
2014——2015学年第 1 学期 合肥学院数理系 实验报告 课程名称:统计软件选讲 实验项目:区间估计与假设检验 实验类别:综合性□设计性□验证性□√ 专业班级: 12级信息与计算科学 姓名:马坤鹏学号: 1207011017 实验地点:数理系数学模型实验室 实验时间: 2014.9.24 指导教师:段宝彬成绩:
一、实验目的 掌握使用SAS对总体参数进行区间估计与假设检验方法。 二、实验内容 1、用INSIGHT对总体参数进行区间估计与假设检验 2、用“分析家”对总体参数进行区间估计与假设检验 3、编程对总体参数进行区间估计与假设检验 三、实验步骤或源程序 1、生成来自标准正态总体的10000个随机数: (1) 求总体的平均值和方差的置信水平为90%的置信区间; (2) 改变随机数的个数,观察并总结样本均值、样本方差的变化以及总体均值和方差的置信区间的变化规律。 2、从某大学总数为500名学生的“数学”课程的考试成绩中,随机地抽取60名学生的考试成绩如表5-6(lx5-2.xls)所示: 表5-6 学生成绩 (1) 分别求500名学生平均成绩的置信水平为98%、90%和85%的置信区间,并观察置信水平与置信区间的关系。 (2) 分别求500名学生成绩的标准差的置信水平为98%和85%的置信区间。 3、装配一个部件时可以采用不同的方法,所关心的问题是哪一个方法的效率更高。劳动效率可以用平均装配时间反映。现从不同的装配方法中各抽取12件产品,记录下各自的装配时间如表5-7(lx5-3.xls)所示: 表5-7 装配时间(单位:分钟) 设两总体为正态总体,且方差相同。问两种方法的装配时间有无显著不同(α = 0.05)?data my.five1; input m n$@@; cards; 31 m 34 m 29 m 32 m 35 m 38 m 34 m 30 m 29 m 32 m 31 m 26 m 26 n 24 n 28 n 29 n 30 n 29 n 32 n 26 n 31 n 29 n 32 n 28 n ; proc ttest h0 = 0alpha = 0.05data= my.five1; var m; class n; run;
北京建筑大学 理学院信息与计算科学专业实验报告 课程名称《数据分析》实验名称数据的基本统计与非参数检验实验地点基C-423 日期2016 . 3 .17 姓名班级学号指导教师成绩 【实验目的】 (1)熟悉数据的基本统计与非参数检验分析方法; (2)熟悉撰写数据分析报告的方法; (3)熟悉常用的数据分析软件SPSS。 【实验要求】 根据各个题目的具体要求,完成实验报告 【实验内容】 根据附件“住房状况调查”给出的相关数据,请选用恰当的分析方法,分别对数据的“家庭收入”、“现住面积”,进行数据的基本统计量分析,撰写相应的分析报告; 根据附件“住房状况调查”给出的相关数据,请选用恰当的分析方法,分别分析不同学历对家庭收入、现住面积是否有显著影响,撰写相应的分析报告。 根据附件“住房状况调查”给出的相关数据,请选用恰当的分析方法,分析家庭收入与10000元是否有显著差异,撰写相应的分析报告。 根据附件“住房状况调查”给出的相关数据,请选用恰当的分析方法,分析婚姻状况对家现住面积是否有显著影响,撰写相应的分析报告。 根据附件“减肥茶数据”给出的相关数据,请选用恰当的分析方法,分析该减肥茶对减肥是否有显著影响,撰写相应的分析报告。 【分析报告】 1. 表一家庭收入和现住面积的基本描述统计量 家庭收入现住面积 N 有效2993 2993 缺失0 0 均值17696.1567 62.7241
均值的标准误279.64310 .47349 中值15000.0000 60.0000 众数10000.00 60.00 标准差15298.80341 25.90383 方差 2.341E8 671.008 偏度 5.546 .910 偏度的标准误.045 .045 峰度55.425 3.078 峰度的标准误.089 .089 百分位数25 10000.0000 45.0000 50 15000.0000 60.0000 75 20000.0000 80.0000 表一说明, 家庭收入方面: 被调查者中家庭收入的均值为17696.16元,中值为15000元,普遍收入为10000元; 家庭收入的标准差和方差都相对较大,所以,各家庭收入之间有明显的差异; 偏度大于零,说明右偏;峰度大于零,说明数据呈尖峰分布; 由家庭收入的四分位数可知,25%的家庭,收入在10000以下,有50%的家庭,收入在15000以下,有75%的家庭,收入在20000以下; 现住面积方面: 被调查者中现住面积的均值为62.724平方米,中值为60平方米,普遍面积为60平方米; 现住面积的标准差和方差都相对较大,所以,各家庭现住面积之间有明显的差异; 偏度近似等于零,说明现住面积数据对称分布;峰度大于零,说明现住面积数据为尖峰分布; 由现住面积的四分位数可知,25%的家庭,现住面积为45平方米以下,有50%的家庭,现住面积在60平方米以下,有75%的家庭,现住面积在80平方米以下。 图一:家庭收入直方图 该图表明,家庭收入分布存在一定的右偏。 图二:现住面积直方图
云南大学滇池学院 方差分析与假设检验实验报告二 学生姓名:方炜学号:20092123080 专业:软件工程 一、实验目的和要求: 1、初步了解SPSS的基本命令; 2、掌握方差分析和假设检验。 二、实验内容: 1、为比较5中品牌的合成木板的耐久性,对每个品牌取4个样本作摩擦试验测量磨损量,得以下数据: (1)它们的耐久性有无明显差异? (2)有选择的作两品牌的比较,能得出什么结果?
