python选择题word打印版
- 格式:docx
- 大小:519.69 KB
- 文档页数:39

(完整版)python真题word一、选择题1.下面的Python程序段运行后的输出结果是()List=[‘10’,25,’猕猴桃’,9,65]Print(List[3])A.25 B.’猕猴桃’C.猕猴桃D.92.以下Python表达式中,哪项的值与其它三项不同()A.len(“my name is james”.split())B.int(4.99)C.sum([1,2,1,1])D.max([1,2,3,4])3.以下哪个不是python关键字()A.cout B.from C.not D.or4.在Python程序设计语言中,表示整除的符号是()A./ B.% C.mod D.//5.设a=2,b=5,在python中,表达式a>b And b>3的值是()A.False B.True C.-1 D.16.如下Python程序段x = 2print (x+1)print (x+2)运行后,变量x的值是()A.2 B.3 C.5 D.7.应用软件是为满足用户不同领域、不同问题的应用需求而设计的软件。
以下不属于应用软件的是()A.Word B.微信C.考试系统D.python8.解释性语言是指源代码不要求预先进行编译,在运行时才进行解释再运行,以下哪一种程序设计语言属于解释性语言()。
A.Python B.C++ C.VB D.C9.下列有关于print命令的描述中,正确的是()A.在打印机里打印相关的文本或者数字等B.可以用来画图C.在屏幕中输出相应的文本或者数字等D.执行语句print(“python”,3.7)时会出错10.Python中“ab ”+“cd”*2的结果是()。
A.abcd2 B.abcdabcd C.abcdcd D.ababcd11.在python中,运行下列程序,正确的结果是()s=0for i in range (1,5):s=s+iprint("i=",i,"s=",s)A.i=4 s=10 B.i=5 s=10 C.i=5 s=15 D.i=6 s=1512.关于python程序设计语言,下列说法错误的是()A.python是一种面向对象的编程语言B.python代码只能在交互环境中运行C.python具有丰富和强大的库D.python是一种解释型的计算机程序设计高级语言13.根据Python中变量命名遵循的规则,正确的是()A.char21 B.2020Py C.Python D.name.ch14.在Python中,Print(abs(-16//5))的执行结果是()A.2.4 B.3 C.4 D.-2.415.在python中,以下哪个选项a 的数据类型为整型()A.a=5 B.a=input() C.a='5' D.a=5.0二、程序填空16.现今信息化时代,信息的传输十分迅速,足不出户便知天下事。

试卷(完整版)python考试复习题库word练习一、选择题1.在Python中,“print(100-33*5%3)”语句输出的是()A.34 B.67 C.100 D.12.算法用Python程序实现,以下代码中哪处语句存在语法错误()A.B.C.D.3.Python中print(66!=66)结果是()。
A.1 B.0 C.True D.False4.python3解释器执行not 1 and 1的结果为()。
A.True B.False C.0 D.15.在教科书中利用Python探究电流和电压、电阻的关系实验里,除了可以通过书中的Jupyter Notebook外,处理数据还可以通过下列()工具实现。
A.Python IDLE B.Xmind C.网络画板D.几何画板6.已知字符串a="python",则a[-1]的值为()A."p" B."n" C."y" D."o"7.下列选项都是属于高级语言的是( )A.汇编语言、机器语言B.汇编语言、Basic语言C.Basic语言、Python语言D.机器语言、Python语言8.关于Python语言的特点,以下选项描述正确的是()A.Python语言不支持面向对象B.Python语言是解释型语言C.Python语言是编译型语言D.Python语言是非跨平台语言9.利用Word 软件编辑了一篇关于“Python简介”的文档,部分界面如图所示,下列说法正确的是()A.该文档中的有2个用户添加了2处批注B.该文档中图片采用的环绕方式为上下型C.该文档中总共有4处修订D.若要对文档中所有的“Python”文字设置为“红色倾斜”格式,用自动更正功能最合适10.在python中,运行以下程序,结果应为()a=5b=7b+=3a=b*20a+=2a=a%bprint(a,b)A.5 7 B.20 10 C.22 7 D.2 1011.以下python程序段运行后,s的值是()n=0s=0while s <= 10:n=n+3s=s+nprint (s)A.0 B.3 C.18 D.3012.Python的序列类型不包括下列哪一种?()A.字符串B.列表C.元组D.字典13.Python中的数据类型float表示()A.布尔型B.整型C.字符串型D.浮点型14.在python中,以下哪个选项a 的数据类型为整型()A.a=5 B.a=input() C.a='5' D.a=5.0 15.Python表达式中,可以使用()控制运算的优先顺序。

【编程】(完整版)Python题库word练习一、选择题1.运行下列 Python程序,结果正确的是( )a=32b=14c=a%bprint(c)A.2 B.4 C.32 D.142.下列python表达式结果最小的是()A.2**3//3+8%2*3 B.5**2%3+7%2**2 C.1314//100%10 D.int("1"+"5")//3 3.下列选项中,可以作为 Python程序变量名的是()A.a/b B.ab C.a+b D.a-b4.在python语言中表示“x属于区间[a,b)”的正确表达式是()A.a≤ x or x < b B.a<= x and x < b C.a≤x and x< b D.a<=x or x<b5.下列哪个语句在Python中是非法的?()A.x = y = z = 1 B.x = (y = z + 1) C.x, y = y, x D.x += y x=x+y 6.已知a = 6,b = -4,则Python表达式 a / 2 + b % 2 * 3 的值为()A.3 B.3.0 C.5 D.5.07.以下()是python文件A.*.mp3B.*.xls C.*.ppt D.*py8.Python程序文件的扩展名是()。
A..python B..pyt C..pt D..py9.已知列表list1=[10,66,27,33,23],则python表达式max(list1)的值为()A.10 B.66 C.5 D.2310.变量K表示某天是星期几(k=1,表示星期一),下列python表达式中能表示K的下一天的是()A.K+1 B.K%7+1 C.(K+1)%7 D.(K+1)%7-1 11.Python中,保留字写法正确的是()A.PRINT()B.Print()C.print()D.Int()12.下列选项中,不属于Python合法变量名的是()A.int32 B.40xl C.self D._name_ 13.Python不支持的数据类型有()。

实用文档试题(完整版)python考试复习题库一、选择题1.以下哪个不是python关键字?A。
coutB。
FalseC。
TrueD。
None2.设a=2,b=5,在python中,表达式a>b And b>3的值是?A。
TrueB。
FalseC。
NoneD。
Error3.在Python中,不同的数据,需要定义不同的数据类型,可用方括号“[]”来定义的是?A。
整数B。
浮点数C。
列表实用文档D。
字符串4.以下python程序段执行后,输出结果为?m=29if m % 3.= 0:print(m。
"不能被3整除")XXX:print(m。
"能被3整除")A。
29不能被3整除B。
m不能被3整除C。
29能被3整除D。
m能被3整除5.Python中变量的命名遵循的规则,不正确的是?A。
以字母或下划线开头,后面可以是字母、数字或下划线。
B。
区分大小写C。
以数字开头,后面可以是字母、数字或下划线。
D。
不能使用保留字6.Python语句"ab"+"c"*2的运行结果是?A。
abc2实用文档B。
abcabcC。
abccD。
ababcc7.Python不支持的数据类型有?A。
字符串B。
整数C。
元组D。
字典8.下列可以导入Python模块的语句是?A。
import moduleB。
fromC。
input moduleD。
def module9.Python使用函数()接收用输入的数据。
A。
accept()B。
input()C。
readline()D。
print()10.以下叙述中正确的是?实用文档A。
Python 3.x与Python 2.x兼容B。
Python语句只能以程序方式执行C。
Python是解释型语言D。
Python语言出现得晚,具有其他高级语言的一切优点11.Python文件的后缀名是?A。
docB。
vbpC。
pyD。

Python习题word练习一、选择题1.Python中“ab ”+“cd”*2的结果是()。
A.abcd2 B.abcdabcd C.abcdcd D.ababcd2.Python输入函数为()。
