
第四章语法分析—自上而下分析
本章要点
1. 语法分析器的功能;
2. 自上而下分析方法,LL(1)文法
3. 递归下降分析程序构造;
4. 预测分析表的构造及预测分析过程;
5. LL(1)分析中的错误处理。
本章目标
理解和掌握语法分析器的功能、自上而下分析所面临的问题、LL(1)分析法、递归下降分析的构造过程、预测分析程序等内容。
本章重点
1.语法分析器的功能,自上而下的基本概念
2.LL(1)文法的条件及其判别,计算first集和follow集
3.递归下降分析方法、预测分析表的构造及其预测过程。
本章难点
1. 非终结符的First集合,产生式候选的First集合,非终结符的follow集合的求解;
2. 左递归消除;
3. 递归下降分析程序的编写;
作业题
一、单项选择题:
1. 高级语言编译程序常用的语法分析方法中,递归下降分析法属于分析法。
a. 自左至右
b. 自顶向下
c. 自底向上
d. 自右向左
2. 上下文无关文法可以用 来描述。
a. 正则表达式
b. 正规文法
c. 扩展的BNF
d. 翻译模式
3. 自上而下分析面临的四个问题中,不包括
a. 需消除左递归;
b. 存在回朔;
c. 虚假匹配;
d. 寻找可归约串
4. 语法分析器接收以________为单位的输入,并产生有关信息供以后各阶段使用。
a. 表达式;
b. 产生式;
c. 单词;
d. 语句;
5. 自上而下分析的主旨是,对任何单词符号串,试图用一切可能的办法,从文法开始符号(根结点)出发,________。
a. 为输入串寻找最右推导;
b. 为输入串寻找最左直接子树;
c. 为输入串建立最右直接子树;
d. 为输入串寻找最左推导;
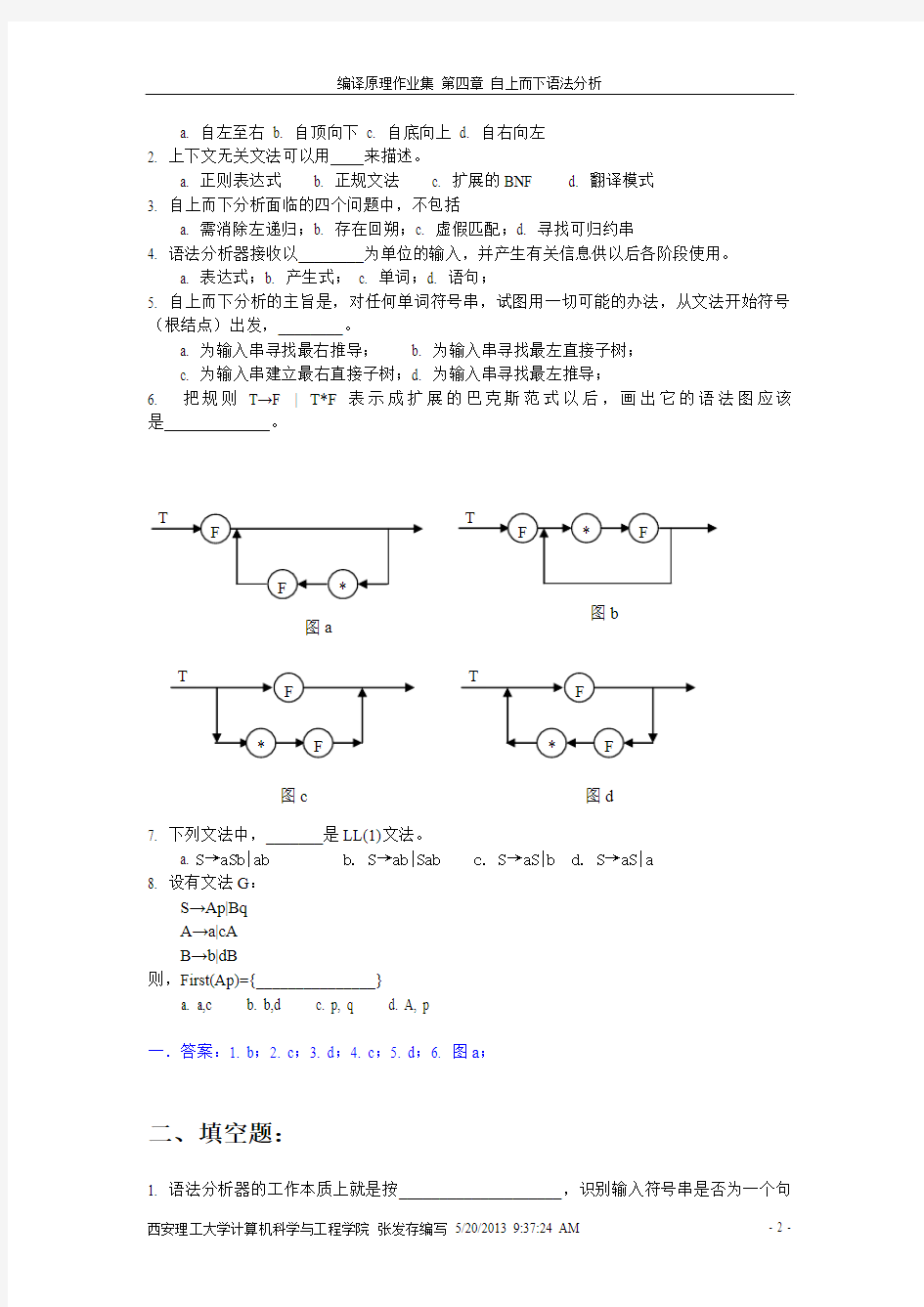
6. 把规则T→F | T*F 表示成扩展的巴克斯范式以后,画出它的语法图应该是 。
图a
图b 图c 图d
7. 下列文法中,_______是LL(1)文法。
a. S →aSb|ab
b. S →ab|Sab
c. S →aS|b
d. S →aS|a
8. 设有文法G :
S→Ap|Bq
A→a|cA
B→b|dB
则,First(Ap)={_______________}
a. a,c
b. b,d
c. p, q
d. A, p
一.答案:1. b ;2. c ;3. d ;4. c ;5. d ;6. 图a ;
二、填空题:
1. 语法分析器的工作本质上就是按____________________,识别输入符号串是否为一个句
子。这里所说的输入串是指由____________________组成的有限序列。
2. 自顶向下分析会遇到的主要问题是____________________和__________________。
3. 自上而下地为输入串建立一棵语法树,就是为输入串寻找一个______________。
4. 在扩充的巴科斯范式中,用______________表示符号或串α的出现可有可无。
5. 对于一个文法,当给出一串符号时,怎么能知道它是不是该文法的一个句子呢?这就要判断,看是否能。
6. 文法exp → exp addop term | term 消除左递归的结果为。
7. 写出E→T | E+T的EBNF范式为。
8. 扩展的巴克斯范式描述语法的好处是,直观易懂,便于表示。
二.答案:1. 文法的产生式,单词符号(文法的终结符)2. 左递归,回溯;3.最左推导;
4. 方括号(或[α]);
5. 从文法的开始符号出发推导出这个输入串。(或:能否建立一棵与输入串相匹配的语法分析树。)
6. exp → term exp′;exp′→ addop term exp′| ε;
7. E→T{+T};
8. 左递归消去和左因子提取。
三、判断题:
1. LL(k)文法都不是二义性的。()
2. 存在一种算法,能判定任何上下文无关文法是否是LL(1)的。( )
3. 一个文法是含有左递归的,如果存在非终结符P,使得P?*αP。()
4. 提取公共左因子的副产品是引进了大量的非终结符和ε产生式。( )
5. 把一个文法改造成任何非终结符的所有后选终结首符集两两不相交的办法是消除左递归。( )
6. 若X∈V T,则FIRST(X)={ X }。( )
7. 一个文法的预测分析表含有多重定义入口,说明该文法是LL(1)的。()
8. 自上而下分析及自下而上分析中的“下”是指被分析的源程序串。()
三.答案:1. √;2. √;3. ×;4. √;5. ×;6. √;7. ×;8. √;
四、名词解释:
1. 左递归;
2. 递归下降分析器;
3. LL(1)文法;
4. 预测分析表
5. 自上而下分析
四.答案:
1.一个文法如果存在非终结符P,P=>+Pα,则称该文法是左递归的。
2. 当一个文法满足LL(1)条件时,可以为它构造一个不带回溯的的自上而下分析程序,该程序是由一组递归过程组成的,每个过程对应文法的一个非终结符。这样的分析程序称为递归
下降分析器。
3. 一个文法G,如果满足以下条件,则称为LL(1)文法:
(1)文法不含左递归;
(2)对于文法中每一个非终结符A的各个产生式的候选首符集两两不相交;
(3)对文法中的每个非终结符A,若它存在某个候选首符集包含ε,则A的First集合和Follow 集合的交集为空。
4. 预测分析表是一个M[A, a]形式的矩阵。其中A为非终结符,a是终结符或“#”。矩阵元素M[A, a]中存放着一条关于A的产生式,指出当A面临输入符号a时所应采取的候选。M[A, a]中也可能存放一个“出错标志”,指出A根本不该面临输入符号a。
5. 自上而下分析是,对任何输入串,试图用一切可能的办法,从文法开始符号(根结点)出发,自上而下地为输入串建立一棵语法树。或者说,为输入串寻找一个最左推导。
五、简答题:
1. 词法分析和语法分析都是对字符串进行识别的,二者有何区别?
