
汽车销量预测
摘要
汽车工业在我国已有50 多年的发展历史, 而汽车产业真正得到快速发展是从上世纪90 年代开始的。现在汽车工业在我国经济中已占有很重要的地位。预测汽车的销售量,无论是对于整体掌控汽车市场的发育与成长态势的政策制定者,还是对于研究市场行情以制定营销策略的汽车厂商而言,都具有极其重要的作用。我们通过网络搜索相关数据,然后运用线性回归及灰色预测对汽车销量进行数学建模分析预测,然后再对模型进行评估修改。
关键词:汽车销量线性回归灰色预测
一.问题重述
1.问题背景
近年来,随着国民经济和社会的进一步发展,汽车工业也逐步成为中国的支柱性产业之一,汽车市场表现出产销两旺的发展态势。而汽车市场是汽车工业的晴雨表,预测汽车的销售量,无论是对于整体掌控汽车市场的发育与成长态势的政策制定者而言,还是对于研究市场行情以制定营销策略的汽车厂商而言,都具有极其重要的作用。
2.需要解决的问题
问题一:影响汽车销量的因素有哪些?
问题二:通过数据建立数学模型并进行预测。
问题三:验证并修改数学模型。
二.问题分析
一.对问题一的分析
在这里我门选取了汽车产量、公路长度、城镇居民收入、GDP这样一些因素来考虑,当然影响汽车销售的因素远不止如此石油价格上涨,银行存款利率等都会对汽车销量有影响。并且这些因素也是相互影响的。这里为了简单考虑我们把每一个因素单独列出来,研究其余汽车销量的关系。我们通过互联网搜索获得以下数据:
二.对问题二的分析
对于问题二我们有两种思路,第一个是通过问题一得到的相关数据及结论运用线性回归
的知识建立数学模型。但是通过线性回归得到的方程却还不够,因为线性方程故事汽车销量
需要知道汽车产量、公路长度、GDP这样一些数据,但我们不知到以后的汽车产量、公路长
度、GDP。这里吗有许多不确定因素所以我们采用灰色预测的方法来预测汽车销量。
三、模型假设与约定
国家经济处于一种正常平稳的发展趋势,不能有类似于08年的金融危机。
四、模型建立
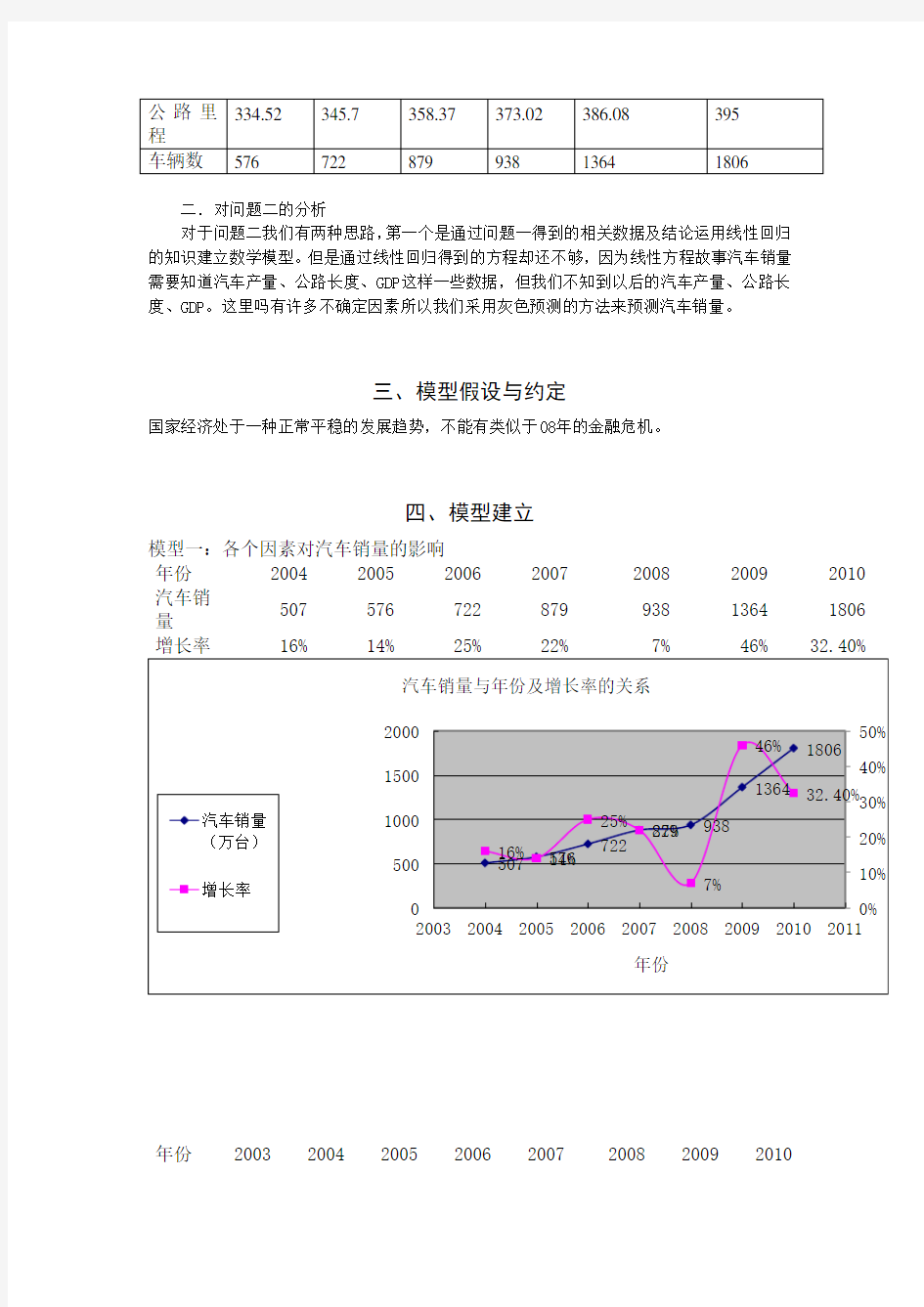
模型一:各个因素对汽车销量的影响
年份2004 2005 2006 2007 2008 2009 2010 汽车销
507 576 722 879 938 1364 1806 量
增长率16% 14% 25% 22% 7% 46%
32.40%
GDP(百亿) 135.82
28
159.87
83
184.93
74
216.31
44
265.81
03
314.04
543
340.90
28
307.98
32
GDP
增长
率
9.30% 9.40% 10.70% 12.00% 13.60% 9.10% 8.60%
年份2004 2005 2006 2007 2008 2009 汽车增长
16% 14% 25% 22% 7% 46% 率
GDP增长
9.40% 10.70% 12.00% 13.60% 9.10% 8.60% 率
年份2005 2006 2007 2008 2009 2010 GDP(百
159.8784 184.9374 216.3144 265.8103 314.0454 340.90281 亿)
公路里
334.52 345.7 358.37 373.02 386.08 395 程
汽车销
576 722 879 938 1364 1806 量
由以上的图表可以看出,汽车的增长量和GDP增长成指数相关,和公路里程数指数性相切合,和人均支配资金数成指数关系,所以我们假设:
车辆销量为Y,GDP为x1,公路里程数为x2,人均支配金额为x3.存在Y=a+b*Inx1+c*Inx2+d*Inx3
模型二:灰色预测法预测汽车销量
1.选取的数据时从04年至10年的汽车销量,时间序列初始值为:
设原始数列为)]7(,),2(),1([)0()0()0()0(x x x x ==[507,577,722,879,934,1364,1807] 2.生成累加序列
把数列各项(时刻)数据依次累加的过程称为累加生成过程。令
,,,2,1,)()(1)0()
1(n k i x k x k
i ==∑=
称所得到的新数列)](,),2(),1([)1()1()1()1(n x x x x =为数列)0(x 的1次累加生成数列。有
)1(x =[507,1064,1786,2665,3599,4963,6670] 3.计算级比
级比:.,,3,2,)
()
1()()1()1(n k k x k x k =-=σ
)2(σ=0.477 )3(σ=0.596 )4(σ=0.670 )5(σ=0.740 )6(σ=0.725 )7(σ=0.744
如果所有的级比都落在可容覆盖区间
),(1
21
2++-=n n e
e
X 内,则数据列)0(x 可
以建立GM(1,1)模型且可以进行灰色预测。
4.建立GM (1.1)模型
u t ax dt
t dx =+)()
()1()
1(
解为
.))1(()()1()
0()
1(a
u
e a u x t x t a +-=--
五、模型求解
模型一的求解:
由mathmatic 软件运行可知:
In[1]:=A={{Log[184.9374],Log[104.93],Log[334.52]},{Log[265.8103],Log[137.858],Log[358.37]},{Log[340.9028],Log[171.747],Log[386.08]}}
Out[1]:={{5.22002,4.65329,5.8127},{5.58278,4.92622,5.88157},{5.8316,5.14602,5.95604}}
In[2]:=b={576,879,1364} Out[2]:={576,879,1364} In[3]:=LinearSolve[A,b]
Out[3]:={-6598.29,10476.3,-2362.1} 及得到公式
Y=10476.3*Inx2-6598.29*x1-2362.1*x3
模型二求解 建立GM (1.1)模型
u t ax dt
t dx =+)()
()1()
1(
a 和u 可以通过如下最小二乘法拟合得到
Y B B B u a T T 1)(-=???
? ?? 式中,
Y 为列向量Y[x (0)(2),x (0)(3),…,x (0)(7)]T ; Y=[557,722,879,934,1364,1807]T B 为构造数据矩阵:
(1)(1)(1)(1)(1)(1)
1/2(1)(2)11/2(2)(3)11/2(1)()1
x x x x x M x M ??
??
-+???
?????
-+???
??
?????--+?????
?
B=??
???????