2、将土质基本相同的一块耕地分成5块,每块又分成均等的4小块。在每块地内把4个品 种的小麦分钟在4小块内,每小块的播种量相同,测得收获量如下: 考察地块和品种对小麦的收获量有无显著影响?并在必要时作进一步比较。 3、为了研究合成纤维收缩率和拉伸倍数对纤维弹性的影响进行了一些试验。收缩率取0,4, 8,12四个水平;拉伸倍数取460,520,580,640四个水平,对二者的每个组合重复作两次试验,所得数据如下:
(1)收缩率,拉伸倍数及其交互作用对弹性有无显著影响? (2)使弹性达到最大的生产条件是什么? 三、实验结果与分析: 1、运行结果截图: 1、结果分析: (1)、Sig<0.05,耐久性有明显差异 (2)、由样本分析,品牌3分为一类;品牌1,2,5分为一类;品牌4分为一类。而品牌3和品牌4差距最大,品牌3的耐久性最差,品牌4的耐久性最好。 2、运行结果截图:
2、结果分析: (1)、地块(A组)Sig>0.05对小麦的收获量无显著影响,品种(B组)Sig<0.05对小麦的收获量有显著影响。 (2)、由图得,地块4最适合种小麦,地块1最不适合种小麦;而品种2的小麦收获量最大,品种4的小麦收获量最小。 3、运行结果截图:
实验报告 假设检验 学院: 参赛队员: 参赛队员: 参赛队员: 指导老师:
一、实验目的 1.了解假设检验的基本内容; 2.了解单样本t检验; 3.了解独立样本t检验;、 4.了解配对样本t检验; 5.学会运用spss软件求解问题; 6.加深理论与实践相结合的能力。 二、实验环境 Spss、office 三、实验方法 1.单样本t检验; 2.独立样本t检验; 3.配对样本t检验。 四、实验过程 实验过程 依题意,设H0:μ= 82,H1:μ>82 (1)定义变量为成绩,将数据输入SPSS;
(2)选择:分析比较均值单样本T检验; (3)将变量成绩放置Test栏中,并在Test框中输入数据82; (4)观察结果 实验结果
结果分析 该题是右尾检验,所以右尾P=2=因为P值明显小于, 表明在水平上变量与检验值有显著性差异,故接受原假设,所以该县的英语教学改革成功。 问题二: 实验过程 依题意,设H0:μ= 500,H1:μ≠500 (1)定义变量为成绩,将数据输入SPSS; 某工艺研究所研究出一种自动装罐机,它可以用来自动装罐头食品,并且可以达到每罐的标准重量为500克。现在需要检验它的性能。假定装罐重量服从正态分布。现随机抽取10罐来检查机器工作情况,这10罐的重量如下:
(2)选择:分析比较均值单样本T检验; (3) 将变量成绩放置Test栏中,并在Test框中输入数据500; 实验结果 结果分析 该题是双检验,所以双尾P=因为P值明显大于, 表明在水平上变量与检验值无显著性差异,故不能拒绝原假设 ,接受备择假设,所以自动装罐机性能良好 问题三: 某对外汉语中心进行了一项汉字教学实验,同一年级的两个平行班参与了该实验。一个班采用集中识字的方式,然后学习课文;另一班采用分散识字的方式,边学习课文边学习生字。为了考察两种教学方式对生字读音的记忆效果是否有影响,教学效果是否有差异,分别从一班和二班随机抽取20人,进行汉字注音考试,请计算二个班的平均成绩、标准差分别是多少两种教学方式对汉字读音的记忆效果是否有差异哪一种教学方式更有效
实验编号:1四川师大SPSS实验报告2017 年3月27日 计算机科学学院2015级5班实验名称:参数假设检验 姓名:唐雪梅学号:2015110538 指导老师:__朱桂琼___ 实验成绩:___ 实验三参数假设检验 一.实验目的及要求 1.了解SPSS 特点结构操作 2.利用SPSS进行简单数据统计 二.实验内容 1.对12名来自城市的学生与14名来自农村的学生进行心理素质测验,他们的分数如下: 城市学生得分:4.75 6.40 2.62 3.44 6.50 5.30 5.60 3.80 4.30 5.78 3.76 4.15 农村学生得分:2.38 2.60 2.10 1.80 1.90 3.65 2.30 3.80 4.60 4.85 5.80 4.25 4.22 3.84 试分析农村学生与城市学生心理素质有无显著差别。 2、一汽车厂商声称其发动机排放标准的一个指标平均低于20个单位。在抽查了10台发动机之后,得到下面的排放数据:17.0、21.7、17.9、22.9、20.7、22.4、17. 3、21.8、24.2、25.4。目的是检验该申明是否正确 3. 用SPSS Samples数据文件“Employee data.sav”资料, 问:清洁工(jobcat=1)的受教育年数(Educational Level)与保管员(jobcat=2)和经理(jobcat=3)的受教育年数是否有显著差异?其中,显著性水平ɑ=0.05. ? 4. 用SPSS Samples数据文件“Employee data.sav”资料, 分析:美国企业现在工资(Current Salary)与过去工资(beginning Salary)是否有显著差异? 三、实验主要流程、基本操作或核心代码、算法片段(该部分如不够填写,请另加附页) 1.数据录入
