
第二章一元线性回归模型
1、最小二乘法对随机误差项u作了哪些假定?说明这些假定条件的意义。
答:假定条件:
(1)均值假设:E(u i)=0,i=1,2,…;
(2)同方差假设:Var(u i)=E[u i-E(u i)]2=E(u i2)=σu2 ,i=1,2,…;
(3)序列不相关假设:Cov(u i,u j)=E[u i-E(u i)][u j-E(u j)]=E(u i u j)=0,i≠j,i,j=1,2,…;
(4)Cov(u i,X i)=E[u i-E(u i)][X i-E(X i)]=E(u i X i)=0;
(5)u i服从正态分布, u i~N(0,σu2)。
意义:有了这些假定条件,就可以用普通最小二乘法估计回归模型的参数。
2、阐述对样本回归模型拟合优度的检验及回归系数估计值显著性检验的步骤。答:样本回归模型拟合优度的检验:可通过总离差平方和的分解、样本可决系数、样本相关系数来检验。
回归系数估计值显著性检验的步骤:
(1)提出原假设H0 :β1=0;
(2)备择假设H1 :β1≠0;
(3)计算t=β1/Sβ1;
(4)给出显著性水平α,查自由度v=n-2的t分布表,得临界值tα/2(n-2);
(5)作出判断。如果|t|
4、试说明为什么∑e i2的自由度等于n-2。
答:在模型中,自由度指样本中可以自由变动的独立不相关的变量个数。当有约束条件时,自由度减少,其计算公式:自由度=样本个数-受约束条件的个数,即df=n-k。一元线性回归中SSE残差的平方和,其自由度为n-2,因为计算残差时用到回归方程,回归方程中有两个未知参数β0和β1,而这两个参数需要两个约束条
件予以确定,由此减去2,也即其自由度为n-2。
5、试说明样本可决系数与样本相关系数的关系及区别,以及样本相关系数与β
^1的关系。
答:样本相关系数r的数值等于样本可决系数的平方根,符号与β1相同。但样本相关系数与样本可决系数在概念上有明显的区别,r建立在相关分析的理论基础之上,研究两个随机变量X与Y之间的线性相关关系;样本可决系数r2建立在回
归分析的理论基础之上,研究非随机变量X对随机变量Y的解释程度。
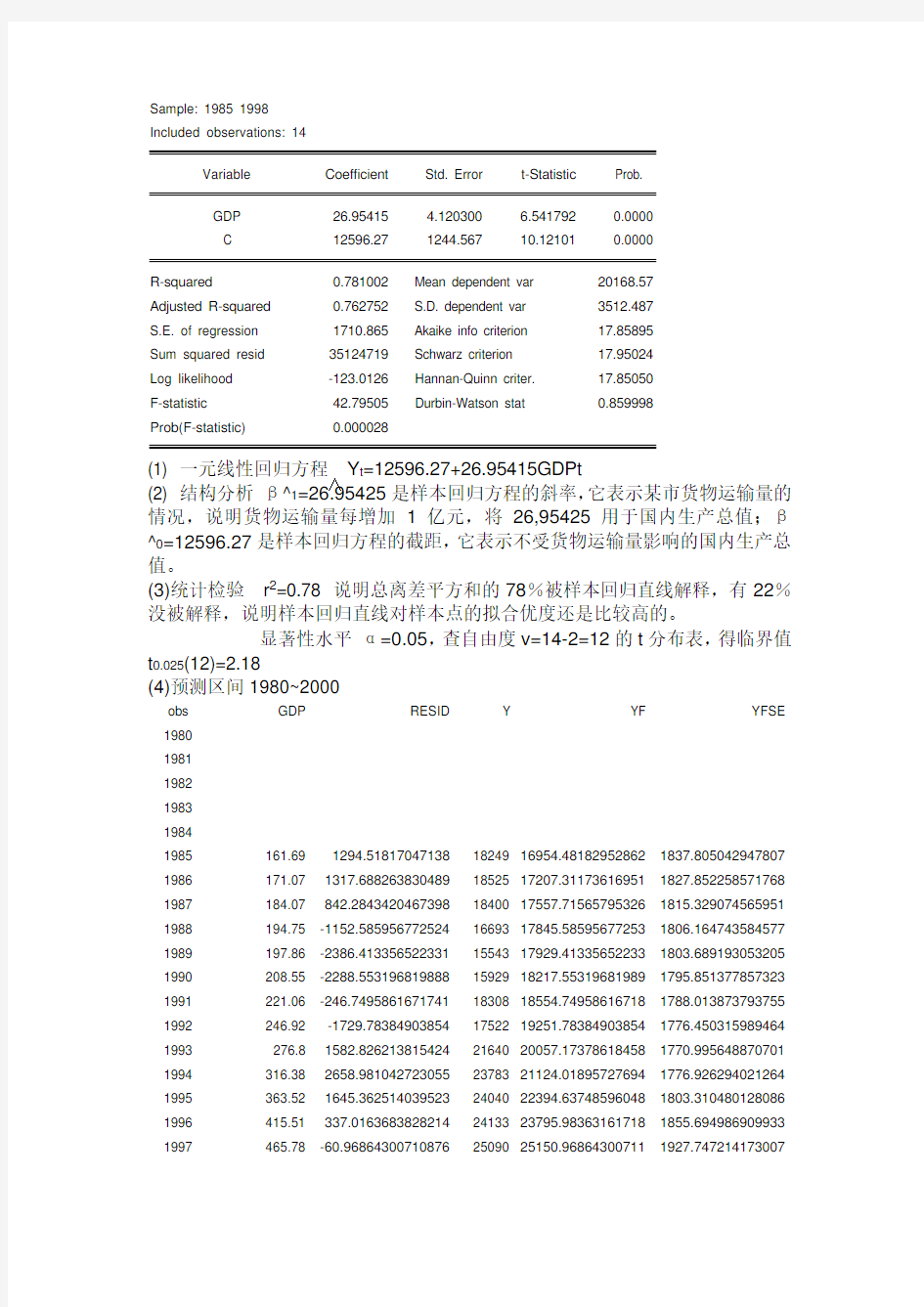
6、已知某市的货物运输量Y(万吨),国内生产总值GDP(亿元,1980年不变
价)1985~1998年的样本观测值见下表(略)。
Dependent Variable: Y
Method: Least Squares
Date: 10/28/13 Time: 10:25
Sample: 1985 1998
Included observations: 14
Variable Coefficient Std. Error t-Statistic Prob.
