03-fatahalian_gpuArchTeraflop_BPS_SIGGRAPH2010
- 格式:pdf
- 大小:2.85 MB
- 文档页数:72
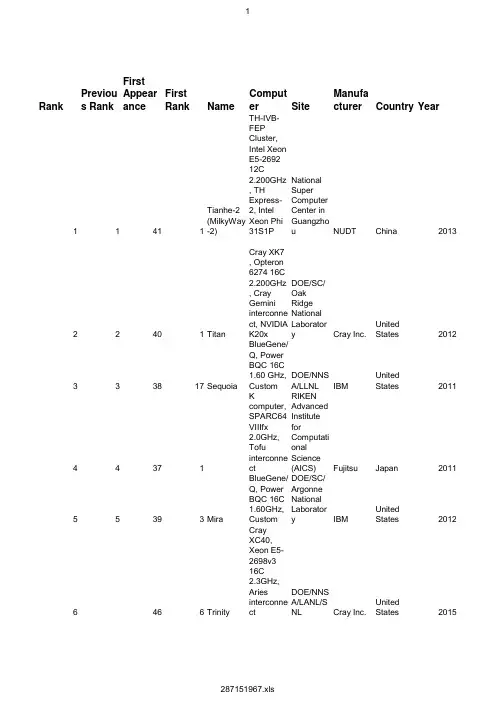
Rank Previous R First AppeaFirst Rank Name Computer Site Manufactu Country YearNUDT China2013 11411Tianhe-2 (MilkTH-IVB-FEP National Supe22401Titan Cray XK7 , O D OE/SC/Oak Cray Inc.United States2012 333817Sequoia BlueGene/Q, DOE/NNSA/L IBM United States2011Fujitsu Japan2011RIKEN Advan44371K computer, SIBM United States2012 55393Mira BlueGene/Q, DOE/SC/Argo6466Trinity Cray XC40, X DOE/NNSA/L Cray Inc.United States2015 7640114Piz Daint Cray XC30, X Swiss NationaCray Inc.Switzerland2012 8234416Hazel Hen Cray XC40, X HLRS - Höch Cray Inc.Germany2015 97457Shaheen II Cray XC40, X King Abdullah Cray Inc.Saudi Arabia2015 108407Stampede PowerEdge CTexas Advan Dell United States2012IBM Germany2012 119398JUQUEEN BlueGene/Q, Forschungsze12103948Vulcan BlueGene/Q, DOE/NNSA/L IBM United States2012 1311377Pleiades SGI ICE X, In NASA/Ames SGI United States2011Cray Inc.United States2015 14124512Abel Cray XC30, X Petroleum Ge15134513Cray CS-Stor Government Cray Inc.United States2015 16144410Cray CS-Stor Government Cray Inc.United States2014 17154464C01N SGI ICE X/Su Tulip Trading Supermicro/S Australia2014 18164516Topaz SGI ICE X, X E RDC DSRC SGI United States2015 19174311HPC2iDataPlex DX Exploration &IBM Italy2014Government Cray Inc.United States2014 20184310Cray XC30, In21194519Thunder SGI ICE X, X A ir Force Res SGI United States2015Information T Fujitsu Japan2015 224622Fujitsu PRIME2320394SuperMUC iDataPlex DX Leibniz RecheIBM/Lenovo Germany2012Lenovo/IBM Germany2015 24214521SuperMUC P IBM NeXtSca Leibniz Reche25224211TSUBAME 2.Cluster Platfo GSIC Center,NEC/HP Japan2013NUDT China2010 2624361Tianhe-1A NUDT YH MPNational Supe27254213cascade Atipa Visione DOE/SC/Paci Atipa Techno United States2013Cray Inc.United States2014 28264419Excalibur Cray XC40, X Army Researc294629Nuri Cray XC40, X Korea Meteor Cray Inc.Korea, South2015 304630Miri Cray XC40, X Korea Meteor Cray Inc.Korea, South2015 31274527Plasma Simu Fujitsu PRIMENational Instit Fujitsu Japan2015Dell Saudi Arabia2015 32284528Makman-2Dell PowerEd Saudi Aramco33294111Pangea SGI ICE X, X T otal Explora SGI France2013NUDT China2014 34304421Tianhe-2 LvLi Tianhe-2 LvLi LvLiang CloudT-Platforms Russia2014 353143129Lomonosov 2T-Platform A-Moscow State3632397Fermi BlueGene/Q, CINECA IBM Italy2012 37334533SwiftLucy Cluster Platfo Government Hewlett-Pack United States2015Cyfronet Hewlett-Pack Poland2015 38494549Prometheus HP Apollo 800DOE/SC/LBN Cray Inc.United States2014 39344318Edison Cray XC30, InEPSRC/UniveCray Inc.United Kingdo2014 40354219ARCHER Cray XC30, In414641Luna Cray XC40, X NOAA Cray Inc.United States2015 424642Surge Cray XC40, X NOAA Cray Inc.United States2015France2014Bull, Atos Gro 43364426Occigen bullx DLC, XeGrand EquipeIBM United States2013 44374217Power 775, P IBM DevelopmECMWF Cray Inc.United Kingdo2014 45394319Cray XC30, InECMWF Cray Inc.United Kingdo2014 46384320Cray XC30, In47404540Salomon SGI ICE X, X I T4Innovation SGI Czech Repub2015IBM United Kingdo2012 48413913Blue Joule BlueGene/Q, Science and TT-Platforms Germany2015 494649JURECA T-Platform V-Forschungsze50424069Spirit SGI ICE X, X A ir Force Res SGI United States2012 51434432Beskow Cray XC40, X KTH - Royal I Cray Inc.Sweden2014France2012Bull, Atos Gro 5244399Curie thin nodBullx B510, X CEA/TGCC-G53454545Gordon Cray XC40, X Navy DSRC Cray Inc.United States2015 54464546Conrad Cray XC40, X Navy DSRC Cray Inc.United States2015Lenovo/IBM Germany2013 55474231iDataPlex DX Max-Planck-GSugon China2010 5648352Nebulae Dawning