
上下文无关文法
形式语言理论中一种重要的变换文法,用来描述上下文无关语言,在乔姆斯基分层中称为2型文法。由于程序设计语言的语法基本上都是上下文无关文法,因此应用十分广泛。
简介
上下文无关文法(Context-Free Grammar, CFG)
在计算机科学中,G = (N, Σ, P, S) 的产生式规则都取如下的形式:V -> w,则称之为上下文无关的,其中V∈N ,w∈(N∪Σ)* 。上下文无关文法取名为“上下文无关”的原因就是因为字符V 总可以被字串w 自由替换,而无需考虑字符V 出现的上下文。一个形式语言是上下文无关的,如果它是由上下文无关文法生成的﹙条目上下文无关语言﹚。
来定义的。另一方面,上下文无关文法又足够简单,使得我们可以构造有效的分析算法来检验一个给定字串是否是由某个上下文无关文法产生的。例子可以参见LR 分析器和LL 分析器。
BNF ﹙巴克斯-诺尔范式﹚经常用来表达上下文无关文法。
文法规则使用相似的表示法。名字用斜体表示(但它是一种不同的字体,所以可与正则表达式相区分)。竖线仍表示作为选择的元符号。并置也用作一种标准运算。但是这里没有重复的元符号(如正则表达式中的星号*),稍后还会再讲到它。表示法中的另一个差别是现在用箭头符号“→”代替了等号来表示名字的定义。这是由于现在的名字不能简单地由其定义取代,而需要更为复杂的定义过程来表示,这是由定义的递归本质决定的。
文法规则是定义在一个字母表或符号集之上。在正则表达式中,这些符号通常就是字符,而在文法规则中,符号通常是表示字符串的记号。我们利用C中的枚举类型定义了在扫描程序中的记号;为了避免涉及到
特定实现语言(例如C
记号。此时的记号就是一个固定的符号,如同在保留字while 中或诸如+或: =这样的特殊符号一样,对于作为表示多于一个串的标识符和数的记号来说,代码字体为斜体,这就同假设这个记号是正则表达式的名字(这是它经常的表示)一样。
上下文无关文法的却利用了与正则表达式中极为类似的命名惯例和运算,二
recursive)。
例子
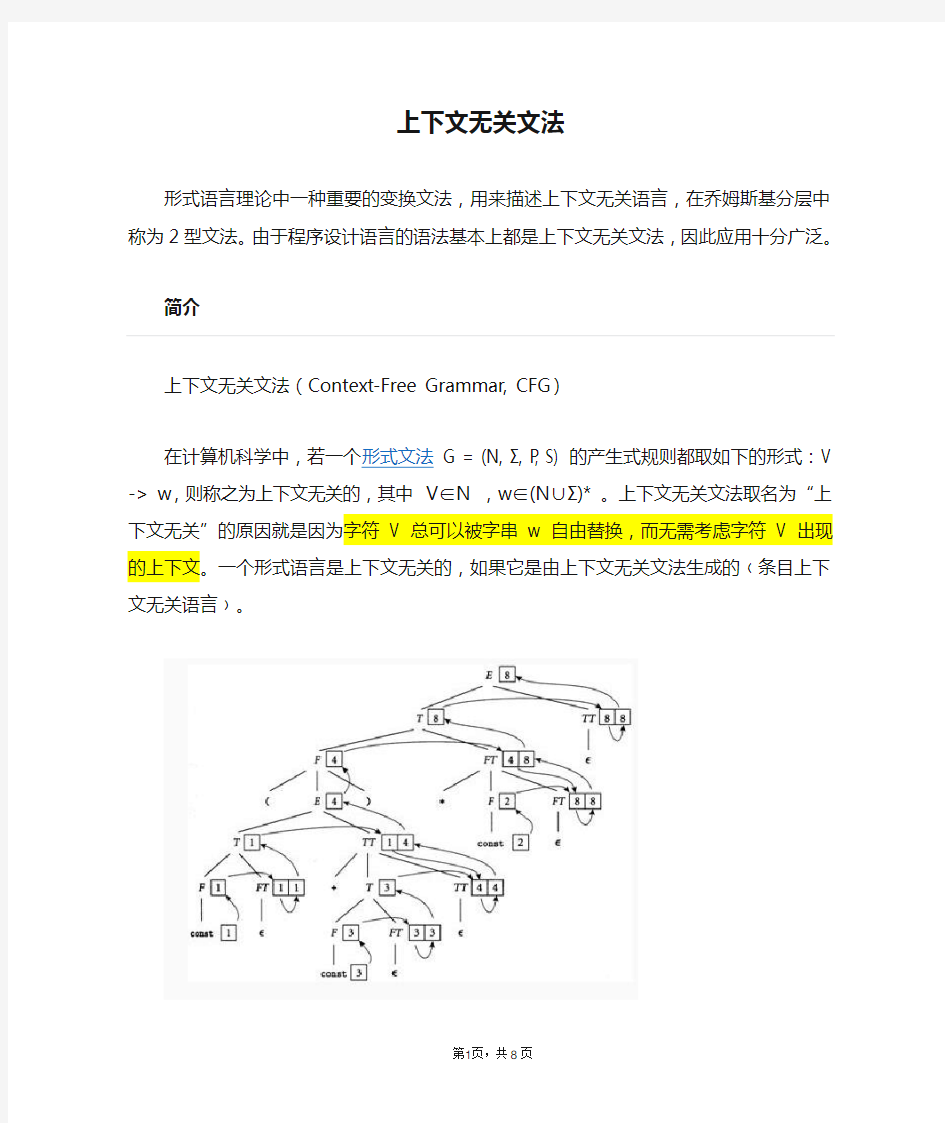
例子1一个简单的上下文无关文法的例子是:S -> aSb | ε 。这个文法产生了语言{anbn : n ≥ 0} 。不难证明这个语言不是正规的。
例子2
这个例子可以产生变量x,y,z 的算术表达式:
S -> T + S | T - S | T
T -> T * T | T / T | ( S ) | x | y | z
例如字串"( x + y ) * x - z * y / ( x + x )" 就可以用这个文法来产生。
例子3
字母表{a,b} 上 a 和 b 数目不相等的所有字串可以由下述文法产生:
S -> U | V
U -> T aU | T aT
V -> TbV | TbT
T -> aTbT | bT aT | ε
这里T 可以产生a 和 b 数目相等的所有字串,U 可以产生a 的数目多于b 的数目的所有字串,V 可以产生a 的数目少于b 的数目的所有字串。范式
每一个不生成空串的上下文无关文法都可以转化为等价的Chomsky 范式或Greibach 范式。这里两个文法等价的含义指它们生成相同的语言。
由于Chomsky 范式在形式上非常简单,所以它在理论和实践上都有应用。比如,对每一个上下文无关语言,我们可以利用Chomsky 范式构造一个多项式算法,用它来判断一个给定字串是否属于这个语言﹙CYK 算法﹚。
同态映射下的性质
对任意正整数n,令…,a n},Σ'n={a'1,…,a'n},定义乔姆斯基变换文法G =(Σ,V,S,P)为(Σn∪Σ'n,S,S,P={S→,S→Sa i Sa'i S|1≤i≤n})。这个文法生成的语言称为代克集。如果把a i看作开括号,把a'i看作相应的闭括号,则n维代克集D n就是由几种不同的括号对组成的配对序列之集合。例如,a1a2a2a'2a2a'1和a1a'1a2a'2a1a'1都属于D2,用括号表示时可以写成(〔()〕)和()〔〕()。
代克集是把正则语言族扩大成上下文无关语言族的工具。对任一上下文无关语言L,必存在两个同态映射h1和h2,以及一个正则语言R,使L=h2【h1(D2)∩R】,其中D2是二维代克集,反之亦然。
更进一步,上下文无关语言族是包含D2,且在同态、逆同态和与正则语言相交三种代数运算下封闭的最小语言族。加上乘积和乘幂闭包两种运算后,此结论仍真。
文法形式和文法的相似性
在两种符号置换的意义下), 许多文法之间有着相似性。把一组彼此相似的文法抽象成一个更高级的形式体系,就叫作文法形式。迄今,文法形式的研究主要集中在上下文无关文法上。
文法形式的具体定义是:给定无限的终结符表Σ∞和无限的非终结符表V∞。任取Σ∞和V∞的非空子集Σ和V,按构造普通文法的方法定义一个四元组G=(Σ,V,S,P)。在G确定以后,任取映射函数ψ,把Σ中每一元素a映为Σ∞中一有限子集ψ(a),把V中每一元素A映为V∞中一个有限子集ψ(A),且当A厵B 时有ψ(A)∩ψ(B)=φ。ψ就是所需的置换。通过它得到一个具体文法ψ(G)=【ψ(Σ),ψ(V),ψ(S),ψ(P)】,其中ψ(P)是把P中所有产生式中的符号作ψ置换后得到的一组新产生式,ψ(Σ),ψ(V)和ψ(S)分别是ψ(P)中出现的终结符集,非终
结符集和出发符号。
这样的G称为文法形式,ψ称为G的一个解释,ψ(G)是G的一个解释文
法,被认为是相似于G。令ψ遍历各种可能的解释,得到的ψ(G)集合称为G的文法性语言族,由此生成的语言集合(ψ(G))称为G的文法性语言族。例如,文法形式{S→aS,S→a}的文法性语言族是正则语言集;{S→SS,S→a}的文法性语言族是上下文无关语言集。
