Oracle数据库安装及运维工作指南
- 格式:docx
- 大小:29.84 KB
- 文档页数:9
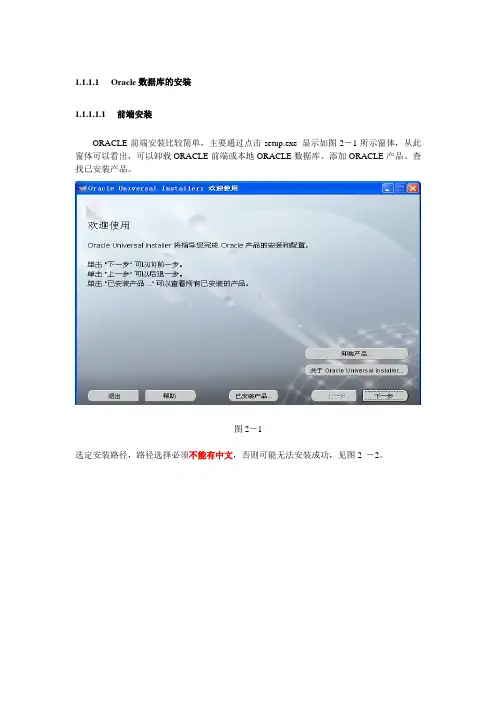
1.1.1.1Oracle数据库的安装1.1.1.1.1前端安装ORACLE前端安装比较简单,主要通过点击setup.exe 显示如图2-1所示窗体,从此窗体可以看出,可以卸载ORACLE前端或本地ORACLE数据库、添加ORACLE产品、查找已安装产品。
图2-1选定安装路径,路径选择必须不能有中文,否则可能无法安装成功,见图2 -2。
图2 -2在选定要安装的产品中选client安装(注意,可以使用oracle for windows安装软件安装,本安装就是使用安装软件安装,因此有可以安装数据库的选项,见图2 -3。
图2 -3如果作单纯配置而没有管理功能的话,可以使用运行时,见图 2 -4,这种安装模式占用空间比较小;或选择自定义,这个选项需要了解oracle部件,安装管理员主要是在后续的说明中如何了解ORACLE当前状态而用。
图2 -4当选完后,一直按下一步操作,提示需要配置可以暂时不做,以后单独配置,这样客户端就安装完成。
1.1.1.1.2客户端配置安装完成后,可以进行客户端配置,在开始菜单按如图3 -1中选Net Manger。
在打开的窗体中选服务命名,见图3 -2。
鼠标点击左边的“+”添加服务命名,在打开的窗体中Net服务名即为以后连接到数据库使用的配置字符串,这个命名应该有一定意义,下次看见就知道配置的是那台服务器,见图3 -3所示。
图3 -3下一步选协议,一般使用TCP/IP协议,见图3 -4所示。
图3 -4配置数据库的服务名或sid, 这个值必须从数据库上查找,查找方法为:用telnet 登录到数据库服务器,一般用oracle用户登录,然后进入监听文件所在目录($ORACLE_HOME/network/admin/),打开监听文件(一般为listener.ora),如下:cd $ORACLE_HOME/network/admin/cat listener.ora………….SID_LIST_LISTENER =(SID_LIST =(SID_DESC =(SID_NAME = PLSExtProc)(ORACLE_HOME = /home/oracle/product/9.2.0)(PROGRAM = extproc))(SID_DESC =(GLOBAL_DBNAME = ora92.domain)(ORACLE_HOME = /home/oracle/product/9.2.0)(SID_NAME = ora92)))……………从如上可以找到服务名:ora92.domain 或sid :ora92,一般情况配置服务名比较好,8i以上基本都使用服务名,如下可以选服务名输入ora92.domain,也可以选sid 输入ora92也能配置成功,见图3 -5所示。

Oracle数据库维护及管理基本手册目录1 目的 (4)2 适用范围 (4)3 适用对象 (4)4 机房值班 (4)4.1 服务器规划........................................................................................ 错误!未定义书签。
4.2 日常巡检............................................................................................ 错误!未定义书签。
4.3 Oracle (4)4.3.1 表空间检查; (4)4.3.2 表碎片整理 (5)4.3.3 表索引整理 (5)4.3.4 检查数据库后台进程是否正常 (6)4.3.5 查看CRS(群集就绪软件)状态是否正常 (6)4.3.6 检查报警日志文件 (6)4.3.7 查看数据库监听状态和监听日志大小 (7)4.3.8 检查数据文件状态是否是ONLINE (8)4.3.9 检查数据库是否有失效的对象 (9)4.3.10 检查数据库服务器性能,记录数据库的cpu使用以及io wait等待 (9)4.3.11 检查数据库服务器磁盘空间使用率 (10)4.3.12 检查数据库备份是否正常 (10)4.3.13 数据库性能监控 (11)4.3.14 历史数据清理 (11)4.3.15 监控数据库JOB执行情况 (11)4.3.16 用户及权限安全监控 (12)4.4 设备重启规范 (13)4.4.1 数据库重启 (13)1目的通过对日常运行维护工作的梳理和沉淀,希望能够形成标准化的运行维护手册,以达到规范工作流程、明确职责分工、提高工作效率的目的,使得复杂的事情简单做,简单的事情重复做。
2适用范围本手册适用于运维部内部的日常维护工作。
3适用对象业务支撑中心运维部数据组。

oracle安装配置教程新中大Oracle数据库安装配置教程本教程旨在提供一个通用的简洁明了的安装教程,有经验的读者可根据自己的实际需要进行相关调整。
本教程所使用数据库版本为Oracle11G,安装步骤可能与读者所使用的安装程序有所不同,请读者根据自己的安装程序进行调整。
重要内容已用红色进行标注。
因为排版原因可能导致图片略小,若读者想要看清图片,可以放大页面查看。
1Oracle数据库服务端安装: (2)2服务端配置数据库监听程序 (4)3Oracle客户端安装程序(同时安装64位和32位客户端) (5) 4客户端配置TNSName (6)5PL/SQL Developer的基本使用 (7)6数据库表空间和用户的建立以及用户的权限赋予脚本 (9)7数据库备份与恢复 (10)1Oracle数据库服务端安装:1.1点击下一步1.2选择创建和配置数据库,下一步1.3选择服务器类1.4选择单实例数据库1.5选择高级安装,下一步1.6根据需要选择语言1.7选择企业版1.8根据需要自行选择位置1.9选择一般用途/事务处理1.10根据自己的需求填写数据库信息一般Oracle服务标识符(SID)和全局数据库名都为orcl1.11字符集如图选择简体中文ZHS16GBK,其余选项按自己需求选择,下一步1.12选择使用Database Control管理数据库1.13按需求选择存储位置1.14不启用自动备份,下一步1.15根据需求填写口令1.16下一步(如果有不满足先决条件的在确认没有问题后点击忽略)1.17点击完成进行安装。
2服务端配置数据库监听程序配置监听程序可以使用Oracle提供的UI界面进行配置,也可以直接修改listener.ora,在此介绍如何使用Net Manager程序进行配置。
2.1打开数据库服务器上的Net Manager。
如图:2.2选中Oracle Net本地配置→本地→监听程序,点击左上角加号2.3根据实际需求输入监听程序名,点击确定2.4选中刚才添加的监听程序,点击添加地址2.5协议选择TCP/IP,主机选择127.0.0.1或者localhost,端口根据需要选择,默认端口为15212.6点击左上角文件→保存网络配置3Oracle客户端安装程序(同时安装64位和32位客户端)由于产品需求,在安装DBCNT的机子上需要安装32位和64位客户端。

Oracle数据库安装及检查指导手册1.文档说明面向人员:业务平台部署和维护人员版本说明:面向Oracle10g、11g版本2.数据库安装2.1.版本选择1)操作系统版本使用64位操作系统(unix、linux、Windows)具体要求版本及补丁安装请参考安装文档。
2)数据库版本10g:10.2.0.5(64位)11g:11.2.0.3(64位)2.2.数据库规划1)总体规划序号内容建议说明1 数据库安装路径ORACLE_BASE=/opt/oracleORACLE_HOME=/opt/oracle/product/10.2.0/db_ 12 数据文件路径/opt/oracle/oradata/<sid> Sid为实例名。
