
第1章绪论
1.简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。
答案:
数据:是客观事物的符号表示,指所有能输入到计算机中并被计算机程序处理的符号的总称。如数学计算中用到的整数和实数,文本编辑所用到的字符串,多媒体程序处理的图形、图像、声音、动画等通过特殊编码定义后的数据。
数据元素:是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。在有些情况下,数据元素也称为元素、结点、记录等。数据元素用于完整地描述一个对象,如一个学生记录,树中棋盘的一个格局(状态)、图中的一个顶点等。
数据项:是组成数据元素的、有独立含义的、不可分割的最小单位。例如,学生基本信息表中的学号、姓名、性别等都是数据项。
数据对象:是性质相同的数据元素的集合,是数据的一个子集。例如:整数数据对象是集合N={0,±1,±2,…},字母字符数据对象是集合C={‘A’,‘B’,…,‘Z’,‘a’,‘b’,…,‘z’},学生基本信息表也可是一个数据对象。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。换句话说,数据结构是带“结构”的数据元素的集合,“结构”就是指数据元素之间存在的关系。
逻辑结构:从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。因此,数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
存储结构:数据对象在计算机中的存储表示,也称为物理结构。
抽象数据类型:由用户定义的,表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称。具体包括三部分:数据对象、数据对象上关系的集合和对数据对象的基本操作的集合。
2.试举一个数据结构的例子,叙述其逻辑结构和存储结构两方面的含义和相互关系。
答案:
例如有一张学生基本信息表,包括学生的学号、姓名、性别、籍贯、专业等。每个学生基本信息记录对应一个数据元素,学生记录按顺序号排列,形成了学生基本信息记录的线性序列。对于整个表来说,只有一个开始结点(它的前面无记录)和一个终端结点(它的后面无记录),其他的结点则各有一个也只有一个直接前趋和直接后继。学生记录之间的这种关系就确定了学生表的逻辑结构,即线性结构。
这些学生记录在计算机中的存储表示就是存储结构。如果用连续的存储单元(如用数组表示)来存放这些记录,则称为顺序存储结构;如果存储单元不连续,而是随机存放各个记录,然后用指针进行链接,则称为链式存储结构。
即相同的逻辑结构,可以对应不同的存储结构。
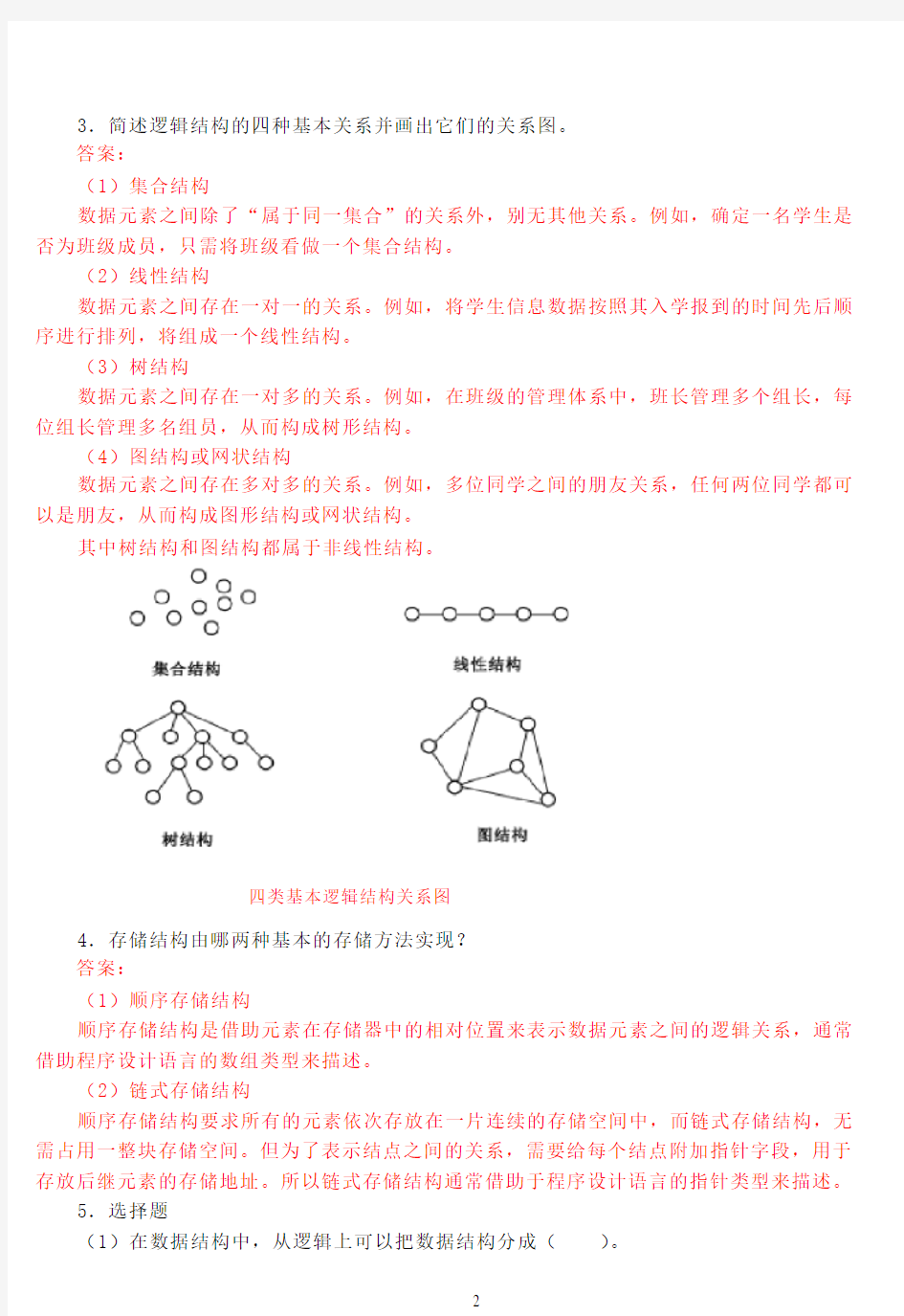
3.简述逻辑结构的四种基本关系并画出它们的关系图。
答案:
(1)集合结构
数据元素之间除了“属于同一集合”的关系外,别无其他关系。例如,确定一名学生是否为班级成员,只需将班级看做一个集合结构。
(2)线性结构
数据元素之间存在一对一的关系。例如,将学生信息数据按照其入学报到的时间先后顺序进行排列,将组成一个线性结构。
(3)树结构
数据元素之间存在一对多的关系。例如,在班级的管理体系中,班长管理多个组长,每位组长管理多名组员,从而构成树形结构。
(4)图结构或网状结构
数据元素之间存在多对多的关系。例如,多位同学之间的朋友关系,任何两位同学都可以是朋友,从而构成图形结构或网状结构。
其中树结构和图结构都属于非线性结构。
四类基本逻辑结构关系图
4.存储结构由哪两种基本的存储方法实现?
答案:
(1)顺序存储结构
顺序存储结构是借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系,通常借助程序设计语言的数组类型来描述。
(2)链式存储结构
顺序存储结构要求所有的元素依次存放在一片连续的存储空间中,而链式存储结构,无需占用一整块存储空间。但为了表示结点之间的关系,需要给每个结点附加指针字段,用于存放后继元素的存储地址。所以链式存储结构通常借助于程序设计语言的指针类型来描述。
5.选择题
(1)在数据结构中,从逻辑上可以把数据结构分成()。
2
A.动态结构和静态结构 B.紧凑结构和非紧凑结构
C.线性结构和非线性结构 D.内部结构和外部结构
答案:C
(2)与数据元素本身的形式、内容、相对位置、个数无关的是数据的()。
A.存储结构 B.存储实现
C.逻辑结构 D.运算实现
答案:C
(3)通常要求同一逻辑结构中的所有数据元素具有相同的特性,这意味着()。
A.数据具有同一特点
B.不仅数据元素所包含的数据项的个数要相同,而且对应数据项的类型要一致
C.每个数据元素都一样
D.数据元素所包含的数据项的个数要相等
答案:B
(4)以下说法正确的是()。
A.数据元素是数据的最小单位
B.数据项是数据的基本单位
C.数据结构是带有结构的各数据项的集合
D.一些表面上很不相同的数据可以有相同的逻辑结构
答案:D
解释:数据元素是数据的基本单位,数据项是数据的最小单位,数据结构是带有结构的各数据元素的集合。
(5)算法的时间复杂度取决于()。
A.问题的规模B.待处理数据的初态
C.计算机的配置D.A和B
答案:D
解释:算法的时间复杂度不仅与问题的规模有关,还与问题的其他因素有关。如某些排序的算法,其执行时间与待排序记录的初始状态有关。为此,有时会对算法有最好、最坏以及平均时间复杂度的评价。
(6)以下数据结构中,()是非线性数据结构
A.树 B.字符串 C.队列 D.栈
答案:A
6.试分析下面各程序段的时间复杂度。
(1)x=90; y=100;
while(y>0)
if(x>100)
{x=x-10;y--;}
else x++;
答案:O(1)
解释:程序的执行次数为常数阶。
(2)for (i=0; i for (j=0; j a[i][j]=0; 答案:O(m*n) 解释:语句a[i][j]=0;的执行次数为m*n。 (3)s=0; for i=0; i for(j=0; j s+=B[i][j]; sum=s; 答案:O(n2) 解释:语句s+=B[i][j];的执行次数为n2。 (4)i=1; while(i<=n) i=i*3; 答案:O(log3n) 解释:语句i=i*3;的执行次数为?log3n?。 (5)x=0; for(i=1; i for (j=1; j<=n-i; j++) x++; 答案:O(n2) 解释:语句x++;的执行次数为n-1+n-2+……+1= n(n-1)/2。(6)x=n; //n>1 y=0; while(x≥(y+1)* (y+1)) y++; 答案:O(n) 解释:语句y++;的执行次数为?n?。 4 第2章线性表 1.选择题 (1)顺序表中第一个元素的存储地址是100,每个元素的长度为2,则第5个元素的地址是()。 A.110 B.108 C.100 D.120 答案:B 解释:顺序表中的数据连续存储,所以第5个元素的地址为:100+2*4=108。 (2)在n个结点的顺序表中,算法的时间复杂度是O(1)的操作是()。 A.访问第i个结点(1≤i≤n)和求第i个结点的直接前驱(2≤i≤n) B.在第i个结点后插入一个新结点(1≤i≤n) C.删除第i个结点(1≤i≤n) D.将n个结点从小到大排序 答案:A 解释:在顺序表中插入一个结点的时间复杂度都是O(n2),排序的时间复杂度为O(n2)或O(nlog2n)。顺序表是一种随机存取结构,访问第i个结点和求第i个结点的直接前驱都可以直接通过数组的下标直接定位,时间复杂度是O(1)。 (3)向一个有127个元素的顺序表中插入一个新元素并保持原来顺序不变,平均要移动的元素个数为()。 A.8 B.63.5 C.63 D.7 答案:B 解释:平均要移动的元素个数为:n/2。 (4)链接存储的存储结构所占存储空间()。 A.分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针 B.只有一部分,存放结点值 C.只有一部分,存储表示结点间关系的指针 D.分两部分,一部分存放结点值,另一部分存放结点所占单元数 答案:A (5)线性表若采用链式存储结构时,要求内存中可用存储单元的地址()。 A.必须是连续的B.部分地址必须是连续的 C.一定是不连续的D.连续或不连续都可以 答案:D (6)线性表L在()情况下适用于使用链式结构实现。 A.需经常修改L中的结点值B.需不断对L进行删除插入 C.L中含有大量的结点D.L中结点结构复杂 答案:B 解释:链表最大的优点在于插入和删除时不需要移动数据,直接修改指针即可。 (7)单链表的存储密度()。 A.大于1 B.等于1 C.小于1 D.不能确定 答案:C 解释:存储密度是指一个结点数据本身所占的存储空间和整个结点所占的存储空间之比,假设单链表一个结点本身所占的空间为D,指针域所占的空间为N,则存储密度为:D/(D+N),一定小于1。 (8)将两个各有n个元素的有序表归并成一个有序表,其最少的比较次数是()。 A.n B.2n-1 C.2n D.n-1 答案:A 解释:当第一个有序表中所有的元素都小于(或大于)第二个表中的元素,只需要用第二个表中的第一个元素依次与第一个表的元素比较,总计比较n次。 (9)在一个长度为n的顺序表中,在第i个元素(1≤i≤n+1)之前插入一个新元素时须向后移动()个元素。 A.n-i B.n-i+1 C.n-i-1 D.I 答案:B (10) 线性表L=(a1,a2,……a n),下列说法正确的是()。 A.每个元素都有一个直接前驱和一个直接后继 B.线性表中至少有一个元素 C.表中诸元素的排列必须是由小到大或由大到小 D.除第一个和最后一个元素外,其余每个元素都有一个且仅有一个直接前驱和直接后继。 答案:D (11) 创建一个包括n个结点的有序单链表的时间复杂度是()。 A.O(1) B.O(n) C.O(n2) D.O(nlog2n) 答案:C 解释:单链表创建的时间复杂度是O(n),而要建立一个有序的单链表,则每生成一个新结点时需要和已有的结点进行比较,确定合适的插入位置,所以时间复杂度是O(n2)。 (12) 以下说法错误的是()。 A.求表长、定位这两种运算在采用顺序存储结构时实现的效率不比采用链式存储结构时实现的效率低 B.