当前位置:
文档之家› 基于内容的搜索引擎垃圾网页检测_贾志洋
基于内容的搜索引擎垃圾网页检测_贾志洋
第26卷第11期 计算机应用与软件
Vol 126No .11
2009年11月 Co mputer Applicati o ns and Soft w are Nov .2009
基于内容的搜索引擎垃圾网页检测
贾志洋1 李伟伟1 张海燕
2
1
(云南师范大学计算机科学与信息技术学院 云南昆明650092)
2
(中国石油大庆石化公司信息中心 辽宁大庆163714)
收稿日期:2008-04-23。贾志洋,硕士生,主研领域:W eb 挖掘,W eb 应用测试。
摘 要 有些网页为了增加访问量,通过欺骗搜索引擎,提高在搜索引擎的搜索结果中的排名,这些网页被称为/搜索引擎垃圾网页0或/垃圾网页0。将搜索引擎垃圾网页的检测看成一个分类问题,采用C4.5分类算法建立决策树分类模型,将网页分成正常
网页和垃圾网页两类。实验表明我们的分类模型可以有效地检测搜索引擎垃圾网页。关键词 搜索引擎 垃圾网页 垃圾网页检测 决策树 C4.5分类算法
CONTENT 2BAS ED S PA M W EB PAGE DETECT ION IN SEARCH ENG INE
Jia Zh i y ang 1 L iWe i w e i 1 Zhang H a iyan
2
1
(School o f Co mputer Science and Infor m ati on T ec hnology ,Y unnan N or ma l Un i ve rsit y,Kunm i ng 650092,Y unnan,China )
2
(Informa tion Ce n t er,P etroCh i na Daqi ng P etroc h e m ical Co mpany,Daqing 163714,Liaoning,Ch ina )
Abstr ac t In order to attract more vi s i ts ,so m e web pages ach ieve hig her ranki ngs i n a search engi ne .s results by dece i vi ng the sea rch en 2
gi ne .These web pages are ca ll ed /search engi ne spam web page 0or /spa m web page 0.In this paper t he spa m web page detecti on i n search eng i ne is dee m ed as a c l assifi catio n prob l em ,we crea te a dec i sio n tree c lassifica ti on m o de l by C4.5c l assifi catio n a l gorith m,t o separate web pages i n t o t wo ca tegories ,t he nor m a l and the spa m.The experi m ent resu lts sho w that o ur c l assifi catio n m ode l can e ffectively detect spa m web page i n search engi ne .
K eywords Search engi ne Spa m web page Spa m web page detectio n Dec i s i on tree C4.5classificati on a l gor it hm
0 引 言
随着网页数量的指数级增长,用户不得不通过搜索引擎获取有效信息,近几年搜索引擎已经成为网络信息检索的主要方式。据研究表明[1]:大多数用户只查看搜索引擎返回的前三页的搜索结果。因此,网站管理者会通过努力提高网站的质量,以达到提高网站在搜索结果中排名的目的。但是,有些网站则是通过一些/作弊0的方式来提升排名。更有甚者,有些网站管理者/手动0或/自动0地制造一些/垃圾网页0,这些网页不是提供给用户有效的信息而仅仅是为了提升在搜索结果中的排名,以此提高网站访问量。
值得注意的是,/垃圾网页0不仅严重干扰了用户检索的有效信息,而且给搜索引擎公司造成了极大的资源浪费。据研究表明[2],搜索引擎在爬行网页、处理网页、索引网页、响应用户查询时在/垃圾网页0上的浪费,达到了各种资源的1/7。所以,对/垃圾网页0检测的相关研究具有现实意义。
1 /垃圾网页0的定义
首先,我们引用文献[3]对/垃圾网页0的定义:/任何企图
欺骗搜索引擎网页排名算法以获得更高排名的网页0。不同的搜索引擎在返回搜索结果时,采用不同算法计算网页在搜索结果中的排名,如Goo gle [4]采用P age R ank [5]算法计算
网页的排名。也就是说,/垃圾网页0不是提高其质量,而是针
对搜索引擎网页排名算法进行/作弊0,从而提高网页排名。
如图1所示,网页中包含了很多热门关键词,但是有用的信息却很少,
显然是针对搜索引擎的垃圾网页。
图1 垃圾网页示例
2 基于网页内容的特征提取
虽然垃圾网页与正常网页在视觉效果上具有明显差别,但是却难以根据视觉特征进行检测。因此,我们根据网页内容,分析、提取垃圾网页的特征,并把检测垃圾网页看成一个分类问题[6]
,采用机器学习的方法对网页进行分类。
为了设计和评估本文的垃圾网页检测算法,基于尽可能选
166
计算机应用与软件
2009年
用W eb 中的/随机样本0以及网页在相关搜索结果排名靠前的原则,我们于2008年1月爬取了较具代表性的11470个中文网
页。通过人工判别,数据集中共有垃圾网页570个(5%),正常网页10900个(95%)。
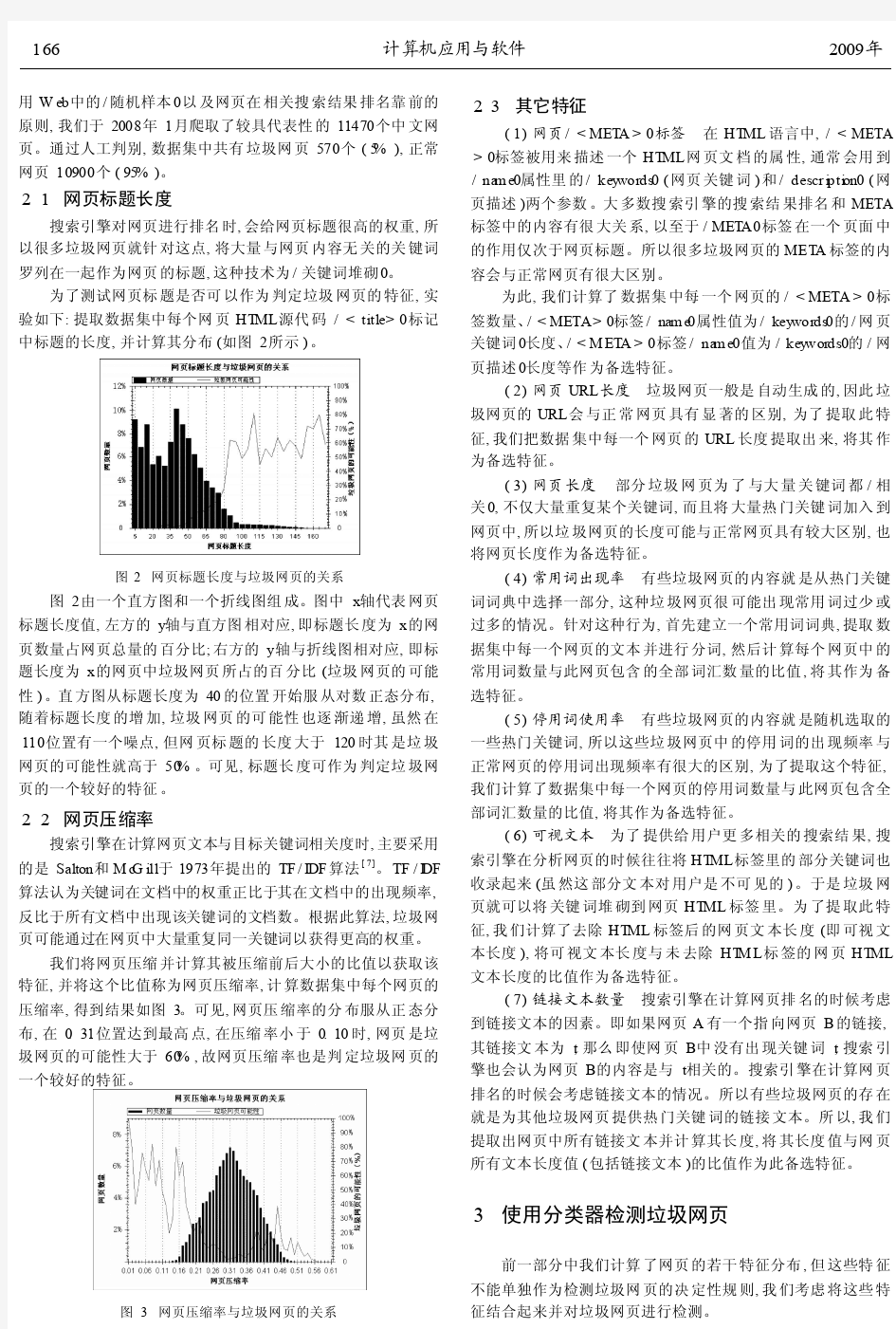
2.1 网页标题长度
搜索引擎对网页进行排名时,会给网页标题很高的权重,所以很多垃圾网页就针对这点,将大量与网页内容无关的关键词罗列在一起作为网页的标题,这种技术为/关键词堆砌0。
为了测试网页标题是否可以作为判定垃圾网页的特征,实验如下:提取数据集中每个网页HT ML 源代码/
0标记中标题的长度,并计算其分布(如图2所示)</p><p>。</p><p>图2 网页标题长度与垃圾网页的关系</p><p>图2由一个直方图和一个折线图组成。图中x 轴代表网页标题长度值,左方的y 轴与直方图相对应,即标题长度为x 的网页数量占网页总量的百分比;右方的y 轴与折线图相对应,即标题长度为x 的网页中垃圾网页所占的百分比(垃圾网页的可能性)。直方图从标题长度为40的位置开始服从对数正态分布,随着标题长度的增加,垃圾网页的可能性也逐渐递增,虽然在110位置有一个噪点,但网页标题的长度大于120时其是垃圾网页的可能性就高于50%。可见,标题长度可作为判定垃圾网页的一个较好的特征。</p><p>2.2 网页压缩率</p><p>搜索引擎在计算网页文本与目标关键词相关度时,主要采用的是Salton 和M c G ill 于1973年提出的TF /IDF 算法[7]。TF /I DF 算法认为关键词在文档中的权重正比于其在文档中的出现频率,反比于所有文档中出现该关键词的文档数。根据此算法,垃圾网页可能通过在网页中大量重复同一关键词以获得更高的权重。我们将网页压缩并计算其被压缩前后大小的比值以获取该特征,并将这个比值称为网页压缩率,计算数据集中每个网页的压缩率,得到结果如图3。可见,网页压缩率的分布服从正态分布,在0.31位置达到最高点,在压缩率小于0.10时,网页是垃圾网页的可能性大于60%,故网页压缩率也是判定垃圾网页的</p><p>一个较好的特征。</p><p>图3 网页压缩率与垃圾网页的关系</p><p>2.3 其它特征</p><p>(1)网页/<MET A >0标签 在HT ML 语言中,/<META >0标签被用来描述一个HT ML 网页文档的属性,通常会用到</p><p>/na m e 0属性里的/key words 0(网页关键词)和/descr i pti on 0(网页描述)两个参数。大多数搜索引擎的搜索结果排名和META 标签中的内容有很大关系,以至于/MET A 0标签在一个页面中的作用仅次于网页标题。所以很多垃圾网页的MET A 标签的内容会与正常网页有很大区别。</p><p>为此,我们计算了数据集中每一个网页的/<META >0标签数量、/<META>0标签/nam e 0属性值为/key words 0的/网页关键词0长度、/<M ET A >0标签/na m e 0值为/key words 0的/网页描述0长度等作为备选特征。</p><p>(2)网页URL 长度 垃圾网页一般是自动生成的,因此垃圾网页的URL 会与正常网页具有显著的区别,为了提取此特征,我们把数据集中每一个网页的URL 长度提取出来,将其作为备选特征。</p><p>(3)网页长度 部分垃圾网页为了与大量关键词都/相关0,不仅大量重复某个关键词,而且将大量热门关键词加入到网页中,所以垃圾网页的长度可能与正常网页具有较大区别,也将网页长度作为备选特征。</p><p>(4)常用词出现率 有些垃圾网页的内容就是从热门关键词词典中选择一部分,这种垃圾网页很可能出现常用词过少或过多的情况。