WEKA入门教程
- 格式:doc
- 大小:232.00 KB
- 文档页数:15

如何使用Weka进行机器学习和数据挖掘1. 引言机器学习和数据挖掘是当今计算机科学领域中非常热门的技术,它们的应用已经渗透到各个行业。
Weka是一个功能强大且易于使用的开源软件工具,广泛应用于机器学习和数据挖掘任务中。
本文将介绍如何使用Weka进行机器学习和数据挖掘,帮助读者快速上手。
2. 安装与配置Weka是使用Java编写的跨平台软件,可以在Windows、Linux 和Mac OS等操作系统上运行。
首先,从Weka官方网站上下载最新版本的Weka软件包。
下载完成后,按照官方提供的安装指南进行安装。
安装完成后,打开Weka软件,在"Tools"菜单下找到"Package Manager",确保所有必需的包(例如data-visualization)都已被安装。
3. 数据预处理在进行机器学习和数据挖掘任务之前,通常需要对原始数据进行预处理。
Weka提供了许多强大的工具来处理数据。
首先,可以使用Weka的数据编辑器加载并查看原始数据集。
然后,可以进行数据清洗,包括处理缺失值、异常值和重复数据等。
Weka还提供了特征选择和降维等功能,帮助提取有意义的特征。
4. 分类与回归分类和回归是机器学习中的两个重要任务。
Weka支持多种分类和回归算法,包括决策树、朴素贝叶斯、支持向量机和神经网络等。
在Weka主界面中,选择"Classify"选项卡,选择相应的算法,并配置参数。
然后,可以使用已经预处理的数据集进行模型训练和测试。
Weka提供了丰富的性能评估指标和可视化工具,帮助分析模型的效果。
5. 聚类分析聚类是一种无监督学习方法,用于将样本划分到不同的组或簇中。
Weka提供了各种聚类算法,如K均值、层次聚类和基于密度的聚类。
在Weka主界面中,选择"Cluster"选项卡,选择相应的算法,并配置参数。
然后,使用预处理的数据集进行聚类分析。

Weka 数据挖掘软件使用指南1.Weka简介该软件是WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过/ml/weka得到。
Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
如果想自己实现数据挖掘算法的话,可以看一看Weka的接口文档。
在Weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
2.Weka启动打开Weka主界面后会出现一个对话框,如图:主要使用右方的四个模块,说明如下:❑Explorer:使用Weka探索数据的环境,包括获取关联项,分类预测,聚簇等;❑Experimenter:运行算法试验、管理算法方案之间的统计检验的环境;❑KnowledgeFlow:这个环境本质上和Explorer所支持的功能是一样的,但是它有一个可以拖放的界面。
它有一个优势,就是支持增量学习;❑SimpleCLI:提供了一个简单的命令行界面,从而可以在没有自带命令行的操作系统中直接执行Weka命令(某些情况下使用命令行功能更好一些)。
3.主要操作说明点击进入Explorer模块开始数据探索环境。
3.1主界面进入Explorer模式后的主界面如下:3.1.1标签栏主界面最左上角(标题栏下方)的是标签栏,分为五个部分,功能依次是:❑Preprocess(数据预处理):选择和修改要处理的数据;❑Classify(分类):训练和测试关于分类或回归的学习方案;❑Cluster(聚类):从数据中学习聚类;❑Associate(关联):从数据中学习关联规则;❑Select attributes(属性选择):选择数据中最相关的属性;❑Visualize(可视化):查看数据的交互式二维图像。
3.1.2载入、编辑数据标签栏下方是载入数据栏,功能如下:❑Open file:打开一个对话框,允许你浏览本地文件系统上的数据文件(.dat);❑Open URL:请求一个存有数据的URL 地址;❑Open DB:从数据库中读取数据;❑Generate:从一些数据生成器中生成人造数据。

