
《管理软件应用》实践考查试卷
请按照以下题目要求,通过SPSS软件分析数据给出结果,并给出对结果的分析
和讨论。
1.10名15岁中学生身高、体重数据如下:
编号 1 2 3 4 5 6 7 8 9 10 性别男男男男男女女女女女
身高(cm) 166.0 189.0 170.0 165.1 172.0 159.4 171.3 158.0 158.6 169.0 体重(kg) 57.0 58.5 51.0 58.0 55.0 44.7 45.4 44.3 42.8 51.5 回答:1男生身高和体重的极小值、极大值?
2女生的身高、体重和体重指数的均数?标准差?
●体重指数=体重(kg)/ 身高(m)2
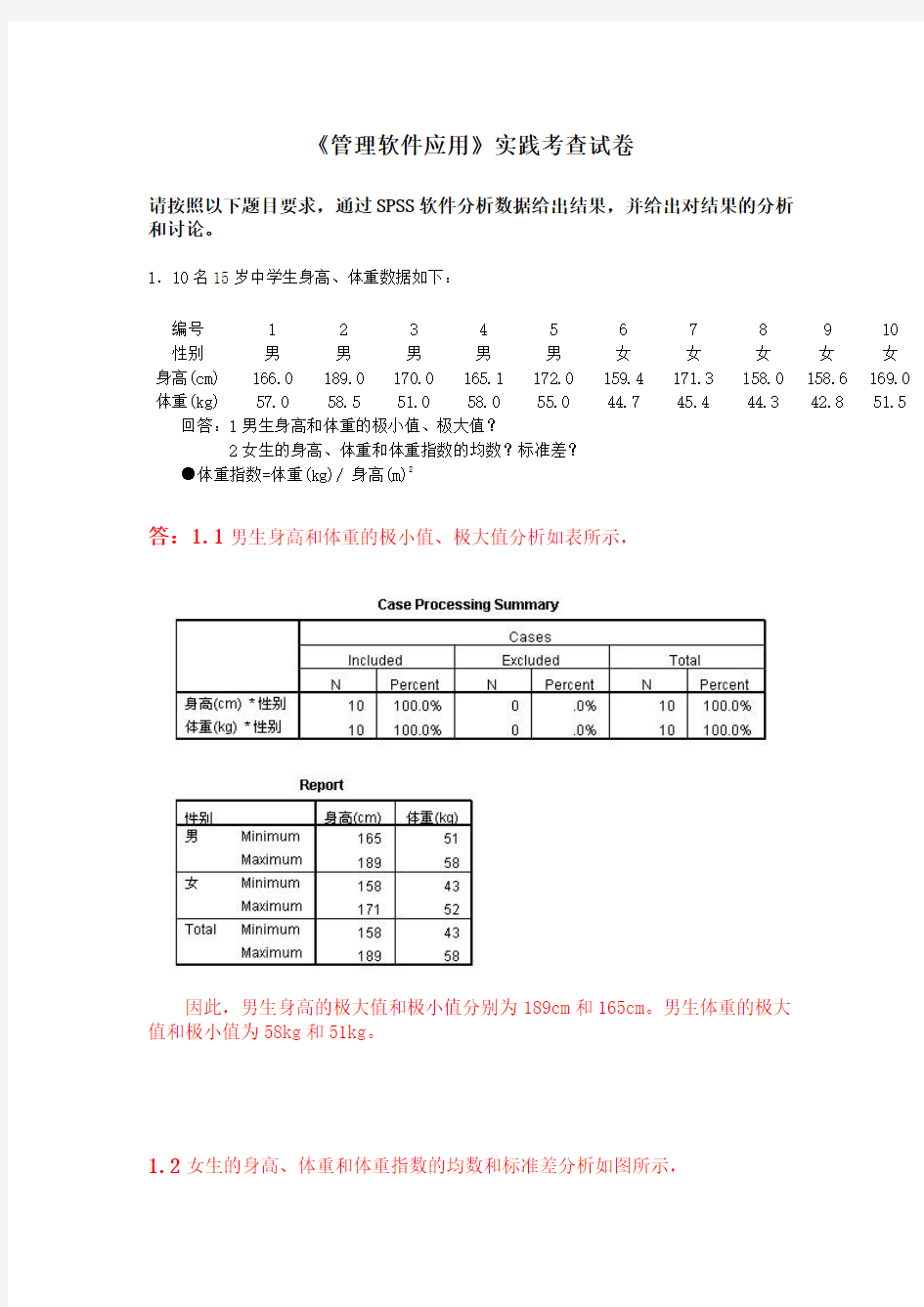
答:1.1男生身高和体重的极小值、极大值分析如表所示,
因此,男生身高的极大值和极小值分别为189cm和165cm。男生体重的极大
值和极小值为58kg和51kg。
1.2女生的身高、体重和体重指数的均数和标准差分析如图所示,
因此女生的身高均数和标准差为163.26cm和6.361,体重均数和标准差为45.74和3.358,体重指数均数和标准差为0.2801和0.01532。
2.现希望评价两位教师的教学质量,试比较其分别任教的甲、乙两班(设两班原成绩相近,
不存在差别)考试后的成绩是否存在差异?
