ZLIB示例教程
- 格式:wps
- 大小:164.00 KB
- 文档页数:16

linux服务器安装PHP扩展zip,zlib⽅法⾸先Linux服务器已安装好PHP以我使⽤的5.4.45为例,我将下载的压缩包放到/root/Downloads/⽬录下解压压缩包:tar -xzvf php-5.4.45.tar.gz安装PHP(忽略 )现在以安装zip扩展为例>> cd /root/Downloads/php-5.4.45/ext/zip>>find / -name phpize>>/usr/local/php/bin/phpize #⽣成⼀些版本配置⽂件>> ./configure --with-php-config=/usr/local/php/bin/php-config>> make && make install最后⼀步安装成功之后会告诉你编译后的地址:Build complete.Don't forget to run 'make test'.Installing shared extensions: /usr/local/php/lib/php/extensions/no-debug-non-zts-20100525/修改php.ini>>find / -name php.ini#查看配置⽂件位置>>vi php.ini #修改php.ini增加 extension=/usr/local/php/lib/php/extensions/no-debug-non-zts-20100525/zip.so>>:wq #保存退出重启服务器>>service nginx restart>>service php-fpm restart去查看phpinfo()吧以上这篇linux服务器安装PHP扩展zip,zlib⽅法就是⼩编分享给⼤家的全部内容了,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。

zlib inflate 用法zlib inflate 是一个用于解压缩数据的库函数,它可以将经过zlib 压缩的数据解压成原始数据。
下面是zlib inflate 的使用步骤:1. 创建一个`z_stream` 结构体(定义在`zlib.h` 中),该结构体包含了用于解压缩数据的相关参数和状态信息。
cz_stream strm;2. 初始化`z_stream` 结构体的参数。
设置`zalloc`、`zfree` 和`opaque` 字段为`NULL`,并调用`inflateInit` 函数初始化`z_stream` 结构体。
cstrm.zalloc = Z_NULL;strm.zfree = Z_NULL;strm.opaque = Z_NULL;int ret = inflateInit(&strm);3. 使用`inflate` 函数解压缩数据。
`inflate` 函数接受一个指向输入数据的指针(`next_in`),输入数据的大小(`avail_in`),一个指向用于存储解压缩后数据的缓冲区的指针(`next_out`)以及缓冲区的大小(`avail_out`)。
调用`inflate` 函数后,会将解压缩后的数据存储在`next_out` 指向的缓冲区中,并更新`next_in` 和`next_out` 的值。
cstrm.avail_in = compressed_data_size;strm.next_in = compressed_data;strm.avail_out = uncompressed_buffer_size;strm.next_out = uncompressed_buffer;ret = inflate(&strm, Z_NO_FLUSH);4. 不断重复步骤3,直到所有压缩数据都被解压缩完。
`inflate` 函数返回值可用于判断解压缩过程是否成功。
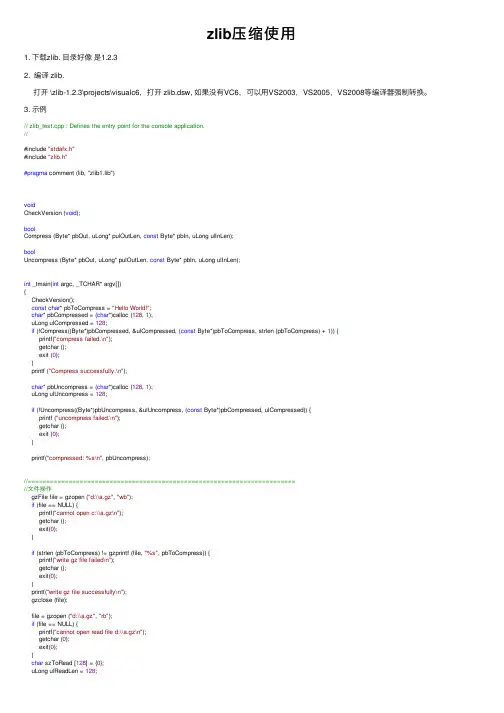
zlib压缩使⽤1. 下载zlib. ⽬录好像是1.2.32. 编译 zlib.打开 \zlib-1.2.3\projects\visualc6,打开 zlib.dsw, 如果没有VC6,可以⽤VS2003,VS2005,VS2008等编译器强制转换。
3. ⽰例// zlib_test.cpp : Defines the entry point for the console application.//#include "stdafx.h"#include "zlib.h"#pragma comment (lib, "zlib1.lib")voidCheckVersion (void);boolCompress (Byte* pbOut, uLong* pulOutLen, const Byte* pbIn, uLong ulInLen);boolUncompress (Byte* pbOut, uLong* pulOutLen, const Byte* pbIn, uLong ulInLen);int _tmain(int argc, _TCHAR* argv[]){CheckVersion();const char* pbToCompress = "Hello World!";char* pbCompressed = (char*)calloc (128, 1);uLong ulCompressed = 128;if (!Compress((Byte*)pbCompressed, &ulCompressed, (const Byte*)pbToCompress, strlen (pbToCompress) + 1)) {printf("compress failed.\n");getchar ();exit (0);}printf ("Compress successfully.\n");char* pbUncompress = (char*)calloc (128, 1);uLong ulUncompress = 128;if (!Uncompress((Byte*)pbUncompress, &ulUncompress, (const Byte*)pbCompressed, ulCompressed)) {printf ("uncompress failed.\n");getchar ();exit (0);}printf("compressed: %s\n", pbUncompress);//========================================================================//⽂件操作gzFile file = gzopen ("d:\\a.gz", "wb");if (file == NULL) {printf("cannot open c:\\a.gz\n");getchar ();exit(0);}if (strlen (pbToCompress) != gzprintf (file, "%s", pbToCompress)) {printf("write gz file failed\n");getchar ();exit(0);}printf("write gz file successfully\n");gzclose (file);file = gzopen ("d:\\a.gz", "rb");if (file == NULL) {printf("cannot open read file d:\\a.gz\n");getchar (0);exit(0);}char szToRead [128] = {0};uLong ulReadLen = 128;if (strlen (pbToCompress) != gzread (file, szToRead, ulReadLen)) {printf("read failed.\n");}printf("read successfully\n");printf("gz file:%s", szToRead);gzclose (file);getchar ();return0;}voidCheckVersion (void){const char* myVersion = ZLIB_VERSION;if (zlibVersion()[0] != myVersion[0]) {fprintf(stderr, "incompatible zlib version\n");getchar ();exit(1);} else if (strcmp(zlibVersion(), ZLIB_VERSION) != 0) {fprintf(stderr, "warning: different zlib version\n");}}boolCompress (Byte* pbOut, uLong* pulOutLen, const Byte* pbIn, uLong ulInLen) {int error = compress(pbOut, pulOutLen, (const Bytef*)pbIn, ulInLen);return (Z_OK == error);}boolUncompress (Byte* pbOut, uLong* pulOutLen, const Byte* pbIn, uLong ulInLen) {int error = uncompress (pbOut, pulOutLen, (const Bytef*)pbIn, ulInLen); return (Z_OK == error);}。