2. 试说明没有一个左递归文法是LL(1)的。
3. 试说明没有一个LL(1)文法是二义性的。
4. 为什么要消除回溯?
5. 为什么要提取左因子?
6. 下面文法是有左递归吗?若有,提取左递归。
Declist→Declist; Decl | Decl
Decl→idList:Type
IdList→Idlist, id | id
Type→ScalarType | array (ScalarTypeList) of Type
ScalarType→id | Bound..Bound
Bound→Sign IntLiteral | id
Sign→+ | - | e
ScalarTypeList→ScalarTypeList, ScalarType | ScalarType
五.答案:
1. 答:词法分析的输入符号串是一个单词,而语法分析的输入符号串是一个句子。词法分析的一个输入符号串是由单个符号组成的单词;语法分析的输入符号串是由词法分析得来的单词组成的句子。
2. 对于任一个左递归文法来说,存在一个A∈V N,有A A...,因此,在文法中必有如下的
规则序列:
A → A1...
A1 → A2...
.....................
An→ Aα|β
Aαβ。显然,FIRST(Aα)∩FIRST(β)≠Φ。因此,没有一个左递归文法是LL(1)的。
3. 解:
设有一个LL(1)文法G是二义性的,那么,一定存在一个W∈L(G),W=a1, a2......, a n,有两棵不同的分析树。如果按最左推导构造这两棵分析树,按么,一定有两个最左推导序列,这来年改革最左推导序列的不同在于,于对某一个A∈V N和当前要匹配的a i(1≤i≤n),分别使用A的两个不同的候选式A→α和A→β进行推导以匹配a i
(i) 若αε且βε,则必有
a i∈FIRST(α)且a i∈FIRST(β),FIRST(α)∩FIRST(β)≠Φ
(ii) 若α和β有一个能推导出ε,比如βε,则
a i∈FIRST(α)且a i∈FOLLOW(A)显然,FIRST(α)∩FOLLOW(A)≠Φ
无论(i)还是(ii),都和G是LL(1)文法矛盾。
4. 假定当前轮到非终结符A去执行匹配任务,A共有n个候选α1、α2、……αn,这时候该用哪一个候选去替换A,原始的办法是采用对所有候选采取“试探”的方法。如果某个候选不成功就需要“回退”。这个回退的过程会导致前次匹配的许多工作推到重来,效率低。而且,最终匹配不成功的时候,难以直到输入串中出错的确切位置。
5. 假定当前轮到非终结符A去执行匹配任务,A共有n个候选α1、α2、……αn,即A→α1|α2|……|αn。A面临的第一个输入符号为a,如果a属于某个First(αi),则用该αi来匹配A。但是,若a既属于某个First(αi),又属于某个First(αj),则说明αi和αi存在共同的左部,也就是说,有共同的左因子。此时无法确定到底是用αi还是用αj来匹配A。所以要消除左因子。
六、应用题
1. 已知文法G[S]:
S → (L) | a
L → L,S | S
ⅰ.消除左递归,若有左因子则提取之;
ⅱ.对(1)中得到的文法求First集合和Follow集合
ⅲ.对(1)中得到的文法构造一个预测分析表;
ⅳ.给出对句子(a,(a,a))上的分析动作
1.答案:将所给文法消除左递归得G′:
S → (L) | a
L → SL′
L′→ ,SL′ |ε
实现预测分析器的不含递归调用的一种有效方法是使用一张分析表和一个栈进行联合控制,下面构造预测分析表:
根据文法G′有
FIRST(S) = { ( , a } FOLLOW(S) = {#, ) , ′,′}
FIRST(L) = { ( , a } FOLLOW(S) = { ) }
FIRST(L′) = {′,′, ε} FOLLOW(L′) = { ) }
2. 考查文法G(s):
S→( T ) | a + S | a
T→T, S | S
ⅰ. 消除文法的左递归,提取公共左因子
ⅱ. 改造后的文法是LL(1)的吗?为什么?
ⅲ. 如果是LL(1)文法,对每个非终结符,写出不带回朔的递归子程序。
2.答案:
ⅰ.消除文法的左递归G ( s ):
S→ ( T ) | a + S | a
T→ S T′
T`→ , S T′| ε
再提取公共左因子,最后得到改造后的文法G[S]:
①S→( T ) | a S′
②S′→ + S | ε
③T→ S T′
④T′→, S T′ | ε
ⅱ.
First(S)={(,a };Follow(S)={#,…,?};First(S?)={+,ε};Follow(S?)= {#,…,?};First(T)={(,a };Follow(T)={ ) };
First(T?)={…,? ,ε}; Follow(T?) ={ ) };
产生式①的两个候选的First集合:
Fist((T))={(},First(aS’)={a}
不相交,满足条件。
产生式②,F irst(S?)∩Follow(S?)=Φ;
产生式④,First(T?)∩Follow(T?)=Φ;
所以,改造后的文法是LL(1)的,
ⅲ.
我们构造不带回溯的递归子程序如下:
①S→( T ) | a S′
PROCEDURE S;
DEGIN
IF SYM=′( ′THEN
BEGIN
ADV ANCE
T;
IF SYM=′ ) ′THEN ADV ANCE
ELSE ERROR
END
ELSE IF SYM=′a′ THEN
BEGIN
ADV ANCE;
END
ELSE ERROR
END;
②S′→ + S | ε
PROCEDURE S′;
BEGIN
IF SYM=′ + ′THEN BEGIN ADV ANCE;S END END;
③T→ S T′
PROCEDURE T;
BEGIIN
S; T ′
END;
④T′→, S T′ | ε
PROCEDURE T′;
BEGIN
IF SYM=′ , ′ THEN
BEGIN
ADVANCE;
S; T′
END
END;
3. 已知文法G[S]:
S → uBDz
B → Br | w
D → EF
E → y | ε
F → x | ε
(a) 求每个非终结符的FIRST和Follow集。
(b) 构造这个文法的LL(1)分析表
(c) 说明这个文法不是LL(1)的;
(d) 尽可能少地修改此文法,使其成为能产生相同语言的LL(1)文法.
