
第一届学生计算语言学研讨会(SWCL2002)专题讲座
汉语词法分析和句法分析技术综述
刘群
北京大学计算语言学研究所
中国科学院计算技术研究所
liuqun@https://www.doczj.com/doc/bc4892067.html,
引言
本文主要介绍一些常用的汉语分析技术。
所谓语言的分析,就是将一个句子分解成一些小的组成部分(词、短语等等)并了解这些部分之间的关系,从而帮助我们把握这个句子的意义。
语言的研究,一般而言存在四个层面:词法层、句法层、语义层和语用层。
同样,语言的分析也存在四个层面:词法分析、句法分析、语义分析和语用分析。
本文主要介绍汉语的词法分析和句法分析技术。这两种技术是汉语分析技术的基础,而且已经发展得比较成熟。文中也会少量提及语义层面和语用层面的一些问题,但不会做深入的探讨。
汉语是一种孤立语(又称分析语),与作为曲折语和黏着语的其他一些语言相比,汉语在语法上有一些特点,仅仅从形式上看,这种特点主要体现在以下几个方面:
1.汉语的基本构成单位是汉字而不是字母。常用汉字就有3000多个
(GB2312一级汉字),全部汉字达数万之多(UNICODE编码收录汉字20000多);
2.汉语的词与词之间没有空格分开,也可以说,从形式上看,汉语中没有“词”
这个单位;
3.汉语词没有形态上的变化(或者说形态变化非常弱),同一个词在句子中
充当不同语法功能时,形式是完全相同的;
4.汉语句子没有形式上唯一的谓语中心词。
这些特点对汉语的分析造成了一定的影响,使得汉语分析呈现出和英语(以及其他一些语言)不同的特点。
不过也不能过分夸大这种不同。我认为,那种以为汉语完全不同于英语,因此有必要重新建立一套分析体系的想法是没有道理的。从现有的研究看,汉语分析所使用的技术和其他语言分析所使用的技术并没有本质的不同,只是应用方式上有所区别(主要体现在词法分析方面)。而且从应用的效果看,没有证据表明,这些技术用来分析汉语比用来分析英语效果更差。
本文结合我们自己的一些工作,比较全面的介绍一下汉语词法分析和句法分析中所使用的各种技术。
1 汉语词法分析
前面说过,汉语在形式上,并没有“词”这一个单位,也就是说,汉语的语素、词、短语、甚至句子之间(词也可以直接成句,称为独词句),都没有明确的界限。
这是不是说,汉语就没有必要做词法分析,可以直接做句法分析呢?
实际并不是这样。因为如果这样做的话,会导致句法分析的搜索空间急剧膨胀,以致无法承受。实际上,根据我们的统计,未定义词在汉语中真实文本中所占的比例并不大,可见绝大部分词都是可以在词典中找到的,如果这些词都要从头开始分析,势必给句法分析带来太多的负担。
不过汉语的词法分析与英语(或其他屈折型语言)的词法分析有很大不同。就英语来说,采用确定的有限状态自动机就已经能基本解决问题,而对于汉语词法分析来说,需要更为复杂的计算工具。就问题的复杂性而言,我认为汉语的词法分析大致相当于英语的词法分析和基本短语分析之和。
1.1汉语词法分析的任务
汉语词法分析包括一下几个任务:
1.查词典
2.处理重叠词、离合词、前后缀
3.未定义词识别
a)时间词、数词处理
b)中国人名识别
c)中国地名识别
d)译名识别
e)其他专名识别
4.切分排歧
5.词性标注
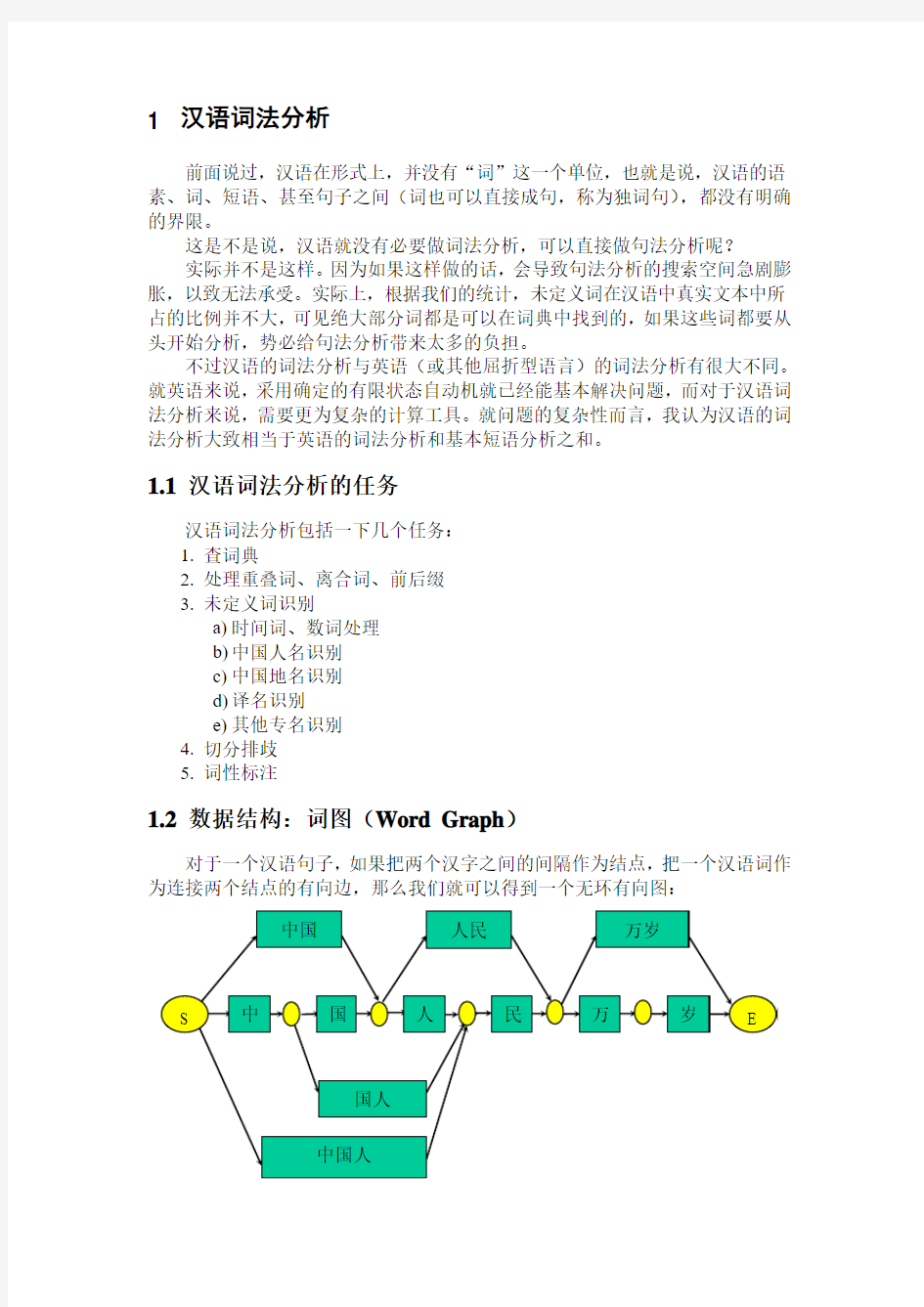
1.2数据结构:词图(Word Graph)
对于一个汉语句子,如果把两个汉字之间的间隔作为结点,把一个汉语词作为连接两个结点的有向边,那么我们就可以得到一个无环有向图:
根据这个数据结构,我们可以把词法分析中的几种操作转化为:
1.给词图上添加边(查词典,处理重叠词、离合词和前后缀);
2.寻找一条起点S到终点E的最优路径(切分排歧);
3.给路径上的边加上标记(词性标注);
1.3词典查询与重叠词、离合词和前后缀的处理
词典查询主要考虑分词词典的数据结构与查询算法的时空消耗问题。
在词典规模不大的时候,各种词典查询算法对汉语词法分析的效率整体影响并不大。不过当词典规模很大时(几十万到上百万数量级),词典查询的时空开销会变得很严重,需要详细设计一个好的词典查询算法。
(孙茂松,2000)一文比较详细的总结了汉语词法分析中使用的几种词典查询算法。(Aho&Corasick,1990)提出的算法(简称AC算法)实现了一种自动机,可以在线性的时间里用一组关键词去匹配一个输入字符串,(Ng&Lua,2002)一文对AC算法中提出的自动机(实际上就是一种词典索引的组织方式)进行了改进,可以快速实现输出汉语句子的多种切分候选结果。对词典查询算法感兴趣的同学可以去查阅这几篇文章,这里不再做详细的介绍。
汉语重叠词的重叠方式有很强的规律,处理起来并不困难。例如汉语的双字形容词的重叠现象主要有三种:AABB、ABAB、A里AB。遇到这种形式的词,只要还原成词语原形AB并查词典即可。
汉语词的前后缀不多,处理也不困难,通过简单的规则,即可这里不做介绍。
离合词的处理稍微复杂一些。现在一般的词法分析器都没有对离合词进行处理,仅仅把分开的离合词作为两个词对待,实际上这样做是不太合理的。离合词中,通常有一个语素的自由度比较差,可以通过这个语素触发,在一定的上下文范围内查找另一个语素,即可发现离合词。
1.4不考虑未定义词的切分排歧
1.4.1 切分歧义的分类
不考虑未定义词的切分排歧问题,也就是我们一般说的切分问题。
一般把切分歧义分为两种结构类型:交集型歧义(交叉歧义)和组合型歧义(覆盖歧义)。
交集型歧义(交叉歧义):“有意见”:我对他有意见。总统有意见他。
组合型歧义(覆盖歧义):“马上”:我马上就来。他从马上下来。
其中交集型歧义占到了总歧义字段的85%以上。
实际语料中出现的情况并不都这么简单,有时会出现非常复杂的歧义切分字段。例如:
公路局正在治理解放大道路面积水问题
其中“治理”“理解”“解放”“放大”“大道”“道路”“路面”“面积”“积水”都是词,考虑到这些单字也都可以成词,这就使得这个句子可能的歧义切分结果非常多。
1.4.2 切分排歧算法概述
这里我们介绍几种最主要的歧义切分算法:
1.全切分:全切分算法可以给出一个句子所有可能的切分结果。由于全切
分的结果数随着句子长度的增加呈指数增长,因此这种方法的时空开销
非常大;
2.最大匹配:从左到右或从右到左,每次取最长词,得到切分结果。分为
前向最大匹配、后向最大匹配和双向最大匹配三种方法。很明显,最大
匹配法无法发现组合型歧义(覆盖歧义),对于某些复杂的交集型歧义(交
叉歧义)也会遗漏;
3.最短路径法:采用动态规划方法找出词图中起点到终点的最短路径,这
种方法比最大匹配法效果要好,但也存在遗漏的情况;
4.交叉歧义检测法:(王显芳,2001-1)给出了一种交叉歧义的检测方法,
可以快速给出句子中所有可能的交叉歧义切分结果,对于改进切分的效
率非常有效;
5.基于记忆的交叉歧义排除法:(孙茂松,1999)考察了一亿字的语料,发
现交集型歧义字段的分布非常集中。其中在总共的22万多个交集型歧义
字段中,高频的4,619个交集型歧义字段站所有歧义切分字段的59.20%。
而这些高频歧义切分字段中,又有4,279个字段是伪歧义字段,也就是说,实际的语料中只可能出现一种切分结果。这样,仅仅通过基于记忆的方
法,保存一种伪歧义切分字段表,就可以使交集型歧义切分的正确率达
到53%,再加上那些有严重偏向性的真歧义字段,交集型歧义切分的正
确率可以达到58.58%。
6.规则方法:使用规则排除切分标注中的歧义也是一种很常用的方法。规
则的形式定义可以非常灵活,如下所示:
@@ 的话(A+B, AB)
CONDITION FIND(R,NEXT,X) {%https://www.doczj.com/doc/bc4892067.html,at=~w} SELECT 1
CONDITION FIND(L,NEAR,X) {%X.yx=听|相信|同意} SELECT 1
CONDITION FIND(L,NEAR,X) {%X.yx=如果|假如|假设|要是|若|如若} SELECT 2
OTHERWISE SELECT 1
可以看到,通过规则可以在整个句子的范围内查找对于排歧有用的信
息,非常灵活。规则方法的主要问题在于知识获取。如果单纯依靠人来
写规则,无疑工作量太大,而且也很难总结得比较全面。也可以通过从
语料库学习的方法来获取规则,如采用错误驱动的基于转换的学习方
法。
7.n元语法:利用大规模的语料库和成熟的n元语法统计模型,可以很容易
将切分正确率提高到很高的正确率。(王显芳,2001-2)和(高山,2001)都说明,使用三元语法,在不考虑未定义词的情况下,就可以将切分的
正确率提高到98%以上。
8.最大压缩方法:(Teahan et. al. 2000)提出了一种基于最大压缩的汉语分
词算法。这是一种自适应的算法,其基本思想是,首先用一个标注语料
库进行训练,在实际标注过程中以最大压缩比为指导来决定切分方式。
这种方法的主要优点是其自适应的特定,可以切分出一些词典中没有出
现的词。
