相关系数确定方法实验
1、下表是平时两次考试的成绩分数,假设其分布为正态,分别用积差相关与等级相关方法计算相关系数,并回答,就这份资料用哪种相关法更恰当?
被试 1 2 3 4 5 6 7 8 9 10
A 86 58 79 64 91 48 55 82 32 75
B 83 52 89 78 85 68 47 76 25 56
解:①求积差相关系数
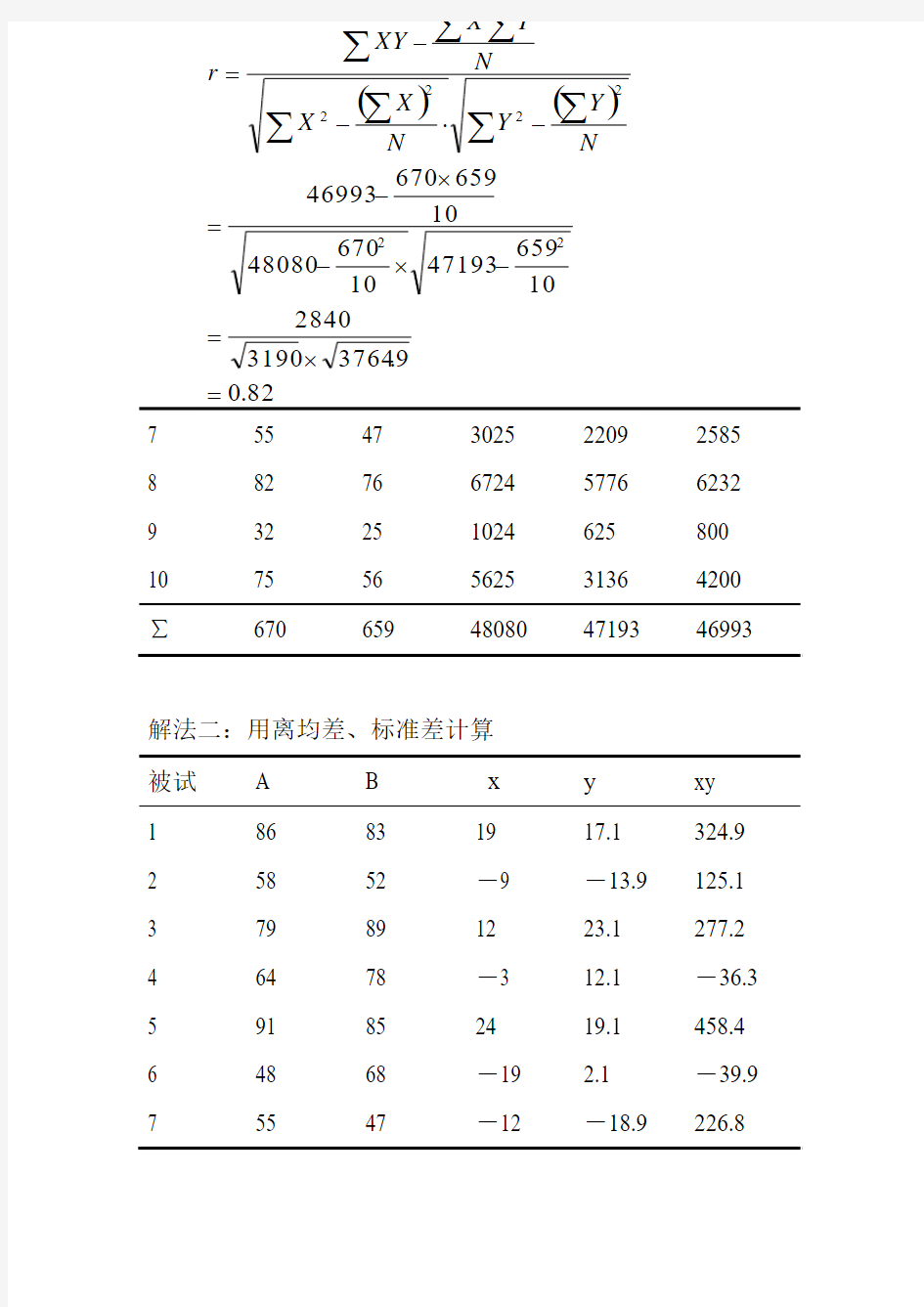
解法一:用原始分数计算
被试 A B X2 Y2 XY
1 86 83 7396 6889 7138
2 58 52 3364 2704 3016
3 79 89 6241 7921 7031
4 64 78 4096 6084 4992
5 91 85 8281 7225 7735
6 48 68 2304 4624 3264
7 55 47 3025 2209 2585
8 82 76 6724 5776 6232
9 32 25 1024 625 800
10 75 56 5625 3136 4200 ∑670 659 48080 47193 46993
解法二:用离均差、标准差计算
被试 A B x y xy
1 86 83 19 17.1 324.9
2 58 52 -9 -13.9 125.1
3 79 89 12 23.1 277.2
4 64 78 -3 12.1 -36.3
5 91 85 24 19.1 458.4
6 48 68 -19 2.1 -39.9
7 55 47 -12 -18.9 226.8
8 82 76 15 10.1 151.5 9 32 25 -35 -40.9 1431.5 10 75 56 8 -9.9 -79.2 ∑
670
659
2840
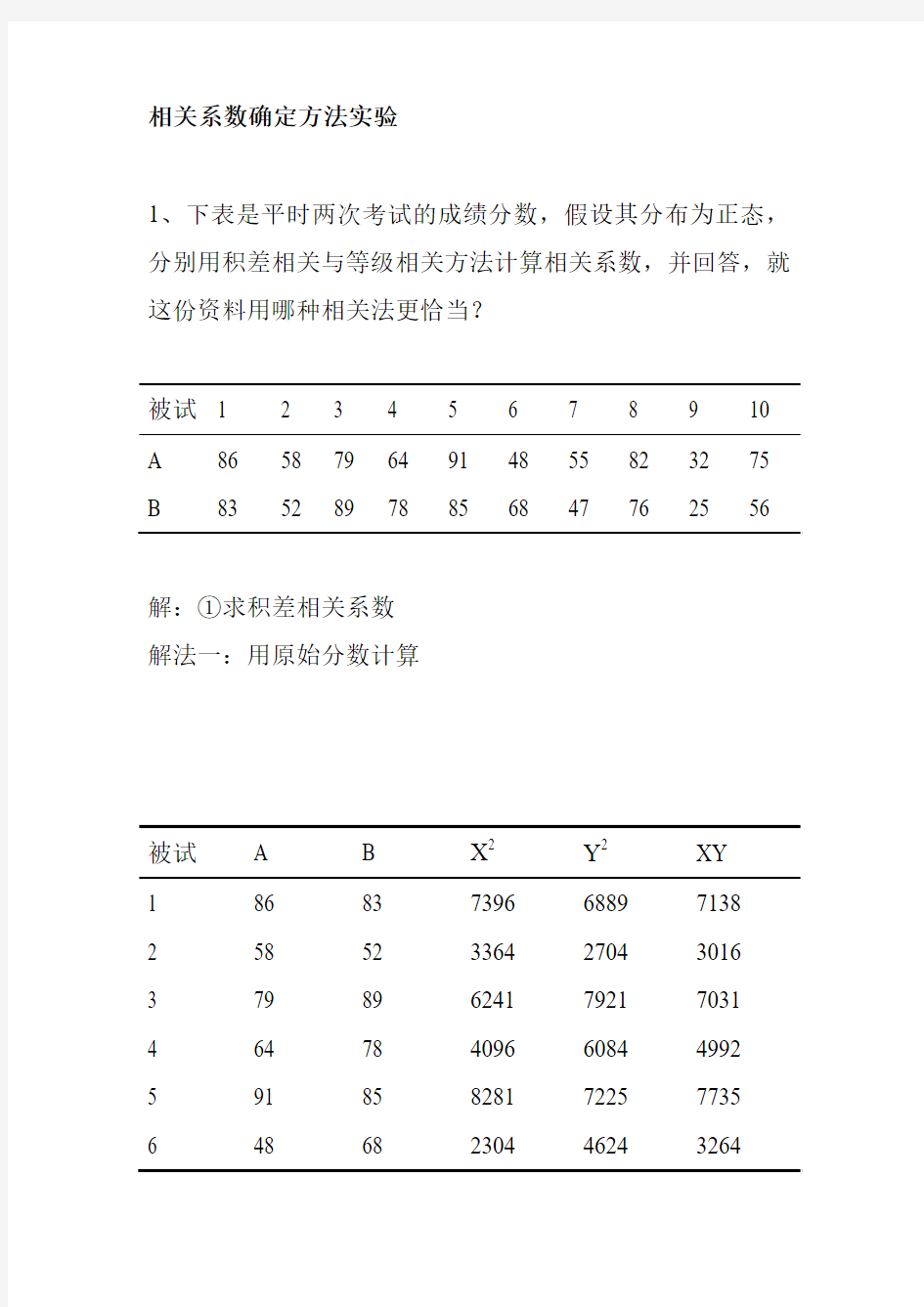
根据表中数据求得:40.19s 86.17s 9.65 67Y ====,,,
X Y X 把∑xy 、N 、s X 、s Y 代入公式得:
82.040
.1986.17102840
=??=
=∑Y
X s Ns xy r
②求等级相关系数 被试 A B R X R Y D D 2 R X R Y 1 86 83 2 3 -1 1 6 2 58 52 7 8 -1 1 56 3 79 89 4 1 3 9 4 4 64 78 6 4 2 4 24 5 91 85 1 2 -1 1 2 6 48 68 9 6 3 9 54 7 55 47 8 9 -1 1 72 8 82 76 3 5 -2 4 15 9 32 25 10 10 0 0 100 10 75 56 5 7 -2 4 35 ∑
55
55
34
368
解法一:
根据表中的计算,已知N=10,∑D 2=34,把N 、∑D 2代入公式,得:
()()79
.01101034
611612
22
=-?-=--
=∑N N D r R 解法二:
根据表中的计算,已知N=10,∑R X R Y =368,把N 、∑R X R Y 代入公式,得:
()()()()79
.01101101036841103
11413=??