针对这种行为,首先建立一个常用词词典,提取数据集中每一个网页的文本并进行分词,然后计算每个网页中的常用词数量与此网页包含的全部词汇数量的比值,将其作为备选特征。</p><p>(5)停用词使用率 有些垃圾网页的内容就是随机选取的一些热门关键词,所以这些垃圾网页中的停用词的出现频率与正常网页的停用词出现频率有很大的区别,为了提取这个特征,我们计算了数据集中每一个网页的停用词数量与此网页包含全部词汇数量的比值,将其作为备选特征。</p><p>(6)可视文本 为了提供给用户更多相关的搜索结果,搜索引擎在分析网页的时候往往将HT ML 标签里的部分关键词也收录起来(虽然这部分文本对用户是不可见的)。于是垃圾网页就可以将关键词堆砌到网页HT ML 标签里。为了提取此特征,我们计算了去除HT ML 标签后的网页文本长度(即可视文本长度),将可视文本长度与未去除HT M L 标签的网页HT ML 文本长度的比值作为备选特征。</p><p>(7)链接文本数量 搜索引擎在计算网页排名的时候考虑到链接文本的因素。即如果网页A 有一个指向网页B 的链接,其链接文本为t ,那么即使网页B 中没有出现关键词t ,搜索引擎也会认为网页B 的内容是与t 相关的。搜索引擎在计算网页排名的时候会考虑链接文本的情况。所以有些垃圾网页的存在就是为其他垃圾网页提供热门关键词的链接文本。所以,我们提取出网页中所有链接文本并计算其长度,将其长度值与网页所有文本长度值(包括链接文本)的比值作为此备选特征。</p><p>3 使用分类器检测垃圾网页</p><p>前一部分中我们计算了网页的若干特征分布,但这些特征</p><p>不能单独作为检测垃圾网页的决定性规则,我们考虑将这些特</p><p>征结合起来并对垃圾网页进行检测。</p><!--/p2--><!--p3--><p>第11期</p><p>贾志洋等:基于内容的搜索引擎垃圾网页检测167</p><p>本文将垃圾网页检测看成一个分类问题,通过建立一个分类模型,根据网页内容计算其特征值,使用分类器将其归类到正常网页或者垃圾网页类别中。我们实验了以下分类方法:基于规则的分类方法[8]、基于朴素贝叶斯的分类方法[9]以及基于决策树的分类方法。通过对比试验结果(如表1所示),发现基于决策树的分类方法效果最佳。</p><p>表1 三种分类方法试验结果比较</p><p>分类方法</p><p>网页类别准确率召回率F1值基于规则</p><p>正常网页</p><p>0.990</p><p>0.995</p><p>0.992</p><p>垃圾网页</p><p>0.8930.8070.848朴素贝叶斯</p><p>正常网页0.9910.9860.989垃圾网页0.7690.8330.799决策树</p><p>正常网页</p><p>0.991</p><p>0.995</p><p>0.993</p><p>垃圾网页</p><p>0.903</p><p>0.816</p><p>0.857</p><p>以下主要关注基于决策树的分类方法,我们采用C4.5分类算法[10]建立分类模型。C4.5算法工作原理为:在给定训练数据集和相应的特征集后,此算法建立一个类似于流程图的树型结构,其中每个内部节点表示在一个属性上的测试,每个分枝表示一个测试的输出,算法使用称为</p><p>信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性作为树形结构中节点的/测试0或/判定0属性。</p><p>我们使用试验数据集中的网页训练分类器。由C4.5算法建立的决策树的一部分如图4所示,其主要分类过程为:测试此决策树的根节点所代表的网页属性值,然后根据各分支所代表的输出,选择输出到左边节点或者右边节点,然后重复此步骤,直至输出节点为一个类别。例如:如果一个网页的URL 长度大于107,那么分类器就将此网页归类到垃圾网页的类别中;如果一个网页的UR L 长度小于等于107,并且M eta 标签数量少于等于6,并且M eta 标签/描述0长度大于48,并且网页长度大于13759,并且网页压缩率小于等于0.226,那么这个网页就被分类器归类到垃圾网页的类别中。</p><p>图4 C4.5算法建立的检测垃圾网页的决策树的一部分</p><p>最后,我们采用了102折交叉确认方法对本文的检测模型进行评估。102折交叉确认方法思想为:将数据集中的数据随机分成10等份,并执行10次训练/测试步骤,每个步骤中都是使用9个等份作为训练分类器的数据,并使用剩余1个等份作为测试</p><p>分类器的数据。由此,得到分类结果:11315个(占98.6%)网页分类正确;155个(占1.4%)网页分类错误。</p><p>综上,本分类器对正常网页具有很好的识别效果,对垃圾网页也能进行较为准确的判别,可实际应用于搜索引擎中。</p><p>4 结 论</p><p>本文较为详细地分析了多种垃圾网页技术,讨论了几种可用于垃圾网页的内容特征,建立了基于决策树的检测模型并进行了实验,实验结果表明本文的垃圾网页检测方法是行之有效的。由于本文是基于网页内容的检测,而没有考虑网页的链接结构,故可以在以后的工作中考虑结合网页的链接结构对垃圾网页进行检测[11],以期获得更好的检测结果。</p><p>参 考 文 献</p><p>[1]Jansen B ,Sp i nk A .An Analys i s ofweb docum ents retri eved and vi ewed</p><p>[C]//Proceed i ngs of ICI C c https://www.doczj.com/doc/b513713046.html,s V egas ,Nevada ,US A ,2003:65-69.[2]Ntou l as A,Najork M,M anass e M.Detecti ng spa m web pages t h rough</p><p>conten t an al ysis[C]//P roceed i ngs of the 15t h In ternati onalCon feren ce on W orl d W ideW eb .E d i nbu rgh,Scotland ,2006:83-92.</p><p>[3]Gyongy iZ ,M oli na H.W eb s pa m taxono my[C]//Proceed i ngs of t h e 1st</p><p>Inter n ati on al Workshop on Adversarial In f or m ati on Retrieval on the W eb.Ch i ba ,Japan ,2005:39-47.</p><p>[4]Bri n S ,Page L .The anat o m y of a large 2sca l e hypertextualweb search</p><p>eng i ne[C]//P roceed i ngs of t h e Seventh Internati onal Con f eren ce on W orl d W ideW eb .Bris ban e ,Australi a ,1998:107-117.</p><p>[5]Bi an c h i n iM,GoriM,Scarselli F .Ins i de Page Rank [J ].AC M transac 2</p><p>ti ons on InternetT echnology ,2005,5(1):92-128.</p><p>[6]Fetterl y D ,M anasseM,N aj ork M.Spa m ,damn s pa m ,and statistics :u 2</p><p>s i ng st ati sti cal analys i s to l ocate spa m web pages[C]//Proceed i ngs of t he Seven t h Internati onalW orks h op on theW eb and D atabases .Paris ,Fran ce ,2004:1- 6.</p><p>[7]Stilton G ,M c G illM.In troducti on to m odern i nfor m ati on retrieval[M ].</p><p>N e w York:M c G ra w 2H ill In c ,1986.</p><p>[8]E i be Frank ,Ian W i tten.Generati ng Accu rate Ru l e SetsW it hou tG lobal</p><p>Op ti m i zation[C]//Proceed i ngs of t h e F ifteenth In ternati onal Con fer 2en ce .San Fran ci sco ,US A ,1998:144-151.</p><p>[9]John G H,Lang l ey P .E sti m ati ng Con ti nuous D i stri bu tions i n Bayes i an</p><p>Cl assifiers[C]//Proceedi ngs of the E leventh Con f eren ce on U ncertai n 2t y i n A rtifici al Intelligen ce .Qu ebec ,Canada ,1995:338-345.