
摘要
人口的数量和结构是影响经济社会发展的重要因素。从20世纪70年代后期以来,我国鼓励晚婚晚育,提倡一对夫妻生育一个孩子。该政策实施30多年来,有效地控制了我国人口的过快增长,对经济发展和人民生活的改善做出了积极的贡献。但另一方面,其负面影响也开始显现。如小学招生人数、高校报名人数逐年下降,劳动人口绝对数量开始步入下降通道,人口抚养比的“拐点”时刻即将到来。这些问题都会对我国的经济和社会健康、可持续发展等产生一系列影响。人口问题日益受到人们的重视。
对于问题一,我们通过多个渠道收集数据,利用SAS和Matlab等软件进行计算分析,我们得到了我国上世纪50年代至今人口和经济的主要变化如下:
对于问题二,这是典型的人口模型,我们建立了4个相应的数学模型,选用了基于以往人口数据的一次线性回归,灰色、时间序列预测,逻辑斯蒂模型和基于年龄结构并生育率、死亡率随时间Leslie人口模型。进行全方位的深刻讨论,在本文假设的条件下,符合中国人口特点,例如,老龄化进程加速、出生人口性别比持续升高等,对中国的人口未来长期发展状况进行了科学性的预测;通过权重关系,建立起了组合模型,特别地在权重问题上,采用了熵权法分配权重,思路巧妙,提高了预测的精确度;建立BP神经网络模型,无需进行模型假设,同时能利用模型自身对复杂的非线性曲线进行拟核,利用拟核函数对人口增长趋势作出了合的预测。本文的模型具有很好的推广性,而且在其它领域发挥很好的效果。
在对中国的人口未来长期发展状况进行了科学性的预测后,我们分析得到计划生育新政策。。。。。。。。。。。。
关键词:微分方程模型;Leslie人口模型;曲线拟合;灰色序列预测
中国人口预测模型
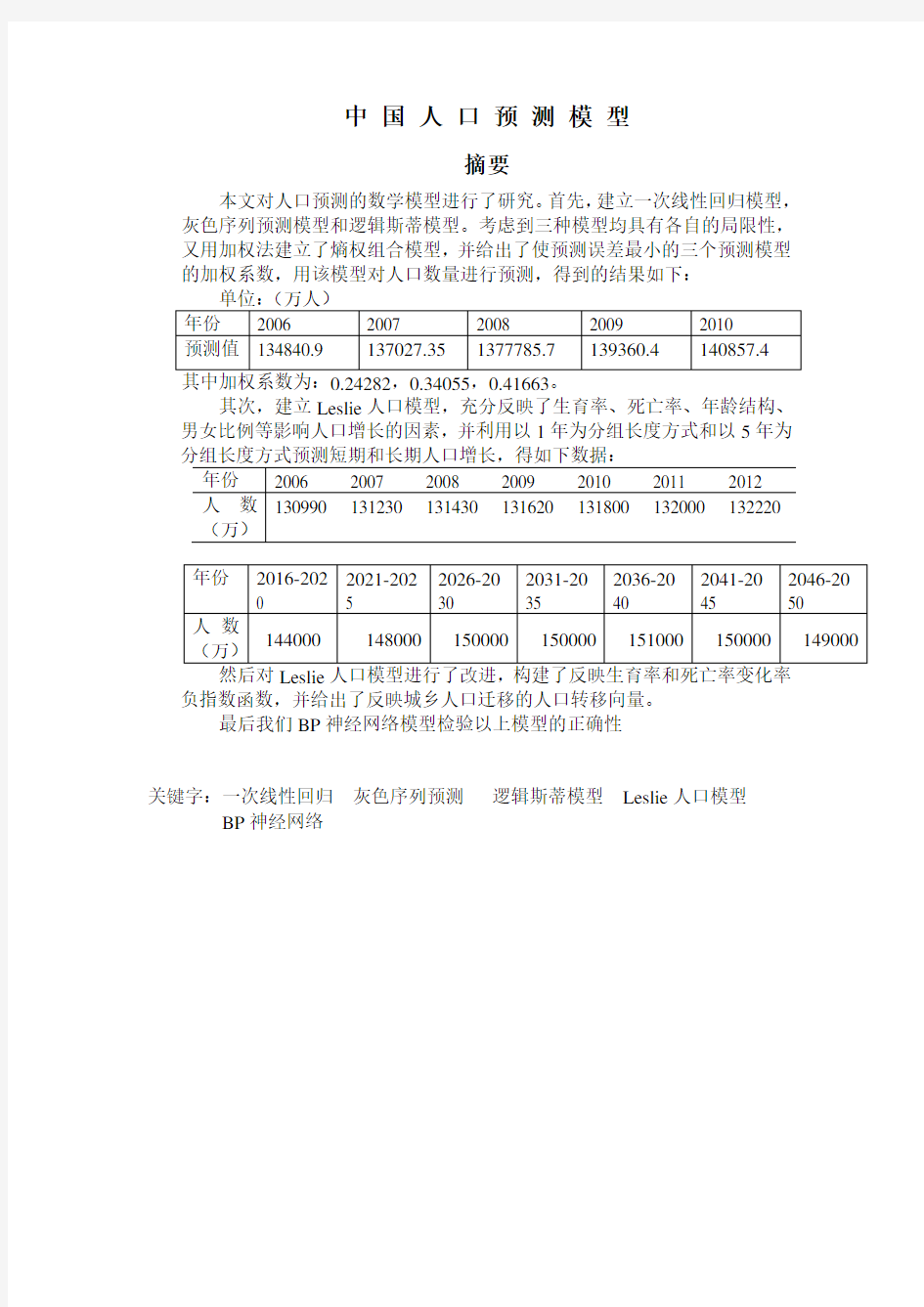
摘要
本文对人口预测的数学模型进行了研究。首先,建立一次线性回归模型,灰色序列预测模型和逻辑斯蒂模型。考虑到三种模型均具有各自的局限性,又用加权法建立了熵权组合模型,并给出了使预测误差最小的三个预测模型的加权系数,用该模型对人口数量进行预测,得到的结果如下:
其次,建立Leslie人口模型,充分反映了生育率、死亡率、年龄结构、男女比例等影响人口增长的因素,并利用以1年为分组长度方式和以5年为
负指数函数,并给出了反映城乡人口迁移的人口转移向量。
最后我们BP神经网络模型检验以上模型的正确性
关键字:一次线性回归灰色序列预测逻辑斯蒂模型Leslie人口模型BP神经网络
一、问题重述
李克强总理代表国务院在2014年政府工作报告中指出:“坚持计划生育基本国策不动摇,落实一方是独生子女的夫妇可生育两个孩子政策。”
人口的数量和结构是影响经济社会发展的重要因素。从20世纪70年代后期以来,我国鼓励晚婚晚育,提倡一对夫妻生育一个孩子。该政策实施30多年来,有效地控制了我国人口的过快增长,对经济发展和人民生活的改善做出了积极的贡献。但另一方面,其负面影响也开始显现。如小学招生人数(1995年以来)、高校报名人数(2009年以来)逐年下降,劳动人口绝对数量开始步入下降通道,人口抚养比的“拐点”时刻即将到来。这些问题都会对我国的经济和社会健康、可持续发展等产生一系列影响。
为此,根据要求回答下列问题:
1.请你们就我国上世纪50年代至今人口和经济的变化做出简要分析。
2.建立关于生育率、死亡率和性别比等多个因素的人口数学模型,分析计划生育新政策(单独二孩政策)对我国未来人口数量,结构及经济的影响;并对模型的结论发表自己的独立见解。
二、问题的基本假设及符号说明
问题假设
1.假设本问题所使用的数据均真实有效,具有统计分析价值。
2.假设本问题所研究的是一个封闭系统,也就是说不考虑我国与其它国家的人口迁移问题。
3.不考虑战争 瘟疫等突发事件的影响
4.在对人口进行分段处理时,假设同一年龄段的人死亡率相同,同一年龄段的育龄妇女生育率相同。
5.假设各年龄段的育龄妇女生育率呈正态分布
6.人类的生育观念不发生太大改变,如没有集体不愿生小孩的想法。 7.中国各地各民族的人口政策相同。
符号说明
()i a t --------------------第t 时间区间内第i 个年龄段人口总数
()i c t --------------------第t 时间区间内第i 个年龄段人口总数占总人口的比例
()k i c t --------------------第t 时间区间内第i 个年龄段中第k 年龄值人口总数占总人口的比例
()A t --------------------第t 时间区间内各年龄段人口总数的向量 ()P t --------------------第t 时间区间各年龄段人口总数向量转移矩阵
()i b t -------------------第t 时间区间内第i 个年龄段人的生育率 ()i d t -------------------第t 时间区间内第i 个年龄段人的死亡率
()k i d t -----------------第t 时间区间内第i 个年龄段中第k 年龄值的死亡率 ()i s t -------------------第t 时间区间内第i 个年龄段人的存活率
()h t --------------------- 第t 时间区间男性人数与女性人数的比值
()i e t ---------------------第t 时间区间内第i 个年龄段育龄妇女的生育率 m---------------------------每个年龄段上年龄值的数目
三 问题分析
本问题是一个关于人口预测的问题,与以往不同,本问题需要根据中国特殊的国情去研究,我们根据对问题的分析并结合实际情况认为对人口产生主要影响的因素有以下四个:生育率、死亡率、年龄结构、男女比例。在这里需要说明的是对于人口产生影响的一些因素,如经济发展状况,生态环境情况、已婚夫妇对生育所持的态度、医疗技术的发展等,我们认为它们对人口的增长是通过作用于以上四个指标而间接发挥作用的。而对于诸如战争爆发、疾病流行等突发因素,由于其不可预测性,我们不考虑
1.生育率
生育率代表育龄妇女生育人口的能力,从一定意义上讲生育率的高低控制着人口增长率高低,通常来说生育率越高人口增长率越高,所以说生育率是人口增长的源头。生育率的影响因素很多,首先是年龄因素,不同年龄段的育龄妇女的生育率不同,通常20岁至30岁的育龄妇女的生育率最强;此外是地域因素,受政策因素、观念认识、周边环境等影响乡村育龄妇女的生育率高于城市育龄妇女的生育率;还有其它因素的影响,比如大规模疾病会降低育龄妇女的生育率。
2.死亡率
死亡率表示一定时期内一个人口群体中死亡的人数占该人口群体的比值,和生育率一样死亡率的高低同样控制着人口增长率高低,如果说生育率是人口增长的源头,则死亡率是人口增长的汇点。同样影响死亡率的因素很多,首先不同年龄段的死亡率不同,通常老年人和刚出生的婴儿的死亡率较高;从长远来看,随着医疗水平的提高,整个人口群体的死亡率将会成下降趋势;此外一些突发事件,如战争、疾病等,将会使使那一段的人口死亡率大幅度提高。
3.年龄结构
年龄结构反映了总体人口在各年龄段分布情况,年龄结构蕴涵的信息量很大,从其中我们可以实现对很多问题的分析,比如从年龄结构我们可以分析出社