????+-+??-=
??
??????+-+?-=∑N N N R R N r Y
X R
③这份资料用积差相关法更恰当,如用等级相关法,其精度要差于积差相关,因此,凡符合计算积差相关的资料,不要用等级相关计算。
2、下列两变量为非正态,选用恰当的方法计算相关。 被试 1 2
3
4
5
6 7 8 9 10 X 13 12 10 10 8 6 6 5 5 2 Y
14
11 11
11 7
7
5
4
4
4
解:两变量为非正态,用斯皮尔曼等级相关法计算相关,且用相同等级的计算公式。解题过程见下表: 学生
语言X 数学Y R X
R Y
D=R X -R Y D 2
1 13 14 1 1 0 0
2 12 11 2
3 -1 1
3 10 11 3.5 3 0.5 0.25
4 10 11 3.
5 3 0.5 0.25
5 8 7 5 5.5 -0.5 0.25
6 6
7 6.5 5.5 1 1
7 6 5 6.5 7 -0.5 0.25
8 5 4 8.5 9 -0.5 0.25
9 5 4 8.5 9 -0.5 0.25
10 2 4 10 9 1 1
N=10 ∑D2=4.5
根据表中数据可知,X(语言)有三个2个数据的等级相同,等级为3.5、6.5、8.5,Y(数学)有一个2个数据的等级相同,等级为5.5,两个3个数据的等级相同,等级为3、9。两对偶等级差的平方和∑D2=4.5,数据对数为N=10。所以有:()
()()()
5.1
12
1
2
2
12
1
2
2
12
1
2
2
12
1
2
2
2
2
=
-
+
-
+
-
=
-=∑
∑n n
C X
()
()()()
833 .2
12
1
2
2
12
1
2
2
121
2 2
12
1
3
3
2
2
=
-
+
-
+
-
=
-=∑
∑n n
C Y
81
5
.11210
1012332
--=--=∑∑X X C N
N 667
.79833
.21210
1012332
--=--=∑∑Y C N
N y 97
.066.1601667.156667.798125
.4667.798122
2
2
22
==
??-+=
??-+=
∑∑∑∑∑y
x D y x r RC
答:语言和数学的相关系数为0.97,说明两者之间相关。 3、问下表中成绩与性别是否有关? 被试 1
2
3
4
5 6 7 8 9 10 性别 男 女 女 男 女 男 男 男 女 女 成绩B
83 91 95 84 89
87
86
85
88
92
解:已知N=10,男生人数为5人,女生人数为5人。 设p 为男生人数的比率,q 女生人数的比率
Xp 为男生在该测验中总分的平均成绩 Xq 为女生在该测验中总分的平均成绩
s t 为所有学生在该测验中总成绩的标准差 则,
60.391
855.010
55.0105=======
t s Xq ,Xp ,q p 把p 、q 、Xp 、Xq 、s t 的值代入公式得:
83.05.05.060.39185=??-=?-=
pq s Xq
Xp r t
pb 答:成绩与性别相关系数为0.83,相关较高,即女生成绩高,男生
成绩低。
4、问下表中成绩A(为正态)与成绩B 是否有关?