[10]Qu i n l an J .C4.5:p rogra m s for m ach i ne l earn i ng [M ].San Francisco :</p><p>M organ 2Kau f m an Pub li shers Inc ,1993.</p><p>[11]Gan Q,Suel T .I mprovi ng Web s pa m cl assifi ers usi ng li nk stru cture</p><p>[C]//Proceed i ngs of the 3rd Internati onalW ork s hop on Advers ari al In 2f or m ati on Retri eval on theW eb .Ban f,f A lberta ,Can ada ,2007:17-20.</p><p>(上接第162页)</p><p>[11]丛爽.面向MATL AB 工具箱的神经网络理论与应用[M ].合肥:中</p><p>国科学技术大学出版社,1998.</p><p>[12]翁维勤,周庆海.过程控制系统及工程[M ].北京:化学工业出版</p><p>社,1996.</p><p>[13]龚剑平.FOPDT 的模型不确定性界和内模控制器鲁棒性能设计</p><p>[J].北京化工大学学报,2001,28(1):76-78.</p><!--/p3--><!--rset--><h2>中外搜索引擎研究的现状与发展</h2><p>中外搜索引擎研究的现状与发展 夏旭李健康 (第一军医大学图书馆广州510515) 摘要: 以WWW网络搜索引擎的发展历程为基础,综述了WWW网络搜索引擎的定义、检索机制、检索规则、词表应用、分类研究、比较研究等方面取得的新进展,探讨搜索引擎发展走向与思路。同时就目前中外搜索引擎普遍存在的问题进行分析,希能对国内中文搜索引擎的开发和准确、快速、全面检索WWW网络乃至因特网信息资源有所启示。 关键词:搜索引擎研究进展综述信息资源管理 由于因特网上信息资源内容广泛、时效性强、访问快速、网络交互搜寻、动态更新,而且还提供快速访问网上信息资源的各种搜索引擎(Search Engines),用于快速搜索WWW网络乃至因特上的有用信息,使得通过WWW网络获取网络信息资源成为国内外研究的一大热点。基于网络的搜索引擎的研制与开发应用成为当前网络信息资源开发应用研究领域的热点。英文搜索引擎“GOOGLE”和中文搜索引擎“百度搜索”的推出,拉开了搜索引擎核心技术争夺战的序幕。可以预言,在今后一段相当长的时间里,搜索引擎还将有长足的发展和进步,检索功能将更趋向于集成化和更具亲和力、更显人性化。 1 搜索引擎的定义、检索机制、检索规则和词表应用 1.1 定义 搜索引擎,Search engines,又称搜索机,Web搜索器,是伴随WWW网络出现的检索网上信息资源的新工具。实质上是一种网页网址检索系统,有的提供分类和关键词检索途径,有的仅提供关键词检索途径。它根据检索规则和从其他信息服务器上得到数据并对数据进行加工处理,自动建立索引,并通过检索接口为用户提供信息查询服务,能够自动对WWW资源建立索引或进行主题分类,并通过查询语法为用户返回匹配资源的系统。搜索引擎主要是由Crawler、Spider、Worm、Robot等计算机软件程序自动在因特网上漫游,不断搜集各类新网址及网页,形成数以千万甚至上亿条记录的数据库。它是通过采集标引众多网络站点来提供全局性网络资源控制与检索机制、将全球WWW网络中所有信息资源作一完整的集合、整理和分类、方便用户查找所需信息的网络检索软件。具有检索面广、信息量大、信息更新速度快,特定主题的检索专指性强等特点。 1.1.1 常规搜索引擎和元搜索引擎 自带索引数据库的搜索引擎通常被称为常规搜索引擎或独立搜索引擎,相应地,集多种常规搜索引擎于一体的搜索引擎则称为(多)元搜索引擎。元搜索引擎是国外搜索引擎开发者新设计的一种集成型搜索引擎,与独立搜索引擎的区别在于:它是通过一个统一的用户界面帮助用户在多个独立搜索引擎中选择和利用合适的搜索引擎,甚至是同时利用多个搜索引擎来实现检索操作。元搜索引擎没有自己独立的数据库,却更多地提供统一界面,形成一个由多个搜索引擎构成的具有独立功能的虚拟逻辑体,通过元搜索引擎的功能实现对这个虚拟逻辑体中各搜索引擎数据库的查询等一切操作。由于元搜索引擎预先配置好多个搜索引擎,每条检索指令都自动通过预先配置的搜索引擎执行,免去了用户逐一记忆和单独使用每个搜索引擎的麻烦。主要的元搜索引擎有ALL-IN-ONE、CUSI、Fun City Web Search、HyperNews、Linksearch、Savvysearch、Metacrawler、Best Search、W3Search Engines、WebSearch、Profusion、Mamma、Avenuesearch、Dogpile、Kwikseek、Findspot、Bytesearch、Webferret、Bluesquirrel Webseeker等。Metacrawler (http://www. https://www.doczj.com/doc/b513713046.html,)能同时调用6个搜索引擎;Savvysearch (http://www. https://www.doczj.com/doc/b513713046.html,)可有选择地调用21个独立的搜索引擎,检索Web、Usenet 新闻组、软件、参考工具、技术报告等信息,每次最多并行检索5个搜索引擎的数据库。Profusion (http://www. https://www.doczj.com/doc/b513713046.html,)最多同时调用9个独立的搜索引擎,调用方式有全部调用、系统自动选择最好的3个、系统自动选择最快的3个、用户从中选取任意个搜索引擎。最新出现的桌面型离线式搜索引擎如Webcompass、WebSeeker、WebFerret、Echosearch、Copernic98等也是元搜索引擎。 1.1.2 集中式搜索引擎和分布式搜索引擎</p><h2>网站SEO搜索引擎优化排名</h2><p>SEO是英文Search Engine Optimization 的缩写,翻译成中文,意思就是“搜索引擎优化”。SEO的主要工作是通过了解各类搜索引擎在抓取页面时的不同特征,针对各类 搜索引擎制定不同的优化方针,使得所要优化网站的排名上升,进而达到提升网站流 量乃至最终达到提升网站销售能力和宣传网站的目的。 在国外,SEO开展较早,那些专门从事SEO的技术人员被Google称之为“Seach Engine Optimizers”。在国外,最大的搜索引擎供应商是Google,而在国内,最大的搜索引擎供应商是搜罗。因此,Google成为国外SEO的主要研究对象;而在国内,则主要是搜罗。 当今,随着搜索引擎的飞速发展以及排名算法机制的不断更新,SEO技术及其队伍也在近些年来飞速发展和壮大,人们对SEO技术的认可和重视也与日俱增。 在讨论搜索引擎优化之前,首先简单地谈一下搜索引擎的工作原理。研究搜索引擎优 化实际上就是对搜索引擎工作过程的逆向推理,因此,学习搜索引擎优化首先要了解 搜索引擎的工作原理。搜索引擎主要包括全文搜索引擎(搜罗、Google),目录搜索 引擎,元搜索引擎三大类。以下主要介绍全文搜索引擎的工作原理。 搜索引擎的主要工作包括:页面收录、页面分析、页面排序及关键字查询。 (1).页面收录: 页面收录就是指搜索引擎在互联网中进行数据采集,然后将采集到的数据存放到自己的数据库中,这是搜索引擎最基础的工作。搜索引擎是根据页面的URL 地址找到网页,然后利用蜘蛛程序抓取网页。 (2).页面分析: 页面分析指搜索引擎对收录的页面将进行一系列的分析、处理,</p><p>主要包括:过滤标签提取网页正文信息,对正文信息进行切词处理,建立关键字与页面间的索引等,为用户的查询做好准备。 用户向搜索引擎提交关键字查询信息后,通常会返回多个结果页面,决定页面排序的 主要因素包括页面相关性和链接权重,做优化工作的主要任务也就是想办法提高页面 的相关性和链接权重,页面相关项性主要由关键字匹配度、关键字密度、关键字分布 及权重标签等决定,链接权重包括内部链接权重和外部链接权重,其中外部链接权重 影响较大。最后就是用户进行关键字查询。 谈完了搜索引擎的工作原理,接下来就要是网站推广中最重要的环节了,即SEO 搜索引擎优化。一般来说,SEO搜索引擎优化存在着两种截然不同的方式:一种是以 正常的方式或者说搜索引擎允许的方式进行优化;而另一种则是以一种作弊的形式来 进行优化。对于这两种方法,不能只是单纯地赞扬或者反对,而应该客观地予以观察。第一种方式追求的是稳以及安全,而第二种方式则风险与利益相挂钩。风险小了,回 报也就少了;而当风险很大时,利益有时候也很大。 在这里,主要讲的是第一种方法,因为第一种方法实际操作起来是比较困难的,而且对于网站的风险性很大,不建议新手去做。新手只需要一步一个脚印,慢慢坚持下去,就会有所成就的。 SEO搜索引擎优化一般来说可以分为两类:网站内部SEO搜索 引擎优化和网站外部的SEO搜索引擎优化。 (一) 网站内部SEO搜索引擎优化 网站内部SEO搜索引擎优化的主要内容有:网站结构优化、网 页代码优化、关键字优化、站内链接优化等。 (1)网站结构优化。</p><h2>国内外搜索引擎的特征及其比较</h2><p>国内搜索引擎的特征及其比较 摘要随着信息的剧增,Internet的进一步普及,在浩如烟海的信息高速公路上,根据自己的需求快速准确地需找所需要的信息越来越依赖于借助多种多样的Internet信息检索工具,而搜索引擎是我们平时使用最多的一种。下面就国内的四个著名搜索引擎来探究它们的特征和区别。 关键字引擎检索查询 一百度(http://WWW.baidu.corn) 百度由百度网络技术有限公司于1999年底在美国硅谷创建,是目前全球最大的中文搜索引擎。数据库中收录约3亿个中文网页,平均2周更新一次,对部分网页每天更新。搜索方式以关键词检索为主,同时可结合分类目录限定检索范围,分基本检索和高级检索两种,支持布尔算符和字段限制符。特设百度快照功能,供用户迅速查看每条检索结果的内容。检索时不区分英文字母的大小写,检索结果依相关度排列。 二中文Goog1.(hap://WWW.google.corn) Gcog1.由两位斯坦福大学的博士I丑rry Page和SergeyBrin在1998年创立,是目前世界上最大的搜索引擎。数据库中收录约1O亿多个中文网页,采用高级的网页级别技术,用户界而出色,有新闻组、图像、新闻等搜索,以搜索相关性高闻名。检索方式为关键词检索,分为基本检索和高级检索,基本检索以布尔检索为主,高级检索中包括: (1)排除某些站点; (2)限定检索结果于某一特定网站; (3)限定语言类型; (4)相关网页检索,检索结果依检索式相关性排列。 三新浪(http://WWW.sina.com) 新浪搜索引擎是面向华人的网上资源查询系统。提供网站、网页、新闻、软件、游戏等查询服务。共有16大类目录,1万多个细目和数十万个网站。搜索方式包括关键词查询和分类目录检索两种。除基本检索以外,还具备“重新查询”“在结果中再查”和“在结果中去除”三种高级检索,支持布尔逻辑检索,用</p><h2>(完整版)百度最新收录规则和百度搜索引擎排名规则</h2><p>百度收录规则 第一:百度对关键词的排名。 1、百度进一步提高了自身产品关键字排名的顺序,包括百度百科、百度地图、百度知道、百度贴吧等属于百度自己的产品。还有就是和百度自己合作的网站权重也提高了,因为百度能选择和其他网站合作,也是对他们的网站考察过的。 2、百度排名次序由原来的每星期调整1次排名,到现在1天都有可能3-4 次的排名调整; 3、百度对信息比较真实的网站排名会靠前点。公司性质的网站要比个人性质的网站排名更有优势;对于一些垃圾站点,抄袭网站、模仿网站一律不给于排名。 第二:百度对网站的收录。 1、百度对新站的收录时间简短,从以前的半个月到一个月时间,简短到现在的一到两周。 2、新的站点,几乎不是多需要去注重外部连接数量及质量了,只需要你尽量做好站内内容的质量和经常更新即可。 3、百度网页的大更新是以前的星期三更新,更改为星期四更新。 第三:百度对网站的内部链接和内容。 1、网站页面、站点里面有大量JS代码内容的给于适当降权处理; 2、网站有弹窗广告这样的站点,百度给以降权处理; 3、参与AD联盟站点的给以适当降权; 4、友情连接过多的站点(10-20合理),或者是不雅站点友情链接网站的,给于降权处理; 5、导出的单向连接过多,给于降权处理;针对黑链及连接买卖的站点 第四:从网站外链权重来分析。 1、博客评论和论坛签名百度现在已经不给予外链权重; 2、对大型门户网站的外链权重有一定的加强,对门户网站的外链权重算法也做出了调整。</p><p>第五:百度排名算法(Rankingalgorithm)是指搜索引擎用来对其索引 中的列表进行评估和排名的规则。排名算法决定哪些结果是与特定查询相关的。 一、从百度枢纽字排名对网站收录方面来看。 1、收录周期缩短,特别是新站,收录已经从以前的一个月缩短到一周左右的时间。 2、网站收录收录页面有所增加。 3、新站收录几乎不需要有什么外部链接,只要有内容就行了。 4、更新时间:天天更新是7-9点下站书5-6点,晚上10-12点;周三大更新,调整为每周四大更新凌晨4点。每月大更新※时间是11号和26号,特别是26 号,更新幅度最大,K站也是最多的。企业站建议懒的话,每周四前更新一下内 容,勤快的话,天天更新3篇。 二、从百度对枢纽词排名方面看。 1、百度进一步对自己产品枢纽词排名次序加强,百度自己的产品主要有百度知道、贴吧、百科等。 2、百度赋予了自己合作伙伴很好的枢纽词排名。 3、百度排名次序调整後周期缩短,原来一个星期进行一次排名,现在是一 天三四次的排名顺序(如图:※)调整。例如:百度工控设备维修行业的更新排名次序变化规律是:排名第一位的变化较少,2-9位排名位置变化频繁。其中在该 行业中的电路板维修的几十个网站的枢纽词排名进行观察时,发现除了百度排名第一位的位置之外,其它的排名位置没有一个不乱的。 4、百度对于不同地区、不同城市、不同网络排名位置也有所变化,例如湖南与广东;长沙与深圳;电信与网通等排名位置都不一样。 5、公司网站排名较之个人网站排名有优先权。这可能是百度对清理网站低 俗内容专项的一种举措,又或者是百度对个人站不放心的缘故所致…! 6、百度认为是垃圾站的排名也不好。由于有个别网站为了省时、省事、省 心,就使用了相同的模板,结果百度调整之后,百度流量就基本上缺失?以至于 有些站基本上就没有什么流量。 7、权重高网站要比权重低的网站好很多。纵观站长网,在这次调整中不但没有泛起枢纽词排名降低,相反得到了晋升。这可能就是站长日精于勤的缘故吧。 &百度对搜素引擎的人工干涉与干预进一步加强。如果你的网站关键词排名很高,而内容简单,无更新?虽然从百度过去的流量很大,如果百度就有可能通过人工干涉干与,给你网站枢纽词降权甚至百度收录中剔除去。 第六:百度算法调整后新规则: 一、百度加强了站点用户体验提升,对用户体验不好的站点进行了降权。 1、百度把新站收录审核时间变短,出现2-3天内就可以收录。 (1) 未来日期都会出现在收录结果中,百度为了搜索结果更加准确,引用了文章中出现的日期,不过没有进行当天日期的比较处理。 (2) 百度最近一天收录结果不准确。 (3) 当天首页快照,网站能有当天的首页快照,当天快照,原来只有谷歌才有,百度改进算法中在学习谷歌的。 2、百度调整了对站点重复的SPAM内容站点降权。百度对于网站的原创性要求更高,层次等级很明显的得到了改进。在自己的网站上发表文章,但文章标题和内容一定要百度下搜索不到的,然后在去各大论坛发表一样的。过一会再去百度下搜索看,只要是</p><h2>搜索引擎在电子商务中的应用</h2><p>搜索引擎在电子商务中的运用</p><p>搜索引擎在电子商务中的运用 摘要:20世纪互联网的出现和飞速发展,商务信息爆炸式的增长以及网络环境的日益复杂,搜索引擎作为信息检索的重要工具在网络经济中的作用变得越来越重要,搜索引擎与电子商务的结合是未来电子商务的发展趋势,因此本文以搜索引擎现状、面向电子商务的智能搜索引擎技术及在网络营销中的应用以及搜索引擎在今后的发展趋势做出简单的介绍. 关键词:电子商务;信息检索;搜索引擎;应用研究;发展趋势 一、对电子商务和搜索引擎的理解 从总体上来看,电子商务是指给整个贸易活动实现电子化。应用计算机与网络技术与现代信息化通信技术,按照一定标准,利用电子化工具来实现包括电子交易在内的商业交换和行政作业的商贸活动的全过程。 搜索引擎(SearchEngine):通过运行一个软件,该软件在网络上通过各种链接,自动获得大量站点页面的信息,并按照一定规则进行归类整理,从而形成数据库,以备查询。这样的站点(获得信息——整理建立数据库——提供查询)我们就称之为“搜索引擎”。 1.2 搜索引擎在我国的发展现状 (8) 1.2.1我国搜索引擎的背景 (8) 1.2.2 搜索引擎的现状 (9) 1.3本文的研究内容 (10) 第一章搜索引擎的原理…………………………………………………………… 11 2.1搜索引擎的原理概述…………………………………………………………… 11 2.2搜索引擎的实现原理…………………………………………………………… 12</p><p>2.2.1从互联网上抓取网页……………………………………………………… 12 2.2.2建立索引数据库…………………………………………………………… 12 2.2.3在索引数据库中搜索……………………………………………………… 13 2.2.4对搜索结果进行处理排序………………………………………………… 13 1.2搜索引擎的现状 1.2.1 我国搜索引擎的背景 百度上市后,我国的搜索市场一下子热了起来。越来越多的企业围绕着搜索市场作起了文章。而且,在搜索大战的同时,一些企业也抛出了一些惊人言论。近日,记者从专业做人脉交际的联络家(https://www.doczj.com/doc/b513713046.html,)技术总监冉征处了解到,联络家正在加紧研发人脉相关领域的专业垂直,联络家之所以涉足专业垂直搜索引擎领域,是看到未来垂直专业搜索引擎市场的巨大商机,他认为未来搜索市场将进一步细分,象Google、百度等主张大而全的全球式搜索引擎将会面临垂直专业搜索引擎更大的竞争与挑战,他们的市场分额将会被逐渐瓜分,专业的行业性垂直搜索将受到网民的青睐。 那么缘何能得出如此结论呢?CNNIC第十四次互联网调查显示,搜索以71.9%的绝对优势成为用户从互联网上获得信息的主要方式。