
第二章课后作业
【第1题】
解:由题可知消费者对糖果颜色得偏好情况(即糖果颜色得概率分布),调查者取500块糖果作为研究对象,则以消费者对糖果颜色得偏好作为依据,500块糖果得颜色分布如下表1、1所示:
表1、1 理论上糖果得各颜色数
由题知r=6,n=500,我们假设这些数据与消费者对糖果颜色得偏好分布就是相符,所以我们进行以下假设:
原假设:类所占得比例为
其中为对应得糖果颜色,已知,
则检验得计算过程如下表所示:
在这里。检验得p值等于自由度为5得变量大于等于18、0567得概率。在Excel 中输入“”,得出对应得p值为,故拒绝原假设,即这些数据与消费者对糖果颜色得偏好分布不相符。
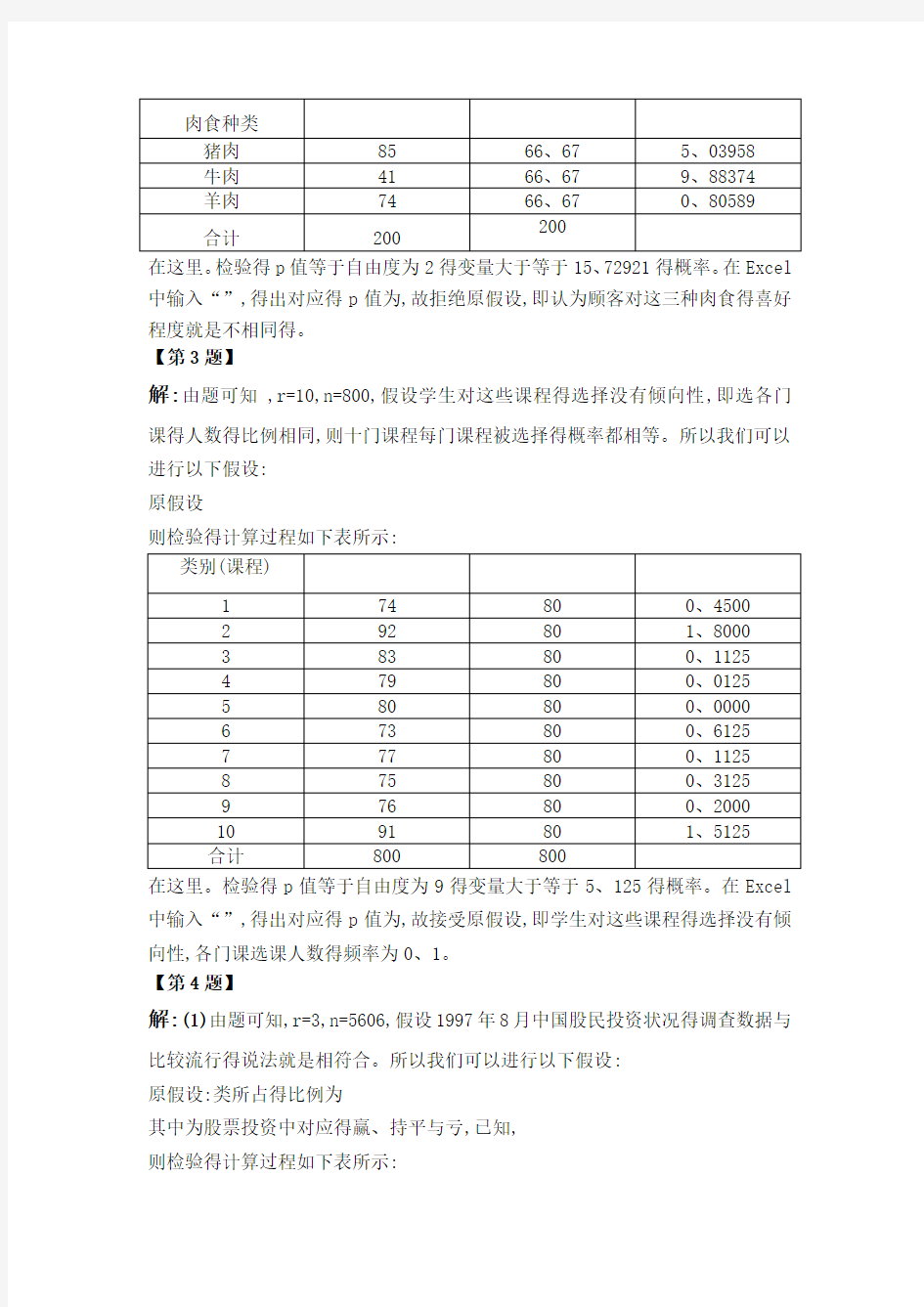
【第2题】
解:由题可知 ,r=3,n=200,假设顾客对这三种肉食得喜好程度相同,即顾客选择这三种肉食得概率就是相同得。所以我们可以进行以下假设:
原假设
则检验得计算过程如下表所示:
在这里。检验得p值等于自由度为2得变量大于等于15、72921得概率。在Excel 中输入“”,得出对应得p值为,故拒绝原假设,即认为顾客对这三种肉食得喜好程度就是不相同得。
【第3题】
解:由题可知 ,r=10,n=800,假设学生对这些课程得选择没有倾向性,即选各门课得人数得比例相同,则十门课程每门课程被选择得概率都相等。所以我们可以进行以下假设:
原假设
则检验得计算过程如下表所示:
在这里。检验得p值等于自由度为9得变量大于等于5、125得概率。在Excel 中输入“”,得出对应得p值为,故接受原假设,即学生对这些课程得选择没有倾向性,各门课选课人数得频率为0、1。
【第4题】
解:(1)由题可知,r=3,n=5606,假设1997年8月中国股民投资状况得调查数据与比较流行得说法就是相符合。所以我们可以进行以下假设:
原假设:类所占得比例为
其中为股票投资中对应得赢、持平与亏,已知,
则检验得计算过程如下表所示:
在这里。检验得p值等于自由度为2得变量大于等于3511、96137得概率。在Excel中输入“”,得出对应得p值为,故拒绝原假设,即认为1997年8月中国股民投资状况得调查数据与比较流行得说法就是不相符合得。
(2)解:由题知股票投资中,赢包括盈利10%及以上、盈利10%以下,符合条件得股民共有151+122=273人;持平可以指基本持平,符合条件得股民共有240人;亏包括亏损不足10%与亏损10%及以上,符合条件得股民共有517+240=757人。
由题可知,r=3,n=1270,假设2003年2月上海青年报上得调查数据与比较流行得说法就是相符合。所以我们可以进行以下假设:
原假设:类所占得比例为
其中为股票投资中对应得赢、持平与亏,已知,
则检验得计算过程如下表所示:
在这里。检验得p值等于自由度为2得变量大于等于188、21372得概率。在Excel中输入“”,得出对应得p值为,故拒绝原假设,即认为2003年2月上海青年报上得调查数据与比较流行得说法就是不相符合得。
【第5题】
解:由题意,我们将“开红花”、“开白花”与“开粉红色花”分别记为,并记所占得比例为,本题所要检验得原假设为:
其中,这些都依赖一个未知参数。在原假设成立时得似然函数为
则对L(p)取对数得
从而有对数似然方程
即。据此求得p 得极大似然估计,从而得到得极大似然估计 。它们分别为0、2025、0、3025与0、495。由此得各类得期望频数得估计值。它们分别为24、3、36、3、132、20与59、4。所以统计量得值为
这里r=3,m=1,r-m-1=1。检验得p 值等于自由度为1得变量。利用Excel 可以算出p 值,故接受原假设,即我们认为以上数据在0、05得水平下与遗传学理论就是相符得。 【第6题】
解:由题意,我们可以得到以下信息:
① 遗传因子得分布律为:(其中p+q+r=1)
②血型得分布律为:
将“O ”血型、“A ”血型、“B ”血型与“AB ”血型这四类血型分别记为,并记所占得比例为,本题所要检验得原假设为:
pq p qr q p pr p r H 2 ,2 ,2p ,p :42322210=+=+==
这些都依赖两个未知参数。在原假设成立时得似然函数为
58
132
132
436
436
748
58132243623742)
2()
22()
22()
1( )2()2()2()(),(pq p q q
q p p
q p pq qr q pr p r q p L ------∝++∝
则对L(p,q)求对数得
pq
p q q q p p q p q p L 2ln 58)22ln(132ln 132)22ln(436ln 436)1ln(748),(ln +--++--++--=对求偏导数得
???
?
??
?=+---+---+---=??=+---+---+---=??0
58221321322287201748ln 058222640224364361748ln q p q q q p q p q L p p q q p p q p p L 利用Mathematica 软件求解(程序编码及运行结果见附录)
解得p 与q 得极大似然估计为,从而得得极大似然估计。它们分别为0、37332、0、43668、0、13220与0、05780。由此得各类得期望频数得估计值。它们分别为373、32、436、68、132、20与57、80。所以统计量得值为
003292
.0 80
.57)80.5758(20.132)20.132132(68.436)68.436436(32.373)32.373374(2
2222
=-+
-+-+-=χ 这里r=4,m=2,r-m-1=1。检验得p 值等于自由度为1得变量。有Excel 可以算出p 值为,故接受,我们认为以上数据与遗传学理论就是相符得。 附录 ①程序代码:
NSolve[{(-748)/(1-p-q)+436/p+(-436)/(2-p-2*q)+0+(-264)/(2-q-2*p)+58/p ==0,(-748)/(1-p-q)+0+(-872)/(2-p-2*q)+132/q+(-132)/(2-q-2*p)+58/q==0},{p,q}]//MatrixForm
②利用Mathematica 软件运行结果: Out[21] //MatrixForm
注:在上述结果中由于p + q = 1-r < 1,所以软件运行得结果中只有第四个解满足条件,即p 与q 得极大似然估计为。 【第7题】
解:由题知,在豌豆实验中,子系从父系(或母系)接受显性因子“黄色”与“青色”
得概率分别为p 与1-p,而子系从父系(或母系)接受显性因子“圆”与“有角”得概率分别为q 与1-q 。
我们将豌豆实验中得到得“黄而圆得”、“青而圆得”、“黄而有角得”与“青而有角得”这四类豌豆分别记为,,,,则这四类豌豆得分布律如下表所示:
将豌豆类型所占得比例记为,则本题所要检验得原假设为:
这些都依赖两个未知参数。在原假设成立时得似然函数为
266280423416423416322210121082315)1()1()2()2( ])1()1[(])1)(2([])1)(2([)]2)(2([),(q p q p q p q p q p p p q q q p pq q p L ----∝--------∝则对L(p,q)求对数得
)
1ln(266)1ln(280)2ln(423)2ln(416ln 423ln 416),(ln q p q p q p q p L -+-+-+-++=对求偏导数得
即得出下列方程:
解得p 与q 得极大似然估计为,从而得得极大似然估计。它们分别为0、56923、0、17898、0、19157与0、06023、由此得各类得期望频数得估计值。它们分别为316、489、99、511、106、511与33、489。所以统计量得值为
082564
.1 489
.33)489.3332(511.106)511.106101(511.99)511.99108(489.316)489.316315(22222
=-+
-+-+-=χ 这里r=4,m=2,r-m-1=1。检验得p 值等于自由度为1得变量。利用Excel 可以算出p 值为,故接受,我们认为观察数据与这样一个遗传学得模型就是相符得。
第七数据分析的定性方法 数据分析是指对你所见、所闻、所读到的信息进行组织以便更好地理解所获信息。通过分析浙西数据,你可以描述状态、进行解释、提出假设、构建理论,并将你的结论与其他结论进行观念。而要实现这一目标,必须首先对所收集的资料进行分类、汇总、建模和解释。 学习目标: ?重述定性与定量数据分析方法的区别; ?理解项目研究过程中三个阶段上所采用的定性数据分析方法; ?了解并应用若干定性数据分析方法; ?讨论各种可用于定性数据分析的计算机程序。 7.1 引言 定性数据分析方法的发展,由原来的操作上的不严谨性而受到批判,如今的广泛运用。 7.2 定性与定量数据分析的异同 回顾: 定性分析与定量分析的异同 数据收集过程中——制定备忘录,思考基本概念单位或基本概念类型 分析过程中采用的方法——内容分析(content analysis)、持续比较分析(constant comparative analysis)、构建矩阵(matrix building)、绘制图表(mapping)、渐进法(successine approximation)、域分析(domain analysis)、分类构架(taxonomy building)、识别理想型(ideal type identification)、构建事件结构和创建模型(event-structure building and modeling )。 定量研究对数据及研究程序的要求——简明、清晰: a)使读者确信并能够证明报告中的结论 b)利用数据进行二次分析 c)使得研究大体上能够被重复 d)更容易发现欺骗或疏忽 7.3 定性分析 概念:把数据按照主题、概念或特征加以分类,进行分析。研究人员提出新概念、规范概念性定义并研究概念之间的关系。 麦尔斯和哈伯曼(1994)提出,数据分析包括三个方面:筛选数据、展示数据和归纳或证明
第一章:一、单选题 1.以下的英文缩写中表示数据库管理系统的是( B)。 A. DB B.DBMS C.DBA D.DBS 2.数据库管理系统、操作系统、应用软件的层次关系从核心到外围分别是(B )。 A. 数据库管理系统、操作系统、应用软件 B. 操作系统、数据库管理系统、应用软件 C. 数据库管理系统、应用软件、操作系统 D. 操作系统、应用软件、数据库管理系统 3.DBMS是(C )。 A. 操作系统的一部分B.一种编译程序 C.在操作系统支持下的系统软件 D.应用程序系统 4.数据库系统提供给用户的接口是(A )。A.数据库语言 B.过程化语言 C.宿主语言D.面向对象语 5.(B )是按照一定的数据模型组织的,长期存储在计算机内,可为多个用户共享的数据的聚集。 A.数据库系统 B.数据库C.关系数据库D.数据库管理系统 6. ( C)处于数据库系统的核心位置。 A.数据模型 B.数据库C.数据库管理系统D.数据库管理员 7.( A)是数据库系统的基础。 A.数据模型B.数据库C.数据库管理系统D.数据库管理员 8.( A)是数据库中全部数据的逻辑结构和特征的描述。 A.模式B.外模式 C.内模式 D.存储模式 9.(C )是数据库物理结构和存储方式的描述。 A.模式 B.外模式 C.内模式D.概念模式 10.( B)是用户可以看见和使用的局部数据的逻辑结构和特征的描述》 A.