
信息可视化
冯艺东汪国平董士海
(北京大学计算机科学技术系,北京100871)
摘 要 我们处在一个信息爆炸的时代。对繁杂的抽象信息之间的复杂关系进行探索的努力,促使了信息可视化这一崭新科学领域的出现,它结合了科学可视化、人机交互、数据挖掘、图像技术、图形学、认知科学等诸多学科的理论和方法。信息可视化与科学可视化的区别在于,科学可视化的研究对象主要是具有几何属性的科学数据,而信息可视化则主要应用于没有几何属性的抽象信息,揭示信息之间的关系和信息中隐藏的特征。本文对信息可视化的概念、意义、主要问题和技术、研究现状作了综述,并简单介绍了我们正在进行的相关研究工作。
关键词 信息可视化可视化结构科学可视化人机交互知识挖掘
1 什么是信息可视化
可视化是这样一个过程,它将数据信息和知识转化为一种视觉形式,充分利用人们对可视模式快速识别的自然能力[1]。可视化将人脑和现代计算机这两个最强大的信息处理系统联系在一起。有效的可视界面使得我们能够观察、操纵、研究、浏览、探索、过滤、发现、理解大规模数据,并与之方便交互,从而可以极其有效地发现隐藏在信息内部的特征和规律。在我们这个信息日益丰富的社会,可视化技术研究和应用开发已经从根本上改变了我们表示和理解大型复杂数据的方式。可视化的影响广泛而深入,引导我们获得新的洞察和有效的决策。
可视化作为一个有组织的科学分支起源于美国国家科学基金会(NSF)的报告《科学计算中的可视化》[2]。在那篇报告里,可视化被设想为这样一种工具,它能够处理大型科学数据,并且能够提高科学家观察数据中现象的能力。虽然最初的概念不见得是这样,但是今天我们讨论科学可视化总是基于物理数据,例如人体、地球、分子等等。计算机用来绘制它们某些可观察的属性。虽然这些可视化也可能源于对这些物理空间的抽象,但是这些信息在本质上仍然是几何的,都是基于物理空间的。
近几年来,随着INTERNET的飞速发展,商业数据的大量计算,电子商务的全面展开,以及数据仓库的大规模应用,产生了一个广泛的需求:可视化技术不仅要用于科学数据,而且要作为一个基本工具,应用于抽象信息,揭示信息之间的关系和信息中隐藏的特征。所有上述这些非物理信息,可以通过映射为一种可视化形式来方便观察,而这些信息都没有明显的空间特征。除了如何绘制关心的对象的可视化属性的问题以外,更重要的问题是如何把非空间抽象信息映射为有效的可视化形式[3]。这就是信息可视化的研究范畴。
信息可视化结合了科学可视化、人机交互、数据挖掘、图像技术、图形学、认知科学等诸多学科的理论和方法,逐步发展起来。信息可视化实际上是人和信息之间的一种可视化界
面,因此交互技术在这里显得尤为重要,传统的人机交互技术几乎都可以得到应用。人机交互是研究人、计算机以及它们相互影响的技术[4]。可以说,信息可视化是研究人、计算机表示的信息以及它们相互影响的技术。
“信息可视化”这个术语第一次出现在Robertson,Card和Mackinlay在1989年发表的文章《用于交互性用户界面的认知协处理器》[5]中。该文认为,硬件系统的图形性能和速度已经使得在用户界面中探索3D和动画成为可能。为了充分利用这些性能,新的软件结构必须支持复杂的异步交互智能体(多智能体问题),并且,还应支持流畅的交互动画(动画问题)。该文认为“信息可视化”是对上述两个问题的解决要求最迫切的领域,因此将该项研究在该领域中进行试验,利用2D和3D动画对象来表示信息和信息的结构。此后,信息可视化方面的研究和文献陆续出现,信息可视化作为一个学科逐渐成长起来。在这个领域,人们更加关心的是认知能力提高的方式,而不是图形的质量。交互性和动画成了这些系统更为重要的特征。
Jim Foley在最近发表的关于计算机图形学的“十大尚未解决的关键问题”[6]一文中,将信息可视化列为第三位。Foley认为,随着存储成本的急剧下降,和随之而来的数据仓库技术的日益普遍,信息可视化将会越来越重要。因为计算机能够处理的信息中,只有很少一小部分是具有几何属性的,而剩下的绝大部分都是没有几何属性的抽象信息。我们可以利用数据挖掘技术获取数据之间的复杂关系,而新的信息可视化技术将帮助我们探究这些关系。因此,对创造性信息可视化方式的探索之路,将永无止境。
2 信息可视化的主要科学问题及相关技术
2.1 信息可视化参考模型
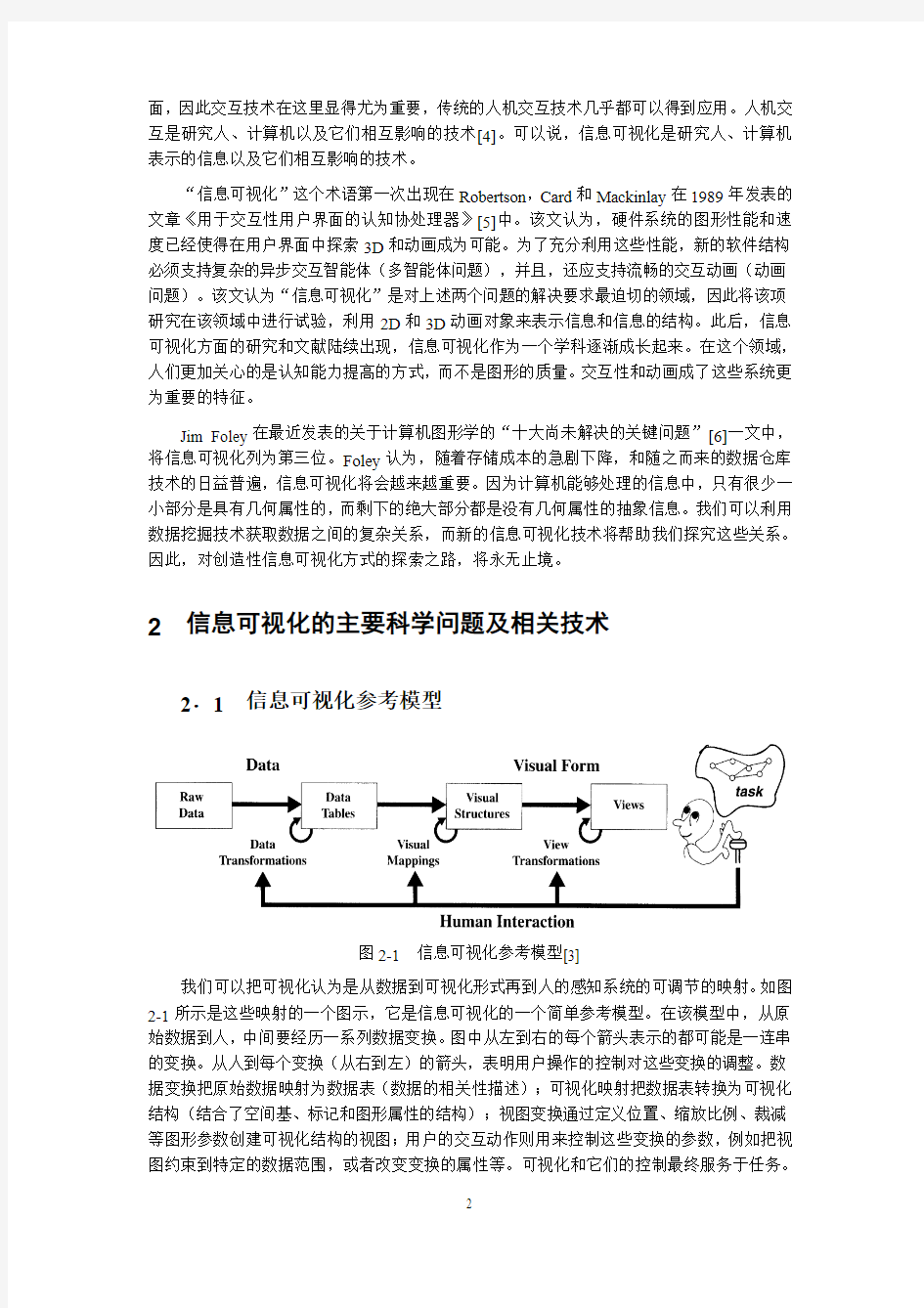
图2-1 信息可视化参考模型[3]
我们可以把可视化认为是从数据到可视化形式再到人的感知系统的可调节的映射。如图2-1所示是这些映射的一个图示,它是信息可视化的一个简单参考模型。在该模型中,从原始数据到人,中间要经历一系列数据变换。图中从左到右的每个箭头表示的都可能是一连串的变换。从人到每个变换(从右到左)的箭头,表明用户操作的控制对这些变换的调整。数据变换把原始数据映射为数据表(数据的相关性描述);可视化映射把数据表转换为可视化结构(结合了空间基、标记和图形属性的结构);视图变换通过定义位置、缩放比例、裁减等图形参数创建可视化结构的视图;用户的交互动作则用来控制这些变换的参数,例如把视图约束到特定的数据范围,或者改变变换的属性等。可视化和它们的控制最终服务于任务。
信息可视化要解决的主要问题就是上述参考模型中的映射、变换及交互控制。
2.2 可视化结构
在信息可视化的参考模型中,其核心是数据表到可视化结构的映射。数据表基于数学关系,可视化结构则基于能够被人的视觉有效处理的图形属性。科学可视化主要集中在物理数据上,与之不同的是,信息可视化的研究主要集中在抽象信息上。在很多情况下,信息本身并不能自动映射到几何物理空间。这个不同意味着许多信息类型没有自然或明显的物理表示形式。因此,一个关键的问题就是发现新的可视化隐喻(可视化结构)来表示信息,并且理解这些隐喻所支持的分析任务。