顺序存储的线性表可以随机存取 C.由于顺序存储要求连续的存储区域,所以在存储管理上不够灵活 D.线性表的链式存储结构优于顺序存储结构 答案:D 解释:链式存储结构和顺序存储结构各有优缺点,有不同的适用场合。 6 (13) 在单链表中,要将s所指结点插入到p所指结点之后,其语句应为()。 A.s->next=p+1; p->next=s; B.(*p).next=s; (*s).next=(*p).next; C.s->next=p->next; p->next=s->next; D.s->next=p->next; p->next=s; 答案:D (14) 在双向链表存储结构中,删除p所指的结点时须修改指针()。 A.p->next->prior=p->prior; p->prior->next=p->next; B.p->next=p->next->next; p->next->prior=p; C.p->prior->next=p; p->prior=p->prior->prior; D.p->prior=p->next->next; p->next=p->prior->prior; 答案:A (15) 在双向循环链表中,在p指针所指的结点后插入q所指向的新结点,其修改指针的操作是()。 A.p->next=q; q->prior=p; p->next->prior=q; q->next=q; B.p->next=q; p->next->prior=q; q->prior=p; q->next=p->next; C.q->prior=p; q->next=p->next; p->next->prior=q; p->next=q; D.q->prior=p; q->next=p->next; p->next=q; p->next->prior=q; 答案:C 2.算法设计题 (1)将两个递增的有序链表合并为一个递增的有序链表。要求结果链表仍使用原来两个链表的存储空间, 不另外占用其它的存储空间。表中不允许有重复的数据。 [题目分析] 合并后的新表使用头指针Lc指向,pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点,从第一个结点开始进行比较,当两个链表La和Lb均为到达表尾结点时,依次摘取其中较小者重新链接在Lc表的最后。如果两个表中的元素相等,只摘取La 表中的元素,删除Lb表中的元素,这样确保合并后表中无重复的元素。当一个表到达表尾结点,为空时,将非空表的剩余元素直接链接在Lc表的最后。 [算法描述] void MergeList(LinkList &La,LinkList &Lb,LinkList &Lc) {//合并链表La和Lb,合并后的新表使用头指针Lc指向 pa=La->next; pb=Lb->next; //pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点 Lc=pc=La; //用La的头结点作为Lc的头结点 while(pa && pb) {if(pa->data //取较小者La中的元素,将pa链接在pc的后面,pa指针后移 else if(pa->data>pb->data) {pc->next=pb; pc=pb; pb=pb->next;} //取较小者Lb中的元素,将pb链接在pc的后面,pb指针后移 else //相等时取La中的元素,删除Lb中的元素 {pc->next=pa;pc=pa;pa=pa->next; q=pb->next;delete pb ;pb =q; } } pc->next=pa?pa:pb; //插入剩余段 delete Lb; //释放Lb的头结点 } (2)将两个非递减的有序链表合并为一个非递增的有序链表。要求结果链表仍使用原来两个链表的存储空间, 不另外占用其它的存储空间。表中允许有重复的数据。 [题目分析] 合并后的新表使用头指针Lc指向,pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点,从第一个结点开始进行比较,当两个链表La和Lb均为到达表尾结点时,依次摘取其中较小者重新链接在Lc表的表头结点之后,如果两个表中的元素相等,只摘取La表中的元素,保留Lb表中的元素。当一个表到达表尾结点,为空时,将非空表的剩余元素依次摘取,链接在Lc表的表头结点之后。 [算法描述] void MergeList(LinkList& La, LinkList& Lb, LinkList& Lc, ) {//合并链表La和Lb,合并后的新表使用头指针Lc指向 pa=La->next; pb=Lb->next; //pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点 Lc=pc=La; //用La的头结点作为Lc的头结点 Lc->next=NULL; while(pa||pb ) {//只要存在一个非空表,用q指向待摘取的元素 if(!pa) {q=pb; pb=pb->next;} //La表为空,用q指向pb,pb指针后移 else if(!pb) {q=pa; pa=pa->next;} //Lb表为空,用q指向pa,pa指针后移 else if(pa->data<=pb->data) {q=pa; pa=pa->next;} //取较小者(包括相等)La中的元素,用q指向pa,pa指针后移 else {q=pb; pb=pb->next;} //取较小者Lb中的元素,用q指向pb,pb指针后移 q->next = Lc->next; Lc->next = q; //将q指向的结点插在Lc 表的表头结点之后 } 8 delete Lb; //释放Lb的头结点 } (3)已知两个链表A和B分别表示两个集合,其元素递增排列。请设计算法求出A与B 的交集,并存放于A链表中。 [题目分析] 只有同时出现在两集合中的元素才出现在结果表中,合并后的新表使用头指针Lc指向。pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点,从第一个结点开始进行比较,当两个链表La和Lb均为到达表尾结点时,如果两个表中相等的元素时,摘取La表中的元素,删除Lb表中的元素;如果其中一个表中的元素较小时,删除此表中较小的元素,此表的工作指针后移。当链表La和Lb有一个到达表尾结点,为空时,依次删除另一个非空表中的所有元素。 [算法描述] void Mix(LinkList& La, LinkList& Lb, LinkList& Lc) { pa=La->next;pb=Lb->next; pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点 Lc=pc=La; //用La的头结点作为Lc的头结点 while(pa&&pb) { if(pa->data==pb->data)∥交集并入结果表中。 { pc->next=pa;pc=pa;pa=pa->next; u=pb;pb=pb->next; delete u;} else if(pa->data else {u=pb; pb=pb->next; delete u;} } while(pa) {u=pa; pa=pa->next; delete u;}∥ 释放结点空间 while(pb) {u=pb; pb=pb->next; delete u;}∥释放结点空间 pc->next=null;∥置链表尾标记。 delete Lb; //释放Lb的头结点 } (4)已知两个链表A和B分别表示两个集合,其元素递增排列。请设计算法求出两个集合A和B 的差集(即仅由在A中出现而不在B中出现的元素所构成的集合),并以同样的形式存储,同时返回该集合的元素个数。 [题目分析] 求两个集合A和B的差集是指在A中删除A和B中共有的元素,即删除链表中的相应结点,所以要保存待删除结点的前驱,使用指针pre指向前驱结点。pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点,从第一个结点开始进行比较,当两个链表La和Lb均为到达表尾结点时,如果La表中的元素小于Lb表中的元素,pre置为La表的工 作指针pa删除Lb表中的元素;如果其中一个表中的元素较小时,删除此表中较小的元素,此表的工作指针后移。当链表La和Lb有一个为空时,依次删除另一个非空表中的所有元素。 [算法描述] void Difference(LinkList& La, LinkList& Lb,int *n) {∥差集的结果存储于单链表La中,*n是结果集合中元素个数,调用时为0 pa=La->next; pb=Lb->next; ∥pa和pb分别是链表La和Lb的工作指针,初始化为相应链表的第一个结点 pre=La; ∥pre为La中pa所指结点的前驱结点的指针 while(pa&&pb) {if(pa->data ∥ A链表中当前结点指针后移 else if(pa->data>q->data)q=q->next; ∥B链表中当前结点指针后移 else {pre->next=pa->next; ∥处理A,B中元素值相同的结点,应删除 u=pa; pa=pa->next; delete u;} ∥删除结点 } } (5)设计算法将一个带头结点的单链表A分解为两个具有相同结构的链表B、C,其中B 表的结点为A表中值小于零的结点,而C表的结点为A表中值大于零的结点(链表A中的元素为非零整数,要求B、C表利用A表的结点)。 [题目分析] B表的头结点使用原来A表的头结点,为C表新申请一个头结点。从A表的第一个结点开始,依次取其每个结点p,判断结点p的值是否小于0,利用前插法,将小于0的结点插入B表,大于等于0的结点插入C表。 [算法描述] void DisCompose(LinkedList A) { B=A; B->next= NULL; ∥B表初始化 C=new LNode;∥为C申请结点空间 C->next=NULL; ∥C初始化为空表 p=A->next; ∥p为工作指针 while(p!= NULL) { r=p->next; ∥暂存p的后继 if(p->data<0) {p->next=B->next; B->next=p; }∥将小于0的结点链入B表,前插法 else {p->next=C->next; C->next=p; }∥将大于等于0的结点链入C表,前插法p=r;∥p指向新的待处理结点。 } } 10 (6)设计一个算法,通过一趟遍历在单链表中确定值最大的结点。 [题目分析] 假定第一个结点中数据具有最大值,依次与下一个元素比较,若其小于下一个元素,则设其下一个元素为最大值,反复进行比较,直到遍历完该链表。 [算法描述] ElemType Max (LinkList L ){ if(L->next==NULL) return NULL; pmax=L->next; //假定第一个结点中数据具有最大值 p=L->next->next; while(p != NULL ){//如果下一个结点存在 if(p->data > pmax->data) pmax=p;//如果p的值大于pmax的值,则重新赋值 p=p->next;//遍历链表 } return pmax->data; (7)设计一个算法,通过遍历一趟,将链表中所有结点的链接方向逆转,仍利用原表的存储空间。 [题目分析] 从首元结点开始,逐个地把链表L的当前结点p插入新的链表头部。 [算法描述] void inverse(LinkList &L) {// 逆置带头结点的单链表 L p=L->next; L->next=NULL; while ( p) { q=p->next; // q指向*p的后继 p->next=L->next; L->next=p; // *p插入在头结点之后 p = q; } } (8)设计一个算法,删除递增有序链表中值大于mink且小于maxk的所有元素(mink 和maxk是给定的两个参数,其值可以和表中的元素相同,也可以不同)。 [题目分析] 分别查找第一个值>mink的结点和第一个值≥maxk的结点,再修改指针,删除值大于mink且小于maxk的所有元素。 [算法描述] void delete(LinkList &L, int mink, int maxk) { p=L->next; //首元结点 while (p && p->data<=mink) { pre=p; p=p->next; } //查找第一个值>mink的结点 if (p) {while (p && p->data // 查找第一个值≥maxk的结点 q=pre->next; pre->next=p; // 修改指针 while (q!=p) { s=q->next; delete q; q=s; } // 释放结点空间 }//if } (9)已知p指向双向循环链表中的一个结点,其结点结构为data、prior、next三个域,写出算法change(p),交换p所指向的结点和它的前缀结点的顺序。 [题目分析] 知道双向循环链表中的一个结点,与前驱交换涉及到四个结点(p结点,前驱结点,前驱的前驱结点,后继结点)六条链。 [算法描述] void Exchange(LinkedList p) ∥p是双向循环链表中的一个结点,本算法将p所指结点与其前驱结点交换。 {q=p->llink; q->llink->rlink=p;∥p的前驱的前驱之后继为p p->llink=q->llink;∥p的前驱指向其前驱的前驱。 q->rlink=p->rlink;∥p的前驱的后继为p的后继。 q->llink=p;∥p与其前驱交换 p->rlink->llink=q;∥p的后继的前驱指向原p的前驱 p->rlink=q;∥p的后继指向其原来的前驱 }∥算法exchange结束。 (10)已知长度为n的线性表A采用顺序存储结构,请写一时间复杂度为O(n)、空间复杂度为O(1)的算法,该算法删除线性表中所有值为item的数据元素。 [题目分析] 在顺序存储的线性表上删除元素,通常要涉及到一系列元素的移动(删第i个元素,第i+1至第n个元素要依次前移)。本题要求删除线性表中所有值为item的数据元素,并未要求元素间的相对位置不变。因此可以考虑设头尾两个指针(i=1,j=n),从两端向中间移动,凡遇到值item的数据元素时,直接将右端元素左移至值为item的数据元素位置。 [算法描述] void Delete(ElemType A[ ],int n) ∥A是有n个元素的一维数组,本算法删除A中所有值为item的元素。 {i=1;j=n;∥设置数组低、高端指针(下标)。 12 while(i {while(i 第3章栈和队列 1.选择题 (1)若让元素1,2,3,4,5依次进栈,则出栈次序不可能出现在()种情况。 A.5,4,3,2,1 B.2,1,5,4,3 C.4,3,1,2,5 D.2,3,5,4,1 答案:C 解释:栈是后进先出的线性表,不难发现C选项中元素1比元素2先出栈,违背了栈的后进先出原则,所以不可能出现C选项所示的情况。 (2)若已知一个栈的入栈序列是1,2,3,…,n,其输出序列为p1,p2,p3,…,pn,若p1=n,则pi为()。 A.i B.n-i C.n-i+1 D.不确定 答案:C 解释:栈是后进先出的线性表,一个栈的入栈序列是1,2,3,…,n,而输出序列的第一个元素为n,说明1,2,3,…,n一次性全部进栈,再进行输出,所以p1=n,p2=n-1,…,pi=n-i+1。 (3)数组Q[n]用来表示一个循环队列,f为当前队列头元素的前一位置,r为队尾元素的位置,假定队列中元素的个数小于n,计算队列中元素个数的公式为()。 A.r-f B.(n+f-r)%n C.n+r-f D.(n+r-f)%n 答案:D 解释:对于非循环队列,尾指针和头指针的差值便是队列的长度,而对于循环队列,差值可能为负数,所以需要将差值加上MAXSIZE(本题为n),然后与MAXSIZE(本题为n)求余,即(n+r-f)%n。 (4)链式栈结点为:(data,link),top指向栈顶.若想摘除栈顶结点,并将删除结点的值保存到x中,则应执行操作()。 A.x=top->data;top=top->link;B.top=top->link;x=top->link; C.x=top;top=top->link;D.x=top->link; 答案:A 解释:x=top->data将结点的值保存到x中,top=top->link栈顶指针指向栈顶下一结点,即摘除栈顶结点。 (5)设有一个递归算法如下 int fact(int n) { //n大于等于0 if(n<=0) return 1; else return n*fact(n-1); } 则计算fact(n)需要调用该函数的次数为()。 A. n+1 B. n-1 C.n D.n+2 答案:A 14 解释:特殊值法。设n=0,易知仅调用一次fact(n)函数,故选A。 (6)栈在()中有所应用。 A.递归调用B.函数调用C.表达式求值D.前三个选项都有答案:D 解释:递归调用、函数调用、表达式求值均用到了栈的后进先出性质。 (7)为解决计算机主机与打印机间速度不匹配问题,通常设一个打印数据缓冲区。主机将要输出的数据依次写入该缓冲区,而打印机则依次从该缓冲区中取出数据。该缓冲区的逻辑结构应该是()。 A.队列 B.栈C.线性表D.有序表 答案:A 解释:解决缓冲区问题应利用一种先进先出的线性表,而队列正是一种先进先出的线性表。 (8)设栈S和队列Q的初始状态为空,元素e1、e2、e3、e4、e5和e6依次进入栈S,一个元素出栈后即进入Q,若6个元素出队的序列是e2、e4、e3、e6、e5和e1,则栈S的容量至少应该是()。 A.2 B.3 C.4 D. 6 答案:B 解释:元素出队的序列是e2、e4、e3、e6、e5和e1,可知元素入队的序列是e2、e4、e3、e6、e5和e1,即元素出栈的序列也是e2、e4、e3、e6、e5和e1,而元素e1、e2、e3、e4、e5和e6依次进入栈,易知栈S中最多同时存在3个元素,故栈S的容量至少为3。 (9)若一个栈以向量V[1..n]存储,初始栈顶指针top设为n+1,则元素x进栈的正确操作是( )。 A.top++; V[top]=x; B.V[top]=x; top++; C.top--; V[top]=x; D.V[top]=x; top--; 答案:C 解释:初始栈顶指针top为n+1,说明元素从数组向量的高端地址进栈,又因为元素存储在向量空间V[1..n]中,所以进栈时top指针先下移变为n,之后将元素x存储在V[n]。 (10)设计一个判别表达式中左,右括号是否配对出现的算法,采用()数据结构最佳。 A.线性表的顺序存储结构 B.队列 C. 线性表的链式存储结构 D. 栈 答案:D 解释:利用栈的后进先出原则。 (11)用链接方式存储的队列,在进行删除运算时()。 A. 仅修改头指针 B. 仅修改尾指针 C. 头、尾指针都要修改 D. 头、尾指针可能都要修改 答案:D 解释:一般情况下只修改头指针,但是,当删除的是队列中最后一个元素时,队尾指针也丢失了,因此需对队尾指针重新赋值。 (12)循环队列存储在数组A[0..m]中,则入队时的操作为()。 A. rear=rear+1 B. rear=(rear+1)%(m-1) C. rear=(rear+1)%m D. rear=(rear+1)%(m+1) 答案:D 解释:数组A[0..m]中共含有m+1个元素,故在求模运算时应除以m+1。 (13)最大容量为n的循环队列,队尾指针是rear,队头是front,则队空的条件是()。 A. (rear+1)%n==front B. rear==front C.rear+1==front D. (rear-l)%n==front 答案:B 解释:最大容量为n的循环队列,队满条件是(rear+1)%n==front,队空条件是rear==front。 (14)栈和队列的共同点是()。 A. 都是先进先出 B. 都是先进后出 C. 只允许在端点处插入和删除元素 D. 没有共同点 答案:C 解释:栈只允许在栈顶处进行插入和删除元素,队列只允许在队尾插入元素和在队头删除元素。 (15)一个递归算法必须包括()。 A. 递归部分 B. 终止条件和递归部分 C. 迭代部分 D. 终止条件和迭代部分 答案:B 2.算法设计题 (1)将编号为0和1的两个栈存放于一个数组空间V[m]中,栈底分别处于数组的两端。当第0号栈的栈顶指针top[0]等于-1时该栈为空,当第1号栈的栈顶指针top[1]等于m时该栈为空。两个栈均从两端向中间增长。