Eviews 基本操作
- 格式:pdf
- 大小:189.83 KB
- 文档页数:9
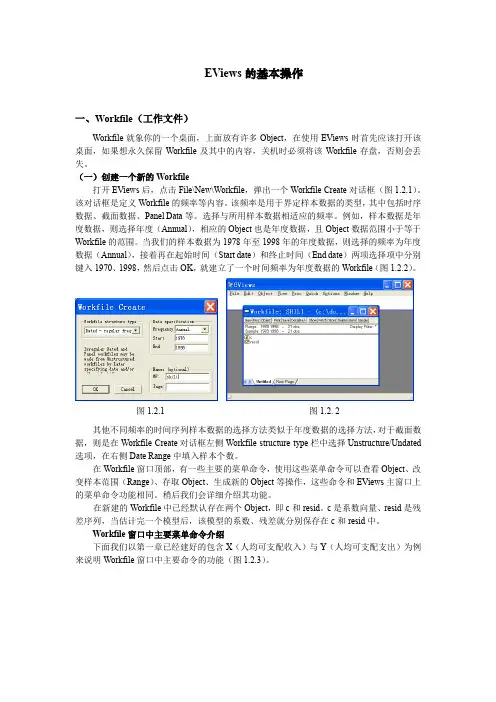
EViews的基本操作一、Workfile(工作文件)Workfile就象你的一个桌面,上面放有许多Object,在使用EViews时首先应该打开该桌面,如果想永久保留Workfile及其中的内容,关机时必须将该Workfile存盘,否则会丢失。
(一)创建一个新的Workfile打开EViews后,点击File\New\Workfile,弹出一个WorkfileCreate对话框(图1.2.1)。
该对话框是定义Workfile的频率等内容。
该频率是用于界定样本数据的类型,其中包括时序数据、截面数据、Panel Data等。
选择与所用样本数据相适应的频率。
例如,样本数据是年度数据,则选择年度(Annual),相应的Object也是年度数据,且Object数据范围小于等于Workfile的范围。
当我们的样本数据为1978年至1998年的年度数据,则选择的频率为年度数据(Annual),接着再在起始时间(Start date)和终止时间(End date)两项选择项中分别键入1970、1998,然后点击OK,就建立了一个时间频率为年度数据的Workfile(图1.2.2)。
图1.2.1图1.2. 2其他不同频率的时间序列样本数据的选择方法类似于年度数据的选择方法,对于截面数据,则是在Workfile Create对话框左侧Workfile structure type栏中选择Unstructure/Undated 选项,在右侧Date Range中填入样本个数。
在Workfile窗口顶部,有一些主要的菜单命令,使用这些菜单命令可以查看Object、改变样本范围(Range)、存取Object、生成新的Object等操作,这些命令和EViews主窗口上的菜单命令功能相同。
稍后我们会详细介绍其功能。
在新建的Workfile中已经默认存在两个Object,即c和resid。
c是系数向量、resid是残差序列,当估计完一个模型后,该模型的系数、残差就分别保存在c和resid中。

Eviews-操作基本命令Eviews是一种用于经济数据建模和分析的软件,可以进行数据处理、拟合模型、进行统计分析等等。
为了更好地使用Eviews进行分析,我们需要了解一些Eviews的基本命令。
以下是一些常用的Eviews操作命令。
数据清理批量修改变量名称使用rename命令可以批量修改变量的名称。
假设我们有一组包含了许多经济指标的数据,我们可以使用以下命令将某一个变量的名称由y1更改为GDP:rename(y1, GDP)创建新变量使用以下语法可以创建新变量:series newvar_name = expr其中newvar_name是新变量的名称,expr是计算新变量值的表达式。
例如,我们可以使用以下语句创建一个名为inflation的新变量,其值等于CPI变量的年度增长率:series inflation = log(CPI) - log(CPI(-1))数据筛选内置命令if用于筛选数据。
例如,假设我们有一个名为gdp的变量,我们可以使用以下语法选择其中gdp大于5000的数据:sample if gdp > 5000行列操作如果我们有一个多元素的数据,例如,一张包含多个行和列的表格,我们可以使用以下命令对其进行操作。
按行排序使用以下命令可以将数据按行排序:series gdpsum = sum(gdp)sort(gdpsum)这里我们使用了内置函数sum编写了一个名称为gdpsum的新变量,并使用sort对新变量进行排序操作。
按列计算统计量可以使用group命令按照某一列进行分组,并计算统计量。
例如,我们可以分成两个组,分别对指标A和B进行求和:group id A Bseries asum = @sum(A)series bsum = @sum(B)数据拟合和评估线性回归我们可以使用ls(least square)命令进行线性回归分析,例如:ls example_data.wf1 y x1 x2其中example_data.wf1是数据文件的路径,y是因变量,x1和x2是自变量。


Eviews软件使用说明Eviews软件使用说明1.引言1.1 背景信息Eviews是一种强大的计量经济学和时间序列分析软件,具有数据管理、统计分析、图形展示等功能。
本文档旨在提供Eviews软件的详细使用说明,帮助用户更好地掌握该软件的功能和操作方法。
2.安装和启动2.1 硬件和软件需求在使用Eviews之前,确认您的计算机符合软件的最低硬件和软件要求,并安装好所需的依赖库和驱动。
2.2 安装Eviews通过Eviews官方网站最新的安装程序,并按照安装向导的提示完成软件的安装。
2.3 启动Eviews双击桌面上的Eviews图标或通过开始菜单中的Eviews快捷方式启动软件。
3.数据导入与管理3.1 导入数据通过Eviews提供的数据导入功能,可以从多种文件格式(如Excel、CSV等)中导入数据。
3.2 数据浏览和编辑在Eviews中,可以方便地浏览和编辑已导入的数据,包括修改列名、调整数据格式等。
3.3 数据变换与处理Eviews提供了多种数据变换和处理的功能,如数据平滑、差分等,以满足用户对数据的需求。
4.统计分析4.1 描述性统计Eviews可以计算出数据集的各种描述性统计量,并相应的报告。
4.2 假设检验通过Eviews提供的假设检验功能,可以对单个变量或多个变量进行各种假设检验,如t检验、F检验等。