可视化结构有三个基本的组成部分:空间基,标记,标记的图形属性。在可视化过程中,数据表被映射为可视化结构,可视化结构在一个空间基中用标记和图形属性对信息进行编码。为了得到一个好的可视化结构,这个映射必须能够保持数据的原有信息,并且只有数据表中的数据才能在可视化结构中被表示。要获得一个好的映射并不是一件很容易的事,因为在可视化结构中很容易出现不必要的数据。映射又必须是能够很容易被人感知的。如果一个映射比其他的映射能够更快地被理解,能够表达更多的差别,或者能够更不容易导致错误,那么这个映射比其他的映射就更有表现力。如何寻求一个好的可视化结构,是信息可视化的一个关键问题。
2.3 视图变换
视图变换交互地改变和增强可视化结构,通过建立图形属性来建立可视化结构的视图,使静态表示变成可视化。可视化存在于时空关系中。视图变换通过利用时间属性能够从可视化中获得比静态情况下更多的信息。有三种常见的视图变换:
1.位置探查位置探查是这样一种视图变换,它利用一个可视化结构中的位置揭示附加的数据信息。
2.视点控制视点控制是利用仿射变换移动(zoom)、摇动(pan)和裁减(clip)视点来进行视图变换。这类变换非常普遍,通过放大可视化结构或改变视点,使得细节可见。另一种视点控制技术叫作overview + detail,同时使用overview和detail两个窗口,overview 窗口提供detail视图的context,并且充当改变detail视图的控制部件,detail窗口用于选定区域的放大或聚焦。
3.变形变形是一种改变可视化结构来生成focus + context视图的可视化变换。在这里,overview和detail被合成了一个可视化结构。可视化空间的物理范围是非常有限的计算机屏幕,相对于可视化空间而言,信息空间几乎是无限的。为了弥补可视化空间和信息空间之间的失衡,增大可视化空间的逻辑范围,就需要用到对可视化空间的变形技术。如果变形能够让用户通过变形感知到更大的未变形的可视化结构,那么这样的变形就是有效的。
2.4 交互和可视化控制
在信息可视化中,交互与从数据映射到可视化形式的变换有关。在信息可视化参考模型中,用户通过操作可视化控制来改变变换过程中的参数,以达到交互的目的。这些控制可以
以单独的用户界面的形式实现(如各种控制按钮或滚动条等),也可以和可视化结构合在一起(如overview + detail)。
很多信息可视化的交互技术在本质上是某种形式的选择方法,通过选择数据表中对象的子集获得当前的可视化结构。这些交互技术可以用来定位数据,揭示数据中的模式,选择变换的参数等,如Details-on-demand技术,Brushing技术等。这些交互技术不仅可以提高用户与信息交互的速度,同时可以避免用户走错方向,解决信息迷途问题。
Furnas在1986年的发表的《通用化鱼眼视图》[7]一文中首次研究了鱼眼视图,这种技术是一种放大某一显示画面中的某块小的局部区域的透镜技术,放大区域的周围退到背景显示,但仍然是可见的。后来有很多人在这项技术的基础上作了很多发展,创造了一系列技术,允许用户观察一个小的中心焦点区域的同时,保持一个较大周围区域的可见性,这就是focus + context技术的含义所在。这种技术可以将一个信息集合的特定部分的细节视图,通过某种方式和该信息集合的总体结构视图混合在一起;也可以认为是在显示一个大的信息空间(context)的同时,其中的一部分以更细节的方式显示(focus)。
3 信息可视化发展现状和研究热点
信息可视化作为一个新的科学领域,目前绝大多数研究工作都还处在发展新技术和构建一些有意思的新系统方面。同时,已经开始出现一些信息可视化方面的实用工具。
下面介绍几个信息可视化领域当前研究的热点问题:
1.层次信息的可视化
抽象信息之间的关系最普遍的一种就是层次关系,如磁盘目录结构,文档管理,图书分类等。层次关系几乎无处不在,并且,在某些情况下,任意的图都可以转化为层次关系[8]。
层次信息的可视化结构最直观的方式就是树型结构。但是传统的树型结构有一个很大的缺点:当结构的层次增多或者节点增多时,该结构需要占据大量的可视化空间。而计算机屏幕所能够提供的可视化空间非常有限,因此必须通过滚动浏览的方式把握整个层次结构,这对于查找某个节点或者获得整个结构的信息非常困难。
图3-1 Cone tree 图3-2 Hyperbolic tree
George G. Robertson等人提出了一种称作cone tree(图3-1)的方法[8]。Cone tree将层次结构在三维空间中均衡排列。层次结构的顶部放置在可视化空间的顶端,每个cone的顶点表示该层结构的顶点,其子节点(三维)均匀排列在该cone的底部。Cone的底的直径随着层次结构的深入逐渐减小,以保证最底层的结构也能在可视化空间中有效表示。每个cone 之间透明遮挡,从而可以保证每个cone可以很容易被感知,还不会妨碍后面的cone。同时佐以旋转、拖动等方便的交互技术,可以很容易实现对复杂层次关系的把握。
Xerox Palo Alto研究中心的用户界面研究组的John Lamping等人提出了一种基于双曲几何的可视化和操纵大型层次结构的focus + context技术,称为Hyperbolic tree[9][10](图3-2)。这种技术将更多的可视化空间给了当前层次结构中当前关注的部分,而同时又能够把整个层次结构显示出来。该技术通过一种规范的算法将层次关系显示在一个双曲平面上,然后将这个双曲平面映射到显示区域中。所选择的映射方式提供了一种鱼眼变形来支持focus和context之间的平滑过渡。Hyperbolic tree通过方便的交互手段很好地解决了层次结构中focus + context之间的平滑过渡问题。目前,这种技术已经有了成熟的产品(Inxight软件公司),用于磁盘目录、网站结构、电子图书馆编目等的可视化。
2.多维信息可视化
我们生活在一个三维物理空间世界中。我们的视觉感知很难脱离前后、左右、上下的三维空间定势。四维信息都很难直观地理解,更何况是更多维的信息。而绝大多数抽象信息又是三维以上的多维信息,如金融信息、股票信息、数据仓库等。因此多维信息的可视化是信息可视化的一个重要目标。
我们之所以能够在二维屏幕上显示三维空间信息,是因为我们的视觉习惯已经在我们的脑海中留下了三维空间的烙印。可以说,我们只能看到三维空间,那么又如何可视化三维以上的多维信息呢?