TC3National SupeIBM United States2012 57504013Yellowstone iDataPlex DX NCAR (Nation585140118Sisu Cray XC40, X CSC (Center Cray Inc.Finland2014Japan2011Bull, Atos Gro 59523828Helios Bullx B510, X International FFujitsu Japan2015Japan Aerosp60534553SORA-MA Fujitsu PRIMESGI Japan2015University of T61544554Sekirei SGI ICE XA, X287151967.xlsSegmentTotal CoresAccelerato Rmax Rpeak Nmax Nhalf Power Mflops/Wa Architectur Research31200002736000338627005490240099600000178081901.54Cluster Research56064026163217590000271125500082092142.77MPP Research1572864017173224201326590078902176.58MPP Research7050240105100001128038411870208012659.89830.18Cluster Research78643208586612100663300039452176.58MPP Research301056081009001107886188479360MPP Research11598473808627100077888534128768023252697.2MPP Research18508805640170740352049737600MPP Academic1966080553699072351749738048028341953.77MPP Academic462462366366516811085201123875000045101145.92Cluster Research4587520500885758720260023012176.82MPP Research3932160429330650331650019722177.13MPP Research1853440408943049709105459520033801209.89Cluster Industry1459200404246053698568338176018002245.81MPP Government728006240035770006131840233600001498.92386.42Cluster Government728006240035770006131840233600001498.92386.42Cluster Industry26544017097635210004470408184780804499.87782.47Cluster Research12420003318950457056057792000Cluster Industry7200042000318800046050003978240012272598.21Cluster Government22598403143520488125425416840MPP Government152692270563126240561048155728000Cluster Academic9216002910000324403230617600Cluster Academic147456028970003185050520192003422.67846.42Cluster Academic86016028136203578266442368001480.831900.03Cluster Academic760325913627850005735685170000001398.611991.26Cluster Research18636810035225660004701000360000010000004040635.15MPP Research194616171720253913033880324032000013841834.63Cluster Government10006402485000368235564414080MPP Research6960002395680289536066612480MPP Research6960002395680289536066612480MPP Research8294402376000262103028604160Cluster Industry760320224968030412804460544011341983.84Cluster Industry110400020980902296320386252802118990.6Cluster Industry17472015321620713903074534236697609972077.62Cluster Academic37120192001849000257587222937600Cluster Academic16384001788878209715200821.882176.57MPP Government5760001703280230400034504320Cluster Academic55728216016700902348640543959208162046.68Cluster Research13382401654702256942100MPP Research11808001642536255052800MPP Research4896001635020203673639504000MPP Research4896001635020203673639504000MPP Academic5054401628770210263039744000934.81742.37Cluster Vendor62944015870001931625003575.63443.84MPP Research8316001552000179625643073520MPP Research8316001552000179625643073520MPP Academic76896527041457730201164128385280Cluster Research131072014311021677722006572178.24MPP Research49476426014247201693440400000045000010161402.28Cluster Government73584014154701530547312883201606881.36Cluster Academic5363201397000197365833672960MPP Research77184013590001667174575752802251603.73Cluster Government61256102481285600204960248384000MPP Government61256102481285600204960248384000MPP Research653200128331214631680012601018.5Cluster Research1206406496012710002984300235929602580492.64Cluster Research72288012576151503590001436.72875.34Cluster Academic40608012500001689293330144006801838.24MPP Academic70560012370001524096487015202200562.27Cluster Research4147201189000131051520329920Cluster Academic3801601178300152064031948800580.92028.4Cluster287151967.xlsProcessor Processor Processor Operating OS Family Accelerato Cores per SProcessor System Mo System