A.time() B.round() C.input( ) D.print()3.在Python中要交换变量a和b中的值,应使用的语句组是()A.a,b = b,a B.a = c ;a = b;b = cC.a = b;b = a D.c = a;b = a;b = c4.下列选项中,可以作为 Python程序变量名的是()A.a/b B.ab C.a+b D.a-b5.下列哪个语句在Python中是非法的?()A.x=y=z=1 B.x=(y=z+1)C.x,y=y,x D.x+=y6.根据Python中变量命名遵循的规则,正确的是()A.char21 B.2020Py C.Python D.name.ch7.关于Python,以下几种说法不正确的是()。
A.Python是一种高级程序设计语言B.Python属于汇编语言,或者说属于低级语言C.Python是一种代表简单主义思想的语言,它具有简单、免费、开源和可移植等特点D.Python是一种面向对象的、解释性计算机语言8.关于python程序设计语言,下列说法不正确的是( )。
A.python源文件以***.py为扩展名B.python的默认交互提示符是:>>>C.python只能在文件模式中编写代码D.python具有丰富和强大的模块9.下列Python程序运行后的输出结果是()。
s=0for i in range(1,10):s=s+iprint("s=",s)A.s=35 B.s=45 C.s=55 D.s=6510.在python中,想输出一行文字,要用到的函数是()。
A.input()B.int()C.print()D.float()11.下列Python表达式中,能正确表示不等式方程|x|>1解的是()A.x>1 or x<-1 B.x>-1 or x<1 C.x>1 and x<-1 D.x>-1 and x<1 12.下列Python表达式中,能正确表示“变量x能够被4整除且不能被100整除”的是()A.(x%4==0) or (x%100!=0)B.(x%4==0) and (x%100!=0)C.(x/4==0) or (x/100!=0)D.(x/4==0) and (x/100!=0)13.Python语言自带的IDLE环境的退出命令是()A.Esc B.close C.回车键D.exit14.下面不是python特性的是():A.免费的B.简单易学C.可移植性好D.是低级语言15.把数式写成Python语言的表达式,下列书写正确的是()。

Python等级考试——第一课优质word(1)练习一、选择题1.Python语句 "ab"+"c"*2 的运行结果是()A.abc2 B.abcabc C.abcc D.ababcc2.在Python中,返回x的绝对值的函数是()。
A.abs(x) B.bin(x) C.all(x) D.input(x)3.以下Python程序运行后的输出结果为()A.0 B.45 C.46 D.3628804.在python语言中表示“x属于区间[a,b)”的正确表达式是()A.a≤ x or x < b B.a<= x and x < b C.a≤x and x< b D.a<=x or x<b5.除python语言之处,还有很多其他程序设计语言。
程序设计语言经历了从机器语言、汇编语言到高级语言的发展过程。
其中python语言是属于()。
A.机器语言B.高级语言C.汇编语言D.自然语言6.根据Python中变量命名遵循的规则,正确的是()A.char21 B.2020Py C.Python D.name.ch7.已知字符串s1="python",s2="Python",则表达式中s1>s2的值为()A.“python”B.“Python”C.True D.False8.以下选项中,不是Python中文件操作的相关函数是()。
A.open () B.load ()C.read () D.write ()9.以下python程序段运行后,y的值是()x=3if x > 3 :y=2*xelse :y=3*x+1print(y)A.10 B.5 C.25 D.2610.下列Python表达式中,能正确表示“变量x能够被4整除且不能被100整除”的是()A.(x%4==0) or (x%100!=0)B.(x%4==0) and (x%100!=0)C.(x/4==0) or (x/100!=0)D.(x/4==0) and (x/100!=0)11.下列定义变量的python程序语句变量赋值错误的是()A.x=y=1 B.x,y=1,2 C.x==1 D.x=1,212.以下不属于高级程序设计语言的是()。

Python试题(附参考答案)一、单选题(共57题,每题1分,共57分)1.关于函数的返回值,以下选项中描述错误的是()A、return可以传递0个返回值,也可以传递任意多个返回值B、函数必须有返回值C、函数可以有return,也可以没有D、函数可以返回0个或多个结果正确答案:B2.字符串是一个字符序列,例如,字符串s,从右侧向左第5个字符用()索引。
A、s[5]B、s[:-5]C、s[0:-5]D、s[-5]正确答案:D3.以下哪个不属于面向对象的特征()A、多态B、复合C、封装D、继承正确答案:B4.关于函数的关键字参数使用限制,以下选项中描述错误的是()A、关键字参数顺序无限制B、关键字参数必须位于位置参数之后C、不得重复提供实际参数D、关键字参数必须位于位置参数之前正确答案:D5.关于列表数据结构,下面描述正确的是()A、不支持in运算符B、必须按顺序插入元素C、可以不按顺序查找元素D、所有元素类型必须相同正确答案:C6.使用()符号对浮点类型的数据进行格式化A、%fB、%cC、%dD、%s正确答案:A7.以下不属于Python语言保留字的是()A、passB、whileC、doD、True正确答案:C8.关于Python语言的注释,以下选项中描述错误的是()A、Python语言的多行注释以'''(三个单引号)开头和结尾B、Python语言的单行注释以#开头C、Python语言的单行注释以单引号'开头D、Python语言有两种注释方式:单行注释和多行注释正确答案:C9.字典对象的______________方法返回字典的“值”列表A、values()B、key()C、keys()D、items()正确答案:A10.以下选项中,不是Python对文件的打开模式的是()A、'r'B、'c'C、'w'D、'+'正确答案:B11.以下关于程序控制结构描述错误的是:A、二分支结构组合形成多分支结构B、Python里,能用分支结构写出循环的算法C、程序由三种基本结构组成D、分支结构包括单分支结构和二分支结构正确答案:B12.下面代码的输出结果是()a=[9,6,4,5]N=len(a)foriinrange(int(len(a)/2)):a[i],a[N-i-1]=a[N-i-1],a[i]print(a)A、[9,6,5,4]B、[5,6,9,4]C、[5,4,6,9]D、[9,4,6,5]正确答案:C13.下列()语句在Python中是非法的A、x+=yB、x=(y=z+1)C、x=y=z=1D、x,y=y,x正确答案:B14.以下代码中calculate()函数属于哪个分类defcalculate(number):Result=0i=1Whilei<=number:result=result+ii +=1ReturnresultResult=calculate(100)print('1~100的累积和为:',result)A、有参有返回值函数B、有参无返回值函数C、无参无返回值函数D、无参有返回值函数正确答案:A15.以下选项中,对于函数的定义错误的是()A、defvfunc(a,*b):B、defvfunc(*a,b):C、defvfunc(a,b=2):D、defvfunc(a,b):正确答案:B16."下面代码的输出结果是()foriinrange(1,10,2):print(i,end=",")"A、1,3,5,7,9,B、1,4,C、1,3,D、1,4,7,正确答案:A17."下面代码的输出结果是()foriinrange(1,6):ifi/3==0:breakelse:print(i,end=",")"A、1,2,3,4,B、1,2,3,4,5,C、1,2,3,D、1,2,正确答案:B18.给出如下代码:importrandomasranlistV=[]ran.seed(100)Foriinrange(10):I=ran. randint(100,999)listV.append(i)以下选项中能输出随机列表元素最大值的是()A、print(max(listV))B、print(listV.reverse(i))C、print(listV.pop(i))D、print(listV.max())正确答案:A19.关于Python字符串,以下选项中描述错误的是()A、字符串是一个字符序列,字符串中的编号叫“索引”B、字符串可以保存在变量中,也可以单独存在C、可以使用datatype()测试字符串的类型D、输出带有引号的字符串,可以使用转义字符\正确答案:C20.下列不是Python语言关键字的是()A、elseB、printC、finallyD、lambda正确答案:B21.下面代码的输出结果是()a=[]foriinrange(2,10):count=0forxinrange(2,i-1):ifi%x==0:count+=1ifcount==0:a。

Python期末试题题库完整_优质word练习一、选择题1.下列 Python 表达式的值为偶数的是()A.12*3%5 B.len(“Welcome”)C.int(3.9)D.abs(-8)2.在Python代码中表示“x属于区间[a,b)”的正确表达式是()。
A.a≤x and x<b B.n<= x or x<b C.x>=a and x<b D.x>=a and x>b 3.12 Python语言语句块的标记是( )A.分号B.逗号C.缩进D./4.除python语言之处,还有很多其他程序设计语言。
程序设计语言经历了从机器语言、汇编语言到高级语言的发展过程。
其中python语言是属于()。
A.机器语言B.高级语言C.汇编语言D.自然语言5.在python中,下列属于字符串常量的是()A."python" B.3.14 C.cnt D.20186.以下叙述中正确的是()。