???????????------1.......5.58161.........42811.........31321.......5.20251..........14251........5.785
Y B B B u a T
T 1)(-=???
? ?? 通过matlab 计算得出
a=-0.2376 u=355.4599
得到预测式子
a
u
e a u x k x
k a +-=--)1()0()1())1(()(?……………………….1式
)1(?)1(+k x
=2073k e 2376.0-1496 在利用累减 )()
0(,k x
=)()1(,k x —)1()
1(,-k x
通过计算得到以下数据
)0(?)1(x
=577 )1(?)1(x
=1132 由模型的得到的05年汽车销量为 )1(?)0(x =555 )2(?)1(x
=1838 由模型的得到的06年汽车销量为 )2(?)0(x =706 )3(?)1(x
=2732 由模型的得到的07年汽车销量为 )3(?)0(x =894 )4(?)1(x
=3866 由模型的得到的08年汽车销量为 )4(?)0(x =1132 )5(?)1(x
=5305 由模型的得到的09年汽车销量为 )5(?)0(x =1439 )6(?)1(x
=7128 由模型的得到的10年汽车销量为 )6(?)0(x =1823 )7(?)1(x
=9441 由模型的预测的11年汽车销量为 )7(?)0(x =2313 由于没有找到11年全年的汽车销量所以11年的作为一个预测值
)8(?)1(x
=12375 由模型的预测的12年汽车销量为 )8(?)0(x =2934 )9(?)1(x
=16095 由模型的得到的13年汽车销量为 )9(?)0(\x =3720 )10(?)1(x
=20813 由模型的得到的14年汽车销量为 )10(?)0(x =4718 )11(?)1(x
=26796 由模型的得到的05年汽车销量为 )11(?)0(x =5983 七、模型检验
模型二的检验:
(1) 残差检验:计算相对残差
6...2,1,0,)
()(?)()()
0()0()0(=-=k k x k x
k x k ε 通过计算得:ε=[0, 0.038, 0.022, -0.017 , -0.212, -0.055, -0.009] 如果对所有的1.0|)(| 2.0|)(| 可以看到除了08年的数据外其余的都还算理想,由于08年出现金融危机,对汽车的销售有一定的影响,所以出现了误差较大的情况 六、模型评价 通过对该模型的检验,该模型能基本描述汽车市场的销量。不过该模型并未考虑经济市场的因素,尤其是类似08年金融危机那样的因素,所以也只能作为一个理想的模型考虑。 还有汽车是属于使用时间比较长的商品,随着社会经济的不断发展,汽车的保有量会趋向与一个较为稳定的数值。类似于人口增长模型。汽车的年销售量也不可能无限之上升,所以该模型也只适用于短时间内的预测。 七、参考文献 高等出版社数学模型(第三版)姜启源谢金星叶俊编 我国汽车销量主要影响因素的分析危高潮西安财经学院学报 中国统计年鉴2011 https://www.doczj.com/doc/b9642774.html,/tjsj/ndsj/2011/indexch.htm 灰色系统模型-清华大学讲义 基于灰色时间序列预测中国汽车销量杨月英,马萍湖州职业技术学院学报 八、附录 矩阵计算程序 >> B=[-785.5 1;-1425 1;-2025.5 1;-3132 1;-4281 1;-5816.5 1] B = 1.0e+003 * -0.7855 0.0010 -1.4250 0.0010 -2.0255 0.0010 -3.1320 0.0010 -4.2810 0.0010 -5.8165 0.0010 >> C=inv(B'*B) C = 0.0000 0.0002 0.0002 0.6406 >> Y=[577;722;879;934;1364;1807] Y = 577 722 879 934 1364 1807 >> D=C*B'*Y D = -0.2376 355.4599 线性拟合程序 In[1]:=A={{Log[184.9374],Log[104.93],Log[334.52]},{Log[265.8103],Log[137.858 ],Log[358.37]},{Log[340.9028],Log[171.747],Log[386.08]}} Out[1]:={{5.22002,4.65329,5.8127},{5.58278,4.92622,5.88157},{5.8316,5.14602,5. 95604}} In[2]:=b={576,879,1364} Out[2]:={576,879,1364} In[3]:=LinearSolve[A,b] Out[3]:={-6598.29,10476.3,-2362.1} 数学建模知识——之新手上路 一、数学模型的定义现在数学模型还没有一个统一的准确的定义,因为站在不同的角度可以有不同的定义。不过我们可以给出如下定义:“数学模型是关于部分现实世界和为一种特殊目的而作的一个抽象的、简化的结构。”具体来说,数学模型就是为了某种目的,用字母、数学及其它数学符号建立起来的等式或不等式以及图表、图像、框图等描述客观事物的特征及其内在联系的数学结构表达式。一般来说数学建模过程可用如下框图来表明:数学是在实际应用的需求中产生的,要解决实际问题就必需建立数学模型,从此意义上讲数学建模和数学一样有古老历史。例如,欧几里德几何就是一个古老的数学模型,牛顿万有引力定律也是数学建模的一个光辉典范。今天,数学以空前的广度和深度向其它科学技术领域渗透,过去很少应用数学的领域现在迅速走向定量化,数量化,需建立大量的数学模型。特别是新技术、新工艺蓬勃兴起,计算机的普及和广泛应用,数学在许多高新技术上起着十分关键的作用。因此数学建模被时代赋予更为重要的意义。二、建立数学模型的方法和步骤 1. 模型准备要了解问题的实际背景,明确建模目的,搜集必需的各种信息,尽量弄清对象的特征。 2. 模型假设根据对象的特征和建模目的,对问题进行必要的、合理的简化,用精确的语言作出假设,是建模至关重要的一步。如果对问题的所有因素一概考虑,无疑是一种有勇气但方法欠佳的行为,所以高超的建模者能充分发挥想象力、洞察力和判断力,善于辨别主次,而且为了使处理方法简单,应尽量使问题线性化、均匀化。 3. 模型构成根据所作的假设分析对象的因果关系,利用对象的内在规律和适当的数学工具,构造各个量间的等式关系或其它数学结构。这时,我们便会进入一个广阔的应用数学天地,这里在高数、概率老人的膝下,有许多可爱的孩子们,他们是图论、排队论、线性规划、对策论等许多许多,真是泱泱大国,别有洞天。