上面这些方法中,前四种方法不需要人工总结规则,也不需要语料库;规则方法需要人工总结规则,比较费时费力;其他几种方法需要大规模的切分语料库为训练的基础。好在目前这种语料库已经可以得到,如(俞士汶等, 2000)。
1.4.3 n 元语法
从上面的介绍可以看到,在有大规模语料库切分语料库的情况下,采用简单的n 元语法,就可以使切分正确率达到相当高的程度。所以我们在这里简单介绍一下n 元语法在汉语分词中的应用。首先简单介绍一下n 元语法的原理。
n 元语法的作用之一,是可以预测一个单词序列出现的概率。n 元语法假设一个单词出现的概率分布只与这个单词前面的n-1个单词有关,与更早出现的单词无关。这样,为了描述这个概率分布,我们需要使用一个n 维数组,这个数组中每一维长度为单词的个数m ,这个数组中元素的个数为m n ,其中元素n i i i a ...21的含义为:在单词串121...-n i i i w w w 后面出现单词n i w 的概率,也就是)...|(121-n n i i i i w w w w p 。
假设我们的单词表中有50,000个单词,如果我们使用一元语法,就是说,假设每个单词出现的频率与其他单词无关,那么所使用的参数实际上就是每个单词出现的词频,参数个数等于50,000。如果我们使用二元语法,就是说,假设每个单词出现的频率只与上一个单词相关,那么所使用的参数就是一个单词后面出现另外一个单词的转移概率,参数个数为50,000×50,000。如果采用三元语法,参数的个数将是50,000的三次方。实际上,由于很多的单词序列在实际的语料库中并不会出现,所以实际上有效的参数数量会少的多。不过,如果这些在训练语料中没有出现的单词序列出现在测试文本中,会导致该文本的预测概率为0。为了避免这种情况,我们就要采用某种策略将这些为概率为0的单词序列赋予一个很小的猜测值,这种策略叫做数据平滑。由于数据稀疏问题的大量存在,数据平滑在任何一种统计模型中都是必须采用的。数据平滑有很多种技术,这里不再一一介绍。
n 元语法是一种非常成熟的语言模型,而且在自然语言处理中被证明是非常有效的。Internet 上有现成的n 元语法的源代码可以下载(如The CMU-Cambridge Statistical Language Modeling toolkit ),而且即使自己编写,也并不太复杂。
我们的实验表明,仅仅使用一元语法(也就是仅使用词频信息),切分的正确率就可以达到92%以上。
1.4.4 基于n 元语法的切分排歧方法
前面我们说了,所谓切分排歧过程,可以看作从词图中选择一条最优路径的过程。利用n 元语法,我们可以对任何一条路径进行概率评分:
)...|()...()...(111121+--=-∏=n i i l
n i i n l w w w p w w p w w w p
算法可采用动态规划方法实现。算法的时间开销与句子长度成正比。
1.5未定义词识别
汉语中,由于词与词之间没有形式上的边界,而且绝大多数的汉字都可以独立成词,因此未定义词的识别问题非常严重。
1.5.1 时间词、数词处理
由于时间词、数词的组成规律性较强,识别起来比较简单。一般采用一个简单的确定性有限状态自动机即可。例如采用下面的有限状态自动机可以识别年份:
1.5.2 中国人名、中国地名、译名和其他专名的识别
中国人名是未定义词中最常见,也是比较容易识别的一类,因为中国人名的姓名用字都有比较强的规律。中国地名的规律性稍差一些。译名的用字非常集中,不过短译名比较容易和其他类型的未定义词混淆。其他专名主要包括组织机构名、企业商标字号等等,这些专名的用字分布也有一定规律,但规律性不是很强,目前识别准确率都不高。
这些类型的未定义词识别,仅仅使用规则方法很难达到好的效果,一般都要进入统计方法。我们这里仅以中国人名为例说明这些类型未定义词的识别方法。有关中国人名识别的研究已经很多:(李建华,2000)、(孙茂松,1995)、(张俊盛,1992)、(宋柔,1993)等。所使用的方法包括规则加统计的方法和纯统计的方法。其中(孙茂松,1995)一文对中国人名用字的分布有比较详细的统计结果。
这里我们主要介绍我们自己使用的一种采用隐马尔可夫模型(HMM)的中国人名识别方法(Zhang et al.,2002,张华平等,2002),我们称之为“基于角色标注的中国人名自动识别方法”。在我们的词法分析系统中,这种方法达到了很好的效果。
1) 人名识别的输入输出
人名识别的输入是一个已经经过粗切分的句子,只是其中的未定义词都没有被识别出来,如:
馆内陈列周恩来和邓颖超生前使用过的物品注意,这个粗切分结果可能是有错误的,如这个句子就把超生合并成了一个词。
在通过中国人名识别程序后,应该把句子中“周恩来”和“邓颖超”这两个人名识别出来。
2) 隐马模型
关于隐马模型,我们这里不再做详细的介绍,只给出一个直观的解释。感兴趣的同学可以取参考(Rabiner,1989)和(翁富良,1998)。隐马模型作为一种简单而有效的数学工具,在自然语言处理、语音识别、生物信息学很多领域得到了广泛的应用。后面我们将要介绍的词性标注,也要使用隐马模型这个工具。隐马模型目前已经发展得非常成熟,在网上也能找到完整的带源代码的软件工具(如HMM Toolkit)。
我们这里以词性标注问题为例,对隐马模型给出一个直观的解释。
隐马模型要解决的问题,就是对于一个单词串(句子),要给这个单词串中的每一个单词做一个标记(例如单词的词性)。并假设从统计规律上说,每一个词性的概率分布只与上一个词的词性有关(也就是一个词性的二元语法),而每一个单词的概率分布只与其词性相关。
如果我们已经有了一个已经标记了词性的语料库,那么我们就可以通过统计得到以下两个矩阵(实际上还有一个初始词性概率分布矩阵):
词性到词性的转移概率矩阵:A = {a ij},a ij = p(X t+1 = q j |X t = q i)
词性到单词的输出概率矩阵:B = {b ik},b ik = p(O t = v k | X t = q i)
这里q1,…,q n是词性集合,v1,…,v m是单词的集合。
对于词性标注问题而言,转移概率矩阵中的一个元素a ij含义的就是上一个词的词性为q i时,下一个词的词性为q j的概率;输出概率矩阵中的一个元素b ik 的含义就是对于一个词性q i来说,对应的词语为v k的概率。
在有了这两个矩阵之后,对于任何一个给定的观察值序列(单词串),我们总可以通过一个Viterbi算法,很快得到一个可能性最大的状态值序列(词性串)。算法的复杂度与观察值序列的长度(句子中的单词个数)成正比。对于Viterbi 算法,我们这里不再详细描述。
3) 中国人名识别中的角色定义
通过上面的介绍我们可以看到,隐马模型处理的问题就是一个标注问题,也就是给一个单词串中的每一个单词做一个标注的问题。
对于词性标注问题而言,这个标注就是词性。
对于中国人名识别问题,我们要标注的是这个单词在人名识别中充当的角色。
4) 语料库的训练
隐马模型的训练需要标记好的语料库。由于这里的标记是我们自己定义的,显然没有现成的语料库可用。不过这个问题并不难解决。由于我们已经有了《人民日报》的切分标记语料库,这个语料库中所有词都标注了词性,其中人名也有专门的标记(nr),我们设计了一个半自动转换程序,只需要很少的人工干预,就可以将《人民日报》语料库的词性标记转换为我们设定的中国人名角色标记。
5) 人名的识别
通过语料库的训练,我们可以得到中国人名识别的隐马模型(三个个概率矩阵)。这样,对于输入的任何一个粗切分结果,我们都可以进行中国人名的角色标注。
为了解决人名与其上下文组合成词的问题,在人名识别之前,我们要对角色U(人名的上文和姓成词)和V(人名的末字和下文成词)进行分裂处理。相应地分裂为KB、DL或者EL。然后,我们在得到的角色序列中寻找一些特定的模式:{BBCD, BBE, BBZ, BCD, BEE, BE, BG, BXD, BZ, CD, EE, FB, Y, XD},凡是匹配成功的序列,我们都认为是一个人名。
以前面的句子为例,我们得到的标注结果(分裂后)就是:
馆/A 内/A 陈列/K 周/B 恩/C 来/D 和/M 邓/B 颖/C 超/D 生/L 前/A
使用/A 过/A 的/A 物品/A
通过模式匹配,得到两个成功的模式(都是BCD),对应的人名就是“周恩来”和“邓颖超”。
6) 实验结果
对12,507个含人名的句子重新进行识别测试实验,无论是封闭测试还是开放测试,准确率、召回率均超过92%以上。因为这种方法下,排除了原来没有人名的句子被识别出人名的错误情况。另外,由于我们的实验规模比已有的一些类似工作的规模都要大得多,其实验结果的可信度也更高。
我们的实验结果中,召回率比较高,而准确率较低,这也对我们的整个词法分析是有利的。由于人名识别只是整个词法分析过程的一个阶段,错误识别出的人名在后续的过程中还有可能被排除掉,但被忽略掉的人名在后续过程中却不可能被重新发现。众所周知,召回率和准确率是互相矛盾的。高召回率、低识别率对于整个词法分析过程是有利的。
1.6 考虑未定义词的切分排歧
前面介绍的切分排歧方法,都没有考虑到未定义词问题。如果把未定义词的因素考虑进来,切分排歧算法应该如何调整呢?
