随机信号分析实验百度
- 格式:docx
- 大小:124.11 KB
- 文档页数:15

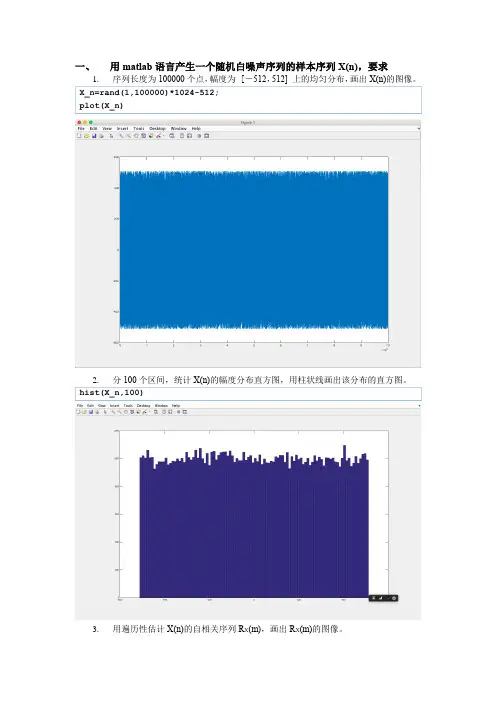
一、用matlab语言产生一个随机白噪声序列的样本序列X(n),要求
3.用遍历性估计X(n)的自相关序列R X(m),画出R X(m)的图像。
二、将一中产生的序列通过一个线性系统,其单位脉冲响应为h(n)=0.9n,n=0,
1,…,100
三、比较X(n)与Y(n)的幅度分布直方图,发生了什么变化。
分析其变化的原
因。
随机信号经过线性系统后,不会增加新的频率分量,但是输出的幅度和相位会发生变化。
白噪声X(n)的幅度基本相同,而Y(n)的幅度基本呈正态分布。
因为均匀白噪声是一种宽带非正态过程,所以通过一有限带宽线性系统后,输出Y(n)近似呈正态分布。
——via 1402011 赵春昊。
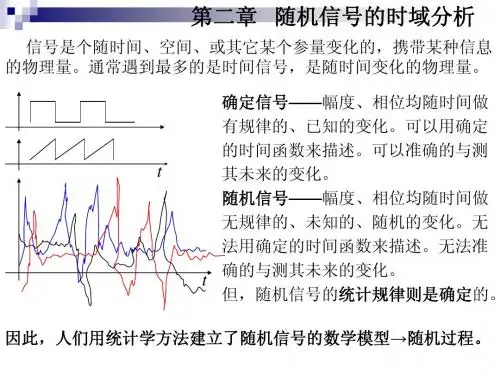
一、基本概念1、随机过程随机信号是非确定性信号,不能用确定的数学关系式来描述,不能预测它未来任何瞬时的精确值,任一次观测值只代表在其变动范围内可能产生的结果之一,但其值的变动服从统计规律。
随机信号的描述必须采用概率和统计学的方法。
对随机信号按时间历程所作的各次长时间观测记录称为样本函数,记作x(t)。
在有限时间区间上的样本函数称为样本记录。
在同一试验条件下,全部样本函数的集合(总体)就是随机过程,以{x(t)}表示,即2、随机信号类型3、平稳随机过程平稳随机过程就是统计特征参数不随时间变化而改变的随机过程。
例如,对某一随机过程的全部样本函数的集合选取不同的时间t进行计算,得出的统计参数都相同,则称这样的随机过程为平稳随机过程,否则就是非平稳随机过程。
如采样记录的均值不随时间变化4、各态历经随机过程若从平稳随机过程中任取一样本函数,如果该单一样本在长时间内的平均统计参数(时间平均)和所有样本函数在某一时刻的平均统计参数(集合平均)是一致的,则称这样的平稳随机过程为各态历经随机过程。
显然,各态历经随机过程必定是平稳随机过程,但是平稳随机过程不一定是各态历经的。
各态历经随机过程是随机过程中比较重要的一种,因为根据单个样本函数的时间平均可以描述整个随机过程的统计特性,从而简化了信号的分析和处理。
但是要判断随机过程是否各态历经的随机过程是相当困难的。
一般的做法是,先假定平稳随机过程是各态历经的,然后再根据测定的特性返回到实际中分析和检验原假定是否合理。
由大量事实证明,一般工程上遇到的平稳随机过程大多数是各态历经随机过程。
虽然有的不一定是严格的各态历经过程,但在精度许可的范围内,也可以当作各态历经随机过程来处理。
事实上,一般的随机过程需要足够多的样本(理论上应为无限多)才能描述它,而要进行大量的观测来获取足够多的样本函数是非常困难或做不到的。
在测试工作中常以一个或几个有限长度的样本记录来推断整个随机过程,以其时间平均来估计集合平均。




随机信号分析李晓峰引言随机信号分析是一门研究信号及其性质的学科,其在现代通信、图像处理、生物医学工程等领域中具有重要的应用价值。
本文将介绍随机信号分析的基本概念、常见的分析方法以及李晓峰教授在随机信号分析领域的研究成果。
随机信号的定义随机信号是指在某个时间段内具有随机性质的信号。
其特点是信号的取值在时间和幅度上都是不确定的,只能通过概率统计的方法来描述。
一个随机信号可以用一个概率密度函数来描述其取值的分布情况。
随机信号有两种基本的分类方式:离散随机信号和连续随机信号。
离散随机信号是在离散的时间点上进行取样的信号,连续随机信号则是在连续的时间上变化的信号。
随机信号分析方法统计特性分析统计特性分析是随机信号分析的基本方法之一,它通过对信号进行统计分析,从而得到信号的数学特性。
常见的统计特性包括均值、方差、自相关函数和谱密度等。
均值是衡量随机信号集中程度的一个指标,它表示信号的中心位置。
方差则用来衡量信号的离散程度,方差越大表示信号的波动性越大。
自相关函数描述了信号在不同时间点之间的相关性,而谱密度则表示信号在不同频率上的能量分布情况。
