
点击查看更多应用技巧
应用技巧
1.1怎样了解某研究课题的总体发展趋势?
检索结果告诉我们找到了152篇“侯建国”院士的文章。(如果有重名的现象,请参考我们随后提供的有关作者甄别工具的应用技巧。)
1.访问Web of Science数据库检索论文
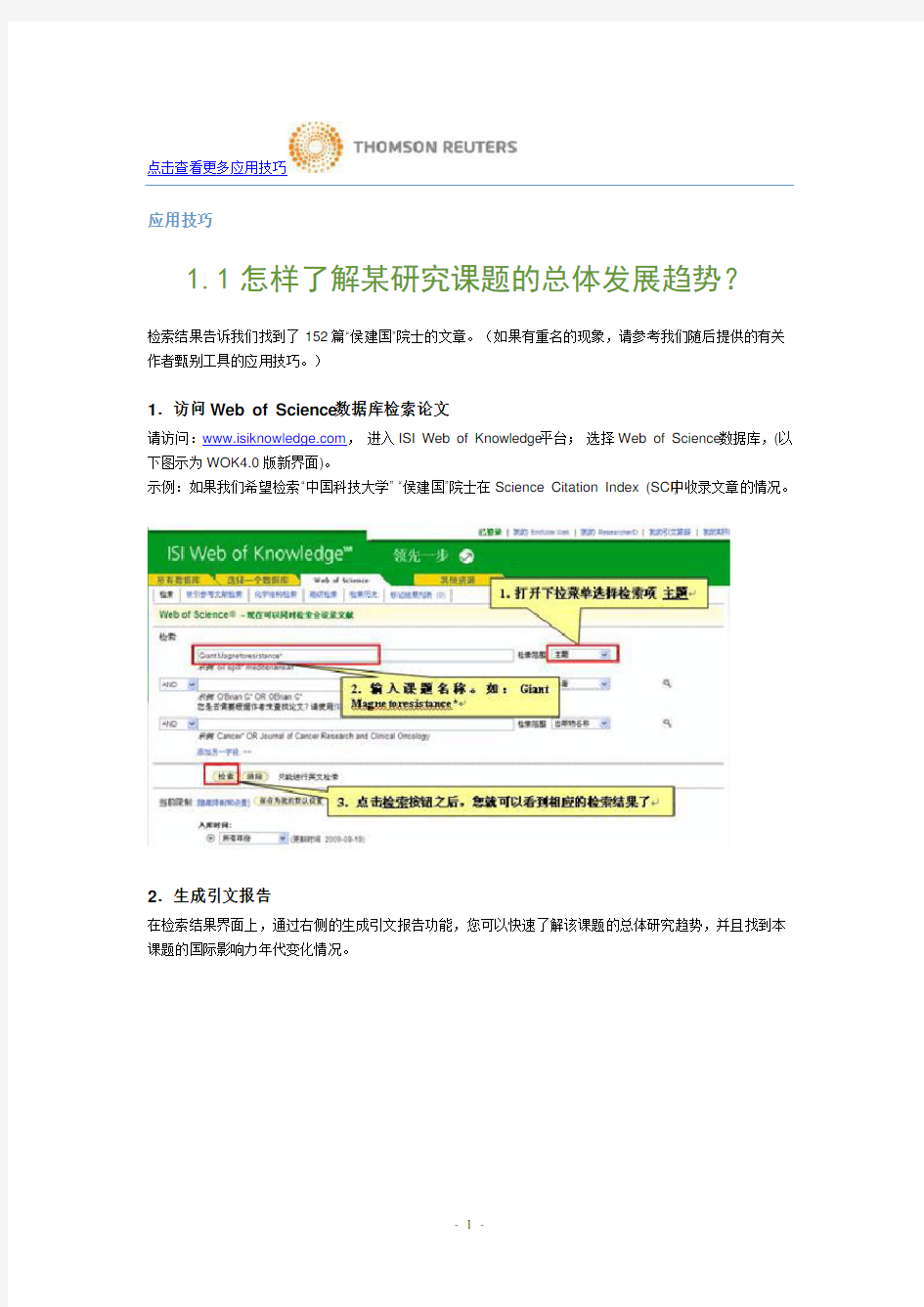
请访问:https://www.doczj.com/doc/ba3364364.html,,进入ISI Web of Knowledge平台;选择Web of Science数据库,(以下图示为WOK4.0版新界面)。
示例:如果我们希望检索“中国科技大学”“侯建国”院士在Science Citation Index (SCI)中收录文章的情况。
2.生成引文报告
在检索结果界面上,通过右侧的生成引文报告功能,您可以快速了解该课题的总体研究趋势,并且找到本课题的国际影响力年代变化情况。
结论:通过Web of Science提供的强大的引文报告功能,您可以点击创建引文报告,自动生成课题引文报告,从而提高您的科研效率。
3 利用分析功能了解课题发展趋势
除了自动创建引文报告之外,您也可以利用分析功能生成论文出版年的图式。并且,利用分析功能您可以任意查看某些出版年的论文情况。
结论:通过Web of Science提供的强大的引文报告功能,您可以点击创建引文报告,自动生成课题引文报告,对总体趋势一览全局。而分析功能可以让您更清晰的了解本课题论文每年的发文量,分属于哪些学科,主要集中在哪些国家地区,以哪些语种发表,哪些机构或哪些作者是本课题的引领者,收录本课题论文最多的期刊和会议有哪些等详细信息。
点击查看更多应用技巧
应用技巧
1.2 如何找到某个课题的综述文献?