4.3 回归分析Eviews拥有强大的回归分析功能,可以进行简单回归、多元回归等各类回归分析,并提供了丰富的回归结果和诊断工具。
5.时间序列分析5.1 时间序列图Eviews可以绘制各种时间序列图形,包括线图、散点图、自相关图等,以帮助用户更好地理解时间序列数据的特征。
5.2 预测模型建立通过Eviews提供的时间序列建模功能,可以建立AR、MA、ARMA等各类时间序列模型,并进行模型的拟合和预测。
5.3 模型诊断与优化Eviews提供了一系列模型诊断与优化工具,如残差分析、模型优化、模型比较等,以帮助用户评估和改进建立的时间序列模型。

Eviews 软件的基本操作一、EViews的启动、退出和主界面 (一)启动EViews :单击Windows 的[开始]按钮,选择[程序]项中的[EViews 3],单击[EViews 3]中的[EViews 3.1]。
(二)EViews 的主界面:图附-1 EViews 主界面1.标题栏 EViews 窗口的顶部是标题栏,标题栏左边是控制框。
标题栏的右边是控制按钮,有[最小化]、[最大化(或还原)]和[关闭]三个按钮:。
2.菜单栏 标题栏下面是菜单栏。
菜单栏上共有9个主菜单项,即[File (文件)]、[Edit (编辑)]、[Objects (对象)]、[View (视图)]、[Procs (过程)]、[Quick (快速)]、[Options (选项)]、[Window (窗口)]、[Help (帮助)]。
单击主菜单项时将拉下其子菜单项。
3.命令窗口菜单栏下面是命令窗口(Command Window ),窗口闪烁的“|”是光标。
用户可在光标位置用键盘输入各种EViews 命令,并按回车键执行该命令。
4.工作区窗口命令窗口下面是EViews 的工作区窗口。
操作过程中打开的各子窗口将在工作区内显示。
5.状态栏EViews 主窗口的底部是状态栏,从左到右分别为:信息栏、路径框、当前数据库框和当前工作文件框。
(三)退出EViews选择[File]=>[Exit]1将退出EViews ,如果工作文件没有保存,系统将提示用户保存文件。
1 这里把菜单选择简记为[ ]=>[ ],如[File]=>[Exit]表示:先单击主菜单的[File]项,然后在其下拉菜单项中单击[Exit]菜单项。
菜单栏工作区 命令窗口 信息框 路径 数据库 工作文件 状 态 栏二、EViews基本对象EViews软件的核心是对象的概念。
使用EViews进行计量分析就是使用和操纵各种各样的对象。
本节将介绍对象容器——工作文件(Workfile)和最基本的对象——序列对象(Series)、组对象(Group)和标量对象(Scalar)。
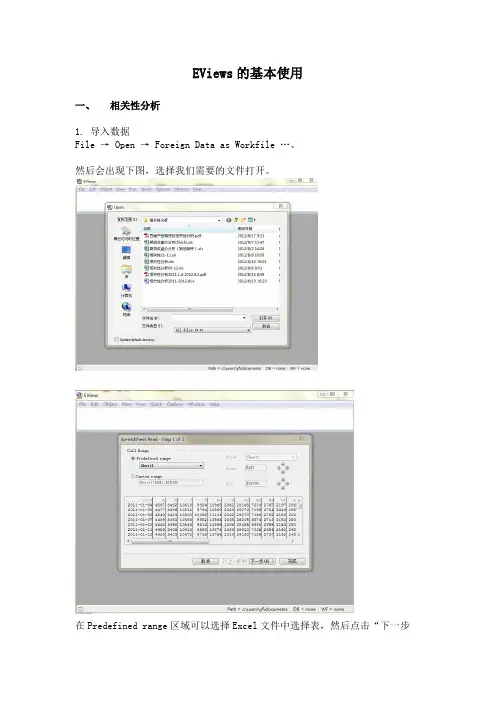
EViews的基本使用一、相关性分析1.导入数据File → Open → Foreign Data as Workfile …、然后会出现下图,选择我们需要的文件打开。
在Predefined range区域可以选择Excel文件中选择表,然后点击“下一步”。
点击“完成”并可成功导入数据。
2.做相关性检验View →Covariance Analysis会出现下图:选择Correlation检验相关性,同时选择Probability确定相关性有意义。
点击“OK”3.分析结果上图是结果的一部分。
上面的数值表示两者的相关系数,下面的数值是两者相关性是否有意义的指标。
一般而言,相关系数在0.8以上我们称两者有高度相关关系,0.8到0.5之间为中度相关,小于0.5视为不相关。
另外,一般Probability的数值小于0.05,表示两者间的相关系数有意义。
二、回归分析1、用以上相同的方法导入数据;2、用以上相同的方法做各X变量间的相关性检验,确定各X变量之间不存在高度相关关系;3、回归分析在主菜单中选择Quick →Estimate Equation…输入回归方程,如方程式为Y= C+α1*X1+α2*X2+……则输入的格式为:Y(空格)C(空格)X1(空格)X2……4、分析结果以上是“沪铜和伦铜,美元指数和道琼斯指数”的回归结果。
一般先看R平方和调整R平方,表示整个模型的拟合程度,越高越好。
然后看F检验,通过F检验表示该模型在统计上有意义。
再看t检验,判断每个系数是否有意义。
一般而言,Prob.大于0.05表示有意义。
然后就可以写出回归方程。
(注:文档可能无法思考全面,请浏览后下载,供参考。
可复制、编制,期待你的好评与关注)。

EViews基本操作与数据分析EViews基本操作与数据分析一、EViews的基本操作与数据处理1、建立工作文件(File/New/Workfile)、数据库(Database)、程序(Program)或文本文件(Text File)。
(1)EViews的界面:菜单栏下面的白色空白区域为命令窗口。
(2)打开空表:Quick/Empty Group。
(3)Workfile的界面:c表示截距序列,resid表示残差序列。
2、输入数据(1)数据分为时间序列数据(Dated-regular Frequency,默认选项)、横界面数据(Unstructured/Undated)和面板数据(Balanced Panel),时间序列的日期间隔符号可以是“:”、“.”或“,”。
Q表示季度,M表示月份,W表示周。