A.Python 3.x与Python 2.x兼容B.Python语句只能以程序方式执行C.Python是解释型语言D.Python语言出现得晚,具有其他高级语言的一切优点7.下列Python程序运行后的输出结果是( )。
s=0for i in range(1,5):s=s+iprint("s=",s)A.s=5 B.s=6 C.s=10 D.s=158.Python的序列类型不包括下列哪一种?()A.字符串B.列表C.元组D.字典9.已知字符串变量x的值是“H”,字符“A”的ASCII值是65,则python表达式chr(ord(x)+2)的值是()A.‘I’B.‘J’C.73 D.7410.下列Python表达式中,能正确表示“变量x能够被4整除且不能被100整除”的是()A.(x%4==0) or (x%100!=0)B.(x%4==0) and (x%100!=0)C.(x/4==0) or (x/100!=0)D.(x/4==0) and (x/100!=0)11.以下哪种语言属于高级程序设计语言()①python ②c++ ③visual basic ④javaA.①②③B.②③C.②③④D.①②③④12.下列不是 Python 程序基本结构的是()。
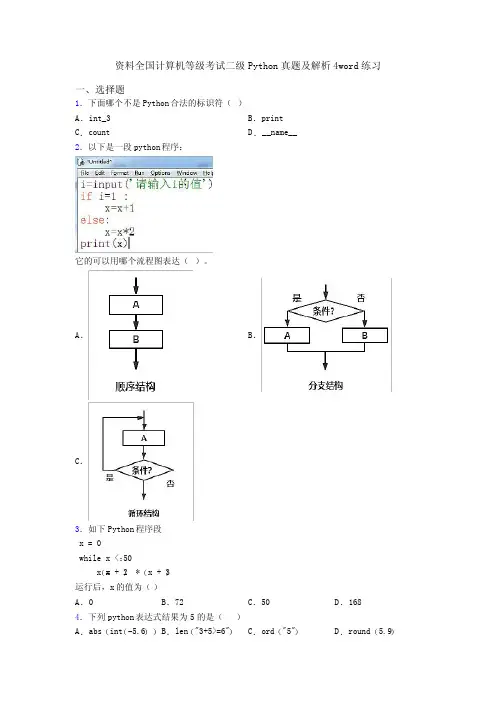
资料全国计算机等级考试二级Python真题及解析4word练习一、选择题1.下面哪个不是Python合法的标识符()A.int_3 B.printC.count D.__name__2.以下是一段python程序:它的可以用哪个流程图表达()。
A.B.C.3.如下Python程序段x = 0while x < 50:x =(x + 2) * (x + 3)运行后,x的值为()A.0 B.72 C.50 D.1684.下列python表达式结果为5的是( )A.abs(int(-5.6))B.len("3+5>=6")C.ord("5")D.round(5.9)5.下列Python语句中,会导致程序运行出错的语句是()A.x=(y=1) B.x,y=y,x C.x=1;y=1 D.x=y=1 6.在Python中,算式5+6*4%(2+8)结果为()A.25B.15C.9D.7.47.Python文件的后缀名是()。
A..doc B..vbp C..py D..exe 8.根据Python中变量命名遵循的规则,正确的是()A.char21 B.2020Py C.Python D.name.ch 9.如下Python程序段for i in range(1,4):for j in range(0,3):print("Python")语句print ("Python")的执行次数是()A.3 B.4 C.6 D.910.在python中,想输出一行文字,要用到的函数是( )。
A.input()B.int()C.print()D.float() 11.Python使用函数()接收用输入的数据A.accept() B.input() C.readline() D.print() 12.Python中用来声明字符串变量的关键字是()A.str B.int C.float D.char 13.在Python中,下面程序段的输出结果是()x=9Print(“x=”,x+1)A.9 B.10 C.x=9 D.x= 10 14.在Python中要交换变量a和b中的值,应使用的语句组是()。

(完整版)Python题库精品word练习一、选择题1.把数式写成Python语言的表达式,下列书写正确的是()。
A.a+b/2a B.a+b/2*a C.(a+b)/2*a D.(a+b)/(2*a) 2.python3解释器执行not 1 and 1的结果为()。
A.True B.False C.0 D.1 3.Python文件的后缀名是()A.pdf B.do C.pass D.py4.下列哪个语句在Python中是非法的?()A.x = y = z = 1 B.x = (y = z + 1) C.x, y = y, x D.x += y x=x+y 5.Python文件的后缀名是()。
A..doc B..vbp C..py D..exe6.在Python中,表达式(21%4)+3的值是()A.2 B.4 C.6 D.87.以下python程序段运行后,s的值是()n=0s=0while s <= 10:n=n+3s=s+nprint (s)A.0 B.3 C.18 D.308.下列选项中,属于Python输入函数的是()。
A.random() B.print() C.Cout() D.input() 9.下列选项中,不属于Python合法变量名的是()A.int32 B.40xl C.self D._name_10.下列不是 Python 程序基本结构的是()。
A.顺序结构B.树形结构C.分支结构D.循环结构11.在Python中,下面程序段的输出结果是()x=9Print(“x=”,x+1)A.9 B.10 C.x=9 D.x= 10 12.下列可以导入Python模块的语句是()A.import moduleB.input moduleC.print moduleD.def module13.下列不被python所支持的数据类型是()A.char B.float C.int D.list14.在Python中,正确的赋值语句是()A.x+y=10 B.x=2y C.x=y=50 D.3y=x+115.下列选项中,能作为python程序变量名的是()A.s%1 B.3stu C.while D.dist16.小新编制了一个python程序如下,但程序无法执行,你帮他找出程序中一共有几处错误()1a=3b=input()c=a+bprint("c")A.1 B.2 C.3 D.417.运行下列 Python程序,结果正确的是( )a=32b=14c=a%bprint(c)A.2 B.4 C.32 D.1418.Python中变量的命名遵循的规则,不正确的是()A.必须以字母或下划线开头,后面可以是字母、数字或下划线。

Python 单选题库一、python 语法基础1、Python 3.x 版本的保留字总数是A.27B.29C.33D.162.以下选项中,不是Python 语言保留字的是A whileB passC doD except3.关于Python 程序格式框架,以下选项中描述错误的是A Python 语言不采用严格的“缩进”来表明程序的格式框架B Python 单层缩进代码属于之前最邻近的一行非缩进代码,多层缩进代码根据缩进关系决定所属范围C Python 语言的缩进可以采用Tab 键实现D 判断、循环、函数等语法形式能够通过缩进包含一批Python 代码,进而表达对应的语义4. 下列选项中不符合Python 语言变量命名规则的是A TempStrB IC 3_1D _AI5.以下选项中,关于Python 字符串的描述错误的是A Python 语言中,字符串是用一对双引号""或者一对单引号'' 括起来的零个或者多个字符B 字符串包括两种序号体系:正向递增和反向递减C 字符串是字符的序列,可以按照单个字符或者字符片段进行索引D Python 字符串提供区间访问方式,采用[N:M]格式,表示字符串中从N 到M 的索引子字符串(包含N 和M)6.给出如下代码TempStr ="Hello World"可以输出“World”子串的是A . print(TempStr[–5:0])B print(TempStr[–5:])C print(TempStr[–5: –1])D print(TempStr[–4: –1])7. 关于赋值语句,以下选项中描述错误的是A a,b = b,a 可以实现a 和b 值的互换B a,b,c = b,c,a 是不合法的C 在Python 语言中,“=”表示赋值,即将“=”右侧的计算结果赋值给左侧变量,包含“=”的语句称为赋值语句D 赋值与二元操作符可以组合,例如&=8. 关于eval 函数,以下选项中描述错误的是A eval 函数的定义为:eval(source, globals=None, locals=None, /)B 执行“>>> eval("Hello")”和执行“>>> eval("'Hello'")”得到相同的结果C eval 函数的作用是将输入的字符串转为Python 语句,并执行该语句D 如果用户希望输入一个数字,并用程序对这个数字进行计算,可以采用eval(input(<输入提示字符串>))组合9. 关于Python 语言的注释,以下选项中描述错误的是A Python 语言有两种注释方式:单行注释和多行注释B Python 语言的单行注释以#开头C Python 语言的多行注释以'''(三个单引号)开头和结尾D Python 语言的单行注释以单引号' 开头10. 关于Python 语言的特点,以下选项中描述错误的是A Python 语言是脚本语言B Python 语言是非开源语言C Python 语言是跨平台语言D Python 语言是多模型语言11.关于import 引用,以下选项中描述错误的是A 可以使用from turtle import setup 引入turtle 库B 使用import turtle as t 引入turtle 库,取别名为tC 使用import turtle 引入turtle 库D import 保留字用于导入模块或者模块中的对象12.下面代码的输出结果是print(0.1+0.2==0.3)A falseB TrueC FalseD true13.下面代码的输出结果是print(round(0.1 + 0.2,1) == 0.3)A 0B 1C FalseD True14. 在一行上写多条Python 语句使用的符号是A 点号B 冒号C 分号D 逗号15. 