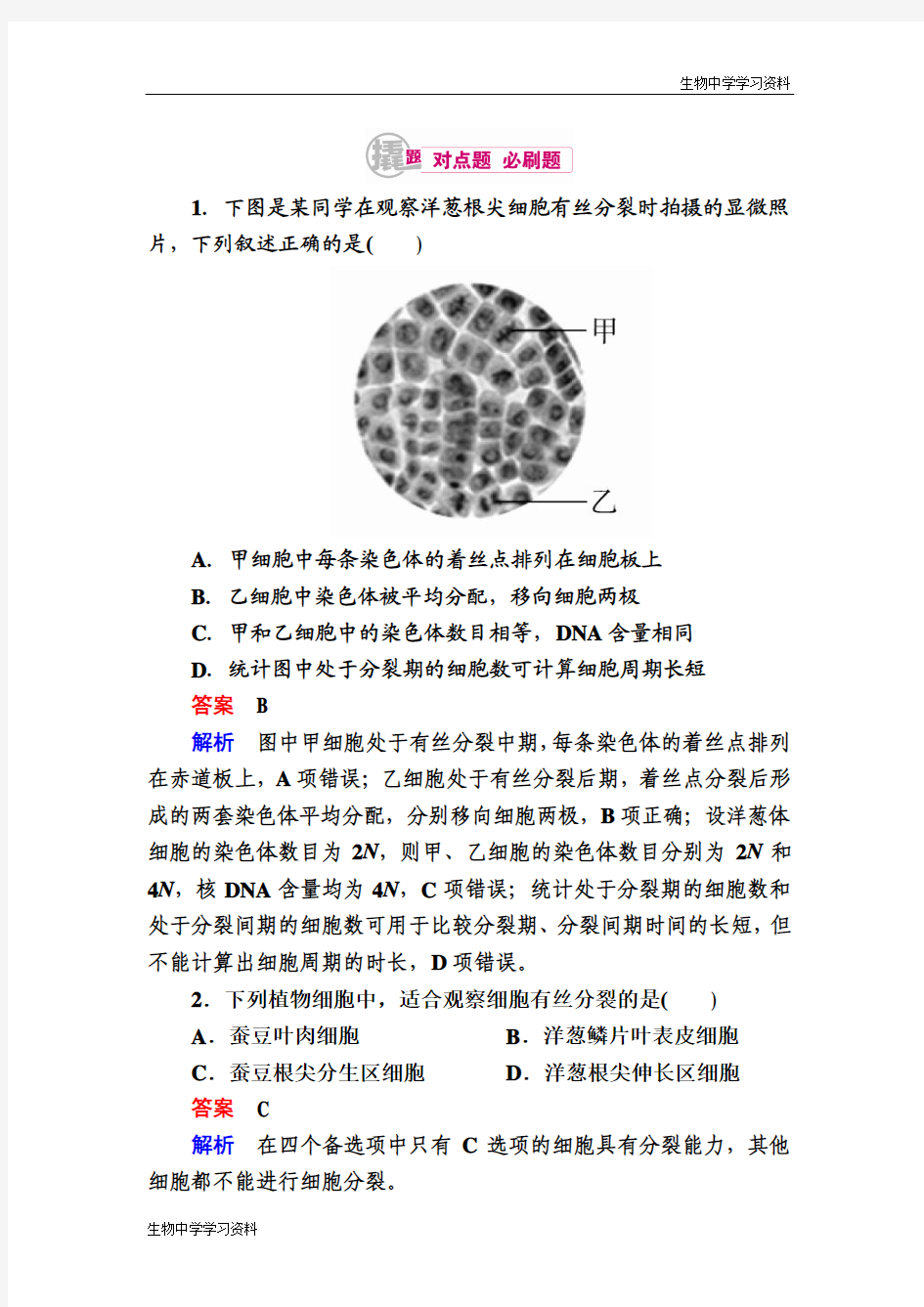

1.下图是某同学在观察洋葱根尖细胞有丝分裂时拍摄的显微照片,下列叙述正确的是()
A.甲细胞中每条染色体的着丝点排列在细胞板上
B.乙细胞中染色体被平均分配,移向细胞两极
C.甲和乙细胞中的染色体数目相等,DNA含量相同
D.统计图中处于分裂期的细胞数可计算细胞周期长短
答案 B
解析图中甲细胞处于有丝分裂中期,每条染色体的着丝点排列在赤道板上,A项错误;乙细胞处于有丝分裂后期,着丝点分裂后形成的两套染色体平均分配,分别移向细胞两极,B项正确;设洋葱体细胞的染色体数目为2N,则甲、乙细胞的染色体数目分别为2N和4N,核DNA含量均为4N,C项错误;统计处于分裂期的细胞数和处于分裂间期的细胞数可用于比较分裂期、分裂间期时间的长短,但不能计算出细胞周期的时长,D项错误。
2.下列植物细胞中,适合观察细胞有丝分裂的是()
A.蚕豆叶肉细胞B.洋葱鳞片叶表皮细胞
C.蚕豆根尖分生区细胞D.洋葱根尖伸长区细胞
答案 C
解析在四个备选项中只有C选项的细胞具有分裂能力,其他细胞都不能进行细胞分裂。
3.下列对于植物细胞有丝分裂步骤解释错误的是()
A.解离过程使用15%盐酸,目的是使细胞易于分散
B.可以选用醋酸洋红对染色体进行染色
C.压片时需要进行研转使细胞分散成均匀一层
D.若镜检时看到细胞如图所示,则可能取材时取错位置
答案 C
解析解离过程使用15%盐酸,目的是使组织中的细胞互相分离开,易于分散,A正确;可以选用醋酸洋红对染色体进行染色,易于观察,B正确;在被弄碎的根尖上盖上盖玻片,复加一块载玻片用拇指轻压,使细胞分散开呈单层细胞,不可研转,C错误;若镜检时看到如图所示成熟区细胞,细胞已经分化,看不到染色体行为,则可能取材时取错位置,D正确。
4.回答下列问题:
(1)在观察大蒜根尖细胞有丝分裂的实验中,常用盐酸酒精混合液处理根尖,用龙胆紫溶液染色。实验中,盐酸酒精混合液的作用是____________________;龙胆紫溶液属于________性染料,能够使细胞中的________着色。
(2)用光学显微镜观察细胞,可以看到细胞核。细胞核的功能可概括为:_____________________________________________________。
答案(1)使组织中的细胞相互分离碱染色体
(2)细胞核是细胞内遗传物质储存、复制和转录的主要场所,是
细胞代谢和遗传的控制中心
解析(1)在观察植物根尖细胞有丝分裂实验中,常先用盐酸酒精混合液处理根尖,使组织中的细胞相互分离开来。为便于观察,常用碱性染料如龙胆紫溶液对染色体进行染色。
(2)细胞核是遗传信息库,是细胞代谢和遗传的控制中心。
如图为某生物细胞有丝分裂过程中染色体数(a)、染色单体数(b)和核DNA分子数(c)的统计图。下列解释一定不正确的是()
A.图①可以用于表示细胞分裂的前期
B.染色体螺旋化程度最高时,可用图①表示三者的数量关系C.间期用图②表示最恰当
D.图③可表示细胞分裂完成
[错解]A或B
[错因分析]对有丝分裂各时期特点的识记不到位,搞不清有丝分裂过程中染色体、染色单体和核DNA的数量关系而错选。
[正解] C