GDP 26.95415 4.120300 6.541792 0.0000
C 12596.27 1244.567 10.12101 0.0000
R-squared 0.781002 Mean dependent var 20168.57
Adjusted R-squared 0.762752 S.D. dependent var 3512.487
S.E. of regression 1710.865 Akaike info criterion 17.85895
Sum squared resid 35124719 Schwarz criterion 17.95024
Log likelihood -123.0126 Hannan-Quinn criter. 17.85050
F-statistic 42.79505 Durbin-Watson stat 0.859998
Prob(F-statistic) 0.000028
(1) 一元线性回归方程Y t=12596.27+26.95415GDPt
∧
(2) 结构分析β^1=26.95425是样本回归方程的斜率,它表示某市货物运输量的情况,说明货物运输量每增加1亿元,将26,95425用于国内生产总值;β^0=12596.27是样本回归方程的截距,它表示不受货物运输量影响的国内生产总值。
(3)统计检验r2=0.78 说明总离差平方和的78%被样本回归直线解释,有22%没被解释,说明样本回归直线对样本点的拟合优度还是比较高的。
显著性水平α=0.05,查自由度v=14-2=12的t分布表,得临界值t0.025(12)=2.18
(4)预测区间1980~2000
obs GDP RESID Y YF YFSE 1980
1981
1982
1983
1984
1985 161.69 1294.51817047138 18249 16954.48182952862 1837.805042947807 1986 171.07 1317.688263830489 18525 17207.31173616951 1827.852********* 1987 184.07 842.2843420467398 18400 17557.71565795326 1815.329074565951 1988 194.75 -1152.585956772524 16693 17845.58595677253 1806.164743584577 1989 197.86 -2386.413356522331 15543 17929.41335652233 1803.689193053205 1990 208.55 -2288.553196819888 15929 18217.55319681989 1795.851377857323 1991 221.06 -246.7495861671741 18308 18554.74958616718 1788.013873793755 1992 246.92 -1729.78384903854 17522 19251.78384903854 1776.450315989464 1993 276.8 1582.826213815424 21640 20057.173******** 1770.995648870701 1994 316.38 2658.981042723055 23783 21124.01895727694 1776.926294021264 1995 363.52 1645.362514039523 24040 22394.63748596048 1803.310480128086 1996 415.51 337.0163683828214 24133 23795.98363161718 1855.694986909933 1997 465.78 -60.96864300710876 25090 25150.96864300711 1927.747214173007
1998 509.1
-1813.62232698188
24505 26318.62232698188 2004.982737266598
1999
2000
620
29307.83732127556 2255.639096466328
单个值预测区间 Y 2000∈[29307.84-2.10×2255.64,29307.84+2.10×2255.64] 均值预测区间 E(Y 2000)∈[29307.84-2.10×2255.64,29307.84+2.10×2255.64] 8、查中国统计年鉴,利用1978~2000的财政收入和GDP 的统计资料,要求以手工和EViews 软件。 (1)散点图
20,000
40,00060,000
80,000
100,000
Y
G D P
Dependent Variable: Y Method: Least Squares Date: 10/29/13 Time: 16:40 Sample: 1978 2000 Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob. GDP 0.986097 0.001548 637.0383 0.0000 C
174.4171
50.39589
3.460939
0.0023
R-squared 0.999948 Mean dependent var 22634.30 Adjusted R-squared 0.999946 S.D. dependent var 23455.82 S.E. of regression 172.6972 Akaike info criterion 13.22390 Sum squared resid 626310.6 Schwarz criterion 13.32264 Log likelihood -150.0748 Hannan-Quinn criter. 13.24873 F-statistic 405817.8 Durbin-Watson stat 0.984085
Prob(F-statistic)
0.000000
一元线性回归方程Y=174.4174+0.98GDP t
经济意义国名收入每增加1亿元,将有0.98亿元用于国内生产总值。
(2)检验r2=99%,说明总离查平方和的99%被样本回归直线解释,仅有1%未被解释,所以说样本回归直线对样本点的拟合优度很高。
显著性水平α=0.05,查自由度v=23-2=21的t分布表,得临界值t0.025(21)=2.08。
(3)预测值及预测区间
obs Y YF YFSE GDP
1978 3645.2 3768.93952756
0003
178.879907887
3616 3645.2
1979 4062.6 4180.53660248
6764
178.774077728
9417 4062.6
1980 4545.60000000
0001
4656.82167002
3003
178.654453123
7366
4545.60000000
0001
1981 4889.5 4998.01138714
0059
178.570634469
0318
4891.60000000
0001
1982 4889.5 4998.01138714
0059
178.570634469
0318
4891.60000000
0001
1983 5330.5 5423.80826532
2558
178.468230113
8803
5323.39999999
9999
1984 5985.6 6054.22036403
0461
178.321108326
6242 5962.7
1985 7243.8 7282.30612616
2203
178.049950484
8901 7208.1
1986 9040.70000000
0001
9065.07170297
124
177.692806300
9931 9016
1987 12050.6 12065.3717992
1504
177.189939863
8916 12058.6
1988 10274.4 10306.7656098
8973
177.469705227
4058 10275.2
1989 12050.6 12065.3717992
1504
177.189939863
8916 12058.6
1990 15036.8 15008.0838044
7724
176.817239439
1318 15042.8
1991 17000.9 16930.4807799
6771
176.638587454
0277 16992.3
1992 18718.3 18582.6870546
1982
176.526126442
3878 18667.8
1993 35260 35017.0857379
8564
177.479184885
4038 35333.9
1994 21826.2 21653.0986794
3883
176.418239372
4463 21781.5
1995 26937.3 26723.6117586
7555
176.528268981
9769 26923.5
1996 35260 35017.0857******* 177.479184885
4038 35333.9 1997 48108.5 47702.24331311228 180.7470770711596 48197.9 1998 59810.5 60122.92955260078 185.9681357044579 60793.7 1999 88479.2 88604.77659126783 204.5612478858191 89677.1 2000 70142.5
70361.48074871261 191.6614042102092 71176.6 2001
104413.7922729122
218.176634678
1298
105709
单个值的预测区间 Y 2000∈[104413.8-2.07×218.2,104413.8+2.07×218.2] 均值预测区间 E(Y 2000)∈[104413.8-2.07×218.2,104413.8+2.07×218.2]
第三章 多元线性回归模型
2、试对二元线性回归模型Y i =β0+β1X 1i +β2X 2i +u i ,i=1,2,3,……n 作回归分析: (1)求出未知参数β0,β1,β2的最小二乘估计量β^0,β^1,β^2; (2)求出随机误差项u 的方差σ2的无偏估计量; (3) 对样本回归方差拟合优度检验;
(4) 对总体回归方程的显著性进行F 检验; (5) 对β1,β2的显著性进行t 检验;
(6) 当X 0=(1,X 10,X 20)时,写出E(Y 0/X 0)的置信度为95%的预测区间。
答:(1)由公式
1
='X X X Y β∧
-(')可得出012βββ∧∧∧,和。其中0
12={}
ββββ∧
,1i 2i
21i
1i 2i 1i 22i 1i
2i
1i 3
'[]
X
X X X X X X X X
X X
X
??
?
= ? ??