给出如下代码s = 'Python is beautiful!'可以输出“python”的是A print(s[0:6].lower())B print(s[:–14])C print(s[0:6])D print(s[–21: –14].lower)16.给出如下代码s = 'Python is Open Source!'print(s[0:].upper())上述代码的输出结果是A PYTHONB PYTHON IS OPEN SOURCEC Python is Open Source!D PYTHON IS OPEN SOURCE!17.以下选项中,符合Python 语言变量命名规则的是A TemplistB !1C (VR)D 5_118. 下列选项中可以准确查看Python 代码的语言版本(3.5.3)的是A >>> import sysB >>> import sys>>> sys.version >>> sys.exc_info()C >>> import sysD >>> import sys>>> sys.version—info >>> sys.path19. 下列选项中可以获取Python 整数类型帮助的是A >>> help(float)B >>> dir(str)C >>> help(int)D >>> dir(int)20. 给出如下代码:>>> x = 3.14>>> eval('x + 10')上述代码的输出结果是A TypeError: must be str, not intB 系统错C 13.14D 3.141021. Python 语言的主网站网址是A https:///B https:///C https://www.python123.io/D https:///pypi22. 下列Python 保留字中,用于异常处理结构中用来捕获特定类型异常的是A defB exceptC whileD pass23. 关于Python 注释,以下选项中描述错误的是A Python 注释语句不被解释器过滤掉,也不被执行B 注释可用于标明作者和版权信息C 注释可以辅助程序调试D 注释用于解释代码原理或者用途24. 以下选项中,不是Python 数据类型的是A 实数B 列表C 整数D 字符串25. 下列Python 保留字中,不用于表示分支结构的是A elifB inC ifD else26.以下选项中,不属于Python 保留字的是A defB importC typeD elif27.以下选项中,对程序的描述错误的是A 程序是由一系列函数组成的B 通过封装可以实现代码复用C 可以利用函数对程序进行模块化设计D 程序是由一系列代码组成的28.利用print()格式化输出,能够控制浮点数的小数点后两位输出的是A {.2}B {:.2f}C {:.2}D {.2f}29.以下选项中可用作Python 标识符的是D it'sA 3B9909B class C30.关于Python 赋值语句,以下选项中不合法的是A x=(y=1)B x,y=y,xC x=y=1D x=1;y=131.以下选项中,不是Python 语言保留字的是A intB delC tryD None32.关于Python 程序中与“缩进”有关的说法中,以下选项中正确的是A 缩进统一为4 个空格B 缩进可以用在任何语句之后,表示语句间的包含关系C 缩进在程序中长度统一且强制使用D 缩进是非强制性的,仅为了提高代码可读性33. 以下选项中可访问字符串s 从右侧向左第三个字符的是A s[3]B s[:-3]C s[-3]D s[0:-3]34. Python3.0 正式发布的年份是A 1990B 2018C 2002D 200835. 以下选项中,不是IPO 模型一部分的是A ProgramB InputC OutputD Process36.以下选项中,不是Python 语言合法命名的是A 5MyGodB MyGod5C _MyGod_D MyGod37.在Python 函数中,用于获取用户输入的是A input()B print()C Eval()D get()38.给标识符关联名字的过程是A 赋值语句B 命名C 表达D 生成语句39. IDLE 菜单中创建新文件的快捷键是A Ctrl+]B Ctrl+FC Ctrl+ND Ctrl+[40. IDLE 菜单中将选中区域缩进的快捷键是A Ctrl+]B Ctrl+SC Ctrl+AD Ctrl+C41. IDLE 菜单中将选中区域取消缩进的快捷键是A Ctrl+OB Alt+C C Ctrl+VD Ctrl+[42. IDLE 菜单中将选中区域注释的快捷键是A Alt+3B Alt+GC Alt+ZD Alt+443. IDLE 菜单中将选中区域取消注释的快捷键是A Alt+ZB Alt+3C Alt+GD Alt+444.IDLE 菜单将选中区域的空格替换为Tab 的快捷键是A Alt+VB Alt+C C Alt+5D Alt+645.IDLE 菜单将选中区域的Tab 替换为空格的快捷键是A Alt+0B Alt+5C Alt+6D Alt+C46.以下选项中,不是Python 打开方式的是A OfficeB Windows 系统的命令行工具C 带图形界面的Python Shell-IDLED 命令行版本的Python Shell-Python 3.x47.查看Python 是否安装成功的命令是A Win + RB PyCharmC python3.4 –vD exit()48.以下选项中,不是Python IDE 的是A PyCharmB Jupyter NotebookC SpyderD R studio49. Python 为源文件指定系统默认字符编码的声明是A #coding:cp936B #coding:GB2312C #coding:utf-8D #coding:GBK50.下面代码的语法错误显示是print "Hello World!"A SyntaxError: Missing parentheses in call to 'printB <built-in function print><o:p></o:p>C NameError: name 'raw_print' is not definedD SyntaxError: invalid character in identifier二、基本数据类型1. 关于Python 的数字类型,以下选项中描述错误的是A 复数类型虚部为0 时,表示为1+0jB 1.0 是浮点数,不是整数C 浮点数也有十进制、二进制、八进制和十六进制等表示方式D 整数类型的数值一定不会出现小数点2. 下面代码的输出结果是x = 12.34print(type(x))A <class 'float'>B <class 'complex'>C <class 'bool'>D <class 'int'>3.下面代码的输出结果是print(pow(2,10))A 100B 12C 1024D 204. 下面代码的输出结果是x=0b1010print(x)A 1024B 10C 16D 2565. 下面代码的输出结果是x=0o1010print(x)A 10B 1024C 520D 27686. 下面代码的输出结果是x=0x1010print(x)A 4112B 520C 10D 10247. 关于Python 的浮点数类型,以下选项中描述错误的是A 浮点数类型与数学中实数的概念一致,表示带有小数的数值B sys.float_info 可以详细列出Python 解释器所运行系统的浮点数各项参数C Python 语言的浮点数可以不带小数部分D 浮点数有两种表示方法:十进制表示和科学计数法8.关于Python 的复数类型,以下选项中描述错误的是A 复数类型表示数学中的复数B 对于复数z,可以用z.imagl 获得实数部分C 复数的虚数部分通过后缀“J”或“j”来表示D 对于复数z,可以用z.real 获得实数部分9.下面代码的输出结果是z = 12.12 + 34jprint(z.real)A 34B 34.0C 12.12D 1210. 下面代码的输出结果是z = 12.34 + 34jprint(z.imag)A 12.12B 34.0C 12D 3411. 下面代码的输出结果是x=10y=–1+2jprint(x+y)A (9+2j)B 11C 2jD 912. 下面代码的输出结果是x=10y=3print(x%y,x**y)A 1 1000B 3 30C 3 1000D 1 3013. 下面代码的输出结果是x=10y=4print(x/y,x//y)A 2 2.5B 2.5 2.5C 2.5 2D 2 214. 下面代码的输出结果是x=10y=3print(divmod(x,y))A 3,1B (3,1)C (1,3)D 1,315. 下面代码的输出结果是x=3.1415926print(round(x,2) ,round(x))A 2 2B 6.28 3C 3.14 3D 3 3.1416. 下面代码的输出结果是a = 5b = 6c = 7print(pow(b,2) –4*a*c)A 104B 系统报错C -104D 3617. 关于Python 字符串,以下选项中描述错误的是A 字符串可以保存在变量中,也可以单独存在B 字符串是一个字符序列,字符串中的编号叫“索引”C 可以使用datatype()测试字符串的类型D 输出带有引号的字符串,可以使用转义字符\18.下面代码的执行结果是a = 123456789b = "*"print("{0:{2}>{1},}\n{0:{2}^{1},}\n{0:{2}<{1},}".format(a,20,b ))A *********123,456,789B ****123,456,789*********123,456,789***** *********123,456,789123,456,789********* 123,456,789*********C ****123,456,789*****D *********123,456,789123,456,789********* 123,456,789******************123,456,789 ****123,456,789*****19. 