
实验一Bayes 分类器设计
本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。
1实验原理
最小风险贝叶斯决策可按下列步骤进行:
(1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==
c
j i
i
i i i P X P P X P X P 1
)
()()
()()(ωωωωω j=1,…,x
(2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险
∑==
c
j j
j
i
i X P a X a R 1
)(),()(ω
ωλ,i=1,2,…,a
(3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即 则k a 就是最小风险贝叶斯决策。
2实验内容
假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
现有一系列待观察的细胞,其观察值为x :
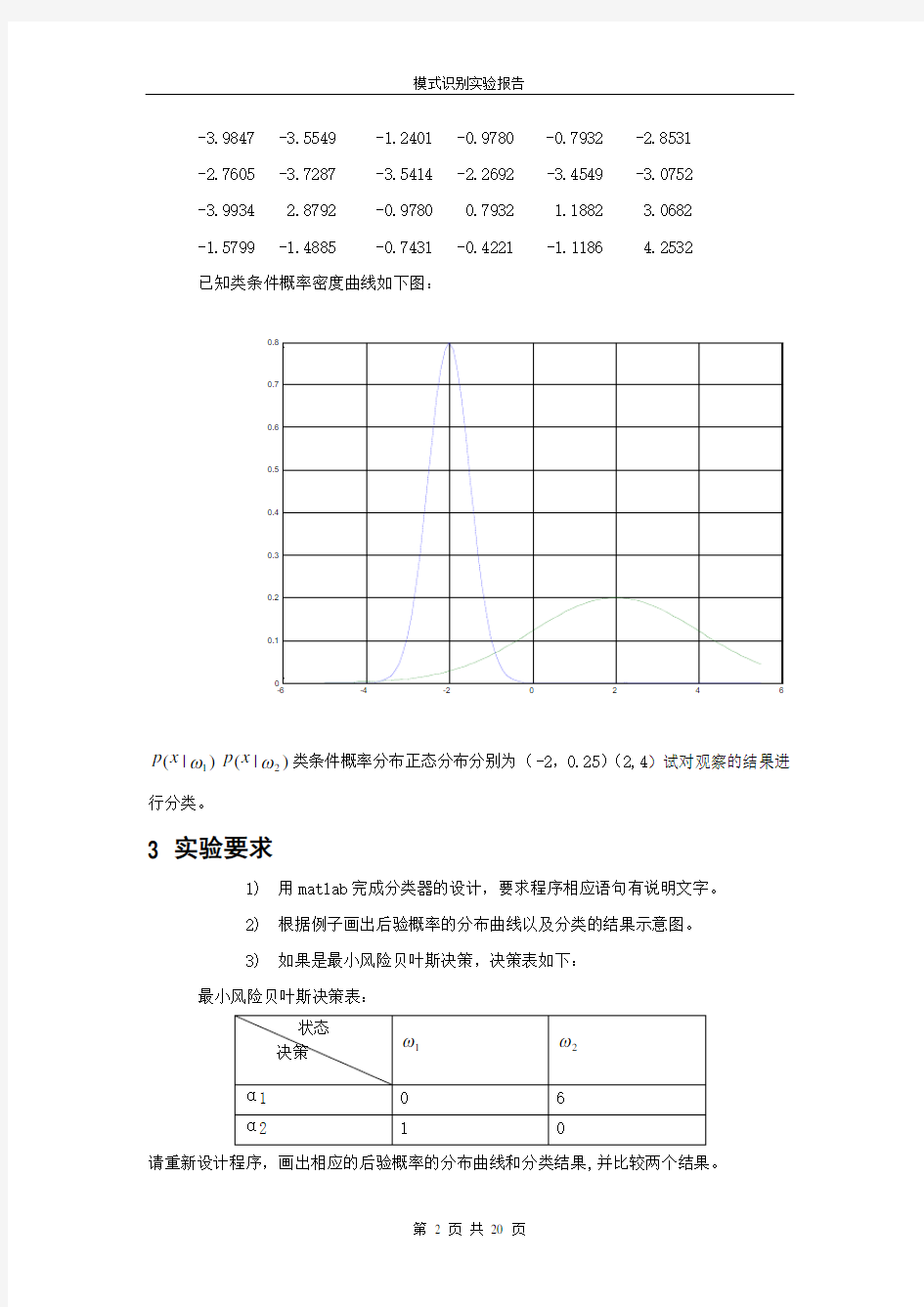
-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率密度曲线如下图:
)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,0.25)(2,4)试对观察的结果进行分类。
3 实验要求
1) 用matlab 完成分类器的设计,要求程序相应语句有说明文字。 2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。 3) 如果是最小风险贝叶斯决策,决策表如下: 最小风险贝叶斯决策表:
请重新设计程序,画出相应的后验概率的分布曲线和分类结果,并比较两个结果。
最小错误率贝叶斯决策
试验程序
x=[-3.9847,-3.5549,-1.2401,-0.9780,-0.7932,
-2.8531,-2.7605,-3.7287,-3.5414 ,-2.2692,-3.4549,-3.0752,-3.9934,2.8792,...
-0.9780,0.7932,1.1882 ,3.0682 ,-1.5799 ,-1.4885 ,-0.7431 ,-0.4221 ,-1.1186 ,4.2532 ]; num=24; %输入的特征值个数
result=zeros(1,num);%存放分类结果
e1=-2; %正常细胞的特征均值
a1=0.5; %正常细胞的特征标准差
e2=2; %异常细胞的特征均值
a2=2; %异常细胞的特征标准差
pw1=0.9; %正常细胞出现的概率
pw2=0.1; %异常细胞出现的概率
for i=1:num
pw1_x=normpdf(x(i),e1,a1)*pw1; %正常细胞后验概率的分子
pw2_x=normpdf(x(i),e2,a2)*pw2; %异常细胞后验概率的分子
if pw1_x>pw2_x
result(i)=1; %识别结果为正常细胞
end
end
a=[-5:0.05:5];
n=numel(a);
pw1_plot=zeros(1,n);
pw2_plot=zeros(1,n);
for j=1:n
pw1_plot(j)=(pw1*normpdf(a(j),e1,a1))/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2));%正常细胞后验概率
pw2_plot(j)=(pw2*normpdf(a(j),e2,a2))/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2));%异常细胞后验概率
end
figure(1);
hold on;
plot(a,pw1_plot,'k-',a,pw2_plot,'r-.');
for k=1:num
if result(k)==1
plot(x(k),-0.1,'b*');%正常细胞分布
else
plot(x(k),-0.1,'rp');%异常细胞分布
end
end
legend('正常细胞后验概率曲线','异常细胞后验概率曲线','正常细胞','异常细胞');
xlabel('样品细胞特征值'); ylabel('后验概率');
title('后验概率分布曲线'); grid on;
实验结果
-5
-4-3-2
-1012345
-0.20
0.2
0.4
0.6
0.8
1
1.2
样品细胞特征值
后验概率
后验概率分布曲线
带—·—的曲线为判决成异常细胞的后验概率曲线; 另一条平滑的曲线为判为正常细胞的后验概率曲线。
根据最小错误概率准则,判决结果见曲线下方,其中“*”代表判决为正常细胞,“五角星”代表异常细胞各细胞分类结果。
最小风险贝叶斯决策分类器设计
实验程序
x = [-3.9847 , -3.5549 , -1.2401 , -0.9780 , -0.7932 , -2.8531 ,-2.7605 , -3.7287 , -3.5414 , -2.2692 ,...