SPSS相关分析实验报告 篇一:spss对数据进行相关性分析实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。 (1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.0000.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为 0.0000.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.0000.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.86650.921,说明它们之间的显著性关系稍有减弱。通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。 三、实验总结 1、熟悉了用spss软件对数据进行相关性分析,熟悉其操作过程。 2、通过spss软件输出的数据结果并能够分析其相互之间的关系,并且解决实际问题。 3、充分理解了相关性分析的应用原理。
实验报告 ——(非参数检验) 实验目的: 1、学会使用SPSS软件进行非参数检验。 2、熟悉非参数检验的概念及适用范围,掌握常见的秩和检验计算方法。 实验内容: 1、某公司准备推出一个新产品,但产品名称还没有正式确定,决定进行抽样调 查,在受访200人中,52人喜欢A名称,61人喜欢B名称,87人喜欢C 名称,请问ABC三种名称受欢迎的程度有无差别?(数据表自建) SPSS计算结果如下: 此题为总体分布的卡方检验。 零假设:样本来自总体分布形态和期望分布没有显著差异。即ABC三种名称受欢迎的程度无差别,分布形态为1:1:1,呈均匀分布。 观察结果,上表为200个观察数据对A、B、C三个名称(分别对应1,2,3)的喜爱的期望频数以及实际观察频数和期望频数的差。从下表中可以看出相伴概
率值为0.007小于显著性水平0.05,因此拒绝零假设,认为样本来自的总体分布与制定的期望分布有显著差异,即A、B、C三种名称受欢迎的程度有差异。 2、某村庄发生了一起集体食物中毒事件,经过调查,发现当地居民是直接饮用 河水,研究者怀疑是河水污染所致,县按照可疑污染源的大致范围调查了沿河居民的中毒情况,河边33户有成员中毒(+)和均未中毒(-)的家庭分布如下:(案例数据run.sav) -+++*++++-+++-+++++----++----+---- 毒源 问:中毒与饮水是否有关? SPSS计算结果如下: 此题为单样本变量值随机检验 零假设:总体某变量的变量值是随机出现的。即中毒的家庭沿河分布的情况随机分布,与饮水无关。 相伴概率为0.036,小于显著性水平0.05,拒绝零假设,因此中毒与饮水有关。 3、某试验室用小白鼠观察某种抗癌新药的疗效,两组各10只小白鼠,以生存日数作为观察指标,试验结果如下,案例数据集为:npara1.sav,问两组小白鼠生存日数有无差别。 试验组:24 26 27 30 32 34 36 40 60 天以上 对照组:4 6 7 9 10 10 12 13 16 16 SPSS计算结果如下: 此题为两独立样本非参数检验。 (1)两独立样本Mann-Whitney U检验:
熟练使用SPSS 17.0进行假设检验[例] 某克山病区测得11例克山病患者与13名健康人的血磷值mmol/L如下,问该地急性克山病患者与健康人的血磷值是否不同。 表1 克山病区调查数据结果 1.录入数据。将组别设为g,可将患者组设为1,健康人设为2,血磷值设为x,如患者组中第一个测量到的血磷值为0.84,则g为1,x为0.84,其他数据均仿此录入,如下图所示。 图1 数据输入界面 2.统计分析。依次选择“Analyze”、“ Compare means”、“ Independent Samples T Test”。
图2 选择分析工具 3.弹出对话框如下图所示,将x选入Test Variables、g选入Grouping Variable,并单击下方的Define Groups按钮,弹出定义组对话框,默认选项为Use Specified Value,在Group1和Group2框中分别填入1和2,即要对组别变量值为1和2的两个组做t检验,另外Options 对话框中可选择置信度和处理缺失值的方法。 图3 选择变量进入右侧的分析列表 SPSS输出的结果和结果说明:
图4 输出结果 表2 统计量描述列表 表3 假设检验结果表 第一个表格是统计描述,给出了两个组的样本数N、均值Mean、标准偏差Std.Deviation、标准误差Std. Error Mean。 第二个表格分两部分 (1)方差齐次检验(Levene 检验)。F=0.032、P(Sig)=0.860 。