3. 答案:
(a) FIRST(S) = { u } FOLLOW(S) = {#}
FIRST(B) = {w } FOLLOW(B) = { r, z }
FIRST(D) = { x, y, ε} FOLLOW(D) = { z }
FIRST(E) = { y, ε} FOLLOW(E) = { x, z }
FIRST(F) = { x, ε } FOLLOW(F) = { z }
(b) 该文法的LL(1)分析表为:
(c) 因为M[B, w]有两个产生式B→Bv, B→w
且FIRST(Bv)=FIRST(w) = { w }
所以不是LL(1)的。
(d) 消除左递归即可。
S→uBDz
B→wB′
B′→rB′ | ε
D → EF
E = y | ε
F = x | ε
4. 已知文法如下:
E→T | E+T T→F | T*F F→i | (E)
构造预测分析表,并给出对输入串i*i+i的分析过程。
4.答案:
首先消除左递归,得到新文法如下:
E→TE′
E′→+TE′|ε
T→FT′
T′→*FT′|ε
F→(E)|i
对每个非终结符构造First和Follow集合:
FIRST(E) = FIRST(T) = FIRST(F) = { ( , i };FIRST(E′) = { + , ε};FIRST(T′) = { * , ε} FOLLOW(E) = FOLLOW(E′) = { ) , # };FOLLOW(T) = FOLLOW(T′) = { + ,) ,# } FOLLOW(F) = { * , + , ) , # }
再通过对文法的每个非终结符的任意候选都构造出First集合:
FIRST(TE′)= {(,i};FIRST(+TE′)={+} ;FIRST(FT′)={(,i};FIRST(*FT′)={*};FIRST((E))={(}
得到预测分析表如下:
对输入串的分析过程如下:
5. 文法G1:
S→a|^|(T)
T→T,S|S
(1) 证明文法G是LL(1)文法。
(2) 构造LL(1)分析表。
(3) 写出句子(a,a)#的分析过程。
5. 答案:
(1)先消除左递归,得到文法G2:
0) S→a
1) S→^
2) S→( T )
3) T→S N2
4) N2→, S N2
5) N2→ε
求非终结符的First和Follow集合:
FIRST FOLLOW S { a,^,( } { #,,,) } T { a,^,( } { ) }
N2 { ,,ε } { ) }
对左部为N2的产生式可知:
FIRST (, S N2)={,}
FIRST (ε)={ε}
FIRST(, S N2) ∩ FIRST(ε)=?;
且:FIRST(N2) ∩ FOLLOW(N2)= ?
所以文法是LL(1)的。
得到预测分析表:
a ^ ( ) , #
S S→a S→^S→( T )
T T→SN2T→SN2T→SN2
N2 N2→εN2→,SN2
也可由预测分析表中无多重入口判定文法是LL(1)的。
对输入串(a,a)#的分析过程为:
可见输入串(a,a)#是文法的句子。
6. 设文法G(S):
S→(L)|aS|a L→L,S|S
(1)消除左递归和提取左因子;
(2)计算每个非终结符的FIRST和FOLLOW;
(3)构造预测分析表。
(4)已知输入串(aa,a)a,该输入串是否文法的句子?给出分析过程。
7. 对于文法
bexpr → bexpr or bterm | bterm
bterm → bterm and bfactor | bfactor
bfactor→ not bfactor | (bexpr) | true | false
构造一个预测分析器(表)。
答案:
消除左递归和提取左因子
bexpr → bterm bexpr′
bexpr′→ or bterm be xpr′ | ε
bterm → bfactor bterm′
bterm′→ and bfactor bterm′ | ε
bfactor→ not bfactor | (bexpr) | true | false
First(bexpr)=First(bterm)=First(bfactor)={ not, (, true,false } First(bexpr′)={ or , ε }
First(bterm′)={ and, ε }
Follow(bexpr)=Follow(bexpr′)={ ) , $ }
Follow(bterm)=Follow(bterm′)={or , ) , $}
Follow(bfactor)={and , or, ) , $}
8. 已知G[R]的产生式如下:
R → R′ | ′T | T
T → TF | F
F → F* | C
C → (R) | a | b
构造它的LL(1)分析表,并写出对输入串a|ba*的分析过程。
答案:
①消除上面文法中的左递归
R → TR′
R′ → ′|′ TR′ | ε
T → FT′
T′→ FT′ | ε
F → CF′
F → *F′ | ε
C → (R) | a | b
②计算FIRST(α)和FOLLOW(A)
③构造LL(1)分析表。
9. 已知文法如下:
S→S*T | S/T | T
T→T+F | T-F | F
F →(S) | i | i e i
构造预测分析表,并给出对输入串i/i*i+i的分析过程。
10. 已知文法:
S→Ac|c
A→Bb|b
B→Sa|a
构造预测分析表,给出对输入串cabc的分析过程。
11. 已知文法G:
S → ( L | a
L → S , L | )
(1)构造文法G 的预测分析表。
(2)若输入串为“(a,)”,请给出语法分析过程。
解(1)
1)求各非终结符的FISRT 集和FOLLOW 集:FIRST(S) = { (, a )
FIRST(L) = { a } FIRST(S) = { (, ), a }
FOLLOW(S) = { ′,′, # }
FOLLOW(L) = FOLLOW(S) ={ ′,′, # }
2
1所示。表1 对输入串“(a,)”的分析过程
12. 给定文法
G=({ i,d,′(′,′)′ },{E,A},E,P)
其中P:
E →iA
E →EA
A → i
A →d
A → (E)
(1)消除左递归;
(2)计算改写后文法中各非终结符的FIRST 集和FOLLOW 集;
(3)构造改写后文法的预测分析表;该文法是LL(1) 文法吗?。解
(1)消除左递归后的文法为:
E → iA E′
E′→ ε | AE′
A → i
A →d
A → ( E )
(2)各非终结符的FISRT集和FOLLOW集
FIRST( E ) ={i}
FIRST(E′) = {i, d, (, ε)
FIRST( A ) ={i, d, ()
FOLLOW( E ) ={), # }
FOLLOW(E′) ={ }, # }
FOLLOW( A ) ={i, d, (, ), # }
(3)改写后文法的预测分析表:
预测分析表中无多重入口,因此该文法是LL(1) 文法.