?∑∑∑∑∑∑∑∑,
i 1i i 2i i '{}Y X Y X Y X Y =∑∑∑ (2) 随机误差项的方差2
σ的无偏差估计量为 2
i
e =n-k-1n-k-1ESS ∑
(3) 求出样本可决系数2
R =R-squared ,修正样本可决系数为
2R =Adjusted-squared,比较2R 和2
R 值大小关系,即可得出样本回归方差拟合优度。
(4) 提出检验的原假设0i 2==0H ββ:,对立假设为 1H :至少有一个i β不等于
零(i =
1,2),由题意得F 的统计量为 F-statistic 。对于给定的显著性水平α,;
从附录4的表1中,查出分子自由度为1f ,分母自由度为2f 的F 分布上侧位
数0.0512f ,f F (,)。由F-statistic 与0.0512f ,f F (,)的值大小关系,可得显著性关系。 (5)提出检验的原假设0i =0i=1,2H β:,,求出t 统计量 i t -statistic 。对于给定的显著性水平α=0.05,;从附录4的表1中,查出t 分布的自由度为f
的t 分布双侧位数0.05t f ()。比较i t -statistic 与0.05t f ()值的大小关系,可得检验结果的显著性关系。
(6)E(Y O |X O )的预测区间:(Y 0-t α/2(v)?S(Y 0),Y 0+t α/2(v)?S(Y 0)) ; Y O 的预测区间:(Y 0-t α/2(v)?S(e 0),Y 0+t α/2(v)?S(e 0) 3、经研究发现,学生用于购买书籍及课外读物的支出与本人受教育年限和其家庭收入水平有关,对18名学生进行调查的统计资料如下表所示(略)。
Dependent Variable: Y Method: Least Squares Date: 10/29/13 Time: 22:18 Sample: 1 18
Included observations: 18
Variable Coefficient Std. Error t-Statistic Prob. X2 0.402289 0.116359 3.457319 0.0035 X1 104.3081 6.409709 16.27345 0.0000 C
-0.962980
30.32507 -0.031755
0.9751
R-squared 0.979722 Mean dependent var 755.1556 Adjusted R-squared 0.977019 S.D. dependent var 258.6819 S.E. of regression 39.21512 Akaike info criterion 10.32701 Sum squared resid 23067.39 Schwarz criterion 10.47541 Log likelihood -89.94312 Hannan-Quinn criter. 10.34748 F-statistic 362.3656 Durbin-Watson stat 2.561545
Prob(F-statistic)
0.000000
回归方程 Y^=-0.96+104.3X1+0.4X2 (2)检验设原假设 H0:βi =0 i=1,2
根据上表中的计算结果知:S(β^1)=6.409709 S(β^2)=0.116359 将S(β^1)和S(β^2)的值代入检验统计量式中,得
T1=β^1÷S(β^1)=16.2735 t2=β^2÷S(β^2)=3.4561
对于给定的显著水平α=0.05,自由度为v=15的双侧分位数t 0.05/2=2.13。因为 t 1>t 0.05/2 t 2>t 0.05/2,所以否定H 0:β1≠0,H 0:β2≠0,即可以认为受教育年限和家庭收入对学生购买书籍以及课外读物有显著性影响。 (3) R 2=RSS/TSS=0.979722 R 2=1-(1-R 2)n-1/n-k-1=0.97702 (4)预测区间 obs
Y
YF
YFSE
X2
X1
ˉ
1 450.5 485.141174769
2648
42.1736550662
4408 171.2 4
2 507.7 486.348041790
1021
42.1036382828
7697 174.2 4
3 613.9 602.765010184
4977
41.6023430378
6757 204.3 5
4 563.4 504.249902599
1888
41.3981428967
1567 218.7 4
5 501.5 504.531504904
0509
41.3921241782
7067 219.4 4
6 781.5 825.903781905
8965
42.9792448369
0921 240.4 7
7 541.799999999
9999
526.295340179
8169
41.4117973376
9013 273.5 4
8 611.1 639.172165313
09
40.5574828341
8582 294.8 5
9 1222.1 1174.95354258
5611
47.4768632431
9662 330.2 10
10 793.2 863.195972849
7693
40.6897005289
6574 333.1 7
11 660.8 667.815142607
6286
41.6323221694
1219 366 5
12 792.7 766.048647888
0758
40.4127190197
3422 350.9 6
13 580.9 560.248532366
0397
43.3098732208
7763 357.9 4
14 612.7 664.999119559
0084
41.4545591551
4781 359 5
15 890.8 878.804786319
2651
40.5530798828
6174 371.9 7
16 1121 1112.92604793
0283
42.4958860743
6637 435.3 9
17 1094.2 1044.26078466
035
43.6391801181
4712 523.9 8
18 1253 1285.14050158
8057
46.3991586393
9679 604.1 10
19 1235.21643582
6087
44.1250725573
2823 480 10
单个值的预测区间Y∈[1235.216-2.13×44.125,1235.216+2.13×44.125] 均值的预测区间E(Y)∈[1235.216-2.13×44.125,1235.216+2.13×44.125]
4、假设投资函数模型估计的回归方程为:
I t=5.0+0.4Y t+0.6I t-1,R2=0.8,DW=2.05,n=24其中I t和Y t分别为第t期投资和国民收入
(1)对总体参数?1,?2的显著性进行检验(α=0.05)
(2)若总离差平方和TSS=25,试求随机误差项u t方差的估计量
(3)计算F统计量,并对模型总体的显著性进行检验(α=0.05)
答:(1)首先提出检验的原假设H0:?1=0,i=1,2,。由题意知t的统计量值为
t1=4.0,t2=3.2。对于给定的显著性水平α=0.05,;从附录4的表1中,查出t分布的自由度为v=21的双侧分数位t0.05/2(21)=1.72。因为t1=4.0> t0.05/2(21)=1.72,所以否定H0,?1显著不等于零即可以认为第t期投资对国民收入有显著影响;t2=3.2 >
t0.05/2(21)=1.72。所以否定H0,?2显著不等于零即可以认为第t期投资对第t-1期投资有显著影响。
(2)R2 =RSS=R2×TSS=0.8×25=20.u t的方差估计量为:
(3)提出检验的原假设H0:?1=?2=0,F===42,对于给定的显著性水平α=0.05,从附录4的表3中,查出分分子自由度为2,分母自由度为21的F分布上侧位数
F0.05/2(21)=3.47。因为F=42>3.47,所以否定H0,总体回归方程存在显著的线性关系,即第t期投资与第t-1期投资和第t期国民收入的线性关系是显著的。
6、已知某地区某农产品收购量Y,销售量X1,出口量X2,库存量X3的1955~1984年的样本观测值见下表。试建立以收购量Y为被解释变量的多元线性回归模型并预测。
根据题意可设方程为Y=β0+β1X1+β2X2+β3X3,利用Eview可知,
Dependent Variable: Y
Method: Least Squares
Date: 10/29/13 Time: 22:55
Sample: 1955 1984
Included observations: 30
Variable Coefficient Std. Error t-Statistic Prob.
X3 0.150971 0.083318 1.811984 0.0816
X2 2.924095 1.655324 1.766480 0.0891
X1 0.919120 0.235896 3.896288 0.0006
C 0.437272 4.050575 0.107953 0.9149
R-squared 0.600052 Mean dependent var 22.13167
Adjusted R-squared 0.553904 S.D. dependent var 14.47259
S.E. of regression 9.666307 Akaike info criterion 7.498736
Sum squared resid 2429.375 Schwarz criterion 7.685562
Log likelihood -108.4810 Hannan-Quinn criter. 7.558503
F-statistic 13.00281 Durbin-Watson stat 1.153567
Prob(F-statistic) 0.000022
回归方程Y=0.437+0.919X1+2.924X2+0.151X3
第四章非线性回归模型的线性化
1.某商场1990年~1998年间皮鞋销售额(万元)的统计资料如下表所示。(表略)
考虑指数模型lnY=α+βt+ut,试利用上表的数据进行回归分析,并预测1999年该商场皮鞋的销售额。
答:
Dependent Variable: Y
Method: Least Squares
Date: 10/30/13 Time: 21:52
Sample: 1990 1998
Included observations: 9
Variable Coefficient Std. Error t-Statistic Prob.