不过我们应当牢记,建立数学模型是为了让更多的人明了并能加以应用,因此工具愈简单愈有价值。 4. 模型求解可以采用解方程、画图形、证明定理、逻辑运算、数值运算等各种传统的和近代的数学方法,特别是计算机技术。一道实际问题的解决往往需要纷繁的计算,许多时候还得将系统运行情况用计算机模拟出来,因此编程和熟悉数学软件包能力便举足轻重。 5. 模型分析 对模型解答进行数学上的分析。“横看成岭侧成峰,远近高低各不同”,能否对模型结果作出细致精当的分析,决定了你的模型能否达到更高的档次。还要记住,不论那种情况都需进行误差分析,数据稳定性分析。例题:一个笼子里装有鸡和兔若干只,已知它们共有 8 个头和 22 只脚,问该笼子中有多少只鸡和多少只兔?解:设笼中有鸡 x 只,有兔 y 只,由已知条件有 x+y=8 2x+4y=22 求解如上二元方程后,得解 x=5,y=3,即该笼子中有鸡 5 只,有兔 3 只。将此结果代入原题进行验证可知所求结果正确。根据例题可以得出如下的数学建模步骤: 1)根据问题的背景和建模的目的做出假设(本题隐含假设鸡兔是正常的,畸形的鸡兔除外) 2)用字母表示要求的未知量 3)根据已知的常识列出数学式子或图形(本题中常识为鸡兔都有一个头且鸡有 2 只脚,兔有 4 只脚) 4)求出数学式子的解答 5)验证所得结果的正确性这就是数学建模的一般步骤三、数模竞赛出题的指导思想传统的数学竞赛一般偏重理论知识,它要考查的内容单一,数据简单明确,不允许用计算器完成。对此而言,数模竞赛题是一个“课题”,大部分都源于生产实际或者科学研究的过程中,它是一个综合性的问题,数据庞大,需要用计算机来完成。其答案往往不是唯一的(数学模型是实际的模拟,是实际问题的近似表达,它的完成是在某种合理的假设下,因此其只能是较优的,不唯一的),呈报的成果是一篇论文。由此可见“数模竞赛”偏重于应用,它是以数学知识为引导计算机运用能力及文章的写作能力为辅的综合能力的竞赛。四、竞赛中的常见题型赛题题型结构形式有三个基本组成部分: 1. 实际问题背景涉及面宽——有社会,经济,管理,生活,环境,自然现象,工程技术,现代科学中出现的新问题等。一般都有一个 一、汽车零部件销售行业分析 1.行业分析 汽车后市场目前在成熟的汽车大国如美国、日本等国家在整个汽车产业链上占据举足轻重的地位,据统计,在这些国家或地区,按照收益比例来计算,整车销售利润通常不足20%,而在汽车零配件、维修养护等汽车后市场中产生的利润超过70%。中国已然成为全球第一大汽车市场,据预测,到2020年中国汽车保有量将超过2亿辆。另一方面,据中国汽车工业协会数据表明,目前我国的汽车零部件企业数量已经达到20多万家,从业人员接近千万,2014年汽车零配件市场销售1.68万亿,预计到2015年中国汽车零配件行业规模产值可达到2.5万亿元人民币。但我国汽车零配件总产值与汽车整车制造业工业总产值比值仅为0.7:1,远低于国际标准的1.7:1。 目前,汽车主机厂四十多家,维修商户(包括4s店)48万家,汽车后服务领域大举迈入互联网时代,B2C、B2B、O2O,未来10年还将保持年增长率20-35%!无论从市场前景、规模还是利润来分析,无一不显示汽车零配件行业发展尚存无限发展空间。 2.目前渠道 众所周知,尽管各大汽车厂商在整车销售上争夺的异常激烈,但在汽车零配件供应等后市场服务上,面对巨大的经济利益驱使,各大主机厂在对于汽车配件销售这一块作法很是一致,以汽配分销为例,纯正维修件分销经营是由主机厂来主导的,大多是通过汽车4S店来直接销售给终端客户,从而获取高额的零配件销售利润。可随着汽车保有量的加大、车主对后市场认知度的提高,单靠4S店垄断售后市场已经远远不能满足市场的需求,市场终归是要回到公平、公开竞争的层面。 4S店之外,以汽配城为主要形式的汽车零配件代理分销渠道,是一种非常有效的汽车零配件及用品的销售渠道,据不完全统计,目前国内大约有20多万个汽车配件销售商店在销售各种汽车零配件,而且他们大都集中在各地的汽配城中。但是由于目前汽配市场普遍缺乏行业管理标准,管理制度上存在很大的缺失,政策上也缺乏进行必要的引导,其现状是经销商的数量大,规模小,素质低,产品质量良莠不齐,假冒伪劣配件充斥市场,这样的结果 2012年北京师范大学珠海分校数学建模竞赛 题目:对中国大学生数学建模竞赛历年成绩的分析与预测 摘要 本文研究的是对自数学建模竞赛开展以来各高校建模水平的评价比较和预测问题。我们将针对题目要求,建立适当的评价模型和预测模型,主要解决对中国大学生数学建模竞赛历年成绩的评价、排序和预测问题。 首先我们用层次分析法来评价广东赛区各校2008年至2011年及全国各大高校1994至2011年数学建模成绩,从而给出广东赛区各校及全国各大高校建模成绩的科学、合理的评价及排序;其次运用灰色预测模型解决广东赛区各院校2012年建模成绩的预测。 针对问题一,首先我们对比了2008到2011年参加建模比赛的学校,通过分析我们选择了四年都参加了比赛的学校进行合理的排序(具体分析过程见表13),同时对本科甲组和专科乙组我们分别进行排序比较。在具体解决问题的过程中,我们先分析得出影响评价结果的主要因素:获奖情况和获奖比例,其中获奖情况主要考虑国家一等奖、国家二等奖、省一等奖、省二等奖、省三等奖,我们采用层次分析法,并依据判断尺度构造出各个层次的判断矩阵,对它们逐个做出一致性检验,在一致性符合要求的情况下,通过公式与matlab求得各大学的权重,总结得分并进行排序(结果见表11);在对广东赛区各高校2012建模成绩预测问题中,我们采用灰色预测模型,我们以华南农业大学为例,得到该校2012年建模比赛获奖情况为:省一等奖、省二等奖、省三等奖及成功参赛奖分别为5、9、8、8(其它各高校预测结果见表10)。 针对问题二,我们对全国各院校的自建模竞赛活动开展以来建模成绩排序采用与问题一相同的数学模型,在获奖情况考虑的是全国一等奖、全国二等奖。运用matlab求解,结果见表12。 针对问题三,我们通过对一、二问排序的解答及数据的分析,得出在对院校进评价和预测时还应考虑到各院的师资力量、学校受重视程度、学生情况、参赛经验等因素,考虑到这些因素,为以后评价高校建模水平提供更可靠的依据。 关键词:层次分析法权向量灰色预测模型模型检验 matlab 我国汽车销售行业分析 引言 自2002年之后,中国汽车行业开始进入爆发式增长阶段,特别是随着私人消费的兴起,轿车需求量开始迅速攀升,并成为推动中国汽车发展的一股重要力量。与此同时,中国在全球汽车产业中的地位也逐渐上升。2007年,中国汽车需求总量为879万辆,在全球市场占比从2001年4.3%上升到2007年的12.2%。 