13. 已知文法:
A→aABe|a
B→Bb|d
ⅰ.消除左递归,若有左因子则提取之;
ⅱ.对(1)中得到的文法求First集合和Follow集合
ⅲ.对(1)中得到的文法构造一个预测分析表;
ⅳ.给出对句子aadb上的分析动作
答案:
改写文法为:
0) A→a N3
1) N3→A B e
2) N3→ε
3) B→d N2
4) N2→b N2
5) N2→ε
Predicting Analysis Table
由预测分析表中无多重入口判定文法是LL(1)的。
14. 已知文法:
S→Aa|b
A→SB
B→ab
(1) 改写文法以消除左递归,若有左因子则提取之;
(2)计算改写后文法中各非终结符的FIRST 集和FOLLOW 集;
(3)构造改写后文法的预测分析表;该文法是LL(1) 文法吗?。
答案:
第1种改写:
S→SBa|b
B→ab
0) S→b N2
1) N2→B a N2
2) N2→ε
由预测分析表中无多重入口判定文法是LL(1)的。
第2种改写:
S→Aa|b
A→AaB|bB
B→ab
0) S→A a
1) S→b
2) A→b B N3
3) N3→a B N3
4) N3→ε
由预测分析表中含有多重入口判定文法不是LL(1)的。
15. 文法:
S→MH|a
H→LSo|ε
K→dML|ε
L→eHf
M→K|bLM
(1)消除左递归;
(2)计算改写后文法中各非终结符的FIRST 集和FOLLOW 集;
(3)构造改写后文法的预测分析表;该文法是LL(1) 文法吗?。
答案:
展开为:
0)S→M H
1)S→a
2)H→L S o
3)H→ε
4)K→d M L
5)K→ε
6)L→e H f
7)M→K
由预测分析表中无多重入口判定文法是LL(1)的。
16. 对下面文法
Expr→-Expr
Expr→(Expr)|Var ExprTail
ExprTail→-Expr |
Var→id VarTail
VarTail→(Expr) |
(1) 构造LL(1)分析表。
(2) 给出对句子id--id((id))的分析过程。
17. 考查文法G(s):
S→( T ) | a + S | a
T→T, S | S
ⅰ. 消除文法的左递归,提取公共左因子
ⅱ. 改造后的文法是LL(1)的吗?为什么?
ⅲ. 如果是LL(1)文法,对输入串a+(a,a)写出分析过程。
编译原理第4章作业 答案 本页仅作为文档封面,使用时可以删除 This document is for reference only-rar21year.March
第四章 习题4.2.1:考虑上下文无关文法: S->S S +|S S *|a 以及串aa + a* (1)给出这个串的一个最左推导 S -> S S * -> S S + S * -> a S + S * -> a a + S * -> aa + a* (3)给出这个串的一棵语法分析树 习题4.3.1:下面是一个只包含符号a和b的正则表达式的文法。它使用+替代表示并运算的符号|,以避免和文法中作为元符号使用的竖线相混淆: rexpr→ rexpr + rterm | rterm rterm→rterm rfactor | rfactor rfactor→ rfactor * | rprimary rprimary→a | b 1)对这个文法提取公因子 2)提取公因子的变换使这个文法适用于自顶向下的语法分析技术吗? 3)提取公因子之后,原文法中消除左递归 4)得到的文法适用于自顶向下的语法分析吗? 解
1)提取左公因子之后的文法变为 rexpr→ rexpr + rterm | rterm rterm→rterm rfactor | rfactor rfactor→ rfactor * | rprimary rprimary→a | b 2)不可以,文法中存在左递归,而自顶向下技术不适合左递归文法 3)消除左递归后的文法
rexpr -> rterm rexpr’ rexpr’-> + rterm rexpr’|ε rterm-> rfactor rterm’ rterm’-> rfactor rterm’|ε rfactor-> rprimay rfactor’ rfactor’-> *rfactor’|ε rprimary-> a | b 4)该文法无左递归,适合于自顶向下的语法分析 习题4.4.1:为下面的每一个文法设计一个预测分析器,并给出预测分析表。可能要先对文法进行提取左公因子或消除左递归 (3)S->S(S)S|ε (5)S->(L)|a L->L,S|S 解 (3) ①消除该文法的左递归后得到文法 S->S’ S’->(S)SS’|ε ②计算FIRST和FOLLOW集合 FIRST(S)={(,ε} FOLLOW(S)={),$} FIRST(S’)={(,ε} FOLLOW(S’)={),$} ③构建预测分析表
第一章习题解答 2.编译程序有哪些主要构成成分?各自的主要功能是什么? 编译程序的主要构成成分有:词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、表格管理程序及出错处理程序。 (1)词法分析程序:从左到右扫描源程序,识别单词及其有关属性; (2)语法分析程序:分析源程序的结构, 判别它是否为相应程序设计语言中的一个合法程序; (3)语义分析程序:审查源程序有无语义错误,为代码生成阶段收集类型信息; (4)中间代码生成程序:将源程序变成一种内部表示形式; (5)代码优化程序:对前阶段产生的中间代码进行变换或进行改造,使生成的目标代码更为高效; (6)目标代码生成程序:把中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码; (7)表格管理程序:保存编译过程中的各种信息; (8)出错处理程序:若编译过程中发现源程序存在错误,则报告错误的性质和错误发生的地点,有些还可以自动校正错误。 3.什么是解释程序?它与编译程序的主要不同是什么? 解释程序接受某个语言的程序并立即运行这个源程序。它的工作模式是一个个的获取、分析并执行源程序语句,一旦第一个语句分析结束,源程序便开始运行并且生成结果,它特别适合程序员交互方式的工作情况。 而编译程序是一个语言处理程序,它把一个高级语言程序翻译成某个机器的汇编或二进制代码程序,这个二进制代码程序再机器上运行以生成结果。 它们的主要不同在于:解释程序是边解释边执行,解释程序运行结束即可得到该程序的运行结果,而编译程序只是把源程序翻译成汇编或者二进制程序,这个程序再执行才能得到程序的运行结果。(当然还有其他不同,比如存储组织方式不同)
第五章 练习5.1.1: 对于图5-1中的SDD,给出下列表达式对应的注释语法分析树: 1)(3+4)*(5+6)n 练习5.2.4: 这个文法生成了含“小数点”的二进制数: S->L.L|L L->LB|B B->0|1 设计一个L属性的SDD来计算S.val,即输入串的十进制数值。比如,串101.101应该被翻译为十进制的5.625。提示:使用一个继承属性L.side来指明一个二进制位在小数点的哪一边。 答: 元文法消除左递归后可得到文法: S->L.L|L L->BL’ L’->BL’|ε B->0|1 使用继承属性L.side指明一个二进制位数在小数点的哪一边,2表示左边,1表示右边 使用继承属性m记录B的幂次 非终结符号L和L’具有继承属性inh、side、m和综合属性syn
练习5.3.1:下面是涉及运算符+和整数或浮点运算分量的表达式文法。区分浮点数的方法是看它有无小数点。 E-〉E+T|T T-〉num.num|num 1)给出一个SDD来确定每个项T和表达式E的类型 2)扩展(1)中得到的SDD,使得它可以把表达式转换成为后缀表达式。使用一个单目运算符intToFloat把一个整数转换为相等的浮点数 答: 练习5.4.4:为下面的产生式写出一个和例5.10类似的L属性SDD。这里的每个产生式表
示一个常见的C语言中的那样的控制流结构。你可能需要生成一个三地址语句来跳转到某个标号L,此时你可以生成语句goto L 1)S->if (C) S1 else S2 2)S->do S1 while (C) 3)S->’{’ L ‘}’; L -> LS|ε 请注意,列表中的任何语句都可以包含一条从它的内部跳转到下一个语句的跳转指令,因此简单地为各个语句按序生成代码是不够的。 第六章 练习6.1.1:为下面的表达式构造DAG ((x+y)-((x+y)*(x-y)))+((x+y)*(x-y)) 答:DAG如下
精品文档 第二章 P36-6 (1) L G ()1是0~9组成的数字串 (2) 最左推导: N ND NDD NDDD DDDD DDD DD D N ND DD D N ND NDD DDD DD D ??????????????????0010120127334 556568 最右推导: N ND N ND N ND N D N ND N D N ND N ND N D ??????????????????77272712712701274434 886868568 P36-7 G(S) O N O D N S O AO A AD N →→→→→1357924680||||||||||| P36-8 文法: E T E T E T T F T F T F F E i →+-→→|||*|/()| 最左推导: E E T T T F T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ?+?+?+?+?+?+?+?+??????+?+?+?+?+?+********()*()*()*()*()*()*() 最右推导: E E T E T F E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ?+?+?+?+?+?+?+?+?????+?+?+?+?+?+?+**********()*()*()*()*()*()*()*() 语法树:/********************************
编译 原理 课后题答案 第二章 P36-6 (1) L G ()1是0~9组成的数字串 (2) 最左推导: N ND NDD NDDD DDDD DDD DD D N ND DD D N ND NDD DDD DD D ??????????????????0010120127334 556568 最右推导: N ND N ND N ND N D N ND N D N ND N ND N D ??????????????????77272712712701274434 886868568 P36-7 G(S) O N O D N S O AO A AD N →→→→→1357924680||||||||||| P36-8 文法: E T E T E T T F T F T F F E i →+-→→|||*|/()| 最左推导: E E T T T F T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ?+?+?+?+?+?+?+?+??????+?+?+?+?+?+********()*()*()*()*()*()*() 最右推导:
E E T E T F E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ?+?+?+?+?+?+?+?+?????+?+?+?+?+?+?+**********()*()*()*()*()*()*()*() 语法树:/******************************** E E F T E + T F F T +i i i E E F T E -T F F T -i i i E E F T +T F F T i i i *i+i+i i-i-i i+i*i *****************/ P36-9 句子iiiei 有两个语法树: S iSeS iSei iiSei iiiei S iS iiSeS iiSei iiiei ???????? P36-10 /************** ) (|)(|S T T TS S →→ ***************/ P36-11 /*************** L1: ε ||cC C ab aAb A AC S →→→ L2:
第一章编译概述 2.典型的编译程序可划分为几部分?各部分的主要功能是什么?每部分都是必不可少的吗? 答:编译程序主要由词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、信息表管理程序、错误检查处理程序组成。 各部分的主要功能如下: 词法分析程序又称扫描器。进行词法分析时,依次读入源程序中的每个字符,依据语言的构词规则,识别出一个个具有独立意义的最小语法单元,即“单词”,并用某个单词符号来表示每个单词的词性是标识符、分界符还是数; 语法分析程序的功能是:对词法分析的结果,根据语言规则,将一个个单词符号组成语言的各种语法类; 语义分析的功能是确定源程序的语义是否正确; 中间代码生成程序的功能是将源程序生成一种更易于产生、易于翻译成目标程序的中间代码; 代码优化程序的功能是将中间代码中重复和冗余部分进行优化,提高目标程序的执行效率; 目标代码生成程序的功能是将中间代码生成特定机器上的机器语言代码; 符号表管理程序的功能是记录源程序中出现的标识符,并收集每个标识符的各种属性信息; 错误处理程序的功能是应对在编译各个阶段中出现的错误做适当的处理,从而使编译能够继续进行。 编译程序的每部分都是必不可少的。 3.解释方式和编译方式的区别是什么? 答:解释方式最终并不生成目标程序,这是编译方式与解释方式的根本区别。解释方式很适合于程序调试,易于查错,在程序执行中可以修改程序,但与编译方式相比,执行效率太低。 4.论述多遍扫描编译程序的优缺点? 答:优点:(1)可以减少内存容量的需求,分遍后,以遍为单位分别调用编译的各个子程序,各遍程序可以相互覆盖;(2)可使各遍的编译程序相互独立,结构清晰;(3)能够进行充分的优化,产生高质量的目标程序;(4)可将编译程序分为“前端”和“后端”,有利于编译程序的移植。 缺点是每遍都要读符号、送符号,增加了许多重复性工作,降低了编译效率。
第一章习题解答 2.编译程序有哪些主要构成成分?各自的主要功能是什么? 编译程序的主要构成成分有:词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、表格管理程序及出错处理程序。 (1)词法分析程序:从左到右扫描源程序,识别单词及其有关属性; (2)语法分析程序:分析源程序的结构, 判别它是否为相应程序设计语言中的一个合法程序; (3)语义分析程序:审查源程序有无语义错误,为代码生成阶段收集类型信息; (4)中间代码生成程序:将源程序变成一种内部表示形式; (5)代码优化程序:对前阶段产生的中间代码进行变换或进行改造,使生成的目标代码更为高效; (6)目标代码生成程序:把中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码; (7)表格管理程序:保存编译过程中的各种信息; (8)出错处理程序:若编译过程中发现源程序存在错误,则报告错误的性质和错误发生的地点,有些还可以自动校正错误。 3.什么是解释程序?它与编译程序的主要不同是什么? 解释程序接受某个语言的程序并立即运行这个源程序。它的工作模式是一个个的获取、分析并执行源程序语句,一旦第一个语句分析结束,源程序便开始运行并且生成结果,它特别适合程序员交互方式的工作情况。 而编译程序是一个语言处理程序,它把一个高级语言程序翻译成某个机器的汇编或二进制代码程序,这个二进制代码程序再机器上运行以生成结果。 它们的主要不同在于:解释程序是边解释边执行,解释程序运行结束即可得到该程序的运行结果,而编译程序只是把源程序翻译成汇编或者二进制程序,这个程序再执行才能得到程序的运行结果。(当然还有其他不同,比如存储组织方式不同)
第四章 词法分析 1.构造下列正规式相应的DFA : (1) 1(0|1)* 101 (2) 1(1010* | 1(010)* 1)* (3) a((a|b)*|ab *a)* b (4) b((ab)* | bb)* ab 解: (1)1(0|1)* 101对应的NFA 为 下表由子集法将NFA 转换为DFA : (2)1(1010* | 1(010)* 1)* 0对应的NFA 为 下表由子集法将 NFA 转换为DFA :
(3)a((a|b)*|ab*a)* b (略) (4)b((ab)* | bb)* ab (略) 2.已知NFA=({x,y,z},{0,1},M,{x},{z})其中:M(x,0)={z},M(y,0)={x,y},M(z,0)={x,z},M(x,1)={x}, M(y,1)=φ,M(z,1)={y},构造相应的DFA。 解:根据题意有NFA图如下
0,1 下表由子集法将NFA转换为DFA: 下面将该DFA最小化: (1)首先将它的状态集分成两个子集:P1={A,D,E},P2={B,C,F} (2)区分P2:由于F(F,1)=F(C,1)=E,F(F,0)=F并且F(C,0)=C,所以F,C等价。由于F(B,0)=F(C,0)=C, F(B,1)=D,F(C,1)=E,而D,E不等价(见下步),从而B与C,F可以区分。有P21={C,F},P22={B}。 (3)区分P1:由于A,E输入0到终态,而D输入0不到终态,所以D与A,E可以区分,有P11={A,E},P12={D}。 (4)由于F(A,0)=B,F(E,0)=F,而B,F不等价,所以A,E可以区分。 (5)综上所述,DFA可以区分为P={{A},{B},{D},{E},{C,F}}。所以最小化的DFA如下: 3.将图 4.16确定化: 图4.16 解:下表由子集法将NFA转换为DFA: 1
第 1 章引论 第1 题 解释下列术语: (1)编译程序 (2)源程序 (3)目标程序 (4)编译程序的前端 (5)后端 (6)遍 答案: (1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。 (2)源程序:源语言编写的程序称为源程序。 (3)目标程序:目标语言书写的程序称为目标程序。 (4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶 段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符 号表管理等工作。 (5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。 (6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。 第2 题 一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。 答案: 一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。其各部分的主要功能简述如下。 词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。 语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。 语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。 中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。 中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
《编译原理》第一次作业参考答案 一、下列正则表达式定义了什么语言(用尽可能简短的自然语言描述)? 1.b*(ab*ab*)* 所有含有偶数个a的由a和b组成的字符串. 2.c*a(a|c)*b(a|b|c)* | c*b(b|c)*a(a|b|c)* 答案一:所有至少含有1个a和1个b的由a,b和c组成的字符串. 答案二:所有含有子序列ab或子序列ba的由a,b和c组成的字符串. 说明:答案一要比答案二更好,因为用自然语言描述是为了便于和非专业的人员交流,而非专业人员很可能不知道什么是“子序列”,所以相比较而言,答案一要更“自然”. 二、设字母表∑={a,b},用正则表达式(只使用a,b, ,|,*,+,?)描述下列语言: 1.不包含子串ab的所有字符串. b*a* 2.不包含子串abb的所有字符串. b*(ab?)* 3.不包含子序列abb的所有字符串. b*a*b?a* 注意:关于子串(substring)和子序列(subsequence)的区别可以参考课本第119页方框中的内容. ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ 《编译原理》第二次作业参考答案 一、考虑以下NFA: 1.这一NFA接受什么语言(用自然语言描述)? 所有只含有字母a和b,并且a出现偶数次或b出现偶数次的字符串. 2.构造接受同一语言的DFA. 答案一(直接构造通常得到这一答案):
答案二(由NFA构造DFA得到这一答案): 二、正则语言补运算 3.画出一个DFA,该DFA恰好识别所有不含011子串的所有二进制串. 1.画出一个DFA,该DFA恰好识别所有不含011子串的所有二进制串.