-3.4549 , -3.0752 , -3.9934 , 2.8792 , -0.9780 , 0.7932 , 1.1882 , 3.0682, -1.5799 , -1.4885 , -0.7431 , -0.4221 , -1.1186 , 4.2532 ] ; disp(x)
pw1=0.9 ;%第一类的先验概率
pw2=0.1 ;%第二类的先验概率
m=numel(x); %样品个数
R1_x=zeros(1,m) ;%判为第一类的条件风险
R2_x=zeros(1,m) ;%判为第二类的条件风险
result=zeros(1,m) ;%识别结果
e1=-2; %第一类的均值
a1=0.5 ;%第一类的标准差
e2=2 ;%第二类的均值
a2=2 ;%第二类的标准差
%决策表
r11=0 ;
r12=2 ;
r21=4 ;
r22=0 ;
%计算条件风险
for i=1:m
R1_x(i)=r11*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2))+r21 *pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2));
R2_x(i)=r12*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2))+r22 *pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2)) ;
end
for i=1:m
if R2_x(i)>R1_x(i)%
result(i)=0;
else
result(i)=1;
end
end
a=[-5:0.05:5];
n=numel(a);
R1_plot=zeros(1,n) ;
R2_plot=zeros(1,n);
for j=1:n
R1_plot(j)=r11*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2))+r 21*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2));
R2_plot(j)=r12*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2))+r 22*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1,a1)+pw2*normpdf(a(j),e2,a2));
end
figure(1)
hold on
plot(a,R1_plot,'b-',a,R2_plot,'g*-')
for k=1:m
if result(k)==0
plot(x(k),-0.1,'b^')
else plot(x(k),-0.1,'go') end; end;
legend('正常细胞','异常细胞','Location','Best') xlabel('细胞分类结果') ylabel('条件风险') title('风险决策曲线') grid on
实验结果
-5
-4-3-2
-1012345
细胞分类结果
条件风险
风险决策曲线
其中带*的绿色曲线代表异常细胞的条件风险曲线; 另一条光滑的蓝色曲线为判为正常细胞的条件风险曲线。
根据贝叶斯最小风险判决准则,判决结果见曲线下方,其中“上三角”代表判决为正常细胞,“圆圈“代表异常细胞。
比较分析:
在图1中,这两个样本点下两类决策的后验概率相差很小,当结合最小风险贝叶斯决策表进行计算时,“损失因素”就起了主导作用,导致出现了相反的结果。
实验二\三多分类Bayes分类器设计
数据集为Mnistall 数据集,加载到内存,解析数据集的组织结构,完成10类手写体数据集的分类问题。
实验原理
首先提取手写体的特征,训练集为28*28的手写体图片,将手写体图片等分为7*7份,每一份的大小为4*4,统计每份中非0像素(即手写体)的个数n,像素占有率大于T(设为0.05)取特征值1,否则取特征值0。
对于要识别的手写体,首先提取特征值,然后计算0~9类的后验概率,后验概率最大即为对应类别
实验内容
%手写体特征值提取函数
function sample_feature=feature_extraction(sample)
%[单个样品的行数,单个样品的列数,训练集的个数]
[image_row,image_col,sample_num]=size(sample);
sample_feature=zeros(49,sample_num);%存储训练集的特征
yuzhi=0.05;%窗口面积比阈值
%提取训练集的特征
for k=1:sample_num
p=1;
for i=1:4:image_row-3
for j=1:4:image_col-3
for m=i:i+3
for n=j:j+3
if (sample(m,n,k)~=0)
%统计手写体中每个窗口中非零像素的个数
sample_feature(p,k)=sample_feature(p,k)+1;
end
end
end
%面积占有率大于yuzhi取特征值为1
if ( (sample_feature(p,k)/16)>yuzhi )
sample_feature(p,k)=1;
else
sample_feature(p,k)=0;
end
p=p+1;
end
end
end
主函数
load mnistAll;
%提取样品库每个手写体的特征
train_feature=feature_extraction(mnist.train_images); train_num=60000;%训练集大小
%求0~9手写数字的特征分布
pw=zeros(1,10);%先验概率
pxw=zeros(49,10);%训练集的类条件概率
for k=1:train_num
i=mnist.train_labels(k)+1;
%统计每类的样品个数
pw(i)=pw(i)+1;
%统计每类的每个特征特征值为1的个数
pxw(:,i)=pxw(:,i)+train_feature(:,k);
end
for i=1:10
%求每类的特征分布概率
pxw(:,i)=(pxw(:,i)+1)/(pw(i)+2);
end
pw=pw/train_num;
pwx=zeros(1,10);%后验概率
test_feature=feature_extraction(mnist.test_images); test_num=10000;%测试样品个数
true_num=0;
for k=1:test_num
pxw_test=zeros(1,10)+1;%测试样品的类条件概率
for i=1:10
%求测试样品的类条件概率
for j=1:49
if(test_feature(j,k)==1)
pxw_test(i)=pxw_test(i)*pxw(j,i);
else
pxw_test(i)=pxw_test(i)*(1-pxw(j,i));
end
end
end
for i=1:10
%测试样品的后验概率的分子
pwx(i)=pw(i)*pxw_test(i);
end
[maxval maxpos]=max(pwx);
y=maxpos-1;
if ( y==mnist.test_labels(k))
true_num=true_num+1;
end
end
识别结果
10000个测试样品中正确识别了6891个,正确率为68.91%
实验四基于Fisher准则的线性分类器设计一、实验目的
本实验旨在让同学进一步了解分类器的设计概念,能够根据自己的设计对线性分类器有更深
刻地认识,理解Fisher 准则方法确定最佳线性分界面方法的原理。
二、实验原理
线性判别函数的一般形式可表示成 0)(w X W X g T += 其中
?????
??=d x x X 1 ??????