(2)t 检验。因方差齐次与不齐方法不同,(Equal variances assumed 方差齐次和Equal variances not assumed 方差不齐),结果分两行给出。由使用者根据方差齐次检验结果来判断。本例尚不能认为方差不齐,故取方差齐次的结果t= 2.524,df 自由度22, 双侧t 检验概率=0.019 即可认为两组间血磷值有差别。结果中还给出了两组间差值的均值标准误差和95%置信区间。
第五章参数估计和假设检验 本章重点 1、抽样误差的概率表述; 2、区间估计的基本原理; 3、小样本下的总体参数估计方法; 4、样本容量的确定方法; 本章难点 1、一般正态分布 标准正态分布; 2、t分布; 3、区间估计的原理; 4、分层抽样、整群抽样中总方差的分解。 统计推断:利用样本统计量对总体某些性质或数量特征进行推断。 两类问题:参数估计和假设检验 基本特点:(1)以随机样本为基础; (2)以分布理论为依据; (3)推断的只是一种可能的结果; (4)是归纳推理和演绎推理的结合。本章主要内容:阐述常用的几种参数估计方法。 第一节参数估计 一、参数估计的基本原理 两种估计方法
点估计 区间估计 1.点估计:以样本指标直接估计总体参数。 点估计优良性评价准则 (1)无偏性。估计量 的数学期望等于总体参数,即 , 该估计量称为无偏估计。 (2)有效性。当 为 的无偏估计时, 方差 越小, 无偏估计越有效。 (3)一致性。对于无限总体,如果对任意 ,有 ,则称 是 的一致估计。 (4)充分性。一个估计量如能完全地包含未知参数信息,即为 充分估计量。 2.点估计的缺点:不能反映估计的误差和精确程度 区间估计:利用样本统计量和抽样分布估计总体参数的可能区间 【例1】CJW 公司是一家专营体育设备和附件的公司,为了监控公司的服务质量, CJW 公司每月都要随即的抽取一个顾客样本进行调查以了解顾客的满意分数。根据以往的调查,满意分数的标准差稳定在20分左右。最近一次对100名顾客的抽样显示,满意分数的样本均值为82分,试建立总体满意分数的区间。 抽样误差 抽样误差:一个无偏估计与其对应的总体参数之差的绝对值。 抽样误差 = (实际未知) 要进行区间估计,关键是将抽样误差E 求解。若 E 已知,则区间可表示为: 区间估计:估计未知参数所在的可能的区间。 区间估计优良性评价要求 θ θ??θ?θθ=?E θ?0> εθ?2)?(θθ-E 0)|?(|=≥-∞ →εθθn n P Lim n θ?θθαθθθ-=1)??(U L P <<[]E x x +-,E
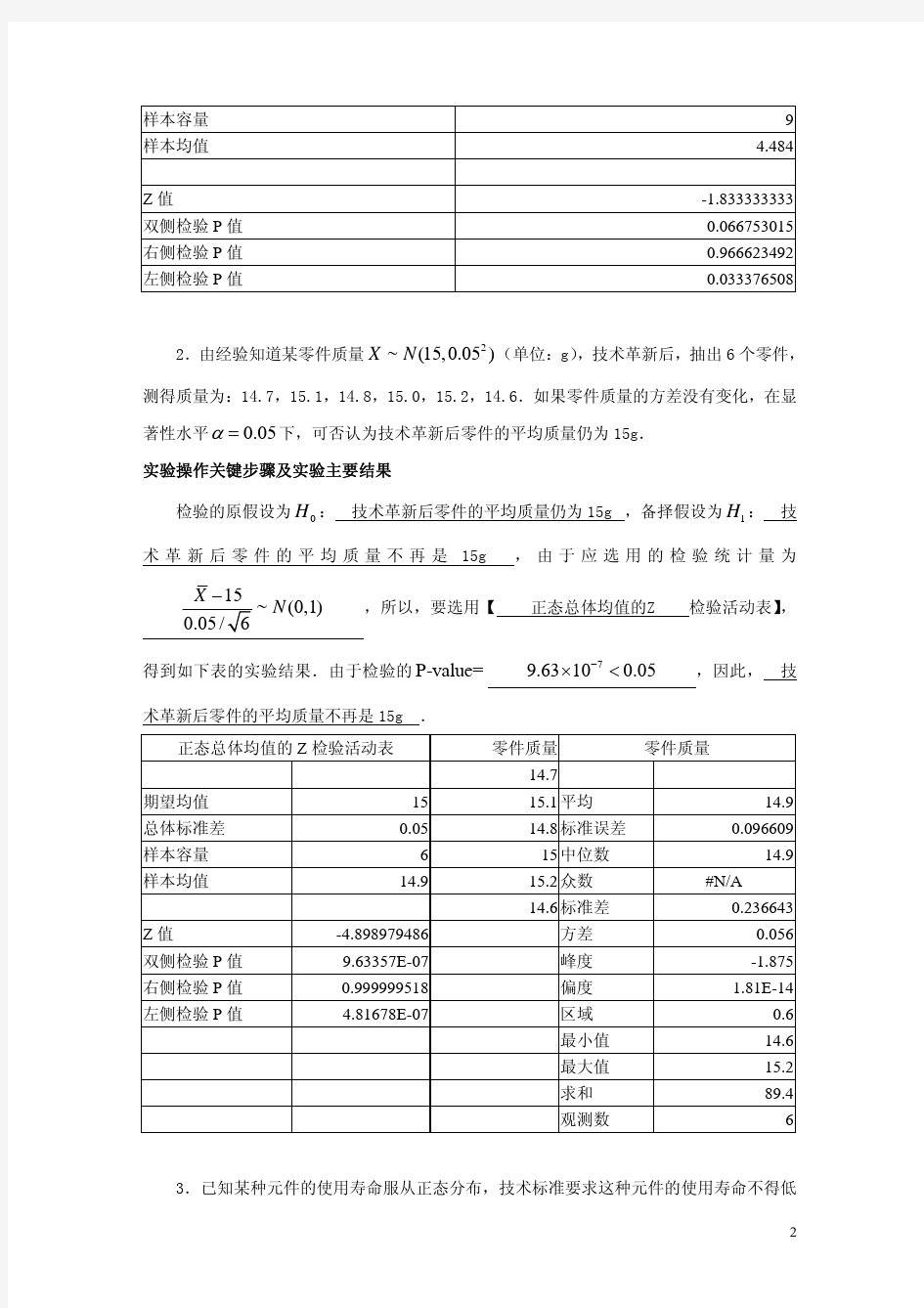
实验报告——第5章统计假设检验 姓名杨秀娟班级人力10001学号 【实验1】 某外企对员工英语水平进行调查,开发部门总结该部门员工英语水平很高,如果按照英语六级考试标准考核,一般平均分为75分。现从开发部门雇员中随机选出11人参加考试,得分如下:80,81,72,60,78,65,56,79,77,87,76 ^ 请问该开发部门的英语水平是否真的很高(即高于75分,且差异显著) 【解】 (1)数据和变量说明 本题所用数据是:外企英语六级考试成绩样本 该文件为11个样本,1个变量,如变量视图 (2)操作方法 (3)结果报告
, 上图为单样本t检验表,第一行注明了用于比较的已知的总体均数为75,下面从左到右依次为t值(t)、自由度(df)、P值(Sig)、两均数的差值、差值的95%可信区间。 由上表可知,t= , P=, P>,接受Ho,与平均成绩75相等,无显著差异,因此,该开发部门的英语水平不是真的很高。 【实验2】 以下是对某产品促销团队进行培训前后的销售业绩数据,试分析该培训是否产生了显著效果。 表5-20 培训前后销售业绩数据 56789 序号123' 4 7488827185 培训前677074~ 97 7687867895 培训后786778{ 98 【解】 (1)数据和变量说明 本文件有2个变量,9个数据 (2)操作方法 *
(3)结果报告 由上表可知,P=, P<,不接受无效假设,有显著差异,所以该培训产生了显著效果。 【实验3】 饲养队制定了两种喂养方案喂猪,希望通过试验了解一下不同喂养方案的喂养效果。
方案一:用一只猪喂不同的饲料所测得的体内钙留存量数据如下: 表 5-21 方案一喂养数据 序号! 1 23456789 饲料1" 饲料2/ 方案二:甲队有11只猪喂饲料1,乙队有9只猪喂饲料2,所得的钙留存量数据如下: ; 表5-22方案二喂养数据 序号12345678· 9 1011甲队饲料1; 乙队饲料2\ 请选用恰当方法对上述两种方案所获得的数据进行分析,研究不同饲料是否使小猪体内钙留存量有显著不同。 【解】 方案一 (1)《 (2)数据和变量说明 答:9个数据,2个变量 (3)操作方法
标题:视觉简单反应时实验报告 作者:孙洁肖红艳普凤梅 班级:09应用心理学 学号:20091740107 20091740109 20091740126 日期:2011年6月24日