(2)EViews也可以直接打开已有文件(Open/EViews Workfile)、外部数据(Foreign Data)、数据库(Database)、程序(Program)或文本文件(T ext File)。
EViews 5.0可以导入其他的外部数据:File/Open/Foreign Data as Workfile。
(3)调用外部数据:File/Import/……。
先建立工作文件,然后才能调用数据,EViews允许调用3种格式的数据:ASCII、Lotus和Excel工作表。
如果原文件已有序列名称,则只需输入序列个数即可。
3、对象(Object)的操作与处理(1)生成新对象(New Object):Equation、Graph、Group、Matrix、Series、Table、Text、V AR等。
(2)对象的编辑:剪切(Cut)、复制(Copy)、粘贴(Paste)、删除(Delete)、合并(Merge)和替代(Replace)等。
(3)对象的命名:对象必须以半角字符命名,不能用中文命名,命名不宜太长。

《计量经济学》E v i e w s上机基本操作前言《计量经济学》作为经济学类各专业的核心课程已开设多年。
多年的教学实践中,我们深感计量经济学软件在帮助同学们更好地学习、理解《计量经济学》基本思想、提高解决实际问题的能力等方面有着重要的作用。
在过去的教学中曾采用过多种版本的软件,包括TSP、Eviews、SPSS、SAS等。
从1998年以来,Eviews逐渐成为计量经济学本科教学的基本软件。
实践证明,Eviews具有自身的特色和优良的性能。
《计量经济学》Eviews上机基本操作,主要介绍Eviews 的基本功能和基本操作,以供同学们参考。
Eviews基本操作第一部分预备知识一、什么是EviewsEviews (Econometric Views)软件是QMS(Quantitative Micro Software)公司开发的、基于Windows平台下的应用软件,其前身是DOS操作系统下的TSP软件。
Eviews软件是由经济学家开发,主要应用在经济学领域,可用于回归分析与预测(regression and forecasting)、时间序列(Time series)以及横截面数据(cross-sectional data )分析。
与其他统计软件(如EXCEL、SAS、SPSS)相比,Eviews功能优势是回归分析与预测,其功能框架见表1.1。
从多方面的因素考虑,本手册不对最新版本的Eviews软件进行介绍,而只是以目前人们使用较为广泛的Eviews3.1版本为蓝本介绍该软件的使用。
Eviews3.1版本是QMS公司1998年7月推出的。
二、Eviews安装Eviews文件大小约11MB,可在网上下载。
下载完毕后,点击SETUP安装,安装过程与其他软件安装类似。
安装完毕后,将快捷键发送的桌面,电脑桌面显示有Eviews3.1图标,整个安装过程就结束了。
双击Eviews按钮即可启动该软件。
(图1.2.1)图1.2.1三、Eviews工作特点初学者需牢记以下两点。


Eviews软件基本操作一、工作文件及建立(一)主窗口简介启动Eviews软件,进入主窗口。
如下图所示:控制按钮标题栏菜单栏窗令命主显示窗口路径状态栏信息栏主窗口图1、标题栏:窗口的顶部是标题栏。
1 、菜单栏:标题栏下是菜单栏。
2,WindowQuick,Options,,,Edit,ObjectsView,Procs,9菜单栏上共有个选项:File 。
用鼠标点击可打开下拉式菜单,显示该部分的具体功能。
HelpSave /保存(Save)、打开(open)、如:File包含一些文件的常用操作命令。
建立(New、退、运行程序(Run)Export)、打印(Print)、读出(As)、关闭(Close)、读入(Import)。
常用的有新建工作文件,打开工作文件,保存工作文件,输入输出数据Exit)出Eviews(文件。
)功能。
在某些特殊的)和粘贴(Paste Edit一般情况下只有复制功能,即拷贝(Copy )等操作。
)、替换(ReplaceFind窗口,该菜单项还包括剪切(Cut)、删除(Delete)、查找(从数据库获取使新New Objects)、包括建立新对象objects提供有关对象的基本操作。
(、复制对Store to DB)/对象(FetchUpdate From DB)、将工作文件中的对象存储到数据库(。
、删除(Delete))CopySelected象()、重命名(Rename View其功能随窗口的不同而变化,主要涉及变量的各种查看方式。
Procs它的功能也是随窗口的不同而变化,其主要功能为变量的预算过程。
提供快速统计分析过程。
Quick 系统参数设定选项。
Options的过程中将会有多个子窗口。
该菜单提供子窗口的切换和关闭在使用EviewsWindow 功能。
帮助功能。
提供索引方式和目录方式的帮助功能。
Help3、命令窗口:菜单栏下是命令窗口。
窗口最左端的竖线是提示符,允许用户在提示符后通过键盘输入EViews(TSP风格)命令。

EViews软件的基本操作1 EViews的启动双击EViews6.exe,进入EViews主窗口2创建工作文件在主窗口菜单上依次点击File\New\Workfile,自动弹出创建工作文件选项卡。
在Workfile structure type选项区共有3种类型,默认状态是Dated-regular frequency类型。
在默认状态Dated-regular frequency类型下,另一选项区Date specification的默认的时间频率为Annual(年度数据),在起始栏和终止栏分别输入相应的日期1990和2004。