Fam Intel Xeon E5Intel IvyBridge2200Kylin Linux Linux Intel Xeon Ph12Intel Xeon E5TH-IVB-FEP TH-IVB ClustLinux NVIDIA Tesla16Opteron 6200Cray XK7 Cray XK Opteron 6274AMD x86_642200Cray Linux EnPower BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenSPARC64 VII Sparc2000Linux Linux None8SPARC64 VII K computerFujitsu ClustePower BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenLinux None16Intel Xeon E5Cray XC40Cray XCXeon E5-2698Intel Haswell2300Cray Linux EnIntel SandyBr2600Cray Linux EnLinux NVIDIA Tesla8Intel Xeon E5Cray XC30Cray XCXeon E5-2670Linux None12Intel Xeon E5Cray XC40Cray XC Intel Haswell2500Cray Linux EnXeon E5-2680Linux None16Intel Xeon E5Cray XC40Cray XCXeon E5-2698Intel Haswell2300Cray Linux EnDell PowerEd Intel SandyBr2700Linux Linux Intel Xeon Ph8Intel Xeon E5PowerEdge CXeon E5-2680Power BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenPower BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenLinux None10Intel Xeon E5SGI ICE X SGI ICEIntel Xeon E5Intel IvyBridge2800SUSE Linux ELinux None16Intel Xeon E5Cray XC30Cray XCXeon E5-2698Intel Haswell2300Cray Linux EnIntel Xeon E5Intel IvyBridge2200Linux Linux NVIDIA Tesla10Intel Xeon E5Cray CS-Stor Cray CS-StorIntel Xeon E5Intel IvyBridge2200Linux Linux NVIDIA Tesla10Intel Xeon E5Cray CS-Stor Cray CS-StorSupermicro C Intel Xeon E5Intel IvyBridge2400CentOS Linux NDIVA M209012Intel Xeon E5SuperBlade SLinux None18Intel Xeon E5SGI ICE X SGI ICEXeon E5-2699Intel Haswell2300SUSE Linux EIntel Xeon E5Intel IvyBridge2800Linux Linux NVIDIA Tesla10Intel Xeon E5iDataPlex DX IBM iDataPlexLinux None12Intel Xeon E5Cray XC30Cray XCIntel Xeon E5Intel IvyBridge2700Cray Linux EnIntel Haswell2300SUSE Linux ELinux NVIDIA Tesla18Intel Xeon E5SGI ICE X SGI ICEXeon E5-2699Fujitsu PRIME SPARC64 XIf Sparc2200Linux Linux None32SPARC64 XIf Fujitsu PRIMEIntel SandyBr2700Linux Linux None8Intel Xeon E5iDataPlex DX IBM iDataPlex Xeon E5-2680Xeon E5-2697Intel Haswell2600Linux Linux None14Intel Xeon E5IBM NeXtSca IBM NeXtScaLinux NVIDIA Tesla6Xeon 5600-seCluster Platfo HP Cluster Pl Intel Nehalem2930SUSE Linux EXeon X5670 6NUDT MPPNUDT YH MPXeon X5670 6Intel Nehalem2930Linux Linux NVIDIA 20506Xeon 5600-seIntel SandyBr2600Linux Linux Intel Xeon Ph8Intel Xeon E5Atipa Visione Atipa Cluster Xeon E5-2670Linux None16Intel Xeon E5Cray XC40Cray XCXeon E5-2698Intel Haswell2300Cray Linux EnIntel Haswell2600Cray Linux EnLinux None12Intel Xeon E5Cray XC40Cray XCXeon E5-2690Linux None12Intel Xeon E5Cray XC40Cray XC Intel Haswell2600Cray Linux EnXeon E5-2690Fujitsu PRIME SPARC64 XIf Sparc1975Linux Linux None32SPARC64 XIf Fujitsu PRIMEXeon E5-2680Intel Haswell2500Redhat Enter Linux None12Intel Xeon E5Dell PowerEd Dell PowerEdLinux None8Intel Xeon E5SGI ICE X SGI ICE Intel SandyBr2600SUSE Linux EXeon E5-2670Intel Xeon E5Intel IvyBridge2200Kylin Linux Linux Intel Xeon Ph12Intel Xeon E5Tianhe-2 LvLi Tianhe-2 LvLiIntel Haswell2600Linux Linux NVIDIA Tesla14Intel Xeon E5T-Platform A-T-Platforms C Xeon E5-2697Power BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenIntel Haswell2500Linux Linux None12Intel Xeon E5Cluster Platfo HP Cluster Pl Xeon E5-2680HP Apollo Xeon E5-2680Intel Haswell2500Linux Linux NVIDIA Tesla12Intel Xeon E5HP Apollo 800Linux None12Intel Xeon E5Cray XC30Cray XCIntel Xeon E5Intel IvyBridge2400Cray Linux EnLinux None12Intel Xeon E5Cray XC30Cray XCIntel Xeon E5Intel IvyBridge2700Cray Linux EnLinux None12Intel Xeon E5Cray XC40Cray XCXeon E5-2690Intel Haswell2600Cray Linux EnIntel Haswell2600Cray Linux EnLinux None12Intel Xeon E5Cray XC40Cray XCXeon E5-2690Bull BullxXeon E5-2690Intel Haswell2600Redhat