图3-3 Table lens
哥伦比亚大学计算机系的Steven Feiner和Clifford Beshers提出了一种基于坐标嵌套的多维可视化结构worlds within worlds[11]。输入变量映射到多个轴组成的坐标系统中,整个高维函数通过将一个坐标系嵌套在另一个坐标系中实现可视化。内部坐标系在外部坐标系中的移动,将导致显示曲面的变化,因为这时候曲面的三个变量(分别由外部坐标系的三个轴
所代表)已经发生了改变。当两个坐标系统在同一个位置的时候,嵌套将会导致闭包。该方法通过将虚拟现实技术用于操纵可视化结构来减少闭包。这种方法表示的信息维数非常有限,并且,为了消除坐标系嵌套引起造成的视觉混乱,必须运用复杂的交互方式,技术实现非常困难。
在数据仓库和信息挖掘中,大型数据表的表示是一个关键问题。大型数据库中的数据基本上全是多维的,如何将大型多维数据表中隐含的特征(即数据之间的关系)用一种直观的方式表示出来,对于信息挖掘至关重要。Xerox Palo Alto研究中心的用户界面研究组的Rao 和Card提出的table lens[12][13](图3-3)技术是可视化和理解大型数据表的一项技术。该技术通过将符号和图形表示融入到一个可操纵的单一的focus + context显示中,以及一些简单的操作(如排序),支持在一个大型数据空间中的浏览,同时又可以很容易地分离关注的特征或模式。它把统计分析和电子表格的易用性结合在了一起,适合于大型数据分析领域,如金融数据、保险数据和药物分析等。应该说table lens是一种很好的多维信息可视化结构。目前,这种技术也已经有了相应的产品(Inxight软件公司)。
3.文档(文本)信息可视化
我们面临的信息中,绝大多数是文本信息,如电子邮件、因特网文档、科学论文、报纸文章等等。文档信息是我们记忆的延伸,我们需要经常和文档信息进行交流。各种文档信息堆积如山,可视化可以帮助我们快捷地从文档信息中获取我们需要的内容和知识。文档信息可视化可以分为两类:一类是对单个文档本身的可视化,另一类是对大型文档集合的可视化。
Stephen G. Eick等人在可视化系统Seesoft中实现了一种对计算机程序进行可视化的方法[14]。通过将程序的每行代码根据其长度映射为一条短线(图3-4),可以实现同时分析多至50000行代码。每条短线的颜色可以用来表示某种关注的统计特征,如红色表示最近修改过的代码,蓝色表示最近最少修改过的代码,等等。Seesoft可以用于可视化各种数据源的数据,例如:版本控制系统,可以跟踪版本时间、程序员、代码目的等;静态分析,如函数调用的位置;动态分析,如特征数据。运用灵活的交互技术,用户可以方便地操纵代码的简化表示,以发现所关注的特征。对某段代码进一步的细致观察可以通过附加窗口显示实际代码来实现。Seesoft可以用于知识发现、项目管理、代码调整,开发方法分析等领域。
图3-4 Seesoft 图3-5 Themespace
对于大型文档集合而言,文档之间的主题或内容相关性对于使用者而言是非常重要的。例如,我们在因特网上搜索信息的时候,非常需要快速把握成千上万的搜索结果与搜索条件之间,以及搜索结果相互之间的相关性,从而可以迅速找到真正需要的信息。美国西北太平洋国家实验室(Pacific Northwest National Laboratory)的科学家们提出了一系列的信息访问和可视化分析工具,这些技术统称为SPIRE(Spatial Paradigm for Information Retrieval and Exploration)。SPIRE可以用于几乎任何类型的大型文档集合,确定文档之间的关系,把他们表示为对人而言非常自然的可视化形式[15]。例如,James A. Wise等人提出的一种对大型文档集合之间的关系进行可视化的方法Themespace(图3-5)[16]。在Themespace中,文档空间中的主题在计算机屏幕上显示为一个自然地形图。Themespace中的山峰表示该处的主题是主导性的,山谷则表示该处的主题相对较弱。山峰或山谷的形状(如是大范围的小丘还是高的尖顶),表示主题信息是如何分布的以及在文档之间是如何关联的。通过这种可视化的方式,可以避免语言处理从而节约用户的脑力工作,对于信息检索和知识挖掘非常有用。
4.Web可视化
可以说,信息爆炸的始作蛹者是因特网。目前,Web上的信息以TB计,这些信息分布在遍及世界各地的上百万个不同的网站上,网站通过文档之间的超链彼此交织在一起。并且,不论Web的规模有多大,有一点是肯定的,它还将继续膨胀。如何方便地利用Web上的信息,成了一个迫切需要解决的问题。然而,目前的信息访问方式却远远不能让人满意。信息可视化在帮助人们理解信息空间的结构,快速发现所需信息等方面将会扮演令人信服的重要角色。
Web是由一个一个的网站组成的,因此,单个网站的可视化在Web可视化中占据着重要的地位。Xerox Palo Alto研究中心用户界面研究组的Ed H. Chi等人提出了一种可视化网站变化的方法[17]。它将Xerox的网站中的7000多个节点重新组织成一个树,在考虑的时间范围内存在的每个节点在树中有一个相应的位置。连线的颜色和粗细根据每个节点的访问量决定。网站的不同时期用不同的树表示。这样可以很容易地发现网站内容的变化和访问量的变化。
Web是一个信息空间,如何可视化它的结构是最重要的。Web空间的结构实际上一个网,目前这方面的研究主要集中在如何有效地可视化信息空间的网络结构方面。
4 我们的研究工作
目前,我们有关信息可视化的研究工作主要集中在如下几个方面:层次信息可视化,多维信息可视化,信息可视化中的交互技术,信息可视化与信息可听化,信息迷途的解决。下面简要介绍一下我们正在进行的两个研究实例。
1.局域网状态及流量可视化
我们在使用网络的过程中经常会遇见这样的情况:网络速度很慢,但是不知道问题出在什么地方。对于网络管理者而言,时刻知道网络状态和流量情况,可以及时排除故障,根据情况调整网络结构,对用户进行有效管理。本实例的目的就是为网络管理者提供一个能够实时监控网络状态和流量的可视化系统。
2.股市信息可视化
股市信息纷繁复杂,股市信息瞬息万变。对于股民而言,“时间就是金钱”有着其直接的现实意义。因此,一个好的可视化系统应能做到帮助股民迅速理解和接受各种信息,发现股市信息中的特征和走势,帮助股民迅速做出决策。本实例的目的就是要构建这样一个股市信息可视化系统。
5 结束语
这是一个前所未有的信息时代,我们每天都处在各种信息的包围之中。需要一种快捷有效的方式帮助我们发现隐藏在庞杂信息当中的模式和知识,帮助我们决策。这就是信息可视化的意义所在。信息的日益丰富决定着将来的用户界面主要是一种信息界面,从某种意义上说,信息可视化代表着下一代用户界面的方向。
参考文献
1. Nahum D. Gershon, Stephen G. Eick. “Information Visualization”, IEEE Computer Graphics
and Applications, 7-8/1997,29-31.
2. B. H. McCormick, T. A. DeFanti, and M. D. Brown, eds., “Visualization in Scientific
Computing”, Computer Graphics, Vol. 21, No. 6, Nov. 1987.
3. Stuart Card, Jock Mackinlay, Ben Shneiderman. Readings in Information Visualization:
Using Vision to Thin k. Morgan Kaufmann, 1999.
4. 董士海、王坚、戴国忠等,《人机交互和多通道用户界面》,科学出版社,1999年8月。
5. G. Robertson, S. K. Card and J. D. Mackinlay. “The Cognitive Co-processor for Interactive
User Interfaces”. Proceedings of the ACM SIGGRAPH symposium on User interface software and technology, 1989, Pages 10 - 18.
6. Jim Foley, “Getting There: The Ten Top Problems Left”, Vision 2000 issue of IEEE
Computer Graphics and Applications.
7. G W Furnas. “Generalized Fisheye Views”. Conference proceedings on Human factors in
computing systems, 1986, Pages 16 – 23
8. George G. Robertson, Jock D. Mackinlay and Stuart K. Card. “Cone Trees: Animated 3D
Visualizations of Hierachical Information”. Human factors in computing systems conference proceedings on Reaching through technology, 1991, Pages 189-194.
9. John Lamping, Ramana Rao and Peter Pirolli. “A focus + context technique based on
hyperbolic geometry for visualizing large hierarchies”. Conference proceedings on Human factors in computing systems , 1995, Pages 401 - 408
10. Lamping, J., and Rao, R. “The Hyperbolic Browser: A Focus + Context Technique for
Visualizing Large Hierarchies”. Journal of Visual Languages and Computing, 7(1), 1996, 33-55.
11. Rao, R., and Card, S. K. “Exploring Large Tables with Table Lens”. In Video Proceedings of
CHI’95, ACM Conference on Human Factors in Computing Systems.
12. Rao, R., and Card, S. K. “The Table Lens: Merging Graphical and Symbolic Representations
in an Interactive Focus + Context Visualization for Tabular Information”. Proceedings of CHI’94, ACM Conference on Human Factors in Computing Systems, New York. 318-322 and 481-482.