在科学研究过程中往往需要从宏观上把握国内外在某一研究领域或专题的主要研究成果、最新进展、研究动态、前沿问题或历史背景、前人工作、争论焦点、研究现状和发展前景等内容,如何快速获取这些信息呢?您可以通过检索综述性文献来方便高效地找到信息。
1.访问Web of Science数据库检索课题
请访问:https://www.doczj.com/doc/ba3364364.html,,进入ISI Web of Knowledge平台;选择Web of Science数据库。如:我们想快速找到有关2007年诺贝尔物理奖获奖课题“巨磁电阻效应-Giant Magnetoresistance”的综述文献。
2.精炼检索结果
在检索结果界面上,通过左侧的精炼检索结果功能您可以快速的了解该课题涉及的学科、文献类型、作者、机构、国家等,甚至通过文献类型选项锁定该课题的高质量综述文献。
结论:通过Web of Science提供的强大的精炼检索结果功能,您可以在文献类型选项下选择Review ,立即从众多的检索结果中锁定高质量的综述。帮助您在检索时更加精准,从而提高您的科研效率。
点击查看更多应用技巧
应用技巧
1.3 怎样找到某个研究中的高影响力论文?
当我们查询文献时,往往会面临海量的检索结果。在这些检索结果中,有哪些文章是高影响力的文献?有哪些文献是研究中的经典论文?有哪些研究论文最经常被同行们写作时引用?其实不难,通过统计每篇文章在Web of Science范围内的被引用次数(被引频次),您就可以直观看到一篇论文的被引用情况。而通过对被引频次进行排序,您可以简便快速的从检索结果中锁定高影响力的论文。如:我们想快速了解2007年诺贝尔物理奖获奖课题“巨磁电阻效应-Giant Magnetoresistance” 中的高影响力论文,您可以这样操作:
1.访问Web of Science数据库检索课题
请访问:https://www.doczj.com/doc/ba3364364.html,,进入ISI Web of Knowledge平台;选择Web of Science数据库。
2.立即锁定高影响力的文章
在检索结果界面上,右上侧是排序选项-排序方式,您可以按照更新日期、被引频次、第一作者、来源出版物等对检索结果进行排序,默认的排序选项是更新日期排序。如果您想找到高影响力的文章,可以选择被引频次排序。
结论:通过Web of Science提供的强大的被引频次排序功能,您可以立即从众多的检索结果中锁定高影响力的文章。此功能可以帮助您在检索时更加精准,从而提高您的科研效率。
点击查看更多应用技巧
应用技巧
1.4 如何从检索结果中快速找到某个学科的相关
论文
您可能经常遇到检索结果太多但又不是您需要的情况,怎样可以改变这种情况呢?其实利用Web of Science提供强大的精炼检索结果功能,您可以简便快速的从检索结果中所定您所关心的学科领域的文献。
1.访问Web of Science数据库检索课题
请访问:https://www.doczj.com/doc/ba3364364.html,,进入ISI Web of Knowledge平台;选择Web of Science数据库。如:我们想快速找到有关2007年诺贝尔物理奖获奖课题“巨磁阻效应-Giant Magnetoresistance”的在材料科学-MATERIALS SCIENCE领域的全貌。
2.精炼检索结果
在检索结果界面上,通过左侧的精炼检索结果功能,您可以快速了解该课题的学科、文献类型、作者、机构、国家等,甚至通过学科类别选项锁定某一学科的相关文献。
结论:通过Web of Science提供的强大的精炼检索结果功能,您可以在学科类别选项下进行选择,立即从众多的检索结果中锁定您关注学科的文献。帮助您在检索时更加精准,从而提高您的科研效率。
点击查看更多应用技巧
应用技巧
1.5 在阅读摘要之后希望获取某篇论文的原文,
应该怎么做?
