
第五章练习题参考解答
练习题
5.1 设消费函数为
Y i = 1 :2X2i 3X3 U i
式中,Y为消费支出;X2i为个人可支配收入;X3i为个人的流动资产;u i为随机误差
2 2 2
项,并且E(u」=O,Var(u」-;「X?i (其中匚为常数)。试回答以下问题:
(1) 选用适当的变换修正异方差,要求写出变换过程;
(2) 写出修正异方差后的参数估计量的表达式。
5.2根据本章第四节的对数变换,我们知道对变量取对数通常能降低异方差性,但
须对这种模型的随机误差项的性质给予足够的关注。例如,设模型为丫二,X "u,对该模型中的变量取对数后得如下形式
In Y =ln * 2lnX Inu
(1)如果In u要有零期望值,u的分布应该是什么?
⑵如果E(u) =1,会不会E(ln u) = 0 ?为什么?
⑶如果E(ln u)不为零,怎样才能使它等于零?
5.3 由表中给出消费Y与收入X的数据,试根据所给数据资料完成以下问题:
(1)估计回归模型丫 = 1 ? jX u中的未知参数1和匕,并写出样本回归模型的书写格式;
(2)试用Goldfeld-Quandt 法和White法检验模型的异方差性;
(3)选用合适的方法修正异方差。
Y X Y X Y X
55 80 152 220 95 140
65 100 144 210 108 145
70 85 175 245 113 150
80 110 180 260 110 160
79 120 135 190 125 165
84 115 140 205 115 180 98 130 178 265 130 185
95 140 191 270 135 190 90 125 137 230 120 200 75 90 189 250
140
205 74 105 55 80 140 210 110 160 70 85 152 220
113 150 75 90
140
225
125 165 65
100 137 230 108 145 74 105 145 240
115
180 80 110 175 245
140 225
84 115 189
250
120 200 79 120 180 260
145 240 90 125 178 265
130 185 98 130 191 270
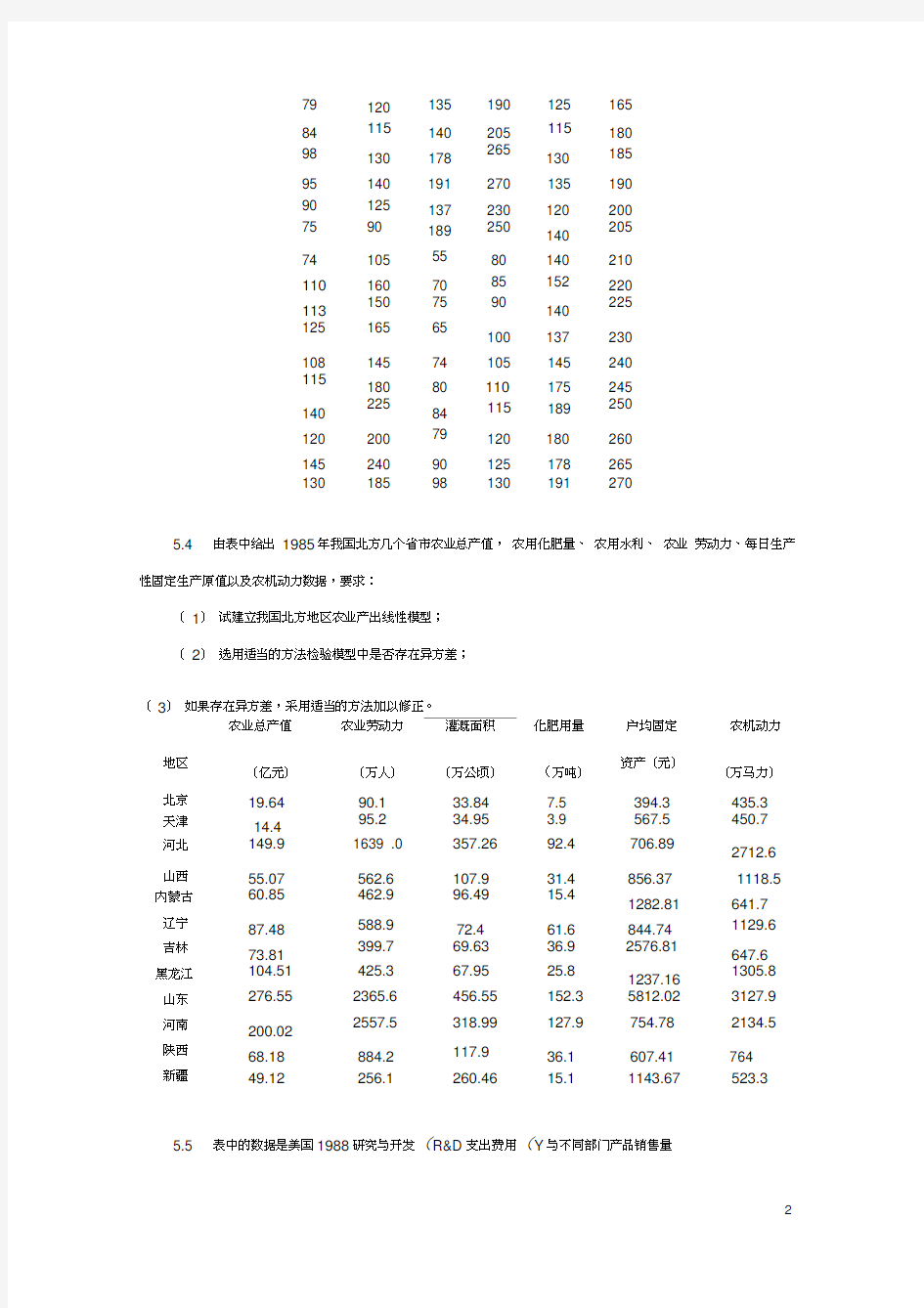
5.4 由表中给出1985年我国北方几个省市农业总产值,农用化肥量、农用水利、农业劳动力、每日生产性固定生产原值以及农机动力数据,要求:
(1)试建立我国北方地区农业产出线性模型;
(2)选用适当的方法检验模型中是否存在异方差;
(3)如果存在异方差,采用适当的方法加以修正。
农业总产值农业劳动力灌溉面积化肥用量户均固定农机动力
地区
(亿元)(万人)(万公顷)(万吨)资产(元)
(万马力)
北京19.64 90.1 33.84 7.5 394.3 435.3 天津14.4 95.2 34.95 3.9 567.5 450.7 河北149.9 1639 .0 357.26 92.4 706.89 2712.6
山西55.07 562.6 107.9 31.4 856.37 1118.5 内蒙古60.85 462.9 96.49 15.4 1282.81 641.7 辽宁87.48 588.9 72.4 61.6 844.74 1129.6 吉林73.81 399.7 69.63 36.9 2576.81 647.6 黑龙江104.51 425.3 67.95 25.8 1237.16 1305.8 山东276.55 2365.6 456.55 152.3 5812.02 3127.9 河南200.02 2557.5 318.99 127.9 754.78 2134.5 陕西68.18 884.2 117.9 36.1 607.41 764