13. Feiner, S. K., and Beshers, C. “Worlds within Worlds: Metaphors for Exploring
n-Dimensional Virtual Worlds”. Proceedings of UIST’90, ACM Symposium on User Interface Software and Technology. 76-83.
14. Eick, S. G., Steffen, J. L., and Sumner, E. E. (1992). “Seesoft – A Tool for Visualizing Line
Oriented Software Statistics”. IEEE Transactions on Software Engineering, 18(11-Nov), 957-968.
15. “Visual Text Analysis”. https://www.doczj.com/doc/ab11671553.html,:2080/infoviz/spire/spire.html
16. Wise, J. A., Thomas, J. J., Pennock, K., Lantrip, D., Pottier, M., Schur, A., and Crow, V.
(1995). “Visualizing the Non-Visual: Spatial Analysis and Interaction with Information from Text Documents”. Proceedings of InfoVis’95, IEEE Symposium on Information Visualization, New York. 51-58, color plate 140.
17. Chi, E. H., Pitkow, J., Machinlay, J., Pirolli, P., Grssweiler, R., and Card S. K.(1998).
“Visualizing the Evolution of Web Ecologies”. Proceedings of CHI’98, ACM Conference on Human Factors in Computing Systems. 400-407.
Information Visualization
Feng Yidong, Wang Guoping, Dong Shihai
(Department of Computer Science & Technology, Peking University, Beijing100871)
Abstract We are living in a time of exploding information. The efforts to explore the complicated relations among complex abstract information give birth to a new field – information visualization, which combines aspects of scientific visualization, human-computer interfaces, data mining, imaging, graphics, and cognition science. Information visualization differs from scientific visualization in that information visualization focuses on abstract information to reveal the relations among information and the features hidden in information, but scientific visualization focuses on geometric scientific data. This article introduces the concept, signification, main problems and technologies, and the state of the art of information visualization, and then introduces some research we are working in this field.
Keywords Information visualization, Visual structure, Scientific visualization, Human-computer interaction, Knowledge mining
信息资源管理文献综述 题目:大数据背景下的信息资源管理 系别:信息与工程学院 班级:2015级信本1班 姓名: 学号:1506101015 任课教师: 2017年6月 大数据背景下的信息资源管理 摘要:随着网络信息化时代的日益普遍,我们正处在一个数据爆炸性增长的“大数据”时代,在我们的各个方面都产生了深远的影响。大数据是数据分析的前沿技术。简言之,从各种各样类型的数据中,快速获得有价值信息的能力就是大数据技术,这也是一个企业所需要必备的技术。“大数据”一词越来越地别提及与使用,我们用它来描述和定义信息爆炸时代产生的海量数据。就拿百度地图来说,我们在享受它带来的便利的同时,无偿的贡献了我们的“行踪”,比如说我们的上班地点,我们的家庭住址,甚至是我们的出行方式他们也可以知道,但我们不得不接受这个现实,我们每个人在互联网进入大数据时代,都将是透明性的存在。各种数据都在迅速膨胀并变大,所以我们需要对这些数据进行有效的管理并加以合理的运用。
关键词:大数据信息资源管理与利用 目录 大数据概念.......................................................... 大数据定义...................................................... 大数据来源...................................................... 传统数据库和大数据的比较........................................ 大数据技术.......................................................... 大数据的存储与管理.............................................. 大数据隐私与安全................................................ 大数据在信息管理层面的应用.......................................... 大数据在宏观信息管理层面的应用.................................. 大数据在中观信息管理层面的应用.................................. 大数据在微观信息管理层面的应用.................................. 大数据背景下我国信息资源管理现状分析................................ 前言:大数据泛指大规模、超大规模的数据集,因可从中挖掘出有价值 的信息而倍受关注,但传统方法无法进行有效分析和处理.《华尔街日
新疆农业大学 专业文献综述 题目:遥感数据管理系统 姓名:古力古拉.约力瓦司 学院:计算机与信息工程学院 专业:信息管理与信息系统 班级:信管071班 学号:074631102 指导教师:蒲智职称:硕士 2011年12月20日 新疆农业大学教务处制
遥感数据管理系统的文献综述 古力古拉蒲智 摘要:随着遥感技术的飞速发展,获取的遥感影像资料也越来越多,而如何有效地存储及管理好这些海量数据,成为当前一个越来越突出的问题。遥感接受数据是遥感影像应用的重要数据来源,因此对待特殊格式的遥感数据的存储和管理成为卫星遥感应用的重要环节。基于VB开发技术建立遥感数据管理平台,实现空间数据的快速查询和属性数据的自动入库等高效管理功能。 关键词:卫星遥感;数据管理;存储;VB开发;数据查询; 引言 随着航天航空技术的发展,遥感技术手段也越来越成熟,其基础数据量也越来越庞大,使得如何有效地存储并管理遥感基础数据成为一个越来越突出的问题。遥感数据信息大多以数字形式存储,包括各种格式和不同级别的影像数据,但是大量数据资料没有得到有效利用,成为影像数据应用的瓶颈。如何有效的存储,管理和利用不断增多和更新的遥感数据是遥感应用中迫切需要解决的数据管理难题。因此必须理顺数据接受,处理,存储,管理和应用各个环节的流程,提高数据应用的效率,以快速获取和解译更加丰富的,有价值的空间数据信息,发挥卫星遥感影像的实时性和快速性优势。 1遥感数据管理的概述 遥感卫星成像工作主要包括两个方面的内容,一部分为信息获取,一部分为数据下传信息获取是指当卫星运行轨迹经过用户要求的观测区域上空时,针对用户圈定的地物目标,安排遥感器在指定工作模式下,获取指定时间内的图像数据下传是指将获取的图像数据通过卫星的数据传输系统,在地面接收站的覆盖范围内传回地面遥感卫星计划管理的任务就是将众多用户的观测申请,转换为满足用户需求符合卫星约束的遥感卫星工作计划卫星遥感数据管理系统是以卫星遥感接受数据作为数据基础,对多种类型和不同级别的卫星接受数据进行数据处理,数据存储和数据管理的系统,解决卫星遥感接收数据管理混乱和查询困难的技术难题,建立卫星接收原始数据库,卫星接收预处理数据库和卫星接收后处理数据库三个空间子数据库实体,开发遥感数据管理软件平台,实现接收数据的空间数据和属性数据的可视化管理,数据入库和多种方式查询的业务化功能。 遥感技术的应用范围 遥感技术广泛用于军事侦察,导弹预警,军事测绘,海洋监视,气象观测和互剂侦检等。在民用方面随着遥感成像技术的发展,遥感技术广泛用于灾害防治,环境监测,城市规划,农作物生长预报,地球资源普查,植被分类,海洋研制,地震监测等方面。 遥感的特点
