 之后如果这个XML的格式作了修改, 那么你必须修改程序, 以保证能 够正确地从修改后的XML中读写数据。如果XML的格式很复杂, 或者牵涉的XML 文件类型众多, 那么这种修改将是一个浩大的工程。 如果我们能找到一种自动适应XML格式的方法, 能够根据当前XML的格式定 义, 自动地读写XML中的数据, 那么就能够节省我们很多精力和时间。能够把这 种技术称为XML绑定技术(XML Binding), 或者称为Object XML。真的有这样的 程序或框架吗? 我们能够用下面的图示来描述Java XML绑定技术: Person <---------------------------->
java对象直接转换成xml格式! import java.io.StringWriter;import javax.xml.bind.JAXBContext; import javax.xml.bind.JAXBException; import javax.xml.bind.Marshaller; import javax.xml.bind.annotation.XmlRootElement;@XmlRootEle ment(name = "Test") public class Test { private String id; private String name; public String getId() { return id; } public void setId(String id) {
this.id = id; } public String getName() { return name; } public void setName(String name) { https://www.doczj.com/doc/be16297051.html, = name; } public static void main(String[] args) throws JAXBException { Test re = new Test(); re.setId("id"); re.setName("name"); StringWriter sw = new StringWriter(); JAXBContext jAXBContext = JAXBContext.newInstance(re.getClass());
XML解析方式介绍 1.DOM4J(Document Object Model for Java) 虽然DOM4J代表了完全独立的开发结果,但最初,它是JDOM的一种智能分支。它合并了许多超出基本XML文档表示的功能,包括集成的XPath支持、XML Schema支持以及用于大文档或流化文档的基于事件的处理。它还提供了构建文档表示的选项,它通过DOM4J API和标准DOM接口具有并行访问功能。从2000下半年开始,它就一直处于开发之中。 为支持所有这些功能,DOM4J使用接口和抽象基本类方法。DOM4J大量使用了API中的Collections 类,但是在许多情况下,它还提供一些替代方法以允许更好的性能或更直接的编码方法。直接好处是,虽然DOM4J付出了更复杂的API的代价,但是它提供了比JDOM大得多的灵活性。 在添加灵活性、XPath集成和对大文档处理的目标时,DOM4J的目标与JDOM是一样的:针对Java 开发者的易用性和直观操作。它还致力于成为比JDOM更完整的解决方案,实现在本质上处理所有Java/XML问题的目标。在完成该目标时,它比JDOM更少强调防止不正确的应用程序行为。 DOM4J是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的Java软件都在使用DOM4J来读写XML,特别值得一提的是连Sun的JAXM也在用DOM4J. 【优点】 ①大量使用了Java集合类,方便Java开发人员,同时提供一些提高性能的替代方法。 ②支持XPath。 ③有很好的性能。 【缺点】 ①大量使用了接口,API较为复杂。 2.SAX(Simple API for XML) SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。一般来说,SAX还比它的替代者DOM快许多。 选择DOM还是选择SAX?对于需要自己编写代码来处理XML文档的开发人员来说,选择DOM还是SAX解析模型是一个非常重要的设计决策。 DOM采用建立树形结构的方式访问XML文档,而SAX 采用的是事件模型。
在java环境下读取xml文件的方法主要有4种:DOM、SAX、JDOM、JAXB 1. DOM(Document Object Model) 此方法主要由W3C提供,它将xml文件全部读入内存中,然后将各个元素组成一棵数据树,以便快速的访问各个节点。因此非常消耗系统性能,对比较大的文档不适宜采用DOM方法来解析。 DOM API 直接沿袭了 XML 规范。每个结点都可以扩展的基于 Node 的接口,就多态性的观点来讲,它是优秀的,但是在Java 语言中的应用不方便,并且可读性不强。 实例: Java代码 1.import javax.xml.parsers.*; 2.//XML解析器接口 3.import org.w3c.dom.*; 4.//XML的DOM实现 5.import org.apache.crimson.tree.XmlDocument; 6.//写XML文件要用到 7.DocumentBuilderFactory factory = DocumentBuilderFactory.newInst ance(); 8. //允许名字空间 9. factory.setNamespaceAware(true); 10. //允许验证 11. factory.setValidating(true); 12. //获得DocumentBuilder的一个实例 13.try { 14. DocumentBuilder builder = factory.newDocumentBuilder(); 15.} catch (ParserConfigurationException pce) { 16.System.err.println(pce); 17.// 出异常时输出异常信息,然后退出,下同 18.System.exit(1); 19.} 20.//解析文档,并获得一个Document实例。 21.try { 22.Document doc = builder.parse(fileURI); 23.} catch (DOMException dom) { 24.System.err.println(dom.getMessage()); 25.System.exit(1); 26.} catch (IOException ioe) { 27.System.err.println(ioe); 28.System.exit(1); 29.}
package com.inspur.test; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStream; import org.jdom.Document; import org.jdom.Element; import org.jdom.output.Format; import org.jdom.output.XMLOutputter; public class FileDemo { /** *@param args */ public static void main(String[] args) { // TODO Auto-generated method stub String filename="c:\\text.xml"; File file=new File(filename); /** *判断文件是否存在.如果文件不存在则生成一个文件 *则生成一个文件;反之则先删除原有文件,生成一个新的文件 */ if(file.exists()){ try { file.delete(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } try { file.createNewFile(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } //创建根节点 Element root=new Element("ObjFlow"); //根节点添加到文档中 Document document=new Document(root); //添加工单基本信息 //创建工单基本信息的节点 Element baseinfo=new Element("BaseInfo"); //创建工单编号节点 Element formOid=new Element("formOid"); //添加工单编号节点内容 formOid.setText("工单编号"); //将工单编号节点添加到基本信息节点下