第1章引言 1、解释下列各词 源语言:编写源程序的语言(基本符号,关键字),各种程序设计语言都可以作为源语言。 源程序: 用接近自然语言(数学语言)的源语言(基本符号,关键字)编写的程序,它是翻译程序处理的对象。 目标程序: 目标程序是源程序经过翻译程序加工最后得到的程序。目标程序 (结果程序)一般可由计算机直接执行。 低级语言:机器语言和汇编语言。 高级语言:是人们根据描述实际问题的需要而设计的一个记号系统。如同自然语言(接近数学语言和工程语言)一样,语言的基本单位是语句,由符号组和一组用来组织它们成为有确定意义的组合规则。 翻译程序: 能够把某一种语言程序(源语言程序)改变成另一种语言程序(目 标语言程序),后者与前者在逻辑上是等价的。其中包括:编译程序,解释程序,汇编程序。 编译程序: 把输入的源程序翻译成等价的目标程序(汇编语言或机器语言), 然后再执行目标程序(先编译后执行),执行翻译工作的程序称为编译程序。 解释程序: 以该语言写的源程序作为输入,但不产生目标程序。按源程序中语句动态顺序逐句的边解释边执行的过程,完成翻译工作的程序称为解释程序。 2、什么叫“遍” 指对源程序或源程序的中间形式(如单词,中间代码)从头到尾扫描一次,并作相应的加工处理,称为一遍。
3、简述编译程序的基本过程的任务。 编译程序的工作是指从输入源程序开始到输出目标程序为止的整个过程,整个过程可以划分5个阶段。 词法分析:输入源程序,进行词法分析,输出单词符号。 语法分析:在词法分析的基础上,根据语言的语法规则把单词符号串分解成各类语法单位,并判断输入串是否构成语法正确的“程序”。 中间代码生成:按照语义规则把语法分析器归约(或推导)出的语法单位翻译成一定形式的中间代码。 优化:对中间代码进行优化处理。 目标代码生成:把中间代码翻译成目标语言程序。 4、编译程序与解释程序的区别 编译程序生成目标程序后,再执行目标程序;然而解释程序不生成目标程序,边解释边执行。 5、有人认为编译程序的五个组成部分缺一不可,这种看法正确吗 编译程序的5个阶段中,词法分析,语法分析,语义分析和代码生成生成是必须完成的。而中间代码生成和代码优化并不是必不可少的。优化的目的是为了提高目标程序的质量,没有这一部分工作,仍然能够得到目标代码。 6、编译程序的分类 目前基本分为:诊断编译程序,优化编译程序,交叉编译程序,可变目标编译程序。
第四章 习题4.2.1:考虑上下文无关文法: S->S S +|S S *|a 以及串aa + a* (1)给出这个串的一个最左推导 S -> S S * -> S S + S * -> a S + S * -> a a + S * -> aa + a* (3)给出这个串的一棵语法分析树 习题4.3.1:下面是一个只包含符号a和b的正则表达式的文法。它使用+替代表示并运算的符号|,以避免和文法中作为元符号使用的竖线相混淆: rexpr→ rexpr + rterm | rterm rterm→rterm rfactor | rfactor rfactor→ rfactor * | rprimary rprimary→a | b 1)对这个文法提取公因子 2)提取公因子的变换使这个文法适用于自顶向下的语法分析技术吗? 3)提取公因子之后,原文法中消除左递归 4)得到的文法适用于自顶向下的语法分析吗? 解 1)提取左公因子之后的文法变为 rexpr→ rexpr + rterm | rterm rterm→rterm rfactor | rfactor rfactor→ rfactor * | rprimary rprimary→a | b 2)不可以,文法中存在左递归,而自顶向下技术不适合左递归文法 3)消除左递归后的文法
rexpr -> rterm rexpr’ rexpr’-> + rterm rexpr’|ε rterm-> rfactor rterm’ rterm’-> rfactor rterm’|ε rfactor-> rprimay rfactor’ rfactor’-> *rfactor’|ε rprimary-> a | b 4)该文法无左递归,适合于自顶向下的语法分析 习题4.4.1:为下面的每一个文法设计一个预测分析器,并给出预测分析表。可能要先对文法进行提取左公因子或消除左递归 (3)S->S(S)S|ε (5)S->(L)|a L->L,S|S 解 (3) ①消除该文法的左递归后得到文法 S->S’ S’->(S)SS’|ε ②计算FIRST和FOLLOW集合 FIRST(S)={(,ε} FOLLOW(S)={),$} FIRST(S’)={(,ε} FOLLOW(S’)={),$} ③ (5) ①消除该文法的左递归得到文法 S->(L)|a
第一章 1、将编译程序分成若干个“遍”是为了。 b.使程序的结构更加清晰 2、构造编译程序应掌握。 a.源程序b.目标语言 c.编译方法 3、变量应当。 c.既持有左值又持有右值 4、编译程序绝大多数时间花在上。 d.管理表格 5、不可能是目标代码。 d.中间代码 6、使用可以定义一个程序的意义。 a.语义规则 7、词法分析器的输入是。 b.源程序 8、中间代码生成时所遵循的是- 。 c.语义规则 9、编译程序是对。 d.高级语言的翻译 10、语法分析应遵循。 c.构词规则 二、多项选择题 1、编译程序各阶段的工作都涉及到。 b.表格管理c.出错处理 2、编译程序工作时,通常有阶段。 a.词法分析b.语法分析c.中间代码生成e.目标代码生成 三、填空题 1、解释程序和编译程序的区别在于是否生成目标程序。 2、编译过程通常可分为5个阶段,分别是词法分析、语法分析中间代码生成、代码优化和目标代码生成。 3、编译程序工作过程中,第一段输入是源程序,最后阶段的输出为标代码生成程序。 4、编译程序是指将源程序程序翻译成目标语言程序的程序。
一、单项选择题 1、文法G:S→xSx|y所识别的语言是。 a. xyx b. (xyx)* c. x n yx n(n≥0) d. x*yx* 2、文法G描述的语言L(G)是指。 a. L(G)={α|S+?α , α∈V T*} b. L(G)={α|S*?α, α∈V T*} c. L(G)={α|S*?α,α∈(V T∪V N*)} d. L(G)={α|S+?α, α∈(V T∪V N*)} 3、有限状态自动机能识别。 a. 上下文无关文法 b. 上下文有关文法 c.正规文法 d. 短语文法 4、设G为算符优先文法,G的任意终结符对a、b有以下关系成立。 a. 若f(a)>g(b),则a>b b.若f(a) 《编译原理》课后习题答案第一章 第 1 章引论 第 1 题 解释下列术语: (1)编译程序 (2)源程序 (3)目标程序 (4)编译程序的前端 (5)后端 (6)遍 答案: (1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。 (2)源程序:源语言编写的程序称为源程序。 (3)目标程序:目标语言书写的程序称为目标程序。 (4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶 段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符 号表管理等工作。 (5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。 (6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。 