
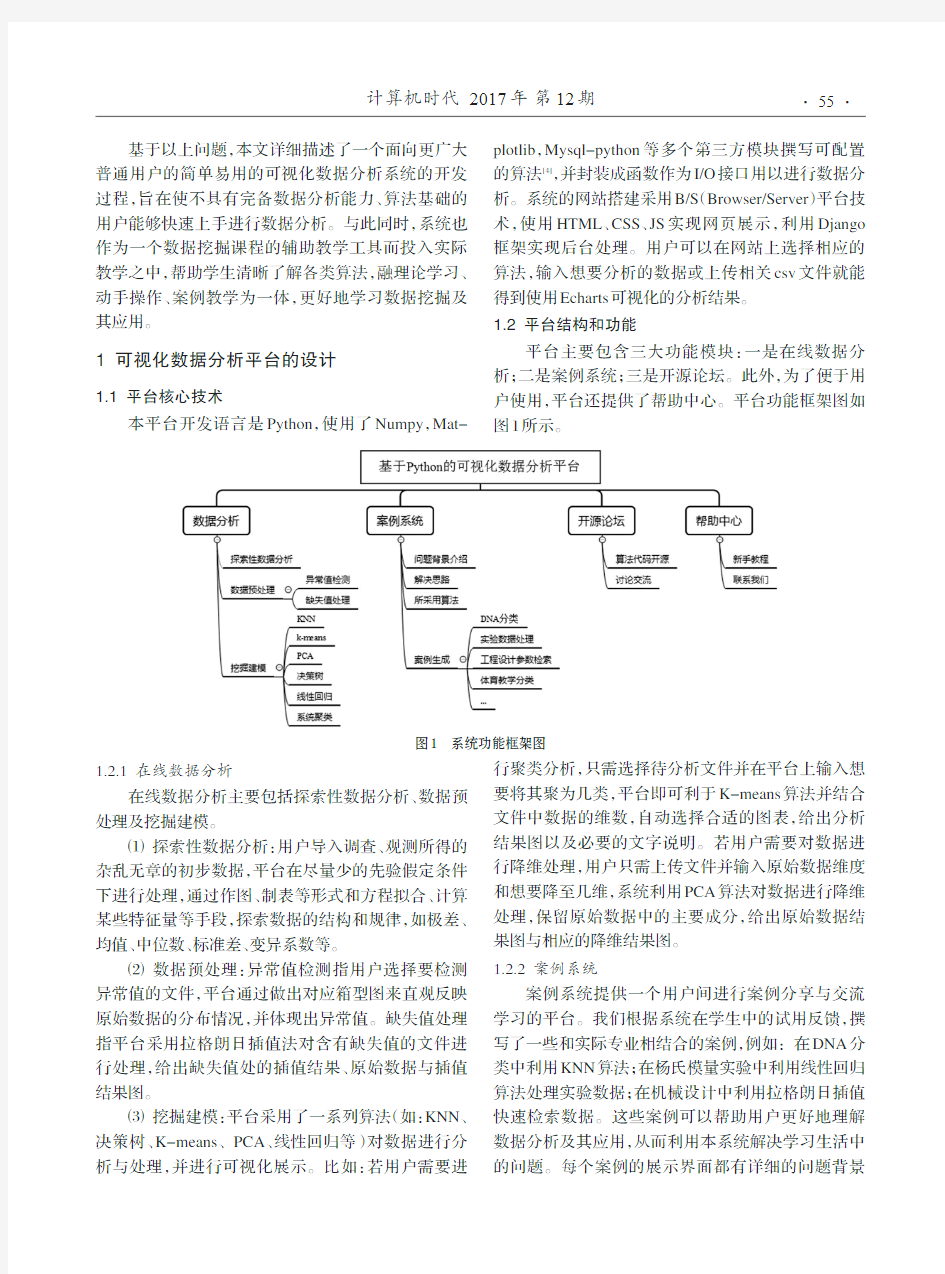
引言 几年后发生了。在使用SAS工作超过5年后,我决定走出自己的舒适区。作为一个数据科学家,我寻找其他有用的工具的旅程开始了!幸运的是,没过多久我就决定,Python作为我的开胃菜。 我总是有一个编写代码的倾向。这次我做的是我真正喜欢的。代码。原来,写代码是如此容易! 我一周内学会了Python基础。并且,从那时起,我不仅深度探索了这门语言,而且也帮助了许多人学习这门语言。Python是一种通用语言。但是,多年来,具有强大的社区支持,这一语言已经有了专门的数据分析和预测模型库。 由于Python缺乏数据科学的资源,我决定写这篇教程来帮助别人更快地学习Python。在本教程中,我们将讲授一点关于如何使用Python 进行数据分析的信息,咀嚼它,直到我们觉得舒适并可以自己去实践。
目录 1. 数据分析的Python基础 o为什么学Python用来数据分析 o Python 2.7 v/s 3.4 o怎样安装Python o在Python上运行一些简单程序 2. Python的库和数据结构 o Python的数据结构 o Python的迭代和条件结构 o Python库 3. 在Python中使用Pandas进行探索性分析
o序列和数据框的简介 o分析Vidhya数据集——贷款的预测问题 4. 在Python中使用Pandas进行数据再加工 5. 使用Python中建立预测模型 o逻辑回归 o决策树 o随机森林 让我们开始吧 1.数据分析的Python基础 为什么学Python用来数据分析 很多人都有兴趣选择Python作为数据分析语言。这一段时间以来,我有比较过SAS和R。这里有一些原因来支持学习Python: ?开源——免费安装 ?极好的在线社区 ?很容易学习 ?可以成为一种通用的语言,用于基于Web的分析产品数据科学和生产中。
《利用python进行数据分析》读书笔记 pandas是本书后续内容的首选库。pandas可以满足以下需求:具备按轴自动或显式数据对齐功能的数据结构。这可以防止许多由于数据未对齐以及来自不同数据源(索引方式不同)的数据而导致的常见错误。. 集成时间序列功能既能处理时间序列数据也能处理非时间序列数据的数据结 构数学运算和简约(比如对某个轴求和)可以根据不同的元数据(轴编号)执行灵活处理缺失数据合并及其他出现在常见数据库(例如基于SQL的)中的关系型运算1、pandas数据结构介绍两个数据结构:Series和DataFrame。Series是一种类似于以为NumPy数组的对象,它由一组数据(各种NumPy数据类型)和与之相关的一组数据标签(即索引)组成的。可以用index和values分别规定索引和值。如果不规定索引,会自动创建0 到N-1 索引。#-*- encoding:utf-8 -*- import numpy as np import pandas as pd from pandas import Series,DataFrame #Series可以设置index,有点像字典,用index索引 obj = Series([1,2,3],index=['a','b','c'])
#print obj['a'] #也就是说,可以用字典直接创建Series dic = dict(key = ['a','b','c'],value = [1,2,3]) dic = Series(dic) #下面注意可以利用一个字符串更新键值 key1 = ['a','b','c','d'] #注意下面的语句可以将Series 对象中的值提取出来,不过要知道的字典是不能这么做提取的 dic1 = Series(obj,index = key1) #print dic #print dic1 #isnull 和notnull 是用来检测缺失数据 #print pd.isnull(dic1) #Series很重要的功能就是按照键值自动对齐功能 dic2 = Series([10,20,30,40],index = ['a','b','c','e']) #print dic1 + dic2 #name属性,可以起名字 https://www.doczj.com/doc/a914180933.html, = 's1' https://www.doczj.com/doc/a914180933.html, = 'key1' #Series 的索引可以就地修改 dic1.index = ['x','y','z','w']