T 4.088333 0.419507 9.745574 0.0000
C -4.186111 2.360696 -1.773253 0.1195
R-squared 0.931357 Mean dependent var 16.25556
Adjusted R-squared 0.921550 S.D. dependent var 11.60163
S.E. of regression 3.249485 Akaike info criterion 5.388000
Sum squared resid 73.91406 Schwarz criterion 5.431828
Log likelihood -22.24600 Hannan-Quinn criter. 5.293420
F-statistic 94.97621 Durbin-Watson stat 0.542289
Prob(F-statistic) 0.000025
根据上表建立回归模型为Y = 4.0883********T - 4.1861111111
根据回归模型知道1999年该商场皮鞋销售量为Y=36.694
2.美国在1790年~1990年间每10年的人口总数Y(百万人)的统计资料如下表所示。(表略)
考虑指数增长模型:Y=Aeαt+u,试利用上表的数据进行回归分析,并预测美国2000年的人口总数。
答:
3.印度在1948年~1964年间的名义货币存量(现金余额)Mt(n),名义国民收入Yt(n),内含价格缩减指数(Implic it Price Deflator,也称综合价格换算系数)Pt,长期利率rt的统计资料如下表所示。用内含价格缩减指数分别除名义货币存量和名义国民收入,得实际货币存量和实际国民收入,记为Mt,Yt。(表略)(1)考虑货币需求函数模型
M t(n)= α0Y tα1r tα2P tα3e ut
利用最小二乘法估计该模型,判断α3估计值的符号是否合理,并对估计的回归方程解释其经济意义。
(2)考虑货币需求函数模型
M t(n)= β0(Y t(n)) β1r tβ2P tβ3e ut
利用最小二乘法估计该模型,说明β1和α1之间的关系。
(3) 考虑货币需求函数模型
M t=λ0Y tλ1r tλ2e ut
利用最小二乘法估计该模型,确定实际货币存量关于实际国民收入及长期利率的弹性。
(4) 考虑货币需求函数模型
()t=αr tβe ut
利用最小二乘法估计该模型,并对估计的回归方程解释其经济意义。
(5)对上述4个模型进行显著性检验,并加以比较。
《计量经济学》期末考试复习资料 第一章绪论 参考重点: 计量经济学的一般建模过程 第一章课后题(1.4.5) 1.什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别? 答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。 计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。 4.建立与应用计量经济学模型的主要步骤有哪些? 答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。 5.模型的检验包括几个方面?其具体含义是什么? 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 第二章经典单方程计量经济学模型:一元线性回归模型参考重点: 1.相关分析与回归分析的概念、联系以及区别? 2.总体随机项与样本随机项的区别与联系?
计量经济学第三章作业 经济131 王晨莹 13013121 15.(1)① 打开材料数据表3-5,获得如图3-5-1所示: 3-5-1 ② 根据题目确定被解释变量为税收收入(T )、解释变量为工业(GY )、进出口总额(IE )、金融业(JR )、交通运输业(JT)、建筑业(JY )。 ③ 建模: t t JY JT JR IE GY T μββββββ++++++=543210 ④ 建立变量组: 在主菜单上Eviews 命令框中直接输入命令“Data T GY IE JR JT JY ”,将直接出现已定义变量名称的数据编辑窗口。如图3-5-2所示:
图3-5-2 ⑤估计模型参数: 在主菜单上依次单击“Quick→Estimate Equation”,弹出对话框,在“Specification”选项卡中输入模型中被解释变量(T)、常数项(C)、解释变量(GY、IE、JR、JT、JY)序列,并选择估计方法及样本区间(1985-2009)。如图3-5-3所示,其结果如图3-5-4所示: 图3-5-3
图3-5-4 ⑥ 参数估计结果分析: 经参数估计后,回归模型为 ∧T = 117.5 - 0.772 GY + 0.232 IE + 1.82 JR + 1.895 JT + 2.853 JY (0.2168) (-3.068) (5.552) (3.184) (2.261) (3.047) 995.02=R ,F=798 , d=0.674 ⑦ 模型中参数表明,在工业、建筑业、进出口、金融业、交通运输业中,建筑业对税收的影响最大,工业(GY )每增加1亿元,税收收入(T )将减少3.068亿元(但不符合经济意义);进出口总额(IE )每增加1亿元,税收收入(T )将增加5.552亿元;金融业(JR )每增加1亿元,税收收入(T )将增加3.184亿元;交通运输业(JT)每增加1亿元,税收收入(T )将增加2.261亿元;建筑业(JY )每增加1亿元,税收收入(T )将增加3.047亿元。抛出这5类因素对税收的影响,政府从其他部门和产业所征收数额为117.48。 (2)多重共线性检验:存在多重共线性 由上图可知,工业的结构参数为负,不符经济意义,故去掉工业得到新的模型:
以往计量经济学作业答案 第一次作业: 1-2. 计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征? 答:计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律(或者说,计量经济学是利用数学方法,根据统计测定的经济数据,对反映经济现象本质的经济数量关系进行研究)。计量经济学的内容大致包括两个方面:一是方法论,即计量经济学方法或理论计量经济学;二是应用,即应用计量经济学;无论是理论计量经济学还是应用计量经济学,都包括理论、方法和数据三种要素。 计量经济学模型研究的经济关系有两个基本特征:一是随机关系;二是因果关系。 1-4.建立与应用计量经济学模型的主要步骤有哪些? 答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和一致性;(3)估计模型参数;(4)模型检验,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。 1-6.模型的检验包括几个方面?其具体含义是什么? 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 第二次作业: 2-1 答:P27 6条 2-3 线性回归模型有哪些基本假设?违背基本假设的计量经济学模