模式B.外模式C.内模式D.概念模式 11.有了模式/内模式映像,可以保证数据和应用程序之间( B)。 A.逻辑独立性B.物理独立性C.数据一致性D.数据安全性 12.数据管理技术发展阶段中,文件系统阶段与数据库系统阶段的主要区别之一是数据库系统( B)。 A.有专门的软件对数据进行管理 B.采用一定的数据模型组织数据 C.数据可长期保存 D.数据可共享 13.关系数据模型通常由3部分组成,它们是(B )。 A. 数据结构、数据通信、关系操作 B. 数据结构、关系操作、完整性约束 C. 数据通信、关系操作、完整性约束 D. 数据结构、数据通信、完整性约束 14.用户可以使用DML对数据库中的数据进行(A )操纵。 A.查询和更新B.查询和删除 C.查询和修改D.插入和修改 15.要想成功地运转数据库,就要在数据处理部门配备( B)。 A.部门经理B.数据库管理员 C.应用程序员 D.系统设计员 16.下列说法不正确的是(A )。 A.数据库避免了一切数据重复 B.数据库减少了数据冗余 C.数据库数据可为经DBA认可的用户共享 D.控制冗余可确保数据的一致性 17.所谓概念模型,指的是( D)。 A.客观存在的事物及其相互联系 B.将信息世界中的信息数据化 C.实体模型在计算机中的数据化表示 D.现实世界到机器世界的一个中间层次,即信息世界 18.数据库的概念模型独立于( A)。 A.具体的机器和DBMS B.E-R图C.数据维护 D.数据库 19.在数据库技术中,实体-联系模型是一种( C)。 A. 逻辑数据模型 B. 物理数据模型 C. 结构数据模型 D. 概念数据模型 20.用二维表结构表示实体以及实体间联系的数据模型为(C )。 A.网状模型 B.层次模型 C.关系模型 D.面向对象模型 二、填空题 1.数据库领域中,常用的数据模型有(层次模型)、网状模型和(关系模型)。 2.关系数据库是采用(关系数据模型)作为数据的组织方式。 3.数据库系统结构由三级模式和二级映射所组成,三级模式是指(内模式、模式、外模式),二级映射是指 (模式/内模式映射、外模式/模式映射)。 4.有了外模式/模式映像,可以保证数据和应用程序之间的(逻辑独立性)。 5.有了模式/内模式映像,可以保证数据和应用程序之间的(物理独立性)。 6.当数据的物理存储改变了,应用程序不变,而由DBMS处理这种改变,这是指数据的(物理独立性)。 三、简答题 1.在一个大型公司的账务系统中,哪种类型的用户将执行下列功能? a)响应客户对他们账户上的各种查询;b)编写程序以生成每月账单;c)为新类型的账务系统开发模式。 答:a)最终用户;b)应用程序员;c)该部门的DBA或其助手。 2.用户使用DDL还是DML来完成下列任务? a)更新学生的平均成绩;b)定义一个新的课程表;c)为学生表格加上一列。 答:a——DML,更新是在操作具体数据;b和c——DDL,建立和修改表结构属于数据定义。 第二章:一、单选题
《数据分析》练习题 1.一个地区某月前两周从星期一到星期五各天的最低气温依次是(单位:℃):x 1, x 2, x 3, x 4, x 5和x 1+1, x 2+2, x 3+3, x 4+4, x 5+5,若第一周这五天的平均最低气温为7℃,则第二周这五天的平均最低气温为 。 2.有10个数据的平均数为12,另有20个数据的平均数为15,那么所有这30个数据的平均数是( ) A .12 B. 15 C. 1 3.5 D. 14 3.一组数据8,8,x ,6的众数与平均数相同,那么这组数据的中位数是 ( ) A. 6 B. 8 C.7 D. 10 4.某校在一次考试中,甲乙两班学生的数学成绩统计如下: 请根据表格提供的信息回答下列问题: (1)甲班众数为 分,乙班众数为 分,从众数看成绩较好的是 班; (2)甲班的中位数是 分,乙班的中位数是 分; (3)若成绩在80分以上为优秀,则成绩较好的是 班;、 (4)甲班的平均成绩是 分,乙班的平均成绩是 分,从平均分看成绩较好的是 班. 5.在方差的计算公式 ()()()222 21210120202010 s x x x ??= -+-+???+-??中, 数字10和20分别表示的意义可以是( ) A .数据的个数和方差 B .平均数和数据的个数 C .数据的个数和平均数 D .数据组的方差和平均数 6..如果将所给定的数据组中的每个数都减去一个非零常数,那么该数组的 ( ) A.平均数改变,方差不变 B.平均数改变,方差改变 C.平均输不变,方差改变 D.平均数不变,方差不变 7..已知7,4,3,,321x x x 的平均数是6,则_____________321=++x x x . 8..已知一组数据-3,-2,1,3,6,x 的中位数为1,则其方差为 . 9..已知一组数据x 1,x 2,x 3,x 4,x 5的平均数是2,方差是 3 1 ,那么另一组数据3x 1-2,3x 2-2,3x 3-2, 3x 4-2,3x 5-2的平均数是和方差分别是 . 10..关于一组数据的平均数、中位数、众数,下列说法中正确的是( ) A.平均数一定是这组数中的某个数 B. 中位数一定是这组数中的某个数 C.众数一定是这组数中的某个数 D.以上说法都不对 分数 50 60 70 80 90 100 人数 甲 1 6 12 11 15 5 乙 3 5 15 3 13 11
数据分析与处理答案 Prepared on 24 November 2020