下面代码的执行结果是a = 10.99print(complex(a))A 10.99B (10.99+0j)C 10.99+0jD 0.9920. 下面代码的执行结果是>>> x = "Happy Birthday to you!">>> x * 3A 系统报错B Happy Birthday to you!C 'Happy Birthday to you!Happy Birthday to you!Happy Birthday to you!'D Happy Birthday to you!Happy Birthday to you!Happy Birthday to you!21. 关于Python 字符编码,以下选项中描述错误的是A ord(x)和chr(x)是一对函数B Python 默认采用Unicode 字符编码C chr(x)将字符转换为Unicode 编码DPython 可以处理任何字符编码文本22.给出如下代码s = "Alice"print(s[::–1])上述代码的输出结果是A ecilAB ALICEC AliceD Alic23.给出如下代码s= "abcdefghijklmn"print(s[1:10:3])上述代码的输出结果是A behkB adgjC behD adg24.给出如下代码for i in range(12):print(chr(ord("♈")+i),end="")以下选项描述错误的是A 输出结果为♈♉♊♋♌♍♎♏♐♑♒♓B 系统报错C chr(x)函数返回Unicode 编码对应的字符Dord("♈")返回"♈"字符对应的Unicode 编码25.下面代码的输出结果是>>> hex(255)A '0eff'B '0off'C '0xff'D '0bff'26.下面代码的输出结果是>>> oct(–255)A '0d–377'B '0o–377'C '–0d377'D '–0o377'27. 下面代码的输出结果是>>> bin(10)A '0o1010'B '0d1010'C '0b1010'D '0x1010'28. 给出如下代码以下选项中描述正确的是for i in range(6):print(chr(ord(9801)+i),end="")A chr ("a")返回"a"字符对应的Unicode 编码B 系统报错C 输出结果为♈♉♊♋♌♍D ord(x)函数返回x 的Unicode 编码对应的字符29.给出如下代码:如下描述错误的是for i in range(10):print(chr(ord("!")+i),end="")A 系统报错B ord("!")返回"!"字符对应的Unicode 编码C 输出结果为!"#$%&'()*D chr(x)函数返回Unicode 编码对应的字符30.下列选项中输出结果是True 的是A >>> isinstance(255,int)B >>> chr(13).isprintable()C >>> "Python".islower()D >>> chr(10).isnumeric()31. 下面代码的输出结果是s1 = "The python language is a scripting language."s1.replace('scripting','general')print(s1)A The python language is a scripting language.B 系统报错C ['The', 'python', 'language', 'is', 'a', 'scripting', 'language.']D The python language is a general language.32. 下面代码的输出结果是s1 = "The python language is a scripting language." s2 = s1.replace('scripting','general')print(s2)A The python language is a scripting language.B ['The', 'python', 'language', 'is', 'a', 'scripting', 'language.']C 系统报错D The python language is a general language.33.下面代码的输出结果是s = "The python language is a cross platform language." print(s.find('language',30))A 系统报错B 40C 11D 1034. 下面代码的输出结果是s = "The python language is a multimodel language."print(s.split(' '))A Thepythonlanguageisamultimodellanguage.B ['The', 'python', 'language', 'is', 'a', 'multimodel', 'language.']C The python language is a multimodel language.D 系统报错35. 下面代码的输出结果是a ="Python"b = "A Superlanguage"print("{:->10}:{:-<19}".format(a,b))A ----Python:A Superlanguage----B ----Python --- A SuperlanguageC The python language is a multimodel language.D Python -------- A Superlanguage36. 以下选项中,输出结果为False 的是A >>> 5 is 5B >>> False !=0C >>> 5 is not 4D >>> 5 != 437. 下面代码的输出结果是>>> True - FalseA 1B -1C TrueD 038. 下面代码的输出结果是a = 2b = 2c = 2.0print(a == b, a is b, a is c)A True False FalseB True False TrueC False False TrueD True True False39. #以下选项中,输出结果为False 的是A >>> 'python' < 'pypi'B >>> 'ABCD' == 'abcd'.upper()C >>> 'python123' > 'python'D >>> ''<'a'40. 下面代码的输出结果是>>> a,b,c,d,e,f = 'Python'>>> bA 1B 出错C ‘y’D 041. 下面代码的输出结果是>>> a = b = c =123>>> print(a,b,c)A 0 0 123B 出错C 1 1 123D 123 123 12342. 下面代码的输出结果是>>> True / FalseA TrueB -1C 0D 系统报错43. 下面代码的输出结果是x = 1x *= 3+5**2print(x)A 29B 28C 13D 1444. 下面代码的输出结果是a = 5/3+5//3print(a)A 5.4B 2.666666666666667C 3.333333D 1445. 下面代码的输出结果是a = "alex"b = a.capitalize()print(a,end=",")print(b)A alex,ALEXB ALEX,alexC alex,AlexD Alex,Alex46. 下面代码的输出结果是a = 20b = a | 3a &= 7print(b ,end=",")print(a)A 6.66667,4B 4,6.66667C 4,23D 23,447. 下面代码的输出结果是a = "ac"b = "bd"c = a + bprint(c)A dbacB abcdC acbdD bdac48. 下面代码的输出结果是str1 = "mysqlsqlserverPostgresQL"str2 = "sql"ncount = str1.count(str2)print(ncount)A 2B 5C 4D 349. 下面代码的输出结果是>>> True / FalseA TrueB 1C 出错D False50.下面代码的输出结果是str1 = "mysqlsqlserverPostgresQL"str2 = "sql"ncount = str1.count(str2,10)print(ncount)A 0B 3C 4D 2三、程序的控制结构1. 关于Python 的分支结构,以下选项中描述错误的是A Python 中if-elif-else 语句描述多分支结构B 分支结构使用if 保留字C Python 中if-else 语句用来形成二分支结构D 分支结构可以向已经执行过的语句部分跳转2. 关于Python 循环结构,以下选项中描述错误的是A break 用来跳出最内层for 或者while 循环,脱离该循环后程序从循环代码后继续执行B 每个continue 语句只有能力跳出当前层次的循环C 遍历循环中的遍历结构可以是字符串、文件、组合数据类型和range()函数等D Python 通过for、while 等保留字提供遍历循环和无限循环结构3.关于Python 循环结构,以下选项中描述错误的是A continue 结束整个循环过程,不再判断循环的执行条件B 遍历循环中的遍历结构可以是字符串、文件、组合数据类型和range()函数等C Python 通过for、while 等保留字构建循环结构D continue 用来结束当前当次语句,但不跳出当前的循环体4.