使用磁盘阵列应放到磁盘阵列上3 数据库软件类型双机热备数据库软件安装在本机磁盘,数据库文件安装在共享存储上4 操作系统要求包括操作系统版本补丁、内核参数,内存、交换分区、/tmp大小等参考官方安装手册54)数据库参数序号内容建议说明1 字符集选择UTF-8需要支持多国语言文字(日、韩等)建议用UTF8,仅中文环境也可以用GBK2 数据库内存大小物理内存×80%3 SGA大小数据库内存×80%4 PGA大小数据库内存×20% 根据应用情况调整5 Session数300 根据应用情况调整6 Redo log 500M 根据应用情况调整3.数据库检查表3.1.操作系统参数检查序号检查内容检查方法接收标准1 版本Redhat Linux:cat /etc/redhat-releaseUname -aWindows:附件:《查看windows操作系统是32位或者64位的方法》64位操作系统,补丁要求参考官方安装手册3.2.数据库版本检查序号检查内容检查方法接收标准1 版本select * from v$version64位企业版3.3.数据库重要参数检查序号检查内容检查方法接收标准1 字符集select value"数据库字符集" fromnls_database_parameters whereparameter='NLS_CHARACTERSET'AL32UTF8 ZHS16GBK2 Control_files3 Sga大小select value/1024/1024"sga size" fromv$parameter where name='sga_target' 4 Pga大小select value/1024/1024"pga size" fromv$parameter wherename='pga_aggregate_target'5 Redo log select b.MEMBER "redo文件名",a.BYTES/1024/1024"文件size" fromv$log a,v$logfile bwhere a.GROUP#=b.GROUP#3.4.数据库运行检查序号检查内容检查方法接收标准1 数据库监听器状态检查以oracle用户执行lsnrctl status结果应该显示连接listener成功信息,并且显示一个和数据库同名的instance为ready或者unknown状态2 数据库告警日志检查在$ORACLE_BASE/admin/<sid>/bdump目录下检查Alert<sid>.log如果没有错误需要反馈,而且此时文件已经超过10m,则将当前Alert<sid>.log重命名为Alert<sid>_当前日期.log,并删除bdump,udump下不需要的.trc文件检查以“ORA-”开头的错误,将近期在日志中持续出现的ORA-错误以及所产生的TRACE文件反馈给公司。

Installer Zero Downtime Database Setup & OperationalGuideOracle Banking Trade FinanceRelease 14.7.0.0.0Part No. F74393-01[November] [2022]Table of Contents1.INSTALLER ZERO DOWNTIME DATABASE SETUP ........................................................................... 1-1 1.1I NTRODUCTION........................................................................................................................................... 1-1 1.2P RE-R EQUISITE........................................................................................................................................... 1-1 1.3Z ERO D OWNTIME D ATABASE S ETUP .......................................................................................................... 1-21.3.1Patch set Database Compilation Process Flow ................................................................................. 1-31.3.2ZDT Installer Stage Sequence Flow................................................................................................... 1-41.3.3Creating Patch set Edition ................................................................................................................. 1-41.3.4Database Setup in Patch set Edition .................................................................................................. 1-41.3.5Application Deployment in Patchset Edition ..................................................................................... 1-51.3.6Edition Switch in Patchset Edition .................................................................................................... 1-51.3.7Application Management in Patchset Edition.................................................................................... 1-51.3.8Database Setup in Base Edition ......................................................................................................... 1-51.3.9Application Deployment in Base Edition ........................................................................................... 1-61.3.10Edition Switch in Base Edition .......................................................................................................... 1-61.3.11Application Management in Base Edition ......................................................................................... 1-61.3.12Drop Patch Set Edition ...................................................................................................................... 1-6 1.4C ONNECTION ROUTING TO D OMAINS USING O RACLE T RAFFIC D IRECTOR ................................................. 1-7 1.5A DDITIONAL I NTEGRATION S OURCE C OMPILATION ................................................................................... 1-7 1.6O PERATIONAL RECOMMENDATIONS ON O THER A PPLICATION C OMPONENTS............................................. 1-8 1.7O PERATIONAL I SSUES AND T ROUBLESHOOTING......................................................................................... 