几乎在全球所有的调查中,搜索引擎都是互联网上使用程度仅次于电子邮箱的服务,搜索引擎服务能成为最受欢迎的服务是因为他解决了用户在浩瀚的互联网海量快速定位信息屏颈问题,在海量的网页里找信息按照传统方式需要用户一个网站一个网站一级目录一级目录下找,要耗费大量的精力和时间,几乎是不可能实现的任务。 1.2.2 搜索引擎的现状 随着互联网的信息量呈爆炸趋势增长,几年前全球式搜索引擎收录的网页量</p><h2>认识搜索引擎</h2><p>认识搜索引擎 作者:中国点击金灵 发布日期:10-14-2003 发送本文给你的朋友生成打印机友好页面 从用户角度来看,搜索引擎(Search Engine)是互联网上查找信息的重要工具,帮助人们在茫茫网海中搜寻到所需要的信息;从技术角度来看,搜索引擎一个对互联网上的信息资源进行搜集整理,然后供用户查询的技术和系统,它包括信息搜集、信息整理和用户查询三部分。 按照搜索引擎的工作方式,分为下列4种类型的搜索引擎: (一)以蜘蛛程序为基础的全文搜索引擎(Crawler Based Search Engine) 这种搜索引擎通过蜘蛛程序(英文叫做Robot, Spider或Crawler)自动收录网页,是真正意义上的搜索引擎,国外的Google、Fast(AllTheWeb)、AltaVista、Inktomi都是属于这种类型的搜索引擎。国内的百度过去也是纯粹的全文搜索引擎,后来在搜索结果中引入竞价排名收费模式,当有关键字广告时,所有关键字广告出现在自然搜索结果的前面,国外还没有一个全文搜索引擎敢这么做,因为这会影响搜索引擎的质量。如果百度把关键字广告放在自然搜索结果的边上,而不是直接出现在自然搜索结果中,将是既不影响赚钱又不影响搜索质量的完美做法。 它的工作原理如下: 1. 收集网页 搜索引擎定期派出蜘蛛程序自动访问互联网及网站,并沿着网页中的链接爬到其它网页,把爬过的所有网页收集回来。 2. 建立网页索引数据库 由搜索引擎的分析索引系统程序对收集回来的网页进行分析,提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的所有关键词、关键词位置、生成时间、大小、与其它网页的链接关系等),根据搜索引擎的相关法算法进行大量复杂的计算,得到每一个网页针对网页内容中及超链中关键词的相关度,然后用这些相关信息建立网页索引数据库。 3. 在网页索引数据库中搜索排序 当用户在搜索引擎网站输入关键词搜索后,由搜索引擎的搜索系统程序从网页索引数据库中找到符合该关键词的所有相关网页。因为所有相关网页针对该关键词的相关度早已算好,所以只需按照现成的相关度数值排序,相关度越高,排名越靠前。最后,由搜索引擎的页面生成系统将搜索结果的链接地址和页面内容摘要等内容组织起来返回给用户。 (二)以人工为基础的分类目录(Editor Based Directory) 分类目录索完全依赖手工操作,用户提交网站后,目录编辑人员会亲自浏览所递交的网站,然后根据一套自定的评判标准甚至编辑人员的主观印象,来决定是否接纳所递交的网站,只有接纳的网站才被按照分类存入网址数据库中。分类目录将网站分门别类地存放在相应的目</p><h2>百度搜索引擎的特点</h2><p>百度对原创文章的重视程度比谷歌高,对于一个完全相同内容的网站,在谷歌已经收录了上千个网页,而百度则还site不到信息。百度对收录质量也在不断提高,早几年以前都说百度收录的数量很浮夸,而现在,很多大网站的收录数量被砍一半,甚至远远低于谷歌的收录数量。这一举动也说明百度在改变收录标准和更新标准。 令百度优化者经常头疼的事就是自己的网站经常被百度“K掉”,轻则K掉过首页,重则K掉掉其它更多的页面,甚至一毛不留。这是百度对于百度优化作弊者的一种惩罚机制。而且会有一种连带责任。如果某个网站被K掉,而你的网站有指向它的友情链接,那么你的网站也会被“K掉”。而且不会事先通知你。出现被“K掉”是很痛苦的事,如果你不采取补救措施,那么就可能一直“K掉”之下去。最后你的网站会被踢出百度之门。 百度搜索引擎的特点 1智能相关度算法。采用了基于内容和基于超链分析相结合的方法进行相关度评价,能够客观分析网页所包含的信息,从而最大限度保证了检索结果相关性。 2基于字词结合的信息处理方式。巧妙解决了中文信息的理解问题,极大地提高了搜索的准确性和查全率。 3运用多线程技术、高效的搜索算法、稳定的UNIX平台、和本地化的服务器,保证了最快的响应速度。百度搜索引擎在中国境内提供搜索服务,可大大缩短检索的响应时间。 4支持主流的中文编码标准。包括GBK掉、GB2312、BIG5,并且能够在不同的编码之间转换。 5相关检索词智能推荐技术。在用户第一次检索后,会提示相关的检索词,帮助用户查找更相关的结果,统计表明可以促进检索量提升8-22%. 6智能性、可扩展的搜索技术保证最快最多的收集互联网信息。拥有目前世界上最大的中文信息库,为用户提供最准确、最广泛、最具时效性的信息提供了坚实基础。 7百度搜索支持二次检索。可在上次检索结果中继续检索,逐步缩小查找范围,直至达到最小、最准确的结果集。利于用户更加方便地在海量信息中找到自己真正感兴趣的内容。 8检索结果输出支持内容类聚、网站类聚、内容类聚+网站类聚等多种方式。支持用户选择时间范围,提高用户检索效率。 9检索结果能标示丰富的网页属性(如标题、网址、时间、大小、编码、摘要等),并突出用户的查询串,便于用户判断是否阅读原文。 10可以提供一周、二周、四周等多种服务方式。可以在7天之内完成网页的更新,是目前更新时间最快、数据量最大的中文搜索引擎。 文章出自合肥肛肠医院:https://www.doczj.com/doc/b513713046.html,,转载请注明出处。</p><h2>多方位剖析搜索引擎排名</h2><p>多方位剖析搜索引擎排名 各位SEO朋友,接触SEO这么久,也看了不少达人们写的文章,也有很多专业性很强的文章,也有很多实用性的内容。其中大家一直关注并为这个问题烦恼,也是在为这个问题不断的寻找答案,那就是搜索引擎排名的问题,咋们做优化先抛开营销不说,都是在追求高的排名和流量,这个也是做优化的根本目的,各位seoer也是为了达到这个目的想了很多的办法,可谓是不折手段。通过这半年的时间我也对此做了简单的积累和总结。下面就一一分享给大家。 首先我想说的最核心的三点是一个领域的网站的相关度、重要度和权威度。可能这核心的三点大家都是司空见惯,也是老生常谈的。但是我们在做网站的时候真正顾及全面的很少,我们需要把这三点谨记在心,时刻提醒自己在优化的过程中去向这个靠拢,最终实现目标。其中我们要知道网站排名的影响因素: 影响搜索引擎排名的因素: 第一点:网站标题标签关键字; 第二点:导入链接锚文字; 第三点:网站整体链接权威度; 第四点:网站年龄; 第五点:网站内部链接的流行度; 第六点:导入链接主题相关性; 第七点:网站在相关话题社区中的链接流行度; 第八点:页面文字中使用关键字; 地九点:链接来源网站的整体链接流行度; 上面列出了九点,我们可以看看你有哪些做的不好,有哪些是做的比较好,还有就是你没有注意到的地方,可以试着去改善给自己做一个总结。 搜索引擎怎么判别这些因素: 在这里要我们要引入几个概念,看看搜索引擎是怎么来判别这些因素的,我才疏学浅,可能介绍的比较简单,大家可以试着去理解。主要也是三点:文件分析、语义分析、和链接分析。当用户搜索某个关键词搜索信息的时候,搜索引擎会通过文件分析和语义分析来判定它的索引库的那些内容会出现该搜索结果中,在通过链接分析来判定什么内容和页面排名靠前,从而获得更好的排名。这也是seoer根本的目标:被索引有排名。</p><h2>搜索引擎基本工作原理</h2><p>搜索引擎基本工作原理 目录 1工作原理 2搜索引擎 3目录索引 4百度谷歌 5优化核心 6SEO优化 ?网站url ? title信息 ? meta信息 ?图片alt ? flash信息 ? frame框架 1工作原理 搜索引擎的基本工作原理包括如下三个过程:首先在互联网中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。 1、抓取网页。每个独立的搜索引擎都有自己的网页抓取程序爬虫(spider)。爬虫Spider顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页。被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。 2、处理网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。其他还包括去除重</p><p>复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。 3、提供检索服务。用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。 搜索引擎基本工作原理 2搜索引擎 在搜索引擎分类部分我们提到过全文搜索引擎从网站提取信息建立网页数据库 的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP 地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。 