若文法形式G作为普通文法时生成的语言(G)是无限集,则称G为非平凡的。此时文法性语言族(G)是一个满主半AFL,反之不然。如满主半AFL({ab│n≥1}),不是一个文法性语言族。
以G1·G2表文法性语言族G1和G2的乘积,1∩2表两者之并,它们仍是文法性语言族。当吇G1G2时,必有G吇G1或G吇G2成立,则称G是素的。正则语言集和线性语言集都是素文法性语言族。任一文法性语言族G必可唯一地分解为它的素因子乘积和:G=(11…1n1)∪…∪(m1…mnm)。其中每个Gij都是素因子。这个分解在乘积运算∪可交换的意义下是唯一的。
文法的二义性
从文法生成语言,可有多种推导公式。例如文法{S→AB,A→a,B→b}可有两种推导:S崊AB崊aB崊ab及S崊AB崊Ab崊ab。若每次都取最左边的非终结符进行推导,如上例中的前一种方式那样,则称为左推导。如果有两种不同的左推导推出同一结果,则称此文法是二义性的,反之是无二义文法。对有些二义性文法,可找到一个等价的无二义文法,生成同一个语言。不具有无二义文法的语言称为本质二义性语言。例如,{S→A,S→a,A→a}是二义性文法。
是本质二义性语言。
上下文无关文法
上下文无关文法
子文法类
可以根据不同的观点取上下文无关文法的子文法。一种观点是根据文法的外形和它们生成的语言族在代数运算下的封闭性。例如,若文法G的产生式只具有下列三种形式之一:A→αBβ,C→γ和S→δ,其中A,B,C∈V,αβγ∈Σ,δ∈(Σ∪V),且δ中至多含k个非终结符,S是出发符号,则称G为k线性文法。1线性文法又称线性文法。全体k线性文法之集合称为元线性文法。元线性语言族在联合和乘积运算下是封闭的,但在求交,求补,乘幂闭包和置换等运算下都不封闭。从包含关系说,正则语言族真包含于线性语言族。对任一k≥1,k线性语言族真包含于k 1线性语言族,元线性语言族真包含于上下文无关语言族。
由于上下文无关文法被广泛地应用于描述计算机语言的语法,因此更重要的是从机械执行语法分解的角度取上下文无关文法的子文法,最重要的一类就是无二义的上下文无关文法,因为无二义性对于计算机语言的语法分解至为重要。在无二义的上下文无关文法中最重要的子类是LR(k)文法,它只要求向前看k个符号即能作正确的自左至右语法分解。LR(k)文法能描述所有的确定型上下文无关语言。
上下文有关文法
上下文有关文法(CSG)是其中任何产生规则的左手端和右手端都可以被终结
更一般性但仍足够有秩序得可以被线性有界自动机所解析。
上下文有关文法的概念是诺姆·乔姆斯基在1950年代作为描述自然语言的语法的一种方式介入的,在自然语言中一个单词是否可以出现在特定位置上要依赖
形式定义
形式文法G = (N, Σ, P, S) 是上下文有关的,如果在P 中所有的规则都有如下形式αAβ → αγβ
这里的 A ∈ N (就是A 是单一非终结符),α,β ∈ (N U Σ)* (就是α 和β 是非终结符和终结符的字符串)而γ ∈ (N U Σ)+ (就是γ 是非终结符和终结符的非空字符串)。
此外还有如下形式的规则
S → ε 假定S 不出现在任何规则的右手端
这里的ε 表示空串是允许的。增加空串允许声明上下文有关语言是上下文无关语言的真子集,而无须作出没有→ε产生式的所有上下文无关文法也是上下文有关文法这种弱一些的声明。
上下文有关这个名称来源自α 和β 形成了 A 的上下文并且决定 A 是否可以被γ 所替代。这不同于不考虑非终结符上下文的上下文无关文法。
如果向语言增加空串的可能性被增加到由(永不包括空串的)不收缩文法所识别的那些字符串中,则这个语言在这两个定义中是同一的。
例子
以下文法生成正规的非上下文无关语言
S → aRc
R → aRT | b
bT c → bbcc
bTT → bbUT
UT → UU
UUc → VUc → Vcc
UV → VV
bVc → bbcc
bVV → bbWV
WV → WW
WWc → TWc → T cc
WT → TT
可以使用更复杂的文法解析和其他有更多字母的语言。aaa bbb ccc 的产生链是:
S
aRc
aaRT c
aaaRTT c
aaabTT c
aaabbUT c
aaabbUUc
aaabbVUc
aaabbVcc
aaabbbccc
aaaa bbbb cccc 的产生链是:
S
aRc
aaRT c
aaaRTT c
aaaaRTTT c
aaaabTTT c
aaaabbUTT c
aaaabbUUT c
aaaabbUUUc
aaaabbUVUc
aaaabbUVcc
aaaabbVVcc
aaaabbbWVcc
aaaabbbWWcc
aaaabbbTWcc
aaaabbbT ccc
aaaabbbbcccc
范式
不生成空串的所有上下文有关文法都可以被变换成等价的Kuroda范式的文法。这个“等价”意味着两个文法生成同样的语言。这种范式一般不是上下文有关的,但却是不收缩文法。
计算的性质和使用
特定字符串s 是否属于特定上下文有关文法G 的语言的判定问题是PSPACE-完全的。实际上,甚至有些上下文有关文法的固定文法识别问题也是PSPACE-完全的。
上下文有关文法的空虚(emptiness)问题(给定上下文有关文法G,吗?)是不可判定的。
已经证实几乎所有自然语言一般的都可以用上下文有关文法来刻画,但是整个CSG 类好像比自然语言要大。更糟糕的是,因为上述CSG 的判定问题是PSPACE-完全的,这使得它们对于实际使用而言是完全不能运做的,因为一般算法将运行指数时间。关于计算语言学的当前进行中的研究关注于公式化是适度上下文有关语言的其他语言类,这种语言如树-邻接文法、组合范畴文法、连结上下文无关文法和线性上下文无关重写系统的判定问题是可行的。这些形式化所生成的语言适当的位于上下文无关和上下文有关语言之间。[1]