1-81. Installer Zero Downtime Database Setup1.1 IntroductionPatch set Installation with Zero downtime (ZDT) requires Installer to use Editions in a Database Schema.Installer is enhanced to use Database Schema Editions and apply the Patch set DB compilation in patch set edition and then Base edition in a staggered manner to achieve Zero Downtime.Installer support establishing JDBC connections through Application, Gateway, ATM etc. To be pointing to a specific edition.The approach is discussed in detail under the following heads.1.2 Pre-RequisiteBelow Privilege must be provided to the Database Schema from SYS Database User.1.ALTER USER <SCHEMA NAME> ENABLE EDITIONS [FORCE];2.GRANT CREATE ANY EDITION TO <SCHEMA NAME>;3.GRANT DROP ANY EDITION TO <SCHEMA NAME>;4.GRANT ALTER SESSION TO <SCHEMA NAME>;5.GRANT EXECUTE on DBMS_SESSION TO <SCHEMA NAME>;Note: Refer to section 1.7 Operational Issues and Troubleshooting.Pre-Installation Configuration:∙ZDT_PATCHING is a property in the file env.properties. Set this property to ‘Y’ if ZDT patching is required and ‘N’ if application should be taken offline when patching is done.∙BASE_EDITION is a property in the file env.properties. This property is used to indicate the Base Edition. For example ‘ORA$BASE’.∙PATCHSET_EDITION is a property in the file env.properties. This property is used to specify the Edition that would be used as the alternate Edition during ZDT Patch-setInstallation. For example, ‘E1’.∙PATCHSET_INSTALLATION is an existing property in the file env.properties. It will have value ‘Y’ for Patch set installation process.Sample Entries in env.properties as given below.R efer “Property File Creation” User Manual section of User manual for detailed procedure to create Property file.Application Domain - Prerequisite:o Two application domains –<Domain1>, <Domain2> required. These Domains will be integrated and controlled with Oracle Traffic Director to support Zero downtime Patching.o By default, <Domain2> will remain inactive (Standby mode) and all JDBC connections to Database (Schema) routed to <Domain1>.Any Bulk upload processing, Batch processing (including End of Day operations) to be planned either to complete before the start or after completion of the Patch Set Compilation / Deployment.1.3 Zero Downtime Database SetupThis section details about the Installer commands and Operational steps required to be done in the same order as specified to achieve Zero Downtime Patch Database Compilation and Application management.1.3.1 Patch set Database Compilation Process Flow1.3.21.3.3 Creating Patch set EditionPatch set Edition creation done using Silent Installer.At the start of Zero downtime Database Setup process, Run ZDTInitRun.bat inWindows (ZDTInitRun.sh for Linux)This will ensure that a new Edition is created with the name configured inenv.properties file for the property ‘PATCHSET_EDITION’Run ZDTStageUpdateRun.bat in Windows (ZDTStageUpdateRun.sh for Linux) tomove to process the next stage operation.1.3.4 Database Setup in Patch set EditionBackend Setup done using Silent Installer.DDL Compilation, Object Compilation and Static Data Loading are part of Backend Setup.Run the SMSDBCompileRun.bat in windows (SMSDBCompileRun.sh in Linux) for SMSschema (DB) compilation.Run the <Product Processor>DBCompileRun.bat to complete DDL Compilation,Object Compilation and Static Data load.For Example: FCUBS INSTALLATION-a. Run ROFCDBCompileRun.bat in windows (ROFCDBCompileRun.sh in linux)Check for the Invalid Count and make sure that the Invalid count is zero.This step will ensure the Database Backend Setup done in Patch set Edition of theSchema.Run ZDTStageUpdateRun.bat in Windows (ZDTStageUpdateRun.sh for Linux)to move to process the next stage operation.1.3.5This section briefs on the Application setup in <Domain 2>∙Generate Application / Gateway Ears and deploy in <Domain2>Application.