2008年1-11月,我国汽车制造行业实现累计工业总产值2,107,810,742,000元,比上年同期增长了17.07%;实现累计产品销售收入2,083,202,551,000元,比上年同期增长了19.11%。2009年1-11月,我国汽车制造行业实现累计产品销售收入2,618,456,203,000元,比上年同期增长了23.03%;实现累计利润总额189,127,867,000元,比上年同期增长了52.75%。 2009年,中国国内市场销售了1360万辆汽车,而此前世界最大的汽车市场——美国仅销售1034万辆。中国已成为世界上最大的轿车和面包车市场。 目前我国汽车市场自主品牌发展态势良好。2010年前10个月,自主品牌乘用车共销售503.81万辆,占乘用车销售总量的45.39%,同比增长1.18个百分点。 受经济危机影响,我国经济发展速度放缓,为了保增长、扩内需、调结构,我国开始实施扩大内需政策、产业调整和振兴规划,促进汽 车消费及汽车产业组织结构优化升级,刺激了国内汽车市场的快速复苏并呈现出较快的发展势头。未来我国汽车行业发展前景看好。一、我国汽车销售渠道模式 1.区域代理制。渠道模式可表述为厂商区域总代理下级代理商最终用户。这种模式与IT渠道的区域代理制 基本一致。这是汽车渠道最早采用的模式,目前使用这种模式 的厂商已较少。 2.特许经销制。渠道模式可表述为厂商特许经销商最终用户。区域代理制实施一段时间后,汽车厂商逐渐发现很难对 经销商的经销行为进行规范,市场价格体系混乱,1996年后,汽车渠道逐渐向特许经销制转变。目前一汽捷达、神龙富康等 采用这种模式。 3.品牌专卖制。渠道模式可表述为厂商专卖店最终用户。 品牌专卖制是1999年发展起来的渠道模式。主要以“三位一体” (包括整车销售、零配件供应、售后服务)专卖店和“四位一 体”(整车销售、零配件供应、售后服务、信息反馈)专卖店 为表现形式。目前广州本田、上海通用是这种模式的代表。二、我国目前汽车销售中存在的问题及解决办法。 1.品牌授权合同不规范,存在强权条款 在我国汽车销售行业中,目前实行的授权合同中有很多强权条款,主要体现在厂家对经销商的商务政策中有过多的限制性条款: 数学建模常用的十种解题方法 摘要 当需要从定量的角度分析和研究一个实际问题时,人们就要在深入调查研究、了解对象信息、作出简化假设、分析内在规律等工作的基础上,用数学的符号和语言,把它表述为数学式子,也就是数学模型,然后用通过计算得到的模型结果来解释实际问题,并接受实际的检验。这个建立数学模型的全过程就称为数学建模。数学建模的十种常用方法有蒙特卡罗算法;数据拟合、参数估计、插值等数据处理算法;解决线性规划、整数规划、多元规划、二次规划等规划类问题的数学规划算法;图论算法;动态规划、回溯搜索、分治算法、分支定界等计算机算法;最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法;网格算法和穷举法;一些连续离散化方法;数值分析算法;图象处理算法。 关键词:数学建模;蒙特卡罗算法;数据处理算法;数学规划算法;图论算法 一、蒙特卡罗算法 蒙特卡罗算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟可以来检验自己模型的正确性,是比赛时必用的方法。在工程、通讯、金融等技术问题中, 实验数据很难获取, 或实验数据的获取需耗费很多的人力、物力, 对此, 用计算机随机模拟就是最简单、经济、实用的方法; 此外, 对一些复杂的计算问题, 如非线性议程组求解、最优化、积分微分方程及一些偏微分方程的解⑿, 蒙特卡罗方法也是非常有效的。 一般情况下, 蒙特卜罗算法在二重积分中用均匀随机数计算积分比较简单, 但精度不太理想。通过方差分析, 论证了利用有利随机数, 可以使积分计算的精度达到最优。本文给出算例, 并用MA TA LA B 实现。 1蒙特卡罗计算重积分的最简算法-------均匀随机数法 二重积分的蒙特卡罗方法(均匀随机数) 实际计算中常常要遇到如()dxdy y x f D ??,的二重积分, 也常常发现许多时候被积函数的原函数很难求出, 或者原函数根本就不是初等函数, 对于这样的重积分, 可以设计一种蒙特卡罗的方法计算。 定理 1 )1( 设式()y x f ,区域 D 上的有界函数, 用均匀随机数计算()??D dxdy y x f ,的方法: (l) 取一个包含D 的矩形区域Ω,a ≦x ≦b, c ≦y ≦d , 其面积A =(b 一a) (d 一c) ; ()j i y x ,,i=1,…,n 在Ω上的均匀分布随机数列,不妨设()j i y x ,, j=1,…k 为落在D 中的k 个随机数, 则n 充分大时, 有 我国汽车营销存在的问题与对策研究 摘要 本文主要论述的内容为现阶段我国汽车营销所存在的问题分析与相应对策 的研究。分析并总结了目前我国汽车营销存在的一些问题和不足,并对这些问题 和不足提出了一些相应的解决方法和对策。以此为基础,提出了一些关于未来我 国汽车营销创新与发展的方向建议。 【关键词】:销售模式;汽车交易市场;特许经营;多品牌经营 ABSTRACT This article discusses the contents of the current stage of China's automobile sales the problems analysis and countermeasures research Analyzed and summarized the current Chinese auto sales some problems and deficiencies and these issues and shortcomings a number of the corresponding solutions and countermeasures. On this basis a number of car sales in China about the future direction of innovation and development proposals Keywords:Sales model automotive market franchise multi-brand business 目录 引言 (1) 一当前我国汽车行业环境 (1) 1.1 解放后我国汽车工业发展的三个阶段 (1) 1.2 国外汽车公司的影响 (2) 二目前我国汽车营销存在的问题 (3) 2.1 营销理念存在问题 (3) 2.2 汽车销售模式存在的问题 (4) 2.3 目前汽车售后服务领域存在的问题 (5) 三对我国汽车营销存在问题的对策研究 (6) 3.1 关于营销理念存在问题相关对策研究 (6) 3.2 针对现有汽车销售模式存在的问题的对策研究 (7) 3.3 汽车售后服务领域存在问题的对策研究 (8) 四我国汽车营销的经验总结及未来发展方向 (9) 4.1 我国汽车营销经验总结 (9) 4.2 来我国汽车营销发展方向 (10) 五总结 (11) 参考文献 (12) 致谢 (13) 龙源期刊网 https://www.doczj.com/doc/b9642774.html, 基于SARIMA的我国汽车销量预测分析 作者:王旭天李政远舒慧生 来源:《中国市场》2016年第01期 [摘要]汽车工业在国民经济中占有重要地位,准确预测汽车销量具有十分重要的意义。