试编写双栈初始化,判断栈空、栈满、进栈和出栈等算法的函数。双栈数据结构的定义如下: Typedef struct {int top[2],bot[2]; //栈顶和栈底指针 SElemType *V; //栈数组 int m; //栈最大可容纳元素个数 }DblStack [题目分析] 两栈共享向量空间,将两栈栈底设在向量两端,初始时,左栈顶指针为-1,右栈顶为m。两栈顶指针相邻时为栈满。两栈顶相向、迎面增长,栈顶指针指向栈顶元素。 [算法描述] 16 (1) 栈初始化 int Init() {S.top[0]=-1; S.top[1]=m; return 1; //初始化成功 } (2) 入栈操作: int push(stk S ,int i,int x) ∥i为栈号,i=0表示左栈,i=1为右栈,x是入栈元素。入栈成功返回1,失败返回0 {if(i<0||i>1){ cout<<“栈号输入不对”< if(S.top[1]-S.top[0]==1) {cout<<“栈已满”< switch(i) {case 0: S.V[++S.top[0]]=x; return(1); break; case 1: S.V[--S.top[1]]=x; return(1); } }∥push (3) 退栈操作 ElemType pop(stk S,int i) ∥退栈。i代表栈号,i=0时为左栈,i=1时为右栈。退栈成功时返回退栈元素 ∥否则返回-1 {if(i<0 || i>1){cout<<“栈号输入错误”< switch(i) {case 0: if(S.top[0]==-1) {cout<<“栈空”< else return(S.V[S.top[0]--]); case 1: if(S.top[1]==m { cout<<“栈空”< else return(S.V[S.top[1]++]); }∥switch }∥算法结束 (4) 判断栈空 int Empty(); {return (S.top[0]==-1 && S.top[1]==m); } [算法讨论] 请注意算法中两栈入栈和退栈时的栈顶指针的计算。左栈是通常意义下的栈,而右栈入栈操作时,其栈顶指针左移(减1),退栈时,栈顶指针右移(加1)。 (2)回文是指正读反读均相同的字符序列,如“abba”和“abdba”均是回文,但“good”不是回文。试写一个算法判定给定的字符向量是否为回文。(提示:将一半字符入栈) [题目分析] 将字符串前一半入栈,然后,栈中元素和字符串后一半进行比较。即将第一个出栈元素和后一半串中第一个字符比较,若相等,则再出栈一个元素与后一个字符比较,……,直至栈空,结论为字符序列是回文。在出栈元素与串中字符比较不等时,结论字符序列不是回文。 [算法描述] #define StackSize 100 //假定预分配的栈空间最多为100个元素 typedef char DataType;//假定栈元素的数据类型为字符 typedef struct {DataType data[StackSize]; int top; }SeqStack; int IsHuiwen( char *t) {//判断t字符向量是否为回文,若是,返回1,否则返回0 SeqStack s; int i , len; char temp; InitStack( &s); len=strlen(t); //求向量长度 for ( i=0; i Push( &s, t[i]); while( !EmptyStack( &s)) {// 每弹出一个字符与相应字符比较 temp=Pop (&s); if( temp!=S[i]) return 0 ;// 不等则返回0 else i++; } return 1 ; // 比较完毕均相等则返回 1 } (3)设从键盘输入一整数的序列:a1, a2, a3,…,a n,试编写算法实现:用栈结构存储输入的整数,当a i≠-1时,将a i进栈;当a i=-1时,输出栈顶整数并出栈。算法应对异常情况(入栈满等)给出相应的信息。 [算法描述] #define maxsize 栈空间容量 void InOutS(int s[maxsize]) //s是元素为整数的栈,本算法进行入栈和退栈操作。 18 {int top=0; //top为栈顶指针,定义top=0时为栈空。 for(i=1; i<=n; i++) //n个整数序列作处理。 {cin>>x); //从键盘读入整数序列。 if(x!=-1) // 读入的整数不等于-1时入栈。 {if(top==maxsize-1){cout<<“栈满”< else s[++top]=x; //x入栈。 } else //读入的整数等于-1时退栈。 {if(top==0){ cout<<“栈空”< else cout<<“出栈元素是”<< s[top--]< } }//算法结束。 (4)从键盘上输入一个后缀表达式,试编写算法计算表达式的值。规定:逆波兰表达式的长度不超过一行,以$符作为输入结束,操作数之间用空格分隔,操作符只可能有+、-、*、/四种运算。例如:234 34+2*$。 [题目分析] 逆波兰表达式(即后缀表达式)求值规则如下:设立运算数栈OPND,对表达式从左到右扫描(读入),当表达式中扫描到数时,压入OPND栈。当扫描到运算符时,从OPND退出两个数,进行相应运算,结果再压入OPND栈。这个过程一直进行到读出表达式结束符$,这时OPND 栈中只有一个数,就是结果。 [算法描述] float expr( ) //从键盘输入逆波兰表达式,以‘$’表示输入结束,本算法求逆波兰式表达式的值。 {float OPND[30]; // OPND是操作数栈。 init(OPND); //两栈初始化。 float num=0.0; //数字初始化。 cin>>x;//x是字符型变量。 while(x!=’$’) {switch {case‘0’<=x<=’9’: while((x>=’0’&&x<=’9’)||x==’.’) //拼数 if(x!=’.’) //处理整数 {num=num*10+(ord(x)-ord(‘0’)); cin>>x;} else //处理小数部分。 {scale=10.0; cin>>x; while(x>=’0’&&x<=’9’) {num=num+(ord(x)-ord(‘0’)/scale; scale=scale*10; cin>>x; } }//else push(OPND,num); num=0.0;//数压入栈,下个数初始化 case x=‘’:break; //遇空格,继续读下一个字符。 case x=‘+’:push(OPND,pop(OPND)+pop(OPND));break; case x=‘-’:x1=pop(OPND);x2=pop(OPND);push(OPND,x2-x1);break; case x=‘*’:push(OPND,pop(OPND)*pop(OPND));break; case x=‘/’:x1=pop(OPND);x2=pop(OPND);push(OPND,x2/x1);break; default: //其它符号不作处理。 }//结束switch cin>>x;//读入表达式中下一个字符。 }//结束while(x!=‘$’) cout<<“后缀表达式的值为”< }//算法结束。 [算法讨论]假设输入的后缀表达式是正确的,未作错误检查。算法中拼数部分是核心。若遇到大于等于‘0’且小于等于‘9’的字符,认为是数。这种字符的序号减去字符‘0’的序号得出数。对于整数,每读入一个数字字符,前面得到的部分数要乘上10再加新读入的数得到新的部分数。当读到小数点,认为数的整数部分已完,要接着处理小数部分。小数部分的数要除以10(或10的幂数)变成十分位,百分位,千分位数等等,与前面部分数相加。在拼数过程中,若遇非数字字符,表示数已拼完,将数压入栈中,并且将变量num恢复为0,准备下一个数。这时对新读入的字符进入‘+’、‘-’、‘*’、‘/’及空格的判断,因此在结束处理数字字符的case后,不能加入break语句。 (5)假设以I和O分别表示入栈和出栈操作。栈的初态和终态均为空,入栈和出栈的操作序列可表示为仅由I和O组成的序列,称可以操作的序列为合法序列,否则称为非法序列。 ①下面所示的序列中哪些是合法的? A. IOIIOIOO B. IOOIOIIO C. IIIOIOIO D. IIIOOIOO ②通过对①的分析,写出一个算法,判定所给的操作序列是否合法。若合法,返回true,否则返回false(假定被判定的操作序列已存入一维数组中)。 答案: ①A和D是合法序列,B和C 是非法序列。 ②设被判定的操作序列已存入一维数组A中。 int Judge(char A[]) //判断字符数组A中的输入输出序列是否是合法序列。如是,返回true,否则返回false。 {i=0; //i为下标。 j=k=0; //j和k分别为I和字母O的的个数。 20 第三章作业及答案 一、单项选择题 1. 标志着以慈禧太后为首的清政府彻底放弃抵抗外国侵略者的事件是() A .《南京条约》的签订 B .《天津条约》的签订 C .《北京条约》的签订 D .《辛丑条约》的签订 2 .清末“预备立宪”的根本目的在于() A .仿效欧美政体 B .发展资本主义 C .延续反动统治 D .缓和阶级矛盾 3.1903年6月,()在上海《苏报》发表《驳康有为论革命书》,批驳康有为所谓“中国之可立宪,不可革命”的谬论 A.陈天华 B.邹容 C.章炳麟 D.梁启超 4.1903年邹容写的()是中国近代史上第一部宣传革命和资产阶级共和国思想的着作 A.《猛回头》 B.《警世钟》 C.《革命军》 D.《驳康有为论革命书》 5.中国近代第一个资产阶级革命的全国性政党是( ) A.强学会 B.兴中会 C.同盟会 D.国民党 6. 孙中山民权主义思想的主张是( ) A.驱除鞑虏 B.恢复中华 C.创立民国 D.平均地权 7.1905年11月,孙中山在《民报》发刊词中将中国同盟会的政治纲领概括为() A.创立民国、平均地权 B.驱除鞑虏、恢复中华、创立合众政府 C.民族主义、民权主义、民生主义 D.联俄、联共、扶助农工 8.武昌起义前同盟会领导的影响最大的武装起义是( ) A.浙皖起义 B.萍浏醴起义 C.镇南关起义 D.黄花岗起义 9.中国历史上第一部具有资产阶级共和国宪法性质的法典是() A.