∙<Domain 2> to be in inactive state (Standby mode).Refer “EAR Building”User Manual section for EAR building steps.1.3.6Run ZDTLoginSwitchRun.bat(ZDTLoginSwitchRun.sh for Linux OperatingSystem).This BAT file execution will ensure all new JDBC connections from application points tothe new Edition created (as maintained by the property PATCHSET_EDITION).Run ZDTStageUpdateRun.bat in Windows (ZDTStageUpdateRun.sh for Linux) tomove to process the next stage operation.1.3.7This section briefs on the <Domain 2> application Sanity and to activate for live transactiontraffic.a. Operational Recommendation briefed in section 1.6 Operational recommendationson Other Application Components to be adhered.b. Start the <Domain 2> Application.c. Sanity Check of Patch set in <Domain 2> Applicationd. All incoming transactions traffic routed to <Domain 2> using Oracle Traffic Directorand,e. <Domain 1> to be made inactive status (Standby mode), once all the existingtransactions in process in <Domain 1> completes its process.1.3.8 Database Setup in Base EditionBackend Setup done using Silent Installer.DDL Compilation, Object Compilation and Static Data Load will be taken care as part ofBackend Setup.Run the SMSDBCompileRun.bat in windows (SMSDBCompileRun.sh in Linux) for SMSschema (DB) compilation.Run the <Product Processor>DBCompileRun.bat to complete Object Compilation.For Example: In case of FCUBS INSTALLATIONa. Run ROFCDBCompileRun.bat in windows (ROFCDBCompileRun.sh in Linux)Check for the Invalid Count and make sure that the Invalid count is zero.This step will ensure the Database Backend Setup is done in Base Edition of the Schema.Run ZDTStageUpdateRun.bat in Windows (ZDTStageUpdateRun.sh for Linux) tomove to process the next stage operation.1.3.9 Application Deployment in Base EditionThis section briefs on the Application setup in <Domain 1>∙Generate Application / Gateway Ears and deploy in Domain1 Application.∙<Domain 1> to be in inactive status (Standby mode).Refer “EAR Building” User Manual section for EAR building steps.1.3.10 Edition Switch in Base EditionRun ZDTLoginSwitchRun.bat (ZDTLoginSwitchRun.sh for Linux)This BAT file execution will ensure all new JDBC connections from application points tothe Base Edition (as maintained by the property BASE_EDITION)Run ZDTStageUpdateRun.bat in Windows (ZDTStageUpdateRun.sh for Linux) tomove to process the next stage operation.1.3.11 Application Management in Base EditionThis section briefs on the <Domain 1> application Sanity and to activate for live transactiontraffic.a. Operational Recommendation briefed in section 1.6 Operational recommendationson Other Application Components to be adhered.b. Start the <Domain 1> Application.c. Sanity Check of Patch set in <Domain 1> Applicationd. All incoming transactions traffic routed to <Domain 1> using Oracle Traffic Directorand,e. <Domain 2> to be made inactive status (Standby mode), once all the existingtransactions in process in <Domain 2> completes its process.1.3.12 Drop Patch Set EditionAt the end of the f Zero downtime Database Setup process, Run ZDTExitRun.bat inWindows (ZDTExitRun.sh for Linux).This will ensure that the Patch Set Edition (as maintained by the propertyPATCHSET_EDITION) dropped.Run ZDTStageUpdateRun.bat in Windows (ZDTStageUpdateRun.sh for Linux) tomove to process the next stage operation.1.4 Connection routing to Domains using Oracle TrafficDirectorIn below representation <Domain 1> as denoted as Green and <Domain 2> as Blue.The Blue-Green deployment process uses two identical environments-Blue and Green. Only one environment is active at a time, serving all the traffic with the load balancer and the other environment is in the standby mode.Example, let us consider that Blue is in standby and Green is active. When the updates are completed