由于假日及其他因素影响,汽车的月度销售数据表现出季节性的特征。文章选用我国2004年1月—2015年1月的汽车月度销售数据为研究对象,构建了具有季节调整的ARIMA模型并用于销量预测,预测结果的平均相对误差可控制在3%以内,模型合理有效,具有良好的参考价值。 [关键词]ARIMA模型;汽车销量;SARIMA预测 [DOI]10.13939/https://www.doczj.com/doc/b9642774.html,ki.zgsc.2016.01.071 1 引言 随着我国经济的快速发展和居民生活水平的提高,汽车在人群中开始逐渐普及,成为许多人的生活必需品。与此同时,汽车工业迅速发展,在国民经济中也扮演着越来越重要的角色,与机械电子、石油化工和建筑业一道构成了我国经济的四大支柱产业,因而如何对汽车销量进行准确的预测具有重要意义。 ARIMA模型是20世纪70年代由博克斯和詹金斯提出的时间序列方法[1][2],所以又被称为博克斯-詹金斯法,其全称是自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model),包含移动平均过程(MA)和自回归过程(AR)两个部分。ARIMA模型发展至今理论已非常成熟,在实践中应用广泛。如龚承刚,王梦等人将ARIMA模型运用到了对湖北省城乡居民收入差距的预测中,预测到未来三年湖北省的城乡居民收入差距比仍处在较高水平。[3]薛蓓蓓运用ARIMA模型对安徽省固定资产投资总额进行了建模和预测,借助Eviews软件给出了短期的预测值。[4]张丽,牛惠芳将SARIMA模型运用到了对我国CPI的分析预测中,对CPI月度数据的变化趋势和季节性进行了分析。[5]虞安和王忠采用引力模型和ARIMA模型对旅游人群进行了预测,对城市管理和旅游秩序的维护工作提供了意见和建议。 [6] 本文将以汽车工业协会公布的汽车销量月度数据为研究对象,根据月度数据同时具有长期趋势效应、季节效应和随机波动的特点,选取具有季节调整的ARIMA模型对汽车销量进行预测。 2 模型 3 建模过程 数学建模的基本步骤 一、数学建模题目 1)以社会,经济,管理,环境,自然现象等现代科学中出现的新问题为背景,一般都有一个比较确切的现实问题。 2)给出若干假设条件: 1. 只有过程、规则等定性假设; 2. 给出若干实测或统计数据; 3. 给出若干参数或图形等。 根据问题要求给出问题的优化解决方案或预测结果等。根据问题要求题目一般可分为优化问题、统计问题或者二者结合的统计优化问题,优化问题一般需要对问题进行优化求解找出最优或近似最优方案,统计问题一般具有大量的数据需要处理,寻找一个好的处理方法非常重要。 二、建模思路方法 1、机理分析根据问题的要求、限制条件、规则假设建立规划模型,寻找合适的寻优算法进行求解或利用比例分析、代数方法、微分方程等分析方法从基本物理规律以及给出的资料数据来推导出变量之间函数关系。 2、数据分析法对大量的观测数据进行统计分析,寻求规律建立数学模型,采用的分析方法一般有: 1). 回归分析法(数理统计方法)-用于对函数f(x)的一组观测值(xi,fi)i=1,2,…,n,确定函数的表达式。 2). 时序分析法--处理的是动态的时间序列相关数据,又称为过程统计方法。 3)、多元统计分析(聚类分析、判别分析、因子分析、主成分分析、生存数据分析)。 3、计算机仿真(又称统计估计方法):根据实际问题的要求由计算机产生随机变量对动态行为进行比较逼真的模仿,观察在某种规则限制下的仿真结果(如蒙特卡罗模拟)。 三、模型求解: 模型建好了,模型的求解也是一个重要的方面,一个好的求解算法与一个合 适的求解软件的选择至关重要,常用求解软件有matlab,mathematica,lingo,lindo,spss,sas等数学软件以及c/c++等编程工具。 Lingo、lindo一般用于优化问题的求解,spss,sas一般用于统计问题的求解,matlab,mathematica功能较为综合,分别擅长数值运算与符号运算。 常用算法有:数据拟合、参数估计、插值等数据处理算法,通常使用spss、sas、Matlab作为工具. 线性规划、整数规划、多元规划、二次规划、动态规划等通常使用Lindo、Lingo,Matlab软件。 图论算法,、回溯搜索、分治算法、分支定界等计算机算法, 模拟退火法、神经网络、遗传算法。 四、自学能力和查找资料文献的能力: 建模过程中资料的查找也具有相当重要的作用,在现行方案不令人满意或难以进展时,一个合适的资料往往会令人豁然开朗。常用文献资料查找中文网站:CNKI、VIP、万方。 五、论文结构: 0、摘要 1、问题的重述,背景分析 2、问题的分析 3、模型的假设,符号说明 4、模型的建立(局部问题分析,公式推导,基本模型,最终模型等) 5、模型的求解 6、模型检验:模型的结果分析与检验,误差分析 7、模型评价:优缺点,模型的推广与改进 8、参考文献 9、附录 六、需要重视的问题 数学建模的所有工作最终都要通过论文来体现,因此论文的写法至关重要: 关于计划生育政策调整对人口数量、结构及其影响的研究 【摘要】 本文着重于讨论两个问题:1、从目前中国人口现状出发,对于中国未来人口数量进行预测。2、针对深圳市讨论单独二胎政策对未来人口数量、结构及其对教育、劳动力供给与就业、养老等方面的影响。 对于问题1从中国的实际情况和人口增长的特点出发,针对中国未来人口的老龄化、出生人口性别比以及乡村人口城镇化等,提出了 Logistic 、灰色预测、等方法进行建模预测。 首先,本文建立了 Logistic 阻滞增长模型,在最简单的假设下,依照中国人口的历 史数据,运用线形最小二乘法对其进行拟合, 对 2014 至 2040 年的人口数目进行了预测, 得出在 2040 年时,中国人口有 14.32 亿。在此模型中,由于并没有考虑人口的年龄、 出生人数男女比例等因素,只是粗略的进行了预测,所以只对中短期人口做了预测,理 论上很好,实用性不强,有一定的局限性。 