在Web of Science数据库中提供了多种途径帮助您获取原文,在某些情况下您可以直接点击全文按钮下载全文,您也可以通过我们给出的其它链接途径来使用。
1.在检索结果概要页面获取原文
这是点击Links按钮后的页面,这里提供了多种获取原文的线索
2.在全记录页面获取原文
在检索结果全记录界面上,也提供了多种获取全文的链接。
结论:通过Web of Science提供的强大的链接功能,您可以1)通过全文链接按钮直接下载全文,2)通过基于OpenURL协议的链接获取全文线索;3)通过图书馆馆藏链接并通过图书馆原文传递服务获取全文;4)直接联系论文作者获取原文。
1. F1值 F1 值是检索性能评价的一个测度,它综合了精度和查全率,将两者赋予同样的重要性来考虑。F1的计算由下面的公式决定 F1 值的其他说法 还表示调和平均值 调和平均数定义为:数值倒数的平均数的倒数。其数值恒小于算术平均数。 计算查准率p 和查全率r 的调和平均数作为度量指标。F 的取值在[0,1]。 2. 查全率 查全率(Recall):检出的相关文档个数与相关文档集合总数的比值,即R=|Ra| / |R| 其中,对某个测试参考集,信息查询实例为I ,I 对应的相关文档集合为R 。假设用某个检索策略对I 进行处理后,得到一个结果集合A 。令Ra 是R 与A 的交集 3. 查准率 查准率(Precision):检出的相关文档个数 与检出文档总数的比值,即P=|Ra| / |A| 4. 支持向量机(SVM ) 解决小样本、非线性及高维模式识别,SVM 将n 维空间中的点,通过一个n-1维的超平面分开。通常这个被称为线性分类器。有很多分类器都符合这个要求。但是我们还希望找到分类最佳的平面,即使得属于两个不同类的数据点间隔最大的那个面,该面亦称为最大间隔超平面。如果我们能够找到这个面,那么这个分类器就称为最大间隔分类器。 5. Deep Web Deep Web 是可以通过Internet 访问的数据库,它们所承载的信息量是目前Internent 的500倍!对Deep Web 网页的爬取有垂直搜索引擎,元搜索引擎 6. 向量空间模型(VSM ) 通过给查询或文档中的索引词分配非二值权值来实现。 文档的向量空间模型 ?词典, ∑={k1,k2,…kt} ?d=
第六章应用层 6-01 因特网的域名结构是怎么样的?它与目前的电话网的号码结构有何异同之处? 答: (1)域名的结构由标号序列组成,各标号之间用点隔开: … . 三级域名 . 二级域名 . 顶级域名 各标号分别代表不同级别的域名。 (2)电话号码分为国家号结构分为(中国 +86)、区号、本机号。 6-02 域名系统的主要功能是什么?域名系统中的本地域名服务器、根域名服务器、顶级域名服务器以及权限域名权服务器有何区别? 答: 域名系统的主要功能:将域名解析为主机能识别的IP地址。 因特网上的域名服务器系统也是按照域名的层次来安排的。每一个域名服务器都只对域名体系中的一部分进行管辖。共有三种不同类型的域名服务器。即本地域名服务器、根域名服务器、授权域名服务器。当一个本地域名服务器不能立即回答某个主机的查询时,该本地域名服务器就以DNS客户的身份向某一个根域名服务器查询。若根域名服务器有被查询主机的信息,就发送DNS回答报文给本地域名服务器,然后本地域名服务器再回答发起查询的主机。但当根域名服务器没有被查询的主机的信息时,它一定知道某个保存有被查询的主机名字映射的授权域名服务器的IP地址。通常根域名服务器用来管辖顶级域。根域名服务器并不直接对顶级域下面所属的所有的域名进行转换,但它一定能够找到下面的所有二级域名的域名服务器。每一个主机都必须在授权域名服务器处注册登记。通常,一个主机的授权域名服务器就是它的主机ISP的一个域名服务器。授权域名服务器总是能够将其管辖的主机名转换为该主机的IP地址。 因特网允许各个单位根据本单位的具体情况将本域名划分为若干个域名服务器管辖区。一般就在各管辖区中设置相应的授权域名服务器。 6-03 举例说明域名转换的过程。域名服务器中的高速缓存的作用是什么? 答: (1)把不方便记忆的IP地址转换为方便记忆的域名地址。 (2)作用:可大大减轻根域名服务器的负荷,使因特网上的 DNS 查询请求和回答报文的数量大为减少。 6-04 设想有一天整个因特网的DNS系统都瘫痪了(这种情况不大会出现),试问还可以给朋友发送电子邮件吗? 答:不能; 6-05 文件传送协议FTP的主要工作过程是怎样的?为什么说FTP是带外传送控制信息?主进程和从属进程各起什么作用? 答: (1)FTP使用客户服务器方式。一个FTP服务器进程可同时为多个客户进程提供服务。FTP 的服务器进程由两大部分组成:一个主进程,负责接受新的请求;另外有若干个从属进程,负责处理单个请求。 主进程的工作步骤: 1、打开熟知端口(端口号为 21),使客户进程能够连接上。 2、等待客户进程发出连接请求。 3、启动从属进程来处理客户进程发来的请求。从属进程对客户进程的请求处理完毕后即终止,但从属进程在运行期间根据需要还可能创建其他一些子进程。 4、回到等待状态,继续接受其他客户进程发来的请求。主进程与从属进程的处理是并发地