会的老年化程度,此外从年龄结构我们可以判断出不同时间段人口出生的情况,比如年龄结构不仅反映了总体人口在各年龄段分布情况,而且考虑到不同年龄段人口生育率、死亡率不同等情况,我们可以在年龄结构中有效反映这些差异4.男女比例
男女比例反映了总体人口中男性与女性人数的比较关系,男女比例值能反映出体人口中男性与女性人数是否协调,男女比例主要受男女出生比和男女死亡率的影响,男女出生比正常范围在103-107,也就是说出生100个女儿的同时会有103 —107个男儿出生,但是在现实社会中,女性死亡率低于男性,以至于男女比例大致维持着稳定的相对稳定,但目前我国男女出生比超过110,这不仅将导致男女比例失调,还会对人口的预测产生影响,所以在人口预测时必须将男女出生·死亡比例问题考虑进去。
考虑到人口预测分为中短期预测和长期预测,两类预测因为涉及的时间长短不同,所以考虑的因素不同,采用的方法不同。
对于中短期预测,我们假设生育率、死亡率、年龄结构、男女比例均维持在同一稳定水平,这样我们采用方法有很多,。
对于长期预测,我们需要考虑生育率、死亡率、年龄结构、男女比例等因素随时间变化,此外城乡人口迁移对城乡人口结构产生影响,尽管以上因素短期内积累效应较小,但在长期中必须考虑。
在预测方法上我们选用了基于以往人口数据的一次线性回归,灰色、时间序列预测,逻辑斯蒂模型和基于年龄结构并生育率、死亡率随时间Leslie人口模型
四 数学模型
4.1.熵权组合模型
有关于人口增长预测的模型很多,比如灰色GM (1,1),移动平均数法,指数平滑法,一元线型回归,马尔萨斯人口模型,宋健人口模型等等,但是每种预测方法的精度往往也不同。组合模型和单个模型比起来,具有较高的预测精度,组合预测的关键就在于确定各个预测方法的权重。
本文将从一个新的角度进行研究,即从信息论的观点出发,根据各个体预测方法误差指标的信息熵,确定组合预测模型的权重,进行人口组合预测模型。
本文选用了一元线性回归法,逻辑斯蒂模型法,灰色GM (1,1)模型法对中国人口增长进行预测。而1978至2005年的数据见本文表一。
.4..1.1灰色预测模型 1.模型建立
灰色系统是指部分信息已知,部分信息未知的系统。灰色系统的理论实质是将无规律的原始数据进行累加生成数列,再重新建模。由于生成的模型得到的数据通过累加生成的逆运算――累减生成得到还原模型,再有还原模型作为预测模型。
预测模型,是拟合参数模型,通过原始数据累加生成,得到规律性较强的序列,用函数曲线去拟合得到预测值。 灰色预测模型建立过程如下:
1) 设原始数据序列()0X 有n 个观察值,()()()()()()(){}
n X X X X 0000,...,2,1=,通过累加生成新序列 ()()()()()()(){}
n X X X X 1111,...,2,1=,利用新生成的序列()1
X 去拟
和函数曲线。
2) 利用拟合出来的函数,求出新生序列()1
X 的预测值序列(1)X
3) 利用(0)(1)(1)()()(1)X k X k X k =--累减还原:得到灰色预测值序列: ()()(){}
00001,2
,...,X X X X n m =+ (共n +m 个,m 个为未来的预测值)。 将序列()0
X 分为0Y 和0Z ,其中0Y 反映()0
X 的确定性增长趋势,0Z 反映()0
X 的平稳周期变化趋势。
利用灰色GM (1,1)模型对()0
X 序列的确定增长趋势进行预测
2 模型求解
根据2006全国统计年鉴数据整理得到全国历年年度人口统计表如表1.
表1:全国历年年底的人口统计
根据上述数据,建立含有20个观察值原始数据序列()0X :
()[]
09625998705105851112704
127627128453129988130756X =利用Matlab 软件对原是数列()0X 进行一次累加,得到新数列为()1
X ,如表2:
表2:新数列()1
X 误差和误差率
1、利用表2,拟合函数,如下:
0.011
624
(1)92800439183784
t x t e +=- 2、精度检验值
c =0.3067 (很好) P =0.9474 (好)
3、得到未来20年的预测值:
表3:全国历年年底的人口统计未来20年预测值
4.1.2一元线性回归法
根据表一中的数据,本文建立一元线性回归模型Y a bX =+进行预测;
Y 为人口数 单位:万人 X 为年份。利用Matlab 软件,用麦夸特法进行回归拟合,得到拟核值及回归方程,如下:
102974.50531572.3805Y X =+ 相关系数:R =0.9359
4.1.3 逻辑斯蒂模型(Logistic growth model )
考虑自然资源和环境对人口的影响,并以m N 记自然资源和环境条件所能允许的最大人口数。把人口增长的速率除以当时的人口数称为人口的净增长率。如果人口的净增长率随着)(t N 的增加而减小,且当m N t N →)(时,净增长率趋于零。因此人口方程可写成
)())
(1()(t N N t N r dt t dN m
-= 其中r 为常数,此模型就叫逻辑斯蒂模型。
我们把1978年至2005年全国历年年底总人口的数值组成一个观察矩阵,其中的每一个数值称之为观察值。本文利用spss 软件,得出与观察值一一映射的拟核值,残差值和cook 距离,见下表:
表九 用spss 软件得到各观察值所对应的拟核值,残差值和标准残差
从新数据得到 F =372.3471 p -值=0.001
本文建立逻辑斯蒂模型:0.8840.185130517.5/(1)x y e --=+
相关系数R =0.9888
4.1.4. 组合模型建立
1、熵权法的概念及基本步骤
熵权法是一种决定指标的方法,我们知道,综合指标取决于单个指标数的确定,一般情况下的权重是根据经验来确定的,但是这种确定权重的方法缺少科学根据,也不能保证确立的综合指标能反映原始指标的大部分信息,且权重的确立因人而异,所以其应用受到了限制,而熵权法就能够避免这些问题,使权重的确立具有科学的根据,具有说服力。熵权法的步骤确立如下: ① 计算第j 项指标下第i 个方案的指标比重1
ij
ij m
ij
i y p y
==
∑
② 计算指标j 的熵值 1
ln m
j ij ij i e k p p ==-∑ (1
ln k m
=
) ③ 计算第j 项指标的差异系数 1j j g e =- ④ 定义权重1
j
ij m
j
i g w g
==
∑
则 ij w 就为熵权法确定的权重。
2、误差指标的选举
为了能全面的各个预测方法以及组合预测的预测效果,必须制定一套切实可行的误差指标。按照预测效果的评价惯例,本文选取如下指标作为参考: (1)、平方和误差
2
1
()n
i i t SSE y y ==-∑
(2)、平均绝对值误差
1
1n
i i t MAE y y n ==-∑
(3)、均方误差
MSE =
(4)、平均绝对值百分比误差
1()
1n i i t i
y y MAPE n y =-=∑
(5)、均方百分比误差
MSPE =
3、组合模型权重的确定
设以选定m 种个体预测方法,n 个误差指标,m 种个体预测方法对应n 个误差指标构成了评价指标值矩阵;
()ij R r m n =?