Enter Linux None12Intel Xeon E5bullx DLC 720POWER7 8C Power3836Linux Linux None8POWER7Power 775IBM pSeriesIntel Xeon E5Intel IvyBridge2700Cray Linux EnLinux None12Intel Xeon E5Cray XC30Cray XCLinux None12Intel Xeon E5Cray XC30Cray XCIntel Xeon E5Intel IvyBridge2700Cray Linux EnIntel Haswell2500CentOS Linux Intel Xeon Ph12Intel Xeon E5SGI ICE X SGI ICEXeon E5-2680Power BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenIntel Haswell2500CentOS Linux NVIDIA Tesla12Intel Xeon E5T-Platform V-T-Platforms C Xeon E5-2680Intel SandyBr2600Redhat Enter Linux None8Intel Xeon E5SGI ICE X SGI ICEXeon E5-2670Linux None16Intel Xeon E5Cray XC40Cray XC Intel Haswell2300Cray Linux EnXeon E5-2698Intel SandyBr2700bullx SUperC L inux None8Intel Xeon E5Bullx B510Bull BullxXeon E5-2680Linux Intel Xeon Ph16Intel Xeon E5Cray XC40Cray XCXeon E5-2698Intel Haswell2300Cray Linux EnIntel Haswell2300Cray Linux EnLinux Intel Xeon Ph16Intel Xeon E5Cray XC40Cray XCXeon E5-2698Intel Xeon E5Intel IvyBridge2800Linux Linux None10Intel Xeon E5iDataPlex DX IBM iDataPlexDawning TC3Dawning Clus Intel Nehalem2660Linux Linux NVIDIA 20506Xeon 5600-seXeon X5650 6Intel SandyBr2600Linux Linux None8Intel Xeon E5iDataPlex DX IBM iDataPlex Xeon E5-2670Linux None12Intel Xeon E5Cray XC40Cray XC Intel Haswell2600Cray Linux EnXeon E5-2690Intel SandyBr2700bullx SUperC L inux None8Intel Xeon E5Bullx B510Bull BullxXeon E5-2680Fujitsu PRIME SPARC64 XIf Sparc1975Linux Linux None32SPARC64 XIf Fujitsu PRIMELinux None12Intel Xeon E5SGI ICE XA SGI ICE Intel Haswell2500SUSE Linux EXeon E5-2680287151967.xlsInterconne Interconne Region Continent TH Express-2Eastern Asia A sia Custom IntercCray Gemini i North Americ Americas Custom IntercNorth Americ AmericasCustom IntercCustom IntercCustom IntercEastern Asia A sia Custom IntercNorth Americ AmericasCustom IntercCustom IntercAries intercon North Americ Americas Custom IntercCustom IntercEuropeAries intercon Western EuroEurope Custom IntercAries intercon Western EuroAries intercon Western Asia Asia Custom IntercInfiniband Infiniband FD North Americ AmericasEuropeWestern EuroCustom IntercCustom IntercNorth Americ Americas Custom IntercCustom IntercInfiniband Infiniband FD North Americ AmericasAries intercon North Americ Americas Custom IntercInfiniband Infiniband FD North Americ Americas Infiniband Infiniband FD North Americ Americas Infiniband Infiniband FD Australia and Oceania Infiniband Infiniband FD North Americ Americas Infiniband Infiniband FD Southern Eur EuropeAries intercon North Americ Americas Custom IntercInfiniband Infiniband FD North Americ Americas Proprietary N T ofu intercon Eastern Asia A siaEurope Infiniband Infiniband FD Western EuroEurope Infiniband Infiniband FD Western Euro Infiniband Infiniband QD Eastern Asia A sia Proprietary N P roprietary Eastern Asia A sia Infiniband Infiniband FD North Americ AmericasAries intercon North Americ Americas Custom IntercAries intercon Eastern Asia A sia Custom IntercAries intercon Eastern Asia A sia Custom IntercProprietary N T ofu intercon Eastern Asia A sia Infiniband Infiniband QD Western Asia AsiaEurope Infiniband Infiniband FD Western EuroCustom IntercEastern Asia A siaTH Express-2Europe Infiniband Infiniband FD Eastern EuropSouthern Eur EuropeCustom IntercCustom IntercInfiniband Infiniband FD North Americ AmericasEurope Infiniband Infiniband FD Eastern EuropAries intercon North Americ Americas Custom IntercEuropeAries intercon Northern EuroCustom IntercAries intercon North Americ Americas Custom IntercAries intercon North Americ Americas Custom IntercEurope Infiniband Infiniband FD Western