mnist手写体数字识别原理
- 格式:docx
- 大小:36.94 KB
- 文档页数:2

使用卷积神经网络进行手写数字识别的技巧手写数字识别是计算机视觉领域的一个重要任务。
近年来,卷积神经网络(Convolutional Neural Network,CNN)在图像分类问题上取得了显著的突破,也成为手写数字识别的主要方法之一。
本文将介绍使用卷积神经网络进行手写数字识别的一些关键技巧。
首先,准备数据集是进行手写数字识别的基础。
MNIST(Modified National Institute of Standards and Technology)是一个常用的手写数字数据集,包含了大量的手写数字图像。
可以使用它作为训练和测试的数据集。
准备好数据集后,我们可以开始构建卷积神经网络模型。
其次,设计合适的卷积神经网络结构是关键。
在手写数字识别任务中,常用的卷积神经网络结构包括LeNet-5、AlexNet、VGGNet和ResNet等。
这些网络结构具有不同的层数和参数量,可以根据任务需求选择适合的网络结构。
一般情况下,浅层网络结构如LeNet-5适用于简单的手写数字识别,而深层网络如ResNet适用于更复杂的手写数字识别任务。
然后,正确设置卷积神经网络的超参数也是非常重要的。
超参数包括学习率、批量大小、卷积核大小、卷积核数量等。
学习率决定了模型在每次迭代中更新的程度,过大或过小都可能导致模型无法收敛或过拟合。
批量大小决定了模型每次训练时使用的样本数量,过大可能导致内存不足,过小可能导致梯度估计不准确。
卷积核大小和数量决定了模型对输入的特征提取能力,需要根据数据集的大小和复杂程度进行合理的选择。
可以通过尝试不同的超参数组合并评估模型性能来选择最优的超参数。
接下来,数据增强是提升模型性能的一个有效方法。
数据增强指的是通过对训练数据进行随机的图像变换来增加数据样本的数量和多样性。
常用的数据增强方法包括旋转、平移、缩放、翻转、加噪声等。
这样可以提高模型的泛化能力,并减轻过拟合的风险。
此外,正则化技术也可以帮助抑制模型的过拟合。

手写识别技术的工作原理手写识别技术是一种将手写输入转化为可编辑、可搜索、可存储的数字文本或字符的技术。
它能够将手写的文字转化为计算机可识别的文本,从而提供更快、更便捷的手写输入方式。
手写识别技术的工作原理主要包括图像预处理、特征提取、模型训练和字符识别四个步骤。
首先是图像预处理。
手写输入被数字化后会得到一个包含手写字符的图像。
为了能够更好地识别手写字符,需要对图像进行预处理。
预处理步骤包括对图像进行二值化处理,将图像中的字符部分与背景部分分离出来;接着进行去噪处理,通过去除影响字符识别的噪声点;最后进行字符分割,将图像中的字符分割为单个字符,以便后续的特征提取和识别。
接下来是特征提取。
在图像预处理之后,需要从分割出的单个字符图像中提取出特征。
特征提取是将图像中的字符转化为计算机可识别的特征向量的过程。
常用的手写字符特征包括笔画宽度、笔画顺序、笔画方向、笔画长度、笔画弯曲度等。
这些特征可以通过数学模型进行计算和提取,并转化为计算机可理解的数字特征向量。
然后是模型训练。
通过特征提取,手写字符的图像就转化为了特征向量。
接下来的工作是利用这些特征向量训练一个模型,使其能够识别出不同的手写字符。
常用的模型包括支持向量机、决策树、神经网络等。
在模型训练过程中,需要准备一个包含大量不同手写字符和对应特征向量的数据集,通过对这些数据进行学习和训练,来使模型能够根据特征向量判断输入的手写字符是属于哪个字符类别的。
最后是字符识别。
在经过图像预处理、特征提取和模型训练的过程后,手写识别系统就能够将手写输入转化为可编辑、可搜索、可存储的数字文本或字符。
在字符识别的过程中,输入的手写字符会被转化为特征向量,然后通过训练好的模型进行分类和识别。
最后,系统将识别出的字符转化为计算机可识别的文本输出。
手写识别技术的工作原理是通过图像预处理、特征提取、模型训练和字符识别四个步骤来实现的。
这些步骤相互配合,通过转化和计算,将手写字符转化为数字文本或字符,并实现数字化的编辑、搜索和存储。

基于LeNet的手写数字识别实验是计算机视觉领域中一个经典的实例,通过对MNIST数据集进行处理和分析,使用LeNet-5神经网络模型实现对手写数字(0-9)的识别。
以下是对该实验的总结:1. 数据集介绍MNIST数据集是计算机视觉领域的经典入门数据集,包含了60,000个训练样本和10,000个测试样本。
这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28x28像素)。
数据集分为训练集、验证集和测试集,方便进行模型训练和性能评估。
2. LeNet-5模型LeNet-5是一种卷积神经网络模型,由Yann LeCun于1998年提出。
尽管其提出时间较早,但在手写数字识别任务上取得了显著的成功。
实验中,我们采用LeNet-5模型对MNIST数据集进行处理。
3. 模型结构LeNet-5模型包括两个卷积层和三个全连接层。
卷积层分别包含6个和16个卷积核,卷积核大小为5x5。
每个卷积层之后跟着一个最大池化层,池化核大小为2x2。
全连接层分别具有64、120和84个神经元。
最后,模型输出10个神经元,对应10个数字类别。
4. 实验流程实验中,首先对数据集进行预处理,将图像缩放到28x28像素。
然后,将数据集划分为训练集、验证集和测试集。
接着,构建LeNet-5模型并使用训练集进行训练。
在训练过程中,采用交叉熵损失函数和随机梯度下降(SGD)优化器。
最后,使用验证集评估模型性能,并选取最优模型在测试集上进行测试。
5. 实验结果经过训练,LeNet-5模型在MNIST数据集上取得了较好的识别效果。
在测试集上,模型对数字的识别准确率达到了98.89%。
实验结果表明,尽管LeNet-5模型相对简单,但在手写数字识别任务上具有较高的准确率。
6. 实验总结基于LeNet的手写数字识别实验展示了卷积神经网络在计算机视觉领域的应用。
通过搭建LeNet-5模型并对MNIST数据集进行处理,实验证明了卷积神经网络在识别手写数字方面的有效性。

利用深度学习技术进行手写体数字识别近年来,由于深度学习技术的不断发展和普及,人工智能领域的应用也越来越广泛,其中手写体数字识别技术就是一个典型的应用场景。
手写体数字识别技术是指通过计算机对手写数字进行自动识别的过程,这项技术已经广泛应用于金融、医疗等领域。
在这篇文章中,我们将探讨利用深度学习技术进行手写体数字识别的原理和方法,并分析其在实际应用中的优势和局限性。
一、手写体数字识别技术的原理手写体数字识别技术的核心是特征提取和分类器设计两个方面。