第j 个指标下第i 种个体方法的指标比重值ij P 为 1/m
i j i j i
j
t P r r ==∑ 第j 个指标的熵值为:
1ln m
j ij ij t E P P ==-∑
记
ln j j e E = 第i 个指标的权重为:
1(1)/(1)
m
j j j t e e θ==--∑ 记矩阵R 中每列最优值为j r *,对该矩阵所有元素做标准化处理,可得:
//i j j ij j ij r r j d r r j *
*??=???指标
的指标值越大越好指标的指标值越小越好
这样,各个体预测方法的熵权评价值i λ,可以表示为:
1
(0,1,2,,
)
m
i j i j t d i m λθ===∑ 将上式进行归一化处理,即可以得到各个个体的权重。
4.1.6熵权组合模型求解
本文利用Matlab 软件对上述的模型、指标进行综合的运算处理,得到熵权系的基本数据资料,见下表:
加权系数为:0.24282,0.34055,0.41663。
4.2.4模型改进
1.考虑到生育率和死亡率是随时间变化的,我们可以定义生育率和死亡率为时间函数
(1)生育率
影响生育率因素有受政策因素、观念认识、周边环境等,通常来说农村的生育率高于城市,为了有效区分这种差异性,我们定义b(t)为反映城、镇、乡平均生育率水平的基准生育率,定义cb(t)、tb(t)、vb(t)分别为城、镇、乡平均生育率 则1()()cb t a b t =?,2()()tb t a b t =?,3()()vb t a b t =?
其中1a 、2a 、3a 为反映生育率高低的系数,系数的大小根据具体情况确定 显然有123a a a <<
考虑到随着时间的推移,计划生育政策深入人心,农村生育率将降低 用下面函数反映这种变化
()(0)bt vb t vb a e -=??
式中a,b 为参考系数
(2)死亡率
随着时间的推移,医疗水平的提高,死亡率将下降,但死亡率中有一部分是非疾病死亡,对于青年人死亡率比较平稳,死亡率变化主要体现在老年人。
定义()i d t 为第t 时间区间内第i 个年龄段人的死亡率
(0),()(0),i i bt
i d i l d t d a e i l
-≤??=???>?? 式中a,b 为参考系数,用来区分青年与中老年
2.考虑到城乡人口转移因素
城乡人口转移将会对城乡人口结构产生影响,因此必须进行研究,考虑到人口主要是从镇转入城,从乡转入城,从乡转入镇
因此定义B(t)为从镇转入城的转移向量,C(t)为从乡转入城的转移向量,D(t)为从乡转入镇的转移向量。 以C(t)为例说明转移向量,
{}1122()()(),()(),,()()n n C t w t v t w t v t w t v t =???
式中()i v t 表示第t 时间区间内第i 个年龄段的农村人数,
()i w t 表示第t 时间区间内第i 个年龄段人的农村转入城市的百分比 则A ’(t)=A(t)+B(t)+C(t) 表示城乡人口转移后的人口向量 每次计算完()(1)(1)A t A t P t =--
再计算A ’(t)=A(t)+B(t)+C(t)
4.2.5模型优缺点分析
1.Leslie 人口模型可以分析不同年龄组生育率与死亡率不同的情况 2.Leslie 人口模型中可以考虑生育率与死亡率随时间变化的情况 3.Leslie 人口模型中可以分析出年龄结构的情况
4.Leslie 人口模型中对给出的关于年龄结构的统计数据要求较高 5.Leslie 人口模型对男女比例不平衡情况反映敏感
6.Leslie 人口模型中选取分组的年龄段长度不同,适于的预测期长短不同
4.3 BP 神经网络人口预测模型
基于BP 神经网络的时间序列预测模型与传统模型不同的是:此模型只需以历史数据作为输入,通过抑制与激活神经结点,自动决定影响性能的参数及影响程度,自动形成模型,无需进行模型假设,再加上神经网络对复杂的非线性系统具有曲线拟核能力,预测能力强,所以是合适的对比检验模型。
matlab 实现:
P 为输入样本矢量集;T 为对应的目标样本矢量集.设:输入样本 p=[1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 ] (年份归一化后的数据)
p=[0.1996 0.1997 0.1998 0.1999 0.2 0.2001 0.2002 0.2003 0.2004 0.2005] 输出样本观测值(对应1996-05年的总人口归一化后的数据):
T=[0.122389 0.123626 0.124761 0.125786 0.126743 0.127627 0.128453 0.129227 0.129988 0.130756]
采用神经网络模型进行运算,系统仿真 产生输入数据的收敛结果见图示:
图6:BP训练函数
表13:BP算法的结果:
五模型优缺点的评判
在上文中,每个模型的后面,针对该模型的优缺点本文都做了深刻地评判,此时就不再重复赘言了,却还没有从宏观角度出发,对本文的所有模型进行整体的优缺点的总评判。
优点:
1、具有很好的创新性,在对传统模型的理解的基础,取模型之长,利用熵权法
对模型进行组合预测,大幅度提高了预测准确度;
2、本文的思路宽阔,在不同时期,建立起不同的模型,能够与实际紧密的联系,
结合当前具体国情,对问题进行求解,使该模型具有很好的推广性和通用性;
3、模型的的计算采用专业软件求解,例如Matlab软件,spss软件,dps软件等,
数据可信度较高。
4、对于题目附录里为涉及到的数据,均到“中国统计局”下载官方数据加以补
充,并且对论文中涉及到的众多影响因素进行了量化处理,使得论文的说服里更强,实际性更高。
缺点
1、影响人口增长预测的动态因素很多,而且不可能都能波及到,所以模型与实
际还是有一些距离的;
2、不同模型在相应的时间阶段具有很高的预测能力,但是一旦脱离了这个时间
阶段,模型的预测能力就会回落。
六全文总结
人口预测就是根据一个国家、一个地区人口的现状,考虑到社会政治经济条件对人口再生产和转化的影响,分析其发展规律,运用科学的方法测算未来某个时期人口的发展状况。人口的预测包括通常指的是中短期预测和长期预测。为了能够提供合理地预测值,本文进行了深刻地研究,建立了4个模型,进行全方位的深刻讨论。
通过,灵敏度的分析比较,模型一适合中短期的预测,模型二综合面广,考虑全面,在本文假设的条件下,就符合中国人口特点,例如,老龄化进程加速、出生人口性别比持续升高,以及乡村人口城镇化都作为模型中的因子元素,对中国的人口未来长期发展状况进行了科学性的预测。
本论文的创新性和技术性主要表现在这几个方面:
1、本文为了提高预测的精确度,对于各种的传统预测方法,有针对性的做了筛
选,通过权重关系,建立起了组合模型,特别地在权重问题上,采用了熵权法分配权重,思路巧妙,可以为以后提供合理参考。
2、本文建立BP神经网络模型,无需进行模型假设,同时能利用模型自身对复
杂的非线性曲线进行拟核,利用拟核函数对人口增长趋势作出了合的预测。
3、本文与计算机实用软件,计算机编程紧密的结合在了一起,在本文中运用了
诸如spss,dps等一些统计性软件,同时利用Matlab进行了一些编程,大大提升了数据的处理能力,也使得数理统计变得不在十分棘手了。
4、本文的模型具有很好的推广性,而且在其它领域发挥很好的效果。
七相关建议
一、最近几年中国人口发展特点
(一)人口增长速度快但增长速度回落
(二)农村人口比重大,但人口城市化快速发展
(三)人口老龄化加剧男女性别比偏高有所回落
二、中国人口的发展趋势
预测中国人口的发展趋势有以下几点:
①目前生育率经过近二十年的控制已达到了较低水平,自然增长率已由1974年
22.2‰下降到1983年的11.5‰,几乎降低了一半,这是世界人口史上罕见的,但生育率继续下降的余地已经不大了。
②由于20世纪60—70年代生育高潮形成的人口年龄结构的影响,在1995年前后形成一个生育高峰,平均每年进入婚育年龄的人数在1100万对以上,生育率的降低较为困难。
③中国目前人口死亡率在世界上是属于较低的,随着经济的迅猛发展,生活水平和医疗水平的进一步提高,死亡率继续下降是有可能的。
④人口城乡结构比较落后,乡村人口比重依然很大,且在相当长的时间里降低乡村的人口生育率仍然较为困难。
综上所述,以目前13亿人口为基础,人口增长率能继续得到控制,到21世纪中期将达到16亿。人口学家普遍认为,这是中国人口的极限,即中国土地可负荷和供养的最大人口数。此后我国人口数会略有回落,并在某一时期到达最佳人口数而稳定下来。
八参考文献
[1]王能超,数值分析简明教程,北京:高等教育出版社,1999
[2] 廉庆荣,线性代数与解析几何,北京:高等教育出版社,2002
[3] 张兴永,MATLAB软件与数学试验,江苏:中国矿业大学出版社,2000
[4] 张兴永,数学建模简明教材,江苏:中国矿业大学出版社,2004
[5] 华东师大数学系,数学分析(第三版),北京:高等教育出版社,1998
[6] https://www.doczj.com/doc/a110023754.html,/(中国国家统计局网)
附录一.:
%%%此程序解决长期预测问题
ht=1.2121 ;total_person_05=130756;kind=9;m=3
%1.1392 1.1721 121.21 表示男女人口比重
%total_person_05表示05年的总人数
%kind表示哪种人口:城市或镇……;
%ht表示05年的男比女的比率;
%a5表示2005年所有人口分年龄段的占的比率
%A表示第t时间段时内各年龄段人口总数占总人口的比例向量
bili=a5(:,kind)+a5(:,kind+2)%比例表示人该年龄段的人口比例,a5(:,kind)男性比率a5(:,kind+2) 女性比率
dead_lv=final_siwang_lv(:,m);
dead_lv=dead_lv/1000;
s=1-dead_lv;
A=bili*total_person_05/100;%各年龄段的人口数
A=A';