[解析]先判断图①②③可表示哪些时期,再根据各时期的特点逐项分析。图②与图①相比,染色体数加倍,染色单体数为零,可表示有丝分裂后期。图③与图②相比,染色体和核DNA数恢复为正常值,可表示有丝分裂末期。
[心得体会]
1.1简述DNA双螺旋结构模型要点 a.DNA两条链逆平行、围绕同中心轴右手螺旋的双链结构,双螺旋结构的直径为2.0nm,螺距为3.4nm。 b.脱氧核糖和磷酸基团构成亲水性骨架位于双螺旋结构的外侧,疏水碱基位于螺旋内侧。每周约10个碱基。 c.两条链借助彼此之间的的氢键结合在一起。AT配对有两个氢键GC配对有三个氢键。每两个碱基对之间的相对旋转角度为36° d.双螺旋结构的表面形成了一个大沟(major groove)和一个小沟(minor groove)。 1.2 名词解释:DNA的变性与复性;DNA分子杂交 DNA的变性:在某些理化因素作用下,DNA双链解开成两条单链的过程。DNA变性的本质是双链间氢键的断裂。 DNA的复性:当变性条件缓慢地除去后,两条解离的互补链可重新配对,恢复原来的双螺旋结构,这一现象称为DNA复性(renaturation) 。 DNA分子杂交:热变性的DNA在缓慢冷却过程中,具有碱基序列互补的不同DNA之间或DNA与RNA之间形成杂环双链的现象称为核酸分子杂交。 1.3 简述核酸分子杂交技术 不同种类的DNA单链分子或RNA分子放在同一溶液中,只要两种单链分子之间存在着一定程度的碱基配对关系,在适宜的条件可以在不同的分子间形成杂化双链(heteroduplex)。这种杂化双链可以在不同的DNA与DNA之间形成,也可以在DNA和RNA分子间或者RNA与RNA 分子间形成。这种现象称为核酸分子杂交 1.4生物体内氨基酸有180多种,组成蛋白质的氨基酸只有(20)种,都是(α-氨基酸)。 1.5 写出氨基酸的结构通式 1.6名词解释:氨基酸的等电点 氨基酸的等电点:调节氨基酸溶液PH值,使氨基酸溶液中的氨基和羧基的解离度完全相等,即氨基酸所带静电荷为0,在电场中既不向阴极移动,也不向阳极移动,此时,氨基酸溶液的PH 值称为该氨基酸的等电点,以符号PI表示。 2.1 Sanger通过氨基酸与(2,4-二硝基氟苯(DNFB))反应测定了胰岛素的序列。 2.2 Edman反应是指用(苯异硫氰酸酯(PITC))与氨基酸的氨基发生反应来测定多肽序列的。 2.3名词解释:肽键与肽平面 肽键:氨基酸与氨基酸之间脱水缩合之后形成肽链其中一个氨基酸上的氨基与另一个氨基酸上的羟基脱水缩合后形成的就叫肽键即-CO-NH-. 肽平面:与肽键相关的6个原子共处于一个平面,称为酰胺平面或肽平面。 肽键具有一定程度的双键性质,参与肽键的六个原子C、H、O、N、Cα1、Cα2不能自由转动,位于同一平面,此平面就是肽平面,也叫酰胺平面。 2.4详细叙述蛋白质的分子结构。 一级结构:组成蛋白质多肽链的线性氨基酸序列。 二级结构:依靠不同氨基酸之间的C=O和N-H基团间的氢键形成的稳定结构,主要为α螺旋和β折叠。 三级结构:通过多个二级结构元素在三维空间的排列所形成的一个蛋白质分子的三维结构。四级结构:用于描述由不同多肽链(亚基)间相互作用形成具有功能的蛋白质复合物分子。 2.5 蛋白质二级结构的有哪几种?