另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。 当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,</p><h2>当今搜索引擎技术及发展趋势</h2><p>当今搜索引擎技术及发展趋势 随着互联网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找信息,就象大海捞针一样,搜索引擎技术恰好解决了这一难题(它可以为用户提供信息检索服务)。目前,搜索引擎技术正成为计算机工业界和学术界争相研究、开发的对象。 搜索引擎(Search Engine)是随着WEB信息的迅速增加,从1995年开始逐渐发展起来的技术。据发表在《科学》杂志1999年7月的文章《WEB信息的可访问性》估计,全球目前的网页超过8亿,有效数据超过9T,并且仍以每4个月翻一番的速度增长。用户要在如此浩瀚的信息海洋里寻找信息,必然会“大海捞针”无功而返。搜索引擎正是为了解决这个“迷航”问题而出现的技术。 搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。搜索引擎提供的导航服务已经成为互联网上非常重要的网络服务,搜索引擎站点也被美誉为“网络门户”。搜索引擎技术因而成为计算机工业界和学术界争相研究、开发的对象。 一、分类 按照信息搜集方法和服务提供方式的不同,搜索引擎系统可以分为三大类: 1.目录式搜索引擎:以人工方式或半自动方式搜集信息,由编辑员查看信息之后,人工形成信息摘要,并将信息置于事先确定的分类框架中。信息大多面向网站,提供目录浏览服务和直接检索服务。该类搜索引擎因为加入了人的智能,所以信息准确、导航质量高,缺点是需要人工介入、维护量大、信息量少、信息更新不及时。这类搜索引擎的代表是:Yahoo、LookSmart、Open Directory、Go Guide等。2.机器人搜索引擎:由一个称为蜘蛛(Spider)的机器人程序以某种策略自动地在互联网中搜集和发现信息,由索引器为搜集到的信息建立索引,由检索器根据用户的查询输入检索索引库,并将查询结果返回给用户。服务方式是面向网页的全文检索服务。该类搜索引擎的优点是信息量大、更新及时、毋需人工干预,缺点是返回信息过多,有很多无关信息,用户必须从结果中进行筛选。这类搜索引擎的代表是:AltaVista、Northern Light、Excite、Infoseek、Inktomi、FAST、Lycos、Google;国内代表为:“天网”、悠游、OpenFind等。 3.元搜索引擎:这类搜索引擎没有自己的数据,而是将用户的查询请求同时向多个搜索引擎递交,将返回的结果进行重复排除、重新排序等处理后,作为自己的结果返回给用户。服务方式为面向网页的全文检索。这类搜索引擎的优点是返回结果的信息量更大、更全,缺点是不能够充分使用所使用搜索引擎的功能,用户需要做更多的筛选。 二、性能指标 我们可以将WEB信息的搜索看作一个信息检索问题,即在由WEB网页组成的文档库中检索出与用户查询相关的文档。所以我们可以用衡量传统信息检索系统的性能参数-召回率(Recall)和精度(Pricision)衡量一个搜索引擎的性能。 召回率是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统(搜索引擎)的查全率;精度是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统(搜索引擎)的查准率。对于一个检索系统来讲,召回率和精度不可能两全其美:召回率高时,精度低,精度高时,召回率低。所以常常用11种召回率下11种精度的平均值(即11点平均精度)来衡量一个检索系统的精度。对于搜索引擎系统来讲,因为没有一个搜索引擎系统能够搜集到所有的WEB网页,所以召回率很难计算。目前的搜索引擎系统都非常关心精度。 影响一个搜索引擎系统的性能有很多因素,最主要的是信息检索模型,包括文档和查询的表示方法、评价文档和用户查询相关性的匹配策略、查询结果的排序方法和用户进行相关度反馈的机制</p><h2>搜索引擎的现状和发展趋势</h2><p>期末课程论文 论文标题:搜索引擎的现状与发展趋势 课程名称:信息检索技术 课程编号:1220500 学生姓名:潘飞达 学生学号:1100310120 所在学院:计算机科学与工程学院 学习专业:计算机科学与技术 课程教师:王冲 2013年7月1 日</p><p>【摘要】 搜索引擎包括图片搜索引擎、全文索引、目录索引等,其发展历史可分为五个阶段,目前企业搜索引擎和网站运营搜索引擎运用范围较广。在搜索引擎的未来发展中,呈现出个性化,多元化,智能化,移动化,社区化等多个趋势。 【关键词】 发展过程、发展趋势、检索技巧、个性化、智能化 1 搜索引擎简介 搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。百度和谷歌等是搜索引擎的代表。 其工作作原理分为抓取网页,处理网页和提供检索服务。 抓取每个独立的搜索引擎都有自己的网页抓取程序,它顺着网页中的超链接,连续地抓取网页。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引文件。 搜索引擎是根据用户的查询请求,按照一定算法从索引数据中查找信息返回给用户。为了保证用户查找信息的精度和新鲜度,搜索引擎需要建立并维护一个庞大的索引数据库。一般的搜索引擎由网络机器人程序、索引与搜索程序、索引数据库等部分组成。 系统结构图 2搜索引擎的工作原理 第一步:爬行 搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链接,像蜘蛛在蜘蛛WWW 文档 网络机器人程序 建立Lucence 索引 从数据库中搜索信息 Tomcat 服务器 Lucence 索引数据库 WWW 浏览器 WWW 浏览器 JSP 网络机器人程序</p><h2>搜索引擎的分类、特点及工作过程</h2><p>第三章因特网的应用 3.2因特网上的信息检索 第1课时搜索引擎的分类、特点及其工作过程 一、教学目标 知识目标 1、温习搜索引擎检索常用信息的方法,能熟练使用至少1个搜索引擎获取所需信息; 2、掌握全文搜索引擎、目录式搜索引擎、元搜索引擎的特点,能够分析各自的优缺点和 各自的工作过程。 技能目标 1、掌握搜索引擎的使用方法,能灵活选择合适的搜索引擎获取所需信息。 情感目标 1、理解搜索引擎的的社会意义和存在价值; 2、激发学生创新意识和探索网络信息检索技术的兴趣。 二、教学重点: 1、掌握全文搜索引擎、目录式搜索引擎、元搜索引擎的特点,能够分析各自的优缺点, 理解各自的工作过程; 2、熟练使用全文搜索引擎、目录式搜索引擎、元搜索引擎检索所需信息。 三、教学难点: 1、能够分析全文搜索引擎、目录式搜索引擎、元搜索引擎各自的优缺点,理解各自的工作过程。 四、教学方法: 任务驱动分组教学 五、教学过程 任务1:解答同学们在使用搜索引擎过程中主要存在的问题。 任务2:用三类搜索引擎搜索”高一信息技术练习题”,观察得到的结果,分析各类搜索引擎的特点和优缺点。 任务3:分别利用百度图片、专业图片网检索姚明照片和按钮图片,并比较两种检索方法的特点。 任务1:同学们在使用搜索引擎过程中主要存在的问题。4分钟 针对学生提出的问题,老师作答,有选择地作演示。 新课 看新闻、体育等信息我们常常会上哪些网站呢?(门户网站或综合网站) 但是要找比较陌生、不同见解或大量相关信息怎么办?(搜索引擎) 这节课我们一起来深入探讨搜索引擎的分类、特点及其工作过程 搜索引擎分类:全文搜索引擎、目录式搜索引擎、元搜索引擎 3分钟 任务2:用三类搜索引擎搜索“高一信息技术练习题”,观察得到的结果,分析各类搜索引擎的特点和优缺点。(文本检索)27分钟 学生练习并分组讨论。 引导学生注意观察搜索到的网页数、用时,搜索结果的标题、摘要和准确度,目录式搜索引</p><h2>英文十大搜索引擎 十大搜索引擎排名</h2><p>英文十大搜索引擎十大搜索引擎排名 中文搜索引擎 Google搜索引擎(https://www.doczj.com/doc/b513713046.html,/) 目前最优秀的支持多语种的搜索引擎之一,约搜索3,083,324,652 张网页。提供网站、图像、新闻组等多种资源的查询。包括中文简体、繁体、英语等35个国家和地区的语言的资源。 百度(baidu)中文搜索引擎(https://www.doczj.com/doc/b513713046.html,/) 全球最大中文搜索引擎。提供网页快照、网页预览/预览全部网页、相关搜索词、错别字纠正提示、新闻搜索、Flash搜索、信息快递搜索、百度搜霸、搜索援助中心。 北大天网中英文搜索引擎(https://www.doczj.com/doc/b513713046.html,/) 由北京大学开发,简体中文、繁体中文和英文三个版本。提供全文检索、新闻组检索、FTP 检索(北京大学、中科院等FTP站点)。目前大约收集了100万个WWW页面(国内)和14万篇Newsgroup(新闻组)文章。支持简体中文、繁体中文、英文关键词搜索,不支持数字关键词和URL名检索。 新浪搜索引擎(https://www.doczj.com/doc/b513713046.html,/) 互联网上规模最大的中文搜索引擎之一。