? ??=d w w w W 21
根据Fisher 选择投影方向W 的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,用以评价投影方向W 的函数为:
2
2
2122
1~~)~~()(S S m m W J F +-= )(211
*m m S W W -=-
上面的公式是使用Fisher 准则求最佳法线向量的解,该式比较重要。另外,该式这种形式的运算,我们称为线性变换,其中21m m -式一个向量,1
-W S 是W S 的逆矩阵,如21m m -是d 维,W S 和1-W S 都是d ×d 维,得到的*
W 也是一个d 维的向量。
向量*
W 就是使Fisher 准则函数)(W J F 达极大值的解,也就是按Fisher 准则将d 维X 空间投影到一维Y 空间的最佳投影方向,该向量*
W 的各分量值是对原d 维特征向量求加权和的权值。
以上讨论了线性判别函数加权向量W 的确定方法,并讨论了使Fisher 准则函数极大的d 维向量*W 的计算方法,但是判别函数中的另一项0W 尚未确定,一般可采用以下几种方法确定0W 如
2
~~2
10m m W +-=
或者 m
N N m N m N W ~~~2
12
2110=++-= 或当1)(ωp 与2)(ωp 已知时可用
[]??????-+-+=2)(/)(ln 2
~~212
1210N N p p m m W ωω
……
当W 0确定之后,则可按以下规则分类,
2
010ωω∈→->∈→->X w X W X w X W T
T
使用Fisher 准则方法确定最佳线性分界面的方法是一个著名的方法,尽管提出该方法的时间比较早,仍见有人使用。
三、实验内容
已知有两类数据1ω和2ω二者的概率已知1)(ωp =0.6,2)(ωp =0.4。
1ω中数据点的坐标对应一一如下:
数据: x1 =
0.2331 1.5207 0.6499 0.7757 1.0524 1.1974 0.2908 0.2518 0.6682 0.5622 0.9023 0.1333 -0.5431 0.9407 -0.2126 0.0507 -0.0810 0.7315
0.3345 1.0650 -0.0247 0.1043 0.3122 0.6655 0.5838 1.1653 1.2653 0.8137 -0.3399 0.5152 0.7226 -0.2015 0.4070 -0.1717 -1.0573 -0.2099 x2 =
2.3385 2.1946 1.6730 1.6365 1.7844 2.0155 2.0681 2.1213 2.4797 1.5118 1.9692 1.8340
1.8704
2.2948 1.7714 2.3939 1.5648 1.9329
2.2027 2.4568 1.7523 1.6991 2.4883 1.7259 2.0466 2.0226 2.3757 1.7987 2.0828 2.0798 1.9449 2.3801 2.2373 2.1614 1.9235 2.2604 x3 =
0.5338 0.8514 1.0831 0.4164 1.1176 0.5536
0.6071 0.4439 0.4928 0.5901 1.0927 1.0756
1.0072 0.4272 0.4353 0.9869 0.4841 1.0992 1.0299 0.7127 1.0124 0.4576 0.8544 1.1275 0.7705 0.4129 1.0085 0.7676 0.8418 0.8784 0.9751 0.7840 0.4158 1.0315 0.7533 0.9548 数据点的对应的三维坐标为
2
x1 =
1.4010 1.2301
2.0814 1.1655 1.3740 1.1829 1.7632 1.9739 2.4152 2.5890 2.8472 1.9539 1.2500 1.2864 1.2614 2.0071 2.1831 1.7909
1.3322 1.1466 1.7087 1.5920
2.9353 1.4664
2.9313 1.8349 1.8340 2.5096 2.7198 2.3148 2.0353 2.6030 1.2327 2.1465 1.5673 2.9414
x2 =
1.0298 0.9611 0.9154 1.4901 0.8200 0.9399 1.1405 1.0678 0.8050 1.2889 1.4601 1.4334 0.7091 1.2942 1.3744 0.9387 1.2266 1.1833
0.8798 0.5592 0.5150 0.9983 0.9120 0.7126
1.2833 1.1029 1.2680 0.7140 1.2446 1.3392 1.1808 0.5503 1.4708 1.1435 0.7679 1.1288 x3 =
0.6210 1.3656 0.5498 0.6708 0.8932 1.4342
0.9508 0.7324 0.5784 1.4943 1.0915 0.7644
1.2159 1.3049 1.1408 0.9398 0.6197 0.6603 1.3928 1.4084 0.6909 0.8400 0.5381 1.3729 0.7731 0.7319 1.3439 0.8142 0.9586 0.7379 0.7548 0.7393 0.6739 0.8651 1.3699 1.1458
数据的样本点分布如下图:
2.5
0.5
1.5
图 1:样本点分布图
四、实验要求
1) 请把数据作为样本,根据Fisher 选择投影方向W 的原则,使原样本向量在该
方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,求出评价投影方向W 的函数,并在图形表示出来。并在实验报告中表示出来,并求使)(w J F 取极大值的*
w 。用matlab 完成Fisher 线性分类器的设计,程序的语句要求有注释。
2) 根据上述的结果并判断(1,1.5,0.6)(1.2,1.0,0.55),(2.0,0.9,0.68),
(1.2,1.5,0.89),(0.23,2.33,1.43),属于哪个类别,并画出数据分类相应的结果图,要求画出其在W 上的投影。
3) 回答如下问题,分析一下W 的比例因子对于Fisher 判别函数没有影响的原
因。
五、实验结果
1、源代码
x1=[0.2331 1.5207 0.6499 0.7757 1.0524 1.1974 ...
0.2908 0.2518 0.6682 0.5622 0.9023 0.1333 ...
-0.5431 0.9407 -0.2126 0.0507 -0.0810 0.7315 ...
0.3345 1.0650 -0.0247 0.1043 0.3122 0.6655 ...
0.5838 1.1653 1.2653 0.8137 -0.3399 0.5152 ...
0.7226 -0.2015 0.4070 -0.1717 -1.0573 -0.2099]';
y1=[2.3385 2.1946 1.6730 1.6365 1.7844 2.0155 ...
2.0681 2.1213 2.4797 1.5118 1.9692 1.8340 ...
1.8704
2.2948 1.7714 2.3939 1.5648 1.9329 ...
2.2027 2.4568 1.7523 1.6991 2.4883 1.7259 ...
2.0466 2.0226 2.3757 1.7987 2.0828 2.0798 ...
1.9449
2.3801 2.2373 2.1614 1.9235 2.2604]';
z1=[0.5338 0.8514 1.0831 0.4164 1.1176 0.5536 ...
0.6071 0.4439 0.4928 0.5901 1.0927 1.0756 ...
1.0072 0.4272 0.4353 0.9869 0.4841 1.0992 ...
1.0299 0.7127 1.0124 0.4576 0.8544 1.1275 ...
0.7705 0.4129 1.0085 0.7676 0.8418 0.8784 ...
0.9751 0.7840 0.4158 1.0315 0.7533 0.9548]'; %存储第一类点
x2=[1.4010 1.2301 2.0814 1.1655 1.3740 1.1829 ...
1.7632 1.9739
2.4152 2.5890 2.8472 1.9539 ...
1.2500 1.2864 1.2614
2.0071 2.1831 1.7909 ...
1.3322 1.1466 1.7087 1.5920
2.9353 1.4664 ...
2.9313 1.8349 1.8340 2.5096 2.7198 2.3148 ...
2.0353 2.6030 1.2327 2.1465 1.5673 2.9414]';
y2=[1.0298 0.9611 0.9154 1.4901 0.8200 0.9399 ...