北京化工大学2016—2017学年第一学期 《生物信息学》期末考试试卷 (A 卷) 班级: 姓名: 学号: 分数: 一 名词解释 (每题2分) 1. 终止密码子 2. 基因组 3. 比对 4. 近邻关系法 5. 最简约树 6. CpG 岛 7. 重复元件 8. α螺旋 9. 同源建模 10. 聚合酶链式反应(PCR ) 二 简答题 (每题5分) 1.图示分子生物学中的中心法则,并注明相应于转录和翻译的各个步骤及相关的重要的酶。 2. 应该根据真核生物基因组的哪些特征,来识别真核基因? 3. 请画出原核生物基因结构图,并分别标出“开放阅读框”、 “RNA 聚合酶起始转录的启动子区域”、“调控蛋白结合的操纵子序列”的位置。 4. 国际上权威的核酸序列数据库有哪些?蛋白质序列数据库有哪些?蛋白质结构数据库有哪些? 三 写出下面perl 程序的运行结果 (共计15分) (1) $a="a",$b="b",$c="c", $d="d"; @name=("Guy","Tom","126","Roy","007"); @list=(2..9); @items=($a,$b,$c, $d); @empty=(); $size=@items; print "@name\n@list\n@items[1]\n@empty";
(2) $num1=50; $num2=100; $num3=0; print $num1 && $num3,"\n"; print $num3 && $num1,"\n"; print $num1 && $num2,"\n"; print $num2 && $num1,"\n"; print $num1 || $num3,"\n"; print $num3 || $num1,"\n"; print $num1 || $num2,"\n"; print $num2 || $num1,"\n"; (3) @name=("PKU","THU","BUCT","SJTU"); print "@name\n"; delete $name[1]; print "@name\n"; print "$name[1]"; $size=@name; print "the size is $size"; 四计算题 1 为以下序列比对确定比对得分:(每小题3分) (1)全局比对:匹配得分=+1,失配得分= -1,起始罚分= -2,长度罚分= -1 TCAGATATACTGAGCTGCT TCAGA-A- ACAGA T -TG - - (2)准全局比对:匹配得分=+1,失配得分=-1,起始罚分=-2,长度罚分=-1 AGTTTGAAACTGTATAT AG - - - ACAAATG-CT - - 2 画出相应于标准Newick格式 ((((A,B),D),E) ((G,H),C))F 的系统发生树。(6分) 3用UPGMA重建系统发生树,距离矩阵如下:(10分)
国内外生物信息学发展状况 1.国外生物信息发展状况 国外非常重视生物信息学的发展各种专业研究机构和公司如雨后春笋般涌现出来,生物科技公司和制药工业内部的生物 信息学部门的数量也与日俱增。美国早在1988年在国会的支持 下就成立了国家生物技术信息中心(NCBI),其目的是进行计 算分子生物学的基础研究,构建和散布分子生物学数据库;欧 洲于1993年3月就着手建立欧洲生物信息学研究所(EBI), 日本也于1995年4月组建了信息生物学中心(CIB)。目前, 绝大部分的核酸和蛋白质数据库由美国、欧洲和日本的3家数 据库系统产生,他们共同组成了 DDBJ/EMBL/Gen Bank国际核 酸序列数据库,每天交换数据,同步更新。以西欧各国为主的 欧洲分子生物学网络组织(EuropeanMolecular Biology Network, EMB Net)是目前国际最大的分子生物信息研究、开 发和服务机构,通过计算机网络使英、德法、瑞士等国生物信 息资源实现共享。在共享网络资源的同时,他们又分别建有自 己的生物信息学机构、二级或更高级的具有各自特色的专业数 据库以及自己的分析技术,服务于本国生物(医学)研究和开 发,有些服务也开放于全世界。 从专业出版业来看,1970年,出现了《Computer Methods and Programs in Biomedicine》这本期刊;到1985年4月, 就有了第一种生物信息学专业期刊《Computer Application
in the Biosciences》。现在,我们可以看到的专业期刊已经很多了。 2 国内生物信息学发展状况 我国生物信息学研究近年来发展较快,相继成立了北京大学生物信息学中心、华大基因组信息学研究中心、中国科学院上海生命科学院生物信息中心,部分高校已经或准备开设生物信息学专业。2002年国家自然科学基金委在生物化学、生物物理学与生物医学工程学学科设立了生物信息学项目,并列入生命科学部优先资助的研究项目。国家 863计划特别设立了生物信息技术主题,从国家需求的层面上推动我国生物信息技术的大力发展[3]。 但是由于起步较晚及诸多原因,我国的生物信息学发展水平远远落后于国外。在PubMed收录的以关键词“Bioinformatics”检索到的历年发表的文章数,可以看出大量的研究文献出现在21世纪以后。其中我国共有138篇占全部5548篇的2.5%,而美国则发表2160篇占全部的39%之多(统计数据截至2004年2月15日)。我国学者在生物信息学领域发表的有高影响力的论文只有不到美国学者发表数量的6%,差距相当大[4]。在生物信息学领域,一些著名院士和教授在各自领域取得了一定成绩,显露出蓬勃发展的势头,有的在国际上还占有一席之地。如北京大学的罗静初和顾孝诚教授在生物信息学网站建设方面、中科院生物物理所的陈润生研究员在EST
龙源期刊网 https://www.doczj.com/doc/a8699923.html, 大学生物信息学教材对比分析 作者:孙添添齐云峰王仁俊金太成刘春明于长春 来源:《现代交际》2017年第06期 摘要:教材是实现教学过程的前提,在整个教学体系中具有重要的地位。教材不仅是获取知识的来源,同时也是促进学生发展的工具。针对教材的分析研究是进行教学改革的基础。因此,对不同教材进行分析研究,选择适合的教材,对于教师是必要工作。本文选取了近10年内,五种生物信息学相关教材,进行分析,以期达到为不同专业对于教材的选择提供参考和建议的目的。 关键词:生物信息学教材分析 中图分类号:G4233文献标识码:A文章编号:1009-5349(2017)06-0019-02 近些年,生物信息学顺应时代变化而成为生命科学的新兴领域。[1]生物信息学主要是对 核酸和蛋白质两个大方向的数据进行处理与分析。[2]目前,生物信息学作为基础课程在各高 校生物科学专业及相关专业开设。