新疆49.12 256.1 260.46 15.1 1143.67 523.3 5.5 表中的数据是美国1988研究与开发(R&D支出费用(Y与不同部门产品销售量
(X)。试根据资料建立一个回归模型,运用Glejser方法和White方法检验异方差,由此决
定异方差的表现形式并选用适当方法加以修正。
单位:百万美兀
工业群体销售量X R&D 费用Y 利润Z
1?容器与包装6375.3 62.5 185.1
2.非银行业金融11626.4 92.9 1569.5
3?服务行业14655.1 178.3 276.8
4.金属与米矿21869.2 258.4 2828.1
5.住房与建筑26408.3 494.7 225.9
6.般制造业32405.6 1083 3751.9
7.休闲娱乐35107.7 1620.6 2884.1
8.纸张与林木产品40295.4 421.7 4645.7
9.食品70761.6 509.2 5036.4
10.卫生保健80552.8 6620.1 13869.9
11.宇航95294 3918.6 4487.8
12.消费者用品101314.3 1595.3 10278.9
13.电器与电子产品116141.3 6107.5 8787.3
14.化工产品122315.7 4454.1 16438.8
15.五金141649.9 3163.9 9761.4
16.办公设备与电算机175025.8 13210.7 19774.5
17.燃料230614.5 1703.8 22626.6
18.汽车293543 9528.2 18415.4 5.6
假设模型为Y =冃+ 02X i +5 ,其中Y为住房支出,X为收入。试求解下列问题
(1) 用OLS求参数的估计值、标准差、拟合优度
(2) 用Goldfeld-Quandt方法检验异方差(假设分组时不去掉任何样本值)
(3) 如果模型存在异方差,假设异方差的形式是c 2 -2X:,试用加权最小二乘法重新
估计!和'-2的估计值、标准差、拟合优度。
5.7 表中给出1969年20个国家的股票价格(Y)和消费者价格年百分率变化( X)的一个横截面数据。
国家股票价格变化率%Y 消费者价格变化率%X
1?澳大利亚 5 4.3
2?奥地利11.1 4.6
3上匕利时 3.2 2.4
4?加拿大7.9 2.4
5?智利25.5 26.4
6?丹麦 3.8 4.2
7?芬兰11.1 5.5
8?法国9.9 4.7
9?德国13.3 2.2
10.印度 1.5 4
11.爱尔兰 6.4 4
12.以色列8.9 8.4
13.意人利8.1 3.3
14.日本13.5 4.7
15.墨西哥 4.7 5.2
16.荷兰7.5 3.6
17.新西兰 4.7 3.6
18.瑞典8 4
19.英国7.5 3.9
20.美国9 2.1
试根据资料完成以下问题:
(1) 将Y对X回归并分析回归中的残差;
(2) 因智利的数据出现了异常,去掉智利数据后,重新作回归并再次分析回归中的残差;
(3) 如果根据第1条的结果你将得到有异方差性的结论,而根据第2条的结论你又得到相反的结论,对此你能得出什么样的结论?