下面代码的输出结果是for s in "HelloWorld":if s=="W":continueprint(s,end="")A HelloB HelloWorldC HelloorldD World5. #下面代码的输出结果是for s in "HelloWorld":if s=="W":breakprint(s,end="")A HelloWorldB HelloorldC WorldD Hello6. 于程序的异常处理,以下选项中描述错误的是A 编程语言中的异常和错误是完全相同的概念B 程序异常发生后经过妥善处理可以继续执行C 异常语句可以与else 和finally 保留字配合使用D Python 通过try、except 等保留字提供异常处理功能7.关于Python 遍历循环,以下选项中描述错误的是A 遍历循环通过for 实现B 无限循环无法实现遍历循环的功能C 遍历循环可以理解为从遍历结构中逐一提取元素,放在循环变量中,对于所提取的每个元素只执行一次语句块D 遍历循环中的遍历结构可以是字符串、文件、组合数据类型和range()函数等8. 关于Python 的无限循环,以下选项中描述错误的是A 无限循环一直保持循环操作,直到循环条件不满足才结束B 无限循环也称为条件循环C 无限循环通过while 保留字构建D 无限循环需要提前确定循环次数9. 下面代码的输出结果是for i in "Python":print(i,end=" ")A P,y,t,h,o,n,B P y t h o nC PythonD P y t h o n10. 给出如下代码:import randomnum = random.randint(1,10)while True:guess = input()i = int(guess)if i == num:print("你猜对了")breakelif i < num:print("小了")elif i > num:print("大了")以下选项中描述错误的是A random.randint(1,10) 生成[1,10]之间的整数B“import random”这行代码是可以省略的C这段代码实现了简单的猜数字游戏D “while True:”创建了一个永远执行的While 循环11. 给出如下代码:a=3while a > 0:a -= 1print(a,end=" ")以下选项中描述错误的是:A a -= 1 可由a = a – 1 实现B 条件a > 0 如果修改为a < 0 程序执行会进入死循环C 使用while 保留字可创建无限循环D 这段代码的输出内容为2 1 012. 下列快捷键中能够中断(Interrupt Execution)Python 程序运行的是A F6B Ctrl + QC Ctrl + CD Ctrl + F6 13.给出如下代码:sum = 0for i in range(1,11):sum += iprint(sum)以下选项中描述正确的是:A 循环内语句块执行了11 次B sum += i 可以写为sum + = iC 如果print(sum) 语句完全左对齐,输出结果不变D 输出的最后一个数字是5514. 关于break 语句与continue 语句的说法中,以下选项中不正确的是A continue 语句类似于break 语句,也必须在for、while 循环中使用Bbreak 语句结束循环,继续执行循环语句的后续语句C 当多个循环语句嵌套时,break 语句只适用于最里层的语句D continue 语句结束循环,继续执行循环语句的后续语句15. random.uniform(a,b)的作用是A生成一个[a, b]之间的随机整数B 生成一个(a, b)之间的随机数C 生成一个均值为a,方差为b 的正态分布D 生成一个[a, b]之间的随机小数16.实现多路分支的最佳控制结构是A ifB tryC if-elif-elseD if-else 17.给出下面代码:age=23start=2if age%2!=0:start=1for x in range(start,age+2,2):print(x)上述程序输出值的个数是:A 10B 12C 16D 1418. 下面代码的执行结果是print(pow(3,0.5)*pow(3,0.5)==3)A TrueB pow(3,0.5)*pow(3,0.5)==3C FalseD 319. 给出下面代码:k=10000while k>1:print(k)k=k/2上述程序的运行次数是:A 14B 1000C 15D 1320. 关于Python 语句P=–P,以下选项中描述正确的是A P 的绝对值B 给P 赋值为它的负数C P=0D P 等于它的负数21. 以下选项中能够实现Python 循环结构的是A loopB do...forC whileD if 22.用来判断当前Python 语句在分支结构中的是A 引号B 冒号C 大括号D 缩进23.以下选项中描述正确的是A 条件24<=28<25 是合法的,且输出为FalseB 条件35<=45<75 是合法的,且输出为FalseC 条件24<=28<25 是不合法的D 条件24<=28<25 是合法的,且输出为True24.于while 保留字,以下选项中描述正确的是A while True: 构成死循环,程序要禁止使用B使用while 必须提供循环次数C 所有while 循环功能都可以用for 循环替代D 使用while 能够实现循环计数25.random库中用于生成随机小数的函数是A randrange()B random()C randint()D getrandbits() 26.以下选项中能够最简单地在列表['apple','pear','peach','orange']中随机选取一个元素的是A sample()B random()C choice()D shuffle() 27.Python 异常处理中不会用到的关键字是A finallyB elseC tryD if28.下面代码的输出结果是for i in range(1,6):if i%3 == 0:breakelse:print(i,end =",")A 1,2,3,B 1,2,3,4,5,6C 1,2,D 1,2,3,4,5,29. 下面代码的输出结果是for i in range(1,6):if i/3 == 0:breakelse:print(i,end =",")A 1,2,3,B 1,2,3,4,5,C 1,2,3,4,D 1,2,30. 下面代码的输出结果是sum = 0for i in range(2,101):if i % 2 == 0:sum += ielse:sum -= iprint(sum)A -50B 51C 50D 4931. 下面代码的输出结果是sum=0for i in range(0,100):if i%2==0:sum-=ielse:sum+=iprint(sum)A -50B 49C 50D -4932. 下面代码的输出结果是for i in range(1,10,2):print(i,end=",")A 1,4,B 1,4,7,C 1,3,5,7,9,D 1,3,33. 下面代码的输出结果是sum = 1for i in range(1,101):sum += iprint(sum)A 5052B 5051C 5049D 505034. 下面代码的输出结果是a = []for i in range(2,10):count = 0for x in range(2,i-1):if i % x == 0:count += 1if count != 0:a.append(i)print(a)A [3 ,5 ,7 ,9]B [4, 6, 8, 9]C [4 ,6 ,8 ,9 ,10]D [2 ,3 ,5 ,7]35. 下面代码的输出结果是x2 = 1for day in range(4,0,-1):x1 = (x2 + 1) * 2x2 = x1print(x1)A 46B 23C 94D 19036. 下面代码的输出结果是for num in range(2,10):if num > 1:for i in range(2,num):if (num % i) == 0:breakelse:print(num)A 4,6,8,9B 2,4,6,8,10C 2,4,6,8D 2,3,5,7,37. 下面代码的输出结果是for n in range(100,200):i = n // 100j = n // 10 % 10k = n % 10if n == i ** 3 + j ** 3 + k ** 3:print(n)A 159B 157C 152D 15338. 下面代码的输出结果是a = 2.0b = 1.0s = 0for n in range(1,4):s += a / bt = aa = a + bb = tprint(round(s,2))A 5.17B 8.39C 3.5D 6.7739. 下面代码的输出结果是for a in ["torch","soap","bath"]:print(a)A torchsoapbathB torch,soap,bathC torch soap bathD torch,soap,bath,40. 下面代码的输出结果是for a in 'mirror':print(a, end="")if a == 'r':breakA mirB mirrorC miD mirror41. 下面代码的输出结果是s = 0while(s<=1):print('计数:',s)s = s + 1A 计数:1B 计数:0 计数:1C 计数:0D 出错42. 下面代码的输出结果是s = 1while(s<=1):print('计数:',s)A s = s计数:0+ 1B 出错C 计数:1计数:0 D 计数:143. 