一、简答题(5×2分, 共10分) 1、请解释质量控制图中三条主要控制线的意义:CL 、UCL 、LCL 未学,不考 2、请解释正交设计表“L 934” 这个符号所指代的意义。如果要做6因素4水平实验,应该选择以下哪一个正交表(不考虑交互作用):L 1645,L 3249 L: 正交; 9:9行或9次实验; 3:3个水平 ; 4:4列或4个因素 选L 3249 二、计算题(90分) 1、某分析人员分别进行4次平行测定,得铅含量分别是、、、、,试分别用3s 法、Dixon 法和Grubbs 检验法判断是否为离群值。(,4=, ,5=)(12分) x =, s=, 3s 法:∣ 应保留 Dixon :70.6360.08 0.89671.8560.08 Q -= =-> ,5=, 应舍去 Grubbs: G 计= 60.0868.455/5.61-=> ,4,应舍去· ·· 2、4次测定结果为:%、%、%、%,根据这些数据估计此样品中铬的含量范围(P=95%)(8分) ( 2.353%903,10.0=?=t P , 3.182%9530.05=?=,t P , 5.841%9930.01=?=,t P ) x =%, s=% 3、用一种新方法测定标准试样中的氧化铁含量(%),得到以下8个数 据:、、、、、、、。标准偏差为%,标准值为%问这种新方法是否可靠(P=95%,,7=)(10分)
x = 34.3034.33 1.770.048 t -==< ,7,所以新方法可靠 4、某小组做加标回收试验考查方法的准确性,测得加标前1000mL 样品浓度为L ,加入浓度为1000mg/L 的标准样品后,测得样品总浓度为L ,求回收率是多少。(8分) 没讲,不考 5、两分析人员测定某试样中铁的含量,得到如下结果: 已知A 的标准偏差s 1=,B 的标准偏差s 2=,请比较两个人测定结果的精密度和准确的有无显着性差异。(12分) F (,4,4)=, t (,8)= F==< F (,4,4),故精密度无显着性差异 t=< t (,8),故准确度无显着性差异 5. 拟考察茶多酚浓度、浸泡时间、维生素C 等3个因素对米粉保鲜效果的影响,实验因素水平表如下表。 请完成下列正交表格,并指出各因素的主次顺序,求出最优水平组合,并做方差分析,填方差分析表,并对实验结果做出讨论(可结合因素指标变化图)。(25分)
6.1.2 如果OUTPUT动作顺序恰当,即使在事务执行过程中发生故障,一致性仍能得到保持。
6.2.3 答案1 若题目是:
第五章习题 1.习题 解:假定两总体服从正态分布,且协方差矩阵21∑=∑,误判损失相同又先验概 即:0.4285711=P 0.5714292=P 又计算可得: (1)(2)25.31622.025,2.416 1.187x x ????==--???????? 并且:-2.38145ln =S 计算广义平方距离函数: 2()1 ()()()()ln 2ln j T j j j j j d p -=--+-x x x S x x S 并计算后验概率: 2 2 2 ??0.5()0.5()1 ?(|)e e j k d d j k P G --==∑x x x 1,2j = 回代判别结果如下:
由此可见误判的回代估计: 0.07141/14* ==r P 若按照交叉确认法,定义广义平方距离如下: 2()1() ()()()()()()()ln 2ln j j j T j j x x x x j d p -=--+-x x x S x x S 逐个剔除, 交叉判别,后验概率按下式计算: 2 2 2 ??0.5()0.5()1 ?(|)e e j k d d j k P G --==∑x x x 1,2j = 通过SAS 计算得到表所示结果。发现同样也是属于G1的4号被误判为G2,因此误判率的交 叉确认估计为* ?1/140.0714c p ==
*121p p p ΦΦ?? =+- ?? ? 其中(1) (2)1(1)(2)?()()T λ -=--x x S x x =, 2 1(1|2)ln (2|1)c p d c p =,又因为(1|2)(2|1)c c c ==,所以288.0ln 1 2==P P d , 最后可得后验概率p 为: 习题 解:(1)在21∑≠∑并且先验概率相同的的假设前提下,建立矩离判别的线性判别函数。利用SAS 的proc discrim 过程首先计算得到总体的协方差矩阵,如表:
答案仅供参考 第一章数据库系统概述 选择题 B、B、A 简答题 1.请简述数据,数据库,数据库管理系统,数据库系统的概念。 P27 数据是描述事物的记录符号,是指用物理符号记录下来的,可以鉴别的信息。 数据库即存储数据的仓库,严格意义上是指长期存储在计算机中的有组织的、可共享的数据集合。 数据库管理系统是专门用于建立和管理数据库的一套软件,介于应用程序和操作系统之间。数据库系统是指在计算机中引入数据库技术之后的系统,包括数据库、数据库管理系统及相关实用工具、应用程序、数据库管理员和用户。 2.请简述早数据库管理技术中,与人工管理、文件系统相比,数据库系统的优点。 数据共享性高 数据冗余小 易于保证数据一致性 数据独立性高 可以实施统一管理与控制 减少了应用程序开发与维护的工作量 3.请简述数据库系统的三级模式和两层映像的含义。 P31 答: 数据库的三级模式是指数据库系统是由模式、外模式和内模式三级工程的,对应了数据的三级抽象。 两层映像是指三级模式之间的映像关系,即外模式/模式映像和模式/内模式映像。 4.请简述关系模型与网状模型、层次模型的区别。 P35 使用二维表结构表示实体及实体间的联系 建立在严格的数学概念的基础上 概念单一,统一用关系表示实体和实体之间的联系,数据结构简单清晰,用户易懂易用 存取路径对用户透明,具有更高的数据独立性、更好的安全保密性。