EuroCustom IntercNorth Americ Americas Custom IntercEuropeAries intercon Northern EuroCustom IntercEuropeAries intercon Northern EuroCustom IntercEurope Infiniband Infiniband FD Eastern EuropNorthern EuroEurope Custom IntercCustom IntercEurope Infiniband Infiniband ED Western Euro Infiniband Infiniband FD North Americ AmericasEurope Custom IntercAries intercon Northern EuroEurope Infiniband Infiniband QD Western EuroAries intercon North Americ Americas Custom IntercAries intercon North Americ Americas Custom IntercEurope Infiniband Infiniband FD Western Euro Infiniband Infiniband QD Eastern Asia A sia Infiniband Infiniband FD North Americ AmericasAries intercon Northern EuroEurope Custom IntercInfiniband Infiniband QD Eastern Asia A sia Proprietary N T ofu intercon Eastern Asia A sia Infiniband Infiniband FD Eastern Asia A sia287151967.xls62553644Garnet Cray XE6, OpERDC DSRC Cray Inc.United States2010Germany2015Bull, Atos Gro63564556Mistral bullx DLC 720DKRZ - DeutsDOE/NNSA/L Cray Inc.United States2011 6457376Cielo Cray XE6, Op654665Lenovo Think Alibaba GRO L enovo China2015 664666Lenovo Think Alibaba GRO L enovo China2015 67584441Magnus Cray XC40, X Pawsey Supe Cray Inc.Australia2014 68594559Cartesius 2Bullx DLC B7SURFsara Bull, Atos GroNetherlands2015 69603929Turing BlueGene/Q, CNRS/IDRIS-IBM France2012IBM United Kingdo2012 70613920DiRAC BlueGene/Q, University of EDOE/SC/LBN Cray Inc.United States2010 7162365Hopper Cray XE6, Op72634446QB-2Dell C8220X Louisiana Op Dell United States2014France2010 7364366Tera-100Bull bullx sup Commissaria Bull, Atos GroInformation T Fujitsu Japan2012 74653918Oakleaf-FXPRIMEHPC F754675Lenovo Think Internet Servi Lenovo China2015Germany2015TU Dresden, Bull, Atos Gro76664566Taurus bullx DLC 720Japan2013Research Ins Hitachi/FujitsuHA8000-tc HT77674236QUARTETTO784678Lonestar 5Cray XC40, X Texas Advan Cray Inc.United States2015 794679Lenovo Think Service Provi Lenovo China2015 80684450Discover SCURackable Clu NASA/Godda SGI United States2014HLRN at ZIB/Cray Inc.Germany2014 816942121Konrad Cray XC40, In82704570HOKUSAI Gr Fujitsu PRIMEAdvanced Ce Fujitsu Japan2015Fujitsu Japan2015 83714571Fujitsu PRIMEMeteorologicaNational Com Fujitsu Australia2012 84724024Fujitsu PRIME85734128Conte Cluster Platfo Purdue Unive Hewlett-Pack United States2013 86744340Spruce A SGI ICE X, In AWE SGI United Kingdo2014 87754455Lightning Cray XC30, InAir Force Res Cray Inc.United States2014 884688Lenovo Think Service Provi Lenovo China2015 894689Lenovo Think Service Provi Lenovo China2015 90764456Piz Dora Cray XC40, X Swiss NationaCray Inc.Switzerland2014 91774036MareNostrum iDataPlex DX Barcelona Su IBM Spain2012Hewlett-Pack United States2015 924692Apollo 6000 XIT Provider (PT-Platforms Russia2011 93783713LomonosovT-Platforms T Moscow State94794579SERC Cray XC40, X Supercomput Cray Inc.India2015 958039102BlueGene/Q, Rensselaer P IBM United States2012Hewlett-Pack China2015Trading Comp964696HP DL360 CluCluster Platfo Intel Hewlett-Pack United States2015 97814581Intel SC D2P4HLRN at Univ Cray Inc.Germany2014 988342120Gottfried Cray XC40, In99844345Faris Cluster Platfo Saudi AramcoHewlett-Pack Saudi Arabia2014Cray Inc.Japan2014 100854163Aterui Cray XC40, X National AstroChina2011National Rese101863814Sunway Blue Sunway BlueLNational Supe102874587XStream Cray CS-Stor Stanford Res Cray Inc.United States2015SGI Japan2015 103884588Sekirei-ACC SGI ICE XA, XUniversity of TLawrence Liv Cray Inc.United States2011 104893815Zin Xtreme-X GreNUDT China2011National SupeNUDT YH MP105903816Tianhe-1A Hu106914349Spruce B SGI ICE X, In AWE SGI United Kingdo2014 