2018年6 月7 日
目录 一、题目 (1) 二、数据 (1) 三、可视化工具(哪一种,选择原因) (1) 四、可视化方案或可视化实现过程 (2) 1、导入数据并进行规范化 (2) 2、数据连接与整理 (2) 3、将地理信息与地图进行结合 (3) 4、设置相关参数 (3) 5、可视化方案 (3) 五、可视化结果 (4) 1、交战阵营可视化 (4) 2、人口统计可视化 (7) 3、死亡人数可视化 (9) 4、时间顺序可视化 (11) 5、人口损失情况可视化 (14) 六、体会 (16)
一、题目 在的可视化课程结束的同时中,本人也开始了数据可视化的大作业的工作。大作业是对前面学过的数据可视化技术的一个总结、回顾和实践。在开始设计前,本人回顾以前所学的内容,明确了本次作业设计所要用到的技术点,成功完成了可视化期末大作业。 大作业要求从网络上下载一组数据(自行获取),选择一种可视化工具(Excel、Tableau、Matlab、Echarts等),设计一种可视化方案实现该数据的可视化,并做适当的数据分析(或挖掘)。 二、数据 本次实验中,我设计的是关于第二次世界大战的数据可视化。原数据为两张表,分别存储了各个国家的人口牺牲情况与各个国家相互之间的战争具体时间、阵营、以及事件。 其中国家数据来源于维基百科中World War II casualties词条下的表格,具体网址为:https://https://www.doczj.com/doc/ab11671553.html,/wiki/World_War_II_casualties#cite_note-187。 而关于时间、阵营与事件的数据来源于维基百科的World War II词条下方的信息,具体网址为:https://https://www.doczj.com/doc/ab11671553.html,/wiki/World_War_II。 两张表之间都以excel形式存在,在导入Tableau数据库的时候,建立两表的关系并对表进行说明。本人在建立过程前引入了一些编号变量,可以进行无视。下面是部分数据截图,具体数据见随文档上交的excel文件。 三、可视化工具(哪一种,选择原因) 在这次的作业中本人选择的可视化工具为Tableau,选择该工具主要有以下原
(2011届) 毕业论文(设计)文献综述 题目:学科领域信息可视化研究--以管理信息系统领域为例 学院:商学院 专业:信息系统与信息管理 班级: 学号: 姓名: 指导教师:
一、前言部分 随着信息的日益丰富和互联网技术的发展,如何在海量数据中获取有效信息这一问题促使信息可视化领域成为当前的研究热点之一。信息可视化(information visualization),有时也被称作数据可视化(data visualization),近几年在国际上得到了广泛的重视。所谓信息可视化,就是将抽象数据用可视的形式表示出来,以利于分析数据、发现规律和支持决策。信息可视化的一个重要分支是引文分析可视化。自从加菲尔德创立引文索引数据库以来,引文分析法越来越多地被用来进行科学结构的分析、科学技术史及其发展规律的研究、科研绩效的评价等方面。它借鉴了很多科学可视化的技术,但又不同于科学可视化。科学可视化中的数据主要是物理世界、自然科学中的数据,例如卫星传回的数据等;而信息可视化中的数据来自社会现实和社会科学的各个方面,一般是比较抽象的数据,如金融数据、商业信息、文献等。信息可视化有以下几个比较突出的优点[1]: 1 提供了一条直观理解大量数据的途径。通过可视化,能够立刻辨别出最重要的信息 2 能够查询到没有预想到的现象。 3 能够发现数据本身的问题。合适的可视化方式可以揭示出数据本身以及人为造成的数据错误。 引文分析主要运用数学和逻辑学等方法对期刊、论文、专著等研究对象的引用和被引用现象和规律进行分析,以便揭示其数量特征和内在规律[2]。因为引文分析要处理大量的抽象的引文数据,信息可视化所具备的诸多优势无疑能促进引文分析应用这项技术。因此引文分析可视化最近几年在国外得到了蓬勃的发展,已经被应用于科学史研究、科学结构分析、知识领域显现等。但我国在这方面的研究层次较低,更多的是理论上的探讨,因此分析探讨国外在这方面研究中所采取的技术与方法对我国的研究无疑具有很强的借鉴意义。 近年来,随着社会信息化的推进和网络应用的日益广泛,信息源越来越庞大。目前已进入前所未有的信息时代。我们每天都处在各种信息的包围之中,需要一种快捷有效的方式帮助我们发现隐藏在庞杂信息当中的模式和知识,帮助我们决策。可视化的目标就是帮助人们增强认知能力,此即信息可视化的意义所在。信息的日益丰富决定着未来用户界面主要是一种信息界面,就某种意义而言,信息可视化代表着下一代用户界面的方向[2]。因为引文分析
第37卷第7期测绘与空间地理信息 GEOMATICS &SPATIAL INFORMATION TECHNOLOGY Vol.37,No.7收稿日期:2014-01-22 作者简介:马宏斌(1982-),男,甘肃天水人,作战环境学专业博士研究生,主要研究方向为地理空间信息服务。 大数据时代的空间数据挖掘综述 马宏斌1 ,王 柯1,马团学 2(1.信息工程大学地理空间信息学院,河南郑州450000;2.空降兵研究所,湖北孝感432000) 摘 要:随着大数据时代的到来,数据挖掘技术再度受到人们关注。本文回顾了传统空间数据挖掘面临的问题, 介绍了国内外研究中利用大数据处理工具和云计算技术,在空间数据的存储、管理和挖掘算法等方面的做法,并指出了该类研究存在的不足。最后,探讨了空间数据挖掘的发展趋势。关键词:大数据;空间数据挖掘;云计算中图分类号:P208 文献标识码:B 文章编号:1672-5867(2014)07-0019-04 Spatial Data Mining Big Data Era Review MA Hong -bin 1,WANG Ke 1,MA Tuan -xue 2 (1.Geospatial Information Institute ,Information Engineering University ,Zhengzhou 450000,China ; 2.Airborne Institute ,Xiaogan 432000,China ) Abstract :In the era of Big Data ,more and more researchers begin to show interest in data mining techniques again.The paper review most unresolved problems left by traditional spatial data mining at first.And ,some progress made by researches using Big Data and Cloud Computing technology is introduced.Also ,their drawbacks are mentioned.Finally ,future trend of spatial data mining is dis-cussed. Key words :big data ;spatial data mining ;cloud computing 0引言 随着地理空间信息技术的飞速发展,获取数据的手 段和途径都得到极大丰富,传感器的精度得到提高和时空覆盖范围得以扩大,数据量也随之激增。用于采集空间数据的可能是雷达、红外、光电、卫星、多光谱仪、数码相机、成像光谱仪、全站仪、天文望远镜、电视摄像、电子 显微镜、CT 成像等各种宏观与微观传感器或设备,也可能是常规的野外测量、人口普查、土地资源调查、地图扫描、 地图数字化、统计图表等空间数据获取手段,还可能是来自计算机、 网络、GPS ,RS 和GIS 等技术应用和分析空间数据。特别是近些年来,个人使用的、携带的各种传感器(重力感应器、电子罗盘、三轴陀螺仪、光线距离感应器、温度传感器、红外线传感器等),具备定位功能电子设备的普及,如智能手机、平板电脑、可穿戴设备(GOOGLE GLASS 和智能手表等),使人们在日常生活中产生了大量具有位置信息的数据。随着志愿者地理信息(Volunteer Geographic Information )的出现,使这些普通民众也加入到了提供数据者的行列。 以上各种获取手段和途径的汇集,就使每天获取的 数据增长量达到GB 级、 TB 级乃至PB 级。如中国遥感卫星地面站现在保存的对地观测卫星数据资料达260TB ,并以每年15TB 的数据量增长。比如2011年退役的Landsat5卫星在其29年的在轨工作期间,平均每年获取8.6万景影像,每天获取67GB 的观测数据。而2012年发射的资源三号(ZY3)卫星,每天的观测数据获取量可以达到10TB 以上。类似的传感器现在已经大量部署在卫 星、 飞机等飞行平台上,未来10年,全球天空、地空间部署的百万计传感器每天获取的观测数据将超过10PB 。这预示着一个时代的到来,那就是大数据时代。大数据具有 “4V ”特性,即数据体量大(Volume )、数据来源和类型繁多(Variety )、数据的真实性难以保证(Veracity )、数据增加和变化的速度快(Velocity )。对地观测的系统如图1所示。 在这些数据中,与空间位置相关的数据占了绝大多数。传统的空间知识发现的科研模式在大数据情境下已经不再适用,原因是传统的科研模型不具有普适性且支持的数据量受限, 受到数据传输、存储及时效性需求的制约等。为了从存储在分布方式、虚拟化的数据中心获取信息或知识,这就需要利用强有力的数据分析工具来将
2017 数据可视化概览及其应 用计算机1406班宋世波20143753