被试 1 2 3 4 5 6 7 8 9 10 成绩A
及格 不
及
格
及
格 不
及
格
及格
不及格
及格
不及格
及格
不及格
成绩B
83 91 95 84 89 87 86 85 88 92
解法一:
88=Xt
60.3=t s
8
.872.88==q X p X
p=5/10=0.5,q=0.5
查正态分布表,当P=0.5时,y=0.39894
代入公式得:
06.039894.05.05.060.38.872.88=??-=?-=
y
pq
s q X p X r t b
解法二:
88=Xt
60.3=t s
8
.872.88==q X p X
p=5/10=0.5,q=0.5
查正态分布表,当P=0.5时,y=0.39894 代入公式得:
07.039894.05.060.3882.88=?-=?-=
y p
s t X p X r t b
相关分析及假设检验 spss 1.概念 变量之间相关,但是又不能由一个或几个变量值去完全和唯一确定另一个变量值的这种关系称为相关关系。相关关系是普遍存在的,函数关系仅仅是相关关系的特例。事物之间有相关关系,不一定是因果关系,也可能仅是伴随关系,但是事物之间有因果关系,则两者必然相关。 相关分析用于分析两个随机变量的关系,可以检验两个变量之间的相关度或多个变量两两之间的相关程度,也可以检验 两组变量之间的相关程度 偏相关分析是指在控制了其他变量的效应以后,对两个变量相关程度的分析。、 2.皮尔逊积差相关系数pearson product-moment correlation coefficient 变量之间的相关程度由相关系数来度量,pearson相关系数是应用最广的一种。它用于检验连续型变量之间的线性相关程度 2.1前提假设 1)正态分布皮尔逊积差相关只适用于双元正态分布的变量,即两个变量都是正态分布,注意只有pearson要求正态分布 如果正态分布的前提不满足,两变量间的关系可能属于非线性相关 2)样本独立样本必须来自总体的随机样本,而且样本必须相互独立 3)替换极值变量中的极端值如极值、离群值对相关系数的影响较大,最好加以删除或代之以均值或中数 2.2相关分析的前提假设检验 一般情况下是对是否满足正态分布进行检验,对于正态分布的检验有好几种方法,总的可分为非参数检验和图形检验法 1)非参数检验法 spss中的1-sample K-S检验,检验样本数据是否服从某种特定的分布,方法有三种 a. Asymptotic only 是一种基于渐进分布的显著性水平的检验指标,通常显著性水平小于0.05则认为显著,适用于大样本。如果 样本过小或分布不好,该指标的适用性会降低 b.Monte Carlo 精确显著性水平的无偏估计,适用于样本过大无法使用渐进方法估计显著性水平的情况,可以不必依赖渐近方法的假设前提 c.Exact 精确计算观测结果的概率值,通常小于0.05即被认为显著,表明横变量和列变量之间存在相关,同时允许用户键入每次检验的最长 时间显著,可以键入1到9999999999之间的数字,但只要一次检验超过指定时间的30分钟,就应该用monte carlo 假设是服从某种分布 所以如果计算出的值比如Asymp. Sig 小于0.05,那么拒绝原假设,说明样本为非正态分布,否则值越大越服从某种分布 单样本K-S首先计算每一阶段实际值与观察值的差异值,再计算每一阶段差异值的绝对值Z,即K-S的Z值,Z值越大,样本服从理论分布的可能性越小 还有一个是2 -sample Kolmogorov—Smirnov用于检验2个样本的分布是相同的假设 2)图形法 spss中graph a.Q-Q正态检验图
附表二:相关系数临界值表 (表中是自由度) n -2 0.10 0.05 0.02 0.01 0.001 n -2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 25 30 35 40 45 50 60 70 80 90 100 0.987 69 0.900 00 0.805 4 0.729 3 0.669 4 0.621 5 0.582 2 0.549 4 0.521 4 0.497 3 0.476 2 0.457 5 0.440 9 0.425 9 0.412 4 0.400 0 0.388 7 0.378 3 0.368 7 0.359 8 0.323 3 0.296 0 0.274 6 0.257 3 0.242 8 0.230 6 0.210 8 0.195 4 0.182 9 0.172 6 0.163 8 0.099 692 0.950 00 0.878 3 0.811 4 0.754 5 0.706 7 0.666 4 0.631 9 0.602 1 0.576 0 0.552 9 0.532 4 0.513 9 0.497 3 0.482 1 0.468 3 0.455 5 0.443 8 0.432 9 0.422 7 0.380 9 0.349 4 0.324 6 0.304 4 0.287 5 0.273 2 0.250 0 0.231 9 0.217 2 0.205 0 0.194 6 0.999 507 0.980 00 0.934 33 0.882 2 0.832 9 0.788 7 0.749 8 0.715 5 0.685 1 0.658 1 0.633 9 0.612 0 0.592 3 0.574 2 0.557 7 0.542 5 0.528 5 0.515 5 0.503 4 0.492 1 0.445 1 0.409 3 0.381 0 0.357 8 0.338 4 0.321 8 0.294 8 0.273 7 0.256 5 0.242 2 0.230 1 0.999 877 0.990 00 0.958 73 0.917 20 0.874 5 0.834 3 0.797 7 0.764 6 0.734 8 0.707 9 0.683 5 0.661 4 0.641 1 0.622 6 0.605 5 0.589 7 0.575 1 0.561 4 0.548 7 0.536 8 0.486 9 0.448 7 0.418 2 0.393 2 0.372 1 0.354 1 0.324 8 0.301 7 0.283 0 0.267 3 0.254 0 0.999 998 8 0.999 00 0.991 16 0.974 06 0.950 74 0.924 93 0.898 2 0.872 1 0.847 1 0.823 3 0.801 0 0.780 0 0.760 3 0.742 0 0.724 6 0.708 4 0.693 2 0.678 7 0.665 2 0.652 4 0.597 4 0.554 1 0.518 9 0.489 6 0.464 8 0.443 3 0.407 8 0.379 9 0.356 8 0.337 5 0.321 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 25 30 35 40 45 50 60 70 80 90 100