然后, 为了减少人口的出生和死亡这些随机事件对预测的影响, 本文建立了 GM(1,1) 灰色预测模型,对 2014 至 2040 年的人口数目进行了预测,同时还用 2002 至 2013 年的 人口数据对模型进行了误差检验,结果表明,此模型的精度较高,适合中长期的预测, 得出 2040 年时,中国人口有 14.22 亿。与阻滞增长模型相同,本模型也没有考虑年龄 一类的因素,只是做出了人口总数的预测,没有进一步深入。 对于问题2针对深圳市人口结构中非户籍人口比重大,流动人口多这一特点,我们采用了灰色GM(1,1)模型,通过matlab 对深圳市自2001至2010年的数据进行拟合,发现其人口变化近似呈线性增长,线性相关系数高达0.99,我们就此认定其为线性相关并给出线性方程。同理,针对其非户籍人口,我们进行matlab 拟合发现,其为非线性相关,并得出相关函数。并做出了拟合函数 0.0419775(1)17255.816531.2t X t e ?+=?-。 对于新政策的实施,我们做出了两个假设。在假设只有出生率改变的情况,人口呈现一次函数线性增加。并拟合出一次函数0.032735617965.017372.5t Y e ?=?-;在假设人口增长率增长20%时,做出了预测如果单独二胎政策实施,到2021年,深圳市常住人口数将会到达1137.98千万人。 关键词:GM(1,1)灰色模型 Logistic 阻滞增长模型 线性拟合 非线性拟合 摘要 中国加入世贸组织以来,国外的汽车企业陆续进入中国市场,我国汽车企业的发展经历了建设、成长、高速发展三个阶段,就现阶段来说,汽车行业发展迅速、势头良好,与汽车相关的行业尤其是4S店如雨后春笋般兴起,各大车企掀起扩张网点的热潮并没有因为原料价格和油价攀升等因素而降低。一场关于汽车行业的讨论日趋白热化。 关键词:汽车行业,发展历程,销售模式,制约瓶颈,前景展望 Abstract Since China's accession to the WTO, foreign car companies have moved into the Chinese market, China's automotive business development experience building, growing, high-speed development in three stages, at this stage, the automotive industry developed rapidly, a good momentum, with car related industries, especially the 4S shops mushrooming in major enterprises set off car craze network expansion is not as raw material prices and lower oil prices and other factors. A discussion on the automobile industry is heating up. Keywords:automotive industry, development, sales model, the bottleneck Prospects 数学建模常用方法 建模常用算法,仅供参考: 1、蒙特卡罗算法(该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟可以来检验自己模型的正确性,是比赛时必 用的方法) 2、数据拟合、参数估计、插值等数据处理算法(比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用M a t l a b作为工具) 3、线性规划、整数规划、多元规划、二次规划等规划类问题(建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通 常使用L i n d o、L i n g o软件实现) 4、图论算法(这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备) 5、动态规划、回溯搜索、分治算法、分支定界等计算机算法(这些算法是算法设计中比较常用的方法,很多场合可以用到竞赛中) 6、最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法(这些问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用) 7、网格算法和穷举法(网格算法和穷举法都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种 暴力方案,最好使用一些高级语言作为编程工具) 8、一些连续离散化方法(很多问题都是实际来的,数据可以是连续的,而计 算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的) 9、数值分析算法(如果在比赛中采用高级语言进行编程的话,那一些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用) 10、图象处理算法(赛题中有一类问题与图形有关,即使与图形无关,论文 中也应该要不乏图片的,这些图形如何展示以及如何处理就是需要解决的问题,通常使用M a t l a b进行处理) 一、在数学建模中常用的方法: 1.类比法 2.二分法 3.量纲分析法 4.差分法 5.变分法 6.图论法 7.层次分析法 8.数据拟合法 9.回归分析法 10.数学规划(线性规划、非线性规划、整数规划、动态规划、目标规划) 11.机理分析 12.排队方法 2018年年百万辆时代来临新能源汽车产业发展将转向市场驱动我国新能源汽车产业初具规模,涌现出一批具有国际竞争力的领军企业。业内人士预计,2017年我国新能源汽车销量将达到70万辆,2018年有望超过100万辆。随着产业补贴政策的不断调整,新能源汽车产业支持方向开始向“扶优扶强”转换,行业全面进入调整升级阶段。业内人士认为,2018年,在补贴退坡加速、外资品牌进入、双积分政策开启等多重因素作用下,我国新能源汽车产业将由政府驱动加速转向市场驱动。 一、迎来快速发展期 中汽协秘书长助理许海东向中国证券报记者表示,按照目前增速,新能源汽车2017年70万辆销量目标应该可以达成。预计2018年新能源汽车销量增速保持在40%至50%,明年新能源汽车销量将超过100万辆。 根据中国汽车工业协会数据,2017年11月,新能源汽车销量11.9万辆,同比增长83%,月度产销量创历史新高;1-11月,新能源汽车销量60.9万辆,同比增长51.4%。 