配置mongodb分片群集(sharding cluster)
- 格式:docx
- 大小:111.45 KB
- 文档页数:12
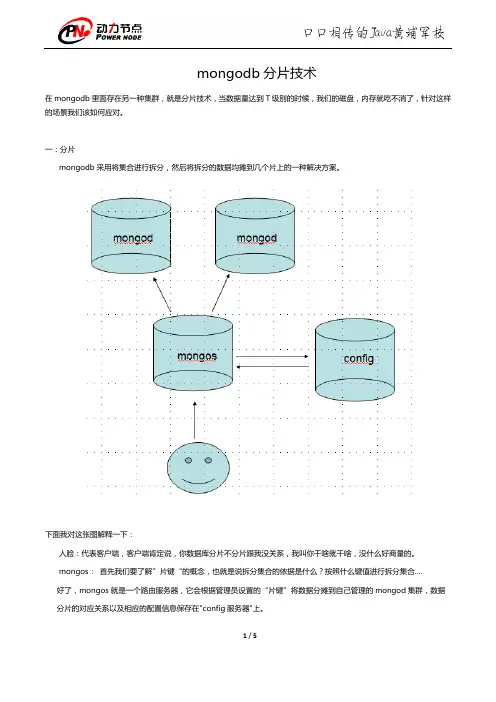
mongodb分片技术在mongodb里面存在另一种集群,就是分片技术,当数据量达到T级别的时候,我们的磁盘,内存就吃不消了,针对这样的场景我们该如何应对。
一:分片mongodb采用将集合进行拆分,然后将拆分的数据均摊到几个片上的一种解决方案。
下面我对这张图解释一下:人脸:代表客户端,客户端肯定说,你数据库分片不分片跟我没关系,我叫你干啥就干啥,没什么好商量的。
mongos:首先我们要了解”片键“的概念,也就是说拆分集合的依据是什么?按照什么键值进行拆分集合....好了,mongos就是一个路由服务器,它会根据管理员设置的“片键”将数据分摊到自己管理的mongod集群,数据分片的对应关系以及相应的配置信息保存在"config服务器"上。
mongod: 一个普通的数据库实例,如果不分片的话,我们会直接连上mongod。
二:实战首先我们准备4个mongodb程序,我这里是均摊在C,D,E,F盘上,当然你也可以做多个文件夹的形式。
1:开启config服务器先前也说了,mongos要把mongod之间的配置放到config服务器里面,理所当然首先开启它,我这里就建立2222端口。
2: 开启mongos服务器这里要注意的是我们开启的是mongos,不是mongod,同时指定下config服务器,这里我就开启D盘上的mongodb,端口3333。
3:启动mongod服务器对分片来说,也就是要添加片了,这里开启E,F盘的mongodb,端口为:4444,5555。
4:服务配置哈哈,是不是很兴奋,还差最后一点配置我们就可以大功告成。
<1> 先前图中也可以看到,我们client直接跟mongos打交道,也就说明我们要连接mongos服务器,然后将4444,5555的mongod交给mongos,添加分片也就是addshard()。
这里要注意的是,在addshard中,我们也可以添加副本集,这样能达到更高的稳定性。

一、介绍随着互联网和大数据技术的不断发展,数据存储和管理的需求也越来越迫切。
在这样的背景下,NoSQL(Not Only SQL)数据库成为了一个备受关注的技术方向。
MongoDB作为NoSQL数据库中的一员,以其高性能、扩展性强、灵活的数据模型等特点,受到了业界的广泛关注和应用。
在实际应用中,随着数据量的增加,单机部署的MongoDB系统已经无法满足高可用、高并发的需求。
构建MongoDB集群已经成为了一种常见的做法,来保证数据的安全性、可靠性和性能。
本文将从零开始,详细介绍如何搭建一个MongoDB集群环境,以满足大规模数据存储和访问的需求。
在本文中,我们将介绍搭建MongoDB集群的前期准备工作、集群架构的设计、搭建过程中的注意事项以及搭建完成后的验证工作。
希望本文能对需要搭建MongoDB集群的读者提供一些帮助。
二、前期准备1. 硬件准备:在搭建MongoDB集群之前,需要做好硬件的准备工作。
包括选择适当配置的服务器、网络设备、磁盘空间等。
根据实际需要和预算,选择性能和可靠性较好的硬件设备。
2. 软件准备:除了硬件设备以外,还需要准备好操作系统、MongoDB数据库软件等。
选择稳定的操作系统版本,并安装MongoDB数据库软件的最新版本。
3. 网络规划:在搭建MongoDB集群之前,需要进行网络规划,包括IP位置区域的规划、子网划分、网络拓扑结构的设计等。
保证所有节点可以互相通信,并且保证数据在集群内的快速传输。
4. 安全性规划:在搭建MongoDB集群时,要考虑数据的安全性。
建议在搭建集群之前,设置好访问控制、认证授权等安全策略,以确保数据不被未授权的访问。
三、集群架构设计1. 架构选择:MongoDB集群可以采用不同的架构,包括副本集、分片集群等。
在设计集群架构时,需要根据实际需要选择合适的架构。
副本集适用于数据量较小,需要高可用的场景;分片集群适用于数据量较大,需要水平扩展的场景。

mongodb 高可用方案在当今的数据应用场景中,高可用性是至关重要的。
对于数据库系统而言,高可用性指的是在出现硬件故障、网络中断或其他意外情况时,仍能保持数据的持久性和可用性。
在大数据时代,如何实现高可用性成为了数据库系统设计的重要一环。
MongoDB作为一款高性能的NoSQL数据库,拥有众多的用户和广泛的应用场景。
为了满足对高可用性的需求,MongoDB提供了多种方案来保证数据的可靠性和持久性。
一、复制集(Replica Set)复制集是MongoDB提供的最基本的高可用性方案之一。
它由一个主节点(Primary)和多个从节点(Secondary)组成。
主节点负责处理所有的写操作,并将写操作的日志(Oplog)传输给从节点进行数据同步。
当主节点发生故障时,选举机制会在从节点中选出新的主节点以继续提供服务。
复制集通过冗余副本的方式来实现数据的持久性和高可用性。
二、分片集群(Sharded Cluster)分片集群是MongoDB提供的一种可水平扩展的高可用性方案。
它将数据集分成多个片(Shard),每个片都是一个独立的MongoDB集群。
每个片都有自己的主节点和多个从节点,实现数据的分布式存储和负载均衡。
分片集群通过将数据分散到多个节点上,提高了系统的吞吐量和可用性。
三、自动故障转移(Automatic Failover)MongoDB通过自动故障转移机制来提高系统的可用性。
当主节点发生故障时,复制集会自动选举出新的主节点,保证系统的连续性。
自动故障转移通常会结合监控机制和心跳检测来实现,及时发现节点的故障并采取相应的措施。
四、数据备份与恢复(Backup and Recovery)备份和恢复是任何高可用性方案中必不可少的一环。
MongoDB提供了多种备份和恢复的方法,如文件系统备份、mongodump/mongorestore工具备份等。
通过定期备份数据,可以在数据丢失或损坏时快速恢复数据并保证系统的可用性。

mongodb集群部署集群配置最少要开启7个mongodb服务:其中configserver不管有多少个复制集都需要3个,sharding最少要有1个(1个也能进⾏分⽚,⽅便以后扩展;每个sharding都有三个mongodb 服务,⼀个主节点,⼀个从节点,⼀个仲裁节点),mongos最少要有1个(mongos可以有⽆限多个,每个都可以访问到mongodb分⽚数据中);扩展时,只需要扩展sharding即可。
每个服务器只需要解压⼀个mongodb安装包即可。
启动mongodb服务时,区分不同的端⼝进⾏启动即可。
集群配置最少需要两台物理服务器和⼀台应⽤服务器:其中两台物理服务器分别安装sharding的主节点和从节点,三个configserver可以安装到任意⼀个或多个服务器上;应⽤服务器安装sharding的仲裁节点和路由节点mongos,还可以安装其他应⽤服务;扩展时每次最少要扩展两台物理服务器,每两个物理服务器分别安装sharding的主节点和从节点,仲裁节点放到别的地⽅,加⼊分⽚即可。
配置启动⽂件如下:config server1:# /usr/local/mongodb/conf/mongo-configsvr.confport = 20000 #端⼝只要相同物理机上不重复即可configsvr=true #说明这是configserverlogpath=/ronglian_data/mongo-configsvr/logs/mongo-configsvr.log #⽇志⽂件位置,不能重复logappend=true #⽇志追加fork = true #后台运⾏dbpath=/ronglian_data/mongo-configsvr/db #数据⽂件位置,不能重复keyFile=/usr/local/mongodb/conf/key.cr #mongdb节点之间的认证,内容随意pidfilepath = /var/run/mongod1.pid #存放进⾏ID的⽂件,不能重复config server2:# /usr/local/mongodb/conf/mongo-configsvr.confport = 20001configsvr=truelogpath=/ronglian_data/mongo-configsvr/logs/mongo-configsvr1.loglogappend=truefork = truedbpath=/ronglian_data/mongo-configsvr/db1keyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongod2.pidconfig server3:# /usr/local/mongodb/conf/mongo-configsvr.confport = 20002configsvr=truelogpath=/ronglian_data/mongo-configsvr/logs/mongo-configsvr2.log logappend=truefork = truedbpath=/ronglian_data/mongo-configsvr/db2keyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongod3.pidsharding1-1:# /usr/local/mongodb/conf/mongo-shard01.confport = 10000replSet = rs01 #说明是哪个复制集shardsvr=true #说明是复制集服务logpath=/ronglian_data/mongo-shard01/logs/mongo-shard01.log logappend=true fork = truedbpath=/ronglian_data/mongo-shard01/dbkeyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongod4.pidsharding1-2:# /usr/local/mongodb/conf/mongo-shard01.confport = 10001replSet = rs01shardsvr=truelogpath=/ronglian_data/mongo-shard01/logs/mongo-shard01-1.log logappend=true fork = truedbpath=/ronglian_data/mongo-shard01/db1keyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongod5.pidsharding1-3:# /usr/local/mongodb/conf/mongo-shard01.confport = 10002replSet = rs01shardsvr=truelogpath=/ronglian_data/mongo-shard01/logs/mongo-shard01-2.log logappend=true fork = truedbpath=/ronglian_data/mongo-shard01/db2keyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongod6.pidsharding2-1:# /usr/local/mongodb/conf/mongo-shard02.confport = 10003replSet = rs02 # 复制集标识shardsvr= true # 启动为Shard服务logpath=/ronglian_data/mongo-shard02/logs/mongo-shard02.log logappend=truefork = true # 后台运⾏dbpath=/ronglian_data/mongo-shard02/dbkeyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongod7.pidsharding2-2:# /usr/local/mongodb/conf/mongo-shard02.confport = 10004replSet = rs02 # 复制集标识shardsvr= true # 启动为Shard服务logpath=/ronglian_data/mongo-shard02/logs/mongo-shard02-1.log logappend=truefork = true # 后台运⾏dbpath=/ronglian_data/mongo-shard02/db1keyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongod8.pidsharding2-3:# /usr/local/mongodb/conf/mongo-shard02.confport = 10005replSet = rs02 # 复制集标识shardsvr= true # 启动为Shard服务logpath=/ronglian_data/mongo-shard02/logs/mongo-shard02-2.log logappend=truefork = true # 后台运⾏dbpath=/ronglian_data/mongo-shard02/db2keyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongod9.pidmongos1:# /usr/local/mongodb/conf/mongos.confconfigdb=192.168.137.2:20000,192.168.137.2:20001,192.168.137.2:20002 # configserver的地址port = 30000 logpath=/ronglian_data/mongos/logs/mongos.loglogappend=truefork = true # 后台运⾏keyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongos10.pidmongos2:# /usr/local/mongodb/conf/mongos.confconfigdb=192.168.137.2:20000,192.168.137.2:20001,192.168.137.2:20002port = 30001logpath=/ronglian_data/mongos/logs/mongos1.loglogappend=truefork = true # 后台运⾏keyFile=/usr/local/mongodb/conf/key.crpidfilepath = /var/run/mongos11.pid启动每个mongodb:configserver:/usr/local/mongodb/bin/mongod –f /usr/local/mongodb/conf/mongo-configsvr.confsharding:/usr/local/mongodb/bin/mongod –f /usr/local/mongodb/conf/mongo-shard01.confmongos:/usr/local/mongodb/bin/mongos –f /usr/local/mongodb/conf/mongos.conf配置复制集成员:> /usr/local/mongodb/bin/mongo -port 10000在mongo终端中输⼊以下命令:>config={_id:'rs01',members:[{_id:0,host:'10.9.47.173:10000'},{_id:1,host:'10.9.47.174:10000'},{_id:2,host:'10.9.47.175:10000',arbiterOnly:true}]}; # 配置参数> rs.initiate(config);#使⽤配置参数初始化Replica Set> rs.status();#查看Replica Set的状态。

mongodb的分片流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!1. 规划分片确定要分片的集合。
选择分片键。
分片键是用于将数据分布到不同分片的字段。

生产MongoDB 分片与集群方案【编者的话】Mongo DB 是目前在IT行业非常流行的一种非关系型数据库(NoSql),其灵活的数据存储方式备受当前IT从业人员的青睐。
Mongo DB很好的实现了面向对象的思想(OO思想),在Mongo DB中每一条记录都是一个Document对象。
本文介绍了一则生产环境下MongoDB实现分片与集群方案的操作实例。
一、mongodb分片与集群拓扑图二、分片与集群的部署1.Mongodb的安装分别在以上3台服务器安装好mongodb安装方法见安装脚本。
2.Mongod 创建单个分片的副本集10.68.4.209①建立数据文件夹和日志文件夹mdkir /data/{master,slave,arbiter}mkdir /data/log/mongodb/{master,slave,arbiter} -p②建立配置文件#master.confdbpath=/data/masterlogpath=/data/log/mongodb/master/mongodb.logpidfilepath=/var/run/mongo_master.pid#directoryperdb=truelogappend=truereplSet=policydbport=10002oplogSize=10000fork=truenoprealloc=trueprofile=1slowms=200#slave.confdbpath=/data/slavelogpath=/data/log/mongodb/slave/mongodb.log pidfilepath=/var/run/mongo_slave.pid#directoryperdb=truelogappend=truereplSet=policydbport=10001oplogSize=10000fork=truenoprealloc=trueprofile=1slowms=200#arbiter.confdbpath=/data/arbiterlogpath=/data/log/mongodb/arbiter/mongodb.logpidfilepath=/var/run/mongo_arbiter.pid#directoryperdb=truelogappend=truereplSet=policydbport=10000oplogSize=10000fork=truenoprealloc=trueprofile=1slowms=200③启动mongodb/etc/init.d/mongodb_master start/etc/init.d/mongodb_slave start/etc/init.d/mongodb_arbiter start④配置主、备、仲裁节点主节点:# /usr/local/mongodb/bin/mongo 10.68.4.209:10002MongoDB shell version: 2.4.9connecting to: 10.68.4.209:10002/test> use adminswitched to db admin>config={ _id:"policydb", members:[ {_id:0,host:'10.68.4.209:1000 2',priority:2}, {_id:1,host:'10.68.4.209:10001',priority:1},... {_id:2,host:'10.68.4.209:10000',arbiterOnly:true}] }; {"_id" : "policydb","members" : [{"_id" : 0,"host" : "10.68.4.209:10002","priority" : 2},{"_id" : 1,"host" : "10.68.4.209:10001","priority" : 1},{"_id" : 2,"host" : "10.68.4.209:10000","arbiterOnly" : true}]}rs.initiate(config) #初始化rs.status() #查看集群状态10.68.4.29①建立数据文件夹和日志文件夹mdkir /data/{master,slave,arbiter}mkdir /data/log/mongodb/{master,slave,arbiter} -p②建立配置文件#master.confdbpath=/data/masterlogpath=/data/log/mongodb/master/mongodb.log pidfilepath=/var/run/mongo_master.pid#directoryperdb=truelogappend=truereplSet=policydb2port=10002oplogSize=10000fork=truenoprealloc=trueprofile=1slowms=200#slave.confdbpath=/data/slavelogpath=/data/log/mongodb/slave/mongodb.log