for sum=1:9%预测45年,5年为一个周期
%ShengYu =[0 0 0 10.876 60.401 82.094 27.307 2.2229 0.044284
0.00021591 0 0 0 0 0 0 0 0]%城市生育率
%ShentYu=[ 0.0000 0 0 20.0279 111.0878 93.1916 11.8241 0.2269 0.0007 0.0000 0.0000 0 0 0 0 0 0 0]%town生育率
ShengYu=[ 0 0 0 61.0809 142.1392 113.2477 30.8924 2.8852 0.0923 0.0010 0.0000 0 0 0 0 0 0 0]%农村生育率
p=zeros(18,18);%p表示p矩阵,
b=ShengYu*5/1000;%为矩阵赋值,第一列为当年按年龄分段生育率
c=1/(1+ht);
b=b*c;%c为当年的女性比率,c=1/(1+ht)
p(:,1)=b;%s为存活率
for i=1:17
p(i,i+1)=s(i);
end
dhj=A(18)
A=A*p;
A(18)=A(18)+s(18)*dhj;
fff(sum,:)=A;
end
附录二.组合模型预测程序:
%%组合模型
%% 一元非线性回归
yt=[96259.0000 98705.0000 105851.0000 112704.0000 114333.0000 15823.0000 117171.0000 118517.0000 119850.0000 121121.0000 122389.0000 123626.0000 124761.0000 125786.0000 126743.0000 127627.0000 128453.0000 129227.0000 129988.0000 130756.0000 ]
yt_=[97077.7451 101458.9137 105412.6482 108940.8426 112057.9144 114787.4901 117159.2664 119206.2898 120962.7665 122462.4186 123737.3420 124817.2841
125729.2541 126497.3789 127142.9323 127684.4757 128138.0659 128517.4964 128834.5488 129099.2384 ]
%%GM模型
yt1=[98705.0000 105851.0000 112704.0000 114333.0000 115823.0000 117171.0000 118517.0000 119850.0000 121121.0000 122389.0000 123626.0000 124761.0000
125786.0000 126743.0000 127627.0000 128453.0000 129227.0000 129988.0000 130756.0000 ] yt_1=[108504.1027 109772.7542 111056.2390 112354.7306 113668.4043 114997.4379 116342.0107 117702.3046 119078.5032 120470.7927 121879.3611 123304.3988
124746.0982 126204.6544 127680.2642 129173.1272 130683.4450 132211.4217 133757.2639 ] %%%%%%%%%%%%%%%%%%%%%%%线性回归
.118517.0000 119850.0000 121121.0000 122389.0000 123626.0000 124761.0000
125786.0000 126743.0000 127627.0000 128453.0000 129227.0000 129988.0000 130756.0000 ] yt_2=[104546.8857 107691.6466 109264.0271 110836.4075 112408.7880 113981.1684 115553.5489 117125.9293 118698.3098 120270.6902 121843.0707 123415.4511
124987.8316 126560.2120 128132.5925 129704.9729 131277.3534 132849.7338 134422.1143 ]
n=20;m=3;
sse=sum((yt-yt_).^2);
mae=sum(abs(yt-yt_))/n;
mse=sqrt(sum((yt-yt_).^2))/n;
mape=sum(abs(yt-yt_)./abs(yt))/n;
mspe=sqrt(sum((abs(yt-yt_)./abs(yt)).^2));
r(1,1)=sse;r(1,2)=mae;r(1,3)=mse;r(1,4)=mape;r(1,5)=mspe;
sse=sum((yt1-yt_1).^2);
mae=sum(abs(yt1-yt_1))/n;
mse=sqrt(sum((yt1-yt_1).^2))/n;
mape=sum(abs(yt1-yt_1)./abs(yt1))/n;
mspe=sqrt(sum((abs(yt1-yt_1)./abs(yt1)).^2));
r(2,1)=sse;r(2,2)=mae;r(2,3)=mse;r(2,4)=mape;r(2,5)=mspe;
sse=sum((yt2-yt_2).^2);
mae=sum(abs(yt2-yt_2))/n;
mse=sqrt(sum((yt2-yt_2).^2))/n;
mape=sum(abs(yt2-yt_2)./abs(yt2))/n;
mspe=sqrt(sum((abs(yt2-yt_2)./abs(yt2)).^2));
r(3,1)=sse;r(3,2)=mae;r(3,3)=mse;r(3,4)=mape;r(3,5)=mspe;
%r(i,j)为一个i*j的矩阵
for j=1:5
for i=1:3
p(i,j)=r(i,j)/sum(r(:,j))
end
end
for j=1:5
E(j)=-sum(p(:,j).*log(p(:,j))); end
for j=1:5
e(j)=E(j)/log(m);
end
for j=1:5
v(j)=(1-e(j))/(sum(1-e));
end
for j=1:5
r_min(j)=min(r(:,j))
end
for i=1:3
for j=1:5
d(i,j)=r_min(j)/r(i,j);
end
end
sum=0;
for i=1:3
for j=1:5
sum=v(j)*d(i,j)+sum;
end
kkkk(i)=sum;
end
附录三.
长期预测各个年龄段的的总人数
(
单位(万人)
如需要更多数据,请来函索取。
中国人口增长预测 摘要: 中国是一个人口大国,人口问题始终是制约我国发展的关键因素之一。根据已有数据,运用数学建模的方法,对中国人口做出分析和预测是一个重要问题。对此,我们建立了短期与长期两种预测人口增长的模型,并对附录中城镇乡的人口演变趋势做拟合与分析。 本文的建模过程选用了1996年到2005年的人口数据。短期人口预测用曲线的直接拟合,分析出人口的增长趋势。人口的出生率与死亡率均符合指数函数bt =+,利 y ae c 用logistic模型求出人口最大上限 x,据此拟合人口增长的指数函数x(t),预测 m 2006-2011年的人口数量。长期预测中,建立灰色动态模型GM(1,1)预测中国人口长期增长趋势。在解系数的过程中运用了最小二乘法,得出预测人口数据的方程)0(?x,并预测2011年到2015年的人口数量。在对中国总人口进行短期和中长期的总体预测后,我们从附件中提取出城、镇、乡三地人口、男女出生性别比、老龄人口比率等相关数据,对中国未来城、镇、乡三地人口比例、男女出生性别比、妇女生育率、老龄人口比率等影响人口发展的主要因素做趋势预测,从而达到了对中国人口全方位的预测。 关键词: 曲线拟合、灰色动态模型、最小二乘法、自然增长率
一、问题的重述 中国是一个人口大国,人口问题始终是制约我国发展的关键因素之一。根据已有数据,运用数学建模的方法,对中国人口做出分析和预测是一个重要问题。 近年来中国的人口发展出现了一些新的特点,例如,老龄化进程加速、出生人口性别比持续升高,以及乡村人口城镇化等因素,这些都影响着中国人口的增长。2007年初发布的《国家人口发展战略研究报告》还做出了进一步的分析。 关于中国人口问题已有多方面的研究,并积累了大量数据资料。附录2就是从《中国人口统计年鉴》上收集到的部分数据。 试从中国的实际情况和人口增长的上述特点出发,建立中国人口增长的数学模型,并由此对中国人口增长的中短期和长期趋势做出预测。 二、符号说明 nianfen 年份 chusheng 出生率 bata0 估计的参数值 nlinfit 非线性拟合函数 1 y出生率函数 2 y死亡率函数 m x人口上限 t 时间 x(t)人口增长函数 X(0)中国各年人口总数 X(1) X(0)的一次累加序列 Z(1) X(1)的紧邻均值生成数列 -a 发展系数 b 灰色作用量 )0(?x人口预测值 c 均方差 k ?相对误差 三、模型的假设 1.假设人口迁入迁出对问题产生的影响可以忽略; 2.忽略社会环境、自然、经济、文化水平的对人口的影响; 3.长期预测中,不考虑出生率、死亡率等因素的影响。 四、模型的建立与求解 4.1中国人口短期预测的模型建立与求解 根据查找资料得到,人口死亡率,出生率与人口增长符合指数增长的模型bt y ae c =+。模型选取了1996年到2005年的全国人口进行nlinfit拟合。(代码见附录一) 处理人口增长函数时,考虑到人口数量受资源等因素的约束,中国人口将有一个上限。定义函数时,用“人口上限与指数函数相减”模式。死亡率、出生率等客观因素很大程度上影响着中国人口的变化趋势。而且随着环境等的因素,中国的总人口最终会趋 向一个固定值,即最大容纳量x m,由logistic模型求出。假设x m 在短时间内不会改变, 则可利用逐年的历史数据来计算出人口增长率的变化情况。 设x(t)为第t年中国总人口数,r为人口的增长率,x m 为中国人口的最大容纳量。