WEKA 3-5-5 Explorer 用户指南原文版本 3.5.5翻译王娜校对 C6H5NO2Pentaho 中文讨论组QQ 群:12635055论坛:/bipub/index.asp/目录1 启动WEKA (3)Explorer (5)2 WEKA2.1 标签页 (5)2.2 状态栏 (5)按钮 (5)2.3 Log状态图标 (5)2.4 WEKA3 预处理 (6)3.1 载入数据 (6)3.2 当前关系 (6)3.3 处理属性 (7)3.4 使用筛选器 (7)4 分类 (10)4.1 选择分类器 (10)4.2 测试选项 (10)4.3 Class属性 (11)4.4 训练分类器 (11)4.5 分类器输出文本 (11)4.6 结果列表 (12)5 聚类 (13)5.1 选择聚类器(Clusterer) (13)5.2 聚类模式 (13)5.3 忽略属性 (13)5.4 学习聚类 (14)6 关联规则 (15)6.1 设定 (15)6.2 学习关联规则 (15)7 属性选择 (16)7.1 搜索与评估 (16)7.2 选项 (16)7.3 执行选择 (16)8 可视化 (18)8.1 散点图矩阵 (18)8.2 选择单独的二维散点图 (18)8.3 选择实例 (19)参考文献 (20)启动WEKAWEKA中新的菜单驱动的 GUI 继承了老的 GUI 选择器(类 weka.gui.GUIChooser)的功能。
它的MDI(“多文档界面”)外观,让所有打开的窗口更加明了。
这个菜单包括六个部分。
1.Programz LogWindow打开一个日志窗口,记录输出到stdout或stderr的内容。
在 MS Windows 那样的环境中,WEKA 不是从一个终端启动,这个就比较有用。
z Exit关闭WEKA。
2.Applications 列出 WEKA 中主要的应用程序。
z Explorer 使用 WEKA 探索数据的环境。

Weka入门教程(1)巧妇难为无米之炊。
首先我们来看看WEKA所用的数据应是什么样的格式。
跟很多电子表格或数据分析软件一样,WEKA所处理的数据集是图1那样的一个二维的表格。
图1 新窗口打开这里我们要介绍一下WEKA中的术语。
表格里的一个横行称作一个实例(Instance),相当于统计学中的一个样本,或者数据库中的一条记录。
竖行称作一个属性(Attrbute),相当于统计学中的一个变量,或者数据库中的一个字段。
这样一个表格,或者叫数据集,在WEKA 看来,呈现了属性之间的一种关系(Relation)。
图1中一共有14个实例,5个属性,关系名称为“weather”。
WEKA存储数据的格式是ARFF(Attribute-Relation File Format)文件,这是一种ASCII文本文件。
图1所示的二维表格存储在如下的ARFF文件中。
这也就是WEKA自带的“weather.arff”文件,在WEKA安装目录的“data”子目录下可以找到。
代码:% ARFF file for the weather data with some numric features%@relation weather@attribute outlook {sunny, overcast, rainy}@attribute temperature real@attribute humidity real@attribute windy {TRUE, FALSE}@attribute play {yes, no}@data%% 14 instances%sunny,85,85,FALSE,nosunny,80,90,TRUE,noovercast,83,86,FALSE,yesrainy,70,96,FALSE,yesrainy,68,80,FALSE,yesrainy,65,70,TRUE,noovercast,64,65,TRUE,yessunny,72,95,FALSE,nosunny,69,70,FALSE,yesrainy,75,80,FALSE,yessunny,75,70,TRUE,yesovercast,72,90,TRUE,yesovercast,81,75,FALSE,yesrainy,71,91,TRUE,no需要注意的是,在Windows记事本打开这个文件时,可能会因为回车符定义不一致而导致分行不正常。

学生实验报告学院:信息管理学院课程名称:数据挖掘教学班级:B01姓名:学号:页脚内容1实验报告1. 实验目的和要求:(1)Explorer界面的各项功能;注意不能与课件上的截图相同,可采用打开不同的数据文件以示区别。
(2)Weka的两种数据表格编辑文件方式下的功能介绍;①Explorer-Preprocess-edit,弹出Viewer对话框;页脚内容2②Weka GUI选择器窗口-Tools | ArffViewer,打开ARFF-Viewer窗口。