摘要:本文主要使用了百度、谷歌等搜索引擎和Web of science数据库对包信和院士的研究内容及其研究成果进行了分析,通过百度、谷歌、个人主页对包信和院士的基本信息进行了解;通过Web of science数据库对包信和院士的研究方向、引文数据、合作者、基金资助机构、出版物进行了了解。并对其2014年5月的一篇文章进行了深入的分析。 一、基本信息 包信和,理学博士,研究员,博士生导师、中科院院士、物理化学家,中国科学院大连化学物理研究所研究员,现任中科院沈阳分院院长,复旦大学常务副校长,兼任中国科学技术大学化学物理系主任。 他的个人工作经历为: 1989年至1995年获洪堡基金资助,在德国马普学会Fritz-Haber研究所任访问学者,1995年应聘回国。 1995年至2000年在中科院大连化学物理研究所工作。 2000年8月至2007年3月任大连化学物理研究所所长。 2003年3月起任中国科技大学化学物理系系主任。 2009年3月起任沈阳分院院长。 2009年当选为中国科学院院士。 2015年9月经教育部研究决定,任命包信和为复旦大学常务副校长 其次在大连化学物理研究所的个人介绍和包信和院士的课题组主页里搜集了对其研究方向的简介: 包信和研究员主要从事表面化学与催化基础和应用研究。发现次表层氧对金属银催化选择氧化的增强效应,揭示了次表层结构对表面催化的调变规律,制备出具有独特低温活性和选择性的纳米催化剂,解决了重整氢气中微量CO造成燃料电池电极中毒失活的难题。发现了纳米催化体系的协同限域效应,研制成碳管限域的纳米金属铁催化剂和纳米Rh-Mn催化剂,使催
化合成气转化的效率成倍提高。在甲烷活化方面,以分子氧为氧化剂,实现了甲烷在80℃条件下直接高效氧化为甲醇的反应;创制了Mo/MCM-22催化剂,使甲烷直接芳构化制苯的单程收率大幅度提高。 二、研究成果分析 利用Web of Science搜索包老师的文章,总共搜索到497篇文章,对检索报告创建引文报告,如图2.1所示。文章被引总频次达到12804次,平均每篇文章被引25.76次,h-index值为56,表示在包老师所发的文章中,每篇被引用了至少56次的论文总共有56篇左图为每年出版的文献数图标,2000年以来,每年出版的文献数量基本稳定,在30篇左右,研究状态保持稳定。其中2015年发表文章篇数最高,2015年是个高产年。 根据每年的引文数图标可以看出,每年的引文数不断上升,表明其发表的文章是有生命力、有价值的。也表明每年发文的质量不断在上涨。 图2.1创建引文报告 对检索结果进行分析。图2.2是对作者进行分析,得到如下图所示的结果,可以看到合作者的信息,其中与293名作者有过合作。其中合作最多的为韩秀文老师(大连化物所)、马丁老师(北京大学)。
WEB全文信息检索技术 摘要:本文探索了在INTERNET网上实现全文检索的技术。计论了从网上信息的标引、分类等预处理到组织信息检索的过程,并就智能检索技术的发展进行了阐述。 关键词:信息检索因特网全文检索 一、前言 Internet网是目前全球最大的、最有影响力的信息网络,它将政府、学校、图书馆、商务场所、研究机构和其它组织中的局域网(LAN)集成为一个单一的、庞大的、跨越全球的通讯网络。越来越多的人们利用这一网络与世界各地的人进行交流。如何利用Internet网获取有价值的信息,已成为科研人员必备的一项基本技能。 因特网是一个开放型的巨大的信息资源库,拥有上千万台以上的主机和过亿的用户;并且由于因特网信息蕴含的无限丰富,信息组织、表达的直观、生动以及信息服务的方便性和多样性,愈来愈多的信息搜索者被其独特的魅力所吸引。而在近几年,因特网用户的数量更是成倍地增长。可见,因特网检索已成为实际上最普及、最受关注、最常涉及的信息检索领域。 二、概述 网上的信息具有数量大、形式多、内容广、专业性不强等特点,给情报搜集、分类、检索等工作带来了新的问题和挑战。如何充分利用因特网上的信息资源正成为情报科学研究者所关注的热点。全文信息检索就是概据Internet信息的特点而发展起来的一种检索方式。它主要指研究对整个文档信息的表示,存储、组织和访问,即根据用户的查询要求,从信息数据库中检索出相关信息资料。 全文检索的中心环节是文件内容表达、信息查询的获得以及相关信息的匹配。一个好的全文信息检索系统不仅要求将输出信息进行相关性排列,还应该能够根据用户的意图、兴趣和特点自适应和智能化地调整匹配机制,获得用户满意的检索输出。 要实现全文检索,首先必须对WEB信息进行预处理。 三、WEB信息的预处理 信息预处理的主要功能是过滤文件系统信息,为文件系统的表达提供一种满意的索引输出。其基本目的是为了获取最优的索引记录,使用户能很容易地检索到所需信息。 (1)格式过滤:信息预处理应该能够过滤不同格式的文档,以及图片、声音、视频等信息。这使得搜索引擎不仅能够检索文字,而且能够检索原始格式文件的所有信息。 (2)语词切分:语词是信息表达的最小单位,而汉语不同于西方语言,其句子的语词间没有分隔符因此需要进行语词切分。常用的语词切分方法有按词典进行最大词组匹配、逆向最大词组匹配、最佳匹配法,联想-回溯法、全自动词典切词等。近年来,又出现了基于神经元网络的和专家系统的分词方法和基于统计和频度分析的分词方法。 (3)词法分析:汉语语词切分中存在切分歧异,如句子“网球拍卖完了”,可以切分为“网球/拍卖完了”,也可以切分为“网球拍/卖完了”。因此需要利用各种上下文知识解决语词切分歧异。此外,还需要对语词进行词法分析,识别出各个语词的词干,以便根据词干建立信息索引。对于英语语词,建立索引之前首先要去除一些停顿词(如常见的功能词“a”,“the”,“it”等)和词根(如“ing”,“ed”,“ly”等)。 (4)词性标注和短语识别:在切分的基础上,利用基于规则和统计的方法进行词性标注。在此基础上,还要利用各种语法规则,识别出重要的短语结构。 (5)自动标引:从网页文档中提取出一组能最大程度上概括其内容特征、可作为用户检索入口的关键性信息,用该组信息对文文件进行标引,使用户可以通过输入关键信息检索到该文文件的简要信息,如标题、摘要、时间、作者和URL等,进一步点击可查询到该文
第六章基于搜索引擎的信息检索 (一)搜索引擎技术原理
搜索引擎技术原理—搜索引擎概述及组成 搜索引擎(Search Engine)是互联网上专门用于检索的网站的统称,目前已多达数百上千种,包括通用万维网搜索引擎(Web Search Engines)、通用元搜索引擎(Meta-Search Engines)和各种专用搜索引擎三大类型。 搜索引擎的起源可以上溯到1990年由加拿大蒙特利尔大学学生Alan Emtage 开发的Archie。Archie用于检索分散在各FTP服务器上的文件,但其工作原理与现在的搜索引擎很接近。1993年底,人们认识到既然所有网页都可能有连向其他网站的链接,那么从跟踪一个网站的链接开始,就有可能检索整个互联网,这一简单想法就是今天搜索引擎的基本原理。1994年,Yahoo!和Lycos问世,成功地使搜索引擎的概念深入人心。1995年后,搜索引擎进入了高速发展时期,被誉为仅次于门户网站的互联网第二大核心技术。搜索引擎的技术原理和检索方法与DIALOG等专业文献型信息检索系统不同,有它自己的特点。
搜索引擎技术原理—搜索引擎概述及组成 (1)搜索器(Searcher) 20世纪90年代,“机器人”(Robot)一词在计算机编程者中用于特指某种能以人类无法达到的速度不间断地执行某项任务的软件程序。由于专门用于检索Web信息的“机器人”程序像蜘蛛一样在网络间爬来爬去,因此,作为Web搜索器的“机器人”就被称为“网络蜘蛛”(Spider)。“网络蜘蛛”的功能就是在互联网中不断漫游,发现和搜集信息。作为一个计算机程序,搜索器日夜不停地运行,尽可能多、尽可能快地搜集各种类型的新信息,并定期更新已经搜集过的旧信息,以避免出现死链接和无效链接。 (2)索引器(Indexer) 索引器的功能是理解搜索器所搜索的信息,从中抽取出索引项,并生成文档库的索引表。索引项有客观索引项和内容索引项两种:客观索引项与文档的语意内容无关,如作者名、URL、更新时间等等;内容索引项则是用来反映文档内容的,如关键词及其权重、短语、单字等等。
Web of Science 数据库的检索与利用 解放军医学图书馆杜永莉 一、引文检索概述 (一)基本概念 1. 引文(Citation):文献中被引用、参考的文献(Cited Work),也称施引文献,其作者称为被引著者(Cited Author)。 2. 来源文献(Source):提供引文的文献本身称为来源文献,其作者称为引用著者(Citing Author)。 3. 引文索引(Citation Index):通过搜集大量来源文献及其引文,并揭示文献之间引用与被引用关系的检索工具。 4. 引文检索:是以被引用文献为检索起点来查找引用文献的过程。 (二)引文的历史回顾 引文的创始人Dr.Eugene Garfield博士是美国科学信息研究所(ISI)的创始人,现在仍然是科学信息研究所的名义董事长,还是美国信息科学协会的前任主席、The Scientist 董事会的主席、Research America董事会的成员。另外他还是文献计量学的创始人。 Dr.Garfield于1955年在Science上发表了具有化时代意义的学术论文:“Citation Indexes for Science: A New Dimension in Documentation through Association of Ideas.”他在这篇文章中描述科研人员可以利用引文加速研究过程、评估工作影响、跟踪科学趋势;阐明引文是学术研究中学术信息获取的重要工具。1957 他创建了美国科学信息研究所(Institute for Scientific Information, ISI)。