java读取文件目录结构并生成xml树,具体实现代码如下: package org.wendong.file; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.InputStream; import java.io.Writer; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.GregorianCalendar; import org.dom4j.Document; import org.dom4j.DocumentHelper; import org.dom4j.Element; /** * 多线程读取本地文件中的所有文件目录结构及文件大小 * @author Administrator * */ public class ThreadReader extends Thread { @Override public void run() { try { Long start = System.currentTimeMillis(); String name = Thread.currentThread().getName(); System.err.println("当前线程名:"+name); File file = new File(name); Document doc = DocumentHelper.createDocument(); Element el = doc.addElement(file.getName()); el = getFile(file, el); File docFile = new File(name+"/目录结构.xml"); if(!docFile.exists()){ docFile.createNewFile(); FileOutputStream fos = new FileOutputStream(docFile); fos.write(doc.asXML().getBytes()); fos.flush(); fos.close(); } Long end = System.currentTimeMillis();
JAVA对象转换成XML() 编者小结:将java对象转换成xml文件很简单,但是将java对象转换成输出结果不转义的形式就相当不易。大家都知道在XML 元素中,"<" 和"&" 是非法的。"<" 会产生错误,因为解析器会把该字符解释为新元素的开始。"&" 也会产生错误,因为解析器会把该字符解释为字符实体的开始。某些文本,比如JavaScript 代码,包含大量"<" 或"&" 字符。为了避免错误,可以将脚本代码定义为CDATA。 CDATA:在标记CDATA下,所有的标记、实体引用都被忽略,而被XML处理程序一视同仁地当作字符数据看待,CDATA的形式如下: CDATA的文本内容中不能出现字符串“]]>”,另外,CDATA不能嵌套。 具体实现过程如下: Java实体类: public class JavaDocu { private int id; private String text; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getText() { return text; }
public void setText(String text) { this.text = text; } } MyXppDriver类: public class MyXppDriver extends XppDriver { public HierarchicalStreamWriter createWriter(Writer out){ return new MyPrettyPrintWriter(out); } } MyPrettyPrintWriter类: public class MyPrettyPrintWriter implements ExtendedHierarchicalStreamWriter { private final QuickWriter writer; private final FastStack elementStack = new FastStack(16); private final char[] lineIndenter; private boolean tagInProgress; private int depth; private boolean readyForNewLine; private boolean tagIsEmpty; private static final char[] AMP = "&".toCharArray(); private static final char[] LT = "<".toCharArray(); private static final char[] GT = ">".toCharArray(); private static final char[] SLASH_R = " ".toCharArray(); private static final char[] QUOT = """.toCharArray(); private static final char[] APOS = "'".toCharArray(); private static final char[] CLOSE = "
package test.xml; import java.io.StringReader; import java.io.StringWriter; import java.util.ArrayList; import java.util.HashMap; import java.util.Iterator; import java.util.LinkedHashMap; import java.util.List; import java.util.Map; import java.util.Set; import org.dom4j.Document; import org.dom4j.io.OutputFormat; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; import net.sf.json.JSON; import net.sf.json.xml.XMLSerializer; public class XmlTest { private final static String XML_DECLARATION = "
encoding=\"utf-8\"?>"; public static String callMapToXML(Map
import org.dom4j.Document; import org.dom4j.DocumentHelper; import org.dom4j.Element; /** * * 构造XML的方法类 * */ public class XMLUtil { private Document document = null; public Document getDocument() { return document; } /** * 构造方法,初始化Document */ public XMLUtil() { document = DocumentHelper.createDocument(); } /**
* 生成根节点 * * @param rootName * @return */ public Element addRoot(String rootName) { Element root = document.addElement(rootName); return root; } /** * 生成节点 * * @param parentElement * @param elementName * @return */ public Element addNode(Element parentElement, String elementName) { Element node = parentElement.addElement(elementName); return node; } /** * 为节点增加一个属性