(3)ARFF文件组成。
2.实验过程(记录实验步骤、分析实验结果)2.1 Explorer界面的各项功能2.1.1 初始界面示意其中:explorer选项是数据挖掘梳理数据最常用界面,也是使用weka最简单的方法。
Experimenter:实验者选项,提供不同数值的比较,发现其中规律。
KnowledgeFlow:知识流,其中包含处理大型数据的方法,初学者应用较少。
Simple CLI :命令行窗口,有点像cmd 格式,非图形界面。
2.1.2 进入Explorer 界面功能介绍(1)任务面板页脚内容3Preprocess(数据预处理):选择和修改要处理的数据。
Classify(分类):训练和测试分类或回归模型。
Cluster(聚类):从数据中聚类。
聚类分析时用的较多。
Associate(关联分析):从数据中学习关联规则。
Select Attributes(选择属性):选择数据中最相关的属性。
Visualize(可视化):查看数据的二维散布图。
(2)常用按钮页脚内容4Openfile:打开文件Open URL:打开URL格式文件Open DB:打开数据库文件Generate:数据生成Undo:撤销操作Edit:编辑数据Save:保存数据文件,可实现文件格式的转换,比如csv 格式文件向ARFF格式文件转换等等。
(3)筛选数据页脚内容5Choose:从这个按钮进去可以选择某个过滤器对数据进行筛选,数据预处理一般使用这个。

weka数据预处理标准化方法说明Weka(Waikato Environment for Knowledge Analysis)是一套用于数据挖掘和机器学习的开源软件工具集,提供了丰富的功能,包括数据预处理、分类、回归、聚类等。
在Weka中,数据预处理是一个关键的步骤,其中标准化是一个常用的技术,有助于提高机器学习算法的性能。
下面是在Weka中进行数据标准化的一般步骤和方法说明:1. 打开Weka:启动Weka图形用户界面(GUI)或使用命令行界面。
2. 加载数据:选择“Explorer”选项卡,然后点击“Open file”按钮加载您的数据集。
3. 选择过滤器(Filter):在“Preprocess”选项卡中,选择“Filter”子选项卡,然后点击“Choose”按钮选择一个过滤器。
4. 选择标准化过滤器:在弹出的对话框中,找到并选择标准化过滤器。
常见的标准化过滤器包括:- Normalize:这个过滤器将数据标准化为给定的范围,通常是0到1。
- Standardize:使用这个过滤器可以将数据标准化为零均值和单位方差。
- AttributeRange:允许您手动指定每个属性的范围,以进行标准化。
5. 设置标准化选项:选择标准化过滤器后,您可能需要配置一些选项,例如范围、均值和方差等,具体取决于选择的过滤器。
6. 应用过滤器:配置完成后,点击“Apply”按钮,将标准化过滤器应用于数据。
7. 保存处理后的数据:如果需要,您可以将标准化后的数据保存到文件中。
8. 查看结果:在数据预处理完成后,您可以切换到“Classify”选项卡,选择一个分类器,并使用标准化后的数据进行模型训练和测试。
记住,具体的步骤和选项可能会因Weka版本的不同而有所差异,因此建议查阅Weka文档或在线资源以获取更具体的信息。
此外,标准化的适用性取决于您的数据和机器学习任务,因此在应用标准化之前,最好先了解您的数据的分布和特征。

weka使用教程Weka是一个强大的开源机器学习软件,它提供了各种功能和算法来进行数据挖掘和预测分析。
以下是一个简单的Wea使用教程,帮助您了解如何使用它来进行数据分析和建模。
1. 安装Weka:首先,您需要下载并安装Weka软件。
您可以从官方网站上下载Weka的最新版本,并按照安装说明进行安装。
2. 打开Weka:安装完成后,打开Weka软件。
您将看到一个欢迎界面,上面列出了各种不同的选项和功能。
选择“Explorer”选项卡,这将帮助您导航和执行不同的任务。
3. 导入数据:在Explorer选项卡上,点击“Open file”按钮以导入您的数据集。
选择您要导入的数据文件,并确认数据文件的格式和结构。
4. 数据预处理:在导入数据之后,您可能需要对数据进行预处理,以清除噪声和处理缺失值。
在Weka中,您可以使用各种过滤器和转换器来处理数据。