1.1405 1.0678 0.8050 1.2889 1.4601 1.4334 ...
0.7091 1.2942 1.3744 0.9387 1.2266 1.1833 ...
0.8798 0.5592 0.5150 0.9983 0.9120 0.7126 ...
1.2833 1.1029 1.2680 0.7140 1.2446 1.3392 ...
1.1808 0.5503 1.4708 1.1435 0.7679 1.1288]';
z2=[0.6210 1.3656 0.5498 0.6708 0.8932 1.4342 ...
0.9508 0.7324 0.5784 1.4943 1.0915 0.7644 ...
1.2159 1.3049 1.1408 0.9398 0.6197 0.6603 ...
1.3928 1.4084 0.6909 0.8400 0.5381 1.3729 ...
0.7731 0.7319 1.3439 0.8142 0.9586 0.7379 ...
0.7548 0.7393 0.6739 0.8651 1.3699
1.1458]'; %存储第二类点
Pw1=0.6
Pw2=0.4
%求第一类点的均值向量m1
m1x=mean(x1(:)) %全部平均
m1y=mean(y1(:)) %全部平均
m1z=mean(z1(:)) %全部平均
m1=[m1x m1y m1z]
%求第二类点的均值向量m2
m2x=mean(x2(:)) %全部平均
m2y=mean(y2(:)) %全部平均
m2z=mean(z2(:)) %全部平均
m2=[m2x m2y m2z]
%求第一类类内离散矩阵S1
S1=zeros(3,3)
for i=1:36
S1=S1+([x1(i),y1(i),z1(i)]'-m1)*([x1(i),y1(i),z1(i)]'-m1)'
end
%求第二类类内离散矩阵S2
S2=zeros(3,3)
for i=1:36
S2=S2+([x2(i),y2(i),z2(i)]'-m2)*([x2(i),y2(i),z2(i)]'-m2)'
end
%求总类内离散度矩阵Sw
Sw=S1+S2
%求向量W*
W=(inv(Sw))*(m1-m2)
%画出决策面
x=0:.1:2.5
y=0:.1:3
[X,Y]=meshgrid(x,y)
Z=(W(1)*X+W(2)*Y)/(-W(3))
mesh(X,Y,Z)
%保持
hold on
%透视决策面
hidden off
%求第一类样品的投影值均值
Y1=0
for i=1:36
Y1=Y1+W'*[x1(i),y1(i),z1(i)]'
end
M1=Y1/36
%求第二类样品的投影值均值
Y2=0
for i=1:36
Y2=Y2+W'*[x2(i),y2(i),z2(i)]'
end
M2=Y2/36
%选取阈值Y0
Y0=(M1+M2)/2+(log(Pw1)/log(Pw2))/70
%判定未知样品类别
X1=[1,1.5,0.6]'
if W'*X1>Y0
disp('点X1(1,1.5,0.6)属于第一类')
plot3(1,0.5,0.6,'or')
else
disp('点X1(1,1.5,0.6)属于第二类')
plot3(1,0.5,0.6,'ob')
end
X2=[1.2,1.0,0.55]'
if W'*X2>Y0
disp('点X2(1.2,1.0,0.55)属于第一类') plot3(1.2,1.0,0.55,'or')
else
disp('点X2(1.2,1.0,0.55)属于第二类') plot3(1.2,1.0,0.55,'ob')
end
X3=[2.0,0.9,0.68]'
if W'*X3>Y0
disp('点X3(2.0,0.9,0.68)属于第一类') plot3(2.0,0.9,0.68,'or')
else
disp('点X3(2.0,0.9,0.68)属于第二类') plot3(2.0,0.9,0.68,'ob')
end
X4=[1.2,1.5,0.89]'
if W'*X4>Y0
disp('点X4(1.2,1.5,0.89)属于第一类') plot3(1.2,1.5,0.89,'or')
else
disp('点X4(1.2,1.5,0.89)属于第二类') plot3(1.2,1.5,0.89,'ob')
end
X5=[0.23,2.33,1.43]'
if W'*X5>Y0
disp('点X5(0.23,2.33,1.43)属于第一类')
plot3(0.23,2.33,1.43,'or')
else
disp('点X5(0.23,2.33,1.43)属于第二类')
plot3(0.23,2.33,1.43,'ob')
end
2、决策面
图2:决策面(红色代表第一类,蓝色代表第二类)3、参数
决策面向量
W =
-0.0798
0.2005
-0.0478
阈值
Y0 =
0.1828
样本点分类
X1 =
1.0000
1.5000
0.6000
点X1(1,1.5,0.6)属于第一类
X2 =
1.2000
1.0000
0.5500
点X2(1.2,1.0,0.55)属于第二类X3 =
2.0000
0.9000
0.6800
点X3(2.0,0.9,0.68)属于第二类X4 =
1.2000
1.5000
0.8900
点X4(1.2,1.5,0.89)属于第二类X5 =
0.2300
2.3300
1.4300
点X5(0.23,2.33,1.43)属于第一类
六、实验分析
1、比例因子
决策面向量W 的比例因子并不影响判别函数。分析如下:
阈值:[]??????-+++=2)(/)(ln 2
~~0Y 212
121N N p p m m ωω
判别函数:
2
100ωω∈→<∈→>X Y X W X Y X W T
T
可以证明,Y0与W T 有关,所以当改变W T 时,判别函数两边同时改变,所以W T 并不影响
判别函数。
名称:模式识别 题目:数字‘3’和‘4’的识别
实验目的与要求: 利用已知的数字样本(3和4),提取样本特征,并确定分类准则,在用测试样本对分类确定准则的错误率进行分析。进一步加深对模式识别方法的理解,强化利用计算机实现模式识别。 实验原理: 1.特征提取原理: 利用MATLAN 软件把图片变为一个二维矩阵,然后对该矩阵进行二值化处理。由于“3”的下半部分在横轴上的投影比“4”的下半部分在横轴上的投影宽,所以可以统计‘3’‘4’在横轴上投影的‘1’的个数作为一个特征。又由于‘4’中间纵向比‘3’的中间‘1’的个数多,所以可以统计‘4’和‘3’中间区域‘1’的个数作为另外一个特征,又考虑‘4’的纵向可能会有点偏,所以在统计一的个数的时候,取的范围稍微大点,但不能太大。 2.分类准则原理: 利用最近邻对测试样本进行分类 实验步骤 1.利用MATLAN 软件把前30个图片变为一个二维矩阵,然后对该矩阵进行二值化处理。 2.利用上述矩阵生成特征向量 3.利用MATLAN 软件把后5个图片变为一个二维矩阵,然后对该矩阵进行二值化处理。 4.对测试样本进行分类,用F矩阵表示结果,如果是‘1’表示分类正确,‘0’表示分类错误。 5.对分类错误率分析 实验原始程序: f=zeros(5,2) w=zeros(35,2) q=zeros(35,2) for i=1:35 filename_1='D:\MATLAB6p5\toolbox\images\imdemos\3\' filename_2='.bmp' a= num2str (i) b=strcat(filename_1,a) c=strcat(b,filename_2) d=imread(c) e=im2bw(d) n=0 for u=1:20 m=0 for t=32:36 if(e(t,u)==0) m=m+1 end end if(m<5) n=n+1 end end
模式识别实验报告
————————————————————————————————作者:————————————————————————————————日期:
实验报告 实验课程名称:模式识别 姓名:王宇班级: 20110813 学号: 2011081325 实验名称规范程度原理叙述实验过程实验结果实验成绩 图像的贝叶斯分类 K均值聚类算法 神经网络模式识别 平均成绩 折合成绩 注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合 2014年 6月