点击OK,在主窗口内弹出工作文件窗口。
工作文件一开始就包含了两个对象,分别为C(系数向量)和resid(残差)。
它们当前的取值分别是0 和NA(空值)。
可以通过鼠标左键双击对象名打开该对象查看其数据。
3 输入数据点击Quick \ Empty Group (Edit Series),进入数据编辑窗口,输入或粘贴数据。
注意,输入数据时最好将被解释变量y放在左起第一列,Eviews 在自动列方程时将默认左起第一列为被解释变量。
向上拖动窗口右侧的滑动条到obs的位置,输入序列名。
点击Name命令,自动弹出Object Name对话框窗口,输入文件名称(或默认为group01),关闭数据输入窗口即可;或直接关闭数据输入窗口,也会弹出提示命名序列组文件的对话框。
4 生成序列从主窗口点击Quick/Generate Series,然后在弹出的公式编辑窗口空白区输入公式LNY=LOG(Y)。
或从工作文件窗口点击Genr亦可弹出公式编辑窗口。
依次生成以下数列:LNX=LOG(X)DX=D(X)X1=X^2X2=1/XT=@TREND(1989)5 编辑数组及序列按住Ctrl 键不放,依次单击选择变量,完成后,单击鼠标右键,在弹出的快捷菜单中点击Open/as Group,弹出数组窗口,其中变量从左至右按选择变量的顺序来排列。
eviews使用指南与案例EViews是一款经济统计软件,广泛应用于经济学、金融学等领域的数据分析和建模工作。
本文将为大家介绍EViews的使用指南和一些实际案例,帮助读者更好地了解和应用EViews。
一、EViews的使用指南1. EViews的安装和启动:首先,用户需要下载并安装EViews软件。
安装完成后,双击桌面上的EViews图标即可启动软件。
2. 数据导入和处理:EViews支持导入多种数据格式,如Excel、CSV等。
用户可以使用“File”菜单中的“Import”选项将数据导入EViews中,并进行必要的数据清洗和处理。
3. 数据探索和描述统计分析:在导入数据后,用户可以使用EViews提供的数据探索功能进行数据分析,包括数据的描述统计分析、数据可视化等。
4. 模型建立和估计:EViews提供了多种经济学模型的建立和估计方法,如回归分析、时间序列分析等。
用户可以通过选择相应的命令和参数来进行模型建立和估计。
5. 模型诊断和检验:在模型建立和估计完成后,用户需要对模型进行诊断和检验。
EViews提供了多种模型诊断和检验的功能,如残差分析、异方差性检验等。
6. 模型预测和模拟:EViews可以基于已建立的模型进行预测和模拟。
用户可以输入新的自变量数据,通过模型预测因变量的值,或者进行模型的蒙特卡洛模拟分析。
7. 结果输出和报告生成:EViews可以将分析结果以表格、图形等形式输出,并支持生成报告和文档。
用户可以选择相应的输出选项和格式,方便结果的展示和分享。
二、EViews的应用案例1. 时间序列分析:使用EViews可以进行时间序列数据的建模和分析。
例如,可以通过ARIMA模型对股票价格进行预测,或者通过VAR模型分析宏观经济变量之间的关系。
2. 经济政策评估:EViews可以用于评估不同经济政策对经济变量的影响。
例如,可以建立一个VAR模型,通过冲击响应分析来评估货币政策对通胀和经济增长的影响。
Eviews 基本操作1.启动Eviews双击 Eviews 图标,出现 Eviews 窗口,它由以下部分组成:标题栏“ Eviews ”、主菜单“文件,编辑,…,帮助”、命令窗口(空白处)和工作区域。
2.产生文件Eviews 的操作在工作文件中进行,故首先要有工作文件,然后进行数据输入、分析等等操作。
)读已存在文件:文件/打开/Workfile 。
(2)新建文件:文件/新建/Workfile ,出现对话框“工作文件范围”,选取或填上数据类型、起止时间。
填好后,得到一个无名字的工作文件,其中有:时间范围、当前工作文件样本范围、Filter、默认方程、系数向量 C 、序列残差附:1Annual选项:可以用四位年份如Start date:1955 End date 1998,在1900年和2000年之间的年份只需要后两位即可。
Quarterly选项: 输入格式为: 1992:1, 65:4, 2002:3年后面只能跟1、2、3、4代表季度。
Monthly选项: 输入格式Examples: 1956:1, 1990:11年后面为月Weekly and daily选项: 在缺省状态下的格式如8:10:97即为October 8, 1997.它的格式可以通过Options/Dates-Frequency……调整Undated or irregular选项:为非日期数据如:Start date:1 End date 100,即为100个数的一个序列。
附:2保存Workfile可以用两种方法保存Workfile,第一种方法点击主窗口中File/SaveAs or File/Save;第二,Workfile窗口中的工具栏中的Save按钮即可以保存。
打开Workfile用File/Open/Workfile的方式可以打开以前保存的Workfile改变workfile的显示方式:选择View/Display Filter,或者双击workfile窗口中的Filter.*就会出现如下的对话框在*号后面填入你想要显示的变量(中间用空格阁开),点OK即可。