下面代码的输出结果是for i in ["pop star"]:passprint(i,end = "")A 无输出B pop starC 出错D popstar44. 给出下面代码:i = 1while i < 6:j = 0while j < i:print("*",end='')j += 1print("\n")i += 1以下选项中描述错误的是:A 第i 行有i 个星号*B 输出5 行C 执行代码出错D 内层循环j 用于控制每行打印的*的个数45. 给出下面代码:for i in range(1,10):for j in range(1,i+1):print("{}*{}={}\t".format(j,i,i*j),end = '') print("")以下选项中描述错误的是:A 内层循环i 用于控制一共打印9 列B 也可使用While 嵌套循环实现打印九九乘法表C 执行代码,输出九九乘法表D 执行代码出错46. 下面代码的输出结果是a = 1.0if isinstance(a,int):print("{} is int".format(a))else:print("{} is not int".format(a))A 出错B 1.0 is intC 无输出D 1.0 is not int47. 下面代码的输出结果是a = {}if isinstance(a,list):print("{} is list".format(a))else:print("{} is {}".format("a",type(a)))A a is listB 出错C 无输出D a is <class 'dict'>48. 下面代码的输出结果是a = [1,2,3]if isinstance(a,float):print("{} is float".format(a))else:print("{} is not float".format(a))A a is floatB a is <class ' float t'>C [1, 2, 3] is not floatD 出错49. 给出下面代码:a = input("").split(",")if isinstance(a,list):print("{} is list".format(a))else:print("{} is not list".format(a))代码执行时,从键盘获得1,2,3,则代码的输出结果是:A 执行代码出错B 1,2,3 is not listC ['1', '2', '3'] is listD 1,2,3 is list50. 给出下面代码:a = input("").split(",")x = 0while x < len(a):print(a[x],end="")x += 1代码执行时,从键盘获得a,b,c,d,则代码的输出结果是:A 执行代码出错B abcdC 无输出D a,b,c,d四、函数和代码复用1.关于递归函数的描述,以下选项中正确的是A 函数名称作为返回值B 包含一个循环结构C 函数比较复杂D 函数内部包含对本函数的再次调用2.关于递归函数基例的说明,以下选项中错误的是A 递归函数必须有基例B 递归函数的基例不再进行递归C 每个递归函数都只能有一个基例D 递归函数的基例决定递归的深度3. 以下选项中,不属于函数的作用的是A 提高代码执行速度B 增强代码可读性C 降低编程复杂度D 复用代码4. 假设函数中不包括global 保留字,对于改变参数值的方法,以下选项中错误的是A 参数是列表类型时,改变原参数的值B 参数是组合类型(可变对象)时,改变原参数的值C 参数的值是否改变与函数中对变量的操作有关,与参数类型无关D 参数是整数类型时,不改变原参数的值5 在Python 中,关于函数的描述,以下选项中正确的是.A 函数eval()可以用于数值表达式求值,例如eval("2*3+1")B Python 函数定义中没有对参数指定类型,这说明,参数在函数中可以当作任意类型使用C 一个函数中只允许有一条return 语句D Python 中,def 和return 是函数必须使用的保留字6.给出如下代码:def func(a,b):c=a**2+bb=areturn ca=10b=100c=func(a,b)+a以下选项中描述错误的是A 执行该函数后,变量a 的值为10B 执行该函数后,变量b 的值为100C 执行该函数后,变量c 的值为200D 该函数名称为func7.在Python 中,关于全局变量和局部变量,以下选项中描述不正确的是A 一个程序中的变量包含两类:全局变量和局部变量B 全局变量不能和局部变量重名C 全局变量在程序执行的全过程有效D 全局变量一般没有缩进8.关于面向对象和面向过程编程描述,以下选项中正确的是A 面向对象编程比面向过程编程更为高级B 所有面向对象编程能实现的功能采用面向过程同样能完成C 面向对象和面向过程是编程语言的分类依据D 模块化设计就是面向对象的设计9.以下选项中,对于递归程序的描述错误的是A 书写简单B 执行效率高C 递归程序都可以有非递归编写方法D 一定要有基例10.下面代码的输出结果是>>>f=lambda x,y:y+x>>>f(10,10)A 100B 10C 20D 10,1011.关于形参和实参的描述,以下选项中正确的是A 参数列表中给出要传入函数内部的参数,这类参数称为形式参数,简称形参B 程序在调用时,将形参复制给函数的实参C 函数定义中参数列表里面的参数是实际参数,简称实参D 程序在调用时,将实参复制给函数的形参12.关于lambda 函数,以下选项中描述错误的是A lambda 不是Python 的保留字B 定义了一种特殊的函数C lambda 函数也称为匿名函数D lambda 函数将函数名作为函数结果返回13 以下选项中,对于函数的定义错误的是A def vfunc(a,b=2):B def vfunc(*a,b):C def vfunc(a,b):D def vfunc(a,*b):14.关于函数的参数,以下选项中描述错误的是A 在定义函数时,如果有些参数存在默认值,可以在定义函数时直接为这些参数指定默认值B 在定义函数时,可以设计可变数量参数,通过在参数前增加星号(*)实现C 可选参数可以定义在非可选参数的前面D 一个元组可以传递给带有星号的可变参数15.关于return 语句,以下选项中描述正确的是A 函数必须有一个return 语句B 函数中最多只有一个return 语句C return 只能返回一个值D 函数可以没有return 语句16.关于函数,以下选项中描述错误的是A 函数是一段具有特定功能的、可重用的语句组B Python 使用del 保留字定义一个函数C 函数能完成特定的功能,对函数的使用不需要了解函数内部实现原理,只要了解函数的输入输出方式即可。
python基础试题(含答案)word一、选择题1.小新编制了一个python程序如下,但程序无法执行,你帮他找出程序中一共有几处错误()1a=3b=input()c=a+bprint("c")A.1 B.2 C.3 D.42.下列不可以用来搭建本地服务器的软件是()(1)Python (2) Excel (3)IIS (4)ApacheA.(1)(2) B.(3)(4) C.(1)(2)(3)(4) D.(1)(2)(4)3.在Python中,input()函数的返回结果的数据类型为()A.Number型B.String型C.List型D.Sets型4.在Python程序设计语言中,用于输入和输出的函数分别是( )A.read( )和write() B.input( )和output()C.input( )和print() D.cin( )和cout( )5.在下列程序设计语言中,属于人工智能语言的是()。
A.PythonB.VBC.PascalD.C6.下列序列拼接错误的是()A.list = [ None ] * 4B.msg = “Python”, ”语言”C.tup = “/”.join( ( “123”, ”234” ) )D.set = { 1, 2, 3 } + { 4, 5, 6 }7.Python不支持的数据类型有()。
A.char B.int C.float D.list8.以下选项中,不是Python中文件操作的相关函数是()。
A.open () B.load ()C.read () D.write ()9.关于Python3.8基础知识的说法中,不正确的是()A.支持中文做标识符B.Python标识符不区分字母的大小写C.Python命令提示符是>>>D.命令中用到的标点符号只能是英文字符10.下列Python表达式的值不是2的是()。
(完整)《Python程序设计》题库及答案一、选择题1. 以下哪个选项是Python中的正确注释方式?A. //这是单行注释B. /这是多行注释/C. #这是单行注释D. ''这是多行注释''答案:C2. Python中,下列哪个变量名是合法的?A. 123varB. var_123C. var 123D. 1var答案:B3. 在Python中,下列哪个操作符用于判断两个变量是否相等?A. ==B. =C. ===D. !=答案:A4. Python中,下列哪个函数用于将字符串转换为整数?A. int()B. str()C. float()D. bool()答案:A5. Python中,下列哪个选项表示列表?A. [1, 2, 3]B. {1, 2, 3}C. (1, 2, 3)D. "123"答案:A二、填空题6. 在Python中,print()函数用于输出信息。
以下代码的输出结果是______。
```pythonprint("Hello, World!")print(1 + 2)```答案:Hello, World! 37. 以下代码的输出结果是______。
```pythonfor i in range(1, 5):print(i i)```答案:1 4 9 168. 以下代码的输出结果是______。