1961 年, ISI 推出了 Science Citation Index , SCI 。一种5卷印刷型刊物,包括613种期刊140万条引文的索引。1966年,ISI发布磁带形式的数据,1989年推出CD-ROM 光盘版,1992年ISI为汤姆森科技信息集团接管(Thomson Scientific),1997年推出系列引文数据库(Web of Science),2001年建立具有跨库检索功能的(ISI Web of Knowledge)。 20世纪30年代中期,另外一个著名计量学家布拉德福(S.C.Bradford)在对大量的期刊分布进行研究之后,得出了布拉德福定律(二八定律),揭示出各学科核心期刊的存在,这些核心期刊组成了所有学科的文献基础,重要论文会发表在相对较少的核心期刊上;因此从文献学的角度,没有必要将已经出版的所有期刊全部收录,从数据库的质量上说,则需要有一套科学的流程筛选高质量期刊,为读者提供高质量的学术信息。 Garfield 博士从建立引文数据库开始,经过几十年的时间,建立了一整套期刊筛选的工作流程,每年从全球出版的学术期刊中,筛选出各学科中质量高、信息量大、使用率高的核心期刊。由于这套流程对期刊一些客观指数的长期跟踪,衍生出了另外两个数据库:期刊引证报告(Journal Citation Reports,JCR)和基本科学计量指标(Essential Science Indicators)。 (三)引文的作用 了解某一课题发生、发展、变化过程;查找某一重要理论或概念的由来;跟踪当前研究热点;了解自已以及同行研究工作的进展;查询某一理论是否仍然有效,而且已经得到证明或已被修正;考证基础理论研究如何转化到应用领域;评估和鉴别某一研究工作在世界学术界产生的影响力;发现科学研究新突破点;了解你的成果被引用情况;引文检索为科研人员开辟了一条新颖、实用的检索途径;同时为文献学、科学学、文献计量学等分析研究提供参考数据,如衡量期刊质量、测定文献老化程度、观察学科之间的渗透交叉关系、评价科研人员的学术水平,引文数据库是不可缺少重要工具。 二、Web of Science的检索途径 (一)科学引文索引简介
1、引文的创始者是(A) A、Eugene Garfield B、S.C.Bradford C、Billings,S.A D、Harris,C.J 2、引文的创始单位是(A) A、ISI B、NLM C、CDC D、NIH 3、ISI推出系列引文数据库(Web of Science)的时间是(D ) A、1956年 B、1989年 C、1990年 D、1997年 4、SCI的局限性不包括(B ) A、主要限于基础科学方面 B、不能囊括多数国际多学科高质量科学期刊 C、收录第三世界国家期刊较少 D、论文被引用情况复杂 5、ISI推出了SCI的时间(C) A、1950年 B、1955年 C、1961年 D、1970年 6、关于引文的作用,以下说法错误的是(D ) A、了解某一课题发生、发展、变化过程 B、引文检索为科研人员开辟了一条新颖、实用的检索途径 C、为文献学、科学学、文献计量学等分析研究提供参考数据 D、直接查找全文数据 7、Web of Knowledge包含的数据库有(D) A、Web of Science B、科学会议录索引、化学反应数据库 C、化学索引数据库、Medline数据库 D、以上皆是 8、关于Web of Science的特点,以下说法错误的是(D ) A、跨学科、精选内容,可以进行引文检索
B、增加了分析、跟踪、写作和管理功能 C、从文献相互关系的角度,提供新的检索途径 D、从著者、标题、分类等角度提供检索途径 9、ISI推出CD-ROM光盘版的时间是(A ) A、1970年 B、1961年 C、1982年 D、1991年 10、在SCI中公共卫生所在的数据库是(B ) A、Web of Science Expanded B、Social Sciences Citation Index C、Arts & Humanities Citation Index D、其他
Web of Science系统 在科技发展与竞争力 分析中应用 周宁丽 2012.10
内容提纲 1.WOS及其功能简介 2.科技文献检索以及分析概念与术语 3.WOS文献检索功能及其利用 4.WOS文献分析功能及其应用 5.WOS引文分析功能及其应用