在特征提取方面,传统方法采用的是手工设计的特征提取算法,例如Zernike moments,SIFT等。
这些方法需要专业领域知识和丰富经验,并且对不同的数据集需要不同的特征提取算法。
然而,随着深度学习技术的发展,我们可以通过神经网络自动学习特征,从而摆脱了手工设计特征的麻烦。
在分类器设计方面,传统方法采用的是一些传统的分类器,例如支持向量机,随机森林等。
这些分类器需要手工调参,并且对于不同的数据集需要不同的分类器。
然而,深度学习技术可以在一定程度上解决这个问题,因为深度神经网络对于各种类型的分类问题具有很好的适应性。
二、深度学习技术在手写体数字识别中的应用深度学习技术已经成为了手写体数字识别领域中的热门技术,例如使用卷积神经网络(CNN)进行手写体数字的分类。
卷积神经网络通过卷积操作将输入的图像特征进行提取,然后将其送入全连接层进行分类。
这种方法已经被广泛应用于手写体数字识别的研究和实践中,并取得了很好的效果。
除此之外,深度学习技术可以借鉴自然语言处理领域的技术,例如使用循环神经网络(RNN)进行手写体数字序列的识别。
循环神经网络可以处理变长的序列数据,因此可以非常适合于手写数字序列的识别。
这种方法已经被广泛应用于手写体数字识别的研究和实践中,并取得了不错的效果。
在实际应用中,手写体数字识别技术面临着一些挑战,例如传感器噪声、字体变体、旋转、尺度缩放等问题。

基于深度学习的手写体数字识别系统研究随着人工智能技术的进步,深度学习已经成为当今最热门的技术之一。
作为一种机器学习的方法,深度学习可以利用大量数据来自动化地发现规律和模式,从而实现准确的预测和分类。
在数字识别领域,深度学习也已经广泛应用,成为手写数字识别的主流技术之一。
本文将探讨基于深度学习的手写数字识别系统的研究,并介绍其技术原理、实现方法和应用前景。
一、技术原理基于深度学习的手写数字识别系统的核心技术是卷积神经网络(Convolutional Neural Network,简称CNN)。
CNN是一种模仿人脑视觉处理机制的神经网络模型,它能够自动从复杂的图像数据中提取特征信息,并进行分类或回归等任务。
在手写数字识别中,CNN可以通过多层卷积、池化和全连接层来输入、处理和输出图像数据,从而实现高效准确的数字识别。
具体来说,CNN的输入数据是一组手写数字图片,它们可以是MNIST等公开数据集或者自己手写的数字图片。
在网络的第一层需要进行一定的图像预处理,如变换尺寸、灰度处理等,将原始图像转换为网络可接受的输入格式。
接下来,在网络的第二层开始进行卷积操作,将输入图片与若干个卷积核进行卷积运算,得到一组新的特征图。
通过多层卷积和池化层的运算,CNN可以自动地学习到输入图片的特征信息,并将其压缩和提取为具有可识别性的特征,最终在全连接层进行分类或回归等任务。
二、实现方法基于深度学习的手写数字识别系统的实现需要提前准备数据集、编写代码和进行模型的训练和测试等步骤。
下面以Keras框架为例,介绍具体的实现方法:1.准备数据集可以使用MNIST等公开数据集,也可以使用自己收集的图片进行训练。
将数据集分为训练集和测试集两部分,其中训练集用于训练模型,测试集用于评估模型的识别准确度和泛化能力。
2.编写代码基于Keras框架,可以采用Python语言编写代码,如下所示:```import kerasfrom keras.models import Sequentialfrom yers import Conv2D, MaxPooling2D, Flatten, Dense#定义CNN模型model = Sequential()#第一层卷积层model.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(28, 28, 1), activation='relu'))#第二层池化层model.add(MaxPooling2D(pool_size=(2, 2)))#第三层卷积层model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))#第四层池化层model.add(MaxPooling2D(pool_size=(2, 2)))#将特征图展开为一维model.add(Flatten())#全连接层model.add(Dense(units=128, activation='relu'))#输出层model.add(Dense(units=10, activation='softmax'))#训练模型pile(optimizer='adam', loss='categorical_crossentropy',metrics=['accuracy'])model.fit(train_images, train_labels, epochs=10, batch_size=128)#测试模型test_loss, test_acc = model.evaluate(test_images, test_labels)print('Test accuracy:', test_acc)```3.模型训练和测试调用model.fit函数进行模型训练,其中需要指定优化器、损失函数、评估指标等参数。

基于神经网络的手写数字识别一、引言在人工智能领域中,图像识别一直是一个热门话题。
随着科技的不断发展,越来越多的方法被提出,其中基于神经网络的手写数字识别方法是一个十分有效的方法。
本文将从几个方面介绍基于神经网络的手写数字识别。
二、神经网络神经网络是一种类似于人脑运作方式的机器学习算法。
它是由许多神经元组成的层级结构,每个神经元都是一个小型的计算单元。
神经网络可以学习和处理数据,它具有自动学习和优化的能力,可以对输入数据进行分类、识别、预测和生成等任务,在图像识别、自然语言处理等方面取得很好的成效。
三、手写数字识别手写数字识别是人工智能领域中最基础的问题之一。
它代表了自然语言理解和识别技术的重要应用。
手写数字识别已经实现了很大的进展并被应用于数字签名、自动银行支票处理、邮票识别、医学 X 射线分析等各种领域。
在这些应用中,唯一的输入是一个数字图像,因此手写数字识别是根据输入图像来预测输出数字标签的一个任务。
四、基于神经网络的手写数字识别4.1 数据集神经网络训练需要大量数据来描述模式。
手写数据集是用于训练模型的重要数据集之一。
MNIST 数据集是一个公共手写数字数据集,其包含 60,000 个训练图像和 10,000 个测试图像。
每个图像都是 28x28 像素的灰度图像,表示数字 0 到 9 中的一个。
神经网络可以通过这些图像来学习和预测给定数字。