目录 CONTENTS 数据可视化概述 Data visualization overview 数据可视化开发工具介绍 Introduction to data visualization development tools 数据可视化技术应用 Data visualization technology application 可视化应用及参考文献 Application and reference
数据可视化概述?Data visualization overview
可视化(Visualization )是利用计算机图形学和图像处理技术,将数据转换成图形或图像在屏幕上显示出来,并进行交互处理的理论、方法和技术。它涉及到计算机图形学、图像处理、计算机视觉、计算机辅助设计等多个领域,成为研究数据表示、数据处理、决策分析等一系列问题的综合技术。 高效 直观 标准 丰富 将海量数据进行抽取、度量、分析进行高效展现,为及时掌握全局动向和应对突发事件提供有效保障。 利用多维交互式报表、三维图形、大屏投影等高新技术,通过多维视角观察数据形态,显著提升对信息的认知。 通过制定可视化标准体系,实现可视化展现规范统一 从大屏投影到普通PC 桌面、Web 网再到移动终端,接收信息不受时间、空间限制。
明确问题 清晰的问题可以有助于避免数据可视化的一个常见毛病:把不相干的事物放在一起比较。假设我们有这样一个数据集(见表1),其中包含一个机构的作者总数、出版物总数、引用总数和它们特定一年的增长率。图1是一个糟糕的可视化案例,所有的变量都被包含在一张表格中。在同一张图中绘制出不同类型的多个变量,通常不是个好主意。注意力分散的读者会被诱导着去比较不相干的变量。比如,观察出所有机构的作者总数都少于出版物总数,这没有任何意义,又或者发现Athena University、Bravo University、Delta Institution三个研究机构的出版物总数依次增长,也没有意义。拥挤的图表难以阅读、难以处理。在有多个Y轴时就是如此,哪个变量对应哪个轴通常不清晰。简而言之,槽糕的可视化项目并不澄清事实而是引人困惑。 从基本的可视化着手 确定可视化项目的目标后,下一步是建 立一个基本的图形。它可能是饼图、线 图、流程图、散点图、表面图、地图、 网络图等等,取决于手头的数据是什么 样子。在明确图表该传达的核心信息时, 需要明确以下几件事: 我们试图绘制什么变量? X轴和轴代表什么? 数据点的大小有什么含义吗? 颜色有什么含义吗? 我们试图确定与时间有关趋势,还 是变量之间的关系? 选择正确的图表类型 数据的规范化(如本例中的相对活跃 指数)是一个很常见也很有效的数据 转换方法,但需要基于帮助读者得 出正确结论的目的使用。如在此例 中,仅仅发现目标机构对某个小领 域非常重视没太大意义。 我们可以把出版量和活跃程度 在同一个图表中展示,以理解各领 域的活跃程度。使用图4的玫瑰图, 各块的面积表示文章数量,半径长 短表示相对活跃指数。注意在此例 中,半径轴是二次的(而图3中是典 型线性的)。图中可以看出,B领域 十分突出,拥有最大的数量(由面积 表示)和最高的相对活跃程度(由半 径长度表示)。 将注意力引向关键信息 用肉眼衡量半径长度可能并不容 易。由于在本例中,相对活跃指 数的1.0代表此领域的全球活跃 程度,我们可以通过给出1.0的 参照值来引导读者,见图5。这 样很容易看出哪些领域的半径超 出参考线。 我们还可以使用颜色帮助读者识 别出版物最多的领域。如图例所 示,一块的颜色深浅由出版物数 量决定。为了便于识别,我们还 可以把各领域名称作为标签(见图 6)。
信息资源管理文献综述题目:大数据背景下的信息资源管理 系别:信息与工程学院 班级:2015级信本1班 姓名: 学号:1506101015 任课教师: 2017年6月
大数据背景下的信息资源管理 摘要:随着网络信息化时代的日益普遍,我们正处在一个数据爆炸性增长的“大数据”时代,在我们的各个方面都产生了深远的影响。大数据是数据分析的前沿技术。简言之,从各种各样类型的数据中,快速获得有价值信息的能力就是大数据技术,这也是一个企业所需要必备的技术。“大数据”一词越来越地别提及与使用,我们用它来描述和定义信息爆炸时代产生的海量数据。就拿百度地图来说,我们在享受它带来的便利的同时,无偿的贡献了我们的“行踪”,比如说我们的上班地点,我们的家庭住址,甚至是我们的出行方式他们也可以知道,但我们不得不接受这个现实,我们每个人在互联网进入大数据时代,都将是透明性的存在。各种数据都在迅速膨胀并变大,所以我们需要对这些数据进行有效的管理并加以合理的运用。 关键词:大数据信息资源管理与利用 目录 大数据概念 (3) 大数据定义 (3) 大数据来源 (3) 传统数据库和大数据的比较 (3) 大数据技术 (4) 大数据的存储与管理 (4)
大数据隐私与安全 (5) 大数据在信息管理层面的应用 (6) 大数据在宏观信息管理层面的应用 (6) 大数据在中观信息管理层面的应用 (7) 大数据在微观信息管理层面的应用 (8) 大数据背景下我国信息资源管理现状分析 (9) 前言:大数据泛指大规模、超大规模的数据集,因可从中挖掘出有价值 的信息而倍受关注,但传统方法无法进行有效分析和处理.《华尔街日 报》将大数据时代、智能化生产和无线网络革命称为引领未来繁荣的大技术变革.“世界经济论坛”报告指出大数据为新财富,价值堪比石油.因此,目前世界各国纷纷将开发利用大数据作为夺取新一轮竞争制高点的重要举措. 当前大数据分析者面临的主要问题有:数据日趋庞大,无论是入库和查询,都出现性能瓶颈;用户的应用和分析结果呈整合趋势,对实时性和响应时间要求越来越高;使用的模型越来越复杂,计算量指数级上升;传统技能和处理方法无法应对大数据挑战. 正文:
计算机图形学论文 学号: 11001010123 专业:信息与计算科学 班级: 110010101 姓名:王俊才 指导教师:傅由甲
一.摘要 计算机图形学(Computer Graphics,简称CG)是一种使用数学算法将二维或三维图形转化为计算机显示器的栅格形式的科学。简单地说,计算机图形学的主要研究内容就是研究如何在计算机中表示图形、以及利用计算机进行图形的计算、处理和显示的相关原理与算法。计算机图形学作为计算机科学与技术学科的一个独立分支已经历了近40年的发展历程。一方面,作为一个学科,计算机图形学在图形基础算法、图形软件与图形硬件三方面取得了长足的进步,成为当代几乎所有科学和工程技术领域用来加强信息理解和传递的技术和工具。计算机图形学在我国虽然起步较晚,然而它的发展却十分迅速。我国的主要高校都开设了多门计算机图形学的课程,并有一批从事图形学基础和应用研究的研究所。在浙江大学建立的计算机辅助与图形学国家重点实验室,已成为我国从事计算机图形学研究的重要基地之一。 关键词:实现2D/3D 图形的算法,纹理映射,发展简史,发展趋势 二、计算机图形学中运用到的技术算法 (1)OpenGL 实现2D/3D 图形的算法 OpenGL(全写Open Graphics Library)是个定义了一个跨编程语言、跨平台的编程接口的规格,它用于三维图象(二维的亦可)。OpenGL是个专业的图形程序接口,是一个功能强大,调用方便的底层图形库。OpenGL是个与硬件无关的软件接口,可以在不同的平台如Windows 95、Windows NT、Unix、Linux、MacOS、OS/2之间进行移植。因此,支持OpenGL 的软件具有很好的移植性,可以获得非常广泛的应用。由于OpenGL是图形的底层图形库,没有提供几何实体图元,不能直接用以描述场景。但是,通过一些转换程序,可以很方便地将AutoCAD、3DS/3DSMAX等3D图形设计软件制作的DXF和3DS模型文件转换成OpenGL 的顶点数组。 OpenGL是一个开放的三维图形软件包,它独立于窗口系统和操作系统,以它为基础开发的应用程序可以十分方便地在各种平台间移植;OpenGL可以与Visual C++紧密接口,便于实现机械手的有关计算和图形算法,可保证算法的正确性和可靠性;OpenGL使用简便,效率高。它具有一下功能: 1.建模:OpenGL图形库除了提供基本的点、线、多边形的绘制函数外,还提供了复杂的三维物体(球、锥、多面体、茶壶等)以及复杂曲线和曲面绘制函数。 2.变换:OpenGL图形库的变换包括基本变换和投影变换。基本变换有平移、旋转、变比镜像四种变换,投影变换有平行投影(又称正射投影)和透视投影两种变换。 3.颜色模式设置:OpenGL颜色模式有两种,即RGBA模式和颜色索引(Color Index)。 4.光照和材质设置:OpenGL光有辐射光(Emitted Light)、环境光(Ambient Light)、漫反射光(Diffuse Light)和镜面光(Specular Light)。材质是用光反射率来表示。
