
专题 1_ 词法分析程序构造原理与实现
李若森 13281132计科1301
一、程序功能描述
[功能]:
完成下述正则文法所描述的C语言子集单词符号的词法分析程序。
[要求]:
(1)给出各单词符号的类别编码。
(2)能发现输入串的错误。
(3)将分析所得二元序列输出到中间文件中。
[文法]:
<标识符>→c|c<余留标识符>
<余留标识符>→d|c
<无符号数>→d<余留无符号数>|.<小数部分>|d
<余留无符号数>→d<余留无符号数>|.<十进小数>|(E|e)<指数部分>|.|d <十进小数>→(E|e)<指数部分>|d<十进小数>|d
<小数部分>→d<十进小数>|d
<指数部分>→d<余留指数>|(+|-)<整指数>|d
<整指数>→d<余留整指数>|d
<余留整指数>→d<余留整指数>|d
<算数运算符>→+|-|*|/|++|--
<关系运算符>→>|<|==|>=|<=|!=
<逻辑运算符>→!|&&|\|\|
<位操作运算符>→>>|<<
<赋值运算符>→=|+=|-=|*=|/=|%=
<特殊运算符>→,|\(|\)|{|}
<分隔符>→;
保留字: void int float double if else for do while
[说明]:
(1)该语言对大小写不敏感
(2)c代表字母a-z&&A-Z,d代表数字0-9。
(3)?/*..*/?以及?//?为程序注释部分。
(4)文法中‘\’为转义字符
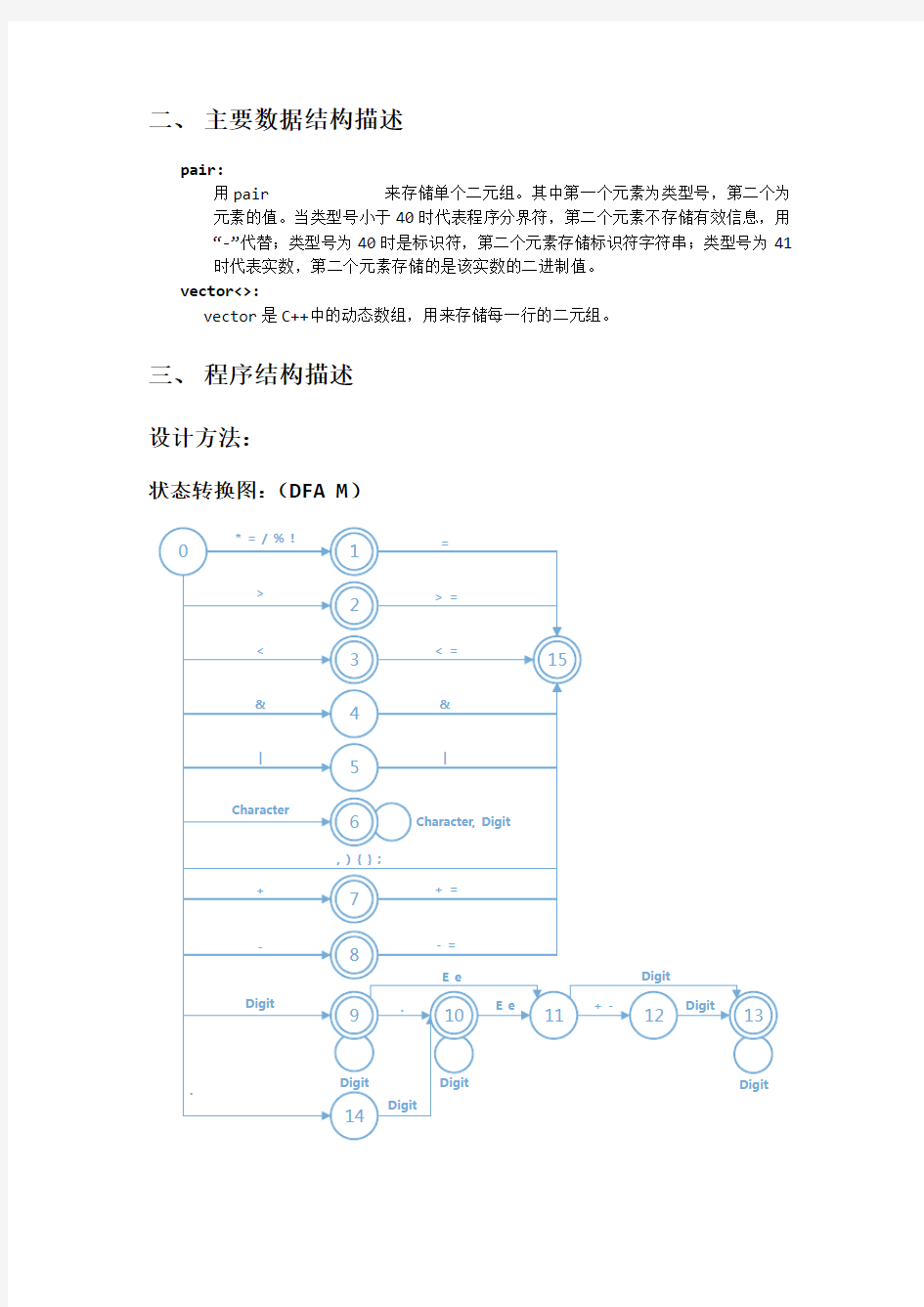
二、主要数据结构描述
pair
用pair
元素的值。当类型号小于40时代表程序分界符,第二个元素不存储有效信息,用
?-?代替;类型号为40时是标识符,第二个元素存储标识符字符串;类型号为41
时代表实数,第二个元素存储的是该实数的二进制值。
vector<>:
vector是C++中的动态数组,用来存储每一行的二元组。
三、程序结构描述
设计方法:
状态转换图:(DFA M)
本实验将标识符分为以下几类
1.算术运算符
+、-、*、/、%、++、--
2.关系运算符
>、<、==、>=、<=、!=
3.逻辑运算符
!、&&、||
4.位操作运算符
<<、>>
5.赋值运算符
=、+=、-=、*=、/=、%=
6.特殊运算符
,、(、)、{、}
7.分隔符
;、/*、*/、//
8.实数
9.标识符
10.保留字
void、int、float、double、if、else、for、do、while 需要识别的关键字及识别码
函数定义:
getOutputName:
void getOutputName( char *inputName, char *outputName );
功能:
得到输出文件名
传入参数:
inputname:需处理的文件的文件名
传出参数:
Outputname:输出文件的文件名
返回值:
(无)
errMsg:
void errMsg( string filename, int rowNo, int colNo, string errmsg ); 功能:
向屏幕输出错误信息
传入参数:
filename:正在处理的文件的文件名称
rowNo:出错行
colNo:出错列
errmsg:错误信息
传出参数:
(无)
返回值:
(无)
noteProcess:
bool noteProcess( string &str, bool ¬eflag );
功能:
预处理,删除字符串内注释
传入参数:
str:需处理的字符串
Noteflag:该字符串是否处于多行注释中
传出参数:
str:处理过的字符串
noteflag:当前行是否处于多行注释中
返回值:
是否成功处理。如果注释匹配则返回true,否则返回false。
print:
void print( FILE *fp, vector
功能:
将结果输出到文件中
传入参数:
fp:输出文件指针
vTable:二元式序列
传出参数:
(无)
返回值:
(无)
isTerminalStage:
bool isTerminalStage( int stage );
功能:
判断当前阶段是否为终结阶段
传入参数:
line:包含该行的字符串
传出参数:
(无)
返回值:
该阶段是否成功解析。是则返回true,否则返回false。
characterType:
int characterType( char ch );
功能:
判断当前字符的类型
传入参数:
ch:待判断字符
传出参数:
(无)
返回值:
该字符的类型对应的值。
dtob:
void dtob( double d, string &str );
功能:
将double类型值转换为二进制表示。
传入参数:
d:待转换的double值
传出参数:
str:该double类型值得二进制表示字符串
返回值:
(无)
addPair:
void addPair( string str, vector
将得到的合法字符串加入到二元式序列中
传入参数:
str:待加入二元式的合法字符串
传出参数:
vTable:更新后的二元式序列
返回值:
(无)
stage_*:
bool stage_*( int &stage, int chtype );//(*从0-17共18个状态) 功能:
单阶段处理
传入参数:
stage:当前阶段
chtype:下一个字符的类别
传出参数:
stage:下一个阶段
返回值:
是否进入下一个合法的阶段。进入返回true,否则返回false。
excute:
bool excute( int &stage, char ch );
功能:
阶段转换
传入参数:
Stage:当前阶段
ch:下一个字符
传出参数:
stage:下一个阶段
返回值:
是否进入下一个合法的阶段。进入返回true,否则返回false。
lineAnalyse:
bool lineAnalyse( string &line, int &colNo,
string &errmsg, vector
功能:
行词法分析
传入参数:
line:包含该行的字符串
colNo:起始处理位置
传出参数:
colNo:处理完成位置
errmsg:错误信息
vTable:该行的二元式序列
返回值:
该行是否成功解析。成功返回true,否则返回false。
四、程序测试
测试用例以及测试结果详见文件夹中test1~test3文本文档以及lexer类型文件。
其中,
test1.txt、test2.txt、test3.txt为测试用例。
test1.lexer、test2.lexer、test3.lexer为测试输出文件。
在命令行中运行lexer [name]即可运行测试用例。
五、实验心得
通过本次专题实验,我更加深刻的理解了词法分析程序的构造以及正则文法到状态转换图的转化问题。本专题所属语言的文法依据右线性正则文法写出来的状态转换图是NFA,需要我们转化为DFA以易于程序实现。
在此次专题实验中,我耗费了一下午来想文法的构造。其文法标识符的分类以及二元式类别表的编辑耗费了我一些时间,另外将文法转化为DFA后依旧出现了一些问题。在设计上是否支持负数输入、双精度浮点类型(double)如何转化为二进制数以及状态转换图中状态的分类等方面产生了一些问题,在经过我思考后解决了上述问题。负数可以在语义上转化为0减去一个数字;经查阅计组数以及网上资料后我完成了double转二进制数的函数,并且精度为二进制下小数点后15位;将状态转换图多次修改后我决定采用最简的形式,生成合法字符串后再进行类别划分,这样可以有效减少状态个数,提高效率。
整个工程我采用了版本管理的形式不断迭代,从最初的一个简单的小程序不断地添加新的功能,最终完成该专题实验。在迭代开发过程中,我对Git操作更加熟悉,对Makefile 有了更加深刻的理解,对开源程序lex的执行逻辑有了更深的理解,且该工程已可以跨平台运行。目前该工程已上传至我的Github仓库中。
课程实验报告课程名称:《编译原理》 专业班级:计算机科学与技术11级10班 学号:XXXXXXX 姓名:X X 指导教师:刘铭 报告日期:2014年6月16日
计算机科学与技术学院 目录 目录 (2) 1 实验一词法分析 (3) 1.1实验目的 (3) 1.2实验要求 (3) 1.3算法思想 (4) 1.4实验程序设计说明 (5) 1.5词法分析实现 (6) 1.6词法实验结果及结果分析 (12) 2 实验二语法分析 (13) 2.1 实验目的 (13) 2.2 实验要求 (13) 2.3 算法思想 (13) 2.4 实验程序设计说明 (15) 2.5 语法分析实现 (15) 4 实验中遇到的问题及解决 (22) 参考资料 (23)
1 实验一词法分析 1.1 实验目的 设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 1.2 实验要求 1、待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 := + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 2、各种单词符号对应的种别码: 表1 各种单词符号对应的种别码 3、词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串;
编译原理实验--词法分析器 实验一词法分析器设计 【实验目的】 1(熟悉词法分析的基本原理,词法分析的过程以及词法分析中要注意的问题。 2(复习高级语言,进一步加强用高级语言来解决实际问题的能力。 3(通过完成词法分析程序,了解词法分析的过程。 【实验内容】 用C语言编写一个PL/0词法分析器,为语法语义分析提供单词,使之能把输入的字符 串形式的源程序分割成一个个单词符号传递给语法语义分析,并把分析结果(基本字, 运算符,标识符,常数以及界符)输出。 【实验流程图】