in the Blue environment, you can use the load balancer to switch the traffic to the Blue environment.Once the Traffic is diverted and directed to the Blue environment using the Load balancer. Health checks are performed for all the components of the currently active Blue environment with traffic.1.5 Additional Integration Source CompilationThis section briefs on any additional Integrations source compilation.o If OFSAA Integration exists in the environment, then run the <ProductProcessor>_OFSAADBCompileRun.bat to complete DDL Compilation, ObjectCompilation and Static Data load.o In both sections 1.3.4 Database Setup in Patch set Edition and 1.3.8 Database Setup in Base Edition the above OFSAA compilation has to be run before the <ProductProcessor>DBCompileRun.batFor Example: In case of FCUBS INSTALLATIONb. Run ROFC_OFSAADBCompileRun.bat in Windows(ROFC_OFSAADBCompileRun.sh in Linux) then,c. Run ROFCDBCompileRun.bat in windows (ROFCDBCompileRun.sh in Linux)1.6 Operational recommendations on Other ApplicationComponentsThis section briefs the recommendations on other application components.o For Zero Downtime patch set Deployment following operational steps / setuprecommended,▪Remote SOA/BPEL setup is recommended.▪Standalone Scheduler Application is recommended.▪As part of Application Management sections 1.3.7 Application Management and1.3.11 Application Management,∙ATM instances to be restarted one by one so that it points to respectiveApplication domain (<Domain 2> or <Domain 1>).∙Scheduler jobs to be paused or stopped as a pre requisite beforediverting the transactions traffic from one Domain to another usingOracle Traffic Director.∙Scheduler jobs has to be started back once the transaction trafficdiverted to the specific domain.1.7 Operational Issues and TroubleshootingThis section briefs on the common issues and its troubleshooting methods.1.If there are objects with version number other than 1 and While enabling editions for theUser <Schema name> in section 1.2 Pre-Requisite will result with the below error“ERROR at line 1:ORA-38820: user has evolved object type “Solution:Below query will list the objects with version number other than one.Select type_name,owner, version# from dba_type_versions whereowner='&SCHEMA_NAME' and VERSION# !='1';Below query’s result to be executed in SQL command prompt to reset the version to one.Select 'ALTER TYPE ' ||TYPE_NAME|| ' RESET;' FROM dba_type_versions whereowner='&SCHEMA_NAME' AND VERSION# !='1';2.Patch set edition will not be dropped in section 1.3.12 Drop Patch Set Edition, if there areactive connections to the schema pointing to Patch set Edition.“Exception in dropping edition java.sql.SQLException: ORA-38805: edition is in use”Clear such sessions and section 1.3.12 Drop Patch Set Edition to process again to get the Patch set Edition droppedBelow query would help to list all editions in the Schema. At the end of process 1.3.12 Drop Patch Set Edition, only Base Edition should present.Select * FROM all_editions1-9Installer Zero Downtime Database Setup & Operational Guide[November] [2022]Version 14.7.0.0.0Oracle Financial Services Software LimitedOracle ParkOff Western Express HighwayGoregaon (East)Mumbai, Maharashtra 400 063IndiaWorldwide Inquiries:Phone: +91 22 6718 3000Fax: +91 22 6718 3001/financialservices/Copyright © [2022] Oracle and/or its affiliates. All rights reserved.Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. Government.This software or hardware is developed for general use in a variety of information management applications. It is not developed or intended for use in any inherently dangerous applications, including applications that may create a risk of personal injury. If you use this software or hardware in dangerous applications, then you shall be responsible to take all appropriate failsafe, backup, redundancy, and other measures to ensure its safe use. Oracle Corporation and its affiliates disclaim any liability for any damages caused by use of this software or hardware in dangerous applications.This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish or display any part, in any form, or by any means. Reverse engineering, disassembly, or de-compilation of this software, unless required by law for interoperability, is prohibited.The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing.This software or hardware and documentation may provide access to or information on content, products and services from third parties. Oracle Corporation and its affiliates are not responsible for and expressly disclaim all warranties of any kind with respect to third-party content, products, and services. Oracle Corporation and its affiliates will not be responsible for any loss, costs, or damages incurred due to your access to or use of third-party content, products, or services.。

银河麒麟服务器操作系统Oracle+数据库安装与配置指南目录第1章配置内核参数 (1)第2章建立ORACLE用户 (3)1.1.在超级用户下创建新的组和用户 (3)1.2.建立O RACLE软件的安装目录 (3)第3章安装ORACLE补丁与JAVA开发包 (4)3.1安装P3006854_9204_LINUX补丁 (4)3.2安装J A V A开发包 (4)3.3软件介质 (4)第4章安装ORACLE DATABASE (5)4.1编辑 (5)4.2启动O RACLE U NIVERSAL I NSTALLER (OUI) (5)第5章创建数据库 (11)5.1编辑 (11)5.2切换到ROOT的终端,安装 OPATCH。
(11)5.3最后切换到ORACLE终端 (11)第6章参数配置建议 (17)第1章配置内核参数Oracle数据库对系统的硬件配置有基本的要求,包括机器主频、磁盘空间和内存大小,但作为服务器的机器一般是满足的,这里就不赘述了。
下面的一些参数需要根据机器系统的实际情况,特别是内存的大小来进行设置,这里假定内存为2G,页面大小为4K。
为使Oracle 数据库管理系统在运行时有更好的性能,应尽量给数据库留出较多的内存。
在以下的内核生成过程中,假设内核源码位于/root/kylin2.0,并定义为环境变量KSROOT。
# cd $KSROOT/arch/i386/conf# cp GENERIC ORACLE# cat >> ORACLEoptions SEMMAP=128options SEMMNI=128options SEMMNS=32000options SEMOPM=250options SEMMSL=250options SHMMAXPGS=65536options SHMMAX=2147479552options SHMALL=524287options SHMMNI=4096options SHMSEG=4096options MAXDSIZ="(1024*1024*1024)"options MAXSSIZ="(1024*1024*1024)"options DFLDSIZ="(1024*1024*1024)"注:根据上面的假定,Kylin页大小为4k ,这样2G的内存,其SHMALL可以为524288,这里设定524287,也是考虑到实际情况,用dmesg工具就可以看到,可用的内存实际上并没有2G,比2G稍少。

3.3开发环境的配置我所做的毕业设计是基于Web的师生互动交流平台,需要用到一系列开发工具。
目前开发平台的搭建需要MyEclipse+JDK+Tomcat,数据库使用Oracle数据库。
3.3.1JDK+Tomcat+MyEclipse开发环境的搭建我下载的是JDK是JDK1.6.0_24,Tomcat是Tomcat6.0,MyEclipse是MyEclipse8.5。
在安装过程中出现过很多问题。
最后,我是按着先安装JDK,然后安装Tomcat,最后安装MyEclipse的顺序进行。
安装JDK的过程比较简单,就是下载下来直接的.exe文件,然后开始安装。
在整个安装过程中都使用默认的路径。
这样比较不容易出错。
然后JDK安装到C:\Program Files\Java\JDK1.6.0_24这个路径下。
安装完JDK之后,我们需要在我的电脑—>属性—>高级选项卡里设置环境变量。
需要设置的三个环境变量是:JA V A_HOME=C:\Program Files\Java\JDK1.6.0_24Path=C:\Program Files\Java\JDK1.6.0_24\bin;Classpath=.;%JA V A_HOME%\lib \tools.jar;%JA V A_HOME%\lib\dt.jar;在设置完这三个环境变量之后,我需要测试一下JDK是否安装成功。
基本的做法是在开始—>cmd后直接输入Javac 看是否会出现如下图:图3.9验证Javac命令之后再输入Java命令,看是否出现如下图:图3.10验证Java命令最后我们还可以输入Java –version查看JDK的版本,如下图3:图3.11 验证Java –version命令如果顺利出先以上三张图,说明JDK配置成功了。
接下来安装Tomcat。
我这里下载的也是.exe文件。
直接开始安装,我使用的都是默认路径。
我把Tomcat安装在C:\Program Files\Apache Software Foundation\Tomcat 6.0。

数据库日常运维操作手册目录1.日维护过程1.1 确认所有的INSTANCE状态正常1.2 检查文件系统的使用(剩余空间)1.3 检查日志文件和trace文件记录1.4 检查数据库当日备份的有效性。
1.5 检查数据文件的状态1.6 检查表空间的使用情况1.7 检查剩余表空间1.8 监控数据库性能1.9 检查数据库系统性能1.10 日常出现问题的处理。
2.每周维护过程2.1 监控数据库对象的空间扩展情况2.2 监控数据量的增长情况2.3 系统健康检查2.4 检查无效的数据库对象2.5 检查不起作用的约束2.6 检查无效的trigger3.月维护过程3.1 Analyze Tables/Indexes/Cluster3.2 检查表空间碎片3.3 寻找数据库性能调整的机会3.4 数据库性能调整3.5 提出下一步空间管理计划数据库日常运维操作手册主要针对ORACLE数据库管理员对数据库系统做定期监控:(1). 每天对ORACLE数据库的运行状态日志文件、备份情况、数据库的空间使用情况、系统资源的使用情况进行检查,发现并解决问题。
(2). 每周对数据库对象的空间扩展情况、数据的增长情况进行监控、对数据库做健康检查、对数据库对象的状态做检查。
(3). 每月对表和索引等进行Analyze、检查表空间碎片、寻找数据库性能调整的机会、进行数据库性能调整、提出下一步空间管理计划。
对ORACLE数据库状态进行一次全面检查1.日维护过程1.1 确认所有的INSTANCE状态正常登陆到所有数据库或例程,检测ORACLE后台进程:$ps –ef|grep ora1.2 检查文件系统的使用(剩余空间)如果文件系统的剩余空间小于20%,需删除不用的文件以释放空间。
#df –k1.3 检查日志文件和trace文件记录检查相关的日志文件和trace文件中是否存在错误。