第六章 相关系数检验 一般来说,在回归模型的基本假设中,有一个假设条件是最为重要的,这就是假设变量之间在概率意义上存在线性关系;亦即)(i Y E =i X βα+或)(i E μ=0。这里的“概率意义”,虽说与确定意义有差别,但由于概率意义的前提必须承认规律的存在;故我认为,这里的“线性关系”与确定意义下的“线性关系”并无根本性的区别。因此,我们可以说,概率意义上的线性关系仍是一般意义上的线性思路或方法,只是分析的条件有所放松而已。 现在我们要问,在建立回归模型时,这个假设条件成立吗?显然需要进行检验,需要建立一种检验方法。 6·1、建立相关系数检验方法的基本思路 实际上,建立相关系数检验方法的基本思路是较为简单和清晰的。其基本思路是:建立一种方法(2R ),希望此方法在测定被解释变量Y 的总的变化中,推出回归直线能够解释的部分有多大;即通过两者之比的大小,来推断回归模型效果的好坏。下面简要介绍其方法的建立过程: 首先,我们有 Y 的总的变化可表示为 : Y Y y i i -= 回归直线能够解释的部分: Y Y y i i -=?? 由此我们可以得到,回归直线没有(或不能)解释的部分为:i i i Y Y e ?-= 因而我们有 Y 的总的变差=∑∑∑++=+=)?2?()?(2 2 22 i i i i i i i e e y y e y y 其中,)(?)?(?)?)(?(?2 22∑∑∑∑∑∑∑- =-=-=i i i i i i i i i i i i i i x x y x y x x y x x y x e y βββββ =0 (注意:i i i i x X Y Y y X Y X Y ββαβαβαβα???????,??,??=---=-=∴+=∴-= ,另外 i i i i i i i x y y y Y Y e β???-=-=-=)。 所以,我们最终有 Y 的总的变差==∑∑∑∑+=++=+=)?()?2?()?(2 2 2 2 22 i i i i i i i i i e y e e y y e y y 亦即, Y 的总的变差=回归直线能够解释的部分部分+回归直线不能够解释的部分
自由度自由度n -m -10.10 0.05 0.01 n -m -10.10 0.05 0.01 10.987690.996920.999882010.018230.010910.0028820.900000.950000.990002020.050680.043320.0258130.805380.878340.958742030.068740.066150.0518940.729300.811400.917202040.079150.080690.0725350.669440.754490.874532050.085730.090380.0880760.621490.706730.834342060.090190.097180.0998670.582210.666380.797682070.093370.102170.1089880.549360.631900.764592080.095730.105950.1161890.521400.602070.734792090.097520.108880.12197100.497260.575980.707892100.098910.111200.12670110.476160.552940.683532110.100010.113070.13062120.457500.532410.661382120.100890.114600.13390130.440860.513980.641142130.101600.115860.13667140.425900.497310.622592140.102170.116900.13903150.412360.482150.605512150.102640.117770.14106160.400030.468280.589712160.103020.118500.14281170.388730.455530.575072170.103320.119110.14432180.378340.443760.561442180.103560.119620.14564190.368740.432860.548712190.103760.120060.14679200.359830.422710.536802200.103910.120420.14780210.351530.413250.525622210.104020.120720.14869220.343780.404390.515102220.104100.120970.14946230.336520.396070.505182230.104160.121170.15015240.329700.388240.495812240.104190.121340.15075250.323280.380860.486932250.104200.121470.15127260.317220.373890.478512260.104190.121570.15173270.311490.367280.470512270.104170.121640.15214280.306060.361010.462892280.104130.121690.15249290.300900.355050.455632290.104080.121720.15279300.295990.349370.448702300.104020.121730.15306310.291320.343960.442072310.103950.121730.15328320.286860.338790.435732320.103870.121700.15348330.282590.333840.429652330.103780.121670.15364340.278520.329110.423812340.103680.121620.15377350.274610.324570.418212350.103580.121560.15388360.270860.320220.412822360.103470.121490.15396370.267270.316030.407642370.103360.121410.15403380.263810.312010.402642380.103240.121320.15407390.260480.308130.397822390.103120.121220.15409400.257280.304400.393172400.103000.121120.15410410.254190.300790.388682410.102870.121010.1541042 0.251210.297320.38434242 0.102740.120900.15408 显著性水平(a ) 显著性水平(a ) 相关系数检验临界值表
权重系数的确定 1、“差异驱动原理” 根据公式j s j k1 m s k ,j1,2,^, 求得各个指标的权重系数,其中 s j21 n x ij x j2,x j 1 n j1 n x ij,j1,2,^ 此方法利用数学理论,较好的避开了在评价中主观因素的影响。但是在现实决策和评价中,评价者的主观信息也是很重要的。 2、 1 基于证据推理与粗集理论的主客观综合评价方法,对复杂问题进行评价时,通常先将其划分成若干个评价单元,根据其逻辑关系进行层次化划分,并构造出相应的指标体系,接着对评价单元内的评价指标进行评价与合成,然后将具有层次性逻辑关系的评价单元状态进行合成,最终达到对系统进行综合评价的目的。不确定知识条件下对于评价单元内属性进行评价与推理的基本模型见图1[1]。在该模型中,ejk表示评价单元内的下层属性,其集合定义为Ek= {e1k…ejk…elk};H= [H1,H2,…,Hn]代表评语集,对应的量化值表示为P(H) = [P(H1),…,P(Hn)];yk表示评价单元内的上层属性。粗集理论在知识发现方面已获得了很大的成功。它可以处理模糊性和不确定性问题,并可根据所给数据直接推得结论[2]。证据推理在处理主观判断问题以及不确定知识的合成方面具有优势。把二者结合起来就可把主观判断和过去可用的知