4.2 网络架构卷积神经网络(Convolutional Neural Network,CNN)是一个有效的图像分类器。
CNN 通过使用卷积、池化和全连接层逐层处理图像,最终输出对图像的分类结果。
在手写数字识别问题中,CNN 模型通常包括三个部分:- 卷积层:用于提取图像中的特征。
- 池化层:用于减少图像的维度,并增强图像的鲁棒性。
- 全连接层:用于对图像进行分类。
4.3 训练模型通过使用所述的 CNN 模型和 MNIST 数据集,我们可以训练一个手写数字识别模型。

K-邻近分类算法——分类MNIST⼿写体数据算法(机器学习实战) k 近邻法(K-nearest neighbor, KNN)是⼀种基本分类于回归⽅法,其在1968年由Cover和Hart提出的。
k 近邻算法采⽤测量不同特征值之间的距离⽅法进⾏分类。
其输⼊为⽰例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。
k 近邻法假设给定⼀个训练数据集,其中的上实例类别已定,分类时,对新的实例,根据其K 个最近邻的训练实⼒的类别,通过多数表决等⽅式进⾏预测。
k 近邻法实际上利⽤训练数据集对特征向量哦那关键进⾏划分,并作为其分类的“模型”。
k 邻近法的基本三要素为: k 值的选择、距离度量以及分类决策规则。
实例:k-近邻算法的⼿写识别系统1.收集数据:提供⽂本⽂件。
2.准备数据:编写函数classify0(),将图像格式转换为分类器使⽤的list格式。
3.分析数据:在Python命令提⽰符中检查数据,确保它符合要求。
4.测试算法:编写函数使⽤提供的部分数据集作为测试样本,测试样本与⾮测试样本的区别在于测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为⼀个错误。
1、该⼿写体数据集合修改⾃"⼿写数字数据集的光学识别"⼀⽂中的数据集合,该⽂登载于2010年10⽉3⽇的UCI机器学习资料库中/ml。
2、准备数据2.1 编写⼀段函数img2vector,将图像转换为向量:该函数创建1x1024的NumPy数组,然后打开给定的⽂件,循环读出⽂件的前32⾏,并将每⾏的头32个字符值存储在NumPy数组中,最后返回数组。
def img2vector(filename):returnVect = zeros((1,1024)) #创建1*1024的数组fr = open(filename) #打开⽂件#循环读出⽂件的前32⾏,并将每⾏的头32个字符值存储在NumPy数组中for i in range(32):lineStr = fr.readline()for j in range(32):returnVect[0, 32*i+j] = int(lineStr[j])return returnVect #返回数组2.2 准备分类:k 邻近算法,此处距离度量采⽤欧式距离度量;classify0() 函数有4个输⼊参数:⽤于分类的输⼊向量是inX,输⼊的训练样本集为dataSet,标签向量为labels ,最后的参数k 表⽰⽤于选择最近邻居的数⽬,其中标签向量的元素数⽬和矩阵dataSet 的⾏数相同。

详解python实现识别⼿写MNIST数字集的程序我们需要做的第⼀件事情是获取 MNIST 数据。
如果你是⼀个 git ⽤⼾,那么你能够通过克隆这本书的代码仓库获得数据,实现我们的⽹络来分类数字git clone https:///mnielsen/neural-networks-and-deep-learning.gitclass Network(object):def __init__(self, sizes):self.num_layers = len(sizes)self.sizes = sizesself.biases = [np.random.randn(y, 1) for y in sizes[1:]]self.weights = [np.random.randn(y, x)for x, y in zip(sizes[:-1], sizes[1:])]在这段代码中,列表 sizes 包含各层神经元的数量。
例如,如果我们想创建⼀个在第⼀层有2 个神经元,第⼆层有 3 个神经元,最后层有 1 个神经元的 Network 对象,我们应这样写代码:net = Network([2, 3, 1])Network 对象中的偏置和权重都是被随机初始化的,使⽤ Numpy 的 np.random.randn 函数来⽣成均值为 0,标准差为 1 的⾼斯分布。
这样的随机初始化给了我们的随机梯度下降算法⼀个起点。
在后⾯的章节中我们将会发现更好的初始化权重和偏置的⽅法,但是⽬前随机地将其初始化。
注意 Network 初始化代码假设第⼀层神经元是⼀个输⼊层,并对这些神经元不设置任何偏置,因为偏置仅在后⾯的层中⽤于计算输出。
有了这些,很容易写出从⼀个 Network 实例计算输出的代码。
我们从定义 S 型函数开始:def sigmoid(z):return 1.0/(1.0+np.exp(-z))注意,当输⼊ z 是⼀个向量或者 Numpy 数组时,Numpy ⾃动地按元素应⽤ sigmoid 函数,即以向量形式。

PyTorchCNN实战之MNIST⼿写数字识别⽰例简介卷积神经⽹络(Convolutional Neural Network, CNN)是深度学习技术中极具代表的⽹络结构之⼀,在图像处理领域取得了很⼤的成功,在国际标准的ImageNet数据集上,许多成功的模型都是基于CNN的。
卷积神经⽹络CNN的结构⼀般包含这⼏个层:1. 输⼊层:⽤于数据的输⼊2. 卷积层:使⽤卷积核进⾏特征提取和特征映射3. 激励层:由于卷积也是⼀种线性运算,因此需要增加⾮线性映射4. 池化层:进⾏下采样,对特征图稀疏处理,减少数据运算量。
5. 全连接层:通常在CNN的尾部进⾏重新拟合,减少特征信息的损失6. 输出层:⽤于输出结果PyTorch实战本⽂选⽤上篇的数据集MNIST⼿写数字识别实践CNN。