第 2 题 一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程 序的总体结构图。 答案: 一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。其各部分的主要功能简述如下。 词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机表达形式。 语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。 语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。 中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式 的中间语言代码,如三元式或四元式。 中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。 目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。 表格管理程序:负责建立、填写和查找等一系列表格工作。表格的作用是记录源程序的 各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。可以说整个编译过程就是造表、查表的工作过程。需要指出的是,这里的“表格管理程序”并不意味着它就是一个独立的表格管理模块,而是指编译程序具有的表格管理功能。 错误处理程序:处理和校正源程序中存在的词法、语法和语义错误。当编译程序发现源 第四章语义分析和中间代码生成 4.1 完成下列选择题: (1) 四元式之间的联系是通过实现的。 a. 指示器 b. 临时变量 c. 符号表 d. 程序变量 (2) 间接三元式表示法的优点为。 a. 采用间接码表,便于优化处理 b. 节省存储空间,不便于表的修改 c. 便于优化处理,节省存储空间 d. 节省存储空间,不便于优化处理 (3) 表达式(┐A∨B)∧(C∨D)的逆波兰表示为。 a. ┐AB∨∧CD∨ b. A┐B∨CD∨∧ c. AB∨┐CD∨∧ d. A┐B∨∧CD∨ (4) 有一语法制导翻译如下所示: S→bAb {print″1″} A→(B {print″2″} A→a {print″3″} B→Aa) {print″4″} 若输入序列为b(((aa)a)a)b,且采用自下而上的分析方法,则输出序列为。a. 32224441 b. 34242421 c. 12424243 d. 34442212 【解答】 (1) b (2) a (3) b (4) b 4.2 何谓“语法制导翻译”?试给出用语法制导翻译生成中间代码的要点,并用一简例予以说明。 【解答】语法制导翻译(SDTS)直观上说就是为每个产生式配上一个翻译子程序(称语义动作或语义子程序),并且在语法分析的同时执行这些子程序。也即在语法分析过程中,当一个产生式获得匹配(对于自上而下分析)或用于归约(对于自下而上分析)时,此产生式相应的语义子程序进入工作,完成既定的翻译任务。 用语法制导翻译(SDTS)生成中间代码的要点如下: (1) 按语法成分的实际处理顺序生成,即按语义要求生成中间代码。 (2) 注意地址返填问题。 (3) 不要遗漏必要的处理,如无条件跳转等。 例如下面的程序段: if (i>0) a=i+e-b*d; else a=0; 在生成中间代码时,条件“i>0”为假的转移地址无法确定,而要等到处理“else”时方可确定,这时就存在一个地址返填问题。此外,按语义要求,当处理完(i>0)后的语句(即“i>0”为真时执行的语句)时,则应转出当前的if语句,也即此时应加入一条无条件跳转指令,并且这个转移地址也需要待处理完else之后的语句后方可获得,就是说同样存在着地址返填问题。对于赋值语句a=i+e-b*d,其处理顺序(也即生成中间代码顺序)是先生成i+e的代码,再生成b*d的中间代码,最后才产生“-”运算的中间代码,这种顺序不能颠倒。 4.3 令S.val为文法G[S]生成的二进制数的值,例如对输入串101.101,则S.val= 5.625。按照语法制导翻译方法的思想,给出计算S.val的相应的语义规则,G(S)如下: G[S]: S→L.L|L 第一次作业答案: 3.12 词法单元描述 3.3.5 b)a*b*……z* c) /\*([^*”]|\*[^/]|\”([^”]*)\”)*\*/ h)b*(a|ab)* 3.7.3d F转G错误,F跳转后的状态子集应包含9 第二次作业答案: 4.2.2 最左推导 S->SS S->S*S S->(S)*S S->(S+S)*S S->(a+S)*S S->(a+a)*S S->(a+a)*a Parse tree: 最右推导: S->SS S->S*a S->(S)*a S->(S+S)*a S->(S+a)*a S->(a+a)*a 无二义性,只能画出一棵语法树。 4.3.2 提取左公因子: S->SS’|(S)|a S’->+S|S|* 消除左递归: S->(S)A|aA , A->BA|?B->S|+S|* FIRST(S) = { a , ( } FIRST(A) = {* , a , ( , + , ?} FIRST(B) = {* , a , ( , +} FOLLOW(S) = { ( , ) , a , * , + , $} LL1 parse table: 转换表如下: match stack input action S$ (a+a)*a$ (S)A$ (a+a)*a$ S->(S)A ( S)A$ a+a)*a$ match( ( aA)A$ a+a)*a$ S->aA (a A)A$ +a)*a$ match a (a BA)A$ +a)*a$ A->BA (a +SA)A$ +a)*a$ B->+S (a+ SA)A$ a)*a$ match + (a+ aAA)A$ a)*a$ S->aA (a+a AA)A$ )*a$ match a (a+a A)A$ )*a$ A->? (a+a )A$ )*a$ A->? (a+a) A$ *a$ match ) (a+a) BA$ *a$ A->BA (a+a) *A$ *a$ B->* (a+a)* A$ a$ match * (a+a)* BA$ a$ A->BA (a+a)* SA$ a$ B- >S (a+a)* aAA$ a$ S->aA (a+a)*a AA$ $ match a (a+a)*a $ $ A->? 例1设有文法G[S]: S →a|(T )| T →T,S|S (1) 试给出句子(a,a,a)的最左推导。 (2) 试给出句子(a,a,a)的分析树 (3) 试给出句子(a,a,a)的最右推导和最右推导的逆过程(即最左规约)的每一步的句柄。 【解】(1) (a,a,a)的最左推导 S=>(T) =>(T,S) =>( T,S,S) =>( S,S,S) =>(a,S,S) =>(a,a,S) =>(a,a,a) (2)(a,a,a)的分析树 S ( T ) T , S S a T , S a (3) (a,a,a)最右推导 最左规约每一步的句柄 S=>(T) 句柄为:(T) =>(T,S) 句柄为:T,S =>(T,a) 句柄为:a =>(T,S,a) 句柄为:T,S =>(T,a,a) 句柄为:第一个a =>(S,a,a) 句柄为:S =>(a,a,a) 句柄为:第一个a 例2已知文法G[Z]: Z →0U|1V U →1Z|1 V →0Z|0 (1) 请写出此文法描述的只含有4个符号的全部句子。 (2) G [Z]产生的语言是什么? (3) 该文法在Chomsky 文法分类中属于几型文法? 【解】(1)0101,0110,1010, 1001 (2)分析G[Z]所推导出的句子的特点:由Z 开始的推导不外乎图1所示的四种情形。 图 1文法G[Z]可能的几种推导 Z 1 U Z U Z 1 Z 1 V Z 1 V 由Z 推导出10或01后就终止或进入递归,而Z 的每次递归将推导出相同的符号串:10或 01。所以 G[Z]产生的语言L(G[Z])={x|x∈(10|01)+ } (3)该文法属于3型文法。 例3 已知文法G=({A,B,C},{a,b,c},P,A), P由以下产生式组成: A→abc A→aBbc Bb→bB Bc→Cbcc bC→Cb aC→aaB aC→aa 此文法所表示的语言是什么? 【解】 分析文法的规则: 每使用一次Bc→Cbcc,b、c的个数各增加一个; 每使用一次aC→aaB或aC→aa, a的个数就增加一个; 产生式Bb→bB、 bC→Cb起连接转换作用。 由于A是开始符号,由产生式A→abc推导得到终结符号串abc;由产生式A→aBbc推导得到B后,每当使用产生式Bb→bB、Bc→Cbcc、bC→Cb、aC→aaB就会递归调用B一次,所产生的a、b、c的个数分别增加一个,因此推导所得的终结符号串为abc、aabbcc、aaabbbccc、…所以文法描述的语言为{ a n b n c n|n>0}. 例4 构造描述语言L(G[S])={(n)n|n≥0} 的文法。 【解】(1)找出语言的一些典型句子: n=0 ε n=1 ( ) n=2 (()) … 所以, L(G[S])={ ε、( ) (())、((()))、…} (2)分析句子的特点: 只含有(和),(和)的个数相同且对称, 句子中所含的符号数可无限, 句子的个数可无限。 (3)凑规则:由 S→ε|() 得到ε|(),由 A→ (S) 得到 (()),(()) 是在()的两边再加上一对()得到,((()))是在(())的两边再加上一对()得到,…所以将上述产生式合并为S→(S) |ε。 (4)得到文法 G[S]: S→(S) |ε (5)检验:语言所有的句子均可由文法G[S]推导出来, 文法G[S]推导出来的所有终结符号串均为语言的句子. 例5 构造描述语言L(G[S])={a m b n |n>m>0} 的文法。 【解】找出语言的一些典型句子:abb、abbb、…、aabbb、aabbbb、…,语言的句子的特点是仅含有a、b, a在b的左边,b的个数大于a的个数,a的个数至少是1。 单独生成c k, k>1 可用产生式 C→c |Cc 句子中要求b的个数大于a的个数,所以得到文法: 作业参考答案 第二章 高级语言及其语法描述 6、(1)L (G 6)={0,1,2,......,9}+ (2)最左推导: N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 N=>ND=>DD=>3D=>34 N=>ND=>NDD=>DDD=>5DD=>56D=>568 最右推导: N=>ND =>N7=>ND7=>N27=>ND27=>N127=>D127=>0127 N=>ND=>N4=>D4=>34 N=>ND=>N8=>ND8=>N68=>D68=>568 7、G:S →ABC | AC | C A →1|2|3|4|5|6|7|8|9 B →BB|0|1|2|3|4|5|6|7|8|9 C →1|3|5|7|9 8、(1)最左推导: E=>E+T=>T+T=>F+T=>i+T=>i+T*F=>i+F*F=>i+i*F=>i+i*i E=>T=>T*F=>F*F=>i*F=>i*(E)=>i*(E+T)=>i*(T+T)=>i*(F+T)=>i*(i+T)=>i*(i+F)=>i*(i+i) 最右推导: E=>E+T=>E+T*F=>E+T*i=>E+F*i=>E+i*i=>T+i*i=>F+i*i=>i+i*i E=>T=>T*F=>T*(E)=>T*(E+T)=>T*(E+F)=>T*(E+i)=>T*(T+i)=>T*(F+i)=>T*(i+i)=>F*(i+i)=>i*(i+i) (2) 9、证明:该文法存在一个句子iiiei 有两棵不同语法分析树,如下所示,因此该文法是二义的。 T F F i F i F i T F i F i S i 第一章引论 本章要点: 1. 正确理解什么是编译程序; 2. 了解编译程序工作的基本过程及各阶段的基本任务; 3. 熟悉编译程序的总体结构框图; 4. 了解编译程序的构造过程和构造工具。 本章目标: 1. 掌握本章的“编译程序”、“交叉编译程序”、“编译前端与编译后端”等基本概念,并能在以后的学习熟练运用; 2. 掌握T形图表示。 本章重点: 1. 概念比较: ①编译程序、解释程序; ②诊断编译程序、优化编译程序; ③交叉编译程序、可变目标编译程序; ④编译前端与编译后端; 2. 编译工作过程的五个阶段; 3. 编译程序总框; 4. 编译程序“移植”。 本章难点 1. 编译程序“移植”; 作业题及参考答案 一、单项选择题: (按照组卷方案,至少8道小题) 1. 如果一个编译程序能产生不同于其宿主机的机器代码,则称它为:。 a. 诊断编译程序 b. 优化编译程序 c. 交叉编译程序 d. 可变目标编译程序 2. 编译程序将高级语言程序翻译成。 a. 机器语言程序或高级语言程序 b. 汇编语言或机器语言程序 c. 汇编语言程序或高级语言程序 d. 中间语言程序或高级语言程序 3. 下面的四个选项中,__________不是编译程序的组成部分。 a. 词法分析程序 b. 代码生成程序 c. 设备管理程序 d. 语法分析程序 4. 现代多数实用编译程序所产生的目标代码都是一种可重定位的指令代码,在运行前必须借助于一个把各个目标模块,包括系统提供的库模块连接在一起,确定程序变量或常数在主存中的位置,装入内存中制定的起始地址,使之成为一个可运行的绝对指令代码的程序。 a. 重定位程序; b. 解释程序; c. 连接装配程序; d. 诊断程序; 5. 从编译程序的角度说,源程序中的错误通常分为两大类。 a. 词法错误和语法错误; b. 语法错误和语义错误; c. 编辑错误和诊断错误; d. 词法错误和语义错误; 6. 下面对编译原理的有关概念正确描述的是:。 a. 目标语言只能是机器语言 b. 编译程序处理的对象是源语言。 c. Lex是语法分析自动生成器 d. 解释程序属于编译程序 7. 目标代码生成阶段所生成的目标代码的形式不可能是。 a. 绝对指令代码 b. 可充定位的指令代码。 c. 汇编指令代码 d. 三地址代码 8. 语义错误是指源程序中不符合语义规则的错误,不包括: a. 非法字符错误 b. 类型不一致错误。 c. 作用域错误 d. 说明错误 一.答案:1. c; 2. b;3. c; 4. c;5. b;6. d;7. d;8.a; 二、填空题: (按照组卷方案,至少8道小题) 1.我们有时把编译程序划分为编译前端和编译后端。前端主要由与有关但与编译原理第二版课后习答案
编译原理教程课后习题答案——第四章
编译原理作业答案最终版
编译原理第一章练习和答案
编译原理课后作业参考答案
编译原理作业集第一章修订版
相关主题
文本预览