实验一、 图像的贝叶斯分类 一、实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念: 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。 最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模式识别中的最小错分概率贝叶斯分类器来解决。以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数可用下式表示为
北京科技大学计算机与通信工程学院 模式分类第二次上机实验报告 姓名:XXXXXX 学号:00000000 班级:电信11 时间:2014-04-16
一、实验目的 1.掌握支持向量机(SVM)的原理、核函数类型选择以及核参数选择原则等; 二、实验内容 2.准备好数据,首先要把数据转换成Libsvm软件包要求的数据格式为: label index1:value1 index2:value2 ... 其中对于分类来说label为类标识,指定数据的种类;对于回归来说label为目标值。(我主要要用到回归) Index是从1开始的自然数,value是每一维的特征值。 该过程可以自己使用excel或者编写程序来完成,也可以使用网络上的FormatDataLibsvm.xls来完成。FormatDataLibsvm.xls使用说明: 先将数据按照下列格式存放(注意label放最后面): value1 value2 label value1 value2 label 然后将以上数据粘贴到FormatDataLibsvm.xls中的最左上角单元格,接着工具->宏执行行FormatDataToLibsvm宏。就可以得到libsvm要求的数据格式。将该数据存放到文本文件中进行下一步的处理。 3.对数据进行归一化。 该过程要用到libsvm软件包中的svm-scale.exe Svm-scale用法: 用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值:lower = -1,upper = 1,没有对y进行缩放)其中,-l:数据下限标记;lower:缩放后数据下限;-u:数据上限标记;upper:缩放后数据上限;-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 )-s save_filename:表示将缩放的规则保存为文件save_filename;-r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放;filename:待缩放的数据文件(要求满足前面所述的格式)。缩放规则文件可以用文本浏览器打开,看到其格式为: y lower upper min max x lower upper index1 min1 max1 index2 min2 max2 其中的lower 与upper 与使用时所设置的lower 与upper 含义相同;index 表示特征序号;min 转换前该特征的最小值;max 转换前该特征的最大值。数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。该文件中的参数可用于最后面对目标值的反归一化。反归一化的公式为: (Value-lower)*(max-min)/(upper - lower)+lower 其中value为归一化后的值,其他参数与前面介绍的相同。 建议将训练数据集与测试数据集放在同一个文本文件中一起归一化,然后再将归一化结果分成训练集和测试集。 4.训练数据,生成模型。 用法:svmtrain [options] training_set_file [model_file] 其中,options(操作参数):可用的选项即表示的涵义如下所示-s svm类型:设置SVM 类型,默
《模式识别与人工智能》课程教学大纲 一、课程基本信息 课程代码:DX3004 课程名称:模式识别与人工智能 课程性质:选修课 课程类别:专业与专业方向课程 适用专业:电气信息类专业 总学时: 64 学时 总学分: 4 学分 先修课程:MATLAB程序设计;数据结构;数字信号处理;概率论与数理统计 后续课程:语音处理技术;数字图像处理 课程简介: 模式识别与人工智能是60年代迅速发展起来的一门学科,属于信息,控制和系统科学的范畴。模式识别就是利用计算机对某些物理现象进行分类,在错误概率最小的条件下,使识别的结果尽量与事物相符。模式识别技术主要分为两大类:基于决策理论的统计模式识别和基于形式语言理论的句法模式识别。模式识别的原理和方法在医学、军事等众多领域应用十分广泛。本课程着重讲述模式识别的基本概念,基本方法和算法原理,注重理论与实践紧密结合,通过大量实例讲述如何将所学知识运用到实际应用之中去,避免引用过多的、繁琐的数学推导。这门课的教学目的是让学生掌握统计模式识别基本原理和方法,使学生具有初步综合利用数学知识深入研究有关信息领域问题的能力。 选用教材: 《模式识别》第二版,边肇祺,张学工等编著[M],北京:清华大学出版社,1999; 参考书目: [1] 《模式识别导论》,齐敏,李大健,郝重阳编著[M]. 北京:清华大学出版社,2009; [2] 《人工智能基础》,蔡自兴,蒙祖强[M]. 北京:高等教育出版社,2005; [3] 《模式识别》,汪增福编著[M]. 安徽:中国科学技术大学出版社,2010; 二、课程总目标 本课程为计算机应用技术专业本科生的专业选修课。通过本课程的学习,要求重点掌握统计模式识别的基本理论和应用。掌握统计模式识别方法中的特征提取和分类决策。掌握特征提取和选择的准则和算法,掌握监督学习的原理以及分类器的设计方法。基本掌握非监督模式识别方法。了解应用人工神经网络和模糊理论的模式识别方法。了解模式识别的应用和系统设计。要求学生掌握本课程的基本理论和方法并能在解决实际问题时得到有效地运用,同时为开发研究新的模式识别的理论和方法打下基础。 三、课程教学内容与基本要求 1、教学内容: (1)模式识别与人工智能基本知识; (2)贝叶斯决策理论; (3)概率密度函数的估计; (4)线性判别函数; (5)非线性胖别函数;
模式识别实验报告 姓名: 班级: 学号: 提交日期:
实验一 线性分类器的设计 一、 实验目的: 掌握模式识别的基本概念,理解线性分类器的算法原理。 二、 实验要求 (1)学习和掌握线性分类器的算法原理; (2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类; (3) 对实现的线性分类器性能进行简单的评估(例如算法使用条件,算法效率及复杂度等)。 三、 算法原理介绍 (1)判别函数:是指由x 的各个分量的线性组合而成的函数: 00g(x)w ::t x w w w =+权向量阈值权 若样本有c 类,则存在c 个判别函数,对具有0g(x)w t x w =+形式的判别函数的一个两类线性分类器来说,要求实现以下判定规则: 1 2(x)0,y (x)0,y i i g g ωω>∈?? <∈? 方程g(x)=0定义了一个判定面,它把两个类的点分开来,这个平面被称为超平面,如下图所示。
(2)广义线性判别函数 线性判别函数g(x)又可写成以下形式: 01 (x)w d i i i g w x ==+∑ 其中系数wi 是权向量w 的分量。通过加入另外的项(w 的各对分量之间的乘积),得到二次判别函数: 因为 ,不失一般性,可以假设 。这样,二次判别函数拥有更多 的系数来产生复杂的分隔面。此时g(x)=0定义的分隔面是一个二阶曲面。 若继续加入更高次的项,就可以得到多项式判别函数,这可看作对某一判别函数g(x)做级数展开,然后取其截尾逼近,此时广义线性判别函数可写成: 或: 这里y 通常被成为“增广特征向量”(augmented feature vector),类似的,a 被称为
模式识别 课程设计 关于黄绿树叶的分类问题 成员:李家伟2015020907010 黄哲2015020907006 老师:程建 学生签字:
一、小组分工 黄哲:数据采集以及特征提取。 李家伟:算法编写设计,完成测试编写报告。 二、特征提取 选取黄、绿树叶各15片,用老师给出的识别算法进行特征提取 %Extract the feature of the leaf clear, close all I = imread('/Users/DrLee/Desktop/kmeans/1.jpg'); I = im2double(I); figure, imshow(I) n = input('Please input the number of the sample regions n:'); h = input('Please input the width of the sample region h:'); [Pos] = ginput(n); SamNum = size(Pos,1); Region = []; RegionFeatureCum = zeros((2*h+1)*(2*h+1)*3,1); RegionFeature = zeros((2*h+1)*(2*h+1)*3,1); for i = 1:SamNum P = round(Pos(i,:)); rectangle('Position', [P(1) P(2) 2*h+1 2*h+1]); hold on Region{i} = I(P(2)-h:P(2)+h,P(1)-h:P(1)+h,:); RegionFeatureCum = RegionFeatureCum + reshape(Region{i},[(2*h+1)*(2*h+1)*3,1]); end hold off RegionFeature = RegionFeatureCum / SamNum 1~15为绿色树叶特征,16~30为黄色树叶特征,取n=3;h=1,表示每片叶子取三个区域,每个区域的特征为3*3*3维的向量,然后变为27*1的列向量,表格如下。
《模式识别》实验报告 一、数据生成与绘图实验 1.高斯发生器。用均值为m,协方差矩阵为S 的高斯分布生成N个l 维向量。 设置均值 T m=-1,0 ?? ??,协方差为[1,1/2;1/2,1]; 代码: m=[-1;0]; S=[1,1/2;1/2,1]; mvnrnd(m,S,8) 结果显示: ans = -0.4623 3.3678 0.8339 3.3153 -3.2588 -2.2985 -0.1378 3.0594 -0.6812 0.7876 -2.3077 -0.7085 -1.4336 0.4022 -0.6574 -0.0062 2.高斯函数计算。编写一个计算已知向量x的高斯分布(m, s)值的Matlab函数。 均值与协方差与第一题相同,因此代码如下: x=[1;1]; z=1/((2*pi)^0.5*det(S)^0.5)*exp(-0.5*(x-m)'*inv(S)*(x-m)) 显示结果: z = 0.0623 3.由高斯分布类生成数据集。编写一个Matlab 函数,生成N 个l维向量数据集,它们是基于c个本体的高斯分布(mi , si ),对应先验概率Pi ,i= 1,……,c。 M文件如下: function [X,Y] = generate_gauss_classes(m,S,P,N) [r,c]=size(m); X=[]; Y=[]; for j=1:c t=mvnrnd(m(:,j),S(:,:,j),fix(P(j)*N)); X=[X t]; Y=[Y ones(1,fix(P(j)*N))*j]; end end
调用指令如下: m1=[1;1]; m2=[12;8]; m3=[16;1]; S1=[4,0;0,4]; S2=[4,0;0,4]; S3=[4,0;0,4]; m=[m1,m2,m3]; S(:,:,1)=S1; S(:,:,2)=S2; S(:,:,3)=S3; P=[1/3,1/3,1/3]; N=10; [X,Y] = generate_gauss_classes(m,S,P,N) 二、贝叶斯决策上机实验 1.(a)由均值向量m1=[1;1],m2=[7;7],m3=[15;1],方差矩阵S 的正态分布形成三个等(先验)概率的类,再基于这三个类,生成并绘制一个N=1000 的二维向量的数据集。 (b)当类的先验概率定义为向量P =[0.6,0.3,0.1],重复(a)。 (c)仔细分析每个类向量形成的聚类的形状、向量数量的特点及分布参数的影响。 M文件代码如下: function plotData(P) m1=[1;1]; S1=[12,0;0,1]; m2=[7;7]; S2=[8,3;3,2]; m3=[15;1]; S3=[2,0;0,2]; N=1000; r1=mvnrnd(m1,S1,fix(P(1)*N)); r2=mvnrnd(m2,S2,fix(P(2)*N)); r3=mvnrnd(m3,S3,fix(P(3)*N)); figure(1); plot(r1(:,1),r1(:,2),'r.'); hold on; plot(r2(:,1),r2(:,2),'g.'); hold on; plot(r3(:,1),r3(:,2),'b.'); end (a)调用指令: P=[1/3,1/3,1/3];
信息与通信工程学院 模式识别实验报告 班级: 姓名: 学号: 日期:2011年12月
实验一、Bayes 分类器设计 一、实验目的: 1.对模式识别有一个初步的理解 2.能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识 3.理解二类分类器的设计原理 二、实验条件: matlab 软件 三、实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1)在已知 ) (i P ω, ) (i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计 算出后验概率: ∑== c j i i i i i P X P P X P X P 1 ) ()() ()()(ωωωωω j=1,…,x 2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑== c j j j i i X P a X a R 1 )(),()(ωω λ,i=1,2,…,a 3)对(2)中得到的a 个条件风险值) (X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的 决策k a ,即()() 1,min k i i a R a x R a x == 则 k a 就是最小风险贝叶斯决策。 四、实验内容 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=; 异常状态:P (2ω)=。 现有一系列待观察的细胞,其观察值为x : 已知先验概率是的曲线如下图:
)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,)(2,4)试对观察的结果 进行分类。 五、实验步骤: 1.用matlab 完成分类器的设计,说明文字程序相应语句,子程序有调用过程。 2.根据例子画出后验概率的分布曲线以及分类的结果示意图。 3.最小风险贝叶斯决策,决策表如下: 结果,并比较两个结果。 六、实验代码 1.最小错误率贝叶斯决策 x=[ ] pw1=; pw2=; e1=-2; a1=; e2=2;a2=2; m=numel(x); %得到待测细胞个数 pw1_x=zeros(1,m); %存放对w1的后验概率矩阵 pw2_x=zeros(1,m); %存放对w2的后验概率矩阵
《模式识别基础》课程标准 (执笔人:刘雨审阅学院:电子科学与工程学院)课程编号:08113 英文名称:Pattern Recognition 预修课程:高等数学,线性代数,概率论与数理统计,程序设计 学时安排:40学时,其中讲授32学时,实践8学时。 学分:2 一、课程概述 (一)课程性质地位 模式识别课基础程是军事指挥类本科生信息工程专业的专业基础课,通信工程专业的选修课。在知识结构中处于承上启下的重要位置,对于巩固已学知识、开展专业课学习及未来工作具有重要意义。课程特点是理论与实践联系密切,是培养学生理论素养、实践技能和创新能力的重要环节。是以后工作中理解、使用信息战中涉及的众多信息处理技术的重要知识储备。 本课程主要介绍统计模式识别的基本理论和方法,包括聚类分析,判别域代数界面方程法,统计判决、训练学习与错误率估计,最近邻方法以及特征提取与选择。 模式识别是研究信息分类识别理论和方法的学科,综合性、交叉性强。从内涵讲,模式识别是一门数据处理、信息分析的学科,从应用讲,属于人工智能、机器学习范畴。理论上它涉及的数学知识较多,如代数学、矩阵论、函数论、概率统计、最优化方法、图论等,用到信号处理、控制论、计算机技术、生理物理学等知识。典型应用有文字、语音、图像、视频机器识别,雷达、红外、声纳、遥感目标识别,可用于军事、侦探、生物、天文、地质、经济、医学等众多领域。 (二)课程基本理念 以学生为主体,教师为主导,精讲多练,以用促学,学以致用。使学生理解模式识别的本质,掌握利用机器进行信息识别分类的基本原理和方法,在思、学、用、思、学、用的循环中,达到培养理论素养,锻炼实践技能,激发创新能力的目的。 (三)课程设计思路 围绕培养科技底蕴厚实、创新能力突出的高素质人才的目标,本课程的培养目标是:使学生掌握统计模式识别的基本原理和方法,了解其应用领域和发展动态,达到夯实理论基础、锻炼理论素养及实践技能、激发创新能力的目的。 模式识别是研究分类识别理论和方法的学科,综合性、交叉性强,涉及的数学知识多,应用广。针对其特点,教学设计的思路是:以模式可分性为核心,模式特征提取、学习、分类为主线,理论上分层次、抓重点,方法上重比较、突出应用适应性。除了讲授传统的、经典的重要内容之外,结合科研成果,介绍不断出现的新理论、新方法,新技术、新应用,开拓学生视野,激发学习兴趣,培养创新能力。 教学设计以章为单元,用实际科研例子为引导,围绕基本原理展开。选择两个以上基本方法,辅以实验,最后进行对比分析、归纳总结。使学生在课程学习中达到一个思、学、用、