试完成以下问题:
(1) 求销售利润岁销售收入的样本回归函数,并对模型进行经济意义检验和统计检验;
(2) 分别用图形法、Glejser方法、White方法检验模型是否存在异方差;
(3) 如果模型存在异方差,选用适当的方法对异方差性进行修正。
5.9下表所给资料为1978年至2000年四川省农村人均纯收入X t和人均生活费支出Y 的数据。
四川省农村人均纯收入和人均生活费支出单位:元/人时间农村人均纯收入农村人均生活费时间农村人均纯收入农村人均生活费
X 支岀Y X 支岀Y 1978 127.1 120.3 1990 557.76 509.16
1979 155.9 142.1 1991 590.21 552.39
1980 187.9 159.5 1992 634.31 569.46 1981 220.98 184.0 1993 698.27 647.43 1982 255.96 208.23 1994 946.33 904.28 1983 258.39 231.12 1995 1158.29 1092.91 1984 286.76 251.83 1996 1459.09 1358.0
3
1985 315.07 276.25 1997 1680.69 1440.4
8
1986 337.94 310.92 1998 1789.17 1440.7
7 1987 369.46 348.32 1999 1843.47 1426.0
6
1988 448.85 426.47 2000 1903.60 1485.3
4
1989 494.07 473.59
数据来源:《四川统计年鉴》2001 年。
(1) 求农村人均生活费支出对人均纯收入的样本回归函数,并对模型进行经济意义检验
和统计检验;
(2) 选用适当的方法检验模型中是否存在异方差;
(3) 如果模型存在异方差,选用适当的方法对异方差性进行修正。
5.10在题5.9中用的是时间序列数据,而且没有剔除物价上涨因素。试分析如果剔除物价上涨因素,即用实际可支配收入和实际消费支出,异方差的问题是否会有所改善?由于缺
乏四川省从1978年起的农村居民消费价格定基指数的数据,以1978年一2000年全国商品零售价格定基指数(以1978年为100)代替,数据如下表所示:
数据来源:《中国统计年鉴》
练习题参考解答
练习题5.1参考解答
2
1
(1)因为f (X 」=x 22,所以取W 2i
,用W 乘给定模型两端,得
X 2i
上述模型的随机误差项的方差为一固定常数,
u i 1
2
Var(-)不Var(uJ 二二
X 2i
X 2i
(2)
根据加权最小二乘法及第四章里(
4.5) 式为
和(4.6)式,可得修正异方差后的参数估计
程
一皱2一际;
、^i^x ; 、W
2i X 32
- x w ,i y *X 3i
、w>i X
2i X
3i
* *
*0
*
*
■-
W 2i y i X 3i —W 2i X 2i i W 2i
y i X 2^
1 W 2i X 2i X 3i
2
*2
* * 2
〔二 W 2i X 2i 〔二 W 2i X 3i -、W 2i X 2i X 3i
其中
练习题5.3参考解答
(1 )该模型样本回归估计式的书写形式为
丫? =9.3475 0.6371 X j
(2.5691)(32.0088)
R 2 = 0.9464, s.e. = 9.0323, F -1023.56
(2)首先,用 Goldfeld-Qua ndt 法进行检验。 a.
将样本按递增顺序排序,去掉
1/4,再分为两个部分的样本,即
m = n 2 = 22。
b ?分别对两个部分的样本求最小二乘估计,得到两个部分的残差平方和,即
X 3i X 2i
X 2i
*2
*2 * * 2
' W 2i X^
、'
W ^i X^ - '、
X 2
、W^i
_ Z W2i
W 2i
丫* W2M
_ '' W 2i
X 3i = X 3i - X3
* *
y =Y —丫
第五章练习题参考解答 练习题 5.1 设消费函数为 i i i i u X X Y +++=33221βββ 式中,i Y 为消费支出;i X 2为个人可支配收入;i X 3为个人的流动资产;i u 为随机误差 项,并且2 22)(,0)(i i i X u Var u E σ==(其中2 σ为常数) 。试回答以下问题: (1)选用适当的变换修正异方差,要求写出变换过程; (2)写出修正异方差后的参数估计量的表达式。 5.2 根据本章第四节的对数变换,我们知道对变量取对数通常能降低异方差性,但须对这种模型的随机误差项的性质给予足够的关注。例如,设模型为u X Y 21β β=,对该模型中的变量取对数后得如下形式 u X Y ln ln ln ln 21++=ββ (1)如果u ln 要有零期望值,u 的分布应该是什么? (2)如果1)(=u E ,会不会0)(ln =u E ?为什么? (3)如果)(ln u E 不为零,怎样才能使它等于零? 5.3 由表中给出消费Y 与收入X 的数据,试根据所给数据资料完成以下问题: (1)估计回归模型u X Y ++=21ββ中的未知参数1β和2β,并写出样本回归模型的书写格式; (2)试用Goldfeld-Quandt 法和White 法检验模型的异方差性; (3)选用合适的方法修正异方差。 Y X Y X Y X 55 80 152 220 95 140 65 100 144 210 108 145 70 85 175 245 113 150 80 110 180 260 110 160
79120135190125165 84115140205115180 98130178265130185 95140191270135190 90125137230120200 7590189250140205 741055580140210 1101607085152220 1131507590140225 12516565100137230 10814574105145240 11518080110175245 14022584115189250 12020079120180260 14524090125178265 13018598130191270 5.4由表中给出1985年我国北方几个省市农业总产值,农用化肥量、农用水利、农业劳动力、每日生产性固定生产原值以及农机动力数据,要求: (1)试建立我国北方地区农业产出线性模型; (2)选用适当的方法检验模型中是否存在异方差; (3)如果存在异方差,采用适当的方法加以修正。 