第二章关系数据库 选择题 C、C、D 简答题 1.请简述关系数据库的基本特征。P48 答:关系数据库的基本特征是使用关系数据模型组织数据。 2.请简述什么是参照完整性约束。 P55 答:参照完整性约束是指:若属性或属性组F是基本关系R的外码,与基本关系S的主码K 相对应,则对于R中每个元组在F上的取值只允许有两种可能,要么是空值,要么与S中某个元组的主码值对应。 3.请简述关系规范化过程。 答:对于存在数据冗余、插入异常、删除异常问题的关系模式,应采取将一个关系模式分解为多个关系模式的方法进行处理。一个低一级范式的关系模式,通过模式分解可以转换为若干个高一级范式的关系模式,这就是所谓的规范化过程。 第三章数据库设计 选择题 B、C、C 简答题 1. 请简述数据库设计的基本步骤。 P66 需求分析设计;概念结构设计;逻辑结构设计;物理结构设计;数据库设计;数据库的运行和维护。 2. 请分别举例说明实体之间联系的三种表现情形。 P74 一对一联系:对于实体集A中的每个实体,实体集B中最多只有一个实体与之联系,反之亦然。举例:班级与班长,每个班只有一个班长,每个班长也只在一个班内任职。 一对多联系:对于实体集A中的每个实体,实体集B中有N个实体与之联系,反之,对于实体集B中的每个实体,实体集A中最多只有一个实体与之联系。举例:班级与班级成员,每个班级对应多个班级成员,每个班级成员只对应一个班级。 多对多联系:对于实体集A中的每个实体,实体集B中有N个实体与之联系,反之,对于实体集B中的每个实体,实体集A中有M个实体与之联系。举例:授课班级与任课教师,每个
第2章 习 题 一、习题 (1)回归模型 15,2,1,22110 =+++=i x x y i i i i εβββ 调用proc reg : ] 由此输出得到的回归方程为: 2100920.049600.045261.3X X y ++=∧ 由最后一列可以看出,使用化妆品的人数X1和月收入X2对化妆品的销售数量有着显著影响。46521.30=∧ β可以理解为该化妆品作为一种必需品每个月的销售量。当购买该化妆品的人数固定时,月收入没增加一个一个单位,改化妆品的销售数量将增加个单位。同理,当购买该化妆品的人均月收入固定时,购买该化妆品的人数每增加一千人,该化妆品的销售数量将增加个单位。 p n SSE -= ∧2 σ 是2σ的无偏估计,所以2σ的估计值是. (2)调用 由此可到线性回归关系显著性检验: 0至少有一个为0:2,1:1210ββββH H ?==
的统计量/(1)/()SSR p MSR F SSE n p MSE -= =-的观测值47.56790=F ,检验的p 值 0001.0)(000<>==F F p p H 另外9989.053902 53845 2=== SST SSR R ,2R 描述了由自由变量的线性关系函数值所能反映的Y 的总变化量的比例。2R 越大,表明线性关系越明显。这些结果均表明Y 与X1,X2之间的回归关系高度显著。 (3)若置信水平05.0=α,由17881.2)12(975.0=t ,利用参数估计值得 到21,0,βββ的置信区间分别为: 对,0β2942.54516.343065.21781.245216.3±=?±,即)7458.8,8426.1(-) 对1β:01318.049600.000605.01781.249600.0±=?±,即)50198.0,48282.0( ) 2β:0021 .000920.00009681.01781.200920.0±=?±,即)00113.0,0071.0(- (4)首先检验X1对Y 是否有显著性影: 假设其约简模型为:15,2, 1,220 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得: 88137.484)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f 由[()()]() ()/R F F SSE R SSE F f f F SSE F f --= 求得检验统计量的值为: 3 .9012/88357.5688357 .5688137.4840=-= F 05.0))13,1(()(0000<>==>==F F P F F p p H 由此拒绝原假设,所以x2对Y 有显著影响。 ~ 同理检验X2对Y 是否有显著性影: 假设其约简模型为:15,2, 1,110 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得: 31872)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f 由[()()]() ()/R F F SSE R SSE F f f F SSE F f --= 求得检验统计量的值为: 12/88357.5688357.56318720-= F 05.0))13,1(()(0000<>==>==F F P F F p p H 由此拒绝原假设,所以x2对Y 有显著影响。
第1章绪论 2 .使用数据库系统有什么好处? 答:使用数据库系统的优点是很多的,既便于数据的集中管理,控制数据冗余,提高数据的利用率和一致性,又有利于应用程序的开发和维护。 6 .数据库管理系统的主要功能有哪些? 答:( l )数据库定义功能;( 2 )数据存取功能; ( 3 )数据库运行管理;( 4 )数据库的建立和维护功能。 8 .试述概念模型的作用。 答:概念模型实际上是现实世界到机器世界的一个中间层次。概念模型用于信息世界的建模,是现实世界到信息世界的第一层抽象,是数据库设计人员进行数据库设计的有力工具,也是数据库设计人员和用户之间进行交流的语言。 12 .学校中有若干系,每个系有若干班级和教研室,每个教研室有若干教员,其中有的教授和副教授每人各带若干研究生;每个班有若干学生,每个学生选修若干课程,每门课可由若干学生选修。请用 E 一R 图画出此学校的概念模型。 答:实体间联系如下图所示,联系-选修有一个属性:成绩。 各实体需要有属性说明,需要画出各实体的图(带属性)或在下图中直接添加实体的属性,比如:学生的属性包括学号、姓名、性别、身高、联系方式等,此略。 13 .某工厂生产若干产品,每种产品由不同的零件组成,有的零件可用在不同的产品上。这些零件由不同的原材料制成,不同零件所用的材料可以相同。这些零件按所属的不同产品分别放在仓库中,原材料按照类别放在若干仓库中。请用 E 一R 图画出此工厂产品、零件、材料、仓库的概念模型。 答:各实体需要有属性,此略。 联系组成、制造、储存、存放都有属性:数量。