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.autograd import Variable# Training settingsbatch_size = 64# MNIST Datasettrain_dataset = datasets.MNIST(root='./data/',train=True,transform=transforms.ToTensor(),download=True)test_dataset = datasets.MNIST(root='./data/',train=False,transform=transforms.ToTensor())# Data Loader (Input Pipeline)train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 输⼊1通道,输出10通道,kernel 5*5self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.mp = nn.MaxPool2d(2)# fully connectself.fc = nn.Linear(320, 10)def forward(self, x):# in_size = 64in_size = x.size(0) # one batch# x: 64*10*12*12x = F.relu(self.mp(self.conv1(x)))# x: 64*20*4*4x = F.relu(self.mp(self.conv2(x)))# x: 64*320x = x.view(in_size, -1) # flatten the tensor# x: 64*10x = self.fc(x)return F.log_softmax(x)model = Net()optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)def train(epoch):for batch_idx, (data, target) in enumerate(train_loader):data, target = Variable(data), Variable(target)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % 200 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.data[0]))def test():test_loss = 0correct = 0for data, target in test_loader:data, target = Variable(data, volatile=True), Variable(target)output = model(data)# sum up batch losstest_loss += F.nll_loss(output, target, size_average=False).data[0]# get the index of the max log-probabilitypred = output.data.max(1, keepdim=True)[1]correct += pred.eq(target.data.view_as(pred)).cpu().sum()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))for epoch in range(1, 10):train(epoch)test()输出结果:Train Epoch: 1 [0/60000 (0%)] Loss: 2.315724Train Epoch: 1 [12800/60000 (21%)] Loss: 1.931551Train Epoch: 1 [25600/60000 (43%)] Loss: 0.733935Train Epoch: 1 [38400/60000 (64%)] Loss: 0.165043Train Epoch: 1 [51200/60000 (85%)] Loss: 0.235188Test set: Average loss: 0.1935, Accuracy: 9421/10000 (94%) Train Epoch: 2 [0/60000 (0%)] Loss: 0.333513Train Epoch: 2 [12800/60000 (21%)] Loss: 0.163156Train Epoch: 2 [25600/60000 (43%)] Loss: 0.213840Train Epoch: 2 [38400/60000 (64%)] Loss: 0.141114Train Epoch: 2 [51200/60000 (85%)] Loss: 0.128191Test set: Average loss: 0.1180, Accuracy: 9645/10000 (96%) Train Epoch: 3 [0/60000 (0%)] Loss: 0.206469Train Epoch: 3 [12800/60000 (21%)] Loss: 0.234443Train Epoch: 3 [25600/60000 (43%)] Loss: 0.061048Train Epoch: 3 [38400/60000 (64%)] Loss: 0.192217Train Epoch: 3 [51200/60000 (85%)] Loss: 0.089190Test set: Average loss: 0.0938, Accuracy: 9723/10000 (97%) Train Epoch: 4 [0/60000 (0%)] Loss: 0.086325Train Epoch: 4 [12800/60000 (21%)] Loss: 0.117741Train Epoch: 4 [25600/60000 (43%)] Loss: 0.188178Train Epoch: 4 [38400/60000 (64%)] Loss: 0.049807Train Epoch: 4 [51200/60000 (85%)] Loss: 0.174097Test set: Average loss: 0.0743, Accuracy: 9767/10000 (98%)Train Epoch: 5 [0/60000 (0%)] Loss: 0.063171Train Epoch: 5 [12800/60000 (21%)] Loss: 0.061265Train Epoch: 5 [25600/60000 (43%)] Loss: 0.103549Train Epoch: 5 [38400/60000 (64%)] Loss: 0.019137Train Epoch: 5 [51200/60000 (85%)] Loss: 0.067103Test set: Average loss: 0.0720, Accuracy: 9781/10000 (98%)Train