视觉简单反应时实验报告 孙洁(20091740107)肖红艳(20091740109)普凤梅(20091740126) (云南民族大学教育学院2009级应用心理学专业昆明 650031) 摘要:本实验采用闪电测反应速度测定装置测量了35名被试的视觉简单反应时,计算了其中3名被试的视觉简单反应时均值及标准差,进行了相应的比较;并对35名被试进行了视觉简单反应时的差异显著性检验,经过分析得到实验结果:(1)3名被试的视觉简单反应时存在很大的差异,特别是被试3的反应时与被试1、被试2的差异很明显;(2)全体被试的视觉简单反应时存在显著性差异,但在35名被试内进行的性别与组别的T检验都得出被试简单反应时不存在显著差别的结果,即本次实验没有存在练习效应。这与前人的实验研究结果相一致,也验证了实验假设的正确性。 关键词:简单反应时;视觉;差异 1.引言 1.1有关反应时的概念 反应时(简称RT)指刺激作用于有机体后到明显的反应开始时所需要的时间。刺激作用于感官引起感官的兴奋,兴奋传到大脑,并对其加工,再通过传出通路传到运动器官,运动反应器接受神经冲动,产生一定反应,这个过程可用时间作为标志来测量,这就是反应时。反应时最早由天文学家发现,后由生理学家和心理学家加以研究和发展。1873年,奥地利生物学家Exner首先提出“反应时间”这个概念。以后Wundt(冯特)把反应时间引用到他的心理实验室里,使得反应时间直接成为了心理学的研究课题。反应时是心理学研究中最重要的反应变量和指标之一,使用反应时作为指标的实验研究,曾对解决心理学理论问题和生活实际问题起到相当大的作用。 通常,反应时可分为简单反应时和选择反应时两类。简单反应时是指给被试呈现单一的刺激,只要求做单一的反应,并且两者是固定不变的,这时刺激与反应之间的时距就是简单反应时。简单反应时的实验已有一百多年的历史,最早始于天文学家对“人差方程”的研究,赫希(Hirsch, A.)在1861-1865 年间测量了视听与触觉的“生理时间”得到简单反应时的时值,光为180ms,声为140ms,触觉为140ms,这些数据到今天还算是相当标准的。 简单反应时比较短,并且具有通道差异性,因为感官换能的时间不同,研究表明训练有素的成人其视觉的简单反应时为150-230ms;此外反应时的个体差异也很大,所以我们提出假设:全体被试的视觉简单反应时存在显著性差异。 1.2实验目的 本实验涉及的是有关视觉简单反应时的研究。验的目的是:(1)学习视觉简单反应时的测定方法及其实验材料的整理与数据的处理;(2)学会比较视觉简单反应时的个体差异,分析全体被试视觉简单反应时是否存在显著性差异。1.3 实验指导语 这是一次视觉反应时间的测量实验,当你听到“预备”口令后,请你注意电脑屏幕的刺激呈现窗;当你看到闪电刺激后,就迅速按“OK”键(鼠标左键)上。不能提前按键或延迟较长时按键,否则测量无效,并重开一组。
假设检验的SPSS实现 、实验目的与要求 1. 掌握单样本 t检验的基本原理和 spss实现方法。 2. 掌握两样本 t检验的基本原理和 spss实现方法。 3. 熟悉配对样本 t检验的基本原理和 spss实现方法。 二、实验内容提要 1. 从一批木头里抽取 5根,测得直径如下(单位: cm),是否能认为这批木头的平均直径是1 2.3cm 12.3 12.8 12.4 12.1 12.7 2. 比较两批电子器材的电阻,随机抽取的样本测量电阻如题表2所示,试比较两批电子器 材的电阻是否相同(需考虑方差齐性的问题) 3. 配对 t检验的实质就是对差值进行单样本t检验,要求按此思路对例课本 13.4进行重新分析,比较其结果和配对 t检验的结果有什么异同。 4.一家汽车厂设计出 3种型号的手刹,现欲比较它们与传统手刹的寿命。分别在传统手刹,型号I、II、和型号 III中随机选取了 5只样品,在相同的试验条件下,测量其使用寿命(单位:月),结果如下: 传统手刹:21.213.417.015.212.0 型号 I :21.412.015.018.924.5 型号 II :15.219.114.216.524.5 型号 III :38.735.839.332.229.6 ( 1)各种型号间寿命有无差别 ? (2)厂家的研究人员在研究设计阶段,便关心型号III 与传统手刹寿命的比较结果。此时应 当考虑什么样的分析方法?如何使用 SPSS实现? 三、实验步骤 为完成实验提要 1. 可进行如下步骤 1. 在变量视图中新建一个数据,在数据视图中录入数据,在分析中选择比较均值,单样本t 检验,将直径添加到检验变量,点击确定。