(一)确定各要素间的相互影响关系 评价博士学位论文水平的要素比较多,各要素 之间存在相互作用、相互影响关系。例如,论文的选题会直接影响其研究成果的实际应用价值和创新性等,而学位论文是否具有创新成果,也是判断其应用价值大小的主要要素;研究生的科学研究能力又直接影响其学术成果的创新性;等等。根据我国博士学位论文评价的实际情况,以及相关专家的研究成果,我们首先理清上述各要素之间的影响关系,再按照解释结构模型法的原理,建立各评价要素的关系矩阵R,即R为8阶方阵,如图1所示。“1”表示评 x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8
附表11(1)相关系数界值表 P(2): 0.50 0.20 0.10 0.05 0.02 0.01 0.005 0.002 0.001 P(1): 0.25 0.10 0.05 0.025 0.01 0.005 0.0025 0.001 0.0005 1 0.707 0.951 0.988 0.997 1.000 1.000 1.000 1.000 1.000 2 0.500 0.800 0.900 0.950 0.980 0.990 0.995 0.998 0.999 3 0.40 4 0.687 0.80 5 0.878 0.934 0.959 0.974 0.98 6 0.991 4 0.347 0.603 0.729 0.811 0.882 0.917 0.942 0.963 0.974 5 0.309 0.551 0.669 0.755 0.833 0.875 0.90 6 0.935 0.951 6 0.281 0.50 7 0.621 0.707 0.789 0.834 0.870 0.905 0.925 7 0.260 0.472 0.582 0.666 0.750 0.798 0.836 0.875 0.898 8 0.242 0.443 0.549 0.632 0.715 0.765 0.805 0.847 0.872 9 0.228 0.419 0.521 0.602 0.685 0.735 0.776 0.820 0.847 10 0.216 0.398 0.497 0.576 0.658 0.708 0.750 0.795 0.823 11 0.206 0.380 0.476 0.553 0.634 0.684 0.726 0.772 0.801 12 0.197 0.365 0.457 0.532 0.612 0.661 0.703 0.750 0.780 13 0.189 0.351 0.441 0.514 0.592 0.641 0.683 0.730 0.760 14 0.182 0.338 0.426 0.497 0.574 0.623 0.664 0.711 0.742 15 0.176 0.327 0.412 0.482 0.558 0.606 0.647 0.694 0.725 16 0.170 0.317 0.400 0.468 0.542 0.590 0.631 0.678 0.708 17 0.165 0.308 0.389 0.456 0.529 0.575 0.616 0.622 0.693 18 0.160 0.299 0.378 0.444 0.515 0.561 0.602 0.648 0.679 19 0.156 0.291 0.369 0.433 0.503 0.549 0.589 0.635 0.665 20 0.152 0.284 0.360 0.423 0.492 0.537 0.576 0.622 0.652 21 0.148 0.277 0.352 0.413 0.482 0.526 0.565 0.610 0.640 22 0.145 0.271 0.344 0.404 0.472 0.515 0.554 0.599 0.629 23 0.141 0.265 0.337 0.396 0.462 0.505 0.543 0.588 0.618 24 0.138 0.260 0.330 0.388 0.453 0.496 0.534 0.578 0.607 25 0.136 0.255 0.323 0.381 0.445 0.487 0.524 0.568 0.597 26 0.133 0.250 0.317 0.374 0.437 0.479 0.515 0.559 0.588 27 0.131 0.245 0.311 0.367 0.430 0.471 0.507 0.550 0.579 28 0.128 0.241 0.306 0.361 0.423 0.463 0.499 0.541 0.570 29 0.126 0.237 0.301 0.355 0.416 0.456 0.491 0.533 0.562 30 0.124 0.233 0.296 0.349 0.409 0.449 0.484 0.526 0.554 31 0.122 0.229 0.291 0.344 0.403 0.442 0.477 0.518 0.546 32 0.120 0.226 0.287 0.339 0.397 0.436 0.470 0.511 0.539 33 0.118 0.222 0.283 0.334 0.392 0.430 0.464 0.504 0.532 34 0.116 0.219 0.279 0.329 0.386 0.424 0.458 0.498 0.525 35 0.115 0.216 0.275 0.325 0.381 0.418 0.452 0.492 0.519 36 0.113 0.213 0.271 0.320 0.376 0.413 0.446 0.486 0.513 37 0.111 0.210 0.267 0.316 0.371 0.408 0.441 0.480 0.507 38 0.110 0.207 0.264 0.312 0.367 0.403 0.435 0.474 0.501 39 0.108 0.204 0.261 0.308 0.362 0.398 0.430 0.469 0.495 40 0.107 0.202 0.257 0.304 0.358 0.393 0.425 0.463 0.490 41 0.106 0.199 0.254 0.301 0.354 0.389 0.420 0.458 0.484 42 0.104 0.197 0.251 0.297 0.350 0.384 0.416 0.453 0.479 43 0.103 0.195 0.248 0.294 0.346 0.380 0.411 0.449 0.474