Epoch: 6 [0/60000 (0%)] Loss: 0.069251Train Epoch: 6 [12800/60000 (21%)] Loss: 0.075502Train Epoch: 6 [25600/60000 (43%)] Loss: 0.052337Train Epoch: 6 [38400/60000 (64%)] Loss: 0.015375Train Epoch: 6 [51200/60000 (85%)] Loss: 0.028996Test set: Average loss: 0.0694, Accuracy: 9783/10000 (98%)Train Epoch: 7 [0/60000 (0%)] Loss: 0.171613Train Epoch: 7 [12800/60000 (21%)] Loss: 0.078520Train Epoch: 7 [25600/60000 (43%)] Loss: 0.149186Train Epoch: 7 [38400/60000 (64%)] Loss: 0.026692Train Epoch: 7 [51200/60000 (85%)] Loss: 0.108824Test set: Average loss: 0.0672, Accuracy: 9793/10000 (98%)Train Epoch: 8 [0/60000 (0%)] Loss: 0.029188Train Epoch: 8 [12800/60000 (21%)] Loss: 0.031202Train Epoch: 8 [25600/60000 (43%)] Loss: 0.194858Train Epoch: 8 [38400/60000 (64%)] Loss: 0.051497Train Epoch: 8 [51200/60000 (85%)] Loss: 0.024832Test set: Average loss: 0.0535, Accuracy: 9837/10000 (98%)Train Epoch: 9 [0/60000 (0%)] Loss: 0.026706Train Epoch: 9 [12800/60000 (21%)] Loss: 0.057807Train Epoch: 9 [25600/60000 (43%)] Loss: 0.065225Train Epoch: 9 [38400/60000 (64%)] Loss: 0.037004Train Epoch: 9 [51200/60000 (85%)] Loss: 0.057822Test set: Average loss: 0.0538, Accuracy: 9829/10000 (98%)Process finished with exit code 0以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。

基于神经网络的手写数字识别模型手写数字识别是一项重要的图像识别任务,它在许多应用领域中具有广泛的应用,如数字验证码识别、自动银行支票处理等。
在过去的几年中,神经网络已经显示出在手写数字识别方面取得了很好的结果。
本文将介绍一种基于神经网络的手写数字识别模型。
为了实现手写数字识别,我们将使用深度学习技术中的卷积神经网络(CNN)模型。
CNN是一种特殊的神经网络结构,它采用了卷积层、池化层和全连接层等组件,以提取图像中的特征并进行分类。
下面是我们将采取的步骤:1. 数据收集与预处理:手写数字识别需要一个大型的标记数据集作为训练数据。
我们可以使用MNIST数据集作为我们的训练数据集。
MNIST数据集包含了60000个训练样本和10000个测试样本,每个样本都是一张28x28像素的灰度图像,对应着一个0-9的数字标签。
在我们开始训练前,我们需要对图像进行预处理,将灰度值归一化并进行标准化处理。
2. 构建卷积神经网络模型:我们将使用Keras库来构建我们的卷积神经网络模型。
该模型由多个卷积层和池化层交替堆叠组成,以及全连接层。
卷积层通过滑动滤波器并执行卷积操作来提取图像的特征,池化层则用于降低特征图的维度。
最后通过全连接层将特征与标签进行映射。
3. 模型训练与优化:在模型构建完成后,我们使用训练集进行模型训练。
我们将使用反向传播算法来更新模型参数,并使用随机梯度下降法作为优化器以找到最优参数。
同时,我们还会使用交叉熵损失函数来计算模型的预测结果与真实标签之间的误差,并通过反向传播算法进行参数调整。
此外,我们还可以采用一些正则化技术,如Dropout 和L2正则化,来防止模型过拟合。
4. 模型评估与测试:在模型训练完成后,我们需要对其进行评估和测试。
我们可将测试集作为模型的输入数据,并使用准确率作为评估指标来衡量模型的性能。
准确率可以通过将模型的预测结果与真实标签进行比较来计算。
通过以上步骤,我们可以构建一个基于神经网络的手写数字识别模型。
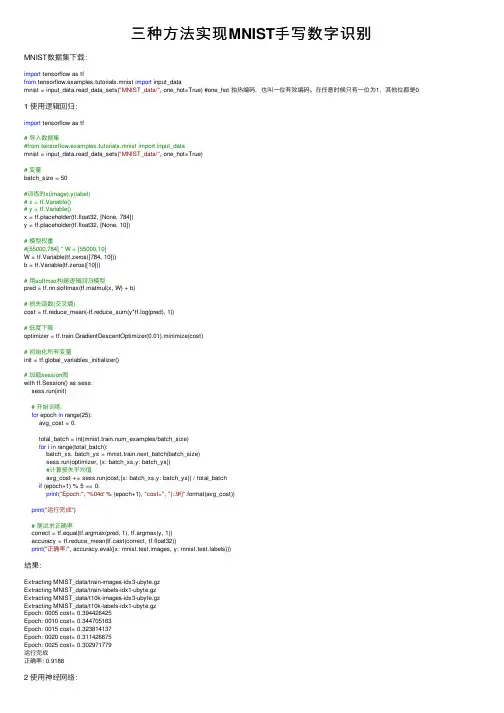
三种⽅法实现MNIST⼿写数字识别MNIST数据集下载:import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #one_hot 独热编码,也叫⼀位有效编码。
在任意时候只有⼀位为1,其他位都是0 1 使⽤逻辑回归:import tensorflow as tf# 导⼊数据集#from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("MNIST_data/", one_hot=True)# 变量batch_size = 50#训练的x(image),y(label)# x = tf.Variable()# y = tf.Variable()x = tf.placeholder(tf.float32, [None, 784])y = tf.placeholder(tf.float32, [None, 10])# 模型权重#[55000,784] * W = [55000,10]W = tf.Variable(tf.zeros([784, 10]))b = tf.Variable(tf.zeros([10]))# ⽤softmax构建逻辑回归模型pred = tf.nn.softmax(tf.matmul(x, W) + b)# 损失函数(交叉熵)cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), 1))# 低度下降optimizer = tf.train.GradientDescentOptimizer(0.01).minimize(cost)# 初始化所有变量init = tf.global_variables_initializer()# 加载session图with tf.Session() as sess:sess.run(init)# 开始训练for epoch in range(25):avg_cost = 0.total_batch = int(mnist.train.num_examples/batch_size)for i in range(total_batch):batch_xs, batch_ys = mnist.train.next_batch(batch_size)sess.run(optimizer, {x: batch_xs,y: batch_ys})#计算损失平均值avg_cost += sess.run(cost,{x: batch_xs,y: batch_ys}) / total_batchif (epoch+1) % 5 == 0:print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))print("运⾏完成")# 测试求正确率correct = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))print("正确率:", accuracy.eval({x: mnist.test.images, y: bels}))结果:Extracting MNIST_data/train-images-idx3-ubyte.gzExtracting MNIST_data/train-labels-idx1-ubyte.gzExtracting MNIST_data/t10k-images-idx3-ubyte.gzExtracting MNIST_data/t10k-labels-idx1-ubyte.gzEpoch: 0005 cost= 0.394426425Epoch: 0010 cost= 0.344705163Epoch: 0015 cost= 0.323814137Epoch: 0020 cost= 0.311426675Epoch: 0025 cost= 0.302971779运⾏完成正确率: 0.91882 使⽤神经⽹络:import tensorflow as tfimport numpy as npfrom tensorflow.examples.tutorials.mnist import input_datadef init_weights(shape):return tf.Variable(tf.random_normal(shape, stddev=0.01))def model(X, w_h, w_o):h = tf.nn.sigmoid(tf.matmul(X, w_h)) # this is a basic mlp, think 2 stacked logistic regressionsreturn tf.matmul(h, w_o) # note that we dont take the softmax at the end because our cost fn does that for us mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)trX, trY, teX, teY = mnist.train.images, bels, mnist.test.images, belsX = tf.placeholder("float", [None, 784])Y = tf.placeholder("float", [None, 10])w_h = init_weights([784, 625]) # create symbolic variablesw_o = init_weights([625, 10])py_x = model(X, w_h, w_o)cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y)) # compute coststrain_op = tf.train.GradientDescentOptimizer(0.05).minimize(cost) # construct an optimizerpredict_op = tf.argmax(py_x, 1)# Launch the graph in a sessionwith tf.Session() as sess:# you need to initialize all variablestf.global_variables_initializer().run()for i in range(100):for start, end in zip(range(0, len(trX), 128), range(128, len(trX)+1, 128)):sess.run(train_op, feed_dict={X: trX[start:end], Y: trY[start:end]})print(i, np.mean(np.argmax(teY, axis=1) ==sess.run(predict_op, feed_dict={X: teX})))结果:0 0.68981 0.82442 0.86353 0.8814 0.88815 0.89316 0.89727 0.90058 0.90429 0.90623 使⽤卷积神经⽹络:import tensorflow as tfimport numpy as npfrom tensorflow.examples.tutorials.mnist import input_databatch_size = 128test_size = 256def init_weights(shape):return tf.Variable(tf.random_normal(shape, stddev=0.01))def model(X, w, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden):l1a = tf.nn.relu(tf.nn.conv2d(X, w, # l1a shape=(?, 28, 28, 32)strides=[1, 1, 1, 1], padding='SAME'))l1 = tf.nn.max_pool(l1a, ksize=[1, 