甲班:85 73 86 77 94 68 82 83 90 88 76 85 87 74 85 80 82 88 90 93
乙班:75 90 62 98 73 75 75 76 83 66 65 78 80 68 87 74 64 68 72 80
答:分析如图所示
可以从第二个表中看出F检验的值为0.747,对应的概率p值为0.393,如果显著性水平为0.05,由于概率p值大于0.05,可以认为两个总体的方差无显著性差异,即方差具备齐性。
3. 为研究长跑运动对增强普通高校学生的心功能效果,对某校15名男生进行实验,经过5个月的长跑锻炼后,看其晨脉是否减少。锻炼前后的晨脉数据如下:
答:
从第二个表中可以看出在显著性水平为0.05时,训练前后的概率p值为0.428,大于0.05,接受零假设,可以认为训练前后的晨脉数据没有明显的线性关系。
从第三个表中可以看出最后一列的双尾检验概率p值为0.001,在置信区间为95%时,显著性水平为0.05,由于概率p值小于0.05,拒绝零假设,可以认为训练后晨脉数有减少。
其中:x1为土壤中含无机磷浓度;
x2为土壤中溶于K2C03溶液并受溴化物水解的无机磷浓度;
x3为土壤中溶于K2C03溶液但不受溴化物水解的无机磷浓度;
y为种植在20°C土壤内的玉米中的可给态磷。
建立数据文件,(1)4个变量之间的相关分析;(2)y关于x1、x2、x3、的线性回归方程。给出分析的结果,并讨论。
答:4.1
从表中第一行可知,土壤中无机磷浓度x1与x2,x3,y的相关系数分别为0.462>0,0.152>0,0.693>0,说明都呈正相关,而相伴概率Sig. 分别为0.054>0.05,0.547>0.05,0.001<0.05,说明x2,x3均与x1无影响。而y受x1的正影响,两者显著相关。
由表第二行可知,x2与x3, y的相关系数分别为0.318>0和0.354>0,说明x2与x3,y都呈正相关,而相伴概率sig. 分别为0.199>0.05和0.149>0.05,说明x3, y均与x2无影响。
由表中第三行可知,x3与y的相关系数为0.362>0,说明x3与y呈正相关,而相伴概率sig.为0.140>0.05,说明x3与y无影响。
4.2 线性回归方程
由表的第一列数据可知相关方程为y=1.785*x1-0.083*x2+0.161*x3。
但是由于x2的显著性概率为0.845>0.05, x3的显著性概率为0.171>0.05, 表示x2, x3的系数与0没有显著性的差异, x2,x3不应当作为解释变量出现在方程中。
而x1的显著性概率为0.005<0.05,表示x1的系数与0有显著性的差异,x1应当作为解释变量出现在方程中。
因此最终相关方程为y=1.785*x1。
5. 对给定数据进行探索性因子分析,分析数据并给出结果的讨论。
答:5.1特征值与方差贡献表
可以看出前两个特征值大于1,同时这两个公共因子的方差贡献率占了89.401%,说明提取这两个公共因子可以解释原变量的绝大部分信息。因此提取这两个变量为第一和第二主成分。
5.2 旋转前的因子载荷矩阵
5.3 旋转后的因子载荷矩阵
在5.2未经旋转的载荷矩阵的表中,因子变量在许多变量上均有较高的载荷,从旋转后的因子载荷矩阵可以看出。因子1在人均国民收入上有较大负荷,因子2在避孕率上有较大负荷。
5.4 因子转换矩阵
上表是因子转换矩阵,表明了因子提取方法是主成分分析,旋转的方法是方差极大法。
5.5
因子系数矩阵,可将所有主成分表示为各个变量的线性组合,即F1=-0.234*zx1+0.175*zx2
F2=0.454*zx1-0.630*zx2
5.6 其他分析
6. 对给定数据进行回归分析,用加权最小二乘法处理异方差问题。答:1、用OLS做出来的结果:
单位行程=36.834-0.014马力-0.005车重(R2=0.904)
2、用WLS做出来的结果:
单位行程=37.107-0.011马力-0.005车重(R2=0.798)
The Research and Analysis of Xiao Mila School: International Business Major: International economy and trade class 1 Member: 李雪竹41002021 夏鸿曲41002022 黄丹妮41002062 丁桑妮41002064 鲜铤41002036 李凯41002002 梅琳41002003
Abstract Since the catering enterprises actively developed in china, our team chooses one of the catering restaurants, Xiao Mila, located in the Liu Lang bay, closed to the east gate of SWUFE. It looks crowded and not very comfortable for eating hot pot. However, it is still very popular and competitive outside the East Gate and has a lot of regular customers. We decided to find out reasons for this odd phenomenon. As it is a typical catering restaurant in that area, the research gives us in-depth knowledge of catering restaurant in college student living area. Our article uses systematic research towards the operating condition of Xiao Mila. Our aims are to understand the in dividual catering businesses? operating condition, and at the same time supplement economic research, respond to our national twelfth five-year development plan, provide guidance for other