实验一Bayes 分类器设计 本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。 1实验原理 最小风险贝叶斯决策可按下列步骤进行: (1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑== c j i i i i i P X P P X P X P 1 ) ()() ()()(ωωωωω j=1,…,x (2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑== c j j j i i X P a X a R 1 )(),()(ωω λ,i=1,2,…,a (3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即 则k a 就是最小风险贝叶斯决策。 2实验内容 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
现有一系列待观察的细胞,其观察值为x : -3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率密度曲线如下图: )|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,0.25)(2,4)试对观察的结果进 行分类。 3 实验要求 1) 用matlab 完成分类器的设计,要求程序相应语句有说明文字。 2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。 3) 如果是最小风险贝叶斯决策,决策表如下:
模式识别理论与方法 课程作业实验报告 实验名称:Generating Pattern Classes 实验编号:Proj01-01 规定提交日期:2012年3月16日 实际提交日期:2012年3月13日 摘要: 在熟悉Matlab中相关产生随机数和随机向量的函数基础上,重点就多元(维)高斯分布情况进行了本次实验研究:以mvnrnd()函数为核心,由浅入深、由简到难地逐步实现了获得N 个d维c类模式集,并将任意指定的两个维数、按类分不同颜色进行二维投影绘图展示。 技术论述:
1,用矩阵表征各均值、协方差2,多维正态分布函数: 实验结果讨论:
从实验的过程和结果来看,进一步熟悉了多维高斯分布函数的性质和使用,基本达到了预期目的。 实验结果: 图形部分: 图1集合中的任意指定两个维度投影散点图形
图2集合中的任意指定两个维度投影散点图形,每类一种颜色 数据部分: Fa= 9.6483 5.5074 2.4839 5.72087.2769 4.8807 9.1065 4.1758 1.5420 6.1500 6.2567 4.1387 10.0206 3.5897 2.6956 6.1500 6.9009 4.0248 10.1862 5.2959 3.1518 5.22877.1401 3.1974 10.4976 4.9501 1.4253 5.58257.4102 4.9474 11.3841 4.5128 2.0714 5.90068.2228 4.4821 9.6409 5.43540.9810 6.2676 6.9863 4.2530 8.8512 5.2401 2.7416 6.5095 6.1853 4.8751 9.8849 5.8766 3.3881 5.7879 6.7070 6.6132 10.6845 4.8772 3.4440 6.0758 6.6633 3.5381 8.7478 3.3923 2.4628 6.1352 6.9258 3.3907
实验报告实验课程名称:模式识别 姓名:班级:学号:
注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合 ; 2015年4月 实验1 图像的贝叶斯分类 实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 实验仪器设备及软件 HP D538、MATLAB ( 实验原理 基本原理 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。此过程中,确定阈值是分割的关键。
对一般的图像进行分割处理通常对图像的灰度分布有一定的假设,或者说是基于一定的图像模型。最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可用模式识别中的最小错分概率贝叶斯分类器来解决。以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数用下式表示 1122()()()p x P p x P p x =+ 式中1p 和2p 分别为 … 212 1()21()x p x μσ--= 222 2()22()x p x μσ-- = 121P P += 1σ、2σ是针对背景和目标两类区域灰度均值1μ与2μ的标准差。若假定目标的灰度较亮,
模式识别实验报告-年月
————————————————————————————————作者: ————————————————————————————————日期:
学院: 班级: 姓名: 学号: 2012年3月
实验一 Bay es分类器的设计 一、 实验目的: 1. 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识; 2. 理解二类分类器的设计原理。 二、 实验条件: 1. PC 微机一台和MA TL AB 软件。 三、 实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1. 在已知 ) (i P ω, )|(i X P ω,c i ,,1 =及给出待识别的X 的情况下,根据贝叶斯 公式计算出后验概率: ∑== c j j j i i i P X P P X P X P 1 ) ()|() ()|()|(ωωωωω c j ,,1 = 2. 利用计算出的后验概率及决策表,按下式计算出采取 i α决策的条件风险: ∑==c j j j i i X P X R 1) |(),()|(ωωαλα a i ,,1 = 3. 对2中得到的a 个条件风险值) |(X R i α(a i ,,1 =)进行比较,找出使条件 风险最小的决策k α,即: ) |(min )|(,,1X R X R k c i k αα ==, 则 k α就是最小风险贝叶斯决策。 四、 实验内容: (以下例为模板,自己输入实验数据) 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为: 正常状态:)(1ωP =0.9; 异常状态:)(2ωP =0.1。
模式识别课程设计
模式识别课程设计 聚类图像分割 一.图像分割概述 图像分割是一种重要的图像分析技术。在对图像的研究和应用中,人们往往仅对图像中的某些部分感兴趣。这些部分常称为目标或前景(其他部分称为背景)。它们一般对应图像中特定的、具有独特性质的区域。为了辨识和分析图像中的目标,需要将它们从图像中分离提取出来,在此基础上才有可能进一步对目标进行测量,对图像进行利用。图像分割就是把图像分成各具特性的区域并提取出感兴趣目标的技术和过程。现有的图像分割方法主要分以下几类:基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法以及基于特定理论的分割方法等。近年来,研究人员不断改进原有的图像分割方法并把其它学科的一些新理论和新方法用于图像分割,提出了不少新的分割方法。 图象分割是图象处理、模式识别和人工智能等多个领域中一个十分重要且又十分困难的问题,是计算机视觉技术中首要的、重要的关键步骤。图象分割应用在许多方面,例如在汽车车型自动识别系统中,从CCD摄像头获取的图象中除了汽车之外还有许多其他的物体和背景,为了进一步提取汽车特征,辨识车型,图象分割是必须的。因此其应用从小到检查癌细胞、精密零件表面缺陷检测,大到处理卫星拍摄的地形地貌照片等。在所有这些应用领域中,最终结