第三部分上下文无关语言和下推自动机 前面介绍的有限自动机是计算的初级模型,它所接受的正规语言不太关心字符串自身的结构。上下文无关文法(CFL)是一种简单的描述语法规则的递归方法,语言中的字符串由这些规则产生。所有的正规语言都能用上下文无关文法描述,它也可以描述非正规语言。上下文无关文法描述的语法规则更复杂多变,可以在相当大的程度上,描述高级程序设计语言的语法和其他一些形式语言。 类似正则语言对应的抽象机模型是有限自动机,CFL也有对应的抽象机模型。CFL对应的计算模型是在有限自动机的基础上增加存储空间得到,并被设想成无限空间(对应有限自动机的有限空间),采用了一种简单的管理模式,栈(stack),这种新的计算模型(或抽象机)称为下推自动机(pushdown automata),下推是栈最典型的操作。有必要在下推自动机中保留非确定性,确定型下推自动机不能接受所有的CFL,但给定一个CFG,容易构造一个相应的非确定型下推自动机,它在识别字符串过程中的移动模拟了文法的推导过程,这个过程称为分析(parse)。分析不是一定需要下推自动机来完成。 CFL仍然不够通用,不能包括所有有意义的、或有用的形式语言。采用类似第五章的技术,我们将给出一些不是CFL的简单例子,这些技术也用于解决与CFL相关的判定问题。 6 上下文无关文法 6.1 上下文无关文法的定义 为了描述我们在第二部分考察的各种语言,包括一些非正则语言,我们引入一种语言的递归定义方法,称为文法。文法与我们熟悉的语言的语法描述相近,是描述语言和分析语言的有力工具。 问题:文法的形式化定义似乎可以模仿有限自动机,比如5元组或6元组之类。 例子6.1 正如我们在例子2.16中所见,字母表{a, b}上的回文语言pal可以用下面的递归方法描述: 1.Λ, a, b∈pal 2.对每个S∈pal,aSa和bSb也属于pal 3.pal中不包含其他字符串 如果将上面的符号S看成一个变量,代表了所有我们希望计算(比如某种递归算法)的pal 的元素,那么上面的规则1和规则2可以非正式地重新表述如下: 1.S的值可以是Λ, a, b 2.每个S可以写成aSa或bSb的形式 如果我们用→表示“可以取值为”,则可以写出下面的式子: S→aSa→abSba→abΛba=abba 上面的产生过程可以总结成下面的两组产生式(或称规则): S→a | b | Λ S→aSa | bSb 符号“|”表示“或”的含义。上式的含义是aSa或bSb,而不是a或b,即连接运算的优先级高于“|”。我们使用的这套术语中,小写字母a和b表示终结符,大写字母S表示非终结符,或称变量。总共有5条规则,或产生式(production)。符号S是非终结符,也是起始终结
作 业 一、选择题 1.、程序中出现的错误常数 3.14.15属于__(A)__。 (A) 语法错误 (B) 词法错误 (C) 语义错误 (D) 警告错误 2、表达式α0 αn 代表____(B)____ 。 (A) 直接推导 (B) 广义推导 (C) 推导 (D) 间接推导 3、文法),},,,{)},(,,*,,({2P +=E F T E i G 其中:产生式P 为: i E F F F T T T T E E |)(|*|→→+→ 则句型T+T*i+F 中的句柄是__(A)___。 (A) T (B) i (C) T*i (D) i+F 4、文法b B a aA A AS AB S →→→,|,|与下列哪个正规式等价__(B)___。 (A)+b aa * (B)b aa * (C)*)(ab (D) *)(ab a ; 第二题:(清华大学年考研试题)已知文法G[S]为: S → dAB A → aA | a B → Bb | ε G[S]产生的语言是什么?(请用自然语言或表达式描述语言特征) 答案:da +b * 第三题:(1) 构造一个文法G ,使得:L(G)={a 2m b m |m>0} (2) 构造一个文法G ,使得:L(G)={a n #b n | n>0} (3) 写出以0开头的8进制无符号整数的文法。
答案:(1) S→aaSb | aab (2) S→aSb | a#b (3) S→0 N N→DN | D D→0|1|2|3|4|5|6|7 四、有文法G[S]: S → a | ( T ) |ε T →T,S | S (1)请给出句子(a,(a,a))的最左、最右推导。 (2)请给出句子(a,(a,a))的短语、直接短语和句柄。答案:(1)最左推导: S=>(T) =>(T,S) =>(S,S) =>(a,S) =>(a,(T)) =>(a,(T,S)) =>(a,(S,S)) =>(a,(a,S)) =>(a,(a,a)) 最右推导: S=>(T) =>(T,S) =>(T,(T)) =>(T,(T,S)) =>(T,(T,a)) =>(T,(S,a)) =>(T,(a,a)) =>(S,(a,a)) =>(a,(a,a))
HUNAN UNIVERSITY 计算理论导引实验报告 题目:上下文无关文法(CFG)学生姓名: 学生学号: 专业班级:计算机科学与技术2班 上课老师: 实验日期:2014-1-5
一、实验目的 (2) 二、实验内容.......................................................................................... 错误!未定义书签。 三、实验代码.......................................................................................... 错误!未定义书签。 四、测试数据以及运行结果 (9) 五、实验感想 (13)