pidfilepath=/var/run/mongo_slave.pid#directoryperdb=truelogappend=truereplSet=policydb2port=10001oplogSize=10000fork=truenoprealloc=trueprofile=1slowms=200#arbiter.confdbpath=/data/arbiterlogpath=/data/log/mongodb/arbiter/mongodb.log pidfilepath=/var/run/mongo_arbiter.pid#directoryperdb=truelogappend=truereplSet=policydb2port=10000oplogSize=10000fork=truenoprealloc=trueprofile=1slowms=200③启动mongodb/etc/init.d/mongodb_master start/etc/init.d/mongodb_slave start/etc/init.d/mongodb_arbiter start④配置主、备、仲裁节点主节点:# /usr/local/mongodb/bin/mongo 10.68.4.209:10002MongoDB shell version: 2.4.9connecting to: 10.68.4.209:10002/test> use adminswitched to db admin> config={ _id:"policydb2", members:[ {_id:0,host:'10.68.4.29:100 02',priority:2}, {_id:1,host:'10.68.4.29:10001',priority:1},... {_id:2,host:'10.68.4.209:10000',arbiterOnly:true}] };{"_id" : "policydb","members" : [{"_id" : 0,"host" : "10.68.4.29:10002","priority" : 2},{"_id" : 1,"host" : "10.68.4.29:10001","priority" : 1},{"_id" : 2,"host" : "10.68.4.29:10000", "arbiterOnly" : true}]}rs.initiate(config) #初始化rs.status() #查看集群状态10.68.4.30①建立数据文件夹和日志文件夹mdkir /data/{master,slave,arbiter}mkdir /data/log/mongodb/{master,slave,arbiter} -p②建立配置文件#master.confdbpath=/data/masterlogpath=/data/log/mongodb/master/mongodb.log pidfilepath=/var/run/mongo_master.pid#directoryperdb=truelogappend=truereplSet=policydb3port=10002oplogSize=10000fork=truenoprealloc=trueprofile=1slowms=200#slave.confdbpath=/data/slavelogpath=/data/log/mongodb/slave/mongodb.log pidfilepath=/var/run/mongo_slave.pid#directoryperdb=truelogappend=truereplSet=policydb3port=10001oplogSize=10000fork=truenoprealloc=trueprofile=1slowms=200#arbiter.confdbpath=/data/arbiterlogpath=/data/log/mongodb/arbiter/mongodb.log pidfilepath=/var/run/mongo_arbiter.pid#directoryperdb=truelogappend=truereplSet=policydb3port=10000oplogSize=10000fork=truenoprealloc=trueprofile=1slowms=200③启动mongodb/etc/init.d/mongodb_master start/etc/init.d/mongodb_slave start/etc/init.d/mongodb_arbiter start④配置主、备、仲裁节点主节点:# /usr/local/mongodb/bin/mongo 10.68.4.209:10002MongoDB shell version: 2.4.9connecting to: 10.68.4.209:10002/test> use adminswitched to db admin> config={ _id:"policydb3", members:[ {_id:0,host:'10.68.4.30:100 02',priority:2}, {_id:1,host:'10.68.4.30:10001',priority:1},... {_id:2,host:'10.68.4.30:10000',arbiterOnly:true}] };{"_id" : "policydb","members" : [{"_id" : 0,"host" : "10.68.4.30:10002","priority" : 2},{"_id" : 1,"host" : "10.68.4.30:10001","priority" : 1},{"_id" : 2,"host" : "10.68.4.30:10000","arbiterOnly" : true}]}rs.initiate(config) #初始化rs.status() #查看集群状态2.Mongod 创建单个分片的配置服务器①创建配置目录10.68.4.209 mkdir /data/config10.68.4.29 mkdir /data/config10.68.4.30 mkdir /data/config②准备配置服务器的配置文件3个服务器的配置服务器的配置文件一致#config.confdbpath=/data/configlogpath=/data/log/mongodb/config/mongodb.logpidfilepath=/var/run/mongo_config.piddirectoryperdb=truelogappend=trueport=10003fork=trueconfigsvr=true③启动配置服务器/etc/init.d/mongodb_config start3.Mongod 创建并配置mongos和开启分片模式①创建日志目录Mkdir -p /data/log/mongodb/mongos/②准备mongos的配置文件#mongos.conflogpath=/data/log/mongodb/mongos/mongodb.logpidfilepath=/var/run/mongo_mongos.pidlogappend=trueport=10004fork=trueconfigdb=10.68.4.209:10003,10.68.4.29:10003,10.68.4.30:1000③启动mongos/etc/init.d/mongodb_mongos start④配置分片sh.addShard("policydb/10.68.4.209:10002")sh.addShard("policydb2/10.68.4.29:10002")sh.addShard("policydb3/10.68.4.30:10002")sh.enableSharding("policydb")db.runCommand({"shardcollection":"policydb.fullPolicyTextInfo_his tory", "key":{"key":1}})db.printShardingStatus() #查看分片状态sh.status({verbose:true})sh.status()3.快速创建副本集和配置服务脚本上图1.图12.图2 config.conf配置文件3.图3附mongodb一键安装脚本:/s/1c0zvP7M附mongodb副本集和配置服务器一键配置脚本:/s/1GuQ0A博文出处:/pwd/blog/411439【编辑推荐】为什么选择使用NoSQL数据库开发如此困难?软件公司为何要放弃MongoDB?NoSQL详解:如何找到对的技术为什么需要选用NoSQL?谷歌新款高性能NoSQL数据库支持HBase接口。

【MongoDB配置篇】MongoDB配置⽂件详解⽬录MongoDB实例的运⾏离不开相应的参数配置,⽐如对数据库存放路径dbpath的配置,对于参数的配置,可以在命令⾏以选项的形式进⾏配置,也可以将配置信息列⼊配置⽂件进⾏配置。
但是,使⽤配置⽂件将会使对mongod和mongos的管理变得更加容易,本篇将会对配置⽂件进⾏详细的讲解。
1 数据库环境[mongod@strong ~]$ mongod --versiondb version v4.2.0git version: a4b751dcf51dd249c5865812b390cfd1c0129c30OpenSSL version: OpenSSL 1.0.1e-fips 11 Feb 2013allocator: tcmallocmodules: nonebuild environment:distmod: rhel62distarch: x86_64target_arch: x86_642 配置⽂件2.1 配置⽂件格式MongoDB配置⽂件使⽤YAML的格式。
2.2 配置⽂件的使⽤对于配置⽂件的使⽤,在mongod或mongos中指定--config或-f选项。