用python进行数据分析 一、样本集 本样本集来源于某高中某班78位同学的一次月考的语文成绩。因为每位同学的成绩都是独立的随机变量,遂可以保证得到的观测值也是独立且随机的 样本如下: grades=[131,131,127,123,126,129,116,114,115,116,123,122,118, 121,126,121,126,121,111,119,124,124,121,116,114,116, 116,118,112,109,114,116,116,118,112,109,114,110,114, 110,113,117,113,121,105,127,110,105,111,112,104,103, 130,102,118,101,112,109,107,94,107,106,105,101,85,95, 97,99,83,87,82,79,99,90,78,86,75,66]; 二、数据分析 1.中心位置(均值、中位数、众数) 数据的中心位置是我们最容易想到的数据特征。借由中心位置,我们可以知道数据的一个平均情况,如果要对新数据进行预测,那么平均情况是非常直观地选择。数据的中心位置可分为均值(Mean),中位数(Median),众数(Mode)。其中均值和中位数用于定量的数据,众数用于定性的数据。 均值:利用python编写求平均值的函数很容易得到本次样本的平均值 得到本次样本均值为109.9 中位数:113 众数:116 2.频数分析 2.1频数分布直方图 柱状图是以柱的高度来指代某种类型的频数,使用Matplotlib对成绩这一定性变量绘制柱状图的代码如下:
Python数据分析与展示教学大纲 课程概述 本课程面向各类编程学习者,讲解利用Python语言表达N维数据并结合数据特点合理展示数据的技术和方法,帮助学习者掌握表示、清洗、统计和展示数据的能力。 本课程介绍Python计算生态中最优秀的数据分析和展示技术,所讲授内容是数据领域最优秀的编程模块,在理学、工程、信息、管理、经济等学科领域具有极其广泛的应用潜力。 本课程共包括内容: (1)Python第三方库NumPy,讲解N维数据的表达及科学计算的基本概念和运算方法; (2)Python第三方库Matplotlib,讲解绘制坐标系、散点图、极坐标图等直观展示数据趋势和特点的方法; (3)Python第三方库Pandas,强大的专业级数据分析和处理第三方库,介绍并讲解Series和DataFrame数据类型的表示和基本使用。 该课程希望传递“理解和运用计算生态,培养集成创新思维”的理念,重点培养学习者运用当代最优秀第三方专业资源,快速分析和解决问题的能力。 本课程是“Python网络爬虫与数据分析”课程的下半部分。“Python网络爬虫与数据分析”课程由“Python网络爬虫与信息提取”和“Python数据分析与展示”两门MOOC课程组成,完整地讲解了数据获取、清洗、统计、分析、可视化等数据处理周期的主要技术内容,培养计算思维、数据思维及采用程序设计方法解决计算问题的实战能力技术。 课程大纲 01 【第〇周】数据分析之前奏 课时 “数据分析”课程内容导学 Python语言开发工具选择
Anaconda IDE的基本使用方法 02 【第一周】数据分析之表示 课时 本周课程导学 单元1:NumPy库入门 单元2:NumPy数据存取与函数 单元3:实例1:图像的手绘效果 03 【第二周】数据分析之展示 课时 本周课程导学 单元4:Matplotlib库入门 单元5:Matplotlib基础绘图函数示例(5个实例) 单元6:实例2:引力波的绘制 04 【第三周】数据分析之概要 课时 本周课程导学 单元7:Pandas库入门 单元8:Pandas数据特征分析 预备知识 本课程需要学习者具备Python语言编程的基本知识和初步技能 参考资料 [1] Python零基础入门教程:《Python语言程序设计基础(第2版)》,嵩天、礼欣、黄天羽著,高等教育出版社,2017.2 [2] 专题参考资料:《利用Python进行数据分析》,Wes McKinney著,O’Reilly & 机械工业出版社,2014.1(该书使用Python 2.x系列,内容略微陈旧,仅做参考,不建议跟踪学习)
大数据可视化分析平台 一、背景与目标 基于邳州市电子政务建设的基础支撑环境,以基础信息资源库(人口库、法人库、宏观经济、地理库)为基础,建设融合业务展示系统,提供综合信息查询展示、信息简报呈现、数据分析、数据开放等资源服务应用。实现市府领导及相关委办的融合数据资源视角,实现数据信息资源融合服务与创新服务,通过系统达到及时了解本市发展的综合情况,及时掌握发展动态,为政策拟定提供依据。 充分运用云计算、大数据等信息技术,建设融合分析平台、展示平台,整合现有数据资源,结合政务大数据的分析能力与业务编排展示能力,以人口、法人、地理,人口与地理,法人与地理,实现基础展示与分析,融合公安、交通、工业、教育、旅游等重点行业的数据综合分析,为城市管理、产业升级、民生保障提供有效支撑。 二、政务大数据平台 1、数据采集和交换需求:通过对各个委办局的指定业务数据进行汇聚,将分散的数据进行物理集中和整合管理,为实现对数据的分析提供数据支撑。将为跨机构的各类业务系统之间的业务协同,提供统一和集中的数据交互共享服务。包括数据交换、共享和ETL 等功能。 2、海量数据存储管理需求:大数据平台从各个委办局的业务系统里抽取的数据量巨大,数据类型繁杂,数据需要持久化的存储和访问。不论是结构化数据、半结构化数据,还是非结构化数据,经过数据存储引擎进行建模后,持久化保存在存储系统上。存储系统要具备高可靠性、快速查询能力。 3、数据计算分析需求:包括海量数据的离线计算能力、高效即
