A binary correlation matrix memory k-nn classifier with hardware implementation
- 格式:pdf
- 大小:641.78 KB
- 文档页数:10
![机器学习算法优缺点改进总结[共5篇]](https://uimg.taocdn.com/9a25822efe00bed5b9f3f90f76c66137ef064f62.webp)
机器学习算法优缺点改进总结[共5篇]第一篇:机器学习算法优缺点改进总结Lecture 1 Introduction to Supervised Learning(1)Expectatin Maximization(EM)Algorithm(期望值最大)(2)Linear Regression Algorithm(线性回归)(3)Local Weighted Regression(局部加权回归)(4)k-Nearest Neighbor Algorithm for Regression(回归k近邻)(5)Linear Classifier(线性分类)(6)Perceptron Algorithm(线性分类)(7)Fisher Discriminant Analysis or Linear Discriminant Analysis(LDA)(8)k-NN Algorithm for Classifier(分类k近邻)(9)Bayesian Decision Method(贝叶斯决策方法)Lecture 2 Feed-forward Neural Networks and BP Algorithm (1)Multilayer Perceptron(多层感知器)(2)BP Algorithm Lecture 3 Rudiments of Support Vector Machine(1)Support Vector Machine(支持向量机)(此算法是重点,必考题)此处有一道必考题Lecture 4 Introduction to Decision Rule Mining(1)Decision Tree Algorithm(2)ID3 Algorithm(3)C4.5 Algorithm(4)粗糙集……Lecture 5 Classifier Assessment and Ensemble Methods(1)Bagging(2)Booting(3)Adaboosting Lecture 6 Introduction to Association Rule Mining(1)Apriori Algorithms(2)FP-tree Algorithms Lecture 7 Introduction to Custering Analysis(1)k-means Algorithms(2)fuzzy c-means Algorithms(3)k-mode Algorithms(4)DBSCAN Algorithms Lecture 8 Basics of Feature Selection(1)Relief Algorithms(2)ReliefF Algorithms(3)mRMR Algorithms最小冗余最大相关算法(4)attribute reduction Algorithms比较了几种分类算法性质。

人工智能题库(附答案)一、单选题(共103题,每题1分,共103分)1.某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?A、自然语言处理B、分类C、聚类D、关联规则发现正确答案:D2.预测分析过程包括:数据的准备、预测模型开发、模型验收和评估、使用PMML实现大数据预测的有效部署。
()是指对数据的采集和整理A、预测模型开发B、评估C、模型验收D、数据的准备正确答案:D3.Google与Facebook分别提出SimCLR与MoCo两个算法,实现在()上学习图像数据表征。
两个算法背后的框架都是对比学习(contrastivelearning)A、标注数据B、无标注数据C、二维数据D、图像数据正确答案:B4.()是一种模拟人类专家解决领域问题的计算机程序系统。
A、进化算法B、专家系统C、遗传算法D、禁忌搜索正确答案:B5.()的输入为对弈的线路或历史记录,而其输出为目标函数的一系列训练样本。
A、实验生成器B、泛化器C、执行器D、评价器正确答案:D6.话题模型中的几个概念不含有?(___)A、话题B、句C、词D、文档正确答案:B7.主成分分析是一种数据降维和去除相关性的方法,它通过()将向量投影到低维空间。
A、非线性变换B、拉布拉斯变换C、z变换D、线性变换正确答案:D8.查看 Atlas300 (3000)加速卡驱动是否安装成功应该使用哪条命令?A、npusim infoB、npu infoC、atlas-Driver infoD、atlas info正确答案:A9.根据机器智能水平由低到高,正确的是()A、计算智能、感知智能、认知智能B、机器智能、感应智能、认知智能C、机器智能、感知智能、认知智能D、计算智能、感应智能、认知智能正确答案:A10.Python中有这样一个示例:types=['娱乐','体育','科技'],在使用列表时,以下哪个选项,会引起索引错误A、types[0]B、types[-1]C、types[-2]D、types[3]正确答案:D11.剪枝分为前剪枝和后剪枝,前剪枝本质就是早停止,后剪枝通常是通过衡量剪枝后()变化来决定是否剪枝。

人工智能习题库与答案一、单选题(共103题,每题1分,共103分)1.()问题更接近人类高级认知智能,有很多重要的开放问题。
A、计算机视觉B、自然语言处理C、语音识别D、知识图谱正确答案:B2.逻辑回归模型中的激活函数Sigmoid函数值范围是A、(0,1)B、[0,1]C、(-∞~∞)D、[-1,1]正确答案:A3.使用什么命令检测基本网络连接?A、routeB、pingC、netstatD、ifconfig正确答案:B4.关于bagging下列说法错误的是:()A、为了让基分类器之间互相独立,需要将训练集分为若干子集。
B、当训练样本数量较少时,子集之间可能有重叠。
C、最著名的算法之一是基于决策树基分类器的随机森林。
D、各基分类器之间有较强依赖,不可以进行并行训练。
正确答案:D5.下列快捷键中能够中断(Interrupt Execution)Python程序运行的是A、F6B、Ctrl+QC、Ctrl+CD、Ctrl+F6正确答案:C6.下列关于深度学习说法错误的是A、LSTM在一定程度上解决了传统RNN梯度消失或梯度爆炸的问题B、CNN相比于全连接的优势之一是模型复杂度低,缓解过拟合C、只要参数设置合理,深度学习的效果至少应优于随机算法D、随机梯度下降法可以缓解网络训练过程中陷入鞍点的问题正确答案:C7.传统GBDT以()作为基分类器A、线性分类器B、CARTC、gblinearD、svm正确答案:B8.半监督支持向量机简称?A、S2VMB、SSVMC、S3VMD、SVMP正确答案:C9.以下不属于人工智能软件的是()。
A、语音汉字输入软件B、百度翻译C、在网上与网友下棋D、使用OCR汉字识别软件正确答案:C10.云计算通过共享()的方法将巨大的系统池连接在一起。
A、CPUB、软件C、基础资源D、处理能力正确答案:C11.下列哪项是自然语言处理的Python开发包?A、openCVB、jiebaC、sklearnD、XGBoost正确答案:B12.神经网络中最基本的成分是()模型。
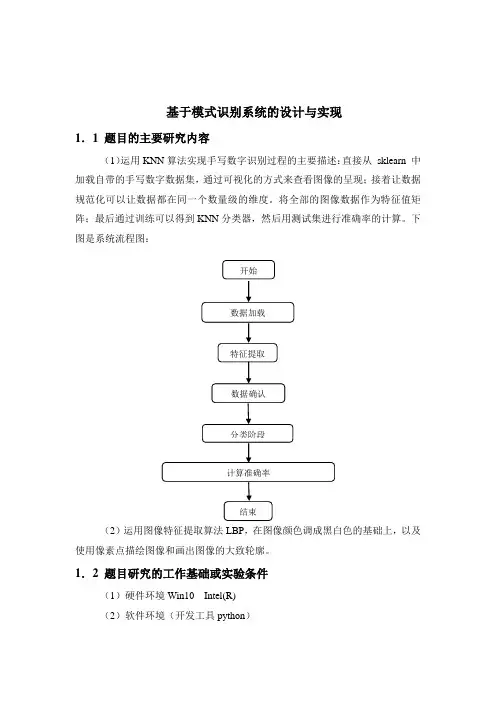
基于模式识别系统的设计与实现1.1 题目的主要研究内容(1)运用KNN算法实现手写数字识别过程的主要描述:直接从sklearn 中加载自带的手写数字数据集,通过可视化的方式来查看图像的呈现;接着让数据规范化可以让数据都在同一个数量级的维度。