1)指定--config选项[mongod@strong ~]$ mongod --config /etc/f2)指定-f选项[mongod@strong ~]$ mongod -f /etc/f3 配置⽂件核⼼选项3.1 systemLog选项1)选项systemLog:verbosity: <int>quiet: <boolean>traceAllExceptions: <boolean>syslogFacility: <string>path: <string>logAppend: <boolean>logRotate: <string>destination: <string>timeStampFormat: <string>component:accessControl:verbosity: <int>command:verbosity: <int># COMMENT additional component verbosity settings omitted for brevity2)说明verbosity:默认为0,值范围为0-5,⽤于输出⽇志信息的级别,值越⼤,输出的信息越多;quiet:mongod或mongos运⾏的模式,在该模式下限制输出的信息,不推荐使⽤该模式;traceAllExceptions:打印详细信息以便进⾏调试;path:⽇志⽂件的路径,mongod或mongos会将所有诊断⽇志信息发送到该位置,⽽不是标准输出或主机的syslog上;logAppend:默认为false,若设为true,当mongod或mongos实例启动时,会将新的条⽬追加到已存在的⽇志⽂件,否则,mongod会备份已存在的⽇志,并创建新的⽇志⽂件;destination:指定⽇志输出的⽬的地,具体值为file或syslog,若设置为file,需指定path,该选项未指定,则将所有⽇志输出到标准输出;timeStampFormat:⽇志信息中的时间格式,默认为iso8601-local,该选项有三个值,分别为ctime、iso8601-utc和iso8601-local;3.2 processManagement选项1)选项processManagement:fork: <boolean>pidFilePath: <string>timeZoneInfo: <string>2)说明fork:默认值为false,设置为true,会激活守护进程在后台运⾏mongod或mongos进程;pidFilePath:指定mongod或mongos写PID⽂件的路径,不指定该值,则不会创建PID⽂件;3.3 cloud选项1)选项cloud:monitoring:free:state: <string>tags: <string>2)说明state:激活或禁⽤免费的MongoDB Cloud监控,该选项有以下三个值,分别为runtime、on和off,默认为runtime;在运⾏时可以通过db.enableFreeMonitoring()和db.disableFreeMonitoring()tags:描述环境上下⽂的可选标记;3.4 net选项1)选项net:port: <int>bindIp: <string>bindIpAll: <boolean>maxIncomingConnections: <int>wireObjectCheck: <boolean>ipv6: <boolean>unixDomainSocket:enabled: <boolean>pathPrefix: <string>filePermissions: <int>tls:certificateSelector: <string>clusterCertificateSelector: <string>mode: <string>certificateKeyFile: <string>certificateKeyFilePassword: <string>clusterFile: <string>clusterPassword: <string>CAFile: <string>clusterCAFile: <string>CRLFile: <string>allowConnectionsWithoutCertificates: <boolean>allowInvalidCertificates: <boolean>allowInvalidHostnames: <boolean>disabledProtocols: <string>FIPSMode: <boolean>compression:compressors: <string>serviceExecutor: <string>2)说明port:MongoDB实例监听客户端连接的TCP端⼝,对于mongod或mongos实例,默认端⼝为27017,对于分⽚成员,默认端⼝为27018,对于配置服务器成员,默认端⼝为27019;bindIp:默认值为localhost。

linux下Mongodb集群搭建:分⽚+副本集三台服务器 192.168.1.40/41/42安装包 mongodb-linux-x86_64-amazon2-4.0.1.tgz服务规划服务器40服务器41服务器42mongos mongos mongosconfig server config server config servershard server1 主节点 shard server1副节点 shard server1仲裁shard server2 仲裁 shard server2 主节点 shard server2 副节点shard server3副节点 shard server3仲裁 shard server3主节点端⼝分配:mongos:28000config:28001shard1:28011shard2:28012shard3:28013主要模块以及配置⽂件1、config server 配置服务器vi /usr/local/mongodb/conf/config.conf40服务器配置⽂件pidfilepath = /usr/local/mongodb/config/log/configsrv.piddbpath = /mydata/mongodb/config/datalogpath = /usr/local/mongodb/config/log/congigsrv.loglogappend = truebind_ip = 192.168.29.40port = 28001fork = true #以守护进程的⽅式运⾏MongoDB,创建服务器进程#declare this is a config db of a cluster;configsvr = true#副本集名称replSet=configs#设置最⼤连接数maxConns=2000041服务器配置⽂件pidfilepath = /usr/local/mongodb/config/log/configsrv.piddbpath = /mydata/mongodb/config/datalogpath = /usr/local/mongodb/config/log/congigsrv.loglogappend = truebind_ip = 192.168.29.41port = 28001fork = true #以守护进程的⽅式运⾏MongoDB,创建服务器进程#declare this is a config db of a cluster;configsvr = true#副本集名称replSet=configs#设置最⼤连接数maxConns=2000042服务器配置⽂件pidfilepath = /usr/local/mongodb/config/log/configsrv.piddbpath = /mydata/mongodb/config/datalogpath = /usr/local/mongodb/config/log/congigsrv.loglogappend = truebind_ip = 192.168.29.42port = 28001fork = true #以守护进程的⽅式运⾏MongoDB,创建服务器进程#declare this is a config db of a cluster;configsvr = true#副本集名称replSet=configs#设置最⼤连接数maxConns=20000启动三台服务器的config servermongod -f /usr/local/mongodb/conf/config.conf登录任意⼀台配置服务器,初始化配置副本集#连接mongo --port 21000#config变量config = {... _id : "configs",... members : [... {_id : 0, host : "192.168.1.40:28001" },... {_id : 1, host : "192.168.1.41:28001" },... {_id : 2, host : "192.168.1.42:28001" }... ]... }#初始化副本集rs.initiate(config)2 配置分⽚副本集(三台机器)配置⽂件vi /usr/local/mongodb/conf/shard1.conf#配置⽂件内容#——————————————–pidfilepath = /usr/local/mongodb/shard1/log/shard1.piddbpath = /mydata/mongodb/shard1/datalogpath = /usr/local/mongodb/shard1/log/shard1.log logappend = truebind_ip = 192.168.29.40port = 28011fork = true#打开web监控#httpinterface=true#rest=true#副本集名称replSet=shard1#declare this is a shard db of a cluster;shardsvr = true#设置最⼤连接数maxConns=20000#配置⽂件内容#——————————————–pidfilepath = /usr/local/mongodb/shard1/log/shard1.piddbpath = /mydata/mongodb/shard1/datalogpath = /usr/local/mongodb/shard1/log/shard1.log logappend = truebind_ip = 192.168.29.41port = 28011fork = true#打开web监控#httpinterface=true#rest=true#副本集名称replSet=shard1#declare this is a shard db of a cluster;shardsvr = true#设置最⼤连接数maxConns=20000#配置⽂件内容#——————————————–pidfilepath = /usr/local/mongodb/shard1/log/shard1.piddbpath = /mydata/mongodb/shard1/datalogpath = /usr/local/mongodb/shard1/log/shard1.log logappend = truebind_ip = 192.168.29.42port = 28011fork = true#打开web监控#httpinterface=true#rest=true#副本集名称replSet=shard1#declare this is a shard db of a cluster;shardsvr = true#设置最⼤连接数maxConns=20000vi /usr/local/mongodb/conf/shard2.confvi /usr/local/mongodb/conf/shard2.conf (shard2和shard3就是上⾯配置⽂件相应地⽅改为2和3就可以了)3、配置路由服务器 mongos先启动配置服务器和分⽚服务器,后启动路由实例:(三台机器)vi /usr/local/mongodb/conf/mongos.conf#内容pidfilepath = /usr/local/mongodb/mongos/log/mongos.pidlogpath = /usr/local/mongodb/mongos/log/mongos.loglogappend = truebind_ip = 0.0.0.0port = 28000fork = true#监听的配置服务器,只能有1个或者3个 configs为配置服务器的副本集名字configdb = configs/192.168.1.40:28001,192.168.1.41:28001,192.168.1.42:28001#设置最⼤连接数maxConns=20000启动三台服务器的mongos servermongos -f /usr/local/mongodb/conf/mongos.conf4、启⽤分⽚⽬前搭建了mongodb配置服务器、路由服务器,各个分⽚服务器,不过应⽤程序连接到mongos路由服务器并不能使⽤分⽚机制,还需要在程序⾥设置分⽚配置,让分⽚⽣效。

mongodb的配置⽂件详解()以下页⾯描述了MongoDB 4.0中可⽤的配置选项。
有关其他版本MongoDB的配置⽂件选项,请参阅相应版本的MongoDB⼿册。
配置⽂件您可以使⽤配置⽂件在启动时配置和实例。
配置⽂件包含与命令⾏选项等效的设置。
请参阅。
使⽤配置⽂件可以简化管理和选项,尤其适⽤于⼤规模部署。
您还可以向配置⽂件添加注释以解释服务器的设置。
在Linux上,/etc/mongod.conf使⽤包管理器安装MongoDB时会包含默认配置⽂件。
在Windows上,安装期间包含默认配置⽂件。
<install directory>/bin/mongod.cfg在macOS上,安装不包含默认配置⽂件; 相反,要使⽤配置⽂件,请创建⼀个⽂件。
⽂件格式在2.6版中更改: MongoDB 2.6引⼊了基于YAML的配置⽂件格式。
的仍是向后兼容性。
MongoDB配置⽂件使⽤格式。
以下⽰例配置⽂件包含可以适应本地配置的⼏个设置:注意YAML不⽀持缩进的制表符:使⽤空格代替。
复制systemLog:destination: filepath: "/var/log/mongodb/mongod.log"logAppend: truestorage:journal:enabled: trueprocessManagement:fork: truenet:bindIp: 127.0.0.1port: 27017setParameter:enableLocalhostAuthBypass: false...包括在官⽅的MongoDB包的Linux软件包init脚本依赖于特定的值,和。
如果在默认配置⽂件中修改这些设置,则可能⽆法启动。
YAML是的超集。
使⽤配置⽂件要配置或使⽤配置⽂件,请使⽤--config选项或-f选项指定配置⽂件,如以下⽰例所⽰:例如,以下⽤途:复制mongod --config /etc/mongod.confmongos --config /etc/mongos.conf您还可以使⽤-f别名指定配置⽂件,如下所⽰:复制mongod -f /etc/mongod.confmongos -f /etc/mongos.conf如果您从软件包安装并使⽤系统的启动了MongoDB ,那么您已经在使⽤配置⽂件。

mongodb 高可用方案MongoDB高可用方案MongoDB是一款开源的NoSQL数据库,因其灵活的数据模型和强大的横向扩展能力而备受欢迎。
在应用中,高可用性是非常重要的,因此本文将介绍一些MongoDB的高可用方案。
一、复制集(Replica Set)复制集是MongoDB中实现高可用的基本组件。
复制集由多个MongoDB实例组成,其中包括一个主节点(Primary)和多个从节点(Secondary),以及一个仲裁节点(Arbiter)。
主节点处理所有的写操作和客户端的读操作,从节点通过复制主节点的数据实现数据备份和读操作的负载均衡。
仲裁节点用于选举主节点。
在复制集中,当主节点发生故障时,从节点会自动发起选举,选举出新的主节点。
这种方式保证了数据的持久性和高可用性。
同时,MongoDB还支持自动故障转移,当主节点恢复后,自动切换为主节点。
二、分片集群(Sharded Cluster)分片集群是MongoDB的横向扩展方案,用于处理大量数据和高并发访问的场景。
分片集群由多个分片(Shard)组成,每个分片存储一部分数据。
客户端将数据按照一定的规则分发到各个分片中进行存储和查询。
在分片集群中,还需要使用一个配置服务器(Config Server)来存储分片集群的元数据信息,如分片映射规则等。
配置服务器的高可用性也是非常重要的,通常采用多副本部署,保证数据的可靠性和一致性。
三、副本集和分片集群的结合应用在实际的应用场景中,可以将副本集和分片集群结合起来使用,从而实现高可用和横向扩展的双重优势。
通常将每个分片部署为一个副本集,每个副本集包含一个主节点和多个从节点。
这样既保证了每个分片的高可用性,又实现了分片集群的横向扩展能力。
在这种方案中,主节点对外提供读写操作,从节点负责数据备份和读操作的负载均衡。
当某个分片的主节点发生故障时,从节点会自动发起选举,选举出新的主节点。
同时,其他分片仍然可以正常工作,确保了整个分片集群的高可用性。

111传媒技术⒈软件版本64位操作系统CentOS6.5+;mongodb3.6社区版;⒉副本集规则和特性2.1 副本集的成员角色、数量副本集由1个主节点P(Primary)、若干个从节点S (Secondary)、仲裁节点A(Arbiter,根据实际情况设定)构成。
每个副本集的节点总数不超过50,最少有3个节点(分片集群排除单节点、主从双节点的情况),如图1所示的2种情况:1主2从,1主1从1仲裁,单箭头表示主从复制,双箭头表示心跳。
图 1 三个节点的副本集结构2.2 副本集选举的大多数选举主节点,需得到大多数成员的支持,这里的大多数,是具有投票权的节点的半数以上, 不一定是副本集节点总数的大多数。
图2 副本集选举的大多数2.3 有投票权的节点总数一个副本集中,有投票权的节点总数不超过7个; 若副本集的节点总数不超过7,默认每个节点都有投票权;若副本集节点总数多于7个,超出7个之外的差额数量的节点,必须设成没有投票权。
比如:副本集节点总数为9,必须设定2个节点没有投票权。
即:若投票节点数量少于副本集节点总数,需要设定差额数量的节点没有投票权。
图2中的容错数,指在能正常选举出主节点的情况下,投票节点失效的最大数量。
只要失效的投票节点不超过容错数,就能正常选举出主节点。
副本集节点总数、有投票权的节点总数,一般都设定为奇数,但不是强制性的。
关于节点数量设成奇数还是偶数,有一种观点认为:如果设成偶数,选举的时候可能出现2个节点得票数一样多的情况,从而选不出主节点。
我们假设这种情况成立,如:节点总数为4,可用节点数为4,可能选不出主节点;再考虑一下节点总数为5,投票节点数量为5,对1个节点停机维护,剩下4个节点可用,也可能选不出主节点。
这显然是个悖论,和mongodb高可用架构的特性不符。
经实验验证,设定为偶数个,只要选举超过半数,同样能选出主节点。
但是,从图2中可以看出,奇数个投票节点,再增加一个成为偶数个,不能提高容错数,反而降低了副本集的稳定性。
高可用的MongoDB 集群1.序言MongoDB 是一个可扩展的高性能,开源,模式自由,面向文档的数据库。
它使用 C++ 编写。
MongoDB 包含一下特点:•面向集合的存储:适合存储对象及JSON形式的数据。
l•动态查询:Mongo 支持丰富的查询方式,查询指令使用 JSON 形式的标记,可轻易查询文档中内嵌的对象及数组。
l•完整的索引支持:包括文档内嵌对象及数组。
Mongo 的查询优化器会分析查询表达式,并生成一个高效的查询计划。
l•查询监视:Mongo 包含一个监控工具用于分析数据库操作性能。
l•复制及自动故障转移:Mongo 数据库支持服务器之间的数据复制,支持主-从模式及服务器之间的相互复制。
复制的主要目的是提供冗余及自动故障转移。
l•高效的传统存储方式:支持二进制数据及大型对象(如:照片或图片)。
l•自动分片以支持云级别的伸缩性:自动分片功能支持水平的数据库集群,可动态添加额外的机器。
l2.背景MongoDB 的主要目标是在键值对存储方式(提供了高性能和高度伸缩性) 以及传统的RDBMS(关系性数据库)系统,集两者的优势于一身。
Mongo 使用一下场景:•网站数据:Mongo 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
l•缓存:由于性能很高,Mongo 也适合作为信息基础设施的缓存层。
在系统重启之后, 由 Mongo 搭建的持久化缓存可以避免下层的数据源过载。
l•大尺寸,低价值的数据:使用传统的关系数据库存储一些数据时可能会比较贵,在此之前,很多程序员往往会选择传统的文件进行存储。
l•高伸缩性的场景:Mongo 非常适合由数十或数百台服务器组成的数据库l•用于对象及JSON数据的存储:Mongo的BSON数据格式非常适合文档格式化的存储及查询。
l注:这里需要说明下,本文旨在介绍高可用的 MongoDB 集群;这里不讨论 Hadoop 平台的 HDFS。
mongodb 高可用方案随着企业对数据存储需求的不断增长,数据库的可用性成为一项至关重要的需求。
MongoDB作为一款非常流行的分布式数据库,为了保证数据在任何情况下都能可靠地提供服务,需要使用高可用方案。
本文将介绍几种常见的MongoDB高可用方案。
一、复制集(Replica Set)复制集是MongoDB内置的一种高可用方案。