前面我们介绍了,采用n 元语法,我们可以从一个词图中选取一条最优路径,作为最好的分词结果。其中,n 元语法的参数可以事先从语料库中训练得到。在未定义词词识别以后,词图中加入了新识别出来的未定义词。不过,由于未定义词可能是语料库没有出现的,无法事先得到未定义词的n 元语法参数。
我们采用的做法是:把每一种类型的未定义词(如中国人名、中国地名等)作为同一个词进行n 元语法的参数估计。在实际计算词图中的一条路径的概率评分时,除了要利用n 元语法的概率评分之外,还要乘上句子中每一个未定义词在该类未定义词中出现的概率。也就是评分函数修改如下:
∏∏∏==+--=-=T t l s ts n i i l n i i n l t
t Type w p w w w p w w p w w w p 11111121))(|()...|()...()...(
其中,Type(t),t=1…T ,表示T 种类型的未定义词,t tl t w w ...1为句子中识别出
来的类型为Type(t)的l t 个未定义词。其中))(|(t Type w p ts 可以由前面的未定义词识别算法得到。
1.7 词性标注
词性标注也是研究得比较充分的一个课题。
总体上说,汉语的词性标准和英语的词性标注在方法上没有明显的不同。 在有大规模标注语料库的情况下,很多方法(特别是统计方法)都可用于解决词性标注问题,而且结果通常也都很好。我们这里不一一列举,只给出常用的两种方法:
1. 隐马模型(HMM ):前面已经介绍了;
2. 错误驱动的基于转换的规则方法(TBL ):这是一种从语料库中学习规则的方法,由于篇幅所限,这里不做详细介绍;
我们使用《人民日报》标注语料库,采用隐马模型,也得到了很好的结果。
1.8词法分析的流程
大家可以看到,词法分析是一个很复杂的过程,其中有很多子任务,而这些子任务又是互相交织在一起的。作为一个完整的词法分析程序,应该如何组织这个过程?子任务之间又应该如何衔接呢?
在具体实现上,各个子任务的顺序并没有明确的规定,例如,前后缀的处理可以在查词典阶段进行,也可以在未定义词识别阶段进行;人名识别可以在查词典之前进行(基于字的模型),也可以在查词典以后进行(基于词的模型),切分和标注可以分别进行,也可以同时进行(高山,2001)。
不过,根据我们的经验,我们在这里提出几条原则,应该说对整个词法分析流程的设计有一定的指导意义:
1.采用一致的数据结构(如词图),有利于各个阶段之间的衔接。这个数据
结构应该有一定的冗余表达能力,能够同时表示多种切分标注的结果;
2.每一个阶段最好能输出几个候选结果,有些歧义现象在某一个阶段无法排
除,可能在下一阶段却很容易解决,提供多个候选结果,有利于总体上减
少错误率;
3.如果采用统计模型,应该尽量在各个统计模型之间建立一定的联系,也就
是前面得到的概率评分值能在后面的阶段中有效的利用起来,最理想的是
建立统一的概率模型,可以得到总体最优的结果。
在我们的系统中,我们采用的词法分析流程如下所示:
1.查词典,重叠词处理;
2.数词、时间词、前后缀处理;
3.粗切分(采用基于词一元语法,保留多个结果);
4.未定义词识别(采用基于角色标注的隐马模型,识别中国人名、中国地
名、译名、其他专名);
5.细切分(采用基于词的二元语法,利用PCFG计算未定义词概率,输出
多个结果);
6.词性标注(采用隐马模型,输出一个或多个结果)。
我们开发的系统ICTCLAS通过大规模的开放测试,实际切分正确率在97%以上,标注正确率约为95%。该系统的源代码可以在自然语言处理开放平台(https://www.doczj.com/doc/bc4892067.html,)下载。
2 汉语句法分析
词法分析的作用是从词典中划分出词,而句法分析的作用是了解这些词之间的关系。所以,句法分析的输入是一个词串(可能含词性等属性),输出是句子的句法结构。
就句法分析所面临的问题而言,汉语和英语及其他语言,都没有太大的不同。二者所采用的技术也都大体一致。
2.1形式语法体系
句法分析一般都依赖于某种语法体系。语法体系的形式丰富多彩,各种语法
形式都有各自的特点。这里简要介绍几种典型的语法形式,主要目的是让读者对语法形式的多样性有一个直观的感受。
不同的语法体系产生的句法结构形式不尽相同。最常见也最直观的句法结构形式是句法树。其他主要的形式有依存关系树(依存语法、范畴语法)、有向图(链语法)、特征结构(HPSG、LFG)等等。
2.1.1 乔姆斯基层次体系
所谓乔姆斯基层次体系(Chomsky Hierarchy),指的是乔姆斯基定义的四种形式语法,这四种语法,这四种语法所产生的语言依据包含关系构成了严格的层次体系。
乔姆斯基层次体系第一次严格地描述了形式语法、语言和自动机之间的关系,在数学、计算机科学和语言学建立起了一道沟通的桥梁。
在乔姆斯基的语法层次体系中,一共定义了四种层次的形式语法,这四种语法可统称为短语结构语法(PSG)。一个PSG形式定义如下:
一个PSG是一个四元组:{ V, N, S, P }, 其中V是终结符的集合(字母表),N是非终结符的集合,S∈N是开始符号,P是重写产生式规则集。
有终结符串的集合。乔姆斯基四种形式语法所导出的语言具有以下关系:
0型语法
1型语法
2型语法
3型语法
正规语法的语法形式最严格,生成的语言最简单,分析起来也最容易(时间复杂度是线性的),可以用有限状态自动机进行分析。有限状态自动机现在广泛应用于各种语言的词法分析中。由于有限状态自动机的高效性,也有人使用它来
进行句法分析(见后面部分分析的介绍),甚至有人用来做机器翻译(Alshawi et al.,2000)。
上下文无关语法虽然不足以刻划自然语言的复杂性,但由于其形式简单,分析效率高(多项式时间复杂度),实际上是句法分析中使用最广泛的一种语言形式。我们后面将要介绍的句法分析算法大多也都是基于上下文无关语法的。
上下文敏感语法分析的时间复杂度是非多项式的(NP问题),而0型文法的分析甚至不是一个可判定性问题(实际上是一个半可判定问题),所以这两种语法形式在实际中都无法得到应用。
2.1.2 乔姆斯基的形式句法理论
乔姆斯基的形式语法理论不仅是现代计算机科学的基础之一,也为语言学的研究打开了一个暂新的局面,对自然科学和社会科学的很多领域都产生了深远的影响,被称为“乔姆斯基革命”,在科学史上具有里程碑式的重要地位。
乔姆斯基的形式语法理论是一个不断演变、不断发展的过程。在1957年,乔姆斯基提出了“转换生成语法理论(TG)”,1970年代,发展成为“标准理论”,在1981年,乔姆斯基又提出了“管辖-约束理论(GB)”,1992年,提出了“最简方案(MP)”。
乔姆斯基的形式语法理论有一个核心思想,就是“普遍语法”的思想。他认为人有先天的语言习得机制,生来就具有一种普遍语法知识,这是人类独有的生理现象。人类各种语言之间共性(原则)是主要的,语言之间的个性(参数)是次要的。因此乔姆斯基后期的语言学理论(GB以后)又称为“原则+参数”的语言学理论。
乔姆斯基早期的转换生成语法还比较简单,后来乔姆斯基语法理论越来越复杂,使得形式化的工作变得非常困难。所以现在计算语言学领域的研究中,已经很少有人采用乔姆斯基的形式语法体系。不过乔姆斯基的形式句法理论在语言学界还是很有生命力的,因为它确实可以解释很多其他理论很难解释的语言现象。
2.1.3 中心词驱动的短语结构语法(HPSG)和词汇功能语法(LFG)
HPSG和LFG属于非乔姆斯基阵营的语法理论中比较有生命力的两种。
他们与乔姆斯基语法理论的本质差别在于没有转换规则(乔姆斯基后期的理论中又称为α-移动),没有浅层结构和深层结构的区别。
从计算机实现的角度看,这两种理论都采用了特征结构这种形式来表达复杂的语言学知识并采用合一算法进行规则的推导。与乔姆斯基的语法理论不同,这两种语法理论都又很好的可实现性。因此这两种理论的发展一直和计算机的结合非常紧密。
有关这两种语法的详细资料,可到互联网上查询相应网站。
LFG:Stanford:https://www.doczj.com/doc/bc4892067.html,/lfg/
Essex:https://www.doczj.com/doc/bc4892067.html,/LFG/
HPSG:https://www.doczj.com/doc/bc4892067.html,/
下面仅通过几个图示简单介绍一下LFG,使读者对LFG有一个直观的映像。
在LFG中,一个句子的结构除了用一棵句法树(c-structure),还用一个特征结构(f-structure)来刻划这个句子的各种句法特征,如下图所示:
相应的,LFG 的规则(包括词典中的词条)除了通常的短语结构规则形式外,还附带一些合一表达式,如下图所示(↑其中表示父结点的特征结构,↓表示本结点的特征结构):
2.1.4 依存语法
依存语法也是一种使用非常广泛的语法形式。
与短语结构语法(PSG )的最大不同在于,依存语法的句法结构表示形式不是一棵句法层次结构的句法树,而是一棵依存树:依存树上的所有结点都是句子中的词,没有非终结符结点。例如句子“我喜欢看古典小说”的依存结构如下图所示:
可以看到,在依存关系树中,丢失了句子中词与词之间的顺序关系。
应该说,依存语法并不是一种严格定义的语法形式。依存语法没有明确定义的规则形式。也没有明确规定依存关系是否要加上标记。实际的应用系统中,一般都会给依存关系加上句法或语义的标记。
1970年,美国计算语言学家J. 罗宾孙(J. Robinson)提出了依存语法的
4条公理:
1.一个句子只有一个成分是独立的;
2.句子中的其它成分直接从属于某一成分;
3.任何一个成分都不能从属于两个或两个以上的成分;
4.如果成分A直接从属于成分B,而成分C在句子中位于A和B之间,
那么,成分C或者从属于A,或者从属于B,或者从属于A和B之间
的某一成分。
这四条公理比较准确界定了一个依存树所要满足的条件,得到了依存语法研究者的普遍接受。
2.1.5 链语法
链语法由美国CMU计算机学院的Daniel Sleator和美国Columbia Uiversity (的Davy Temperley共同提出,最早的文章是1991年的一个技术报告,题目是“Parsing English with a Link Gra mmar”。
链语法的网址是:https://www.doczj.com/doc/bc4892067.html,/link。
链语法词典中的词条如下图所示:
上面的一些词组成的一个句子通过句法分析得到下面的结构:
链语法的一个显著特点是分析的结果不是一棵句法树,而是一个有向图。
链语法的另一个特点是没有句法规则,只有几条简单的原则,用于规定句法成分之间互相结合的方式。链语法的语法知识都存放在词典中。
链语法的网站上提供了链语法分析器的完整源代码。
2.1.6 范畴语法
范畴语法语法的特点在于,把句法分析的过程变成了一种类似分数乘法中进行的“约分”运算。
举一个简单的例子:我喜欢红苹果。
在词典中,句子中的几个词分别表示为:
我:N
喜欢:N/S\N
红:N/N
苹果:N
句法分析的过程表现为:
红+苹果:N/N + N => N
喜欢+红苹果:N\S/N + N => N\S
我+喜欢红苹果:N+N\S => S
和链语法一样,在范畴语法中,也没有规则,只有几条简单的原则,规定范畴之间如何进行“约分”,所有的语法信息都表现在词典中。
范畴语法在现在的形式语义学理论中有很重要的作用。
范畴语法的网站是:https://www.doczj.com/doc/bc4892067.html,/ai/CG/。
2.2句法分析算法
句法分析的过程就是将小的语法成分组合成大的语法成分的过程。虽然各种语法的形式相差很大,不过在句法分析的过程中采用的分析算法都是类似的(也有少数语法有自己特有的句法分析算法)。
2.2.1 常见的分析算法
常见的句法分析算法包括:
1.自顶向下分析算法;
2.自底向上分析算法;
3.左角分析算法;
4.CYK算法;
5.Marcus确定性分析算法;
6.Earley算法;
7.Tomita算法(GLR算法);
8.Chart算法;
等等。
这些算法都有各自的优缺点和适用的场合,由于篇幅关系,我们难以一一介绍。
目前应用得最为广泛的句法分析算法是Tomita算法和Chart算法。
Tomita算法是传统的LR分析算法的一种扩展,所有又被称为Generalized LR (GLR)算法。和LR算法一样,GLR算法也是一种移进-规约(Shift-Reduce)算法。GLR算法对传统LR算法的改进主要体现在:
1)GLR分析表允许有多重入口(即一个格子里有多个动作),这样就克服
了传统LR算法无法处理歧义结构的缺点;
2)将线性分析栈改进为图分析栈处理分析动作的歧义(分叉);
3)采用共享子树结构来表示局部分析结果,节省空间开销
4)通过节点合并,压缩局部歧义。
对于Tomita算法,我们这里不做详细的介绍。我们主要介绍的是Chart分析算法。实际上,Chart分析算法是非常灵活的,通过修改Chart算法中的分析策略,很容易模拟很多种形式的其他算法,例如自顶向下的分析算法、自底向上的分析算法和左角分析算法等等。这也是Chart分析算法得到广泛应用的原因之一。
2.2.2 Chart算法
1) 一个简单的文法
算法的介绍,最直观的做法莫过于通过一个例子来说明。我们这里也不例外。
考虑一个句子1:我是县长派来的。
词典中的词条有:
(1)R →我
(2)N →县长
(3)V →是| 派| 来
所使用的规则为:
(1)S → NP VP
(2)NP → R
(3)NP → N
(4)NP → Sφ的
(5)VP → V NP
(6)Sφ→ NP VPφ
(7)VPφ→ V V
其中Sφ、VPφ分别表示带空位的S和VP,这里大家可以不必管它的含义,只要把Sφ和VPφ分别看成两个独立的短语类型即可。
2) Chart数据结构
Chart(有人译为线图)是Chart算法中最重要的数据结构。
与前面介绍的词图表示法有点类似,线图是把词与词之间的间隔作为结点,把词和短语当作连接结点的边。于是这个句子可以用词图表示为:
这个图上,我们不仅标出了每条边的标记,还标出了产生该边的规则。
注意:“我是县长”和“我是县长派来的”都是句子。
3) 活跃边与非活跃边
我们注意到,“我是县长”和“我是县长派来的”都是由规则S → NP VP生1这里借用了白硕2001(计算语言学教程讲义)中的例子,特此向白硕研究员表示感谢。
成的,而且其中“NP”都是对应同一个结点(“我”)。也就是说,这两次规则使用的过程中,有一个冗余的操作:将规则右部的第一个结点NP与同一个结点(“我”)进行匹配。如果规则很多,Chart的结构很复杂,这种冗余是很严重的。那么,我们能不能消除这种冗余操作呢?答案是可以。在Chart算法中,将边分为两种,一种叫做非活跃边,就是上图中我们已经见过的这种边。另一种叫做活跃边,用于记录一条规则部分被匹配的情形。于是,规则S → NP VP生成结点“我是县长”的匹配过程可以记录为两条活跃边和一条非活跃边:
其中“匹配程度”用规则中加入句点来表示,其中句点的位置表示规则已经匹配成功的位置(从左边开始)。用Chart表示如下:
S→
在Chart算法中,还有一个重要的数据结构,称为“日程表(Agenda)”。
Chart分析的过程就是一个不断产生新的边的过程。但是每一条新产生的边并不能立即加入到Chart中,而是要放到日程表(Agenda)中。
日程表(Agenda)实际上是一个边的集合,用于存放已经产生,但是还没有加入到Chart中的边。日程表(Agenda)中边的排序和存取方式,是Chart算法执行策略的一个重要方面(后面将要介绍)。
5) Chart算法的基本流程
Chart算法就是一个由日程表驱动的不断循环的过程:
(1)按照初始化策略初始化日程表(Agenda);
(2)如果日程表(Agenda)为空,那么分析失败;
(3)每次按照日程表组织策略从日程表(Agenda)中取出一条边;
(4)如果取出的边是一条非活跃边,而且覆盖整个句子,那么返回成功;
(5)将取出的边加入到Chart中,执行基本策略和规则调用策略,将产生
的新边又加入到日程表(Agenda)中;
(6)返回第(2)步。
这个算法流程当中,各项基本策略都是可以调整的,通过调整这些策略,可
以得到不同的分析算法。下面我们主要介绍如果通过调整这些策略来改变分析算法。
6) 初始化策略
Chart分析算法开始执行以前,要先将日程表(Agenda)初始化。对于自底向上和自顶向下的分析算法,要采用不同的初始化策略:
自底向上分析的规则调用策略:
(2)将所有单词(含词性)边加入到日程表(Agenda)中。
自顶向下分析的规则调用策略:
(1)将所有单词(含词性)边加入到日程表(Agenda)中;
(2)对于所有形式为:S→W的规则,产生一条形式为<0, 0, S→.W>的边,
并加入到日程表(Agenda)中;
7) 基本策略
在Chart算法中,边是逐条被加入到Chart中的。每一条边在被加入到Chart 中时,都要执行以下基本策略:
(1)如果新加入一条活跃边形式为:
那么对于Chart中所有形式为:
(2)如果新加入一条活跃边形式为:
那么对于Chart中所有形式为:
上面A、B为非终结符,W1、W2、W3为终结符和非终结符组成的串,其中W1、W2允许为空,W3不允许为空。
8) 规则调用策略
自底向上的分析和自顶向下的分析中,要使用不同的规则调用策略:
自底向上分析的规则调用策略:
如果要加入一条形式为
那么对于所有形式为B→C W2的规则,产生一条形式为
自顶向下分析的规则调用策略:
如果要加入一条形式为
那么对于所有形式为B→W的规则,产生一条形式为
9) 日程表组织策略
通过日程表组织的不同策略,可以分别实现深度优先和广度优先等句法分析策略:
深度优先的日程表组织策略:
将日程表按照堆栈的形式,每次从日程表中取出最后加入的结点;
广度优先的日程表组织策略:
将日程表按照队列的形式,每次从日程表中取出最早加入的结点;
10) 细节处理
前面的讨论中忽略了两个细节,在实现一个系统时应该考虑到:
(1)考虑到可能通过多种途径生成一条完全相同的边,所以每次从日程表
(Agenda)中取出一条新边加入Chart时,要先检查一下Chart中是否已
经有相同的边,如果有,那么删除这条边,直接进入下一个循环;
(2)为了生成最后的句法结构树,每一条边中还应该记录其的子句法成分所
对应的边。
11) 例子
下面我们按照自底向上的初始化策略和规则调用策略以及深度优先的日程表组织策略,给出上述例句(“我是县长派来的”)的分析过程(略)。
12) 讨论
通过上面的介绍,大家可以看到,Chart分析算法是一种非常灵活的分析算法,通过修改分析过程中的一些具体策略,Chart分析算法可以模拟很多种其他句法分析算法。
如果你有兴趣,完全可以自己尝试修改这些策略,以实现新的句法分析算法。
另外,(白硕&张浩,2002)中,把Tomita算法中“向前看(look ahead)”的思想结合到Chart分析算法中,提出了一种“角色反演算法”,可以减少Chart 分析算法中垃圾边的数量而又不影响最后的分析结果,提高分析的效率。
2.2.3 基于统计的句法分析算法
随着统计方法在NLP中的复兴,各种统计的句法分析算法也开始得到广泛的研究,并取得了很大的进展。
纯粹基于规则的句法分析算法有以下缺点:
1.歧义问题:如何总众多的歧义结构中选择合理的结构?规则方法无法给
出满意的答复;
2.鲁棒性问题:对于不符合语法的句子,规则方法无法给出满意的猜测;
3.规则冲突问题:规则增加时规则之间的冲突变得非常严重,规则调试非
常困难,后面的规则往往会抵消前面规则的作用,使得系统总体效果无
法改善。
由于基于统计的概率句法分析算法都需要句法树库作为训练数据(无指导的统计句法分析算法也有人尝试过,效果非常糟糕),这使得句法树库的建设成为了实现统计句法分析算法的前提。好在现在已经开始有了一些这种语料库,如LDC提供的英语和汉语句法树库。其中汉语的句法树库规模较小,含10万汉语词语,约4千个汉语句子,主要的数据来源是新华社新闻稿。
下面我们我们先介绍统计句法分析方法的两种类型的模型,然后介绍几种典型的统计的句法分析算法:
1) 分析模型与语言模型
任何统计模型,最基本的都是一个归一性假设。
统计句法分析的两类模型的区别就在于归一性假设上。
在分析模型中,假设对于任何一个句子,其所有的可能的分析树的概率之和为1:
其中,G 表示该分析模型,s 表示一个句子,t 表示该句子的一种可能的分析结果(句法树)。
而在语言模型中,假设从一种语言中推导出的所有句子结构(句法树)的概率为1,而一个句子的概率为其所有可能的句子结构(句法树)的概率之和:
初看上去,好像分析模型比较符合我们的推理过程。不过,在实际的研究工作中,语言模型应用更多。因为实现的时候,分析模型需要正例和反例同时进行训练,这在处理上比较困难。而语言模型只需要即可进行训练。从已有的研究工作看,语言模型的效果也更好一些。 2) 统计句法分析的评价标准
在统计句法分析研究中,一般使用以下几个参数作为评价标准:
标记正确率(Labeled Precision )
标记召回率(Labeled Recall )
交叉括号数(Crossing Brackets )
所谓交叉括号数,就是与标准语料库中发生边界冲突的结点数目,类似于汉语词切分中的交叉歧义字段数。
3) 概率上下文无关语法
概率上下文无关语法的基本思想就是给传统的上下文无关语法加上概率信∑=t G s t P where G s t P 1),|(),,|(),|(max arg ^G s t P t t =∑∈=})(:{1)(L t yield t t P ∑∑
===t s t yield t t P t s P s P })(:{)(),()(),(max arg )(),(max arg )|(max arg ^s t P s P s t P s t P t t t t ===parse proposed in ts constituen of number parse proposed in ts constituen correct of number LP =parse treebank in ts constituen of number parse proposed in ts constituen correct of number LR =parse treebank the in t constituen a with boundaries t constituen violate which ts constituen of number CB =
层次分析法,又称“直接成分分析法”,是对句法单位(包括短语和句子)的直接成分进行结构层次分析的方法。由于切分过程中尽可能采用二分,所以层次分析法又称作“二分法”。 1、基本分析原则 语法从表面上看是线性排列的符号序列。线性排列是指按照时间先后顺序说出或写出的形式。但是语法结构却是有层次性的,层次是指句法单位在组合时所反映出来的不同的先后顺序。 表层的线性关系背后暗含着隐性的层次关系。小的语法单位是大语法单位的组成部分,大的语法单位是由小的语法单位组合而成的,本身又可以成为更大语法单位的组成部分。 语法结构的每个层次一般直接包含比它小的两个语法单位,这两个小的语法单位就是直接成分。每一个直接成分又可以包含更小的直接成分。 例如: 我们进行社会调查 |主||____谓_______| |_述 | 宾____ | |_定)中 | 层次分析法就是逐层将一个句法单位(联合短语等由多个直接成分组成的短语除外)切分成两个直接成分,直到不能再切分为止的句子分析方法。 2、分析过程 层次分析法的分析过程主要包括两个步骤:第一步是切分结构层次,第二步是确定结构关系。 例如: 他去年去了一趟美国。 |__||___________________| 主谓关系 |___||______________| 状中关系 |________| |__| 述宾关系 |_| |___| 述补关系
切分过程中应注意: ①第一步切分非常重要,第一步切分不当,后面便容易全都切错。 ②必须逐层切分,直至分析出每个实词,语素不需要切分。 ③为避免切分过程中的遗漏,一般采用从左到右、从上到下、逐块切分的分析步骤。 3、层次分析法的图解表示 层次分析法中常用的图解表示法是切分法、组合法和树形图。 ①切分法 切分法是最常用的方法,将所要分析的短语或句子作为一个整体,从大到小,逐层切分。 例如: 申奥成功有助于中国的改革与开放。 |_ 主 __| |______ 谓 ________________| |主| |谓| |_述_ |______ 宾___________| |__ 定_)_ 中 _______| | 联 + 合 | ②组合法 组合法是把所要分析的短语或句子切分到单词,然后从小到大,依次组合起来。例如: 他弟弟在北京念大学 |_定中_| |_介宾_| |_述宾_| | |____状中____| |_____主谓______| ③树形图
近五年来对外汉语词汇教学研究综述 本文对近五年来对外汉语词汇教学的有关研究进行了综述,内容涉及有关对外汉语词汇具体教学方法的研究、对外汉语词汇教学具体方法以外的有关研究和有关对外汉语词汇教学的总结性研究,目的是探讨当前存在的问题以及今后进一步研究的方向。 标签:对外汉语词汇教学综述 外国留学生在习得汉语的过程中,要掌握语音、词汇和语法三大语言要素。其中,词汇习得是对外汉语习得的核心,贯穿于汉语习得的全过程。对外汉语词汇教学是对外汉语语言要素教学中不可或缺的重要组成部分,它不仅是对外汉语教学的基础和开端,而且还贯穿于整个教学活动,处于对外汉语语言要素教学的中心位置。近五年来学者们越来越重视对外汉语词汇教学的研究,据统计,从2004年1月到2009年6月仅发表在四种核心期刊上的有关研究文章就有36篇。即《世界汉语教学》8篇,《语言教学与研究》13篇,《汉语学习》4篇,《语言文字应用》11篇。本文主要基于以上四种核心期刊的36篇相关文章对近五年来对外汉语词汇教学作一个综述。 一、有关对外汉语词汇具体教学方法的研究 近五年来有关对外汉语词汇具体教学方法的研究文章有很多,涉及的内容也很广泛。 在近义词、同义词等词汇方面:敖桂华(2008)阐述了近义词辨析的教学对策,揭示了近义词辨析的途径和方法,即辨析近义词应该从以下三个方面入手:辨析语义,探究语义上的细微差别;深入语境,捕捉用法的差异;区别词性,认知词性的语法功能。对教师教学和外国留学生学习汉语近义词具有一定的指导意义。 吴琳(2008)针对同义词教学的复杂性提出了运用系统化程序化的方法建立分层有序的同义词异同对比项目系统,这样同义词就有了一个具体的操作流程,教起来更加方便。系统化程序化的方法还可以用来解决其他易混词语的教学,对对外汉语词汇教学、教材编写以及辞典编纂都有一定的参考意义。 刘春梅(2007)对《汉语水平词汇与汉字等级大纲》中的单双音同义名词的应用实例进行了统计分析,结果表明:70.59%的单音词和30.23%的双音词在使用中有偏误,并且这些偏误分布是不均衡的;单双音同义名词偏误的主要类型有语义差异引起的偏误、色彩的偏误、音节限制引起的偏误、受量词修饰引起的偏误等。产生这些偏误的原因有教材、教师和工具书等。 孟凯(2009)对对外汉语教学中的反义属性词教学及相关的词汇教学提出了以下四点建议:重视反义属性词语义与构词以及义项上的显著对应性;反义属性词中容易引起过度类推的语义与构词或义项上的不对应要着重强调;教师应帮助留
现代汉语语法的五种分析方法
现代汉语语法的五种分析方法 很有用,请好好学习之。 北语之声论坛专业精华转贴 现代汉语语法的五种分析方法是语法学基础里 很重要的一个内容,老师上课也会讲到,我在这 里把最简略的内容写在下面,希望能对本科生的专业课学习有所帮助 详细阐释中心词分析法、层次分析、变换分析法、语义特征分析法和语义指向分析的具体内涵:一. 中心词分析法: 分析要点: 1.分析的对象是单句; 2.认为句子又六大成分组成——主语、谓语(或述语)、宾语、补足语、形容词附加语(即定语)和副词性附加语(即状语和补语)。 这六种成分分为三个级别:主语、谓语(或述语)是主要成分,宾语、补足语是连 带成分,形容词附加语和副词性附加语是附加成分; 3.作为句子成分的只能是词; 4.分析时,先找出全句的中心词作为主语和谓
语,让其他成分分别依附于它们; 5.分析步骤是,先分清句子的主要成分,再决定有无连带成分,最后指出附加成分。 标记: 一般用║来分隔主语部分和谓语部分,用══标注主语,用——标注谓语,用~~~~~~标注宾语,用()标注定语,用[ ]标注状语,用< >标注补语。 作用: 因其清晰明了得显示了句子的主干,可以一下子把握住一个句子的脉络,适合于中小学语文教学,对于推动汉语教学语法的发展作出了很大贡献。 还可以分化一些歧义句式。比如:我们五个人一组。 (1)我们║五个人一组。(2)我们五个人║一组。 总结:中心词分析法可以分化一些由于某些词或词组在句子中可以做不同的句子成分而造成的歧义关系。 局限性: 1.在一个层面上分析句子,
层次性不强; 2.对于一些否定句和带有修饰成分的句子,往往难以划分; 如:我们不走。≠我们走。 封建思想必须清除。≠思想清除。 3. 一些由于句子的层次关系 不同而造成的歧义句子无法分析; 如:照片放大了一点儿。咬死了猎人的狗。 二. 层次分析: 含义: 在分析一个句子或句法结构时,将句法构造的层次性考虑进来,并按其构造层次逐层进行分析,在分析时,指出每一层面的直接组成成分,这种分析就叫层次分析。 朱德熙先生认为,层次分析不能简单地将其看作是一种分析方法,而是应当看做一种分析原则,是必须遵守的。(可以说说为什么) 层次分析实际包含两部分内容:一是切分,一是定性。切分,是解决一个结构的直接组成成分到底是哪些;而定性,是解决切分所得的直接组成成分之间在句法上是什么关系。
《现代汉语》句法结构理解 词与词组合构成句法结构.句法结构可以是词组也可以独立成句例如"他去"这个句法结构可以是主谓词组也可以单独成句.词组与句子的区别在"语法单位"一节已讨论过了.本章所涉及的"句法结构"(或"结构")若不用作句子与"词组"或"短语"同义. (注,本人在原文基础上用蓝字加注释,理解不一定对;令本人进行了文档结构编排,供学术研究之用,如有侵权,请联系本人文库账号) 1句法结构的分类 1.1从部组合的方式看 1.1.1基本结构 句法结构的基本类型有主谓、动宾、偏正、补充、联合五种.这五种类型体现了汉语的基本语法关系我们把它们叫作基本句法结构分别称为主谓结构、动宾结构、偏正结构、补充结构和联合结构. 1.1.1.1主谓结构 结构部两个成分之间有述和被述关系.例如: 鲜花盛开身体好今天晴天门开了窗台上放着一盆鲜花 1.1.1.2动宾结构 结构部两个成分之间有支配与被支配关系.例如: 去是老师买一本写钢笔站着一个人 1.1.1.3偏正结构 结构部两个成分之间有修饰和被修饰的关系.例如: A高尚的情操崇高理想南国风光春天般的温暖他的到来老人的孤独这部著作的出版 B都去很好应该去认真学习严格地训练慢慢地走 A组是"定语+中心语"(即为"定中关系")B组是"状语+中心语"(即"状中关系").