席数据查询需求和低时延的实时计算能力。随着数据量的不断增加,需要数据平台具备线性扩展能力和强大的分析能力,支撑不断增长的数据量,满足未来政务各类业务工作的发展需要,确保业务系统的不间断且有效地工作。 4、数据关联集中需求:对集中存储在数据管理平台的数据,通过正确的技术手段将这些离散的数据进行数据关联,即:通过分析数据间的业务关系,建立关键数据之间的关联关系,将离散的数据串联起来形成能表达更多含义信息集合,以形成基础库、业务库、知识库等数据集。 5、应用开发需求:依靠集中数据集,快速开发创新应用,支撑实际分析业务需要。 6、大数据分析挖掘需求:通过对海量的政务业务大数据进行分析与挖掘,辅助政务决策,提供资源配置分析优化等辅助决策功能,促进民生的发展。
工程大数据分析平台 随着大数据时代来临、无人驾驶和车联网的快速发展,汽车研发部门需要处理的数据量激增、数据类型不断扩展。相关数据涵盖车内高频CAN 数据和车外ADAS 视频非结构化数据、位置地理空间数据、车辆运营数据、用户CRM 数据、WEB 数据、APP 数据、和MES 数据等。 在此背景下,整车厂研发部门关心的是:如何将企业内部的研发、实验、测试、生产数据,社会用户的用车数据,互联网第三方数据等结合起来,将异构数据和同构数据整合到一起,并在此基础上,实现业务系统、分析系统和服务系统的一体化;怎样利用深度的驾驶员行为感知、智能的车辆预防性维护、与实时的环境状态交互,通过大数据与机器学习技术,建立面向业务服务与产品持续优化的车联网智能分析;最终利用数据来为产品研发、生产、销售、售后提供精准的智能决策支撑。这些都是整车厂在大数据时代下亟待解决的问题。 针对这一需求,恒润科技探索出以EXCEEDDATA 大数据分析平台为核心的汽车工程大数据整体解决方案。借助EXCEEDDATA 大数据分析平台,企业可以集成、处理、分析、以及可视化海量级别的数据,可实现对原始数据的高效利用,并将原始数据转化成产品所需的智能,从而改进业务流程、实现智慧决策的产业升级。 产品介绍: ●先进的技术架构 EXCEEDDATA 采用分布式架构、包含集成处理(ETL)与分析挖掘两大产品功能体系,共支持超过20 多个企业常见传统数据库和大数据源系统,超过50 多个分析处理算法、以及超过丰富的可视化智能展现库。用户可以自主的、灵活的将各种来源的原始数据与分析处
理串联应用,建立科学的数据模型,得出预测结果并配以互动的可视化智能,快速高效的将大数据智能实现至业务应用中。 平台包括分布式大数据分析引擎、智能终端展示、以及API。大数据分析引擎为MPP 架构,建立在开源的Apache Hadoop 与Apache Spark 之上,可简易的scale-out 扩展。在分析引擎的基础上包含数据源库、数据转换匹配器、数据处理操作库、机器学习算法库、可视化图形库等子模块。智能终端展示为行业通用的B/S 架构,用户通过支持跨操作系统和浏览器的HTML5/JS 界面与API 来与平台互动。
《大数据分析与挖掘》课程教学大纲 一、课程基本信息 课程代码:16054103 课程名称:大数据分析与挖掘 英文名称:Big data analysis and mining 课程类别:专业选修课 学时:48(理论课:32, 实验课:16) 学 分:3 适用对象: 软件工程专业、计算机科学与技术 考核方式:考查 先修课程:多媒体技术、程序设计、软件工程 二、课程简介 本课程从大数据挖掘分析技术实战的角度,结合理论和实践,全方位地介绍基于Python语言的大数据挖掘算法的原理与使用。本课程涉及的主题包括基础篇和实战篇两部分, 其中基础篇包括:数据挖掘基础,Python数据分析简介,数据探索,数据预处理和挖掘建模;实战篇包括:电力窃漏电用户自动识别,航空公司客户价值分析,中医证型关联规则挖掘,基于水色图像的水质评价,家用电器用户行为分析与事件识别,应用系统负载分析与磁盘容量预测和电子商务网站用户行为分析及服务推荐。 本课程不是一个泛泛的理论性、概念性的介绍课程,而是针对问题讨论基于Python语言机器学习模型解决方案的深入课程。教师对于上述领域有深入的理论研究与实践经验,在课程中将会针对这些问题与学员一起进行研究,在关键点上还会搭建实验环境进行实践研究,以加深对于这些解决方案的理解。通过本课程学习,目的是让学生能够扎实地掌握大数据分析挖掘的理论与应用。 This course introduces the principle and application of big data mining algorithm based on Python language comprehensively from the perspective of big data mining analysis technology practice, combining theory and practice. This course covers two parts, the basic part and the practical part. The basic part includes: basic data mining, introduction to Python data analysis, data exploration, data preprocessing and mining modeling. Practical article included: electric power leakage automatic identification of the user, airlines customer value analysis, TCM syndrome association rule mining, based on water quality evaluation of color image, household electrical appliances