20 .试述数据库系统三级模式结构,这种结构的优点是什么? 答:数据库系统的三级模式结构由外模式、模式和内模式组成。 外模式,亦称子模式或用户模式,是数据库用户(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。 模式,亦称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。模式描述的是数据的全局逻辑结构。外模式涉及的是数据的局部逻辑结构,通常是模式的子集。 内模式,亦称存储模式,是数据在数据库系统内部的表示,即对数据的物理结构和存储方式的描述。 数据库系统的三级模式是对数据的三个抽象级别,它把数据的具体组织留给DBMs 管理,使用户能逻辑抽象地处理数据,而不必关心数据在计算机中的表示和存储。数据库系统在这三级模式之间提供了两层映像:外模式/模式映像和模式/内模式映像,这两层映像保证了数据库系统中的数据能够具有较高的逻辑独立性和物理独立性。 22 .什么叫数据与程序的物理独立性?什么叫数据与程序的逻辑独立性?为什么数据库系统具有数据与程序的独立性? 答:数据与程序的逻辑独立性是指用户的的应用程序与数据库的逻辑结构是相互独立的。 数据与程序的物理独立性是指用户的的应用程序与存储在磁盘上的数据库中数据是相互独立的。 当模式改变时(例如增加新的关系、新的属性、改变属性的数据类型等),由数据库管理员对各个外模式/模式的映像做相应改变,可以使外模式保持不变。应用程序是依据数据的外模式编写的,从而应用程序不必修改,保证了数据与程序的逻辑独立性,简称数据的逻辑独立性。 当数据库的存储结构改变了,由数据库管理员对模式/内模式映像做相应改变,可以使模式保持不变,从而应用程序也不必改变,保证了数据与程序的物理独立性,简称数据的物理独立性。数据库管理系统在三级模式之间提供的两层映像保证了数据库系统中的数据能够具有较高的逻辑独立性和物理独立性。
第三章 误差和分析数据的处理 作业及答案 一、选择题(每题只有1个正确答案) 1. 用加热挥发法测定BaCl 2·2H 2O 中结晶水的质量分数时,使用万分之一的分析天平称样0.5000g ,问测定结果应以几位有效数字报出?( D ) [ D ] A. 一位 B. 二位 C .三位 D. 四位 2. 按照有效数字修约规则25.4507保留三位有效数字应为( B )。 [ B ] A. 25.4 B. 25.5 C. 25.0 D. 25.6 3. 在定量分析中,精密度与准确度之间的关系是( C )。 [ C ] A. 精密度高,准确度必然高 B. 准确度高,精密度不一定高 C. 精密度是保证准确度的前提 D. 准确度是保证精密度的前提 4. 以下关于随机误差的叙述正确的是( B )。 [ B ] A. 大小误差出现的概率相等 B. 正负误差出现的概率相等 C. 正误差出现的概率大于负误差 D. 负误差出现的概率大于正误差 5. 可用下列何种方法减免分析测试中的随机误差( D )。 [ D ] A. 对照实验 B. 空白实验 C. 仪器校正 D. 增加平行实验的次数 6. 在进行样品称量时,由于汽车经过天平室附近引起天平震动产生的误差属于( B )。 [ B ] A. 系统误差 B. 随机误差 C. 过失误差 D. 操作误差 7. 下列表述中,最能说明随机误差小的是( A )。 [ A ] A. 高精密度 B. 与已知含量的试样多次分析结果的平均值一致 C. 标准偏差大 D. 仔细校正所用砝码和容量仪器 8. 对置信区间的正确理解是( B )。 [ B ] A. 一定置信度下以真值为中心包括测定平均值的区间 B. 一定置信度下以测定平均值为中心包括真值的范围 C. 真值落在某一可靠区间的概率 D. 一定置信度下以真值为中心的可靠范围 9. 有一组测定数据,其总体标准偏差σ未知,要检验得到这组分析数据的分析方法是否准确可靠,应该用( C )。 [ C ] A. Q 检验法 B. G(格鲁布斯)检验法 C. t 检验法 D. F 检验法 答:t 检验法用于测量平均值与标准值之间是否存在显著性差异的检验------准确度检验 F 检验法用于两组测量内部是否存在显著性差异的检验-----精密度检验 10 某组分的质量分数按下式计算:10 ???= m M V c w 样,若c =0.1020±0.0001,V=30.02±0.02, M=50.00±0.01,m =0.2020±0.0001,则对w 样的误差来说( A )。 [ A ] A. 由“c ”项引入的最大 B. 由“V ”项引入的最大