EViews的基本操作EViews 的基本操作实验目的:初步了解EViews 软件,掌握EViews 的基本操作1. EViews 主窗口EViews 是基于Windows 操作系统的计量分析软件,它的前身是1981 年发布的MicroTSP 。
EViews 大部分的数据处理是面对经济时间序列数据,但是这并不妨碍它对大量的截面数据处理同样表现出卓越的功能。
EViews 利用了现代软件开发中的可视化技术,可以使用鼠标,通过点击 Windows 命令、修改对话框选项等完成相关数据处理过程,同时也可以利用 EViews的命令行窗口和批处理程序完成同样的数据处理过程。
正确安装并运行EViews 后,我们将会看到EViews 窗口(如图 1 EViews 窗口所示)。
标题栏主菜单命令窗口下拉式菜单工作区域默认数据库消息区当前工作文件默认路径图 1 EViews 窗口2. 工作文件基础EViews 的大部分操作都是在工作文件的基础上完成的,因此工作文件构成了EViews 的基础。
对EViews 的基本操作离不开对工作文件的操作,以下部分介绍如何新建、保存、读取、修改一个工作文件。
2.1 新建一个工作文件(Creating a Workfile )使用EViews 的第一步通常就是新建一个工作文件。
建立一个工作文件可以按下列顺序点击EViews 的主菜单:File→New →Workfile 。
此时打开下列对话框。
图 2 新建一个工作文件在图 2 新建一个工作文件所示的对话框中,用户需要根据实际数据的特点,指定工作文件的数据频率(workfile frequency ),以及工作文件的范围,即开始日期(start date )和结束日期(end date )。
关于数据频率,对话框中提供了八种不同的选择,其含义和输入格式如下Annual ,即年度数据Semi-annual,即半年度数据,具体表示为年份跟着一个冒号或句点,和一个半年数。
Eviews统计分析软件的基本使用方法一、介绍Eviews是一款专为经济学家和金融学家设计的统计分析软件,它提供了丰富的数据分析和计量经济模型建立功能。
本文将介绍Eviews的基本使用方法,包括数据导入、数据处理、计量经济模型建立和结果分析等方面。
二、数据导入使用Eviews进行统计分析的第一步是将数据导入软件中。
Eviews支持多种数据格式,包括Excel、CSV和SPSS等。
用户可以选择“File”菜单下的“New”选项来创建新的数据文件,然后选择“Import”选项将数据文件导入。
在导入数据时,用户需要指定数据的类型、路径和文件名等信息。
三、数据处理导入数据后,用户可以对数据进行处理和清洗,以准备后续的分析工作。
Eviews提供了多种数据处理功能,包括数据排序、变量选择、缺失值处理和数据转换等。
用户可以通过简单的拖放操作或者使用命令来完成这些处理任务。
四、计量经济模型建立Eviews的核心功能之一是计量经济模型的建立和估计。
用户可以通过Eviews提供的拖放界面来构建模型,也可以使用Eviews的命令语言进行模型编写。
Eviews支持多种计量经济模型,包括线性回归模型、时间序列模型和面板数据模型等。
用户可以根据自己的需求选择适合的模型进行建立。
五、模型估计建立模型后,用户需要对模型进行估计和检验。
Eviews提供了多种估计方法,包括最小二乘法、广义最小二乘法和面板数据估计等。
用户可以选择合适的估计方法,并根据需要进行参数估计和假设检验。
Eviews会根据用户的选择自动进行结果计算,并提供相应的输出。
六、结果分析完成模型估计后,用户需要对结果进行分析和解释。
Eviews提供了丰富的结果分析工具,包括参数估计的显著性检验、残差分析、模型拟合度检验和模型比较等。
用户可以通过简单的图表和统计量来展示和解释模型的结果。
七、时间序列分析除了建立和估计计量经济模型,Eviews还提供了强大的时间序列分析功能。
1.EVIEWS基础 (3)1.1. E VIEWS简介 (3)1.2. E VIEWS的启动、主界面和退出 (3)1.3. E VIEWS的操作方式 (6)1.4. E VIEWS应用入门 (6)1.5. E VIEWS常用的数据操作 (15)2.一元线性回归模型 (24)2.1. 用普通最小二乘估计法建立一元线性回归模型 (24)2.2. 模型的预测 (30)2.3. 结构稳定性的C HOW检验 (34)3. 多元线性回归 (39)3.1. 用OLS建立多元线性回归模型 (39)3.2. 函数形式误设的RESET检验 (45)4. 非线性回归 (48)4.1. 用直接代换法对含有幂函数的非线性模型的估计 (48)4.2. 用间接代换法对含有对数函数的非线性模型的估计 (50)4.3. 用间接代换法对CD函数的非线性模型的估计 (53)4.4. NLS对可线性化的非线性模型的估计 (55)4.5. NLS对不可线性化的非线性模型的估计 (58)4.6. 二元选择模型 (62)5. 异方差 (68)5.1. 异方差的戈得菲尔德——匡特检验 (68)5.2. 异方差的WHITE检验 (72)5.3. 异方差的处理 (75)6. 自相关 (79)6.1. 自相关的判别 (79)6.2. 自相关的修正 (83)7. 多重共线性 (87)7.1. 多重共线性的检验 (87)7.2. 多重共线性的处理 (92)8. 虚拟变量 (94)8.1. 虚拟自变量的应用 (94)8.2. 虚拟变量的交互作用 (99)8.3. 二值因变量:线性概率模型 (101)9. 滞后变量模型 (105)9.1. 自回归分布滞后模型的估计 (105)9.2. 多项式分布滞后模型的参数估计 (110)10. 联立方程模型 (115)10.1. 联立方程模型的单方程估计方法 (115)10.2. 联立方程模型的系统估计方法 (119)21.Eviews基础1.1. Eviews简介Eviews:Econometric Views(经济计量视图),是美国QMS公司(Quantitative Micro Software Co.,网址为)开发的运行于Windows环境下的经济计量分析软件。