结构部两个成分之间有补充与被补充的关系.例如: 打扫干净好极了走出来跑了两趟好得很听得清楚高兴得跳起来 1.1.1.5联合结构 结构部有两个或两个以上的成分它们之间有并列或选择关系.例如: 语言文学准确鲜明生动谦虚谨慎研究决定少而精 讨论并通过容和形式今天或明天 1.1.2非基本结构 除了上述五种句法结构以外还有同位连动兼语紧缩等结构. 1.1. 2.1同位结构 结构部两个成分从不同的角度复指同一个人或事物.例如: 英雄城革命摇篮井冈山他们俩你自己雷锋同志坚医师工人周大勇 1.1. 2.2连动结构 主语相同的两个或两个以上的动词性成分连用它们之间没有主谓动宾偏正补充联合等关系;中间没有语音停顿书面上没有逗号隔开没有关联词语;动词性成分之间有先后方式目的等关系.例如: 走过去开门站着说话坐在台上看球赛赖着不走借书看有理由提出 (连动结构可以看成:基本结构的组合,走过去+开门整体式一个偏正结构,其中走过去是补充结构;站着说话:站着+说话是偏正,站着是补充;坐在台上看球赛:坐在台上+看球赛是偏正,坐在台上是补充,看球赛是动宾;赖着不走:赖着+不走是偏正,赖着是补充,不走是偏正;借书看:借书+看偏正,借书动宾) 1.1. 2.3兼语结构 由一个动宾结构和一个主谓结构套合而成动宾结构的宾语兼作主谓结构的主语.例如: 领着我们走请他讲一讲使他相信送他出国叫他来托他帮忙派小王去
汉语语用研究概述 王道英 (上海市徐汇区业余大学,上海200032) [关键词]语用学;语法;语义;语境;篇章 [摘要]随着句法、语义研究的深入,语用学独特的解释能力已越来越多地引起人们的注意。本文主要从语用学的产生与发展、语用学的引进,探索适合于汉语的语用学理论,以及从语境、语篇的角度等方面对汉语语用研究做了较为全面的介绍和简要的评述。 [中图分类号]H03[文献标识码]A[文章编号]1003-7365(2003)04-0046-07 The Survey of Chinese Pragmatic Studies WANG Dao-ying (Shanghai Xuhui Community College,Shanghai200032) Key words:pragmatics;grammar;semantics;context;tex t Abstract:As the further studies on sy ntax and semantics w ent on,the unique feature of prag matics at-tracts more and more people.s attention.This paper attem pts to survey the Chinese pragmatic studies in follow ing aspects:the orig in and development of pragmatics,the introduction of pragmatics to Ch-i na,apply ing pragmatic theory to Chinese,and individual field and the pragmatic studies in tex t and context.Meanw hile,w e make a brief comment on it. k1引言 传统语法分析研究的语料是孤立的句子,可以是自造的,也可以是经过一番剪裁改编的实例。分析的注意力集中在类型的异同上。研究的对象是静态的、脱离语境的成品(陈平1987)。因此,在以往的句法和语义研究中,很多问题都不能得到圆满的解释。语用学结合语境研究动态的语言,在很多方面有其独特的解释力,已越来越多地引起人们的注意。 k2语用学的产生与发展 /语用学0(pragm atics)这个术语由美国哲学家莫里斯(M orris)1938年在他的5符号理论基础6(Foundations of the T heory of Signs)一书中首先提出。他指出符号学(semiotics)包括三个部分:句法学(syntactics or syntax)、语义学(se-mantics)和语用学(prag matics)。语用学研究的是/符号和解释者的关系0(1938),后又易为/研究符号的来源、用法及其在行为中出现时所产生的作用0(1946)。莫里斯对符号学的划分得到哲学家和逻辑学家卡纳普(R.Carnap)的支持。50年代中期至70年代初期,语用学的研究取得了重大进展。语言哲学家巴尔-希勒尔(Bar-Hi-l lel)1954年提出的指引词语(indexical expres-sions)是语用学的具体研究对象;英国哲学家奥斯汀(Austin)提出的言语行为理论(Theory of Speech Act)(由J.C.Urmson1962年整理成书),美国哲学家塞尔(J.Searle)1969的5言语行 1 o[作者简介]王道英,女,上海师范大学语言研究所2000级博士研究生,主要从事语用研究。 本文在写作过程中,承蒙导师范开泰的悉心指导,特此致谢。
对外汉语教学语法体系研究综述 本文对近二十年来对外汉语教学语法体系的研究进行综述。文章首先简要回顾对外汉语教学语法体系的确立,然后系统地总结各家之说,附以笔者个人的观点和总结。 标签:对外汉语教学语法体系对外汉语教学语法体系 引言 随着对外汉语教学这一学科的不断发展,对外汉语教学语法体系的研究也逐渐成为学界关注的问题之一。特别是20世纪90年代以来这一问题日益引起国内外学者的重视,并且存在着是否需要体系、有无体系和是否形成了体系之争。争论也促进了研究的深入。本文主要对近20年来对外汉语教学语法体系的研究进行综述,首先对这一体系的建立进行回顾。 一、对外汉语教学语法体系的产生和特点 对外汉语教学语法体系是存在的,这一点毋庸置疑。它不仅是学科发展成熟的标志,也是编写教材、进行汉语水平考试标准和等级大纲的重要依据。对外汉语教学语法体系随着1958年《汉语教科书》的出版而定型,它奠定了对外汉语教学语法体系的基本模式,被称为对外汉语教学语法体系的奠基之作。 此书完成于结构主义语法风靡中国之时,它吸收了结构主义语法研究的最新成果,对外汉语教学和汉语语言研究同步进行,创造了“理论——实践”双向研究的成功范例,所确立的语法系统和对语法项目的选择、切分、解释、编排等注意到了外国人学习语言的特点和学习汉语的难点。基本上体现了合理性和实用性,然而这一新的体系也必然存在弊端。 随着新的语言理论和新的教学观念不断提出,特别是汉语本体研究和对外汉语教学研究的不断深入,这套语法体系的局限性也不断暴露出来。20世纪80年代后期,特别是90年代以来,研究者开始对这一语法体系提出质疑,并提出要研究和修改现有的语法体系。 二、主要研究概况 对外汉语语法体系需要修改,相关学者已经达成共识,但是如何修改,是修改还是重建,各家的看法并不一致,以下是近20年来不同学者对对外汉语教学语法体系的修改意见。 (一)在原有体系的基础上进行修订、完善 崔永华(1990)认为,《汉语教科书》中的语法体系理论基础太陈旧,体系
浅析现代汉语语法中句法结构的分类类型 摘要:现代汉语的语法中,词和词相搭配构成短语和句子,在这个过程中所形成的结构就是句法结构。句法结构是构成句子的基本要素和框架,也是现代汉语在交流过程中的基本原则。对句法结构的分析是现代汉语构词成句固定性的要求。本文通过对相关例子的枚举和分析,浅要探析现代汉语语法中句法结构的主要类型。 关键词:现代汉语语法句法结构搭配分类 词与词组合构成句法结构.句法结构可以是词组也可以独立成句。从内部组合的方式看句法结构的基本类型有:主谓、动宾、偏正、补充、联合五种。这五种类型体现了汉语的基本语法关系。我们把它们叫作基本句法结构。分别称为主谓结构、动宾结构、偏正结构、补充结构和联合结构。 一.基本句法结构的分类 1主谓结构 主谓结构是指结构内部两个成分之间有陈述和被陈述关系.例如:“鲜花盛开”中鲜花为主语,盛开为谓语,两个词之前呈现陈述与被陈述的关系。 与之类似的还有:身体好,今天晴天,门开了,窗台上放着一盆鲜花,等。 2动宾结构 结构内部两个成分之间有支配与被支配关系.例如:“上车”中动词“上”支配名词“车”,新城动宾结构。 因此,“去北京”“是老师”“买一本”“写钢笔”“站着一个人”等结构都属于动宾结构。3偏正结构 偏正结构是指结构内部两个成分之间有修饰和被修饰的关系.例如:“帅哥”中形容词“帅”修饰名词“哥”,两个成分构成偏正结构。与之属于同类的还有“高尚的情操”“崇高理想”“南国风光”“春天般的温暖”“他的到来”等。 以上所叙述的是偏正结构中"定语+中心语"(即为"定中关系")。除此之外偏正结构中还有一种情况,例如:“都去”“很好”“应该去”“认真学习”“严格地训练”“慢慢地走”,这些属于是"状语+中心语"(即"状中关系")。 4补充结构 结构内部两个成分之间有补充与被补充的关系.例如: “打扫干净”“好极了”“走出来”“跑了两趟”“好得很”“听得清楚”等,以补语补充中心语(动词、形容词)的形式出现。 5联合结构 结构内部有两个或两个以上的成分它们之间有并列或选择关系.例如: “语言文学”“准确鲜明生动”“谦虚谨慎”“研究决定”“少而精”“讨论并通过”“内容和形式”“今天或明天”中,前后几个成分的关系是相对单独并列或选择的,所以称为联合式结构。 二.特殊句法结构分类。 除了上述五种基本句法结构以外,汉语中还有同位、连动、兼语、紧缩等特殊形式结构的存在。 1.同位结构 结构内部两个成分从不同的角度复指同一个人或事物,例如: “首都北京”中“首都”从功能和象征意义上、“北京”从名称上指代同一座城市,因此构成同位结构。与此相类似的还有:“英雄城南昌”“革命摇篮井冈山”“他们俩”“你自己”等。
现代汉语语法研究
论现代汉语语法研究历史 学院名称:人文社科学院专业:汉语言文学 班级:13东策划 姓名:丁玎 学号:2013801102 指导教师姓名:程树铭 指导教师职称:教授
2014年6月 摘要:通过对语法历史发展的回顾,即八十年代以后,汉语语法学者借鉴国外语法理论,发掘汉语事实,探讨适合于汉语的分析方法,在汉语的语法范畴、语法关系、语法单位以及语法表达功能等方面都进行广泛的探究这段历史,充分领悟现代汉语语法在现代汉语中的重要性,帮助我们更好掌握语法知识,能使我们再以后的语言表达能力上更上一层楼。 关键字:语法关系,语法单位,语法表达功能 语言是由语音形式、语义内容、结构关系三个方面构成的统一体,三个方面缺一不可,互相作用,构成了语言。语音是语言的形式部分,词汇是语言的意义部分,语法是语言单位的关系部分,说的是符号与符号怎样组合的问题。三个部分在语言中的作用,我们可以这样简单来表述:没有语音形式,语言就无法存在,