【实验步骤】 1(提取pl/0文件中基本字的源代码 while((ch=fgetc(stream))!='.') { int k=-1; char a[SIZE]; int s=0; while(ch>='a' && ch<='z'||ch>='A' && ch<='Z') { if(ch>='A' && ch<='Z') ch+=32; a[++k]=(char)ch; ch=fgetc(stream); } for(int m=0;m<=12&&k!=-1;m++) for(int n=0;n<=k;n++) {
if(a[n]==wsym[m][n]) ++s; else s=0; if(s==(strlen(wsym[m]))) {printf("%s\t",wsym[m]);m=14;n=k+1;} } 2(提取pl/0文件中标识符的源代码 while((ch=fgetc(stream))!='.') { int k=-1; char a[SIZE]=" "; int s=0; while(ch>='a' && ch<='z'||ch>='A' && ch<='Z') { if(ch>='A' && ch<='Z') ch+=32; a[++k]=(char)ch; ch=fgetc(stream); } for(int m=0;m<=12&&k!=-1;m++) for(int n=0;n<=k;n++) { if(a[n]==wsym[m][n]) ++s; else s=0; if(s==(strlen(wsym[m]))) {m=14;n=k+1;} } if(m==13) for(m=0;a[m]!=NULL;m++) printf("%c ",a[m]);
编译原理实验报告实验名称:实验一编写词法分析程序 实验类型:验证型实验 指导教师:何中胜 专业班级:13软件四 姓名:丁越 学号: 电子邮箱: 实验地点:秋白楼B720 实验成绩: 日期:2016年3 月18 日
一、实验目的 通过设计、调试词法分析程序,实现从源程序中分出各种单词的方法;熟悉词法分析 程序所用的工具自动机,进一步理解自动机理论。掌握文法转换成自动机的技术及有穷自动机实现的方法。确定词法分析器的输出形式及标识符与关键字的区分方法。加深对课堂教学的理解;提高词法分析方法的实践能力。通过本实验,应达到以下目标: 1、掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法。 2、掌握词法分析的实现方法。 3、上机调试编出的词法分析程序。 二、实验过程 以编写PASCAL子集的词法分析程序为例 1.理论部分 (1)主程序设计考虑 主程序的说明部分为各种表格和变量安排空间。 数组 k为关键字表,每个数组元素存放一个关键字。采用定长的方式,较短的关键字 后面补空格。 P数组存放分界符。为了简单起见,分界符、算术运算符和关系运算符都放在 p表中 (编程时,还应建立算术运算符表和关系运算符表,并且各有类号),合并成一类。 id和ci数组分别存放标识符和常数。 instring数组为输入源程序的单词缓存。 outtoken记录为输出内部表示缓存。 还有一些为造表填表设置的变量。 主程序开始后,先以人工方式输入关键字,造 k表;再输入分界符等造p表。 主程序的工作部分设计成便于调试的循环结构。每个循环处理一个单词;接收键盘上 送来的一个单词;调用词法分析过程;输出每个单词的内部码。 ⑵词法分析过程考虑 将词法分析程序设计成独立一遍扫描源程序的结构。其流程图见图1-1。 图1-1 该过程取名为 lexical,它根据输入单词的第一个字符(有时还需读第二个字符),判断单词类,产生类号:以字符 k表示关键字;i表示标识符;c表示常数;p表示分界符;s表示运算符(编程时类号分别为 1,2,3,4,5)。 对于标识符和常数,需分别与标识符表和常数表中已登记的元素相比较,如表中已有 该元素,则记录其在表中的位置,如未出现过,将标识符按顺序填入数组id中,将常数 变为二进制形式存入数组中 ci中,并记录其在表中的位置。 lexical过程中嵌有两个小过程:一个名为getchar,其功能为从instring中按顺序取出一个字符,并将其指针pint加1;另一个名为error,当出现错误时,调用这个过程, 输出错误编号。 2.实践部分
《LL(1)分析器的构造》实验报告 一、实验名称 LL(1)分析器的构造 二、实验目的 设计、编制、调试一个LL(1)语法分析器,利用语法分析器对符号串的识别,加深对语法分析原理的理解。 三、实验内容和要求 设计并实现一个LL(1)语法分析器,实现对算术文法: G[E]:E->E+T|T T->T*F|F F->(E)|i 所定义的符号串进行识别,例如符号串i+i*i为文法所定义的句子,符号串ii+++*i+不是文法所定义的句子。 实验要求: 1、检测左递归,如果有则进行消除; 2、求解FIRST集和FOLLOW集; 3、构建LL(1)分析表; 4、构建LL分析程序,对于用户输入的句子,能够利用所构造的分析程序进行分析,并显示出分析过程。 四、主要仪器设备 硬件:微型计算机。 软件: Code blocks(也可以是其它集成开发环境)。 五、实验过程描述 1、程序主要框架 程序中编写了以下函数,各个函数实现的作用如下: void input_grammer(string *G);//输入文法G