中国人口预测模型 摘要 本文对人口预测的数学模型进行了研究。首先,建立一次线性回归模型,灰色序列预测模型和逻辑斯蒂模型。考虑到三种模型均具有各自的局限性,又用加权法建立了熵权组合模型,并给出了使预测误差最小的三个预测模型的加权系数,用该模型对人口数量进行预测,得到的结果如下: 其次,建立Leslie人口模型,充分反映了生育率、死亡率、年龄结构、男女比例等影响人口增长的因素,并利用以1年为分组长度方式和以5年为 负指数函数,并给出了反映城乡人口迁移的人口转移向量。 最后我们BP神经网络模型检验以上模型的正确性 关键字:一次线性回归灰色序列预测逻辑斯蒂模型Leslie人口模型BP神经网络
一、问题重述 1. 背景 人口增长预测是随着社会经济发展而提出来的。由于人类社会生产力水平低,生产发展缓慢,人口变动和增长也不明显,生产自给自足或进行简单的以货易货,因而对未来人口发展变化的研究并不重要,根本不用进行人口增长预测。而当今社会,经济发展迅速,生产力达到空前水平,这时的生产不仅为了满足个人需求,还要面向社会的需求,所以必须了解供求关系的未来趋势。而人口增长预测是对未来进行预测的各环节中的一个重要方面。准确地预测未来人口的发展趋势,制定合理的人口规划和人口布局方案具有重大的理论意义和实用意义。 2. 问题 人口增长预测有短期、中期、长期预测之分,而各个国家和地区要根据实际情况进行短期、中期、长期的人口预测。例如,中国人口预期寿命约为70岁左右,因此,长期人口预测最好预测到70年以后,中期40—50年,短期可以是5年、10年或20年。根据2007年初发布的《国家人口发展战略研究报告》(附录一)及《中国人口年鉴》收集的数据(附录二),再结合中国的国情特点,如老龄化进程加速,人口性别比升高,乡村人口城镇化等因素,建立合理的关于中国人口增长的数学模型,并利用此模型对中国人口增长的中短期和长期趋势做出预测,同时指出此模型的合理性和局限性。 二、问题的基本假设及符号说明 问题假设 1. 假设本问题所使用的数据均真实有效,具有统计分析价值。 2. 假设本问题所研究的是一个封闭系统,也就是说不考虑我国与其它国家的人口迁移问题。 3. 不考虑战争 瘟疫等突发事件的影响 4. 在对人口进行分段处理时,假设同一年龄段的人死亡率相同,同一年龄段的育龄妇女生育率相同。 5. 假设各年龄段的育龄妇女生育率呈正态分布 6.人类的生育观念不发生太大改变,如没有集体不愿生小孩的想法。 7.中国各地各民族的人口政策相同。 符号说明 ()i a t --------------------第t 时间区间内第i 个年龄段人口总数 ()i c t --------------------第t 时间区间内第i 个年龄段人口总数占总人口的比例 ()k i c t --------------------第t 时间区间内第i 个年龄段中第k 年龄值人口总数占总人口 的比例 ()A t --------------------第t 时间区间内各年龄段人口总数的向量 ()P t --------------------第t 时间区间各年龄段人口总数向量转移矩阵
题目:人口增长模型的确定 摘要 人口问题已成为当前世界上最普遍关注的问题之一,人口增长规律的发现以及人口增长的预测问题对一个国家制定长远的发展规划有着非常重要的意义。本文分别使用了马尔萨斯人口指数增长模型和阻滞增长模型,以美国1790-1980年间每隔10年的人口数量为依据,对接下来的每隔十年进行了预测五次人口数量。通过对比我们可以发现阻滞增长模型在预测准确度方面要明显优于原始的马尔萨斯人口指数增长模型。 关键词:人口增长;马尔萨斯人口指数增长模型;阻滞增长模型;人口预测
一、问题重述 1.1 问题背景 1790-1980年间美国每隔10年的人口记录如下表所示。 表1 人口记录表 1.2 问题提出 我们需要解决以下问题: 1.试用以上数据建立马尔萨斯(Malthus)人口指数增长模型,并对接下来的每隔十年预测五次人口数量,并查阅实际数据进行比对分析。 2.如果数据不相符,再对以上模型进行改进,寻找更为合适的模型进行预测,并对两次预测结果进行对比分析。 3.查阅资料找出中国人口与表1同时期的人口数量,用以上建立的两个模型进行人口预测与分析。 二、问题分析 首先,我们运用Matlab 软件绘制出1790到1980年的美国人口数据图,如图1。 17801800182018401860188019001920194019601980 050 100 150 200 250
图1 1790到1980年的美国人口数据图 从图表中我们可以清晰地看到人口数在1790—1980年是呈增长趋势的,而且我们很容易发现上述图表和我们学过指数函数的图表有很大的相似性,所以我们很自然想到建立指数模型。因此我们首先建立马尔萨斯模型,马尔萨斯生物总数增长定律指出:在孤立的生物群体中,生物总数N的变化率与生物总数成正比。 三、问题假设 为简化问题,我们做出如下假设: (1)在模型中预期的时间内,人口不会因发生大的自然灾害,突发事件或战争而受到大的影响; (2)所给出的数据具有代表性,能够反映普遍情况; (3)一段时间内我国人口死亡率不发生大的波动; (4)在查阅的资料与文献中,所得数据可信; (5)假设人口净增长率为常数。 四、变量说明 在此,对本文所使用的符号进行定义。 表2 变量说明 符号符号说明 N(0)起始年人口容纳量 N(t)t年后人口容纳量 t年份 r增长率 五、模型建立 5.1 问题一:马尔萨斯(Malthus)人口指数增长模型 设:t表示年份(起始年份t=0),r表示人口增长率,N(t)表示t年后的人口数量。 当考察一个国家或一个很大地区的人口时,N(t)是很大的整数。为了利用微积分这一数学工具,将N(t)视为连续、可微函数。记初始时刻(t=0)的人口为N(0),人口增长率为r,r是单位时间内N(t)的增量与N(t)的比例系数。根据r是常数的基本假设,于是N(t)满足如下的微分方程: dN(t)/dt=r*N(t) (5-1) 由这个线性常系数微分方程容易解出: N(t)=N(0)e rt(5-2) 表明人口将按指数规律无限增长(r>0)。将以t年为单位,上式表明,人口以e r为公
实验24 人口预测的最小二乘模型 据统计,上世纪六十年代世界人口数据如下: 表24-1 世界人口数据(单位:亿) 年1960 1961 1962 1963 1964 1965 1966 1967 1968 人口29.72 30.61 31.51 32.13 32.34 32.85 33.56 34.20 34.83 的方法就是数据拟合方法。 一、问题分析 据人口增长的统计资料和人口理论,当人口总数N 不是很大时,在不长的时期内,人口增长率与人口数N成正比,这就是著名的马尔萨斯人口模型,用微分方程描述为 dN =(24.1) bN dt 其中,b为人口增长系数。用分离变量法解常微分方程,得ln N = b t + a,即 =(24.2) ()a bt N t e+ 由此可知,马尔萨斯模型是人口数量按指数函数递增的模型。由于指数函数表达式中a和b均未知,需要用人口数据来确定。即用指数函数对数据进行拟合,确定指数函数中参数使指数函数与人口数据偏差(残差平方和)尽可能小。下图是经数所拟合后的指数函数图形与原始数据散点图的对比,残差平方和为3.6974×10- 4 图24-1指数函数图形与原始数据散点图 为了计算方便,将上式两边同取对数,还原为ln N = a + b t,令 y = ln N或N = e y
- 160 - 第三章 综合实验 160 变换后的拟合函数为 y (t ) = a + b t (24-3) 由人口数据取对数(y = ln N )计算,得下表 表24-2 世界人口数据(单位:亿) 二、求解超定方程组的数学原理 根据表中数据及等式a + b t k = y k ( k = 1,2,……,9)可列出关于两个未知数a 、b 的9个方程的线性方程组 ????? ??? ?? ?? ???=+=+=+=+=+=+=+=+=+5505 .319685322.319675133.319664920.319654763.319644698.319634503.319624213.319613918.31960b a b a b a b a b a b a b a b a b a (24-4) 由于这一问题中方程数目多于未知数个数,被称为超定方程组,用矩阵形式表示 为 AU = f (24-5) 显然A 矩阵的行数大于列数。求解这一类方程组的数学原理是将等式左、右同时乘以A 的转置矩阵,得新的线性方程组 A T AU =A T f (24-6) 令G =A T A , b = A T f 。得系数矩阵为方阵的线性方程组。 GU=b 求解得原方程组的最小二乘解(广义解)。由于原方程组一般无解,将最小二乘解代入下式计算 R = f – A U (24-7) 通常会得非零向量,这一向量称为残差。残差的内积可以用来度量最小二乘解的逼近程度。
数学建模l o g i s t i c人口 增长模型 集团档案编码:[YTTR-YTPT28-YTNTL98-UYTYNN08]
Logistic 人口发展模型 一、题目描述 建立Logistic 人口阻滞增长模型 ,利用表1中的数据分别根据从1954年、1963年、1980年到2005年三组总人口数据建立模型,进行预测我国未来50年的人口情况.并把预测结果与《国家人口发展战略研究报告》中提供的预测值进行分析比较。分析那个时间段数据预测的效果好并结合中国实情分析原因。 二、建立模型 阻滞增长模型(Logistic 模型)阻滞增长模型的原理:阻滞增长模型是考虑到自然资源、环境条件等因素对人口增长的阻滞作用,对指数增长模型的基本假设进行修改后得到的。阻滞作用体现在对人口增长率r 的影响上,使得r 随着人口数量x 的增加而下降。若将r 表示为x 的函数)(x r 。则它应是减函数。于是有: 0)0(,)(x x x x r dt dx == (1) 对)(x r 的一个最简单的假定是,设)(x r 为x 的线性函数,即 ) 0,0()(>>-=s r sx r x r (2)