《钦定宪法大纲》 B.《中华民国临时约法》 C.《中华民国约法》 D.《试训政纲领》 10.南京临时政府中占领导和主体地位的派别是() A .资产阶级维新派 B .资产阶级保皇派 C .资产阶级立宪派 D .资产阶级革命派 11. 辛亥革命取得的最大成就是() A.推翻了封建帝制 B.促进了资本主义的发展 C.使人民获得了一些民主自由权利 D.打击了帝国主义的殖民势力 12.清帝被迫退位,在中国延续两千多年的封建帝制终于覆灭的时间是()。 A、1911年10月10日 B、1912年1月1日 C、1912年2月12日 D、1912年4月1日 13.中国第一次比较完全意义上的资产阶级民主革命是指()。 A、辛亥革命 B、国民革命 C、北伐战争 D、抗日战争 14.1915年,()在云南率先举起反袁护国的旗帜,发动护国战争 A.黄兴 B.段祺瑞 C.蔡锷 D.孙中山 15.资产阶级革命派开展护国运动的主要原因是 ( ) A.袁世凯指使刺杀宋教仁 B.袁世凯强迫国会选举他为正式大总统 C.袁世凯解散国会 D.袁世凯复辟帝制 16.袁世凯为复辟帝制不惜出卖主权,与日本签订了卖国的() A.中日共同防敌军事协定 B.承认外蒙自治 第1章绪论 1.1 简述下列术语:数据,数据元素、数据对象、数据结构、存储结构、数据类型和抽象数据类型。 解:数据是对客观事物的符号表示。在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。 数据元素是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。 数据对象是性质相同的数据元素的集合,是数据的一个子集。 数据结构是相互之间存在一种或多种特定关系的数据元素的集合。 存储结构是数据结构在计算机中的表示。 数据类型是一个值的集合和定义在这个值集上的一组操作的总称。 抽象数据类型是指一个数学模型以及定义在该模型上的一组操作。是对一般数据类型的扩展。 1.2 试描述数据结构和抽象数据类型的概念与程序设计语言中数据类型概念的区别。 解:抽象数据类型包含一般数据类型的概念,但含义比一般数据类型更广、更抽象。一般数据类型由具体语言系统内部定义,直接提供给编程者定义用户数据,因此称它们为预定义数据类型。抽象数据 类型通常由编程者定义,包括定义它所使用的数据和在这些数据上所进行的操作。在定义抽象数据类型中的数据部分和操作部分时,要求只定义到数据的逻辑结构和操作说明,不考虑数据的存储结构和操作的具体实现,这样抽象层次更高,更能为其他用户提供良好的使用接口。 1.3 设有数据结构(D,R),其中 {}4,3,2,1d d d d D =,{}r R =,()()(){}4,3,3,2,2,1d d d d d d r = 试按图论中图的画法惯例画出其逻辑结构图。 解: 1.4 试仿照三元组的抽象数据类型分别写出抽象数据类型复数和有理数的定义(有理数是其分子、分母均为自然数且分母不为零的分数)。 解: ADT Complex{ 数据对象:D={r,i|r,i 为实数} 数据关系:R={ 课后作业:完成题库1、4、7、8、9、10、12、25题 01利润的概述 02所得税费用 利润是指企业在一定会计期间的经营成果。利润包括收入减去费用后的净额、直接计入当期利润的利得和损失等。 2.利润的构成 ①营业利润=营业收入-营业成本-税金及附加-销售费用-管理费用-财务费用+投资收益(减损失)+公允价值变动收益(减损失)-资产减值损失+其他收益 ②利润总额=营业利润+营业外收入-营业外支出 ③净利润=利润总额-所得税费用 习题解惑 【例题?单选题】下列各项中,影响当期营业利润的是()。 A.处置固定资产净损益 B.自然灾害导致原材料净损失 C.支付委托代销商品的手续费 D.溢价发行股票支付的发行费用 【答案】C 【解析】选项A计入营业外收支,选项B计入营业外支出,选项D冲减资本公积。 【例题?多选题】下列各项中,既影响营业利润又影响利润总额的业务有()。 A.计提坏账准备计入资产减值损失科目中 B.转销确实无法支付的应付账款 C.出售单独计价包装物取得的收入 D.转让股票所得收益计入投资收益 【答案】ACD 【解析】选项B,计入营业外收入,不影响营业利润。 营业外收支的账务处理 (一)营业外收入账务处理 1.处置非流动资产利得 处置固定资产通过“固定资产清理”科目核算,其账户余额转入营业外收入或营业外支出; 2.确认盘盈利得、捐赠利得 盘盈利得应通过“待处理财产损溢”科目核算 【例题?计算题】某企业将固定资产报废清理的净收益8000元转作营业外收入 写出会计分录。 【答案】 借:固定资产清理8000 贷:营业外收入-非流动资产处置利得8000 习题解惑 【例题?计算题】某企业在现金清查中盘盈200元,按管理权限报经批准后转入营业外收入。写出下列情况时的会计录: ①发现盘盈时: ②经批准转入营业外收入时: 【答案】 ①发现盘盈时: 借:库存现金200 贷:待处理财产损溢200 ②经批准转入营业外收入时: 借:待处理财产损溢200 贷:营业外收入200 【例题?多选题】下列各项中应计入营业外收入的有()。 A.出售持有至到期投资的净收益 B.无法查明原因的现金溢余 C.出售无形资产的净收益 D.出售投资性房地产的净收益 【答案】BC 【解析】选项A,计入投资收益;选项D,计入其他业务收入。 【例题?单选题】下列各项中,不应计入营业外收入的是()。 A.债务重组利得 B.处置固定资产净收益 C.收发差错造成存货盘盈 D.确实无法支付的应付账款 【答案】C 【解析】存货盘盈冲减管理费用。 所得税费用 (一)所得税费用的构成 所得税费用是指企业确认的应从当期利润总额中扣除的所得税费用。包括当期所得税和递延所得税两部分。 数据结构基础及深入及考试 复习资料 习题及实验参考答案见附录 结论 1、数据的逻辑结构是指数据元素之间的逻辑关系。即从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。 2、数据的物理结构亦称存储结构,是数据的逻辑结构在计算机存储器内的表示(或映像)。它依赖于计算机。存储结构可分为4大类:顺序、链式、索引、散列 3、抽象数据类型:由用户定义,用以表示应用问题的数据模型。它由基本的数据类型构成,并包括一组相关的服务(或称操作)。它与数据类型实质上是一个概念,但其特征是使用与实现分离,实行封装和信息隐蔽(独立于计算机)。 4、算法:是对特定问题求解步骤的一种描述,它是指令的有限序列,是一系列输入转换为输出的计算步骤。 5、在数据结构中,从逻辑上可以把数据结构分成( C ) A、动态结构和表态结构 B、紧凑结构和非紧凑结构 C、线性结构和非线性结构 D、内部结构和外部结构 6、算法的时间复杂度取决于( A ) A、问题的规模 B、待处理数据的初态 C、问题的规模和待处理数据的初态 线性表 1、线性表的存储结构包括顺序存储结构和链式存储结构两种。 2、表长为n的顺序存储的线性表,当在任何位置上插入或删除一个元素的概率相等时,插入一个元素所需移动元素的平均次数为( E ),删除一个元素需要移动的元素的个数为( A )。 A、(n-1)/2 B、n C、n+1 D、n-1 E、n/2 F、(n+1)/2 G、(n-2)/2 3、“线性表的逻辑顺序与存储顺序总是一致的。”这个结论是( B ) A、正确的 B、错误的 C、不一定,与具体的结构有关 4、线性表采用链式存储结构时,要求内存中可用存储单元的地址( D ) A、必须是连续的 B、部分地址必须是连续的C一定是不连续的D连续或不连续都可以 5、带头结点的单链表为空的判定条件是( B ) A、head==NULL B、head->next==NULL C、head->next=head D、head!=NULL 6、不带头结点的单链表head为空的判定条件是( A ) A、head==NULL B、head->next==NULL C、head->next=head D、head!=NULL 7、非空的循环单链表head的尾结点P满足( C ) A、p->next==NULL B、p==NULL C、p->next==head D、p==head 8、在一个具有n个结点的有序单链表中插入一个新结点并仍然有序的时间复杂度是( B ) A、O(1) B、O(n) C、O(n2) D、O(nlog2n) 9、在一个单链表中,若删除p所指结点的后继结点,则执行( A ) 1、怎样理解鸦片战争是中国近代史的起点? 鸦片战争是中国近代史的开端,原因有四: 第一,战争后中国的社会性质发生了根本性变化,由一个落后封闭但独立自主的封建国家沦为一个半殖民地半封建社会。 第二,中国的发展方向发生变化,战前中国是一个没落的封建大国,封建制度已经腐朽,在缓慢地向资本主义社会发展;而鸦片战争后中国的民族资本主义不可能获得正常发展,中国也就不可能发展为成熟的资本主义社会,而最终选择了社会主义道路。 第三,社会主要矛盾发生变化,战前中国的主要矛盾是农民阶级与封建地主阶级的矛盾,而战后主要矛盾则包括农民阶级和地主阶级的矛盾及中华民族与外国殖民侵略者的矛盾,也就是社会主要矛盾复杂化。 第四,是革命任务发生变化,原先的革命任务是反对本国封建势力,战后则增加了反对外国殖民侵略的任务,革命的性质也由传统的农民战争转为旧民族主义革命。 2、怎样认识近代中国的主要矛盾、社会性质及其基本特征? (1)近代中国的主要矛盾 帝国主义和中华民族的矛盾;封建主义和人民大众的矛盾是近代中国的主要矛盾。 (2)社会性质:半殖民地半封建的性质。 中国社会的半殖民地半封建社会,是近代以来中国在外国资本主义势力的入侵及其与中国封建主义势力相结合的条件下,逐步形成的一种从属于资本主义世界体系的畸形的社会形态。(3)基本特征 第一,资本——帝国主义侵略势力日益成为支配中国的决定性力量。 第二,中国的封建势力日益衰败并同外国侵略势力相勾结,成为资本——帝国主义压迫、奴役中国人民的社会基础和统治支柱。 第三,中国的自然经济基础虽然遭到破坏,但是封建剥削制度的根基——封建地主的土地所有制成为中国走向近代化和民主化的严重障碍。 第四,中国新兴的民族资本主义经济虽然已经产生,但是发展很缓慢,力量很软弱,且大部分与外国资本——帝国主义和本国封建主义都有或多或少的联系。 第五,由于近代中国处于资本——帝国主义列强的争夺和间接统治之下,近代中国各地区经济、政治和文化的发展是极不平衡的,中国长期处于不统一状态。 