Eviews 基本操作1.启动Eviews双击 Eviews 图标,出现 Eviews 窗口,它由以下部分组成:标题栏“ Eviews ”、主菜单“文件,编辑,…,帮助”、命令窗口(空白处)和工作区域。
2.产生文件Eviews 的操作在工作文件中进行,故首先要有工作文件,然后进行数据输入、分析等等操作。
)读已存在文件:文件/打开/Workfile 。
(2)新建文件:文件/新建/Workfile ,出现对话框“工作文件范围”,选取或填上数据类型、起止时间。
填好后,得到一个无名字的工作文件,其中有:时间范围、当前工作文件样本范围、Filter、默认方程、系数向量 C 、序列残差附:1Annual选项:可以用四位年份如Start date:1955 End date 1998,在1900年和2000年之间的年份只需要后两位即可。
Quarterly选项: 输入格式为: 1992:1, 65:4, 2002:3年后面只能跟1、2、3、4代表季度。
Monthly选项: 输入格式Examples: 1956:1, 1990:11年后面为月Weekly and daily选项: 在缺省状态下的格式如8:10:97即为October 8, 1997.它的格式可以通过Options/Dates-Frequency……调整Undated or irregular选项:为非日期数据如:Start date:1 End date 100,即为100个数的一个序列。
附:2保存Workfile可以用两种方法保存Workfile,第一种方法点击主窗口中File/SaveAs or File/Save;第二,Workfile窗口中的工具栏中的Save按钮即可以保存。
打开Workfile用File/Open/Workfile的方式可以打开以前保存的Workfile改变workfile的显示方式:选择View/Display Filter,或者双击workfile窗口中的Filter.*就会出现如下的对话框在*号后面填入你想要显示的变量(中间用空格阁开),点OK即可。
3.输入数据(1)从键盘输入:快速的/空组(编辑系列) ,打开组窗口,产生一个无标题“组”;按列在表中输入序列名(在 OBS )及其数据,每输入一个数据完,敲一次进入。
(2)从 excel 复制数据:先取定 excel 中的数据区域,选“复制”;其次,打开 Eview ,同 2-- ( 2 ),建工作文件,使样本区域包含与被复制数据同样多的观察值个数;第三,击快速的/空组(编辑系列) ;第四,按向上滚动指针,击数据区 OBS 右边的单元格,点编辑/粘贴,于是,在工作文件中有被复制的数据序列的图标。
(3)从 excel 复制部分数据到已存在的序列中:取定要复制的数据,复制之;打开包含已存在序列的组窗口,使之处于编辑模式(开关键是 edit+/- );将光标指到目标单元格,点编辑/粘贴,其它同 3-- ( 2 )。
4.从Excel工作表中读取数据击 Procs/导入/Read-Lotus-Excel ,选取文件类型为 Text-ASCII 或 Excel.xls ,打开文件;在对话框中,选取要打开的序列名,多个之间用空格隔开(如全用原序列名,输入序列的个数即可)。
5. 执行Eviews命令的几种方式以执行最小二乘法为例:方式1:使用窗口快捷命令: “Quick”→ “Estimate Equation”→ “Method”→“LS”,在对话框中依次输入因变量与自变量,如“Y c X1 X2 X3”方式2:在“Command”窗口中输入命令:LS Y c X1 X2 X3方式3:编程并执行程序:“File” → “New”→ “Program”;输入命令:LS Y c X1 X2 X3;按“Run”执行命令Matrix Algebra1、矩阵定义如何在Eviews中 定义各种矩阵The most basic method of assigning matrix values is to assign a value for a specific row and column element of the matrix. Simply enter the matrix name, followed by the row and column indices, in parentheses, and then an assignment to a scalar value.For example, suppose we declare the matrix A:matrix(2,2) aa(1,1) = 1a(2,1) = 4vector(7) y = 2rowvector(12) z = 3matrix(10,2) zdata = 5matrix ydata = zdatamatrix(10,10) xdata = ydata2.