catering enterprises. The investigative manner of this article is through the issuance of the form of questionnaire survey to the crowd who ate in the Xiao Mila. After the investigation, we use the statistics we got to analyze the research questions. The methods of analysis are quantitative analysis and qualitative analysis, the Comparative Method Our conclusions of the reasons for Xiao Mila?s success are its unique flavor, locality, and low price and its awesome reputation among students; the shortages of this restaurant are its inefficient service and poor sanitation. Our team also gets the conclusion that different in gender groups have different attitude towards to Xiao Mila. This difference do not only indicate the difference in female?s and male?s thinking patterns, but also point out the way for Xiao Mila to attract customers of a certain gender. Then through discussion, we come up with a suggestion that it should overcome its shortages while holding on to its best position in flavor and price. Keywords Xiao Mila; College Students; Consumption; Analysis; SWOT 1. Introduction Along with the economy development and people's living standard improving, our tertiary industry especially catering industry is developing vigorously. Especially those young, good-tasted college students with appreciating ability,
教育统计学课后作业 一、P118 1 题目:10位大一学生平均每周所花的学习时间与他们的期末考试成绩见表6-17.试问: (1)学习时间与考试成绩之间是否相关? (2)比较两组数据谁的差异程度大一些? (3)比较学生2与学生9的期末考试测验成绩。 表6-17 学习时间与期末考试成绩 1 2 3 4 5 6 7 8 9 10 学习时间考试成绩40 58 43 73 18 56 10 47 25 58 33 54 27 45 17 32 30 68 47 69 解题步骤: (1)第一步:定义变量:“xuexishijian”、“xuexichengji”后,输入数据.如下图: 1
第二步:单击选择“分析(Analyze)”中的“相关(Correlate)”中的“双变量(Bivariate Correlations)”, 将上图中的“xuexishijian”和“xuexichengji”添加到右边变量框中,如下图: 第三步:点击“确定“后,输出结果如下图: 第四步:分析结果
3 由上图可知:学习时间与学习成绩之间的pearson 相关系数为0.714,p (双侧)为0.20。自由度 df=10-2=8时,查“皮尔逊积差相关系数显著临界值表”知:r 0.05= 0.623 ; r 0.01=0.765。 因为0.765 > 0.714 >0.623,所以在0.05水平上学习时间和学习成绩是相关显著的。 (2)SPSS 软件分析结果如下图: 由上图可知:学习时间标准差和平均值为:S 1=12.037 ?X 1= 29.00 ;学习时间标准差和平均值为:S 2=12.437?X 2=56.00 根据差异系数公式可知: 学习时间差异系数为:%100?=X S CV S =12.037/29.00×100%=41.51% 学习成绩差异系数为:%100?= X S CV S =12.437/56.00×100%=22.27% 有上述结果可知学习时间差异程度大于学习成绩差异程度。 (4) 把学生2和学生9的期末考试成绩转化成标准分数: Z 2=(X -?X) /S= (73—56)/12.437=1.367 Z 9=(X-?X)/S=(68—56)/12.437=0.965 由上计算可知:学生2期末考试测验成绩优于学生9的期末考试测验成绩。 二、P119 2 题目:某班数学的平均成绩为90,标准差10;化学的平均分为85,标准差为8;物理的平均分为79,标准差为15.某生这三科成绩分别为95,80,80.试问 (1) 该生在哪一学科上突出一些? (2) 该班三科成绩的差异度如何?有无学习分化现象? (3) 该生的学期分数是多少? (4) 三科的总平均和总标准差是多少? 解题步骤:
CHAPTER 15 西北研究院蔡嘉驰131246 15.4 (i) What we choose is part of u t. Then gMIN t and u t are correlated, which causes OLS to be biased and inconsistent. (ii) I think it is uncorrelate because gGDP t controls for the overall performance of the U.S. economy. (iii) The change of U.S. minimum may someway change the state minimum and vice versa. If the state minimum is always the U.S. minimum, then gMIN t is exogenous in this equation and we would just use OLS. 15.7 (i) Because students that would do better anyway are also more likely to attend a choice school. (ii) Since u1 does not contain income, random assignment of grants within income class means that grant designation is not correlated with unobservables such as student ability, motivation, and family support. (iii) The reduced form is choice= π0 + π1faminc + π2grant + v2, and we need π2≠ 0. (iv) The reduced form for score is just a linear function of the exogenous variables: score= α0 + α1faminc + α2grant + v1. This equation allows us to directly estimate the effect of increasing the grant amount on the test score, holding family income fixed.So it is useful. C15.1 (i) The regression of log(wage) on sibs gives
课程名称:《SPSS分析方法与应用》 课程号: 2007422 一、单项选择题(共112小题) 1、试题编号:1000110,答案:RetEncryption(D)。 SPSS的安装类型有() A. 典型安装 B.压缩安装 C.用户自定义安装 D.以上都是 2、试题编号:1000310,答案:RetEncryption(D)。 数据编辑窗口的主要功能有() A.定义SPSS数据的结构 B.录入编辑和管理待分析的数据 C.结果输出 和B 3、试题编号:1000410,答案:RetEncryption(A)。 ()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。 4、试题编号:1000510,答案:RetEncryption(D)。 ()是SPSS为用户提供的基本运行方式。 A.完全窗口菜单方式 B.程序运行方式 C.混合运行方式 D.以上都是 5、试题编号:1000810,答案:RetEncryption(D)。 ()是SPSS中有可用的基本数据类型 A.数值型 B.字符型 C.日期型 D.以上都是 6、试题编号:1000910,答案:RetEncryption(D)。 spss数据文件的扩展名是( ) A..htm B..xls C..dat D..sav 7、试题编号:1001010,答案:RetEncryption(B)。 数据编辑窗口中的一行称为一个() A.变量 B.个案 C.属性 D.元组 8、试题编号:1001110,答案:RetEncryption(C)。
变量的起名规则一般:变量名的字符个数不多于() A. 6 B. 7 C. 8 D. 9 9、试题编号:1001210,答案:RetEncryption(A)。 统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 B.定距型数据 C.定序型数据 D.定类型数据 10、试题编号:1001310,答案:RetEncryption(A)。 在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 B.降序排序 C.不排序 D.可升可降 11、试题编号:1001810,答案:RetEncryption(A)。 SPSS算术表达式中,字符型()应该用引号引起来。 A 常量 B变量 C算术运算符 D函数 12、试题编号:1001910,答案:RetEncryption(A)。 复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 B AND C OR D都不是 13、试题编号:1002010,答案:RetEncryption(A)。 数据选取的方法中,()是按符合条件的数据进行选取。 A 按指定条件选取 B 随即选取 C选取某一区域内样本 D过滤变量选取 14、试题编号:1002110,答案:RetEncryption(B)。 通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的。 A 数据转置 B 加权处理 C 数据才分 D以上都是 15、试题编号:1002210,答案:RetEncryption(A)。 SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 B 加权处理 C 数据才分 D以上不都是 16、试题编号:1002310,答案:RetEncryption(B)。 SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。 A、哈佛大学 B、斯坦福大学 C、波士顿大学 D、剑桥大学 17、试题编号:1002710,答案:RetEncryption(D)。 SPSS中进行参数检验应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 18、试题编号:1002810,答案:RetEncryption(A)。 SPSS中进行输出结果的保存应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 19、试题编号:1002910,答案:RetEncryption(C)。 SPSS中进行数据的排序应选择()主窗口菜单。 A、视图 B、编辑 C、数据 D、分析