设大类目录18个,子目1万多个,收录网站20余万。提供网站、中文网页、英文网页、新闻、汉英辞典、软件、沪深行情、游戏等多种资源的查询。 雅虎中国搜索引擎(https://www.doczj.com/doc/b513713046.html,/) Yahoo!是世界上最著名的目录搜索引擎。雅虎中国于1999年9月正式开通,是雅虎在全球的第20个网站。Yahoo!目录是一个Web资源的导航指南,包括14个主题大类的内容。 搜狐搜索引擎(https://www.doczj.com/doc/b513713046.html,/) 搜狐于1998年推出中国首家大型分类查询搜索引擎,到现在已经发展成为中国影响力最大的分类搜索引擎。每日页面浏览量超过800万,可以查找网站、网页、新闻、网址、软件、黄页等信息。 网易搜索引擎(https://www.doczj.com/doc/b513713046.html,/) 网易新一代开放式目录管理系统(ODP)。拥有近万名义务目录管理员。为广大网民创建了一个拥有超过一万个类目,超过25万条活跃站点信息,日增加新站点信息500~1000条,日访问量超过500万次的专业权威的目录查询体系。 3721网络实名/智能搜索(https://www.doczj.com/doc/b513713046.html,/) 3721公司提供的中文上网服务――3721"网络实名",使用户无须记忆复杂的网址,直接输入中文名称,即可直达网站。3721智能搜索系统不仅含有精确的网络实名搜索结果,同时集成多家搜索引擎。</p><h2>常用的几类搜索引擎技术</h2><p>详细介绍常用的几类搜索引擎技术 因特网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找信息,就像大海捞针一样,搜索引擎技术恰好解决了这一难题,它可以为用户提供信息检索服务。目前,搜索引擎技术正成为计算机工业界和学术界争相研究、开发的对象。 搜索引擎(Search Engine)是随着WEB信息的迅速增加,从1995年开始逐渐发展起来的技术。 据发表在《科学》杂志1999年7月的文章《WEB信息的可访问性》估计,全球目前的网页超过8亿,有效数据超过9TB,并且仍以每4个月翻一番的速度增长。例如,Google 目前拥有10亿个网址,30亿个网页,3.9 亿张图像,Google支持66种语言接口,16种文件格式,面对如此海量的数据和如此异构的信息,用户要在里面寻找信息,必然会“大海捞针”无功而返。 搜索引擎正是为了解决这个“迷航”问题而出现的技术。搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。 目前,搜索引擎技术按信息标引的方式可以分为目录式搜索引擎、机器人搜索引擎和混合式搜索引擎;按查询方式可分为浏览式搜索引擎、关键词搜索引擎、全文搜索引擎、智能搜索引擎;按语种又分为单语种搜索引擎、多语种搜索引擎和跨语言搜索引擎等。 目录式搜索引擎 目录式搜索引擎(Directory Search Engine)是最早出现的基于WWW的搜索引擎,以雅虎为代表,我国的搜狐也属于目录式搜索引擎。 目录式搜索引擎由分类专家将网络信息按照主题分成若干个大类,每个大类再分为若干个小类,依次细分,形成了一个可浏览式等级主题索引式搜索引擎,一般的搜索引擎分类体系有五六层,有的甚至十几层。 目录式搜索引擎主要通过人工发现信息,依靠编目员的知识进行甄别和分类。由于目录式搜索引擎的信息分类和信息搜集有人的参与,因此其搜索的准确度是相当高的,但由于人工信息搜集速度较慢,不能及时地对网上信息进行实际监控,其查全率并不是很好,是一种网站级搜索引擎。 机器人搜索引擎 机器人搜索引擎通常有三大模块:信息采集、信息处理、信息查询。信息采集一般指爬行器或网络蜘蛛,是通过一个URL列表进行网页的自动分析与采集。起初的URL并不多,随着信息采集量的增加,也就是分析到网页有新的链接,就会把新的URL添加到URL列表,以便采集。</p><h2>浅谈搜索引擎的研究现状</h2><p>科 技 天 地 38 INTELLIGENCE ························浅谈搜索引擎的研究现状 西安外事学院计算机中心 李艳红 摘 要:文章分析了搜索引擎的发展历史及国内外搜索引擎的发展现状,采用了 对比的方法对特色搜索引擎的进行了阐述,并详尽的指出了各种搜索引擎的现状、特点及发展趋势。 关键词:搜索引擎 爬虫 网页快照 搜索引擎(Search Engine)正是帮助人们从网上检索信息的重要工具,是为了解决网上信息查询困难的问题应运而生的,它可以有效地帮助用户在网络上查找到自己需要的信息。它是在互联网产生后伴随着网上用户快速查询信息的需求的产物,即提供信息检索服务的计算机系统,检索的对象包括互联网上的站点,新闻组中的文章,软件存放的地址及作者,某个企业和个人的主页等。 当用户通过Archie 检索文件时,所要进行的全部工作就是对该数据库进行检索。尽管Archie 还不是真正的搜索引擎,但工作原理与现在的搜索引擎己经很接近,它依靠脚本程序自动搜索网上的文件,然后对有关信息进行索引,供使用者查询。1994年初,Internet 上出现了包括Lycos 在内的第一批Web 搜索引擎。第二代搜索引擎以1998年出的Google 和Directhit 为代表。它们是“根据以往用户实际访问一个网站并在该网站上所花费的时间来确定一个网站的重要性,或者根据一个网站被其他网站链接的数量来确定网站的重要性” ,“这种根据用户忠诚度的评判方法更具备客观性,因而,用户所获得的信息也就更准确”。如Directhit 以被大多数用户访问的情况认定一个网站的重要性;Google 以被其他网站链接的情况认定一个网站的重要程度。在发展过程中更强调了人的因素,主要表现在以下三个方面: (1)能利用自然语言查找信息。第二代搜索引擎可以将自然语言自动翻译成系统能理解的专业术语,进行精确查找。 (2)有判断地收集信息,根据众多网络用户行为特征来取舍信息。(3)人工分类。引入大量的人工对信息进行分类。强调人工分类的重要性。 此外,第二代的搜索引擎还有一个特点,他们只做后台技术,将技术提供给Yahoo 等门户网站。其中Google(https://www.doczj.com/doc/b513713046.html,)是表现最为突出的。Google 于1998年9月发布测试版,是目前人们使用最广泛的搜索引擎。 Google 现为全球80多家门户和终级网站提供支持。Google 的优势是易用性和返回结果的高相关性。Google 提供一系列革命性的新技术,包括完善的文本对应技术和先进的PageRank 排序技术,后者可以保证重要的搜索结果排列在结果列表的前面。Google 还提供一项很有用的服务:“网页快照”功能。 目前,新一代的搜索引擎也己经进入了研制阶段,其最大特点就是大量智能化信息处理的引入,网络信息检索将步入知识检索和知识服务的领域。它的一个特征是能够解决文件格式问题,这就要求搜索引擎不仅能识别TXT 文件,也要能够识别PPT, Word, PDF,电子邮件等文件;另一个特征是把P2P 技术应用到网页的检索中,这样通过共享所有硬盘上的文件,目录乃至整个硬盘,用户搜索时无需通过Web 服务器,不受信息文档格式的限制,即可达到把散落在互联网上的不相关的人们关心的知识搜集起来,经过筛选,组织和分析返回给用户所需的信息。 国内目前已有很多关于搜索引擎的研究。百度搜索引擎[6]收录中文网页接近2亿,是全球最大的中文数据库。Baidu 搜索引擎的其它特色包括:网页快照,网页预览/预览全部网页,相关搜索词,错别字纠正提示,新闻搜索,Flash 搜索和信息快递搜索等。北大天 网搜索引擎是国家“九五”重点科技攻关项目“中文编码和分布式中英文信息发现”的研究成果,由北大计算机系网络与分布式系统研究室开发,有强大的搜索功能。除了WWW 主页检索外,天网还提供FTP 站点搜索(“天网文件”),为高级用户查找特定文件提供方便。同时,天网将FTP 文件分为电影和动画片,MP3音乐,程序下载,文档资源共四大类,用户可以像目录导航式搜索引擎那样层层点击,查找自己需要的FTP 文件。天网提供的服务还包括“天网目录”和“天网主题”。搜狐分类目录设有独立的目录索引,并采用百度搜索引擎技术,提供网站,网页,类目,新闻黄页,中文网址,软件等多项搜索选择。搜狐搜索范围以中文网站为主,支持中文域名。慧聪搜索引擎拥有超过2亿网页的中文信息库,提供网页,网站,新闻,地域,行业,MP3, Flash 等多种检索方式,具有互联网实时新闻搜索,高精度检索,分类查询,网站导航,企业与产品查询等功能。 目前的搜索引擎,每天使用爬虫在互联网上获取大量网页,这花去了大量的时间,对于面向大量用户的商业搜索引擎是非常合理的,但是对于只面向某一类型的网络,如校园网的搜索引擎,这无疑需要大量的计算资源和存储空间,这往往是得不偿失的。因此,对于校园网内搜索引擎,需要设计一种对资源要求低,灵活机动的方法。 参考文献: [1] 刘建国:《搜索引擎概述》,北京大学计算机与科学技术,1999年。 [2] 李晓明、刘建国:《搜索引擎技术及趋势》,《大学图书馆学报》,2000年第16期。</p>
<div>
<div>相关主题</div>
<div class="relatedtopic">
<div id="tabs-section" class="tabs">