//将文法G预处理得到产生式集合P,非终结符、终结符集合U、u, int eliminate_1(string *G,string *P,string U,string *GG);//消除文法G中所有直接左递归得到文法GG int* ifempty(string* P,string U,int k,int n);//判断各非终结符是否能推导为空 string* FIRST_X(string* P,string U,string u,int* empty,int k,int n);求所有非终结符的FIRST集 string FIRST(string U,string u,string* first,string s);//求符号串s=X1X2...Xn的FIRST集 string** create_table(string *P,string U,string u,int n,int t,int k,string* first);//构造分析表 void analyse(string **table,string U,string u,int t,string s);//分析符号串s 2、编写的源程序 #include 实验3LL(1)文法构造 一、实验目的 熟悉LL(1)文法的分析条件,了解LL(1)文法的构造方法。 二、实验内容 1、编制一个能够将一个非LL(1)文法转换为LL(1)文法; 2、消除左递归; 3、消除回溯。 三、实验要求 1、将一个可转换非LL(1)文法转换为LL(1)文法,要经过两个阶段,1)消除文 法左递归,2)提取左因子,消除回溯。 2、提取文法左因子算法: 1)对文法G的所有非终结符进行排序 2)按上述顺序对每一个非终结符Pi依次执行: for(j=1; j< i-1;j++) 将Pj代入Pi的产生式(若可代入的话); 消除关于Pi的直接左递归: Pi-> Piα|β,其中β不以Pi开头,则修改产生式为: Pi —>βPi′ Pi′—> αPi′|ε 3)化简上述所得文法。 3、提取左因子的算法: A —>δβ1|δβ2|…|δβn|γ1|γ2|…|γm (其中,每个γ不以δ开头) 那么,可以把这些产生式改写成 A —> δA′|γ1| γ2…|γm A′—>β1|β2|…|βn 4、利用上述算法,实现构造一个LL(1)文法: 1)从文本文件g.txt中读入文法,利用实验1的结果,存入实验1设计的数据结构; 2)设计函数remove_left_recursion()和remove_left_gene()实现消除左递归和提取左因子算法,分别对文法进行操作,消除文法中的左递归和提出左因 子; 3)整理得到的新文法; 4)在一个新的文本文件newg.txt输出文法,文法输出按照一个非终结符号一行,开始符号引出的产生式写在第一行,同一个非终结符号的候选式用“|”分隔的 方式输出。 四、实验环境 PC微机 DOS操作系统或Windows操作系统 Turbo C程序集成环境或Visual C++ 程序集成环境 五、实验步骤 1、学习LL(1)文法的分析条件; 2、学习构造LL(1)文法的算法; 3、结合实验1给出的数据结构,编程实现构造LL(1)文法的算法; 4、结合实验1编程和调试实现对一个具体文法运用上述算法,构造它的LL(1)文法形式; 5、把实验结果写入一个新建立的文本文件。 六、测试数据 输入数据: 编辑一个文本文文件g.txt,在文件中输入如下内容: ? 正确结果: 本实验的输出结果是不唯一的,根据消除左递归是选择非终结符号的顺序不同, 或选择新的非终结符号的不同,可能会得到不同的结果,下面只是可能的一个结果: 1、 P->P之类的),也不含以ε为右部的产生式。 一个文法要能进行LL(1)分析,那么这个文法应该满足:无二义性,无左递归,无左 编译技术实验报告 实验题目:词法分析 学院:信息学院 专业:计算机科学与技术学号: 姓名: 一、实验目的 (1)理解词法分析的功能; (2)理解词法分析的实现方法; 二、实验内容 PL0的文法如下 …< >?为非终结符。 …::=? 该符号的左部由右部定义,可读作“定义为”。 …|? 表示…或?,为左部可由多个右部定义。 …{ }? 表示花括号内的语法成分可以重复。在不加上下界时可重复0到任意次 数,有上下界时可重复次数的限制。 …[ ]? 表示方括号内的成分为任选项。 …( )? 表示圆括号内的成分优先。 上述符号为“元符号”,文法用上述符号作为文法符号时需要用引号…?括起。 〈程序〉∷=〈分程序〉. 