SPSS操作实验 (作业1) 作为华夏儿女都曾为有着五千年的文化历史而骄傲过,作为时代青年都曾为中国所饱受的欺压而愤慨过,因为我们多是炎黄子孙。然而,当代大学生对华夏文明究竟知道多少呢 某研究机构对大学电气、管理、电信、外语、人文几个学院的同学进行了调查,各个学院发放问卷数参照各个学院的人数比例,总共发放问卷250余份,回收有效问卷228份。调查问卷设置了调查大学生对传统文化了解程度的题目,如“佛教的来源是什么”、“儒家的思想核心是什么”、“《清明上河图》的作者是谁”等。调查问卷给出了每位调查者对传统文化了解程度的总得分,同时也列出了被调查者的性别、专业、年级等数据信息。请利用这些资料,分析以下问题。 问题一:分析大学生对中国传统文化的了解程度得分,并按了解程度对得分进行合理的分类。 问题二:研究获得文化来源对大学生了解传统文化的程度是否存在影响。 要求: 直接导出查看器文件为.doc后打印(导出后不得修改) 对分析结果进行说明,另附(手写、打印均可)。 于作业布置后,1周内上交 本次作业计入期末成绩
答案 问题一 操作过程 1.打开数据文件作业。同时单击数据浏览窗口的【变量视图】按钮,检查各个 变量的数据结构定义是否合理,是否需要修改调整。 2.选择菜单栏中的【分析】→【描述统计】→【频率】命令,弹出【频率】对 话框。在此对话框左侧的候选变量列表框中选择“X9”变量,将其添加至【变量】列表框中,表示它是进行频数分析的变量。 3.单击【统计量】按钮,在弹出的对话框的【割点相等组】文本框中键入数字 “5”,输出第20%、40%、60%和80%百分位数,即将数据按照题目要求分为等间隔的五类。接着,勾选【标准差】、【均值】等选项,表示输出了解程度得分的描述性统计量。再单击【继续】按钮,返回【频率】对话框。
习题一(与第三章内容配套) 1.数据文件:《公司职工》 1)按照以下标准,给指定的变量观察值分组: (1)变量:educ(受教育年限) 中学:educ≤12;大学: 12<educ≤16;研究生:educ≥17 (2)变量:age(年龄) 青年:age<40;中年:40≤age<60;老年:age≥60 (3)变量:salary(当前薪金) 低收入:salary≤20000;中收入:20000<salary≤40000;高收入:salary>40000 2)统计老、中、青年各组的人数及占全体职工的比率。 3)统计不同性别的职工中,高、中、低收入的人数,及占全体职工人数的比率。 4)在不同的受教育组中,按性别(gender)统计的不同职务(jobcat)的人数及占全体职工人数的比率。 5)同3),但还要统计每一组的平均当前薪金(salary)、最大当前薪金和最小当前薪金。 2.数据文件:《学生考试成绩》 1)按以下要求,将成绩score分为五等:优:score≥90;良:80≤score<90;中:70≤score<80;及格:60≤score<70;不及格:score<60。 2)按照以上五个等级,统计每一个等级的人数及占总体的比率: (1)总体取全体参加考试的学生; (2)总体取每一个班级; (3)总体取男生及女生。 3)求全体参加考试学生的总平均成绩、每一班的平均成绩以及男、女生的平均成绩。 4)全体学生成绩的中位数是多少?男、女生成绩的中位数分别是多少?成绩在60分(含)以上的学生占全体学生的比率是多少?80%的学生成绩不低于多少分?每一班的最高分与最低分分别是多少? 5)在每一个班级中,分男、女生统计不同成绩等级的学生人数及每一等级的平均分、最高分与最低分。 答案: 1. 1)
SPSS软件操作练习 参考书:《生物统计学》张勤主编(第2版) 一、均数差异显著性检验 (一)单个样本t测验 (二)独立样本测验(两个样本重组比较) (三)两个样本配对比较 二、方差分析 (一)单因素方差分析(样本量相等、样本量不等) 三、相关回归分析 相关分析:Analyze→Correlate→Bivariate(简单相关) 相关回归:Analyze→Regression→Linear 注意:Dependent:因变量y Independent:自变量x 四、卡方测验 (一)独立性:Date Weight→Cases→Frequency Variable(观察值)→ok Analyze→Descriptive Statistics→Crosstabs→Row(行)、Columns(列)→Statistics→Chi-Square (二)适合性测验:Date Weight→Cases→Frequency Variable(观察值)→ok Analyze→Nonparametric Tests→Chi-Squareic(注意比例的填写) 五、两因素方差分析 (一)两因素无重复值方差分析 (二)两因素有重复值方差分析 一、均数差异显著性检验 (一)单个样本t测验 P66 例5.1
One-Samp le Test -1.035 16 .316-1.00000 -3.0486 1.0486 Vit t df Sig. (2-tailed)Mean Dif f erence Lower Upper 95% Conf idence Interv al of the Dif f erence Test Value = 21 由结果可知:t=-1.035 sig=0.316>0.05 该批罐头的平均维生素C 与规定的21mg/g 无显著差异。 注:Sig.(2-tailed) 双侧检验概率 95% confidence.... 差值的95%置信下线和置信上线 (二)独立样本测验(两个样本重组比较) P70 例5.3
吉林财经大学 《SPSS统计软件分析》作业(2010——2011学年第一学期) 学院信息学院 专业班级电子商务0806班 学生姓名王瑞霞 学号1403080616
1、对未分组资料频数分析 从中国统计局中获得从11月21日至30日国内50个城市主要食品平均价格变动情况,以该数据为例为例,进行频数分析。 首先输入数据: 选择Analyze中Descriptive Statistics——Frequencies,打开Frequencies对话框;将需处理的变量键入变量框中
单击Statistics…按钮统计量子对话框12指标,选中所需要计算的指标: 单击Charts …按钮,选择需绘制的统计图: 单击OK按钮开始运行,运行结果为:
从上图中可以看出数据中缺失值为0,花生油的平均价格104.84是最高的,而巴氏牛奶的平均价格1.81最低,全部食品平均价格的平均数为16.5327,标准差为22.4668,各种食品的平均价格差距较大。