zlib⽤法说明1. 如何获得zlib2. ⽤VC++6.0打开把下载的源代码解压打开,VC6.0的⼯程已经建好了,在\projects\visualc6. 双击zlib.dsw, 可以在VC++6.0中看到⾥⾯有3个⼯程: zlib 是库⽂件(编译设置选中 win32 lib debug / release), ⼯程example 是如何使⽤ zlib.lib 的⽰例, ⼯程minigzip是如何⽤ zlib 提供的函数读写.gz⽂件的⽰例(*.gz的⽂件⼀般Linux下⽐较常⽤).3. 如何加⼊到我的⼯程编译好 zlib.lib 后, 你就得到了调⽤⼀个静态库所需要的所有⽂件了(zlib.lib, zlib.h, zconf.h). 如何调⽤静态库不⽤我说了吧.4. ⽤zlib能⼲什么先来看看 zlib 都提供了那些函数, 都在zlib.h中,看到⼀堆宏不要晕,其实都是为了兼容各种编译器和⼀些类型定义.死死抓住那些主要的函数的原型声明就不会受到这些东西的影响了.关键的函数有那么⼏个:(1)int compress (Bytef *dest, uLongf *destLen, const Bytef *source, uLong sourceLen);把源缓冲压缩成⽬的缓冲, 就那么简单, ⼀个函数搞定(2) int compress2 (Bytef *dest, uLongf *destLen,const Bytef *source, uLong sourceLen,int level);功能和上⼀个函数⼀样,都⼀个参数可以指定压缩质量和压缩数度之间的关系(0-9)不敢肯定这个参数的话不⽤太在意它,明⽩⼀个道理就好了:要想得到⾼的压缩⽐就要多花时间(3) uLong compressBound (uLong sourceLen);计算需要的缓冲区长度. 假设你在压缩之前就想知道你的产度为sourcelen 的数据压缩后有多⼤, 可调⽤这个函数计算⼀下,这个函数并不能得到精确的结果,但是它可以保证实际输出长度肯定⼩于它计算出来的长度(4) int uncompress (Bytef *dest, uLongf *destLen,const Bytef *source, uLong sourceLen);解压缩(看名字就知道了:)(5) deflateInit() + deflate() + deflateEnd()3个函数结合使⽤完成压缩功能,具体⽤法看 example.c 的test_deflate()函数. 其实 compress() 函数内部就是⽤这3个函数实现的(⼯程 zlib 的 compress.c ⽂件)(6) inflateInit() + inflate() + inflateEnd()和(5)类似,完成解压缩功能.(7) gz开头的函数. ⽤来操作*.gz的⽂件,和⽂件stdio调⽤⽅式类似.想知道怎么⽤的话看example.c 的 test_gzio() 函数,很easy.(8) 其他诸如获得版本等函数就不说了.总结: 其实只要有了compress() 和uncompress() 两个函数,在⼤多数应⽤中就⾜够了.题外话: 我最初看到zlib的源代码时被好多宏吓倒了,呵呵,后来仔细看下去才发现原来接⼝那么简单. ⾄于那些英⽂说明也没想象中的那么难懂.只要有尝试的勇⽓,总能有些收获.#include <iostream>#include <stdlib.h>#include "zlib.h"using namespace std;#define MaxBufferSize 1024*10void main(){int i;FILE* File_src;FILE* File_tmp;FILE* File_dest;unsigned long len_src;unsigned long len_tmp;unsigned long len_dest;unsigned char *buffer_src = new unsignedchar[MaxBufferSize];unsigned char *buffer_tmp = new unsignedchar[MaxBufferSize];unsigned char *buffer_dest = new unsignedchar[MaxBufferSize];File_src = fopen("src.txt","r");len_src = fread(buffer_src,sizeof(char),MaxBufferSize-1,File_src);for(i = 0 ; i < len_src ; ++i){cout<<buffer_src[i];}cout<<endl;compress(buffer_tmp,&len_tmp,buffer_src,len_src);File_tmp = fopen("tmp.txt","w");fwrite(buffer_tmp,sizeof(char),len_tmp,File_tmp);for(i = 0 ; i < len_tmp ; ++i){cout<<buffer_tmp[i];}cout<<endl;uncompress(buffer_dest,&len_dest,buffer_tmp,len_tmp);File_tmp = fopen("tmp.txt","r");File_dest = fopen("dest.txt","w");fwrite(buffer_dest,sizeof(char),len_dest,File_dest);for(i = 0 ; i < len_dest ; ++i){cout<<buffer_dest[i];}cout<<endl;}Write to file :char * pchData = "xxx..." ;gzFile fData = gzopen(pchFile,"wb");gzwrite(fData,pchData,strlen(pchData));gzclose(fData);read from file :char pchData[1024];gzFile fData = gzopen(pchFile,"rb");int n = gzread(fData,pchData,1024);gzclose(fData);---------------------------------------------------------------------------------------------------------------- HANDLE hFile, hFileToWrite;CString strFilePath;m_ctrEdit.GetWindowText(strFilePath);//打开要进⾏压缩的⽂件hFile = CreateFile(strFilePath, // file nameGENERIC_READ, // open for readingFILE_SHARE_READ, // share for readingNULL, // no securityOPEN_EXISTING, // existing file onlyFILE_ATTRIBUTE_NORMAL, // normal fileNULL); // no attr. templateif (hFile == INVALID_HANDLE_VALUE){AfxMessageBox("Could not open file to read"); // process errorreturn;}HANDLE hMapFile, hMapFileToWrite;//创建⼀个⽂件映射hMapFile = CreateFileMapping(hFile, // Current file handle.NULL, // Default security.PAGE_READONLY, // Read/write permission.0, // Max. object size.0, // Size of hFile."ZipTestMappingObjectForRead"); // Name of mapping object.if (hMapFile == NULL){AfxMessageBox("Could not create file mapping object");return;}LPVOID lpMapAddress, lpMapAddressToWrite;//创建⼀个⽂件映射的视图⽤来作为sourcelpMapAddress = MapViewOfFile(hMapFile, // Handle to mapping object.FILE_MAP_READ, // Read/write permission0, // Max. object size.0, // Size of hFile.0); // Map entire file.if (lpMapAddress == NULL){AfxMessageBox("Could not map view of file");return;}//////////////////////////////////////////////////////////////////////////////////DWORD dwFileLength,dwFileLengthToWrite;dwFileLength = GetFileSize(hFile, NULL);m_dwSourceFileLength = dwFileLength;//因为压缩函数的输出缓冲必须⽐输⼊⼤0.1% + 12 然后⼀个DWORD⽤来保存压缩前的⼤⼩, // 解压缩的时候⽤,当然还可以保存更多的信息,这⾥⽤不到dwFileLengthToWrite = (double)dwFileLength*1.001 + 12 + sizeof(DWORD);//以下是创建⼀个⽂件,⽤来保存压缩后的⽂件hFileToWrite = CreateFile("demoFile.rar", // demoFile.rarGENERIC_WRITE|GENERIC_READ, // open for writing0, // do not shareNULL, // no securityCREATE_ALWAYS, // overwrite existingFILE_ATTRIBUTE_NORMAL , // normal fileNULL); // no attr. templateif (hFileToWrite == INVALID_HANDLE_VALUE){AfxMessageBox("Could not open file to write"); // process errorreturn;}hMapFileToWrite = CreateFileMapping(hFileToWrite, // Current file handle.NULL, // Default security.PAGE_READWRITE, // Read/write permission.0, // Max. object size.dwFileLengthToWrite, // Size of hFile."ZipTestMappingObjectForWrite"); // Name of mapping object.if (hMapFileToWrite == NULL){AfxMessageBox("Could not create file mapping object for write");return;}lpMapAddressToWrite = MapViewOfFile(hMapFileToWrite, // Handle to mapping object.FILE_MAP_WRITE, // Read/write permission0, // Max. object size.0, // Size of hFile.0); // Map entire file.if (lpMapAddressToWrite == NULL){AfxMessageBox("Could not map view of file");return;}//这⾥是将压缩前的⼤⼩保存在⽂件的第⼀个DWORD⾥⾯LPVOID pBuf = lpMapAddressToWrite;(*(DWORD*)pBuf) = dwFileLength;pBuf = (DWORD*)pBuf + 1;////////////////////////////////////////////////////////////////////////这⾥就是最重要的,zlib⾥⾯提供的⼀个⽅法,将源缓存的数据压缩⾄⽬的缓存//原形如下://int compress (Bytef *dest, uLongf *destLen, const Bytef *source, uLong sourceLen);//参数destLen返回实际压缩后的⽂件⼤⼩。