〈分程序〉∷= [〈变量说明部分〉][〈过程说明部分〉]〈语句〉 〈变量说明部分〉∷=V AR〈标识符〉{,〈标识符〉}:INTEGER; 〈无符号整数〉∷=〈数字〉{〈数字〉} 〈标识符〉∷=〈字母〉{〈字母〉|〈数字〉} 〈过程说明部分〉∷=〈过程首部〉〈分程序〉{;〈过程说明部分〉}; 〈过程首部〉∷=PROCEDURE〈标识符〉; 〈语句〉∷=〈赋值语句〉|〈条件语句〉|〈过程调用语句〉|〈读语句〉|〈写语句〉|〈复合语句〉|〈空〉 〈赋值语句〉∷=〈标识符〉∶=〈表达式〉 〈复合语句〉∷=BEGIN〈语句〉{;〈语句〉}END 〈条件〉∷=〈表达式〉〈关系运算符〉〈表达式〉 〈表达式〉∷=〈项〉{〈加法运算符〉〈项〉} 〈项〉∷=〈因子〉{〈乘法运算符〉〈因子〉} 〈因子〉∷=〈标识符〉|〈无符号整数〉|'('〈表达式〉')' 〈加法运算符〉∷=+|- 〈乘法运算符〉∷=* 〈关系运算符〉∷=<>|=|<|<=|>|>= 〈条件语句〉∷=IF〈条件〉THEN〈语句〉 〈字母〉∷=a|b|…|X|Y|Z 〈数字〉∷=0|1|2|…|8|9 实现PL0的词法分析 编译原理实验报告 班级 姓名: 学号: 自我评定: 实验一词法分析程序实现 一、实验目的与要求 通过编写和调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将字符形式的源程序流转化为一个由各类单词符号组成的流的词法分析方法。 二、实验内容 根据教学要求并结合学生自己的兴趣和具体情况,从具有代表性的高级程序设计语言的各类典型单词中,选取一个适当大小的子集。例如,可以完成无符号常数这一类典型单词的识别后,再完成一个尽可能兼顾到各种常数、关键字、标识符和各种运算符的扫描器的设计和实现。 输入:由符合或不符合所规定的单词类别结构的各类单词组成的源程序。 输出:把单词的字符形式的表示翻译成编译器的内部表示,即确定单词串的输出形式。例如,所输出的每一单词均按形如(CLASS,VALUE)的二元式编码。对于变量和常数,CLASS字段为相应的类别码;VALUE字段则是该标识符、常数的具体值或在其符号表中登记项的序号(要求在变量名表登记项中存放该标识符的字符串;常数表登记项中则存放该常数的二进制形式)。对于关键字和运算符,采用一词一类的编码形式;由于采用一词一类的编码方式,所以仅需在二元式的CLASS字段上放置相应的单词的类别码,VALUE字段则为“空”。另外,为便于查看由词法分析程序所输出的单词串,要求在CLASS字段上放置单词类别的助记符。 三、实现方法与环境 词法分析是编译程序的第一个处理阶段,可以通过两种途径来构造词法分析程序。其一是根据对语言中各类单词的某种描述或定义(如BNF),用手工的方式(例如可用C语言)构造词法分析程序。一般地,可以根据文法或状态转换图构造相应的状态矩阵,该状态矩阵同控制程序便组成了编译器的词法分析程序;也可以根据文法或状态转换图直接编写词法分析程序。构造词法分析程序的另外一种途径是所谓的词法分析程序的自动生成,即首先用正规式对语言中的各类单词符号进行词型描述,并分别指出在识别单词时,词法分析程序所应进行的语义处理工作,然后由一个所谓词法分析程序的构造程序对上述信息进行加工。如美国BELL实验室研制的LEX就是一个被广泛使用的词法分析程序的自动生成工具。 总的来说,开发一种新语言时,由于它的单词符号在不停地修改,采用LEX等工具生成的词法分析程序比较易于修改和维护。一旦一种语言确定了,则采用手工编写词法分析程序效率更高。 四、实验设计 1)题目1:试用手工编码方式构造识别以下给定单词的某一语言的词法分析程序。 语言中具有的单词包括五个有代表性的关键字begin、end、if、then、else;标识符;整型常数;六种关系运算符;一个赋值符和四个算术运算符。参考实现方法简述如下。 单词的分类:构造上述语言中的各类单词符号及其分类码表。 表I 语言中的各类单词符号及其分类码表 单词符号类别编码类别码的助记符单词值 实验1-3 《编译原理》S语言词法分析程序设计方案 一、实验目的 了解词法分析程序的两种设计方法之一:根据状态转换图直接编程的方式; 二、实验内容 1.根据状态转换图直接编程 编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。 具体任务有: (1)组织源程序的输入 (2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件 (3)删除注释、空格和无用符号 (4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。 (5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。 标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址 注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。 常量表结构:常量名,常量值 三、实验要求 1.能对任何S语言源程序进行分析 在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。 2.能检查并处理某些词法分析错误 词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。 