可视化空间数据挖掘研究综述 贾泽露1,2 刘耀林2 (1. 河南理工大学测绘与国土信息工程学院,焦作,454000;2. 武汉大学资源与环境科学学院,武汉,430079)摘要:空间数据挖掘针对的是更具有可视化要求的地理空间数据的知识发现过程,可视化能提供同用户对空间目标心理认知过程相适应的信息表现和分析环境,可视化与空间数据挖掘的结合是该领域研究发展的必然,并已成为一个研究热点。论文综述了空间数据挖掘和可视化的研究现状,重点阐述了空间数据挖掘中的可视化化技术及其应用,并对可视化空间数据挖掘的发展趋势进行了阐述。 关键词:数据挖掘;空间数据挖掘;数据可视化;信息可视化;GIS; 空间信息获取技术的飞速发展和各种应用的广泛深入,多分辨率、多时态空间信息大量涌现,以及与之紧密相关的非空间数据的日益丰富,对海量空间信息的综合应用和处理技术提出了新的挑战,要求越来越高。空间数据挖掘技术作为一种高效处理海量地学空间数据、提高地学分析自动化和智能化水平、解决地学领域“数据爆炸、知识贫乏”问题的有效手段,已发展成为空间信息处理的关键技术。然而,传统数据挖掘“黑箱”作业过程使得用户只能被动地接受挖掘结果。可视化技术能为数据挖掘提供直观的数据输入、输出和挖掘过程的交互探索分析手段,提供在人的感知力、洞察力、判断力参与下的数据挖掘手段,从而大大地弥补了传统数据挖掘过程“黑箱”作业的缺点,同时也大大弥补了GIS重“显示数据对象”轻“刻画信息结构”的弱点,有力地提高空间数据挖掘进程的效率和结果的可信度[1]。空间数据挖掘中可视化技术已由数据的空间展现逐步发展成为表现数据内在复杂结构、关系和规律的技术,由静态空间关系的可视化发展到表示系统演变过程的可视化。可视化方法不仅用于数据的理解,而且用于空间知识的呈现。可视化与空间数据挖掘的结合己成为必然,并已形成了当前空间数据挖掘1与知识发现的一个新的研究热点——可视化空间数据挖掘(Visual Spatial Data Mining,VSDM)。VSDM技术将打破传统数据挖掘算法的“封闭性”,充分利用各式各样的数据可视化技术,以一种完全开放、互动的方式支持用户结合自身专业背景参与到数据挖掘的全过程中,从而提高数据挖掘的有效性和可靠性。本文将对空间数据挖掘、可视化的研究概况,以及可视化在空间数据挖掘中的应用进行概括性回顾总结,并对未来发展趋势进行探讨。 一、空间数据挖掘研究概述 1.1 空间数据挖掘的诞生及发展 1989年8月,在美国底特律市召开的第一届国际联合人工智能学术会议上,从事数据库、人工智能、数理统计和可视化等技术的学者们,首次出现了从数据库中发现知识(knowledge discovery in database,KDD)的概念,标志着数据挖掘技术的诞生[1]。此时的数据挖掘针对的 作者1简介:贾泽露(1977,6-),男,土家族,湖北巴东人,讲师,博士,主要从事空间数据挖掘、可视化、土地信息系统智能化及GIS理论、方法与应用的研究和教学工作。 作者2简介:刘耀林(1960,9- ),男,汉族,湖北黄冈人,教授,博士,博士生导师,武汉大学资源与环境科学学院院长,现从事地理信息系统的理论、方法和应用研究和教学工作。
信息资源管理文献综述题目:大数据背景下的信息资源管理系别:信息与工程学院 班级:2015级信本1班 姓名: 学号:1506101015 任课教师: 2017年6月
大数据背景下的信息资源管理 摘要:随着网络信息化时代的日益普遍,我们正处在一个数据爆炸性增长的“大数据”时代,在我们的各个方面都产生了深远的影响。大数据是数据分析的前沿技术。简言之,从各种各样类型的数据中,快速获得有价值信息的能力就是大数据技术,这也是一个企业所需要必备的技术。“大数据”一词越来越地别提及与使用,我们用它来描述和定义信息爆炸时代产生的海量数据。就拿百度地图来说,我们在享受它带来的便利的同时,无偿的贡献了我们的“行踪”,比如说我们的上班地点,我们的家庭住址,甚至是我们的出行方式他们也可以知道,但我们不得不接受这个现实,我们每个人在互联网进入大数据时代,都将是透明性的存在。各种数据都在迅速膨胀并变大,所以我们需要对这些数据进行有效的管理并加以合理的运用。 关键词:大数据信息资源管理与利用 目录 大数据概念 (2) 大数据定义 (2) 大数据来源 (2) 传统数据库和大数据的比较 (3) 大数据技术 (3) 大数据的存储与管理 (4) 大数据隐私与安全 (4) 大数据在信息管理层面的应用 (5) 大数据在宏观信息管理层面的应用 (5) 大数据在中观信息管理层面的应用 (6) 大数据在微观信息管理层面的应用 (7) 大数据背景下我国信息资源管理现状分析 (8)
前言:大数据泛指大规模、超大规模的数据集,因可从中挖掘出有价值 的信息而倍受关注,但传统方法无法进行有效分析和处理.《华尔街日 报》将大数据时代、智能化生产和无线网络革命称为引领未来繁荣的 大技术变革.“世界经济论坛”报告指出大数据为新财富,价值堪比 石油.因此,目前世界各国纷纷将开发利用大数据作为夺取新一轮竞 争制高点的重要举措. 当前大数据分析者面临的主要问题有:数据日趋庞大,无论是入 库和查询,都出现性能瓶颈;用户的应用和分析结果呈整合趋势,对 实时性和响应时间要求越来越高;使用的模型越来越复杂,计算量指 数级上升;传统技能和处理方法无法应对大数据挑战. 正文: 大数据概念 大数据定义 维基百科对大数据的定义则简单明了:大数据是指利用常用软件工具捕获、管理和处理数据所耗时间超过可容忍时间的数据集。也就是说大数据是一个体量特别大,数据类别特别大的数据集,并且这样的数据集无法用传统数据库工具对其内容进行抓取、管理 大数据来源 1)来自人类活动:人们通过社会网络、互联网、健康、金融、经济、交通等活动过程所产生的各类数据,包括微博、病人医疗记录、文字、图形、视频等
基于微课近五年研究成果的研究 摘要:本文从微课的内涵与特点、微课的研究状况、微课翻转课堂、微课的质疑对微课的研究状况进行了近5年的分析。对微课的认识由形式到内容、由片面到全面、由感性到理性、不断丰富和发展的过程;学术界对微课的研究也是呈逐年增长的趋势;微课和翻转课堂共同作用可以充分发挥学生在学习中的主体作用;微课热是暂时的,微课却是长期的,因为微课符合了网络时代学习碎片化的需要。 关键词:微课;内涵与特点;研究状况;翻转课堂; 二十一世纪,互联网技术迅猛发展,方便快捷的移动设备广泛普及。与此同时,现代社会人们对学习方式的多元化需求不断增长。以高科技产品为传播媒体、能满足任何人随时随地学习的微课,便应运而生。 然而微课并非中国本土产物,而是“舶来品”2011年,中国广东省佛山市举办了中小学微课设计与制作大赛。佛山教育局在大赛中首次正式给出“微课”概念。2011年,“佛山市中小学优秀微课作品展播平台”和“微课网”创立,微课自此开启了在实践层面上的建设与发展。2014年举办的中国外语微课大赛,全国已有28个省筹备参与。由此可见,微课的影响已经由广州一省逐步扩展到河北、河南、四川、云南、江西、浙江、内蒙、辽宁、广西、海南、山西等多省及北京、重庆、上海和天津市。微课在中国通过短短的几年时间,经历了由区域到全国、由中小学到高校的发展趋势演变,内容所涉及的学科也越来越丰富。对微课研究也成了学术界一个很热的话题,介于此,我想从学者们对微课的解读、微课的研究状况、微课的发展课堂的理论研究以及对微课的理解的误区探讨近些年来学者们对微课的研究。 (一)微课的内涵与特点 微课又称微课例或微课堂,主要以视频的方式记录课堂某学科知识点的教与学,此外还包括与其相关的教学设计、课件素材、教学反思、练习测试、学生反馈、专家同行点评等多种教学辅助资源。一个“微”字就可以说明微课的关键所在。“微”字意味着微课的上课时间短,而时间的短暂决定了课堂的学习内容少而精。 微课是个“舶来品”,国内对微课内涵的认识经历了一个循序渐进的过程。胡铁生是教育硕士,中学电教高级教师。他2012年起担任全国中小学教师微课大赛评委,专注于微课等领域的实践与研究。他在2011年、2012年和2013年三个不同时期分别给出了微课的定义: (1)2011年,胡老师把微课定义为“以教学视频为载体,针对某个知识点或教学环节,而开展的各种教学资源的有机结合体。 (2)2012年,他定义微课是包含与教学相配套的“微教案”“微练习”“微课件”“微反思”及“微点评”等支持性、扩展性资源的新型网络课程资源。(3)2013年,胡老师定义微课是“基于网络运行的、不受时空限制的微型网络课程资源。” 通过把胡铁生老师不同时间对微课的定义进行对比,可以发现,从2011年到2013年,以胡老师为代表的微课研究专家们对微课的认识由最初的把微课定义为
收稿日期:2003-01-04 基金项目:国家973基金(G2000077906)资助;中科院知识创新项目(CX020019)资助. 作者简介:芮小平,博士研究生,研究方向为“网络三维地理信息系统”,E -mail :ruix p @yahoo .com .cn ;赵扬,硕士研究生,研究方向为组建式地理信息系统,E -mail :davyonn et @https://www.doczj.com/doc/ab11671553.html,. 空间信息多维可视化技术综述 芮小平1,赵 扬3,杨崇俊2,张彦敏3 1 (北京交通大学交通运输学院,北京100044) 2(中国科学院 遥感应用研究所遥感科学重点实验室,北京100101) 3(中国矿业大学 (北京)资源开发工程系,北京100083) 摘 要:可视化技术的出现为分析和处理海量信息提供了新的手段.将空间信息多维可视化的实现方法分为基于2变量的多信息可视化、基于多变量的多维信息可视化和基于动画的多维信息可视化三类,并详细讨论了这三类方法的各 种实现算法. 关键词:可视化;空间;多维信息中图分类号:T P 391 文献标识码:A 文章编号:1000-1220(2004)09-1636-05 Survey on the Visualization of Multidimensional Spatial Information RU I Xia o-ping 1,ZHAO Ya ng 3,Y AM G Cho ng -jun 2,Z HAN G Ya n-min 3 1( School of Traff ic and Transportation ,Beijing Jiaoton g University ,Beijing 100044,China ) 2( The State Key Laboratory of Remote Sensing Information S ciences ,Institure of Remote Sensin g Applications , Ch ines e Acad my of Sciences ,Beijing 100101,Ch ina ) 3( Dep artmen t of Resou rce Develop ment En gineering ,China Un iverstiy of Mining & Technolog y Beijng ,Beijing 100083,China ) Abstract :T he v isualizatio n techno log ies give us new w ays to analy sis and pro cess massiv e infor matio n.This paper div ides visua lization technologies o f the multidimensional info rma tio n into th ree par ts :T ech niques ba sed o n 2-v ariate displays,multiva ria te visualization techniques,techniques based on anima tio n.The a utho r intr oduced kinds of v isuali zation alg o rithm s in this paper a nd these alg orithms indica te the resear ch sta te of visua liza tion o f spatial multidimensional infor matio n in recent y ea rs. Key words :v isualizatio n ;spa tial ;multidimensio nal info rma tion 1 引 言 科学计算可视化自20世纪80年代提出以来,迅速发展成为一个新兴的学科,其理论和技术对空间信息的表达和分析 产生了巨大的影响,这种影响可以归纳为两个方面:一方面,从技术层次来讲,可视化技术与GIS 技术的结合,促进了GIS 地学数据的图形表达;另一方面,从理论层次来讲,可视化不仅是通过计算机图形显示来表达数据,本质上是人们建立某种事物(或某人)在脑海中的意象,是人们对空间信息认知和交流的过程[1].