一、实验目的 1、掌握上下文无关文法概念。 2、掌握用动态规划算法验证某个字符串w是否属于某上下文无关文法。 二、实验内容 对于任意给定的一个上下文无关文法,并对任意字符串w, 用动态规划算法判断是否有w∈L(G)。 编写一个算法/程序,对于给定的输入
第2章习题解答 1.文法G[S]为: S->Ac|aB A->ab B->bc 写出L(G[S])的全部元素。 [答案] S=>Ac=>abc 或S=>aB=>abc 所以L(G[S])={abc} ============================================== 2. 文法G[N]为: N->D|ND D->0|1|2|3|4|5|6|7|8|9 G[N]的语言是什么? [答案] G[N]的语言是V+。V={0,1,2,3,4,5,6,7,8,9} N=>ND=>NDD.... =>NDDDD...D=>D......D =============================================== 3.已知文法G[S]: S→dAB A→aA|a B→ε|bB 问:相应的正规式是什么?G[S]能否改写成为等价的正规文法?[答案] 正规式是daa*b*;
相应的正规文法为(由自动机化简来): G[S]:S→dA A→a|aB B→aB|a|b|bC C→bC|b 也可为(观察得来):G[S]:S→dA A→a|aA|aB B→bB|ε ===================================================================== ========== 4.已知文法G[Z]: Z->aZb|ab 写出L(G[Z])的全部元素。 [答案] Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbb L(G[Z])={a n b n|n>=1} ===================================================================== ========= 5.给出语言{a n b n c m|n>=1,m>=0}的上下文无关文法。 [分析] 本题难度不大,主要是考上下文无关文法的基本概念。上下文无关文法的基本定义是:A->β,A∈Vn,β∈(Vn∪Vt)*,注意关键问题是保证a n b n的成立,即“a与b的个数要相等”,为此,可以用一条形如A->aAb|ab的产生式即可解决。 [答案] 构造上下文无关文法如下: S->AB|A A->aAb|ab B->Bc|c [扩展]
1 引言 几乎所有程序设计语言都是通过上下文无关文法来定义的。一个原因在于它们拥有足够强的表达力来表示大多数程序设计语言的语法,而且从另外一方面,上下文无关文法又足够简单,使得我们可以构造有效的分析算法来检验一个给定字符串是否是由某个上下文无关文法产生的。具体的例子可以参见LR分析器和LL分析器. 2 定义 上下文无关文法(英语:context-free grammar,缩写为CFG),在计算机科学中,若 一个形式文法G = (V, Σ, P, S) 的产生式规则都取如下的形式:A -> α,则谓之。其中A∈V ,α∈(V∪Σ)*。上下文无关文法取名为“上下文无关”的原因就是因为字符 A 总可以被字符串α自由替换,而无需考虑字符 A 出现的上下文。一个形式语言是上下文无关的,如果它是由上下文无关文法生成的. 正则语言和正则表达式,一个正则表达式可以用来表示一个句子集合(正则语言),且每个正则表达式都可以构造出有限状态自动机来判断任意的句子是否属于这个句子集合。因此,用正则表达式来表示正则语言是精确的、可操作的。 那么,可以用正则表达式来表示程序语言(比如 C 语言)所代表的句子集合吗? 很遗憾,答案是否定的。正则表达式毕竟太简单了,无法来表示程序语言这样复杂级别的句子集合。 为了表示程序语言的句子集合,需要采用表达能力更强大的工具——上下文无关语 法(context-free grammar)。 下面以一个简单的例子来说明什么是上下文无关语法,假设有一种非常非常原始的语言,我们把它成为 X 语言,它的句子只有:主语谓语宾语这样一种结构,主语中 只有我、你、他三个词,谓语中只有吃一个词.宾语中只有饭、菜两个词。我们 把它的语法写出下面这样的形式: 语句 -> 主语谓语宾语 主语 -> 我 主语 -> 你 主语 -> 他 谓语 -> 吃 宾语 -> 饭 宾语 -> 菜 可以看出, X 语言总共只有 6 个句子: { 我吃饭, 我吃菜, ..., 他吃菜 }。也就是说,我们可以用上面这个语法来表示 X 语言这个集合,我们可以从第一行的“语句 -> 主语谓语宾语” 开始,分别将主、谓、宾替换成可用的词,从而将所有满足语法的句子都推导出来。对于任意一个句子,我们也可以将句子和此语法来对比,判断它是否属于满足 X 语言。 上面这个语法中的每一行形如“语句 -> 主语谓语宾语” 的式子称为产生式(production)。 产生式左侧的符号(语句、主语、谓语和宾语)称为非终结符(nonterminal), 代表可以继续扩展或产生的符号,也就是说,当在某条产生式的右边遇到了此非终结符的时候,总是可以用本产生式的右边来替换这个非终结符。 而“我、你、他、吃、饭、菜” 这些符号是 X 语言中的词,无法再产生新的符号了,称为终结符(terminal)。终结符只能出现在产生式的右边,非终结符则左边和右边都可以出现。