一个复制集是由多个MongoDB实例组成的,其中包括一个主节点(Primary)和多个从节点(Secondary),还有一个可选的仲裁节点(Arbiter)。
主节点负责处理所有写操作和大部分读操作,从节点复制主节点的数据,提供读取请求的负载均衡和故障转移能力。
仲裁节点用于在发生主节点故障时进行选举,确保复制集的正常运行。
二、分片集群(Sharding)分片集群是MongoDB另一种高可用的方案。
在大规模数据存储的场景下,单个MongoDB实例无法满足性能需求,需要通过分片将数据分布到多个MongoDB实例上。
分片集群由多个分片服务器和至少一个路由器组成。
分片服务器负责存储数据的分片,路由器负责将请求路由到正确的分片服务器上。
通过增加分片服务器和路由器,可以实现横向扩展,提高系统的吞吐量和可用性。
三、副本集内的故障转移(Failover)在复制集中,主节点是负责处理写操作和大部分读操作的关键节点。
当主节点发生故障时,需要进行故障转移,将一个从节点升级为新的主节点,确保系统的可用性。
MongoDB提供了自动故障转移机制,当主节点宕机后,从节点会自动发起选举,选举出新的主节点。
由于复制集中的从节点是实时复制主节点的数据,故障转移不会导致数据丢失。
四、多数据中心部署(Multi Data Center Deployment)对于全球化的企业来说,实现多数据中心部署是保证高可用性的重要手段。
在不同的地理位置部署MongoDB实例,可以提供更好的性能和容灾能力。
在配置多数据中心部署时,需要考虑数据同步、网络延迟和故障转移等方面的问题。
mongodb分⽚部署Mongodb 分⽚部署配置mongodb集群,⽐如在3个server上配置 3 shard的Mongodb集群:架构:1.每⽚数据需要3个mongod server,2个为主从数据节点;1个为仲裁节点(arbiter),不存数据。
⼀共三⽚,可以做成:20.220-mongo1: 20001(sh1主),20002(sh2从),20003(sh3仲裁)20.221-mongo2: 20002(sh2主),20003(sh3从),20001(sh1仲裁)20.222-mongo3: 20003(sh3主),20001(sh1从),20002(sh2仲裁)2. 需要3个mongod config server,登录3台机器执⾏如下20.220-mongo1: 19999echo 'export PATH=$PATH:/usr/local/mongodb/bin' >> /etc/profiletar zxvf mongodb-linux-x86_64-2.6.0.tgzmv mongodb-linux-x86_64-2.6.0 /usr/local/mongodbmkdir -p /usr/local/mongodb/{etc,date,log}cd /usr/local/mongodb/datemkdir sh1mkdir sh2mkdir sh3mkdir cf1mkdir cf2mkdir cf320.221-mongo2: 19998echo 'export PATH=$PATH:/usr/local/mongodb/bin' >> /etc/profiletar zxvf mongodb-linux-x86_64-2.6.0.tgzmv mongodb-linux-x86_64-2.6.0 /usr/local/mongodbmkdir -p /usr/local/mongodb/{etc,date,log}cd /usr/local/mongodb/datemkdir sh1mkdir sh2mkdir sh3mkdir cf1mkdir cf2mkdir cf320.222-mongo3: 19997echo 'export PATH=$PATH:/usr/local/mongodb/bin' >> /etc/profiletar zxvf mongodb-linux-x86_64-2.6.0.tgzmv mongodb-linux-x86_64-2.6.0 /usr/local/mongodbmkdir -p /usr/local/mongodb/{etc,date,log}cd /usr/local/mongodb/datemkdir sh1mkdir sh2mkdir sh3mkdir cf1mkdir cf2mkdir cf33. mongos server 作为⼊⼝192.168.20.220: 200001.启动mongod datanode service/usr/local/mongodb/bin/mongod --fork --rest --replSet sh1 --shardsvr --oplogSize 40000 --dbpath /usr/local/mongodb/date/sh1 --logpath /usr/local/mongodb/log/sh1.log --port 20001 /usr/local/mongodb/bin/mongod --fork --rest --replSet sh2 --shardsvr --oplogSize 40000 --dbpath /usr/local/mongodb/date/sh2 --logpath /usr/local/mongodb/log/sh2.log --port 20002 /usr/local/mongodb/bin/mongod --fork --rest --replSet sh3 --shardsvr --oplogSize 40000 --dbpath /usr/local/mongodb/date/sh3 --logpath /usr/local/mongodb/log/sh3.log --port 200032.配置每⽚的 replica set,即每3台配成⼀个replica set互备20.220-mongo1:主机mongo 192.168.20.220:20001/adminuse admin;config = {_id: 'sh1', members:[{_id:0, host: '192.168.20.220:20001'},{_id:1, host: '192.168.20.221:20001'},{_id:2, host: '192.168.20.222:20001', arbiterOnly: true}]}rs.initiate(config) //初始化repl setrs.status() //看结果是否成功建成repl set20.221-mongo2:主机mongo 192.168.20.221:20002/adminuse admin;config = {_id: 'sh2', members:[{_id:0, host: '192.168.20.221:20002'},{_id:1, host: '192.168.20.222:20002'},{_id:2, host: '192.168.20.220:20002', arbiterOnly: true} ]}rs.initiate(config) //初始化repl setrs.status() //看结果是否成功建成repl set20.222-mongo3:主机mongo 192.168.20.222:20003/adminuse admin;config = {_id: 'sh3', members:[{_id:0, host: '192.168.20.222:20003'},{_id:1, host: '192.168.20.220:20003'},{_id:2, host: '192.168.20.221:20003', arbiterOnly: true} ]}rs.initiate(config) //初始化repl setrs.status() //看结果是否成功建成repl set3.执⾏启动 config server:/usr/local/mongodb/bin/mongod --fork --rest --configsvr --port 19999 --dbpath /usr/local/mongodb/date/cf1/ --logpath /usr/local/mongodb/log/cf1.log20.221-mongo2/usr/local/mongodb/bin/mongod --fork --rest --configsvr --port 19998 --dbpath /usr/local/mongodb/date/cf2/ --logpath /usr/local/mongodb/log/cf2.log20.222-mongo3/usr/local/mongodb/bin/mongod --fork --rest --configsvr --port 19997 --dbpath /usr/local/mongodb/date/cf3/ --logpath /usr/local/mongodb/log/cf3.log4.启动 mongos server/usr/local/mongodb/bin/mongos --configdb 192.168.20.220:19999,192.168.20.221:19998,192.168.20.222:19997 --logpath /usr/local/mongodb/log/mongos.log --logappend --fork --port 200005. 配置mongo 分⽚集群mongo 192.168.20.220:20000/adminmongos> db.runCommand({addshard:"sh1/192.168.20.220:20001,192.168.20.221:20001",name:"sh1"});mongos> db.runCommand({addshard:"sh2/192.168.20.221:20002,192.168.20.222:20002",name:"sh2"});mongos> db.runCommand({addshard:"sh3/192.168.20.222:20003,192.168.20.220:20003",name:"sh3"});mongos> db.runCommand({listshards:1})6. 激活数据库分⽚登录mongos:>use admin;>db.runCommand( { enablesharding : "dbname" } );>db.runCommand( { shardcollection : "dbname.collectionname", key :{ "keyfield" :1 }});注意分⽚使⽤的keyfield需要是表索引。