将全部的图像数据作为特征值矩阵;最后通过训练可以得到KNN分类器,然后用测试集进行准确率的计算。
下图是系统流程图:(2)运用图像特征提取算法LBP,在图像颜色调成黑白色的基础上,以及使用像素点描绘图像和画出图像的大致轮廓。
1.2 题目研究的工作基础或实验条件(1)硬件环境Win10 Intel(R)(2)软件环境(开发工具python)1.3 数据集描述(1)手写数字数据集:包含1797个0-9的手写数字数据,每个数据由8 * 8 大小的矩阵构成,矩阵中值的范围是0-16,代表颜色的深度。
(2)在网上下载的16张演员图像1.4 特征提取过程描述(1)手写数字数据集中的1797个数据,代表了0~9是个数字类别,每个数据由8 * 8 大小的矩阵构成,矩阵中值的范围是0-16,代表颜色的深度,颜色越深,矩阵中的值越大。
根据颜色的深度可以描绘出大致轮廓,因此可以判断此数据属于那一个数。
(2)运用cv2.cvtColor将原图像进行灰色处理,接着利用图像特征提取算法:LBP,实现在灰色图像的基础上用像素点处理,再用filters.sobel对图像进行轮廓的提取。
1.5 分类过程以及准确率描述(1)通过上文的特征提取过程,将1797个包含0-9的手写数字的数据,识别出了0、1、2、3、4、5、6、7、8、9十个数,如果以0~9中的每个数代表一类,这样就把1797个数据集分成了0~9一共十个类别。
分割数据,将25%的数据作为测试集,其余作为训练集,创建KNN分类器对准确率进行计算。
(2)无分类过程1.6 主要程序代码(要求必须有注释)(1)程序一:from sklearn.model_selection import train_test_splitfrom sklearn import preprocessingfrom sklearn.metrics import accuracy_scorefrom sklearn.datasets import load_digitsfrom sklearn.neighbors import KNeighborsClassifierimport matplotlib.pyplot as plt#加载数据digits = load_digits()data = digits.data#数据探索print(data.shape)# 查看第七幅图像print(digits.images[6])# 第七幅图像代表的数字含义print(digits.target[6])# 将第七幅图像显示出来plt.gray()plt.imshow(digits.images[6])plt.show()# 分割数据,将25%的数据作为测试集,其余作为训练集train_x, test_x, train_y, test_y = train_test_split(data, digits.target, test_size=0.25, random_state=33)# 采用Z-Score规范化ss = preprocessing.StandardScaler()train_ss_x = ss.fit_transform(train_x)test_ss_x = ss.transform(test_x)# 创建KNN分类器knn = KNeighborsClassifier(n_neighbors=4)knn.fit(train_ss_x, train_y)predict_y = knn.predict(test_ss_x)print("KNN准确率: %.4lf" % accuracy_score(test_y, predict_y))(2)程序二:import skimageimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Imageimport cv2# settings for LBPradius = 1 # LBP算法中范围半径的取值n_points = 8 * radius # 领域像素点数# 读取图像image = cv2.imread('D:\SogouDownload/a/16.jpeg')#显示到plt中,需要从BGR转化到RGB,若是cv2.imshow(win_name, image),则不需要转化#显示原图像image1 = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)plt.subplot(111)plt.imshow(image1)plt.show()#将图像颜色调成灰色image = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)plt.subplot(111)plt.imshow(image, plt.cm.gray)plt.show()#利用像素点描绘图像lbp = local_binary_pattern(image, n_points, radius)plt.subplot(111)plt.imshow(lbp, plt.cm.gray)plt.show()#进行轮廓提取edges = filters.sobel(image)plt.subplot(111)plt.imshow(edges, plt.cm.gray)plt.show()1.7 运行结果及分析(1)第七幅图像(2)图像特征后的图像(示例)原图像描绘图像轮廓用像素点处理图像。



A Binary Correlation Matrix Memory k-NNClassifier with Hardware Implementation
Ping Zhou, Jim Austin and John KennedyComputer Science, University of York, York YO10 5DD, UK[Zhoup|austin]@cs.york.ac.uk
AbstractThis paper describes a generic and fast classifier that uses a binary CMM(Correlation Matrix Memory) neural network for storing and matching a largeamount of patterns efficiently, and a k-NN rule for classification. To meetCMM input requirements, a robust encoding method is proposed to convertnumerical inputs into binary ones with the maximally achievable uniformity.To reduce the execution bottleneck, a hardware implementation of the CMMis described, which shows the network with on-board training and testingoperates at over 200 times the speed of a current mid-range workstation, andis scaleable to very large problems. The CMM classifier has been tested onseveral benchmarks and, comparing with a simple k-NN classifier, it gave lessthan 1% lower accuracy and over 4 and 12 times speed-ups in software andhardware respectively.