概率密度函数分析随机信号的概率密度函数描述了信号取值的概率分布情况。
常见的概率密度函数包括高斯分布、均匀分布和指数分布等。
高斯分布是最常用的概率密度函数之一,其形状呈钟型曲线,具有对称性。
均匀分布则表示信号的取值在一个区间上是均匀分布的,而指数分布则表示信号的取值在一个时间段内的分布服从指数规律。
谱分析谱分析是通过对随机信号进行频域分析来研究其频率成分的分析方法。
常见的谱分析方法有功率谱密度分析和相关函数分析。
功率谱密度分析可以用来分析信号在不同频率上的能量分布情况,通过功率谱密度分析可以得到信号的频谱图。
相关函数分析则是通过对信号进行自相关操作,得到信号的相关函数,从而分析信号在不同频率上的相关性。
李晓峰教授的研究成果李晓峰教授是我国著名的随机信号分析专家,他在随机信号分析领域做出了许多重要的研究成果。

《随机信号分析》试验报告班级班学号_______________姓名_________________实验一1、熟悉并练习使用下列 Matlab 的函数,给出各个函数的功能说明和内部参数 的意义,并给出至少一个使用例子和运行结果:1)randn()产生随机数数组或矩阵,其元素服从均值为 0,方差为 1 的正态分布1) Y = randn产生一个伪随机数 2) Y = randn(n) 产生 n x n 的矩阵, 的正态分布其元素服从均值为0,方差为 13)Y = randn(m,n)产生 m x n 的矩阵, 的正态分布其元素服从均值为0,方差为 14) Y= randn([m n]) 产生 m x n 的矩阵, 的正态分布其元素服从均值为0,方差为 1选择( 2)作为例子,运行结果如下: >> Y = randn(3)1.3005 0.0342 0.97920.2691 0.9913 -0.8863 -0.1551 -1.3618 -0.3562生成n 々随机矩阵,其元素在(0, 1)内 生成mxn 随机矩阵 生成m x n 随机矩阵生成mxn 和x …随机矩阵或数组 生成m x n 和x …随机矩阵或数组 生成与矩阵 A 相同大小的随机矩阵 选择( 3)作为例子,运行结果如下:>> Y = rand([3 4])Y =0.05790.0099 0.1987 0.19883)normrnd()产生服从均值为mu 标准差为sigma 的随机数, mu 和sigma 可以为向量、矩阵、或多维数组。
(2)R = normrnd (mu,sigma,v ) 产生服从均值为 mu 标准差为 sigma 的随机数,v 是一个行向量。
如果v 是一个1 X 2的向量, 则R 为一个1行2列的矩阵。
如果v 是1X n 的, 那么R 是一个n 维数组(3)R = normrnd (mu,sigma,m,n ) 产生服从均值为 mu 标准差为 sigma 的随机数,2)rand()(1)Y = rand(n) (2)Y = rand(m,n) (3)Y = rand([m n])(4) Y = rand(m,n,p,…) (5) Y = rand([m n p …]) (6) Y = rand(size(A)) 0.3529 0.81320.1389 0.2028 0.6038 0.2722 0.0153 0.7468产生服从正态分布的随机数(1)R= normrnd(mu,sigma)标量m和n是R的行数和列数。
选择(3)作为例子,运行结果如下:>> R = normrnd(1,1,3,4)R =1.41172.1139 1.9044 0.66384.1832 3.0668 1.1677 2.71431.86362.0593 2.29443.62364)mean()(1)M = mean(A) 如果A是一个向量,则返回A的均值。
如果A是一个矩阵,则把A的每一列看成一个矩阵,返回一个均值(每一列的均值)行矩阵(2)M= mean(A,dim) 返回由标量dim标定的那个维度的平均值。
如(A,2)是一个列向量,包含着A中每一行的均值。