8 上下文无关语言和非上下文无关语言 8.1 上下文无关语言的泵引理 从第6章到第7章,我们给出了两种描述CFL的模型,CFG和PDA。这两种模型都没有提供直接、明确的方法来判断一个形式语言不是CFL。然而,正如例子6.7对自然语言的一个简单考察,我们发现CFG存在描述能力的局限。本节中,我们精确定义和讨论CFL的一个性质,它类似于正则语言的泵引理。利用这个性质能够发现许多不是CFL的语言。 正则语言的泵引理基于这样的事实,如果一个足够长的输入字符串x导致FA在状态转移中,到达某个状态超过一次,即接受路径上存在回路,根据回路容易将x分成三部分,u是回路之前的字符串,v是回路的字符串,w是回路后的字符串,那么在回路上的多次重复,得到的新的字符串也应该被FA接受,即对任意的m>=0,uv m w被FA接受。如果我们用CFG生成(而不是PDA移动)CFL,容易得到类似的观察。设CFG G的一个推导出现同一个非终结符的嵌套重复,如下面的形式, S?*vAz?*vwAyz?*vwxyz 其中,v, w, x, y, z∈∑*。推导过程中,出现了A?*wAy,我们可以多次重复这个推导过程,如 S?*vAz?*vwAyz?*vw2Ay2z?*vw3Ay3z?*...?*vw m Ay m z 又由于A?*x,因此所有这类字符串vxz, vwxyz, vw2xy2z, ..., vw m xy m z都输入语言L(G)。 为了将上面的观察总结成CFL的泵引理,我们必须说明对于足够长的字符串的推导过程中都会出现非终结符的嵌套重复。同时我们也尽量发现分解得到的5个子串:v, w, x, y, z,的一些性质。这类似于我们处理正则语言的泵引理。 在6.6节,我们证明了所有的CFG产生式都可以改写成Chomsky范式,而不会影响CFG 接受语言的能力(唯一的影响是不能接受空字符,由于此处仅仅关心足够长的字符串,因此这个影响可以忽略)。因此我们的讨论可以局限在Chomsky范式(CNF)表示的CFG,显然这类文法得到的推导树都是二叉树,即每个父节点至多有两个子节点。 我们先定义几个与二叉树相关的概念。路径是一串节点组成的序列,前后节点之间有父子关系;路径的长度是路径包含的节点的个数;二叉树的高度是最长路径的长度。由于非终结符数目有限,如果推导树足够高,那么存在一个路径,某个非终结符在该路径上出现了两次,即出现了前面提到的嵌套重复现象。 引理8.1 任给h>=1,如果二叉树的叶结点个数>2h-1,那么该二叉树的高度>h。 证明:这是一个数学问题。我们用数学归纳法证明它的逆反命题:如果二叉树的高度<=h,那么二叉树的叶节点个数<=2h-1。 1.归纳基础,h=1,此时二叉树只有一个根节点,它也是唯一的叶结点,命题成立。 2.归纳推理,设k>=1时,命题成立。要证明k+1时,命题也成立。设二叉树T的高度为 k+1,则它的根节点的两个子树(以子节点为跟的二叉树)的叶节点数都<=2k-1,因此T 的叶节点数<=2k-1+2k-1=2k。得证。 定理8.1 G=(V, ∑, S, P)是形式为CNF的CFG,共有p个非终结符,则对每个长度>=2p+1的属于L(G)的字符串,都能找到5个字符串v, w, x, y, z满足下面的条件: u=vwxyz |wy|>0 |wxy|<=2p+1 vw m xy m z∈L(G), ?m>=0 证明:根据引理8.1,任何一个生成u的推导树高度>=p+2,即至少存在一个长度>=p+2的路径,不妨设d是其中的一个,显然d的最底部是一个终结符,其上的符号都是非终结符,共
第3章、上下文无关语言习题解答 - 练习 3.1 回忆一下例3.3中给出的CFG G 4。为方便起见,用一个字母重新命名它的变元如下: E →E +T|T T →T ×E|F F →(E )|a 给出下述字符串的语法分析树和派生。 a. a b. a+a c. a+a+a d. ((a)) 答: a. E T F a ??? b. E E T T F F a a a ?+?+?+?+ c. E E T E T F T F a F a a a a a ?+?++?++?++?++ d. ()()()(())(())(())(())E T F E T F E T F a ????????? 3.2 a. 利用语言A={a m b n c n | m,n ≥0}和B={a n b n c m | m,n ≥0}以及例3.20(语言B={a n b n c n | n ≥0}不是上下文无关的),证明上下文无关语言在交的运算下不封闭。 b. 利用(a)和DeMorgan 律(定理1.10),证明上下文无关语言在补运算下不封闭。 证明: a.先说明A,B 均为上下文无关文法,对A 构造CFG C 1 S →aS|T|ε T →bTc|ε //生成b n c n 对B,构造CFG C 2 S →Sc|R|ε R →aRb |ε //生成a n b n 由此知 A,B 均为上下文无关语言。 由例3.20, A ∩B={a n b n c n |n ≥0}(假设m ≤n )不是上下文无关语言,所以上下文无关语言在交的运算下不封闭。
b. 用反证法。 假设CFL 在补运算下封闭,则对于(a)中上下文无关语言A,B ,A ,B 也为CFL 。因为CFL 对并运算封闭,所以A B U 也为CFL ,进而知道A B U 为CFL 。由DeMorgan 定律A B A B =U I ,得出A B I 是CFL 。 这与(a)的结论矛盾,所以CFL 对补运算不封闭。 3.3 设上下文无关文法G : R →XRX|S S →aTb|bTa T →XTX|X|ε X →a|b 回答下述问题: a. G 的变元和终结符是什么?起始变元是哪个? 答:变元是:R ,X ,S ,T ;起始变元是R 。终结符是:a ,b ,ε b. 给出L(G)中的三个字符串。答:ab ,ba ,aab 。 c. 给出不在L(G)中的三个字符串。答:a ,b ,ε。 d. 是真是假:T aba ?。答:假 e. 是真是假:* T aba ?。答:真 f. 是真是假:T T ?。答:假 g. 是真是假:* T T ?。答:假 h. 是真是假:* XXX aba ?。答:真 i. 是真是假:* X aba ?。答:假 j. 是真是假:* T XX ?。答:真 k. 是真是假:* T XXX ?。答:真 l. 是真是假:*X ε?。答:假 m. 用普通的语言描述L(G):