A 连接到每个需管理的系统使用secureCRT远程登陆工具B 对每个数据库,进入到数据库的bdump目录,unix系统中BDUMP目录通常是$ORACLE_BASE/<SID>/bdump#$ORACLE_BASE/<SID>/bdumpC 使用Unix 和linux ‘tail’命令来查看alert_<SID>.log文件#tail $ORACLE_BASE/<SID>/bdump/alert_<SID>.logD 如果发现任何新的ORA-错误,记录并解决1.4 检查数据库当日备份的有效性。

Oracle数据库安装及运维工作指南金蝶软件(中国)有限公司K3 CLOUD 基础系统部2017-04-10张华福本文主要强调ORACLE 数据库服务器环境的安装软件及版本,以及安装完成后的后续完善工作。
以确保数据库以比较完善的状态投入生产,尽可能避免已知的问题影响生产库的运营。
文章不涉及到软件的安装方法步骤。
1 服务器系统软件,数据库版本安装推荐:1 数据库服务器的操作系统,推荐使用ORACLE 。
2 数据库软件版本,要求安装11204,单节点或RAC环境均可,推荐使用RAC。
2 数据库安装创建完毕后,需要进行下列的完善工作,1 打上最新的补丁集,如:ORACLE 11204,截止至2017年4月,ORACLE11204 数据库, 当前最新版本的补丁集为日发布的,--rac 版本,--纯数据库版。
请按照补丁集上的,把补丁集打到GI, 数据库上。
2 初始化参数,下面的参数值,只是通常情况下的设置(或可根据服务器的硬件条件自行修改配置),要想系统效率最优,得依据数据库实际的运行情况逐步作微调(注意,下面的命令,在RAC和单节点环境下,稍有不同)。
alter profile default LIMIT PASSWORD_LIFE_TIME UNLIMITED;alter system set processes=500 scope=spfile sid='*';alter system set control_file_record_keep_time=21 scope=spfile sid='*';alter system set open_cursors=300 scope=spfile sid='*';alter system set session_cached_cursors=300 scope=spfile sid='*';alter system set audit_trail=NONE scope=spfile sid='*';alter system set recyclebin=off scope=spfile sid='*';alter system set log_archive_dest_1='location=use_db_recovery_file_dest' scope=both sid='*';alter system set fast_start_mttr_target = 30 scope=both sid='*';alter system set streams_pool_size=100m scope=spfile sid='*';alter system set archive_lag_target = 1200;alter system set "_optimizer_use_feedback"= false scope=spfile sid='*';alter system set "_optimizer_invalidation_period"=60 scope=both sid='*';修改结束后,需重启数据库,才能确保上述修改生效。

Oracle数据库维护和管理手册1Oracle 数据库维护和管理手册作者孙德金审核分类数据库子类Oracle更新时间 -11-24关键字Oracle 维护和管理摘要Oracle 运行维护、管理、日常巡检主要适linux用环境文档控制2文档修订记录版本号变化状态变更内容修改日期变更人0.01 C .11.24 孙德金*变化状态:C――创立,A——增加,M——修改,D——删除文档审批信息版本号审核人审核日期批准人批准日期备注目录1 概述................................................................................................... 错误!未定义书签。
1.1 目的 ....................................................................................... 错误!未定义书签。
1.2 范围 ................................................................................. 错误!未定义书签。
31.3 预期读者 ......................................................................... 错误!未定义书签。
1.4 术语定义 ......................................................................... 错误!未定义书签。
1.5 参考资料 ......................................................................... 错误!未定义书签。
2 CRS的管理 ...................................................................................... 错误!未定义书签。

金蝶云星空ORACLE 数据库安装及完善工作要求金蝶软件(中国)有限公司金蝶云星空基础系统部2018-06-27张华福本文主要强调ORACLE 数据库服务器环境的安装软件及版本,以及安装完成后的后续完善工作。
以确保数据库以比较健壮的状态投入生产,尽量避免已知的问题影响生产库的运营。
文章不涉及到软件的安装方法步骤。
1 服务器系统软件,数据库版本安装推荐:1 数据库服务器的操作系统,推荐使用ORACLE LINUX6.9。
2 数据库软件版本,要求安装11204企业版(不支持标准版),单节点或RAC环境均可,推荐使用RAC。
2 数据库安装创建完毕后,需要进行下列的完善工作,1 打上最新的补丁集,如:ORACLE 11204,截止至2018年04月,ORACLE11204 数据库, 当前最新版本的补丁集为20180417日发布(使用CSI服务号,到ORACLE的SUPPRT网站下载),此外,还需要打上下列小补丁(ONE-OFF PATCH):14275161,16086769_112041,16311211_11204171017,17306264_11204170418,18841764,18498878_112040,19174639_112040,19678658_11204171017,19692824(使用linux7时才需要),19855835_112044,20907061_11204180116,22113854_112040,23665623_11204171017,24739928_11204180417,24921392,p2*******_112040_Linux-x86-64.zip -- GI 版本,p2*******_112040_Linux-x86-64.zip --纯数据库版。
提示:1 PSU补丁集在单节点环境使用纯数据库版,在RAC 环境使用GI版本。
2 优先打补丁集(强烈建议),再打小补丁(建议)。
ORACLE 11g(OS oracle linux 6.4)数据库安装手册概述:本文档中安装oracle数据库过程中,操作系统采用oracle linux 6.4(64位),数据库版本为:11.2.0.31.将安装介质上传至服务器2.修改服务器主机名[root@cxdb ~]# vi /etc/hosts3.配置系统限制[root@cxdb ~]# vi /etc/security/limits.d/90-nproc.conf4.关闭防火墙[root@rac81 ~]# service iptables stopiptables:清除防火墙规则:[确定]iptables:将链设置为政策ACCEPT:filter [确定]iptables:正在卸载模块:[确定][root@rac81 ~]# chkconfig iptables off5.修改安全限制[root@cxdb ~]# vi /etc/sysconfig/selinux6.删除Oracle用户[root@cxdb ~]userdel oracle[root@cxdb ~]rm -rf /home/oracle[root@cxdb ~]rm -rf /var/mail/oracle[root@cxdb ~]groupdel oinstall[root@cxdb ~]groupdel dba7.创建用户组,Oracle用户创建组[root@cxdb ~]groupadd -g 1000 oinstall[root@cxdb ~]groupadd -g 1010 dba创建用户[root@cxdb ~]useradd -u 1101 -g oinstall -G dba oracle [root@cxdb ~]mkdir -p /opt/u01/app/oracle/product/11.2.0.3 [root@cxdb ~]chown -R oracle:oinstall /opt/u01/app/ [root@cxdb ~]chmod -R 775 /opt/u01[root@cxdb ~]passwd oracle8.设置Oracle用户的环境变量9.安装数据库软件使用VNC进入linux桌面在root用户下打开oracle的桌面切换用户进入介质目录,执行安装命令点击next点击yes 点击next点击next 点击next点击next 点击next点击next 点击next点击next 点击Install打开一个命令行,在root用户下执行上面的两个脚本执行完以上连个命令后,点击OK点击close。