其教学质量的高低对于培养学生的综合能力具有重要的意义。[3]因此,各高校在教材选择、课程安排、教学内容、实践教学等方面不断进行改进。[4]优秀的生物信息学教材是提高教学质量的基础。对不同的教材进行对比分析,从中选取适合相关专业的教材,是教师的必要工作。本文对五种生物信息学教材进行分析,为不同专业对于教材的选择提供参考和建议。 一、研究方法及教材简介 (一)文献研究法 笔者主要从以下三个方面进行文献检索。首先,搜索与生物信息学教材分析相关的著作。其次,利用中国知网、万方数据库等检索与教材分析相关的期刊论文。最后,借鉴优秀教师的教案,仔细阅读并进行分析。深入了解相关生物信息学教材分析的背景以便进行整理分析。 (二)对比研究法 本文主要选取了五种生物信息学教材,根据教材的基本框架结构及特点,对其进行对比分析,分析总结不同教材之间异同。 二、生物信息学教材分析 随着课程改革的不断完善,针对不同地区、不同专业,教材的使用也趋向多元化。生物信息学教材是教师进行教学活动的基础。对不同的生物信息学教材进行对比,以便教师作出最适合的选择。如表1所示,对五种教材从宏观角度进行内容上的分析。
生物信息学在医学数据分析中的应用 1.前言 随着信息技术的飞速发展,医疗数据以爆炸般的速度积累增长,特别是临床医疗数据的大量积累,但是如何有效的整合和利用这些数据进行科学研究,这就对有效数据的管理和挖掘提出了更高的要求。 近年来,数据挖掘得到迅速发展,并逐渐应用到现实生活中,在分类分析方面表现相当出色,因此,已有专家将数据挖掘技术与基因表达数据分类问题相结合,发掘基因之间的关联联系,基因表达正常与非正常的活动范围,由此来理解基因表达的内在规律[1],给疾病的诊断和预测、新特药的设计提供新的思路和方法。但目前医学数据的整合还存在以下问题: 一是医院临床数据通常是分散存在的。分布于医院信息系统、检验信息系统、检查信息系统、电子病历系统等医院建立的各种信息系统当中,有的甚至存在于医生手写的随访记录本当中,这样分散存在的数据不利于收集、整合与分析。 二是以往的临床科学研究都是以手工的方式去收集和整合数据,数据的可靠性和准确性得不到保证,而且容易产生数据丢失。与此同时,人工收集数据工作量大,数据采集速度慢、试验周期长的状况,这对临床科研数据的统计和分析结果的准确性提出来质疑。 三是在对手工搜集到的分散的数据资源进行统计分析和查询的过程中,效率滞后,容易影响科研进度。 针对上述几个问题,为确保收集数据的准确性、有效性和完整性,以便进行统计分析,基于临床科研的数据管理系统应运而生。 2. 支持向量机在医疗数据中的应用 在疾病检测中,单一的生理信息不足以反映人体的健康状况,因此对多种生理信息综合分析是十分有必要的。在心脏病的诊断中就涉及诸如年龄、血压、心跳等几种,甚至几十种理化指标。医生综合这些检测的数据,根据自己的经验、知觉和见解等对人体的健康状况做出某种诊断。显然,这种诊断是主观性的,对同一个人,有时不同的医生甚至会做出截然相反的判别。多生理信息融合( Information Fusing)技术可以直接从原始样本数据出发建立某种规则模型,并将这种模型在计算机上实现,利用这一模型可以帮助医生对待测人体做出更客
生物信息学(4/6) HGP,类基因组计划(Human Genome Project) 遗传图谱(genetic map)又称连锁图谱(linkage map),它是以具有遗传多态性(在一个遗传位点上具有一个以上的等位基因,在群体中的出现频率皆高于1%)的遗传标记为“路标”,以遗传学距离(在减数分裂事件中两个位点之间进行交换、重组的百分率,1%的重组率称为1cM)为图距的基因组图。 物理图谱(physical map)是指有关构成基因组的全部基因的排列和间距的信息,它是通过对构成基因组的DNA分子进行测定而绘制的。 转录图谱是在识别基因组所包含的蛋白质编码序列的基础上绘制的结合有关基因序列、位置及表达模式等信息的图谱。 生物信息学:采用信息科学技术,借助数学、生物学的理论、方法,对各种生物信息(包括核酸、蛋白质等)的收集、加工、储存、分析、解释的一门学科 结构生物学是以生物大分子特定空间结构、结构的特定运动与生物学功能的关系为基础,来阐明生命现象及其应用的科学。 系统发生(phylogeny)——是指生物形成或进化的历史 系统发生学(phylogenetics)——研究物种(遗传学特征)之间的进化关系,认为特征相似的物种在遗传学上接近.系统发生的结果常以系统发生树表示; 系统发生树(phylogenetic tree)——表示形式,描述物种(遗传学特征: 形态, 基因序列, 蛋白质序列等等) 之间进化关系(系统发生树: 物种(遗传特征)之间的关系;进化树: 从低等到高等, 有始有终) EST:大量表达序列标签(Expressed Sequence Tag,EST) SSR:简单重复序列(SSR,simple sequenee Respts),也称作微卫星DNA (Mierosatellite DNA)是指一类由几个(多为1-6个)碱基组成的基元串联重复而成的DNA序列,在染色体上呈随机分布,由于重复次数不同及重复程度的不完全而造成了每个座位的多态性。 SNP:单核苷酸多态性 PDB:蛋白质数据库(Protein Data Bank,PDB) ▲生物信息学主要研究两种信息载体:DNA分子、蛋白质分子 ▲生物信息学研究的内容: 课本上版本PPt简化版本 1.生物信息的收集、储存、管理与提供 2.基因组序列信息的提取和分析 3.功能基因组分析 4.生物分子设计 5.药物设计 6.生物信息分析的技术与方法研究 7.应用于发展研究 8.系统生物学研究1、生物分子数据的收集与管理 2、数据库搜索及序列比较 3、基因组序列分析 4、基因表达数据的分析与处理 5、蛋白质结构预测 ▲生物信息学之父:马来西亚的美籍学者林华安(Hwa A. Lim,林博士) ▲生物信息学的热点领域:1.人类基因组计划2.人类蛋白质组计划3.新药开发中的应用 4.基因芯片5.生物信息学与医学 ▲生物分子信息的特征:生物分子信息数据量大、生物分子信息复杂、生物分子信息之间存在着密切的联系 ▲Linux系统的主要特征:开放性、多用户、多任务。