地区农业总产值农业劳动力灌溉面积化肥用量户均固定农机动力(亿元)(万人)(万公顷)(万吨)资产(元)(万马力) 北京19.6490.133.847.5394.3435.3天津14.495.234.95 3.9567.5450.7河北149.91639 .0357.2692.4706.892712.6山西55.07562.6107.931.4856.371118.5内蒙古60.85462.996.4915.41282.81641.7辽宁87.48588.972.461.6844.741129.6吉林73.81399.769.6336.92576.81647.6黑龙江104.51425.367.9525.81237.161305.8山东276.552365.6456.55152.35812.023127.9河南200.022557.5318.99127.9754.782134.5陕西68.18884.2117.936.1607.41764 新疆49.12256.1260.4615.11143.67523.3 5.5表中的数据是美国1988研究与开发(R&D)支出费用(Y)与不同部门产品销售量
第三章练习题及参考解答 为研究中国各地区入境旅游状况,建立了各省市旅游外汇收入(Y ,百万美元)、旅行社职工人数(X1,人)、国际旅游人数(X2,万人次)的模型,用某年31个省市的截面数据估计结果如下: i i i X X Y 215452.11179.00263.151?++-= t= R 2= 92964.02=R F= n=31 1)从经济意义上考察估计模型的合理性。 2)在5%显着性水平上,分别检验参数21,ββ的显着性。 3)在5%显着性水平上,检验模型的整体显着性。 练习题参考解答: (1)由模型估计结果可看出:从经济意义上说明,旅行社职工人数和国际旅游人数均与旅游外汇收入正相关。平均说来,旅行社职工人数增加1人,旅游外汇收入将增加百万美元;国际旅游人数增加1万人次,旅游外汇收入增加百万美元。这与经济理论及经验符合,是合理的。 (2)取05.0=α,查表得048.2)331(025.0=-t 因为3个参数t 统计量的绝对值均大于048.2)331(025.0=-t ,说明经t 检验3个参数均显着不为0,即旅行社职工人数和国际旅游人数分别对旅游外汇收入都有显着影响。 (3)取05.0=α,查表得34.3)28,2(05.0=F ,由于34.3)28,2(1894.19905.0=>=F F ,说明旅行社职工人数和国际旅游人数联合起来对旅游外汇收入有显着影响,线性回归方程显着成立。 表给出了有两个解释变量2X 和.3X 的回归模型方差分析的部分结果:
表 方差分析表 1)回归模型估计结果的样本容量n 、残差平方和RSS 、回归平方和ESS 与残差平方和RSS 的自由度各为多少 2)此模型的可决系数和调整的可决系数为多少 3)利用此结果能对模型的检验得出什么结论能否确定两个解释变量2X 和.3X 各自对Y 都有显着影响 练习题参考解答: (1) 因为总变差的自由度为14=n-1,所以样本容量:n=14+1=15 因为 TSS=RSS+ESS 残差平方和RSS=TSS-ESS=66042-65965=77 回归平方和的自由度为:k-1=3-1=2 残差平方和RSS 的自由度为:n-k=15-3=12 (2)可决系数为:265965 0.99883466042 ES R TSS S = == 修正的可决系数:2 2 2 115177 110.998615366042 i i e n R n k y --=-=-?=--∑∑ (3)这说明两个解释变量 2X 和.3X 联合起来对被解释变量有很显着的影响,但是还不 能确定两个解释变量2X 和.3X 各自对Y 都有显着影响。 经研究发现,家庭书刊消费受家庭收入及户主受教育年数的影响,表中为对某地区部分家庭抽样调查得到样本数据: 表 家庭书刊消费、家庭收入及户主受教育年数数据
计量经济学题库 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学 B.数学 C.经济学 D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量 B.解释变量 C.被解释变量 D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( A )。 A.内生变量 B.外生变量 C.滞后变量 D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。 A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量 B.政策变量 C.内生变量 D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用
1、已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X (45.2)(1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题: (1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 答:(1)系数的符号是正确的,政府债券的价格与利率是负相关关系,利率的上升会引起政府债券价格的下降。 (2)i Y 代表的是样本值,而i ?Y 代表的是给定i X 的条件下i Y 的期望值,即?(/)i i i Y E Y X =。此模型是根据样本数据得出的回归结果,左边应当是i Y 的期望值,因此是i ?Y 而不是i Y 。 (3)没有遗漏,因为这是根据样本做出的回归结果,并不是理论模型。 (4)截距项101.4表示在X 取0时Y 的水平,本例中它没有实际意义;斜率项-4.78表明利率X 每上升一个百分点,引起政府债券价格Y 降低478美元。 2、有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y var Adjusted R-squared 0.892292 F-statistic 75.55898 (1)说明回归直线的代表性及解释能力。 (2)在95%的置信度下检验参数的显着性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在95%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其