第 5 章上下文无关文法及语言 现在我们把注意力从正则语言转移到另外一大类语言上来,它们叫做“上下文无关语言”。这个语言类有着自然、递归的表示方法,这种表示方法叫做“上下文无关文法”。从1960年以来,上下文无关文法一直在编译技术中扮演着重要的角色。它们能够把分析器(一类用来在编译过程中发掘源程序结构的程序)的实现从一种费时的、不通用方式的设计工作转变成为一种能够很快完成的工作。近年来,上下文无关文法也被用来描述文档格式:XML(eXtensible Markup Language 可扩展标记语言)中使用的DTD(Document-Type Definition 文档类型定义)就是用来描述Web上的信息交换格式的。 在本章中,我们将首先介绍上下文无关文法的表示方法,然后将介绍怎样用文法来定义语言。我们将会讨论到“语法分析树”──对一个文法处在它所表示的语言的字符串中结构的图形描述。语法分析树是对一个编程语言的语法分析器的产物,也是通常用来获得程序结构的途径。 上下文无关语言还有另外一种等价的自动机表示叫做“下推自动机”。我们将在第6章介绍下推自动机。虽然它不如有穷自动机重要,但仍然要介绍它,原因是作为一种语言的定义机制来说,它跟上下文无关文法具有等价性,后面在第7章研究如何判定上下文无关语言以及研究上下文无关语言的封闭性时,这种等价性是非常有用的。 5.1 上下文无关文法 这一章的内容将从非形式化地介绍上下文无关文法的表示法开始。形式化的定义会在读者了解到这些文法的一些重要的能力之后给出。届时我们将会说明怎样形式地定义一个文法,并将介绍一种叫作“推导”的过程:它能够决定在一个文法的语言中到底有哪些串。 5.1.1一个非形式化的例子 下面来考虑一个“回文(palindrome)”的语言。“回文”是指正向和反向读起来都一样的串,比如otto或者madamimadam(“Madam, I’m Adam,”引自Eve在Eden的花园里听到的第一句话)。换句话说,串w是一个回文当且仅当w = w R。考虑简单些的情况——只需要描述字母表{0, 1}上的回文,这个语言包括像0110,11011这样的串,也包括空串ε,但不包括像011或0101这样的串。 很容易验证这个0,1上的回文语言L pal不是正则语言,要做到这点只需要使用泵引理即可:假设L pal是一个正则语言,令n是与其相关的常数,考虑回文串w = 0n10n,如果L pal 是正则的,那么我们就能够把w写为w = xyz,其中y由第一组0中的若干个(但至少一个)构成。接下来,如果L pal是正则的话那么xz也应该在L pal里。然而由于xz的两端的0的个数不同,进而可知它不可能是回文串,由此得出的矛盾可以推翻前面关于L pal是正则语言的假设。 对于什么样的0,1串在L pal里,有一个自然的、递归的定义,它从一个最基本的显然属于L pal中的串开始,接着利用一个最直观的思想:如果一个串在L pal里,那么它开头和结尾
上下文无关文法 形式语言理论中一种重要的变换文法,用来描述上下文无关语言,在乔姆斯基分层中称为2型文法。由于程序设计语言的语法基本上都是上下文无关文法,因此应用十分广泛。 简介 上下文无关文法(Context-Free Grammar, CFG) 在计算机科学中,G = (N, Σ, P, S) 的产生式规则都取如下的形式:V -> w,则称之为上下文无关的,其中V∈N ,w∈(N∪Σ)* 。上下文无关文法取名为“上下文无关”的原因就是因为字符V 总可以被字串w 自由替换,而无需考虑字符V 出现的上下文。一个形式语言是上下文无关的,如果它是由上下文无关文法生成的﹙条目上下文无关语言﹚。 来定义的。另一方面,上下文无关文法又足够简单,使得我们可以构造有效的分析算法来检验一个给定字串是否是由某个上下文无关文法产生的。例子可以参见LR 分析器和LL 分析器。
BNF ﹙巴克斯-诺尔范式﹚经常用来表达上下文无关文法。 文法规则使用相似的表示法。名字用斜体表示(但它是一种不同的字体,所以可与正则表达式相区分)。竖线仍表示作为选择的元符号。并置也用作一种标准运算。但是这里没有重复的元符号(如正则表达式中的星号*),稍后还会再讲到它。表示法中的另一个差别是现在用箭头符号“→”代替了等号来表示名字的定义。这是由于现在的名字不能简单地由其定义取代,而需要更为复杂的定义过程来表示,这是由定义的递归本质决定的。
文法规则是定义在一个字母表或符号集之上。在正则表达式中,这些符号通常就是字符,而在文法规则中,符号通常是表示字符串的记号。我们利用C中的枚举类型定义了在扫描程序中的记号;为了避免涉及到 特定实现语言(例如C 记号。此时的记号就是一个固定的符号,如同在保留字while 中或诸如+或: =这样的特殊符号一样,对于作为表示多于一个串的标识符和数的记号来说,代码字体为斜体,这就同假设这个记号是正则表达式的名字(这是它经常的表示)一样。 上下文无关文法的却利用了与正则表达式中极为类似的命名惯例和运算,二 recursive)。 例子 例子1一个简单的上下文无关文法的例子是:S -> aSb | ε 。这个文法产生了语言{anbn : n ≥ 0} 。不难证明这个语言不是正规的。 例子2 这个例子可以产生变量x,y,z 的算术表达式: S -> T + S | T - S | T T -> T * T | T / T | ( S ) | x | y | z 例如字串"( x + y ) * x - z * y / ( x + x )" 就可以用这个文法来产生。 例子3 字母表{a,b} 上 a 和 b 数目不相等的所有字串可以由下述文法产生: S -> U | V U -> T aU | T aT