【神经⽹络与深度学习】ZLIB介绍zlib类库提供了很多种压缩和解压缩的⽅式,由于时间的关系我只学习⼀下内容,以下是我在实现web 服务器压缩数据⽹页中使⽤到⼀些函数和常⽤数据结构、常量等。
zlib使⽤过程压缩过程:deflateInit() ->deflate() ->deflateEnd(); 对应的解压过程 inflateInit() -> inflate() -> inflateEnd();压缩过程:deflateInit2() ->deflate() ->deflateEnd(); 对应的解压过程 inflateInit2() -> inflate() -> inflateEnd();zlib使⽤的实例请看:注释内容详细(英⽂)(来⾃百度百科,本⼈未加正式,请谅解)常⽤的数据结构typedef struct z_stream_s {z_const Bytef *next_in; //要压缩数据的⾸地址uInt avail_in; //压缩数据的长度uLong total_in; //压缩数据缓冲区的长度Bytef *next_out; //压缩数据保存位置。
uInt avail_out; //存放压缩数据位置的⾸地址uLong total_out; //存放压缩数据位置的⼤⼩z_const char *msg; //存放最近的错误信息,NULL表⽰没有错误struct internal_state FAR *state; /* not visible by applications */alloc_func zalloc; /* used to allocate the internal state */free_func zfree; /* used to free the internal state */voidpf opaque; /* private data object passed to zalloc and zfree */int data_type; // 表⽰数据类型,⽂本或者⼆进制uLong adler; /* adler32 value of the uncompressed data */uLong reserved; /* reserved for future use */} z_stream;对于z_stream我们⼀般使⽤z_stream stream;在deflateInit()或者inflateInit()前设置的参数,初始化参数设置stream.zalloc = Z_NULL;stream.zfree = Z_NULL;stream.opaque = Z_NULL;stream.avail_in = 0;stream.next_in = Z_NULL;在deflate()或inflate前设置的参数,压缩前的参数设置strm.avail_in = in_len;strm.next_in = in;strm.avail_out = out_len;strm.next_out = out;常⽤的常量⽤来设置压缩和解压缩时,结果数据输出的⽅式,具体区别没有看懂的(为了避免误导⼤家,⼤家尽量看/manual.html英⽂帮助吧)#define Z_NO_FLUSH 0 //没有缓存,直接写⼊到结果中#define Z_PARTIAL_FLUSH 1#define Z_SYNC_FLUSH 2#define Z_FULL_FLUSH 3#define Z_FINISH 4 //采⽤此种⽅式,压缩将会变成单步执⾏。

数组压缩传输 c语言数组压缩传输是一种常见的数据压缩技术,用于减小数据传输和存储的大小。
在 C 语言中,可以使用 zlib 和 gzip 等库来进行数组压缩传输。
其中,zlib 库提供了压缩和解压缩两个功能,而 gzip 库只提供了压缩功能。
下面是一个使用 zlib 库进行数组压缩传输的示例代码:```c#include <stdio.h>#include <stdlib.h>#include <string.h>#include <zlib.h>#define CHUNK_SIZE 1024int main() {// 原始数据char data[] = "Hello, world!";int data_len = strlen(data);// 压缩后的数据char compressed_data[CHUNK_SIZE];int compressed_len;// 初始化压缩器z_stream c_stream;memset(&c_stream, 0, sizeof(c_stream));deflateInit(&c_stream, Z_DEFAULT_COMPRESSION);// 开始压缩c_stream.next_in = (Bytef *) data;c_stream.avail_in = data_len;do {c_stream.next_out = (Bytef *) compressed_data;c_stream.avail_out = CHUNK_SIZE;deflate(&c_stream, Z_FINISH);compressed_len = CHUNK_SIZE - c_stream.avail_out;// 在这里将压缩后的数据发送给接收端// ...} while (c_stream.avail_out == 0);// 结束压缩deflateEnd(&c_stream);return 0;}```在这个示例代码中,我们首先定义了一个原始数据,然后定义了一个用于存储压缩后的数据的字符数组(大小为 1024)。

python⽤模块zlib压缩与解压字符串和⽂件的⽅法python中zlib模块是⽤来压缩或者解压缩数据,以便保存和传输。
它是其他压缩⼯具的基础。
下⾯来⼀起看看python⽤模块zlib压缩与解压字符串和⽂件的⽅法。
话不多说,直接来看⽰例代码。
例⼦1:压缩与解压字符串import zlibmessage = 'abcd1234'compressed = press(message)decompressed = zlib.decompress(compressed)print 'original:', repr(message)print 'compressed:', repr(compressed)print 'decompressed:', repr(decompressed)结果original: 'abcd1234'compressed: 'x 9cKLJN1426 01 00 0b f8 02U'decompressed: 'abcd1234'例⼦2:压缩与解压⽂件import zlibdef compress(infile, dst, level=9):infile = open(infile, 'rb')dst = open(dst, 'wb')compress = pressobj(level)data = infile.read(1024)while data:dst.write(press(data))data = infile.read(1024)dst.write(compress.flush())def decompress(infile, dst):infile = open(infile, 'rb')dst = open(dst, 'wb')decompress = zlib.decompressobj()data = infile.read(1024)while data:dst.write(decompress.decompress(data))data = infile.read(1024)dst.write(decompress.flush())if __name__ == "__main__":compress('in.txt', 'out.txt')decompress('out.txt', 'out_decompress.txt')结果⽣成⽂件out_decompress.txt out.txt问题——处理对象过⼤异常>>> import zlib>>> a = '123'>>> b = press(a)>>> b'x 9c342 06 00 01- 00 97'>>> a = 'a' * 1024 * 1024 * 1024 * 10>>> b = press(a)Traceback (most recent call last):File "<stdin>", line 1, in <module>OverflowError: size does not fit in an int总结以上就是关于python模块zlib压缩与解压的全部内容,希望本⽂的内容对⼤家学习或者使⽤python能有⼀定的帮助,如果有疑问⼤家可以留⾔交流,谢谢⼤家对的⽀持。

cocos creator zlib 用法-回复在Cocos Creator游戏开发引擎中,zlib是一种用于数据压缩和解压缩的开源库。
它提供了一系列的函数和工具,可以将数据压缩成小尺寸的字节流,或将被压缩的数据还原为原始数据。
在本篇文章中,我将以主题“Cocos Creator zlib用法”为基础,一步一步地回答您关于zlib的问题,帮助您更好地理解和使用此功能。
第一步,安装zlib库要使用zlib库,首先需要将其安装在Cocos Creator项目中。
以下是在Cocos Creator中安装zlib的步骤:1. 打开Cocos Creator项目。
2. 在项目目录下,找到`./frameworks/runtime-src/Classes`文件夹。
3. 在`Classes`文件夹中,创建一个新的文件夹,命名为`zlib`。
4. 找到zlib库的源代码,可以通过官方网站(5. 将下载的zlib源代码解压缩,并将其中的`zlib.h`和`zlib.c`文件复制到`./frameworks/runtime-src/Classes/zlib`文件夹中。
完成上述步骤后,zlib库就已经成功安装在Cocos Creator项目中了。
第二步,导入zlib库已经安装了zlib库后,接下来需要在Cocos Creator项目中导入并使用它。
以下是导入zlib库的步骤:1. 打开Cocos Creator项目。
2. 在项目资源管理器中找到需要使用zlib库的脚本文件。
3. 在脚本文件中的顶部,添加以下代码:const zlib = require('./zlib/zlib.js');这样就完成了zlib库的导入。
第三步,使用zlib进行数据压缩在Cocos Creator中,可以使用zlib库提供的函数来对数据进行压缩。