第五章经典单方程计量经济学模型:专门问题 一、内容提要 本章主要讨论了经典单方程回归模型的几个专门题。 第一个专题是虚拟解释变量问题。虚拟变量将经济现象中的一些定性因素引入到可以进行定量分析的回归模型,拓展了回归模型的功能。本专题的重点是如何引入不同类型的虚拟变量来解决相关的定性因素影响的分析问题,主要介绍了引入虚拟变量的加法方式、乘法方式以及二者的组合方式。在引入虚拟变量时有两点需要注意,一是明确虚拟变量的对比基准,二是避免出现“虚拟变量陷阱”。 第二个专题是滞后变量问题。滞后变量包括滞后解释变量与滞后被解释变量,根据模型中所包含滞后变量的类别又可将模型划分为自回归分布滞后模型与分布滞后模型、自回归模型等三类。本专题重点阐述了产生滞后效应的原因、分布滞后模型估计时遇到的主要困难、分布滞后模型的修正估计方法以及自回归模型的估计方法。如对分布滞后模型可采用经验加权法、Almon多项式法、Koyck方法来减少滞项的数目以使估计变得更为可行。而对自回归模型,则根据作为解释变量的滞后被解释变量与模型随机扰动项的相关性的不同,采用工具变量法或OLS法进行估计。由于滞后变量的引入,回归模型可将静态分析动态化,因此,可通过模型参数来分析解释变量对被解释变量影响的短期乘数和长期乘数。 第三个专题是模型设定偏误问题。主要讨论当放宽“模型的设定是正确的”这一基本假定后所产生的问题及如何解决这些问题。模型设定偏误的类型包括解释变量选取偏误与模型函数形式选取取偏误两种类型,前者又可分为漏选相关变量与多选无关变量两种情况。在漏选相关变量的情况下,OLS估计量在小样本下有偏,在大样本下非一致;当多选了无关变量时,OLS估计量是无偏且一致的,但却是无效的;而当函数形式选取有问题时,OLS估计量的偏误是全方位的,不仅有偏、非一致、无效率,而且参数的经济含义也发生了改变。在模型设定的检验方面,检验是否含有无关变量,可用传统的t检验与F检验进行;检验是否遗漏了相关变量或函数模型选取有错误,则通常用一般性设定偏误检验(RESET检验)进行。本专题最后介绍了一个关于选取线性模型还是双对数线性模型的一个实用方法。 第四个专题是关于建模一般方法论的问题。重点讨论了传统建模理论的缺陷以及为避免这种缺陷而由Hendry提出的“从一般到简单”的建模理论。传统建模方法对变量选取的
计量经济学作业第5章(含答案)
第5章习题 一、单项选择题 1.对于一个含有截距项的计量经济模型,若某定性因素有m个互斥的类型,为将其引入模型中,则需要引入虚拟变量个数为() A. m B. m-1 C. m+1 D. m-k 2.在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出Y 对实际可支配收入X的回归关系明显不同。现以1991年为转折时期,设虚拟变 量,数据散点图显示消费函数发生了结构性变化:基本消费部分下降了,边际消费倾向变大了。则城镇居民线性消费函数的理论方程可以写作() A. B. C. D. 3.对于有限分布滞后模型 在一定条件下,参数可近似用一个关于的阿尔蒙多项式表示(),其中多项式的阶数m必须满足() A. B. C. D. 4.对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数据就会( ) A. 增加1个 B. 减少1个 C. 增加2个 D. 减少2个 5.经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序列相关性就转化为() A.异方差问题 B. 多重共线性问题
C.序列相关性问题 D. 设定误差问题 6.将一年四个季度对因变量的影响引入到模型中(含截距项),则需要引入虚拟变量的个数为() A. 4 B. 3 C. 2 D. 1 7.若想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(Y代表消费支出;X代表可支配收入;D 2、D 3 表示虚拟变量)() A. B. C. D. 二、多项选择题 1.以下变量中可以作为解释变量的有() A. 外生变量 B. 滞后内生变量 C. 虚拟变量 D. 先决变量 E. 内生变量 2.关于衣着消费支出模型为:,其中 Y i 为衣着方面的年度支出;X i 为收入, ? ? ? =女性 男性 1 2i D; ? ? ? =大学毕业及以上 其他 1 3i D 则关于模型中的参数下列说法正确的是() A.表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出(或少支出)差额 B.表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消费支出方面多支出(或少支出)差额 C.表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 三、判断题
第二章主要公式 资料地址:https://www.doczj.com/doc/ab210956.html,/jl 1、回归模型概述 (1)相关分析与回归分析 经济变量之间的关系:函数关系、相关关系 相关关系:单相关和复相关,完全相关、不完全相关和不相关,正相关与负相关,线性相关和负相关,线性相关和非线性相关。 相关分析: ——总体相关系数XY ρ= ——样本相关系数()() n i i XY X X Y Y r --= ∑ ——多个变量之间的相关程度可用复相关系数和偏相关系数度量 回归分析:相关关系 + 因果关系 (2)随机误差项:含有随机误差项是计量经济学模型与数理经济学模型的一大区别。 (3)总体回归模型 总体回归曲线:给定解释变量条件下被解释变量的期望轨迹。 总体回归函数:(|)()i i E Y X f X = 总体回归模型:(|)()i i i i i Y E Y X f X μμ=+=+ 线性总体回归模型:011,2,...,i i i Y X i n ββμ=++= (4)样本回归模型 样本回归曲线:根据样本回归函数得到的被解释变量的轨迹。 (线性)样本回归函数: 01???i i Y X ββ=+ (线性)样本回归模型:01???i i i Y X e ββ=++ 2、一元线性回归模型的参数估计 (1)基本假设 ① 解释变量:是确定性变量,不是随机变量 var()0i X = ② 随机误差项:零均值、同方差,在不同样本点之间独立,不存在序列相关等 ()01,2,...,i E i n μ== 2var()1,2,...,i i n μσ==