基于上下文无关文法的句法分析
常宝宝 北京大学计算语言学研究所 chbb@https://www.doczj.com/doc/9f1053784.html,
句法分析导引
以“词”为单位的分析技术
词语切分(segmentation, tokenization) 形态分析(morphological analysis, lemmatization, stemming) 词类标注(part-of-speech tagging) ……
以“句”为单位的分析技术
句法分析(syntactic parsing) ……
以“篇”为单位的分析技术
指代分析(anaphora resolution) ……
句法分析关心句子的组成规律(词如何组成句子?)
句法学(syntax)
In linguistics, syntax is the study of the rules, or "patterned relations", that govern the way the words in a sentence come together. It concerns how different words are combined into clauses, which, in turn, are combined into sentences. From Wikipedia, the free encyclopedia 语言学中研究句子组成规则的学科是句法学
句子成分分析
句子是词的线性序列,但词和词之间结合的松紧程度 并不一样。
今天 上午 我们 有 两 节 课
句子在构造上具有层次性,较小的成分还可以进一步 组成较大的成分。
今天 上午 我们 有 两 节 课 | | | | | | | | |
不同性质的成分可以有不同的句法功能和分布,可以 区分成不同的类型。
名词短语 (可以充当主谓结构中的主语、述宾结构中的宾语等) 两节课 动词短语 (可以充当主谓结构中的谓语等)
上下文无关文法 百科名片 形式语言理论中一种重要的变换文法,用来描述上下文无关语言,在乔姆斯基分层中称为2型文法。由于程序设计语言的语法基本上都是上下文无关文法,因此应用十分广泛。 目录[隐藏] 简介 例子 范式 同态映射下的性质 文法形式和文法的相似性 文法的二义性 子文法类 [编辑本段] 简介 上下文无关文法(Content-Free Grammar, CFG) 在计算机科学中,若一个形式文法G = (N, Σ, P, S) 的 上下文无关文法 产生式规则都取如下的形式:V -> w,则称之为上下文无关的,其中V∈N ,w∈(N ∪Σ)* 。上下文无关文法取名为“上下文无关”的原因就是因为字符V 总可以被字串w 自由替换,而无需考虑字符V 出现的上下文。一个形式语言是上下文无关的,如果它是由上下文无关文法生成的﹙条目上下文无关语言﹚。 上下文无关文法重要的原因在于它们拥有足够强的表达力来表示大多数程序设计语言的语法;实际上,几乎所有程序设计语言都是通
上下文无关文法 过上下文无关文法来定义的。另一方面,上下文无关文法又足够简单,使得我们可以构造有效的分析算法来检验一个给定字串是否是由某个上下文无关文法产生的。例子可以参见LR 分析器和LL 分析器。 BNF ﹙巴克斯-诺尔范式﹚经常用来表达上下文无关文法。 文法规则使用相似的表示法。名字用斜体表示(但它是一种不同的 上下文无关文法 字体,所以可与正则表达式相区分)。竖线仍表示作为选择的元符号。并置也用作一种标准运算。但是这里没有重复的元符号(如正则表达式中的星号*),稍后还会再讲到它。表示法中的另一个差别是现在用箭头符号“→”代替了等号来表示名字的定义。这是由于现在的名字不能简单地由其定义取代,而需要更为复杂的定义过程来表示,这是由定义的递归本质决定的。 同正则表达式类似,文法规则是定义在一个字母表或
《编译原理》考试试题及答案(附录) 一、判断题: 1.一个上下文无关文法的开始符,可以是终结符或非终结符。 ( X ) 2.一个句型的直接短语是唯一的。 ( X ) 3.已经证明文法的二义性是可判定的。( X ) 4.每个基本块可用一个DAG表示。(√) 5.每个过程的活动记录的体积在编译时可静态确定。(√) 6.2型文法一定是3型文法。( x ) 7.一个句型一定句子。 ( X ) 8.算符优先分析法每次都是对句柄进行归约。 (应是最左素短语) ( X ) 9.采用三元式实现三地址代码时,不利于对中间代码进行优化。(√) 10.编译过程中,语法分析器的任务是分析单词是怎样构成的。 ( x ) 11.一个优先表一定存在相应的优先函数。 ( x ) 12.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。 ( ) 13.递归下降分析法是一种自下而上分析法。 ( ) 14.并不是每个文法都能改写成LL(1)文法。 ( ) 15.每个基本块只有一个入口和一个出口。 ( ) 16.一个LL(1)文法一定是无二义的。 ( ) 17.逆波兰法表示的表达试亦称前缀式。 ( ) 18.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。 ( ) 19.正规文法产生的语言都可以用上下文无关文法来描述。 ( ) 20.一个优先表一定存在相应的优先函数。 ( ) 21.3型文法一定是2型文法。 ( ) 22.