python数据分析过程示例
引言 几年后发生了。在使用SAS工作超过5年后,我决定走出自己的舒适区。作为一个数据科学家,我寻找其他有用的工具的旅程开始了!幸运的是,没过多久我就决定,Python作为我的开胃菜。 我总是有一个编写代码的倾向。这次我做的是我真正喜欢的。代码。原来,写代码是如此容易! 我一周内学会了Python基础。并且,从那时起,我不仅深度探索了这门语言,而且也帮助了许多人学习这门语言。Python是一种通用语言。但是,多年来,具有强大的社区支持,这一语言已经有了专门的数据分析和预测模型库。 由于Python缺乏数据科学的资源,我决定写这篇教程来帮助别人更快地学习Python。在本教程中,我们将讲授一点关于如何使用Python 进行数据分析的信息,咀嚼它,直到我们觉得舒适并可以自己去实践。
目录 1. 数据分析的Python基础 o为什么学Python用来数据分析o Python 2.7 v/s 3.4 o怎样安装Python o在Python上运行一些简单程序2. Python的库和数据结构 o Python的数据结构 o Python的迭代和条件结构
o Python库 3. 在Python中使用Pandas进行探索性分析 o序列和数据框的简介 o分析Vidhya数据集——贷款的预测问题 4. 在Python中使用Pandas进行数据再加工 5. 使用Python中建立预测模型 o逻辑回归 o决策树 o随机森林 让我们开始吧 1.数据分析的Python基础 为什么学Python用来数据分析 很多人都有兴趣选择Python作为数据分析语言。这一段时间以来,我有比较过SAS和R。这里有一些原因来支持学习Python:
实训:Python数据分析 〖实训目的〗 了解Python基本编程语法,掌握Python进行数据载入、预处理、分析和可视化的方法。 〖实训内容与步骤〗 1.在Python中导入数据 (1)读取CSV文件 CSV文件是由由逗号分割字段构成的数据记录型文件。我们可以方便地把 EXCEL中的电子表格存储为CSV文件。例如,我们有一份CSV 数据是英国近些年的降雨量统计数据,可以从以下网址找https://https://www.doczj.com/doc/a914180933.html,/dataset/average-temperature-and-rainfall-england-and- source/3fea0f7b-5304-4f11-a809-159f4558e7da) 从EXCEL中看到的数据如下图2-53所示: 图2-53 读取CSV文件 如果这个文件被保存在以下位置: D:\data\uk_rain_2014.csv 我们可以在Python中利用Pandas库将它导入: >>>import pandas as pd >>>df = pd.read_csv('d:\\data\\uk_rain_2014.csv', header=0) 这里需要注意的是,因为windows下用于分割目录的“\”符号在Python中被用于转义符(转义符就是用来输入特殊符号的引导符号,例如\n是回车,\r是换行等),因此“\”本身在Python语言中需要通过“\\”来输入。 以上两行程序就将这个csv文件导入成pandas中的一种类型为Dataframe的对象中,并给这个对象起名为df。
为了验证我们确实导入了这个数据文件,我们可以把df的内容打印出来:>>>print df Water Year Rain (mm) Oct-Sep Outflow (m3/s) Oct-Sep Rain (mm) Dec-Feb \ 0 1980/81 1182 5408 292 1 1981/8 2 1098 5112 257 2 1982/8 3 1156 5701 330 3 1983/8 4 993 426 5 391 4 1984/8 5 1182 5364 217 5 1985/8 6 102 7 4991 304 6 1986/8 7 1151 5196 295 7 1987/88 1210 5572 343 8 1988/89 976 4330 309 9 1989/90 1130 4973 470 10 1990/91 1022 4418 305 11 1991/92 1151 4506 246 121992/93 1130 5246 308 (2)读取EXCEL文件 因为EXCEL文件本身可以方便地另存为CSV文件,所以把EXCEL文件导入Python的一种办法就是将EXCEL中的数据表另存为CSV文件,然后利用上一节的方法将CSV导入Python。 