cov(,)0;,1,2,...,i j i j i j n μμ=≠= ③ 随机误差项与解释变量:不相关 cov(,)01,2,...,i i X i n μ== ④ (针对最大似然法和假设检验)随机误差项: 2~(0,)1,2,...,i N i n μσ= ⑤ 回归模型正确设定。 【前四条为线性回归模型的古典假设,即高斯假设。满足古典假设的线性回归模型称为古典线性回归模型。】 (2)参数的普通最小二乘估计(OLS ) 目标:21 min n i i e =∑ 对于一元线性回归模型:011,2,...,i i i Y X i n ββμ=++= 正规方程组: 011 011 ?? 2[()]0??2[()]0n i i i n i i i i Y X X Y X ββββ==?--+=????--+=??∑∑ 解得: 011 112 211??()()?()n n i i i i i i n n i i i i Y X X X Y Y x y X X x βββ====?=-???--?==??-?? ∑∑∑∑ (3)最大似然估计(ML ) 对于一元线性回归模型:011,2,...,i i i Y X i n ββμ=++= 重要的基本假设: 2~(0,)1,2,...,cov(,)0;,1,2,...,var()01,2,...,i i j i N i n i j i j n X i n μσμμ?=? =≠=?? ==? 得到:2 01~(,)1,2,...,i i Y N X i n ββσ+= 【且cov(,)0;,1,2,...,i j Y Y i j i j n =≠=,这个对最大似然法的估计很重要】 则目标:12,,...,n Y Y Y 的联合概率密度最大,即
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【B 】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分 析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒 等关系。 三、简答题 ⒈什么是计量经济学?它与统计学的关系是怎样的? 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从经济理论和经济模型出发进行计量经济分析的过程,也是对经济理论证实或证伪的过程。这些是以处理数
第一题: 一、研究的目的和要求 亚洲各国人均寿民对国民生活具有重要的参考价值,也是人民日常生活中密切关注的问题。为此,在生活中一些因素比如人均GDP则反映了生活条件对寿命的影响,成人识字率也就是受教育的程度是否对寿命也有相应的影响,从这方面看,受教育的程度反应在生活环境的各个方面。而一岁儿童疫苗接种可能反映的是早期因素对未来身体等方面的影响。那么这些因素是否对寿命有影响呢?对此,可以进行研究,以便发现因素的影响,这样就能有效地采取相应的措施,对这些影响因子进行调整,这些对如何`提高人均寿命是具有指导意义的。 二、模型设定 为了分析亚洲各国人均寿民分别与按购买力平价计算的人均GDP、成人识字
率、一岁儿童疫苗接种率的关系,选择“亚洲各国人均寿命”(单位:/年)为被解释变量;分别选择按购买力平价计算的人均GDP(单位:100美元)(用X1表示),成人识字率(单位:%)(用X2表示)、一岁儿童疫苗率(单位:%)(用X3表示)为解释变量。 为了分析亚洲各国人均寿命(Y)分别与按购买力平价计算的GDP(X1)、成人识字率(X2)、一岁儿童疫苗接种率(X3)的数量关系,可以运用eviews去做计量分析。利用eviews做简单线性回归分析的基本步骤如下: 1.建立工作文件 首先,双击Eviews图标,进入Eviews主页。依次点击File/New/Workfile,在出现对话框的菜单中选择文件数据的类型,本利分析的是亚洲各国的人均寿命的横截面数据,则选择“integer date”。在“Start date”中输入开始顺序号“1”,在“end data”中输入最后顺序号“22”。点击“ok”出现未命名的“Workfile UNTITLED”工作框。其中已有对象:“c”为截距项,“resid”为剩余项。 若要将工作文件存盘,点击窗口上方的“Save”,在“Save as”对话框中选择存盘路径,并输入工作文件名,再点击“OK”,文件即被保存,并确定了文件名。 2.输入数据 在“Quick”菜单中点击“Empty Group”,出现数据编辑窗口。可以在Eviews 命令框中分别输入data X1 Y,data X2 Y,data X3 Y。回车出现“Group”窗口数据编辑框,在对应的Y,X1,X2,X3下输入数据。还可以直接从Excel、word 等文档的数据表中直接将对应数据粘贴到Eviews的数据表中。若要对数据存盘,点击“File/Save”。 3.作Y与X的相关图形
计量经济学(第四版)习题参考答案 潘省初
第一章 绪论 试列出计量经济分析的主要步骤。 一般说来,计量经济分析按照以下步骤进行: (1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项? 为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。 什么是时间序列和横截面数据? 试举例说明二者的区别。 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。 横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。 估计量和估计值有何区别? 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。在一项应用中,依据估计量算出的一个具体的数值,称为估计值。如Y 就是一个估计量,1 n i i Y Y n == ∑。现有一样本,共4个数,100,104,96,130,则 根据这个样本的数据运用均值估计量得出的均值估计值为 5.1074 130 96104100=+++。 第二章 计量经济分析的统计学基础 略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间 N S S x = = 4 5= 用 =,N-1=15个自由度查表得005.0t =,故99%置信限为 x S t X 005.0± =174±×=174± 也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH 备择假设 120:1≠μH 检验统计量 () 10/2510/25 X X μσ-Z == == 查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH 备择假设 : 2500:1≠μH ()100/1200.83?480/16 X X t μσ-= === 查表得 131.2)116(025.0=-t 因为t = < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