果很大程度上依赖于图象分割的结果。因此为了对物体进行特征的提取和识别,首先需要把待处理的物体(目标)从背景中划分出来,即图象分割。但是,在一些复杂的问题中,例如金属材料内部结构特征的分割和识别,虽然图象分割方法已有上百种,但是现有的分割技术都不能得到令人满意的结果,原因在于计算机图象处理技术是对人类视觉的模拟,而人类的视觉系统是一种神奇的、高度自动化的生物图象处理系统。目前,人类对于视觉系统生物物理过程的认识还很肤浅,计算机图象处理系统要完全实现人类视觉系统,形成计算机视觉,还有一个很长的过程。因此从原理、应用和应用效果的评估上深入研究图象分割技术,对于提高计算机的视觉能力和理解人类的视觉系统都具有十分重要的意义。 二.常用的图像分割方法 1.基于阈值的分割方法 包括全局阈值、自适应阈值、最佳阈值等等。阈值分割算法的关键是确定阈值,如果能确定一个合适的阈值就可准确地将图像分割开来。阈值确定后,将阈值与像素点的灰度值比较和像素分割可对各像素并行地进行,分割的结果直接给出图像区域。全局阈值是指整幅图像使用同一个阈值做分割处理,适用于背景和前景有明显对比的图像。它是根据整幅图像确定的:T=T(f)。但是这种方法只考虑像素本身的灰度值,一般不考虑空间特征,因而对噪声很敏感。常用的全局阈值选取方法有利用图像灰度直方图的峰谷法、最小误差法、最大类间方差法、最大熵自动阈值法以及其它一些方法。
实验报告 实验课程名称:模式识别 :王宇班级:20110813 学号:2011081325 注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合
2014年6月 实验一、图像的贝叶斯分类 一、实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念: 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值围的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。 最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模
2015年12月
实验一 Bayes 分类器的设计 一、 实验目的: 1. 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识; 2. 理解二类分类器的设计原理。 二、 实验条件: 1. PC 微机一台和MATLAB 软件。 三、 实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1. 在已知)(i P ω,)|(i X P ω,c i ,,1 =及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==c j j j i i i P X P P X P X P 1)()|() ()|()|(ωωωωω c j ,,1 = 2. 利用计算出的后验概率及决策表,按下式计算出采取i α决策的条件风险: ∑==c j j j i i X P X R 1) |(),()|(ωωαλα a i ,,1 = 3. 对2中得到的a 个条件风险值)|(X R i α(a i ,,1 =)进行比较,找出使条件风险最小的决策k α,即: )|(m i n )|(,,1X R X R k c i k αα ==, 则k α就是最小风险贝叶斯决策。 四、 实验内容: 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为: 正常状态:)(1ωP =0.9; 异常状态:)(2ωP =0.1。 现有一系列待观察的细胞,其观察值为x : -3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531
-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 )|(1ωx P )|(2ωx P 类条件概率分布正态分布分别为(-2,0.25)(2,4)。决策表为011=λ(11λ表示),(j i ωαλ的简写),12λ=6, 21λ=1,22λ=0。 试对观察的结果进行分类。 五、 实验程序及结果: 试验程序和曲线如下,分类结果在运行后的主程序中:
《模式识别》实验报告 模式识别实验内容 实验一高斯分布 【实验目的】 对模式识别有一个初步的理解,能够根据自己的设计对高斯分布有一个深刻地认识。【实验条件】 matlab软件 【实验原理】 正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。若随机变量X服从一个数学期望为μ、方差为σ^2的高斯分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。因其曲线呈钟形,因此人们又经常称之为钟形曲线。我们通常所说的标准正态分布是μ=0,σ=1的正态分布。 【实验内容】 1.使用matlab函数画出一维高斯分布图,自行设计取值范围,数学期望以及方差。 2.使用matlab函数画出二维高斯分布图,自行设计取值范围,数学期望以及方差。预测图形如下:
【实验程序】 x=[-10:0.01:10]; y=normpdf(x,0,1);%正态分布函数。figure; axes1=axes('Pos',[0.10.10.850.85]); plot(x,y); set(axes1,'YLim',[-0.010.43],'XLim',[-33]);【实验结果和数据】
【实验分析】 1.当x<μ时,曲线上升;当x>μ时,曲线下降。当曲线向左右两边无限延伸时,以x轴为渐近线。 2.正态曲线关于直线x=μ对称。 3.σ越大,正态曲线越扁平;σ越小,正态曲线越尖陡。 4.在正态曲线下方和x轴上方范围内区域面积为1。3σ原则:P(μ-σ 实验一 Bayes 分类器设计 【实验目的】 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻 地认识,理解二类分类器的设计原理。 【实验原理】 最小风险贝叶斯决策可按下列步骤进行: (1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==c j i i i i i P X P P X P X P 1)()() ()()(ωωωωω j=1,…,x (2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑==c j j j i i X P a X a R 1)(),()(ωωλ,i=1,2,…,a (3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最 小的决策k a ,即 ()()1,min k i i a R a x R a x ==L 则k a 就是最小风险贝叶斯决策。 【实验内容】 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。 现有一系列待观察的细胞,其观察值为x : -3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率是的曲线如下图: )|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为N (-2,0.25)、N (2,4) 试对观察的结果进行分类。 【实验要求】 1) 用matlab 完成基于最小错误率的贝叶斯分类器的设计,要求程序相应语句有说明 文字,要求有子程序的调用过程。 2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。 3) 如果是最小风险贝叶斯决策,决策表如下: 最小风险贝叶斯决策表:模式识别实验报告-实验一-Bayes分类器设计汇总
相关主题
文本预览