当然,Pandas也提供了直接读取EXCEL文件的方法。同样,如果相应的EXCEL 文件放在D:\data\uk_rain_2014.xlsx,我们同样可以在Python中利用Pandas库将它导入: >>>import pandas as pd >>>df = pd.read_excel('d:\\data\\uk_rain_2014.xlsx') 同样,我们也可以把df的内容打印出来作为验证。 将数据导入Python之后,我们就可以对数据进行分析了。但在数据量很大的时候,我们往往需要从数据中提取和筛选出一部分数据来进行针对性的分析。 2.数据提取和筛选 仍然针对上面导入的英国天气数据,由于数据有很多行,我们希望只看到数据的前5行: >>> df.head(5) Water Year Rain (mm) Oct-Sep Outflow (m3/s) Oct-Sep Rain (mm) Dec-Feb \
《Python数据分析与应用》教学大纲课程名称:Python数据分析与应用 课程类别:必修 适用专业:大数据技术类相关专业 总学时:64学时(其中理论36学时,实验28学时) 总学分:4.0学分 一、课程的性质 大数据时代已经到来,在商业、经济及其他领域中基于数据和分析去发现问题并做出科学、客观的决策越来越重要。数据分析技术将帮助企业用户在合理时间内获取、管理、处理以及整理海量数据,为企业经营决策提供积极的帮助。数据分析作为一门前沿技术,广泛应用于物联网、云计算、移动互联网等战略新兴产业。有实践经验的数据分析人才已经成为了各企业争夺的热门。为了推动我国大数据,云计算,人工智能行业的发展,满足日益增长的数据分析人才需求,特开设Python数据分析与应用课程。 二、课程的任务 通过本课程的学习,使学生学会使用Python进行科学计算、可视化绘图、数据处理,分析与建模,并详细拆解学习聚类、回归、分类三个企业案例,将理论与实践相结合,为将来从事数据分析挖掘研究、工作奠定基础。 三、课程学时分配
四、教学内容及学时安排 1.理论教学
2.实验教学
五、考核方式 突出学生解决实际问题的能力,加强过程性考核。课程考核的成绩构成= 平时作业(10%)+ 课堂参与(20%)+ 期末考核(70%),期末考试建议采用开卷形式,试题应包括基本概念、绘图、分组聚合、数据合并、数据清洗、数据变换、模型构建等部分,题型可采用判断题、选择、简答、应用题等方式。 六、教材与参考资料 1.教材 黄红梅,张良均.Python数据分析与应用[M].北京:人民邮电出版社.2018. 2.参考资料
Python数据可视化实战第1期
法律声明 【声明】本视频和幻灯片为炼数成金网络课程的教学资料,所有资料只能在课程内使用,不得在课程以外范围散播,违者将可能被追究法律和经济责任。 课程详情访问炼数成金培训网站 https://www.doczj.com/doc/a914180933.html,
Python数据可视化实战—课程概要 1. Python基本绘图 2. Python简单图形绘制 3. 常见图形绘制 4. 完善统计图形 5. Python高级绘图一之图形样式 6. Python高级绘图二之实现多张图并存 7. Python高级绘图三实现共享坐标轴 8. Python精美制图一之ggplot 9. Python精美制图二之seaborn 10. Python精美制图三之pyecharts
第一章Python基本绘图 ? 1.1 Python绘图常用库介绍? 1.2 相关参数 ? 1.3 简单案例实践
1.1 Python绘图常用库介绍 matplotlib作为Python的基本绘图库,是Python中应用最广泛的绘图工具包之一,matplotlib能和其他很多库结合,如pandas等 ?Matplotlib库 matplotlib作为Python的基本绘图库,是Python中应用最广泛的绘图工具包之一,matplotlib能和其他很多库结合,如pandas等 ?其他库 包括ggplot2和seaborn,还有pyecharts库等都是第三方绘图库,可以优化Python图形,使得Python数据可视化结果更加美观
matplotlib.plot是最常见的绘图的模块,语法如下: plt.plot(x,y,ls=,lw=,c=,marker=,markersize=,markeredgecolor=,markerfacecolor, label=) x: x轴上的数值 y: y轴上的数值 ls: 折线的风格(‘-‘, ’--‘, ’-.‘和':‘) lw: 线条宽度 c: 颜色 marker: 线条上点的形状 markersize: 线条上点的大小 markeredgecolor: 点的边框色 markerfacecolor: 点的填充色 label: 文本标签
Python数据挖掘与机器学习实战—选题大纲(一组一章,第一章除外)