一、指标权重的确定 1.综述 目前关于属性权重的确定方法很多,根据计算权重时原始数据的来源不同,可以将这些方法分为三类:主观赋权法、客观赋权法、组合赋权法。 主观赋权法是根据决策者(专家)主观上对各属性的重视程度来确定属性权重的方法,其原始数据由专家根据经验主观判断而得到。常用的主观赋权法有专家调查法(Delphi法)、层次分析法(AHP )[106-108]、二项系数法、环比评分法、最小平方法等。本文选用的是利用人的经验知识的有序二元比较量化法。 主观赋权法是人们研究较早、较为成熟的方法,主观赋权法的优点是专家可以根据实际的决策问题和专家自身的知识经验合理地确定各属性权重的排序,不至于出现属性权重与属性实际重要程度相悖的情况。但决策或评价结果具有较强的主观随意性,客观性较差,同时增加了对决策分析者的负担,应用中有很大局限性。 鉴于主观赋权法的各种不足之处,人们又提出了客观赋权法,其原始数据由各属性在决策方案中的实际数据形成,其基本思想是:属性权重应当是各属性在属性集中的变异程度和对其它属性的影响程度的度量,赋权的原始信息应当直接来源于客观环境,处理信息的过程应当是深入探讨各属性间的相互联系及影响,再根据各属性的联系程度或各属性所提供的信息量大小来决定属性权重。如果某属性对所有决策方案而言均无差异(即各决策方案的该属性值相同),则该属性对方案的鉴别及排序不起作用,其权重应为0;若某属性对所有决策方案的属性值有较大差异,这样的属性对方案的鉴别及排序将起重要作用,应给予较大权重.总之,各属性权重的大小应根据该属性下各方案属性值差异的大小来确定,差异越大,则该属性的权重越大,反之则越小。 常用的客观赋权法[109-110]有:主成份分析法、熵值法[111-112]、离差及均方差法、多目标规划法等。其中熵值法用得较多,这种赋权法所使用的数据是决策矩阵,所确定的属性权重反映了属性值的离散程度。
权重的确定方法 权重是一个相对的概念,是针对某一指标而言。某一指标的权重是指该指标在整体评价中的相对重要程度。在模糊决策中,权重至关重要,他反映了各个因素在综合决策过程中所占有的地位和所起的作用,直接影响决策的结果。通常是根据经验给出权重,不可否认这在一定程度上能反映实际情况,但凭经验给出的权重有时不能客观的反映实际情况,导致评判结果“失真”。比较客观的权重的判定方法有如下几种: 1.确定权重的统计方法 1.1专家估测法 该法又分为平均型、极端型和缓和型。主要根据专家对指标的重要性打分来定权,重要性得分越高,权数越大。优点是集中了众多专家的意见,缺点是通过打分直接给出各指标权重而难以保持权重的合理性。 设因素集U={n u u u ,...,2,1},现有k 个专家各自独立的给出各个因素i u (i=1,2,...,n )的权重, ∑==k j ij i a k a 11(i=1,2,...,n ),即)1,...,1,1(1 1211∑∑∑====k j nj k j j k j j a k a k a k A 。 1.2加权统计方法 当专家人数k<30人时,可用加权统计方法计算权重。 按公式i s i i k x w a ∑==1计算(其中s 为序号数)然后可得权重A 。 1.3频数统计方法 由所有专家独立给出的各个因素的权重,得到权重分配表,对各个因素i u (i=1,2,...,n )进行但因素的权重统计实验,步骤如下: 第一步:对因素i u (i=1,2,...,n )在它的权重ij a (j=1,2,...,k)中找出最大值i M 和最小值i m , 即{}ij k j i a M ≤≤=1max ,{} ij k j i a m ≤≤=1min . 第二步;适当选取整数p,利用公式p m M i i -计算出权重分为p 组的组距,并将权重从小到大分 为p 组. 第三步:计算出落在每组内权重的频数和频率. 第四步:根据频数和频率的分布请况,取最大频率所在分组的组中值为因素i u 的权重i a (i=1,2,...,n ),从而得权重A=(n a a a ,...,,21). 1.4因子分析权重法 根据数理统计中因子分析方法,对每个指标计算共性因子的累积贡献率来定权。累积贡献率越大,说明该指标对共性因子的作用越大,所定权数也越大。 1.5信息量权数法 根据各评价指标包含的分辨信息来确定权数。采用变异系数法,变异系数越大,所赋的
权重的确定方法 ——数学建模协会A.权重简介 在统计理论和实践中,权重是表明各个评价指标(或者评价项目)重要性的权数,表示各个评价指标在总体中所起的不同作用。权重有不同的种类,各种类别的权重有着不同的数学特点和经济含义,一般有以下几种权重。 按照权重的表现形式的不同,可分为绝对数权重和相对数权重。相对数权重也称比重权数,能更加直观地反映权重在评价中的作用。 按照权重的形成方式划分,可分为人工权重和自然权重。自然权重是由于变换统计资料的表现形式和统计指标的合成方式而得到的权重,也称为客观权重。人工权重是根据研究目的和评价指标的内涵状况,主观地分析、判断来确定的反映各个指标重要程度的权数,也称为主观权重。 按照权重形成的数量特点的不同划分,可分为定性赋权和定量赋权。如果在统计综合评价时,采取定性赋权和定量赋权的方法相结合,获得的效果更好。 按照权重与待评价的各个指标之间相关程度划分,可分为独立权重和相关权重。 独立权重是指评价指标的权重与该指标数值的大小无关,在综合评价中较多地使用独立权重,以此权重建立的综合评价模型称为“定权综合”模型。 相关权重是指评价指标的权重与该指标的数值具有函数关系,例如,当某一评价的指标数值达到一定水平时,该指标的重要性相应的减弱;或者当某一评价指标的数值达到另一定水平时,该指标的重要性相应地增加。相关权重适用于评价指标的重要性随着指标取值的不同而发生变化的条件下,基于相关权重建立的综合评价模型被称为“变权模型”。比如评估环境质量多采用“变权综合”模型。 确定权重的方法较多,这里介绍统计平均法、变异系数法和层次分析法,这些也是实际工作种常用的方法。 B.确定权重的原则 一、系统优化原则 在评价指标体系中,每个指标对系统都由它的作用和贡献,对系统而言都有它的重要性。所以,在确定它们的权重时,不能只从单个指标出发,而是要处理好各评价指标之间的关系,合理分配它们的权重。应当遵循系统优化原则,把整体最优化作为出发点和追求的目标。在这个原则指导下,对评价指标体系中各项评价指标进行分析对比,权衡它们各自对整体的作用和效果,然后对它们的相对重要性做出判断。确定各自的权重,即不能平均分配,又不能片面强调某个指标、单个指标的最优化,而忽略其他方面的发展。在实际工作中,应该使每个指标发挥其应有的作用。 二、评价者的主观意图与客观情况相结合的原则 评价指标权重反映了评价者和组织对人员工作的引导意图和价值观念。当他们觉得某项指标很重要,需要突出它的作用时,就必然各该指标以较大的权数。但现实情况往往与人们的主观意愿不完全一致,比如,确定权重时要考虑这样几个问题:(1)历史的指标和现实的指标;(2)社会公认的和企业的特殊性;(3)同行业、同工种间的平衡。所以,必须同时考虑现实情况,把引导意图与现实情况结合起来。前面已经讲过,评价经营者的经营业绩应该把经济效益和社会效益同时加以考虑。 三、民主与集中相结合的原则 权重是人们对评价指标重要性的认识,是定性判断的量化,往往受个人主观因素的影响。不