选择(2)作为例子,运行结果如下:>>A =3 4 5 6 745) var()r、、 . 、$.求方差(1)V = var(X)(2)V = var(X,w) 返回X的每一列的方差,即返回一个行向量。
计算方差时加上权重w选择(2)作为例子,运行结果如下:>> X=[1:1:5;1:2:10];V=var(X,1)V =0 0.2500 1.0000 2.2500 4.00006)xcorr()计算互相关(1) c=xcorr(x,y)(2)c=xcorr(x) 计算x,y 的互相关计算x 的自相关选择(2)作为例子,运行结果如下:R=normrnd(1,2,3)c=xcorr(R)c =-2.0953 0.8081 5.4014 -1.6986 0.6551 4.37871.6072 -0.6198 -4.1432-1.2036-0.8064 -4.4636 -3.2012 0.2046 2.1184 1.4050 0.4327 2.18189.1743 1.7032 -8.7548 1.7032 2.2426 -0.3519 -8.7548 -0.3519 12.8829-1.2036-3.2012 1.4050 -0.8064 0.2046 0.4327 -4.4636 2.1184 2.1818-2.0953-1.6986 1.6072 0.8081 0.6551 -0.6198 5.4014 4.3787 -4.14327) periodogram()计算功率谱密度[Pxx,w]=periodogram(x) 计算x的功率谱密度运行结果如下:X=[-20:4:20];Y=periodogram(X);plot(Y)8) fft()离散傅里叶变换(1)Y = fft(X)返回向量X用快速傅里叶算法得到的离散傅里叶变换,如果X是一个矩阵,则返回矩阵每一列的傅里叶变换(2)Y = fft(X,n) 返回n点的离散傅里叶变换,如果X的长度小于n,X的末尾填零。
如果X的长度大于n,则X被截断。
当X是一个矩阵时,列的长度也服从同样的操作。
选择(1)作为例子,运行结果如下:X=0:0.1:1;Y=fft(X)Y =Columns 1 through 55.5000 -0.5500 + 1.8731i -0.5500 + 0.8558i -0.5500 + 0.4766i-0.5500 + 0.2512iColumns 6 through 10-0.5500 + 0.0791i -0.5500 - 0.0791i -0.5500 - 0.2512i -0.5500 - 0.4766i -0.5500 - 0.8558iColum n 11-0.5500 - 1.8731i9) n ormpdf()求正态分布概率密度函数值Y = normpdf(X,mu,sigma)对每一个X 中的值返回参数为 mu,sigma 的正 态分布概率密度函数值运行结果如下:>> x=-5:0.1:5;y=normpdf(x,1,2);plot(x,y)10) normcdf()求正态分布概率分布函数值P = normcdf(X,mu,sigma)对每一个X 中的值返回参数为 mu,sigma 的 累计分布函数值运行结果如下:>> p = no rmcdf(1:4,0,1) p =0.8413 0.9772 0.9987 1.000011) u nifpdf()求连续均匀分布的概率密度函数值 Y = un ifpdf(X,A,B) 运行结果如下:对每一个X 中的值返回参数为A,B 的均匀分布函数值>> x = 1:0.1:3; y = un ifpdf(x,1,2) y =□n.12O.D60 D2Colum ns 1 through 101 1 1 1 1 1 1 1 1 1Colum ns 11 through 201 0 0 0 0 0 0 0 0 0Colum n 2112) un ifcdf()求连续均匀分布的概率分布函数值P = un ifcdf(X,A,B) 对每一个X中的值返回参数为A,B的均匀分布累计分布函数值运行结果如下:>> y=u nifcdf(0.5,-1,1) y =0.750013) raylpdf()求瑞利概率密度分布函数值Y = raylpdf(X,B) 对每一个X中的值返回参数为B的瑞利概率分布函数值运行结果如下:x = 0:024;p = raylpdf(x,1);14) raylcdf()求瑞利分布的概率分布函数值P = raylcdf(X,B) 对每一个X中的值返回参数为B的瑞利分布的累计分布函数值运行结果如下: x = 0:025; p = raylcdf(x,1);Plot(x,p)15) exppdf()求指数分布的概率密度函数值Y = exppdf(X,mu) 对每一个X中的值返回参数为mu的瑞利分布的概率密度函数值运行结果如下:>> y = exppdf(3,2:6)y =0.1116 0.1226 0.1181 0.1098 0.101116) expcdf()求指数分布的概率分布函数值P = expcdf(X,mu) 对每一个X中的值返回参数为mu的瑞利分布的概率分布函数值运行结果如下:>> x = 0:0.2:5;p = expcdf(x,2);plot(x,p)17) chol()对称正定矩阵的Cholesky 分解 (1) R=chol(X) 产生一个上三角阵R,使R'R=%若X 为非对称正定,则输出一个出错信息(2) [R,p]=chol(X) 不输出出错信息。
当X 为对称正定的,则p=0, R 与上述格式得到的结果相同;否则 p 为一个正整数。
如果 X 为满秩矩阵,则R 为一个阶数为q=p-1的上三角阵, 且满足R'R=X(1:q,1:q)。
选择(2)作为例子,运行结果如下>> n =4;X = pascal( n);R = chol(X) R =1 1 1 1 0 123 0 0 1 3 0 00 118) ksde nsity()计算概率密度估计R = n ormrnd(2,1);[f, xi] = ksde nsity(R);plot(xi,f)(1) [f,xi] = ksdensity(x)(2)f = ksdensity(x,xi)选择(1)作为例子,运行结果如下:计算向量x 样本的一个概率密度估计,返 回向量f 是在xi 各个点估计出的密度值 计算在确定点xi 处的估计值19)hist()画直方图 (1)n = hist(Y) (2) n = hist(Y,x) (3) n = hist(Y,nbins) 运行结果如下:将向量丫中的元素分成10个等长的区间,再返 回每区间中元素个数,是个行向量 画以x 元素为中心的柱状图 画以n bi ns 为宽度的柱状图20) int()对符号表达式s 中确定的符号变量计算计算不定积分 对符号表达式s 中指定的符号变量V 计算不定积分• 符号表达式s 的定积分,a,b 分别为积分的上、下限 符号表达式s 关于变量v 的定积分,a,b 为积分的上下限1/2*x A 22、产生高斯随机变量 (1) 产生数学期望为0,方差为1的高斯随机变量; (2) 产生数学期望为2,方差为5的高斯随机变量;(3) 利用计算机求上述随机变量的100个样本的数学期望和方差,并与理论 值比较;解:(1) randn (3,4)ans =0.9572 0.1419 0.7922 0.0357 0.4854 0.4218 0.9595 0.8491 0.8003 0.9157 0.6557 0.9340 (2) normrnd(2,5A0.5,3,4) ans =0.4658 3.80366.5414 3.81546.0902 2.3977 -1.4405 -2.8379 1.3752 1.9891 -1.3931 3.8373(3) 若 x=randn(1,100) y=mea n(x)z=var(x,1) 经matlab 运行后得到:-0.0102 z =Y=ra nd(80,2);hist(Y,8)计算积分 (1) int(s) (2) int(s,v) (3) int(s,a,b) (4) int(s,v,a,b) 运行结果如下: >> syms x;int(x) ans =1.0122 计算结果中均值与方差均为随机变量,经多次运算,均值与方差均变化较大,但他们的值均可近似认为是0和1。