如果一个文法存在某个句子对应两棵不同的语法树,则文法是二义性的。 ( ) 二、填空题: 1.( 最右推导 )称为规范推导。 2.编译过程可分为(词法分析),(语法分析),(语义分析和中间代码生成),(代码优化)和(目 标代码生成)五个阶段。 3.如果一个文法存在某个句子对应两棵不同的语法树,则称这个文法是()。 4.从功能上说,程序语言的语句大体可分为()语句和()语句两大类。 5.语法分析器的输入是(),其输出是()。 6.扫描器的任务是从()中识别出一个个()。 7.符号表中的信息栏中登记了每个名字的有关的性质,如()等等。 8.一个过程相应的DISPLAY表的内容为()。 9.一个句型的最左直接短语称为句型的()。 10.常用的两种动态存贮分配办法是()动态分配和()动态分配。 11.一个名字的属性包括( )和( )。 12.常用的参数传递方式有(),()和()。 13.根据优化所涉及的程序范围,可将优化分成为(),()和()三个级别。 14.语法分析的方法大致可分为两类,一类是()分析法,另一类是()分析法。 15.预测分析程序是使用一张()和一个()进行联合控制的。 16.常用的参数传递方式有(),()和()。 17.一张转换图只包含有限个状态,其中有一个被认为是()态;而且实际上至少要有一个()态。
上下文无关文法的基本概念 定义:上下文无关文法G是一个四元组G = (N,T,P,S),其中 N是非终结符的有限集合; T是终结符或单词的有限集合,它与N不相交; P是形如A →α的产生式的有限集合,其中A∈N,α∈V﹡,V=T∪N S是N中的区分符号,称为开始符号或句子符号。V中的符号称为文法符号,包括终结符和非终结符。 特殊情况:A →ε空产生式 例如,if语句结构的文法产生式表示: stmt →if expr then stmt else stmt Backus - Naur范式(Backus-Naur form)或BNF文法 符号的使用约定: 符号是终结符: 字母表中比较靠前的小写字母,如a,b,c等。 操作符,如+、-等。 标点符号,如括号、逗号等。 数字0,1, (9) 黑体串,如id、if等。 符号的使用约定: 下列符号是非终结符: 字母表中比较靠前的大写字母,如A、B、C等。 字母S,它常常代表开始符号。 小写斜体名字,如expr、stmt等。 字母表中比较靠后的大写字母,如X、Y、Z等,表示文法符号,也就是说,可以是非终结符也可以是终结符。 符号的使用约定: 字母表中比较靠后的小写字母,如u,v,…,z等,表示终结符号的串。 小写希腊字母,如α、β、γ等,表示文法符号的串。因此,一个通用产生式可以写作A →α,箭头左边(产生式左部)是一个非终结符A,箭头右边是文法符号串(产生式右部)。 符号的使用约定: 如果A →α1、A →α2、…、A →αk 是所有以A为左部的产生式(称为A产生式),则可以把它们写成A →α1|α2|…|αk,我们将α1、α2、…、αk称为A的候选式。除非另有说明,否则第一个产生式左部的符号是开始符号。 例1考虑下面的关于简单算术表达式的文法,非终结符为<表达式>和<运算符>,终结符有ID,+,-,*,/,↑,(,)。产生式有 <表达式> → <表达式> <运算符> <表达式> <表达式> → (<表达式>) <表达式> → - <表达式> <表达式> →ID <运算符> → + <运算符> → - <运算符> → * <运算符> → / <运算符> →↑
例题2.1 是非题 1.因名字都是用标识符表示的,故名字与标识符没有区别。() 2.正规文法产生的语言都可以用上下文无关文法来描述。() 3.上下文无关文法比正规文法具有更强的描述能力。() 分析 1.标识符是高级语言中定义的字符串,一般是以英文字母开头(包括大小写字母)的,由数字、字母和一些特殊字符(如下划线等)组成的一定长度(不同的高级语言对标识符的长度的规定不同)的字符串,它只是一个标志,没有其它含义。名字是用标识符表示的,但名字不仅仅是一个字符串,它还具有属性和值,就象一个人的名字不仅仅是一个符号,对于认识这个人的人来说,它还代表着这个人,因此本题错。 2.乔姆斯基把文法分成4种类型,从4种文法的形式化描述来看,它们的差别主要在对规则形式的约束上。0型文法的规则形式是:每个产生式α→β都满 足,α∈(V N ∪V T )*且至少含有一个非终结符,β∈(V N ∪V T )*,0型文法也叫短语 文法。1型文法的规则形式是:每个产生式α→β均满足|α|≤|β|,仅仅S→ε例外,且S不得出现在任何产生式的右部,1型文法也称上下文有关文法,从两种文法的规则形式来看,1型文法对规则形式的约束比0型文法强,1型文法能描述的语言0型文法也能描述,而0型文法能描述的语言1型文法不一定能够描述,1 型文法是0型文法的特例。2型文法的规则形式是A→β,其中A∈V N ,β∈(V N ∪ V T )*,2型文法也称上下文无关文法,分析2型文法的规则形式不难发现,2型文法是1型文法的特例,也是0型文法的特例。3型文法的规则形式是A→αB或 A→α,其中α∈,A、B∈V N ,3型文法也称正规文法,可以看出3型文法是前面3种文法的特例。从上面的分析可以,正规文法是上下文无关文法的特例,可以用正规文法描述的语言,其正规文法描述的形式也是上下文无关文法的描述形式,即可以用上下文无关文法描述,因此本题对。 3.上下文无关文法是2型文法,正则文法是3型文法,从上题的分析可以看出,3型文法是2型文法的特例,3型文法可以描述的语言都可以用2型文法来描述,而2型文法可以描述的语言则不一定能用3型文法来描述。即2型文法比3型文法的描述能力强,因此本题对。 例题2.2 填空题 1.程序语言是由()和()两方面定义的。 3.文法G所产生的句子的全体的(),将它记为()