点击“Preprocess”选项卡,然后选择适当的过滤器和转换器来定义您的预处理流程。
5. 数据探索:在数据预处理之后,您可以使用Weka的可视化工具来探索您的数据。
点击“Classify”选项卡,然后选择“Visualize”选项。
这将显示您的数据集的可视化图表和统计信息。
6. 建立模型:一旦您对数据进行了足够的探索,您可以使用Weka的各种机器学习算法建立模型。
在“Classify”选项卡上选择“Choose”按钮,并从下拉菜单中选择一个适当的分类算法。
然后,使用“Start”按钮训练模型并评估模型的性能。
7. 模型评估:一旦您建立了模型,您可以使用Weka提供的评估指标来评估模型的性能。
在“Classify”选项卡上,选择“Evaluate”选项,Weka将自动计算模型的准确性、精确度、召回率等指标。
8. 导出模型:最后,一旦您满意您的模型性能,您可以将模型导出到其他应用程序或格式中。
在Weka中,点击“Classify”选项卡,选择“Save model”选项,并指定模型的保存位置和格式。
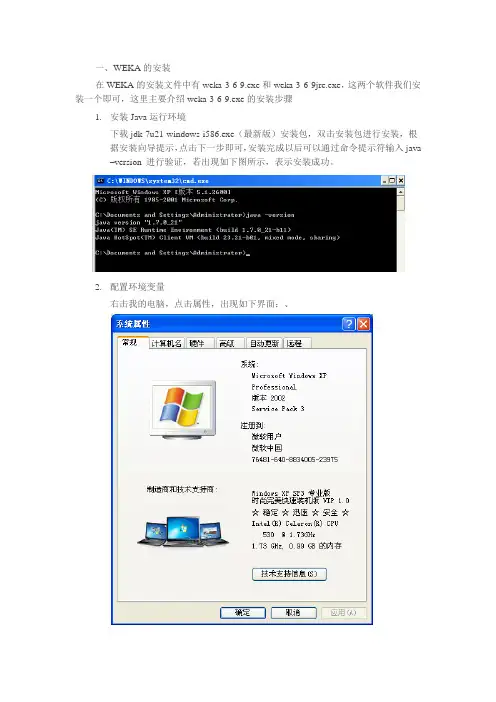
一、WEKA的安装在WEKA的安装文件中有weka-3-6-9.exe和weka-3-6-9jre.exe,这两个软件我们安装一个即可,这里主要介绍weka-3-6-9.exe的安装步骤1.安装Java运行环境下载jdk-7u21-windows-i586.exe(最新版)安装包,双击安装包进行安装,根据安装向导提示,点击下一步即可,安装完成以后可以通过命令提示符输入java–version 进行验证,若出现如下图所示,表示安装成功。
2.配置环境变量右击我的电脑,点击属性,出现如下界面:、选择高级——>环境变量,如图所示:出现环境变量配置界面:双击Path,然后出现编辑系统变量窗口:在变量值编辑框中,将光标移动至最后,添加一个分号“;”,然后将java的jdk安装路径追加到编辑框最后,我的系统中安装路径为:C:\ProgramFiles\Java\jdk1.7.0_21\bin,所以在编辑框最后写入:“; C:\ProgramFiles\Java\jdk1.7.0_21\bin”,即可完成环境变量的配置。
3.weka-3-6-9.exe双击此文件开始进行安装,在出现的窗口中点击Next,然后点击I Agree,再点击Next,此时出现如下窗口,Browse左边的区域是WEKA的默认安装路径,我们可以点击Browse选择我们想要安装WEKA的位置,然后点击窗口下方的NEXT,也可以不点击Browse直接将WEKA安装到默认的目录下,即直接点击窗口下方的NEXT,在新出现的窗口中点击Install开始安装,等待几秒种后点击Next,在新窗口中会有一个Start Weka单选框(默认情况下是选中的),如果我们想安装完成后就启动WEKA,那么我们就直接点击新窗口下方的FINISH 完成安装,如果我们不想立即启动WEKA可以单击Start Weka前面的单选框,然后点击FINISH即可完成安装,此时WEKA已经安装到我们的电脑中。



简介和回归简介什么是数据挖掘?您会不时地问自己这个问题,因为这个主题越来越得到技术界的关注。
您可能听说过像 Google 和 Yahoo! 这样的公司都在生成有关其所有用户的数十亿的数据点,您不禁疑惑,“它们要所有这些信息干什么?”您可能还会惊奇地发现 Walmart 是最为先进的进行数据挖掘并将结果应用于业务的公司之一。
现在世界上几乎所有的公司都在使用数据挖掘,并且目前尚未使用数据挖掘的公司在不久的将来就会发现自己处于极大的劣势。
那么,您如何能让您和您的公司跟上数据挖掘的大潮呢?我们希望能够回答您所有关于数据挖掘的初级问题。
我们也希望将一种免费的开源软件 Waikato Environment for Knowledge Analysis (WEKA) 介绍给您,您可以使用该软件来挖掘数据并将您对您用户、客户和业务的认知转变为有用的信息以提高收入。
您会发现要想出色地完成挖掘数据的任务并不像您想象地那么困难。
此外,本文还会介绍数据挖掘的第一种技术:回归,意思是根据现有的数据预测未来数据的值。
它可能是挖掘数据最为简单的一种方式,您甚至以前曾经用您喜爱的某个流行的电子数据表软件进行过这种初级的数据挖掘(虽然 WEKA 可以做更为复杂的计算)。
本系列后续的文章将会涉及挖掘数据的其他方法,包括群集、最近的邻居以及分类树。
(如果您还不太知道这些术语是何意思,没关系。