以下是一个使用zlib进行数据压缩的示例代码:javascript压缩数据const dataToCompress = "This is the data to be compressed."; const compressedData = zlib.deflateSync(dataToCompress, { level: zlib.constants.Z_BEST_COMPRESSION });打印压缩后的数据console.log("压缩后的数据: ", compressedData.toString("base64"));在上述示例代码中,我们使用了`zlib.deflateSync(dataToCompress, { level: zlib.constants.Z_BEST_COMPRESSION })`函数对`dataToCompress`进行了压缩,并将压缩后的数据存储在`compressedData`变量中。

node.js使⽤zlib模块进⾏数据压缩和解压操作⽰例本⽂实例讲述了node.js使⽤zlib模块进⾏数据压缩和解压操作。
分享给⼤家供⼤家参考,具体如下:我们可以使⽤ zlib 模块来对数据进⾏压缩和解压处理,减⼩数据体积,加快传输速度。
⼀、通过创建转换流,对⽂件进⾏压缩和解压const fs = require('fs');const zlib = require('zlib');const path = require('path');function gzip($src) {fs.stat($src, function (err, stats) {if (stats.isFile()) {let rs = fs.createReadStream($src);//zlib.createGzip()创建⼀个gzip转换流,是⼀个可读可写流。
//通过管道将数据读取出来写⼊gzip流,然后⼜通过管道写⼊⼀个⽂件流中$dst = path.join(__dirname, path.basename($src) + '.gz');rs.pipe(zlib.createGzip()).pipe(fs.createWriteStream($dst));}});}function ungzip($src) {fs.stat($src, function (err, stats) {if (stats.isFile()) {let rs = fs.createReadStream($src);//zlib.createGunzip()创建⼀个gunzip转换流$dst = path.join(__dirname, path.basename($src, '.gz'));rs.pipe(zlib.createGunzip()).pipe(fs.createWriteStream($dst));}});}//压缩⽂件gzip('./1.txt');//解压⽂件ungzip('./1.txt.gz');zlib.createDeflate() 和 zlib.createInflate() 的使⽤⽅法与上⾯类似,这⾥就不作演⽰了。

zlib库压缩和解压字符串STLstring的实例详解zlib库压缩和解压字符串STL string的实例详解场景1.⼀般在使⽤⽂本json传输数据, 数据量特别⼤时,传输的过程就特别耗时, 因为带宽或者socket的缓存是有限制的, 数据量越⼤,传输时间就越长. ⽹站⼀般使⽤gzip来压缩成⼆进制.说明1.zlib库可以实现gzip和zip⽅式的压缩, 这⾥只介绍zip⽅式的⼆进制压缩, 压缩⽐还是⽐较可观的, ⼀般写客户端程序已⾜够.2.修改了⼀下zpipe.c的实现, 其实就是把读⽂件改为读字符串, 写⽂件改为写字符串即可.例⼦// test_zlib.cpp : 定义控制台应⽤程序的⼊⼝点。
//#include "stdafx.h"#include <string>#include <iostream>#include <memory>#include <assert.h>#include "zlib.h"// E:\software\Lib\compress\zlib-1.2.5\src\examples// zpipe.c#define CHUNK 16384/* Compress from file source to file dest until EOF on source.def() returns Z_OK on success, Z_MEM_ERROR if memory could not beallocated for processing, Z_STREAM_ERROR if an invalid compressionlevel is supplied, Z_VERSION_ERROR if the version of zlib.h and theversion of the library linked do not match, or Z_ERRNO if there isan error reading or writing the files. */int CompressString(const char* in_str,size_t in_len,std::string& out_str, int level){if(!in_str)return Z_DATA_ERROR;int ret, flush;unsigned have;z_stream strm;unsigned char out[CHUNK];/* allocate deflate state */strm.zalloc = Z_NULL;strm.zfree = Z_NULL;strm.opaque = Z_NULL;ret = deflateInit(&strm, level);if (ret != Z_OK)return ret;std::shared_ptr<z_stream> sp_strm(&strm,[](z_stream* strm){(void)deflateEnd(strm);});const char* end = in_str+in_len;size_t pos_index = 0;size_t distance = 0;/* compress until end of file */do {distance = end - in_str;strm.avail_in = (distance>=CHUNK)?CHUNK:distance;strm.next_in = (Bytef*)in_str;// next posin_str+= strm.avail_in;flush = (in_str == end) ? Z_FINISH : Z_NO_FLUSH;/* run deflate() on input until output buffer not full, finishcompression if all of source has been read in */do {strm.avail_out = CHUNK;strm.next_out = out;ret = deflate(&strm, flush); /* no bad return value */if(ret == Z_STREAM_ERROR)break;have = CHUNK - strm.avail_out;out_str.append((const char*)out,have);} while (strm.avail_out == 0);if(strm.avail_in != 0); /* all input will be used */break;/* done when last data in file processed */} while (flush != Z_FINISH);if(ret != Z_STREAM_END) /* stream will be complete */return Z_STREAM_ERROR;/* clean up and return */return Z_OK;}/* Decompress from file source to file dest until stream ends or EOF.inf() returns Z_OK on success, Z_MEM_ERROR if memory could not be allocated for processing, Z_DATA_ERROR if the deflate data isinvalid or incomplete, Z_VERSION_ERROR if the version of zlib.h and the version of the library linked do not match, or Z_ERRNO if thereis an error reading or writing the files. */int DecompressString(const char* in_str,size_t in_len, std::string& out_str) {if(!in_str)return Z_DATA_ERROR;int ret;unsigned have;z_stream strm;unsigned char out[CHUNK];/* allocate inflate state */strm.zalloc = Z_NULL;strm.zfree = Z_NULL;strm.opaque = Z_NULL;strm.avail_in = 0;strm.next_in = Z_NULL;ret = inflateInit(&strm);if (ret != Z_OK)return ret;std::shared_ptr<z_stream> sp_strm(&strm,[](z_stream* strm){(void)inflateEnd(strm);});const char* end = in_str+in_len;size_t pos_index = 0;size_t distance = 0;int flush = 0;/* decompress until deflate stream ends or end of file */do {distance = end - in_str;strm.avail_in = (distance>=CHUNK)?CHUNK:distance;strm.next_in = (Bytef*)in_str;// next posin_str+= strm.avail_in;flush = (in_str == end) ? Z_FINISH : Z_NO_FLUSH;/* run inflate() on input until output buffer not full */do {strm.avail_out = CHUNK;strm.next_out = out;ret = inflate(&strm, Z_NO_FLUSH);if(ret == Z_STREAM_ERROR) /* state not clobbered */break;switch (ret) {case Z_NEED_DICT:ret = Z_DATA_ERROR; /* and fall through */case Z_DATA_ERROR:case Z_MEM_ERROR:return ret;}have = CHUNK - strm.avail_out;out_str.append((const char*)out,have);} while (strm.avail_out == 0);/* done when inflate() says it's done */} while (flush != Z_FINISH);/* clean up and return */return ret == Z_STREAM_END ? Z_OK : Z_DATA_ERROR;}int _tmain(int argc, _TCHAR* argv[]){const char* buf = "01010101010101010101010000000000000000000000000000011111111111111""01010101010101010101010000000000000000000000000000011111111111111""01010101010101010101010000000000000000000000000000011111111111111""01010101010101010101010000000000000000000000000000011111111111111""01010101010101010101010000000000000000000000000000011111111111111""01010101010101010101010000000000000000000000000000011111111111111""01010101010101010101010000000000000000000000000000011111111111111""01010101010101010101010000000000000000000000000000011111111111111""01010101010101010101010000000000000000000000000000011111111111111""01010101010101010101010000000000000000000000000000011111111111111""qwertyuiop[]";std::cout << "========= CompressString ===========" << std::endl;std::cout << "Source Buffer Size: " << strlen(buf) << std::endl;std::string out_compress;assert(CompressString(buf,strlen(buf),out_compress,Z_DEFAULT_COMPRESSION) == Z_OK);std::cout << "Compress Buffer Size: " << out_compress.size() << std::endl;std::cout << "========= DecompressString ===========" << std::endl;std::string out_decompress;assert(DecompressString(out_compress.c_str(),out_compress.size(),out_decompress) == Z_OK);std::cout << "Decompress Buffer Size: " << out_decompress.size() << std::endl;assert(!out_pare(buf));return 0;}输出:========= CompressString ===========Source Buffer Size: 662Compress Buffer Size: 38========= DecompressString ===========Decompress Buffer Size: 662参考如有疑问请留⾔或者到本站社区交流讨论,感谢阅读,希望能帮助到⼤家,谢谢⼤家对本站的⽀持!。

c语⾔使⽤zlib实现⽂本字符的gzip压缩与gzip解压缩⽹络上找到的好多⽅法在解压缩字符串的时候会丢失字符,这⾥是解决⽅法:基于此,笔者修改了⼀下,由于是初学者,只按照编译器不报错的原则修改了⼀下,能运⾏打开vc++6.0新建控制台程序程序,配置好zdll.lib,把zlib1.dll放置到合适的位置主程序main.cpp如下#include <string.h>#include <stdio.h>#include <stdlib.h>#include "zlib.h"int main(){const char *istream = "some foo汉字";uLong srcLen = strlen(istream)+1; // +1 for the trailing `\0`uLong destLen = compressBound(srcLen); // this is how you should estimate size// needed for the bufferunsigned char* ostream = (unsigned char*)malloc(destLen);int res = compress(ostream, &destLen, (const unsigned char *)istream, srcLen);// destLen is now the size of actuall buffer needed for compression// you don't want to uncompress whole buffer later, just the used partif(res == Z_BUF_ERROR){printf("Buffer was too small!\n");return1;}if(res == Z_MEM_ERROR){printf("Not enough memory for compression!\n");return2;}unsigned char *i2stream = ostream;char* o2stream = (char *)malloc(srcLen);uLong destLen2 = destLen; //destLen is the actual size of the compressed bufferint des = uncompress((unsigned char *)o2stream, &srcLen, i2stream, destLen2);printf("%s\n", o2stream);return0;}。
zlib使用实例Zlib是一个广泛使用的数据压缩库,可用于在计算机系统中进行数据压缩和解压缩。
它是开放源代码的,具有高效的压缩算法和快速的解压缩速度,被广泛应用于各种领域。
在使用zlib进行数据压缩和解压缩之前,我们首先需要了解一些基本概念和原理。
Zlib库提供了一系列函数,可以用来压缩和解压缩数据。
其中,最常用的函数是zlib.h头文件中的deflate()和inflate()函数。
deflate()函数用于压缩数据,而inflate()函数用于解压缩数据。
下面我们通过一个实例来演示如何使用zlib进行数据压缩和解压缩。
假设我们有一个文本文件,需要进行压缩和解压缩操作。
我们需要在程序中包含zlib.h头文件,并使用zlib库提供的函数进行初始化。
然后,我们可以打开待压缩的文件,并创建一个输出文件用于存储压缩后的数据。
接下来,我们可以使用zlib库提供的deflate()函数进行数据压缩。
该函数接受一个输入缓冲区和一个输出缓冲区作为参数,将输入数据压缩后存储到输出缓冲区中。
我们可以使用循环来分批次地读取输入数据,并将压缩后的数据写入到输出文件中。
当我们完成数据压缩后,可以关闭输入和输出文件,并释放相关的资源。
此时,我们已经成功地将文本文件进行了压缩。
接下来,我们需要使用zlib库提供的inflate()函数进行数据解压缩。
与数据压缩类似,我们需要打开一个输入文件用于读取压缩数据,并创建一个输出文件用于存储解压后的数据。
然后,我们可以使用zlib库提供的inflate()函数进行数据解压缩。
该函数接受一个输入缓冲区和一个输出缓冲区作为参数,将输入数据解压缩后存储到输出缓冲区中。
同样地,我们可以使用循环来分批次地读取输入数据,并将解压后的数据写入到输出文件中。
当我们完成数据解压缩后,可以关闭输入和输出文件,并释放相关的资源。
此时,我们已经成功地将压缩后的数据解压缩还原成原始的文本文件。
通过上述实例,我们可以看到,使用zlib进行数据压缩和解压缩是一项相对简单的任务。
⽤zlib完成压缩⽂件要把⼏个⽂件合并成⼀个压缩⽂件,⾸先想到的开源库就是zlib1、下载zlib其实使⽤哪个格式都可以,我这⾥选的是zip格式,下载之后解压2、编译zlib库因为我使⽤的windows系统,所以去找vstudio下的内容。
解压之后在.\zlib-1.2.11\contrib\vstudio\下看到对应不同的vc版本。
选择⼀个最新的版本,在vc14中找到zlibvc.sln,双击打开因为我⽤的vs是2017版本,会提⽰这个问题,点取消就可以了zlibvc项⽬下内容如下:其中编译zlibvc就可以⽣成zlib的lib库和dll库,其他project都依赖zlibvc。
minizip是zlib压缩⽂件的⽰例,miniunz是解压⽰例。
图省事直接全部⽣成,但是⽣成失败,报错信息如下:去报错路径找到bld_md64.bat,右键编辑查看内容:ml64.exe /Flinffasx64 /c /Zi inffasx64.asmml64.exe /Flgvmat64 /c /Zi gvmat64.asm在cmd中输⼊ml64.exe,输出'ml64.exe' 不是内部或外部命令,也不是可运⾏的程序或批处理⽂件。
意思是ml64.exe没找到,⽤everything查找⼜确实能找到ml64.exe把bat⽂件中的ml64.exe改成绝对路径"C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin\amd64\ml64.exe" /Flinffasx64 /c /Zi inffasx64.asm "C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin\amd64\ml64.exe" /Flgvmat64 /c /Zi gvmat64.asm 为了保留案发现场把⽂件另存为⼀个新的⽂件,起名为bld_ml64_2.bat回到zlibvc.sln,右键zlibvc,点击属性-⽣成事件-预先⽣成事件,编辑命令⾏:cd ..\..\masmx64bld_ml64_2.bat保存,重新编译,成功3、学习minizip的使⽤过程全部⽣成也可以⽣成minizip,这时候就可以通过debug学习minizip的使⽤过程了。
php启⽤zlib压缩⽂件的配置⽅法