第六,在资本——帝国主义和封建主义的双重压迫下,中国的广大人民特别是农民日益贫困化以致大批破产,过着饥寒交迫和毫无政治权力的生活。 3、如何理解近代中国的两大历史任务及其相互关系? (1)近代中国的两大历史任务: 第一,争取民族独立,人民解放;第二,实现国家富强,人民富裕。 (2)近代中国的两大历史任务的相互关系: 争取民族独立,人民解放和实现国家富强,人民富裕这两个历史任务,是互相区别又互相紧密联系的。 第一,由于腐朽的社会制度束缚着生产力的发展,阻碍着经济技术的进步,必须首先改变这种制度,争取民族独立和人民解放,才能为实现国家富强和人民富裕创造前提,开辟道路。第二,实现国家富强和人民富裕是民族独立,人民解放的最终目的和必然要求。 第一章 1、资本-帝国主义侵略给中国带来了什么? 习题1 一、单项选择题 A1.数据结构是指()。 A.数据元素的组织形式 B.数据类型 C.数据存储结构 D.数据定义 C2.数据在计算机存储器内表示时,物理地址与逻辑地址不相同的,称之为()。 A.存储结构 B.逻辑结构 C.链式存储结构 D.顺序存储结构 D3.树形结构是数据元素之间存在一种()。 A.一对一关系 B.多对多关系 C.多对一关系 D.一对多关系 B4.设语句x++的时间是单位时间,则以下语句的时间复杂度为()。 for(i=1; i<=n; i++) for(j=i; j<=n; j++) x++; A.O(1) B.O(2n) C.O(n) D.O(3n) CA5.算法分析的目的是(1),算法分析的两个主要方面是(2)。 (1) A.找出数据结构的合理性 B.研究算法中的输入和输出关系 C.分析算法的效率以求改进 D.分析算法的易懂性和文档性 (2) A.空间复杂度和时间复杂度 B.正确性和简明性 C.可读性和文档性 D.数据复杂性和程序复杂性 6.计算机算法指的是(1),它具备输入,输出和(2)等五个特性。 (1) A.计算方法 B.排序方法 C.解决问题的有限运算序列 D.调度方法 (2) A.可行性,可移植性和可扩充性 B.可行性,确定性和有穷性 C.确定性,有穷性和稳定性 D.易读性,稳定性和安全性 7.数据在计算机内有链式和顺序两种存储方式,在存储空间使用的灵活性上,链式存储比顺序存储要()。 A.低 B.高 C.相同 D.不好说 8.数据结构作为一门独立的课程出现是在()年。 A.1946 B.1953 C.1964 D.1968 9.数据结构只是研究数据的逻辑结构和物理结构,这种观点()。 A.正确 B.错误 C.前半句对,后半句错 D.前半句错,后半句对 1 文件系统阶段的数据管理有些什么缺陷试举例说明。 文件系统有三个缺陷: (1)数据冗余性(redundancy)。由于文件之间缺乏联系,造成每个应用程序都有对应的文件,有可能同样的数据在多个文件中重复存储。 (2)数据不一致性(inconsistency)。这往往是由数据冗余造成的,在进行更新操作时,稍不谨慎,就可能使同样的数据在不同的文件中不一样。 (3)数据联系弱(poor data relationship)。这是由文件之间相互独立,缺乏联系造成的。 2 计算机系统安全性 (1)为计算机系统建立和采取的各种安全保护措施,以保护计算机系统中的硬件、软件及数据; (2)防止其因偶然或恶意的原因使系统遭到破坏,数据遭到更改或泄露等。 3. 自主存取控制缺点 (1)可能存在数据的“无意泄露” (2)原因:这种机制仅仅通过对数据的存取权限来进行安全控制,而数据本身并无安全性标记 (3)解决:对系统控制下的所有主客体实施强制存取控制策略 4. 数据字典的内容和作用是什么 数据项、数据结构 数据流数据存储和加工过程。 5. 一条完整性规则可以用一个五元组(D,O,A,C,P)来形式化地表示。 对于“学号不能为空”的这条完整性约束用五元组描述 D:代表约束作用的数据对象为SNO属性; O(operation):当用户插入或修改数据时需要检查该完整性规则; A(assertion):SNO不能为空; C(condition):A可作用于所有记录的SNO属性; P(procdure):拒绝执行用户请求。 6.数据库管理系统(DBMS) :①即数据库管理系统(Database Management System),是位于用户与操作系统之间的 一层数据管理软件,②为用户或应用程序提供访问DB的方法,包括DB的建立、查询、更 新及各种数据控制。 DBMS总是基于某种数据模型,可以分为层次型、网状型、关系型、面 向对象型DBMS。 7.关系模型:①用二维表格结构表示实体集,②外键表示实体间联系的数据模型称为关系模 型。 8.联接查询:①查询时先对表进行笛卡尔积操作,②然后再做等值联接、选择、投影等操作。 联接查询的效率比嵌套查询低。 9. 数据库设计:①数据库设计是指对于一个给定的应用环境,②提供一个确定最优数据模 型与处理模式的逻辑设计,以及一个确定数据库存储结构与存取方法的物理设计,建立起 既能反映现实世界信息和信息联系,满足用户数据要求和加工要求,又能被某个数据库管 理系统所接受,同时能实现系统目标,并有效存取数据的数据库。 10.事务的特征有哪些 事务概念 原子性一致性隔离性持续性 11.已知3个域: D1=商品集合=电脑,打印机 D3=生产厂=联想,惠普 求D1,D2,D3的卡尔积为: 12.数据库的恢复技术有哪些 数据转储和和登录日志文件是数据库恢复的 数据结构与算法基础知识总结 1 算法 算法:是指解题方案的准确而完整的描述。 算法不等于程序,也不等计算机方法,程序的编制不可能优于算法的设计。 算法的基本特征:是一组严谨地定义运算顺序的规则,每一个规则都是有效的,是明确的,此顺序将在有限的次数下终止。特征包括:(1)可行性; (2)确定性,算法中每一步骤都必须有明确定义,不充许有模棱两可的解释,不允许有多义性; (3)有穷性,算法必须能在有限的时间内做完,即能在执行有限个步骤后终止,包括合理的执行时间的含义; (4)拥有足够的情报。 算法的基本要素:一是对数据对象的运算和操作;二是算法的控制结构。 指令系统:一个计算机系统能执行的所有指令的集合。 基本运算和操作包括:算术运算、逻辑运算、关系运算、数据传输。算法的控制结构:顺序结构、选择结构、循环结构。 算法基本设计方法:列举法、归纳法、递推、递归、减斗递推技术、回溯法。 算法复杂度:算法时间复杂度和算法空间复杂度。 算法时间复杂度是指执行算法所需要的计算工作量。 算法空间复杂度是指执行这个算法所需要的内存空间。 2 数据结构的基本基本概念 数据结构研究的三个方面: (1)数据集合中各数据元素之间所固有的逻辑关系,即数据的逻辑结构; (2)在对数据进行处理时,各数据元素在计算机中的存储关系,即数据的存储结构; (3)对各种数据结构进行的运算。 数据结构是指相互有关联的数据元素的集合。 数据的逻辑结构包含: (1)表示数据元素的信息; (2)表示各数据元素之间的前后件关系。 数据的存储结构有顺序、链接、索引等。 线性结构条件: (1)有且只有一个根结点; (2)每一个结点最多有一个前件,也最多有一个后件。 非线性结构:不满足线性结构条件的数据结构。 3 线性表及其顺序存储结构 1.怎样认识近代中国的主要矛盾、社会性质及其基本特征? (1)近代中国的主要矛盾 帝国主义和中华民族的矛盾;封建主义和人民大众的矛盾是近代中国的主要矛盾。中国近代社会的两对主要矛盾是互相交织在一起的,而帝国主义和中华民族的矛盾,是最主要的矛盾。 (2)社会性质:半殖民地半封建的性质。 中国社会的半殖民地半封建社会,是近代以来中国在外国资本主义势力的入侵及其与中国封建主义势力相结合的条件下,逐步形成的一种从属于资本主义世界体系的畸形的社会形态。 鸦片战争前的中国社会是封建社会。鸦片战争以后,随着外国资本-帝国主义的入侵,中国社会性质发生了根本性变化:独立的中国逐步变成半殖民地的中国;封建的中国逐步变成半封建的中国。 (3)基本特征 第一,资本--帝国主义侵略势力不但逐步操纵了中国的财政和经济命脉,而且逐步控制了中国的政治,日益成为支配中国的决定性力量。 第二,中国的封建势力日益衰败并同外国侵略势力相勾结,成为资本--帝国主义压迫、奴役中国人民的社会基础和统治支柱。 第三,中国的自然经济基础虽然遭到破坏,但是封建剥削制度的根基--封建地主的土地所有制依然在广大地区内保持着,成为中国走向近代化和民主化的严重障碍。 第四,中国新兴的民族资本主义经济虽然已经产生,并在政治、文化生活中起了一定作用,但是在帝国主义封建主义的压迫下,他的发展很缓慢,力量很软弱,而且大部分与外国资本--帝国主义和本国封建主义都有或多或少的联系。 第五,由于近代中国处于资本--帝国主义列强的争夺和间接统治之下,近代中国各地区经济、政治和文化的发展是极不平衡的,中国长期处于不统一状态。 第六,在资本--帝国主义和封建主义的双重压迫下,中国的广大人民特别是农民日益贫困化以致大批破产,过着饥寒交迫和毫无政治权力的生活。 中国半殖民地半封建社会及其特征,是随着帝国主义侵略的扩大,帝国主义与中国封建势力结合的加深而逐渐形成的。 2.如何理解近代中国的两大历史任务及其相互关系? (1)近代中国的两大历史任务: 第一,争取民族独立,人民解放;第二,实现国家富强,人民富裕。 (2)近代中国的两大历史任务的相互关系: 争取民族独立,人民解放和实现国家富强,人民富裕这两个历史任务,是互相区别又互相紧 第1章概论 1. 数据结构是一门研究非数值计算的程序设计问题中,数据元素的①C、数据信息在计算机中的②A以及一组相关的运算等的课程。 ①A.操作对象B.计算方法C.逻辑结构D.数据映象 ②A.存储结构B.关系C.运算D.算法 2. 计算机算法指的是① C ,它必具备输入、输出和② B 等五个特性。 ① A. 计算方法 B. 排序方法 C. 解决问题的有限运算序列 D. 调度方法 ② A. 可行性、可移植性和可扩充性 B. 可行性、确定性和有穷性 C. 确定性、有穷性和稳定性 D. 易读性、稳定性和安全性 3.下面程序段的时间复杂度是D for(i=0;i 第一章数据库系统概述 选择题 1实体-联系模型中,属性是指(C) A.客观存在的事物 B.事物的具体描述 C.事物的某一特征 D.