我们将在这个系列一一介绍。
)回页首什么是数据挖掘?数据挖掘,就其核心而言,是指将大量数据转变为有实际意义的模式和规则。
并且,它还可以分为两种类型:直接的和间接的。
在直接的数据挖掘中,您会尝试预测一个特定的数据点—比如,以给定的一个房子的售价来预测邻近地区的其他房子的售价。
在间接的数据挖掘中,您会尝试创建数据组或找到现有数据的模式—比如,创建“中产阶级妇女”的人群。
实际上,每次的美国人口统计都是在进行数据挖掘,政府想要收集每个国民的数据并将它转变为有用信息。
Weka入门教程3. 分类与回归背景知识WEKA把分类(Classification)和回归(Regression)都放在“Classify”选项卡中,这是有原因的。
在这两个任务中,都有一个目标属性(输出变量)。
我们希望根据一个样本(WEKA 中称作实例)的一组特征(输入变量),对目标进行预测。
为了实现这一目的,我们需要有一个训练数据集,这个数据集中每个实例的输入和输出都是已知的。
观察训练集中的实例,可以建立起预测的模型。
有了这个模型,我们就可以新的输出未知的实例进行预测了。
衡量模型的好坏就在于预测的准确程度。
在WEKA中,待预测的目标(输出)被称作Class属性,这应该是来自分类任务的“类”。
一般的,若Class属性是分类型时我们的任务才叫分类,Class属性是数值型时我们的任务叫回归。
选择算法这一节中,我们使用C4.5决策树算法对bank-data建立起分类模型。
我们来看原来的“bank-data.csv”文件。
“ID”属性肯定是不需要的。
由于C4.5算法可以处理数值型的属性,我们不用像前面用关联规则那样把每个变量都离散化成分类型。
尽管如此,我们还是把“Children”属性转换成分类型的两个值“YES”和“NO”。
另外,我们的训练集仅取原来数据集实例的一半;而从另外一半中抽出若干条作为待预测的实例,它们的“pep”属性都设为缺失值。
经过了这些处理的训练集数据在这里下载;待预测集数据在这里下载。
我们用“Explorer”打开训练集“bank.arff”,观察一下它是不是按照前面的要求处理好了。
切换到“Classify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。
3.5版的WEKA中,树型框下方有一个“Filter...”按钮,点击可以根据数据集的特性过滤掉不合适的算法。
我们数据集的输入属性中有“Binary”型(即只有两个类的分类型)和数值型的属性,而Class变量是“Binary”的;于是我们勾选“Binary attributes”“Numeric attributes”和“Binary class”。
大数据导论实验报告
实验一
姓名abc
学号asadsdsa
报告日期
实验一
一.实验目的
1实验开源工具Weka的安装和熟悉;
2.数据理解,数据预处理的实验;
二.实验内容
1.weka介绍
2.数据理解
3.数据预处理
4.保存处理后的数据
三.实验过程
1.导入数据并修改选项
2.用weka.filters.unsupervised.attribute.ReplaceMissingValues处理缺失值
3.用weka.filters.unsupervised.attribute.Discretize离散化第一列数据
4.用weka.filters.unsupervised.instance.RemoveDuplicates删除重复数据
5.用weka.filters.unsupervised.attribute.Discretize离散化第六列数据
6.用weka.filters.unsupervised.attribute.Normalize归一化数据
7.保存数据
四.实验结果与分析
1.数据清理后的对比图,上面的是处理前的图,下图是处理后的图
分析:通过两图对比可发现图一中缺失的数据在图二中已经添加上。
2.离散化第一行后的对比图,图片为离散化之后的效果图
分析:此次处理目标为第一列,可发现处理后‘age’这一列的数据离散化了。
3.删除重复数据之后的效果图
5.离散化第六列后的效果图
分析:此次处理目标为第六列,可清楚看到发生的变化6.归一化后的效果图
此次处理的目标是10,12,13,14列,即将未离散化的数值列进行归一化处理。
矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。