第六章自相关习题参考答案 练习题6.1参考解答: (1)建立回归模型,回归结果如下: Dependent Variable: Y Method: Least Squares Date: 05/06/10 Time: 22:58 Sample: 1960 1995 Included observations: 36 Coefficient Std. Error t-Statistic Prob. X 0.935866 0.007467 125.3411 0.0000 C -9.428745 2.504347 -3.764951 0.0006 R-squared 0.997841 Mean dependent var 289.9444 Adjusted R-squared 0.997777 S.D. dependent var 95.82125 S.E. of regression 4.517862 Akaike info criterion 5.907908 Sum squared resid 693.9767 Schwarz criterion 5.995881 Log likelihood -104.3423 Hannan-Quinn criter. 5.938613 F-statistic 15710.39 Durbin-Watson stat 0.523428 Prob(F-statistic) 0.000000 估计结果如下 t t X Y 0.93594287.9?+-= Se = (2.5043) (0.0075) t = (-3.7650) (125.3411) R2 = 0.9978,F = 15710.39,d f = 34,DW = 0.5234 (2)对样本量为36、一个解释变量的模型、5%显著水平,查DW 统计表可知,dL=1.411,dU= 1.525,模型中DW
下表列出了某年中国部分省市城镇居民每个家庭平均全年可支配收入X与消费性支出Y 的统计数据。 地区可支配收入 (X)消费性支出 (Y) 地区可支配收入 (X) 消费性支出 (Y) 北京10349.69 8493.49 浙江9279.16 7020.22 天津8140.50 6121.04 山东6489.97 5022.00 河北5661.16 4348.47 河南4766.26 3830.71 山西4724.11 3941.87 湖北5524.54 4644.5 内蒙古5129.05 3927.75 湖南6218.73 5218.79 辽宁5357.79 4356.06 广东9761.57 8016.91 吉林4810.00 4020.87 陕西5124.24 4276.67 黑龙江4912.88 3824.44 甘肃4916.25 4126.47 上海11718.01 8868.19 青海5169.96 4185.73 江苏6800.23 5323.18 新疆5644.86 4422.93 (1)试用普通最小二乘法建立居民人均消费支出与可支配收入的线性模型; (2)检验模型是否存在异方差性; (3)如果存在异方差性,试采用适当的方法估计模型参数。 解: (1)a.建立对象,录入可支配收入X与消费性支出Y,如下图: b. 设定一元线性回归模型为: 点击主界面菜单Quick\Estimate Equation,在弹出的对话框中输入Y、C、X,操作
(2)a.生成残差序列。在工作文件中点击Object\Generate Series…,在弹出的窗口中,在主窗口键入命令如下“e1=resid^2”得到残差平方和序列e1。如下图: (3)a. 设定一元线性回归模型为:
第10章联立方程模型 一、单选 1、如果联立方程中某个结构方程包含了所有的变量,则这个方程为() A、恰好识别 B、过度识别 C、不可识别 D、可以识别 2、下面关于简化式模型的概念,不正确的是() A、简化式方程的解释变量都是前定变量 B、简化式参数反映解释变量对被解释的变量的总影响 C、简化式参数是结构式参数的线性函数 D、简化式模型的经济含义不明确 3、对联立方程模型进行参数估计的方法可以分两类,即:( ) A、间接最小二乘法和系统估计法 B、单方程估计法和系统估计法 C、单方程估计法和二阶段最小二乘法 D、工具变量法和间接最小二乘法 4、在结构式模型中,其解释变量( ) A、都是前定变量 B、都是内生变量 C、可以内生变量也可以是前定变量 D、都是外生变量 5、如果某个结构式方程是过度识别的,则估计该方程参数的方法可用() A、二阶段最小二乘法 B、间接最小二乘法 C、广义差分法 D、加权最小二乘法 6、当模型中第i个方程是不可识别的,则该模型是( ) A、可识别的 B、不可识别的 C、过度识别 D、恰好识别 7、结构式模型中的每一个方程都称为结构式方程,在结构方程中,解释变量可以是前定变量,也可以是( ) A、外生变量 B、滞后变量 C、内生变量 D、外生变量和内生变量 8. 在完备的结构式模型 A、Y t B.Y t – 1 C.I t D.G t 9. 在完备的结构式模型 A.方程1 B.方程2 C.方程3 D.方程1和2 10.联立方程模型中不属于随机方程的是() A.行为方程 B.技术方程 C.制度方程 D.恒等式 11.结构式方程中的系数称为() A.短期影响乘数 B.长期影响乘数 C.结构式参数 D.简化式参数 12.简化式参数反映对应的解释变量对被解释变量的 A.直接影响 B.间接影响 C.前两者之和 D.前两者之差 13.对于恰好识别方程,在简化式方程满足线性模型的基本假定的条件下,间接最小二乘估 计量具备() A.精确性 B.无偏性 C.真实性 D.一致性 二、多选 1、当结构方程为恰好识别时,可选择的估计方法是() A、最小二乘法 B、广义差分法 C、间接最小二乘法 D、二阶段最小二乘法 E、有限信息极大似然估计法 2、对联立方程模型参数的单方程估计法包括( ) A、工具变量法 B、间接最小二乘法 C、完全信息极大似然估计法 D、二阶段最小二乘法 E、三阶段最小二乘法
《计量经济学》第6章习题 一、单项选择题 1.当模型存在严重的多重共线性时,OLS 估计量将不具备( ) A .线性 B .无偏性 C .有效性 D .一致性 2.如果每两个解释变量的简单相关系数比较高,大于( )时则可认为存在着较严重的多重共线性。 A .0.5 B .0.6 C .0.7 D .0.8 3.方差扩大因子VIF j 可用来度量多重共线性的严重程度,经验表明,VIF j ( )时,说明解释变量与其余解释变量间有严重的多重共线性。 A .小于5 B .大于1 C .小于1 D .大于10 4.对于模型01122i i i i Y X X u βββ=+++,与r 23等于0相比,当r 23等于0.5时,3 ?β的方差将是原来的( ) A .2倍 B .1.5倍 C .1.33倍 D .1.25倍 5.无多重共线性假定是假定各解释变量之间不存在( ) A .线性关系 B .非线性关系 C .自相关 D .异方差 二、多项选择题 1.多重共线性包括( ) A .完全的多重共线性 B .不完全的多重共线性 C .解释变量间精确的线性关系 D .解释变量间近似的线性关系 E .非线性关系 2.多重共线性产生的经济背景主要由( ) A .经济变量之间具有共同变化趋势 B .模型中包含滞后变量 C .采用截面数据 D .样本数据自身的原因 E .模型设定误差 3.多重共线性检验的方法包括( ) A .简单相关系数检验法 B .方差扩大因子法 C .直观判断法 D .逐步回归法 E .DW 检验法 4.修正多重共线性的经验方法包括( ) A .剔除变量法 B .增大样本容量 C .变换模型形式 D .截面数据与时间序列数据并用 E .变量变换 5.严重的多重共线性常常会出现下列情形( ) A .适用OLS 得到的回归参数估计值不稳定 B .回归系数的方差增大 C .回归方程高度显著的情况下,有些回归系数通不过显著性检验 D .回归系数的正负号得不到合理的经济解释 E .预测精度降低 一、单项选择题 1.C 2.D 3.D 4.C 5.A 二、多项选择题 1.AB 2.ABCD 3.ABCD 4.ABCDE 5.ABCDE
1、家庭消费支出(Y )、可支配收入(1X )、个人个财富(2X )设定模型下: i i i i X X Y μβββ+++=22110 回归分析结果为: LS 18/4/02 Error T-Statistic Prob. C ________ 2X - ________ 2X R-squared ________ Mean dependent var Adjusted R-squared . dependent var . of regression ________ Akaike info criterion Sum squared resid Schwartz criterion Log likelihood - 31.8585 F-statistic Durbin-Watson stat Prob(F-statistic) 补齐表中划线部分的数据(保留四位小数);并写出回归分析报告。 由表可知,9504.02=R 故 9614.01 10310) 9504.01(12=----=R 回归分析报告如下: 由以上结果整理得: t= 9614.02=R n=10 从回归结果来看,9614.02=R ,9504.02=R ,3339.87=F ,不够大,则模型的拟合优度不是很好. 模型说明当可支配收入每增加1元,平均说来家庭消费支出将减少元,当个人财富每增加1元,平均来说家庭消费支出将增加元。 参数检验:
在显着性水平上检验1β,2β的显着性。 365.2)310(7108.0025.01=-<-=t t Θ 故接受原假设,即认为01=β。 365.2)310(7969.1025.02=-<=t t Θ 故接受原假设,即认为02=β。 即模型中,可支配收入与个人财富不是影响家庭消费支出的显着因素。 2、为了解释牙买加对进口的需求 ,根据19年的数据得到下面的回归结果: se = R 2= 2 R = 其中:Y=进口量(百万美元),X 1=个人消费支出(美元/年),X 2=进口价格/国内价格。 (1) 解释截距项,及X 1和X 2系数的意义; 答:截距项为,在此没有什么意义。1X 的系数表明在其它条件不变时,个人年消费量增加1美元,牙买加对进口的需求平均增加万美元。2X 的系数表明在其它条件不变时,进口商品与国内商品的比价增加1美元,牙买加对进口的需求平均减少万美元。 (2)Y 的总离差中被回归方程解释的部分,未被回归方程解释的部分; 答:由题目可得,可决系数96.02=R ,总离差中被回归方程解释的部分为96%,未被回归方程解释的部分为4%。 (3)对回归方程进行显着性检验,并解释检验结果; 原假设:0:210==ββH 计算F 统计量 16 04.0296.01=--=k n RSS k ESS F =192 63.3)16,2(19205.0=>=F F Θ 故拒绝原假设,即回归方程显着成立。 (4)对参数进行显着性检验,并解释检验结果。 对21ββ进行显着性检验 96.174.210092.002.0) ?(?05.011`11=>=-=-=t SE t βββ 故拒绝原假设,即1β显着。 96.12.1084.001.0) ?(?05.02222=<=-=-=t SE t βββ 故接受原假设,即2β不显着。 4.根据某地1961—1999年共39年的总产出Y 、劳动投入L 和资本投入K 的年度 数据,运用普通最小二乘法估计得出了下列回归方程: ,DW= 式下括号中的数字为相应估计量的标准误。 (1)解释回归系数的经济含义; (2)系数的符号符合你的预期吗为什么
热工测量仪表作业参考 答案 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
第一、二章 一.名词解释 以测 1.测量:人们借助专门工具,通过试验和对试验数据的分析计算,将被测量X 量单位U倍数μ显示出来的过程,即X =μU。 2.热工测量:指压力,温度等热力状态参数的测量,通常还包括一些与热力生产过程密切相关的参数的测量,如测量流量,液位震动,位移,转速和烟气成分等。 3标准量:即U ,测量单位。U必须是国际或国家公认的,理论约定的,必须是稳定的可以计量的传递。 4.环节:在信号传输过程中,仪表中每一次信号转换和传输可作为一个环节。 5.传递函数:静态下每个环节的输出与输入之比,称为该环节的传递函数。 6.可靠性:作为仪表的质量指标之一,是过程检验仪表的基本要求,目前常用有效性表示。 7.精密度:对同一被测量进行多次测量所得测量值重复一致的程度,或者说测定值分布的密集度。 准确度:对同一被测量进行多次测量,测定值偏移被测量真值的程度。 精确度或者精度:精密度与准确度的综合指标。 8.绝对误差:仪表的指示值与实际值的差值。 9.基本误差:在规定的工作条件下,仪表量程范围内各示值误差中的绝对值最大者称为仪表的基本误差。 10.仪表精度:仪表在测量过程中所能达到的精确程度。 去掉百分号后余下的数字 11.准确度等级:仪表最大引用误差表示的允许误差r yu 称为该仪表的准确度等级。 12.线性度:对于理论上具有线性“输入—输出”特性曲线的仪表,由于各种原因,实际特性曲线往往偏离线性关系,它们之间最大偏差的绝对值与量程之比的百分数,称之为线性度。 13.回差:输入量上升和下降时,同一输入量相应的两输出量平均值之间的最大差值与量程之比的百分数称为仪表的回差。 14.重复性:同一工况下,多次按同一方向输入信号作全量程变化时,对应于同一输入信号值,仪表输入值的一致程度称为重复性。
第十章练习题参考解答 练习题 10.1下表是某国的宏观经济数据(GDP——国内生产总值,单位:10亿美元;PDI——个人可支配收入,单位:10亿美元;PCE——个人消费支出,单位:10亿美元;利润——公司税后利润,单位:10亿美元;红利——公司净红利支出,单位:10亿美元)。 某国1980年到2001年宏观经济季度数据
(1)画出利润和红利的散点图,并直观地考察这两个时间序列是否是平稳的。 (2) 应用单位根检验分别检验两个时间序列是否是平稳的。 10.2下表数据是1970-1991年美国制造业固定厂房设备投资Y和销售量X,以10亿美元计价,且经过季节调整,根据该数据,判断厂房开支和销售量序列是否平稳? 10.3 根据习题10.1的数据,回答如下问题: (1) 如果利润和红利时间序列并不是平稳的,而如果你以利润来回归红利,那么回归 的结果会是虚假的吗?为什么?你是如何判定的,说明必要的计算。 (2) 取利润和红利两个时间序列的一阶差分,确定一阶差分时间序列是否是平稳的。 10.4 从《中国统计年鉴》中取得1978年-2005年全国全社会固定资产投资额的时间序
列数据,检验其是否平稳,并确定其单整阶数。 10.5 下表是1978-2003年中国财政收入Y和税收X的数据(单位:亿元),判断lnY 和lnX的平稳性,如果是同阶单整的,检验它们之间是否存在协整关系,如果协整,则建立相应的协整模型。 (1)10.6下表是某地区消费模型建立所需的数据,对实际人均年消费支出C和人均年收人Y(单位:元)
分别取对数,得到lc ly 和: (2) 对lc ly 和进行平稳性检验。 (3) 用EG 两步检验法对lc ly 和进行协整性检验并建立误差修正模型。 分析该模型的经济意义。 练习题参考解答 练习题10.1参考解答 利润和红利的散点图如下: 从图中看出,利润和红利序列存在趋势,均值和方差不稳定,因此可能非平稳。下面用ADF 检验是否平稳。选择带截距和时间趋势的模型进行估计,结果如下:
计量经济学作业第5章(含答案)
、单项选择题 1 ?对于一个含有截距项的计量经济模型,若某定性因素有 D. m-k 2 ?在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例 如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出 丫 对实际可支配收入X 的回归关系明显不同。现以1991年为转折时期,设虚拟变 [1 1991# WS D =< 量 r [O f 1毀坪以前,数据散点图显示消费函数发生了结构性变化:基本 消费部分下降了,边际消费倾向变大了。贝U 城镇居民线性消费函数的理论方程 可以写作( ) A. h 二几+耳扎+如)拓+斗 3. 对于有限分布滞后模型 在一定条件下,参数儿可近似用一个关于【的阿尔蒙多项式表示 ),其中多项式的阶数 m 必须满足( ) A .障匚上 B . m k C . D .用上上 4. 对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数 据就会( ) A.增加1个 B.减少1个 C.增加2个 D.减 少2个 5. 经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序 列相关性就转化为( ) A. m B. m-1 C. m+1 将其引入模型中,则需要引入虚拟变量个数为( m 个互斥的类型,为 ) B. C. Y 讦 A+ +"0+ 斗 D.