75 假设检验 Ⅰ.学习目的 假设检验包括参数检验与非参数检验,是一种最能体现统计推断思想和特点的方法。通过本章学习,要求:1.掌握统计检验的基本原理,理解该检验的规则及犯两类错误的性质;2.熟练掌握总体均值、总体成数及总体方差指标的各种检验方法,包括:z 检验、t 检验和p 值检验;3.掌握2 检验、符号检验、秩和检验及游程检验四种基本的非参数检验方法。 Ⅱ.课程内容要点 第一节 假设检验的基本原理 一、假设检验的基本原理 “小概率原理”:小概率事件在一次试验中几乎是不会发生的。 事先所做的假设,是假设检验中关键的一项工作。它包括原假设和备选假设两部分。原假设是建立在假定原来总体参数没有发生变化的基础之上的。备选假设是原假设的对立,是在否认原假设之后所要接受的,通常这是我们真正感兴趣的一个判断。 二、假设检验的规则与两类错误 1、假设检验的规则 假设检验的步骤: (1)首先根据实际应用问题确定合适的原假设0H 和备选假设1H ; (2)确定检验统计量,通过数理统计分析确定该统计量的抽样分布;
(3)给定检验的显著性水平α。在原假设成立的条件下,结合备选假设的定义,由检验统计量的抽样分布情况求出相应的临界值,该临界值为原假设的接受域与拒绝域的分界值; (4)从样本资料计算检验的样本统计量,并将其与临界值进行比较,判断是否接受或拒绝原假设。 从检验程序我们可以看出,统计量的取值范围可以分为接受域和拒绝域两个区域。拒绝域正是统计量取值的小概率区域。按照我们将这个拒绝域安排在所检验统计量的抽样分布的某一侧还是两端,可以将检验分为单侧检验或双侧检验。双侧检验中,又可以根据拒绝域,是在左侧还是在右侧而分为左侧检验和右侧检验。对于这些双侧、左、右单侧检验,我们要结合备选假设来考虑。 在检验规则中,我们经常碰到两种重要的检验方法:z检验与t检验。 p值检验的原理:给出原假设后,在假定原假设正确的情况下,参照备选假设,可以计算出检验统计量超过或者小于(还要依照分布的不同、单侧检验、双侧检验的差异而定)由样本所计算的检验统计量的数值的概率,这便是p值;而后将此概率值跟事先给出的显著性水平值α进行比较。如果该值小于α,否定原假设,取对应的备选假设。如果该值大于α,我们不就能否定原假设。 2、两类错误 H实际为真,但我们却依据样本信息,做出拒绝的错误结论当原假设 时,称为“弃真”错误;当原假设实际为假,而我们却错误接受时,称为“纳伪”错误。通常记显著性水平α为犯“弃真”错误的可能性大小,β为犯“纳伪”错误的可能性大小。由于两类错误是一对矛盾,在其他条件不变得情况下,减少犯“弃真”错误的可能性大小(α),势必增大犯“纳伪”错误的可能性大小(β),也就是说,β的大小和显著性水平α的大小成相反方向变化。 三、检验功效 -可以用来表明所做假设检验工作好坏的一个指标,我们称之为检1β 76
实验报告 非参数检验 学院: 参赛队员: 参赛队员: 参赛队员: 指导老师:
目录 一、实验目的 (1) 1.了解假设检验的基本内容; (1) 2.了解卡方检验; (1) 3.了解二项分布检验; (1) 4.了解两个独立样本检验; (1) 5.学会运用spss软件求解问题; (1) 6.加深理论与实践相结合的能力。 (1) 二、实验环境 (1) 三、实验方法 (1) 1.卡方检验; (1) 2.二项分布检验; (1) 3.两个独立样本检验。 (1) 四、实验过程 (1) 问题一: (1) 1.1实验步骤 (2) 1.1.1输入数据 (2) 1.1.2选择:数据 加权个案 (2) 1.1.3选择:分析→非参数检验→旧对话框→卡方 (2) 1.1.4将变量面值放入检验变量列表 (3) 1.1.5观察结果 (3) 1.2输出结果 (3) 1.3结果分析 (3) 问题二: (3) 2.1问题叙述 (3) 2.2提出假设 (4) 2.3实验步骤 (4) 2.3.1导入excel文件数据 (4) 2.3.2二项分布检验 (5) 2.3.3输出结果 (6) 2.4结果分析 (6) 问题三: (6) 3.1实验步骤 (6) 3.1.1数据的输入 (6) 3.1.2选择 (7) 3.1.3检验变量 (7) 3.2输出结果 (7) 3.3结果分析 (9) 五、实验总结 (9)
参数检验 一、实验目的 1.了解假设检验的基本内容; 2.了解卡方检验; 3.了解二项分布检验; 4.了解两个独立样本检验; 5.学会运用spss软件求解问题; 6.加深理论与实践相结合的能力。 二、实验环境 Spss、office 三、实验方法 1.卡方检验; 2.二项分布检验; 3.两个独立样本检验。 四、实验过程 问题一:
S P S S的参数检验和非 参数检验 公司内部档案编码:[OPPTR-OPPT28-OPPTL98-OPPNN08]
实验报告 SPSS的参数检验和非参数检验 学期:_2013__至2013_ 第_1_学期 课程名称:_数学建模专业:数学 实验项目__SPSS的参数检验和非参数检验实验成绩:_____ 一、实验目的及要求 熟练掌握t检验及其结果分析。熟练掌握单样本、两独立样本、多独立样本的非参数检验及各种方法的适用范围,能对结果给出准确分析。 二、实验内容 使用指定的数据按实验教材完成相关的操作。 1、给幼鼠喂以不同的饲料,用以下两种方法设计实验: 方式1:同一鼠喂不同的饲料所测得的体内钙留存量数据如下: 方式2:甲组有12只喂饲料1,乙组有9只喂饲料2,所测得的钙留存量数据如下:
请选用恰当方法对上述两种方式所获得的数据进行分析,研究不同饲料是否使幼鼠体内钙的留存量有显着不同。 2、为分析大众对牛奶品牌是否具有偏好,随机挑选超市收集其周一至 周六各天三种品牌牛奶的日销售额数据,如下表所示: 请选用恰当的非参数检验方法,以恰当形式组织上述数据进行分析,并说明分析结论。 实验报告附页 三、实验步骤 (一) 方式1: 1、打开SPSS软件,根据所给表格录入数据,建立数据文件; 2、选择菜单Analyze-Compare means-Paired-Samples T Test,出现窗口; 3、把检验变量饲料1,饲料2 选择到Paired Variables框,单击OK。方式2: 1、打开SPSS软件,根据所给表格录入数据,建立数据文件; 2、选择菜单Analyze-Compare means-Independent-Samples T Test,出现窗口 3、选择检验变量饲料到Test Variable(s)框中。 4、选择总体标志变量组号到Grouping Variables框中。 5、单击Define Groups按钮定义两总体的标志值1、2,单击OK。
第六章参数估计和假设检验 教学目的及要求:了解参数的点估计、区间估计的含义,掌握区间估计的几个概念,包括置信水平、置信区间、小概率事件,熟练掌握参数区间估计的计算方法,了解不同抽样组织形式下的参数估计,掌握参数估计中样本量的确定。了解假设检验的原假设和备择假设的含义,假设检验的两类错误,掌握总体均值的检验方法。 本章重点与难点:区间估计的计算与总体均值的假设检验方法。 计划课时:授课6课时;技能训练2课时。 授课特点:案例教学 第一节点估计和区间估计 一、总体参数估计概述 ?1、总体参数估计定义 ?就是以样本统计量来估计总体参数,总体参数是常数,而统计量是随机变量。 ?2、参数估计应满足的两个条件 二、参数的点估计 ?用样本的估计量直接作为总体参数的估计值 例如:用样本均值直接作为总体均值的估计 例如:根据一个抽出的随机样本计算的平均分数为80分,我们就用80分作为全班考试成绩的平均分数的一个估计值,这就是点估计。 再例如,要估计一批产品的合格率,根据抽样结果合格率为96%,将96%直接作为这批产品合格率的估计值,这也是点估计 三、参数的区间估计 (一)参数的区间估计的含义 ?区间估计:计算抽样平均误差,指出估计的可信程度,进而在点估计的基础上,确定总体参数的所在范围或区间。
(二)有关区间估计的几个概念 置信水平 1. 将构造置信区间的步骤重复很多次,置信区间包含总体参数真值的次数所占的比例称为置信水平 2. 表示为 (1 - α% ) α 为是总体参数未在区间内的比例 3. 常用的置信水平值有 99%, 95%, 90% 相应的显著性水平α 为0.01,0.05,0.10 置信区间 1. 由样本统计量所构造的总体参数的估计区间称为置信区间 2. 统计学家在某种程度上确信这个区间会包含真正的总体参数,所以给它取名为置信区间 3. 用一个具体的样本所构造的区间是一个特定的区间,我们无法知道这个样本所产生的区间是否包含总体参数的真值 我们只能是希望这个区间是大量包含总体参数真值的区间中的一个,但它也可能是少数几个不包含参数真值的区间中的一个 4. 由样本均值的抽样分布可知,在重复抽样或无限总体抽样的情况下,样本均值的数学期望等于总体均值, 5. 样本均值的标准差为 由此可知样本均值落在总体均值μ的两侧各为一个抽样标准差范围内的概率为0。6873 落在总体均值两个抽样标准差范围内的概率为0。9545 落在总体均值三个抽样标准差范围内的概率为0。9973 影响区间宽度的因素 1.总体数据的离散程度,用 σ 来测度 2.样本均值标准差 3.置信水平 (1 - α),影响 z 的大小 评价估计量的标准 x n x σ σ=
大理大学实验报告 课程名称生物医学统计分析 实验名称非参数检验(卡方检验) 专业班级 姓名 学号 实验日期 实验地点 2015—2016学年度第 2 学期
Fisher 的精确检验:精确概率法计算的卡方值(用于理论数E<5)。 不同的资料应选用不同的卡方计算方法。 例为2*2列联表,df=1,须用连续性校正公式,故采用“连续校正”行的统计结果。 X2=,P(Sig)=<,表明灭螨剂A组的杀螨率极显着高于灭螨剂B组。 例 表3 治疗方法* 治疗效果交叉制表 计数 治疗效果 123 合计 治疗方法11916540 21612836 31513735合计504120111 分析:表3是治疗方法* 治疗效果资料分析的列联表。 表4 卡方检验 X2值df渐进 Sig. (双侧) Pearson 卡方 1.428a4.839
似然比4.830线性和线性组合.5141.474 有效案例中的 N111 a. 0 单元格(.0%) 的期望计数少于 5。最小期望计数为。 分析:表4是卡方检验的结果。自由度df=4,表格下方的注解表明理论次数小于5的格子数为0,最小的理论次数为。各理论次数均大于5,无须进行连续性校正,因此可以采用第一行(Pearson 卡方)的检验结果,即 X2=,P=>,差异不显着,可以认为不同的治疗方法与治疗效果无关,即三种治疗方法对治疗效果的影响差异不显着。 例 表5 灌溉方式* 稻叶情况交叉制表 计数 稻叶情况 123 合计 灌溉方式114677160 2183913205 31521416182合计4813036547 分析:表5是灌溉方式* 稻叶情况资料分析的列联表。