生物信息学在医学领域的应用研究现状 摘要生物信息学是研究生物信息处理(采集、管理和分析应用),并从中提取生物学新知识的一门科学,它连接生物数据和医学科学研究。生物信息数据库几乎覆盖了生命科学的各个领域,截止至2010年,总数已达1230个。生物信息学已不断渗透到医学领域的研究中。生物信息学在医学领域中主要应用于医学基础研究、临床医学、药物研发和建立与医学有关的生物信息学数据库。 关键词生物信息学,医学,应用 前言据统计,生物学信息正以每14个月翻一倍的速度增长。随着基因组及蛋白质序列数据库的快速增长,以及从这些序列中获取最大信息的需求,生物信息学(bioinformatics)作为一门独立学科应运而生。简言之,生物信息学就是利用计算和分析工具去收集、解释生物学数据的学科。生物信息学是一门综合学科,是计算机科学、数学、物理、生物学的结合。它对于管理现代生物学和医学数据具有重大意义,其研究成果将对人类社会和经济产生巨大推动作用。生物信息学的基础是各种数据库的建立和分析工具的发展。 数据库 迄今为止,生物学数据库总数已达500个以上。归纳起来可分为4大类:即基因组数据库、核酸和蛋白质一级结构数据库、生物大分子三维空间结构数据库,以及以上述3类数据库和文献资料为基础构建的二级数据库。 生物信息学在临床医学上的应用 1.疾病相关基因的发现:很多疾病的发生与基因突变或基因多态性有关。发 现新基因是当前国际上基因组研究的热点,使用生物信息学的方法是发现新基因的重要手段。目前发现新基因的主要方法有多种:(1)基因的电脑克隆:所谓基因的“电脑克隆”, 就是以计算机和互联网为手段,发展新算法,对公用、商用或自有数据库中存储的表达序列标签(express sequence tags,EST)进行修正、聚类、拼接和组装, 获得完整的基因序列, 以期发现新基因。(2)通过多序列比对从基因组DNA 序列中预测新基因[1]:从基因组序列预测新基因,本质上是把基因组中编码蛋白质的区域和非编码蛋白质的区域区分开来。(3)发现单核苷酸多态性[2]:现在普遍认为SNPs研究是人类基因组计划走向应用的重要步骤。这主要是因为SNPs将提供一个强有力的工具,用于高危群体的发
生物信息学在生物医学文献中自动提取疾 病基因点突变信息的运用 生物信息学(Bioinformatics)一词由美籍学者林华安博士(Hwa A.Lim)首先创造和使用。生物信息学是多学科的交叉产物,涉及生物、数学、物理、计算机科学、信息科学等多个领域。狭义的讲,生物信息学是对生物信息的获取、存储、分析和解释;计算生物学则是指为实现上述目的而进行的相应算法和计算机应用程序的开发。这两门学科之间没有严格的分界线,统称为生物信息学。生物医学研究的重要目标就是找到突变和相应的疾病表型。但是大多数的疾病相关的突变数据都以文本的形式埋藏在生物医学文献之中,缺乏必要的结构来便于检索和查找。 信息的快速更新和持续增长的文献储存使得提取这些突变信息变得困难。蛋白质和DNA的突变信息储存在像Mendelian inheritance in man(OMIM)和Swiss-Prot 等数据库中。数据挖掘的方法从这些数据库中提取突变信息可以达到0.98的准确性,但是还没有正确的自动转到疾病相关的突变的方法。现有算法可以实现鉴定点突变(比如MutationFinder)或者突变和其相关的基因以及蛋白质的名称(比如MEMA和MuteXe)。大多数“突变+基因”的方法可以通过各自不同的界面和算法来实现对点突变信息的表述和文本数据收集。比如:Mutation Grab采用基于图表的(Graph based)的方法,而MutationMiner采用结构可视化的方法来表现。但是所有方法都关注于提取点突变和相关基因的正确性。 新的高效的从生物医学文献中鉴别点突变以及他们和疾病表型的关系。结合了数据挖掘(data mining)和序列分析(sequence analysis)来鉴定点突变和相关疾病。采用PubMed引擎来从MEDLINE中检索一系列摘要。将词汇索引控制在MEDLINE's Medical Subject Heading (MeSH)。根据MeSH提交一个简单的查询“mutation"然后下载所有可用的摘要,为XML格式。用MetaMap来鉴定疾病 状态。在生物领域中,最大的词汇资源为United Medical Language System (UMLS)Metathesaurus。MetaMap是专门发现Metathesaurus中的生物医学实体的软件。用MetaMap来鉴定题目和摘要中的疾病的名称。其方法如下:(1) EMU突变抽取工具被用来从突变疾病相关的文库中来鉴定和检索突变。同时也从文本中识别基因的名称。(2)应用一个过滤器(SEQ_Filter)来排除所有氨基酸和报道的相关蛋白序列中的不同的突变。(3) SEQ前后的结果可以人为建立一个全注释的疾病突变数据库。 首先,用EMU来鉴定基因信息。在生物医学文献中,基因和蛋白质的记录没有一个标准的形式。所以自动抽取基因和蛋白质信息是在数据挖掘上的一个很大的挑战。我们采用在内部词典中来进行字串查找(string look up)来确的基因的名字。使用Human Gnome Organization(HUGO)和National Center for Biotechnology Information (NCBI)的数据库来进行。所有和密码子一样的基因名称被除去了。其次,用SEQ_Filter来过滤氨基酸位置上不一致的突变。对于在摘要中鉴定的基因名称和突变,都可以在NCBI中查找了相应的蛋白质信息。对于每个蛋白质,根据相应位置上的突变来确定野生型的氨基酸。如果在突变位置的野生型氨基酸(或者突变型)至少有一个相关的蛋白质,那么基因和突变之间的联系证明是有效的。最后,建立黄金标准(gold standards)。和疾病基因相
5. 论述CRISPR/CAS9和TALENs基因编辑的原理和各自的优缺点?(25分) CRISPR/Cas9是细菌和古细菌在长期演化过程中形成的一种适应性免疫防御,可用来对抗入侵的病毒及外源DNA。CRISPR/Cas9 系统通过将入侵噬菌体和质粒 DNA 的片段整合到 CRISPR 中,并利用相应的 CRISPR RNAs(crRNAs)来指导同源序列的降解,从而提供免疫性。 (1)原理:系统的工作原理是 crRNA( CRISPR-derived RNA )通过碱基配对与 tracrRNA (trans-activating RNA )结合形成 tracrRNA/crRNA 复合物,此复合物引导核酸酶 Cas9 蛋白在与 crRNA 配对的序列靶位点剪切双链DNA。而通过人工设计这两种 RNA,可以改造形成具有引导作用的sgRNA (singleguide RNA ),足以引导 Cas9 对 DNA 的定点切割。 作为一种 RNA 导向的 dsDNA 结合蛋白,Cas9 效应物核酸酶是已知的第一个统一因子(unifying factor),能够共定位 RNA、DNA 和蛋白,从而拥有巨大的改造潜力。将蛋白与无核酸酶的 Cas9( Cas9 nuclease-null)融合,并表达适当的 sgRNA ,可靶定任何 dsDNA 序列,而 sgRNA 的末端可连接到目标DNA,不影响 Cas9 的结合。因此,Cas9 能在任何 dsDNA 序列处带来任何融合蛋白及 RNA,这为生物体的研究和改造带来巨大潜力。 (2)优缺点:CRISPR (Clustered Regularly Interspersed Short Palindromic Repeats)是细菌用来抵御病毒侵袭/躲避哺乳动物免疫反应的基因系统。科学家们利用RNA引导Cas9核酸酶可在多种细胞(包括iPS)的特定的基因组位点上进行切割,修饰。 Rudolf Jaenisch 研究组将Cas9与Te1和Tet2特异的sgRNA共注射到小鼠的受精卵中,成功得到双基因敲除的纯合子小鼠,效率高达80%。他们将Cas9/sgRNA 与带突变序列的引物共注射,能准确在小鼠两个基因引入所要的点突变。在ES细胞中他们更是成功的一次敲除了五个基因。与ZFN/TALEN相比,CRISPR/Cas更易于操作,效率更高,更容易得到纯合子突变体,而且可以在不同的位点同时引入多个突变。但该系统是否有脱靶效应尚需进一步的研究。 TALENs(transcription activator-like (TAL) effector nucleases)的中文名为转录激活因子样效应物核酸酶,是基因组编辑核酸酶三大类之一。它是实现基因敲除、敲入或转录激活等靶向基因组编辑的里程碑。 (1)原理:TALENs充分利用植物病原菌黄单胞菌(Xanthomonas)自然分泌的蛋白---即激活子样效应物(TAL effectors, TALEs)---的功能:该蛋白能够识别特异性DNA碱基对。人们可以设计一串合适的TALEs来识别和结合到任何特定序列,如果再附加一个在特定位点切断DNA双链的核酸酶,就可以构建出TALEN,利用这种TALEN就可以在细胞基因组中引入新的遗传物质。相对锌指核酸酶(zinc-finger nuclease, ZFN)而言,TALEN能够靶向更长的基因序列,而且也更容易构建。但是直到现在,人们一直都没有一种低成本的而且公开能够获得的方法来快速地产生大量的TALENs。 (2)优缺点:相比于传统的锌指核酸酶(ZFNs)技术,TALENs具有独特的优势:设计更简单,特异性更高。缺点有:具有一定细胞毒性,模块组装过程繁琐,
生物信息学在医学领域的应用前沿 摘要:生物信息学是有生命科学、信息学、数学、物理、化学等学科相互交融而形成的新兴学科。生物信息数据库几乎覆盖了生命科学的各个领域,截止至2010年,总数已达1230个。生物信息学已不断渗透到医学领域的研究中。生物信息学在医学领域中主要应用于医学基础研究、临床医学、药物研发和建立与医学有关的生物信息学数据库。 关键词:生物信息学;医学;基因;应用 生物信息学是20世纪80年代以来随着人类基因组生命科学与信息科学以及数学、物理、化学等学科相互交融而形成的新兴学科,是当今最具发展前途的学科之一。人类基因组计划的顺利推进产生了海量基因数据,这些数据中蕴藏着丰富的生物学内涵,如果能充分挖掘并加以利用,可能揭示出很多对人类有用的信息。生物信息学已经成为生物学、医学、农学、遗传学、细胞生物学等学科发展的强大推动力量。随着生物信息学研究的深入与发展,它已不断渗透到医学领域的研究中。近年来,伴随着对基因组的研究不断深入,部分应用领域取得了令人瞩目的突破,其潜在的经济利益更是吸引了众多国家、企业及大量科研人员投入到相关研究中,生物信息学得到了迅猛的发展。 一、主要数据库 数据库是生物信息学的主要内容,各种数据库几乎覆盖了生命科学的各个领域。截止至2010年,生物信息数据库总数已达1230个。生物信息数据可可分为一级数据库和二级数据库。一级数据库的数据都直接来源于实验获得的原始数据,只经过简单的归类整理和注释,如Genbank数据库、SWISS-PROT数据库;二级数据库是在一级数据库、实验数据和理论分析的基础上针对特定目标衍生而来,是对生物学知识和信息的进一步整理,如人类基因组图谱库GDB。 在医学领域中常用的生物信息数据库主要有:核酸类数据库,如NCBI核苷酸序列数据库(Gen Bank )、欧洲核苷酸序列数据库(EMBL)、日本DNA 数据库(DDB)等;蛋白相关数据库,如蛋白质数据库(SWISS-PROT)、蛋白质信息资源库(HR)、Entrez 的蛋白三维结构数据库(MMDB)、蛋白质交互作用数据库(DIP)等;疾病相关数据库,包括综合临床数据库,如NCBI疾病基因数据库、Gene Cards等;遗传性疾病数据库,如遗传性疾病数据库(GDB)、人类遗传性疾病数据库(Gene Dis)等;肿瘤相关数据库,如肿瘤基因组解剖工程(CGAP)等;心血管疾病相关数据库,如心血管疾病相关生物医学数据库(Cardio)、心脏疾病计划及临床决策支持系统(HDP &CDM)等;免疫性疾病数据库,如免疫功能分子数据库( HMM)、免疫缺陷资源库(IDR)等;药物相关数据库,如药物和疾病数据库(Drugs)、FDA药品评审与研究中心(CDER)等。 二、生物信息学在医学领域的应用 2.1 生物信息学在医学基础研究中的应用 2.1.1 新基因的发现与鉴定 疾病的发生发展与特异基因的改变有关,鉴定与疾病相关的基因是科学家在积极探索的一个方向,对治疗某些疑难杂症带来新的契机。发现新基因是当前国际上基因组研究的热点,使用生物信息学的方法是发现新基因的重要手段。现在很多疾病的致病基因已经发现,包括癌症、肥胖、哮喘、心脑血管病等,其中与癌症相关的原癌基因约有1000个,抑癌基因约有100个。 目前发现新基因的主要方法有以下3种:①通过多序列比对从基因组DNA序列中预测新基因,其本质是把基因组中编码蛋白质的区域和非编码蛋白质的区域区分开来。②基因的电子克隆,即以计算机和互联网为手段,通过发展新算法,对生物信息数据库中存储的表达序列标签进行修正、聚类、拼接和组装,获得完整的基因序列,以期发现新基因。③发现单核苷酸多态性。 例如,2010年我国学者通过生物信息学EST 拼接技术,RT-PCR等技术,克隆出30个人类未知功能的新基因,并通过生物信息学分析该基因
生物信息学札记(第4版) 樊龙江 浙江大学作物科学研究所 浙江大学生物信息学研究所 浙江大学IBM生物计算实验室 2017年9月 本材料已由浙江大学出版社出版:《生物信息学》,樊龙江主编,2017 部分内容可通过下列网址获得: https://www.doczj.com/doc/a8699923.html,/bioinplant/