1079235112Endeavor Intel Cluster, Intel Intel United States2011 10846108Lenovo Think Alibaba GRO L enovo China2015 10946109Lenovo Think Alibaba GRO L enovo China2015 11046110Lenovo Think Alibaba GRO L enovo China2015Cray CS300 1Center for Co Cray Inc.Japan2014 111934351COMA (PACSSGI ICE X, X N ational Instit SGI Japan2015 112944594Numerical MaDell United States2015 11346113HiperGator 2.PowerEdge CUniversity of F114954595Earth System S ugon Cluste LASG/Institut Sugon China2015 11546115Inspur TS100Internet Servi Inspur China2015Hewlett-Pack United States2013 11610841115Palmetto2HP SL250s G Clemson Univ117964136iDataPlex DX Indian Institut IBM India2013 1189739100Cetus BlueGene/Q, DOE/SC/ArgoIBM United States2012 119983930Zumbrota BlueGene/Q, EDF R&D IBM France2012 120994068BGQ BlueGene/Q, SOSCIP/LKS IBM Canada2012IBM Switzerland2013 1211004247EPFL Blue Br BlueGene/Q, Swiss Nationa1221013931Avoca BlueGene/Q, Victorian Life IBM Australia2012 1231024249iDataPlex DX Max-Planck-GLenovo/IBM Germany2013287151967.xlsResearch15052801167000150528056855040MPP Research3734401139240149376032348160Cluster Research142272011100001365811003980278.89MPP Industry8400001101600336000050200000Cluster Industry8400001101600336000050200000Cluster Research3571201097558148561931597440MPP Academic38880010885101327104308160007061541.8Cluster Academic98304010733271258291004932177.13MPP Academic9830401073327125829100493.122176.6MPP Research153408010540001288627453734402910362.2MPP Academic230401344010520001473600179916805002104Cluster Research138368010500001254550492633604590228.76Cluster Academic76800010430001135411405888001176.8886.3Cluster Industry10000001038400320000060000000Cluster Academic34656010299401386240277248006201661.19Cluster Academic2220721571281018000150223637090560Cluster Academic3004801017040124999730923520MPP Industry10800001013472397440056920000Cluster Research3124801000520129991740953600Cluster Academic449280991525142571531103990MPP Research345600989600109209619069440Cluster Research345600989600109209619069440Cluster Research53504097860011128833290496561792Cluster Academic77520684009767631341096179308805101915.22Cluster Research44520095873499724831752000855.11121.2Cluster Government561120957600121201922688400MPP Industry900000954720374400056920000Cluster Industry900000954720374400056920000Cluster Research302400944800125798428857600MPP Academic4889609250581017037001015.6910.85Cluster Industry288000914688115200000Cluster Academic78660298209019001700210215039902800322.11Cluster Academic311040901506124416032451840MPP Academic819200894439104857600410.92176.78MPP Industry368000856521.2153088000Cluster Industry306720833916122688039443200Cluster Academic403200829805124139530016800MPP Industry409600816578.691750400Cluster Academic254400801400105830437422720568.51409.67MPP Research13720007959001070160337512001074741.06Cluster Academic1482013520781300100169212072960Cluster Academic155528640777400110016019353600255.33045.05Cluster Research462080773700961126.432604001630200924.16837.19Cluster Research53248286727717001342751220000001155.07668.1MPP Research35640076750479833600684.51121.26Cluster Industry5139242944758873933481.515645440387.21959.9Cluster Industry700000756880224000050200000Cluster Industry700000756880224000050200000Cluster Industry700000756880224000050200000Cluster Academic556644782474599799850216384000365.82039.36Cluster Research2505607417481002240180403204051831.48Cluster Academic2918407380651073971350016003841922.04Cluster Academic249120738000996480422300005401366.67Cluster Industry15640102007301001085552147512702253244.89Cluster Academic169969380721900978801.215160320Cluster