2017年,国家出台了多项新能源汽车相关政策,覆盖范围包括补贴、基础设施、宏观统筹、技术研发等多个方面,推动实现《中国制造2025》和《节能与新能源汽车产业发展规划(2012-2020年)》中的重要战略目标。其中,2017年9月公布的《乘用车企业平均燃料消耗量与新能源汽车积分并行管理办法》(简称“双积分政策”)被普遍认为奠定了未来中国新能源汽车产业格局。该项政策将于2018年4月1日起实施,2019年开始正式考核。 中国汽车工程学会常务副理事长张进华对中国证券报记者表示,双积分政策实施以后,新能源汽车产业将通过积分制借助市场的力量倒逼企业,推动企业加速电动化转型,政府补贴也将逐渐退出,通过市场调节激励新能源汽车发展。 国家对于产业的补贴政策正在加速退出,2020年以后,新能源汽车补贴将全面退出。这也意味着政府主导的培育市场模式进入尾声,企业主导培育市场新阶段开启,市场即将面临后补贴时代带来的考验。 业内人士表示,由于电池成本的昂贵以及充电基础设施的落后,后补贴时代新能源汽车依然处于弱势。市场预计要到2025年,新能源汽车才能达到燃油汽车相同的购买经济性,未来3-8年里新能源汽车产业发展仍然需要政策持续支持。张进华认为:“随着补贴的加速退出,应该在纯电动汽车和插电式混合动力汽车上继续保持一定程度的税收优惠。补贴退出、税收保留将有助于新能源汽车产业的持续健康发展。” 随着国家禁售燃油车时间表研究计划提上议程,长安、北汽等自主品牌也相继抛出传统燃油车禁售时间表。2017年以来,吉利、长安、长城等越来越多的企业加速推出混合动力汽车以应对平均燃料消耗量挑 数学建模中常见的十 大模型 精品文档 数学建模常用的十大算法==转 (2011-07-24 16:13:14) 转载▼ 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MA TLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MATLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 2.1 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢?随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 2.2 数据拟合、参数估计、插值等算法 数据拟合在很多赛题中有应用,与图形处理有关的问题很多与拟合有关系,一个例子就是98 年美国赛A 题,生物组织切片的三维插值处理,94 年A 题逢山开路,山体海拔高度的 收集于网络,如有侵权请联系管理员删除 实验十三 商品需求量的预测 【实验目的】 1.了解回归分析的基本原理和方法。 2.学习用回归分析的方法解决问题,初步掌握对变量进行预测和控制。 3.学习掌握用MATLAB 命令求解回归分析问题。 【实验内容】 现有某种商品的需求量、消费者的平均收入、商品价格的统计数据如表1所示,试用所提供的数据预测消费者平均收入为1000、商品价格为6时的商品需求量。 【实验准备】 现实生活中,一切事物都是相互关联、相互制约的。我们将变化的事物看作变量,那么变量之间的相互关系,可以分为两大类:一类是确定性关系,也叫作函数关系,其特征是一个变量随着其它变量的确定而确定,如矩形的面积由长宽确定;另一类关系叫相关关系,其特征是变量之间很难用一种精确的方法表示出来,如商品销量与售价之间有一定的关联,但由售价我们不能精确地计算出销量。不过,确定性关系与相关关系之间没有一道不可逾越的鸿沟,由于存在实际误差等原因,确定性关系在实际问题中往往通过相关关系来体现;另一方面,当对事物内部规律了解得更加深刻时,相关关系也可能转化为确定性关系。 1.回归分析的基本概念 回归分析就是处理变量之间的相关关系的一种数学方法,它是最常用的数理统计方法,能解决预测、控制、生产工艺化等问题。由相关关系函数确定形式的不同,回归分析一般分为线性回归、非线性回归和逐步回归,在这里我们着重介绍线性回归,它是比较简单的一类回归分析,在实际问题的处理中也是应用得较多的一类。 回归分析中最简单的形式是 y =0β+1βx +ε (x 、y 为标量) (1) 固定的未知参数0β,1β称为回归系数,自变量x 称为回归变量,ε是均值为零的随机变量,它是其他随机因素对 y 的影响,是不可观察的,我们称(1)为一元线性回归。它的一个自然推 广是x 是多元变量,形如 y =0β+1β1x +…+m βm x +ε (2) m ≥2,我们称为多元线性回归,或者更有一般地 汽车销量预测 摘要 汽车工业在我国已有50 多年的发展历史, 而汽车产业真正得到快速发展是从上世纪90 年代开始的。现在汽车工业在我国经济中已占有很重要的地位。预测汽车的销售量,无论是对于整体掌控汽车市场的发育与成长态势的政策制定者,还是对于研究市场行情以制定营销策略的汽车厂商而言,都具有极其重要的作用。我们通过网络搜索相关数据,然后运用线性回归及灰色预测对汽车销量进行数学建模分析预测,然后再对模型进行评估修改。 关键词:汽车销量线性回归灰色预测 一.问题重述 1.问题背景 近年来,随着国民经济和社会的进一步发展,汽车工业也逐步成为中国的支柱性产业之一,汽车市场表现出产销两旺的发展态势。而汽车市场是汽车工业的晴雨表,预测汽车的销售量,无论是对于整体掌控汽车市场的发育与成长态势的政策制定者而言,还是对于研究市场行情以制定营销策略的汽车厂商而言,都具有极其重要的作用。 2.需要解决的问题 问题一:影响汽车销量的因素有哪些? 问题二:通过数据建立数学模型并进行预测。 问题三:验证并修改数学模型。 二.问题分析 一.对问题一的分析 在这里我门选取了汽车产量、公路长度、城镇居民收入、GDP这样一些因素来考虑,当然影响汽车销售的因素远不止如此石油价格上涨,银行存款利率等都会对汽车销量有影响。并且这些因素也是相互影响的。这里为了简单考虑我们把每一个因素单独列出来,研究其余汽车销量的关系。我们通过互联网搜索获得以下数据: 二.对问题二的分析 对于问题二我们有两种思路,第一个是通过问题一得到的相关数据及结论运用线性回归的知识建立数学模型。但是通过线性回归得到的方程却还不够,因为线性方程故事汽车销量需要知道汽车产量、公路长度、GDP这样一些数据,但我们不知到以后的汽车产量、公路长度、GDP。这里吗有许多不确定因素所以我们采用灰色预测的方法来预测汽车销量。 三、模型假设与约定 国家经济处于一种正常平稳的发展趋势,不能有类似于08年的金融危机。 