札记前言 第一版 这份材料是我学习和讲授《生物信息学》课程时的备课笔记,材料大多是根据当时收集的一些外文资料翻译编辑而成。学生在学习过程中经常要求我给他们提供一些中文的讲义或材料,这促使我把我的这份笔记整理并放到网上,供大家参考。要提醒使用者的是,这份材料仅是根据我对生物信息学的一些浮浅的认识整理而成,其中的错误和偏颇只能请读者自鉴了。 2001年6月 第二版 自1999年开始接触生物信息学以来,一晃已近六年,而本札记也近四岁了。2001和2002年中国科学院理论物理所的郝柏林院士在浙江大学首次开设生物信息学研究生课程,我作为他的助教系统地学习了生物信息学;同时,借着我国水稻基因组测序计划的机遇,在他的带领下从2001年开始从事水稻基因组分析,从此自己便完全投入到这一崭新、引人入胜的领域中来。 不断有来信向我索要本札记的电子版文件,同时在不少网站上看到推荐该札记的内容。生物信息学、基因组学等发展很快,现在再回头审看该札记,有些部分已惨不忍读,这促使我下决心更新它。但因时间和学识问题,还是有不少部分自己不甚满意,就只有待日后再努力了。欢迎告诉我札记中的BUG,我的信箱fanlj@https://www.doczj.com/doc/a8699923.html, 或bioinplant@https://www.doczj.com/doc/a8699923.html,。 2005年3月30日 第三版 近年来高通量测序技术产生的序列数据大量出现(如小RNA和大规模群体SNP数据),本次更新根据这一进展增加了两章内容,分别是第七章有关小RNA的分析和第八章遗传多态性及正向选择检测。两章内容由我的博士生王煜为主编写,李泽峰和刘云参与了文献整理。另外还更新了第四章有关水稻基因组分析一节。 2010年1月 第四版 2014年浙江大学开展本科生教材建设工作,我当时作为系主任要带头,就承诺编写我主讲的《生物信息学》教材。编写教材的确不是一件容易的事,经过几番挣扎和多方努力,总算完成了编写,算是了却了一桩心思。该教材内容比较完整,也跟踪了生物信息学领域的最新进展。我就权且把该教材内容作为札记的第四版,也算给该札记一个完美的结尾。 2017年9月
浙江大学2017年医学院推免生名单蔡欣雨180医学院071006神经生物学 湛丽180医学院071006神经生物学 陈杜180医学院071006神经生物学 俞洁180医学院071006神经生物学 徐敏馨180医学院071006神经生物学 陈铭180医学院071006神经生物学 王燚锋180医学院071006神经生物学 陈晗180医学院071006神经生物学 吴宁义180医学院071006神经生物学 成山180医学院071006神经生物学 郑迪旸180医学院071006神经生物学 孙艺璇180医学院071006神经生物学 汶晨曦180医学院071006神经生物学 何晶180医学院071006神经生物学 叶真珍180医学院071007遗传学 杨巍巍180医学院071007遗传学 聂于斐180医学院071009细胞生物学 陈雯雯180医学院071009细胞生物学 李梦杰180医学院071009细胞生物学 钱心怡180医学院071009细胞生物学 郑鹏180医学院071009细胞生物学 孙娅琴180医学院071010生物化学与分子生物学 刘家琪180医学院071010生物化学与分子生物学 张真真180医学院071010生物化学与分子生物学 廖益娇180医学院071010生物化学与分子生物学 沈洁180医学院071010生物化学与分子生物学 代晓晴180医学院071010生物化学与分子生物学 刘桥180医学院071011生物物理学 蔡震180医学院0710Z1生物信息学 李逸森180医学院0710Z1生物信息学 郑双双180医学院100101人体解剖与组织胚胎学 林和风180医学院100101人体解剖与组织胚胎学 刘倩茹180医学院100101人体解剖与组织胚胎学 路超杰180医学院100102免疫学 王鹏飞180医学院100102免疫学 王振180医学院100102免疫学 支佳琦180医学院100102免疫学 王琼艳180医学院100103病原生物学 第23页,共65 页 姓名拟录取学院代码拟录取学院拟录取专业代码拟录取专业名称备注
浅谈生物信息学在生物医药方面的应用 生物信息学(Bioinformatics)是在生命科学的研究中,以计算机为工具对生物信息进行储存、检索和分析的科学。它是当今生命科学和自然科学的重大前沿领域之一,同时也将是21世纪自然科学的核心领域之一。其研究重点主要体现在基因组学(Genomics)和蛋白质组学(Proteomics)两方面,具体说就是从核酸和蛋白质序列出发,分析序列中表达的结构功能的生物信息。 具体而言,生物信息学作为一门新的学科领域,它是把基因组DNA序列信息分析作为源头,在获得蛋白质编码区的信息后进行蛋白质空间结构模拟和预测,然后依据特定蛋白质的功能进行必要的药物设计。基因组信息学,蛋白质空间结构模拟以及药物设计构成了生物信息学的3个重要组成部分。是结合了计算机科学、数学和生物学的一门多学科交叉的学科。它依赖计算机科学、工程和应用数学的基础,依赖实验和衍生数据的大量储存。他将各种各样的生物信息如基因的DNA序列、染色体定位、基因产物的结构和功能及各种生物种间的进化关系等进行搜集、分类和分析,并实现全生命科学界的信息资源共享。 从生物信息学研究的具体内容上看,生物信息学可以用于序列分类、相似性搜索、DNA序列编码区识别、分子结构与功能预测、进化过程的构建等方面的计算工具已成为变态反应研究工作的重要组成部分。针对核酸序列的分析就是在核酸序列中寻找过敏原基因,找出基因的位置和功能位点的位置,以及标记已知的序列模式等过程。针对蛋白质序列的分析,可以预测出蛋白质的许多物理特性,包括等电点分子量、酶切特性、疏水性、电荷分布等以及蛋白质二级结构预测,三维结构预测等。 基因芯片是基因表达谱数据的重要来源。目前生物信息学在基因芯片中的应用主要体现在三个方面。 1、确定芯片检测目标。利用生物信息学方法,查询生物分子信息数据库,取得相应的序列数据,通过序列比对,找出特征序列,作为芯片设计的参照序列。 2、芯片设计。主要包括两个方面,即探针的设计和探针在芯片上的布局,必须根据具体的芯片功能、芯片制备技术采用不同的设计方法。 3、实验数据管理与分析。对基因芯片杂交图像处理,给出实验结果,并运用生物信息学方法对实验进行可靠性分析,得到基因序列变异结果或基因表达分析结果。尽可能将实验结果及分析结果存放在数据库中,将基因芯片数据与公共数据库进行链接,利用数据挖掘方法,揭示各种数据之间的关系。 大规模测序是基因组研究的最基本任务,它的每一个环节都与信息分析紧密相关。目前,从测序仪的光密度采样与分析、碱基读出、载体标识与去除、拼接与组装、填补序列间隙,到重复序列标识、读框预测和基因标注的每一步都是紧