Research38016071922079073300789.66910.8Cluster Research655360715551838861003282181.56MPP Industry65536071555183886100328.752176.58MPP Academic655360715551838861003282181.56MPP Research65536071555183886100328.72176.91MPP Research65536071555183886100328.752176.58MPP Research158409240709700101310010483200269.942629.1Cluster287151967.xls7Opteron 16C AMD x86_642500Linux Linux None16Opteron 6200Cray XE6Cray XEBull Bullx Xeon E5-2680Intel Haswell2500Bullx Linux Linux None12Intel Xeon E5bullx DLC 720Opteron 6136AMD x86_642400Linux Linux None8Opteron 6100Cray XE6Cray XEIntel Haswell2500Linux Linux None12Intel Xeon E5Lenovo Think Lenovo Think Xeon E5-2680Intel Haswell2500Linux Linux None12Intel Xeon E5Lenovo Think Lenovo Think Xeon E5-2680Linux None12Intel Xeon E5Cray XC40Cray XC Xeon E5-2690Intel Haswell2600Cray Linux EnIntel Haswell2600bullx SCS Linux None12Intel Xeon E5Bullx DLC B7Bull Bullx Xeon E5-2690Power BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenPower BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenOpteron 6172AMD x86_642100Linux Linux None12Opteron 6100Cray XE6Cray XEIntel Xeon E5Intel IvyBridge2800Redhat Enter Linux NVIDIA Tesla10Intel Xeon E5Dell C8220X Dell PowerEdBull Bullxbullx super-noXeon X7560 8Intel Nehalem2260Linux Linux None8Xeon 5500-seFujitsu Cluste SPARC64 IXf Sparc1848Linux Linux None16SPARC64 IXf PRIMEHPC FXeon E5-2650Intel Haswell2000Linux Linux None10Intel Xeon E5Lenovo Think Lenovo ThinkBull Bullx Xeon E5-2680Intel Haswell2500Bullx Linux Linux None12Intel Xeon E5bullx DLC 720Intel SandyBr2700Redhat Enter Linux NVIDIA K20/K8Intel Xeon E5HA8000-tc HTQuartetto Clu Xeon E5-2680Intel Haswell2600Cray Linux EnLinux None12Intel Xeon E5Cray XC40Cray XC Xeon E5-2690Intel Haswell2300Linux Linux None12Intel Xeon E5Lenovo Think Lenovo Think Xeon E5-2670Linux None14Intel Xeon E5Rackable Clu Rackable Clu Intel Haswell2600SUSE Linux EXeon E5-2697Linux None12Intel Xeon E5Cray XC40Cray XCIntel Xeon E5Intel IvyBridge2400Cray Linux EnFujitsu PRIME SPARC64 XIf Sparc1975Linux Linux None32SPARC64 XIf Fujitsu PRIMESPARC64 XIf Sparc1975Linux Linux None32SPARC64 XIf Fujitsu PRIMEFujitsu PRIMEFujitsu Cluste Intel SandyBr2600Linux Linux None8Intel Xeon E5Fujitsu PRIMEXeon E5-2670Intel SandyBr2600Linux Linux Intel Xeon Ph8Intel Xeon E5Cluster Platfo HP Cluster Pl Xeon E5-2670Linux None10Intel Xeon E5SGI ICE X SGI ICEIntel Xeon E5Intel IvyBridge2800SUSE Linux ELinux None12Intel Xeon E5Cray XC30Cray XCIntel Xeon E5Intel IvyBridge2700Cray Linux EnIntel Haswell2600Linux Linux None10Intel Xeon E5Lenovo Think Lenovo Think Xeon E5-2660Intel Haswell2600Linux Linux None10Intel Xeon E5Lenovo Think Lenovo Think Xeon E5-2660Linux None12Intel Xeon E5Cray XC40Cray XC Intel Haswell2600Cray Linux EnXeon E5-2690Intel SandyBr2600Linux Linux None8Intel Xeon E5iDataPlex DX IBM iDataPlex Xeon E5-2670HP Apollo Xeon E5-2680Intel Haswell2500Linux Linux None12Intel Xeon E5Apollo 6000 XT-Platforms T T-Platforms C Intel Nehalem2930Linux Linux NVIDIA 20706Xeon 5600-seXeon X5670 6Intel Haswell2500Cray Linux EnLinux None12Intel Xeon E5Cray XC40Cray XC Xeon E5-2680Power BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenHP Cluster Pl Intel Haswell2600Linux Linux None8Intel Xeon E5HP DL360 CluXeon E5-2640Intel Haswell2500Linux Linux None12Intel Xeon E5Cluster Platfo HP Cluster Pl Xeon E5-2680Linux None12Intel Xeon E5Cray XC40Cray XCIntel Xeon E5Intel IvyBridge2400Cray Linux EnIntel Xeon E5Intel IvyBridge2800Linux Linux None10Intel Xeon E5Cluster Platfo HP Cluster PlLinux None12Intel Xeon E5Cray XC40Cray XC Xeon E5-2690Intel Haswell2600Cray Linux