矩阵运算2.1 矩阵转置matrix y = @transpose(x)2.2 矩阵加减matrix(6,4) xdata=6matrix(6,4) ydata=4matrix(6,4) zdata=xdata-ydata2.3 矩阵乘法内积:vector(8) x1=2vector(8) x2=3matrix x=@inner(x1)matrix y=@transpose(x1)*x2二次形:scalar z = vec1*@inverse(matrix)*@transpose(vec1)2.4 行列式matrix(4,4) xscalar xdet=@det(x)2.5 矩阵求逆matrix(4,4) xmatrix xinv=@inverse(x)2.6 矩阵求迹matrix(4,4) xscalar xinv=@trace(x)2.7 矩阵求特征根与特征向量sym(4,4) xvector v1 = @eigenvalues(x)matrix m2 = @eigenvectors(x)2.8 矩阵求秩scalar rank1 = @rank(m1)3.矩阵数值的提取及其与其他对象之间的转化3.1 从矩阵中提取向量或子块matrix(10, 10) m1vector v1 = @vec(m1)vector v2 = @columnextract(m1,3)vector v3 = @rowextract(m1,4)vector v4 = @columnextract(sym1,5)The @vec function creates a 100 element vector, V1, from the columns of M1 stacked one on top of another. V2 will be a 10 element vector containing the contents of the third column of M1 while V3 will be a 10 element vector containing the fourth row of M1. The @vec, @rowextract, and @columnextract functions also work with sym objects. V4 is a 10 element vector containing the fifth column of SYM1.You can also copy data from one matrix into a smaller matrix using @subextract. For example:matrix(20,20) m1=1matrix m2 = @subextract(m1,5,5,10,7)matrix m3 = @subextract(m1,5,10)matrix m4 = m1M2 is a matrix containing a submatrix of M1 defined by taking the part of the matrix M1 beginning at row 5 and column 5 and ending at row 10 and column 7. M3 is the matrix taken from M1 at row 5 and column 10 to the last element of the matrix (row 20 and column 20). In contrast, M4 is defined to be an exact copy of the full matrix.3.2 从时间序列中生成矩阵smpl 1963:3 1993:6group mygrp hsf gmpyqvector xvec = gmpyqmatrix xmat = mygrpThese statements create the vector XVEC and the two column matrix XMAT containing the non-missing series and group data from 1963:3 to 1993:6. Note that if GMPYQ has a missing value in 1970:01, and HSF contains a missing value in 1980:01, both observations for both series will be excluded from XMAT.When performing matrix assignment, you may refer to an element of a series, just as you would refer to an element of a vector, by placing an index value in parentheses after the name. An index value i refers to the i-th element of the series from the beginning of the workfile range. For example, if the range of the current annual workfile is 1961 to 1980, the expression GNP(6) refers to the 1966 value of GNP. These series element expressions may be used in assigning specific