设自然资源和环境条件所能容纳的最大人口数量m x ,当m x x =时人口不再 增长,即增长率0)(=m x r ,代入(2)式得 m x r s = ,于是(2)式为 )1()(m x x r x r -= (3) 将(3)代入方程(1)得: ?? ? ??=-=0 )0()1(x x x x rx dt dx m (4) 解得: rt m m e x x x t x --+= )1( 1)(0 (5) 三、模型求解 用Matlab 求解,程序如下: t=1954:1:2005; x=[60.2,61.5,62.8,64.6,66,67.2,66.2,65.9,67.3,69.1,70.4,72.5,74.5,76.3,78.5,80.7,83,85.2,87.1,89.2,90.9,92.4,93.7,95,96.259,97.5,98.705,100.1,101.654,103.008,104.357,105.851,107.5,109.3,111.026,112.704,114.333,115.823,117.171,118.517,119.85,121.121,122.389,123.626,124.761,125.786,126.743,127.627,128.453,129.227,129.988,130.756]; x1=[60.2,61.5,62.8,64.6,66,67.2,66.2,65.9,67.3,69.1,70.4,72.5,74.5,76.3,78.5,80.7,83,85.2,87.1,89.2,90.9,92.4,93.7,95,96.259,97.5,98.705,100.1,101.654,103.008,104.357,105.851,107.5,109.3,111.026,112.704,114.333,115.823,117.171,118.517,119.85,121.121,122.389,123.626,124.761,125.786,126.743,127.627,128.453,129.227,129.988]; x2=[61.5,62.8,64.6,66,67.2,66.2,65.9,67.3,69.1,70.4,72.5,74.5,76.3,78.5,80.7,83,85.2,87.1,89.2,90.9,92.4,93.7,95,96.259,97.5,98.705,100.1,101.654,103.008,104.357,105.851,107.5,109.3,111.026,112.704,114.333,115.823,117.171,118.517,119.85,121.121,122.389,123.626,124.761,125.786,126.743,127.627,128.453,129.227,129.988,130.756]; dx=(x2-x1)./x2; a=polyfit(x2,dx,1); r=a(2),xm=-r/a(1)%求出xm 和r x0=61.5; f=inline('xm./(1+(xm/x0-1)*exp(-r*(t-1954)))','t','xm','r','x0');%定义函数 plot(t,f(t,xm,r,x0),'-r',t,x,'+b'); title('1954-2005年实际人口与理论值的比较')
中国人口预测模型 天津师范大学数学科学学院 1003班 刘瑶(10505135)周丽(10505110) 2013年6月17日星期一
中 国 人 口 预 测 模 型 摘 要 为了加快中国的经济建设进程,全面落实科学的发展观,按照构建社会主义和谐社会的要求,实现人口与经济社会资源环境的协调和可持续发展。我们确定人口发展战略,必须既着眼于人口本身的问题,又处理好人口与经济社会资源环境之间的相互关系,构建社会主义和谐社会,统筹解决人口数量、素质、结构、分布等问题。 本文是以《中国人口统计年鉴》公布的部分人口数据为基准(其他部分数据通过网站查询得到),通过合理的假设和数学模型得到了对于中国人口增长预测的统计模型。对Leslie 人口模型改进,构建了反映生育率和死亡率变化率负指数函数。基于leslie 的改 进模型: (t)X B B B +(t)X A A A =t)▽n +X(t 22) -(n 3 2112) -(n 3 21 此模型考虑到了生育率的变化,并是针对总人口分布处理的,克服了leslie 模型的不足,很适合做长期预测。得到结论:人口数量先增大后减小,峰值出现在2040年,届时人口数量将达到最大,为15.869亿。 关键词: 人口预测, Leslie 人口模型改进 , 长期预测 一 问题的背景 中国是世界上人口最多的发展中国家,人口多,底子薄,耕地少,人均占有资源相对不足,是我国的基本国情,人口问题一直是制约中国经济发展的首要因素。新中国成立50多年来,我国人口发展经历了前30年高速增长和后20年低速增长两大阶段:从建国初期到上世纪70年代初,中国人口再生产由旧中国的高出生、高死亡率进入高出生、低死亡率的人口高增长时期,1950-1975年人口出生率始终保持在30‰以上, 最高达到37‰(附录1)。70年代以后,人口过快增长的势头得到迅速扭转,人口出生率、自然增长率、妇女总和生育率有了明显下降,人口出生率由70年代初的33‰大幅度下降到80年代的21‰, 妇女总和生育率也由6下降到2.3左右。90年代以来,随着我国经济高速发展,人民文化和健康水平逐步提高,计划生育工作的不断深入,在20-29岁生育旺盛人数年均超过1亿的情况下, 人口出生率依然呈现大幅下降的趋势,到2000年底人口出生率从1990年的21.06‰下降到14.03‰,自然增长率由1990年的14.39‰下降到7.58‰, 妇女总和生育率也下降到2以下。进入90年代末期, 我国人口再生产实现了低出生、低死亡、低增长的历史性转变,我国用20多年时间完成了国外近200年的历程。到2000年底全国总人口为12.6743亿, 成功实现了“九五”计划将人口控制在13亿的奋斗目标。 中国政府自1980年在全国城乡实行计划生育基本国策以来成果卓著,据国家计生委“计划生育投入与效益研究”课题组的研究成果,20年共少生2.5亿个孩子。若从70年代算起,至今至少少生3亿人口,这有效地控制了人口的快速增长,为中国现代化建设、全面实现小康打下坚实的基础, 这同时也是对世界人口的增长和控制做出了杰出贡献。但是由于中国人口基数大,人口增长问题依然十分严峻,1990-1999年每年平均净增人口约1300万,这仍然对我国社会和经济产生巨大的压力。在我国现代化进程中,必须实现人口与经济、社会、
上传是为了分析数学的乐趣,请粘贴复制的时候也多思考哈。为了更多的学子们 2014 年数学建模论文 第二套 题目:人口增长模型的确定 专业、姓名:土木135 提交日期:2015/7/2 晚上
题目:人口增长模型的确定 摘要 对美国人口数据的变化进行拟合,并进行未来人口预测,在第一个模型中,考虑到人口连续变化的规律,用微分方程的方法解出其数量随时间变化的方程,用 matlab 里的 cftool 工具箱求出参数,即人口净增长率 r=, 对该模型与实际数据进行对比,并计算了从 1980年后每隔10 年的人口数据,与实际对比,有很大出入。因此又改进出更为符合实际的阻滞增长模型,应用微分方程里的分离变量法和积分法解出其数量随时间变化的方程,求出参数人口增长率r=和人口所能容纳最大值 x m =, 与实际数据对比,拟合得很好,并预测出 1980年后每隔 10 年的人口数据,与实际对比,比较符合。为了便于比较两个模型与实际数据的描述情况作对比,又做出了两个模型与实际数据的对比图,以及两个模型的误差图。 关键词:人口预测微分方程马尔萨斯人口增长模型阻滞增长模型 一、问题重述 1790-1980 年间美国每隔 10 年的人口记录如下表所示 表 1 人口记录表 试用以上数据建立马尔萨斯 (Malthus) 人口指数增长模型,并对接下来的每隔十年预测五次人 口数量,并查阅实际数据进行比对分析。 如果数据不相符,再对以上模型进行改进,寻找更为合适的模型进行预测。 二、问题分析 由于题目已经说明首先用马尔萨斯人口增长模型来刻划,列出人口增长指数增长方程并求解,并进行未来 50 年内人口数据预测,但发现与实际数据有较大出入。考虑到实际的人口增长率是受实际情况制约的,因此,使人口增长率为一变化的线性递减函数,列出人口增长微分方程,求出其方程解,并预测未来五十年内人口实际数据。 三、问题假设
全国大学生数学建模竞赛 承诺书 我们仔细阅读了中国大学生数学建模竞赛的竞赛规则. 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮 件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问 题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他 公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正 文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反 竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C/D中选择一项填写): A 我们的参赛报名号为(如果赛区设置报名号的话): 所属学校(请填写完整的全名):西安理工大学 参赛队员 (打印并签名) :1. 2. 3. 指导教师或指导教师组负责人 (打印并签名): 日期: 20011 年 7 月4 日赛区评阅编号(由赛区组委会评阅前进行编号):