1 IntroductionDesirable characteristics of Correlation Matrix Memory (CMM) neural networks includesimple and quick training, and highly flexible and fast search ability [1]. Whereas mostneural networks need a long iterative training times, a CMM is trained using an one-shot storage mechanism and simple binary operations. The CMM has been used as amatch engine in a number of successful applications, e.g. symbolic reasoning in theAURA (Advanced Uncertain Reasoning Architecture) approach [2], chemical structurematch [4] and post code matching. This work investigates its use for patternclassification tasks. It is known that the k-NN rule [5] is applicable to a wide range ofclassification problems. However, this method is too slow to use for many applicationswith large amounts of data. To speed up, previous researchers have considered reducingtraining data [6] and improving computational efficiency via complex pre-processing oftraining data [7]. In contrast to these, a CMM is a simple, general and powerfulapproach which can be used to store a large number of training patterns efficiently, andto retrieve both exact and near matches quickly for a test pattern. Therefore, thecombination of CMM and k-NN techniques may result in a generic and fast classifier.For most classification problems, patterns are in the form of multi-dimensional realnumbers, and appropriate quantisation and encoding are needed to convert them intobinary inputs to a CMM. A robust quantisation and encoding method is developed tomeet requirements for CMM input codes, such as uniformity, orthogonality andBritish Machine Vision Conference215
sparseness [3], and to overcome the common problem of identical data points in manyapplications, e.g. background of images or normal features in a diagnostic problem.The execution of the CMM was quickly identified as the bottle neck in theprocessing by an analysis of the AURA [2] method. To reduce this bottleneck, theCMM has been implemented in dedicated hardware, that is the PRESENCEarchitecture. The primary aim is to improve the execution speed over conventionalworkstations in a cost effective way. This work was also motivated by the needs ofmany research projects applying the CMM to commercial problems mentioned above.The next section discusses the CMM for pattern classification and the robust uniform(RU) encoding method, followed by descriptions of the PRESENCE architecture (thehardware implementation of the CMM). Experimental results are presented in Section4, and concluding remarks in the last section.
2 CMM for Pattern ClassificationFigure 1 shows the architecture of the CMM classifier. The RU encoder (as detailed in2.2) quantises numerical inputs and generates binary codes; the CMM engine storestraining patterns and matches stored patterns close to a test pattern to supply to aconventional k-NN module for classification. Both the CMM and k-NN modules areneeded as the CMM is fast but produces spurious errors as a side effect [3]. These areremoved through the application of the k-NN rule. More specifically, the speed of theclassifier benefits from the use of the CMM for fast training and matching to pre-select asub-set patterns from a large amount of training data; the accuracy gains from theapplication of the k-NN rule to the sub-set in the original space to reduce informationloss and noise in the encoding and match processes.