或从下列选题中选择:(除第1讲) 选题名称内容结构内容要求 第1讲 机器学习与Python库(该讲不可选)解释器Python3.6与IDE:Anaconda/Pycharm 1.Python基础:列表/元组/字典/类/文件 2.numpy/scipy/matplotlib/panda 的介绍和典型使用 3.多元高斯分布 4.典型图像处理 5.scikit-learn的介绍和典型使用 6.多种数学曲线 7.多项式拟合 8.快速傅里叶变换FFT 9.奇异值分解SVD 10.Soble/Prewitt/Laplacian算子 与卷积网络 代码和案例实践 1.卷积与(指数)移动平均线 2.股票数据分析 3.实际生产问题中算法和特征的关系 4.缺失数据的处理 5.环境数据异常检测和分析 第2讲回归线性回归 1.Logistic/Softmax回归 2.广义线性回归 3.L1/L2正则化 4.Ridge与LASSO 5.Elastic Net 6.梯度下降算法:BGD与SGD 7.特征选择与过拟合 8.Softmax回归的概念源头 9.最大熵模型 10.K-L散度 代码和案例实践 1.股票数据的特征提取和应用 2.泰坦尼克号乘客缺失数据处理和存活率 预测 3.环境检测数据异常分析和预测 4.模糊数据查询和数据校正方法 5.PCA与鸢尾花数据分类 6.二手车数据特征选择与算法模型比较 7.广告投入与销售额回归分析 8.鸢尾花数据集的分类
第3讲 决策树和随机森林熵、联合熵、条件熵、KL散度、互信息 1.最大似然估计与最大熵模型 2.ID3、C4.5、CART详解 3.决策树的正则化 4.预剪枝和后剪枝 5.Bagging 6.随机森林 7.不平衡数据集的处理 8.利用随机森林做特征选择 9.使用随机森林计算样本相似度 10.异常值检测 代码和案例实践 1.随机森林与特征选择 2.决策树应用于回归 3.多标记的决策树回归 4.决策树和随机森林的可视化 5.社会学人群收入预测 6.葡萄酒数据集的决策树/随机森林分类 7.泰坦尼克乘客存活率估计 第4讲SVM 线性可分支持向量机 1.软间隔 2.损失函数的理解 3.核函数的原理和选择 4.SMO算法 5.支持向量回归SVR 6.多分类SVM 代码和案例实践: 1.原始数据和特征提取 2.调用开源库函数完成SVM 3.葡萄酒数据分类 4.数字图像的手写体识别 5.MNIST手写体识别 6.SVR用于时间序列曲线预测 7.SVM、Logistic回归、随机森林三者的 横向比较 第5讲聚类各种相似度度量及其相互关系 1.Jaccard相似度和准确率、召回率 2.Pearson相关系数与余弦相似度 3.K-means与K-Medoids及变种 4.AP算法(Sci07)/LPA算法及其应用 5.密度聚类DBSCAN/DensityPeak(Sci14) 6.谱聚类SC 7.聚类评价和结果指标 代码和案例实践: 1.K-Means++算法原理和实现 2.向量量化VQ及图像近似 3.并查集的实践应用 4.密度聚类的异常值检测 5.谱聚类用于图片分割 第6讲 隐马尔科夫模型 HMM 主题模型LDA 1.词潜入和word2vec 2.前向/后向算法 3.HMM的参数学习 4.Baum-Welch算法详解 5.Viterbi算法详解 6.隐马尔科夫模型的应用优劣比较 7.共轭先验分布 https://www.doczj.com/doc/a914180933.html,place平滑 9.Gibbs采样详解 代码和案例实践: 1.敏感话题分析 2.网络爬虫的原理和代码实现 3.LDA开源包的使用和过程分析 4.HMM用于中文分词
本文由我司收集整编,推荐下载,如有疑问,请与我司联系 python数据分析与挖掘实战 2018/03/29 11 第六章分别使用了LM神经网络和CART 决策树构建了电力窃漏电用户自动识别模型,章末提出了拓展思考--偷漏税用户识别。 ?第六章及拓展思考完整代码https://github/dengsiying/Electric_leakage_users_automatic_identify.git ?项目要求:汽车销售行业在税收上存在多种偷漏税情况导致政府损失大量税收。汽车销售企业的部分经营指标能在一定程度上评估企业的偷漏税倾向,附件数据提供了汽车销售行业纳税人的各个属性和是否偷漏税标识,请结合各个属性,总结衡量纳税人的经营特征,建立偷漏税行为识别模型。 ?项目步骤: ?数据初步探索分析数据预处理模型选择与建立模型比较1.数据初步探索分析?一共124个样本,16个属性。 ?先用Excel看下不同销售类型和销售模式下的输出频率分布。 ? ?图1 不同销售类型下的偷漏税频率分布? ?图2 不同销售模式下的偷漏税频率分布?可以看到所有销售类型和销售模式都有异常偷漏税情况,由图1可以看出来国产轿车异常数最高,但是与正常数相比,可以明显看出来大客车的异常数远高于正常数,说明大客车更多的存在偷漏税情况。同样由图2可以看出来一级代理商、二级及二级以下代理商的更多的多的存在偷漏税情况。 ?接下来用python进行分析。分异常和正常两类看下数值型经营指标。 ?datafile = ‘Taxevasion identification.xls’df = pd.read_excel(datafile)#print(data.describe().T)df_normal = df.iloc[:,3:16][df[u”输出”]==“正常”]df_abnormal=df.iloc[:,3:16][df[u’输出’]==‘异 常’]df_normal.describe().T.to_excel(‘normal.xls’)df_abnormal.describe().T.to_excel(‘abn