本实验要求处理以下两种错误(编号分别为1,2): 1:非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。 2:源程序文件结束而注释未结束。注释格式为:/* …… */ 四、保留字和特殊符号表 编译原理上机实验试题 一、实验目的 通过本实验使学生进一步熟悉和掌握程序设计语言的词法分析程序的设计原理及相关的设计技术, 如何针对确定的有限状态自动机进行编程序;熟悉和 掌握程序设计语言的语法分析程序的设计原理、熟悉 和掌握算符优先分析方法。 二、实验要求 本实验要求:①要求能熟练使用程序设计语言编程;②在上机之前要有详细的设计报告(预习报告); ③要编写出完成相应任务的程序并在计算机上准确 地运行;④实验结束后要写出上机实验报告。 三、实验题目 针对下面文法G(S): S→v = E E→E+E│E-E│E*E│E/E│(E)│v │i 其中,v为标识符,i为整型或实型数。要求完成 ①使用自动机技术实现一个词法分析程序; ②使用算符优先分析方法实现其语法分析程序,在 语法分析过程中同时完成常量表达式的计算。 1、题目(见“编译原理---实验题目.doc,“实验题目”中的第一项) 2、目的与要求(见“编译原理---实验题目.doc”) 3、设计原理: (1)单词分类:标识符,保留字,常数,运算符,分隔符等等 (2)单词类型编码 (3)自动机 4、程序流程框图 5、函数原型(参数,返回值) 6、关键代码(可打印,只打印关键代码) 7、调试: (1)调试过程中遇到的错误,如何改进的; (2)需要准备测试用例(至少3个,包含输入和输出)——(可打印) 8、思考: (1)你编写的程序有哪些要求是没有完成的,你觉得该采用什么方法去完成; (2)或者是你觉得程序有哪些地方可以进一步完善,简述你的完善方案。 1、题目(见“编译原理---实验题目.doc,“实验题目”中的第二项) 2、目的与要求(见“编译原理---实验题目.doc”) 3、设计原理:构造出算法优先关系表 4、程序流程框图 5、函数原型(参数,返回值) 6、关键代码(可打印,只打印关键代码) 7、调试: (1)调试过程中遇到的错误,如何改进的; (2)需要准备测试用例(至少3个,包含输入和输出)——(可打印) 8、思考: (1)你编写的程序有哪些要求是没有完成的,你觉得该采用什么方法去完成; (2)或者是你觉得程序有哪些地方可以进一步完善,简述你的完善方案。 本代码只供学习参考: 词法分析源代码: #include 编译原理实验报告 课程:编译原理 系别:计算机系 班级:11网络 姓名:王佳明 学号:110912049 教师:刘老师 实验小组:第二组 1 实验一熟悉C程序开发环境、进行简单程序的调试 实验目的: 1、初步了解vc++6.0环境; 2、熟悉掌握调试c程序的步骤: 实验内容: 1、输入下列程序,练习Turbo C 程序的编辑、编译、运行。 #include 实验二词法分析器 一、实验目的: 设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。 二、实验要求: 1.对给定的程序通过词法分析器弄够识别一个个单词符号,并以二元式(单词种别码,单词符号的属性值)显示。而本程序则是通过对给定路径的文件的分析后以单词符号和文字提示显示。 2.本程序自行规定: (1)关键字"begin","end","if","then","else","while","write","read", "do", "call","const","char","until","procedure","repeat" (2)运算符:"+","-","*","/","=" (3)界符:"{","}","[","]",";",",",".","(",")",":" (4)其他标记如字符串,表示以字母开头的标识符。 (5)空格、回车、换行符跳过。 在屏幕上显示如下: ( 1 , 无符号整数) ( begin , 关键字) ( if , 关键字) ( +, 运算符) ( ;, 界符) ( a , 普通标识符) 三、使用环境: Windows下的visual c++6.0; 四、调试程序: 1.举例说明文件位置:f:、、11.txt目标程序如下: begin x:=9 if x>0 then x:=x+1; while a:=0 do 3 实验一文法的机内表示与输入输出 实验题目:文法的机内表示与输入输出 实验目的:输入文法,按照所提供的各种要求输出所需结果。 实验准备:在学习了规则和有关文法的一些基本概念后,用本实验来加深各个概念间的关系。例如规则、文法、识别符、Chomsky文法、终结符、 非终结符等。 设计考虑: 实验代码: #include 实验2 词法分析程序的设计 一、实验目的 掌握计算机语言的词法分析程序的开发方法。 二、实验内容 编制一个能够分析三种整数、标识符、主要运算符和主要关键字的词法分析程序。 