计量经济学作业第5章(含答案)
、单项选择题 1 ?对于一个含有截距项的计量经济模型,若某定性因素有 D. m-k 2 ?在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。例 如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出 丫 对实际可支配收入X 的回归关系明显不同。现以1991年为转折时期,设虚拟变 [1 1991# WS D =< 量 r [O f 1毀坪以前,数据散点图显示消费函数发生了结构性变化:基本 消费部分下降了,边际消费倾向变大了。贝U 城镇居民线性消费函数的理论方程 可以写作( ) A. h 二几+耳扎+如)拓+斗 3. 对于有限分布滞后模型 在一定条件下,参数儿可近似用一个关于【的阿尔蒙多项式表示 ),其中多项式的阶数 m 必须满足( ) A .障匚上 B . m k C . D .用上上 4. 对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数 据就会( ) A.增加1个 B.减少1个 C.增加2个 D.减 少2个 5. 经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序 列相关性就转化为( ) A. m B. m-1 C. m+1 将其引入模型中,则需要引入虚拟变量个数为( m 个互斥的类型,为 ) B. C. Y 讦 A+ +"0+ 斗 D.
A.异方差冋 题 B.多重 共线性问题
问题 6. 将一年四个季度对因变量的影响引入到模型中(含截 距项),则需要引入虚 拟变量的个数为( ) A. 4 B. 3 C. 2 D. 1 7. 若 想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比 较适合(丫代表消费支出;X 代表可支配收入;D 2、D 3表示虚拟变量) () A.Yj"+陆+野 B . 二、多项选择题 1. 以下变量中可以作为解释变量的有 ( ) A.外生变量 B.滞后内生变量 C.虚 拟变量 D.先决变量 E.内生变量 2. 关于衣着消费支出模型为:h 吗+叩左+必史+勺3工』』+ "逅+色,其中 丫为衣着万面的年度支出;X 为收入, 1 女性 "i 大学毕业及以上 D = : D 3i =J o 男性, 3i 其他 则关于模型中的参数下列说法正确的是( ) A. $表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出 (或少 支出)差额 B. 珂表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消 费支 出方面多支出(或少支出)差额 C. 5表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以 下文凭 者在衣着消费支出方面多支出(或少支出)差额 D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消 费支出方面多支出(或少支出)差额 E. 表示性别和学历两种属性变量对衣着消费支出的交互影响 、判断题 1 ?通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容 C.序列相关性问题 D.设定误差 £ =坷++以叭JQ+舛 C. 】 D 丄吗皿吗+风+儿
1.3 某市居民家庭人均年收入服从4000X =元, 1200σ=元的正态分布, 求该市居民家庭人均年收入:(1)在5000—7000元之间的概率;(2)超过8000元的概率;(3)低于3000元的概率。 (1) ()() ()()()2,0,15000700050007000( ) 2.50.835( 2.5)62 X N X X X N X X X X P X P F F X X P σσ σ σ σ σ-∴---∴<<=< < --=<<= Q :: 根据附表1可知 ()0.830.5935F =,()2.50.9876F = ()0.98760.5935 500070000.1971 2 P X -∴<<= = PS : ()()5000700050007000( ) 55( 2.5) 2.5660.99380.79760.1961 X X X X P X P X X P σ σ σ σ---<<=< < -??=<<=Φ-Φ ? ??=-=
在附表1中,()() F Z P x x z σ=-< (2)()80001080003X X X X X P X P P σσσ?? ??--->=>=> ? ?? ? ? ? =0.0004 (3)()3000530006 X X X X X P X P P σσσ???? ---<=<=<- ? ?? ? ? ? =0.2023 ()030001050300036X X X X X X P X P P σ σσσ???? ----<<=<< =-<<- ? ? ???? =0.2023-0.0004=0.20191.4 据统计70岁的老 人在5年内正常死亡概率为0.98,因事故死亡的概率为0.02。保险公司开办老人事故死亡保险,参加者需缴纳保险费100元。若5年内因事故死亡,公司要赔偿a 元。应如何测算出a ,才能使公司可期望获益;若有1000人投保,公司可期望总获益多少? 设公司从一个投保者得到的收益为X ,则
第五章习题2 根据经济理论建立计量经济模型 i i 10i X Y μββ++= 应用EViews 输出的结果如图1所示。 图1 用普通最小二乘法的估计结果如下: )29,...,2,1(707955.013179.58=+=∧ i X Y i i 利用上述结果计算残差∧ =i i i Y -Y e 。观察i e 的取值,好像随i X 的变化而变化,怀疑模型存在异方差性,下面通过等级相关系数和戈德菲尔特—夸特方法检验随机误差项的异方差性。 1.斯皮尔曼等级相关系数检验 按照斯皮尔曼等级相关检验的步骤,先将X 的样本观测值从小到大排列并划分等级,然后将i e 从小到大划分等级,计算i X 的等级与相应产生的i e 的等级的差i d 及2i d ,详见表1。 表1