实验五 假设检验 一、实验目的与实验要求 掌握平均数的比较与检验,包括单样本、独立样本、配对样本 二、实验内容详细介绍 t 检验是用小样本检验总体参数,特点是在均方差不知道的情况下,可以检验样本平均 数的显著性。 1.单样本的均值检验 1)基本数学原理 对单个正态总体并且方差未知的情况,用下面的统计量来检验其平均数的显著性(假设样本均值与总体均值相等,即0μμ=) x T = 当原假设成立时,上面的统计量应该服从自由度为1n -的t 分布。 简单的说,单样本均值检验是检验单个样本的均值是否与给定的常数之间存在差异。这个给定的常数就是总体均值。 单一样本的T 检验: 零假设H 0:样本平均数Mean=常数(检验值) 2)SPSS 实现 方法:“Analyze ”|“Compare Means ”|“One-Sample T Test ”
图1 (1 )Test列表框:将其中对应变量名对应的变量数据进行均值检验 (2)Test Value文本框:在该文本框中输入总体均值。默认值为0。 (3)Options按钮:利用单击该按钮打开的对话框,设置检验时采用的置信度和缺失值的处理。打开的对话框如图3所示 图3 该样本的均值与总体均值之间没有显著差别。(设α=0.05) 要求: 1.输入数据到SPSS中,并保存为Bend.sav文件;(提示:只需要建一个变量) 2.对上述数据进行均值检验,给出输出结果并对输出结果进行分析 提示:(结果中比较有用的值:样本平均数Mean和Sig显著性概率值) 输出结果中各变量中文解释如下: N:数据个数 对其中变量名对应的变量数 据进行均值检验 输入总体 均值
管理统计实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p 值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。 三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。 (1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为 0.000<0.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击Analyze correlate partial,系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.000<0.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.8665<0.921,说明它们之间的显著性关系稍有减弱。
实验报告 课程名称:数理统计实践 项目名称:参数假设检验 姓名:龚成 班级:科121 学号:121617 指导教师:徐红敏 数理系信息与计算科学专业
北京石油化工学院数理系 参数假设检验-实验报告 假设检验 1、 实验目的与要求 1.1实验目的 (1)掌握Matlab 中有关假设检验的操作命令; (2)掌握利用Matlab 软件对单个正态总体均值,方差置信区间的假设检验 (3)掌握利用Matlab 软件对两个正态总体均值差,方差比置信区间的假设检验 1.2实验要求 通过实验加深对假设检验的基本概念的和基本思想的理解,提升对matlab 软件的熟练度和对常用程序的使用。 2、 相关背景知识介绍 假设检验指的是在用数理统计方法检验产品的时候,先作出假设,在根据抽样的结果在一定可靠程度对原假设做出判断的一种方法。在总体的分布函数未知或者只知形式不知参数的情况下,为了推出总体的的未知特征,提出的关于总体的假设,而对于这个假设的结果我们是否接受的决断过程,就叫做假设检验。 一般地,我们会给出2个相互对立的假设01H H ,,然后通过具体的问题获取的信息选择一个合适的检测量,在按照假设决定该检测量的拒绝区域,如果该检测量落在拒绝区域里面,则选择拒绝0H 选择1H ,如果该检测量落在拒绝区域外面,则选择0H 拒绝1H 。然而由于作出决策的样本不能完全代表总体,如果小概率事件发生或者样本混入了错误值或者由于其他原因导致样本失真,当实际上0H 为真时仍然有可能作出拒绝0H 的决策或实际上0H 为假时仍然有可能作出接受0H 的决策(除非样本就等于总体,否则无法消除这个可能),犯这种错误的概率记为00000H 0P H H P H P H μμ∈(当为真,拒绝)或(拒绝)或(拒绝)。在大多数情况下,我们无法排除这类错误(P 0P 1≈ ,0),但是可以通过增加样本容量使之接近总体让错误被“稀释”。一般地我们为了减少0H 为真时作出拒绝0H 的决策的概率,我们因此我们给出一个较小的数