三、实验要求 1、根据以下的正规式,编制正规文法,画出状态图; 标识符<字母>(<字母>|<数字字符>)* 十进制整数0 | ((1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*) 八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)* 十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)* 运算符和界符+ - * / > < = ( ) ; 关键字if then else while do 2、根据状态图,设计词法分析函数int scan( ),完成以下功能: 1)从文本文件中读入测试源代码,根据状态转换图,分析出一个单词, 2)以二元式形式输出单词<单词种类,单词属性> 其中单词种类用整数表示: 0:标识符 1:十进制整数 2:八进制整数 3:十六进制整数 运算符和界符,关键字采用一字一符,不编码 其中单词属性表示如下: 标识符,整数由于采用一类一符,属性用单词表示 运算符和界符,关键字采用一字一符,属性为空 3、编写测试程序,反复调用函数scan( ),输出单词种别和属性。 四、实验环境 PC微机 DOS操作系统或Windows 操作系统 Turbo C 程序集成环境或Visual C++ 程序集成环境 五、实验步骤 1、根据正规式,画出状态转换图; 实验一词法分析程序实现 一、实验目得与要求 通过编写与调试一个词法分析程序,掌握在对程序设计语言得源程序进行扫描得过程中,将字符流形式得源程序转化为一个由各类单词符号组成得流得词法分析方法 二、实验内容 基本实验题目:若某一程序设计语言中得单词包括五个关键字begin、end、if、then、else;标识符;无符号常数;六种关系运算符;一个赋值符与四个算术运算符,试构造能识别这些单词得词法分析程序(各类单词得分类码参见表I)。 表I语言中得各类单词符号及其分类码表 输入:由符合与不符合所规定得单词类别结构得各类单词组成得源程序文件。 输出:把所识别出得每一单词均按形如(CLASS,VALUE)得二元式形式输出,并将结果放到某个文件中。对于标识符与无符号常数,CLASS字段为相应得类别码得助记符;V AL UE字段则就是该标识符、常数得具体值;对于关键字与运算符,采用一词一类得编码形式,仅需在二元式得CLASS字段上放置相应单词得类别码得助记符,V ALUE字段则为“空". 三、实现方法与环境 词法分析就是编译程序得第一个处理阶段,可以通过两种途径来构造词法分析程序.其一就是根据对语言中各类单词得某种描述或定义(如BNF),用手工得方式(例如可用C语言)构造词法分析程序。一般地,可以根据文法或状态转换图构造相应得状态矩阵,该状态矩阵连同控制程序一起便组成了编译器得词法分析程序;也可以根据文法或状态转换图直接编写词法分析程序。构造词法分析程序得另外一种途径就是所谓得词法分析程序得自动生成,即首先用正规式对语言中得各类单词符号进行词型描述,并分别指出在识别单词时,词法分析程 编译原理实验报告 实验一 一、实验名称:词法分析器的设计 二、实验目的:1,词法分析器能够识别简单语言的单词符号 2,识别出并输出简单语言的基本字.标示符.无符号整数.运算符.和界符。 三、实验要求:给出一个简单语言单词符号的种别编码词法分析器 四、实验原理: 1、词法分析程序的算法思想 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 2、程序流程图 (1 (2)扫描子程序 3 五、实验内容: 1、实验分析 编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符。字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。 2 实验词法分析器源程序: #include 词法分析器实验报告 一、实验目的 选择一种编程语言实现简单的词法分析程序,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 : = + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 各种单词符号对应的种别码: 表各种单词符号对应的种别码 词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根 据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 主程序示意图: 主程序示意图如图3-1所示。其中初始包括以下两个方面: ⑴关键字表的初值。 