第一章数据库系统概述 选择题 1实体-联系模型中,属性是指(C) A.客观存在的事物 B.事物的具体描述 C.事物的某一特征 D.某一具体事件 2对于现实世界中事物的特征,在E-R模型中使用(A) A属性描述B关键字描述C二维表格描述D实体描述 3假设一个书店用这样一组属性描述图书(书号,书名,作者,出版社,出版日期),可以作为“键”的属性是(A) A书号B书名C作者D出版社 4一名作家与他所出版过的书籍之间的联系类型是(B) A一对一B一对多C多对多D都不是 5若无法确定哪个属性为某实体的键,则(A) A该实体没有键B必须增加一个属性作为该实体的键C取一个外关键字作为实体的键D该实体的所有属性构成键 填空题 1对于现实世界中事物的特征在E-R模型中使用属性进行描述 2确定属性的两条基本原则是不可分和无关联 3在描述实体集的所有属性中,可以唯一的标识每个实体的属性称为键 4实体集之间联系的三种类型分别是1:1 、1:n 、和m:n 5数据的完整性是指数据的正确性、有效性、相容性、和一致性 简答题 一、简述数据库的设计步骤 答:1需求分析:对需要使用数据库系统来进行管理的现实世界中对象的业务流程、业务规则和所涉及的数据进行调查、分析和研究,充分理解现实世界中的实际问题和需求。 分析的策略:自下而上——静态需求、自上而下——动态需求 2数据库概念设计:数据库概念设计是在需求分析的基础上,建立概念数据模型,用概念模型描述实际问题所涉及的数据及数据之间的联系。 3数据库逻辑设计:数据库逻辑设计是根据概念数据模型建立逻辑数据模型,逻辑数据模型是一种面向数据库系统的数据模型。 4数据库实现:依据关系模型,在数据库管理系统环境中建立数据库。 二、数据库的功能 答:1提供数据定义语言,允许使用者建立新的数据库并建立数据的逻辑结构 2提供数据查询语言 3提供数据操纵语言 4支持大量数据存储 5控制并发访问 三、数据库的特点 答:1数据结构化。2数据高度共享、低冗余度、易扩充3数据独立4数据由数据库管理系统统一管理和控制:(1)数据安全性(2)数据完整性(3)并发控制(4)数据库恢复 第二章关系模型和关系数据库 选择题 1把E-R模型转换为关系模型时,A实体(“一”方)和B实体(“多”方)之间一对多联系在关系模型中是通过(A)来实现的
定性数据分析第二章 课后答案
第二章课后作业 【第1题】 解:由题可知消费者对糖果颜色的偏好情况(即糖果颜色的概率分布),调查 者取500块糖果作为研究对象,则以消费者对糖果颜色的偏好作为依据,500块糖果的颜色分布如下表1.1所示: 表1.1 理论上糖果的各颜色数 由题知r=6,n=500,我们假设这些数据与消费者对糖果颜色的偏好分布是相符,所以我们进行以下假设: 原假设::0H 类i A 所占的比例为)6,...,1(0==i p p i i 其中i A 为对应的糖果颜色,)6,...,1(0=i p i 已知,16 10=∑=i i p 则2χ检验的计算过程如下表所示: 在这里6=r 。检验的p 值等于自由度为5的2χ变量大于等于18.0567的概率。在Excel 中输入“)5,0567.18(chidist =”,得出对应的p 值为
05.00028762.0<<=p ,故拒绝原假设,即这些数据与消费者对糖果颜色的偏好 分布不相符。 【第2题】 解:由题可知 ,r=3,n=200,假设顾客对这三种肉食的喜好程度相同,即顾 客选择这三种肉食的概率是相同的。所以我们可以进行以下假设: 原假设 )3,2,1(3 1 :0==i p H i 则2χ检验的计算过程如下表所示: 在这里3=r 。检验的p 值等于自由度为2的2χ变量大于等于15.72921的概率。在Excel 中输入“)2,72921.15(chidist =”,得出对应的p 值为 05.00003841.0<<=p ,故拒绝原假设,即认为顾客对这三种肉食的喜好程度是 不相同的。 【第3题】 解:由题可知 ,r=10,n=800,假设学生对这些课程的选择没有倾向性,即选 各门课的人数的比例相同,则十门课程每门课程被选择的概率都相等。所以我们可以进行以下假设: 原假设)10,...,2,1(1.0:0==i p H i 则2χ检验的计算过程如下表所示:
定性分析和定量分析的区别和联系 定性--用文字语言进行相关描述 定量--用数学语言进行描述 定性分析与定量分析应该是统一的,相互补充的;; 定性分析是定量分析的基本前提,没有定性的定量是一种盲目的、毫无价值的定量;; 定量分析使之定性更加科学、准确,它可以促使定性分析得出广泛而深入的结论 定量分析是依据统计数据,建立数学模型,并用数学模型计算出分析对象的各项指标及其数值的一种方法。定性分析则是主要凭分析者的直觉、经验,凭分析对象过去和现在的延续状况及最新的信息资料,对分析对象的性质、特点、发展变化规律作出判断的一种方法。相比而言,前一种方法更加科学,但需要较高深的数学知识,而后一种方法虽然较为粗糙,但在数据资料不够充分或分析者数学基础较为薄弱时比较适用,更适合于一般的投资者与经济工作者。因此,本章以后几节所做的分析基本上以定性分析为主。但是必须指出,两种分析方法对数学知识的要求虽然有高有低,但并不能就此把定性分析与定量分析截然划分开来。事实上,现代定性分析方法同样要采用数学工具进行计算,而定量分析则必须建立在定性预测基础上,二者相辅相成,定性是定量的依据,定量是定性的具体化,二者结合起来灵活运用才能取得最佳效果。 不同的分析方法各有其不同的特点与性能,但是都具有一个共同之处,即它们一般都是通过比较对照来分析问题和说明问题的。正是通过对各种指标的比较或不同时期同一指标的对照才反映出数量的多少、质量的优劣、效率的高低、消耗的大小、发展速度的快慢等等,才能为作鉴别、下判断提供确凿有据的信息。 应用: 在证据法学研究中,定性分析方法和定量分析方法各有长处,可以相辅相成。但是由于我国证据法学的研究人员比较熟悉定性分析方法,所以有必要特别强调定量分析方法的功能和重要性。例如,我们不仅要分析某个证据规则是好还是不好,而且要分析其利弊比例……等等 专利分析法分为定量分析和定性分析两种。定量分析即对专利文献的外部特征(专利文献的各种著录项目)按照一定的指标(如专利数量)进行统计,并对有关的数据进行解释和分析。定性分析是以专利的内容为对象,按技术特征归并专利文献,使之有序化的分析过程。通常情况下需要将二者结合才能达到较好的效果。