生物信息学在医学上的应用 Bioinformatics application in medicine 【摘要】:生物信息学是利用计算和分析工具收集、解释生物学数据的学科,其基础是4大类生物学数据库。生物信息学在疾病相关基因的发现、新的药物分子靶点的发现、创新药物设计以及基因芯片的设计与数据处理等医学应用研究方面将发挥重要作用。 【abstract 】: bioinformatics is use of calculation and analysis tools of data collection, explain biology subject, the foundation is four major categories biology database. Bioinformatics in disease genes found new drugs, the molecular target discovery, innovative drug design and gene chip design and data processing and other medical application research will play an important role. 【关键词】:医学信息学计算机生物学 【key words 】: medical informatics computational biology 【正文】:生物信息学(Bioinformatics)是上个世纪8O年代以来随着人类基因组 计划的启动而兴起的集生命科学、计算机科学和信息科学为一体的交叉学科。是用数理和信息科学的理论、观点和方法去研究生命现象,对呈现指数增长的DNA 和蛋白质的序列和结构等生物学数据进行收集、整理、储存、发布、提取、加工分析和研究,达到认识生命起源、遗传和发育的本质的目的。现已成为生物学、医学、农学遗传学和细胞生物学等学科的强大推动力量。当前生物信息学的主要任务包括以下几个方面: ①基因组相关信息的收集、存储、管理与提供。②新基因的发现与鉴定。⑧非编码区信息结构分析。④生物进化的研究。⑤完整基因组的比较研究。⑥基因组信息分析方法的研究。⑦大规模基因功能表达谱分析。⑧蛋白质末端序列、分子空间的预测、模拟和分子设计。⑨药物设计等。为此生命科学家们在不断地生产和更新以数据库和软件为主的各种生物信息工具。本文就生物信息学在医药学方面的应用状况和前景做一讨论。 (一)、生物技术制药 生物技术药物或称生物药物是集生物学、医学、药学的先进技术为一体,以组合化学、药学基因(功能抗原学、生物信息学等高技术为依托,以分子遗传学、分子生物、生物物理等基础学科的突破为后盾形成的产业。现在,世界生物制药技术的产业化已进入投资收获期,生物技术药品已应用和渗透到医药、保健食品和日化产品等各个领域,尤其在新药研究、开发、生产和改造传统制药工业中得到日益广泛的应用,生物制药产业已成为最活跃、进展最快的产业之一。 目前生物制药主要集中在以下几个方向: 1、肿瘤在全世界肿瘤死亡率居首位,美国每年诊断为肿瘤的患者为100万,死于肿瘤者达54.7万。用于肿瘤的治疗费用1020亿美元。肿瘤是多机制的复杂疾病,目前仍用早期诊断、放疗、化疗等综合手段治疗。今后10年抗肿瘤
2016-2017研究生《生物信息学》课程复习思考题 1.简述什么是NCBI数据库,其主要数据组成并以你最熟悉某个功能为例说明其应用。 2.假如你得到一段未知基因的DNA片段,如何分析该未知基因的功能和家族类别(包括系统发育树的构建)。 3.简述NCBI BLAST种类;说明Basic Blast的主要功能。 4、根据所学的生物信息学内容,结合自己的专业,浅谈一下生物信息学在所学专业或研究中的应用 5、蛋白质的二级结构及各自的特征 6、MM-PBSA方法的概述 7、结合你科研可能遇到的问题,谈谈你如何看待生物信息学的学习的意义? 8、你认为BCBI数据库的哪几个模块功能对你实验研究的最有帮助,需要上课重点讲述和演示? 9、对于NCBI数据库、及VectorNT、Oligo软件或其他在线软件资源,除了教师上课进行基本功能演示外,你认为如何教学或自学效果好? 10、分别测得15名健康人和13名III度肺气肿病人痰中α1抗胰蛋白酶含量(g/L)如下表: 健康人肺气肿病人 2.7 3.6 2.2 3.4 4.1 3.7 4.3 5.4 2.6 3.6 1.9 6.8 1.7 4.7 0.6 2.9 1.9 4.8 1.3 5.6 1.5 4.1 1.3 3.3 1.7 4.3 1.3 1.9
(1)根据表中数据,计算方差齐性,得到F=1.19 ,小于F0.05(12,14)=2.53, 应选用什么检验方法来比较两组人群抗胰蛋白酶含量是否不同?为什么 选择该方法? (2)计算的检验统计量为 5.63。查找该检验方法相应界值表:自由度为26时,α=0.05,数值为2.056;α=0.001,数值为3.707。确定P值范 围并推断两组人群抗胰蛋白酶含量是否有差异? 11、同源建模技术有多大的应用价值? 12,分子动力学模拟及分子力学这二者与力场是什么关系? 13,分子模拟的概念 14,分子模拟的主要计算方法 15,分子模拟的主要应用 16,蛋白质的二级结构及各自的特征 17,同源建模定义及其理论基础 18,同源建模的四个关键点 19,分子力学与分子力场的基本概念 20,常见的分子力场及各自的特点 21,能量最小化方法及各自的特点 22,分子动力学模拟(MD)的概念 23,能量最小化(EM)与分子动力学模拟(MD)的关系 24,分子对接的概念及意义 25,分子对接的一般过程
2017年《临床医学检验》复习题(十四) 单选题-1/知识点:试题 各种蛋白质的含氮量平均约为 A.8% B.12% C.16% D.20% E.24% 单选题-2/知识点:试题 蛋白质在等电点时的特征是 A.在对称作用下定向移动 B.溶解度升高 C.不易沉淀 D.分子带的电荷较多 E.分子净电荷为零 单选题-3/知识点:试题 肝细胞病变时,下列何种蛋白质合成不减少 A.α球蛋白 B.纤维蛋白原 C.白蛋白
E.凝血酶原 单选题-4/知识点:章节测试 关于尿液标本留取的要求,错误的是 A.告知患者留尿检验目的 B.提供给患者合格的留尿容器 C.检验申请单应全面详细 D.可电子信息系统开具检验申请 E.随机尿为最佳尿标本 单选题-5/知识点:试题 Raji细胞的表面标志的特点是 A.有C1q受体、C3d受体,无C3b受体 B.有C1q受体、C3d受体、C3b受体 C.无C1q受体、C3d受体,有C3b受体 D.无C1q受体、C3b受体,有C3d受体 E.有C1q受体,无C3b受体、C3d受体 单选题-6/知识点:试题 机体的绝大多数细胞都是通过哪种方式获得能量的 A.有氧氧化 B.无氧酵解
D.磷酸戊糖途径 E.糖醛酸途径 单选题-7/知识点:试题 引物在DNA复制中的作用是 A.提供起始模板 B.激活引物酶 C.提供复制所需的5′-磷酸 D.提供复制所需的3′-羟基 E.激活DNApolⅢ 单选题-8/知识点:综合复习题 小管液中的Na浓度通过什么影响肾素分泌 A.肾小球 B.近球小管 C.髓袢 D.远端小管和集合管 E.致密斑 单选题-9/知识点:试题 正常人体阴道菌群的主要优势菌是 A.链球菌