但是不论是iis 还是apache默认都只压缩html类静态⽂件,对于php⽂件需要模块配置才可⽀持(iis7.5中开启动态+静态压缩也可以),于是利⽤php⾃⾝功能到达gzip的效果也成为⼀项合理的诉求。
实现的⽅法很简单,打开php⽬录下的php.ini⽂件,
复制代码代码如下:
zlib.output_compression = Off
;zlib.output_compression_level = -1output_buffering = Off
修改成
复制代码代码如下:
zlib.output_compression =On
zlib.output_compression_level = 5
output_buffering = 4096
需要说明的是以下⼏点
⼀、;zlib.output_handler必须保持注释掉,因为此参数和前⾯的设置冲突——官⽅的说法。
⼆、⼀般情况下缓存是4k(output_buffering = 4096)。
三、zlib.output_compression_level 建议参数值是1~5,6以上实际压缩效果提升不⼤,cpu占⽤却是⼏何增长。
最后通过firebug查看请求头和回应头,实际上gzip效果已经显⽰,或者通过站长gzip检测⼯具也显⽰gzip有效。
centos zlib用法在CentOS系统中,Zlib是一个常用的数据压缩库,可以用于在程序中对数据进行压缩和解压缩。
它提供了简单易用的接口,使得开发者可以轻松地在自己的应用中实现数据压缩功能。
要使用Zlib库,在CentOS系统中,首先需要安装Zlib开发包。
可以通过以下命令来安装:```sudo yum install zlib-devel```安装完成后,就可以在自己的程序中使用Zlib库了。
在程序中使用Zlib库的一种常见方式是使用zlib.h头文件,并通过一些函数来实现数据压缩和解压缩的功能。
这些函数包括:- `deflateInit()`和`inflateInit()`:用于初始化压缩和解压缩上下文。
- `deflate()和inflate()`:用于执行实际的压缩和解压缩操作。
- `deflateEnd()和inflateEnd()`:用于释放压缩和解压缩上下文。
下面是一个简单的示例程序,展示了如何使用Zlib库进行数据压缩和解压缩:```c#include <stdio.h>#include <stdlib.h>#include <string.h>#include <zlib.h>void compress_data(const char* input, int input_size, char** output, int* output_size) {int chunk_size = 1024;int ret;z_stream strm;char* output_buffer = (char*)malloc(chunk_size * sizeof(char));strm.zalloc = Z_NULL;strm.zfree = Z_NULL;strm.opaque = Z_NULL;ret = deflateInit(&strm, Z_DEFAULT_COMPRESSION);if (ret != Z_OK) {fprintf(stderr, "deflateInit failed\n");return;}strm.avail_in = input_size;strm.next_in = (Bytef*)input;strm.avail_out = chunk_size;strm.next_out = (Bytef*)output_buffer;while (1) {ret = deflate(&strm, Z_FINISH);if (ret == Z_STREAM_END) {break;}if (ret != Z_OK) {fprintf(stderr, "deflate failed\n");deflateEnd(&strm);free(output_buffer);return;}if (strm.avail_out == 0) {*output = (char*)realloc(*output, (*output_size + chunk_size) * sizeof(char)); memcpy(*output + *output_size, output_buffer, chunk_size);*output_size += chunk_size;strm.next_out = (Bytef*)output_buffer;strm.avail_out = chunk_size;}}int remaining = chunk_size - strm.avail_out;*output = (char*)realloc(*output, (*output_size + remaining) * sizeof(char));memcpy(*output + *output_size, output_buffer, remaining);*output_size += remaining;deflateEnd(&strm);free(output_buffer);}void decompress_data(const char* input, int input_size, char** output, int* output_size) {int chunk_size = 1024;int ret;z_stream strm;char* output_buffer = (char*)malloc(chunk_size * sizeof(char));strm.zalloc = Z_NULL;strm.zfree = Z_NULL;strm.opaque = Z_NULL;ret = inflateInit(&strm);if (ret != Z_OK) {fprintf(stderr, "inflateInit failed\n");return;}strm.avail_in = input_size;strm.next_in = (Bytef*)input;strm.avail_out = chunk_size;strm.next_out = (Bytef*)output_buffer;while (1) {ret = inflate(&strm, Z_NO_FLUSH);if (ret == Z_STREAM_END) {break;}if (ret != Z_OK) {fprintf(stderr, "inflate failed\n");inflateEnd(&strm);free(output_buffer);return;}if (strm.avail_out == 0) {*output = (char*)realloc(*output, (*output_size + chunk_size) * sizeof(char)); memcpy(*output + *output_size, output_buffer, chunk_size);*output_size += chunk_size;strm.next_out = (Bytef*)output_buffer;strm.avail_out = chunk_size;}}int remaining = chunk_size - strm.avail_out;*output = (char*)realloc(*output, (*output_size + remaining) * sizeof(char));memcpy(*output + *output_size, output_buffer, remaining);*output_size += remaining;inflateEnd(&strm);free(output_buffer);}int main() {const char* input = "This is a test string.";int input_size = strlen(input);char* compressed_data = NULL;int compressed_size = 0;char* decompressed_data = NULL;int decompressed_size = 0;compress_data(input, input_size, &compressed_data, &compressed_size);decompress_data(compressed_data, compressed_size, &decompressed_data, &decompressed_size);printf("Original data: %s\n", input);printf("Compressed data: %s\n", compressed_data);printf("Decompressed data: %s\n", decompressed_data);free(compressed_data);free(decompressed_data);return 0;}```通过这个示例程序,我们可以看到如何使用Zlib库在CentOS系统中进行数据压缩和解压缩。
zlib的简单使⽤1. 下载zlib库 2. ⽰例源代码#include <stdio.h>#include <string.h>#include "zlib.h"#pragma comment(lib, "zlib.lib")int main(int argc, char *argv[]){char buf[1024];char destbuf[1024];char buf2[1024];unsigned long lDestLen = 1024;memset(buf, 0, sizeof(buf));memset(destbuf, 0, sizeof(destbuf));memset(buf2, 0, sizeof(buf2));unsigned long srcLen = 64;for(int i=0; i<srcLen; ++i){buf[i] = i;}buf [32] = 0;int iRet = ::compress((Bytef *)destbuf, &lDestLen, (Bytef *)buf, srcLen);if (Z_OK == iRet){printf("compress ok dest len %d\n", lDestLen);unsigned long lBuf2Len = 1024;iRet = ::uncompress((Bytef *)buf2, &lBuf2Len, (Bytef *)destbuf, lDestLen);if (Z_OK == iRet){printf("uncompress ok dest len %d\n", lBuf2Len);if (lBuf2Len != srcLen){printf("uncompress len Different\n");}else if (memcmp(buf, buf2, lBuf2Len) != 0){printf("uncompress data