series values to matrix elements, or to assign matrix values to a specific series element. For example:smpl 61 90group groupx inv gdp m1vector v = @convert(gdp)matrix x = @convert(groupx)X is a matrix with the first column containing data from INV, the second column from GDP, and the third column from M1.3.3 矩阵与序列之间的相互转化由序列到矩阵STOMExample:sample smpl_cnvrt.set 1950 1995smpl 1961 1990group group1 gnp gdp moneyvector(46) vec1matrix(3,30) mat1stom(group1,mat1)While the operation of stom is similar to @convert, stom is a command and cannot be included in a matrix expression. Furthermore, unlike @convert, the destination matrix or vector must already exist and have the proper dimension.stomna (Series TO Matrix with NAs) works identically to stom, but does not exclude observations for which there are missing values. The elements of the series for the relevant sample will map directly into the target vector or matrix. Thus,smpl 1951 2000vector(50) gvectorstom(gdp,gvector)It will always create a 50 element vector GVECTOR that contains the values of GDP from 1951 to 2000, including observations with NAs.mtos (Matrix TO Series) takes a matrix or vector and copies its data into an existing series or group, using the current workfile sample or a sample that you provide.由矩阵到序列MTOSExamples:mtos(mat1,group1)mtos(vec1,resid)mtos(mat2,group1,smpl1)As with stom the destination series or group must already exist and the destination dimension given by the sample must match that of the source vector or matrix.Eviews中的常用函数及应用1.一般函数@abs(x) @log(x) @exp(x) @inv(x) @sqrt(x)=sqr(x) d(x)=x-x(-1) dlog(x)=log(x)-log(x(-1))|x| lnx e x 1/x@pch(x)=(x-x(-1))/x(-1) @seas(n) (seasonal dummy) @obs(X)(观察值个数N)@mean(X)@max(X) @min(X) @sum(X) @var(X)(分母n)@cor(X,Y) @cov(X,Y)@stdev(x)(分母n-1)@sumsq(x)(平方和) @sin(x) @cos(x) @tan(x)@c开头指CDF=Prop(X≤x); @d开头指概率密度值; @q开头指逆CDF=q*:Prop(X≤q*)=p; @r开头指随机数生成器@cchisq(x,v) @dchisq(x,v) @qchisq(p,v) @rchisq(v)@cfdist(x,v1,v2) @dfdist(x,v1,v2) @qfdist(p,v1,v2) @rfdist(v1,v2) @ctdist(x,v) @dtdist(x,v) @qtdist(p,v) @rtdist(v)@cnorm(x) @dnorm(x) @qnorm(p) @rnorm如@qtdist(0.05,1)=-6.314, @cfdist(60.71,12,1)=0.90,又如自由度为12的t统计量的5%显著水平(双尾)的临界值可由命令窗口输入“=@qtdist(0.975,12)”得到(为2.179)@chisq(x,v) @fdist(x,v1,v2) @tdist(x,v) (to facilitate the computation of p-values)如“=@tdist(3.45,12)”=Prop(|t(12)|>3.45)=0.0048(如显著性水平为1%,则可拒绝原假设),其中3.45是此t统计量样本值的绝对值。