可视化技术把人和机器以一种直觉而自然的方式统一起来,这无疑使人们在3维世界中,用以前不可想象的手段来获取信息和发挥自己的创造性.由于可视化技术在信息处理与分析方面具有不可比拟的优越性,它已经成为信息爆炸时代人们分析和驾驭信息的有力工具.与其它领域的信息相比,空间信息具有信息量大,情况复杂等特点,借助可视化技术可以帮助我们更加全面和准确的了解复杂的空间信 息并进一步分析空间变化规律. 多维性是空间现象的本质特征,同时也是虚拟G IS 管理空间信息一个的基本特点.空间多维信息的可视化为解释空间现象的本质提供了新的手段,它对复杂空间现象的理解起着越来越重要的作用.由于时间维和其它专题维的引入,使地球空间多维信息的表达方法体系得到了极大的提升,许多在传统可视化中不可想象的方法由于计算机图形学的发展变得可能. 2 多维信息可视化技术的分类 由于多维信息的复杂性,很难用简单的标准对现有多维信息可视化技术进行分类.本文根据可视化技术的目的、类型以及数据的维数,将多维信息可视化技术分为如下三类.2.1 基于2变量的多维可视化技术 这种方法由基本的2变量显示以及可同步观察这个2变 第25卷第9期 2004年9月 小型微型计算机系统M IN I -M I CRO SY ST EM S V o l.25No.9 Sep .2004
现如今,数据可视化由于数据分析的火热也变得火热起来,不过数据可视化并不是一个新技术,虽然说数据可视化相对数据分析来说比较简单,但是数据可视化却是一个十分重要的技术。在这篇文章中我们就给大家介绍一下关于数据可视化的现状以及数据可视化的发展趋势。 首先我们说一下国外的数据可视化的发展现状,其实在外国,数据可视化是一个成熟的技术,他们借助数据可视化技术,有很多的视觉化传播媒体使用图像化的方式进行传播信息,从而 提升了自己的影响力。像一些知名的媒体比如卫报、芝加哥论坛报、BBC、ABC等,都是用 数据可视化让自身影响力大大提高。其实随着电脑技术的成熟和搜索引擎技术的发展,政府 信息公开化,众包模式的兴起,人们获取和解读数据的可能性大大提高,基于数据挖掘、理 解数据基础上的数据新闻可视化,成为新闻叙事手段一个新的发展方向和突破。 那么国内的数据可视化的发展现状是什么呢?其实我国媒体利用数据可视化进行新闻报道处 于刚刚起步阶段。这是因为在过去,我们借助于常用饼状图、柱状图、表格等形式来美化版面,通过数字加空镜头、画外音的形式宣扬某一领域的发展历程。这种报道方式陈旧,内容 抽象化,语言机关化公文化,流于表面,难以让受众真正理解和思考数字的纵深意义,揭示 事件发展的方向和趋势。所以说,要想改变这一状态,就需要不破不立。现在有很多的媒体 都显示了我国数据可视化相比过去有所发展。 那么数据可视化的发展趋势与现存问题是什么呢?其实在未来数据可视化的发展历程中,数 据的处理能力为核心,交互式可视化是新趋势。数据可视化新闻对新兴技术的依赖,暴露出
传统媒体的短板。数据可视化使受众与媒体的关系发生根本变化,得以感受到传统报道难以 揭示的现象和规律。当然需要注意的是,我们相信数据的力量但不能只靠数据,数据也可能 存在误差,要避免数据偏差和数据失真,就要学会去除噪音数据的干扰和不断修正的方法。 加之数据可视化新闻制作周期长、人力成本高,与新闻的时效性存在一定冲突都有待于未来 技术的进一步发展来提升报道质量,缩短报道时间。另外,尽管主流媒体和新兴媒体在新闻 报道中做了大量数据可视化的尝试,但其发展仍然面临着受众关注度不高、数据源开发有限、相关专业人才匮乏等问题。所以说我国的数据可视化还有很长的路要走。 在这篇文章中我们给大家介绍了很多关于数据可视化的相关知识,具体包括国内外的数据可 视化的发展现状以及数据可视化的发展趋势与现存问题,通过这些内容我们可以更好地理解 数据可视化。
大数据外文翻译参考文献综述 (文档含中英文对照即英文原文和中文翻译) 原文: Data Mining and Data Publishing Data mining is the extraction of vast interesting patterns or knowledge from huge amount of data. The initial idea of privacy-preserving data mining PPDM was to extend traditional data mining techniques to work with the data modified to mask sensitive information. The key issues were how to modify the data and how to recover the data mining result from the modified data. Privacy-preserving data mining considers the problem of running data mining algorithms on confidential data that is not supposed to be revealed even to the party
running the algorithm. In contrast, privacy-preserving data publishing (PPDP) may not necessarily be tied to a specific data mining task, and the data mining task may be unknown at the time of data publishing. PPDP studies how to transform raw data into a version that is immunized against privacy attacks but that still supports effective data mining tasks. Privacy-preserving for both data mining (PPDM) and data publishing (PPDP) has become increasingly popular because it allows sharing of privacy sensitive data for analysis purposes. One well studied approach is the k-anonymity model [1] which in turn led to other models such as confidence bounding, l-diversity, t-closeness, (α,k)-anonymity, etc. In particular, all known mechanisms try to minimize information loss and such an attempt provides a loophole for attacks. The aim of this paper is to present a survey for most of the common attacks techniques for anonymization-based PPDM & PPDP and explain their effects on Data Privacy. Although data mining is potentially useful, many data holders are reluctant to provide their data for data mining for the fear of violating individual privacy. In recent years, study has been made to ensure that the sensitive information of individuals cannot be identified easily. Anonymity Models, k-anonymization techniques have been the focus of intense research in the last few years. In order to ensure anonymization of data while at the same time minimizing the information