权重的确定方法 一、权重的概念 用若干个指标进行综合评价是,其对被评价的作用,从评价目标来看并不是同等重要。在统计综合评价中,权属的大小反映了评价指标的重要程度,权数大的评价指标重要程度大,权数小的评价指标重要程度小。一般有两种表现形式:一是绝对数(频数)表示,另一种是用相对数(频率)表示。 (1)从含信息的多少来考虑。权数越大,评价指标所包含信息越多。 (2)从指标的区分能力来考虑,全数越大,说明评价指标区别被评价对象的能力越强。 二、权重的确定方法 对实际问题选定被综合的指标后,确定各指标的权的值的方法有很多种。概括起来,权重的确定方法从总体上可归为三大类:即主观赋权评价法、客观赋权评价法及组合集成赋权法。 (一)主观赋权法 所谓主观赋权法,就是指基于决策者的知识经验或偏好,通过按重要性程度对各指标(属性)进行比较、赋值和计算得出其权重的方法。对于主观赋权法的研究,目前已取得的主要成果有:层次分析法(AHP 法)、专家调研法(Delphi 法)。 1、德尔菲法 德尔菲法又称为专家法,其特点在于集中专家的知识和经验,确定各指标的权重,并在不断的反馈和修改中得到比较满意的结果。基本步骤如下: (1)选择专家。这是很重要的一步,选得好不好将直接影响到结果的准确性。一般情况下,选本专业领域中既有实际工作经验又有较深理论修养的专家10~30人左右,并需征得专家本人的同意。 (2)将待定权重的p 个指标和有关资料以及统一的确定权重的规则发给选定的各位专家,请他们独立的给出各指标的权数值。 (3)回收结果并计算各指标权数的均值和标准差。 (4)将计算的结果及补充资料返还给各位专家,要求所有的专家在新的基础上确定权数。 (5)重复第(3)和第(4)步,直至各指标权数与其均值的离差不超过预先给定的标准为止,也就是各专家的意见基本趋于一致,以此时各指标权数的均值作为该指标的权重。 此外,为了使判断更加准确,令评价者了解已确定的权数把握性大小,还可以运用“带有信任度的德尔菲法”,该方法需要在上述第(5)步每位专家最后给出权数值的同时,标出各自所给权数值的信任度。这样,如果某一指标权数的任任度较高时,就可以有较大的把握使用它,反之,只能暂时使用或设法改进。 2、层次分析法(AHP 法) 层次分析法(analytic hierarchy process, AHP)是70年代由著名运筹学家T.L.Saaty 提出的。 方法:多属性决策中,由决策者对所有评价指标进行两两比较,得判断矩阵() ij n n U u ?=, 其中ij u 为评价指标i s 与j s 比较而得的数值,取值为1至9之间的奇数,分别表示前者指标比后者指标同等重要、较重要、很重要、非常重要、绝对重要;当取值为1至9之间的偶数时,分别表示指标两两相比的重要性程度介于两个相邻奇数所表示的 重要性程度之间,且1 ij ji u u =。则:() 1 1 ()1,2,,n n j ij i W u j n ===∏ (二)、客观赋权法 客观赋权法,它是基于各方案评价指标值的客观数据的差异而确定各指标的权重的方法。目前,关于客观赋权法的主要研究成果有:基于“差异驱动”原理的赋权方法,可分为突出整体差异的“拉开档次法”和突出局部差异的“均方差法”、“嫡值法”以及“极差法”、“离差法”。 1、主成分分析法 方法:把多项评价指标综合成z 个主成分,再以这z 个主成分的贡献率为权数构造一个综合指标,并据此作出判断 特点:用:个线性无关的主成分代替原有的n 个评价指标,当这n 个评价指标的相关性较高时,这种方法能消除指标间信息的重叠;而且能根据指标所提供的信息,通过数学运算而主动赋权 2“拉开档次”法
相关系数显著性检验表(完整润色版)
11 (1) 相关系数界值表 0.10 0.05 0.988 0.900 0.805 0.729 0.669 0.621 0.582 0.549 0.521 0.497 0.476 0.457 0.441 0.426 0.412 0.400 0.389 0.378 0.369 0.360 0.352 0.344 0.337 0.330 0.323 0.317 0.311 0.306 0.301 0.296 0.291 0.287 0.283 0.279 0.275 0.271 0.267 0.264 0.261 0.257 0.254 0.251 0.248 0.246 0.05 0.025 0.997 0.950 0.878 0.811 0.755 0.707 0.666 0.632 0.602 0.576 0.553 0.532 0.514 0.497 0.482 0.468 0.456 0.444 0.433 0.423 0.413 0.404 0.396 0.388 0.381 0.374 0.367 0.361 0.355 0.349 0.344 0.339 0.334 0.329 0.325 0.320 0.316 0.312 0.308 0.304 0.301 0.297 0.294 0.291 0.02 0.01 1.000 0.980 0.934 0.882 0.833 0.789 0.750 0.715 0.685 0.658 0.634 0.612 0.592 0.574 0.558 0.542 0.529 0.515 0.503 0.492 0.482 0.472 0.462 0.453 0.445 0.437 0.430 0.423 0.416 0.409 0.403 0.397 0.392 0.386 0.381 0.376 0.371 0.367 0.362 0.358 0.354 0.350 0.346 0.342 0.01 0.005 1.000 0.990 0.959 0.917 0.875 0.834 0.798 0.765 0.735 0.708 0.684 0.661 0.641 0.623 0.606 0.590 0.575 0.561 0.549 0.537 0.526 0.515 0.505 0.496 0.487 0.479 0.471 0.463 0.456 0.449 0.442 0.436 0.430 0.424 0.418 0.413 0.408 0.403 0.398 0.393 0.389 0.384 0.380 0HH 附表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 0.50 0.20 P(1): 0.25 0.10 0.707 0.951 0.500 0.800 0.404 0.687 0.347 0.603 0.309 0.551 0.281 0.507 0.260 0.472 0.242 0.443 0.228 0.419 0.216 0.398 0.206 0.380 0.197 0.365 0.189 0.351 0.182 0.338 0.176 0.327 0.170 0.317 0.165 0.308 0.160 0.299 0.156 0.291 0.152 0.284 0.148 0.277 0.145 0.271 0.141 0.265 0.138 0.260 0.136 0.255 0.133 0.250 0.131 0.245 0.128 0.241 0.126 0.237 0.124 0.233 0.122 0.229 0.120 0.226 0.118 0.222 0.116 0.219 0.115 0.216 0.113 0.213 0.111 0.210 0.110 0.207 0.108 0.204 0.107 0.202 0.106 0.199 0.104 0.197 0.103 0.195 0.102 0.192 0.00! 