没有词汇的内容意义,语言就是一个毫无作用的空壳,没有语法,语言就是一盘杂乱而毫无章法的散沙。例如:山上草在吃牛儿--牛儿在山上吃草从上面的一些组合的例子可以看出,语法虽然是看不见摸不着的东西,可是它又是实实在在的,客观存在于语言之中的。一种语言,即使是最原始的语言,也得有一套语法规则系统,指导人们按照已有的规则去组织符号,构成表达思想的句子,否则,像上面所举的例子那样,同样的意思同样的词语,不同的人完全自说自话,别人就根本不可能理解你说的什么内容,语言也就不可能成为人类的交际工具了。 语法是语言结构的三个要素之一,而且从某种意义上说是最重要而又最容易被人忽视的一个要素。简单地说语法就是用词造句的规则系统,它是词的构成规则、变化规则、组合规则的总和。而从八十多年来,汉语语法学者借鉴国外语法理论,发掘汉语事实,探讨适合于汉语的分析方法,在汉语的语法范畴、语法关系、语法单位以及语法表达功能等方面都进行了广泛的探究。 汉语语法学者从一开始就关注语法范畴的确立问题,数十年来关于"词类"问题的广泛讨论和不懈探究就是一部汉语基本语法范畴的确立历史。和其他语言的研究者一样,汉语语法学者首先准确地辨析出了名词、动词、形容词这样的基本词类范畴,但在分析手续上却遇到了许多西方学者所未曾遇到的难题。因为汉语几乎没有可供辨识的外在词形标记,在确定词类成员的问题上就很难得出明确的结论。早期的汉语语法学者看到英语这样形态
汉语句法分析方法的嬗变 综述:我国古代就有学者对语言进行研究,但我们的研究更多的是音韵、文字等方面,而语法一直是我们研究的弱点,我国的语法研究起步晚,可以说是以《马氏文通》为起点,它奠定了汉语传统语法学的基础。不难发现,我国的语法研究深受西方语言法学研究的影响,当然关于句法分析的研究也是如此。关于汉语句法分析的研究,从20世纪80年代初以来,一直都没有停止过,先后出现了中心词分析法与层析分析法相结合的方法、变换分析法、语义特征分析法、配价分析法、语义指向分析法等汉语句法分析方法。 摘要: 汉语是一门简单而又复杂的语言,为了让我们更好地了解汉语,语言学家想出了一些方法来解释说明语言中的种种现象,我们称之为“句法分析法”。经过许多学者的努力,到目前已经有不少的研究成果了。众多学者站在不同的专业角度研究出了不同的分析方法来解释语言现象。如层次分析法、变换分析法、语义特征分析法、配价分析法等。那关于汉语句法分析的研究进行了这么多年,其中历经了哪些演变?结合所学知识,我对此做了以下分析。 关键词:句法分析、演变、汉语、作用 正文: 汉语是一门简单而又复杂的语言,为了让我们更好地了解汉语,语言学家想出了一些方法来解释说明语言中的种种现象,我们称之为“句法分析法”。所谓句法分析就是指对句子中的词语语法功能进行分析,比如“我来晚了”,这里“我”是主语,“来”是谓语,“晚了”是补语。迄今为止,众多学者已经研究出了许多不同的分析方法来解释语言现象,从句子成分分析法、层次分析法、变换分析法、语义特征分析法、配价分析法到语义指向分析法,句法分析逐步走上兼顾形式和意义的道路,可以说句法分析在自然语言处理领域中具有十分重要的地位。 句子成分分析法(也叫中心词分析法)是我国语言研究中最早使用的一种句法分析法,黎锦熙在《新著国语文法》中首次提出了“六大句子成分说”,为句子成分分析法的产生奠定了基础。对于这句子成分分析法,我们比较熟悉。所谓句子成分分析法是从句法结构的关系意义出发,对句子的成分功能或作用分析的方法,即用各种方法标出基本成分(主语、谓语、宾语)和次要成分(定语、状语、补语)。这种分析方法,分析的对象是句子,认定句子有六个大的句子成分,即所谓的主语、谓语、宾语、定语、状语、补语。在一个句子中,做句子成分的原则上都只能是词,而且分析时,应该先找出全句的中心词作为主语和述语,再看述语是哪一种动词,决定它后面有无连带成分宾语或补足语,最后指出句中所有的附加成分——形容性附加语和副词性补足语。 句子成分分析法的优点是:第一,容易找出句子的脉络;第二,可以分析由中国特色的句子,如兼语句。但是它只能分析单句中的主谓句,不能分析单句中的非主谓句,不能分析复句,也无法分析句组;分析歧义句的能力差,忽视了句子的层次性。 句子成分分析法被语言教学界广泛接受和使用,中小学教学一般采用这种方法来给学生进行句法分析。它对推动汉语教学语法的发展做出了很大的贡献。 在句子成分分析法之后,又一句子分析法出现在我国的语言界——层次分析法。它是美国著名语言学家布龙菲尔德在20世纪30年代提出的一种语言分析方
第一讲现代汉语研究概述 1.2现代汉语研究概述 20世纪中国语言学由于马建忠的《马氏文通》的问世,可以说是我国现代科学意义上的语言学的发展历史。汉字的研究一直占有很重要的位置。30年代,唐兰先生强调“文字的形体研究”,他的《古文字学导论》标志着的汉字学的建立。近二三十年还加强了对汉代以后,现代汉字以前的文字的研究,特别是俗字的整理和研究,并形成了汉字学的一个新分支——现代汉字学。70年代末以来由于各种因素的推动,汉语音韵学的研究进入了一个鼎盛的时期。这一时期的训诂学也有了一定的发展,该时期训诂学的基本任务是解释文献字词。汉语语法研究也进入了鼎盛时期。下面主要从语法、语音、词汇、语用、对外汉语教学交叉学科等方面进行简要的说明。 1.2.1现代汉语语法方面: 在20世纪的一百年里,我国语言学的发展中要属汉语语法学的发展最快,成果最显著。汉语语法研究是从古代汉语语法开始的,《马氏文通》是一部古代汉语语法研究专著。但从黎锦熙《新著国语文法》这第一部白话文语法著作于1924年问世以来,现代汉语语法研究一直是本世纪汉语语法研究的主流。40年代出现了20世纪前半叶现代汉语语法研究的鼎盛时期,王力的《中国现代汉语》和《中国语法理论》,吕叔湘的《中国文法要略》,高名凯的《汉语语法论》是该时期的代表作都采用了“三品说”(丹麦叶斯柏森《语法哲学》首品——
主语、宾语、中心语,次品——谓语、定语,末品——状语、补语)。当今世界语言学领域普遍关注和运用的一些语法思想和分析方法,如“动词中心说”、“语义格”、“动词配价”、“范畴论”、“语用分析”、“变换分析”、“篇章分析”等等,在这一时期的著作中都有体现,只是没有上升到理论层面加以论述和阐释。(如朱德熙著作中的动词的“向”,就相当于“价”)新中国成立后,吕叔湘和朱德熙合著的《语法修辞讲话》起到了“匡谬正误”的作用。语法知识的普及大大促进了现代汉语语法的教学与研究工作。与此同时,随着赵元任的《北京口语语法》(李荣译)一书的翻译出版,美国描写语言学理论方法开始影响着现代汉语语法的研究。这个时期(50-60年代)的语法一直停留在词语和句子成分的充当上。 古代汉语语法的研究,自《马氏文通》以后,还有以王力(50年代)为代表的研究古代汉语为主的语法学家。他开创了汉语语法研究的历时研究,这为汉语语法史研究奠定了基础。80年代后,古代汉语语法研究有了可喜的变化。不论在研究队伍、研究方法、研究理念都有了明显的变化。如“要有明显的时代观点,语料不可古今杂糅”、“必须注重语法的系统性,要从语法系统去思考问题”、“要注意吸取各种语言学理论中有利于古代汉语语法研究的东西”、“加强专书、断代语法研究”以及“既要有定性分析,又要有定量分析”等,开展了语法化的研究,出现了一批较好的研究成果。 近代汉语语法研究始于20年代末,黎锦熙和吕叔湘分别发表了很多研究近代汉语“把”字结构和个别代词、量词、虚词的研究。黎
对外汉语专业发展概况文献综述 0709600103 李鑫洁 一、引言 中华民族同世界各民族友好往来的历史有多久,对外汉语教学的历史就有多久。中国同世界各国交往的密切程度,以及国力的强弱,直接影响着对外汉语教学的兴衰。至新中国成立以后,对外汉语教学逐渐成为一门学科和一项语言教育事业。目前这项事业正以崭新的姿态、面向世界、迎接未来。 以此为背景,我们尝试对对外汉语教学事业从20世纪50年代初开创至今的50多年历史中该领域内主要贡献者的观点进行综合分析、归纳整理,并梳理其时间逻辑发展的顺序,力求更直观、更系统、更有层次性地理解对外汉语专业的发展概况。 本文对文献的综述基本上按照对外汉语事业的实际发展进程展开。第二部分介绍对外汉语专业出现的历史渊源和初创阶段。第三部分介绍巩固和发展阶段中、围绕对外汉语事业提出的各种理论与见解。第四部分细致分析对外汉语专业的现状和趋势、展望对外汉语专业的发展前景。 二、历史渊源与初创阶段 (一)历史渊源 西汉时,我国周边的少数民族就有人来当时的长安学习汉语。而中国真正对外国人进行汉语教学的历史可以追溯到东汉。至唐代,由于国力强盛,世界上许多国家都派留学生来中国学习,如日本派遣了十几次“遣唐使”,每批几百人;新罗统一朝鲜半岛后,也派遣留学生到长安,每批有百余人。以后的各个朝代也都有留学生来中国学习(元代实行霸权,留学生数量锐减),其中《老乞大》、《朴事通》等就是明初教朝鲜人学习汉语口语(北京口语)的教材。而明末金尼阁的《西儒耳目资》和清末威妥玛的《语言自迩集》可算当时影响较广的汉语教材。民国期间,中国政府也同外国政府交换了少数留学生,当时也有许多知名学者先后从事过对外汉语教学或相关工作。如老舍先生在1924~1929年间,在英国伦敦大学东方学院担任汉语讲师,他当年讲课的录音,至今还保存在伦敦。 (二)初创阶段(20世纪50年代初期—20世纪60年代初期) 尽管中国角外国人学习汉语的历史悠久,然而作为一门专业学科的“对外汉语”是一门年轻的学科。由于是一门新兴的学科,因此在其迅速发展的同时,社会上、学术界乃至本学科内部对本学科的名称、性质、任务等基本问题尚有不同的看法,甚至存在一些争议。一个学科的名称是该学科的内容和学科的本质特点的反映。在对外汉语专业的起步阶段,学术界对这个学科的名称提出了一些不同看法,这些不同看法也反映了人们对这个学科的认识: 1.“对外汉语”:目前除了本科有对外汉语专业或对外汉语系外,少数学校已经有“对外汉语”专业硕士点和博士点,如北京语言大学把国内唯一一个国家研究基地叫做“对外汉语研究中心”,该中心主任赵金铭教授的专论《对外汉语研究的基本框架》都使用“对外汉语”作为学科名。 2.“对外汉语教学”:这一名称基本上能体现教授外国人学习汉语这个学科的特点和内涵,但客观上说,由于有“教学”两字,很容易让人把它归入教育学或学科教学论等学科中去。
现代汉语句法分析中的变换分析法 摘要:对变换分析法在汉语语法学界的发展运用作较全面的分析阐述并对变换现象加以分类,分析变换的方法和原则,阐明变换的作用,归纳分析这方面的研究成果,也指出了变换分析的局限性。关键词:变换分析;句法分析;汉语 我们想要认识和了解语言,就要对其作深一层的分析,要了解其中的规则,句法分析就是必不可少的。从句法的角度来解释说明种种语言现象,就称之为“句法分析”。句法分析经历了长时间的发展,逐渐形成了句子成分分析法、层次分析法、变换分析法、语义特征分析法、配价分析法、语义指向分析法等多种方法。 首先一般比较熟悉的是句子成分分析法,它可以让人一下子把握住一个句子的脉络,但它不大关注语法结构的层次性。由于它的这一局限性,便出现了层次分析法,层次分析法将句法结构的层次性考虑进来,按其构造层次逐层进行分析,但它不能揭示句法结构内部的实词之间的语义结构关系,特别是歧义。要揭示这种隐含在句子里边的实词与实词之间的语义结构关系,就得寻求新的分析手段,于是变换分析法就又适应这种需要而产生了,成为最易于和普遍运用的一种方法。 一、什么是变换分析法 关于变换的思想,早在1942年出版的吕叔湘的《中国文法要略》一书里就有了。之后,吕叔湘在《中国文法要略》中讨论了句子和词组相互转换的问题,但未具体展开。50年代,海里斯和乔姆斯基