中国人口增长模型 摘要:人口数量的变化,关系到一个国家的未来。认识人口数量的变化规律,建立人口模型,能过较准确的预报,是有效控制人口增长的前提。针对题目所提要求,我们首先建立了Malthus模型。此模型假设人口增长率为常数,即人口按指数增长。但实际上人口增长率受环境、资源等多重因素影响,并不是常数。用Malthus模型计算1982~2005年的中国人口总量并与实际值比较发现,在短期内(1982~1995)Malthus模型能过较准确的计算出人口总量,但中长期的计算值误差较大,所以此模型只适用于短期的人口预测。为使人口预报特别是中长期预报更好地符合实际情况,必须修改指数增长模型关于人口增长率是常数这个基本假设。分析人口增长到一定数量后增长率下降的主要原因,注意到,自然资源、环境条件等因素对人口起着阻滞作用,并随着人口的增加,阻滞作用越来越大。假设人口增长率随着人口总量的增加线性递减,从而建立了性能更好的Logistic 模型。经对比发现,作为短期预测,Malthus模型和Logistic模型不相上下,但作为中长期预测Logistic模型比Malthus模型更合理一些。
人口增长的预测 关键字:人口数平衡点方程模型运动预测曲线稳定增长人口 一题目: 请在人口增长的简单模型的基础上。 " (1)找到现有的描述人口增长,与控制人口增长的模型; " (2)深入分析现有的数学模型,并通过计算机进行仿真验证; " (3)选择一个你们认为较好的数学模型,并应用该模型对未来20年的某一地区或国家的人口作出有关预测; " (4)就人口增长模型给报刊写一篇文章,对控制人口的策略进行论述。 二摘要: 本次建模是依照已知普查数据,利用Logistic模型,对中国人口的增长进行预测。首先假设人口增长符合Logistic模型,即引入常数,用来表示自然环境条件所能容许的最大人口数。并假设净增长率为,即净增长率随着人口数N(t)增长而减小,当N(t) 时,净增长率趋于零。按照这个假设,。用参数=3.0,r=0.0386, =1908, =14.5。画出N=N(t)的图像,作为人口增长模型的一种近似。 做微分方程解的定性分析,求出N=N(t)的驻点和拐点,按照函数作图方法列出定性分析表,作出相轨迹的运动图。当初始人口<时,方程的解单调递增到地趋向,这意味着如果使用Logistic模型描述人口增长,则人口发展地总趋势是渐增到最大人口数,因此可作为人口的预测值,也称谓平衡点。 用导数做稳定分析,为判断平衡点是否为稳定,可在平面上绘制f(x)的图象,然后像函数绘图那样,用导数进行定性分析,通过图看出人口数N(t)按时间是递增的,当人口数未达到饱和状态的时候,将逐渐地趋向,这意味着是稳定的平衡点。按该模型,未来人口的数量将随着时间的演化,从初始状态出发达到极限状态,这样就给出了人口的未来预测。 三问题的提出 1.Malthus模型 英国统计学家Malthus(1766-1834)发现人口增长率是一个常数。设t时刻人口为N(t),因为人口总数很大,可近似把N(t)当作连续变量处理。Malthus的假设是:在人口的自然增长过程中,净相对增长率(出生率减去死亡率)是常数,即单位时间内人口的增长量与人口总数成正比。根据这个假设有: , (1.1) 这是一个最简单的可分离变量方程,用符号微分方程求解器desolve容易求得方程的解为:如果人口的增长符合Malthus的模型,则意味着人口数量呈指数级数增长,最终结果是人口爆炸。 2.Logistic模型 1938年,荷兰生物数学家Verhulst引入常数,用来表示自然环境条件所能容许的最大人口数。并假设净增长率为,即净增长率随着人口数N(t)增长而减小,当N(t) 时,净增长率趋于零。按照这个假设(1.1)式可改为: ,(2.1) 上述方程为可分离变量方程,可直接求解。也可用符号微分方程解题器求它的解: N=dsolve(’DN=r*(1-N/Nm)*N’,’N(t0)=N0’) N=Nm/(1+exp(-r*t)*exp(t0*r)*(Nm-N0)/N0) 化简后得: 四利用数学模型对中国人口的预测
人口增长预测 数学实验 指导教师:何仁斌 城市建设与环境工程学院环境工程1班 姓名:郑惋月 学号:20096545
人口增长预测 摘要:人口问题是当前世界上人们最关心的问题之一.认识人口数量的变化规律,作出较准确的预报,是有效控制人口增长的前提。 本文主要介绍了两个最基本的人口模型,即人口指数增长模型和阻滞增长模型,并利用美国1790年至1980年人口统计数据,对模型做出检验,最后用它预测2010年美国人口。 模型一:建立了指数增长模型,根据规律建立模型公式——年增长率r不变。我们要验证该模型是否适用。取题目中给出的数据1790年至1900年的,数据拟合用MATLAB软件计算的增长率r以及初始人口数。讲以上两参数带入公式,算的人口数量,将之与实际人口数相比较画出对比图形,发现比较相符。又取1790至2000年的数据,重复刚才步骤。发现算出数据前半部分相符,但后半部分明显增加的比实际数据快。所以,Malthus人口模型只适用于短期,并不适用于长期的人口预测。因为人口在增长到一定程度时,由于资源和环境对人口增长的阻滞作用使增长率下降。 模型二:建立了阻滞增长人口阻滞增长模型,利用题目中给出的数据。根据公式做出人口的时间变化率与人口容量的关系图,以及人口与时间的关系图。选择1860年至1990年的数据(去掉个别异常数据),用MATLAB软件计算出增长率和人口容量。根据得到的数据带入公式的到计算的人口数量与实际数据作比较。可以看出这个模型的吻合度相当好,由于阻滞增长人口模型。可以据此模型有效的预测在以后一段时间内如2020的美国人口增长。依次内推也可以利用此模型来预测世界人口在相当一段时间内的人口增长。 模型三:对模型进行了进一步的修正。 最后,分别对三模型进行优缺点评价与改进。 关键字:人口预测; matlab软件;人口指数增长模型;阻滞增长模型
关于计划生育政策调整对人口数量、结构及其影响的研究 【摘要】 本文着重于讨论两个问题:1、从目前中国人口现状出发,对于中国未来人口数量进行预测。2、针对深圳市讨论单独二胎政策对未来人口数量、结构及其对教育、劳动力供给与就业、养老等方面的影响。 对于问题1从中国的实际情况和人口增长的特点出发,针对中国未来人口的老龄化、出生人口性别比以及乡村人口城镇化等,提出了 Logistic 、灰色预测、等方法进行建模预测。 首先,本文建立了 Logistic 阻滞增长模型,在最简单的假设下,依照中国人口的历 史数据,运用线形最小二乘法对其进行拟合, 对 2014 至 2040 年的人口数目进行了预测, 得出在 2040 年时,中国人口有 14.32 亿。在此模型中,由于并没有考虑人口的年龄、 出生人数男女比例等因素,只是粗略的进行了预测,所以只对中短期人口做了预测,理 论上很好,实用性不强,有一定的局限性。 然后, 为了减少人口的出生和死亡这些随机事件对预测的影响, 本文建立了 GM(1,1) 灰色预测模型,对 2014 至 2040 年的人口数目进行了预测,同时还用 2002 至 2013 年的 人口数据对模型进行了误差检验,结果表明,此模型的精度较高,适合中长期的预测, 得出 2040 年时,中国人口有 14.22 亿。与阻滞增长模型相同,本模型也没有考虑年龄 一类的因素,只是做出了人口总数的预测,没有进一步深入。 对于问题2针对深圳市人口结构中非户籍人口比重大,流动人口多这一特点,我们采用了灰色GM(1,1)模型,通过matlab 对深圳市自2001至2010年的数据进行拟合,发现其人口变化近似呈线性增长,线性相关系数高达0.99,我们就此认定其为线性相关并给出线性方程。同理,针对其非户籍人口,我们进行matlab 拟合发现,其为非线性相关,并得出相关函数。并做出了拟合函数 0.0419775(1)17255.816531.2t X t e ?+=?-。 对于新政策的实施,我们做出了两个假设。在假设只有出生率改变的情况,人口呈现一次函数线性增加。并拟合出一次函数0.032735617965.017372.5t Y e ?=?-;在假设人口增长率增长20%时,做出了预测如果单独二胎政策实施,到2021年,深圳市常住人口数将会到达1137.98千万人。 关键词:GM(1,1)灰色模型 Logistic 阻滞增长模型 线性拟合 非线性拟合
实验24 人口预测的最小二乘模型 表 24-1 世界人口数据(单位 亿) 年 1960 1961 1962 1963 1964 1965 1966 1967 1968 人口 29.72 30.61 31.51 32.13 32.34 32.85 33.56 34.20 34.83 根据表中数据,预测公元2000年世界人口会超过 60亿。作出这一预测结果所用 的方法就是数据拟合方法。 一、问题分析 据人口增长的统计资料和人口理论,当人口总数 N 不是很大时,在不长的 时期内,人口增长率与人口数 N 成正比,这就是著名的马尔萨斯人口模型,用微 分方程描述为 由此可知,马尔萨斯模型是人口数量按指数函数递增的模型。由于指数函数表达 式中a 和b 均未知,需要用人口数据来确定。即用指数函数对数据进行拟合,确 定指数函数中参数使指数函数与人口数据偏差(残差平方和)尽可能小。下图是 经数所拟合后的指数函数图形与原始数据散点图的对比,残差平方和为 3.6974 杓-4 为了计算方便,将上式两边冋取对数,还原为 y = ln N 或 In N = a + b t ,令 N = e y 变换后的拟合函数为 dN dt bN 其中,b 为人口增长系数。用分离变量法解常微分方程,得 N(t) a bt e (24.1) In N = b t + a ,即 (24.2) 图24-1指数函数图形与原始数据散点图