```pythona = [1, 2, 3]b = a.copy()a.append(4)print(b)```答案:[1, 2, 3]9. 以下代码的输出结果是______。
```pythondef my_function(a, b):return a + bprint(my_function(2, 3))```答案:510. 以下代码的输出结果是______。
```pythona = 10b = 20a, b = b, aprint(a, b)```答案:20 10三、编程题11. 编写一个Python程序,实现以下功能:- 输入一个整数n,计算并输出1到n(包括n)的所有整数之和。
(完整版)python真题word练习一、选择题1.以下Python中变量的命名正确的是()A.1a=4B.print=5C._A=2D.a+b=32.Python输入函数为()。
A.time() B.round() C.input( ) D.print() 3.下列语言中()不属于高级语言A.python B.VC C.JAVA D.汇编语言4.在python 语言中,下列表达式中不是关系表达式()A.m==n B.m>=n C.m or n D.m!=n 5.python语言的特点()。
A.简单B.免费、开源C.可移植性D.以上都是6.下列Python表达式的值不是2的是()。
A.3%2 B.5//2 C.1*2 D.1+3/3 7.下列哪个语句在Python中是非法的?()A.x = y = z = 1 B.x = (y = z + 1)C.x, y = y, x D.x += y8.如下Python程序段for i in range(1,4):for j in range(0,3):print ("Python")语句print ("Python")的执行次数是()A.3 B.4 C.6 D.99.关于Python语言的特点,以下选项描述正确的是()A.Python语言不支持面向对象B.Python语言是解释型语言C.Python语言是编译型语言D.Python语言是非跨平台语言10.在Python语言中,用来定义函数的关键字是()。
A.return B.def C.function D.import 11.以下哪种语言属于高级程序设计语言()①python ②c++ ③visual basic ④javaA.①②③B.②③C.②③④D.①②③④12.Python中用来声明字符串变量的关键字是()A.str B.int C.float D.char 13.下列不是Python中所有循环必须包含的是()。
试卷(完整版)python真题word练习一、选择题1.以下Python中变量的命名正确的是()A.1a=4B.print=5C._A=2D.a+b=32.下列变量名在Python中合法的是()A.36B B.F55# C.for D._Good3.在Python代码中表示“x属于区间[a,b)”的正确表达式是()。
A.a≤x and x<b B.n<= x or x<b C.x>=a and x<b D.x>=a and x>b 4.Python中,赋值语句,“c=c-b”等价于()A.b-=cB.c-b=cC.c-=bD.c==c-b5.下列哪个语句在Python中是非法的?()A.x = y = z = 1 B.x = (y = z + 1) C.x, y = y, x D.x += y x=x+y 6.除python语言之处,还有很多其他程序设计语言。
程序设计语言经历了从机器语言、汇编语言到高级语言的发展过程。
其中python语言是属于()。
A.机器语言B.高级语言C.汇编语言D.自然语言7.根据Python中变量命名遵循的规则,正确的是()A.char21 B.2020Py C.Python D.name.ch8.下列选项中,合法的Python变量名是()A.print B.speed C. D.a#29.Python程序文件的扩展名是()。
A..python B..pyt C..pt D..py10.下列选项中,属于Python输出函数的是()。
A.random() B.print() C.sqrt() D.input()11.以下选项中,不是Python中文件操作的相关函数是()。
A.open () B.load ()C.read () D.write ()12.运行Python程序的过程中出现了如下图错误提示,原因是()。
A.变量名51study太长B.应该写成"chinese" =51studyC.“chinese”应该写成“chinaˈs”D.变量名51study不符合python语言规范,变量名不能以数字开头13.以下哪种语言属于高级程序设计语言()①python ②c++ ③visual basic ④javaA.①②③B.②③C.②③④D.①②③④14.在Python中,正确的赋值语句是()A.x+y=10 B.x=2y C.x=y=50 D.3y=x+115.下列选项中,不能作为python程序变量名的是()A.abc B.abc123 C.123abc D.abc__123 16.Python的关系运算符中,用来表示不等于的符号是()A.= = B.!= C.>= D.<=17.下面哪个不是Python合法的标识符()A.int32 B.40XL C.self D.__name__18.下列选项中不能正确表达Python中的赋值语句的是()A.X,Y=5,8 B.X=Y=5 C.X =Y+X D.10=X+Y19.可以被计算机直接执行的语言是( ) , Python语言属于( )语言。
资料(完整版)Python题库word练习一、选择题1.下列选项中,属于Python输出函数的是()。
A.random() B.print() C.sqrt() D.input()2.在Python中要交换变量a和b中的值,应使用的语句组是()A.a,b = b,a B.a = c ;a = b;b = cC.a = b;b = a D.c = a;b = a;b = c3.下列python表达式结果最小的是()A.2**3//3+8%2*3 B.5**2%3+7%2**2 C.1314//100%10 D.int("1"+"5")//3 4.( ) 不是程序设计高级语言。
A.PythonB.BasicC.C++D.伪代码5.下列选项中,可以作为 Python程序变量名的是()A.a/b B.ab C.a+b D.a-b6.在Python中,正确的赋值语句是()A.x+y=10 B.x=2y C.x=y=50 D.3y=x+17.在Python中,表达式2**3的结果是()A.5 B.8 C.6 D.38.下列变量名在Python中合法的是()A.36B B.F55# C.for D._Good9.在Python中,判断n是否为偶数的表达式是()A.n/2=0B.n%2==0C.n%2=0D.n/2==010.下列Python语句中,会导致程序运行出错的语句是()A.x=(y=1) B.x,y=y,x C.x=1;y=1 D.x=y=111.如下Python程序段for i in range(1,4):for j in range(0,3):print ("Python")语句print ("Python")的执行次数是()A.3 B.4 C.6 D.912.以下叙述中正确的是()。
A.Python 3.x与Python 2.x兼容B.Python语句只能以程序方式执行C.Python是解释型语言D.Python语言出现得晚,具有其他高级语言的一切优点13.利用Word 软件编辑了一篇关于“Python简介”的文档,部分界面如图所示,下列说法正确的是()A.该文档中的有2个用户添加了2处批注B.该文档中图片采用的环绕方式为上下型C.该文档中总共有4处修订D.若要对文档中所有的“Python”文字设置为“红色倾斜”格式,用自动更正功能最合适14.Python输入函数为()。
试题(完整版)python考试复习题库word练习一、选择题1.以下属于计算机高级语言的是()A.Python B.自然语言C.汇编语言D.机器语言2.数据分析的处理工具错误的()A.Access B..Excel C.python D.SQL3.在Python中,Print(abs(-16//5))的执行结果是()A.2.4 B.3 C.4 D.-2.44.在Python中,表达式2**3的结果是()A.5 B.8 C.6 D.35.下列Python表达式的值不是2的是()。
A.3%2 B.5//2 C.1*2 D.1+3/36.下列选项都是属于高级语言的是( )A.汇编语言、机器语言B.汇编语言、Basic语言C.Basic语言、Python语言D.机器语言、Python语言7.下列关于Python语言变量声明的说法中,正确的是()A.Python中的变量不需要声明,变量的赋值操作即是变量声明和定义的过程B.Python中的变量需要声明,变量的声明对应明确的声明语句C.Python中的变量需要声明,每个变量在使用前都不需要赋值D.Python中的变量不需要声明,每个变量在使用前都不需要赋值8.已知字符串s1="python",s2="Python",则表达式中s1>s2的值为()A.“python”B.“Python”C.True D.False9.在python中,想输出一行文字,要用到的函数是()。
A.input()B.int()C.print()D.float()10.在Python语言中,用来定义函数的关键字是()。
A.return B.def C.function D.import11.以下哪种语言属于高级程序设计语言()①python ②c++ ③visual basic ④javaA.①②③B.②③C.②③④D.①②③④12.在Python中以下语句正确的是()。
矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。