1. WOS 及其功能简介 ?WOS 简介 WOS(Web of Science)数据库是汤森路透科技集团创建的WOK(ISI web of Knowledge)信息平台中的一个系统。 ?WOS 数据资源 3个引文数据库:Science Citation Index Expanded (SCI-EXPANDED) --1900-至今 (涵盖8,200种核心期刊) Social Sciences Citation Index (SSCI) --1996-至今(涵盖2,800种核心期刊) Conference Proceedings Citation Index -Science (CPCI-S) --1990-至今(涵盖60,000个会 议录) 1个化学数据库: Current Chemical Reactions (CCR-EXPANDED) --1986-至今 ?WOS 主要功能 1.收录、引用、主题文献检索 2.文献与引文统计分析 3. 文献管理与跟踪 ?WOS 学科领域 (1)自然科学、工程技术、生物医 学等150 多个学科领域 (2)人文社科50多个学科领域
2. 1 科技文献收引检索概念 ?科技论文收录检索 选用权威的文献检索系统(如:WOS、ISTP、EI、PUMED、 SCOPAS、CSCD、CSSCI),对其数据库系统收录所发表的期刊、会议文献进行检索 ?科技论文引文检索 利用权威的文献检索系统(如:WOS、ISTP、EI、PUMED、 SCOPAS、CSCD、CSSCI),对其数据库系统收录的期刊、会议文献的引用频次进行查询,对其引文进行检索 ?课题(主题)文献检索 利用权威的文献检索系统(如:WOS、ISTP、EI、PUMED、 SCOPAS、CSCD、CSSCI),对某学科、研究主题进行相关文献检索
web of Science数据库几个标识(DOI、UT、IDS Number、ISSN、ISBN)的含义 无论是检索机构还是文章作者,对于web of Science数据库记录格式中出现的DOI、UT、IDS Number、ISBN ISSN等英文标识不尽了解,经咨询ISI公司及相应的检索后,把这些标识的意思做简要说明。 (1)DOI(Digital Object Unique Identifier):对象唯一标识符 传统方式是采用URL对因特网上数字资源进行标识,用户点击URL链接即可访问对应的数字资源。然而URL所代表的只是数字资源的物理位置,并不是数字资源本身,一旦资源的物理位置发生变化,原来的URL将成为―死链‖。因此,仅仅使用URL来代表数字对象和链接已经不能适应分布式动态环境的要求。数字对象唯一标识符(Digital Object Unique Identifier)由此产生,它并非只是一个不重复的字符串,真正有用的唯一标识标符系统应该是一套包括名称空间、唯一标识符、命名机构、命名登记系统和解析系统5 个部分的完整体系。 简要地说,对所标识的数字对象而言,DOI相当于人的身份证,具有唯一性。保证了在网络环境下 对数字化对象的准确提取,有效地避免重复。一个网络对象(各种数字资源)一个编号例如——DOI:10.1134/S1061920808010020 (2)UT(Unique Article Identifier)是文章的唯一识别符——收录号 UT –Unique Article Identifier字段是ISI (现在公司名称Thomson Reuters)分配给一篇文章的唯一识别符。可以唯一地识别一条参考文献。它没有显示在Web of Science文章的全记录页里,当输出记录保存为HTML格式时,可以看到UT字段文章的唯一标识符。一篇文章一个编号 例如——UT ISI:000259889100041 (3)IDS Number——检索号 Thomson Reuters Document Solution? 编号。此号码是识别期刊和期号的唯一编号,用于订阅Document Solution 中的文献的全文。一本期刊每一期发表的文章都是一个IDS号。一个期刊的一期对应一个编号 例如——IDS Number:358AR (4)ISSN 国际标准期刊号(International Standard Serial Number),是标识定期出版物(如期刊)和电子出版物的唯一编号,共八位。一个期刊一个编号 (5)ISBN 国际标准书号(International Standard Book Number) 是一种机器读取的唯一标识符,可准确无误地标识书籍。 例如——ISBN:7-5023-4424-1
Web of Science (SCIE,SSCI,AHCI,CPCI) 登录https://www.doczj.com/doc/ba3364364.html, 资源简介: Web of Science 是汤森路透科技集团(Thomson Reuters)的产品,Web of Science 包括著名的三大引文索引数据库(SCIE,SSCI,A&HCI)。本馆开通试用的数据库如下: 科学引文索引(Science Citation Index Expanded,简称SCIE),被公认为世界范围最权威的科学技术文献的索引工具,能够提供科学技术领域最重要的研究成果。提供8600多种涵盖176 个学科的世界一流学术科技期刊的文献信息。 