某一具体事件 2对于现实世界中事物的特征,在E-R模型中使用(A) A属性描述B关键字描述C二维表格描述D实体描述 3假设一个书店用这样一组属性描述图书(书号,书名,作者,出版社,出版日期),可以作为“键”的属性是(A) A书号B书名C作者D出版社 4一名作家与他所出版过的书籍之间的联系类型是(B) A一对一B一对多C多对多D都不是 5若无法确定哪个属性为某实体的键,则(A) A该实体没有键B必须增加一个属性作为该实体的键C取一个外关键字作为实体的键D该实体的所有属性构成键 填空题 1对于现实世界中事物的特征在E-R模型中使用属性进行描述 2确定属性的两条基本原则是不可分和无关联 3在描述实体集的所有属性中,可以唯一的标识每个实体的属性称为键 4实体集之间联系的三种类型分别是1:1 、1:n 、和m:n 5数据的完整性是指数据的正确性、有效性、相容性、和一致性 简答题 一、简述数据库的设计步骤 答:1需求分析:对需要使用数据库系统来进行管理的现实世界中对象的业务流程、业务规则和所涉及的数据进行调查、分析和研究,充分理解现实世界中的实际问题和需求。 分析的策略:自下而上——静态需求、自上而下——动态需求 2数据库概念设计:数据库概念设计是在需求分析的基础上,建立概念数据模型,用概念模型描述实际问题所涉及的数据及数据之间的联系。 3数据库逻辑设计:数据库逻辑设计是根据概念数据模型建立逻辑数据模型,逻辑数据模型是一种面向数据库系统的数据模型。 4数据库实现:依据关系模型,在数据库管理系统环境中建立数据库。 二、数据库的功能 答:1提供数据定义语言,允许使用者建立新的数据库并建立数据的逻辑结构 2提供数据查询语言 3提供数据操纵语言 4支持大量数据存储 5控制并发访问 三、数据库的特点 答:1数据结构化。2数据高度共享、低冗余度、易扩充3数据独立4数据由数据库管理系统统一管理和控制:(1)数据安全性(2)数据完整性(3)并发控制(4)数据库恢复 第二章关系模型和关系数据库 选择题 1把E-R模型转换为关系模型时,A实体(“一”方)和B实体(“多”方)之间一对多联系在关系模型中是通过(A)来实现的 《数据结构基础教程》习题解答(新) 第1章习题解答 一、填空 1.数据就是指所有能够输入到计算机中被计算机加工、处理得符号得集合。 2.可以把计算机处理得数据,笼统地分成数值型与非数值型两大类。 3.数据得逻辑结构就就是指数据间得邻接关系。 4.数据就是由一个个数据元素集合而成得。 5.数据项就是数据元素中不可再分割得最小标识单位,通常不具备完整、确定得实际意义,只就是反映数据元素某一方面得属性。 6.数据就是以数据元素为单位存放在内存得,分配给它得内存区域称为存储结点。 7.每个数据元素都具有完整、确定得实际意义,就是数据加工处理得对象。 8.如果两个数据结点之间有着逻辑上得某种关系,那么就称这两个结点就是邻接得。 9.在一个存储结点里,除了要有数据本身得内容外,还要有体现数据间邻接关系得内容。 10.从整体上瞧,数据在存储器内有两种存放得方式:一就是集中存放在一个连续得内存存储区中;一就是利用存储器中得零星区域, 分散地存放在内存得各个地方。 11.在有些书里,数据得“存储结构”也称为数据得“物理结构”。 12.“基本操作”就是指算法中那种所需时间与操作数得具体取值无关得操作。 二、选择 1.在常见得数据处理中, B 就是最基本得处理。 A.删除 B.查找 C.读取 D.插入 2.下面给出得名称中, A 不就是数据元素得同义词。 A.字段 B.结点 C.顶点 D.记录 3. D 就是图状关系得特例。 A.只有线性关系 B.只有树型关系 C.线性关系与树型关系都不 D.线性关系与树型关系都 4.链式存储结构中,每个数据得存储结点里 D指向邻接存储结点得指针,用以反映数据间得逻辑关系。 A.只能有1个 B.只能有2个 C.只能有3个 D.可以有多个 5.本书将采用 C 来描述算法。 A.自然语言 B.流程图(即框图) C.类C语言 D.C语言 6.有下面得算法段: for (i=0; i 第一章绪论 一、选择题 1.组成数据的基本单位是() (A)数据项(B)数据类型(C)数据元素(D)数据变量 2.数据结构是研究数据的()以及它们之间的相互关系。 (A)理想结构,物理结构(B)理想结构,抽象结构 (C)物理结构,逻辑结构(D)抽象结构,逻辑结构 3.在数据结构中,从逻辑上可以把数据结构分成() (A)动态结构和静态结构(B)紧凑结构和非紧凑结构 (C)线性结构和非线性结构(D)内部结构和外部结构 4.数据结构是一门研究非数值计算的程序设计问题中计算机的(①)以及它们之间的(②)和运算等的学科。 ① (A)数据元素(B)计算方法(C)逻辑存储(D)数据映像 ② (A)结构(B)关系(C)运算(D)算法 5.算法分析的目的是()。 (A)找出数据结构的合理性(B)研究算法中的输入和输出的关系 (C)分析算法的效率以求改进(D)分析算法的易懂性和文档性 6.计算机算法指的是(①),它必须具备输入、输出和(②)等5 个特性。 ① (A)计算方法(B)排序方法(C)解决问题的有限运算序列(D)调度方法 ② (A)可执行性、可移植性和可扩充性(B)可行性、确定性和有穷性 (C)确定性、有穷性和稳定性(D)易读性、稳定性和安全性 二、判断题 1.数据的机内表示称为数据的存储结构。() 2.算法就是程序。() 3.数据元素是数据的最小单位。() 4.算法的五个特性为:有穷性、输入、输出、完成性和确定性。() 5.算法的时间复杂度取决于问题的规模和待处理数据的初态。() 三、填空题 1.数据逻辑结构包括________、________、_________ 和_________四种类型,其中树形结构和图形结构合称为_____。 2.在线性结构中,第一个结点____前驱结点,其余每个结点有且只有______个前驱结点;最后一个结点______后续结点,其余每个结点有且只有_______个后续结点。 3.在树形结构中,树根结点没有_______结点,其余每个结点有且只 有_______个前驱结点;叶子结点没有________结点,其余每个结点的后续结点可以_________。 4.在图形结构中,每个结点的前驱结点数和后续结点数可以 _________。 5.线性结构中元素之间存在________关系,树形结构中元素之间存 在______关系,图形结构中元素之间存在_______关系。 6.算法的五个重要特性是_______、_______、______、_______、 一、判断题 (第一章绪论) 1.数据元素是数据的最小单元。 答案:错误 2.一个数据结构是由一个逻辑结构和这个逻辑结构上的基本运算集构成的整体。 答案:错误 3.数据的存储结构是数据元素之间的逻辑关系和逻辑结构在计算机存储器内的映像。 答案:正确 4.数据的逻辑结构是描述元素之间的逻辑关系,它是依赖于计算机的。 答案:错误 5.用语句频度来表示算法的时间复杂度的最大好处是可以独立于计算机的软硬件,分析算法的时间 答案:正确 (第二章线性表) 6.取顺序存储线性表的第i个元素的时间同i的大小有关。 答案:错误 7.线性表链式存储的特点是可以用一组任意的存储单元存储表中的数据元素。 答案:正确 8.线性链表的每一个节点都恰好包含一个指针域。 答案:错误 9.顺序存储方式的优点的存储密度大,插入和删除效率不如练市存储方式好。 答案:正确 10.插入和删除操作是数据结构中最基本的两种操作,所以这两种操作在数组中也经常使用。答案:错误 (第三章栈) 11.栈是一种对进栈和出栈作了限制的线性表。 答案:错误 12.在C(或C++)语言中设顺序栈的长度为MAXLEN,则top=MAXLEN表示栈满。答案:错误 13.链栈与顺序栈相比,其特点之一是通常不会出现满栈的情况。 答案:正确 14.空栈就是所有元素都为0上的栈。 答案:错误 15.将十进制数转换为二进制数是栈的典型应用之一。 答案:正确 (第四章队列) 16.队列式限制在两端进行操作的线性表。 答案:正确 17.判断顺序队列为空的标准是头指针和尾指针都指向同一结点。 答案:错误 18.在循环链列队中无溢出现像。 答案:错误 19.在循环队列中,若尾指针rear大于头指针front,则元素个数为rear-front。 答案:正确 20.顺序队列和循环队列关于队满和队空的判断条件是一样的。 答案:错误 (第五章串) 21.串是n个字母的有限序列。 答案:错误 22.串的堆分配存储是一种动态存储结构。 上篇综述作业及答案 一、单项选择题 1.中国封建社会的基本生产结构是:() A.手工业 B.农业经济 C.工业 D.小农经济 2.19世纪初,大肆向中国走私鸦片的国家是( ) A.美国 B.英国 C.日本 D.俄国 3.中国近代史上的第一个不平等条约是:() A.《望厦条约》B.《南京条约》C.《辛丑条约》 D.《马关条约》 4.《南京条约》中割让的中国领土是:() A.香港岛 B.九龙 C.新界 D.台湾 5.第一次鸦片战争中,美国强迫清政府签订的不平等条约是() A.《黄埔条约》 B.《虎门条约》 C.《望厦条约》 D.《瑷珲条约》 6.中国近代史的起点是:() A. 第一次鸦片战争 B. 第二次鸦片战争 C. 中日甲午战争 D. 八国联军侵华战争 7. 第一次鸦片战争后,中国逐步演变为:() A. 封建主义性质的国家 B. 半殖民地半资本主义性质的国家 C. 资本主义性质的国家 D. 半殖民地半封建性质的国家 8.标志着中国半殖民地半封建社会起点的事件是() A.英国的鸦片走私 B. 林则徐的虎门禁烟 C.1840年第一次鸦片战争 D.第二次鸦片战争 9.鸦片战争后,中国社会最主要的矛盾是:() A.地主阶级和农民阶级的矛盾B.资本—帝国主义和中华民族的矛盾C.封建主义和人民大众的矛盾D.清朝统治和汉族的矛盾 10.鸦片战争前,中国社会经济中占统治地位的是:() A.商品经济B.封建经济C.半殖民地经济D.资本主义经济 11.近代中国的历史表明,要争取争得民族独立和人民解放必须首先进行:() A. 反对帝国主义侵略的斗争 B. 反帝反封建的资产阶级民主革命 C. 反对封建主义压迫的斗争 D. 反对资产阶级的社会主义革命 12.在近代中国,实现国家富强和人民富裕的前提条件是:() A. 反对帝国主义的侵略 B. 争得民族独立和人民解放 C. 推翻封建主义的统治 D. 建立资本主义制度 13.中国工人阶级最早出现于:() A.十九世纪四、五十年代 B.十九世纪六十年代 C.十九世纪六、七十年代 D.十九世纪七十年代 14.