四、模型建立 模型一:各个因素对汽车销量的影响 数学建模方法模型 一、统计学方法 1 多元回归 1、方法概述: 在研究变量之间的相互影响关系模型时候用到。具体地说:其可以定量地描述某一现象和某些因素之间的函数关系,将各变量的已知值带入回归方程可以求出因变量的估计值,从而可以进行预测等相关研究。 2、分类 分为两类:多元线性回归和非线性线性回归;其中非线性回归可以通过一定的变化转化为线性回归,比如:y=lnx 可以转化为 y=u u=lnx 来解决;所以这里主要说明多元线性回归应该注意的问题。 3、注意事项 在做回归的时候,一定要注意两件事: (1) 回归方程的显著性检验(可以通过 sas 和 spss 来解决) (2) 回归系数的显著性检验(可以通过 sas 和 spss 来解决) 检验是很多学生在建模中不注意的地方,好的检验结果可以体现出你模型的优劣,是完整论文的体现,所以这点大家一定要注意。 4、使用步骤: (1)根据已知条件的数据,通过预处理得出图像的大致趋势或者数据之间的大致关系; (2)选取适当的回归方程; (3)拟合回归参数; (4)回归方程显著性检验及回归系数显著性检验 (5)进行后继研究(如:预测等) 2 聚类分析 1、方法概述 该方法说的通俗一点就是,将 n个样本,通过适当的方法(选取方法很多,大家可以自行查找,可以在数据挖掘类的书籍中查找到,这里不再阐述)选取 m 聚类中心,通过研究各样本和各个聚类中心的距离 Xij,选择适当的聚类标准,通常利用最小距离法(一个样本归于一个类也就意味着,该样本距离该类对应的中心距离最近)来聚类,从而可以得到聚类结果,如果利用sas 软件或者 spss 软件来做聚类分析,就可以得到相应的动态聚类图。这种模型的的特点是直观,容易理解。 2、分类 聚类有两种类型: (1) Q型聚类:即对样本聚类; (2) R型聚类:即对变量聚类; 通常聚类中衡量标准的选取有两种: (1) 相似系数法 (2) 距离法 聚类方法: (1) 最短距离法 (2) 最长距离法 (3) 中间距离法 (4) 重心法 (5) 类平均法 (6) 可变类平均法 (7) 可变法 2013年1月中国汽车销量排行榜超级完整版排名车型所属厂商所属品牌1月销量 1 朗逸上海大众大众48267 2 福克斯长安福特福特33632 3 凯越上海通用别克30264 4 赛欧上海通用雪佛兰29063 5 帕萨特上海大众大众27930 6 速腾一汽大众大众26184 7 瑞纳北京现代现代25684 8 轩逸东风日产日产24769 9 科鲁兹上海通用雪佛兰24477 10 捷达一汽大众大众24033 11 悦动北京现代现代23882 12 英朗上海通用别克23694 13 朗动北京现代现代22177 14 宝来一汽大众大众20045 15 QQ 奇瑞汽车奇瑞18622 16 帝豪EC7 吉利汽车帝豪18516 17 迈腾一汽大众大众17273 18 腾翼C30 长城汽车长城17238 19 POLO 上海大众大众17208 20 奥迪A6 一汽大众奥迪16706 21 桑塔纳上海大众大众15927 22 起亚K2 东风悦达起亚15028 23 阳光东风日产日产14420 24 世嘉神龙汽车雪铁龙13413 25 凯美瑞广汽丰田丰田12768 26 K3 东风悦达起亚12741 27 明锐上海大众斯柯达12561 28 速锐比亚迪比亚迪12116 29 高尔夫一汽大众大众11924 30 北斗星昌河铃木11859 31 花冠一汽丰田丰田11553 32 F3 比亚迪比亚迪11190 33 夏利天津一汽夏利11094 34 L3 比亚迪比亚迪11075 35 骐达东风日产日产10466 36 奥迪A4 一汽大众奥迪10215 37 荣威350 上海汽车荣威9808 38 君威上海通用别克9707 39 5系华晨宝马宝马9600 40 君越上海通用别克9271 41 E5 奇瑞汽车奇瑞9153 42 马自达6 一汽轿车马自达9106 43 风云2 奇瑞汽车奇瑞8898 44 长安逸动长安汽车长安8861 45 卡罗拉一汽丰田丰田8761 46 和悦江淮汽车江淮8596 47 索纳塔北京现代现代8429 48 奔奔迷你长安汽车长安8365 49 迈锐宝上海通用雪佛兰7880 50 标致308 神龙汽车标致7823 51 悦翔长安汽车长安7672 52 昊锐上海大众斯柯达7451 53 悦翔V3 长安汽车长安7327 54 思迪锋范广汽本田本田7286 55 蒙迪欧致胜长安福特福特7068 56 腾翼C50 长城汽车长城6829 57 奥拓长安铃木铃木6709 58 雅阁广汽本田本田6579 59 奔腾B50 一汽轿车奔腾6572 60 比亚迪F0 比亚迪比亚迪6407 61 菱悦东南汽车东南6300 62 思域东风本田本田6178 63 风神H30 东风乘用风神6120 64 启辰D50 东风日产启辰6070 65 自由舰吉利汽车全球鹰5948 66 大众CC 一汽大众大众5783 67 锐志一汽丰田丰田5629 68 H230 沈阳华晨中华5538 数学建模常用的十大算法==转 (2011-07-24 16:13:14) 转载▼ 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MA TLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MA TLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 2.1 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢?随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 2.2 数据拟合、参数估计、插值等算法 数据拟合在很多赛题中有应用,与图形处理有关的问题很多与拟合有关系,一个例子就是98 年美国赛A 题,生物组织切片的三维插值处理,94 年A 题逢山开路,山体海拔高度的插值计算,还有吵的沸沸扬扬可能会考的“非典”问题也要用到数据拟合算法,观察数据的数学建模知识及常用方法
汽车零部件销售行业分析权威版分析
对中国大学生数学建模竞赛历年成绩的分析与预测
我国汽车销售行业分析
数学建模常用的十种解题方法
汽车营销存在的问题与对策研究
基于SARIMA的我国汽车销量预测分析
数学建模的基本步骤
数学建模 人口模型 人口预测
我国汽车行业发展现状及前景
数学建模常用方法
新能源汽车产业结构调整
数学建模中常见的十大模型讲课稿
数学建模——商品需求量的预测
数学建模汽车销量预测
数学建模方法模型
2013年1月中国汽车销量排行榜超级完整版
数学建模中常见的十大模型
相关主题
文本预览