mongodb分布式集群搭建⼿记⼀、架构简介⽬标单机搭建mongodb分布式集群(副本集 + 分⽚集群),演⽰mongodb分布式集群的安装部署、简单操作。
说明在同⼀个vm启动由两个分⽚组成的分布式集群,每个分⽚都是⼀个PSS(Primary-Secondary-Secondary)模式的数据副本集;Config副本集采⽤PSS(Primary-Secondary-Secondary)模式。
⼆、配置说明端⼝通讯当前集群中存在shard、config、mongos共12个进程节点,端⼝矩阵编排如下:|编号|实例类型|监听端⼝||-|-||1|mongos|25001||2|mongos|25002||3|mongos|25003||4|config|26001||5|config|26002||6|config|26003||7|shard1|27001||8|shard1|27002||9|shard1|27003||10|shard2|27004||11|shard2|27005||12|shard2|27006|内部鉴权节点间鉴权采⽤keyfile⽅式实现鉴权,mongos与分⽚之间、副本集节点之间共享同⼀套keyfile⽂件。
账户设置管理员账户:admin/Admin@01,具有集群及所有库的管理权限应⽤账号:appuser/AppUser@01,具有appdb的owner权限关于初始化权限keyfile⽅式默认会开启鉴权,⽽针对初始化安装的场景,Mongodb提供了,可以在⾸次安装时通过本机创建⽤户、⾓⾊,以及副本集初始操作。
三、准备⼯作1. 下载安装包wget https:///linux/mongodb-linux-x86_64-rhel70-3.6.3.tgz2. 部署⽬录解压压缩⽂件,将bin⽬录拷贝到⽬标路径/opt/local/mongo-cluster,参考以下命令:tar -xzvf mongodb-linux-x86_64-rhel70-3.6.3.tgzmkdir -p /opt/local/mongo-clustercp -r mongodb-linux-x86_64-rhel70-3.6.3/bin /opt/local/mongo-cluster3. 创建配置⽂件cd /opt/local/mongo-clustermkdir confA. mongod 配置⽂件 mongo_node.confmongo_node.conf 作为mongod实例共享的配置⽂件,内容如下:storage:engine: wiredTigerdirectoryPerDB: truejournal:enabled: truesystemLog:destination: filelogAppend: trueoperationProfiling:slowOpThresholdMs: 10000replication:oplogSizeMB: 10240processManagement:fork: truenet:http:enabled: falsesecurity:authorization: "enabled"选项说明可B. mongos 配置⽂件 mongos.confsystemLog:destination: filelogAppend: trueprocessManagement:fork: truenet:http:enabled: false4. 创建keyfile⽂件cd /opt/local/mongo-clustermkdir keyfileopenssl rand -base64 756 > mongo.keychmod 400 mongo.keymv mongo.key keyfilemongo.key 采⽤随机算法⽣成,⽤作节点内部通讯的密钥⽂件5. 创建节点⽬录WORK_DIR=/opt/local/mongo-clustermkdir -p $WORK_DIR/nodes/config/n1/datamkdir -p $WORK_DIR/nodes/config/n2/datamkdir -p $WORK_DIR/nodes/config/n3/datamkdir -p $WORK_DIR/nodes/shard1/n1/datamkdir -p $WORK_DIR/nodes/shard1/n2/datamkdir -p $WORK_DIR/nodes/shard1/n3/datamkdir -p $WORK_DIR/nodes/shard2/n1/datamkdir -p $WORK_DIR/nodes/shard2/n2/datamkdir -p $WORK_DIR/nodes/shard2/n3/datamkdir -p $WORK_DIR/nodes/mongos/n1mkdir -p $WORK_DIR/nodes/mongos/n2mkdir -p $WORK_DIR/nodes/mongos/n3以config 节点1 为例,nodes/config/n1/data是数据⽬录,⽽pid⽂件、⽇志⽂件都存放于n1⽬录以mongos 节点1 为例,nodes/mongos/n1 存放了pid⽂件和⽇志⽂件四、搭建集群1. Config副本集按以下脚本启动3个Config实例WORK_DIR=/opt/local/mongo-clusterKEYFILE=$WORK_DIR/keyfile/mongo.keyCONFFILE=$WORK_DIR/conf/mongo_node.confMONGOD=$WORK_DIR/bin/mongod$MONGOD --port 26001 --configsvr --replSet configReplSet --keyFile $KEYFILE --dbpath $WORK_DIR/nodes/config/n1/data --pidfilepath $WORK_DIR/nodes/config/n1/db.pid --logpath $WORK_DIR/nodes/config/n1/db.log --config $CONFFILE $MONGOD --port 26002 --configsvr --replSet configReplSet --keyFile $KEYFILE --dbpath $WORK_DIR/nodes/config/n2/data --pidfilepath $WORK_DIR/nodes/config/n2/db.pid --logpath $WORK_DIR/nodes/config/n2/db.log --config $CONFFILE $MONGOD --port 26003 --configsvr --replSet configReplSet --keyFile $KEYFILE --dbpath $WORK_DIR/nodes/config/n3/data --pidfilepath $WORK_DIR/nodes/config/n3/db.pid --logpath $WORK_DIR/nodes/config/n3/db.log --config $CONFFILE 待成功启动后,输出⽇志如下:about to fork child process, waiting until server is ready for connections.forked process: 4976child process started successfully, parent exiting此时通过ps 命令也可以看到3个启动的进程实例。
mongodb3.6集群搭建:分⽚+副本集mongodb是最常⽤的nosql数据库,在数据库排名中已经上升到了前六。
这篇⽂章介绍如何搭建⾼可⽤的mongodb(分⽚+副本)集群。
在搭建集群之前,需要⾸先了解⼏个概念:路由,分⽚、副本集、配置服务器等相关概念。
先来看⼀张图:从图中可以看到有四个组件:mongos、config server、shard、replica set。
mongos,数据库集群请求的⼊⼝,所有的请求都通过mongos进⾏协调,不需要在应⽤程序添加⼀个路由选择器,mongos⾃⼰就是⼀个请求分发中⼼,它负责把对应的数据请求请求转发到对应的shard服务器上。
在⽣产环境通常有多mongos作为请求的⼊⼝,防⽌其中⼀个挂掉所有的mongodb请求都没有办法操作。
config server,顾名思义为配置服务器,存储所有数据库元信息(路由、分⽚)的配置。
mongos本⾝没有物理存储分⽚服务器和数据路由信息,只是缓存在内存⾥,配置服务器则实际存储这些数据。
mongos第⼀次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新⾃⼰的状态,这样 mongos 就能继续准确路由。
在⽣产环境通常有多个 config server 配置服务器,因为它存储了分⽚路由的元数据,防⽌数据丢失!shard,分⽚(sharding)是指将数据库拆分,将其分散在不同的机器上的过程。
将数据分散到不同的机器上,不需要功能强⼤的服务器就可以存储更多的数据和处理更⼤的负载。
基本思想就是将集合切成⼩块,这些块分散到若⼲⽚⾥,每个⽚只负责总数据的⼀部分,最后通过⼀个均衡器来对各个分⽚进⾏均衡(数据迁移)。
replica set,中⽂翻译副本集,其实就是shard的备份,防⽌shard挂掉之后数据丢失。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提⾼了数据的可⽤性,并可以保证数据的安全性。
MongoDB分⽚在部署和维护管理中常见事项的总结分⽚(sharding)是MongoDB将⼤型集合分割到不同服务器(或者说集群)上所采⽤的⽅法,主要为应对⾼吞吐量与⼤数据量的应⽤场景提供了⽅法。
和既有的分库分表、分区⽅案相⽐,MongoDB的最⼤区别在于它⼏乎能⾃动完成所有事情,只要告诉MongoDB要分配数据,它就能⾃动维护数据在不同服务器之间的均衡。
⼀. 分⽚的集群组件1.Mongos 【路由】作为请求的访问⼊⼝,所有的请求都由mongos来路由、分发、合并,这些动作对客户端driver透明,⽤户连接mongos就像连接mongod⼀样使⽤。
Mongos会根据请求类型及shard key将请求路由到对应的Shard。
2.Config Server 【配置服务器】存储Sharding Cluster 的所有元数据,所有的元数据都存储在config数据库;*保存每个分⽚上的chunk的信息 * 保存chunk上的⽚键范围。
3. Shard 【分⽚】存储应⽤数据记录。