条形图、饼形图以及直方图是用不同的图形表示方法来说明数据的指标,其实质是一样的,从图中可以看出平均价格在0—22元之间的食品是最多的,20—40元之间的食品数次之,接下来是40—60元之间的食品,不存在平均价格在60—100之间的食品。 2、以食品平均价格为依据对数据进行分组并对分组后的数据进行频数分析: Transform —Recode—Into same V ariables ,将要分组的变量放入Numeric 栏中,单击Old and new V alues分组:
分组结果如下图所示: 回到数据编辑窗,定义变量的V alue labels : 再对食品平均价格进行频数分析,分析结果如下截图所示
期末实践考查 一、一家消费者调查有限公司,它为许多企业提供消费者态度和消费者行为的调查。在一项研究中,客户要求调查消费者的消费特征,此特征可以用来预测用户使用信用卡的支付金额。研究人员收集了50位消费者的年收入、家庭人口和每年使用信用卡支付的金额数据。试按照客户要求进行分析,给出分析报告(数据见附表)。 Descriptive Statistics Mean Std. Deviation N 消费金额(元)3964.06 933.494 50 年收入(元)43480.00 14550.742 50 家庭人口(人) 3.42 1.739 50 Correlations 消费金额(元)年收入(元)家庭人口(人)Pearson Correlation 消费金额(元) 1.000 .631 .753 年收入(元).631 1.000 .173 家庭人口(人).753 .173 1.000 Sig. (1-tailed) 消费金额(元). .000 .000 年收入(元).000 . .115 家庭人口(人).000 .115 . N 消费金额(元)50 50 50 年收入(元)50 50 50 家庭人口(人)50 50 50 Model Summary b Model R R Square Adjusted R Square Std. Error of the Estimate 1 .909a.826 .818 398.091
ANOVA b Model Sum of Squares df Mean Square F Sig. 1 Regression 35250755.672 2 17625377.836 111.218 .000a Residual 7448393.148 47 158476.450 Total 42699148.820 49 Coefficients a Model Unstandardized Coefficients Standardized Coefficients t Sig. B Std. Error Beta 1 (Constant) 1304.905 197.655 6.602 .000 年收入(元) .033 .004 .516 8.350 .000 家庭人口(人) 356.296 33.201 .664 10.732 .000 结果分析:由题目可知客户要求,是根据消费者年收入、家庭人口来预测其每年使用信用卡支付的金额数据,属于多元线性回归问题,其中年收入和家庭人口 看作两个自变量,每年信用卡支付金额看作因变量。 由分析得: 121304.9050.033356.296y x x =++ y :信用卡支付金额 1x :年收入 2x :家庭人口 拟合优度检验2R 为0.818,回归方程能很好的代表样本数据。回归方程F 检验和回归系数T 检验的相伴概率都小于显著性水平,拒绝零假设即回归方程和回归系数都具显著型。 二、下表为运动员与大学生的身高(cm )与肺活量(cm3)的数据,考虑到身高与肺活量有关,而一般运动员的身高高于大学生,为进一步分析肺活量的差异是否由于体育锻炼所致,试作控制身高变量的协方差分析,并给出分析报告。
《SPSS软件应用》教案 ●复习一:数据库结构建立 ●复习二:数据合并 ●复习三:定距数据的分组 有两种方法:一是在transform下的visual bander(可视离散化)栏完成;一是在transform转换中的compute计算变量来完成。 由于Computer需要自己定义变量标签,Visual Bander直接选择显示变量标签,因此在分组的时候,通常采取Visual Bander来实现。 第四讲数据编码和计数 教学原因:由于录入好的数据,有时候并不能够直接用来分析,因此需要对变量进行重组或者称为转换,将数据重新编码、组合等; 教学目的:培养学生根据研究主题的需要,对变量数据进行转换。 教学内容:对数据进行重新编码和计数。 一、Recode的重新编码功能 功能:用于从原变量值按照某种对应关系生成新变量值,可以将新值赋给原变量,也可生成新变量。 如果是13.0,则实现路径:Transform——Recode——into the same variables(编码为相同变量)/into different variables(编码为不同变量);如果是16.0及以上,则直接是Transform——recode into different variable。我们一般要求重新编码为一个新变量,目的是为了保持原有变量数据。
[例题:对自己的受教育情况(a6.1)的变量值重新编码为高中低] 解释:原变量的取值是如下,因此,我们可以考虑将1-3设置为低教育程度,4-6设置为中等教育程度,7及以上设置为高等教育程度。 具体实现过程: 第一步,单击Transform——recode into different variables( SPSS 13.0使用)或Recode into different variable (重新编码为不同变量时,16.0及以上使用)时,出现下窗口: 第二步,将左边的变量(自己的受教育情况)选中,然后移入右边Input variable →output variable( 输入变量→输出变量) 空白栏中,具体如下图所示:
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。