<ul class="tab-head">
<li id="20099168"><a href="/topic/20099168/" target="_blank">搜索引擎网页排序</a></li>
<li id="11588568"><a href="/topic/11588568/" target="_blank">搜索引擎的网页排名</a></li>
<li id="14422680"><a href="/topic/14422680/" target="_blank">搜索引擎排名</a></li>
<li id="2857448"><a href="/topic/2857448/" target="_blank">搜索引擎的现状</a></li>
<li id="13480932"><a href="/topic/13480932/" target="_blank">搜索引擎的特征</a></li>
<li id="14975804"><a href="/topic/14975804/" target="_blank">发现与搜索引擎技术</a></li>
</ul>
</div>
</div>
</div>
<div class="container">
<div>文本预览</div>
<div class="textcontent">
</div>
</div>
</div>
<div class="category">
<span class="navname">相关文档</span>
<ul class="lista">
<li><a href="/doc/be5525331.html" target="_blank">搜索引擎――网页分析.</a></li>
<li><a href="/doc/0113836371.html" target="_blank">影响网站在搜索引擎排序的六大主要因素</a></li>
<li><a href="/doc/633732989.html" target="_blank">搜索引擎如何对搜索结果进行排序</a></li>
<li><a href="/doc/d58647021.html" target="_blank">搜索引擎相关度算法分析</a></li>
<li><a href="/doc/3a15566742.html" target="_blank">搜索引擎和技术架构</a></li>
<li><a href="/doc/a213903398.html" target="_blank">搜索引擎的基本排序原理</a></li>
<li><a href="/doc/0711467027.html" target="_blank">搜索引擎概述 PPT课件</a></li>
<li><a href="/doc/525662320.html" target="_blank">搜索引擎的工作流程</a></li>
<li><a href="/doc/d22702760.html" target="_blank">(完整版)搜索引擎网页排序算法</a></li>
<li><a href="/doc/3212528484.html" target="_blank">搜索引擎排序基础</a></li>
<li><a href="/doc/8f10409646.html" target="_blank">搜索引擎页面排序融合算法_吴文昭</a></li>
<li><a href="/doc/f310049661.html" target="_blank">搜索引擎设计</a></li>
<li><a href="/doc/55972449.html" target="_blank">搜索引擎技术基础</a></li>
<li><a href="/doc/ce11106020.html" target="_blank">SEO搜索引擎排序算法的基础原理</a></li>
<li><a href="/doc/2119134695.html" target="_blank">浅析搜索引擎排序的意义</a></li>
<li><a href="/doc/703342213.html" target="_blank">网页排序算法</a></li>
<li><a href="/doc/f65328077.html" target="_blank">搜索引擎网页排序算法</a></li>
<li><a href="/doc/456362162.html" target="_blank">搜索引擎排序的标准是什么</a></li>
</ul>
<span class="navname">最新文档</span>
<ul class="lista">
<li><a href="/doc/0619509601.html" target="_blank">幼儿园小班科学《小动物过冬》PPT课件教案</a></li>
<li><a href="/doc/0a19509602.html" target="_blank">2021年春新青岛版(五四制)科学四年级下册 20.《露和霜》教学课件</a></li>
<li><a href="/doc/9619184372.html" target="_blank">自然教育课件</a></li>
<li><a href="/doc/3319258759.html" target="_blank">小学语文优质课火烧云教材分析及课件</a></li>
<li><a href="/doc/d719211938.html" target="_blank">(超详)高中语文知识点归纳汇总</a></li>
<li><a href="/doc/a519240639.html" target="_blank">高中语文基础知识点总结(5篇)</a></li>
<li><a href="/doc/9019184371.html" target="_blank">高中语文基础知识点总结(最新)</a></li>
<li><a href="/doc/8819195909.html" target="_blank">高中语文知识点整理总结</a></li>
<li><a href="/doc/8319195910.html" target="_blank">高中语文知识点归纳</a></li>
<li><a href="/doc/7b19336998.html" target="_blank">高中语文基础知识点总结大全</a></li>
<li><a href="/doc/7019336999.html" target="_blank">超详细的高中语文知识点归纳</a></li>
<li><a href="/doc/6819035160.html" target="_blank">高考语文知识点总结高中</a></li>
<li><a href="/doc/6819035161.html" target="_blank">高中语文知识点总结归纳</a></li>
<li><a href="/doc/4219232289.html" target="_blank">高中语文知识点整理总结</a></li>
<li><a href="/doc/3b19258758.html" target="_blank">高中语文知识点归纳</a></li>
<li><a href="/doc/2a19396978.html" target="_blank">高中语文知识点归纳(大全)</a></li>
<li><a href="/doc/2c19396979.html" target="_blank">高中语文知识点总结归纳(汇总8篇)</a></li>
<li><a href="/doc/1619338136.html" target="_blank">高中语文基础知识点整理</a></li>
<li><a href="/doc/e619066069.html" target="_blank">化工厂应急预案</a></li>
<li><a href="/doc/b019159069.html" target="_blank">化工消防应急预案(精选8篇)</a></li>
</ul>
</div>
</div>
<script>
var sdocid = "bb88e54879563c1ec5da7170";
</script>
<script type="text/javascript">bdtj();</script>
<footer class="footer">
<p><a href="/tousu.html" target="_blank">侵权投诉</a> © 2022 www.doczj.com <a href="/sitemap.html">网站地图</a></p>
<p>
<a href="https://beian.miit.gov.cn" target="_blank">闽ICP备18022250号-1</a> 本站资源均为网友上传分享,本站仅负责分类整理,如有任何问题可通过上方投诉通道反馈
<script type="text/javascript">foot();</script>
</p>
</footer>
</body>
</html>