⼆. 分⽚优势1.对集群进⾏抽象,让集群“不可见”,分⽚对应⽤系统是透明的。
Mongos是专有路由进程,其会将客户端发来的请求准确⽆误的路由到集群中的⼀个或者⼀组服务器上,同时会把接收到的响应拼装起来发回到客户端。
2.保证集群总是可读写将MongoDB的分⽚和复制集功能结合使⽤,在确保数据分⽚到多台服务器的同时,也确保了每分数据都有相应的备份,可以确保有服务器坏掉时,其他的从库可以⽴即接替坏掉的部分继续⼯作。
提⾼了集群的可⽤性和可靠性。
3.使集群易于扩展当系统需要更多的空间和资源的时候,MongoDB使我们可以按需⽅便的扩充系统容量。
三. 分⽚部署注意事项(常见错误)1.配置可复制集作为分⽚节点与配置单独使⽤的可复制集基本⼀样。
但启动参数中需指定—shardsvr参数。
否则,在启动数据库分⽚时报错:{"code" : 193,"ok" : 0, "errmsg" : "Cannot accept sharding commands if not started with --shardsvr“}。
配置mongodb分片群集(sharding cluster) 这是一种可以水平扩展的模式,在数据量很大时特给力,实际大规模应用一般会采用这种架构去构建monodb系统。
要构建一个 MongoDB Sharding Cluster,需要三种角色: Shard Server: mongod 实例,用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个relica set承担,防止主机单点故障
Config Server: mongod 实例,存储了整个 Cluster Metadata,其中包括 chunk 信息。
Route Server: mongos 实例,前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
Sharding架构图: 本例实际环境架构 本例架构示例图:
分别在3台机器运行一个mongod实例(称为mongod shard11,mongod shard12,mongod shard13)组织replica set1,作为cluster的shard1
1. 分别在3台机器运行一个mongod实例(称为mongod shard21,mongod shard22,mongod shard23)组织replica set2,作为cluster的shard2 2. 每台机器运行一个mongod实例,作为3个config server 3. 每台机器运行一个mongs进程,用于客户端连接
主机 IP 端口信息
Server1 10.1.1.1 mongod shard11:27017 mongod shard21:27018 mongod config1:20000 mongs1:30000 Server2 10.1.1.2 mongod shard12:27017 mongod shard22:27018 mongod config2:20000 mongs2:30000
Server3 10.1.1.3 mongod shard13:27017 mongod shard23:27018 mongod config3:20000 mongs3:30000
软件准备
软件准备 1. 创建用户 groupadd -g 20001 mongodb useradd -u 20001 -g mongodb mongodb passwd mongodb
2. 安装monodb软件 su – mongodb tar zxvf mongodb-linux-x86_64-1.6.2.tar 安装好后,目录结构如下: $ tree mongodb-linux-x86_64-1.6.2 mongodb-linux-x86_64-1.6.2 |– GNU-AGPL-3.0 |– README |– THIRD-PARTY-NOTICES `– bin |– bsondump |– mongo |– mongod |– mongodump |– mongoexport |– mongofiles |– mongoimport |– mongorestore |– mongos |– mongosniff `– mongostat 1 directory, 14 files
3. 创建数据目录 根据本例sharding架构图所示,在各台sever上创建shard数据文件目录 Server1: su – monodb cd /home/monodb mkdir -p data/shard11 mkdir -p data/shard21 Server2: su – monodb cd /home/monodb mkdir -p data/shard12 mkdir -p data/shard22 Server3: su – monodb cd /home/monodb mkdir -p data/shard13 mkdir -p data/shard23
配置relica sets 1. 配置shard1所用到的replica sets: Server1: cd /home/mongodb/mongodb-linux-x86_64-1.6.2/bin ./mongod –shardsvr –replSet shard1 –port 27017 –dbpath /home/mongodb/data/shard11 –oplogSize 100 –logpath /home/mongodb/data/shard11.log –logappend –fork
Server2: cd /home/mongodb/mongodb-linux-x86_64-1.6.2/bin ./mongod –shardsvr –replSet shard1 –port 27017 –dbpath /home/mongodb/data/shard12 –oplogSize 100 –logpath /home/mongodb/data/shard12.log –logappend –fork
Server3: cd /home/mongodb/mongodb-linux-x86_64-1.6.2/bin ./mongod –shardsvr –replSet shard1 –port 27017 –dbpath /home/mongodb/data/shard13 –oplogSize 100 –logpath /home/mongodb/data/shard13.log –logappend –fork
初始化replica set 用mongo连接其中一个mongod,执行: > config = {_id: ’shard1′, members: [ {_id: 0, host: '10.1.1.1:27017'}, {_id: 1, host: '10.1.1.2:27017'}, {_id: 2, host: '10.1.1.3:27017'}] }
> rs.initiate(config); 同样方法,配置shard2用到的replica sets: server1: cd /home/mongodb/mongodb-linux-x86_64-1.6.2/bin ./mongod –shardsvr –replSet shard2 –port 27018 –dbpath /home/mongodb/data/shard21 –oplogSize 100 –logpath /home/mongodb/data/shard21.log –logappend –fork
server2: cd /home/mongodb/mongodb-linux-x86_64-1.6.2/bin ./mongod –shardsvr –replSet shard2 –port 27018 –dbpath /home/mongodb/data/shard22 –oplogSize 100 –logpath /home/mongodb/data/shard22.log –logappend –fork
server3: cd /home/mongodb/mongodb-linux-x86_64-1.6.2/bin ./mongod –shardsvr –replSet shard2 –port 27018 –dbpath /home/mongodb/data/shard23 –oplogSize 100 –logpath /home/mongodb/data/shard23.log –logappend –fork
初始化replica set 用mongo连接其中一个mongod,执行: > config = {_id: ’shard2′, members: [ {_id: 0, host: '10.1.1.1:27018'}, {_id: 1, host: '10.1.1.2:27018'}, {_id: 2, host: '10.1.1.3:27018'}] }
> rs.initiate(config); 到此就配置好了二个replica sets,也就是准备好了二个shards 配置三台config server Server1: mkdir -p /home/mongodb/data/config ./mongod –configsvr –dbpath /home/mongodb/data/config –port 20000 –logpath /home/mongodb/data/config.log –logappend –fork #config server也需要dbpath
Server2: mkdir -p /home/mongodb/data/config ./mongod –configsvr –dbpath /home/mongodb/data/config –port 20000 –logpath /home/mongodb/data/config.log –logappend –fork
Server3: mkdir -p /home/mongodb/data/config ./mongod –configsvr –dbpath /home/mongodb/data/config –port 20000 –logpath /home/mongodb/data/config.log –logappend –fork
配置mongs 在server1,server2,server3上分别执行: ./mongos –configdb 10.1.1.1:20000,10.1.1.2:20000,10.1.1.3:20000 –port 30000