Different\n");}else{printf("uncompress data same\n");}}else{printf("uncompress error: %d\n", iRet);}}else{printf("compress error: %d\n", iRet);}return 0;}using System.Runtime.InteropServices;namespace Server{public enum ZLibError:int{Z_OK = 0,Z_STREAM_END = 1,Z_NEED_DICT = 2,Z_ERRNO = (-1),Z_STREAM_ERROR = (-2),Z_DATA_ERROR = (-3),Z_MEM_ERROR = (-4),Z_BUF_ERROR = (-5),Z_VERSION_ERROR = (-6),}public enum ZLibCompressionLevel:int{Z_NO_COMPRESSION = 0,Z_BEST_SPEED = 1,Z_BEST_COMPRESSION = 9,Z_DEFAULT_COMPRESSION = (-1)}public class ZLib{[DllImport("zlib.dll")]public static extern ZLibError compress(byte[]dest,ref int destLength,byte[]source,int sourceLength);[DllImport("zlib.dll")]public static extern ZLibError compress2(byte[]dest,ref int destLength,byte[]source,int sourceLength,ZLibCompressionLevel level); [DllImport("zlib.dll")]public static extern ZLibError uncompress(byte[]dest,ref int destLen,byte[]source,intsourceLen);}}。
Node.jsAPI详解之zlib模块⽤法分析⽬录Constants(常量)Optionszlib.constantszlib.createDeflate(options)zlib.createInflate(options)zlib.createDeflateRaw(options)zlib.createInflateRaw(options)zlib.createGzip(options)zlib.createGunzip(options)zlib.createUnzip(options)Convenience Methods(简便⽤法)本⽂实例讲述了Node.js API详解之 zlib模块⽤法。
分享给⼤家供⼤家参考,具体如下:Node.js API详解之 zlibzlib模块提供通过 Gzip 和 Deflate/Inflate 实现的压缩功能,可以通过这样使⽤它:const zlib = require('zlib');压缩或者解压数据流(例如⼀个⽂件)通过zlib流将源数据流传输到⽬标流中来完成:const gzip = zlib.createGzip();const fs = require('fs');const inp = fs.createReadStream('input.txt');const out = fs.createWriteStream('input.txt.gz');inp.pipe(gzip).pipe(out);zlib 可以⽤来实现对 HTTP 中定义的 gzip 和 deflate 内容编码机制的⽀持。
HTTP 的 Accept-Encoding 头字段⽤来标记客户端接受的压缩编码。
注意: 下⾯给出的⽰例⼤幅简化,⽤以展⽰了基本的概念。
使⽤ zlib 编码成本会很⾼, 结果应该被缓存。
// 客户端请求⽰例const zlib = require('zlib');const http = require('http');const fs = require('fs');const request = http.get({ host: '',path: '/',port: 80,headers: { 'Accept-Encoding': 'gzip,deflate' } });request.on('response', (response) => {const output = fs.createWriteStream('_index.html');switch (response.headers['content-encoding']) {// 或者, 只是使⽤ zlib.createUnzip() ⽅法去处理这两种情况case 'gzip':response.pipe(zlib.createGunzip()).pipe(output);break;case 'deflate':response.pipe(zlib.createInflate()).pipe(output);break;default:response.pipe(output);break;}});// 服务端⽰例// 对每⼀个请求运⾏ gzip 操作的成本是⼗分⾼昂的.// 缓存压缩缓冲区是更加⾼效的⽅式.const zlib = require('zlib');const http = require('http');const fs = require('fs');http.createServer((request, response) => {const raw = fs.createReadStream('index.html');let acceptEncoding = request.headers['accept-encoding'];if (!acceptEncoding) {acceptEncoding = '';}// 注意:这不是⼀个合适的 accept-encoding 解析器.// 查阅 /Protocols/rfc2616/rfc2616-sec14.html#sec14.3if (/\bdeflate\b/.test(acceptEncoding)) {response.writeHead(200, { 'Content-Encoding': 'deflate' });raw.pipe(zlib.createDeflate()).pipe(response);} else if (/\bgzip\b/.test(acceptEncoding)) {response.writeHead(200, { 'Content-Encoding': 'gzip' });raw.pipe(zlib.createGzip()).pipe(response);} else {response.writeHead(200, {});raw.pipe(response);}}).listen(1337);Constants(常量)说明:这些被定义在 zlib.h 的全部常量同时也被定义在 require('zlib').constants 常量上.注意: 以前, 可以直接从 require('zlib') 中获取到这些常量, 例如 zlib.Z_NO_FLUSH.⽬前仍然可以从模块中直接访问这些常量, 但是不推荐使⽤.demo:const zlib = require('zlib');// 可接受的 flush 值.zlib.constants.Z_NO_FLUSHzlib.constants.Z_PARTIAL_FLUSHzlib.constants.Z_SYNC_FLUSHzlib.constants.Z_FULL_FLUSHzlib.constants.Z_FINISHzlib.constants.Z_BLOCKzlib.constants.Z_TREES// 返回压缩/解压函数的返回值. 发送错误时为负值, 正值⽤于特殊但正常的事件.zlib.constants.Z_OKzlib.constants.Z_STREAM_ENDzlib.constants.Z_NEED_DICTzlib.constants.Z_ERRNOzlib.constants.Z_STREAM_ERRORzlib.constants.Z_DATA_ERRORzlib.constants.Z_MEM_ERRORzlib.constants.Z_BUF_ERRORzlib.constants.Z_VERSION_ERROR// 压缩等级.zlib.constants.Z_NO_COMPRESSIONzlib.constants.Z_BEST_SPEEDzlib.constants.Z_BEST_COMPRESSIONzlib.constants.Z_DEFAULT_COMPRESSION// 压缩策略zlib.constants.Z_FILTEREDzlib.constants.Z_HUFFMAN_ONLYzlib.constants.Z_RLEzlib.constants.Z_FIXEDzlib.constants.Z_DEFAULT_STRATEGYOptions说明:每⼀个类都有⼀个 options 对象. 所有的选项都是可选的.注意:⼀些选项只与压缩相关, 会被解压类忽视.demo:const zlib = require('zlib');const Options = {flush: zlib.constants.Z_NO_FLUSH,finishFlush: zlib.constants.Z_FINISH,chunkSize: 16*1024,windowBits 2, //值在8..15的范围内,这个参数的值越⼤,内存使⽤率越⾼,压缩效果越好。
Usage ExampleWe often get questions about how the deflate() and inflate() functions should be used. Users wonder when they should provide more input, when they should use more output, what to do with a Z_BUF_ERROR, how to make sure the process terminates properly, and so on. So for those who have read zlib.h (a few times), and would like further edification, below is an annotated example in C of simple routines to compress and decompress from an input file to an output file using deflate() and inflate() respectively. The annotations are interspersed between lines of the code. So please read between the lines. We hope this helps explain some of the intricacies of zlib.人们经常疑惑如何使用 deflate 函数和 inflate 函数,用户们不知道什么时候应该提供更大的输入缓存,或者什么时候提供更大的输出缓存,以及如何处理Z_BUF_ERROR 错误,如何确保处理进程被正确终结掉,等等。