常用Python数据分析工具汇总 Python是数据处理常用工具,可以处理数量级从几K至几T不等的数据,具有较高的开发效率和可维护性,还具有较强的通用性和跨平台性。Python可用于数据分析,但其单纯依赖Python本身自带的库进行数据分析还是具有一定的局限性的,需要安装第三方扩展库来增强分析和挖掘能力。 Python数据分析需要安装的第三方扩展库有:Numpy、Pandas、SciPy、Matplotlib、Scikit-Learn、Keras、Gensim、Scrapy等,以下是对该第三方扩展库的简要介绍: 1. Numpy Python没有提供数组功能,Numpy可以提供数组支持以及相应的高效处理函数,是Python数据分析的基础,也是SciPy、Pandas等数据处理和科学计算库最基本的函数功能库,且其数据类型对Python数据分析十分有用。 2. Pandas Pandas是Python强大、灵活的数据分析和探索工具,包含Series、DataFrame 等高级数据结构和工具,安装Pandas可使Python中处理数据非常快速和简单。 3. SciPy SciPy是一组专门解决科学计算中各种标准问题域的包的集合,包含的功能有最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算等,这些对数据分析和挖掘十分有用。 4. Matplotlib
Matplotlib是强大的数据可视化工具和作图库,是主要用于绘制数据图表的Python库,提供了绘制各类可视化图形的命令字库、简单的接口,可以方便用户轻松掌握图形的格式,绘制各类可视化图形。 5. Scikit-Learn Scikit-Learn是Python常用的机器学习工具包,提供了完善的机器学习工具箱,支持数据预处理、分类、回归、聚类、预测和模型分析等强大机器学习库,其依赖于Numpy、Scipy和Matplotlib等。 6. Keras Keras是深度学习库,人工神经网络和深度学习模型,基于Theano之上,依赖于Numpy和Scipy,利用它可以搭建普通的神经网络和各种深度学习模型,如语言处理、图像识别、自编码器、循环神经网络、递归审计网络、卷积神经网络等。 7. Gensim Gensim是用来做文本主题模型的库,常用于处理语言方面的任务,支持TF-IDF、LSA、LDA和Word2Vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算、信息检索等一些常用任务的API接口。 8. Scrapy Scrapy是专门为爬虫而生的工具,具有URL读取、HTML解析、存储数据等功能,可以使用Twisted异步网络库来处理网络通讯,架构清晰,且包含了各种中间件接口,可以灵活的完成各种需求。 以上是对Python数据分析常用工具的简单介绍,有兴趣的可以深入学习研究一下相关使用方法!
python数据分析学习方法 数据分析是大数据的重要组成部分,在越来越多的工作中都扮演着重要的角色,Python可以利用各种Python库,如NumPy、pandas、matplotlib以及IPython 等,高效的解决各式各样的数据分析问题,那么该如何学习Python数据分析呢? 大数据作为一门新兴技术,大数据系统还不完善,市场上存在的资料也很零散,只有少数大数据资深技术专家才掌握真正的大数据技术,老男孩教育徐培成老师拥有丰富的大数据实践经验,掌握大数据核心技术,大数据实战课程体系完善,能够让学员学到真本领! 老男孩教育Python与数据分析内容: 1. Python介绍、Python环境安装、Python体验 2. Python基础、语法、数据类型、分支、循环、判断、函数 3. Python oop、多线程、io、socket、模块、包、导入控制 4. Python正则表达式、Python爬虫实现 5. 行列式基础、转置、矩阵定义、矩阵运算、逆矩阵、矩阵分解、矩阵变换、矩阵的秩 6. Python对常用矩阵算法实现 7. Python常用算法库原理与使用、numpy、pandas、sklearn 8. 数据加载、存储、格式处理 9. 数据规整化、绘图与可视化 Python与数据分析是老男孩教育大数据开发课程的一部分,除此之外,老男孩教育大数据开发课程还包括:Java、Linux、Hadoop、Hive、Avro与Protobuf、
ZooKeeper、HBase、Phoenix、Flume、SSM、Kafka、Scala、Spark、azkaban等,如此全面的知识与技能,你还在等什么?赶紧报名学习吧!