第一部分 数据整理考试题 1建立以下数据的数据文件: 对所建立的数据文件进行以下处理: ⑴计算每个学生的总成绩、平均成绩,并按照总成绩的大小进行排序(转换-计算变量,数据-排序个案) ⑵设Z Y X 、、分别表示语文、数学、化学,对称其进行以下处理: ①X X =' ②5+='Y Y (x1=sqrt(x)) ③对化学成绩,若是男生,5+='Z Z (转换-计算变量) 若是女生:10+= 'Z Z ④把数学成绩分成优、良、中三个等级,规则为优(X ≥85),良(75≤X ≤ 84),中(X ≤74),并进行汇总统计。(转换-重新编码为不同变量,频数分析) 2 在一次智力测验中,共有10个选择题,每题有A,B,C,D 四个答案,8个被测对象的答卷如下表。已知第1、6、10题的正确答案为A ,第4、5、7、8题的正确答案为B, 第2、9题的正确答案为C, 第3题的正确答案为D,请建立合适的数据文件,统计每个被测对象的总成绩(满分100)。(转换-对个案内的值计数,选择题号,再定义值 A or B C D 然后添加,转换-计算变量,Q+W+E+R 再乘以10就是总成绩) 3某个汽车收费站在每10分钟内统计到达车辆的数量,共取得20次观察数据,分别是:27、30、3l 、33、16、20、34、24、19、27、21、28、32、22、15、33、26、26、38、24,现要求以5为组距,对上述资料进行分组整理。(再重新转换-重新编码为不同变量) 4 练习加权处理功能: ⑴练习课本案例3-8(p84).(加权销售量,再分析-描述统计-描述,只添加单价,均值即是当天平均价格)
第1题:基本统计分析1 分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。 1、基本思路: (1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。分组后进行频数分析并绘制带正态曲线的直方图。 (2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。 操作步骤: (1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。 存取款金额1 频率百分比有效百分比累积百分比 有效1.00 82 34.6 34.6 34.6 2.00 76 32.1 32.1 66.7 3.00 10 4.2 4.2 70.9 4.00 22 9.3 9.3 80.2 5.00 47 19.8 19.8 100.0 合计237 100.0 100.0 (2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。 统计量 存(取)款金额 20岁以下 N 有效 1 缺失 0 百分位数 25 50.00 50 50.00 75 50.00 20~35岁 N 有效 131 缺失 0 百分位数 25 500.00 50 1000.00 75 5000.00 35~50岁 N 有效 73 缺失 0 百分位数 25 500.00 50 1000.00 75 4500.00 50岁以上 N 有效 32 缺失 0 百分位数 25 525.00 50 1000.00 75 2000.00 结果及结果描述: 频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
SPSS统计练习题及答案 一、选择题(选择类) (A)1、在数据中插入变量的操作要用到的菜单是: A Insert Variable; B Insert Case; C Go to Case; D Weight Cases (C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是: A Sort Cases; B Select Cases; C Compute; D Categorize Variables (C)3、Transpose菜单的功能是: A 对数据进行分类汇总; B 对数据进行加权处理; C 对数据进行行列转置; D 按某变量分割数据 (A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明: A. 按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别; B. 三种城市身高没有差别的可能性是0.043; C. 三种城市身高有差别的可能性是0.043; D. 说明城市不是身高的一个影响因素 (B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异; B 服用某种药物前后病情的改变情况; C 服用药物和没有服用药物的病人身体状况的差异; D性别和年龄对雇员薪水的影响 二、填空题(填空类) 6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。 7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。 8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。 三、名词解释(问答类) 9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。 10、Chi-Square test:卡方检验,它是非参数检验的一种方法,来检验变量的几个取值所占百分比是否和我们期望的比例没有统计学差异。比如我们在人群中抽取了一个样本,可以用该方法来分析四种血型所占的比例是否相同(都是25%),或者是否符合我们所给出的一个比例(如分别为10%、30%、40%和20%)。 四、简答题(问答类) 11、用SPSS对数据进行分析的基本流程是什么? 答:(1)、将数据输入SPSS,并保存; (2)、进行必要的预分析(分布图、均数标准差等的描述等),以确定应采用的检验方法; (3)、按题目要求进行统计分析; (4)、保存和导出分析结果。 12、对数据进行方差分析时,Univariate菜单和Multivariate菜单最大的区别是什么? 答:当因变量只有一个时,使用Univariate菜单,当因变量不止一个时,使用Multivariate菜单。 13、简述SPSS打开其它格式数据的几种方法? 答:(1)、直接打开:选择菜单File==>Open==>Data或直接单击快捷工具栏上的打开按钮; (2)、使用数据库查询打开:选择菜单File==>Open Database==>New Query,根据向导打开数据; (3)、使用文本向导读入文本文件:选择菜单File==>Read Text Data 14、指定数据按某个变量进行排序需要用到哪个菜单?