数据分析师常见的7道笔试题目及答案 导读:探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧重于已有假设的证实或证伪。以下是由小编为您整理推荐的实用的应聘笔试题目和经验,欢迎参考阅读。 1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map 进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP 中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP 日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是: 第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树 /hash_map等),并取出出现频率最大的100个词(可以用含 100 个结点的最小堆),并把100
第一章 1、试说明数据、数据库、数据库管理系统和数据库系统的概念以及它们之间的关系。 答:(1)数据(Data):描述事物的符号记录称为数据。数据的种类有数字、文字、图形、图像、声音、正文等。数据与其语义是不可分的。 (2)数据库(Database,简称DB):数据库是长期储存在计算机内的、有组织的、可共享的数据集合。数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。(3)数据库系统(Database System,简称DBS):数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。 (4)数据库管理系统(Database Management System,简称DBMS ):数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。DBMS的主要功能包括数据库的建立和维护功能、数据定义功能、数据组织存储和管理功能、数据操作功能、事务的管理和运行功能。 它们之间的联系:数据库系统包括数据库、数据库管理系统、应用系统、数据库管理员,所以数据库系统是个大的概念。数据库是长期存储在计算机内的有组织、可共享的大量的数据集合,数据库管理系统是由管理员操作管理数据库的查询、更新、删除等操作的,数据库应用系统是用来操作数据库的。 2、数据管理技术的发展主要经历了哪几个阶段? 答:两个阶段,文件管理和数据库管理。
3、比较用文件管理和用数据库管理数据的主要区别。 答:数据库系统与文件系统相比实际上是在应用程序和存储数据的数据库之间增加了一个系统软件,即数据库管理系统,使得以前在应用程序中由开发人员实现的很多繁琐的操作和功能,都可以由这个系统软件完成,这样应用程序不再需要关心数据的存储方式,而且数据的存储方式的变化也不再影响应用程序。而在文件系统中,应用程序和数据的存储是紧密相关的,数据的存储方式的任何变化都会影响到应用程序,因此不利于应用程序的维护。 4、数据库系统由哪几部分组成,每一部分在数据库系统中的作用大致是什么? 答:数据库系统由三个主要部分组成,即数据库、数据库管理系统和应用程序。数据库是数据的汇集,它以一定的组织形式存于存储介质上;数据库管理系统是管理数据库的系统软件,它可以实现数据库系统的各种功能;应用程序指以数据库数据为核心的应用程序。 第二章 1、解释数据模型的概念,为什么要将数据模型分成两个层次? 答:数据模型是对现实世界数据特征的抽象。数据模型一般要满足三个条件:第一是数据模型要能够比较真实地模拟现实世界;第二是数据模型要容易被
Excel数据分析 单选题 ?1、数据透视表被形象地形容为企业经营管理中的什么部分?(10 分) ?A 血液 ?B 骨架 ?C 皮肤 ?D 肌肉 正确答案:A ?2、需要选择整张报表进行透视表计算时,可以怎样操作?(10 分) ?A Ctrl+a快选整张表格 ?B 鼠标在最左行,变为黑色箭头时可以全选行 ?C 鼠标移动至报表内部可自动选择整张报表 正确答案:C ?3、在数据透视表中,需要对某一字段进行对比分析时,应将该数据放在哪类标签中更便利? (10 分)
?A 报表筛选 ?B 列标签 ?C 行标签 ?D 西格玛数值(∑) 正确答案:B ?4、需要为单元格中的信息添加单位时,在设置单元格选项卡中,选择哪个功能项操作?(10 分) ?A 常规 ?B 文本 ?C 特殊 ?D 自定义 正确答案:D ?5、需要为数据进行比重分析时,选择值字段设置中的哪个选项?(10 分) ?A
值汇总方式 ?B 值显示方式 正确答案:B ?6、如何对汇总表中的单个数据进行核查操作?(10 分) ?A 在原明细表中生成新的汇总数据 ?B 双击该单元格查看对应汇总数据 ?C 以上方法都可以 正确答案:C ?7、汇总表中的标题字段可以自定义吗?(10 分) ?A 可以 ?B 不可以 正确答案:A 多选题 ?1、创建数据透视表的方式?(10 分) A 创建一个新工作表,点击“数据透视表”,选择一个表或区域
B 创建一个新工作表,点击“数据透视表”,选择外部数据源 C 点选明细表中有效单元格,再点击“数据透视表”选项 D 点选明细表中任意单元格,再点击“数据透视表”选项 正确答案:B C 判断题 ?1、数据透视表是Excel中一种交互式的工作表,可以根据用户的需要按照不同关键字段来提取组织和分析数据。(10 分) ?A 正确 ?B 错误 正确答案:正确 ?2、汇总表中的数据如果需要修正时,不可以直接更改,必须返回原明细表修改对应的原始数据。(10分) ?A 正确 ?B 错误 正确答案:正确