Without further adieu, here is the program zpipe.c:/* zpipe.c: example of proper use of zlib's inflate() and deflate() Not copyrighted -- provided to the public domainVersion 1.4 11 December 2005 Mark Adler *//* Version history:1.0 30 Oct 2004 First version1.1 8 Nov 2004 Add void casting for unused return valuesUse switch statement for inflate() return values 1.2 9 Nov 2004 Add assertions to document zlib guarantees1.3 6 Apr 2005 Remove incorrect assertion in inf()1.4 11 Dec 2005 Add hack to avoid MSDOS end-of-line conversions Avoid some compiler warnings for input and output buffers*/We now include the header files for the required definitions. From stdio.h we use fopen(), fread(), fwrite(), feof(), ferror(), and fclose() for file i/o, and fputs() for error messages. From string.h we use strcmp() for command line argument processing. From assert.h we use the assert() macro. From zlib.h we use the basic compression functions deflateInit(), deflate(), and deflateEnd(), and the basic decompression functions inflateInit(), inflate(), and inflateEnd().#include <stdio.h>#include <string.h>#include <assert.h>#include "zlib.h"This is an ugly hack required to avoid corruption of the input and output data on Windows/MS-DOS systems. Without this, those systems would assume that the input and output files are text, and try to convert theend-of-line characters from one standard to another. That would corrupt binary data, and in particular would render the compressed data unusable. This sets the input and output to binary which suppresses the end-of-line conversions. SET_BINARY_MODE() will be used later on stdin and stdout, at the beginning of main().这段代码是为了防止在WIN/MS-DOS系统上出现输入输出的问题。
如果没有这段代码,上述操作系统会将输入、输出文件视为文本,将zlib文件中可能存在的EOF字符转换为它们自己的标准。
这会破坏二进制数据,尤其会使压缩数据不可用。
这段代码将输入输出均设置为二进制模式,消除了EOF转换的问题,将会在main函数里用到。
#if defined(MSDOS) || defined(OS2) || defined(WIN32) ||defined(__CYGWIN__)# include <fcntl.h># include <io.h># define SET_BINARY_MODE(file) setmode(fileno(file), O_BINARY)#else# define SET_BINARY_MODE(file)#endifCHUNK is simply the buffer size for feeding data to and pulling data from the zlib routines. Larger buffer sizes would be more efficient, especially for inflate(). If the memory is available, buffers sizes on the order of 128K or 256K bytes should be used.CHUNK是向zlib流程输入数据及提取数据的缓冲区大小。
缓冲区越大,压缩、解压效率越高,尤其是解压。
如果内存足够,尽量使用128K、256K之类的大小。
#define CHUNK 16384The def() routine compresses data from an input file to an output file. The output data will be in the zlib format, which is different from the gzip or zip formats. The zlib format has a very small header of only two bytes to identify it as a zlib stream and to provide decoding information, and a four-byte trailer with a fast check value to verify the integrity of the uncompressed data after decoding.def()函数从输入文件压缩数据,写入输出文件。
输出文件是zlib格式(与gzip 和zip不同)的。
Zlib格式有一个2字节的头部,标识这是一个zlib流,并提供解压信息;还有一个4字节的尾部,是用来在解压后校验数据完整性的。
/* Compress from file source to file dest until EOF on source.def() returns Z_OK on success, Z_MEM_ERROR if memory could not be allocated for processing, Z_STREAM_ERROR if an invalid compression level is supplied, Z_VERSION_ERROR if the version of zlib.h and the version of the library linked do not match, or Z_ERRNO if there isan error reading or writing the files. */int def(FILE *source, FILE *dest, int level){Here are the local variables for def(). ret will be used for zlib return codes. flush will keep track of the current flushing state for deflate(), which is either no flushing, or flush to completion after the end of the input file is reached. have is the amount of data returned from deflate(). The strm structure is used to pass information to and from the zlib routines, and to maintain the deflate() state. in and out are the input and output buffers for deflate().ret保存zlib函数的返回值flush跟踪deflate()的flushing状态,要么是无flushing,要么在读到输入文件底后全部flushhave是deflate()返回的数据数量strm是核心结构in和out是deflate()的输入输出缓冲区int ret, flush;unsigned have;z_stream strm;unsigned char in[CHUNK];unsigned char out[CHUNK];The first thing we do is to initialize the zlib state for compression using deflateInit(). This must be done before the first use of deflate(). The zalloc, zfree, and opaque fields in the strm structure must be initialized before calling deflateInit(). Here they are set to the zlib constantZ_NULL to request that zlib use the default memory allocation routines. An application may also choose to provide custom memory allocation routines here. deflateInit() will allocate on the order of 256K bytes for the internal state. (See zlib Technical Details.)首先我们要用deflateInit()初始化zlib状态。