第二部分SPSS软件的应用指南 第一章数据文件 数据文件是统计分析的基础,它提供系统分析所需的数据。数据文件既可由SPSS系统数据文件编辑窗口产生,也可以以其他数据库文件或电子表格的数据文件转换生成。 第一节数据文件的建立命令 一、定义变量(Define Variable) 定义变量就是建立数据文件的结构,输入数据之前要定义变量。打开SPSS系统,进入SPSS的数据编辑窗口。在数据编辑窗口的左下方有两个工选择的按钮,分别是数据浏览和变量浏览。如图1~2: 图2 数据浏览和变量浏览 选定数据浏览(Data View),系统进入数据输入、编辑、修改状态;选定变量浏览(Variable View),系统进入变量定义、修改状态。 当选定变量浏览状态后,可看见在窗口上方有一行英文标记,即变量属性标记。
:变量名。在其下面的方格里输入变量名,英文、中文都可,系统默认值为V AR00001,如变量名都采取系统默认,则依次为V AR00002、V AR00003…。如不采用系统默认值。其变量名的命名有以下原则: ⑴变量名不能多于8个字符(一个汉字为两个字符); ⑵英文名,首字符必须是字母,其后可为除“?”、“!”、“*”的以外字符,不能以“-”、“.”作为变量名的最后一个字符; ⑶变量名不能与SPSS保留字相同。SPSS保留字有:ALL、AND、BY、EQ、GE、GT、LE、LT、NE、NOT、OR、TO、WTTH; ⑷变量名英文字母不区分大小写。 :变量类型。系统默认为数值型(Numeric)。如需重新定义,则点击,后面出现“…”,点击“…”,进入数据类型对话框,如图3 图中, :标准数值类型变量,默认长度为8位,小数位数2位。SPSS中多数变量都是数值型变量。 :带逗点的数值变量。从小数点向左右三位一小节,用逗点分节。 :带圆点的数值变量。从小数点向左右三位一小节,用圆点分节,小数点用逗点表示。 :科学计数法的数值变量。 :日期时间型变量。比较常用的是“mm/dd/yyyy”型,即月月/日日/年年年年,如08/15/2000表示2000年8月15日。 :带美元($)符号的变量。 :用户自定义型变量。可通过Edit Option Data实现。 :字符型变量。默认长度为8位。 :变量数据位数长度。默认为8位。 :变量数据的小数位数长度。默认为2位。 :变量标签。在此栏中可输入中、英文字符,用以对变量进行说明。例如:性别变量名用英文“sex”表示,则变量标签可用中文“性别”标识。变量标签的字符最多可达255个。 :变量数值标签。对某些用数值代码输入的数据,此项是对数值的说明。如:1表示
《SPSS统计软件》课程作业 要求:数据计算题要求注明选用的统计分析模块和输出结果;并解释结果的意义。完成后将作业电子稿发送至 1. 某单位对100名女生测定血清总蛋白含量,数据如下: 计算样本均值、中位数、方差、标准差、最大值、最小值、极差、偏度和峰度,并给出均值的置信水平为95%的置信区间。 解: 描述 统计量标准误 血清总蛋白含量均值.39389 均值的95% 置信区间下限 上限 5% 修整均值 中值 方差
标准差 极小值 极大值 范围 四分位距 偏度.054.241 峰度.037.478 样本均值为:;中位数为:;方差为:;标准差为:;最大值为:;最小值为:;极差为:;偏度为:;峰度为:;均值的置信水平为95%的置信区间为:【,】。 2. 绘出习题1所给数据的直方图、盒形图和QQ图,并判断该数据是否服从正态分布。解:
正态性检验 Kolmogorov-Smirnov a Shapiro-Wilk 统计量 df Sig. 统计量 df Sig. 血清总蛋白含量 .073 100 .200* .990 100 .671 a. Lilliefors 显着水平修正 *. 这是真实显着水平的下限。 表中显示了正态性检验结果,包括统计量、自由度及显着性水平,以K-S 方法的自由度sig.=,明显大于,故应接受原假设,认为数据服从正态分布。 3. 正常男子血小板计数均值为9 22510/L , 今测得20名男性油漆工作者的血小板计数值(单位:9 10/L )如下: 220 188 162 230 145 160 238 188 247 113 126 245 164 231 256 183 190 158 224 175 问油漆工人的血小板计数与正常成年男子有无异常