y(t) = a + b t (24-3) 由人口数据取对数(y = In N )计算,得下表 表24-2世界人口数据(单位:亿) 二、求解超定方程组的数学原理 根据表中数据及等式a + b t k = y k ( k = 1, 2, ……,9)可列出关于两个未知数 a、b的9个方程的线性方程组 a 1960 b 3.3918 a 1961 b 3.4213 a 1962 b 3.4503 a 1963 b 3.4698 a 1964 b 3.4763 a 1965 b 3.4920 a 1966 b 3.5133 a 1967 b 3.5322 a 1968 b 3.5505 (24-4) 由于这一问题中方程数目多于未知数个数,被称为超定方程组,用矩阵形式表示为 AU = f (24-5) 显然A矩阵的行数大于列数。求解这一类方程组的数学原理是将等式左、右同时 乘以A的转置矩阵,得新的线性方程组 A T AU =A T f (24-6) 令G =A T A, b = A T f。得系数矩阵为方阵的线性方程组。 GU=b 求解得原方程组的最小二乘解(广义解)。由于原方程组一般无解,将最小二乘解 代入下式计算 R = f -A U (24-7) 通常会得非零向量,这一向量称为残差。残差的内积可以用来度量最小二乘解的 逼近程度。 三、问题求解的计算机实验 输入下面命令
l e s l i e人口增长模型 模型 Company Document number:WTUT-WT88Y-W8BBGB-BWYTT-19998
人口增长预测模型 摘要 本文建立了我国人口增长的预测模型,对各年份全国人口总量增长的中短期和长期趋势作出了预测,并对人口老龄化、人口抚养比等一系列评价指标进行了预测。最后提出了有关人口控制与管理的措施。 模型Ⅰ:建立了Logistic人口阻滞增长模型,利用附件2中数据,结合网上查找补充的数据,分别根据从1954年、1963年、1980年到2005年三组总人口数据建立模型,进行预测,把预测结果与附件1《国家人口发展战略研究报告》中提供的预测值进行分析比较。得出运用1980年到2005年的总人口数建立模型预测效果好,拟合的曲线的可决系数为。运用1980年到2005年总人口数据预测得到2010年、2020年、2033年我国的总人口数分别为亿、亿、亿。 模型Ⅱ:考虑到人口年龄结构对人口增长的影响,建立了按年龄分布的女性模型(Leslie模型):以附件2中提供的2001年的有关数据,构造Leslie矩阵,建立相应 Leslie模型;然后,根据中外专家给出的人口更替率,构造Leslie矩阵,建立相应的 Leslie模型。 首先,分别预测2002年到2050年我国总人口数、劳动年龄人口数、老年人口数(见附录8),然后再用预测求得的数据分别对全国总人口数、劳动年龄人口数的发展情况进行分析,得出:我国总人口在2010年达到亿人,在2020年达到亿人,在2023年达到峰值亿人;预测我国在短期内劳动力不缺,但须加强劳动力结构方面的调整。 其次,对人口老龄化问题、人口抚养比进行分析。得到我国老龄化在加速,预计本世纪40年代中后期形成老龄人口高峰平台,60岁以上老年人口达亿人,比重达%;65岁以上老年人口达亿人,比重达%;人口抚养呈现增加的趋势。 再次,讨论我国人口的控制,预测出将来我国育龄妇女人数与生育旺盛期育龄妇女人数,得到育龄妇女人数在短期内将达到高峰,随后又下降的趋势的结论。 最后,分别对模型Ⅰ与模型Ⅱ进行残差分析、优缺点评价与推广。 关键词 Logistic人口模型 Leslie人口模型人口增长预测 MATLAB软件
一、问题重述 人口的数量和结构是影响经济社会发展的重要因素。从20世纪70年代后期以来,我国实行计划生育政策,有效地控制了我国人口的过快增长,对经济发展和人民生活的改善做出了积极的贡献。但该政策实施30多年来,其负面影响也开始显现。如临近超低生育率水平、人口老龄化、出生性别比失调等问题,这些对经济社会健康、可持续发展将产生一系列影响,引起了中央和社会各界的重视。党的十八届三中全会提出了开放单独二孩,今年以来许多省、市、自治区相继出台了具体的政策。政策出台前后各方面人士对开放“单独二孩”的效应进行了大量的研究和评论。 党的十八届三中全会《决定》提出,启动实施单独两孩政策。这是新时期我国生育政策的重大调整完善,备受社会关注。 请解决以下问题: (1)针对国家卫生计生委副主任王培安单独二孩不会导致人口大增的人口预测,根据每十年一次的全国人口普查数据,建立模型,对单独二孩会不会导致人口大增进行分析,并发表自己的独立见解。 (2)建立数学模型,针对深圳市讨论计划生育新政策(可综合考虑城镇化、延迟退休年龄、养老金统筹等政策因素,但只须选择某一方面作重点讨论)对未来人口数量、结构及其对教育、劳动力供给与就业、养老等方面的影响。 二、问题分析 问题1、启动实施单独二胎政策,是经过充分的论证和评估的。对于我国目前为什么要放开二胎政策这个问题,以及为什么单独二孩不会导致人口大增是有以下情况决定的。 进入本世纪以来,我国人口形势发生了重大变化。一是生育水平稳中趋降,我国目前总和生育率为1.5-1.6,如果不实行单独二胎新政策,总和生育率将继续下降。二是人口结构性问题,劳动年龄人口开始减少,人口老龄化速度加快,出生人口性别比长期偏高。三是家庭规模持续缩减。四是城乡居民生育意愿发生很大变化,少生优生、优育优教的生育观念正在形成。 通过建立动态差分方程模型预测老龄化的人口数、劳动人口数以及总人口数。根据预测的数据画出老龄化程度的趋势图和人口红利的趋势图,最终通过分析老龄化程度、生育率高低、出生性别比例和人口红利变化来验证单独二孩政策的必要性以及单独二孩不会导致人口大增的预测。
中国人口预测模型 专业:数学与应用数学姓名:蒲世吉指导教师:焦玉娟 摘要本文针对我国人口现状,综合考虑城镇和乡村男女性比率、出生率、死亡率及国内人口迁移等因素,建立人口发展方程,结合最优控制原理及曲线拟合等技术,分别建立了城镇和乡村男、女性人口变化模型.通过实际数据的检验,结果表明该模型能够较好地刻画我国目前的人口现状,从而用它可以预测我国人口的未来发展趋势并为国家进行相关人口政策的制定提供必要的理论指导. 根据模型预测,在2015年,我国人口将达到139846万人;在2030年,我国人口将达到峰值144679万人;在2050年将达到141527万人.这与国家人口发展战略研究报告中预测的数据接近.从全国总人口变化曲线上直接看来,在国家人口政策相对稳定的情况下,2030年后我国人口逐渐有所减少. 关键词人口模型,人口发展方程,最优化控制原理,人口增长率 ABSTRACT This paper concerns the status of our country's population,with consideration of the sex ratio ,birthrate ,mortality and inland migration of counties and towns, this paper establish both the male and female population model of the chinese counties and towns with optimal control theory and curve fitting and so on. Through checking the model with real data, the results manifest that this model
中国人口增长预测模型 张孟琦、王光昭、陈阔 指导教师:杨亚莉 (空军工程大学,西安 L25) 摘要:本文从中国60年代开始出现的回声婴儿潮现象,以及如今中国城乡人口生育差异和男女比例失调等特点出发,将市、镇、乡中不同性别人口按年龄段分别处理,并引入农村人口向城镇迁移的因素,建立起一个关于中国人口增长的常微分方程组初值问题的数学模型和Leslie矩阵迭代模型。还利用该模型对中国未来人口的增长变化进行了预测。并通过MATLAB软件编程分别建立长、短期男女人口比例模型,针对男女比例失调问题,就中国男女比例变化趋势对未来中国人口的增长变化的影响进行了预测与讨论。 关键词:回声婴儿潮;男女比例;老龄化;城镇化
1、引言: 近年来中国出生人口性别比持续升高,第五次全国人口普查为117,2003年抽样调查为119,个别省份超过130。2005年1%抽样调查为118.58。城乡均出现异常,农村失调程度更为严重。预计到2020年,20-45岁男性将比女性多3000万人左右。同时,中国也是目前世界上唯一一个采取干涉生育措施的国家,因此我们想就此对我国未来男女比例的影响做出分析。 在这里我们要引入回声婴儿潮(Echo baby boom)的概念来分析我国的人口情况。下图(底图来源:世界银行)是中国1962年以来40多年间的人口自然增长率曲线(蓝色): 因为1962年之前有过5年左右的非自然增长,所以我们把50年代的数据不计入分析过程。进入60年代,随着“三年困难时期”结束,生产在一定程度上恢复稳定,又加上鼓励生育,所以在1962
年-1971年期间第一个稳定的婴儿潮B,其峰值发生在1966年(红线1)。70年代中期开始调整了生育政策,并且随着生产生活的模式的变化,之后人口增长率陡降。80年代以后,婴儿潮B的大多数女性开始进入生育年龄(当时全国平均是22岁),开始迎来了第二批稳定生育高峰,婴儿潮C,这个C的形状是B的复制,就像回声一样一波一波的,所以称为(第一)回声婴儿潮,发生在1982年-1991其峰值出现在1988年(红线2,即1966+22,完全符合生育年龄均值)。现阶段是平均生育年龄是27岁,随着回声婴儿潮C中出生的人口逐渐进入生育年龄,理论上潮D的峰值应该出现在2015年,但是尽管现在全国已经放开二孩政策,近几年的曲线却较为平缓,回声婴儿潮D并没有如期而至。通过分析,我们认为这主要是由于人们生育观念改变导致的,因而我们可以认为在未来如果不考虑世界大战、重大灾害等重大事件,总人口自然增长率将不会有较大波动,我们将在这个条件下建立模型推算未来的男女比例。 2.模型的预备知识 2.1模型假设 1)不考虑国境间人口流动对人口统计的影响; 2)不考虑所统计的数字中的人口漏报的现象; 3)不考虑各地方生育法规的灵活性政策对全国人口政策影响; 4)不考虑针对少数民族的特殊政策;