* @param thisElement * @param attributeName * @param attributeValue */ public void addAttribute(Element thisElement, String attributeName, String attributeValue) { thisElement.addAttribute(attributeName, attributeValue); } /** * 为节点增加多个属性 * * @param thisElement * @param attributeNames * @param attributeValues */ public void addAttributes(Element thisElement, String[] attributeNames, String[] attributeValues) { for (int i = 0; i < attributeNames.length; i++) { thisElement.addAttribute(attributeNames[i], attributeValues[i]); } }
Java解析XML文件 ========================================== xml文件 <?xml version="1.0" encoding="GB2312"?> <RESULT> <VALUE> <NO>A1234</NO> <ADDR>四川省XX县XX镇XX路X段XX号</ADDR> </VALUE> <VALUE> <NO>B1234</NO> <ADDR>四川省XX市XX乡XX村XX组</ADDR> </VALUE> </RESULT> ========================================== 1)DOM(JAXP Crimson解析器) DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准。DOM是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。DOM以及广义的基于树的处理具有几个优点。首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。它还可以在任何时候在树中上下导航,而不是像SAX那样是一次性的处理。DOM使用起来也要简单得多。 import java.io.*; import java.util.*; import org.w3c.dom.*; import javax.xml.parsers.*; public class MyXMLReader{ public static void main(String arge[]){ long lasting =System.currentTimeMillis(); try{ File f=new File("data_10k.xml"); DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); DocumentBuilder builder=factory.newDocumentBuilder(); Document doc = builder.parse(f); NodeList nl = doc.getElementsByT agName("VALUE"); for (int i=0;i<nl.getLength();i++){ System.out.print("车牌号码:" +
1.Socket的Util辅助类 import https://www.doczj.com/doc/be16297051.html,.*; import java.io.*; /** * 2.socket的Util辅助类 * * @author willson * */ public class ClientSocket { private String ip; private int port; private Socket socket = null; DataOutputStream out = null; DataInputStream getMessageStream = null; public ClientSocket(String ip, int port) { this.ip = ip; this.port = port; } /** * 创建socket连接 * * @throws Exception * exception */ public void CreateConnection() throws Exception { try { socket = new Socket(ip, port); } catch (Exception e) { e.printStackTrace(); if (socket != null) socket.close(); throw e; } finally { } } // 发送消息 public void sendMessage(String sendMessage) throws Exception { try { out = new DataOutputStream(socket.getOutputStream()); if (sendMessage.equals("Windows")) { out.writeByte(0x1);
import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.util.Date; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Set; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.NodeList; import sun.misc.BASE64Encoder; public class XmlWord { private Map
package XML; import java.io.FileOutputStream; import java.io.OutputStreamWriter; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; public class DomTest { private Document doc;
//获得DOM树,元素的添加删除都会用到DOM树所以抽出一个方法来 public void document(){ try { // 1.创建解析工厂对象 DocumentBuilderFactory factory = DocumentBuilderFactory .newInstance(); // 2.通过解析器工厂对象创建解析器对象 DocumentBuilder document = factory.newDocumentBuilder(); // 3.指定解析XML文件,parse("路径")里面写的是文件的路径,并不是文件名。我这里是在这个项目里面,所有写的是相对路径。 doc = document.parse("NewFile.xml"); } catch (Exception e) { } } //解析XML文件
java里有个properties类可以用它来读取XML文件xml文件: Xml代码
第一种DOM 实现方法: Java代码 import java.io.File; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document; import org.w3c.dom.NodeList; public class MyXMLReader2DOM { public static void main(String arge[]) { long lasting = System.currentTimeMillis(); try { File f = new File("data_10k.xml"); DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(f); NodeList nl = doc.getElementsByTagName("VALUE"); for (int i = 0; i < nl.getLength(); i++) { System.out.print("车牌号码:"+ doc.getElementsByTagName("NO").item(i).getFirstChild().getNodeValue()); System.out.println("车主地址:"+ doc.getElementsByTagName("ADDR").item(i).getFirstChild().getNodeValue()); System.out.println("运行时间:" + (System.currentTimeMillis() - lasting) + "毫秒"); } } } catch (Exception e) { e.printStackTrace();