关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下: Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,}; 图3-1 (2)程序中需要用到的主要变量为syn,token和sum 扫描子程序的算法思想: 首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn 用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。 电子科技大学 实验报告 学生姓名:学号:指导教师: 实验地点:实验时间: 一、实验室名称:计算机学院软件工程实验室 二、实验项目名称:词法分析器的设计与实现 三、实验学时:4学时 四、实验原理 1.编译程序要求对高级语言编写的源程序进行分析和合成,生成目标程序。词法分析是对源程序进行的首次分析,实现词法分析的程序为词法分析程序。 2.词法分析的功能是从左到右逐个地扫描源程序字符串,按照词法规则识别出单词符号作为输出,对识别过程中发现的词法错误,输出相关信息。 3.状态转换图是有限有向图,是设计词法分析器的有效工具。 五、实验目的 通过设计词法分析器的实验,使同学们了解和掌握词法分析程序设计的原理及相应的程序设计方法,同时提高编程能力。 六、实验内容 实现求n!的极小语言的词法分析程序,返回二元式作为输出。 七、实验器材(设备、元器件) 1.操作系统:Windows XP 2.开发工具:VC6.0 3.普通PC即可 八、实验步骤 (1)启动VC6.0,创建空白工程项目。选择菜单中的“文件”->“新建”->“项目”,在弹出的对话框中,左边的“项目类型”框中,选择“Visual C++ 项目”,在右边框中,选择“空项目(.Net)”,在对话框下边,选择工程文件存放目录及输入名称,如Example1,单击“确定”。 (2)建立相应的单词符号与种别对照表; (3)根据状态转换图编写相应的处理函数; (4)完成词法分析器; (5)编译与调试以上程序; (6)生成相应的*.dyd文件,作为后面语法分析的输入文件。 九、实验数据及结果分析 可以对源程序进行词法分析,如果有错给出出错信息和所在行数,如果无错则生成二元式文件。 十、实验结论 本实验程序较好地完成了词法分析程序的设计与实现,能够对所给文法的程序进行词法分析,在没有词法错误的时候生成相应的二元式文件。该实验程序可一次性给出源程序中的词法错误。 十一、总结及心得体会 通过该实验,对词法分析程序的设计,以及运用C语言进行编程有了更深刻的理解,同时加深了自己对词法分析程序的原理的理解与掌握,提高了自己的动手能力。 十二、对本实验过程及方法、手段的改进建议 程序设计合理,代码可进一步优化。 报告评分: 指导教师签字: 编译原理实验报告 合肥工业大学计算机科学与技术 完成日期:2013.6.3 实验一词法分析设计 一、实验功能: 对输入的txt文件内的内容进行词法分析: 由文件流输入test.txt中的内容, 对文件中的各类字符进行词法分析 打印出分析后的结果; 二、程序结构描述:(源代码见附录) 1、利用Key[]进行构造并存储关键字表;利用optr[]进行构造并存储运算符表;利用separator[]进行构造并存储分界符表; 2、bool IsKey(string ss) {}判断是否是关键字函数若是关键字返回true,否则返回false; bool IsLetter(char c) {}判断当前字符是否字母,若是返回true,否则返回false; bool IsDigit(char c) {}判断当前字符是否是数字,若是返回true,否则返回false; bool IsOptr(string ss) {}判断当前字符是否是运算符,若是返回true,否则返回false; bool IsSeparator(string ss) {}判断当前字符是否是分界符,若是返回true,否则返回false; void analyse(ifstream &in) {}分析函数构造; 关系运算符通过switch来进行判断; 三、实验结果 实验总结: 词法分析的程序是自己亲手做的,在实现各个函数时花了不少功夫, 1、要考虑到什么时候该退一字符,否则将会导致字符漏读甚至造成字符重复读取。 2、在实现行数和列数打印时要考虑到row++和line++应该放在什么位置上才可以,如当读取一个\n时line要增加一,而row需要归0处理,在读取某一字符串或字符后row需要加一; 3、对于关系运算符用switch结构进行选择判断即可解决一个字符和两个字符的运算符之间的差异; 4、将自己学过的知识应用到实践中是件不怎么容易的事情,只有亲身尝试将知识转化成程序才能避免眼高手低,对于知识的理解也必将更加深刻。编译原理实验报告3-LL(1)文法构造
编译原理实验词法分析实验报告
编译原理实验报告
实验1-3-《编译原理》词法分析程序设计方案
编译原理实验题目及报告要求
编译原理实验词法分析语法分析
编 译 原 理 实 验 报 告
编译原理实验报告1
编译原理实验报告2词法分析程序的设计
编译原理实验报告一
编译原理实验报告(词法分析器语法分析器)
编译原理词法分析实验报告
编译原理标准实验报告
编译原理实验报告-合肥工业大学版
相关主题
文本预览