EnOthers975Linux Linux None16ShenWei Sunway BlueLSunway BlueL ShenWei procIntel Xeon E5Intel IvyBridge2800Linux Linux NVIDIA Tesla10Intel Xeon E5Cray CS-Stor Cray CS-StorIntel Haswell2500SUSE Linux ELinux NVIDIA Tesla12Intel Xeon E5SGI ICE XA SGI ICE Xeon E5-2680Appro Xtreme Intel SandyBr2600RHEL 6.2Linux None8Intel Xeon E5Xtreme-X GreXeon E5-2670NUDT MPPNUDT YH MPXeon X5670 6Intel Nehalem2930Linux Linux NVIDIA 20506Xeon 5600-seLinux None10Intel Xeon E5SGI ICE X SGI ICEIntel Xeon E5Intel IvyBridge2800SUSE Linux EIntel Xeon E5Intel IvyBridge2700Linux Linux Intel Xeon Ph12Intel Xeon E5Intel Cluster I ntel ClusterIntel Haswell2000Linux Linux None10Intel Xeon E5Lenovo Think Lenovo Think Xeon E5-2650Intel Haswell2000Linux Linux None10Intel Xeon E5Lenovo Think Lenovo Think Xeon E5-2650Intel Haswell2000Linux Linux None10Intel Xeon E5Lenovo Think Lenovo Think Xeon E5-2650Cray CS300 Intel Xeon E5Intel IvyBridge2500Linux Linux Intel Xeon Ph10Intel Xeon E5Cray CS300 1Linux None12Intel Xeon E5SGI ICE X SGI ICE Intel Haswell2500SUSE Linux EXeon E5-2680Dell PowerEd Xeon E5-2698Intel Haswell2300Redhat Enter Linux None16Intel Xeon E5PowerEdge CIntel Haswell2500Linux Linux None12Intel Xeon E5Sugon Cluste Sugon Cluste Xeon E5-2680Intel Xeon E5Intel IvyBridge2600CentOS Linux NVIDIA Tesla8Intel Xeon E5Inspur TS100Inspur ClusteIntel SandyBr2400Linux Linux NVIDIA Tesla8Intel Xeon E5Cluster Platfo HP Cluster Pl Xeon E5-2665Intel SandyBr2600Linux Linux None8Intel Xeon E5iDataPlex DX IBM iDataPlex Xeon E5-2670Power BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenPower BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenPower BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenPower BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenPower BQC 1PowerPC1600Linux Linux None16Power BQC BlueGene/Q IBM BlueGenIntel Xeon E5Intel IvyBridge2800Linux Linux NVIDIA Tesla10Intel Xeon E5iDataPlex DX IBM iDataPlex287151967.xls。

30502011,V ol.32,No.9计算机工程与设计Computer Engineering and Design0引言多体问题是天体物理学、流体力学以及分子动力学的基本问题之一,是高性能计算领域最具代表性、最有影响力以及最有挑战性的问题之一[1]。
目前,解决多体问题的方法主要有暴力计算法,树结构算法和PM(particle mesh)算法[2]。
而树结构算法主要有BH(Barnes-Hut)算法[3]和FMM(fast multipole method)算法[4]。
FMM算法由于算法的复杂度为O(n)且计算精度可控,有着广泛的应用。
多体问题是一个复杂巨大的问题,仅从算法上降低复杂度还不能满足科学计算速度的要求。
越来越多的人开始研究利用GPU对FMM算法进行加速,而PP(particle-particle)问题是其中最耗时也是最难的实现加速的部分。
主要由于在树结构中,各粒子的计算量大小不一,这样容易造成的负载不平衡,降低GPU(graphic processing unit)的效率;显存空间的限制使得可计算的规模不大。
如何降低负载不平衡对GPU效率的影响和解决显存空间限制是研究的重点。
目前,已有许多利用GPU对PP问题进行加速的研究成果。
例如:Belleman[5]等人在2007年提出一种利用CUDA技术对暴力算法进行加速。
2007年Hamada[6]等人实现了105个粒子的多体问题。
Nyland[7]等人利用CUDA加速50倍。
Belleman[8]模拟实现了131072个粒子的多体问题。
Stock[9]等人在GPU上实现了模拟涡流问题树结构算法。
Gumerov[10]等人在NVIDIA GeForce8800GTX GPU上实现了FMM算法加速比达到30-60倍。
Hamada[11]等人实现了16777216个粒子的涡流算法,性能达到20.2TFlops,之后,Hamada[12]等人又对算法进行改进,性能达到40TFlops。

2011年英伟达GPU技术大会亚洲站简介本次大会是英伟达GPU技术大会(GTC)全球系列活动中的下一场重要盛会。
大会将聚焦GPU计算在科学、学术界以及商业领域中促成的最新进步与研究项目。
它不仅能够让人们更加深入地认识高性能计算,而且能够将这些使用GPU解决重大计算难题的科学家、工程师、研究员以及开发者联系在一起。
此前英伟达在以色列、日本、新加坡以及台湾等地举办了多场GTC盛会,吸引了数以千计各行各业以及各个学科的与会者。
在这些GTC盛会成功经验的基础之上,GPU技术大会亚洲站将于12 月14-15日在北京国家会议中心举行。
为期两天的GPU技术大会亚洲站,旨在分享GPU给科学和计算带来的变革性的影响。
在两天的繁忙日程大会中,英伟达™ (NVIDIA®) 首席执行官兼联合创始人黄仁勋将发表主题演讲,为大家介绍英伟达最新的GPU计算技术以及未来愿景。
期间还将包括主题演讲、圆桌讨论会、展示会、新兴企业峰会、学术海报、专题报告以及60 场以上的讲习会,专门面向利用GPU处理复杂计算难题的开发商、程序员以及研究科学家。
在GPU 技术大会亚洲站上,来自顶尖科学研究机构的科学家们将参与到一系列演讲、技术分享会、辅导课程、小组论坛和圆桌讨论会中。
他们旨在向与会者分享GPU 如何改变高性能计算(HPC) 行业以及GPU如何帮助加速解决学者、研究人员、科学家以及开发者所面临的复杂计算难题。
活动期间还将召开两场重要的研讨会。
亿亿次级(Exascale) 研讨会将由东京工业大学、中国科学院过程工程研究所、瑞士国家超级计算中心以及英伟达联合主讲;GPU 加速基因组研讨会将汇集来自北京基因组研究所(BGI)、南开大学、德国美因茨大学以及上海交通大学等机构的著名科学家。
除了主题演讲和教育性会议以外,还有新兴企业与技术峰会以及英伟达™ CUDA™ 学生研讨会。
在峰会上,大有前景的企业将与大家分享可改变当今计算机行业面貌的最新技术。