0.00 2 0.0025 0.00 1 1.000 1.00 0.995 0.99 8 0.974 0.98 6 0.942 0.96 3 0.906 0.93 5 0.870 0.90 5 0.836 0.87 5 0.805 0.84 7 0.776 0.82 0.750 0.79 5 0.726 0.77 2 0.703 0.75 0.683 0.73 0.664 0.71 1 0.647 0.69 4 0.631 0.67 8 0.616 0.62 2 0.602 0.64 8 0.589 0.63 5 0.576 0.62 2 0.565 0.61 0.554 0.59 9 0.543 0.58 8 0.534 0.57 8 0.524 0.56 8 0.515 0.55 9 0.507 0.55 0.499 0.54 1 0.491 0.53 3 0.484 0.52 6 0.477 0.51 8 0.470 0.51 1 0.464 0.50 4 0.458 0.49 8 0.452 0.49 2 0.446 0.48 6 0.441 0.48 0.435 0.47 4 0.430 0.46 9 0.425 0.46 3 0.420 0.45 8 0.416 0.45 3 0.411 0.44 9 0.407 0.44 4 0.001 0.0005 1.000 0.999 0.991 0.974 0.951 0.925 0.898 0.872 0.847 0.823 0.801 0.780 0.760 0.742 0.725 0.708 0.693 0.679 0.665 0.652 0.640 0.629 0.618 0.607 0.597 0.588 0.579 0.570 0.562 0.554 0.546 0.539 0.532 0.525 0.519 0.513 0.507 0.501 0.495 0.490 0.484 0.479 0.474 0.469 收集于网络,如有侵权请联系管理员删除
3.3 评价因素权重确定的基本理论 权重是一个相对的概念,在评价因素体系中每个因素对实现评价目标和功能的相对重要程度就是该因素的权重。权重是综合评价的重要信息,一组评价指标体系相对应的权重组成权重体系。一组权重体系{W i|i=i,2,…,n}必须满足下述两个条件: (1)0 < wi < 1,i=1,2,…,n。(3-1 ) n (2)w i 1 (3-2) i1 其中n 是权重指标的个数 一级指标和二级指标权重的确定: 设某一评价的一级指标体系为{V i |i=1,2,…,n}其对应权重体系为{W i|i=1,2,…,n}则有: (1) 0 < W i < 1 , i=1,2,…,n。(3-3) n ( 2) W i 1 (3-4) i1 如果该评价的二级指标体系为{V j |i=1,2,…,n ; j=1,2,…,m},则其对应的权重体系为{W j|i=1,2,…,n ; j=1,2,…,m}应满足: (1) 0< w i < 1 , i=1,2,…,n。(3-5) n ( 2) W i 1 (3-6) i1 nm ( 3) W i W ij = 1 (3-7) i1j1 对于三级、四级指标可以以此类推。权重体系是相对指标体系来确定的。首先必须有指标体系,然后才有相应权重系数。指标权重的选择实际也是对系统评价指标进行排序的过程,而且权重值的构成应符合以上的条件。
3.4权重确定的方法 权重确定的方法很多,主要有主成分分析法、德尔菲法(Delphi )、层次分析法 (AHP。本文中主要运用层次分析法来确定评价因素的权重。 层次分析法通过分析复杂系统所包含的因素及相关关系,将系统分解为不同 的要素,并将这些要素划规不同层次,从而客观上形成多层次的分析结构模型。将每一层次的各要素进行两两比较判断,按照一定的标度理论,得到其相对重要程度的比较标度,建立判断矩阵。通过计算判断矩阵的最大特征值极其相应的特征向量,得到各层次要素的重要性次序,从而建立权重向量【5】。 层次分析法确定权重的步骤: (1)建立树状层次结构模型。在本文中,该模型就是安全评价因素体系。 (2)确立思维判断定量化的标度。在两个因素相互比较时,需要有定量的标度,假设使用前面的标度方法,则其含义如表4-1所示, 按表4-1标度方法来确定标度。 表3-1层次分析法判断标度确定原则 标度含义 1表示两个因素相比具有等性 3表示两个因素相比一个因素比另一个因素稍微重要 5表示两个因素相比一个因素比另一个因素明显重要 7表示两个因素相比一个因素比另一个因素强烈重要 9表示两个因素相比一个因素比另一个因素极端重要 2、4、6、8为上述相邻判断的中值 (3)构造判断矩阵。运用两两相比的方法,对各相关元素进行两两相比较评分,根据中间层若干指标,可得到若干两两比较判断矩阵。 (4)计算权重。这一步将解决n个元素A , A2,…A n权重的计算问题,对于表4-2的两两比较的方法得到矩阵A,解矩阵特征根,计算权重向量和特征根max的方法有“和积法”、“方根法”、和“根法”。 本文选用了计算较为简便的“和积法”,其计算步骤如下: ①对A按列规范化,即对判断矩阵A每一列正规化: a ij a ij n (i,j =1,2,…,n )(3-8) a ij
变异系数又称“标准差率”,是衡量资料中各观测值变异程度的另一个统计量。当进行两个或多个资料变异程度的比较时,如果度量单位与平均数相同,可以直接利用标准差来比较。如果单位和(或)平均数不同时,比较其变异程度就不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。 标准差与平均数的比值称为变异系数,记为C.V。变异系数可以消除单位和(或)平均数不同对两个或多个资料变异程度比较的影响。 标准变异系数是一组数据的变异指标与其平均指标之比,它是一个相对变异指标。 变异系数有全距系数、平均差系数和标准差系数等。常用的是标准差系数,用CV(Coefficient of Variance)表示。 CV(Coefficient of Variance):标准差与均值的比率。 用公式表示为:CV=σ/μ 作用:反映单位均值上的离散程度,常用在两个总体均值不等的离散程度的比较上。若两个总体的均值相等,则比较标准差系数与比较标准差是等价的。 变异系数又称离散系数。 cpa中也叫“变化系数”
Analyze-Descriptive,计算出标准差和均值,然后用标准差除以均值就算出变异系数了 如何用SPSS软件计算两个变量之间的相关系数? 怎么判定相关是不是显著相关呢? analyze-correlate-bivariate-选择变量 OK 输出的是相关系数矩阵 相关系数下面的Sig.是显著性检验结果的P值,越接近0越显著。另外,表格下会显示显著性检验的判断结果,你看看表格下的解释就知道,比如“**. Correlation is significant at the 0.01 level (2-tailed).” 就是说,如果相关系数后有"**"符号,代表在0.01显著性水平下显著相关 粗略判断的方法是,相关系数0.8以上,可以认为显著相关了 在这个图表中,你说的R值就是皮尔逊相关系数~(pearson correlation) r>0 代表两变量正相关,r<0代表两变量负相关。