国内哪些做大数据决策分析平台或公司比较有优势? 大数据类的公司1、大数据决策平台,帆软。帆软是商业智能和数据分析平台提供商,从报表工具到商业智能BI,有十多年的数据应用的底子,在这个领域很成熟,但是很低调。像帆软的FineBI,可以部署自带的FineIndex(类cube,数据仓库),有数据缓存机制,可实现定量更新,定时更新,减少了数据仓库的建设维护。还有FineDirect(直连)可直接连接数据仓库或数据库,主要针对Hadoop一类的大数据平台和实时数据分析的需求。2、数据库,大数据平台类,星环,做Hadoop生态系列的大数据底层平台公司。Hadoop 是开源的,星环主要做的是把Hadoop不稳定的部分优化,功能细化,为企业提供Hadoop大数据引擎及数据库工具。 3、云计算,云端大数据类,阿里巴巴,明星产品-阿里云,与亚马逊AWS抗衡,做公有云、私有云、混合云。实力不差,符合阿里巴巴的气质,很有野心。 4、大数据存储硬件类,浪潮,很老牌的IT公司,国资委控股,研究大数据方面的存储,在国内比较领先。BI Hadoop的案例Hadoop是个很流行的分布式计算解决方案,是Apache的一个开源项目名称,核心部分包括HDFS及MapReduce。其中,HDFS 是分布式文件系统,MapReduce是分布式计算引擎。时至今日,Hadoop在技术上已经得到验证、认可甚至到了成熟
期,同时也衍生出了一个庞大的生态圈,比较知名的包括HBase、Hive、Spark等。HBase是基于HDFS的分布式列式数据库,HIVE是一个基于HBase数据仓库系统。Impala 为存储在HDFS和HBase中的数据提供了实时SQL查询功能,基于HIVE服务,并可共享HIVE的元数据。Spark是一个类似MapReduce的并行计算框架,也提供了类似的HIVE的Spark SQL查询接口,Hive是基于hadoop的数据分析工具。很多企业比如银行流水作业很多,数据都是实时更新且数据量很大。会采用hadoop作为底层数据库,借由中间商处理底层数据,然后通过BI系统去连接这些中间数据处理厂商的中间表,接入处理数据,尤其以星环、华为这类hadoop大数据平台商居多,使用也较为广泛。以星环大数据帆软大数据BI工具FineBI的结合为例。由于星环也是处理hadoop下的hive数据库,其本质都是差不多的,可以使用Hive提供的jdbc驱动,这个驱动同样可以让FineBI连接星环的数据库并进行一些类关系型数据库的sql语句查询等操作。将这些驱动拷贝到BI工程下面,然后重启BI服务器。重启后可以建立与星环数据库的数据连接,最后通过连接进行数据查询。关于FineBI的FineIndex和FineDirect功能hadoop是底层,hive是数据库,上述案例采用的是FineIndex (cube连)连接,用的是hiveserver的方式进行数据连接的;数据连接成功之后,将hive数据库中的表添加到业务包
大数据分析平台技术要求 1.技术构架需求 采用平台化策略,全面建立先进、安全、可靠、灵活、方便扩展、便于部署、操作简单、易于维护、互联互通、信息共享的软件。 技术构架的基本要求: ?采用多层体系结构,应用软件系统具有相对的独立性,不依赖任何特定的操作系统、特定的数据库系统、特定的中间件应用服务器和特定的硬 件环境,便于系统今后的在不同的系统平台、不同的硬件环境下安装、 部署、升级移植,保证系统具有一定的可伸缩性和可扩展性。 ?实现B(浏览器)/A(应用服务器)/D(数据库服务器)应用模式。 ?采用平台化和构件化技术,实现系统能够根据需要方便地进行扩展。 ?
2. 功能指标需求 2.1基础平台 本项目的基础平台包括:元数据管理平台、数据交换平台、应用支撑平台。按照SOA的体系架构,实现对XX数据资源中心的服务化、构件化、定制化管理。 2.1.1元数据管理平台 根据XX的业务需求,制定统一的技术元数据和业务元数据标准,覆盖多种来源统计数据采集、加工、清洗、加载、多维生成、分析利用、发布、归档等各个环节,建立相应的管理维护机制,梳理并加载各种元数据。 具体实施内容包括: ●根据业务特点,制定元数据标准,要满足元数据在口径、分类等方面的 历史变化。 ●支持对元数据的管理,包括:定义、添加、删除、查询和修改等操作, 支持对派生元数据的管理,如派生指标、代码重新组合等,对元数据管 理实行权限控制。 ●通过元数据,实现对各类业务数据的统一管理和利用,包括: ?基础数据管理:建立各类业务数据与元数据的映射关系,实现统一 的数据查询、处理、报表管理。 ?ETL:通过元数据获取ETL规则的描述信息,包括字段映射、数据转 换、数据转换、数据清洗、数据加载规则以及错误处理等。
基于工业互联网的大数据分析平台钢结构制造全过程成本分析与工艺优化 引言:中建钢构广东有限公司是国家高新技术企业,是中国最大的钢结构产业集团——中建钢构有限公司的隶属子公司,年加工钢结构能力20 万吨,是国内制造特级的大型钢结构企业,是国内首批取得国内外双认证(欧标、美标)的钢结构企业。中建钢构具有行业领先的建筑信息化、智能化产品,自主研发了国际领先的钢结构全生命周期管理平台,开发了ERP、设备能像管理系统、库存管理系统等信息系统,搭建了基于工业互联网的大数据分析管理平台。同时,公司正实施建设全球首条钢结构智能制造生产线,实现涵盖切割、分拣、搬运、焊接、仓储、物流、信息化的智能化生产。该产线获批成为2017 年国家工信部智能制造新模式应用项目,并被科技部立项作为国家“十三五”重点课题。中建钢构广东有限公司率先践行“中国制造2025”,成为国内装配式建筑领域首个智能化工厂,并获得2018 年广东省工程技术研发中心、2018 年广东省两化融合试点企业;2018 年广东省级企业技术中心;2017 年广东省智能制造试点示范项目;2017 年广东省制造业与互联网融合试点示范。
目录 案例 1 (1) 一、项目概况 (3) 1.项目背景 (3) 2.项目简介 (3) 3.项目目标 (4) 二、项目实施概况 (5) 1. 项目总体架构和主要内容 (5) 1)总体功能架构 (5) 2)建设内容详细介绍 (5) 三、下一步实施计划 (18) 1.平台覆盖范围扩大与共享应用细化 (18) 2.项目经验总结与成果转化 (19) 四、项目创新点和实施效果 (19) 1.项目先进性及创新点 (19) 2.实施效果 (20)