Oracle 10G数据库安装手册(Win2K操作系统)一、序言此文档只适用于安装学习或实习环境,对于生产环境,应当在安装前对诸如操作系统、存储设施、网络等进行认真规划,再实施安装与配置。
本安装手册在windows版本5.1 Service Pack 3测试,安装过程与结果完全正确。
二、安装前的准备1.配置主机名打开“系统属性”面板,选择“计算机名”如下图:选中并执行“更改”,给计算机取一个直观的名字,在此例中为“dbserver”。
如下图:选择并运行“其它(M)”,给主机取一个虚拟的域名(DNS后缀),此例用“”(在真实的生产环境,机器名和域名由网络管理员与DBA共同规划)。
如下图所示:选择“确定”,系统要求重启,重启完成以后,再做进一步配置。
2.配置主机名表一般来说,学习用机都是由DHCP动态分配IP地址。
为了不让数据库服务和其它数据管理服务因IP地址变化而出现故障,安装前最好配置一下主机上的主机名表,配置信息如下图所示:注:主机名表“hosts”文件驻留于<windows安装目录>\systems32\drivers\etc 下,我的实验机器是“C:\WINDOWS\system32\drivers\etc”,“dbserver”是我的机器名,“”是我实验机器的DNS后缀。
3.下载安装包实验者可以在下载安装包,注意版本号与支持的操作系统类型。
天府学院的学生可以从“ftp:///compute-team/杨大友/database/数据库安装包/”下载,下载“10201_database_win32.zip”并解压到一个目录,例如:d:\databaseSource。
三、安装数据库服务器1.找到安装包中的setup.exe并运行它。
如下图:安装程序请求填写“主目录位置”等相关信息,在此例中填写如下信息:安装方法:基本安装Oracle主目录位置:D:\oracle\db10g全局数据库名:数据库口令:testdb123填写后的表单如下图所示:注:是数据库宿主机的DNS后缀。
Oracle 数据库安装手册1 软件环境系统分区:◆/ 10G◆/swap 4G(为物理内存容量的2倍)◆/home 大小视应用决定操作系统:◆RedHat Enterprise Linux As4(U2)64位建议安装全部组件◆GCC编译器版本2.96-3.2兼容库:⏹compat-gcc-7.3-2.96.128⏹compat-gcc-c++-7.3-2.96.128⏹compat-libstdc++-7.3-2.96.128⏹compat-libstdc++-devel-7.3-2.96.128⏹如不符合以上标准请对GCC降级(var目录下)确保系统主机名和IP地址参考命令vi /etc/hostsHostname 显示主机名称2 Oracle安装步骤以root用户登录X-Window,点击鼠标右键新开一个终端窗口。
允许Oracle在终端窗口安装时访问X-Window,输入如下命令:# xhost +创建用户组oinstall、dba,命令如下:# groupadd oinstall# groupadd dba创建oracle用户目录,命令如下:# mkdir –p /home/oracle创建oracle用户和设置密码,命令如下:# useradd –g oinstall –G dba oracle –d /u1/app/oracle# passwd oracle修改用户oracle用户的主目录权限和属主,命令如下:(此步也可在图形界面中操作)# chown –R oracle:oinstall /home/oracle# chmod –R 755 /home/oracle配置内核参数文件/etc/sysctl.conf:修改文件/etc/sysctl.conf,增加以下内容:kernel.shmall = 2097152kernel.shmmax = 2147483648kernel.shmmni = 4096kernel.sem = 250 32000 100 128fs.file-max = 65536net.ipv4.ip_local_port_range = 1024 65000net.core.rmem_default = 262144net.core.rmem_max = 262144net.core.wmem_default = 262144net.core.wmem_max = 262144增加保存后,使设置生效,输入如下命令:# sysctl-p配置SHELL参数文件/etc/security/limits.conf:修改文件/etc/security/limits.conf,增加以下内容:oracle soft nproc 2047oracle hard nproc 16384oracle soft nofile 1024oracle hard nofile 65536配置文件/etc/profile,增加以下内容:if [ $USER = "oracle" ]; thenif [ $SHELL = "/bin/ksh" ]; thenulimit -p 16384ulimit -n 65536elseulimit -u 16384 -n 65536fifi切换到oracle用户,命令如下:#su - oracle编辑文件.bash_profile,设置文件权限掩码,在最后追加如下内容:umask 022运行如下命令,使配置生效:$ source .bash_profile运行如下命令,开始安装oracle:$安装文件路径/runInstaller按提示进行安装,具体情况视需要设置。
Oracle 数据库运维手册(v 100220)作者黄沛审核分类数据库子类Oracle更新时间2010-7关键字Oracle 运维服务摘要Oracle 日常监控、运行维护主要适Windows、linux用环境版本说明拟制/修改责任人拟制/修改日期修改内容/理由版本号目录版本说明 (2)1 工作环境准备 (4)1.1 oracle客户端安装 (4)1.1.1 下载介质 (4)1.1.2 安装客户端 (5)1.1.3 测试客户端 (7)1.2 配置oracle客户端连接 (8)1.2.1 tnsname配置 (8)1.3 oracle管理工具-toad安装配置 (11)1.3.1 安装toad (11)1.3.2 toad连接数据库 (12)1.4 metalink账号申请 (14)2运行环境监控 (16)2.1 系统环境监控 (16)2.2数据库运行状况监控 (17)2.3 日常性能监控 (17)2.3.1 Oracle 9i图形工具-Performance Manager监控顶层会话及顶层SQL (17)2.3.2 Oracle10g OEM工具监控顶层会话及获取SQL详细信息 (20)3日常数据库管理 (25)3.1检查警告日志文件中最新错误信息 (25)3.2系统运行状况快照采集(oracle 9i) (26)3.3 Oracle 10g OEM图形管理工具实现系统快照采集 (27)4 数据库表空间监控 (38)4.1 SQL脚本方式查看 (38)4.2 图形界面查看表空间使用率 (39)4.3 Oracle 10g OEM表空间管理 (39)5 数据库备份及日志清理 (41)5.1 Oracle 物理备份(RMAN) (41)概述该手册进行Oracle数据库的日常工作,能有效的把握Oracle后台数据库的整体运行健康状况,通过收集相关重要信息分析,能很好的防范即将出现的系统风险,系统出现问题后尽快的定位问题,现场解决一部分常规数据库问题。
矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。