近代中国产生的新的被压迫阶级是:() A农民阶级B工人阶级C资产阶级 D民族资产阶级 15.中国的资产阶级出现于:() A.十九世纪四、五十年代 B.十九世纪六十年代 C.十九世纪六、七十年代 D.十九世纪七十年代 单项答案1. D 2.B 3. B 4. A 5. C 6. A 7.D 8. C 9. B 10. B 11.B 12. B 13. A 14. B 15. C 第 1 章绪论 课后习题讲解 1. 填空 ⑴()是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。 【解答】数据元素 ⑵()是数据的最小单位,()是讨论数据结构时涉及的最小数据单位。 【解答】数据项,数据元素 【分析】数据结构指的是数据元素以及数据元素之间的关系。 ⑶从逻辑关系上讲,数据结构主要分为()、()、()和()。 【解答】集合,线性结构,树结构,图结构 ⑷数据的存储结构主要有()和()两种基本方法,不论哪种存储结构,都要存储两方面的内容:()和()。 【解答】顺序存储结构,链接存储结构,数据元素,数据元素之间的关系 ⑸算法具有五个特性,分别是()、()、()、()、()。 【解答】有零个或多个输入,有一个或多个输出,有穷性,确定性,可行性 ⑹算法的描述方法通常有()、()、()和()四种,其中,()被称为算法语言。 【解答】自然语言,程序设计语言,流程图,伪代码,伪代码 ⑺在一般情况下,一个算法的时间复杂度是()的函数。 【解答】问题规模 ⑻设待处理问题的规模为n,若一个算法的时间复杂度为一个常数,则表示成数量级的形式为(),若为n*log25n,则表示成数量级的形式为()。 【解答】Ο(1),Ο(nlog2n) 【分析】用大O记号表示算法的时间复杂度,需要将低次幂去掉,将最高次幂的系数去掉。 2. 选择题 ⑴顺序存储结构中数据元素之间的逻辑关系是由()表示的,链接存储结构中的数据元素之间的逻辑关系是由()表示的。 A 线性结构 B 非线性结构 C 存储位置 D 指针 【解答】C,D 【分析】顺序存储结构就是用一维数组存储数据结构中的数据元素,其逻辑关系由存储位置(即元素在数组中的下标)表示;链接存储结构中一个数据元素对应链表中的一个结点,元素之间的逻辑关系由结点中的指针表示。 在计算机局域网中,常用通信设备有(ABD) A集线器 B交换机 C调制解调器 D路由器 线缆标准化工作主要由哪一儿歌协会制定?(C) A OSI B ITU-T C EIA D IEEE 802协议族是由以下面那一个组织定义?(C) A OSI B EIA C IEEE D ANSI 衡量网络性能的两个主要指标为(AC) A带宽 B可信度 C延迟 D距离 局域网区别其他网络主要体现在以下(ABCD)方面。 A网络所覆盖的物理范围 B网络所使用的传输技术 C网络的拓扑结构 D带宽 会产生单点故障的是下列(ABC)拓扑结构 A总线型 B环型 C网状结构 D星型 数据交换技术包括(ABC) A电路交换 B报文交换 C分组交换 D文件交换 (B)拓扑结构会受到网络中信号反射的影响? A网型 B总线型 C环型 D星型 OSI参考模型按照顺序有哪些层?(C) C应用层、表示层、会话层、传输层、网络层、数据链路层、物理层在OSI七层模型中,网络层的功能有(B) A确保数据的传送正确无误 B确定数据包如何转发与路由 C在信道上传比特流 D纠错与流控 在OSI七层模型中,(B)哪一层的实现对数据加密。 A传输层 B表示层 C应用层 D网络层 网络层传输的数据叫做(B) A比特 B包 C段 D帧 TCP/IP协议栈中传输层协议有(AC) A TCP B ICMP C UDP D IP 数据从上到下封装的格式为(B) A比特包帧段数据 B数据段包帧比特 C比特帧包段数据 D数据包段帧比特 物理层定义了物理接口的哪些特性?(ABCD) A机JIE特性 B电气特性 C功能特性 D接口特性 细同轴电缆(10Base2)传输距离约达(A)粗同轴电缆(10Base5)的传输距离为(B) A 200米 B 500米 C 150米 D 485米 通常在网吧里,LAN采用的拓扑结构和网线类型为(C) A总线型和STP B总心型和UTP C形型和UTP D环型和STP 双绞线电缆为什么能代替网络中的细同轴电缆。(D) A双绞线电缆可靠性高 B双绞线电缆抗噪性更好 C细同轴电缆更廉价 D双绞线电缆更便于安装 在布线时,细缆和粗缆通常应用在(D)拓扑结构中。 单元练习1 一.判断题(下列各题,正确的请在前面的括号内打√;错误的打╳ ) (√)(1)数据的逻辑结构与数据元素本身的内容与形式无关。 (√)(2)一个数据结构就是由一个逻辑结构与这个逻辑结构上的一个基本运算集构成的整体。 (ㄨ)(3)数据元素就是数据的最小单位。 (ㄨ)(4)数据的逻辑结构与数据的存储结构就是相同的。 (ㄨ)(5)程序与算法原则上没有区别,所以在讨论数据结构时可以通用。 (√)(6)从逻辑关系上讲,数据结构主要分为线性结构与非线性结构两类。 (√)(7)数据的存储结构就是数据的逻辑结构的存储映像。 (√)(8)数据的物理结构就是指数据在计算机内实际的存储形式。 (ㄨ)(9)数据的逻辑结构就是依赖于计算机的。 (√)(10)算法就是对解题方法与步骤的描述。 二.填空题 (1)数据有逻辑结构与存储结构两种结构。 (2)数据逻辑结构除了集合以外,还包括:线性结构、树形结构与图形结构。(3)数据结构按逻辑结构可分为两大类,它们就是线性结构与非线性结构。(4)树形结构与图形结构合称为非线性结构。 (5)在树形结构中,除了树根结点以外,其余每个结点只有 1 个前趋结点。 (6)在图形结构中,每个结点的前趋结点数与后续结点数可以任意多个。 (7)数据的存储结构又叫物理结构。 (8)数据的存储结构形式包括:顺序存储、链式存储、索引存储与散列存储。(9)线性结构中的元素之间存在一对一的关系。 (10)树形结构结构中的元素之间存在一对多的关系, (11)图形结构的元素之间存在多对多的关系。 (12)数据结构主要研究数据的逻辑结构、存储结构与算法(或运算) 三个方面的内容。 (13)数据结构被定义为(D,R),其中D就是数据的有限集合,R就是D上的关系的有限集合。 (14)算法就是一个有穷指令的集合。 (15)算法效率的度量可以分为事先估算法与事后统计法。 (16)一个算法的时间复杂性就是算法输入规模的函数。 (17)算法的空间复杂度就是指该算法所耗费的存储空间 ,它就是该算法求解问题规模n的函数。 (18)若一个算法中的语句频度之与为T(n)=6n+3nlog2n,则算法的时间复杂度为O(nlog2n) 。 中国近代史纲要课后习题答案 1怎样认识近代中国的主要矛盾、社会性质? (1)近代中国的主要矛盾 帝国主义和中华民族的矛盾;封建主义和人民大众的矛盾是近代中国的主要矛盾。中国近代社会的两对主要矛盾是互相交织在一起的,而帝国主义和中华民族的矛盾,是最主要的矛盾。(2)社会性质:半殖民地半封建的性质。 中国社会的半殖民地半封建社会,是近代以来中国在外国资本主义势力的入侵及其与中国封建主义势力相结合的条件下,逐步形成的一种从属于资本主义世界体系的畸形的社会形态。鸦片战争前的中国社会是封建社会。鸦片战争以后,随着外国资本-帝国主义的入侵,中国社会性质发生了根本性变化:独立的中国逐步变成半殖民地的中国;封建的中国逐步变成半封建的中国。 2.如何理解近代中国的两大历史任务及其相互关系? (1)近代中国的两大历史任务: 第一,争取民族独立,人民解放;第二,实现国家富强,人民富裕。 (2)近代中国的两大历史任务的相互关系: 争取民族独立,人民解放和实现国家富强,人民富裕这两个历史任务,是互相区别又互相紧密联系的。 第一,由于腐朽的社会制度束缚着生产力的发展,阻碍着经济技术的进步,必须首先改变这种制度,争取民族独立和人民解放,才能为实现国家富强和人民富裕创造前提,开辟道路。近代以来的历史表明,争得争取民族独立和人民解放,必须进行反帝反封建的民主革命。第二,实现国家富强和人民富裕是民族独立,人民解放的最终目的和必然要求。 第一章反对外国侵略的斗争 3.中国近代历次反侵略战争失败的根本原因是什么? 第一,近代中国社会制度的腐败是反侵略战争失败的根本原因。 在1840年以后中国逐渐沦为半殖民地半封建社会的过程中,清王朝统治者从皇帝到权贵,大都昏庸愚昧,不了解世界大势,不懂得御敌之策。由于政治腐败、经济落后和文化保守,一方面使清朝统治阶级封闭自守,妄自尊大,骄奢淫逸,盲目进攻;另一方面又使统治者和清军指挥人员在战争面前完全没有应变的能力和心态,不适应于近代战争,不少将帅贪生怕死,临阵脱逃,有的甚至出卖国家和民族的利益。清政府尤其害怕人民群众,担心人民群众动员起来会危及自身统治,所以不敢发动和依靠人民群众的力量。 清朝统治集团在对外战争中妥协退让求和投降的一系列做法,已经使他失去在中国存在的理由,不推翻他是不能取得反侵略战争胜利的。 第二,近代中国经济技术的落后是反侵略战争失败的另一个重要原因。 当时的英国已经历过工业革命,资本主义生产力获得突飞猛进的发展,而中国仍停留在封建的自然经济水平上。经济技术的落后直接造成军事装备的落后,军队指挥员不了解近代军事战术,从而造成军队素质和战斗力的低下。 经济技术落后是反侵略战争失败的重要原因,但并不表明经济技术落后就一定在反侵略战争中失败。正是因为当时的中国政府不能很好地组织反侵略战争,不能发动和利用人民群众的力量,甚至压制人民群众,其失败是不可避免的。 第二章对国家出路的早期探索 4、如何认识太平天国农民战争的意义和失败的原因、教训? (1)太平天国农民战争的意义 太平天国起义虽然失败了,但它具有不可磨灭的历史功绩和重大的历史意义。 第一,太平天国起义沉重打击了封建统治阶级,强烈震撼了清政府的统治根基,加速了清王近代史纲要习题及答案
严蔚敏版数据结构课后习题答案-完整版
课后作业完成题库1、4、7、8、9、10、12、25题
数据结构(第4版)习题及实验参考答案数据结构复习资料完整版(c语言版)
近代史课后习题答案
数据结构习题及参考答案
课后习题及答案
数据结构与算法基础知识总结
中国近代史纲要课后习题答案
数据结构 习题答案
(完整版)数据库课后习题及答案
《数据结构基础教程》习题及解答
数据结构习题及答案——严蔚敏
实用数据结构基础(第四版)课后习题知识讲解
近代史纲要 上篇综述 习题及答案
数据结构习题与答案
课后题
实用数据结构基础参考答案
近代史课后题答案整理
相关主题
文本预览