分别在结构语言学和生成语法的框架下展开了转换的研究。而继海里斯之后,在中国朱德熙先生在变换分析上作出了重要的贡献。在《语法讲义》中,朱先生充分运用了变换分析的方法来解释许多层次分析法不能解决的问题,在分化歧义句式、层次切分、判断词类以及分化语义角色等方面都发挥了重要作用意义。 变换分析法是通过移位、添加、删除、替换等方法来考察具有内在联系的不同句法结构之间联系的一种分析方法,即按照一定的规则,把甲句变成乙句。它是根据句法格式的相关性,是两种结构不同的句式之间根据依存关系的变换。目的是通过变换分辨句法结构的异同,看清句子结构的特点。朱德熙先生首先提出变换分析法,并在国内最早运用这种理论进行实践。例如: a台上坐着主席团可以转换为: a1主席团坐在台 b 操场上放着电影b1 操场上正在放电影 这两组例句都是“处所名词+动词+助词+名词”,是相同的结构,但在语义关系上还存在区别。 具体的来看,变换分析法可以分为两类来更清楚地加以认识:(1)当句法同义时 1.我打破了杯子。 可变换为: a、杯子被我打破了。 c、我把杯子打破了。 虽然转换成不同的句子格式,但是施事受事都未发生变化,意思
学 生 实 习 报 告 实 习 名 称 学年论文 院 部 名 称 人文学院 专 业 对外汉语 班 级 09对外汉语 学 生 姓 名 李国军 学 号 0902105045 实 习 地 点 江宁校区 指 导 教 师 衣玉敏 实习起止时间: 2012 年5月16日至 2012年6月20日 金陵科技学院教务处制
金陵科技学院学生实习鉴定表 学生实习报告撰写要求: (1)格式要求:封面——学院:公办写人文学院,民办写龙蟠学院;纸张——A4纸;文献综述标题:字体——黑体,字号——小三,格式——居中;正文内容:字体——宋体,字号——小四,行距——固定值20磅;左右页边距:3厘米。 (2)内容要求:按照文献综述的结构和行文格式,从选题中选择一题练习撰写文献综述,字数不少于3000字。 附实习报告。
对外汉语教学中“被”字句研究综述 一、研究背景 对外汉语的教学与研究问题自上世纪80年代以来就广受众学者的注目,对外汉语发展势头日益猛烈。目前,学界学者就对外汉语教学研究指出了两条发展道路,其一是细化教学语法,其二是简化教学语法。细化教学语法以虚词和句型作为主要研究对象在对长达二十多年的教学教育领域已硕果累累;相反,语法的简化研究则被相对忽视了。近年来,我国学者研究到“被”字句在汉语本体中占有很大的意义,“被”字句愈发受到了众学者研究青睐,学术界对“被”字句的发展过程做出了系统一致的研究,他们对不同时期的材料进行了详细的解读和分析,得出了可信度较高的结论。被字句基于这样坚实有力的基础其发展变化规律也具有强烈的说服信。“被”字句在对外汉语教学中的研究愈显出其重要性。 本文就被字句研究参考研读了大量文献,对被字句近二十年来的发展做简要评析,粗略展示被字句在对外汉语中的框架,对部分问题进行探讨,为共促语言文化做贡献。 二、研究现状 各学者根据大量文献提供的资料从如下几个方面展开探讨分析: (一)被动句本体研究 1.被动句式的提出 1924年黎锦熙的白话文语法著作《新著国语文法》是现代汉语被动句式的鼻祖,该作者认为,动词有两种形式,即被动与散动。随后,朱德熙、王力、吕叔湘等诸位大师先后以句法结构、句法发展、语义等逐个领域对现代汉语被动表达发表了研究看法,他们尤为重视被字句的发展。时至今日,语法学界仍旧对汉语被动句保持着谨慎的研究态度;诸学者们透过不同的视角,引证不同的理论,时刻对被字句进行着方位系统的研究。 2. 被动句式的研究探索及发展 刘进(2009)在《近代汉语被字句研究中的主要问题》中研究了“被”字是如何出现的,也就是被字句是如何实现其被动句式的变化的,其对“被”字的语义关系提出了质疑,指明“被”字作为语义关系仅表达了改字作用的微小部分,这部分或许并不重要,要深刻挖掘“被”字更为深层的意义要从话语的选题、性质等方面着手研究;刘殉(2000)《对外汉语教育学引论》中区别了汉语和英语的被动句式;邢福义(1996)《汉语语法学》文章中表述了被字句是可以在文章中广泛使用的;诸如此方面的研究不胜枚举。目前被动句式的研究越来越完善、细致。首先对被动句式的研究越来越细致化,分类也随之精细起来,赵清永(1993)
】《现代汉语》句法结构 词与词组合构成句法结构.句法结构可以是词组也可以独立成句例如"他去香港"这个句法结构可以是主谓词组也可以单独成句.词组与句子的区别在"语法单位"一节已讨论过了.本章所涉及的"句法结构"(或"结构")若不用作句子与"词组"或"短语"同义. 一句法结构的分类 (一)从内部组合的方式看句法结构的基本类型有主谓动宾偏正补充联合五种.这五种类型体现了汉语的基本语法关系我们把它们叫作基本句法结构分别称为主谓结构动宾结构偏正结构补充结构和联合结构. 1主谓结构 结构内部两个成分之间有陈述和被陈述关系.例如: 鲜花盛开身体好今天晴天门开了窗台上放着一盆鲜花 2动宾结构 结构内部两个成分之间有支配与被支配关系.例如: 去北京是老师买一本写钢笔站着一个人 3偏正结构 结构内部两个成分之间有修饰和被修饰的关系.例如: A高尚的情操崇高理想南国风光春天般的温暖他的到来 老人的孤独这部著作的出版 B都去很好应该去认真学习严格地训练慢慢地走 A组是"定语+中心语"(即为"定中关系")B组是"状语+中心语"(即"状中关系").
结构内部两个成分之间有补充与被补充的关系.例如: 打扫干净好极了走出来跑了两趟好得很听得清楚 高兴得跳起来 5联合结构 结构内部有两个或两个以上的成分它们之间有并列或选择关系.例如: 语言文学准确鲜明生动谦虚谨慎研究决定少而精 讨论并通过内容和形式今天或明天 除了上述五种句法结构以外还有同位连动兼语紧缩等结构. A同位结构 结构内部两个成分从不同的角度复指同一个人或事物.例如: 英雄城南昌革命摇篮井冈山他们俩你自己雷锋同志赵坚医师 工人周大勇 B连动结构 主语相同的两个或两个以上的动词性成分连用它们之间没有主谓动宾偏正补充联合等关系;中间没有语音停顿书面上没有逗号隔开没有关联词语;动词性成分之间有先后方式目的等关系.例如: 走过去开门站着说话坐在台上看球赛赖着不走借书看 有理由提出
《现代汉语语法研究》第三讲现代汉语语法的句法分析这里的句法是指语法的句法结构平面。词语与词语按照一定的方式组合起来,构成一定的句法结构,对句法结构进行分析,就是句法分析。在这一讲里,我们主要讲三个问题: 1、句法结构的结构类型 2、句法结构的结构成分 3、句法结构的分析一、句法结构的结构类型1、句法结构的分类词语与词语按照一定的方式组合起来,构成一定的句法结构。根据构成句法结构的词语的性质和结构方式,我们可以把句法结构分成不同的类型。由实词与实词构成的句法结构,根据实词与实词之间不同的结构方式分为不同的类。主要有:联合结构、偏正结构、动宾结构、中补结构、主谓结构、连动结构、兼语结构、同位结构、方位结构、量词结构。由实词与虚词构成的句法结构,根据虚词的标志特征分为不同的类。主要有:“的”字结构、介词结构、比况结构、“所”字结构这些不同的结构,从结构形式上讲又可以分为两类:复合式和附加式。(1)、复合式由实词与实词构成的句法结构,其中联合结构、偏正结构、动宾结构、中补结构、主谓结构、连动结构、兼语结构、同位结构是复合式。 ①偏正结构由修饰语和中心语两部分组成,一前一后。如:“他的哥哥”“明天回来”②动宾结构两部分构成,前一部分是动词,后一部分是动词涉及的对象。例如:“考大学”“想念亲人”③中补结构
两部分组成,后一部分补充说明前一部分,中补短语的中心语通常是谓词性词语,如:“跑得快”(中心语为动词)“好得很”(中心语为形容伺)④主谓结构两部分组成,前一部分是主语,是被陈述的对象,后一部分是谓语,是陈述前一部分的。如:⑤兼语结构由一个动宾短语和一个主谓短语套叠而成,动宾短语的宾语兼作主谓短语的主语。如:⑥连动结构由不止一个动词性词语连用,隐含同一个主语,各部分之间没有关联词语,没有语音停顿,也没有联合,偏正、主谓、补充等关系,这样的短语叫连动短语。如:⑦联合结构由两个或两个以上的部分组成,各部分之间具有并列、顺承、选择、递进等关系。如:“城市乡村”“我和你”⑧同位结构两部分组成,这两部分从不同的方面称说同一个人或物。构成同位的两项词语必须是两个不同的词语,而且必须是复指关系,即在同一个句法位置上指同一个对象。如:“古城西安”、“通讯员小王”。(2)、附加式由实词与虚词构成的句法结构都是附加式的,由实词与实词构成的方位结构、量词结构也可看成附加式。①方位结构由方位名词附加在其他词或短语的后面组成,表示处所,范围或时间。如:“教室里”“操场上”“整洁的房间里”“毕业前”“前进中”“会议结束之前””吃完饭后”②量词结构由数词或代词加上量词组成,如:“一个”“五次”“这件”“那位”③“的”字结构由结构助词“的”
北语之声论坛专业精华转贴 现代汉语语法的五种分析方法是语法学基础里很重要的一个内容,老师上课也会讲到,我在这里把最简略的内容写在下面,希望能对本科生的专业课学习有所帮助 详细阐释中心词分析法、层次分析、变换分析法、语义特征分析法和语义指向分析的具体内涵: 一. 中心词分析法: 分析要点: 1.分析的对象是单句; 2.认为句子又六大成分组成——主语、谓语(或述语)、宾语、补足语、形容词附加语(即定语)和副词性附加语(即状语和补语)。 这六种成分分为三个级别:主语、谓语(或述语)是主要成分,宾语、补足语是连 带成分,形容词附加语和副词性附加语是附加成分; 3.作为句子成分的只能是词; 4.分析时,先找出全句的中心词作为主语和谓语,让其他成分分别依附于它们; 5.分析步骤是,先分清句子的主要成分,再决定有无连带成分,最后指出附加成分。 标记: 一般用║来分隔主语部分和谓语部分,用══标注主语,用——标注谓语,用~~~~~~标注宾语,用()标注定语,用[ ]标注状语,用< >标注补语。 作用: 因其清晰明了得显示了句子的主干,可以一下子把握住一个句子的脉络,适合于中小学语文教学,对于推动汉语教学语法的发展作出了很大贡献。 还可以分化一些歧义句式。比如:我们五个人一组。 (1)????????我们║五个人一组。 (2)????????我们五个人║一组。 总结:中心词分析法可以分化一些由于某些词或词组在句子中可以做不同的句子成分而造成的歧义关系。 局限性:
1.????????在一个层面上分析句子,层次性不强; 2.????????对于一些否定句和带有修饰成分的句子,往往难以划分; 如:我们不走。≠我们走。 封建思想必须清除。≠思想清除。 3.????????一些由于句子的层次关系不同而造成的歧义句子无法分析; 如:照片放大了一点儿。???咬死了猎人的狗。 二. 层次分析: 含义: 在分析一个句子或句法结构时,将句法构造的层次性考虑进来,并按其构造层次逐层进行分析,在分析时,指出每一层面的直接组成成分,这种分析就叫层次分析。 朱德熙先生认为,层次分析不能简单地将其看作是一种分析方法,而是应当看做一种分析原则,是必须遵守的。(可以说说为什么) 层次分析实际包含两部分内容:一是切分,一是定性。切分,是解决一个结构的直接组成成分到底是哪些;而定性,是解决切分所得的直接组成成分之间在句法上是什么关系。 基本精神: 1.????????承认句子或句法结构在构造上有层次性,并在句法分析上严格按照内部的构造层次 进行分析; 2.????????进行分析时,要明确说出每一个构造层面的直接组成成分;3.????????分析时只管直接成分之间的语法结构关系,不管间接成分之间的语法结构关系或句 法结构中实词与实词之间的语义结构关系; 优越性: 1.????????注意到了句子构造的层次性; 如:??他??刚??来???????我们??便宜??他了 ?????│ │__│?????????│???│___│