2, 2, 1], # l1 shape=(?, 14, 14, 32)strides=[1, 2, 2, 1], padding='SAME')l1 = tf.nn.dropout(l1, p_keep_conv)l2a = tf.nn.relu(tf.nn.conv2d(l1, w2, # l2a shape=(?, 14, 14, 64)strides=[1, 1, 1, 1], padding='SAME'))l2 = tf.nn.max_pool(l2a, ksize=[1, 2, 2, 1], # l2 shape=(?, 7, 7, 64)strides=[1, 2, 2, 1], padding='SAME')l2 = tf.nn.dropout(l2, p_keep_conv)l3a = tf.nn.relu(tf.nn.conv2d(l2, w3, # l3a shape=(?, 7, 7, 128)strides=[1, 1, 1, 1], padding='SAME'))l3 = tf.nn.max_pool(l3a, ksize=[1, 2, 2, 1], # l3 shape=(?, 4, 4, 128)strides=[1, 2, 2, 1], padding='SAME')l3 = tf.reshape(l3, [-1, w4.get_shape().as_list()[0]]) # reshape to (?, 2048)l3 = tf.nn.dropout(l3, p_keep_conv)l4 = tf.nn.relu(tf.matmul(l3, w4))l4 = tf.nn.dropout(l4, p_keep_hidden)pyx = tf.matmul(l4, w_o)return pyxmnist = input_data.read_data_sets("MNIST_data/", one_hot=True)trX, trY, teX, teY = mnist.train.images, bels, mnist.test.images, bels trX = trX.reshape(-1, 28, 28, 1) # 28x28x1 input imgteX = teX.reshape(-1, 28, 28, 1) # 28x28x1 input imgX = tf.placeholder("float", [None, 28, 28, 1])Y = tf.placeholder("float", [None, 10])w = init_weights([3, 3, 1, 32]) # 3x3x1 conv, 32 outputsw2 = init_weights([3, 3, 32, 64]) # 3x3x32 conv, 64 outputsw3 = init_weights([3, 3, 64, 128]) # 3x3x32 conv, 128 outputsw4 = init_weights([128 * 4 * 4, 625]) # FC 128 * 4 * 4 inputs, 625 outputsw_o = init_weights([625, 10]) # FC 625 inputs, 10 outputs (labels)p_keep_conv = tf.placeholder("float")p_keep_hidden = tf.placeholder("float")py_x = model(X, w, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden)cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y)) train_op = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)predict_op = tf.argmax(py_x, 1)# Launch the graph in a sessionwith tf.Session() as sess:# you need to initialize all variablestf.global_variables_initializer().run()for i in range(10):training_batch = zip(range(0, len(trX), batch_size),range(batch_size, len(trX)+1, batch_size))for start, end in training_batch:sess.run(train_op, feed_dict={X: trX[start:end], Y: trY[start:end],p_keep_conv: 0.8, p_keep_hidden: 0.5})test_indices = np.arange(len(teX)) # Get A Test Batchnp.random.shuffle(test_indices)test_indices = test_indices[0:test_size]print(i, np.mean(np.argmax(teY[test_indices], axis=1) ==sess.run(predict_op, feed_dict={X: teX[test_indices],Y: teY[test_indices],p_keep_conv: 1.0,p_keep_hidden: 1.0})))结果:0 0.94531251 0.97656252 0.99218753 0.988281254 0.9843755 0.99218756 0.9843757 0.99218758 0.988281259 0.99609375。
专栏在PaddlePaddle上实现MNIST手写体数字识别来源:百度PaddlePaddle不久之前,机器之心联合百度推出PaddlePaddle 专栏,为想要学习这一平台的技术人员推荐相关教程与资源。
在框架解析和安装教程的介绍之后,本次专栏将教你如何在 PaddlePaddle 上实现 MNIST 手写数字识别。
目录•数据集的介绍•定义神经网络•开始训练模型•导入依赖包•初始化 Paddle•获取训练器•开始训练•使用参数预测•初始化 PaddlePaddle•获取训练好的参数•读取图片•开始预测•所有代码•项目代码•参考阅读数据集的介绍如题目所示, 本次训练使用到的是 MNIST 数据库的手写数字, 这个数据集包含60,000 个示例的训练集以及10,000 个示例的测试集. 图片是 28x28 的像素矩阵,标签则对应着 0~9 的 10 个数字。