计算等级相关系数 2334d 1 i 2i =∑= 0.42512329 -292334 6- 1N -N d 6- 1r 3 3 1i 2i =?==∑= 对等级相关系数进行检验,提出原假设与备择假设 ) ,(),(::28 1 0N 1-N 10N ~r 0 H 0H 10=≠=ρρ 构造Z 统计量 2.2495428*0.4251231 -N 1r Z ===
给定显著水平0.05=α,查正态分布表,得 1.96Z 2 =α因为 1.962.24954Z >=, 所以应拒绝原假设,接收备择假设,即等级相关系数显著,说明其随机误差项存在异方差性。 2. 戈德菲尔特—夸特方法检验 将X 的样本观测值按升序排列,Y 的样本观测值按原来与X 样本观测值的对应关系进行排列,略去中心7个数据,将剩下的22个样本观测值分成容量相等的两个子样本,每个子样本的样本观测值个数均为11。排列结果见表2。 用第一个子样本估计模型,得到的结果如图2所示: 图2
第三章 一元线性回归模型 P56. 3.3 从某公司分布在11个地区的销售点的销售量()Y 和销售价格()X 观测值得出以下结果: 519.8X = 217.82Y = 23134543i X =∑ 1296836i i X Y =∑ 2539512i Y =∑ (1)、估计截距0β和斜率系数1β及其标准误,并进行t 检验; (2)、销售的总离差平方和中,样本回归直线未解释的比例是多少? (3)、对0β和1β分别建立95%的置信区间。 解:(1)、设01i i Y X ββ=+,根据OLS 估计量有: μ()() () 1 1 1 11 1 2 2 2 22211 112 =129683611519.8217.820.32313454311519.8 N N N N N i i i i i i i i i i i i i N N N N i i i i i i i i N Y X Y X N Y X N X NY Y X N X Y N X N X X N X N X X β=========---= = ??--- ? ?? -??==-?∑∑∑∑∑∑∑∑∑ μμ01 217.820.32519.851.48Y X ββ=-=-?= 残差平方和: $ ( )μ( ) μμμ() μμμμ() μμμμ2 2 2 1 12 2 222 201111111 22222222010101011111111=225395121N N i i i i i N N N N N N i i i i i i i i i i i i N N N N N i i i i i i i i i i i u RSS TSS ESS Y Y Y Y Y Y Y Y Y X N N Y X X Y N X X ββββββββββ===============-=---????--+=-+ ? ???????=-++=-++ ??? =-∑∑∑∑∑∑∑∑∑∑∑∑∑∑()22151.480.32313454320.3251.4811519.8997.20224 ?+?+????=另解:对$( )μ( )2 2 2 11 N N i i i i i u RSS TSS ESS Y Y Y Y ====-=---∑∑∑,根据OLS 估计μμ01Y X ββ=-知μμ01 +Y X ββ=,因此有
计量经济学课后习题答 案汇总 标准化工作室编码[XX968T-XX89628-XJ668-XT689N]
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列 分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系 和恒等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从
期中练习题 1、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则是指( ) A .使∑=-n t t t Y Y 1)?(达到最小值 B.使∑=-n t t t Y Y 1达到最小值 C. 使 ∑=-n t t t Y Y 1 2 ) (达到最小值 D.使 ∑=-n t t t Y Y 1 2)?(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为 ?ln 2.00.75ln i i Y X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( ) A. 0.75 B. 0.75% C. 2 D. 7.5% 3、设k 为回归模型中的参数个数,n 为样本容量。则对总体回归模型进行显著性检验的F 统计量与可决系数2 R 之间的关系为( ) A.)1/()1()/(R 2 2---=k R k n F B. )/(1)-(k )R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. ) 1()1/(22R k R F --= 6、二元线性回归分析中 TSS=RSS+ESS 。则 RSS 的自由度为( ) A.1 B.n-2 C.2 D.n-3 9、已知五个解释变量线形回归模型估计的残差平方和为 8002=∑t e ,样本容量为46,则随机误 差项μ的方差估计量2 ?σ 为( ) A.33.33 B.40 C.38.09 D. 20 1、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2i )Var(u i σ= C. 0)u E(u j i ≠ D.随机解释变量X 与随机误差i u 不相关 E. i u ~),0(2i N σ 2、对于二元样本回归模型i i i i e X X Y +++=2211???ββα,下列各式成立的有( ) A.0 =∑i e B. 0 1=∑i i X e C. 0 2=∑i i X e D. =∑i i Y e E. 21=∑i i X X 4、能够检验多重共线性的方法有( ) A.简单相关系数矩阵法 B. t 检验与F 检验综合判断法 C. DW 检验法 D.ARCH 检验法 E.辅助回归法