社会科学引文索引(Social Sciences Citation Index,简称SSCI),收录3100多种涵盖56个学科的世界一流学术性社会科学期刊的文献信息。 艺术与人文引文索引(Arts & Humanities Citation Index,简称A&HCI),收录艺术与人文学科领域内1,600多种学术期刊,数据可回溯至1975年。同时还从Web of Science 收录的8,000多种科技与社会科学期刊中,筛选出与艺术人文相关的学术文献。 会议论文引文索引(Conference Proceedings Citation Index,简称CPCI),汇聚了全球最重要的学术会议信息,包括专著、丛书、预印本以及来源于期刊的会议论文,提供了综合全面、多学科的会议论文资料。其内容分为两个版本:Conference Proceedings Citation Index - Science (CPCI-S,原ISTP);Conference Proceedings Citation Index - Social Science & Humanities (CPCI-SSH,原ISSHP)。 Web of Science (SCIE,SSCI,A&HCI,CPCI)数据库的特色 利用Web of Science可以快速检索科研信息,可以全面了解有关某一学科、某一课题的研究信息。在提供文献的书目与文摘信息的同时,Web of Science(SCIE,SSCI,AHCI,CPCI)设置了"引文索引"(Citation Index),提供该文献所引用的所有参考文献信息以及由此而建立的引文索引,揭示了学术文献之间承前启后的内在联系,帮助科研人员发现该文献研究主题的起源、发展以及相关研究。还可通过Email和RSS定制主题及引文跟踪服务,随时把握最新研究动态,跟踪国际学术前沿。 Web of Science收录各学科领域中权威、有影响力的期刊,由于其严格的选刊标准和引文索引机制,使得Web of Science(SCIE,SSCI,AHCI,CPCI)在作为文献检索工具的同时,也成为文献计量学和科学计量学的最重要基本评价工具之一。 免费学习资源: 数据库使用指南下载:https://www.doczj.com/doc/ba3364364.html,/productraining/
点击查看更多应用技巧 应用技巧 1.1怎样了解某研究课题的总体发展趋势? 检索结果告诉我们找到了152篇“侯建国”院士的文章。(如果有重名的现象,请参考我们随后提供的有关作者甄别工具的应用技巧。) 1.访问Web of Science数据库检索论文 请访问:https://www.doczj.com/doc/ba3364364.html,,进入ISI Web of Knowledge平台;选择Web of Science数据库,(以下图示为WOK4.0版新界面)。 示例:如果我们希望检索“中国科技大学”“侯建国”院士在Science Citation Index (SCI)中收录文章的情况。 2.生成引文报告 在检索结果界面上,通过右侧的生成引文报告功能,您可以快速了解该课题的总体研究趋势,并且找到本课题的国际影响力年代变化情况。
结论:通过Web of Science提供的强大的引文报告功能,您可以点击创建引文报告,自动生成课题引文报告,从而提高您的科研效率。 3 利用分析功能了解课题发展趋势 除了自动创建引文报告之外,您也可以利用分析功能生成论文出版年的图式。并且,利用分析功能您可以任意查看某些出版年的论文情况。
结论:通过Web of Science提供的强大的引文报告功能,您可以点击创建引文报告,自动生成课题引文报告,对总体趋势一览全局。而分析功能可以让您更清晰的了解本课题论文每年的发文量,分属于哪些学科,主要集中在哪些国家地区,以哪些语种发表,哪些机构或哪些作者是本课题的引领者,收录本课题论文最多的期刊和会议有哪些等详细信息。
点击查看更多应用技巧 应用技巧 1.2 如何找到某个课题的综述文献? 在科学研究过程中往往需要从宏观上把握国内外在某一研究领域或专题的主要研究成果、最新进展、研究动态、前沿问题或历史背景、前人工作、争论焦点、研究现状和发展前景等内容,如何快速获取这些信息呢?您可以通过检索综述性文献来方便高效地找到信息。 1.访问Web of Science数据库检索课题 请访问:https://www.doczj.com/doc/ba3364364.html,,进入ISI Web of Knowledge平台;选择Web of Science数据库。如:我们想快速找到有关2007年诺贝尔物理奖获奖课题“巨磁电阻效应-Giant Magnetoresistance”的综述文献。 2.精炼检索结果 在检索结果界面上,通过左侧的精炼检索结果功能您可以快速的了解该课题涉及的学科、文献类型、作者、机构、国家等,甚至通过文献类型选项锁定该课题的高质量综述文献。