每张图片都经过了大小归一化和居中处理. 该数据集的图片是一个黑白的单通道图片, 其中图片如下:该数据集非常小, 很适合图像识别的入门使用, 该数据集一共有4 个文件, 分别是训练数据和其对应的标签, 测试数据和其对应的标签. 文件如表所示:这个数据集针对 170 多 M 的 CIFAR 数据集来说, 实在是小太多了. 这使得我们训练起来非常快, 这能一下子激发开发者的兴趣。
在训练时, 开发者不需要单独去下载该数据集,PaddlePaddle 已经帮我们封装好了, 在我们调用 paddle.dataset.mnist 的时候, 会自动在下载到缓存目录/home/username/.cache/paddle/dataset/mnist 下, 当以后再使用的时候, 可以直接在缓存中获取, 就不会去下载了。
定义神经网络我们这次使用的是卷积神经网络LeNet-5,官方一共提供了3 个分类器,分别是 Softmax 回归,多层感知器,卷积神经网络 LeNet-5,在图像识别问题上,一直是使用卷积神经网络较多。
基于模式识别的手写数字识别算法研究1. 引言手写数字识别是计算机视觉领域中的一个重要研究课题,也是现代生活中广泛应用的一个方面。
例如,银行支票自动识别、邮政编码识别等都离不开手写数字的识别。
因此,研究和改进手写数字识别算法具有重大的现实意义。
本文将从基于模式识别的角度,对手写数字识别算法进行研究。
2. 数据集介绍在进行手写数字识别算法的研究之前,我们需要获取一个有效的数据集。
常用的手写数字数据集有MNIST和SVHN等。
在本文中,我们选择使用MNIST数据集。
该数据集包含了60000张训练图像和10000张测试图像,每张图像都是一个28x28的灰度图像。
3. 特征提取与预处理在进行手写数字识别之前,我们需要进行特征提取和预处理。
特征提取是指将原始图像转化为计算机可以理解和处理的特征表示形式。
常用的特征提取方法有傅里叶变换、小波变换等。
对于手写数字识别,我们可以使用提取像素值的方法,即将每个像素点的灰度值作为特征。
预处理是指在特征提取之前,对图像进行一些必要的处理,以消除噪声和干扰。
常用的预处理方法有平滑、滤波和边缘检测等。
在本文中,我们使用简单的二值化处理方法,即将图像转化为黑白二值图像,以便于后续的特征提取和模式识别。
4. 模式识别算法模式识别是指通过对数据集的学习,将输入的图像判别为相应的数字。
常用的模式识别算法有K近邻算法、支持向量机(SVM)算法和深度学习算法等。
在本文中,我们选择使用基于深度学习的卷积神经网络(CNN)算法进行手写数字识别。
卷积神经网络是一种具有层次结构的神经网络,能够有效地从图像中提取特征。
它由多个卷积层、池化层和全连接层组成。
其中,卷积层通过在特定区域上进行滤波操作,提取图像中的局部特征;池化层通过对特定区域内的特征进行统计汇总,实现特征的降维和平移不变性;全连接层则负责将提取到的特征映射到相应的类别上。
5. 模型训练与评估在进行手写数字识别算法的研究之前,我们需要对模型进行训练和评估。
手写识别原理
手写识别是一种将手写文字转换为可编辑、可搜索的数字文本的技术。
它在现
代社会中得到了广泛的应用,例如在银行支票处理、邮政编码识别、表格数据录入等领域。
手写识别的原理主要包括预处理、特征提取、分类识别三个步骤。
首先,预处理是手写识别的第一步,它的主要目的是对手写图像进行处理,使
得后续的特征提取和分类识别能够更加准确地进行。
预处理的步骤包括图像的二值化、去噪、分割等。
二值化是将手写图像转换为黑白两色的图像,去噪是去除图像中的杂乱像素点,分割是将连续的手写文字分割成单个的字符或单词,以便后续的处理。
其次,特征提取是手写识别的关键步骤,它的主要目的是从预处理后的图像中
提取出对于识别具有代表性的特征。
特征提取的方法有很多种,常见的包括傅里叶描述子、Zernike矩、链码等。
这些方法可以从不同的角度对手写文字进行描述,
提取出不同的特征信息,为后续的分类识别提供重要的依据。
最后,分类识别是手写识别的最终目标,它的主要目的是根据特征提取的结果,将手写文字识别为对应的数字或文字。
分类识别的方法包括模板匹配、神经网络、支持向量机等。
这些方法可以根据提取的特征信息,通过训练模型来实现对手写文字的自动识别。
总的来说,手写识别的原理是通过预处理、特征提取和分类识别三个步骤,将
手写文字转换为可编辑、可搜索的数字文本。
在实际应用中,手写识别技术还面临着诸如不规则手写、噪声干扰、多语种识别等挑战,但随着深度学习等技术的发展,手写识别的准确率和稳定性将会得到进一步提高,为人们的生活带来更多的便利。
mnist手写体数字识别原理
MNIST(Modified National Institute of Standards and Technology)是一个包含手写数字图像的常用数据集,常常被
用来评估机器学习算法在图像识别任务上的性能。
MNIST数据集包含了60,000张训练图像和10,000张测试图像,这些图像都是灰度图,尺寸为28x28像素。
每个图像都有一个对应的标签,标签表示图像中所示的数字。
手写数字识别的原理通常是使用机器学习算法构建一个分类器,该分类器可以将输入的图像分类为0-9的数字。
下面是一种常
见的手写数字识别原理:
1. 数据预处理:MNIST图像通常会进行一些预处理操作,如
图像灰度化、归一化和去除噪声等。
2. 特征提取:通过特征提取算法,将图像转换为特征向量,以便机器学习算法能够对其进行处理和分类。
常见的特征提取方法包括边缘检测、HOG(Histogram of Oriented Gradients)和SIFT(Scale-Invariant Feature Transform)等。
3. 模型训练:使用训练数据集,将特征向量和对应标签作为输入,通过机器学习算法(如SVM、神经网络等)进行模型的
训练。
模型的目标是通过学习标签与特征之间的关系,使得能够准确地对新的未知图像进行分类。
4. 模型评估和优化:使用测试数据集对模型进行评估,评估指
标通常为准确率。
如果模型表现不佳,可以进行参数调整、特征选择、数据增强等优化方法来提升算法性能。
5. 预测和应用:经过训练的模型可以用于预测未知图像的标签,从而实现手写数字的识别。
可以利用该模型来实现各种应用,如自动邮件分类、数字识别等。
需要注意的是,这只是一种常见的手写数字识别原理,实际应用中可能还会有其他的方法和技术。
此外,近年来深度学习方法(如卷积神经网络)在手写数字识别任务上取得了显著的成功,成为了一种常用的手写数字识别方法。