A.异方差冋 题 B.多重 共线性问题
问题 6. 将一年四个季度对因变量的影响引入到模型中(含截 距项),则需要引入虚 拟变量的个数为( ) A. 4 B. 3 C. 2 D. 1 7. 若 想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(丫代表消费支出;X 代表可支配收入;D 2、D 3表示虚拟变量) () A.Yj"+陆+野 B . 二、多项选择题 1. 以下变量中可以作为解释变量的有 ( ) A.外生变量 B.滞后内生变量 C.虚 拟变量 D.先决变量 E.内生变量 2. 关于衣着消费支出模型为:h 吗+叩左+必史+勺3工』』+ "逅+色,其中 丫为衣着万面的年度支出;X 为收入, 1 女性 "i 大学毕业及以上 D = : D 3i =J o 男性, 3i 其他 则关于模型中的参数下列说法正确的是( ) A. $表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出 (或少 支出)差额 B. 珂表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消 费支 出方面多支出(或少支出)差额 C. 5表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以 下文凭 者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消 费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 、判断题 1 ?通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容 C.序列相关性问题 D.设定误差 £ =坷++以叭JQ+舛 C. 】 D 丄吗皿吗+风+儿
第二章 (6) 直接工程费=4530+24160+1510=30200(元) 直接费=30200+5700(措施费)=35900(元) 间接费=35900×5%=1795(元) 利润=(35900+1795) ×7%=2638.65(元) 税金=(35900+1795+2638.65) ×3.41%=1375.38(元) 工程造价=35900+1795+2638.65+1375.38=41709.03(元)
P61 (1)工作延续时间=%) 18%2%2%3(154+++-=72(h) 时间定额=72/8=9(工日/t) 产量定额=1/3=0.11(t/工日) (2)每吨型钢支架的定额人工消耗量=(9+12)×(1+10%)=23.10(工日/t) (3)每10t 型钢支架工程的单价 人工费=23.1×22.5×10=5197.50(元) 材料费=1.06×3600×10+380×10=41960(元) 机械费=490×10=4900(元) 定额单价=5197.50+41960+4900=52057.50(元)
P94 (1)解: 地下室:600m2 架空层:600 m2 1-12层:11×600=6600 m2 (设备层不计) 其中二层减去:-200 m2 电梯机房:40 m2 雨篷:24/2=12 m2 车棚:(100+160)/2=130 m2 以上合计:600+600+6600-200+40+12+130=7782 m2 P95 (2)解: 24×80+(3×2.4+7.4×2.4)×2=1920+49.92=1969.92 m2
P163 (1)解: 1-1剖 L挖外=(6.0+3.3×6+1.5+7.0+1.7)×2=(25.8+10.2)×2=72m L挖内:7-(0.6+0.3)×2=5.2m 4.4-1.7-(0.6+0.3)×2=0.9m [4.4-(0.6+0.3)×2]×7=18.2m (4.4+1.4+2.4)-(0.6+0.3)×2=6.4m L挖内=5.2+0.9+18.2+6.4=30.7m H=1.75-0.45=1.3m,放坡系数=0.5 V挖=(1.2+0.3×2+0.5×1.3)×1.3×(72+30.7)=327.1m3 L垫外=72m L垫内:7-0.7×2=5.6m 4.4-1.7-0.7×2=1.3m (4.4-0.7×2)×7=21.0m (4.4+1.4+2.4)-0.7×2=6.8m L垫内=5.6+1.2+21.0+6.8=34.7m V垫=1.4×0.1×(72+34.7)=14.94m3 V1-1挖土=327.1+14.94=342.04m3 2-2剖: L内挖=3.3×5-(0.6+0.3)×2=14.7m V挖=(2.6+0.3×2+0.5×1.3)×1.3×14.7=73.57m3 L垫=3.3×5-0.7×2=15.1m V垫=(2.6+0.2)×0.1×15.1=4.23m3 V2-2挖土=73.57+4.23=77.8m3 V总挖=342.04+77.8=419.84 m3
一:绘制时间序列图 根据1970-1991年的美国制造业固定厂房设备投资Y和销售量X的数据在Eviews中录入数据得到固定厂房设备投资Y时间序列图如下 由上图我们可以看出该时间序列可能存在趋势和截距项所以我们选择ADF检验的模型对其检验是否为平稳序列。 二:ADF检验结果
从检验的结果可以看出,在1%、5%、10%三个显着水平下,单位根检验的Mackinnon的临界值分别为、、,t检验统计量为远远大于相应的临界值,从而不能拒绝原假设,即可以说明固定厂房设备投资Y存在单位根,是非平稳数列。 三:根据1970-1991年的美国制造业固定厂房设备投资Y和销售量X的数据在Eviews 中录入数得到销售量X的时间序列图如下 由上图我们可以看出该时间序列可能存在趋势和截距项所以我们选择ADF检验的模型对其检验是否为平稳序列。 四ADF检验结果
从检验的结果可以看出,在1%、5%、10%三个显着水平下,单位根检验的Mackinnon的临界值分别为、、,t检验统计量为远大于相应的临界值,从而不能拒绝原假设,即可以说明销售量X存在单位根,是非平稳数列。 五:单整阶数检验
从检验的结果可以看出,在1%、5%、10%三个显着水平下,单位根检验的Mackinnon的临界值分别为、、,t检验统计量为,小于于相应的临界值,从而能拒绝原假设,即可以说明销售量X已经不存在单位根,是平稳数列。即是二阶单整。
从 检 验 的 结 果 可 以 看 出, 在 1%、 5%、 10% 三 个 显 着 水 平 下, 单 位 根 检 验 的 Mac kin non 的 临 界 值分别为、、,t检验统计量质为.小于相应的临界值,从而能拒绝原假设,即可以说明固定厂房设备投资Y已经存在单位根,是平稳数列。即是二阶单整。
1、改革开放以来,随着经济的发展,在中国城乡居民收入快速增长的同时,城乡居民的消费水平也迅速增长。经济学界的一种观点认为,20世纪90年代中期以后由于经济体制、住房、医疗、养老等社会保障体制的变化,使居民的消费行为发生了明显改变。请以城镇居民人均收入水平和消费水平的数据为依据,通过建立合适的模型检验上述的观点是否正确? 建立的模型为: cs t =75.85 + 0.799*inc t +789.67D1-0.14*D t* inc t + u t, t= 1,2,3… (25.38)(0.01) (49.19) (-12.75) R2 = 0.999 根据估计的结果,1997年及以前,收入增加1单位,消费增加0.799单位,1997以后,收入增加1单位,消费增加(0.659)单位,且D t* inc t的系数的t检验是显著的,说明1997年以后由于经济体制、住房、医疗、养老等社会保障体制的变化,居民的消费减少。 1997年以前的消费模型。。。 1997年以后的。。。。。。。。 2、根据我国1978年以来GDP数据建立GDP对数序列对象,判别该序列的平稳性,并根据自相关和偏自相关系数,建立GDP对数序列的ARMA或ARIMA模型。 用ADF单位根检验得到结论:ln(gdp)单位根检验结果如图1,根据p值不能够拒绝原假设。 t-Statistic Prob.* Augmented Dickey-Fuller test statistic -2.881835 0.1812 Test critical values: 1% level -4.273277 5% level -3.557759 10% level -3.212361
第10章模型设定与实践 问题 10.1 模型设定误差有哪些类型?如何诊断? 答:模型设定误差主要有以下四种类型: 1.漏掉一个相关变量; 2.包含一个无关的变量; 3.错误的函数形式; 4.对误差项的错误假定。 诊断的方法有:1.侦察是否含有无关变量;2.残差分析,拉姆齐(Ramsey)的RESET检验法,DM(Davidsion-MacKinnon:戴维森麦-克金龙)检验;3.拟合优度、校正拟合优度、系数显著性、系数符合的合理性。 10.2 模型遗漏相关变量的后果是什么? 答:模型遗漏相关变量的后果是:所有回归系数的估计量是有偏的,除非这个被去除的变量与每一个放入的变量都不相关。常数估计量通常也是有偏的,从而预测值是有偏的。由于放入变量的回归系数估计量是有偏的,所以假设检验是无效的。系数估计量的方差估计量是有偏的。 10.3 模型包含不相关变量的后果是什么? 答:模型包含不相关变量的后果是:系数估计量的方差变大,从而估计量的精度下降。10.4 什么是嵌套模型?什么是非嵌套模型? 答:如果两个模型不能被互相包容,即任何一个都不是另一个的特殊情形,便称这两个模型是非嵌套的。如果两个模型能互相包容,即其中一个是另一个的特殊情形,便称这两个模型是嵌套的。 10.5 非嵌套模型之间的比较有哪些方法? 答:非嵌套模型之间的比较方法有:拟合优度或校正拟合优度、AIC(Akaike’s information criterion)准则、SIC(Schwarz’s information criterion)准则和HQ(Hannnan-Qinn criterion)准则。拉姆齐(Ramsey)的RESET检验法,DM(Davidsion-MacKinnon:戴维森麦-克金龙)检验。 习题 10.6 对数线性模型在人力资源文献中有比较广泛的应用,其理论建议把工资或收入的对数
2015-2016年第2学期 计量经济学大作业 论文名称:中国货币流通量、货款额 和居民消费水平指数分析 学号:姓名:专业: 学号:姓名:专业: 学号:姓名:专业: 选课班级:A05任课老师:陶长琪评语: 教师签名:批阅日期:
一、摘要 经济与货币流通量是相辅相成密不可分的,经济的发展必然会带来货币流通量的增加,进而也会带来消费的增加。而一个国家贷款额的多少和居民消费水平指数的大小往往能够在某种程度上反映该国家经济的发展水平。因此,经济将货币流通量、贷款额和居民消费水平指数紧密地联系起来。 计量经济学可以帮助我们通过建立多元线性模型来反应货币流通量、贷款额和居民消费水平指数三者之间的关系。我们可以通过进行拟合优度检验,F检验,显著性检验,异方差检验,相关性检验和多重共线性检验等多种检验方法最终确定模型,使得建立的模型达到最优的结果。 最后通过对模型的进一步分析,我们可以得出货币流通量、货款额和居民消费水平指数三者之间的关系,即贷款额与居民消费水平指数的增加均会导致货币流通量的增加。 关键字:货币流通量,贷款额,居民消费水平指数,多元线性模型
Abstract Economic and monetary circulation is complementary to close, the development of economy will inevitably bring about the increase of monetary circulation, and also can bring consumption increase. A national loan amount how many and dweller consumption level index size tend to a certain extent reflects the development level of national economy.Thus, the economy will the amount of money in circulation, the loan amount and dweller consumption level index closely linked. Econometrics can help us through the establishment of multiple linear models to response the amount of money in circulation, the loan amount and dweller consumption level index of the relationship between the three.We can through the goodness-of-fit testing ,and F inspection, significant inspection, heteroscedastic inspection , the inspection and multiple linear correlation of inspection to determine the final model, makes the establishment of the model to achieve the optimal result. Based on further analysis of the model, we can conclude that the amount of money in circulation, the amount of goods and dweller consumption level index of the relationship between the three, namely, the loan amount and consumption level of exponential increase will lead to the increase of the amount of money in circulation. Key words: The amount of money in circulation, the loan amount dweller consumption level index, multivariate linear model
学习-----好资料 y=c(1)+c(2)*x 8、下表列出了某年中国部分省市城镇居民每个家庭平均全年可支配收入X与消费性支出Y的统计数据。 obs X Y 10349.69 2001 10349.69 8140.5 2002 8140.5 5129.05 2003 5129.05 5357.79 2004 5357.79 4810 2005 4810 4912.88 2006 4912.88 5661.16 2007 5661.16 4724.11 4724.11 2008 4766.26 4766.26 2009 5524.54 2010 5524.54 6218.73 2011 6218.73 9761.57 2012 9761.57 11718.01 2013 11718.01 6800.23 6800.23 2014 9279.16 2015 9279.16 6489.97 6489.97 2016 5124.24 2017 5124.24 4916.25 2018 4916.25 5169.96 5169.96 2019 5644.86 5644.86 2020 散点图如图所示:更多精品文档. 学习-----好资料
9000800070006000Y5000400030001200080004000100006000X )线性分析如表所示:1(Dependent Variable: Y Method: Least Squares Date: 11/22/11 Time: 21:56 Sample: 2001 2020 Included observations: 20 Y=C(1)+C(2)*X Prob. t-Statistic Coefficient Std. Error 0.1053 159.6773 1.705713 272.3635 C(1) 0.0000 0.023316 32.38690 C(2) 0.755125 0.983129 Mean dependent var R-squared 5199.515 Adjusted R-squared 0.982192 S.D. dependent var 1625.275 S.E. of regression 13.69130 216.8900 Akaike info criterion Sum squared resid 13.79087 846743.0 Schwarz criterion Log likelihood 1.670234 -134.9130 Durbin-Watson stat )异方差性检验2(从大到小排序,去掉中间x检验。在对Q20个样本按—首先采用G8. 估计,样本容量均为个个体,对前后两个样本进行4OLS更多精品文档.学习-----好资料 前一个样本的估计结果如表所示: Dependent Variable: Y Method: Least Squares Date: 11/22/11 Time: 22:17 Sample: 2001 2008 Included observations: 8 Y=C(1)+C(2)*X Prob. Std. Error t-Statistic Coefficient 0.7032 530.8892 C(1) 212.2118 0.399729
第十章 联立方程组模型 第一节 联立方程组模型概述 一、问题的提出 1、单一方程模型存在的条件是单向因果关系。 2、对于变量之间存在的双向因果关系,则需要建立联立方程组模型。 3、经济现象的表现多以系统或体系的形式进行,仅用单一方程来反映存在局限性。 二、联立方程组的概念 1、联立方程组模型的定义。 由一个以上的相互联系的单一方程组成的系统(模型),每一个单一方程中包含了一个过多个相互联系(相互依存)的内生变量。联立方程组表现的是多个变量间互为因果的联立关系。 联立方程组与单一方程的区别是估计联立方程组模型的参数必须考虑联立方程组所能提供的信息(包括联立方程组里方程之间的关联信息),而单一方程模型的参数估计仅考虑被估计方程自身所能提供的信息。 2、联立方程组模型的例子。 (1)一个均衡条件下市场供给与需求的关系。 ) 3()2(0 )1(012101110s i d i i i s i i i d i Q Q u P Q u P Q =>++=<++=βββααα 称(1)式为需求方程,(2)式为供给方程,(3)式为供需均衡式;d i Q 表示需求量,s i Q 表示供给量,i P 表示价格,i i u u 21,分别为(1)式和(2)式的随机误差项。按照经济学基本原理,商品的供给与商品的需求共同作用于价格,反过来,价格也要分别决定商品的供给与需求。这就是方程(1)与方程(2)的作用机制,如果考虑了均衡条件,这又是方程(3)的作用。因此,通过这一联
立方程组将上述商品的供需与价格的相互作用过程得到了反映。 (2)一个凯恩斯宏观经济模型。 011012(4)(5)(6) t t t t t t t t t t C Y u I Y u T C I G ββαα=++=++=++ 式中,C 表示消费,Y 表示国民总收入(又GDP ,实际上它们是有区别的),I 表示私人投资,G 表示政府支出,u1、u2分别为消费函数和投资函数中的随机误差项。 三、联立方程组模型的基本问题(即联立方程组模型的偏倚性) 1、内生解释变量与随机误差项的相关性。 2、直接对联立方程组模型运用OLS 法,所得的参数估计值是有偏的,并且是不一致的。 例如,设凯恩斯收入决定模型为 [][]01) (11)1() 0)(())(())())(((),cov(1)(11) 1(11)(111)1(1 01 2 21 11 1 1011101 1100110110≠-=-=-==-=--=-= -∴-+-=-+-+-=-+ -+-= ∴++=-+++=∴+=<<++=βσβββββββββββββββββββββU E U U E U E U Y E Y E U E U Y E Y E U Y U Y E Y I U E I Y E U I Y U I Y I U Y Y I C Y U Y C t t t t t t t t t t t t t t t t t t t t t t t t t 表明内生变量Y 在作解释变量时与随机误差U 相关。 对凯恩斯模型中的消费函数求参数的估计,有(用离差形式表示)